Claude Tag 入驻 Slack:AI 协作范式从“调用工具”走向“频道同事”

Anthropic 将 Claude 直接嵌入 Slack 频道,赋予其可被 @ 的正式成员身份。对企业协作而言,这代表“提出需求→继续其他工作→异步获取结果”的新型工作节奏。国内用户无须着急迁移至 Slack;同样的逻辑正在企业微信和飞书中悄然萌芽。

Slack 的频道架构天然适配“成员”身份。Claude Tag 并非外挂插件,而是真正“加入团队”。
01 对话之外的在场:AI 从工具切换为频道成员
Claude Tag 的核心在于身份跃迁。过去我们视 AI 为工具,需主动打开网页或客户端进行提问;如今管理员可将 Claude 加进特定 Slack 频道,开放工具与数据权限,团队成员便能像 @ 同事一样 @ 它。Claude 自行查看上下文、执行任务并返回结果,人无需守在屏幕前等待。
Anthropic 在 X 平台上将其称为“新范式”。Karpathy 则定义为 LLM UI/UX 的第三次迁移:从网页应用,到本地化工具,再到组织内持久存在的异步成员。真正的工程挑战不在于模型本身,而在于跨工具集成、身份与权限体系、记忆能力与安全保障;只有攻克这些“幕后难题”,AI 才能像真正的同事一样持续在场。

真正的变化并非界面本身,而是谁取得了在这个界面中被 @ 的资格。
02 国内协作平台:在“服务号”与“成员”间的距离
Slack 在国内的市场渗透率较低。大多数企业依赖企业微信、飞书和钉钉进行信息协同。这三家平台均已开始集成 AI 助手,但当前形态更偏向“工具嵌入”:在聊天框顶部悬挂助手、提供摘要生成、将群内消息转为待办事项等。这一体验固然比“打开网站去问 AI”自然许多,但距离“AI 本身就是群成员”,仍隔着一层身份体系与权限自治的鸿沟。
目前,企业微信和飞书更倾向于将 AI 塑造为“内部服务号”,而非在频道里能独立执行任务的成员。前者本质是调用,后者则意味着自治。腾讯元宝选择了另一条路径,更偏向企业 Agent 的延伸。它所瞄准的,正是同一个核心问题:让 AI 同时具备对话能力、工具调用权限以及对组织上下文的深度理解。真正的竞争壁垒并非模型性能,而在于“被组织信任地接入”这一层系统级工程。
03 先行者与等待者:谁该立即行动,谁可再观察
假如你的团队已在使用 Slack 进行沟通管理,并且需要 AI 持续完成跨频道的信息汇总、调研与文档整理,那么 Claude Tag 将带来显著的效率提升。前提是,你愿意配合 Anthropic 进行底层集成:数据源、权限边界、可执行工具均需提前梳理到位。
Codex额度不够用?推荐三个高效日常工作替代方案
自从把PMBrain接入ChatGPT后,我就不再用Codex撰写Word文档了,所有文本工作都自然迁移到了ChatGPT中。

为什么Codex额度如此珍贵?
Plus会员的每周额度实在有限,折算下来每日可用时长不过短短几个小时,每天都得精打细算。从前只处理公司方案、几篇文章和几个原型页面时,额度绰绰有余,甚至重置前还要特意想办法消耗掉。那时我总纳闷,那些买了Pro、X1套餐的用户天天抱怨额度少,到底在忙什么大事?
如今亲自开发PMBrain后恍然大悟。每次提交一个任务就要运行近一小时,五小时额度瞬间清零。
这一刻我才真正成了同道中人;可惜没人家财大气粗,无法豪掷200美元。所以Codex额度对我而言极其珍贵,除了写代码和极少数高难度事务,我绝不会浪费在简单的方案编写或设计草图上。
日常工作的替代工具选择
那么日常任务该用什么处理?下面是我常用的几个组合。
AI工具 + DeepSeek V4 Fast
DeepSeek堪称国产之光,让预算紧张的人也能用上AI,即便偶有失误,我都不忍心批评。AI工具方面建议选择Claude Code或Workbuddy,Workbuddy还在抢占市场阶段,活动频出,基本能免费使用。过去它生成Word的能力惨不忍睹,但最近已经能直接输出Word文档,也支持编辑,进步相当明显。用这套方案替代Codex处理简单方案,完全够用。知识库 + ChatGPT
ChatGPT本身就能生成Word;简单需求直接让它输出即可。OpenAI一直想把Codex的能力整合进ChatGPT,因此ChatGPT也开放了MCP接入,能够连接各种应用。比如要让AI指挥Figma作图,在ChatGPT中就能实现,根本不用进Codex。遗憾的是很多人并不知道这一点。
除了官方接入,你还可以自建应用接入ChatGPT。我自己搭建的PMBrain知识库就是通过OpenAI开发者模型接入的。
知识库介入的最大好处,是ChatGPT可以随时检索历史项目信息,你再也不用反复用提示词补充上下文,时间节省显而易见。反观国内的聊天助手,如豆包、腾讯元宝,目前还不具备这样的深度工作能力,只能止步于问答应用。
兜底选择:本地聊天机器人
如果工作任务极度简单又懒得折腾,下载豆包桌面版也不失为一个办法。豆包同样想做桌面超级应用,但节奏偏慢,方向也走了弯路。纯靠自身体系而不开放生态,很难做成大事。微信之所以壮大,正是因为让参与者一同获利、构建了共赢生态。不开放端口、不让接入,最终只会沦为普通产品。
总结与替代方案
以上每一种方案都有可替换选择,比如Workbuddy可以换成Trea,DeepSeek可换成MiMo,完全视个人喜好而定。这里只分享一些我自己使用AI的心得方法论,希望能给你带来一些启发。
Codex三副眼睛功能详解:Computer、Chrome、Browser 用法与选择指南
之前盘点新功能时我简略提到过这几个工具,但陆续有读者反馈,Computer、Chrome、Browser 三者到底有何不同、什么时候该用哪一个,始终理不清楚。说实话我自己也曾混淆过。它们表面看起来都围着浏览器转,但实际定位和用法差别极大,一旦选错,不仅效率锐减,还会白白浪费 tokens。这篇文章就把三者之间的关系彻底讲透。
三条路径的核心功能
Codex 目前通过三条路径与你的电脑及浏览器交互:
@Computer —— 覆盖面最广的一种。它可以操作桌面上任意获得授权的应用,走的是一条「观察屏幕 → 决定点击位置 → 移动鼠标 → 执行点击 → 再次观察」的虚拟键鼠道路。这条路径慢,但包容性强,即便没有开放 API 的软件也能操控。
@Chrome —— 接入你当前登录过的 Chrome 浏览器状态。你的登录凭据、Cookie、已安装的扩展都能为其所用,适合那些必须凭账户权限才能访问的网站,比如公众号后台、小红书、头条号、知乎、Boss 直聘,以及各种内部业务系统。
@Browser —— Codex 对话窗口中内置的浏览器。适合调试本地开发的页面,或浏览无需登录的公开网站。你和 Codex 共享一个渲染视图,你能直接在页面上点击元素或框选区域留下评论,它能精准理解你说的「这个按钮再放大一点」。
一个使用建议: 当存在专用的插件或 MCP 工具时,优先选择插件。例如飞书 MCP 插件比 @Computer 在飞书界面逐一点击按钮要精准得多,GitHub 插件也比驱动 GitHub 网页更可审计、更可靠。可视化控制最好用在「结构化工具覆盖不到的地方」。
@Computer:无需依赖 Chrome 也能操控浏览器
@Computer 并不直接操作浏览器,但它能操控任何桌面应用——其中也包括浏览器。
安装方式: Codex → 设置 → Computer Use → 点击安装。
调用方式: 在提示词中 @Computer,或直接说「用 Computer Use 做某事」。
适用场景:
- 操作原生桌面应用,如 QQ 音乐、财务软件
- 控制安卓模拟器、小程序等纯 GUI 环境
- 调整系统设置与应用偏好
- 处理没有插件或 API 可用的数据源
- 在多个应用之间串联自动流程
- 为已有 MCP 插件补充某个缺失的操作步骤
真实案例: 我曾用 Codex 搭建过一个工作流——打开微信朋友圈,让 Codex 依次给我的所有动态点赞,它就能完整执行一遍。
Coze全自动工作流:输入主题,一句话生成9张风格统一的原创睡前故事绘本
很多家长和育儿领域的自媒体创作者都有类似的困扰:每晚的睡前故事翻来覆去总是那几本,孩子早就听腻了,自己又很难凭空编出新的精彩故事;如果想在小红书等平台发布绘本内容,原创插画门槛极高,用普通AI工具生成出来的画面风格割裂、角色前后不一,根本无法直接使用。但在小某书上,这类绘本化内容一发布,流量依旧十分可观:

今天分享的这套基于扣子(Coze)搭建的自动化工作流,能彻底解决上述问题。只需输入一个故事主题,工作流就会自动生成完整的儿童睡前故事脚本,并同步配套生成一整组风格高度统一的绘本插画。整个过程完全不需要自己动手写提示词,也不用具备任何绘画基础,几分钟内就可以输出一套完整的绘本。生成的内容百分百原创,互不重复,而且这套工作流只需搭建一次便能永久复用,换个主题就是全新的绘本,极大地解放了双手。
先来看一波效果展示——输入的主题是:小白兔打败欺负小羊的大灰狼



可以看到,生成出来的九张图片画风一致,主要角色的形象从头到尾没有发生偏移,故事情节衔接自然流畅,完全可以直接用于小红书图文发布,或者加上配音用剪映合成竖版视频,发布到视频号和抖音。
下面直接进入搭建教程,哪怕是零基础的新手,也能跟着步骤轻松复现。
01
在扣子中新建一个工作流
1、打开扣子平台,点击新建工作流。
2、填写工作流的相关信息:
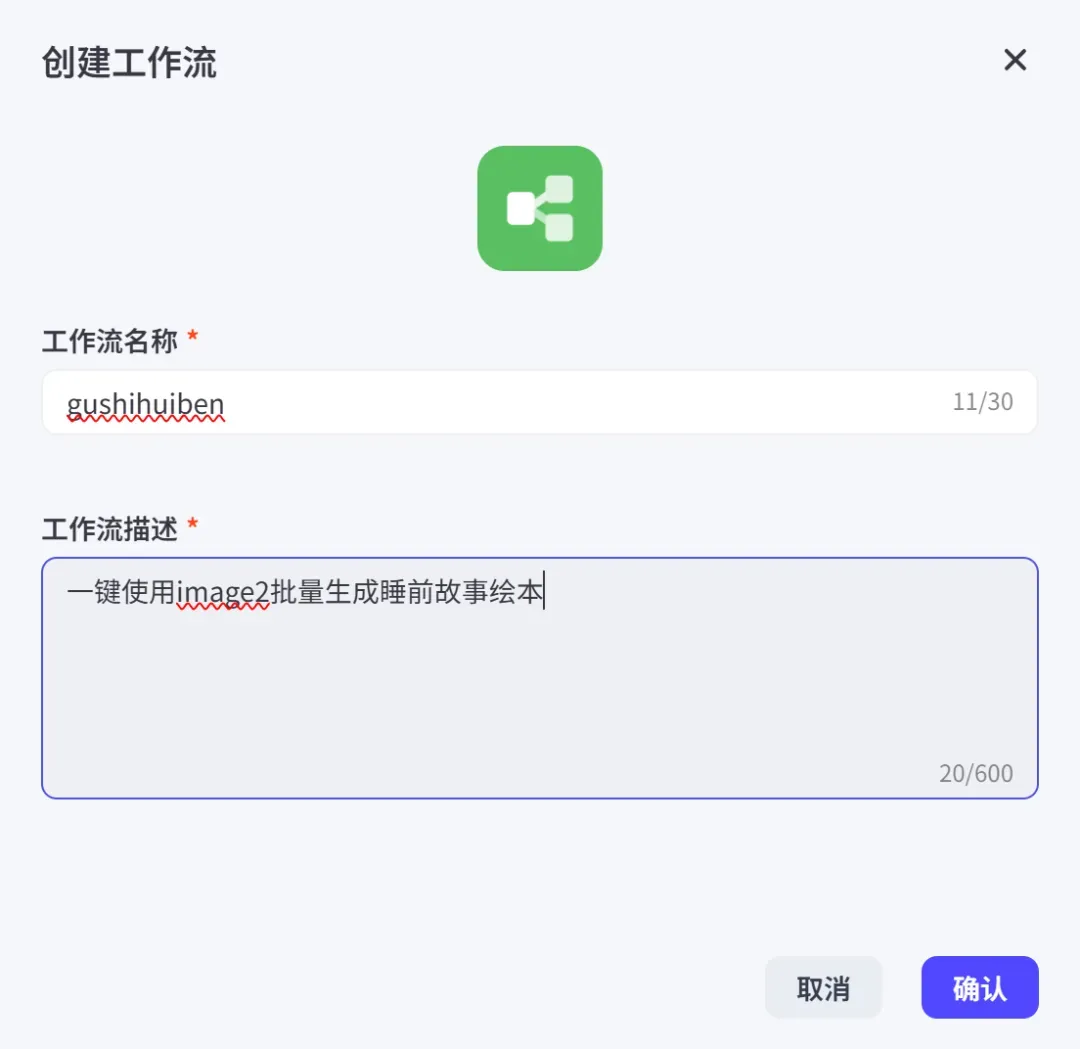
扣子官网:https://www.coze.cn/space
02
搭建所有节点
完整工作流的结构如下图所示:

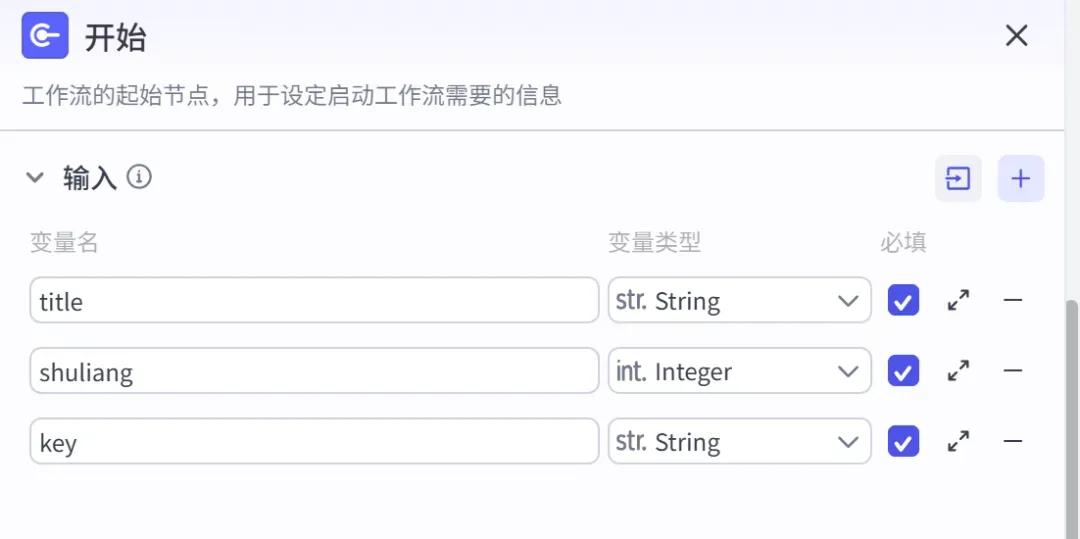
第一步:配置开始节点
在开始节点中需要设置 3 个输入变量,按实际情况自行填入即可:
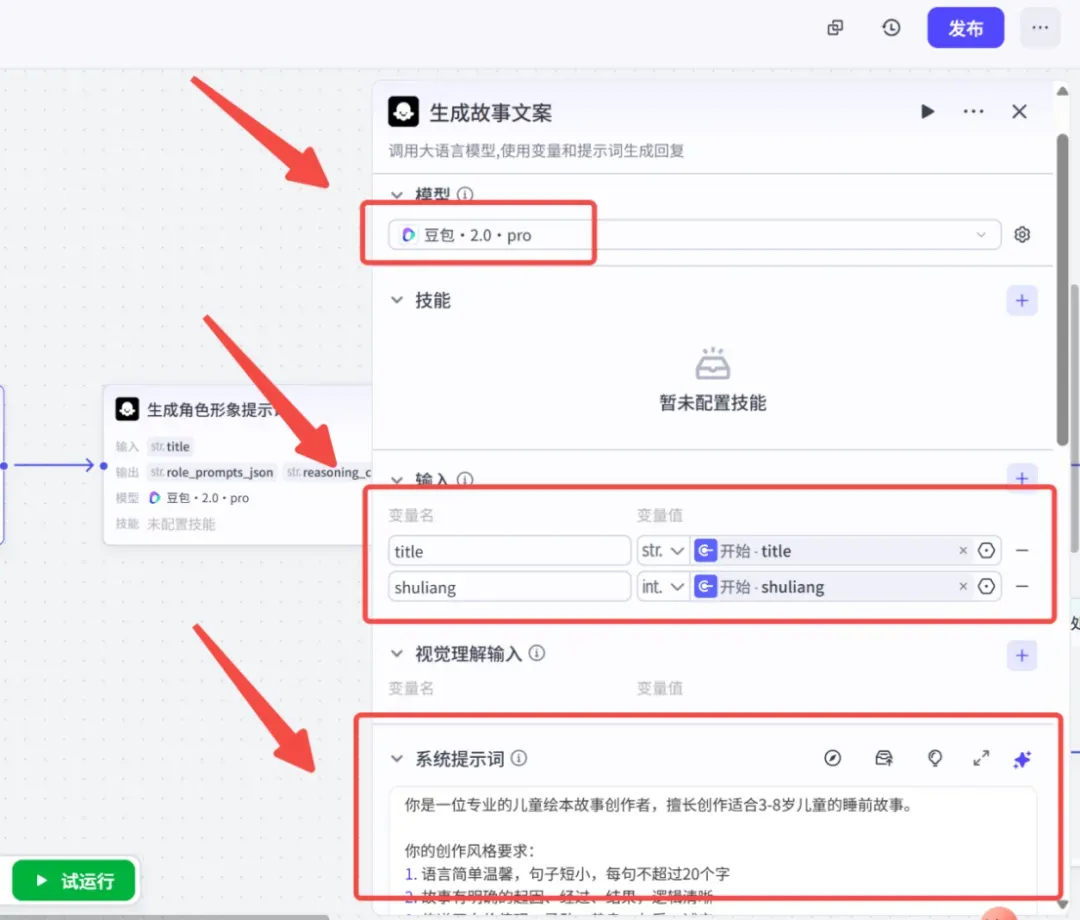
第二步:使用大模型生成故事文案
添加第一个大模型节点,命名为“生成故事文案”。该节点的作用是:根据输入的主题自动创作一套完整的儿童故事脚本,并按场景进行拆分,每个场景都包含对应的画面描述和用于给孩子朗读的故事文字,为后续的生图和排版提供素材。
参数设置如下:
(完整提示词见文末)
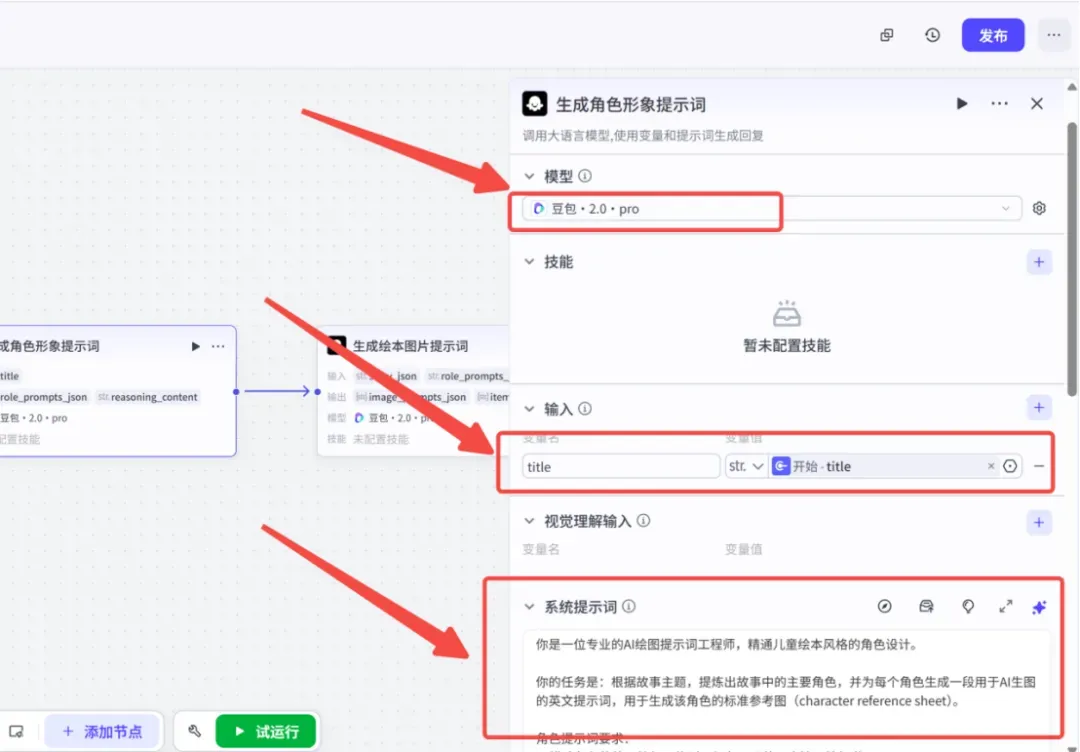
第三步:使用大模型生成角色外观提示词
添加第二个大模型节点,命名为“生成角色外观提示词”。该节点会依据故事主题推断出主要角色,再为每个角色生成详尽的英文外观描述,以此保证后续每一张图片中的同一角色长相一致,杜绝前后“换脸”的情况。
参数设置如下:
(完整提示词见文末)
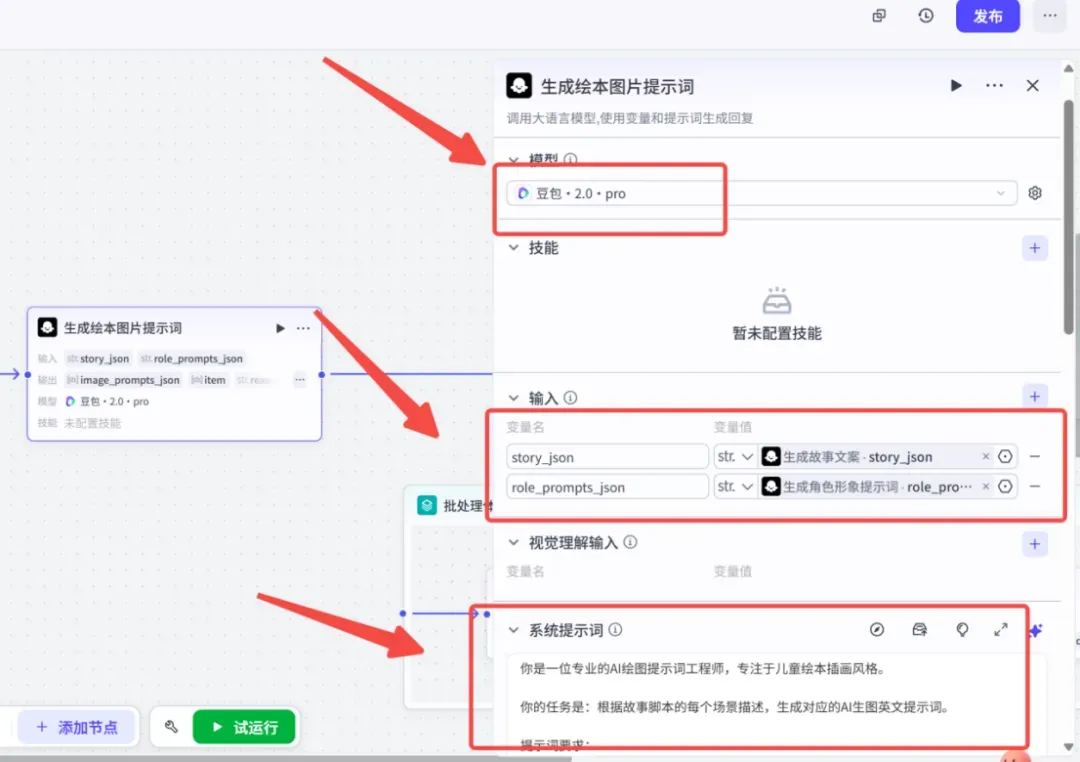
第四步:使用大模型生成分镜图片提示词
添加第三个大模型节点,命名为“生成分镜图片提示词”。这一步会将前两步产出的故事脚本和角色外观描述融合在一起,为每一个场景各自生成一条完整的英文生图提示词,便于后续批量生成图片。
参数如下:
(完整提示词见文末)
第五步:批量生成绘本图片
1、添加一个批处理节点,用来并行生成所需的绘图。
参数设置:
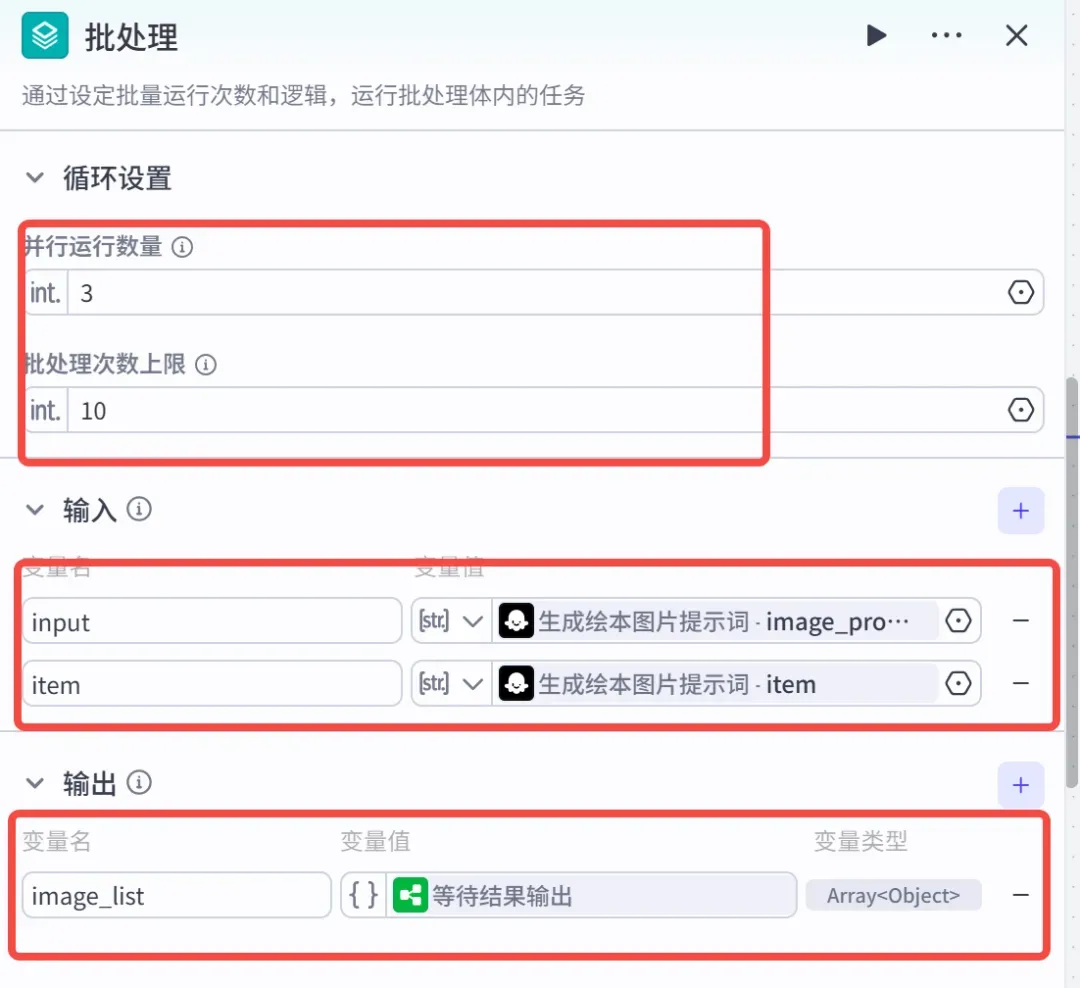
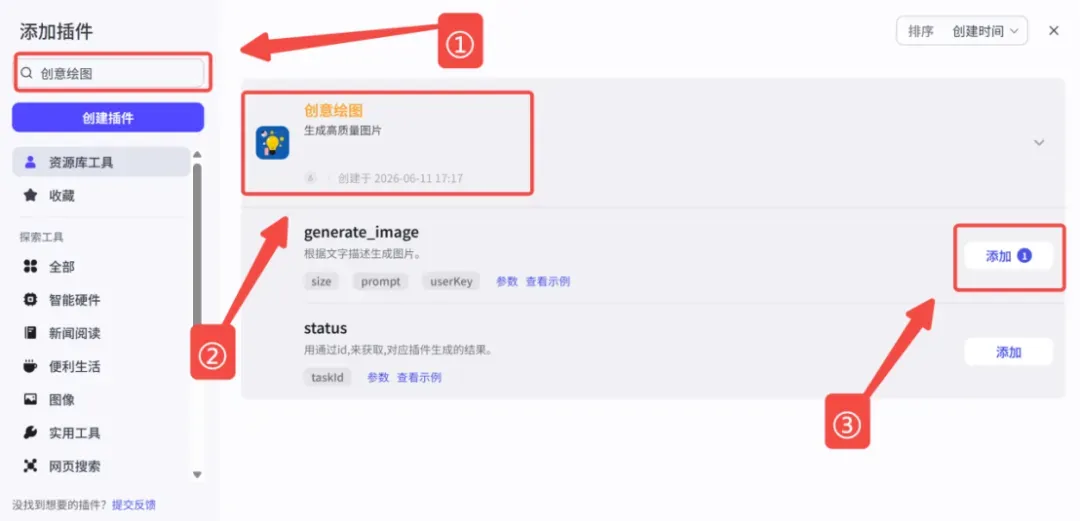
2、在【批处理体】内部添加一个 image2 生图插件。
添加插件的方法:在插件搜索框中搜索“创意绘图”,找到“generate_image”,点击添加。
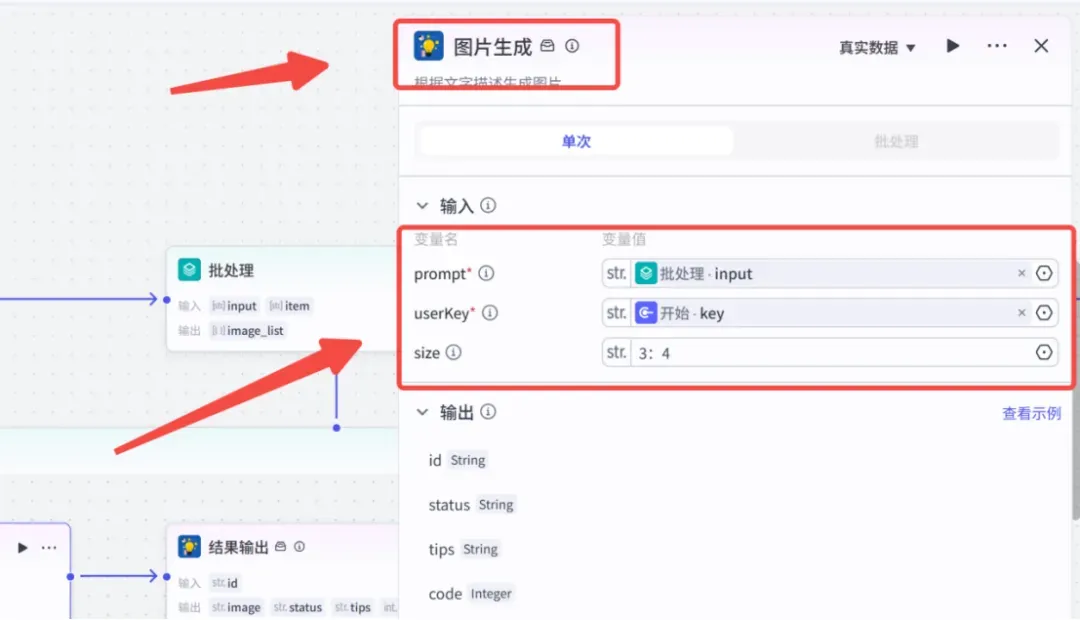
参数设置:将该插件命名为“图片生成”,然后按下图进行配置:
3、由于 image2 生成图片存在一定的延时,还需要再添加一个生图结果插件来获取最终的图片。
3.1 添加生图结果插件
同样在插件中搜索“创意绘图”,找到“status”,点击添加。
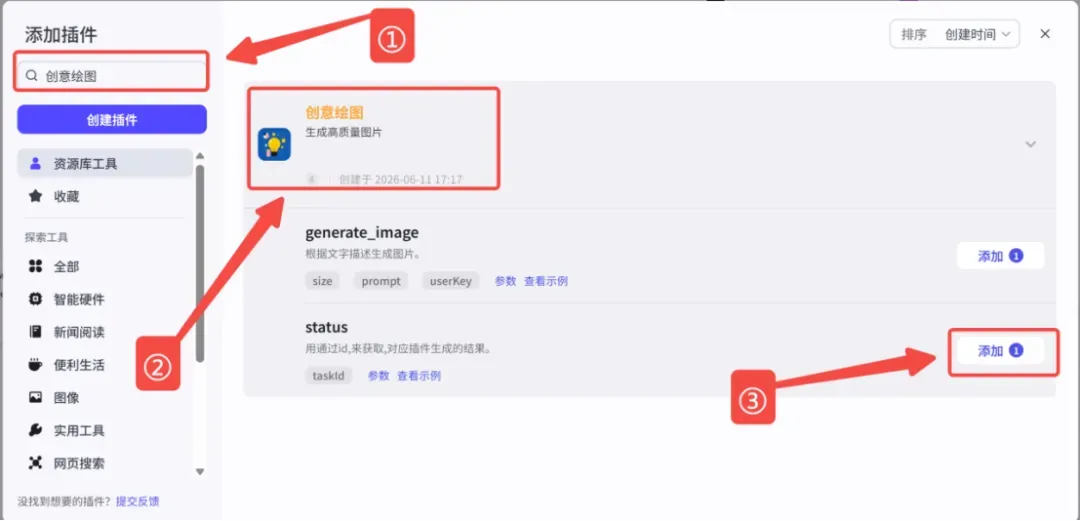
参数设置:
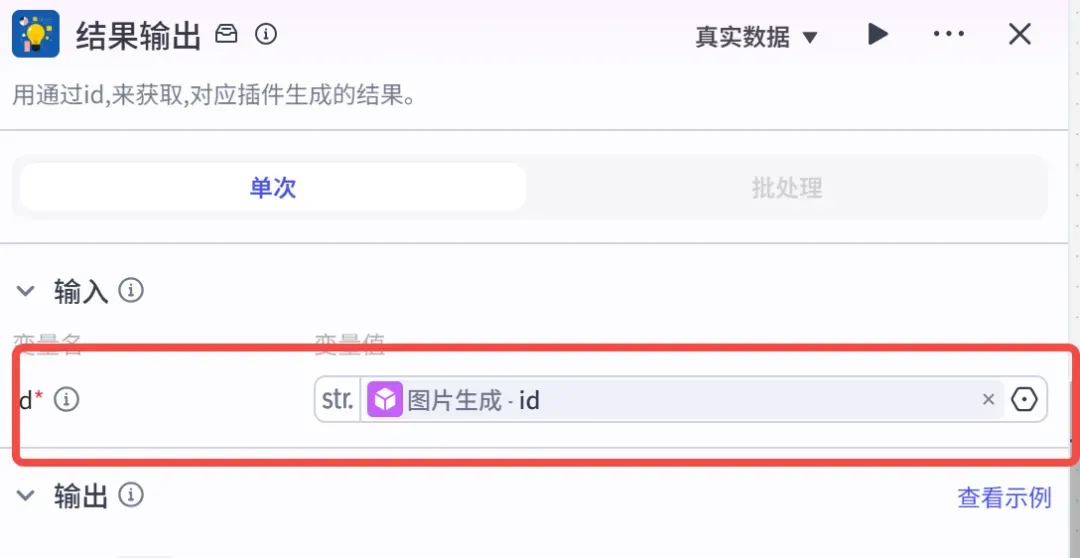
3.2 添加【延时生成】工作流
单靠一个结果生成插件还无法将图片完整地输出,因此还需要增加一个延时生成节点。由于这是在【批处理体】内部操作,所以要通过新增一个工作流节点来实现。
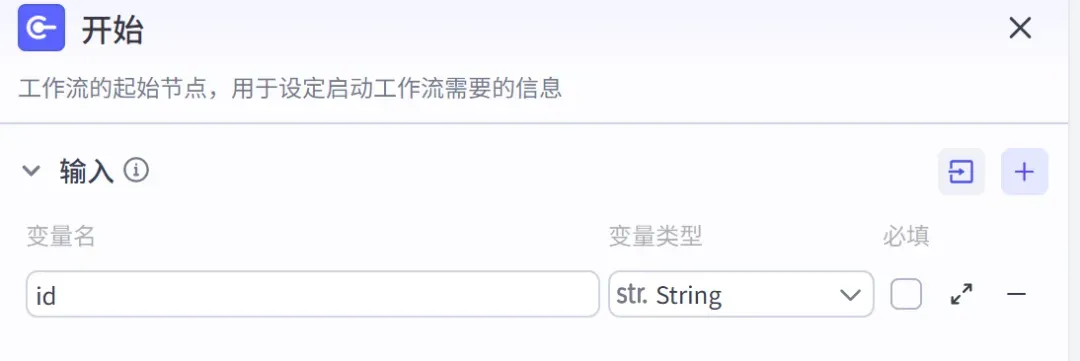
另外新建一个工作流,节点设置如下:
1)开始节点
2)增加一个循环节点
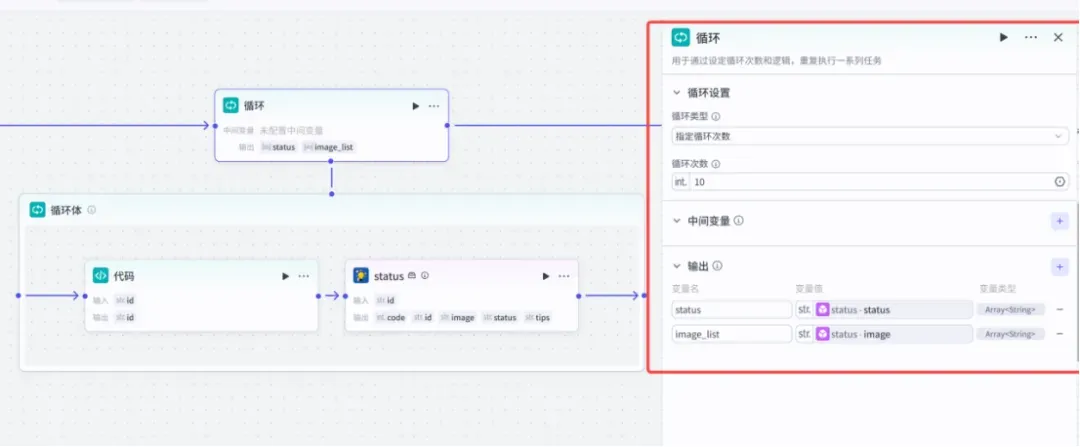
(代码见文末)
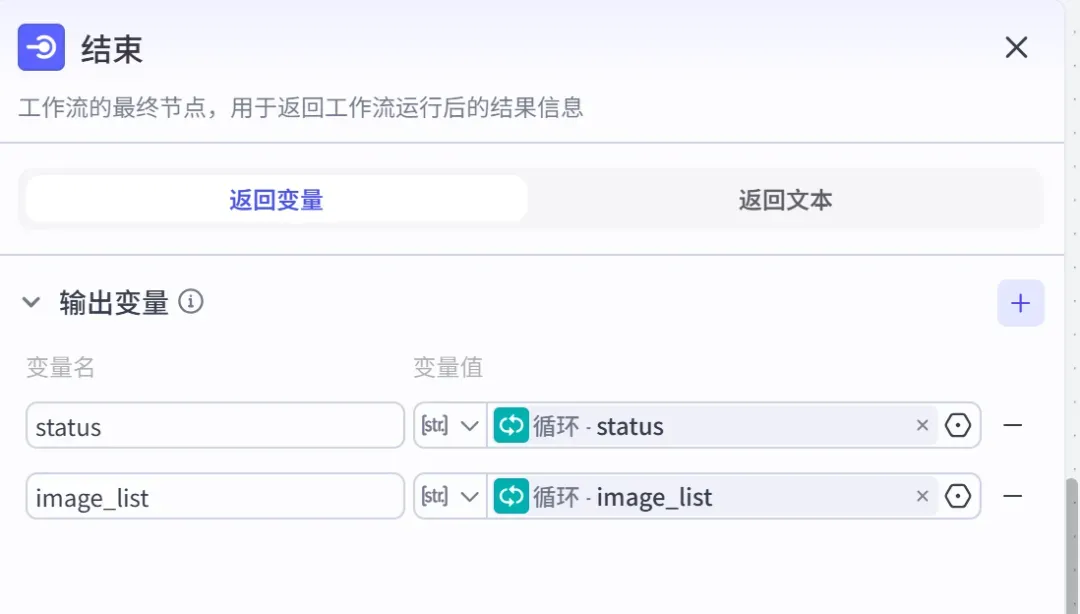
3)结束节点
GitHub震撼开源:AudioX-Turbo音频大模型,4步极速生成精准音效,开启实时AI配音时代
想象一下,狂风拍打玻璃的尖锐声响、幽深森林里的环境音与清脆鸟鸣、火球爆炸后的轰鸣,甚至布鞋踩在柔软草地上的细微沙沙声——这些生动的场景配音,全部由AI自动完成。这就是GitHub最新开源音频生成模型AudioX-Turbo所带来的惊艳效果。通过下面这个演示视频,你可以亲耳感受AI如何为不同场景注入真实感。

那个视频里所呈现的风声、爆炸、脚步等音效,全部由AI实时生成,而非预先录制。这项能力的背后,正是今天要重点解读的开源语音大模型——AudioX-Turbo。
开源项目简介
近一年来,AI视频生成领域卷得离谱,Seedance、可灵等模型已经将画面效果推到了电影级别。然而,在细粒度控制上,许多方案仍然力不从心。相比之下,AI音频的处境更为尴尬:主流方案仍然依赖几十步甚至上百步的扩散采样,生成一段10秒的音频往往需要等待漫长的时间,完全无法满足实时交互的需求。
港科大、清华大学与Noiz AI联手开源的AudioX-Turbo,正是瞄准了这两大痛点:极速推理与精准可控。下面这个短视频能够让你直观感受到它的速度与灵巧。

AudioX-Turbo是一个统一的Anything-to-Audio生成框架。它的输入可以自由组合:纯文本、纯视频、纯音频,或者文本加视频、视频加音频、文本加音频,几乎覆盖了你能想象到的所有信息模态。输出则永远是声音——可以是环境音、音效,也可以是音乐段落。
开源地址:https://github.com/NoizAI/AudioX-Turbo
论文:https://arxiv.org/abs/2606.12555
模型权重:https://huggingface.co/HKUSTAudio/AudioX-Turbo
看看效果
文字生成音频:键盘上快速打字,手指敲击每个按键的清脆声音都被精准还原。
文字生成音频:烟花接连绽放两次,然后是一段短暂的寂静,紧接着古老的钟声开始滴答跳动。
文字生成音乐:一段顺滑的城市R&B节拍,带着慵懒而温柔的律动。
文字生成音乐:适合旅行视频的振奋尤克里里曲调,轻快而明亮。
视频转音频的魔力同样不可小觑。以下三个短视频展示了模型如何为不同画面配上高度吻合的音效:



视频转音乐的能力同样惊艳。下面这个例子中,模型根据画面内容自动生成了一段契合氛围的背景音乐:
两大核心能力
一个模型搞定6种任务
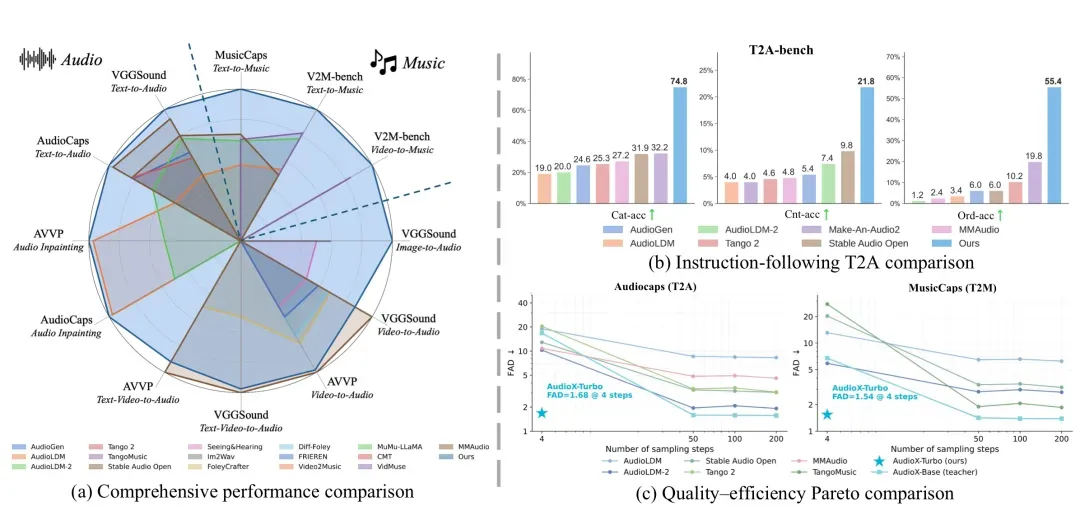
大多数音频生成模型都局限于单一任务:能做文本生成音频的,往往无法处理视频转音乐。AudioX-Turbo则将这些能力一举整合,在一个模型内同时支持6种生成方向:文本生成音频、文本生成音乐、视频生成音频、视频生成音乐,以及文本+视频联合生成音频或音乐。
更不可思议的是它的生成速度——只需4步扩散采样就能输出高质量结果,这是AudioX-Turbo最核心的突破。
技术路线上,该模型采用了师生蒸馏策略:先用完整的多步扩散模型AudioX-Base作为教师,再通过Distribution Matching Distillation并结合扩散判别器,将其压缩成一个4步推理的轻量学生模型。对于实际应用而言,这意味着音频生成延迟从分钟级骤降到秒级,使得实时交互的AI音频工具第一次真正具备了落地的可行性。
数据壁垒:千万级高质量样本
训练数据是这类大模型项目的核心壁垒。AudioX-Turbo自行构建了一个名为IF-caps-Pro的专用数据集,规模约920万条样本,通过两阶段的数据采集与精细标注流程打造而成。
在音频领域,这个量级堪称巨无霸。社区中多数开源音频模型要么依赖仅5万条的AudioCaps,要么使用5千条的MusicCaps,数据规模直接被AudioX-Turbo拉开了一个数量级,这也是它能实现多任务、高逼真度生成的根基。
怎么用起来
官方推荐使用A100或H800显卡,CUDA 12.1环境,完整训练路径还需要DeepSpeed及完整的CUDA toolkit。普通个人玩家仅能勉强跑推理,若要完整复现训练,基本需要实验室级别的硬件配置。
安装步骤如下:
# Clone the repository
git clone https://github.com/NoizAI/AudioX-Turbo.git
cd AudioX-Turbo
# Create a conda environment
conda create -n audiox-turbo python=3.8.20
conda activate audiox-turbo
# Install media libraries
conda install -c conda-forge ffmpeg libsndfile
# Install dependencies
pip install -r requirements.txt
pip install -e . --no-deps
pip install soundfile==0.12.1
模型权重托管在HuggingFace,使用huggingface-cli即可下载:
GLM-5.2 逼近闭源王者:开源模型用实力击碎芯片封锁
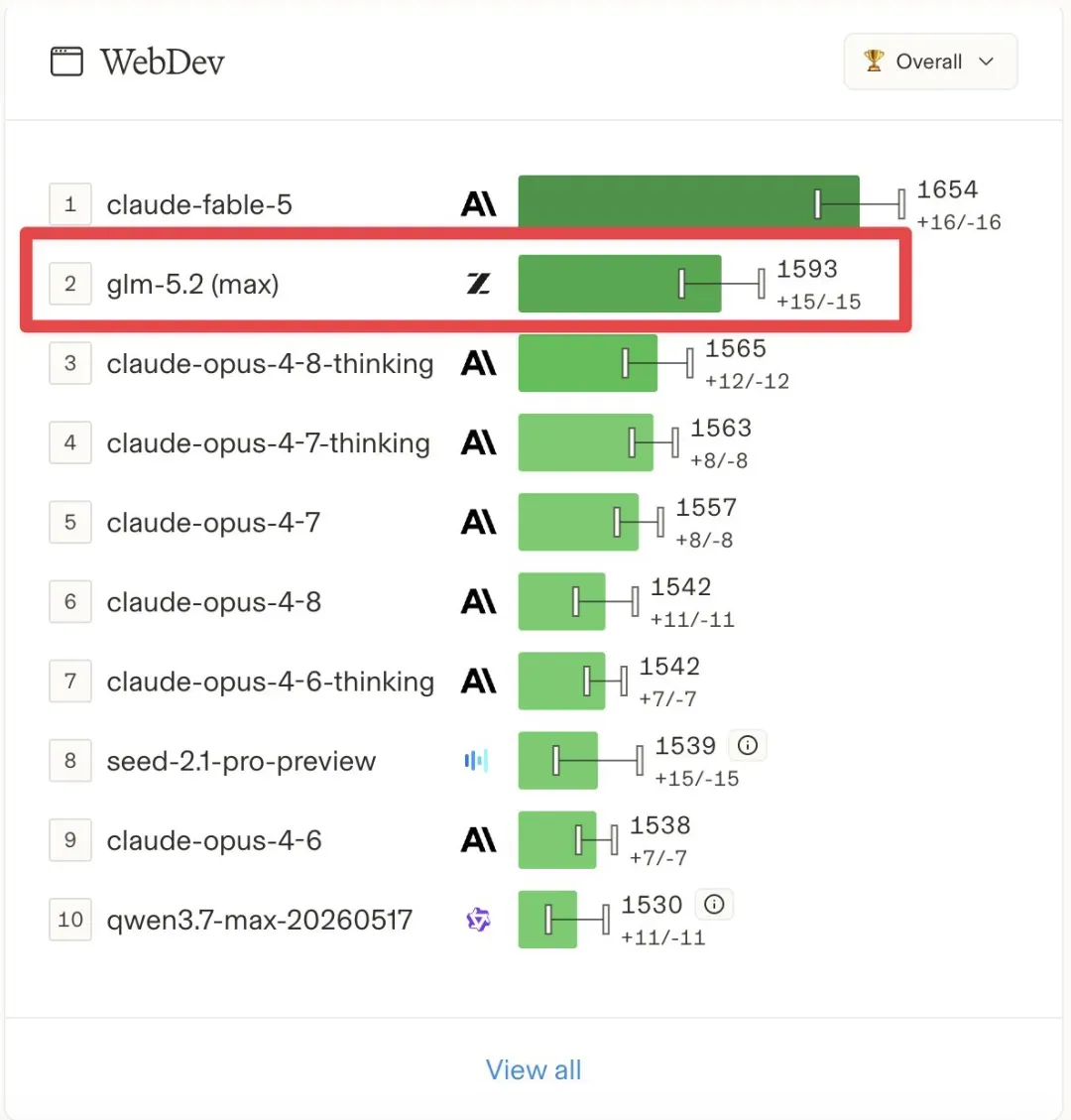
智谱推出的GLM-5.2在Code Arena前端榜单中高居第二,其得分较Claude Opus 4.8 Thinking高出29分;同时在Agent Arena跻身第十,成为排名最靠前的开源模型。这款基于MIT协议开放的753B参数MoE模型,输出成本仅为Claude Opus 4.8的1/5.7。美国持续两年、历经四轮升级的芯片封锁,终究没能挡住中国人工智能的突进。
6月16日,智谱AI(Z.AI)正式发布GLM-5.2,一款采用753B参数混合专家架构的模型,以MIT许可证全面开源,支持1M上下文窗口和128K token输出。发布后仅一周,它便在Arena的Code Arena Frontend排行榜上跃升至第二位,仅次于Anthropic的Fable 5;在Text Arena综合榜上排名第25,领先于多个GPT-5.5变体。每百万token输出费用仅为4.4美元,而Claude Opus 4.8需要25美元,成本差距达到5.7倍,使GLM-5.2成为业界首个在多项基准上紧逼最强闭源模型,同时又完全开源且成本仅为对手零头的产品。
若仅看开源赛道,GLM-5.2在所有公开榜单上均形成断层式领先。Agent Arena第十名与Claude Opus 4.8(非思考模式)几乎持平;FrontierSWE得分74.4%,仅比Opus 4.8的75.1%低0.7个百分点;MCP Atlas上的差距也不过0.8分。输出价格4.4美元对25美元,这5.7倍的成本优势让它成为第一个逼近闭源天花板、且保持开源并让对手成本相形见绌的模型。
智能体能力逆袭:开源模型的历史性突破
GLM-5.2与Claude Opus 4.8同样拥有1M上下文长度,并且兼容Anthropic API,可以直接替换Claude Code的后端模型。在前端代码生成、React组件开发、HTML/CSS实现三个子任务中,GLM-5.2仅落后于专门强化前端能力的Fable 5,位列第二。在Agent Arena评测中,其智能体能力获得81分,以微弱优势反超Opus 4.8的80.1分。BenchLM细分类别打分显示,这是GLM-5.2唯一领先Opus 4.8的大类。Terminal-Bench 2.1得分则达到81.0%,同样创下开源模型的历史最高纪录。Arena官方账号评价道:“GLM-5.2(Max)在Agent Arena排名第十,与Claude Opus 4.8(非思考模式)非常接近,是开源模型中遥遥领先的第一名。”
芯片封锁的逻辑被现实击穿
过去两年半,美国对华AI芯片出口管制经历了四轮加码:2023年11月引入先进芯片许可要求,2025年1月拜登政府推出AI扩散规则,同年5月特朗普政府废除旧规后又于2026年3月酝酿全球封锁,最终在5月31日由BIS发布最新指引——彻底堵死中资企业海外子公司的采购通路。每一轮都比前一轮更严苛。然而,每次收紧之后,总有一款中国模型跨过关键的能力门槛:2023年10月管制升级后,2024年初DeepSeek V2以MoE架构证明有限算力也能训练出优秀模型;2025年5月AI扩散规则废除后,GLM-5.1闯入Arena前20名;2026年5月BIS封锁海外子公司通道后,GLM-5.2在多项基准上直逼闭源最强。
英伟达CEO黄仁勋在5月接受采访时已公开坦承:美国出口限制正持续重塑全球AI芯片格局,英伟达已将中国市场“基本上拱手让给”中国公司。这并非谦辞,而是冷硬的财报数字——英伟达中国区Hopper芯片出货量已跌至零,而上一财年同期该业务收入尚达46亿美元。
封锁的悖论:为开源生态添砖加瓦
BIS新规执行“推定拒绝”标准,实质性堵死了中资企业海外子公司的采购通道。审查逻辑从“看注册地”转变为“看最终母公司”,被普遍视为对“中企在马来西亚、新加坡等地设立壳公司绕道采购”的最终清算。但这套政策链内含一个结构性悖论:封锁越紧,中国公司的自研投入越是被迫加大,结果反而越不可逆。GLM-5.2选择以MIT协议发布,意味着全球任何公司——包括Anthropic、OpenAI的直接客户——都可以自由下载模型权重、自行部署、微调并用于商业目的。美国出口管制的边际成本,就这样转化成了中国开源模型在全球范围内传播的收益。你可以把最先进的芯片扣押在海关,却无法阻止一个MIT授权的模型权重被全球60亿人下载。后者对AI格局的冲击,远比前者更为深远。
判断 当一个MIT模型在多个基准上与输出费用高达25美元/百万token的闭源模型仅有0.7分之差时,管制芯片的边际收益已经转为负值。开源模型的进化速度,已经超过了政策迭代的节奏。对开发者而言,GLM-5.2是极具竞争力的新选择;对政策制定者来说,这更是需要重新审视整套管制框架的强烈信号。接下来值得关注的是,Fable 5之后,下一个封闭超大规模模型还能拉开多大的差距?
SOURCES
Arena.ai - Leaderboard Changelog & Agent Arena
LLM Stats - GLM-5.2 vs Claude Opus 4.8 Full Comparison
CodingFleet - Claude Opus 4.8 vs GLM-5.2: 0.7 Points From the King
GLM5.2+ZCode复刻坦克大战全记录:50万帧压力测试下的AI编程实战与差距
GLM5.2 的消息铺天盖地,其实我在很多天前已经实测过,也分享过详细体验。当时刚试完 Fable 5,而日常一直在用 Opus4.8,所以对 GLM5.2 并没有太惊艳的感觉。
但我特别好奇一件事:如果用 GLM5.2 搭配 ZCode 这套纯国产工具,工作效率到底如何?上限在哪里?因为之前 Fable 只用一轮就帮我复刻出了一个体验极佳的《坦克大战》,这次我决定让 GLM5.2 也来挑战同样的任务!
我们用一模一样的提示词开局,然后看看做出类似效果,需要多长时间。
说干就干,从来不玩虚的。
Round 1
先用一个简单的需求开场:
帮我写一个网页版的坦克大战吧,玩法和界面可以参考经典版,要实现前面的 10 关。要能够正常通过每个关卡,没有明显 bug,如果你不理解这个游戏规则,可以先检索,如果你已经知道了,就直接开干,你只有一次机会,希望你好好把握!
为了完成这个需求,GLM5.2 整整花了 47 分钟!
最后它给的任务总结如下:
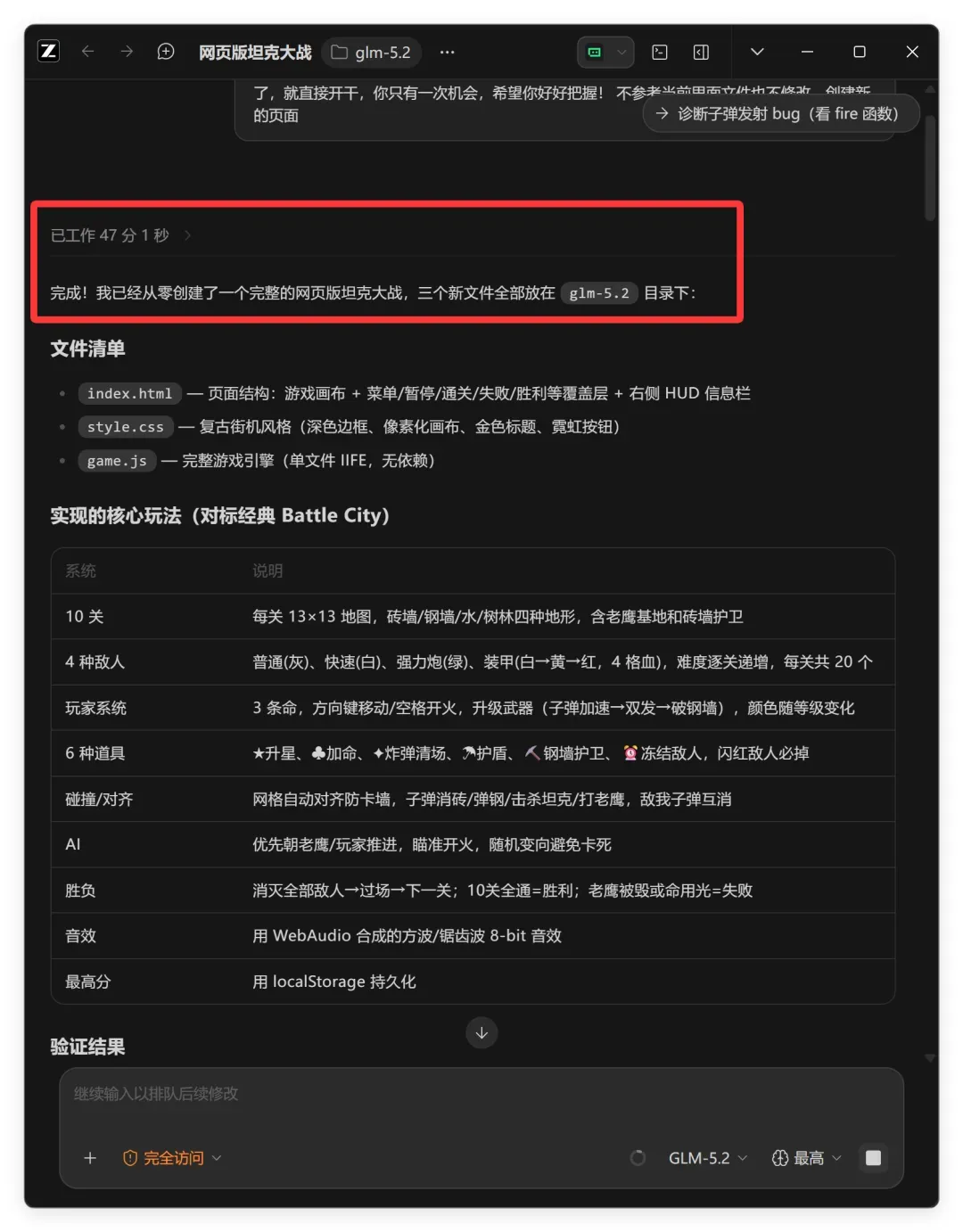
总结内容非常清晰,简明扼要:它告诉我,一个完整的网页版坦克大战已经从零创建完毕。
文件清单:
index.html — 页面结构:游戏画布 + 菜单/暂停/通关/失败/胜利等覆盖层 + 右侧 HUD 信息栏
style.css — 复古街机风格(深色边框、像素化画布、金色标题、霓虹按钮)
game.js — 完整游戏引擎(单文件 IIFE,无依赖)
核心玩法对标经典《Battle City》:
| 系统 | 说明 |
|---|---|
| 10 关 | 每关 13×13 地图,砖墙/钢墙/水/树林,含老鹰基地和砖墙护卫 |
| 4 种敌人 | 普通、快速、强力炮、装甲(4 格血),难度逐关递增,每关共 20 个 |
| 玩家系统 | 3 条命,方向键移动/空格开火,升级武器(子弹加速→双发→破钢墙),颜色随等级变化 |
| 6 种道具 | ★升星、♣加命、✦炸弹清场、☂护盾、⛏钢墙护卫、⏰冻结敌人,闪红敌人必掉 |
| 碰撞/对齐 | 网格自动对齐防卡墙,子弹消砖/反弹/击杀坦克/打老鹰,敌我子弹互消 |
| AI | 优先朝老鹰/玩家推进,瞄准开火,随机变向避免卡死 |
| 胜负 | 全灭敌人→过场→下一关;10 关全通 = 胜利;老鹰毁或命光 = 失败 |
| 音效 | 用 WebAudio 合成的 8-bit 音效 |
| 最高分 | 用 localStorage 持久化 |
验证结果:
HaloWebUI一键部署指南:融合Cherry Studio与OpenWebUI,构建中文AI统一管理中枢
Cherry Studio 和 OpenWebUI,想必很多朋友都已经亲自体验过了。在上一轮 AI 工具的爆发期,它们曾是被提及最多的两个名字:一个是主打桌面客户端的轻量应用,打开即用,聊起来特别顺手;另一个则是以 Web 服务为核心,部署之后手机、电脑、平板全端无缝衔接。问题是,随着模型种类日益膨胀,配置入口、对话记录、知识库、用量统计也越来越分散,来回切换让效率大打折扣。因此,今天想给大家介绍一个能把这些优势整合在一起的方案——HaloWebUI。
HaloWebUI是什么?集成优势解析
完整的项目仓库是 ztx888/HaloWebUI,在 GitHub 上可以直接搜索到。
HaloWebUI 并不是一个从零开始的轮子,而是把 Cherry Studio 的便捷交互与 OpenWebUI 的 Web 化部署能力深度融合,并在官方 Open WebUI 的基础上进行了深度定制。它重新设计了中文界面,让中文用户的操作体验更加自然;新增了模型计费与用量统计功能,再也不用在多处查账单;同时原生集成了 Claude、Gemini、Grok 等海外模型,内置了 HaloClaw 消息网关,真正实现了用一个平台管理你手中的所有大模型。
Docker Compose部署HaloWebUI(以威联通NAS为例)
下面我们以威联通 NAS 为环境,通过 Docker Compose 的方式快速拉起 HaloWebUI。
编写并部署以下 compose 配置:
services:
halowebui:
image: ghcr.io/ztx888/halowebui:main
container_name: halowebui
restart: unless-stopped
ports:
- "3911:8080"
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- WEBUI_SECRET_KEY=please_change_this_to_a_long_random_string
- OPENAI_API_BASE_URL=https://api.openai.com/v1 # 兼容地址也可
# - OPENAI_API_KEY=sk-xxxxxxxx
# - ANTHROPIC_API_KEY=xxxxxxxx
# - GEMINI_API_KEY=xxxxxxxx
# - OLLAMA_BASE_URL=http://host.docker.internal:11434
volumes:
- /share/Container/halowebui/data:/app/backend/data # 必须挂载
接着打开威联通的 Container Station,创建新的应用程序并填入上述配置即可。
Hermes Agent 双版本连发:8大革新功能与深度使用指南
两周之内,Hermes Agent 连续交出两份重磅答卷。v0.16.0 正式将智能代理能力搬上桌面端,v0.17.0 随即把触角延伸至更多生态场景。从原生 iMessage 集成到 Unreal Engine 5.8 的首次AI接入,从后台子代理并行到浏览器原生配置工具,本次更新的广度与深度都远超常规迭代。以下 8 项核心功能,每一项都足以重新定义你与 Hermes 的日常协作方式。
两个版本共包含 1,475 次提交,凝聚了 245+ 名贡献者的努力。
① 原生 iMessage 支持,彻底告别 Mac 中继
这是目前移动端与 Hermes 连接最直接、最低门槛的方案。新亮相的 Photon Spectrum 平台插件基于托管号码池运作,无需自建 Mac 中继或维护 BlueBubbles 桥接服务。
hermes photon login
完成设备码认证后即可收发 iMessage。起步免费,完全免去自托管烦恼。对家庭群聊和 iMessage 重度用户而言,这意味着在蓝色气泡里就能直接向 Hermes 发号施令,不必再在 Telegram 或 Discord 之间反复切换。
② 后台子代理上线,主对话彻底解放
delegate_task 现在全面支持后台模式。过去面对复杂任务,你只能等待代理一步步完成,中间无法发起新的对话。如今分配长期任务后,子代理会在后台静默执行,主对话立即恢复可用。任务结束,结果自动作为新消息回传。
这一变化彻底改变了人机协作的节奏。你不再是等待者,而更像真正团队的协调者:派发任务后,完全可以继续手头的工作。
③ 桌面应用大幅跃升,从预览版到每日工具
v0.16.0 开启的桌面端体验,在 v0.17.0 中获得了数十项关键增强:
▸ 独立窗口弹出 — 任意聊天可拖出成为单独窗口,多任务并行时不再困在单一视图
▸ 模型选择器移到底部 — 状态栏内一键切换模型,无需深入设置菜单
▸ 子代理监视窗 — 实时活动流在独立面板滚动更新,后台进展一目了然
Hermes 学习空间构建指南:从杂乱想法到可复用技能的蜕变之路
别再直接把混乱的想法丢给 Hermes 让它“记住”。真正的 /learn 循环,始于一个先研究、再审查、最后才沉淀的空间。你需要的不是随机记忆倾倒,而是一个能沉淀你个人品味与上下文的工作室。
在 Discord 里,你可以创建一个名为 #learnables 的私人频道,每个话题都会自动延展成独立的线程。在 Telegram 里,则可以开设 Learnables 论坛群组,用论坛话题或回复链来组织内容。随便丢进一个模糊的念头,比如“我的代理怎么处理 Stripe 争议?”,剩下的交给 Hermes。
它会先为你搭建一个研究室——而不是立刻创建技能。这个研究室里会汇集官方文档和主要来源、真实示例、常见失误、实用命令、关键链接、粗略工作流、需要忽略的噪音,以及给你的开放问题。接下来,轮到你了。你可以注入自己的语气偏好、约束条件,加入支持流程、项目特定上下文,告诉它保留什么、剔除什么。只有在你亲自审阅并校准后,说一句“learn this”,Hermes 才会把整个经过你品味过滤的线程转化成可复用的学习工作流程。
这才是真正的学习闭环:
研究 → 组织 → 你修正 → 学习清洁版本。
那个在学习前短暂出现的研究空间,就是技能变得出色的地方。
为 Hermes 搭建 Learnables 工作流程
目标
在 Discord 或 Telegram 中为 Hermes 添加一个研究/审查空间,让 /learn 命令变得更有价值。
核心理念
你不必一开始就写出完美的笔记。你只需要丢下一个杂乱的话题,让 Hermes 先研究、后等待你添加自己的上下文和品味,最后用“learn this”来批准。学习的是你审核过的内容,而不是原始混乱。
平台行为细则
Discord
- 使用或创建名为 #learnables 的私人频道。
- 该频道内的每一条顶级消息会自动展开为独立线程。
- Hermes 在线程内回复研究/上下文包。
- 你在该线程内审查、补充。
- 当你发出“learn this”时,Hermes 会从整个线程的学习材料中提炼技能。
Telegram(论坛话题模式)
- 启用论坛话题后,创建或使用 Learnables 论坛群组。
- 每个新话题对应一条学习条目,独立存在。
- Hermes 在话题内回复研究/上下文包。
- 你在话题内完成审查。
- 说出“learn this”,Hermes 从整个话题中学习。
Telegram(回复链模式,无论坛话题)