蓝牙智能睡眠眼罩选品全攻略:2026年市场分析与DTC品牌破局策略

一、市场概览
全球睡眠耳机市场正在经历高速扩张。根据Grand View Research数据,2025年全球睡眠耳机市场规模为2.3亿美元,预计到2033年将攀升至5.4亿美元,年复合增长率(CAGR)11.4%。DataIntelo的另一份报告则显示,2025年该市场规模为3.2亿美元,2034年有望达到7.8亿美元,CAGR 10.4%。
在细分品类中,头带式/眼罩式睡眠耳机占据了最大的市场份额,达到38.6%(2025年),是蓝牙睡眠眼罩真正的竞技主战场。此外,整个睡眠健康经济在2025年估计约为780亿美元(DataIntelo),为这一品类提供了宏大的叙事支撑。
区域分布
- 北美:占据34.7%的份额(约1.11亿美元),是全球最大的单一市场。美国CDC估计,超过7000万美国人受到慢性睡眠障碍困扰
- 欧洲:约占27.3%(~0.87亿美元),其中德国与英国合计贡献欧洲市场的14.5%以上
- 亚太:份额约25%(~0.80亿美元),但CAGR高达12.1%,为全球增速最快。中国有38.2%的城市工作者报告存在慢性睡眠困难
关键趋势
1. 睡眠障碍危机持续深化:WHO估计睡眠问题影响着全球45%的人口,发达国家中10-30%的成年人患有慢性失眠
2. 从“听音频”演进到“智能助眠”:消费者已不再满足于简单的蓝牙播放,转而期待内置白噪音、睡眠追踪、智能闹钟等整合功能
3. DTC+社交电商爆发:2025年线上渠道占睡眠耳机总销量的54.3%,TikTok Shop成为自然流量的重要来源
4. Sleenova开创“离线音频”先河:率先推出无需手机即可播放白噪音的睡眠眼罩,点燃了“去手机化”的趋势
二、竞争格局
| 品牌/型号 | 价格 | 评分 | 评价数 | 核心卖点 | 致命弱点 |
|---|---|---|---|---|---|
| Manta SOUND | $159 | 4.2★ | ~500 | C形眼杯100%遮光+零压感+磁吸可拆卸模块+24h续航 | 价格昂贵且无App/白噪音、无WiFi/睡眠追踪、仅限DTC官网购买 |
| SleepPhones Wireless | $99.95-119.95 | 3.8★ | ~3,000 | 美国制造+医生设计+24h续航+免费App+毛绒/透气双面料 | BT5.0老旧/micro-USB非USB-C/头带式遮光差/4h充电慢/无3D眼杯设计 |
| LC-dolida 3D | $15-25 | 4.3★ | 27,000+ | 3D记忆棉眼杯+BT5.4+性价比之王+可水洗 | 电池6-12个月衰退/扬声器易位移/无App/无白噪音/白牌感强/鼻梁处漏光 |
| MUSICOZY 头带 | $15-20 | 4.3★ | 7,000+ | 14h续航+BT5.4+天鹅绒棉+双用途(运动+睡眠) | 头带遮光仅95%/扬声器位移/开机音量爆响/鼻垫数月被压扁 |
| MUSICOZY 3D Silk | $50-70 | 4.4★ | ~1,500 | 6A级22姆米真丝+超薄扬声器+3D遮光+14h续航+无硬质魔术贴 | 魔术贴粘力数周减弱/眼窝深度不足/趴睡线缆位置不适/无App |
| TOPOINT 3D | $30-45 | 4.3★ | ~2,000 | 竹棉+96kHz高解析音频+6层遮光+15h续航+环保 | 无自动关机/无内置白噪音/夏季闷热/头围大者偏紧 |
| LC-dolida Silk | $50-70 | 4.3★ | ~5,000 | 22姆米真丝+99.99%遮光+15h续航+附赠耳塞+收纳袋 | 缎面易滑落/扬声器位移/无弹力带大头围偏紧/无App/无白噪音 |
| Sleenova | $30-40 | 4.2★ | 55 | 唯一内置离线白噪音(3种模式)不需手机+可水洗+18个月质保 | 实测续航仅6-7h/边缘漏光/模式切换不直观/评价数量极少 |
| RENPHO Eyeris 1V | $35-60 | 4.4★ | 27,000+ | 热敷+气压按摩+语音控制+蓝牙音乐+内置雨声海浪声景 | 1.46磅过重不适合整夜使用/振动可能加重头痛/电池不可更换/非遮光眼罩 |
| LIGHTIMETUNNEL | $15-20 | 4.2★ | ~18,000 | 3D记忆棉+BT5.0+10h续航+可水洗+性价比突出 | BT5.0老旧/面具无音量键/侧睡扬声器压迫/暗光找键困难 |
三、用户痛点分析
美团LongCat免费公测加码:每日1.2亿Token+1M超长上下文,限时白嫖攻略
美团 LongCat-2.0-Preview 第二轮内测正式进入爆发期,开发者福利再升级。每日四个固定时段准时放量——09:00、15:00、21:00、23:00,建议提前设好提醒⏰,错过只能等下一场。
免费额度相当能打,入手即赚
• 新用户起步日额:500 万 Tokens
• 活跃后最高日额:1.2 亿 Tokens
• 每天零点刷新额度,前一日剩余不会累积,鼓励高频使用,无需囤积
• 当前仅开放公测通道,不提供付费购买选项,正是“白嫖”窗口期
01
三步开通内测权限
① 创建账户
前往 longcat.chat API 开放平台,用手机号验证即可轻松完成注册。
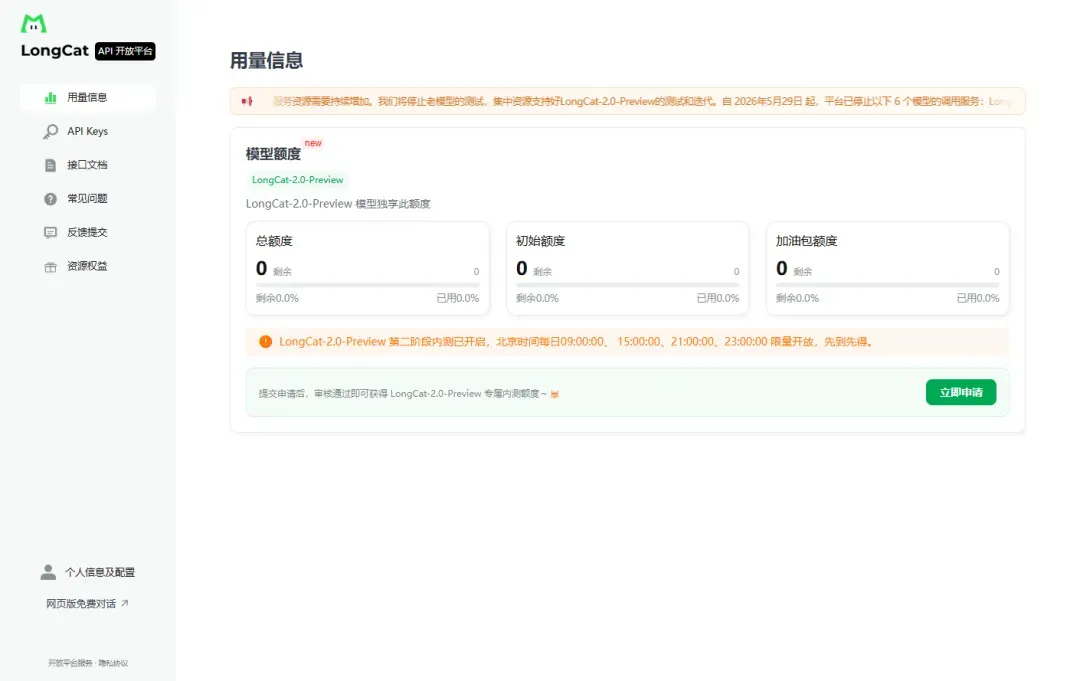
② 获取 API 密钥
登录后进入 API Keys 管理页,点击“创建API Key”生成专属密钥。重点提醒:密钥仅在生成时展示一次,必须立即保存到安全位置,忘记就只能重新创建。
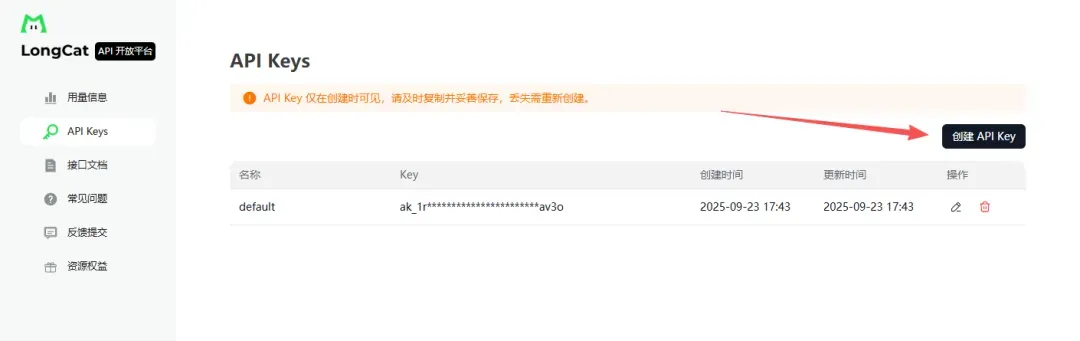
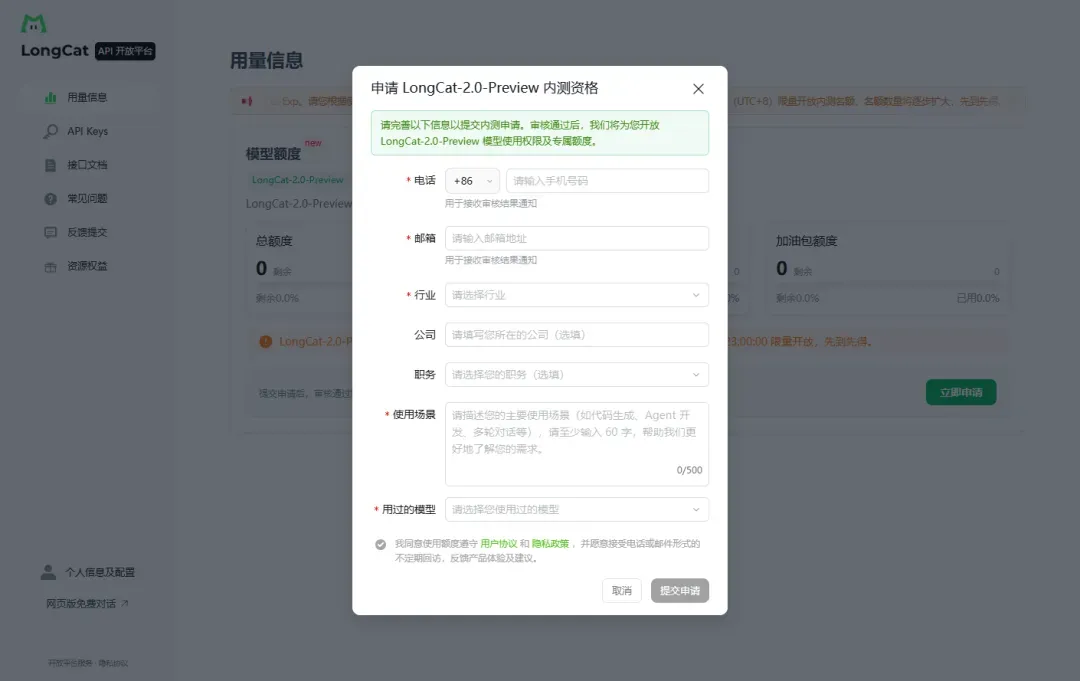
③ 提交内测申请
通过审核后,专享内测额度会自动注入你的账户,无需额外手动领取。
02
零门槛接入与模型能力
无论你原先基于 OpenAI 还是 Anthropic 格式开发,均可平滑替换,无需重构代码:
| 格式 | 端点地址 | 接口路径 |
| OpenAI | https://api.longcat.chat/openai | /v1/chat/completions |
| Anthropic | https://api.longcat.chat/anthropic | /v1/messages |
只需修改 base URL 和相应路径,旧的调用逻辑基本保值。
模型核心参数
• 模型名称:LongCat-2.0-Preview
• 模型定位:高性能 Agentic 模型
• 上下文窗口:1M Tokens,长文档、全量代码库可轻松灌入
• 最大输出长度:128K Tokens,从容应对长篇写作与复杂代码生成
免费AI工具Agnes全模态API深度评测:周调用4.11万亿Token,4K图像与1M上下文接入实战
Agnes AI 近期对其免费开放的全模态能力进行了重大升级,目前提供文本、图片、视频 API,TTS 语音能力也正在灰度测试中。
文本模型为 Agnes-2.0-Flash,支持 1M Token 上下文;图片模型 Agnes-Image-2.1-Flash 可生成最高 4K 图像;视频模型 Agnes-Video-2.0 支持 720P / 1080P 输出。这些能力可以直接嵌入到以下工作流里:
- 生成 4K 封面、商品图、人像、城市夜景和图标;
- 处理长文档、代码库、会议记录等长材料;
- 通过本地工具把文本模型接入开发流程;
- 用视频 API 完成图生视频和分镜草稿;
- 通过官方 GitHub Issues 跟踪开发进度、已知问题和错误处理建议。
Agnes 官方在 GitHub 上专门建立了 Issues 反馈区和 Projects 看板,方便用户集中反馈问题并跟进进度。
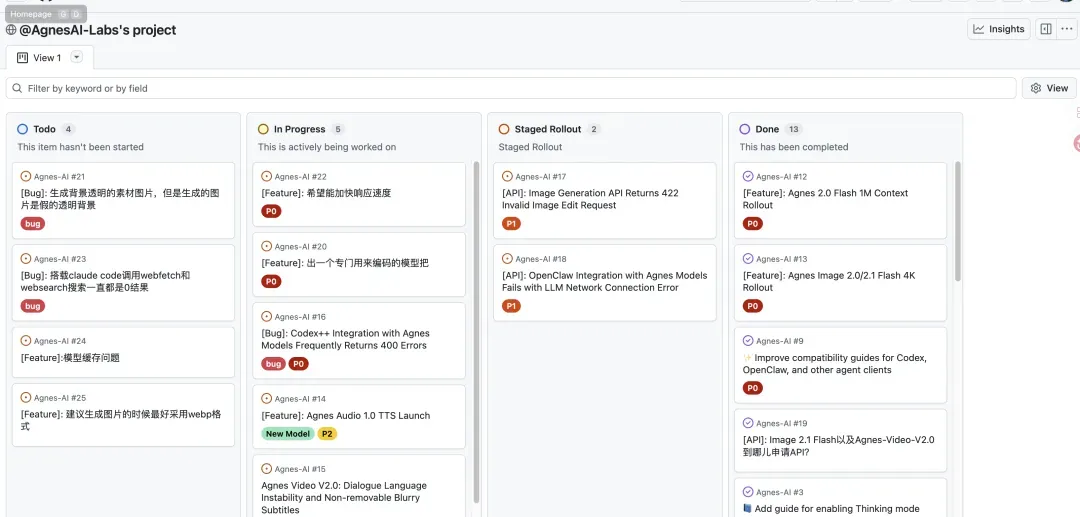
地址:
**https://github.comhttps://watermelonwater.tech/insights_imgs/免费ClaudeCode等AI工具被薅爆3.webp)
- 文本模型
Agnes-2.0-Flash贡献约2.67T Token; - 图片与视频模型
Agnes-Image-2.1-Flash、Agnes-Video-2.0合计贡献约1.44T Token; - 图片模型周度生成
567 万+张; - 视频模型周度生成
237 万+秒。
这些数字比单纯宣称“免费开放”更具参考价值。文本侧的 2.67T Token 表明 Agent、多轮对话、文档处理和代码任务等高 Token 消耗场景正在大量运转;图片和视频侧合计 1.44T Token,叠加 567 万+ 张图片与 237 万+ 秒视频,证明视觉生成并非附带功能,用户确实在批量试产素材。
企业级开源AI开发平台MonkeyCode:GitHub 3.4k Star,免费私有部署打造团队编程Agent
近期在北京与AI圈朋友交流,发现一个共同趋势:每个人都在打磨专属的AI Agent或工作平台。苍何有自己的开源项目WeSight,甲木搭建了写作Agent,袋鼠帝沉淀出Skills库,刘聪维护着自己的开源包,阿真则迭代出了自媒体专用skill……每个人都握着一张独特的底牌。
前些天,沃垠AI群中也聊到类似话题,黄啊码的一句话令人深思:“虽然我觉得别人的东西好用,但不适合自己的场景就是没用。”
这句话值得反复琢磨。我们真正需要沉淀的,并不是追逐最热门的工具,而是打磨出一套精准契合自身节奏的体系——可能是一条工作流,一个Agent,或是一个Skills库。
如果你的日常任务涉及编程,这篇文章为你介绍一个特别适合团队协作的AI开发平台「MonkeyCode」。该项目开源免费,目前在GitHub已收获3.4k Star。
开源地址:
github.com/chaitin/MonkeyCode

一手体验
下面详细拆解一下MonkeyCode到底是什么,以及如何使用。
MonkeyCode并非普通的Vibe Coding工具。它内置了开发环境管理、AI模型管理、AI任务管理、项目需求管理等能力,是一套面向团队的企业级AI开发平台。
用一个类比来理解两者的差异:
Vibe Coding工具,就像直接在菜市场拿起刚摘的蔬菜(浏览器环境)吃(即时生成HTML文件)。而MonkeyCode则覆盖了从种植(编写代码)、加工(构建工具)到运输(版本控制)的完整链条,保障了菜品的质量、供应效率和可追溯性。
简而言之,MonkeyCode是一个配备了完整开发环境的Coding Agent。
1)私有化部署
MonkeyCode支持离线私有化部署,对重视数据隐私的企业和团队非常友好——所有代码和数据完全运行在内网,不出本地。
最低配置建议:
- MonkeyCode控制台:2核 / 4 GB / 40 GB
- 开发环境宿主机:8核 / 16 GB / 100 GB
安装支持离线和联网两种模式。
联网安装(推荐):
bash -c "$(curl -fsSL 'https://monkeycode-ai.com/online/install')"
离线安装:
curl -fL -o monkeycode-offline-linux-amd64.tgz \
https://monkeycode-release.oss-cn-hangzhou.aliyuncs.com/public/offline-package/monkeycode-offline-linux-amd64.tgz
tar -zxvf monkeycode-offline-linux-amd64.tgz
cd monkeycode-offline-linux-amd64/
sh install.sh
安装完成后,通过浏览器访问 https://<控制节点IP> 即可进入控制台登录页面。
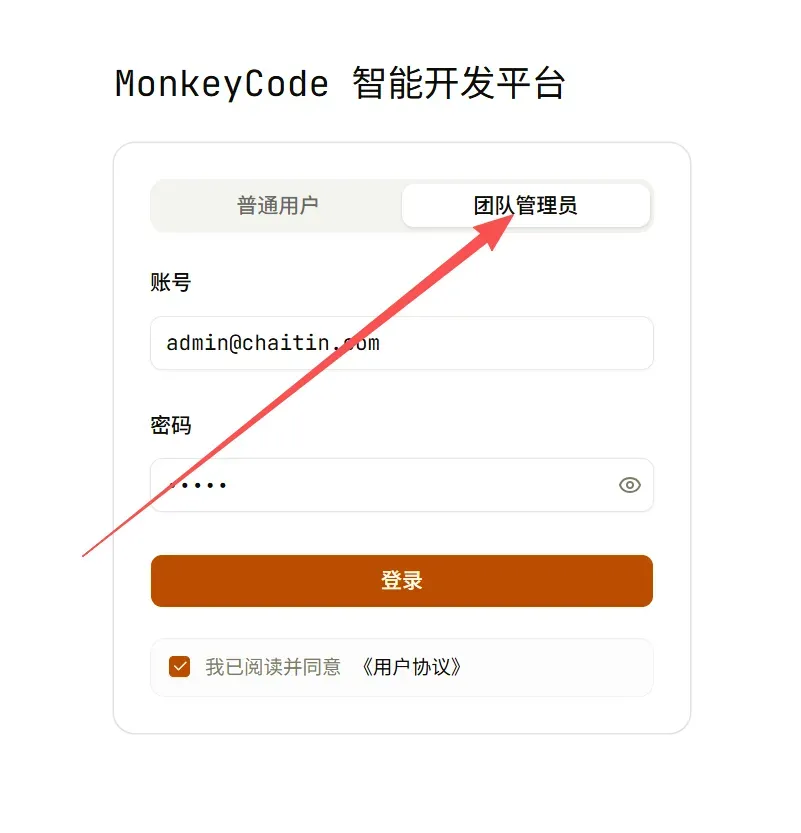
使用管理员账号登录后,进入开发环境页面,配置开发策略。
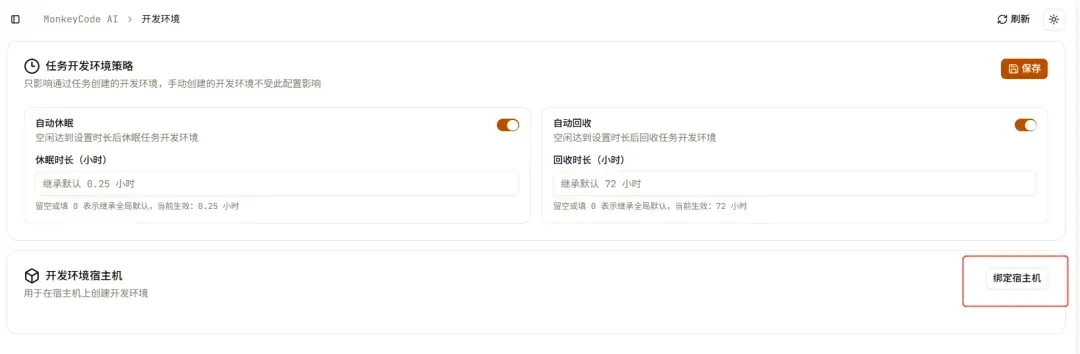
点击“绑定宿主机”,页面会生成一条绑定命令。
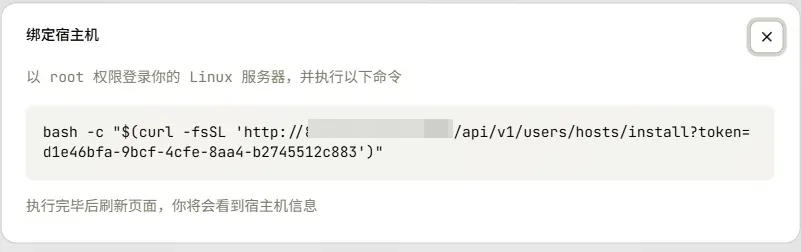
登录到提前准备好的宿主机服务器,执行该命令,宿主机便会出现在控制台中。
这里解释一下“宿主机”的角色——它相当于AI Agent的执行沙箱,后续所有AI开发任务都在这个隔离、安全、可控的环境中运行。
在后台,可以添加团队成员并分配权限。
MonkeyCode支持自由配置模型,可接入coding plan,只需填写正确的API地址、密钥和模型名称。
日本Fugu Ultra模型深度剖析:号称对标Fable5,实为多模型智能调度中枢
今天一打开手机,就看到了一条相当“新鲜”的资讯!
据说日本推出了一款名为 Fugu Ultra 的模型,性能可以直接比肩 Fable 5 和 Mythos!
接着有人贴出了下面这张图:
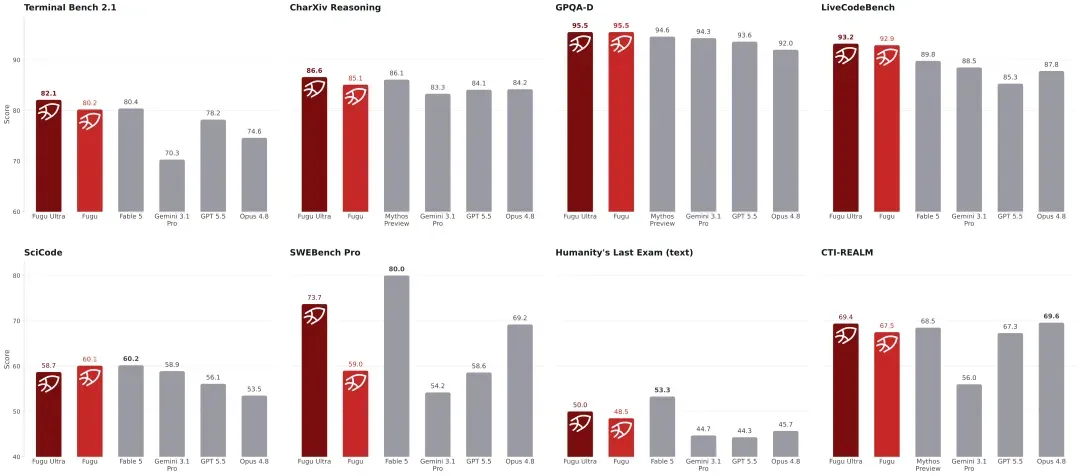
单看图表,的确有一种很强的压迫感!
部分基准测试的数据甚至压过了 Mythos 和 Fable 5!
编程能力优于 Opus 4.8,略逊于 Fable 5。
数据确实亮眼。以前几乎没听说过日本冒头的模型,这次突然刷屏,好奇心立刻被拉满了。
于是我仔细挖了一下背后的信息:
Sakana AI 于 2026 年 6 月 22 日正式发布了这款新品。它真正的差异化核心在于:并不是又一个更庞大的基础模型,而是“一个被训练来调度其他模型的模型”——像指挥家一样运作的语言模型。
对外,它表现得与普通模型毫无二致:你只需调用一个 API 端点;对内,它却是一整条多智能体编排系统。Fugu 会自行判断——简单问题直接回答,复杂的多步任务则临时组建并协调一支“专家模型小分队”,模型选择、任务分配、结果验证、答案合成全部在内部消化,调用方的代码完全感知不到多智能体的复杂度。它甚至还能递归调用自己。
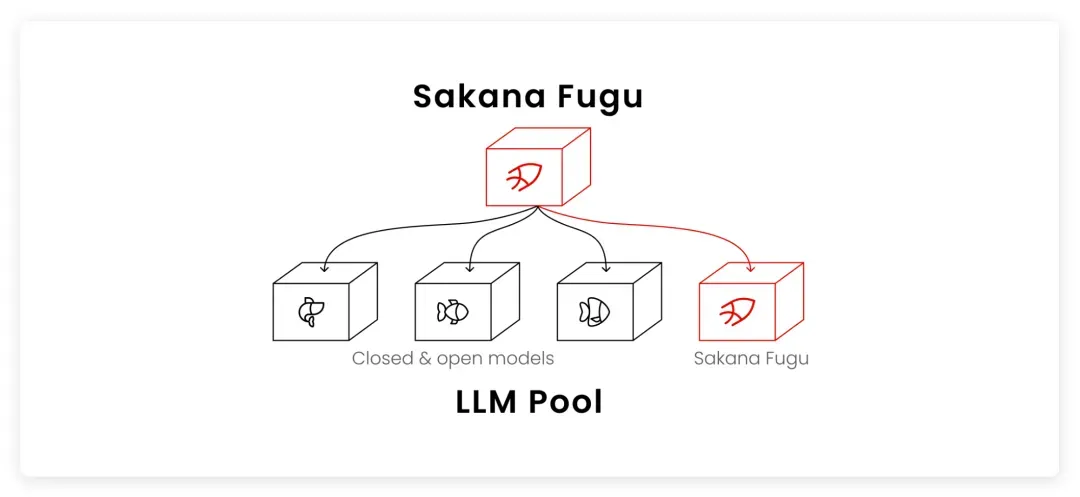
这……这不就是一个“智能中转站”吗?就跟 OpenAI 不同模型之间的“内部路由”差不多!拿这个去和 Mythos、Fable 5 直接对标,多少有点黑色幽默。
如果说从对标 Mythos 的角度切入确实有点滑稽,但如果从它自身的卖点出发,倒是真有点儿意思。
核心卖点解析
1. 单一 API,隐藏所有复杂度
一个兼容 OpenAI 的端点,把“多智能体系统”的麻烦事统统封装掉。你不需要自己搭编排框架,也不用操心路由和调度。
2. 前沿性能,但不绑定单一厂商
官方宣称 Fugu Ultra 在工程、科学、推理等高难度基准上能与 Anthropic 的 Fable 5、Mythos Preview 等顶级模型“平起平坐”,并声称在多项应用上超越 Gemini 3.1 Pro、Opus 4.8 和 GPT-5.5。(值得留意:这些是 Sakana 自己报告的数据,第三方对比基准以外的部分还有待独立验证。)
树莓派Arch Linux ARM详细安装指南:从零打造高度定制的极简系统

实话实说:Arch Linux 看起来有些令人畏惧。但如果你愿意折腾,又想完全掌控自己的树莓派,它确实是一个很棒的选择。唯一的问题是,标准的 x86 版 Arch 无法在树莓派上运行,你需要一个专门为 ARM 处理器构建的版本。下面我将一步步带你完成安装。
你可以通过下载 Arch Linux 的 ARM 版(而非主发行版)在树莓派上使用它。这个版本专门针对 ARM 架构构建,支持近几代所有树莓派型号。
虽然安装流程比典型的系统安装要稍微复杂一些,但整体思路其实很直接。跟着走一遍,你也能在这个过程中学到许多 Linux 底层的工作方式。现在,让我们一起动手构建一台属于自己的 ArchPi 吧。
目录
开始安装前需要准备的硬件与软件
第一步:用树莓派系统制作可启动 U 盘
第二步:为 Arch 准备好 SD 卡
第三步:将 Arch Linux ARM 安装到树莓派
第四步:树莓派上的首次 Arch 启动与基本配置
第五步:安装后的工作——获取新软件与桌面环境
开始安装前需要准备的硬件与软件
在动手之前,先快速检查一下,确保你手上的硬件和软件能支持树莓派安装 Arch。
硬件
下面列出的部件,大多是你平时玩树莓派就会用到的。唯一需要特别留意的是,你需要额外准备一个 U 盘。
- 树莓派:Arch 目前支持的型号包括树莓派 4、3、2 以及 Zero 2。官方的镜像要求至少 512MB 内存,这些受支持型号的 RAM 都满足要求。建议优先使用标准型号,例如树莓派 4B 或 3B+,以获得更强的计算性能。
- 电源适配器:强烈建议使用官方树莓派电源,避免因供电不足导致各种奇怪的问题。
- 键盘和鼠标:插上普通的 USB 键盘和鼠标即可。
- SD 卡:8GB 的 SD 卡就够安装 Arch 了,但我更推荐使用 32GB 或更大容量的卡,以免日后存储捉襟见肘。
- U 盘:我们将先从 U 盘启动树莓派,这样就能腾出 SD 卡插槽,专门用来给 Arch 安家。
软件
树莓派必备神器 Pi-Apps:一键安装所有软件,零基础也能轻松上手

Pi-Apps 已成为树莓派平台上最便捷的软件安装工具之一。许多新手最初以为在树莓派上装软件会很简单,但实际操作后很快发现,在 Linux 环境下部署应用远比想象中复杂:有些程序需要键入终端命令,有些必须手动安装依赖,网上流传的大量教程版本过时、内容残缺。正是这些痛点让 Pi-Apps 在树莓派生态中广受欢迎。

作为一款专为树莓派硬件打造的热门应用商店,Pi-Apps 让用户彻底告别四处查找安装教程的日子。只需浏览分类清晰的软件列表,轻点几下就能完成程序安装。无论你拿树莓派来编写代码、组建媒体串流设备、搭建智能家居、开展人工智能实验,还是运行复古游戏机,Pi-Apps 都能大幅简化整个操作流程。
为什么新手在树莓派上安装软件会遇到困难?
树莓派官方系统基于 Linux 构建,操作逻辑与传统 Windows、macOS 桌面系统截然不同。Linux 功能强大、自由度极高,但对于没有命令行使用经验的用户,一开始会感到无从下手。
绝大多数树莓派相关项目,都需要用户完成以下步骤:
- 手动安装各类依赖库
- 输入终端指令
- 编辑配置文件
- 处理各种兼容性报错
- 前往 GitHub 等代码仓库查找资源
- 一步步跟着冗长繁琐的教程操作
即使是有一定经验的玩家,也可能花费数小时修复损坏的软件包或补全缺失的运行库。新手更是难以分辨应该选择哪种安装方式。例如,有的软件依赖 APT 包管理器,有的需要通过 Python 的 pip 安装,还有的需要借助 Docker 容器或 Snap 软件包。入门门槛被瞬间抬高,初次接触树莓派的用户尤其深有体会。
而 Pi-Apps 这一强大的软件管理器,正是通过高度自动化的流程,解决了上述绝大多数复杂操作。
Pi-Apps 是什么?
Pi-Apps 是一款免费且开源的树莓派系统专用应用管理工具。更多详情可访问其官方网站:https://pi-apps.io/
它提供图形化界面,浏览、安装、更新、修复和卸载软件都可以一键完成。
你再也不用从网页上复制一串串命令粘贴到终端里,只需在 Pi-Apps 的菜单中选中目标软件,点击安装即可,使用效率极高。
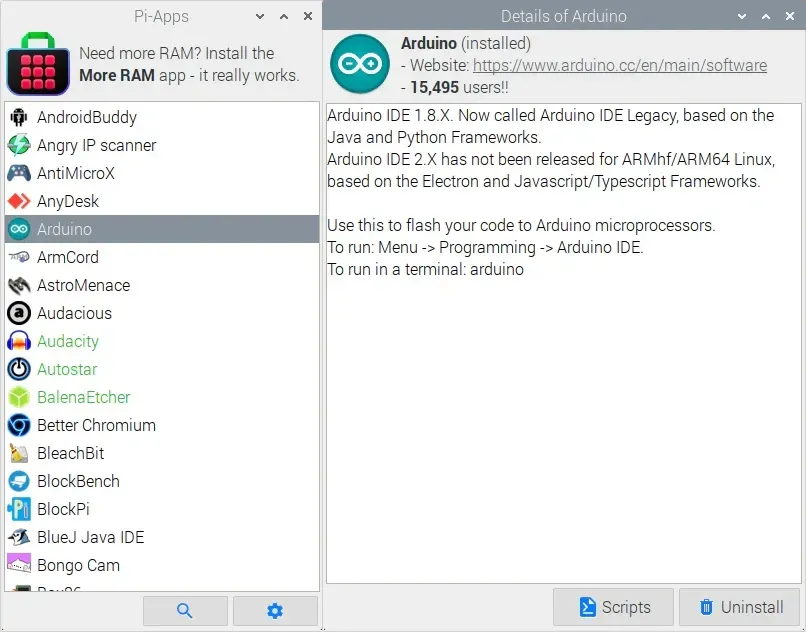
在后台,Pi-Apps 会自动下载配套的安装脚本、补齐所有依赖、完成软件各项配置,同时在桌面生成快捷方式。
它兼容众多主流树莓派机型,包括当前大量 AI 项目所使用的树莓派 5:
- 树莓派 4
- 树莓派 5
- 树莓派 Zero 2 W
- 树莓派 400
Pi-Apps 在树莓派官方系统(Raspberry Pi OS)上体验最佳,部分软件也能在其他基于 Debian 的 Linux 发行版上正常运行。
微信读书技能功能上线:Claude Code 一键安装与配置指南
微信读书近期正式开放了全新的技能功能(Skills),通过将阅读服务能力封装为标准化的 Skill,用户可以在 Claude Code 等智能助手环境中直接调用,实现书籍检索、笔记管理、阅读数据查询等自动化操作。该功能大幅降低了接入门槛,只需简单几步即可完成配置。
如何获取密钥并安装 Skill
访问官方技能页面:
https://weread.qq.com/r/weread-skills
进入页面后扫码即可获得专属的访问密钥(Key)。该密钥用于在 AI 助手端完成身份授权,确保数据安全。
在 Claude Code 终端中执行以下安装指令:
安装这个 skill : weread.qq.com/r/weread-skills
执行完毕后,助手会提示需要输入 Key。将上一步获取的 Key 粘贴并发送,Claude Code 会自动完成后续的配置工作,整个流程只需几十秒。
功能验证
安装配置完成后,可以通过简单的指令测试 Skill 是否正常运行。例如要求助手列出书架中的某本书籍,或者查询读书时长统计,如果返回正确结果则表示一切就绪。
测试示例截图:
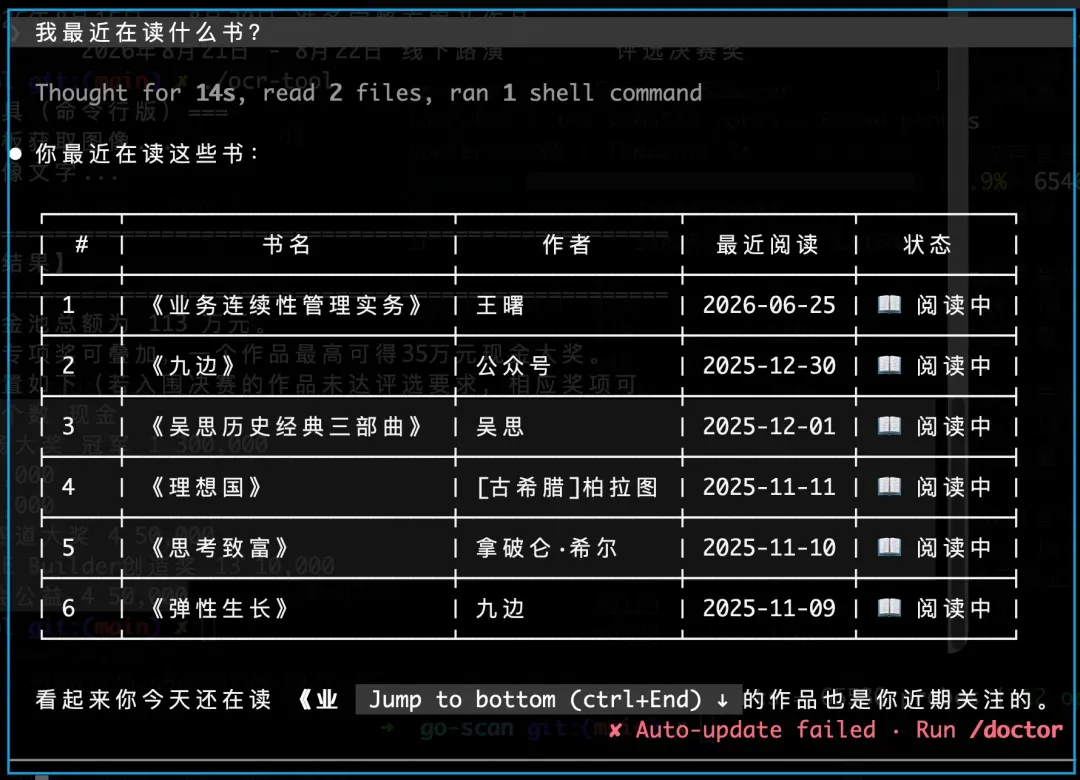
技能能力一览
该 Skill 覆盖了微信读书的核心能力,支持的功能包括但不限于:书架管理、笔记同步与查询、阅读进度获取、书籍搜索推荐等,未来还会不断扩展。
能力展示截图:
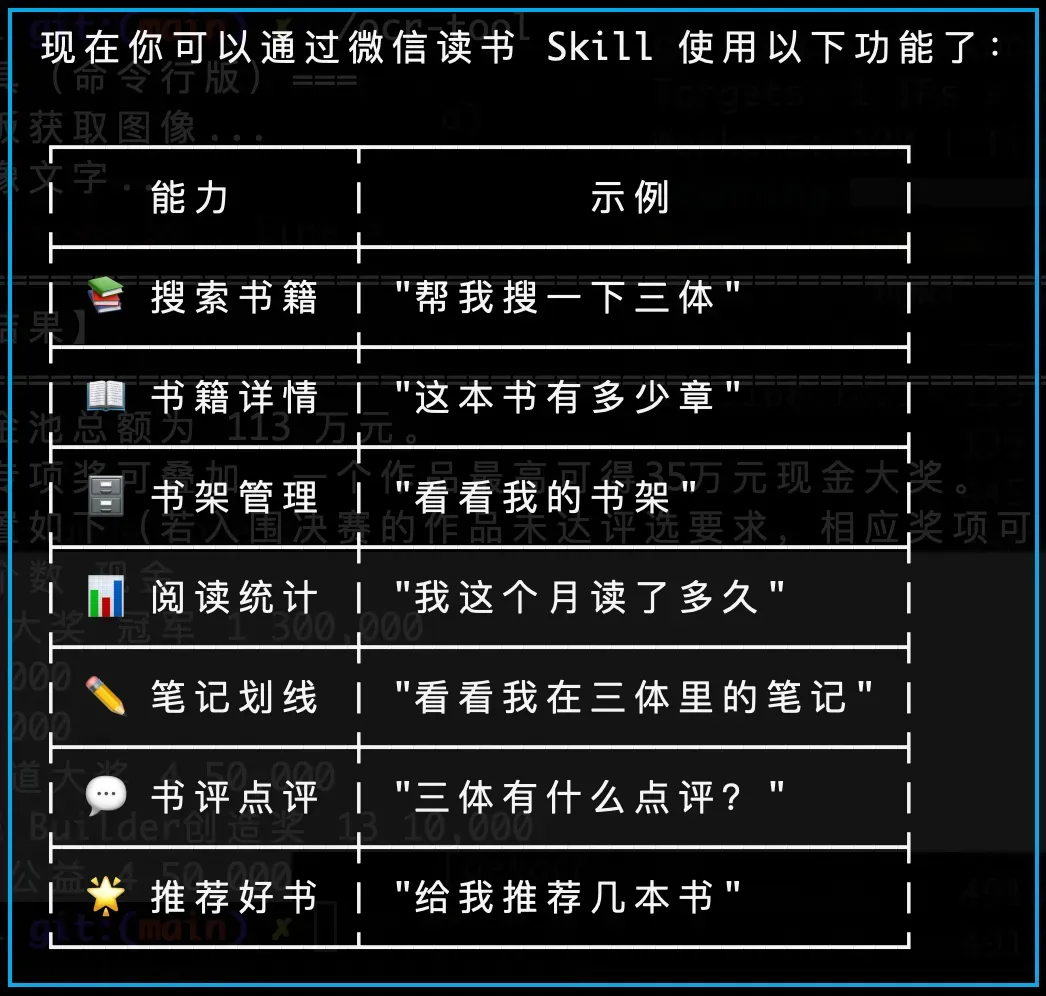
这一技能的开放,让微信读书真正走出了 App 边界,与用户的个性化 AI 工作流深度结合,为深度阅读者和知识管理爱好者提供了全新的生产力工具。
全文完。
智能自冷冰淇淋机选品分析:$199真空带与TikTok爆款机会洞察
一、市场全景与增长驱动力
全球家庭自动冰淇淋机赛道正进入高速增长通道。DataIntelo 统计显示,2025年该品类全球规模约 28亿美元,预计2034年将攀升至 49亿美元,年复合增长率 (CAGR) 达 7.2%。QY Research 针对“全自动冰淇淋机”细分给出的数据则更为聚焦:2024年 11.25亿美元 → 2030年 13.91亿美元,CAGR 3.6%。Future Data Stats 对冰淇淋机全盘估值为 2025年 25亿美元 → 2033年 42亿美元,CAGR 6.3%;而 GMInsights 相对谨慎,认为2025年约为 17亿美元,2026‑2035年 CAGR 5.8%。
无论采用哪套数据,有一件事非常明确:搭载自冷式压缩机 (compressor self-cooling) 的细分产品是所有方向中增速最亮眼的一条子赛道。它从根本上解决了传统冰淇淋机“内胆需预先冷冻 16‑24 小时”的致命伤。典型如 Ninja Creami,凭借“预冷冻基料 + 高速搅拌”这种逆向创新路线,定价仅 $230 便成为现象级爆款,但用户必须为此付出提前整整 24 小时冻结基料的时间成本。
区域市场分布:北美占约 38%,是体量最大的市场,得益于根深蒂固的 DIY 冰淇淋文化;欧洲约 28%,意大利 gelato、德国和法国市场对高端机型需求强劲;亚太区约占 25%,以 8.5% 以上的复合增速领跑全球,中国、日本、韩国的城市中产群体是核心推动力。内容热度同样惊人:TikTok 上 #NinjaCreami 累计播放已突破 60 亿次,#IceCream 超 200 亿次,#Dessert 超 100 亿次,自制甜品内容已成为 TikTok 第三大主流品类。
二、竞争格局:哑铃型市场中的品牌分层
| 品牌 | 型号 | 价格 | 评分 | 核心卖点 | 致命短板 |
|---|---|---|---|---|---|
| Ninja | Creami Deluxe (NC501) | $230 | 4.6★ | 11合1预设/24oz容量/无压缩机/TikTok爆款 | 必须预冻24h/噪音大/无自冷 |
| Breville | Smart Scoop BCI600XL | $499‑600 | 4.5★ | 内置压缩机/12档硬度/自动感应/不锈钢机身/1.6qt | 极贵/19磅重/无Wi‑Fi与App/1.5小时才能出成品 |
| Whynter | ICM‑201SB | $249‑329 | 4.2★ | 压缩机/2.1qt大容量/LCD定时/不锈钢/无需预冻 | 体积大/偏重/无智能联动/无保温/压缩机启动噪声 |
| Cuisinart | ICE‑60W Cool Creations | $69‑89 | 4.4★ | 2qt/20分钟出/3种模式/经典品牌/性价比 | 仍需预冻内胆/无压缩机/无Wi‑Fi与App |
| Cuisinart | ICE‑21P1 (入门款) | $50‑70 | 4.5★ | 1.5qt/经典/价格杀手/品牌认知高 | 必须预冻/全塑料/无智能/容量偏小 |
| GreenPan | Frost | $229‑279 | 4.3★ | 自冷压缩机/3档硬度/15分钟/复古设计 | 新品口碑薄弱/无App/1.5qt稍小 |
| Ninja | Swirl by Creami | $329‑379 | 4.5★ | 可做软冰淇淋/13档/自挤花/无需预冻粉 | 仍需预冻13小时以上/占地大/价格高/依旧依赖预冻 |
| De‘Longhi | Gelateria | $249‑329 | 4.3★ | 意大利血统/2L/不锈钢/专攻gelato | 需预冻/偏重/无智能/App体验一般 |
整个市场呈现典型的“哑铃型”结构:$50‑100 红海区以 Cuisinart ICE‑21、ICE‑60W 等预冻款为代表,完全无智能和 Wi‑Fi;$230‑380 智能爆款区由 Ninja Creami 系列占据,虽依赖预冻却依靠 TikTok 成为爆款;$500+ 高端压缩机区则被 Breville Smart Scoop、Whynter 等重且贵的机型把控。$150‑249 自冷 + 智能的品牌真空带暴露得十分明显——当前市面上没有一款产品能同时做到“自冷压缩机 + Wi‑Fi/App 联动 + 1.5L 以上容量 + 精美设计 + 售价低于 $250”。
字节 Trae Work 全面体验:Seed 2.1 Pro 免费使用指南与办公编程实战评测
字节跳动推出的全新 Seed 2.1 Pro 模型近期引发关注,而第一时间免费体验的途径便是通过其 Trae Work 应用。本文将手把手带你完成安装设置,深入体验手机远程协作、办公 Work 模式和编程 Code 模式,全面展示这款智能体的实际表现与落地能力。
近段时间,Codex 类产品的声音似乎小了一些,但国内相似形态的软件开始活跃起来。此前我们已介绍过智谱版的“Codex”——ZCode,今天则聚焦字节版“Codex”及最新豆包 Seed 2.1 Pro 模型。
重点提示:Trae Work 内所有模型对所有用户免费开放。
昨天白天 3.1 Pro 仍无法使用,排队人数过千,但晚间就已解锁,使用体验非常流畅,同时跑几个项目也毫无压力。
下面来看具体配置与体验。
安装与初始设置
前往官网下载安装包,双击启动,按引导一路“下一步”即可完成安装。
安装后的主界面如下:
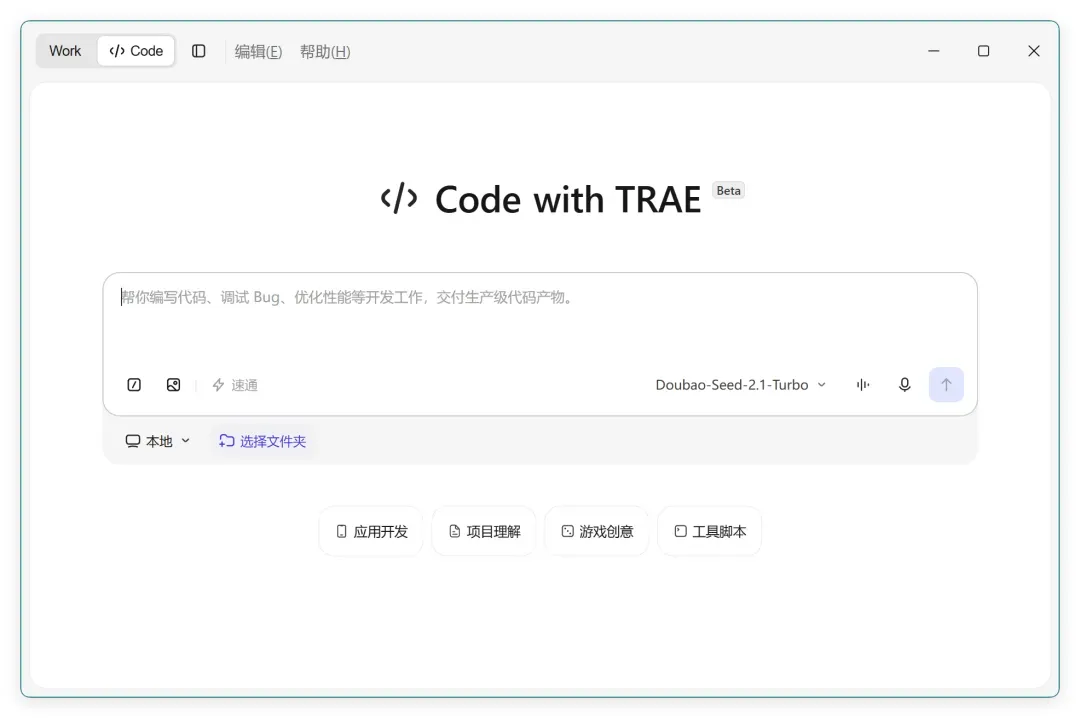
Trae Work 明显借鉴了 Codex 的设计思路,同时吸收了 Claude 的模块化结构,将核心功能分为办公(Work)与编程(Code)两大场景,并支持手机远程控制。这类通用智能体应有的能力一应俱全,字节的产品体验一向出色,单从软件流畅度来看,已是国内顶尖水准。
接下来从三个维度展开介绍。
手机远程:无缝同步,随时在线
尽管一年中真正使用远程功能的次数可能不多,但它的无缝对话同步非常吸引人。Codex 需要多端科学上网才能顺畅运行,而 Trae Work 在无需专线环境下即可直接连接,灵活流畅。
安装手机版后,几乎可以实现无感同步:
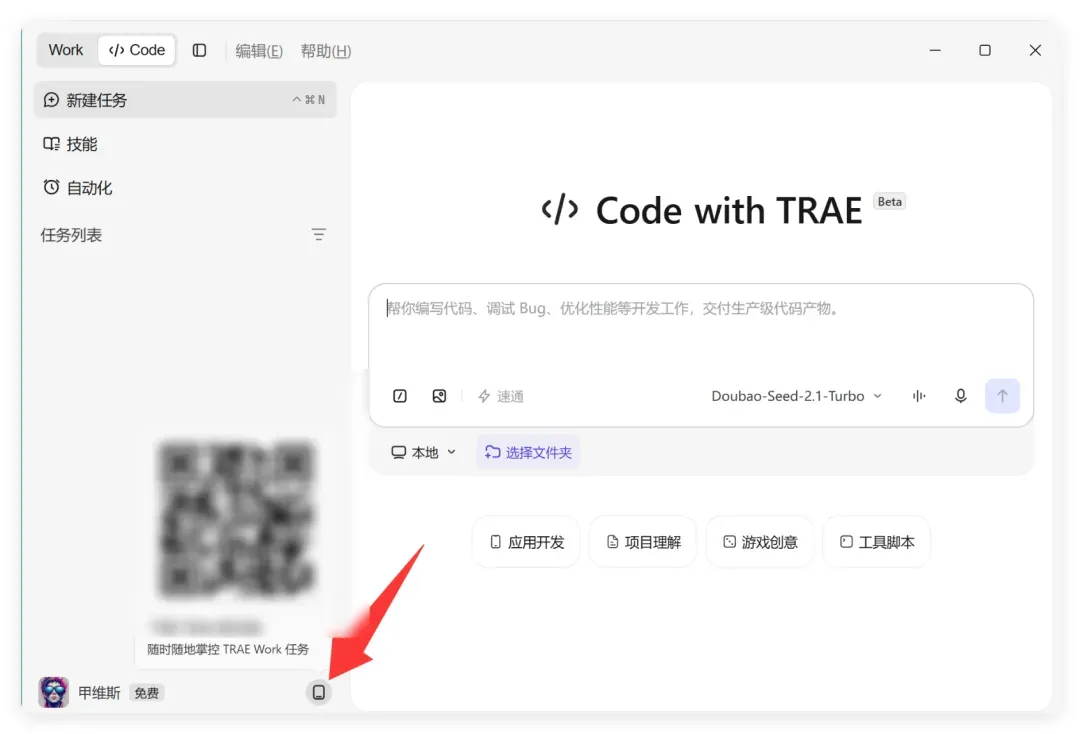
桌面端提供远程配置入口,点击即可进入设置界面。

实际上无需复杂配置,核心是开启控制权限。
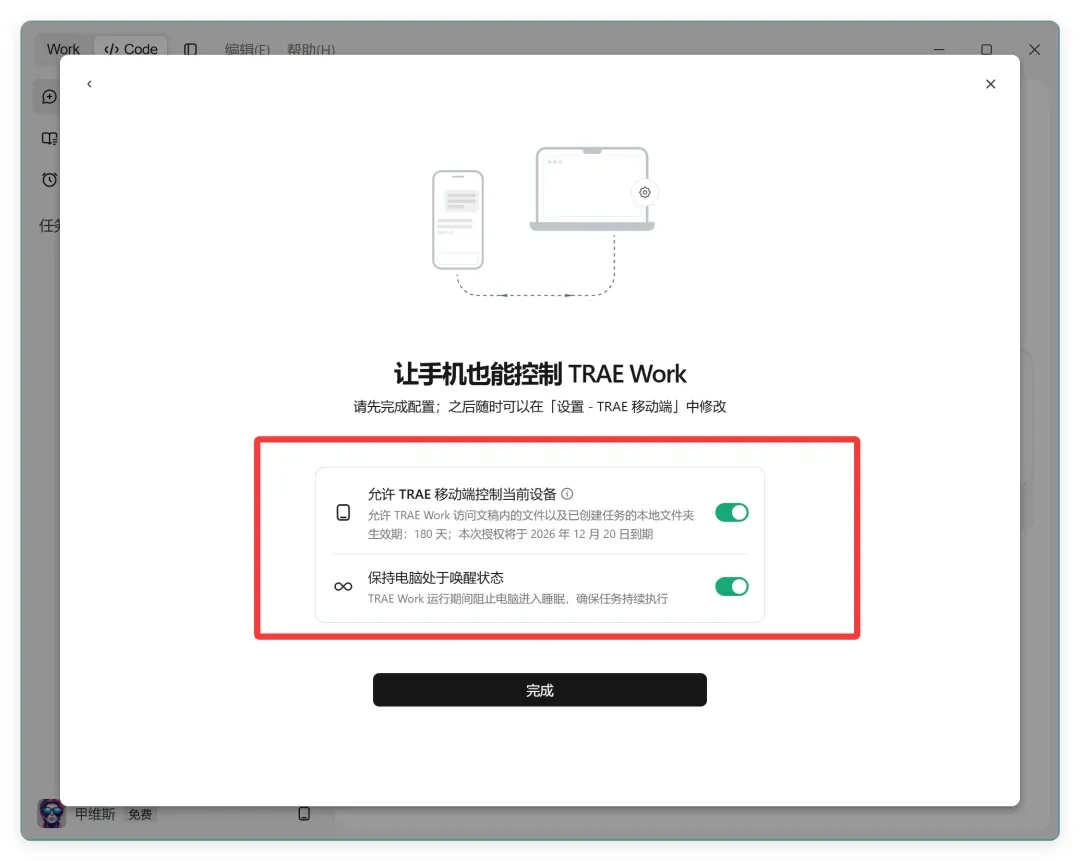
这一步有两个选项:允许移动端控制当前设备,以及保持电脑唤醒状态。我通常全部启用,因为 PC 常年不关机,笔记本合盖也能持续运行。
点击完成后,所有对话记录、任务进度都会实时同步:
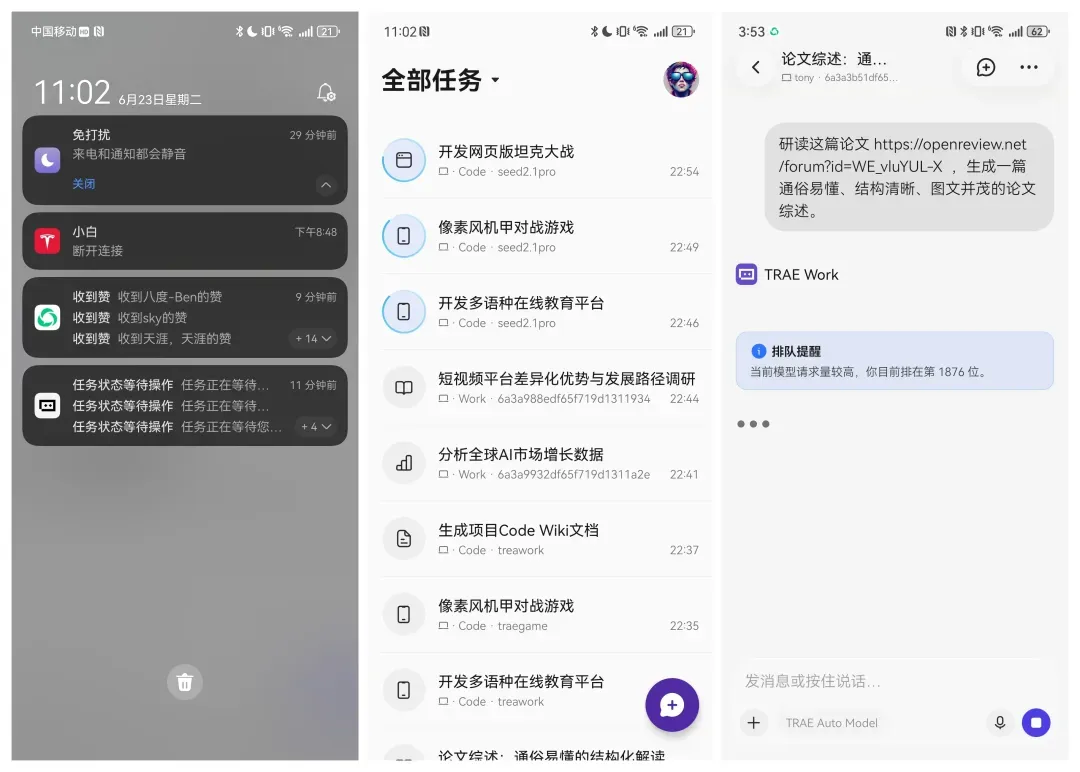
同步涵盖消息通知、任务列表以及详细的对话信息,响应丝滑。与 ZCode 偏向专业开发者不同,Trae Work 更贴合大众用户,使用门槛低,体验更友好。
此前我主要依赖 GPT 与 Claude 的手机版进行远程操作,但在国内设备组合上稍有不便。现在可以直接用 Mate 系列手机配合 Windows 设备,走 Trae 这一条线路。