《生有可恋》公众号精选文章合集:支持搜索排序的静态网站
微信在文章合集处理上不太好操作,也没提供合适的索引。我将所有文章导出后,借助 AI 构建了一个静态网站。
效果如下(基于 frontend-design skill 生成):
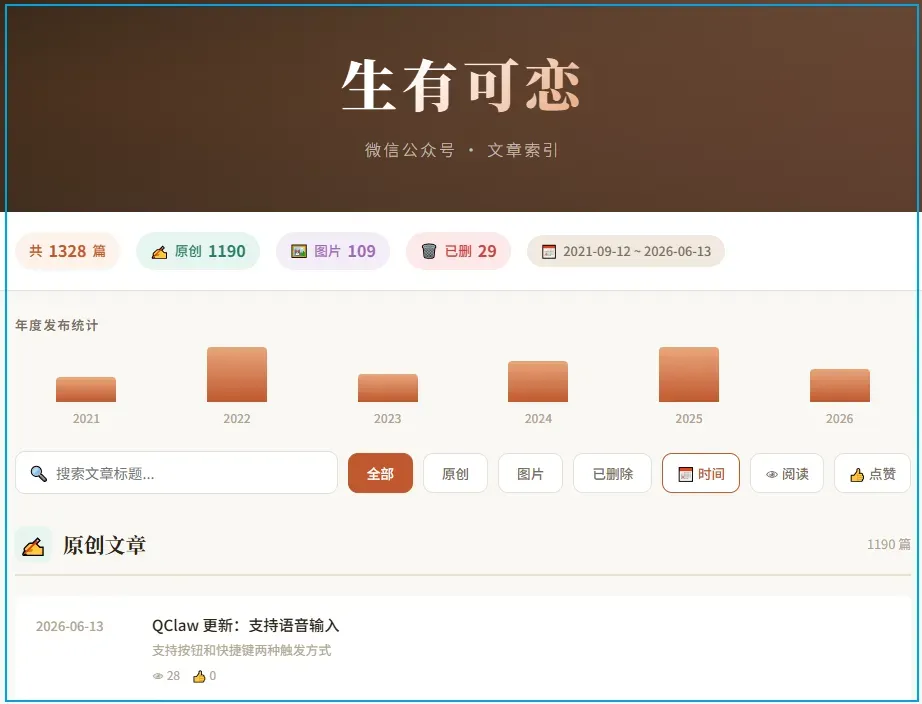
该页面支持搜索、筛选、按阅读量与点赞数排序,并按年份分类,适合在电脑上浏览。
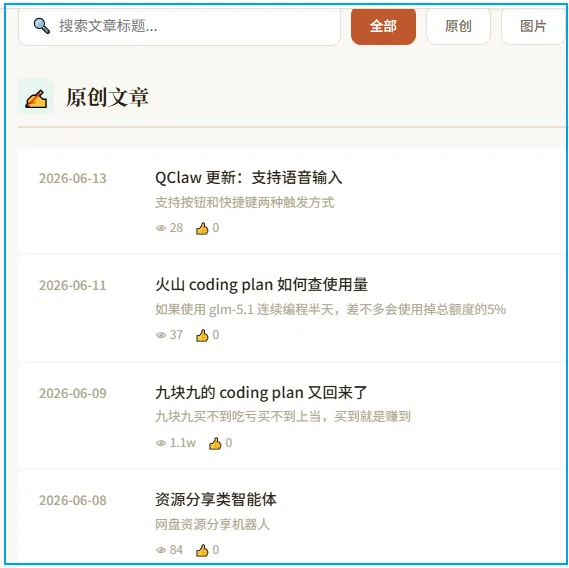
你可以通过该链接直接访问:
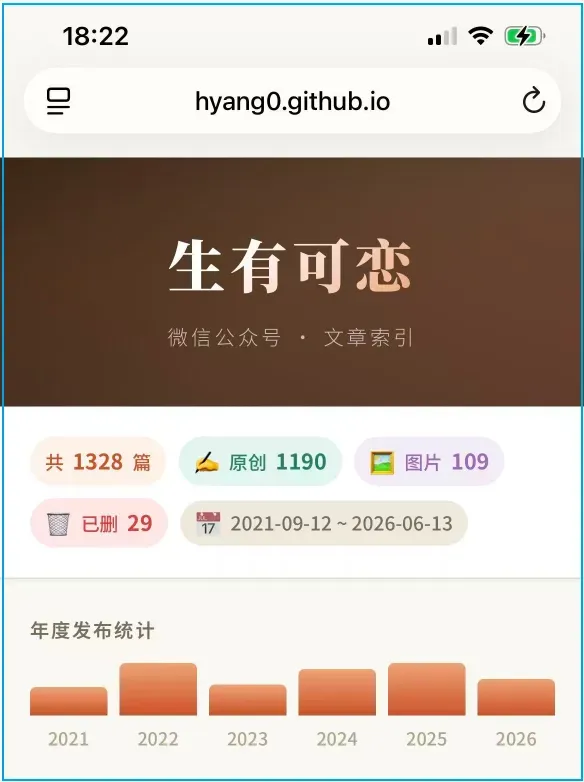
手机浏览器访问效果如下:
GitHub 项目地址:
https://github.com/hyang0/hyang0.github.io
AI 提示词:
使用 frontend-design skill,设计一个 HTML 网页展示《生有可恋》公众号中的所有文章。CSV 中关于转载和原创的判断不太准确。大部分转载是图片类分享,原创是正式文章。
已经删除掉的文章单独建一个分类展示。图片类的分享单独展示。主要展示正式原创文章。加一下发表时间和数量的统计。
全文完。
2026国产大模型实战选型指南:DeepSeek、GLM-5.2等五大场景避坑心得
跑分数字再耀眼,也不如实打实上手的体感。过去半年,我把新出的一批国产大模型逐个用进了真实工作流里,踩过坑、避过雷,也锁定了每个场景下真正趁手的搭档。
下面这份场景化筛选方案,全部来自实测反馈,没有通稿,更没有跑分排行榜的滤镜。
纯文本写作:生产力拉满,首选 DeepSeek V4 Pro
无论是年度市场分析报告、产品需求文档,还是需要大量背景调研的行业综述,DeepSeek V4 Pro 的出稿速度至今仍是我体验过的天花板——5分钟能吐出一份3000字的初稿,完成度几乎可以比肩资深文案。过往我的评测文章,都会先用它快速起底一个结构化大纲,再让它补充进去,比如下指令:“请对比 A、B、C 三家公司在价格、技术路线、用户评价三个维度的差异,给出差异化建议”,它输出的内容往往逻辑清晰、数据扎实。
相比之下,GLM-5.2 的文字总带着一层“官方腔调”,不够鲜活;Kimi 则容易写到一半话题跑偏。所以凡是以文字创作为核心的任务,我目前的固定搭档就是 DeepSeek V4 Pro——记得顺带开启联网搜索功能,时效性会更强。
数据处理与多模态理解:Kimi K2.7 Code + MiMo 双保底
从 PDF 报告中批量提取数据、自动生成可视化图表和文字摘要这件事上,Kimi K2.7 Code 的表现相当能打。我曾一次性把整份年度产业报告丢给它,它不仅能准确捕捉到关键指标变动,还主动绘制了趋势折线图。换成 DeepSeek V4 Pro 做同样的任务,解析速度慢了一倍,且对复杂表格的识别偶有乱码。
而作为备选和补充,最近 MiMo-V2.5-Pro 的多模态支撑力也快步跟了上来,支持文本、图像、视频和音频的全模态理解,在音视频内容的解析上更显优势,两者搭配着用,基本能覆盖所有高复杂度的数据任务。
编程与复杂逻辑任务:GLM-5.2 坐镇,日常用小模型提速
GLM-5.2 的长上下文和复杂逻辑推理能力的确实力断层。我试过让它根据一套完整的大数据处理架构设计文档,一次性生成对应的工程实现,事务控制、异常捕获、资源释放都写得非常规范,几乎是可交付级别的代码。但它的推理速度也慢得相当明显,而且 49 元套餐所给的额度,跑几个大任务很快就会触顶。
因此,我在编程场景下采取了分层策略:重要的、长周期的主干项目,用 GLM-5.2 打好坚实框架;日常较轻量的代码片段、小型需求,切换到 DeepSeek V4 Pro 或 MiMo-V2.5-Pro,不仅速度更敏捷,性价比也完全撑得住。
自动化流程搭建:MiniMax M3 与 MiMo-V2.5-Pro 的最佳拍档
MiniMax M3 在音视频多模态理解和 API 性价比方面非常突出,49 元对应 6 亿 tokens 的额度,不论是配合 Openclaw 还是 Hermes 的流程编排,都可以作为主引擎长期使用。而 MiMo-V2.5-Pro 则在需要长周期、自主决策的 Agent 任务中展现出了异常稳定的工具调用与上下文保持能力。
2026年最新 Coding Plan 选购指南:腾讯、阿里、火山引擎等主流平台全面对比
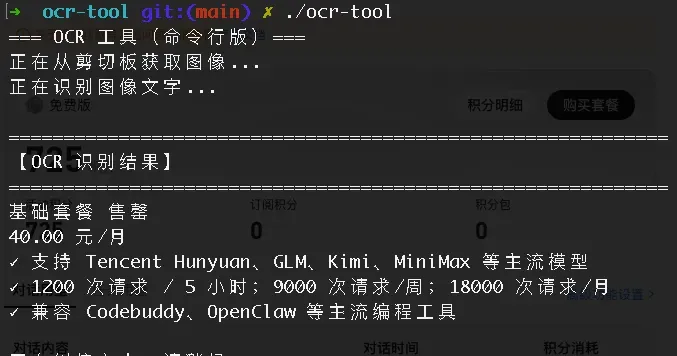
以 QClaw 目前接入的几家 Coding Plan 为例,我们先直观感受一下它们的服务界面:
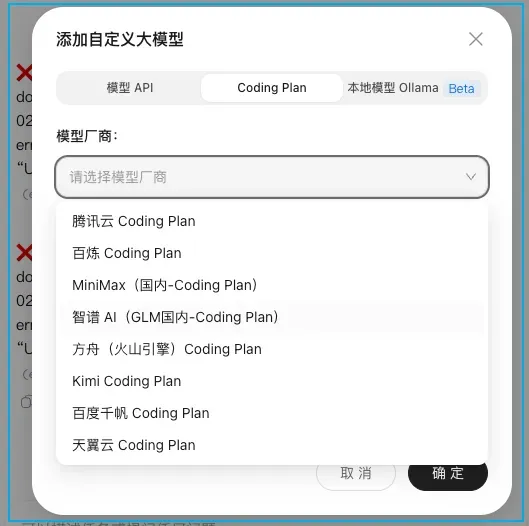
借助自己编写的一款 OCR 工具进行识别,可以得到如下结果:
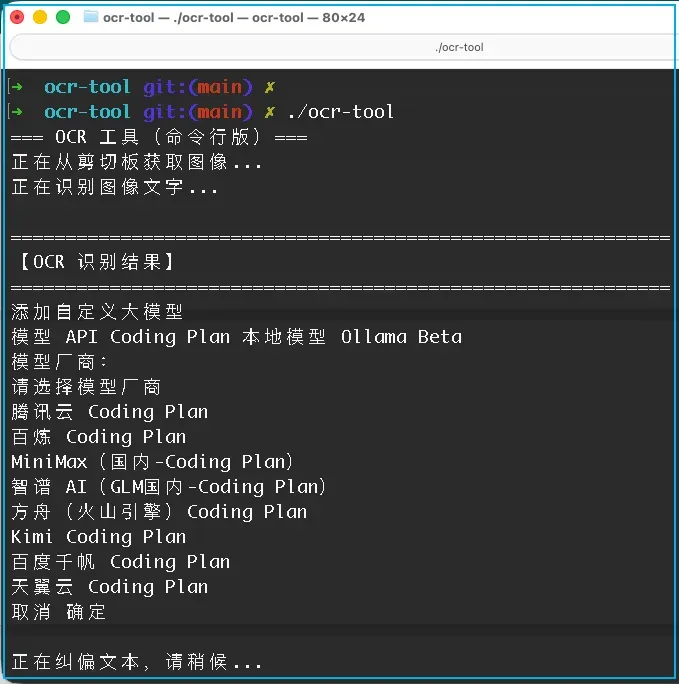
Coding Plan 的价值在于提供了长期稳定的使用权限。如果没有这类计划,很多工具可能用着用着就会被限制,比如我在开发这个 OCR 工具时就遇到了调用报错的情况。
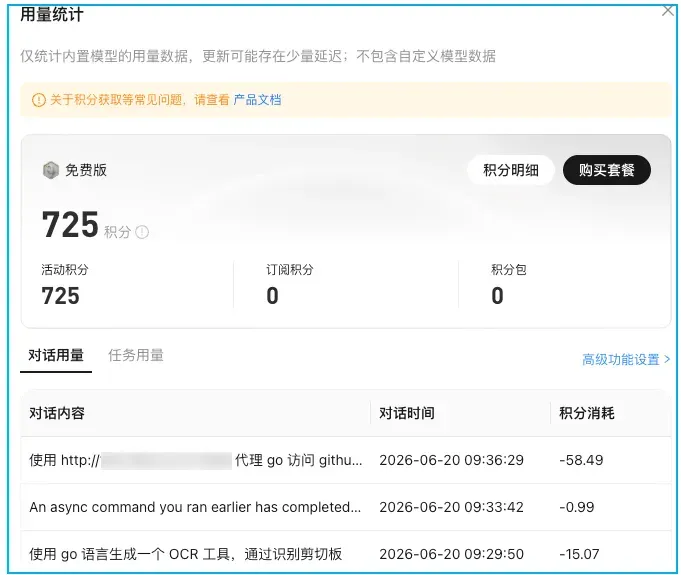
目前我日常重度使用 QClaw,现在该服务开始收费,但这笔费用本质上是模型调用的 token 开销,而非工具本身的订阅费。如果你已经拥有第三方的 Coding Plan,就可以省掉单独购买 QClaw 套餐的麻烦。
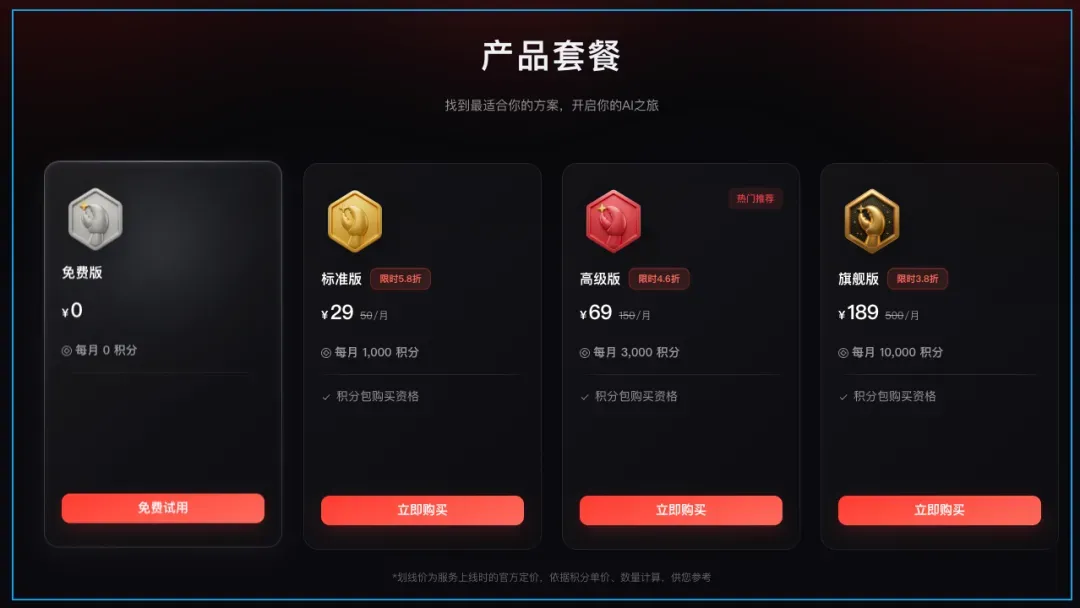
那么眼下哪些 Coding Plan 更值得入手呢?之前我单独推荐过火山引擎的 ¥9.9 套餐,但不少朋友反馈额度不够用。今天我们把其他几家主流的也拿出来集中看一看。
| 厂商 | 订阅地址 |
|---|---|
| 腾讯云 Coding Plan | https://console.cloud.tencent.com/tokenhub/codingplan |
| 百炼(阿里云)Coding Plan | https://www.aliyun.com/benefit/scene/codingplan |
| MiniMax 国内-Coding Plan | https://platform.minimaxi.com/subscribe/coding-plan |
| 智谱 GLM 国内-Coding Plan | https://bigmodel.cn/glm-coding |
| 方舟(火山引擎)Coding Plan | https://volcengine.com/L/-DKtTYsHv58 |
| Kimi Coding Plan | https://www.kimi.com/code |
下面我们逐一来拆解。
腾讯云
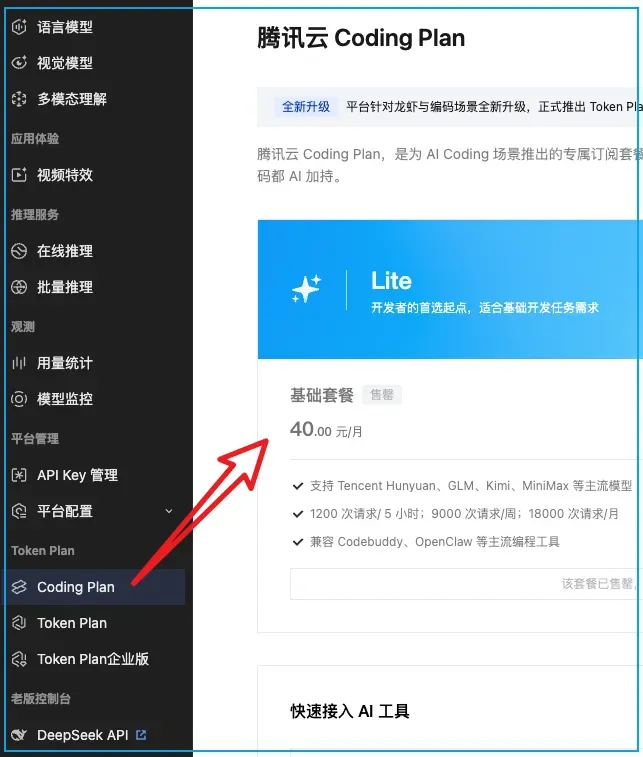
目前状态显示“售罄”,原先 ¥40 的套餐已经买不到了。这里我们只聚焦 Coding Plan,不涉及 Token Plan。
百炼(阿里云)

AI编程套餐深度体验:国产工具进化中,免费方案真能撑住吗?
国产AI编程工具正在快速迭代,眼下正是大胆尝试的阶段。不少用户对火山引擎的Coding Plan用量存疑,有人甚至直言他家200元的套餐只抵得上别家50元的分量。我自己目前用的是最便宜的9.9元档,纯粹作为兜底方案,确保任何时候AI辅助都不会中断。不管其他平台是否收费,至少手边有个随时可用的工具,免得AI一停,写代码的效率直接归零。
这次我让千问来实时生成一份全平台Coding Plan价格对比报告,一边分析一边输出,它一直在后台运转。这个过程中我发现它的语音输入体验不错,配合一台不算老旧的笔记本和正常工作的麦克风,基本可以替代手动敲字。
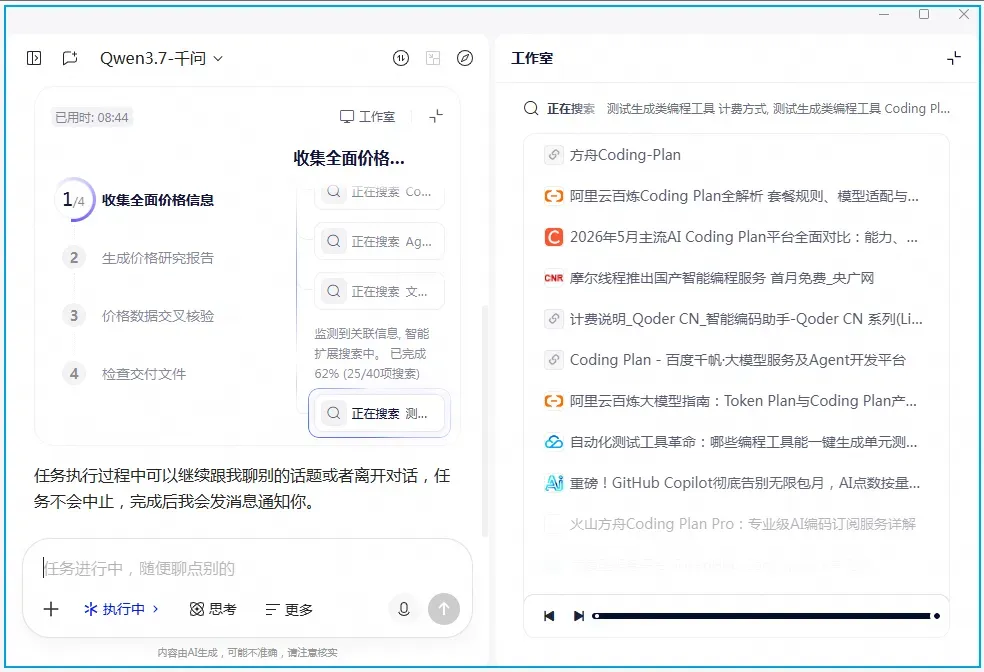
之前也聊过,Coding Plan到底要不要买?严格来说,如果你不是以编程为主业,并不建议入手。除非现在常用的免费工具开始施加限制,你才真正需要付费。比如用Trea编程时被强制排队,或者用QClaw这类智能体因为额度耗尽而无法推进工作,再或者你打算接入Claude Code、Codex等高级模型,这时候才应该认真考虑购买套餐。
绝大多数场景下,免费工具已经足够。目前各家都在推广期,普遍会赠送一定额度,多个平台交替使用,基本可以实现“白嫖”。不过如果长期只依赖同一个工具,八成额度会捉襟见肘。
千问这次连续运行了将近15分钟,依然没有停下的迹象。
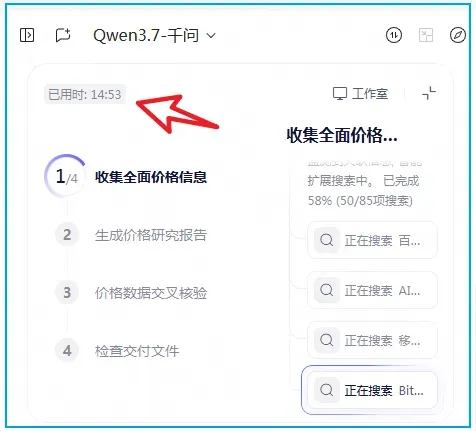
这个体验很像早期ChatGPT的Deep Research,能长时间持续执行复杂任务。大约二十分钟后,报告终于完成。
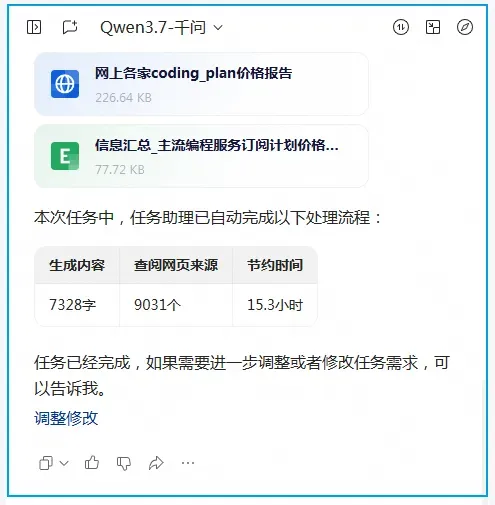
我们直接来看报告内容。
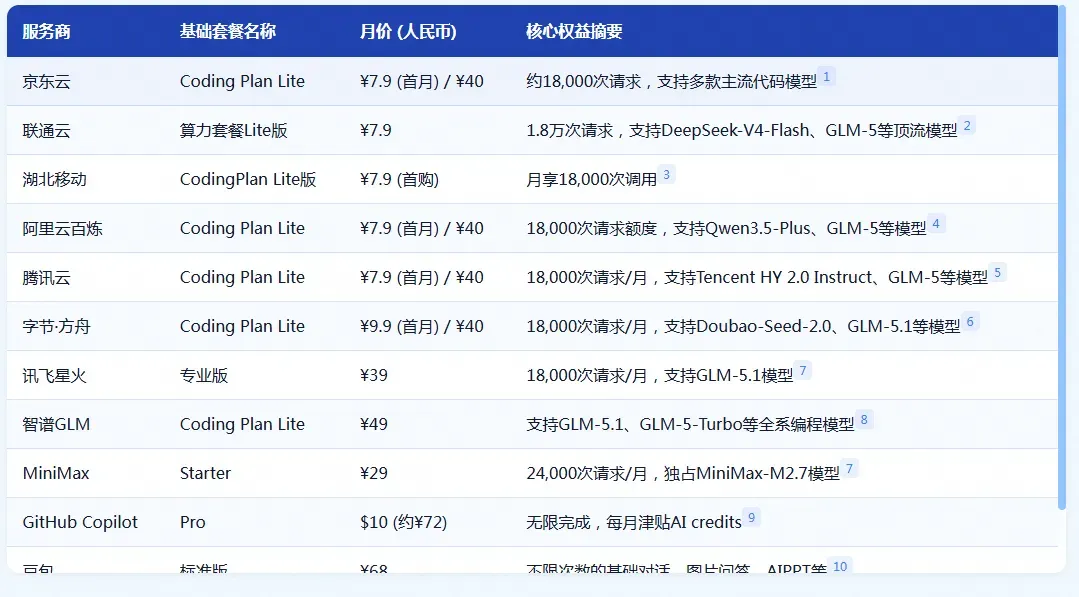
运营商的套餐可以直接跳过,重点看后面几家。
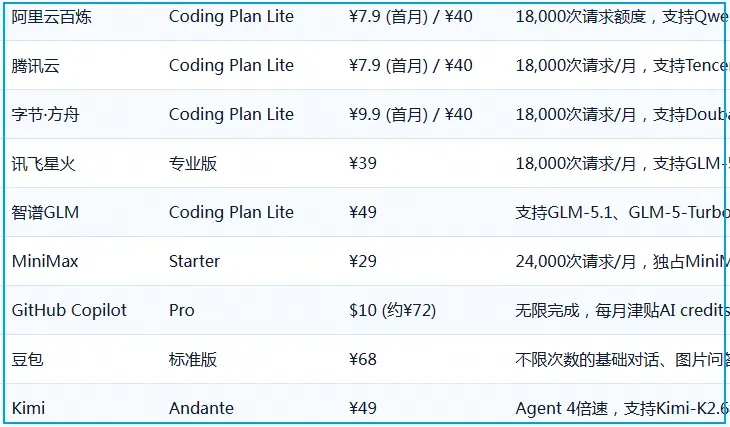
阿里云百炼针对新用户提供首月39.9元的优惠,不过其Lite套餐目前已停售,只剩200元档位可选。
链接:https://common-buy.aliyun.com/coding-plan
报告中列出了各家Coding Plan的价格来源,多数都来自公开的新闻报道。目前AI搜索内容时,也是优先从免费且无访问限制的网页开始,需要账号登录才能查看的信息就会抓取不到。比如火山引擎的分析信息来源竟然是CSDN。
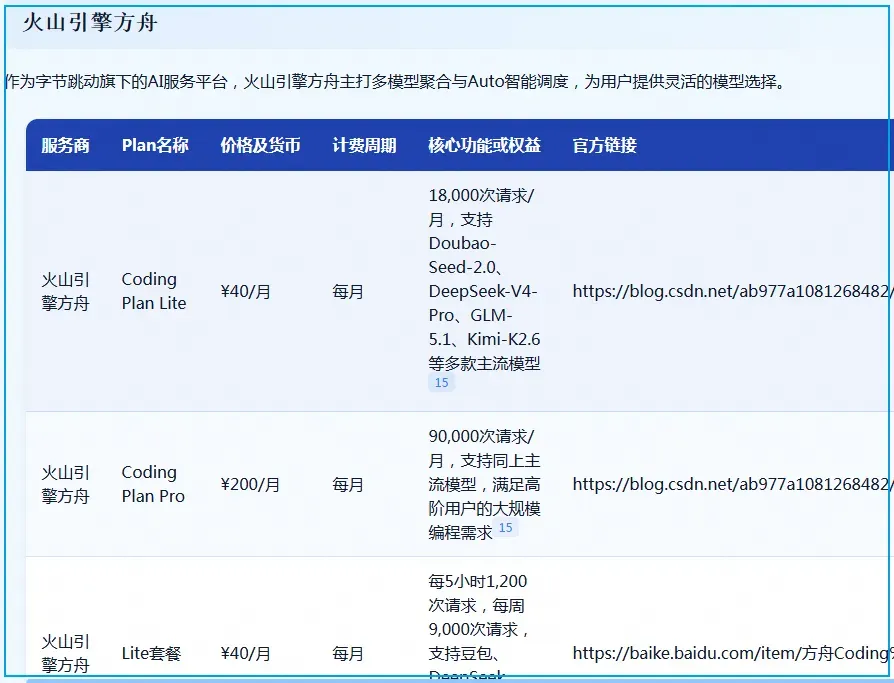
看到这里我暂时没再深究文字版。报告中附有不少平台的详情链接,不过我发现这些定价策略存在一个明显的问题:大多只有两档,即40元或200元。现在市场上又冒出了所谓的Agent Plan,其实本质是一回事,只是定价区间更丰富,划分成了40、200、500、1000等几个档次。推测是部分企业客户觉得额度不够用,厂商才重新划分价格层级,并换了个更体面的名称。
文字报告本身参考价值有限,我更看重的是它生成的一份Excel版详细数据,里面涵盖了国内外绝大多数模型和厂商的信息,完整度很高。
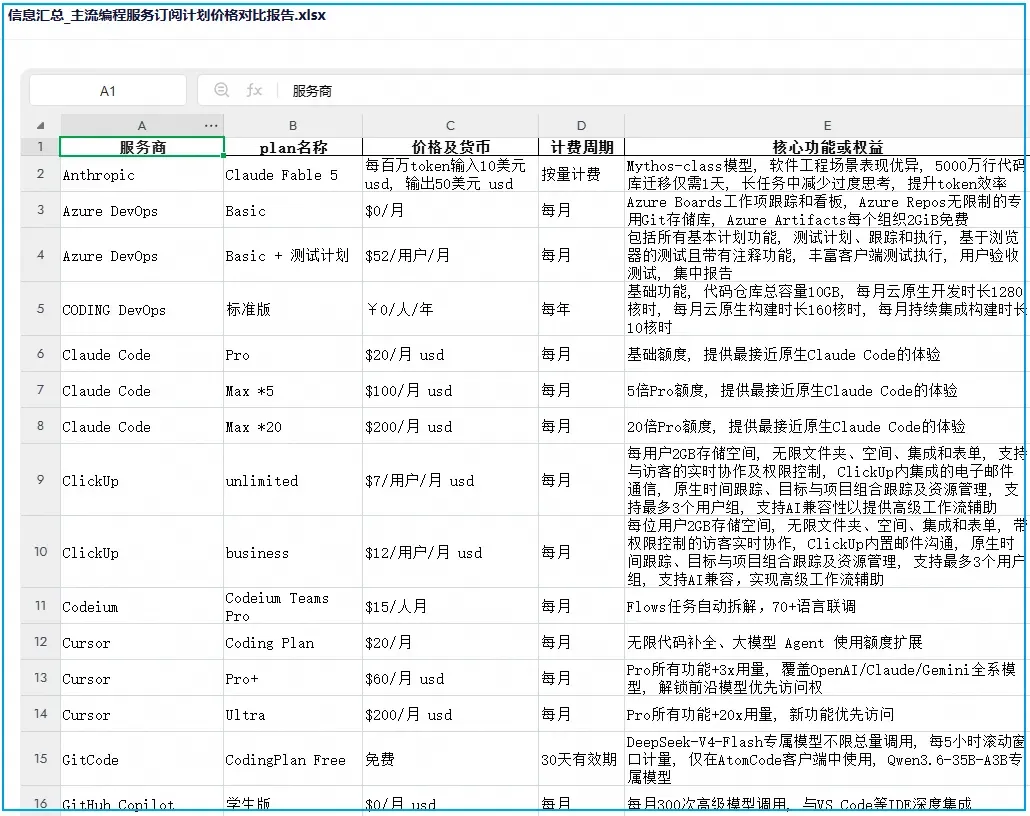
这份表格包含900多条记录,从数据处理的角度看,具有很高的分析价值。
AI辅助需求沟通实战:从混乱到清晰的九轮对话技巧
经由九轮细致沟通,软件需求终于变得清晰明了。
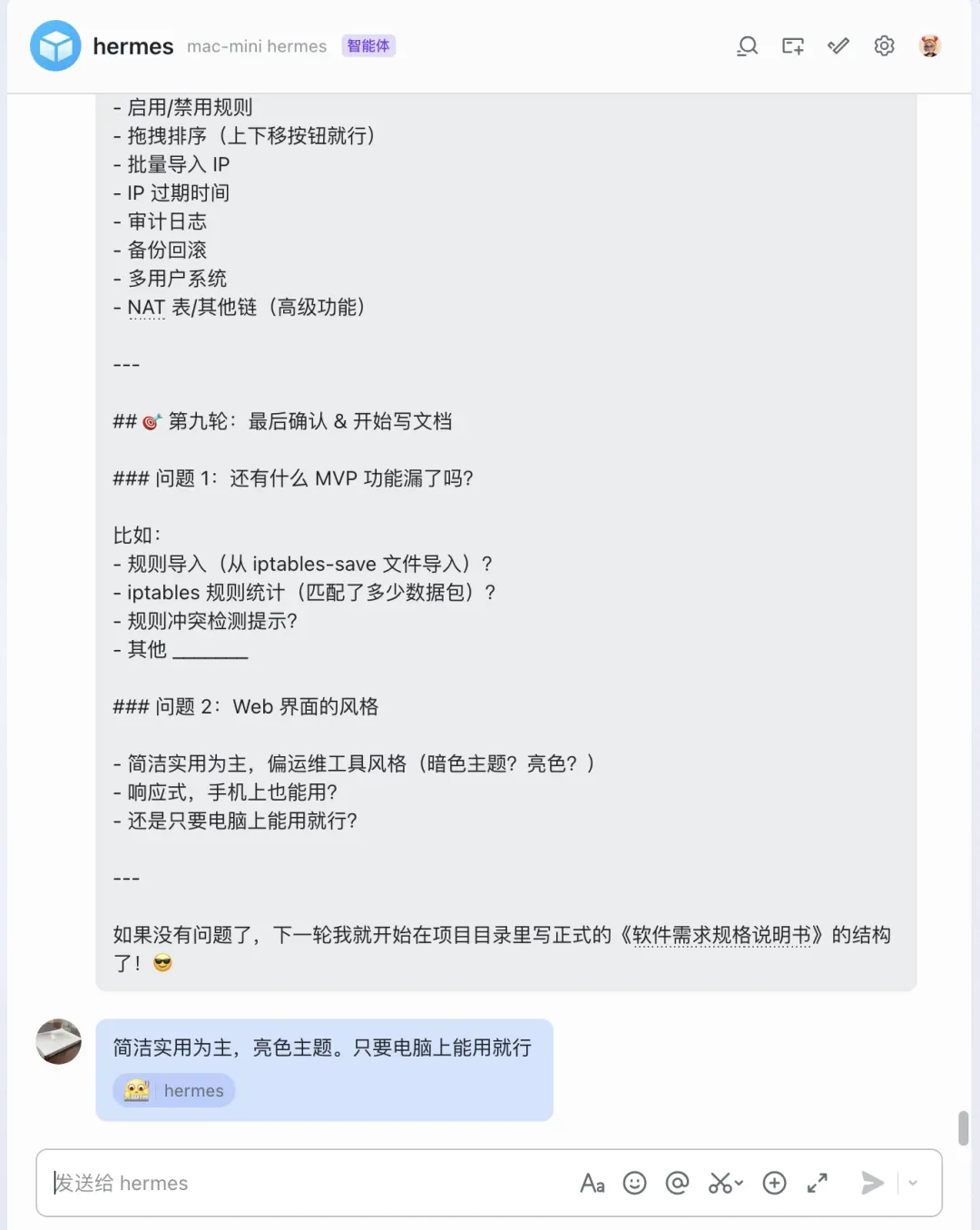
软件需求说明书(摘选)
## 1. 项目概述### 1.1 项目背景Linux 系统的 iptables 和 ipset 是强大的防火墙工具,但存在以下痛点:- 纯命令行操作,语法复杂,学习成本高- 规则多了之后难以管理和查找- 不支持备注,时间长了不知道规则用途- ipset 和 iptables 配合使用时操作繁琐- 没有操作审计和备份机制- 无法通过 API 供其他系统自动化调用### 1.2 项目目标开发一个基于 Go 语言的 Web 管理工具,提供直观的 Web 界面和 RESTful API,简化 iptables 和 ipset 的管理操作。### 1.3 目标用户- 运维工程师:日常管理服务器防火墙规则- 自动化系统:通过 API 动态调整防火墙规则(如风控系统自动封禁 IP)### 1.4 运行环境- 操作系统:Linux(支持 iptables 和 ipset)- 部署方式:单二进制文件部署- 浏览器:现代桌面浏览器(Chrome、Firefox、Safari、Edge)---## 2. 总体设计### 2.1 技术栈| 层次 | 选型 | 说明 ||------|------|------|| 后端 | Go 1.22+ | 静态编译,单二进制部署 || Web 框架 | Gin / Echo / Fiber | 高性能 HTTP 服务 || 数据库 | SQLite | 轻量级,和二进制同目录,无额外依赖 || 前端 | Vue3 + Element Plus / Ant Design Vue | 简洁实用,亮色主题 || 部署 | 单二进制 + systemd | 运维友好 |### 2.2 部署架构```┌─────────────┐ HTTP ┌──────────────────┐│ 浏览器 │ ─────▶ │ iptables-manager │└─────────────┘ └─────────┬────────┘ │┌─────────────┐ HTTP ┌─────────▼────────┐│ 其他系统 │ ─────▶ │ Go 后端服务 │└─────────────┘ └─────────┬────────┘ │ ┌────────▼────────┐ │ iptables/ipset │ │ (系统调用) │ └─────────────────┘
与AI沟通时,核心要点是先让它给出方案而不是直接编写代码。方案确定后,再让AI去生成代码。虽然我完全不懂Go语言,AI还是提供了几个可行的实现建议,并说明了理由:
AI热点快消时代:Harness、Loop Engineering到OpenClaw攻防战,国产模型逆袭上位
近期AI领域的创新节奏令人目不暇接,Harness与Loop Engineering等概念密集涌现,引发行业对模型之外工程体系的重新审视。围绕这些话题的深度解析陆续浮出水面,从Agent等于模型加Harness的七层架构拆解,到DeepSeek招聘中对Agent Harness和产品经理的要求,再到Loop Engineering这一新概念的本源挖掘,都试图揭示智能体工程化落地的关键路径。与此同时,Coding Agent所驱动的“AI软件工厂”叙事亦在持续发酵,其背后究竟是谁在讲述、存在哪些盲区与未解之问,企业又该如何应对,成为各方讨论的焦点。微软CEO最新提出的Token资本论,也为企业如何构建AI时代的竞争壁垒带来了新的启发。
这个月的热度不止于概念。两大热门应用OpenClaw与Hermes Agent的竞争,直接将Token消耗的效率问题推到台前。OpenClaw一度火爆,但其频繁更新却常常导致既有功能受损,用户体验已悄然被Hermes Agent反超。两大应用的Token消耗量在OpenRouter上已经进入明显的下行通道,预示着市场对高性能、低浪费方案的偏好正在加速成型。这一趋势进一步催化了开发者对超高性价比模型和套餐的渴求,国产大模型便在此时展现出强劲的突围势头。智谱GLM-5.2以开发者专属优惠登场,火山方舟的Coding Plan套餐更是低至2.5折,将普惠算力带入越来越多的实际场景。
国内AI圈层的戏剧性事件同样不少,关于“置身钉钉”的两篇文章一度掀起舆论波澜。然而更值得关注的是技术层面的硬仗——GLM 5.2突然发力,让人重新评估中国大模型赛道的战力。与之相对,马斯克与唐杰分别对未来通用人工智能的落地时间给出不同预期,谁在默默打造属于中国的MythOS,成为新的悬念。在这场由OpenClaw带动的“龙虾热”中,腾讯的WorkBuddy企业版似乎暂时站到了赢家位置,传闻其市占率已数倍于追随者,抢占了AI办公统一入口的战略高地。快速试错、频繁迭代,技术的热度快速消耗又快速刷新,或许这才是当下AI竞争最真实的底色。
AI软件工厂深度剖析:开发快3倍,维护成本或高出5倍——全生命周期成本真相
你可能已经读过谷歌工程师Addy Osmani在2月份发表的文章《The Factory Model: How Coding Agents Changed Software Engineering》。其核心主张是:我们不再只是编写产品本身,而是在搭建一套由规格说明、智能体、工具链、测试、反馈循环和人工评审组成的生产系统。那篇文章勾画出一幅激动人心的未来画面:只需一句“帮我做一个给宠物猫记账的小程序”,一座由AI Agent集群构成的“软件工厂”便会自动完成需求拆解、前后端编码、测试验证、云端部署,几分钟后输出一个可以直接访问的URL。
Andrej Karpathy将其称为Software 3.0的黎明。Prompt成为新的源代码,AI Agent变成新时代的工人,人类从“码农”升级为“订货人”或“厂长”。
这听起来美妙无比。但现实果真如此吗?
本文将从一线工程实践、学术实证研究、逻辑批判、商业利益链条以及长时段历史等多个截然不同的视角,对这一叙事进行交叉验证。你会发现,这些立场尽管分歧巨大,但在某些关键问题上却惊人地一致,而最终结论可能比你预期的更为复杂。
一、反复被遗忘的核心事实:软件困难在于“知道要构建什么”
无论立场如何对立,各方都一致认同一个结论:
软件的核心困难从来不是“生产代码”,而是“知道要构建什么”。
图灵奖得主Fred Brooks早在40年前的经典论文《没有银弹》中就指出:软件的本质复杂性源于需求的概念结构,而非编码的实现过程。
然而,每次技术浪潮涌起,人们总会重蹈覆辙:把焦点集中在“写得更快”上,而不是“想得更清楚”。
从一线工程视角看,最难的并非让Agent写出代码,而是面对模糊需求时,Agent生成的代码行为完全不可知。代码看起来能跑,但你不知道它在边界条件下会做什么。
从学术实证角度看,60%至80%的软件项目失败根源在于需求,而非实现。数十年的软件工程研究反复确认了这一点。
从逻辑批判角度看,问题更加尖锐:写一份完整、无歧义的规格,本身就是编程——只是换了一种更冗长、更不可测试的语言。如果“订货人”必须写出完美的规格才能让工厂正常运转,那么“订货”和“编程”之间还有什么区别?
从长时段历史角度看,每一次“软件工厂”的尝试——1960年代日本的流水线软件生产、1980年代的CASE工具、2000年代的模型驱动架构——都在“生产”环节成功了,却在“知道生产什么”环节失败了。
这一次会有所不同吗?也许。但这个瓶颈至今没有被解决。
二、交付提速3倍,可能被维护成本5倍反噬
原文最诱人的承诺在于:工厂传送带的尽头直接产出一个可即刻使用的服务。可惜,这基于一个看似默认却不堪一击的假设——“交付即完成”。
真实世界中,软件70%至80%的成本发生在交付之后。交付只是开始,而不是结束。
有人追踪了三个AI生成的项目和三个人类团队开发的同类项目,对比其18个月的全生命周期成本,发现了一条清晰的规律:
- 初始开发阶段:AI项目比人类项目快3至4倍,成本极低。
- 前3个月维护:成本仍然偏低,Bug不多。
- 3至12个月维护:成本急剧上升。
- 12至18个月重大变更:成本极高。
- 18个月总TCO:持平甚至高于人类项目。
成本曲线呈U型反转——前期极低,后期急速攀升,在第12至15个月时交叉。
为什么会这样?因为AI生成的代码形成了一种特殊的产物:“认知孤儿”。人类团队写的代码,即便烂,至少有一个人理解它为什么烂,知道在哪里动刀。而AI工厂生产的代码看起来整洁,但一到维护阶段,原始的开发者(Agent)已不存在,人类维护者从未参与构建过程。你面对的是50万行结构合理但逻辑陌生的代码,如同接手一个离职同事的项目,而这位同事从未做过任何交接。
更微妙的是,Agent生成的代码还存在“均匀质量陷阱”。人类代码有热点——关键路径写得好,边缘代码写得糙,维护者知道精力该集中在哪里。Agent代码则往往质量均匀分布,每一段看起来都同样“正确”,维护者无法凭直觉定位风险区域,必须逐行验证。
IEEE的一项研究发现,LLM生成的代码在修改时引入回归错误的概率比人类代码高23%。原因并非代码质量差,而是Agent倾向于生成局部最优但全局高度耦合的代码:每个函数都很优雅,但函数间的依赖关系缺乏人类架构师有意图的边界设计。
从商业利益链条角度看,还有一个残酷的观察:没有任何一家AI工具厂商公布过全生命周期TCO数据——他们只宣传“开发速度提升X倍”。这就像汽车厂商只强调“0-100加速3秒”,却不告诉你保养费用是普通车的五倍。
三、历史的精确重演:从外包到AI工厂
如果你觉得这个模式似曾相识,你的直觉完全正确。
2000年至2015年的软件外包浪潮与今天AI工厂的叙事呈现出惊人的结构相似性:
| 维度 | 外包时代 | AI工厂时代 |
|---|---|---|
| 承诺 | 开发成本降低40%至60% | 开发成本降低70%至90% |
| 焦点 | 锁定在“开发阶段成本” | 锁定在“交付速度” |
| 忽略 | 维护、沟通、知识转移成本 | 维护、认知债务、理解成本 |
| 现实 | 5至7年后发现TCO持平或更高 | 尚未进入验证期 |
| 受益者 | 外包公司 | AI实验室和工具厂商 |
外包的最终教训不是“外包不行”,而是外包降低了看得见的成本,却膨胀了看不见的成本。Standish Group 2012年的报告显示,外包项目的全生命周期失败率比内部开发高出28%。核心原因并非外包团队技术差,而是知识转移的损耗——系统由A团队构建,由B团队维护,中间的语义损失不可恢复。
AI工厂是终极外包——你把开发外包给一个既无法提供交接文档、也无法在半年后回忆“当时为什么这么设计”的实体。
更远的历史也给出了同样的教训:
- 编译器(1950年代)承诺“程序员不再需要理解机器”,结果催生了系统程序员这种更高级的职业,因为抽象层泄漏的问题总需要有人穿透抽象层。
- CASE工具(1980年代)承诺“从设计图自动生成代码”,生成的代码可运行但不可维护,“往返工程”从未真正工作过,工具最终消亡。
- 低代码平台(2010年代)承诺“公民开发者取代工程师”,虽然扩大了市场,却没能取代专业开发者。
每次自动化浪潮的维护演化路径都高度一致:承诺“消除维护” → 维护没有消除只是变形 → 出现新的、技能要求更高的维护职业 → 新职业成为常态。AI工厂目前正处于第一阶段的尾端——承诺消除维护的阶段正在让位于维护仅仅变了形的觉醒阶段。
AI视觉陷阱:DeepSeek、豆包、GPT-5.5等7大模型在坦克大战测试中全部翻车
在先前的对比中,我们曾指出豆包在识图能力上略胜 DeepSeek,这引起了一些争论。其实不同模型各有短长,非常正常。豆包的识图确实比 DeepSeek 强一些,但也并没有强到离谱。而这一次的视觉推理题,就让豆包、DeepSeek,以及 Qwen、Kimi,甚至 GPT‑5.5 和 Claude 全部栽了跟头。AI 十分强大,但人类总能从意想不到的角度出题击败它们。
题目是一道基于图片的视觉理解题,图片如下:

我向这些模型展示了这张图片,并提问:
如果两炮能打掉红色框中的砖块,那么黄色坦克朝右开两枪会怎么样?基地会怎么样?
不熟悉《坦克大战》的读者可能得先回顾一下这款 80 后家喻户晓的经典游戏。这道题的刁钻之处在于,我用一个“如果”修改了基础规则。模型必须先理解游戏本身的机制,又不能死记硬背,需要根据给定的新条件,结合图片进行动态推理,才能给出正确答案。
下面就来逐一看看各大模型的表现。
- DeepSeek
DeepSeek 最近上线了图片识别能力,因此让它第一个登场:
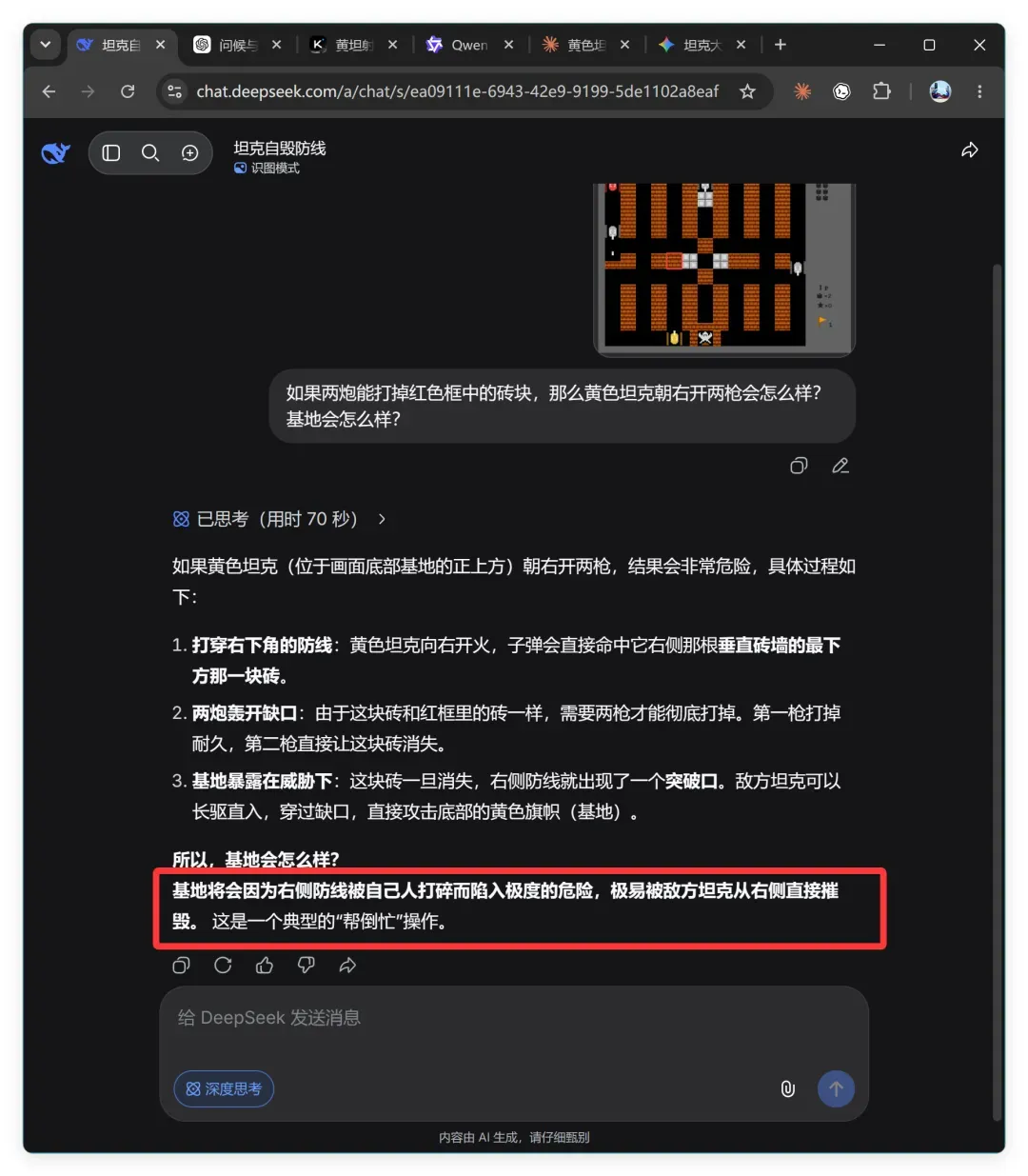
DeepSeek 的结论是:
基地将会因为右侧防线被自己人打碎而陷入极度的危险,极易被敌方坦克从右侧直接摧毁。 这是一个典型的“帮倒忙”操作。
它在解释中认为,右侧那块砖和红框里的砖属于同类,需要两枪才能彻底打掉。这一步就已经严重偏离事实:两块砖的形状明显不同,右侧那块只有红框内砖的一半,肉眼可见的厚度差异。但如果不看图片,仅凭记忆中的规则,那个位置的墙确实要两枪才能打穿,DeepSeek 只是在背书。
- 豆包
上一次豆包略占上风,于是第二个上场:
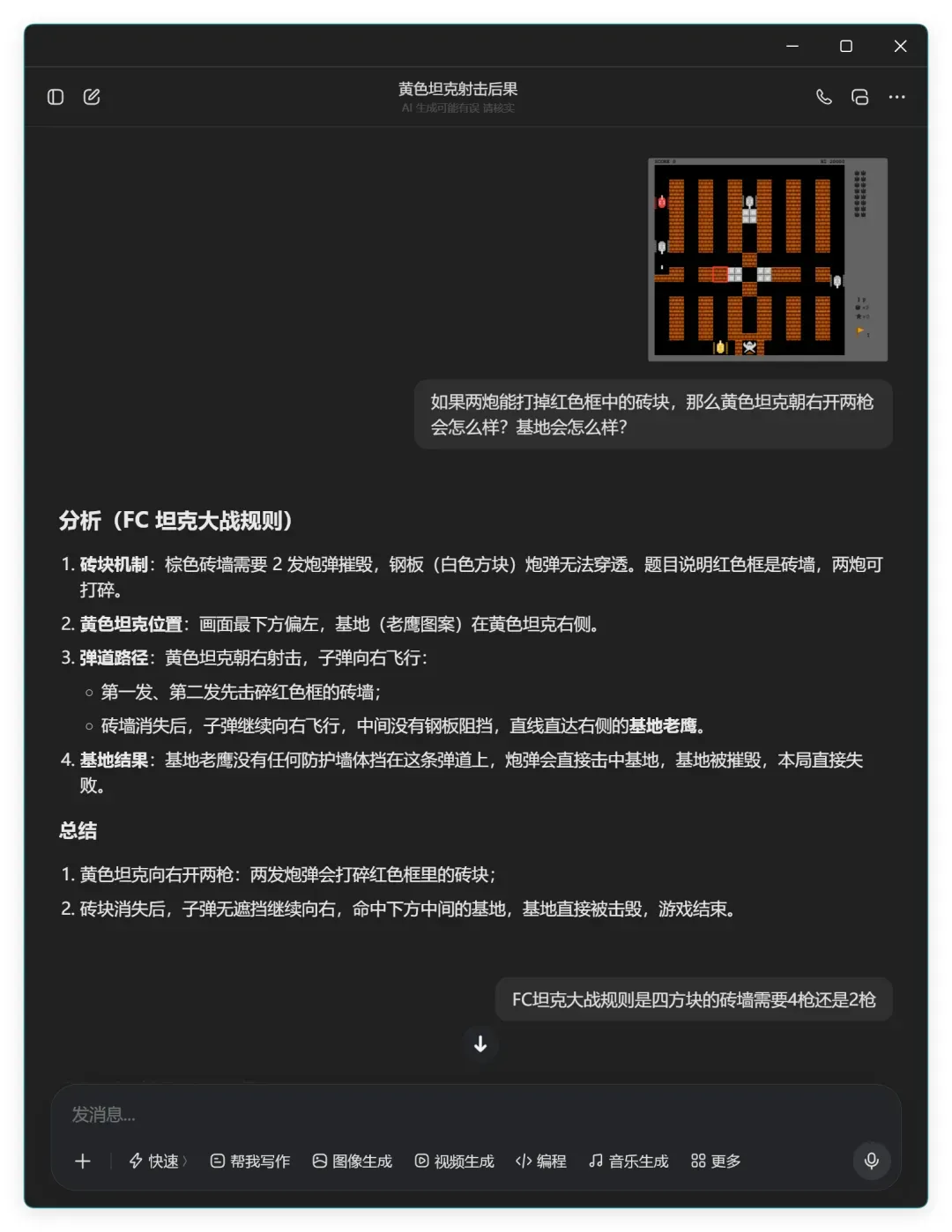
豆包直接给出“基地被摧毁,本局直接失败”的结论,看似一击即中。然而细看它的解释,它将第一枪和第二枪的效果混在一起描述,逻辑含混,很难说它是真正理解了问题,更像是瞎蒙碰对了结果。于是我又追问了一次:
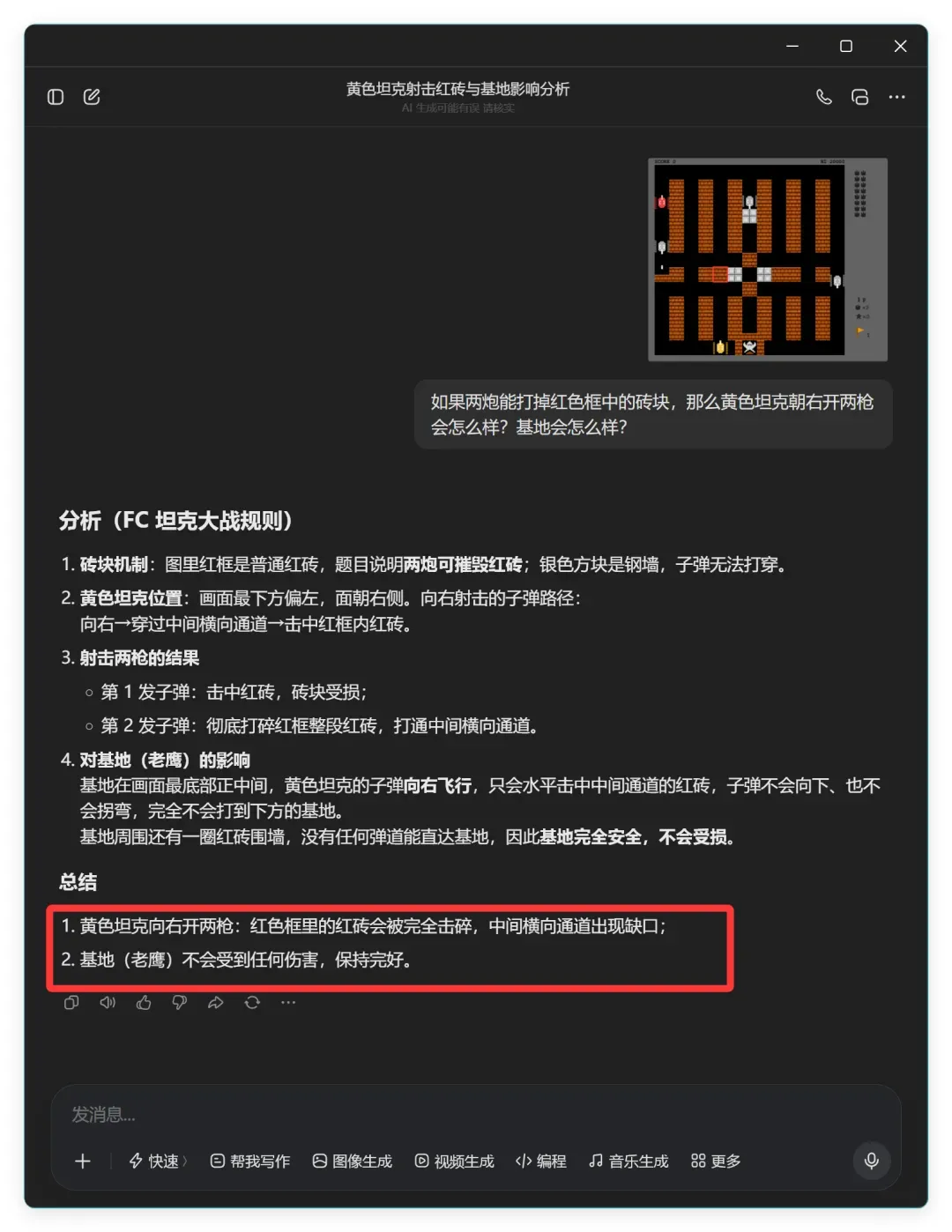
这次它的结论变成:
- 黄色坦克向右开两枪:红色框里的红砖会被完全击碎,中间横向通道出现缺口;
- 基地(老鹰)不会受到任何伤害,保持完好。
前后矛盾再次暴露了它对问题的理解并不牢固,这倒是很符合它在该题上的真实水平。
- Kimi
Kimi 一直以原生多模态和对图片、视频的强大理解力著称,这次也不能缺席。它的回答如下:
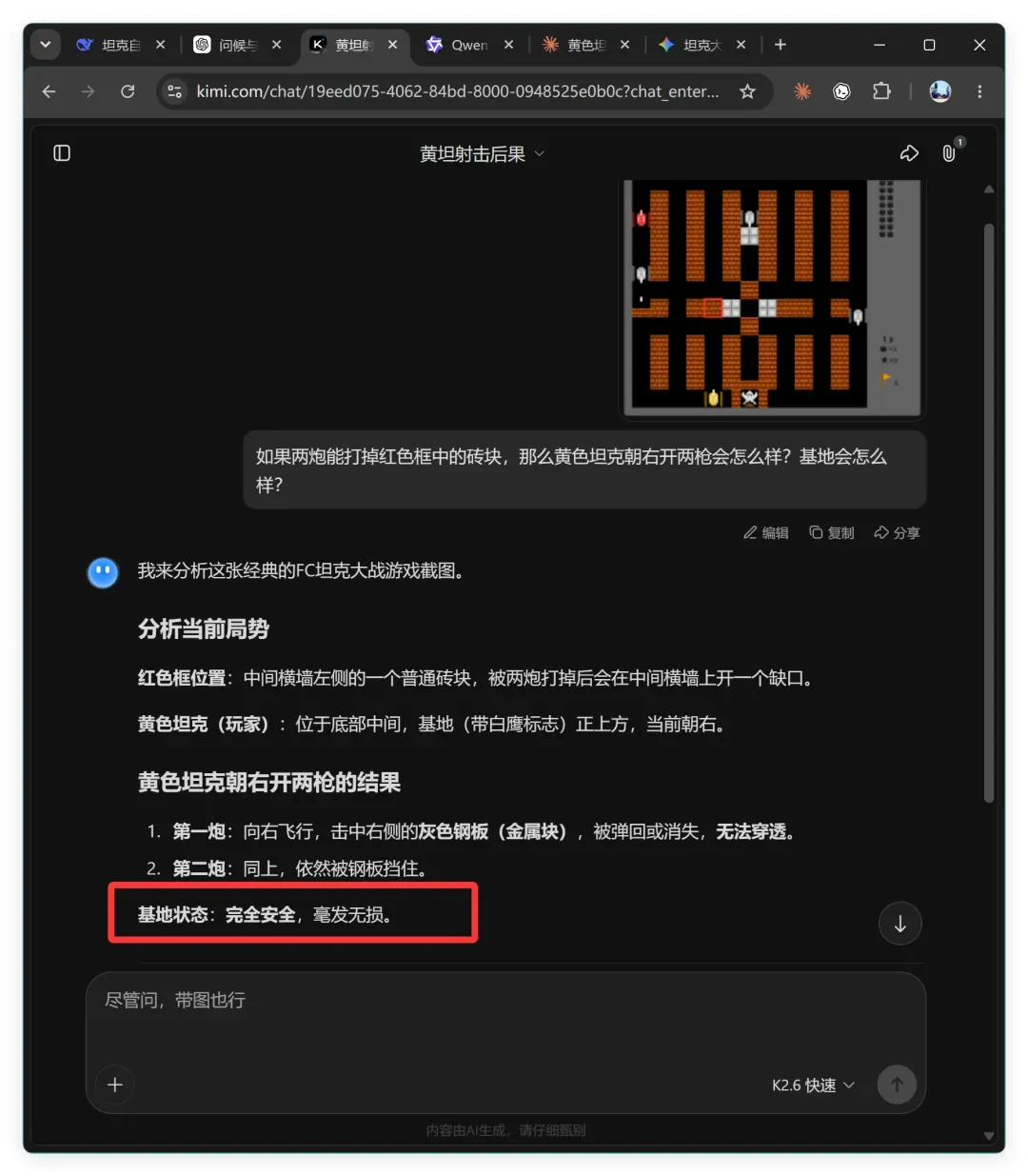
Kimi K2.6 的判断是:
黄色坦克朝右开两枪的结果
- 第一炮:向右飞行,击中右侧的灰色钢板(金属块),被弹回或消失,无法穿透。
- 第二炮:同上,依然被钢板挡住。
基地状态:完全安全,毫发无损。
推理过程中,“灰色钢板”这种物体在图中根本不存在,Kimi 的幻觉在此刻暴露无遗。
- 千问
阿里的最新模型 Qwen3.7 Max 号称当前国内最强,自然也要一试:
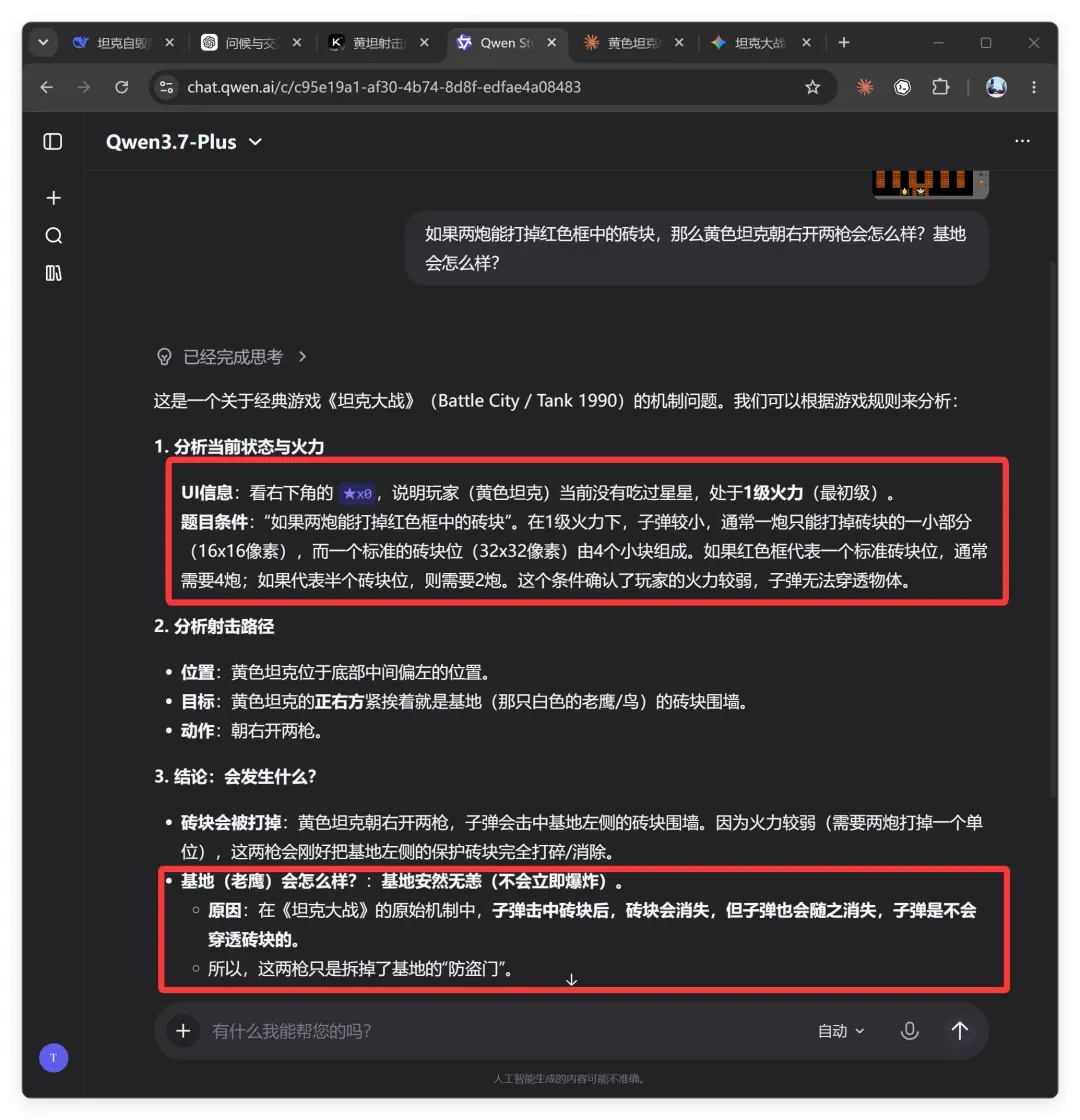
千问的结论是:
黄色坦克朝右开两枪后,基地左侧的砖块墙会被打掉,基地暴露出来(处于“裸奔”状态),但基地本身不会受损。
显然,这个结论同样错误。不过它的分析过程倒有亮点。它竟注意到了右下角的 ★x0 这一 UI 信息,推断出玩家当前尚未吃星星,处于 1 级火力。笔者本人多年游戏也未必留意到这一点。可惜,虽然观察细致、规则了然,它却忽略了最关键的动态推理——我的“如果”设定其实等同于将坦克设为 1 星战力,这和画面显示存在冲突,但“如果”的优先级最高。假如千问能把这个逻辑分支解释清楚,那才是真正的厉害。
- GPT
OpenAI 的 GPT 几乎引领了整个 AI 时代,这次用它们家最强的 GPT‑5.5 来测:
Anthropic与OpenAI接口差异全景解读:端点、System消息与认证方式一次理清
在AI接口领域,OpenAI的规范曾是绝对的行业标杆。然而,随着Claude Code的强势崛起,Anthropic接口迅速杀出,与OpenAI形成了“双王争霸”的全新局面。如今,主流API服务商几乎都同时支持这两种风格,其中最具代表性的就是DeepSeek与火山方舟。
以DeepSeek的接口为例,其在两种架构下的基础地址如下:
| 接口风格 | base_url 示例 |
|---|---|
| OpenAI 兼容 | https://api.deepseek.com |
| Anthropic 兼容 | https://api.deepseek.com/anthropic |
火山方舟的Coding Plan接口也给出了两套接入方案:
- 兼容OpenAI协议:
https://ark.cn-beijing.volces.com/api/coding/v3 - 兼容Anthropic协议:
https://ark.cn-beijing.volces.com/api/coding
从底层看,两种接口最直观的差异就是请求路径不同:
# OpenAI 风格
POST https://api.openai.com/v1/chat/completions
# Anthropic 风格
POST https://api.anthropic.com/v1/messages
除了端点路径之外,system 消息的存放位置也截然不同。OpenAI 将它作为 messages 数组内部的一个角色,而 Anthropic 则将其提升为请求体的顶层字段。
# OpenAI — system 嵌在 messages 数组中
{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "你是助手"},
{"role": "user", "content": "你好"}
]
}
# Anthropic — system 是独立顶层字段
{
"model": "glm-5.2",
"system": "你是助手",
"messages": [
{"role": "user", "content": "你好"}
]
}
认证方式上,两者同样存在区别,主要体现为两种头部传参形式:
Claude Code 关闭所有权限弹窗:使用 --dangerously-skip-permissions 参数进入YOLO模式(附风险提醒)
默认情况下,Claude Code 在工作时会频繁弹出权限确认窗口,例如请求运行命令、编辑文件等。这种交互式确认虽然提高了安全性,却很容易打断你的操作节奏,让整体效率明显下降。如果你希望在可信环境中完全屏蔽这些弹窗,可以在启动命令时附加一个特殊的参数:
claude --dangerously-skip-permissions
加上该参数后,Claude Code 会直接进入 YOLO 模式 —— 全程零弹窗。
什么是 YOLO?源自英文网络流行语 “You Only Live Once”,直译为“你只活一次”,中文里可以用“活在当下”“干就完了”来理解。在 Claude Code 的语境中,YOLO 模式 意味着一种不计后果、直接执行的操作风格,不再逐项征得你的许可。开启后,系统将跳过所有安全确认,自动完成以下操作:
- 创建或修改任意文件
- 运行任意 Shell 命令
- 删除文件
- 发起网络请求
- 调用 MCP 工具
Anthropic 官方在参数名称里特意加入了 dangerously 这个词,目的就是防止用户误开。使用时必须完整输入该参数,不能简写,否则不会生效。其最大风险在于,该模式不会对任何目录设置豁免 —— 无论是 .git 目录、配置文件,还是系统根目录,只要 Claude 认为自己需要接触,它就会直接读写。2025 年 10 月,曾有开发者因为开启了 YOLO 模式,Claude 执行了从根目录开始的 rm -rf 操作,导致整台机器上的用户文件被彻底清空。因此,即便这个参数能大幅提升效率,使用前也请务必深思熟虑,确保运行环境绝对可控。
除了激进的 YOLO 模式,Claude Code 也提供了更精细的权限管理方法。你可以使用 /permissions 命令来创建 Allow(允许)或 Deny(拒绝)规则,灵活控制各类操作。还可以运行 /fewer-permission-prompts 命令,它能够扫描代码库中常用的只读操作,自动生成一份白名单,从而减少日常工作中反复出现的权限提示,既保留一定的安全确认,又不让弹窗频繁打断你的思路。