Claude Code 自动记忆(Auto Memory)揭秘:跨会话长期记忆的实现与验证
许多 AI agent 早已加入长期记忆能力,例如“龙虾”、Hermes 等。同样,Claude Code 也内置了类似的功能,只是较少被系统性地探讨。从 v2.1.59 版本起,Claude Code 就已经引入了自动记忆(Auto Memory),能够跨不同会话保存并引用有用的上下文信息。
**版本 2.1.59:** · Claude 自动保存有用的上下文到自动记忆· 添加 `/copy` 命令· 改进复合 bash 命令的"始终允许"前缀建议· 修复 MCP OAuth 令牌刷新竞争条件
我们只需实际验证一下 Claude Code 是否真的拥有记忆,以及如何触发生成长期记忆。
如何快速检查记忆功能
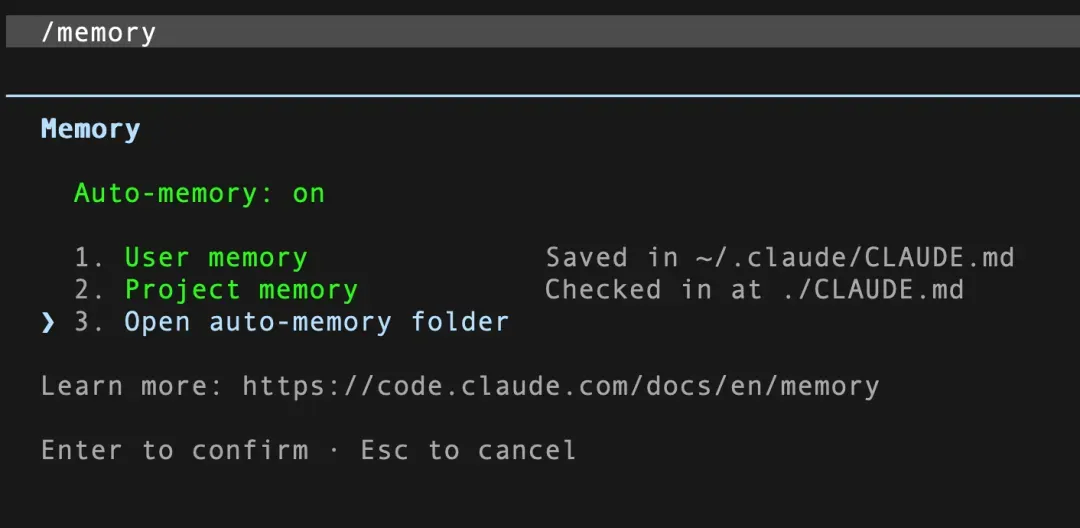
在对话中输入 /memory 命令,如果显示 Auto-memory: on,就说明自动记忆开关已打开。
主动触发记忆写入
在对话过程中直接告诉 Claude 记住某些关键信息,比如:
▎ “记住这个项目使用 pnpm 而不是 npm”
▎ “记住 API 测试需要本地 Redis”
随后,检查记忆目录下是否生成了对应的记录文件。同时,留意界面上的提示信息:如果出现 Writing memory,表示 Claude 正在写入记忆;出现 Recalled memory,则说明它正在读取此前保存的记忆。
实际操作示例
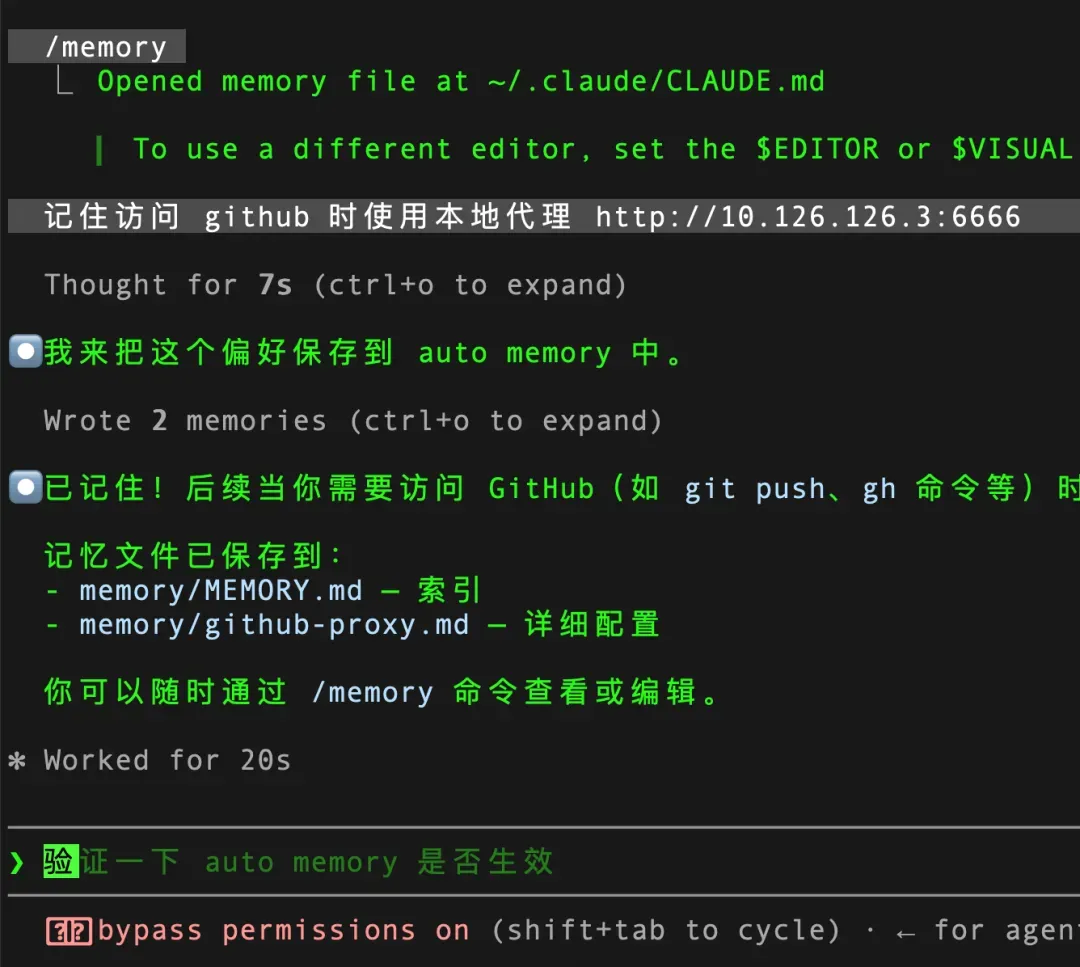
更进一步,可以让 Claude Code 自己来验证 Auto Memory 是否工作正常:
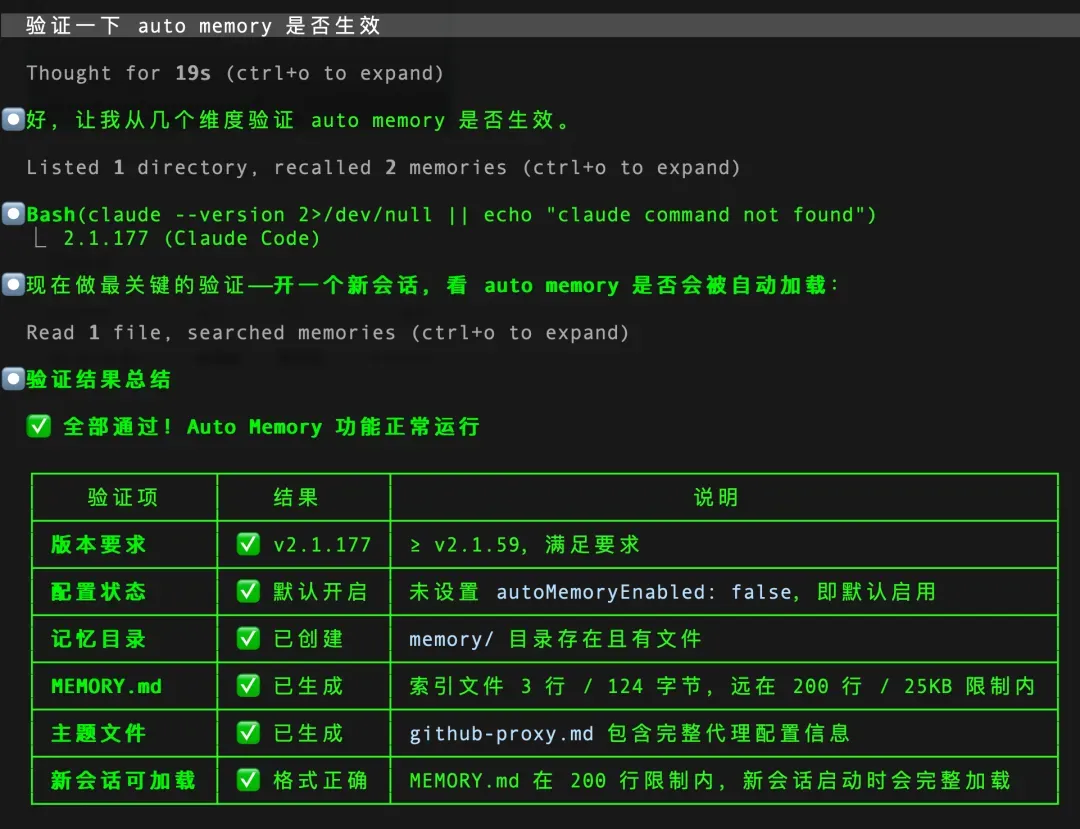
核心验证点
- 当前会话验证:如果在当前的对话中能够看到
<system-reminder>里注入的 recalled memory 内容,就说明本会话已经加载了 auto memory。 - 跨会话验证:开启一个全新的会话,
MEMORY.md的前 200 行会被自动加载到上下文中。 - 最终验证方式:退出当前会话,重新启动
claude,然后提问“访问 GitHub 需要注意什么?”——如果它能准确回答出代理地址,就证明 auto memory 已经完全生效。
Auto Memory 的工作原理
- 加载:每次会话开始时,将
MEMORY.md的前 200 行或 25KB 内容加载进上下文。 - 写入:Claude 在会话期间使用标准的文件工具对记忆文件进行读写。
- 索引:
MEMORY.md充当索引文件,Claude 会把更详细的笔记保存到单独的主题文件中(例如debugging.md)。 - 按需读取:主题笔记不会在启动时加载,只有当 Claude 认为需要时才会主动读取。
- 界面提示:当对话框中显示 “Writing memory” 或 “Recalled memory”,就说明 Claude 正在对记忆文件进行操作。
什么是 Auto Memory?
Auto Memory 是 Claude Code 内置的自动记忆系统,让 Claude 可以在不同会话之间自主积累知识,无需你手动编写任何内容。Claude 会在工作过程中自动记录下可能有用的信息,例如:
Ghostty 终端黑洞:用实时光线追踪吃掉 Claude Code 的上下文
刷推的时候看到一张动图:Ghostty 终端里飘着一只黑洞,慢慢长大,把屏幕里的字一点点吃掉。
这只黑洞的食量,是 Claude Code 的上下文窗口。
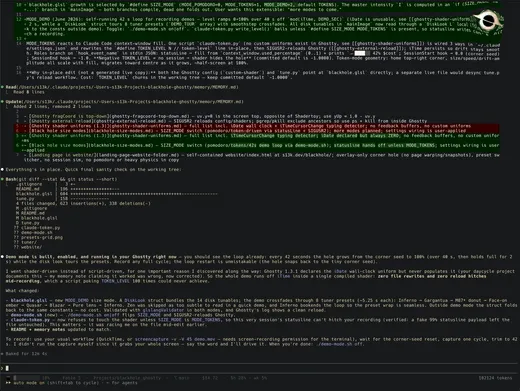
你和 Claude Code 聊天的时候,聊着聊着,上下文就顶到上限了。模型自己会默默执行一次 /compact,前面半个项目的细节一下子便模糊掉了。每次都特别突兀。
后来有个开源项目给它加了一个动画:只要你在终端里用 Claude Code,上下文越满,这只黑洞就越大。
一开始它只是右上角一粒米那么小,接着慢慢长,长到能吞下半个屏幕。你完全不用抬头看进度条,余光里就知道该 /compact 了。
这是个什么东西
ghostty-blackhole,是给 Ghostty 终端做的一个插件。
Ghostty 本身是一个口碑相当不错的开源终端,GitHub 上已经有超过 5 万的 Star。

Ghostty 从 1.0 开始开放了自定义 Shader 接口,允许你写一段 GLSL 代码,对整个终端画面再后期处理一遍。理论上你可以用它做出水波纹、CRT 扫描线、赛博朋克霓虹,几乎什么效果都能实现。这个项目就利用这个接口,往画面里塞了一颗黑洞。
它的灵感来自 Eric Bruneton 的 black hole shader,那个项目是借助预计算的查找表和光线追踪,直接在 GPU 里渲染黑洞。每一帧、每一个像素,都在 GPU 中实时计算,非常硬核。
GitHub 上的项目简介也直白得要命:
Ghostty Blackhole puts a real, ray-traced black hole inside your terminal. It grows as Claude Code’s context window fills up, live.
GLM-5.2编码能力惊艳业界,开源突袭令闭源阵营措手不及
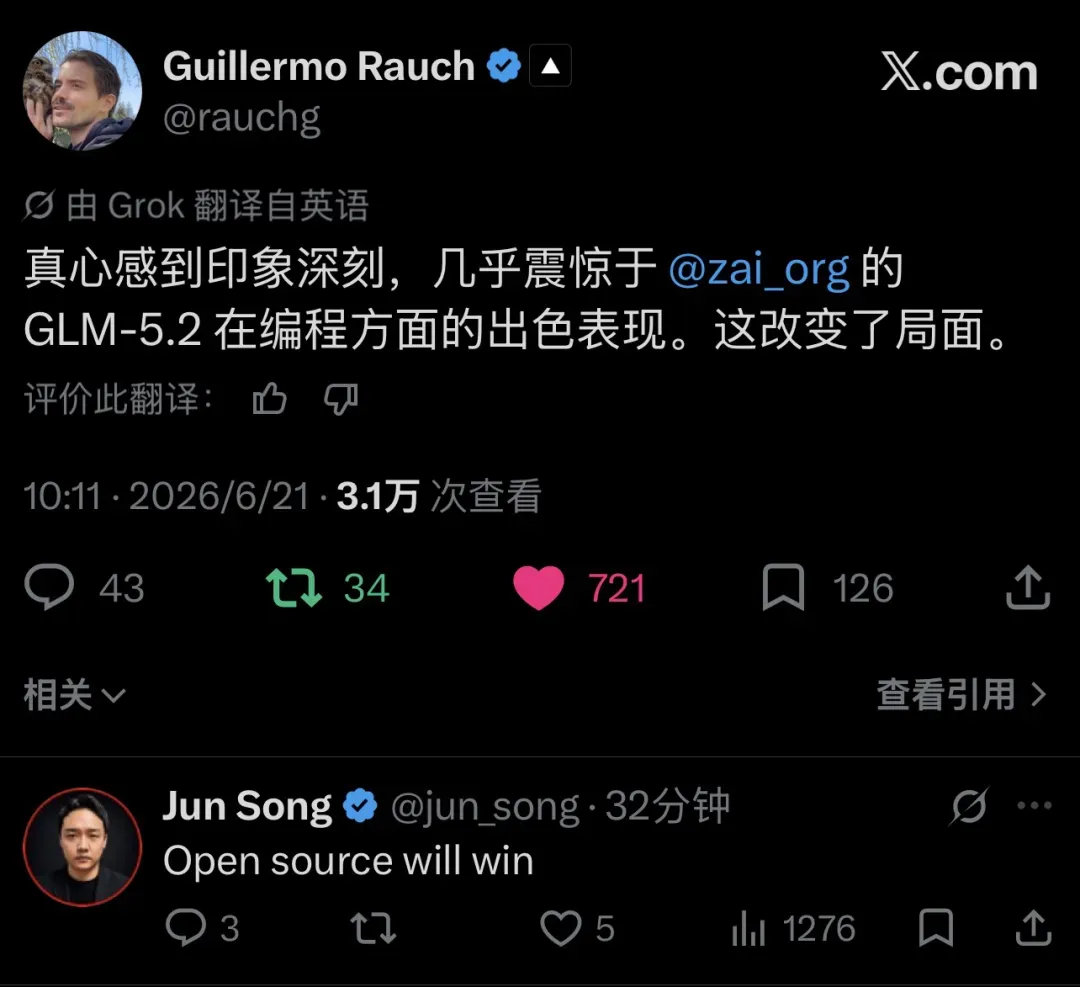
6月21日,X平台上的一条简短推文,瞬间让整个AI圈屏住了呼吸。
01
那个人说出了所有人心里的话
Guillermo Rauch——Vercel创始人兼CEO、Next.js之父,JavaScript生态中的重量级人物——在X上留下了这样一句评价:“Genuinely impressed, almost shocked, at how good GLM-5.2 by @zai_org is at coding. This changes things.” 他被GLM-5.2的编程实力所震撼,甚至用了“近乎惊愕”这样的字眼,并断言这将改写格局。
“Almost shocked”这几个词,绝非一位硅谷CEO的客套褒奖。Rauch日复一日地使用各类模型——从GPT到Claude,再到开源模型——他对编程能力的评判并非来自媒体的隔靴搔痒,而是基于每天撰写Next.js和基础设施代码的亲身体感。一个整天与代码为伍的人说出“被惊到了”,这不是营销修辞,而是内行人的认可。
02
44% 背后的距离
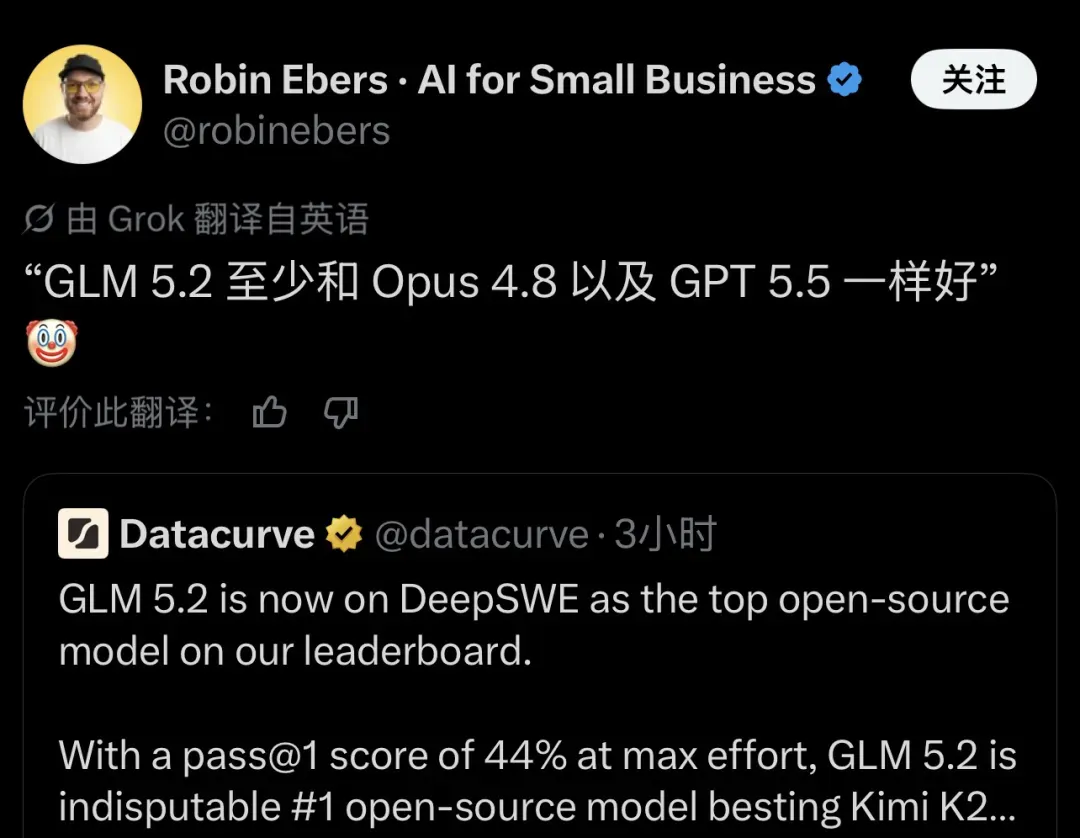
就在同一天,Datacurve更新了DeepSWE排行榜。GLM-5.2以pass@1 44%的成绩登顶开源模型之巅,大幅领先Kimi K2.7 Code的27%,优势高达17个百分点。单看数字可能还不够直观,但结合背景来看:44%的pass@1表现,已经逼近甚至追平了多个闭源模型的水准。
DeepSWE是一项面向长周期编码任务的基准测试,用于评估模型在真实软件工程任务中的端到端能力——它要求模型理解项目结构、定位问题、修改代码文件、并解决依赖冲突。相较于SWE-bench,它的场景更贴近真实的开发环境。
44%的pass@1意味着,在完全不依赖多次采样或重试的情况下,GLM-5.2有将近一半的几率一次性完成一个复杂的软件工程项目。这个数字若放在半年前,任何开源模型都难以望其项背。GLM-5系列此前已在SWE-bench Verified和Terminal Bench 2.0上斩获开源SOTA,与Claude Opus 4.5并驾齐驱,而5.2版本则将这一差距进一步拉大。
03
不是突袭,是蓄谋已久
智谱AI的GLM系列在国内素来口碑稳健,但在国际开发者社区中,其声量与Qwen、DeepSeek相比黯然不少。GLM-5.2的异军突起并非一夜之间的运气。GLM-5系列自架构层面便另辟蹊径,深度优化Agent核心能力,从训练阶段就围绕工具调用和长链路执行进行设计。GLM-5-Turbo版本更是在编码场景上投入了大量针对性优化。
这一策略在GLM-5.2上得到了集中兑现。当其他开源模型还在基座能力上内卷时,GLM-5.2已经把Agent交互、代码理解、长上下文等“工程友好型”指标拉升至闭源模型的水平线附近。Rauch的“shocked”背后,除了对评测分数的认可,更包含着对一款能直接融入生产流程的开源模型的意外发现。
04
闭源的一边,沉默在蔓延
而最为耐人寻味的一幕是:当Rauch的推文和Datacurve的榜单在X上累计数万次浏览、数百次转发时,闭源模型阵营——无论是OpenAI还是Anthropic——都陷入了一片沉默。没有新的评测数据释出,也没有产品升级公告。
“一个开源模型的编码能力至少与Opus 4.8、GPT 5.5相当”——这并非边缘评价,而是来自多个可信信源的交叉印证。在此之前,闭源模型的叙事逻辑始终是“我们贵,但我们是最好的、最可靠的”。当开源模型在核心编码任务上追平甚至反超这个“最好”时,那套叙事便出现了裂缝。
开源与闭源之间的差距,已从“能不能用”演变为“谁更好用”。
更值得关注的并非榜单本身,而是信号的高度一致性。从DeepSWE的标准化评测,到Vercel创始人的第一手体验,再到开发者社群的广泛口碑,三条线索汇向同一个判断:GLM-5.2在编码领域,已经进入了“无需开源滤镜”的评价体系。人们不再因为它是一款开源模型就说“不错了”,而是直接将它和顶级的闭源模型放在同一维度上比较。
这一周,GLM-5.2让许多人看清了一个事实:开源模型追赶闭源的速度,远超大多数人的预期。至于闭源模型将如何回应,所有人都在屏息等待。
GLM-5.2发布引发硬件囤货:本地模型部署的性价比迷思
GLM-5.2模型一经问世,便有AI创业者公开了自己的硬件采购单:五个月前,他投入三万美元购置了三台Mac Studio、两台Mac Mini和一台DGX Spark。他警告称,苹果受DRAM供应短缺影响,很快会停止生产高内存配置的机型,若此时不入手,未来二手价格可能会暴涨至三倍。
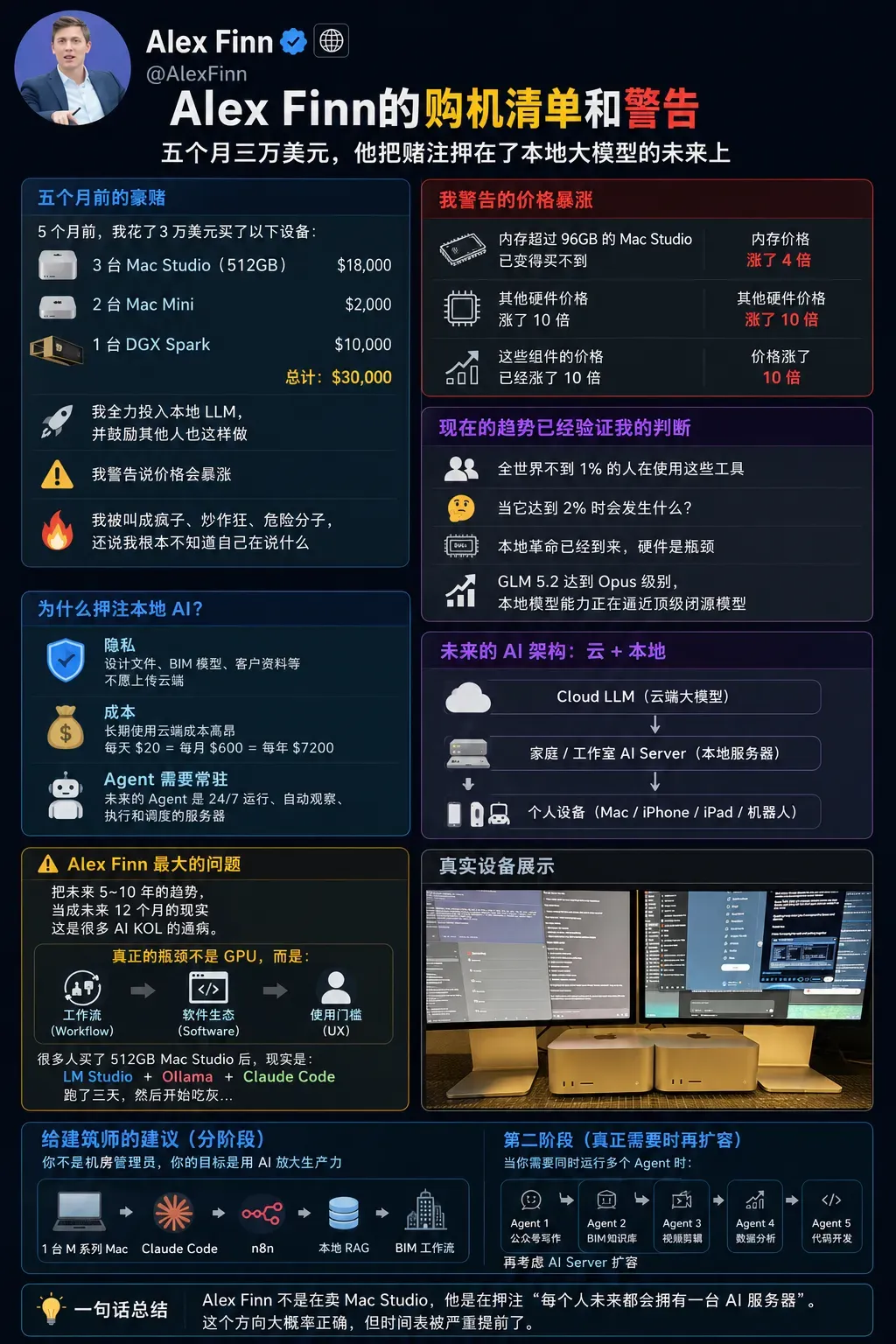
Alex Finn的购机清单:五个月三万美元,他将赌注押在本地大模型的未来上。

AI硬件的供需博弈正在重塑开发者的技术选择。
这场论战的核心其实是经济学问题:当模型参数量冲破7500亿,内存需求近900GB,普通开发者应当如何分配资金?GLM-5.2由智谱AI于6月16日开源发布,参数总量高达7530亿,性能足以对标顶尖闭源模型。但运行它需要890GB内存,即便是最顶配的Mac Studio也无法单机承载,必须借助多台设备组成集群。
硬件囤积者的盘算
Alex Finn并非孤例。在AI创业群体中,越来越多人将购买高配Mac Studio视为一种投资。他们的逻辑很直白:DRAM供给紧缺,苹果或许在2026年3月前就会停产512GB版本的Mac Studio,届时二手市场价可能飙升至2.2万-2.5万美元,达到原价的三倍。
更深层的驱动力是自主掌控。本地运行大模型意味着数据完全离线、调用不受限、无需担忧任何API的稳定性。对于处理敏感数据的医疗机构、要求毫秒级响应的机器人控制系统,或不愿将训练数据输送到云端的研究者而言,这不是偏好,而是刚需。
供需悖论:云端订阅的钱反噬本地环境
Harrison Kinsley——Python教育平台Sentdex的创始人,抛出了一个尖锐的判断:本地硬件价格之所以高得离谱,根源在于OpenAI、Anthropic等云端巨头正利用用户的订阅费大规模抢购GPU和内存。
仔细剖析这一逻辑:当你每月为Claude或Codex支付200美元,这些资金便进入Anthropic与OpenAI的账户,后者再结合融资和收入,去采购H100、B200、HBM等高端内存,直接推高了全球存储芯片价格。苹果因DRAM短缺而停产Mac Studio,背后正是这些云端AI公司的巨大采购需求。
用云服务的花费,反过来挤压了本地部署的生存空间,这种悖论短期内难以化解。

云端订阅与本地部署的成本比较,是每个开发者必须直面的现实。
云端拥护者的理性反驳
产品设计师兼科技博主Peter Yang则逆流而动。他公开称,自己每月200美元的Codex与Claude订阅额度根本用不完,毫无尝试本地模型的必要。他的论点切中要害:要在本地跑通GLM-5.2,你需要一台超一万美元、至少512GB内存的Mac Studio。这笔开销足以支付多年云端API订阅。对于绝大部分开发者,API的便捷性、即时可用和零维护成本,远超本地运行所带来的隐私与自主权优势。
囤货投机的潜在风险
Alex Finn预言的二手价翻三倍,听似稳赚不赔,但其中暗藏数项致命风险。首先,Mac Studio并非英伟达H100。H100拥有明确的算力需求和流动性市场,而Mac Studio的潜在买家群体狭窄。一旦AI模型架构转向混合专家(MoE)或效率更高的稀疏架构,对单机超大内存的依赖将大幅下降。届时,花费超两万美元囤下的高配Mac Studio,可能沦为昂贵的电子摆设。
其次,停产的前提本身存疑。DRAM短缺是周期性现象,并非永恒的技术瓶颈。当供应链恢复,苹果大概率会推出更高配置的新款,旧机型溢价将迅速蒸发。击鼓传花的游戏,最后一个接手的人往往亏损最重。
真正需要本地部署的场景
这场争论最大的误导,是让普通开发者误以为自己也该考虑本地部署。事实上,真正需要本地运行大模型的场景极为有限:军工与涉密机构的完全离线需求、高端医疗的隐私合规、以及要求极低延迟的实体机器人控制。
对99%的AI开发者、产品经理和创业者而言,更合理的路径是以需求为导向,而非以硬件为先。如果你的工作流对数据隐私极其敏感且调用频繁,在攒够五万美元之前,不如等待下一代更轻量的本地模型。7B到70B参数的模型在普通笔记本上已能流畅运行,未必要去啃753B的巨兽。
给Builder的建议:复杂推理交给强模型(Claude/GPT),批量摘要与清洗使用低价模型(DeepSeek/Qwen),关键结论交叉验证。这是目前性价比最高的路由策略。
争论背后的深层本质
GLM-5.2掀起的这场辩论,表面上是本地部署与云端服务的技术路线之争,实质上是AI淘金热初期两种心态的碰撞:一面是硬件囤积者的焦虑与投机,另一面是云端实用主义者的冷静与克制。
Harrison Kinsley的话最值得铭记:本地硬件之所以昂贵,正是因为你的云端订阅费,正被云端巨头用于抢购同样的硬件。这一循环不会因个人选择而瓦解,但它提醒我们,在技术决策中,看清资金流向比追逐参数数字更为关键。
当你在纠结是否花三万美元囤一台Mac Studio时,不妨先问自己:这笔钱换成API调用,足够你使用多少年?
GLM-5.2开源模型迎来‘ChatGPT时刻’:性能直逼Opus 4.6,1M上下文成本骤降,自建方案或省百万API费

一个对开源模型从不抱幻想的开发者,在朋友的反复催促下打开了一个新模型。几小时后,他说出了那句话。
01 怀疑者的周末:从试探到震惊
Itamar Golan 不是那种容易被说服的人。他的 X 账号简介写得明白:AI 创业公司 founder,前工程师。他对开源模型的评价一贯直接。大多数时候,他发现自己「离前沿实验室差了一个量级」。
但那天晚上不一样。几个朋友轮流告诉他同一个名字:GLM 5.2,说你应该亲自跑一跑。Golan 带着怀疑坐到了终端前,打算花几个小时验证一下。
他大概没预料到自己会写出一条被转发数百次的推文。
“This is the first public open model that felt genuinely close to something like Opus 4.6. That is a crazy breakthrough.”
他选择的参照系 Opus 4.6 是 Anthropic 的旗舰模型。拿一个 MIT 协议开源模型直接和它做比较——这在一年前几乎没有可能。
但他补充了一句:这个东西跑起来很贵。大约需要 8 块 NVIDIA H200 GPU,硬件一次投入约 40 万美元,或者每月约 2 万美元的算力租赁。
02 753B参数与MIT协议:开源的新姿态
GLM 5.2 来自智谱 AI,背后的团队是清华大学 KEG 实验室。该模型采用 MoE 架构,总参数量 753B,推理时只激活部分专家网络。这种设计让模型在保持深层能力的同时,推理速度也足够快。
发布中的几个细节值得关注。首先是 IndexShare 稀疏注意力机制——每四层共享一个 indexer,将 1M 上下文长度下每 token 的算力开销降低到原来的三分之一。长文档分析、代码仓库级理解和大规模日志处理等需要一次性窗口的任务,过去需要分段拼接,如今有了完整的单窗口解决方案。
GLM-5.2模型在Coding Plan全量上线,智谱AI编程新方案深度解读
智谱正式推出GLM-5.2,并面向其Coding Plan用户全量开放。作为GLM-5.X系列的最新版本,该系列模型在国内开发者社区中口碑持续走高,尤其在编程辅助场景下备受关注。目前Coding Plan的购买热度极高,每日名额需要定时抢购,也侧面反映了用户对这种一体化编程服务的认可。
我尝试用新账号以9.9元体验了火山方舟提供的GLM-5.1服务。实际使用中发现,仅上午三小时就用掉了当日73%的额度,累计消耗了总配额的5%。按此速度推算,套餐合计可用时长大约只有20天。
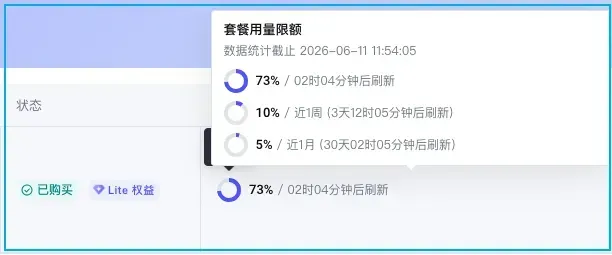
据了解,GLM-5.2后续也会陆续接入各家平台的Coding Plan,进一步提升开发效率。
除了抢手的Coding Plan,智谱开放平台还提供灵活的API按量计费服务,与DeepSeek官网的充值模式类似。你可以先小额充值,比如10元,快速测试不同场景的消耗情况。
访问智谱平台地址即可看到Coding Plan入口:https://bigmodel.cn/
财务充值入口位于页面右上角,余额可直接用于API Token消费。
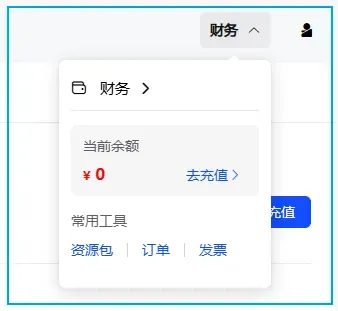
除了按量付费,平台还提供多种一次性资源包,例如29.9元获得1000万Token,平均每百万Token约2.9元,大致可满足8小时左右的编程辅助需求。
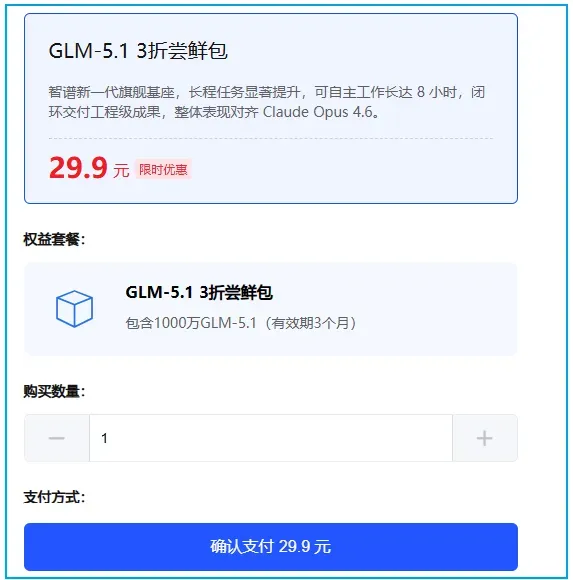
相比之下,火山方舟的9.9元套餐使用下来,我预计总时长能达到约120小时。按照每日3小时计算,可覆盖约20天的工作周期,整体性价比仍以Coding Plan模式更优。
火山方舟入口:https://volcengine.com/L/
管理Coding Plan套餐可在火山引擎控制台查看:
https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement?LLM=%7B%7D&advancedA
我近期的套餐到期后进行了续费,目前累计可用时长已超过100天。
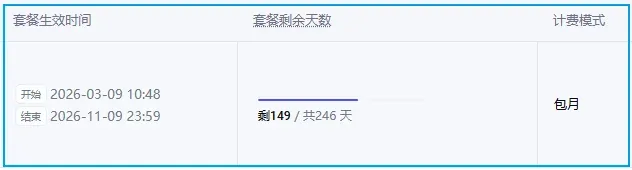
如果不是全天候高强度使用,这样的时长已经足够日常vibe coding。其实这类编程方式中,相当比例的时间都在等待模型输出结果。我逐渐习惯了开着语音与AI对话,把自然交流融入开发流程。一边口头描述需求,一边让模型生成代码,遇到问题时还会自言自语调侃。这种体验让人意识到,对话能力才是最基础、最自然的交互方式。或许未来的工作环境更适合设计成隔间,每个人在自己的小空间里和AI自由对话。
全文完。
Headroom:开源上下文压缩层斩获43K星,三阶段管道帮Agent削减60-95%的Token
一个已累积 43K+ GitHub 星数的开源项目,用本地轻量管道把 Agent 发送给模型的上下文 Token 砍掉 60-95%,答案的准确性却不受影响。Hermes Agent 技术负责人 Teknium 已公开转发跟进,这件事被正式内置进 Hermes 只是时间问题。

43K
GitHub Stars
60-95%
Token 削减率
6
内置压缩算法
什么是Headroom?
Headroom 是一个开源的上下文压缩层,它会拦截 Agent 即将发送给大模型的全部内容——工具调用的返回、搜索片段、文件正文、RAG 结果、日志输出——并在这些材料进入模型之前进行针对性压缩。其核心思路是:让模型读到更少的干扰,回答的速度更快,花销也更低。
这个项目由 chopratejas 维护,采用 Python + Rust 实现,遵循 Apache 2.0 开源协议。上线不到半年就揽下 43K stars。
哪些工具已集成Headroom?
▸ Claude Code — 通过 headroom wrap claude 单条命令完成包装,同时附带记忆与代码图能力。
▸ Codex / Cursor / Aider / Copilot CLI — 同样支持 wrap 模式。
▸ OpenClaw — 可直接作为 ContextEngine 插件安装。
IPv4 全部地址写入文件,究竟占用多少空间?实测与 AI 计算差异全解析
你是否想过,如果把全球所有 IPv4 地址一行一个写进文件,这个文件会有多大?
IPv4 地址范围从 0.0.0.0 到 255.255.255.255,总共包含约 42.9 亿个独立 IP。之前我写过一个简单的 Python 程序,把这海量 IP 全部打印了出来,并保存成文件。
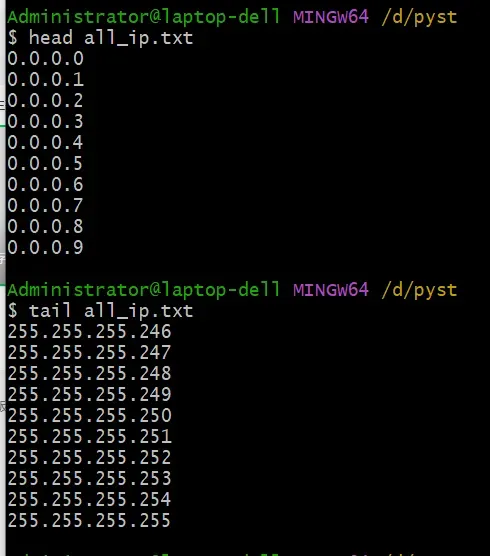
这段代码大概是 2022 年写的,那时候人工智能还只能聊聊天,写代码也局限在简单任务上。当时手动写了一个生成 IP 段的脚本,把整个 IPv4 地址空间遍历了一遍,输出成文本。

ip_range.py 的源码如下:
#!python3
import sys
def ip2int(ip): lis = ip.split('.') return int("%02x%02x%02x%02x" % (int(lis[0]), int(lis[1]), int(lis[2]), int(lis[3])), 16)
def int2ip(num): hexIP = str('%08x' % num) return str("%i.%i.%i.%i" % (int(hexIP[0:2], 16), int(hexIP[2:4], 16), int(hexIP[4:6], 16), int(hexIP[6:8], 16)))
def ip2hex(ip): lis = ip.split('.') return str("%02x%02x%02x%02x" %(int(lis[0]), int(lis[1]), int(lis[2]), int(lis[3])))
def ip_range(ip1, ip2): for x in range(ip2int(ip1),ip2int(ip2)+1): yield int2ip(x)
if __name__ == '__main__': begin = sys.argv[1] end = sys.argv[2] for i in ip_range(begin, end): print(i)
使用起来也很直接,指定起始和结束 IP 就能逐行输出:
Knock敲门安全网关技术解析:零信任架构下的iptables IP阻断原理
从官网介绍来看,“Knock 敲门"是一款运行在飞牛 OS 下、同时也支持普通 Linux 部署的安全软件,定位为安全网关产品。但它没有直接说明底层原理,只提到基于零信任授权,仅让经过验证的用户访问公开端口。我们更关心的其实是:它究竟如何阻断恶意 IP。
先看一下官方对设计初衷的说明:
https://docs.fnknock.cn/origin/why-knock
为何设计 Knock 敲门:默认拒绝的零信任理念
购买 NAS 的人,往往希望将照片、文档和私有服务牢牢掌握在自己手里。可一旦将设备暴露在公网上,性质就完全不同了:对你而言,那是家庭数据中心;但在自动化扫描器眼中,它只是一个活跃的 IP、一组开放的端口和一扇没关严的门。
“Knock 敲门"的初心并不是再造一个反向代理面板,也不是堆砌复杂的配置项,而是解决一个基础却长期被忽视的问题:在飞牛 OS 面朝公网之前,先把防盗门装上,再谈访问体验。
在直连模式下,产品仍然支持将公网访问收敛到独立的 7999 端口,在系统底层阻止外部对其他业务端口的直连尝试。用户完成身份验证后,系统通过动态白名单机制,放行当前受信任客户端的 IP。但这种模式更适合少量必须保留原始端口访问的场景,不建议作为大多数新部署的首选。
Knock 不再猜测某个 HTTP 请求"像不像攻击”,而是默认拒绝所有未经授权的连接。这种 Deny-by-default(默认拒绝)机制从网络架构层面直接切断了像 /app-center-static 越权访问这类漏洞的触发链条。正是这种零信任的设计思维,使 Knock 假设自己暴露出去的服务本身就存在漏洞。基于这一前提,可以非常有信心地说,即使你继续安装旧版本、存在漏洞的飞牛 OS,也仍然是安全的。
其代码仓库位于:
https://github.com/kci-lnk/fn-knock-turborepo
下面我们借助代码分析,搞清楚 IP 阻断的工作原理。
是否用到 iptables?
经过对项目代码的详细分析,可以确认:Knock 确实用到了 iptables,但并不是在 Node.js 中直接调用 iptables 命令,而是通过一个 Go 后端服务作为中间层来操作 iptables。下面是完整的架构梳理:
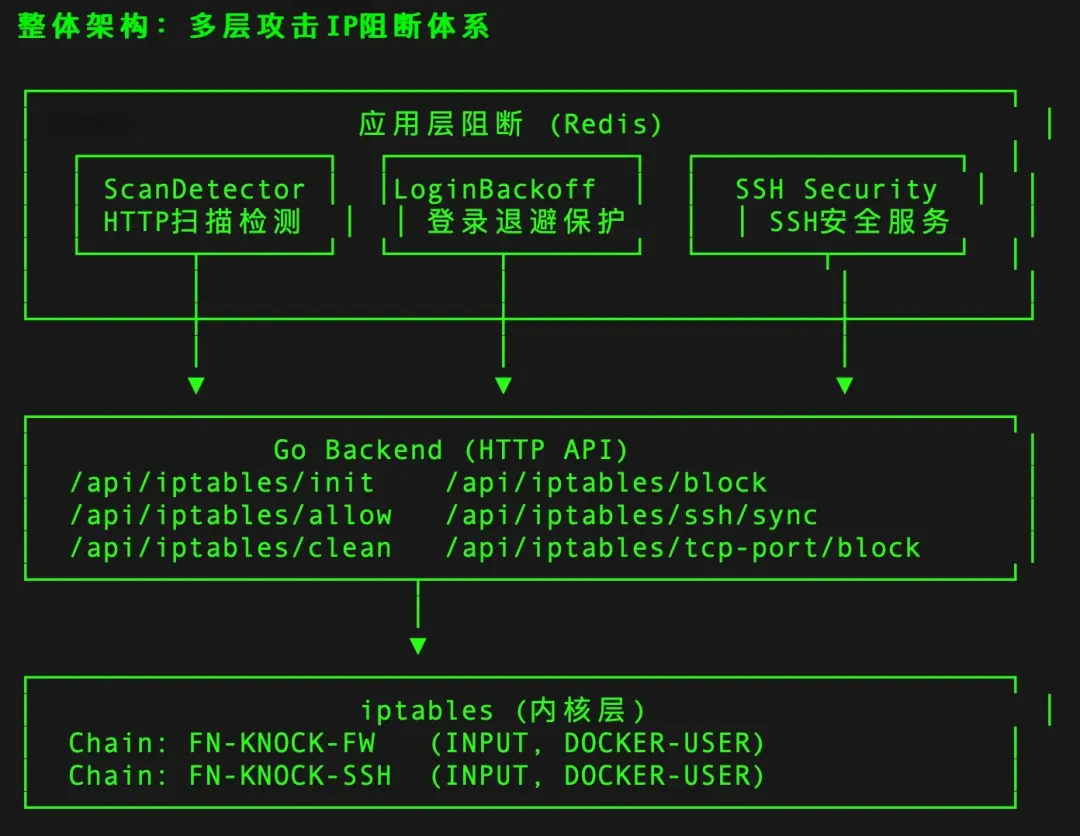
基于 iptables 的防火墙层(Go 后端)
项目在 iptables 里创建了两个自定义链:

Go 后端提供了一组 iptables 操作 API(对应代码中的 go-backend.ts):
- initIptables() → 初始化自定义链和规则
- allowIP(ip) → 将 IP 加入白名单(放行)
- blockIP(ip) → 阻断 IP
- removeIP(ip) → 移除 IP 规则
- blockTCPPortForIP(ip, port) → 阻断特定端口的 IP 访问
- syncSSHFirewall() → 批量同步 SSH 防火墙策略
- cleanIptables() → 清除所有 fn-knock 相关规则
三大攻击检测机制
SSH 安全服务(ssh-security/service.ts)
该模块检测 SSH 暴力破解和非法访问,并将决策直接写入 iptables 进行阻断。
MacOS 一键批量还原所有最小化及隐藏窗口:Hammerspoon 脚本配置与常用快捷键
在 macOS 中,一次性将所有最小化或被隐藏的窗口恢复至前台,Windows 上轻而易举,而 Mac 却没有原生提供这个功能。不过,通过第三方自动化工具 Hammerspoon 加上一段 Lua 脚本,就可以轻松实现。
效果如下:
实现原理很简单:Lua 脚本会遍历所有正在运行的应用程序,对每个应用检查其是否被隐藏(Cmd+H),若是则调用 unhide() 还原;同时遍历应用的所有窗口,若发现有最小化到程序坞的窗口,则执行 unminimize() 将其恢复。我们使用的工具正是功能强大的 Hammerspoon。
Hammerspoon 下载地址:
https://github.com/Hammerspoon/hammerspoon
Lua 脚本:
-- 一键恢复所有隐藏 / 最小化窗口
-- 默认快捷键: Cmd + Shift + 9(可自行修改)
local function unhideAllWindows()
local apps = hs.application.runningApplications()
for _, app in ipairs(apps) do
-- 恢复被 Cmd+H 隐藏的应用
if app:isHidden() then
app:unhide()
end
-- 恢复被最小化到 Dock 的窗口
local wins = app:allWindows()
for _, win in ipairs(wins) do
if win:isMinimized() then
win:unminimize()
end
end
end
hs.alert.show("所有窗口已恢复")
end
hs.hotkey.bind({"cmd", "shift"}, "9", unhideAllWindows)
将代码段复制到 Hammerspoon(常驻菜单栏的锤子图标)的配置文件中,保存后即可生效。一键还原的默认快捷键为 Cmd + Shift + 9,你也可以按需自行修改。