DeepSeek DSPark 推理加速:Token 成本跌至 0.03 美元/百万,智能已廉价到无法计量

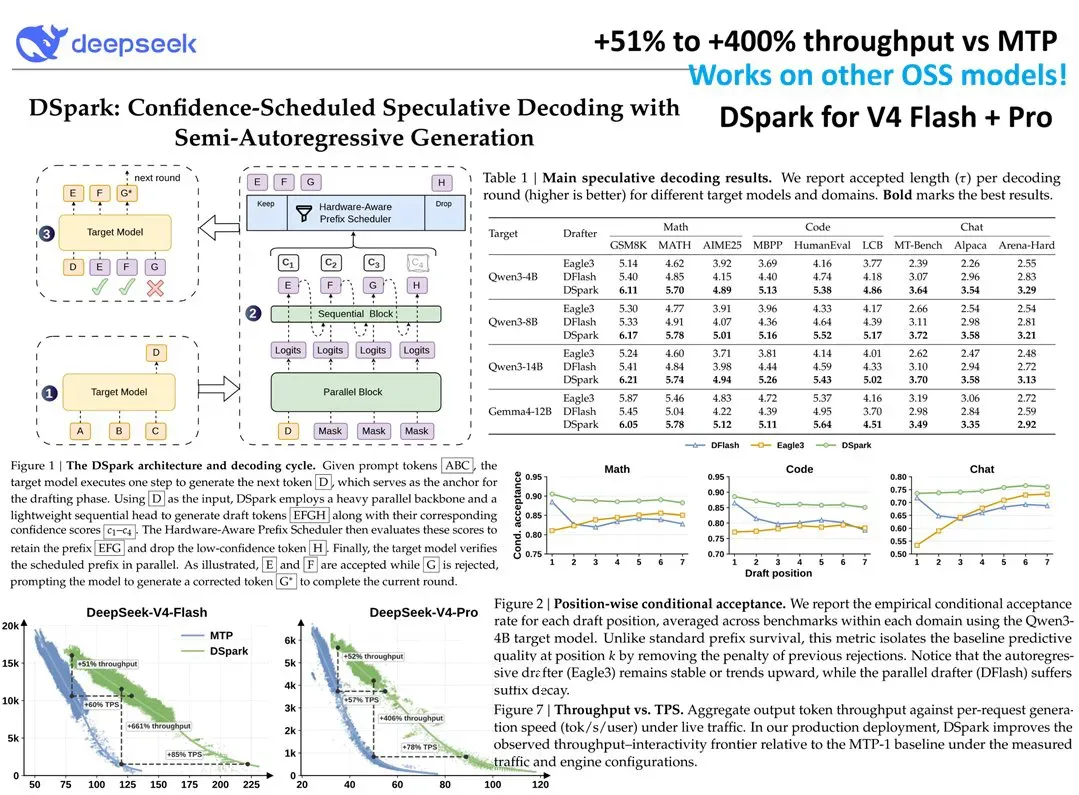
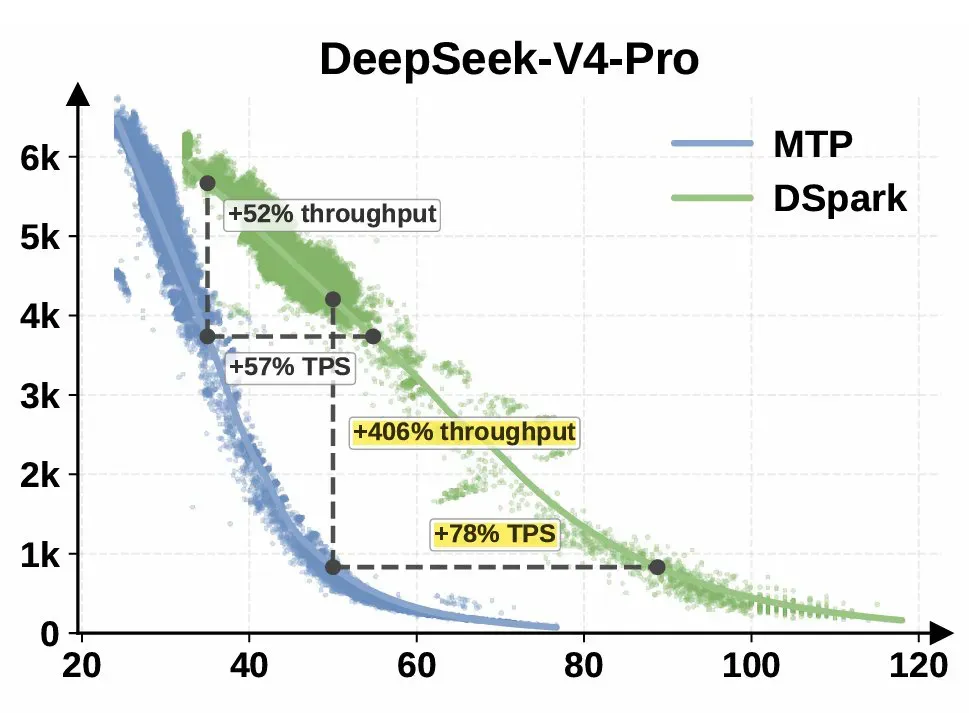
一篇论文在 Hacker News 上引发了超过 300 层的热辩。DeepSeek 采用“先猜测、后验证”的推测解码方案,把推理吞吐量提升了 51%–400%,社区同时看到了技术红利、开源驱动力和定价权的历史拐点。
16%–31%
数学/代码任务提升
729
Hacker News 热度分
2-3x
整体推理加速比
DeepSeek 的最新论文 DSPark 一举登上 Hacker News 热门榜首(729 热度分、305 条评论),社区评分达 8.0/10。中文社区也同步热烈转发讨论。有网友翻译成了一句调侃:“你怎么能不喜欢 DeepSeek 呢,感谢温锋大人继续让智能变得太廉价以至于无法计量。”这句话看似玩笑,实则点中了三个层面的实质变化:技术路线在转变,开源策略在迭代,定价逻辑也随之重构。
推测解码并非全新概念,但 DeepSeek 将其打造成了可落地的生产级方案
DSpark 的本质是让一个小模型快速生成候选 token,再由主模型批量验证。这在学术上被称为 speculative decoding,Google 早在 2022 年就提出了框架;Gemma 4 今年也发布了多词预测(MTP)代码,NVIDIA 的 Nemotron 3 Super 同样搭载了 MTP。DeepSeek 的独特贡献在于,它提供了一整套可训练、可评估、可部署的完整技术栈:DeepSpec 开源项目包含了数据准备、草稿模型训练、基准评测全流程,且默认支持 DSSpark、DFlash、Eagle3 三种算法。
此次发布的特别之处在于,DeepSeek 直接将两种成品模型部署到了 Hugging Face 上:DeepSeek-V4-Flash-DSpark 和 DeepSeek-V4-Pro-DSpark。用户无需自行训练草稿模型,下载后即可使用;官方声明在保证输出质量不打折的情况下实现了更快的 token 生成,整体推理速度提升 2 至 3 倍。对于已经熟悉 DeepSeek-V4 的开发者而言,这无异于一次零摩擦的性能飞跃。
社区中也出现了不同看法。有观点指出,Qwen 3.6 和 Step 更早将 MTP 实现为与主模型共享内部状态的单文件方案,而 DeepSeek 将草稿头放在独立文件中,推理引擎需要额外“粘合”。拥护者则认为分离式设计反而更灵活,草稿模型可以独立替换、独立训练,不受主模型版本约束。这无关对错,只是不同的工程取舍。
Firecrawl 免 Key 调用模式正式开放:每月免费 1000 次额度,MCP/CLI/REST 全体系支持
Firecrawl 官方近期发布了一项更新:从即日起,使用 Firecrawl 不再需要申请 API Key、无需配置环境变量,直接调用接口即可,并且每个月自动赠送 1000 次免费调用额度。
Firecrawl 是一个专门为 AI 应用设计的网页数据接口。它能够将任意网页转化为 AI 可直接读取的干净 Markdown 或结构化数据。向它提供一个网址,就会返回:
- 清晰的正文 Markdown(自动剔除导航栏、广告、页脚等干扰内容)
- 或者定义好 schema 的结构化 JSON
- 也可按需获取截图、原始 HTML、元数据等
功能还覆盖网页爬取、本地文件解析、arXiv 语义搜索、异步浏览器研究 Agent,以及 GitHub 仓库信息搜索等。
开源项目简介
该项目目前已位居社区 Top 100 仓库之列,收获了超过 13 万 Star。据官方数据,已有超过 15 万家公司正在使用,其中包括 Apple、Canva、Lovable、Stanford、Zapier、Replit 等知名机构。由于完全开源,在开发者中尤为受欢迎。
Firecrawl 提供的 MCP 被安装次数已突破 40 万,很可能是全球安装量最大的 MCP 之一。它拥有三大核心能力:
- Search:对整个互联网进行搜索,每条结果直接附带完整的网页内容。
- Scrape:抓取单个页面,支持 JavaScript 渲染和动态加载。
- Interact:让 AI 能够在网页上执行点击、填表、翻页、登录等操作流程。
这使得 Firecrawl 如同 AI Agent 的眼睛和双手,让 Agent 既能看见网页,又能操作网页。在 AI 联网这个赛道上,它实质上已成为事实标准。
本次更新最核心的变化就是「无 Key 模式」,三个入口同步上线:
GLM-5.2词链推理排第29:分数翻倍背后的效率暗礁
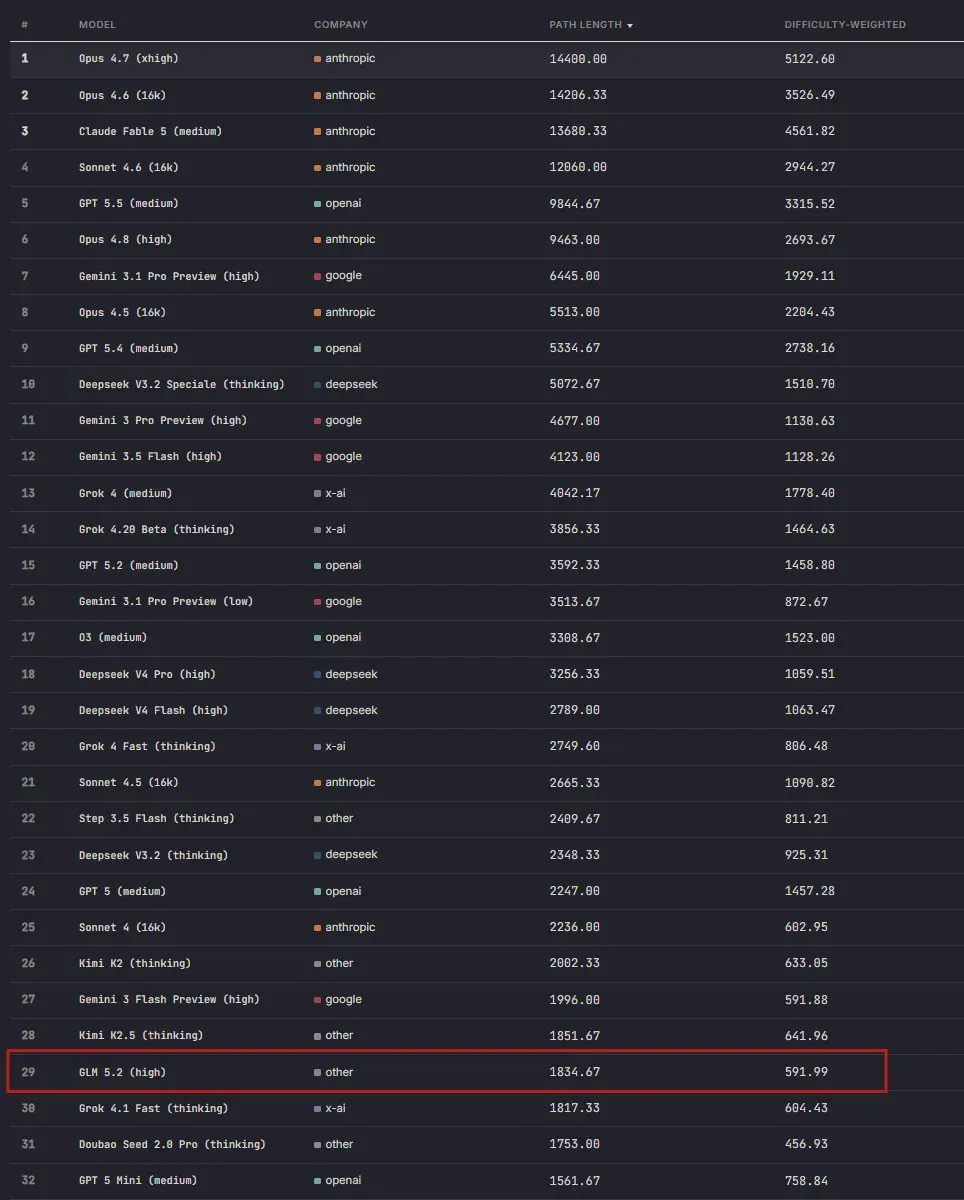
GLM-5.2 在最近一次词链评测中拿到 1834 分,位列全部 139 个模型中的第 29 名。这个位置多少有些尴尬:相比上一代 GLM-5 仅 987 分,进步幅度相当可观,可在整个榜单里依然够不到第一集团,更不用说与 DeepSeek-V4、Kimi 等竞品正面竞争。
- 排名:29 / 139
- 分数跃升:GLM-5(987)→ GLM-5.2-high(1834)
- Token 消耗对比:Kimi-K2.5(≈19k) vs GLM-5.2(≈32k)
LisanBench 考的并非复杂数学,而是一种特殊的词链推理
第一次看到“LisanBench”这个名称,很容易联想到高等数学或代码生成,实际规则却很纯粹:给出一个英文单词作为起点,模型每一步只能插入、替换或删除一个字母,不断生成不重复的有效词汇,尽可能拉长链条。每一步都必须保证新词真实存在,并且不能重复使用之前的单词,更不能走进死胡同。每个起点词会被测试 3 次,最终在 50 个不同起点上统计总分和难度加权分。
举个例子,如果起点是 love,一条可能的链条可以是:
- 插入 r →
lover - 替换 l 为 c →
cover - 删除 r →
cove - 再删 e →
cov(如果字典中没有cov,这一步就算无效)
一句话总结:LisanBench 检测的不是知识储备,而是规则执行、词汇广度、路径规划、记忆去重与持续执行这五项基础能力的综合在线表现。
成绩单看涨幅喜人,但排名与效率不足同样真实
榜单上,GLM-5.2-high 的 Path Length 达到 1834.67,比前代 GLM-5 的 986.83 增长了近一倍。单从纵向提升看,这无疑是一次实实在在的阶段性突破。
但当把视线拉到横向,第 29 名在 139 个模型里仅属中等偏上。榜首被 Anthropic 的 Opus 4.7(xhigh)以 14408 分占据,紧随其后的 GPT-5.5(medium)、Gemini 3.1 Pro、Grok 4 等组成领跑阵营。DeepSeek-V3.2 Speciale(thinking)排名第 9,Difficulty-Weighted 达到 1510;DeepSeek-V4 Pro(high)位列 18,而 Kimi-K2.5(thinking)正好排在第 28 名。也就是说,GLM-5.2 与同圈的 Kimi-K2.5 互有胜负,但还不具备压制这些直接对手的实力。
HermesMoA虚拟模型平民化:一键多专家混合,轻松超越Opus与GPT-5.5

Hermes 把“多模型编排”从底层实现推进到了前台,让你能像切换普通模型一样直接选用。无需重新训练,不用编写繁琐的提示词,安装后输入 /moa 即可启用。重点是:这种组合式对话的使用感受,与你熟悉的单模型交流截然不同。
+8%
vs Opus 4.8
+11%
vs GPT-5.5
1 条命令/moa 切换
近期 AI 社区流传一句话:最顶级的模型都被大公司封闭着,只有少数人摸得到。紧接着,Hermes Agent 将 MoA 做成虚拟模型,并在即将发布的 HermesBench 中测出“比 Opus 4.8 强 8%、比 GPT-5.5 强 11%”的成绩。数字乍听震撼,但很多人都没搞清 MoA 究竟是什么,与你常常听到的“调教大模型”“提示词预设”“后训练”又有哪些本质区别。如果你只关心“这东西怎么用?是不是花钱买个黑盒?”,那这篇文章正是为你准备的。
MoA 通俗解释:像给模型配了参谋团
MoA 全称 Mixture of Agents,即“多专家混合”。有过办公协作经验的人一眼就能看明白:遇到一个问题,先同时扔给 3 到 5 个内部专家分别独立思考,接着由一位汇总者把各家观点揉成一份最终答案交付给你,这位汇总者还有权调用工具完成后续动作。
官方 PR number 46081 讲得更直接:参考模型只能获得对话上下文,不能调用工具;而汇总模型 (aggregator) 可以调用工具,并以“模型身份”输出结果。也就是说,MoA 并非某个新模型,而是给现有模型配备了一批参谋和一名能动手的秘书的调度机制。
三大常见误区,逐一澄清
第一种:认为这是重新训练了一个大模型。 并非如此。调教与后训练修改的是模型权重,而 MoA 完全没有碰触权重,它属于系统层面的调度,并非对模型本体的增强。
第二种:认为这只不过加了一套高级提示词预设。 也不是。提示词预设是用一段文字告诉模型“你应当如何回答”,MoA 则是并行调用多个模型,再由汇总者做融合。两者改变的对象不同:提示词调整的是“怎么写指令”,MoA 调整的是“谁参与思考、谁来总结”。
第三种:认为这等同于给我后训练了一个专属模型。 依然错误。Post-training 是针对单一模型做指令微调、RLHF、DPO、GRPO 等技术。MoA 不训练任何基座模型,它的智能来自于现有模型的组合。打个比方,你不会指望“召集几位顾问开一场会”就能催生出新的技术专利。
编排调教一组专家所产生的成本,远远低于从零训练出具有同等智能的新基座。
这里顺便点出一个更根本的判断:到了 2026 年这个时间点,AI 的基础能力已经足够强。性价比最高的优化,是把现有组合与编排策略调教通顺。MoA 这件事值不值得做,关键看你能不能将调好的“组合”常态化复用,而不是每一次都当成单个项目去折腾。
OpenRouter匿名模型Owl Alpha疑为美团LongCat‑2.0:10.1T月调用量隐秘登顶
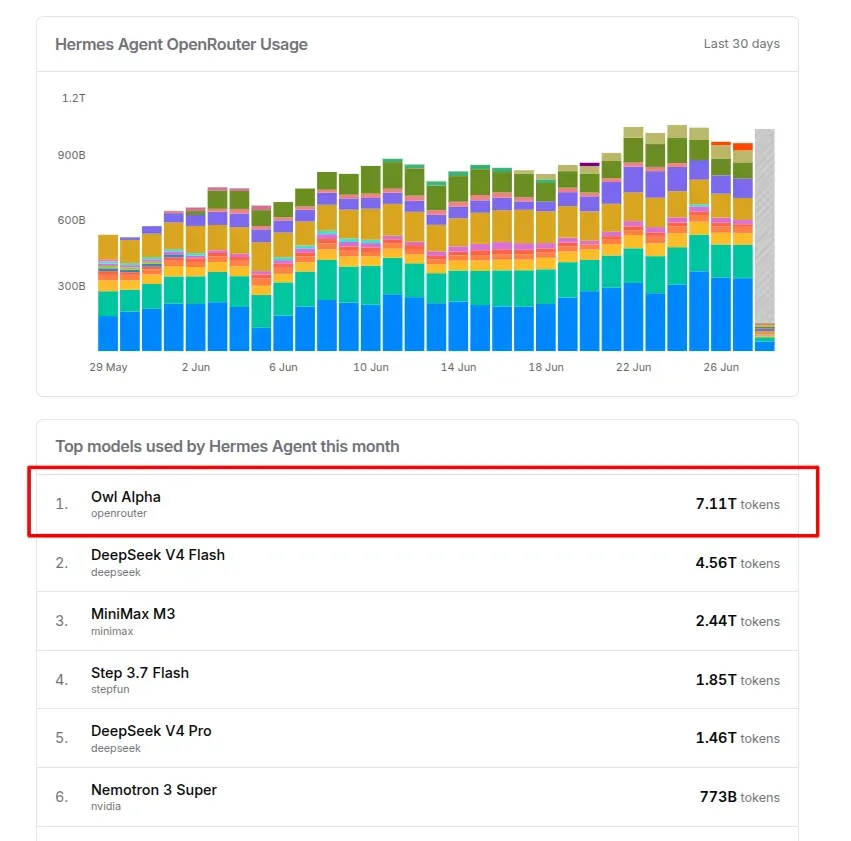
一则未经官方证实的消息正在迅速发酵:OpenRouter 上增速最猛的匿名模型“Owl Alpha”,极有可能就是美团还未发布的 LongCat-2.0-Preview。仅凭公开的调用数据,就足以看清它为什么能无声无息地冲到榜首。
10.1T 月 token 用量
+242% 月环比增长
匿名运行为主,已持续近两个月
在 OpenRouter 的生态里,模型可以用“马甲”身份上线运行,“Owl Alpha”就是一个典型。它已经在平台上默默运转了数月,用户看到的只有这个代号,谁都猜不透背后的团队和公司。
但社区里一条尚未被任何一方证实的小道消息,突然把人们的目光拉了回来:不少业内人士判断,它的真实身份就是美团尚未对外披露的 LongCat-2.0-Preview。这个猜测之所以一下就火了,是因为 LongCat 系列的技术规格和 Owl Alpha 暴露出来的调用体量,恰好能对上。
1.6T参数、48B动态激活:架构猜想背后的工程取舍
如果美团真在打磨新一代基座模型,1.6T 这个参数量并不离谱。真正值得细看的是所谓的“动态激活容量”:多份技术预期都提到,它在推理时不是全量运行,而是只激活大约 33B 到 56B 的参数。对一线云厂商来说,这个范围的激活量,更容易把吞吐和成本压下来。
另一边,原生支持 1M token 上下文窗口已经慢慢成为新模型的“简历标配”。如果 LongCat-2.0 能拿出这个规格,说明美团早已把工程侧的资源对齐到头部序列的竞速上。
目前这些参数信息仍只是第三方描述的拼凑,美团还没有给出任何官方回应。
匿名模型为什么不再被当成“新玩家”
行业对匿名模型已经形成了一套不算新鲜的判断模板:跑榜数据稳、架构说得明白、价格不高、但来源始终成谜。这回 Owl Alpha 几乎踩中了所有点:调用量不但没跌,反而持续爬坡。
OpenRouter 的统计显示,它在 Hermes Agent 上排名第一,Claude Code 第二,OpenClaw 第三。三个使用场景完全不同的客户端同时挤进前三,说明这个模型早就把“讲故事”和“被真实工程链路选中”这两件事区分得很清楚了。
更有意思的是,在 OpenRouter 这种按 token 计费的自由路由平台上,调用量不单单是“用户偏爱”的信号,更是工程链路的压力测试结果。常年霸占前三,意味着各 Agent 栈已经把它当作稳定依赖。
谁先打破沉默:美团还是 OpenRouter?
眼下的悬念主要有两个。第一个:美团会让 LongCat-2.0 继续藏在幕后多久?第二个:OpenRouter 会不会在某个阶段要求匿名模型完成身份披露?这两个问题的答案,很可能只是同一件事的两种表述。
对终端用户来说,匿名并不总是坏事:规范和安全边界还没清晰之前,调用成本会更低一些。但如果这层伪装只是为了规避品牌合规冲突,或者绕过审查要求,那“匿名”就变成了一道竞争护栏。
当你的下一个 Agent 调用撞上匿名模型时
这件事最直接的影响,是改变了“选模型”的参照系。过去大家按名称来挑,旗舰越贵越好;现在则进入了在同一资源池里挑“静默来客”的时期。你需要多追问几个问题:这个模型属于哪家公司?它会不会被突然下架?调用量级代表的是市场策略还是真实的刚性需求?
结论并不复杂:匿名模型的匿名期通常极短。对目前正在使用它的人来说,更安全的做法是把“快速试错”和“批次可用”拆成两件事。试错窗口依然很便宜,但生产级的迁移,最好手里握着一份来源文档。

Windows下Claude Code流畅运行优化全攻略:告别卡顿与输出不全
在 macOS 上使用 Claude Code 的体验通常非常流畅,而在 Windows 环境中的表现则远不如前者丝滑。造成这种差异的根本问题在于 Windows 的命令行环境令人纠结。
具体来说,主要存在以下几个痛点:
- Claude Code 默认调用 PowerShell。
- 即便安装了 Git Bash,Claude Code 也会部分使用它,但 PowerShell 仍可能暗中介入,形成灰色地带。
- 在 Git Bash 中输出会被缓存截断,导致大段代码或对话内容偶尔无法完整显示,影响交互。
解决这些难题的最佳方式,就是让 Claude Code 自行处理。例如,对于默认调用 PowerShell 的问题,可以提示它检查并禁用相关设置。你可以通过以下命令快速复查环境配置:
$ cat .claude/settings.json | grep -i claude_code "CLAUDE_CODE_USE_POWERSHELL_TOOL": "0"
将有关 CLAUDE_CODE_USE_POWERSHELL_TOOL 的说明提交给 Claude Code,它就会自动完成相应配置。
至于 Git Bash 输出被截断的问题,建议改用 Windows Terminal 来运行 Claude Code。安装好 Windows Terminal 后,在其中启动 Claude Code 的效果会比直接在 Git Bash 中操作好很多。特别是在使用中文输入法时,Git Bash 下总是容易出现显示异常,这与它本身的交互模式有关。Git Bash 本身并不是为丰富的交互对话场景设计的,敲击普通命令还勉强可以,但一旦进入多轮对话,就会显得非常难受。
切换到 Windows Terminal 后,体验改善十分明显:
产品经理必读:化解四类职场冲突的底层逻辑与实战心法
产品经理的日常远不止画原型和写PRD。当资源冲突、认知差异、权力边界与情绪摩擦交织在一起时,如何把方案从文档推进到上线才是真正的考验。本文将拆解四类典型冲突的底层逻辑,提供从利益分配到情感账户的实战解法,揭秘产品经理在复杂协作中的翻译者与交易者角色。
———— / BEGIN / ————
做产品经理这些年,我在不同类型的公司都待过,越往后越发现一件事:产品设计本身当然重要,但很多时候,真正磨人的不是方案怎么画,而是方案怎么被推进。
产品经理这个岗位有一个天然尴尬的位置:它常常被单拎在产品团队里,却又处在研发、设计、测试、运营、业务、老板诉求的交汇处。对外,它是需求入口;对内,它又像资源出口。需求从四面八方来,最后经常变成一句话:“你是产品,你来协调一下。”
老板要结果,业务要速度,研发要稳定,设计要完整,测试要风险可控。每个人说的都没错,但放在同一张排期表里,就会变成冲突。
所以这篇文章不想讲“如何做一个更会说话的人”。那当然重要,但不够。产品经理应对冲突,很多时候不是把话说圆,而是把代价讲清楚,把责任说在前面,把关系别搞死。

一、冲突本质:不是沟通不畅,而是协同失调
很多产品经理刚入行时,会把所有冲突都归因于“沟通不到位”。开发不排期,是我没讲清楚;设计不改稿,是我没表达好;测试不放行,是我没解释风险。这个反思有价值,但也容易把自己拖进过度自责里。
后来我慢慢发现,很多冲突不是单点沟通问题,而是几类矛盾叠在一起。
第一类是目标与资源冲突。开发说“排期满了做不完”,测试说“这周没时间测”,老板说“这个需求这周就要”。表面上是时间不够,本质上是零和博弈。你的业务目标是快一点、多一点,对方的职能目标是稳一点、少返工一点。
第二类是认知与标准冲突。你觉得某个交互逻辑很反人类,设计师觉得这是高级的留白;你觉得某个边角料问题不修也能上线,测试觉得这是原则性 P0 缺陷。这里没有绝对对错,只有评价体系不互通。
第三类是流程与权力边界冲突。比如项目卡住了,你为了效率绕过执行层开发,直接去找他的直属领导敲排期。对方表面答应,私下可能觉得你越权、打小报告,后面开始消极抵抗。此时冲突已经不只是事本身,而是对方的安全感和专业地盘被破坏了。
第四类是人际与情绪摩擦。无论你提什么,对方都习惯性反驳;群里沟通时总是阴阳怪气。这通常是“情感账户”已经透支。可能是上次项目你让他背了锅,也可能只是长期合作中积累了不爽。此时“对事不对人”已经不完全有效,因为对方可能就是在对人不对事。
判断冲突类型很重要。资源冲突要谈交易,标准冲突要拿证据,边界冲突要补安全感,情绪摩擦要先修关系。拿错工具,只会越处理越糟。
二、显性规则一:先绑定共同利益,再谈个人诉求
在我第一份产品经理工作时,前辈跟我讲过一句话:跨部门推动任何改变之前,先想清楚这件事对对方是利好还是利空。
这句话听起来很朴素,但越工作越觉得对。职场里很多时候是多做多错、少做少错。如果一件事对对方完全没有好处,还要额外承担风险,那别人凭什么配合你?只靠“我是产品,所以你得听我的”,基本是最无效的沟通。
产品经理也不能太天真,以为只要把业务价值讲清楚,别人就会自然配合。很多时候,对方不是不懂价值,而是不想为这个价值承担额外成本。说白了,冲突处理不是单纯沟通,而是利益和风险的重新分配。
所谓共同利益,不是开会时喊一句“为了公司和用户”。它要被翻译成对方听得懂的语言。
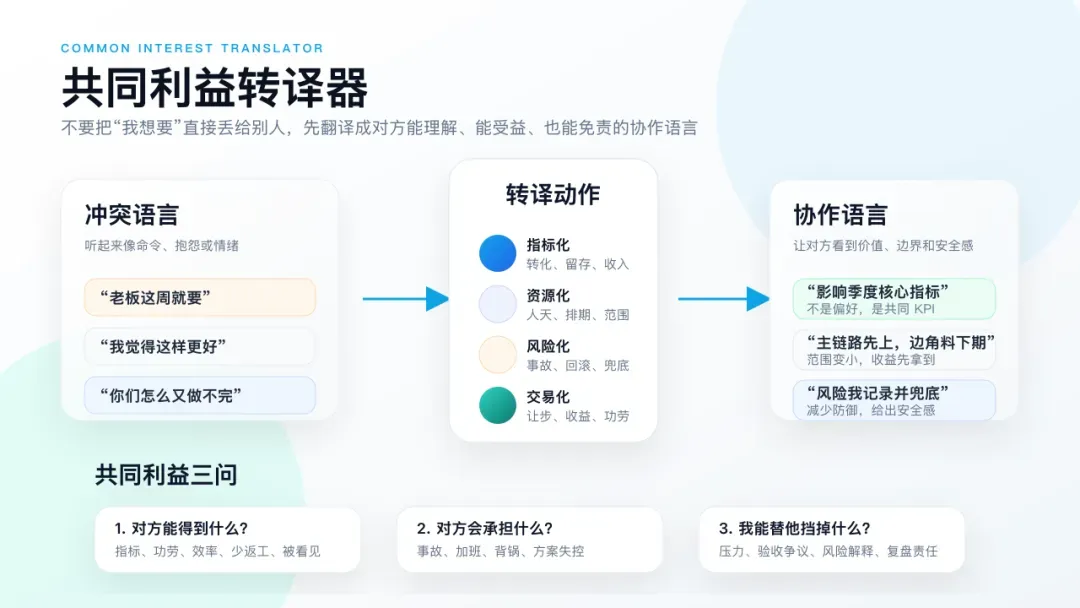
比如面对目标与资源冲突,产品经理确实要学会“扯虎皮”。老板要求、季度重点、战略项目,这些压力源不是不能用。但如果只说“老板这周就要”,本质上是在把压力扔给别人,对方只会本能防御。
更有效的说法是把需求转成共同利益:
“这个功能对应本季度核心转化指标,如果这周能先把主链路上掉,下周就能开始收数据。边角料交互我可以拆到二期,测试风险我来记录并对需求方解释。”
这句话里至少有三层信息:为什么要做、可以先不做什么、风险谁来兜。对方听到的就不只是催进度,而是一个可以交易的方案。
产品经理要避免一个人推着车走。很多时候,产品、开发、测试、设计虽然不是同一个直属领导,但都在一个大研发团队里,往上看会有共同的大部门目标。你要做的不是用头衔压人,而是把大家的利益绑到同一辆车上。
这里还有一个现实技巧:学会传导压力,而不是独自吞压力。面对需求方的压力,产品不要永远大包大揽。必要时带着开发、测试一起去听业务方诉求,让他们看到真实业务压力,也让需求方看到真实研发成本。
这不是甩锅,而是让两边都看见真实约束。产品一直挡在中间,业务会觉得研发不配合,研发会觉得产品在添油加醋,最后只有产品被两边消耗。
三、显性规则二:面对不同角色,切换不同语言
内部协作最容易踩的坑,是产品经理用同一种沟通方式面对所有人。对老板讲业务价值,对开发也讲业务价值;对设计讲用户体验,对测试也讲用户体验。结果就是你说得很努力,对方听得很疲惫。
因为每个岗位真正关心的东西不一样。

面对开发,要用逻辑和边界说话。开发最讨厌的不是需求本身,而是需求变更、逻辑不清和被催进度。你说“加个字段”,实际可能是跨库联表、底层数据结构调整、历史脏数据处理和接口兼容。这里存在天然的信息不对称,开发掌握着技术复杂度的解释权。
这也是为什么产品经理不能完全不懂技术。不是为了自己写代码,而是为了打破“技术黑盒”。当对方说“底层逻辑要重构”“这个接口不支持”时,你至少要能追问:影响范围在哪里?有没有绕过方案?只影响新数据还是历史数据?是否可以先用配置或兜底逻辑解决?合理的技术反问,会让对方知道你不是来画饼的,也不是可以随便糊弄的。
实现方式可以妥协,但核心业务价值不能随意放掉。如果冲突过大,可以升级找对方领导协调资源,但要记住:升级的对象是资源和优先级,不是私人审判。
我以前也犯过一个错:项目卡住时,第一反应就是找对方领导。事情确实推进了,但后面那个开发明显不愿意再主动沟通,评审会上也只回答最小必要信息。后来我才意识到,对方不一定是不配合,而是觉得自己被绕开了。
这类账不会立刻爆,但会在下一个项目里还回来。
面对设计,要平衡美感和可用性。设计师容易陷入对视觉完整性的坚持,而产品更关心业务路径、转化效率和用户习惯。更隐性的点是,很多设计师会把 UI 界面视为未来作品集的一部分。你觉得只是一个按钮样式,他可能觉得这是自己的专业表达。
所以面对设计,少说“我觉得不好看”,多说“这里会影响用户下一步决策”。如果你觉得某个方案不合理,可以拿竞品、数据、用户访谈、点击热区来说话。颜色、排版、插画风格这些不影响核心转化的地方,尽量尊重设计专业;但交互路径、信息层级、关键按钮优先级这些影响业务逻辑的地方,产品要温和但坚定。
面对测试,要给风险口径和兜底方案。测试通常相对好协调,因为他们更关注风险是否可解释。很多项目里,带 bug 上线并不少见,关键在于这个 bug 是不是已知、影响范围多大、有没有回滚方案、谁承担上线决策。产品如果敢做风险兜底,敢把风险同步给需求方,测试往往不会为了一个边角料问题和你死磕到底。
但这不意味着可以轻视测试。测试最怕口头承诺,今天说“这个问题不影响”,明天线上出了事故又没人认。所以和测试协作时,要把风险等级、影响范围、上线口径写进文档或群里。不是为了留下甩锅证据,而是为了让团队对同一件事有同一份记忆。
四、隐性规则:工作靠流程推进,也靠情感账户润滑
上面说的都是明规则。明面上,大家靠流程、文档、会议、排期推进工作。但水面之下,很多事情其实靠信任余额和非正式关系润滑。
为什么同样一个稍微不合理的需求,别的 PM 能让开发加个班搞定,你却怎么都推不动?很多时候不是他话术比你高级,而是他平时在“情感账户”里有余额。在读《高效能人士的七个习惯》这本书时,里面有一章讲的从“个人成功”过渡到“公众成功”,重点描述了情感账户的作用。
比如上次开发出了线上小问题,他帮忙对外扛了一下;比如评审会上,他没有把功劳全揽到产品身上,而是特意说“这个方案是开发同学一起补齐的”;再比如平时一起吃饭、喝咖啡,聊过一些工作之外的话题。到了关键时刻,对方会觉得“这个人值得帮一次”。
这不是鼓励讨好,也不是让产品经理变成社交型人格。它只是说明一个事实:职场协作里,人情世故永远存在。你可以不擅长,但不能假装它不存在。
尤其是流程与权力边界冲突,事后修复非常重要。假设你因为项目卡住,确实找了对方领导协调。事情推进了,但执行层开发心里有疙瘩。这个时候不要继续用领导压他,也不要去戳穿他的敷衍。更好的方式是单独约个咖啡,姿态放低一点,底线踩实一点。
可以这么说:
“上次我直接找你领导,是因为那个节点确实被业务卡死了,不是想绕过你。后面方案还是你来主导,我这边配合把需求范围和优先级压清楚。”
这段话的重点不是道歉姿态,而是把控制权还给对方。很多消极抵抗,本质上不是因为事情多难,而是因为对方觉得自己被架空了、丢了面子。你把面子补回来,后面才有合作空间。
五、遭遇冲突前,先问自己六个问题
如果把这些经验压成一个标准流程,又会变得很像培训课件。真实工作里,冲突经常没有那么干净:会议开到一半,老板突然插一句;开发在群里只回一个“做不了”;测试在上线前突然抛出一个风险;设计师沉默半天,最后说“这个我不认同”。
所以现在我遇到冲突时,不会先想着套步骤,而是先问自己几个问题。
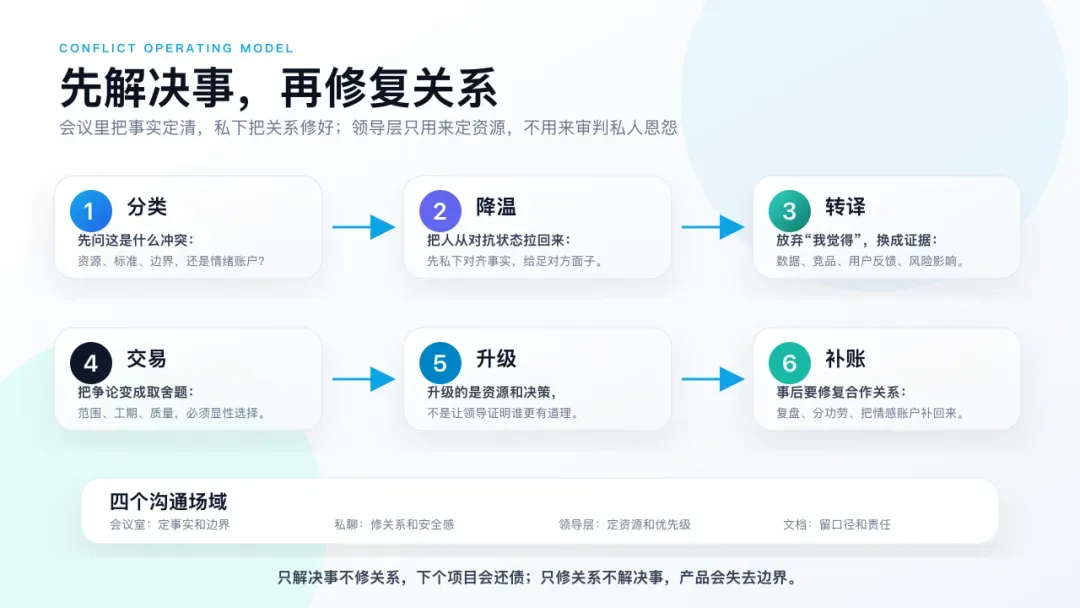
第一个问题:这到底是在吵事,还是在吵成本?
很多排期冲突表面上是在说“做不完”,实际上是在说“为什么这个成本要我来承担”。如果是资源问题,就不要继续讲愿景,直接把范围、工期、质量摊开,让决策者做选择。
产品经理直觉训练实战:在数据失效时,如何让第六感成为判断利器
当数据与直觉打架,产品经理该怎么选?这篇文章从我的亲身经历出发,解剖了那些数据一路绿灯却最终惨败的功能背后,直觉提前发出的预警信号。通过分析大脑的“离线计算”机制和真实案例的复盘,梳理出一套把模糊的“感觉”转化为可检验的决策框架,并给出三条训练产品直觉的实操建议。
刚入行那几年,我最不信的就是“直觉”。
开会时前辈说“我感觉这个方向不太对”,我嘴上不说,心里却在嘀咕:感觉?先把数据拿出来看看。靠感觉做决策,跟扔骰子有什么区别?
那时的我坚信一套清晰的产品流程:看数据→找问题→出方案→小流量验证→看数据→定生死。每一步都得量化、可追踪、可归因。逻辑链必须闭合,结论必须有凭有据。任何说不清来源的判断,放在我这里都会被重审。
结果怎样?被打脸的次数,两只手都数不过来。
后来我才慢慢意识到,那些看上去“说不清”的判断,并不是没来由,而是来源藏得太深——深到意识层面够不着,但大脑其实已经算完了。那个被叫做“直觉”的东西,其实是经验的压缩包,是你踩过的每一个坑、摔过的每一次跤、复盘过的每一次失败,在潜意识里沉降下来的一套模式识别系统。
今天,我想聊聊这些年是怎样从“唯数据论”的产品经理,一步步走到重视直觉、学会驾驭直觉的。
初识直觉:一次让我信念动摇的功能上线
大概六七年前,我们准备上线一个全新的功能。
当时的各项数据都很漂亮:用户调研显示83%的人“有兴趣使用”,竞品也做了类似功能,增长曲线可观,内部评审顺利通过。立项、排期、开发、测试,一切都按部就班。上线前一周,我一遍遍看着数据报告,却总觉得哪里不对。
我说不出具体哪里有问题。用户研究做了,数据分析跑了,逻辑推演也推了无数遍,所有理性的指征都在说“没问题”。可心里就是不踏实,像鞋子里钻了一粒小石子,走一步硌一下。
团队征询我的意见,我回了一句:“再等等,让我再想想。”开发负责人看着我的眼神,我读懂其中含义:你是不是在拖延?
可我当时真的辩无可辩,因为拿不出任何理由。数据没有毛病,逻辑没有漏洞,我凭什么去说服别人延期?
最终,这个功能还是按时上线了。
结果呢?上线一个月,使用率不到预期的20%。用户并没有像调研时说的那样“有兴趣”。那个数据好看的用户调研,在真实使用场景里完全失准。我们花了三个月做出来的功能,又在三个月后花了两个月才把它下线。
复盘时我不停地问自己:当初那个“不对劲”,到底是什么?
后来我想通了——其实是我隐约感觉到,这个功能正在解决一个根本不成立的问题。用户说的“有兴趣”,更像是在回答“这个功能听起来不错”,而不是“我真的缺这个功能”。我经历过太多次类似的场景:用户在接受访谈时,永远比实际使用中更热情、更开放、更愿意尝试新东西。可回到真实场景里,他们忙、懒、怕麻烦,根本不会去碰那些“锦上添花但不痛不痒”的东西。
这些片段的经验在当时没能浮出意识水面,但它们钻进了我的潜意识,混合成一种说不清的“不安感”。
从那以后,我开始认真对待这种“感觉”。
直觉的本质:潜意识中的模式匹配引擎
把直觉简单归为“感觉”,是一种偷懒的说辞。我更愿意这样理解直觉:它是大脑在意识之外完成的一整套模式匹配计算。
我们的意识一次只能处理极为有限的信息——差不多7±2个组块。但潜意识却可以并行处理海量信息,包括很多你根本没注意、甚至没意识到自己注意到的细节。
举个例子:你见过一万个用户的使用行为。即便你不可能记住每一次,但你的大脑记住了“多数用户会在这个环节停滞”“这个区域用户很容易忽略”“这类文案的点击率普遍不高”。这些模式不需要你主动去调取,当新的情境出现时,大脑就会自动去对碰历史模式,然后输出一个结果——这个结果就是所谓的“直觉”。
回想一下做产品的过程,这样的瞬间是不是经常出现:
- 看到一个设计方案,第一反应就是“不行”;
- 听到一个运营活动,下意识就觉得“效果不会好”;
- 翻阅一个新功能原型,心里那个声音会说“用户不会这么用”。
这些“第一反应”并不是凭空冒出来的。它们源自你在过去几年甚至十几年里,看过无数个类似方案、活动、原型之后,大脑自动做了一次相似度匹配,并把匹配结果迅速告诉你——“这个东西看上去很像之前那个失败的”。
只是大脑没有用语言告诉你“因为A、B、C三个原因,所以这个方案风险偏高”,而是直接丢给你一个感觉:“别走这条路。”
直觉的盲区:一次代价高昂的误判
说了直觉那么多好话,也得坦诚讲讲它不靠谱的时候。
大概四五年前,我们尝试做一个全新的方向。项目启动会上,我一听完方案,强烈的抗拒感就冒了上来——“不行,这个方向肯定走不通”。至于为什么,我说不出,就是感觉不对。
可因为上一次的教训,我选择相信直觉,这次我异常坚决地否掉了这个方向,连小规模验证都没做。
结果半年后,市场上跑出来一个类似的产品,做得很风生水起。虽然细节不完全一样,但核心逻辑跟我当初否掉的那个八九不离十。
我懊恼极了。不止是因为错过,更是因为我突然意识到:原来我的直觉并不总是对的,可我却在这一次给了它过高的信任。
那之后,我认真反思了自己的直觉运作机制。我发现,当直觉发出“不行”的信号时,其实藏着两种截然不同的情况:
- 一种是“这个方向存在本质性问题”——这种直觉比较可靠;
- 另一种却是“这个方向我很陌生”——这种直觉,不过是路径依赖。
大脑在判断一个不熟悉的方向时,会自动调用过往经验去套它。但如果这个方向和以往的经验确实不同,那么“感觉不对”就仅仅意味着“我不习惯”,而非“它不合理”。
自那以后,我给自己安了一个直觉校准器:每当直觉跳出来说“不行”的时候,我先反问自己一句——“是因为它真的有风险,还是因为它陌生?”
直觉与数据的协奏:一个四步决策框架
如今在评判一个产品决策时,我基本会遵循这样一个流程:
第一步,先用直觉产生假设。
无论拿到什么需求、方案、方向,我会先让自己去“感受”一下。不分析、不拆解、不看数据,就凭第一反应去体会:这个方向让我兴奋还是焦虑?这个方案让我觉得靠谱还是别扭?
在这一步,我会刻意不让理性那么快介入。因为理性一进来,就很容易把直觉发出的微弱信号压下去。先让直觉把话说完,哪怕它说得没头没尾。
第二步,用逻辑拆解直觉。
把直觉做出的判断记录下来之后,再开始追问:如果直觉说“这个方案不行”,那具体不行在哪里?是用户价值不清晰?是技术实现成本太高?是和我们现有的能力衔接不好?还是仅仅因为它和以前长得不一样?
这一步的目的,是把直觉转译成可以被验证的命题。直觉丢给你一个结论,你则要用理性去寻找论据。
第三步,用数据去检验这些命题。
一旦翻译成具体命题,就不再模糊。去找数据验证:如果直觉说“用户不会这么用”,那就看看类似场景下用户的实际路径;如果直觉说“这个功能使用率高不了”,那就找找历史上可类比的案例;如果直觉说“总感觉有风险”,那就把可能的风险点一条条列出来,逐一排查。
数据的意义不在于百分之百证实或证伪直觉,而在于能把原本模糊的直觉,转变成一个个具体的判断维度。
第四步,用直觉做出最后的落槌。
当所有逻辑和数据的分析都已经穷尽,却还是两边各有道理,或者信息根本不足以做决定的时候,最后的补位,我选择交还给直觉。
为什么?因为所有分析工具都有它的边界——样本可能有偏差,逻辑可能会遗漏,假设也可能出错。在巨大的不确定性面前,直觉就是你所有经验的合集。它可能说不清道理,但它已经用几万小时的数据训练过你自己的大脑。
这个框架未必完美,但在实践中帮我有力地避开了几类常见错误:既避免了一味盲从直觉而错失机会,也防止了完全忽视直觉而再一次踩进同样的坑。
培养“产品感”:给新人三个可落地的训练法
不少人问过我:你说直觉可以练,那对一个新人来说到底该怎么练?
我觉得这件事没办法一键速成,但确实有路径可循。分享三个我最受用的方法。
第一个:多看少断,把观察前置。
很多新人产品经理一上来就习惯做判断——“这个功能好”“那个设计糟”。判断做得多,观察自然就少了。
我的习惯是,不管用哪个App,遇到任何设计,先问自己三个问题——“它为什么长成这个样子?”“它在解决谁的什么具体问题?”“如果交给我改,我会从哪里着手?”
这三个问题搁置了“好不好”的结论,只追问“为什么”和“怎么做”。不急着下好坏论断,先投入地做一个观察者和推演者。这件事坚持久了,大脑会自动积攒大量模式,直觉的素材库便会越来越充实。
第二个:刻意复盘,把失败刻成训练数据。
直觉不准,往往不是因为经验不够,而是因为经验没有被有效编码。你踩过一百个坑,但如果每一个坑都只是“踩过即忘”,那大脑就很难从中构建出真正有效的模式匹配。
这些年让我受用最深的一个习惯是:每一次失败的产品决策,我都逼自己写一份简短的复盘,只回答三个问题——
- 当初我做出了什么判断?
- 判断的依据是什么?
- 事后回看,我当时到底忽略了什么?
不需要长篇大论,几百字足矣。这个动作把一瞬间的“感觉”转化成了可供回顾的“记忆”,让模糊的经验变成日后能被随时调取的判断依据。
第三个:在压力场景中做出决策。
从传声筒到决策者:产品经理的10个关键需求提问
初入产品经理这行时,我最害怕听到的五个字就是:“这个很简单”。业务方轻飘飘一句“你帮我加个功能就行”,那感觉,就像开发同学听到“稍微改改就行”一样,拳头瞬间就硬了。听上去仿佛顺手带杯奶茶一样随意,但后来我无数次发现,需求事故的起点,往往就藏在“很简单”这三个字里。前面没有人把问题剖开问透,后面研发追着我问“规则是什么”,测试堵着我问“异常怎么处理”,老板最后劈头盖脸一句“为什么做完没效果”。我只能表面镇静,心里抱头咆哮:救命,不是说他是个“简单的”需求吗,怎么一落地就全是坑?
在坑里滚过几回之后,我终于悟出了一件事:接到需求的瞬间,别急着把“我要一个功能”翻译成一页页原型和按钮。先问清楚——它究竟在解决谁的什么问题,为什么值得投入资源,又该做到什么程度才算真正成功。这么说可能有点抽象,于是我把它拆成了下面这10个提问。
一、先问背景:这个需求到底从哪儿冒出来的?
需求可不是石头缝里蹦出来的孙悟空。它可能有无数种来源:一次用户投诉,一个业务目标,老板的一句话,竞品的突然上新,一次数据异常,一个政策合规要求,或者是对某个大客户的承诺。
来源不同,处理逻辑就完全不同。用户反馈说“找不到入口”,你未必真要新增一个入口,说不定是信息架构已经乱成一团。业务方喊“转化低”,不一定要立刻甩出一张优惠券,很可能是因为流程太长、信任感缺失,或者关键信息根本没展示清楚。老板说“竞品有这个功能,我们也要有”,我第一反应绝不是打开 PRD 模板。竞品做了,不代表我们现在就该做;竞品做得漂亮,也不代表它对我们的用户真的有用。
我通常会连追三个问题: 1.这个需求具体是从哪里来的? 2.当前到底发生了什么问题? 3.为什么非得是现在做不可?
第三个问题尤其致命。很多需求不是不能做,而是不该现在做。有没有时间窗口?有没有业务大节点?是不是对客户的承诺?监管还是合规要求?如果答案全是“没有”,那它可能只停留在“想做”,远远没到“必须做”的程度。
我以前带过一位从其他部门转来的产品经理,经历了两三年,我给了她一个相对成熟的小项目练手。小姑娘积极性确实高,但没多久我就察觉出不对劲:客户问题反馈量反而涨了,开发天天加班。一了解才知道,但凡有人提个需求,她就照单全收,原样转发给开发,系统越堆越臃肿,凭空多出了一堆没人用的功能,甚至开始影响大部分客户的正常业务流程。我不得不紧急叫停,做一轮大瘦身。
新人PM很容易把“有人提了”等同于“我得接了”。但现实中,我们从来不是需求收纳箱。第一时间不该去当搬运工,而该先去判断:这到底是不是一个值得排进迭代的真问题。
二、再问目标:做完以后,谁会切实变好?
一个只有功能描述、没有目标的需求,就好比你跟厨师说“我要吃个东西”,却不说是一顿早餐、一份减脂餐,还是一桌商务宴请。
我现在审视需求,会先把它拆成两种价值:业务价值和用户价值。业务价值可能是增收、降本、提转化、减流失、提效率;用户价值则可能意味着更快、更省事、更准确,或者体验更顺畅。
听着挺理论,但往地上一落就变成一句话:这个功能上线后,终究想让哪个指标变得更好?是转化率提高?是使用率上去?是任务完成率抬头?是处理时长下降?还是投诉率、退款率下来了,GMV涨了,客服量降了,或者实实在在地省下了运营成本?
如果对方只丢出一句“就是体验优化”,我一般不会轻易放行。不是说“体验优化”不好,而是这两个字太容易变成万能胶,什么都能往上粘,到最后谁也说不清到底做得好不好。
我会继续往下挖: -用户现在到底卡在哪一步? -我们希望他少点几步?少等多久?少问几次客服?少填多少错误的字段?
把目标问得足够细,后面才有验收的硬依据。否则等到上线,大家只能对着页面干巴巴地感慨:“嗯,看着挺舒服的。”至于有没有用,只能交给玄学。产品经理,不能只当气氛组。
三、确认用户和场景:别为“幻想中的用户”做产品
很多需求出来,开头永远都是“用户需要”。但“用户”究竟是谁?是C端消费者,是运营同学,是销售,是客服,是后台管理员,是商家,是机构客户,是老板本人,还是隔壁部门那位每次开会都脑洞大开的同事?
角色不同,场景就天差地别。同样是“导出数据”,运营可能想看每日趋势,销售可能要按客户维度筛选,财务要核对金额,管理者可能只需要一张汇总表。你如果只听“导出”两个字,就兴冲冲画了一个Excel导出按钮,后续几乎必然被追着补字段、改权限、换格式、调频率。
我通常会把场景问到足够立体的程度: -用户在什么时间点会用到这个功能? -他从哪个入口进来? -当时他正在完成什么核心任务? -这个需求发生前、发生中、发生后,整个流程分别是什么? -它是高频刚需,是低频但重要,还是一次性的临时救急?
这一步问起来略显啰嗦,但非常救命。产品方案不是飘在半空的抽象概念,它必须落在一个具体的角色、一个具体的任务、一条具体的路径里。场景问不清楚,后面画原型就很容易画成“功能陈列柜”——什么东西都有,但每一样都半吊子,用户根本不知道怎么用。
四、划清范围:这期做什么、不做什么,要说透人话
新人产品经理最容易踩的一个坑,就是下意识觉得需求范围越大越完整。后来我被现实狠狠教育了一番:范围越模糊,项目就越容易变成大型许愿池。
今天说App要做,明天说Web端也得有,后天说后台配置不能少,再过两天外加开放接口、小程序、H5、数据导出、精细权限分级、历史数据兼容,全都一股脑涌进来。每个功能都被包装成“顺便一下”,最后研发同学看我的眼神里,写满了克制。
所以接需求时,一定要摊开来问: -这次主要解决什么核心问题? -哪些明确属于本期范围? -哪些确定暂不做,原因是什么? -是否涉及多个端?App、Web、后台、小程序、H5、开放接口? -是否涉及不同角色、权限、组织层级、地区、业务线? -有没有历史数据、存量用户、老流程兼容的问题需要特殊处理?
这里有个小技巧:不要只干巴巴写上“暂不支持”。最好说清楚为什么暂不做,以及后续满足什么条件会再考虑。比如:“本期仅支持运营后台手动配置,不做用户端自助修改,因为当前重点在于快速验证运营策略的有效性;若使用率超过X%,再启动用户自助能力的评估。”
这样写不是为了显摆专业,而是为了大幅减少之后的扯皮,也让开发在设计时能提前预留扩展接口,避免后续大动干戈。范围的边界越早画清楚,项目就越不会在中途偷偷长胖。
五、业务规则要抠细:魔鬼不是藏在细节里,魔鬼就是细节
需求讨论时,大家都爱对着页面高谈阔论,最容易漏掉的恰恰是规则。但真正让项目延期的,往往不是哪个页面的摆放,而是那些毫不起眼的规则漏洞。
条件是什么?状态有哪些?计算逻辑怎么定?有什么限制条件?优先级排序规则是什么?失败、超时、重复提交、撤销、驳回、误操作,每一步该怎样处理?谁能查看,谁能修改,谁能审批,谁能导出?功能权限和数据权限到底是不是一回事?通知什么时候发,发给谁,通过站内信、短信、邮件还是企业微信?
这些问题碎得让人头皮发麻,但它们恰是决定产品能不能真正跑起来的筋骨。
有人写需求,就写一句“支持审批”。但“支持审批”四个字的背后,很可能藏着一整套状态流转:待处理、处理中、已通过、已驳回、已取消、已撤回、已过期。每个状态下能不能编辑?能不能再次提交?通知给谁?相关数据算在哪一天?权限变更之后,历史单据怎么处理?
你看,一个“审批”足以把人彻底打醒。写规则之前,宁愿前面多问两轮,也比上线前临时抱佛脚到处补洞强。临时补洞最伤,因为它通常不是补一个洞就行,而是扯出一整串洞,补着补着就四处漏风了。
六、数据和指标提前定:别等上线了才开始吵“怎么算”
数据这件事,最怕的就是上线之后才去回想。一旦上线后才发现没埋点、没报表、没看板、没导出,或者指标口径没人统一,大家便会自动进入那个经典扯皮环节:
“你说的完成率,是提交完就算完成,还是审核完成才算?” “转化率的分母,算访问用户还是点击用户?” “历史数据能不能对齐对比?” “为什么你这边拉出来的数据,跟我这边天差地别?”
每次听到这些,我的血压都会礼貌性升高。所以需求承接阶段,我总要提前确认好: -需要采集哪些数据? -是否需要埋点、报表、看板、导出接口? -指标口径到底怎么定义,务必白纸黑字写清楚? -是否需要和历史数据做对比? -有没有数据权限、数据安全、隐私合规方面的硬性要求?
尤其是口径定义,千万不要想当然地觉得“大家都懂”。现实工作里的一大半事故,就是从“我以为你也这么理解”悄无声息开场的。
七、技术影响别装作看不见:产品不写代码,但要清楚代码会疼
产品经理不一定非得会写代码,但不能对系统影响完全无感。一个需求要改动哪些系统或模块?是不是依赖第三方接口、数据中台、支付、消息、CRM、ERP?对性能、稳定性、容量有没有特殊要求?会不会冲击现有流程,影响老用户?需不需要灰度方案、功能开关、回滚预案?部署方式是SaaS、本地化,还是政务云?
这些问题不提前问清楚,前期方案画得再美,到了落地环节也可能寸步难行。
以前我也觉得灰度、开关、回滚完全是技术同学要操心的事。直到亲身经历过一次线上改动把老用户流程彻底冲垮,我才明白,产品在设计方案时就该想好:万一出了问题,怎么退?上线从来不是一场剪彩仪式,而是系统开始接受真实世界暴打的起点。你不能只想着它成功时的样子,也必须想好它失败时有没有退路。
八、判断优先级:不是所有需求都值得大张旗鼓
需求源源不断,资源永远不够,这是产品经理日常工作的背景音。所以接需求时,不能只问“能不能做”,更得问“值不值得这样大费周章地做”。
从生成到交付:TRAE Work Design 模式如何让 AI 设计稿真正落地
过去两年,许多团队已经尝试过 AI 设计工具:输入一句描述,几十秒就能得到一页界面;上传一份需求,快速产出几套 UI 方案;甚至无需设计背景,也能“画”出像样子的产品界面。初次体验的确令人兴奋,但一旦试图把这些设计稿用到真实项目里,问题便接踵而来。
页面看起来不错,却不符合团队既定的视觉规范。有时只是想微调某个元素,AI 却将整张页面推翻重来。好不容易改到满意,还得重新梳理标注、补齐交互说明,才能交给开发落地。慢慢地你会发现,AI 设计最核心的挑战并不是“能不能生成好看的图”,而是生成的成果究竟能不能真正进入生产,被反复使用和迭代。
因此,当了解到 TRAE SOLO 已升级为 TRAE Work,且 Design 模式全量上线后,我立即用一个真实项目完整地体验了一遍。
体验下来,TRAE Work Design 模式并非简单地在现有产品里塞进一个“AI 出图”功能,而是尝试把设计放回完整的 AI 工作流中:从需求背景到界面生成,从画布编辑到原型交互,再到导出 Figma、代码甚至直接进入 Code 模式交付。设计不再停留在一次性灵感图上,而成为可以被持续推进、可直接协作、可直接交付的生产环节——这才是这次升级真正有趣的地方。
打通需求到代码:Design 模式重新衔接 AI 工作流
要理解 Design 模式为什么不是又一个新功能,不能只看它能不能生成页面,而要把它放到整个产品工作流中去观察。过去,我们用 AI 工具往往解决单点任务:写一段代码、产出一页 UI、梳理一份需求、快速搭个原型。每个环节看似都提效了,但彼此之间常常割裂。
然而真实的产品工作从来不是由孤立的任务拼装而成。一个页面从想法到上线,往往要经过需求梳理、信息架构、视觉设计、原型沟通、代码实现和持续迭代。每个环节都会继承前序信息,也影响后续决策。分散在不同工具里工作时,信息便在一次次切换中被损耗——产品经理在文档里写清楚的需求背景,到了设计阶段又要重新解释;设计稿里已经定型的交互逻辑,到了开发阶段还要再同步一遍。大量时间没有花在真正的创造上,而是消耗在复制信息、补充上下文和反复对齐上。
正因如此,TRAE Work Design 模式的价值不只在于提升 AI 设计稿的生产可用性。站在整体工作流的角度看,它还有一个更重要的作用:将原本割裂在需求与开发之间的设计环节重新接了回来。
通过 Work、Design、Code 三种模式,需求分析、界面生成、原型搭建和代码实现被放进了同一套产品框架里,不同阶段之间的衔接更加直接。在这次体验中,我先在 Work 模式里完成了竞品分析和市场研究,让 TRAE 产出一份 MVP 版 PRD;随后切换到 Design 模式,直接基于这份 PRD 生成设计稿;调整好效果后,再通过 Code 模式进行代码实现。
整个过程能让人更直观地看到,TRAE Work 正把需求、设计和开发放入同一条连贯的生产线里。当然,流程串起来只是第一步,Design 模式能否真正用于生产,关键还要看它如何处理设计规范、持续编辑和后续交付等深水区问题。
下面我将结合项目的实际体验,重点展开 Design 模式在这些层面上的做法。
设计即生产:让 AI 产出可修改、可协作、可交付的成果