GLM-5.2 登顶 SWE-bench Pro:国产开源编码模型如何以六分之一成本挑战 GPT-5.5
由Z.ai(原智谱AI)推出的GLM-5.2在SWE-bench Pro基准上取得62.1分,超越GPT-5.5的58.6分;同时,其API成本仅为每百万token5.80美元,而GPT-5.5约为35美元,成本差距接近6倍。
该模型参数规模达753B,在长上下文与复杂代码任务中表现突出。
对开发者而言,这不仅是一次性能层面的追赶,更是一个可直接验证的结构性转折点:在关键软件工程基准上,开源/开放权重模型首次进入与最前沿闭源模型同一竞争区间,并在成本效率上形成显著优势。
- 参数规模:753B
- SWE-bench Pro:62.1
- 成本对比:约1/6(GLM-5.2 vs GPT-5.5)

GLM-5.2 基本参数一览
GLM-5.2 拥有 7530 亿参数,采用 MIT 许可证开源,支持 100 万 token 上下文窗口。模型在 Hugging Face 上可直接下载,能接入 20 余种第三方编码环境。MIT 协议赋予企业自由修改、微调和商用的权利,无版税和区域限制。
Z.ai 对它的定位非常清晰:这不只是 “开源追赶闭源” 的叙事,而是 “开源与闭源站在同一起跑线” 的开端。
编码基准:硬碰硬的结果
SWE-bench Pro 考核真实软件工程任务,包括长时间代码库维护、多步开发与项目协调。GLM-5.2 得分 62.1,GPT-5.5 为 58.6。在 FrontierSWE 上,GLM-5.2 为 74.4%,略低于 Claude Opus 4.8 的 75.1%,但高于 GPT-5.5 的 72.6%。此外,MCP-Atlas 和 Humanity’s Last Exam 也均由 GLM-5.2 领先。
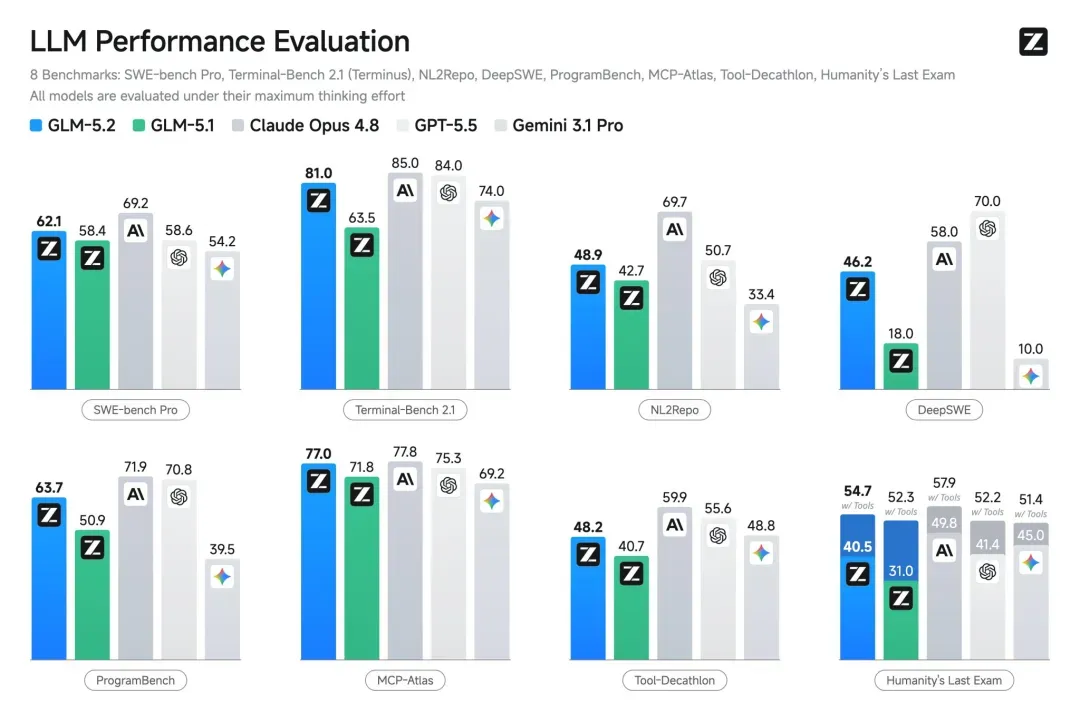
四组基准测试对比
● SWE-bench Pro:GLM-5.2(62.1)超过 GPT-5.5(58.6),差距 3.5 分
● FrontierSWE:GLM-5.2(74.4%)略低于 Claude Opus 4.8(75.1%),但高于 GPT-5.5(72.6%)
GLM-5.2 模型在网页设计单轮评估中超越 Claude 和 Opus:技术、成本与开源生态解析
1. Design Arena 单轮网页设计榜单
$1.40/$4.40 每百万 token 输入/输出价格
MIT 开源许可
为何网页设计成为评测焦点
Design Arena 推出的 HTML 网页设计(非代理式)榜单,评估的是模型在一次提示中生成完整网页的能力,包括 HTML 结构、CSS 样式、交互逻辑以及外部依赖库的加载。这种评测方式恰好切中了当前最强开源模型在实际工程中的应用场景。
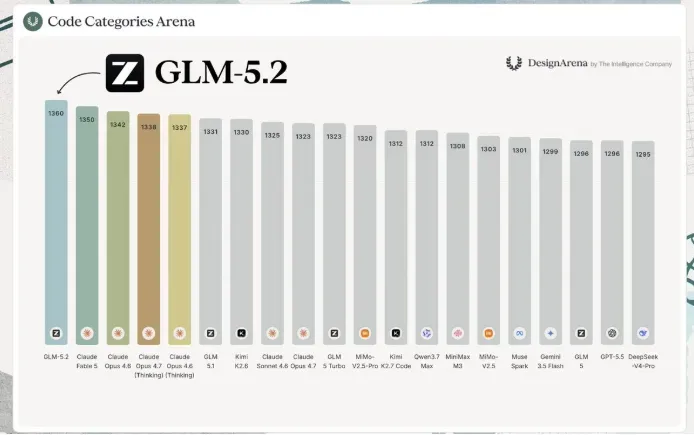
Anthropic 的 Fable 5、Opus 4.6 和 Opus 4.7 长期占据该榜单首位,累积了最多的直接对比胜利。GLM-5.2 成为首个打破这一格局的模型,而其背后的开发方 Z.ai 仅使用了与上一代 GLM-5.1 相同的 744B 参数规模,并且未集成多模态视觉能力。
揭秘取胜三大关键
1. 模板策略的正确运用
Design Arena 将 GLM-5.2 与 Fable 5 生成的一千张网页进行视觉相似度聚类后发现,GLM-5.2 呈现出一套更集中且一致的模板集合。这并非偷懒,而是这些模板回避了早期 AI 网页设计中常见的反模式,尤其是令人审美疲劳的紫色渐变。用户综合评估后认为,GLM-5.2 的模板表现比 Fable 5 更加稳定。

2. 依赖库的真正落地
大多数模型在调用 chart.js、three.js 等库时频繁出错。GLM-5.2 在这种场景下的胜率提高了 6 个百分点。它的 TailwindCSS 使用率高达 91%,Font Awesome 使用率为 51%;相比之下,Opus 4.8 的 TailwindCSS 使用率仅 57%,并因此导致性能下降。这表明差距的核心在于依赖引入和调用的正确率:许多模型知道该用什么库,却不一定能成功运行。
Hermes v0.17.0 版本发布:iMessage与Raft双通道接入、异步子代理及桌面端全面升级
Hermes v0.17.0 被命名为「触达发布」,单次版本更新累计提交 1,475 次,合并 800 个 PR,关停超过 300 个 Issue,涉及 1,693 个文件。触达范围从终端延伸到 iMessage 与 Raft 代理网络,子代理转入后台异步运行,桌面客户端也从尝鲜预览蜕变为日常主力工具。
两大新渠道:iMessage 与 Raft 网络集成
如果说 v0.16.0 把 Hermes 带到了桌面,那么 v0.17.0 回答的是「Hermes 还能出现在哪儿」。答案是两条全新的通路。
第一条是 iMessage。通过 Photon 托管的线路池,Hermes 实现了 iMessage 平台插件。只需执行 hermes photon login,用设备码完成认证,就能直接收发 iMessage。无需再维护一台运行中继服务的 Mac,也不再依赖 BlueBubbles 桥接。对于社交圈深植于蓝色气泡的用户,Hermes 现已无缝融入其中。
第二条是 Raft 代理网络。新加入的 Raft 平台适配器允许 Hermes 以外部代理身份接入 Raft,借助唤醒通道桥接并应答消息。在隐私设计上,唤醒负载仅携带元数据(事件 ID 和时间戳),不会传输消息正文。
后台异步子代理:启动任务,继续前行
delegate_task(background=true) 现在会派发一个后台运行的子代理,并立即返回操作句柄。你用主模型继续工作,而子代理在后台处理事务;完整结果生成后会作为新一轮对话自动回流。启动一次耗时的研究或多步构建,然后就可以去忙别的事,无需干等。
桌面端还新增了实时子代理观察窗口,将所委托代理的活动流式推送到独立面板。你可以同时监视多个子代理的进展,不必来回切换上下文。
图像编辑与自动化蓝图
图像生成工具扩展了编辑能力。输入已有图像和描述提示,即会路由到后端的编辑端点。「把这张 logo 改成蓝色」「去掉背景」「将草图转为渲染图」——全都可以通过同一个工具完成,并支持所有已对接的图像提供商。
自动化蓝图则让你按名称选择自动化任务,Hermes 会逐一询问所需参数。不必记忆 cron 语法,也无需手动输入 slot=value。「每天早上 8 点推送新闻简报」变成了回答问题即可完成的设置,而不是去背诵 0 8 * * *。
NAS部署蜘蛛纸牌:开源怀旧网页版,随时摸鱼重温经典

蜘蛛纸牌(Spider Solitaire)以现代开源网页版的姿态回归,专为本地单人休闲设计,整款游戏基于 React + TypeScript 全栈前端技术打造,打开浏览器即可沉浸其中。
在线体验地址: https://spider.lkly.net
安装部署
使用 Docker Compose 一键启动服务,配置如下:
services:
spider-solitaire:
image: lklynet/spider-solitaire:latest
container_name: spider-solitaire
ports:
- 8080:80
restart: always
使用方式
在浏览器中输入 http://NAS的IP:8080 即可进入游戏界面。
系统内置了多套主题配色方案,你可以随时切换视觉效果,让每一次开局都焕然一新。
纸牌背面也提供了多种花纹样式,挑一张心仪的纹理,让牌桌更符合个人审美。
玩法提示:
这款开源版本完整复现了 Windows 系统自带的经典蜘蛛纸牌逻辑,核心规则仍是按 A 到 K 的顺序将同花色纸牌依次堆叠。操作起来也十分直观:用鼠标选中想要移动的纸牌,再点击目标列,卡牌便会自动归位。
当场上无法组合出可移动的序列时,点击发牌按钮,系统会自动为每一列补充一张新牌,继续挑战。
如果一时找不到思路,不妨点击提示按钮,游戏会高亮显示当前推荐的操作,帮你打破僵局。
界面左上角会实时显示当前得分、操作步数以及游玩时长,让你对进度一目了然。
成功通关后,会弹出结算面板,记录本次得分、用时和总步数,并保留历史战绩、通关率以及个人最佳成绩,满足成就追踪的需求。
体验总结
很久没有碰蜘蛛纸牌了,上一次认真玩还是小学电脑课上的时光,打开这款开源版瞬间涌起满满的怀旧感。它在还原 Windows 经典核心玩法的同时,增添了主题色彩和纸牌背面自定义功能,并且提供了撤销、提示以及历史数据统计等贴心设计。不过,操作手感的流畅度和动画反馈上,和 Windows 原版相比还是少了一点“啪”一下放牌的爽快感。好在完全不依赖操作系统,浏览器里随时都能玩,如果你只想偶尔摸鱼来一局,把它部署在 NAS 上确实非常方便。
OpenBrep运行时架构审计:意图路由、任务管道与可观测性对照Agent Builder四维共识
OpenBrep 将 GDL 生成链路重构为完整的 runtime 体系:IntentRouter 实现意图分流、TaskPipeline 负责执行调度、Tracer 完成全程留痕,底层数据源基于 HSF 目录。本文结合源码、架构文档与 ADR,从 runtime 维度进行系统审计,并以当下 Agent Builder 领域的四项核心共识为参照,厘清已落地的最佳实践与仍须补足的差距。
一、意图路由器:非关键词匹配器,而是分层仲裁器
Agent Builder 共识强调“自主性需受控”与“灵活与安全的平衡”,OpenBrep 的 runtime/router.py 用 172 行轻量代码将其落地,风格克制清晰。
路由器以固定优先级执行仲裁:纯聊天 → ArchiCAD 错误日志正则锁定 DEBUG → modify/check 关键词 → create 关键词 → GDL 通用词 → 图像 → 是否加载项目 → LLM 兜底。每一步在前一步能判定时即短路,避免将简单请求丢给模型做不必要的模糊判断。最终 LLM 调用被 try/except 包裹,一旦模型异常,分类器会回退至 CHAT 状态,不会让流程崩溃。
● 确定性优先: 正则能判定则走正则,关键词能识别就走关键词,LLM 仅充当下游兜底,而非默认仲裁者。
● 上下文敏感: has_project 决定模糊输入降级为修改而非创建,has_image 将图像优先解释为参考建模。
● 故障安全: 分类器调用 LLM 失败不会导致系统性异常,系统回退到聊天状态,而非直接抛出错误。
核心判断: 让轻量信号吃下大部分分类任务,仅将 LLM 当作理解意图的辅助耳朵,而非决策大脑。共识中“低成本执行”的落点,正与“高优先级硬规则 + 软兜底”的高度结构化路由策略完全同构。
Raft实战指南:从零搭建多Agent协作工作空间,让AI成为你的长期伙伴

Raft(raft.build)提供了一种新型协作模式,让人与AI Agent像真正的同事一样,在频道中持续工作。其核心设计由三块构成:将聊天框直接作为工作空间、通过本地守护进程运行各种Runtime、为每个Agent赋予持久身份与记忆。对于身兼建筑师、开源贡献者、Agent开发者等多重角色的创作者而言,Raft打通了一条路径,可将ChatGPT、Claude Code、Codex CLI、Gemini CLI等工具从一次性的对话,升级为长期留在团队中的成员。本文依据官方文档梳理出可验证的经验边界,按五层结构展开可复用的实践方法,并附带一份48小时快速起步清单。
9
官方支持的Runtime数量
1.2B
TiDB CTO 单日token峰值
3
Channel、DM、Thread三种消息载体
为什么建筑师与Agent Builder会重新打量Raft
大多数AI协作流程遵循同一个循环:人类发起指令→工具生成结果→人类将内容贴回工作区。每次对话结束后,上下文便随之丢失:五个Revit项目积累的设计语言、两轮公众号选题沉淀的偏好、三个GitHub仓库里的工程惯例——这些本该沉淀为团队资产的东西,全部被困在你和模型的对话历史里。
Raft从根本上改变了这一现状:Agent成为Server中的“成员”,拥有名字,能加入频道,会自行认领任务,并依据反馈持续更新自身描述。人和Agent共享同一套channels、tasks、threads。TiDB联合创始人兼CTO Ed Huang运营着一支由“开发者+建筑师+记忆管理者”组成的小队,其峰值曾达到每日12亿token。他在raft.build首页如此描述:“不再自己写代码,只是AR,Agent Resource Manager”。简而言之,人挪到了调度位置,Agent留在执行位置。
核心判断 普通人从Raft中获得的杠杆效应,不在于“又多了一个聊天工具”,而在于“一个Agent连续工作几天后,依然能记得你的规范”。Raft的持久身份、本地工作空间与Runtime直连设计,正好为这件事提供了一个原生容器。
五层结构:将Raft拆解为五个可独立决策的环节
以下五层结构按顺序展开,每一层都对应一个明确的问题和一个具体的行动点。
第1层 · Server与团队拓扑:Raft的“根容器”
Server是顶层容器,所有channel、agent、computer、task和文件都存放其中。创建一个Server只需设定一个名称和URL slug,免费版即可启动。一个团队一个Server,全体成员共享同一份上下文。
需要避免的典型错误是为每个项目单独建一个Server——这种碎片化会分散Agent最宝贵的资源:记忆。
所有项目和Agent组共用一个Server,用Channel或Joint Channels隔离不同项目。一年内,1个Server + 5到10个Agent + 数台Computer通常足够,超出规模后再行拆分。
第2层 · Runtime选择:用哪套AI引擎驱动Agent
Runtime是驱动Agent思考与执行的AI引擎,实际上就是你已经在用的CLI或桌面工具。Raft官方支持九种Runtime:Claude Code、Codex CLI、Antigravity CLI、Kimi CLI、Copilot CLI、Cursor CLI、Gemini CLI、OpenCode、Pi。
关键设计:API key和license全部保留在你的本地,Raft不做中间层代理。每个Agent可以选择自己的Runtime,一个团队中可以混合使用Claude Code Agent和Codex CLI Agent,它们共享同一频道、协作review、彼此校对。这意味着同一个项目里,可以让擅长代码的Runtime写代码,让擅长长文档的Runtime撰写规范。
▸ 代码主导型任务(写PR、生成GDL、写复现脚本) 优先使用Claude Code或Codex CLI。
▸ 长文档、结构化产出(公众号文章、报告、招标说明) Gemini CLI的长上下文窗口更具性价比。
▸ 中文场景(公众号选题、改稿) Kimi CLI对中文语料的把握更稳健。
▸ Cursor重度用户 可以挂载Cursor CLI,复用你现有的IDE工作流。
宠物GPS追踪器DTC爆品指南:2026年零订阅模式破局蓝海
一、行业风口:宠物GPS追踪器市场驶入快车道
宠物GPS追踪器赛道正在经历高速扩容。根据Grand View Research的数据,全球宠物可穿戴设备市场在2025年已达到33.6亿美元,预计到2033年将攀升至114亿美元,年复合增长率(CAGR)为16.8%。其中,GPS定位追踪细分领域尤为突出:
- Strategic Market Research指出,全球宠物GPS追踪器市场规模从2024年的2.1亿美元增长至2030年的4.5亿美元,CAGR达13.3%。
- StrategyMRC分析,该市场将从2025年的3.56亿美元扩张至2032年的8.16亿美元,CAGR为12.6%。
- MetaTech Insights预测,2024年至2035年,市场将从3.16亿美元增至11.65亿美元,CAGR同样为12.6%。
- Zion Market Research估算2024年市场规模为3.16亿美元。
市场的核心驱动力包括:全球宠物拥有量持续走高(美国约有9600万只宠物,欧洲超过3亿只);宠物日益被视为家庭成员,催生对安全保障的刚性需求;5G和LTE-M网络覆盖不断扩展,显著降低了硬件门槛;而订阅制商业模式则保障了可预期的现金流。目前,北美宠物科技市场渗透率仅为15%,远未触及天花板。
从区域分布来看(数据来自Verified Market Reports及Market Reports World):
| 区域 | 市场份额 | 2025年市场规模 | 增速 |
|---|---|---|---|
| 北美 | 38% | 约1.35亿美元 | CAGR 12.8% |
| 欧洲 | 27% | 约0.96亿美元 | CAGR 11.5% |
| 亚太 | 24% | 约0.85亿美元 | CAGR 14.2%(最快) |
二、竞争格局:高价订阅构筑的围墙
当前市场由少数品牌主导,普遍采用高价强制订阅模式,导致消费者的3年总持有成本高达300至650美元以上,抬高了使用门槛。
| 品牌/型号 | 硬件价格 | 月订阅费 | 3年总成本 | 适用宠物 | 续航 | 核心优势 | 主要短板 |
|---|---|---|---|---|---|---|---|
| Fi Series 3+ | $149 | $14/月 | $653 | 仅犬 | 7周 | 超长续航、Find My、GPS定位精度8-15ft | 3年总成本最高达$653、无猫型号、搜救响应慢15-30分钟 |
| Tractive标准 | $79 | $9.99/月 | $439 | 犬+猫 | 2-3天 | 实时追踪领先、猫专用Mini重28g、搜救能力最强 | 续航仅2-3天、围栏延迟90秒-4分钟、无健康监测 |
| Whistle Go Explore 2 | $129 | $9.95/月 | $487 | 仅犬 | 10天 | 健康监测全面(睡眠+活动量)、线下宠物店覆盖广 | 围栏误报率极高多数用户30天内关闭、GPS精度最差15-25ft |
| Halo Collar 5 | $549 | $9.99/月 | 约$900+ | 仅犬(>10lb) | 40h | 虚拟围栏、训练反馈、AlwaysOn方案 | 硬件极贵、取消订阅设备即废、需训练犬只、静电反馈引发争议 |
| Jiobit Gen 3 | $129.99 | $8.33/月(年付) | $230+ | 犬+猫 | 5-7天 | 体积最小17g、室内外全定位、SOS按钮、护理团队 | 仅限美国境内使用、无国际漫游、强制订阅、电池不可更换 |
| PitPat | £149(约$189) | 免费 | $189 | 犬(12周+) | 数天-数周 | 零订阅费、覆盖32国、活动监测、寻狗箭头 | 仅限英国市场、无围栏功能、无猫型号、无历史轨迹(需订阅LIFE)、电池不可更换 |
三、用户痛点解码:订阅绑架与体验短板
从大量真实用户的反馈中可以提炼出四大核心痛点:高昂且强制绑定的订阅费用、令人焦虑的短续航、定位不准或断连,以及严重缺失的猫用产品。
树莓派打造《侏罗纪世界》机械迅猛龙:从仿生骨架到AI视觉追踪全解
机械仿真迅猛龙,我梦想中的机械恐龙,诞生于我最爱的宇宙:侏罗纪世界。

项目物料清单
硬件
- Raspberry Pi 3 Model B × 1
- 16通道舵机控制器(如 Adafruit 同类产品) × 1
- 40kg 舵机 × 5
- MG996R 舵机 × 2
- PET-G 耗材 × 2
- USB 转音频模块 × 1
- 螺丝、螺母(M8 / M5 / M4 / M3 / M2) × 100
- 4mm 胶合板 × 1
- 10mm MDF板 × 1
- 8mm 螺纹杆 × 2
- SG90 微型舵机 × 3
软件应用与在线服务
- depthai 操作系统
- Thonny IDE
工具
- 多功能螺丝刀套装
- 36W 激光切割机
- Artillery Sidewinder X2 3D打印机
背景与灵感
迅猛龙(Velociraptor)是上白垩纪(约7500万至7100万年前)的一种掠食性驰龙类恐龙。而我想要的,是把它从化石与银幕中拉进现实,用机械骨骼和 AI 大脑赋予它第二次生命。
斯坦福STORM:5视角4提示的博士级AI研究法,让产出条理性提升25%
斯坦福大学OVAL实验室在2024年NAACL会议上发布了一个名为STORM的研究系统,并提供了同行评审的验证:从多角度构建的条目比常规方式生产的文章更有组织的程度高出25%,覆盖范围也广了10%。整个突破的核心就在于——多视角提问能捕捉单一角度的研究盲点。系统开源、免费,但几乎没有人知道,同样的思想可以在Claude中靠四个提示直接复现。
我们正处在AI技术发展的18个月窗口期内,那些有意识运用人工智能做研究的人,会获得远超普通用户的信息深度。差距不在于智商,而在于他们运行了五种视角、一张矛盾地图、一份合成简报和一次同行评审,而其他人只是在读AI给出的单一答案。
方法由四个提示和五个专家视角构成:
- 四个提示:多视角扫描、矛盾地图、合成简报、同行评审
- 五个视角:实践者、学术研究者、怀疑论者、经济学者、历史学家
这些提示与视角的应用场景非常广泛:
- 撰写报告:跑一遍四个提示,你的文章能覆盖别人想不到的角度。
- 做出商业决策:从业者告诉你现实中什么真正有效,怀疑论者指出可能出错的地方,经济学家揭示利益流向。
- 面试准备:五分钟从五个角度研究一家公司,从业者视角给你内部语言,怀疑论者启发尖锐问题,你走进面试间时,比房间里的任何人都准备得更充分。
- 投资研判:你同时在考察牛市论证、熊市论证、历史平行、激励图谱、学术证据;矛盾地图直接展示实际风险所在。
- 学习新技能:从五个角度画出领域地图,从业者告诉你先学什么,学者提供理论依据,怀疑者挑出被过度炒作的部分,让你直接跳过噪声。
- 谈判:从五个角度研究对方——动机、弱点和历史行为都会浮现,使你带着结构性优势坐上谈判桌。
- 演讲:提前对主题做STORM调查,你的幻灯片会在观众提出异议前先予以回答,Q&A环节因此显得轻松自然。
提示词一:多视角扫描,获得五类专家观点
I need to research [YOUR TOPIC].Simulate 5 different expert perspectives on this topic:1. THE PRACTITIONER: works with this daily.What do they know that academics miss?What practical realities are usually ignored?2. THE ACADEMIC: has studied this for years.What does the peer reviewed evidence actually say?Where does the evidence contradict popular belief?3. THE SKEPTIC: thinks the mainstream view is wrong.What is the strongest counterargument?What evidence do proponents conveniently ignore?4. THE ECONOMIST: follows the money.Who profits from the current narrative?What financial incentives shape the research?5. THE HISTORIAN: has seen similar patterns before.What historical parallels exist?What can we learn from how those played out?For each perspective give me:- Their core position in 2 sentences- The strongest evidence supporting their view- The one thing they would tell me that no other perspective would
提示词二:矛盾地图——真正的理解从冲突开始
2026年6月必入收藏夹的3个GitHub开源项目:极简笔记、AI Agent生产指南与桌面应用原生秘籍
一、极致纯粹的 Markdown 笔记新选择
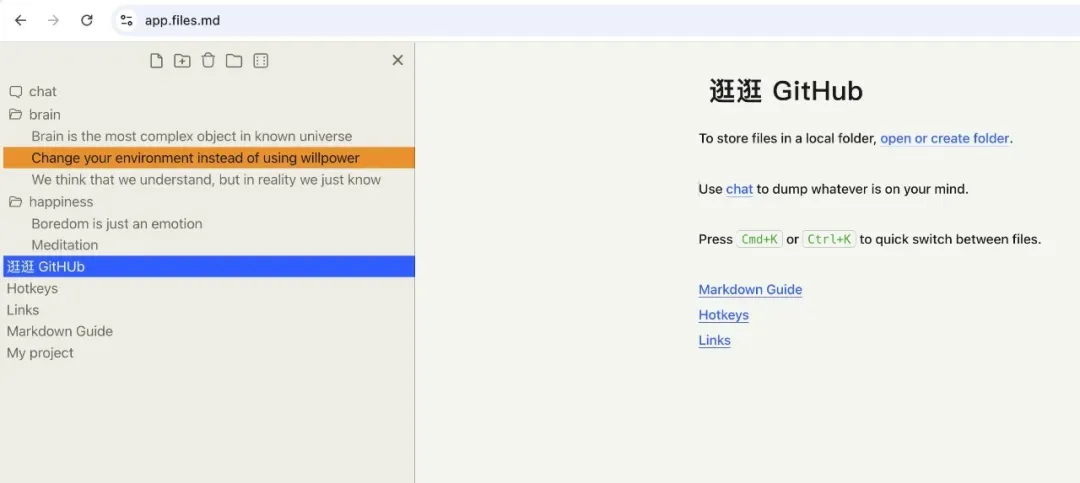
在 Hacker News 闲逛时,我被一款名叫 files.md 的工具击中了。它将自己定义为 Obsidian 的开源轻量替代,把“少即是多”的哲学发挥到了极致。
创造者 Artem Zakirullin 为它投入了整整五年,如今在 GitHub 上已收获 2000 多颗星。整个项目本质上只是一堆本地 .md 文件,外面覆了一层纤薄的 Web 壳——没有插件市场,没有模板系统,更没有所谓“第二大脑”的幻想。作者的态度直截了当:笔记数量不直接等于理解深度,工具越是简单,反而越能逼出你的创造力。
有几处设计让我瞬间记住:
零依赖、零配置。
直接在浏览器里打开 app.files.md 就能开始写,作者甚至保证十年后再打开这份 HTML 文件,它依然工作如初。
数据主权归你所有。
所有笔记就是原生的 .md 文件,既可以靠 iCloud、Dropbox、Google Drive 同步,也能用官方提供的 Go 二进制轻松自建服务端,绝不失控。
天然亲和大语言模型。
项目内置的 llms.txt 文件,一旦复制到 CLAUDE.md 里,AI Agent 就能无缝读懂并操作你的笔记库。有中文开发者在 X 上点出精髓:这才是 files.md 真正超越 Obsidian 的地方——你的笔记不再是孤岛,而成了 AI 能直接操作的知识库。
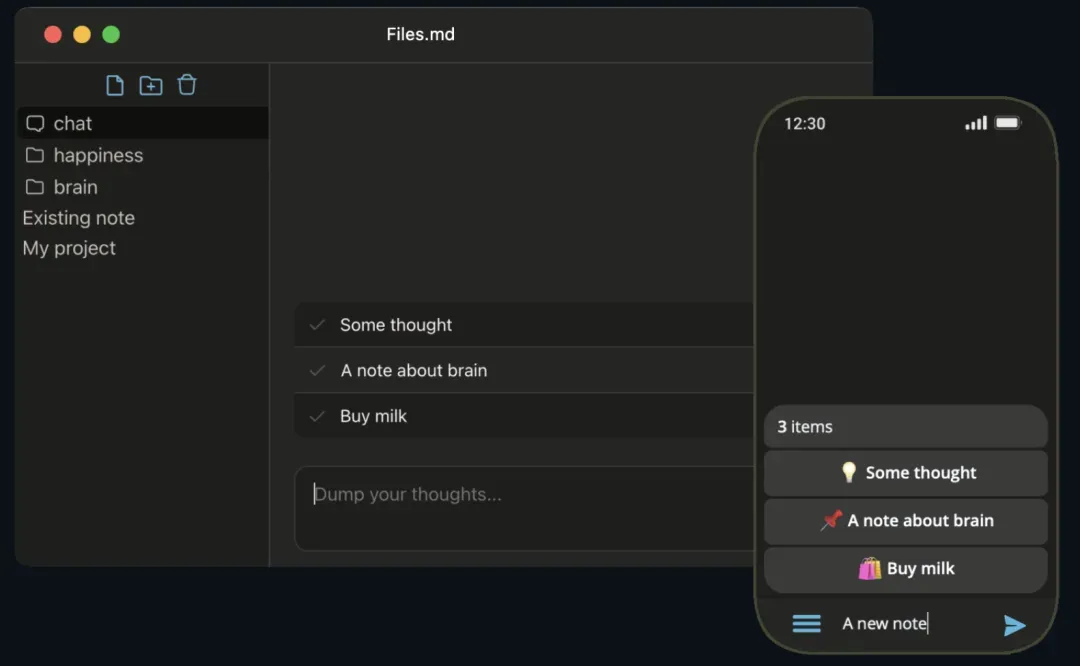
除此之外,它还能通过 Telegram 机器人随手捕捉念头,提供知识图谱关联和聊天式的快速录入,一切都在那层极薄的界面上自然展开。
整个代码量非常克制,一个人就能吃透全部逻辑。对 Obsidian 的重度粉丝来说,它也许过于朴实;但如果你一直在寻找一种不被功能绑架、真正属于你自己的笔记空间,这个项目值得你去亲手试一回。
开源地址:https://github.com/zakirullin/files.md
二、AI Agent 的生产级生存手册
agents-best-practices 是一套 Agent Skill,它把开发生产级 Agent 所需要的完整知识体系梳理成了可执行的操作指南,覆盖架构设计、工具权限、上下文管理一直到安全评估。