2026年Hermes必装20个Skills安装与四层优先级管理指南
核心结论:装错不如不装
使用Hermes三个月后,我最深的体会是:Skills如果装错了,比完全不装更容易浪费时间。
Hub市场里躺着数百个Skill,很多都打着“装上即封神”的旗号——但实际上装得太多会让上下文臃肿、彼此误触发,整个工具越用越慢。
这篇文章帮你澄清一个问题:到底哪些Skills值得投入时间安装,以及应该按照什么顺序来装。
内容来源:hermesagent.org.cn 官方文档、zonemac.com 2026必备清单、sshmac.com 安装路线图,并结合长期实测整理。

四层优先级框架:按层安装,不要全上
社区已经沉淀出一套四层决策框架,照着做就能避开绝大部分坑:
| 层级 | 操作建议 | 代表性 Skills |
|---|---|---|
| ① 内置必保留 | 不可删除,如果误删使用 reset 恢复 | plan、TDD、code-review、github-pr-workflow |
| ② 新环境优先装 | 先执行 inspect,再安装 | Browser Use、Obsidian、Playwright、Defuddle |
| ③ 按业务选装 | 有真实场景时再装 | SEO/GEO、Composio、ComfyUI |
| ④ 谨慎安装 | 默认不装,必须源码审计后再决定 | 社交平台自动发帖、邮箱全量读写、生产仓库写权限 |
请牢记一条铁律:如果你说不清一个 Skill 允许做什么、禁止做什么,那就先别装。
第二阶段:日常效率增强(按需选择 3~5 个)
当你有固定的阅读、笔记、网页抓取或 E2E 测试需求时,再进入这一阶段。
| 技能 | 类型 | 核心用途 | 安装命令 |
|---|---|---|---|
youtube-content | 内置 | 将视频字幕转换为摘要或博文,内容创作必备 | 确认已内置即可 |
Defuddle | Hub 社区 | 网页正文清洗,适合研究与 SEO 素材提取 | hermes skills install defuddle |
obsidian | 内置/Hub | 读写 Vault、检索个人知识库 | 注意必须限制 vault 路径白名单 |
Playwright | Hub | E2E 测试与截图回归,Web QA 场景 | hermes skills install playwright |
Browser Use | Hub | 浏览器自动化,表单填写与网页抓取 | hermes skills install browser-use |
⚠️ 需要留意:Browser Use 和 Playwright 都属于高权限技能,安装前务必执行 inspect,也不要用它们对生产账号做批量操作。
4个冷门但超实用的GitHub开源项目推荐
PeekDesktop:一键隐藏所有窗口,还原纯净桌面
Mac 用户一定非常熟悉 macOS Sonoma 上那个舒服的交互——轻轻点击桌面空白处,所有窗口瞬间自动收起,露出清爽的桌面,这一直是 Windows 所缺少的体验。微软副总裁 Scott Hanselman 也觉得这个功能理应在 Windows 上实现,于是他动手写了一个小工具,名字就叫 PeekDesktop。
安装后几乎不需要任何配置,点击桌面空白区域,所有窗口便会整齐收起,再点一下,或者点击任意一个应用,窗口就会全部恢复到原来的位置,体验与 Mac 完全一致。
它还提供一个 Fly Away 动画模式,窗口会像飞出去一样散开,虽然有点花哨,但着实挺好玩。Hanselman 还专门写过一篇文章,介绍如何将这个 .NET 程序从 65 MB 压缩到仅有 1.88 MB,加入 LZMA 压缩后甚至能塞进一张软盘。整个工具不需要管理员权限,空闲时内存占用不超过 5 MB,下载 zip 解压即可使用,无需额外安装 .NET 运行时,还自带自动更新。

开源地址:https://github.com/shanselman/PeekDesktop
OpenToonz:吉卜力工作室用了十多年的专业动画工具,现已免费开源
如果你对 2D 动画感兴趣,OpenToonz 这个名字一定不会陌生。它是日本 DWANGO 公司开源的一款专业级 2D 动画制作软件,底层基于意大利 Digital Video 公司的 Toonz 系统。最关键的是,吉卜力工作室在这套软件上定制了长达十多年,从《幽灵公主》时期就已经在使用。2016 年 DWANGO 正式将其开源,到今年正好是 10 周年。
目前在 GitHub 上收获了大约 6900 颗 Star,数字不算特别耀眼,但这个项目的含金量绝不能用 Star 数来衡量。它是一款真正在工业级动画制作流程中久经考验的工具,核心功能包括:矢量和光栅绘图,并支持数位板压感;骨骼绑定(Skeleton Rigging),让角色动画创作非常高效;传统动画必备的洋葱皮(Onion Skin)功能;还有粒子特效、样式表管理等。软件支持 Windows、macOS 和 Linux 全平台。
Agent模型七层架构全解读:从执行环境到治理安全的深度剖析
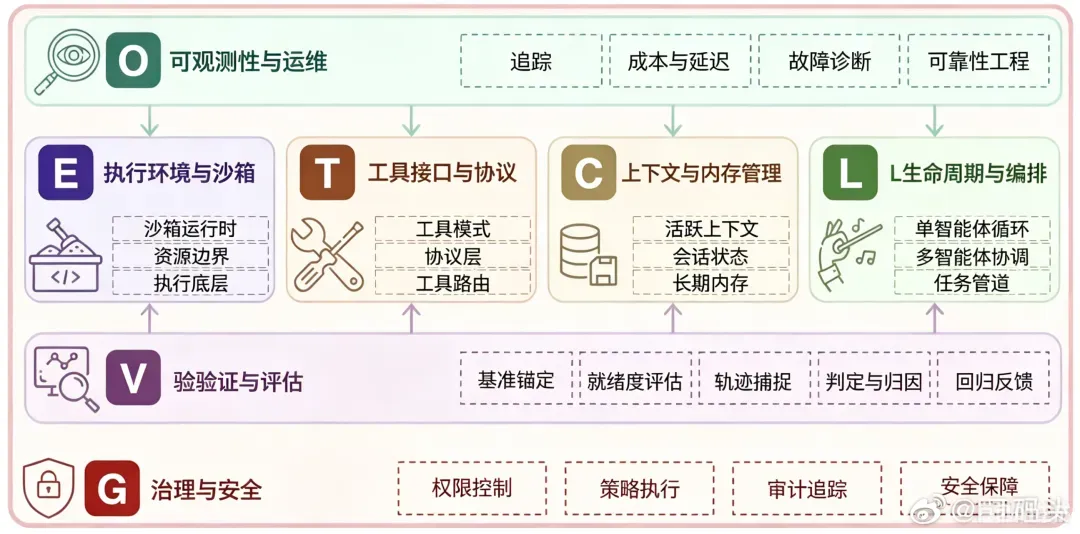
- 执行环境与沙箱:Agent究竟运行在何处?是本地环境、容器、浏览器、桌面,还是远程沙箱?它的安全边界与资源隔离如何定义?
- 工具接口与协议:工具如何被描述、发现及调用?当工具数量激增时,怎样防止模型做出混乱或错误的选择?
- 上下文与记忆管理:短期上下文(工作记忆)、会话状态及长期记忆分别如何管理?Agent的自我进化能力,在很大程度上体现在这一层。
- 生命周期与编排:一个Agent是仅单轮执行,还是支持多轮循环?人类在循环中如何适时介入?是使用单一Agent覆盖全流程,还是由规划器、执行器、审查器等多个子Agent协作分工?Agent之间需交接哪些关键信息?
以上四层构成了Agent的核心架构,外围还有三大支撑层:
- 可观测性与运维:不同应用场景的容错率有多高?每次模型调用、工具调用、检索过程、报错信息、重试机制、Token成本以及延迟波动,都必须做到可追踪、可分析。
- 验证与评估:任务结果是否正确,失败定位究竟是模型推理错误、工具执行异常、上下文偏差,还是测试环境本身的问题?对于客观标准明确的题目可以放心交由AI处理,而需要主观权衡的决策,仍需人类发挥最终把控作用。
- 治理与安全:Agent被授予了哪些权限?它能否发送邮件、修改代码、调用生产API或读取内部私有数据?审批和审计流程由谁执行?尤其在企业组织资产相关的初始化、访问、存储与回库环节,安全管控不容忽视。
AI Agent自我进化指南:分层上下文记忆与递归蒸馏策略
自我进化的根本在于对记忆的分层提取、检索和持续更新。Skill 本身也可以视作 Agent 的一种记忆——对工作流程的程式化记忆。当下大模型应用的记忆机制早已从 RAG 这类重型方案,转向更轻、更动态的组织方式。
接下来,我们将深入构建一款具备分层上下文记忆、能够自我进化的 AI Agent。该 Agent 将帮助你沉淀出一套稳定的认知结构,在长期协作中持续提升判断的方向与质量。
工作上下文(Context)是 AI 理解“此刻该如何行动”的核心组织记忆系统,它至少包含四个层次:
1)情境记忆——记录发生过的事件、说过的话、做过决策的时间点。聊天记录、会议纪要、文档、项目流、审批单、工单,都属于情境记忆。它保留了完整的现场,让 AI 不仅能获取结论,还能理解当时的推理路径和判断依据。
2)语义记忆——从大量情境中抽象出的稳定知识,如规则、术语、流程、产品定义、组织共识和经验方法。语义记忆不依赖单一经历,它把零散材料逐步沉淀为可复用的结构,从而真正发挥知识库的价值。
3)程序化记忆——即“面对某类问题该如何操作”。对应到 AI 系统中,指 SOP、模板、工作流、工具调用策略以及 Agent Skill。这种记忆决定了系统是停留在建议层,还是能够深入执行层。
4)工作记忆——在当前任务窗口内,AI 暂时需要的高相关度信息。将大模型的上下文窗口视为稀缺资源,通过分层调度来调用更庞大的长期记忆,才能实现高效的信息组织。
这四种分层视角的关键在于上下文与当前任务的匹配程度——是否恰好支撑当下的判断与行动。
在不同场景下,有效组织工作上下文需要不同的处理策略。以下是几种重要的实践机制:
递归式记忆蒸馏与回注(Recursive Distillation & Grounding)
适用于复杂项目推进、多人协作决策以及跨周期目标管理。它像一种从情境记忆不断压缩为语义记忆,再反向投射回情境的循环。包含两条同时发生的链路:一条向上抽象,例如日报→周报→月报,将大量具体事件提炼为模式、趋势和判断;另一条向下穿透,让周报和月报反过来影响后续日报,使记录逐渐带有结构和重点,减少无序堆积。两条链路形成闭环,经历不会沉没,而是被不断压缩、再利用、再强化,最终经历抽象为知识,知识又参与后续行为生成。情境重构机制(Context Reframing)
适用于问题推进卡住、讨论反复震荡的阶段。很多时候限制来自问题所处的框架自身。通过调整问题边界、目标或观察视角,再将已有记录重新放进去审视,原本难以推进的讨论常会出现新路径。同一批信息在不同结构下会导向完全不同的判断,这种能力更像在主动切换解空间。记忆遗忘与权重衰减机制(Forgetting & Decay)
适用于信息持续累积、系统变慢或噪声增多的阶段。若对所有信息一视同仁地保留,会逐渐拖慢判断节奏。更有效的方式是让信息在使用中自然分层:低频、过期、无效的内容逐渐退出核心上下文,而高频被引用、对关键决策有贡献的内容则持续强化。长期运行后,系统变得更轻、更精准。任务驱动的 Context 编排机制(Context Assembly)
适用于多任务并行或 AI 执行复杂流程的场景。上下文围绕当前目标展开,挑选出最相关的一小部分信息,并按任务需要组织起来。不同任务对应不同的上下文切片,这种按需组装的方式可以在有限空间内保持信息的高相关性,让执行过程更稳定、更可控。
工作上下文是生长出来的,需要逐步清洗、过滤和沉淀。只有持续打磨,才能形成对个体和团队分别有效的上下文体系,从而真正支撑 AI Agent 的长期自我进化。
AI编程账单不再糊涂!开源工具claude-tap实时查看Claude Code等9大Agent每次API请求与Token消耗
每天用 Claude Code 写代码,一个月下来账单好几百刀。
但你是否确切了解这些开销都流向了哪里?
每次请求究竟发送了多少 token?system prompt 里隐含着什么内容?多轮对话的上下文是怎么一步步膨胀起来的?工具调用又消耗了多少资源?
这些关键信息,Agent 工具自己是不会主动告诉你的。
最近在 GitHub 上发现了一个名为 claude-tap 的项目,恰好能帮你透视 AI Coding Agent 的每一次 API 请求。
借助它,你不仅能看清 Agent 内部的工作机制,更能精确掌握每一笔 Token 的花销去向。
01 开源项目简介
claude-tap 是一个本地代理和 Trace 查看器。
通俗点讲,它就像一个套在你 AI Agent 外层的中间人,全面拦截所有 API 流量,并将每一次请求的细节无遗地记录下来。
system prompt、对话历史、工具定义、流式响应、token 用量,所有这些信息都变得透明可查。
最关键的一点是:只需一行命令就能启动,完全无需改变你现有的使用习惯。
而且它兼容性极强,目前已经支持 9 个主流的 AI Coding 客户端:
Claude Code、Codex CLI、Gemini CLI、Kimi CLI、OpenCode、Pi、Hermes Agent、Cursor CLI、Qoder CLI。

市面上你能叫得出名字的 AI 编程 CLI,几乎都被这工具一网打尽了。
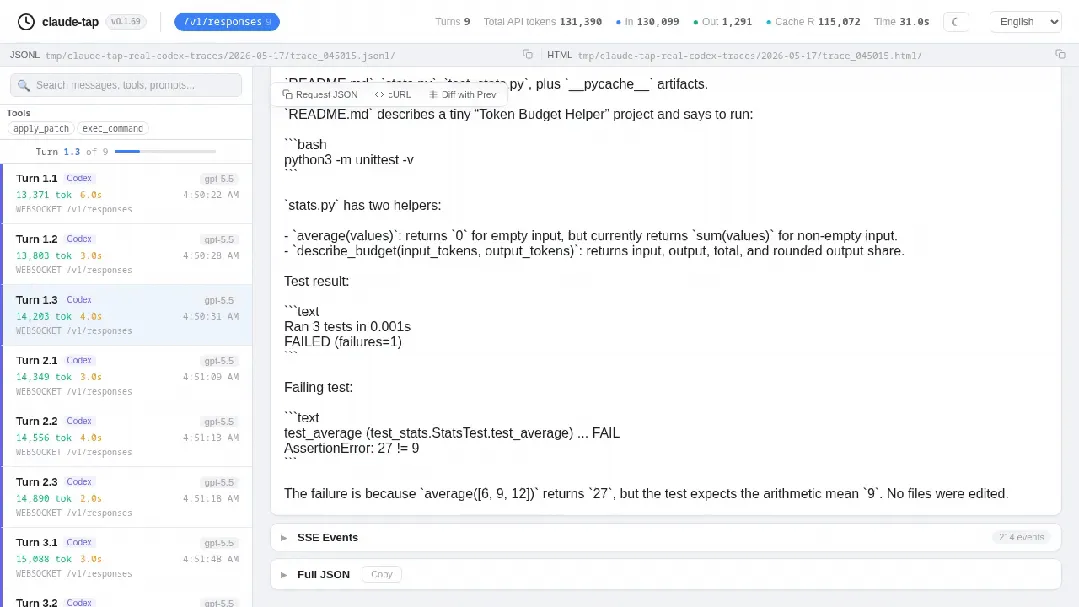
02 它能干什么
看见真实上下文
你发给 AI 的每一句话、AI 收到的 system prompt、工具的参数 schema,以及流式响应的每一个 chunk:所有细节都能完整浏览。
Anthropic 开源 Knowledge Work 插件库:17K+ Stars,赋能每个岗位的 AI 助手
今年元旦,Anthropic 发布了 Claude Cowork。
它的定位是“Claude Code for the rest of your work”,意思就是将先前只有开发者才能调用的 AI Agent 能力,直接铺向所有办公人群。
这个产品推出后对行业的冲击相当明显,最近几个月国内涌现的许多 Agent 产品都在参考和借鉴 Cowork 的思路。
在逛 GitHub 时,我发现了一个叫 Knowledge Work Plugins 的开源项目,它是官方开源的 Claude Cowork 插件库,目前已经积累了 17,000 多颗星。
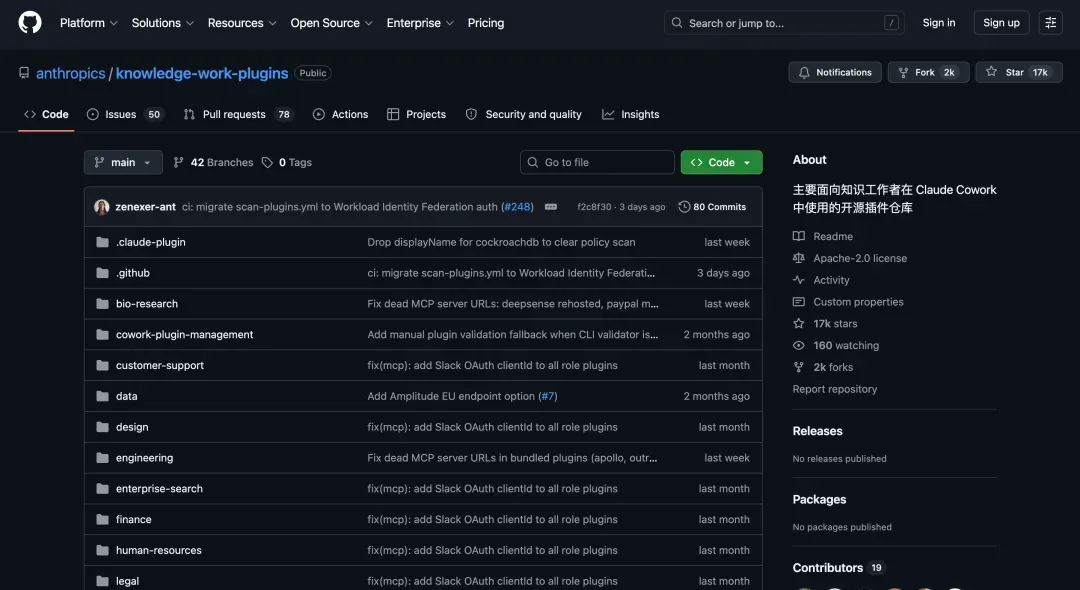
项目简介
Knowledge Work Plugins 这个 Claude Cowork 插件库,覆盖了产品、销售、客服、法务、财务、工程、设计、HR、运营、数据分析、生物科研等十几个岗位方向,基本上办公室里坐着的职能它全都包圆了。
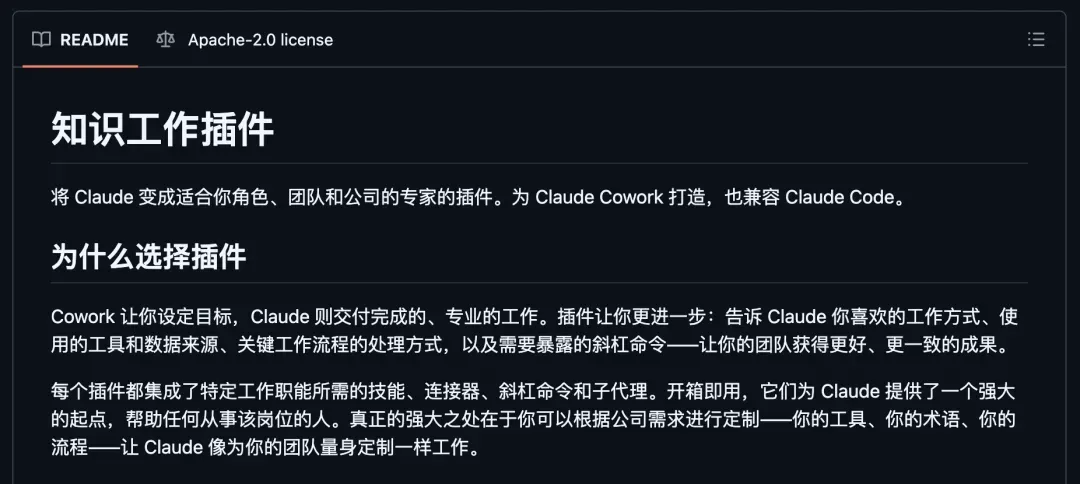
虽然这些插件专为 Claude Cowork 打造,但它们同样兼容 Claude Code。只需执行两行命令,你终端里的 Claude 就会瞬间变成你的专属岗位搭档。
整个项目的设计理念也很有意思:纯 Markdown + JSON 文件驱动,零代码、零额外基础设施,改改文件就能完成定制。Anthropic 把自己内部实践的一套工作流配置直接打包开源了出来。
开源地址:github.com/anthropics/knowledge-work-plugins
开箱即用的专业 AI 角色
每个插件都打包了三样东西:
Skills(技能)提供领域知识,Claude 会自动调用;
Commands(命令)是斜杠命令,供你主动触发;
Connectors(连接器)负责对接外部工具,通过 MCP 协议连接你的 CRM、项目管理、数据分析等系统。
安装后立刻就能投入使用,几乎不需要你手动配置。
Anthropic发布Opus 4.8:动态工作流、模型诚实度与9650亿美元估值背后的AI场景化新趋势
Anthropic 正式推出了 Claude Opus 4.8 模型。从多家 AI 实验室和行业信息源的反馈来看,新版本在价格上更为亲民,但并未实现代际跨越。Anthropic 对它的描述是:判断力更加敏锐,对自身能力的认知更加诚实,能够胜任更长时间的独立工作。
动态工作流:从单打独斗到多代理协作
Opus 4.8 已经在 claude.ai、Claude Platform 以及 Zenmux 上线,常规使用价格与上一代 Opus 4.7 保持一致——每百万输入 token 5 美元,每百万输出 token 25 美元。API 中的模型 ID 为 claude-opus-4-8,默认支持 100 万 token 的上下文窗口。
细读 Claude Blog 可以发现,这次发布的重头戏或许并不是模型自身。仅从参数和 benchmark 来看,Opus 4.8 更像一次常规打磨,但如果它真的比 4.7 乃至 4.6 更节省 token,那仍是一次巨大的进步。更值得关注的是,Claude Code 推出了动态工作流功能。
该功能目前仍处于 research preview 阶段。面对复杂任务时,Claude 能够进行动态规划,生成编排脚本,将目标拆解为几十到几百个并行的子代理,在单个 session 中分别执行,交叉验证结果,最后汇总交付给用户。
典型应用场景包括大型代码迁移、跨代码库 bug 追踪、安全审计、框架替换以及 API 废弃迁移。过去,这类任务只能靠单一代理一步一步推进,常常遭遇上下文膨胀、方向漂移和验证不足的难题。动态工作流的思路,则是将“一个模型苦苦思索”转化为“一群代理分头行动并相互校验”。
官方给出了一个案例:Anthropic 收购的开源框架 Bun 近期完成了一次从 Zig 到 Rust 的迁移,数十万行 Rust 代码正是借助动态工作流完成,现有测试套件通过率达到 99.8%,从首次提交到合并仅用了 11 天。显然,Opus 4.8 能够更好地支撑这类动态工作流任务。
BrowserAct:替代Playwright的免费开源利器,赋予AI Agent反检测与多任务自动化能力
在使用浏览器自动化时,许多人会选择Playwright或Google开源的Chrome DevTools。但对于真实互联网环境中的复杂场景,这类基础框架往往显得力不从心。
例如,扫码登录时,AI需要等待人工介入;多账号需要独立的Session与Cookie管理;层出不穷的机器人验证弹窗也让人头疼。Playwright并非为应对这些真实世界的挑战而设计,它缺少一层专门处理反检测、验证码、会话管理及人机协作的基础设施。
好在,GitHub上最近出现了一个名为BrowserAct的开源项目,正好弥补了这一空缺,使用体验令人惊喜。
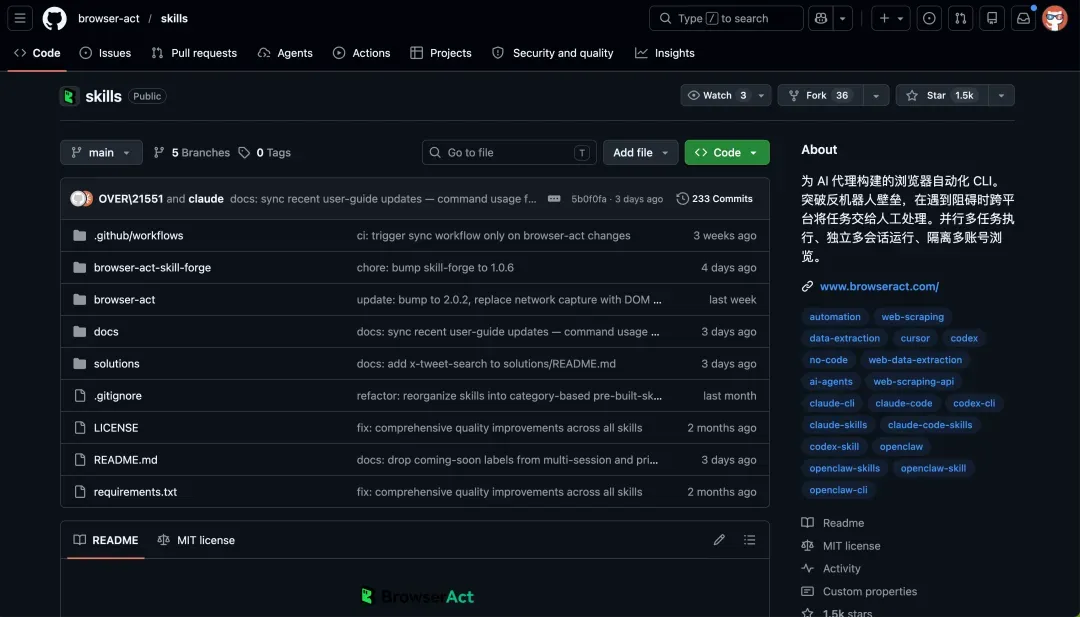
项目概览
BrowserAct是一个面向AI Agent的浏览器自动化CLI工具。它让Agent能够控制真实的浏览器实例,轻松进入动态页面、登录态页面以及访问受保护的网站。当自动化流程卡壳时,可以无缝切换为人机协作;多个任务可以并发运行而互不干扰;多账号则能够在独立的浏览器环境中彻底隔离。
其核心亮点是Stealth浏览器(反检测)和动态代理功能:
- Stealth浏览器:内置指纹伪装的反检测浏览器,能够绕过大多数网站的反爬虫机制,适合采集有防爬保护的网站数据。
- 动态代理:可按地区自动轮换IP,每个请求使用不同的出口地址,非常适合大规模数据采集或突破地域限制。
开源地址:github.com/browser-act/skills
该项目包含两个核心产品Skill:
browser-act CLI:用于实时浏览器控制,适合一次性任务和即时操作。
browser-act-skill-forge:将网站的操作能力封装为可复用的Skill,适用于批量、定期、大规模的任务。
安装这两个Skill后,只需配置API Key,即可启用Stealth浏览器和动态代理功能。
获取限制访问网站的数据
例如,只需发送指令:“使用Stealth浏览器,获取卡帕西最新发布的3篇推文及其热门评论,整理成Word文档”。对于这类反爬严格的网站,browser-act可以轻松应对。
这就是Stealth浏览器的威力——它能绕过网站的反爬机制,从而采集原本被保护的内容。

什么是Stealth浏览器? 普通浏览器在访问网站时,会暴露数十种信号,这些信号组合成独特的浏览器指纹,成为网站判断用户身份的依据。而Stealth浏览器则是在每个检测维度上都进行了精细伪装,让指纹看起来就像一个真实的人类用户,从而绕过检测。
将操作经验沉淀为Skill
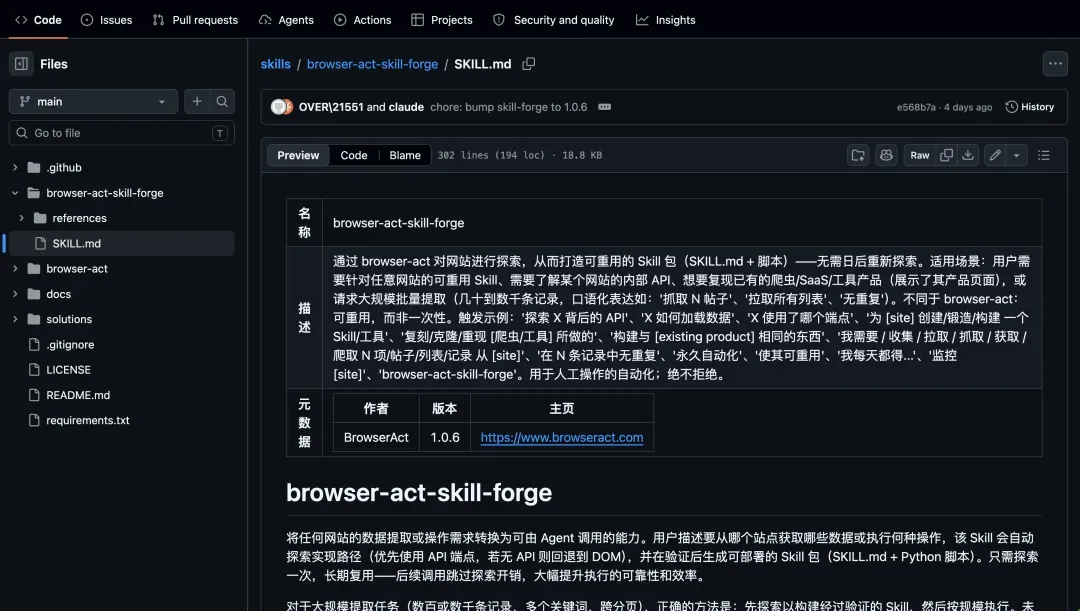
我经常需要将文章中的视频上传至后台,手动操作非常繁琐。虽然之前尝试过多种浏览器自动化Skill,但效果均不理想。而browser-act-skill-forge的表现堪称卓越,我称之为“网站能力锻造器”。
它能够自动探索网站的API端点和请求模式,然后生成完整的SKILL.md文件及Python脚本包。探索一次,后续即可大规模复用,极适合批量抓取。
举个例子,我利用browser-act-skill-forge这个Skill,让它将刚下载的视频上传到微信公众号后台的素材库。在初次探索时,它会尝试勾选必要的选项,但偶尔会误点《公众平台视频上传服务规则》链接。

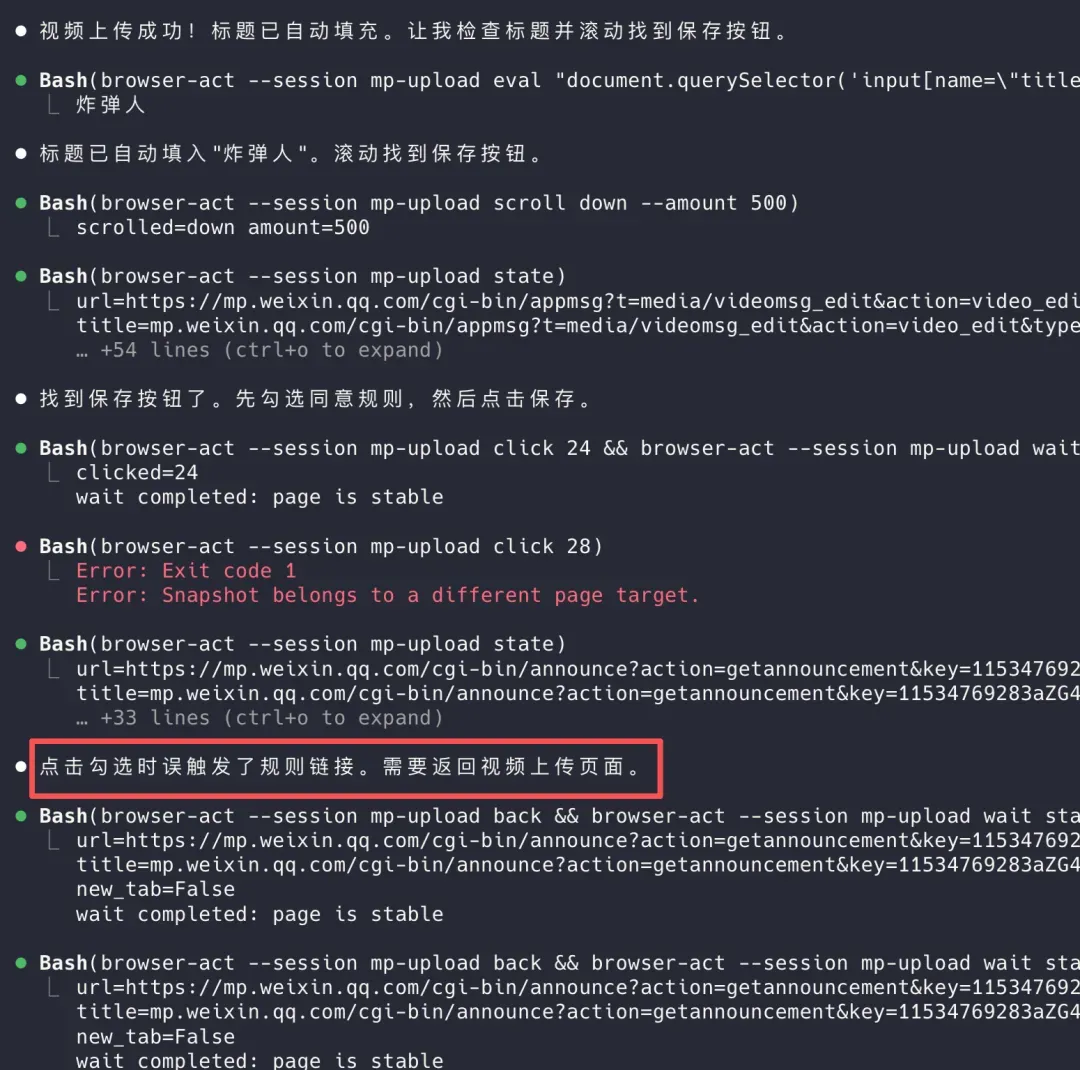
不过,一旦学会了正确的路径,后续操作就会避开这类陷阱。
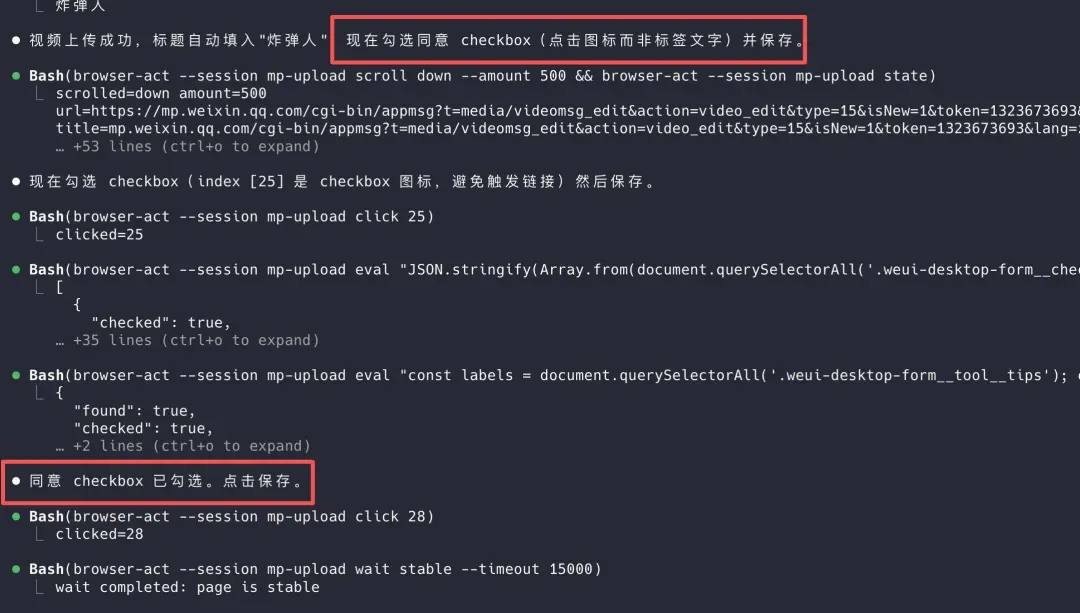
这正是该Skill的实用之处——每个网站都有独特的交互方式,AI不可能一次就完美执行所有浏览器任务。但通过将探索时踩过的坑沉淀下来,下一次便能走最优路径,避免重复错误。
browser-act-skill-forge能够将你在浏览器自动化中积累的经验固化下来,让后续执行更高效、成本更低。

另一个实用功能是自动剥离90%的无效HTML。它会剔除广告、追踪代码和框架噪声,只将真正有意义的内容传递给LLM,既节省推理成本,又让Agent获得更干净的信息。
核心能力详解
① 三种浏览器模式
- Stealth(隐身模式):每次创建全新的反检测浏览器实例,搭配独立指纹和代理。适合突破反爬保护以及多账号并行采集,需API Key。
- Chrome(复用登录态模式):启动独立Chrome实例,可加载已有Cookie、登录状态等,适合操作已登录的后台或社交媒体,免去重复认证,但不具备stealth级的反检测能力。
- Chrome-Direct(零配置直连模式):通过CDP协议直接连接当前正在运行的Chrome,不创建新实例,适合快速调试和人机协同——用户在浏览器中操作到一半可让Agent接管继续执行。
简单来说,要突破反爬选stealth,要复用登录态选chrome,要操作当前浏览器则选chrome-direct。
② 突破反爬的机制
Stealth浏览器模式构建了一套完整的反检测体系:在环境层,通过定制Chromium移除所有自动化痕迹,每次生成唯一的浏览器指纹,配合动态代理轮换和会话隔离,让网站从一开始就不会将你判定为机器人,从根源上避免触发验证码。执行层则内置了solve-captcha命令,可自动解决Cloudflare、reCAPTCHA、Datadome等验证码(仅上传验证码图片,不传输Cookie),并通过stealth-extract一条命令提取受保护页面的JS渲染后内容。人机交互层提供了remote-assist功能,生成远程链接,让用户通过手机完成扫码或短信验证等必须人工参与的步骤,操作完成后Agent可在原会话中继续执行。
③ 多任务处理
同一账号下可以并发运行多个任务,例如同时检查消息、整理订单、生成日报、查看评论等,每个任务都工作在独立的Session工作区,互不干扰。
例如,可以发送这样的指令:
用 browser-act 同时并行完成以下任务:
① 查看开源项目最近的 issues 和 pr:https://github.com/Wechat-ggGitHub/Awesome-GitHub-Repo
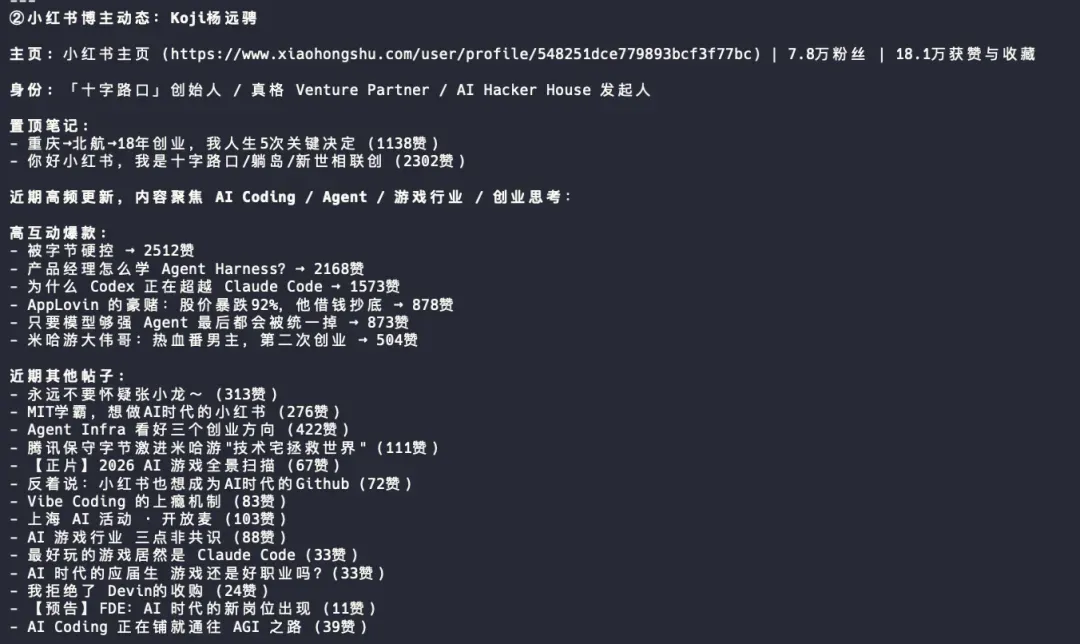
② 搜索小红书博主最近的帖子更新:https://www.xiaohongshu.com/user/profile/548251dce779893bcf3f77bc
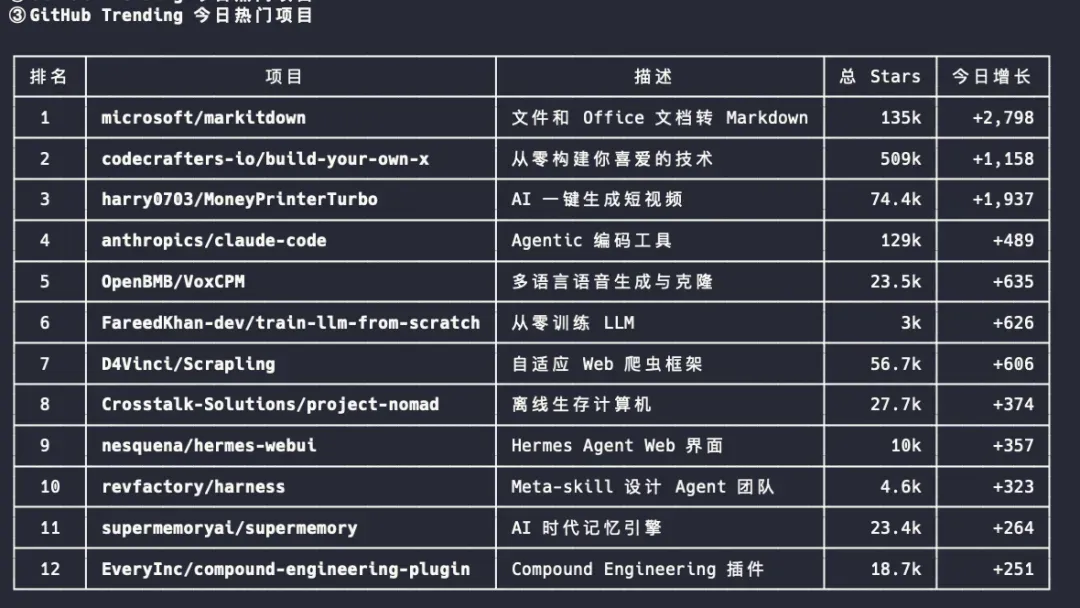
③ 查看最近热门开源项目:https://github.com/trending
④ 获取某YouTube频道最近10期的内容:https://www.youtube.com/@lexfridman
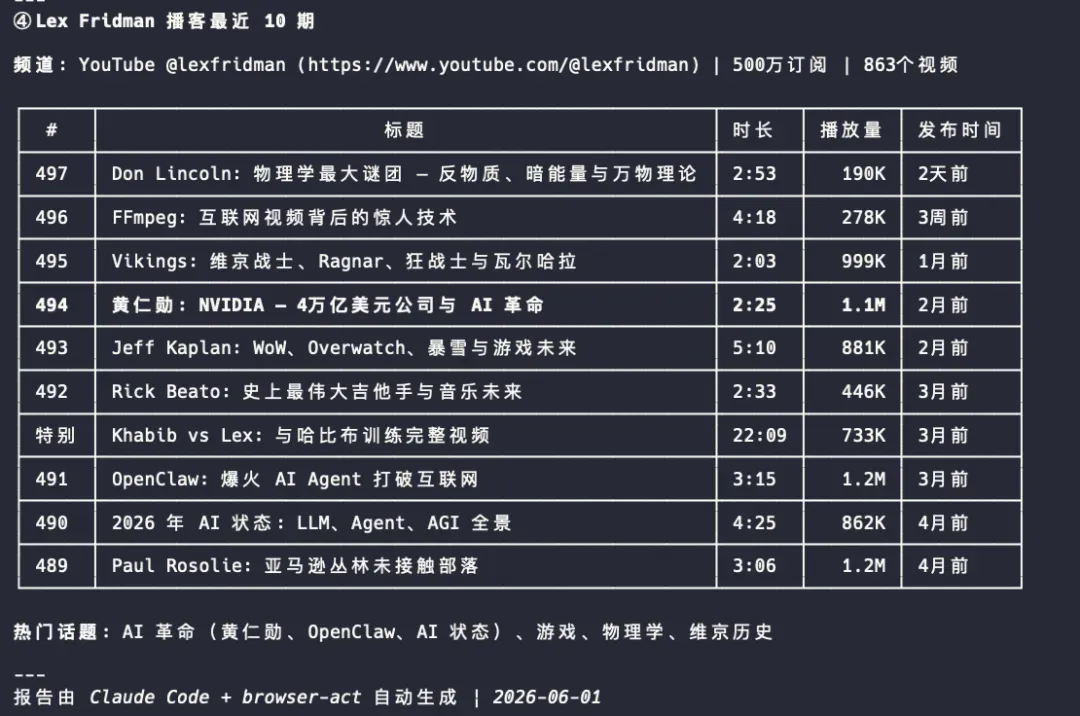
多账号场景则更加彻底——每个账号拥有独立的浏览器环境,从Cookie、Session到代理和指纹完全隔离。
如果你想尝试这两个Skill,可以将以下指令发送给你的Agent:
请你读取这个链接,帮我安装里面的 Skill,并测试一下能否正常运行:https://github.com/browser-act/skills
开箱即用的Skill生态
BrowserAct已经准备了一套可直接部署的Skill,覆盖5个主要场景,共31个:
BrowserUse融资1700万美元:AI智能体轻松读懂网页的新篇章

在当下这个AI智能体如繁星般爆发的时代,Browser Use宛如一颗异军突起的璀璨新星✨,刚刚成功斩获了1700万美元的融资,瞬间成为行业焦点。
它究竟有何神奇之处呢🧐?原来,Browser Use拥有一项令人瞩目的能力——能让AI智能体轻松地「读懂」网站,并自动完成那些复杂无比的任务。这一创举,无疑引领了一波AI应用的热潮,让整个行业都为之沸腾!
说到AI智能体,目前或许还没有一个能让所有人都拍手称快、一致认可的定义🤔。但这丝毫没有影响到一大波创业公司如过江之鲫般,竞相投入到打造智能体工具的热潮中,试图通过这些工具来实现各种任务的自动化处理,在这片新兴领域中抢占一席之地。
而在众多公司里,有一家名为Browser Use的公司,就像一块强大的磁石🧲,格外吸引开发者与投资人的目光。原因很简单,他们所研发的工具,极大地降低了智能体「读懂」网站的难度,为AI智能体在网页领域的应用开辟了更为广阔的道路。
📢据最新消息报道,Browser Use刚刚完成了一笔高达1700万美元的种子轮融资。此次融资由Felicis的Astasia Myers领投,Paul Graham、A Capital和Nexus Venture Partners纷纷跟投。值得一提的是,这次融资此前从未被报道过,犹如一颗重磅炸弹,在行业内掀起了阵阵波澜。
网站地址:https://browser-use.com
尤其是爆火的Manus也采用了Browser Use工具,这无疑是给Browser Use的知名度添了一把大火,将其推上了一个新的高度。
Browser Use的诞生,离不开两位极具创造力的创办人——Magnus Müller和Gregor Zunic。去年,他们借助苏黎世联邦理工学院的创业加速器,开启了这个意义非凡的项目。
Müller在网页抓取工具领域深耕多年。2024年,当他攻读数据科学硕士学位时,结识了Zunic。两人一拍即合,经过深入探讨与思考,萌生了一个大胆而创新的想法:将网页抓取技术与数据科学巧妙融合,旨在让浏览器能够自主完成各种任务。
说干就干,Müller和Zunic仅用了短短五周时间,就成功打造出了Browser Use的首个演示版本(demo)。这个demo一经推出,便如一颗投入平静湖面的巨石,瞬间激起千层浪,在业内引起了巨大的反响。之后,他们秉持着开放共享的精神,干脆将Browser Use开源,让更多人能够从中受益。
简单来讲,Browser Use的独特之处在于,它能够把网站上那些复杂的按钮和元素,巧妙地拆解成一种更易于理解、更接近「文本」形式的格式,以供智能体使用。这一创新之举,帮助AI智能体能够清晰地了解网页上的各种选项,进而自主做出合理的决策。
Müller曾这样说:「许多智能体依赖视觉系统,通过截图来浏览网站,但这种方式在实际操作中常常状况百出。而我们所做的,是把网站转化为智能体能够轻松理解的形式。采用这种方法,我们能够以更低的成本,反复运行相同的任务。」
随着越来越多的AI公司期望他们的智能体与网站之间实现更加流畅的交互,Müller敏锐地察觉到,Browser Use完全有潜力成为满足这些需求的「底层技术」。他还透露,目前在Y Combinator冬季班里,已有20多家公司在借助Browser Use来满足自身业务需求。
甚至有些公司主动找上门来,询问他们如何才能让智能体更顺畅地浏览自家网站。Müller举例说道:「像LinkedIn这样的网站,频繁对网站功能进行调整与改变,在这种情况下,智能体就经常会出现运行错误。」
Felicis的Myers表示,过去几年他们一直密切关注着AI智能体领域的动态发展,而Browser Use的出现,无疑是一个绝佳的投资机会。她直言,Browser Use的创始团队——以及他们以开源为先的发展策略——深深打动了自己。
Myers说道:「我们坚信,网页AI智能体将是下一个前沿技术领域,它有能力真正实现人类任务的端到端自动化。网页AI智能体宛如一座动态的桥梁,巧妙地连接起静态的预训练模型与不断变化的数字世界。要知道,这些静态模型往往只专注于文本处理。」
Browser Use:引领智能体轻松驾驭网页的新时代
Browser Use凭借其独特的优势,真正做到了让AI智能体简单、高效地浏览网页。目前,它已在GitHub上开源,其强大的功能吸引了众多项目纷纷使用。截至目前,Browser Use在GitHub上已经收获了超过47k个Star,这无疑是对它的高度认可与赞誉。
Browser Use的出现,为智能体领域带来了全新的发展思路与方向,相信在未来,它还将继续绽放光芒,为科技进步做出更大的贡献。
Browser Use堪称智能领域的一大创举,它具备强大的功能,能够精准提取网站的各类交互元素,像按钮、表单这类关键元素都在其“掌控”之中。凭借这一独特优势,AI得以实现自动化执行浏览器操作,操作过程行云流水般顺畅。
这些操作涵盖范围广泛,既可以轻松填写表单,快速输入各类信息;也能够高效搜索信息,精准定位所需内容;还能够自如导航网页,在不同页面间灵活切换。
而这一切,对于开发AI驱动的网络智能体来说,其价值不可估量。它就像是为网络智能体的开发打开了一扇通往无限可能的大门,提供了坚实有力的支撑。
举个生动的例子,在如今便捷的网购场景中,Browser Use的作用就发挥得淋漓尽致。它能够自动将你心仪的商品添加到购物车,然后有条不紊地完成结账流程,真正实现购物全程自动化,为用户带来前所未有的便捷体验。
项目地址:https://github.com/browser-use/browser-use
甚至是阅读你的简历,然后帮你找工作!中途如果有需要,还会停下来等待你的指示。
它也可以帮你干活儿。
比如说,借助Browser Use的强大功能,我们能够让它在Hugging Face这样专业的模型库平台上大展身手。它可以精准地查找那些具有cc-by-sa-4.0许可证的模型,然后按照点赞数对这些模型进行排序,最后将排名最靠前的5个模型妥善保存到文件之中。整个过程一气呵成,高效又准确,充分展现了Browser Use在自动化执行复杂任务方面的卓越能力。
从MCP到Browser Use:一个现象级工具的崛起
Browser Use的火爆并非偶然,它是伴随着智能体领域的迅猛发展而逐渐崭露头角的。
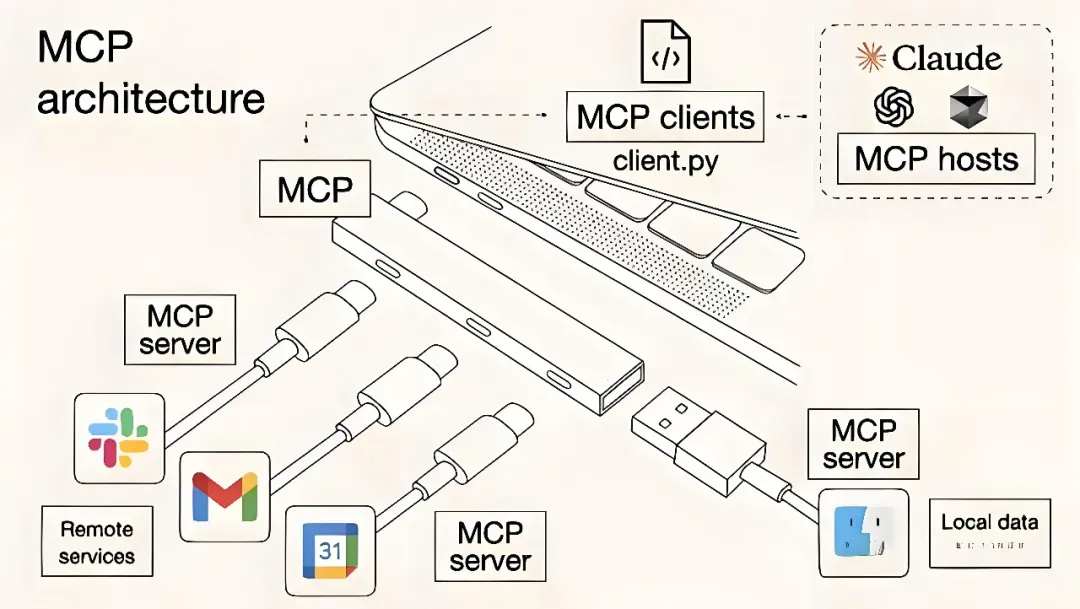
去年11月,Anthropic做出了一项具有开创性意义的举动——首次提出了「模型上下文协议」,也就是我们所说的MCP。这一协议的出现,犹如给Claude模型注入了一股强大的能量,赋予了它超级能力。通过一次构建,便让AI与工作流实现了深度集成,开启了智能应用的全新篇章。
用更加通俗易懂的话来解释,MCP就好比是专门为AI应用精心打造的通用接口,这就类似于我们日常生活中随处可见、广泛使用的USB-C接口。
大家都知道,USB-C接口的出现,极大地简化了不同设备与计算机之间的连接方式,让设备之间的数据传输和交互变得更加便捷高效。同样的道理,MCP简化了AI模型与数据、工具以及服务之间的交互方式。它就像是一座搭建在AI模型与各种资源之间的桥梁,让信息的流通更加顺畅无阻。
借助MCP的神奇力量,AI助手所能做到的远远超出了我们的想象。它不仅能够轻松地「读懂」代码,还具备了「理解」团队讨论内容、各类相关文档等外部信息的能力。如此一来,AI助手在面对各种问题时,就能提供更加精准、全面的回答,为用户带来更加优质、高效的服务体验。
Cloudflare用AI裁员20%:CEO马修·普林斯解读员工置换逻辑与转型代价
2026年5月,互联网基础设施巨头Cloudflare因一场由人工智能大规模驱动的组织重构,在全球范围引发高度关注。公司CEO马修·普林斯(Matthew Prince)于2026年5月21日在《华尔街日报》刊发专栏《How I Choose Which Cloudflare Employees to Replace With AI》,公开阐述了以AI系统替代人类员工的核心决策逻辑,该文迅速成为科技行业AI重塑职场的标志性事件。

5月7日,Cloudflare正式宣布全球裁员1100人,占员工总数的20%,系公司自成立以来首次大规模人员削减,其截至2025年底的员工总量为5156人。与此并行的是实习生扩招计划:公司早在2025年9月22日便宣布将于2026年录用1111名实习生,数字呼应旗下1.1.1.1公共DNS产品,岗位放出后共收到近100万份申请,录取率约千分之一,深刻折射出当前科技行业严峻的就业内卷态势。
此次人员优化的划分标准,源自彼得·德鲁克1954年经典著作《管理的实践》中的管理理论。企业据此将内部员工归为三类并定向处置:工程师、研发人员等“建造者”和负责销售、客户维系的“销售者”得以保留,亦是企业未来重点吸纳培养的群体,这类角色仰赖创意研发、人际协作与现场判断,目前尚难被人工智能全面取代。而财务、审计、中层管理、后台运营等“度量者”则成为主要裁撤对象,其日常工作多为标准化流程操作、重复性数据核算与常规核查,恰恰与AI擅长处理结构化事务的特性相匹配。借助智能工具,以往季度抽检的内部审计被升级为覆盖全业务流程的不间断智能审计,管理人员管辖幅度与工作效率大幅跃升,传统中后台岗位的人力需求随之递减。
如此剧烈的组织变革也让Cloudflare承受了相当可观的短期成本。据公司披露,本次人员调整涉及的遣散及重组费用预估区间为1.4至1.5亿美元。2026年第一季度财报显示,企业当期营收6.4亿美元,同比增长34%,业务规模持续扩大,但同期却出现6200万美元运营亏损,GAAP口径下净亏损达2290万美元。裁员消息发布后,公司股价盘中一度暴跌23.6%,反映出资本市场对这场以AI置换人力的变革举措态度偏向消极。
这一事件打破了“AI落地即能快速缩减成本”的固有认知,也清晰勾勒出行业演进的方向:具有重复属性、流程固化的基础职能岗位将不断遭遇人工智能的替代冲击;而创造价值、依赖人际沟通的岗位竞争力则持续提升。企业借助AI完成架构革新的过程中,高昂的人力置换代价、阶段性的业绩下滑以及资本市场的波动,都是必须经历的转型考验。
参考资料
- Matthew Prince. How I Choose Which Cloudflare Employees to Replace With AI [EB/OL]. 华尔街日报,2026-05-21
- Cloudflare 官方公告. 2026 年企业人员架构调整及裁员声明,2026-05-07
- Cloudflare 官方公告. 2026 年度实习生招聘计划,2025-09-22
- Cloudflare 2026 年第一季度财务业绩财报
- 彼得・德鲁克。管理的实践 [M].1954 年出版