Codex 三大新功能:应用快照上下文、/goal 超长任务与锁屏自动操作
最近 Codex App 迎来了一系列密集更新,2026 年 4 月以来,该工具经历了脱胎换骨的升级,接入 GPT‑5.5 后,价格相较 Opus 展现出更强的竞争力,工程能力持续提升,交互体验也越发顺手。更值得注意的是,Codex 几乎每天都有更新,外界推测其背后可能有一个 Agent 团队在彻夜不停地迭代——自己迭代自己,已成为这个时代软件的典型特征。
今天打开 Codex,发现又推送了一个大版本,共带来三处重大改进:应用快照、/goal 超长任务正式上线,以及锁屏操作。这些功能绝非表面文章,实际体验后才能真正体会到价值,因此值得逐一细看。
1
应用快照的说明位于 Codex 设置中:
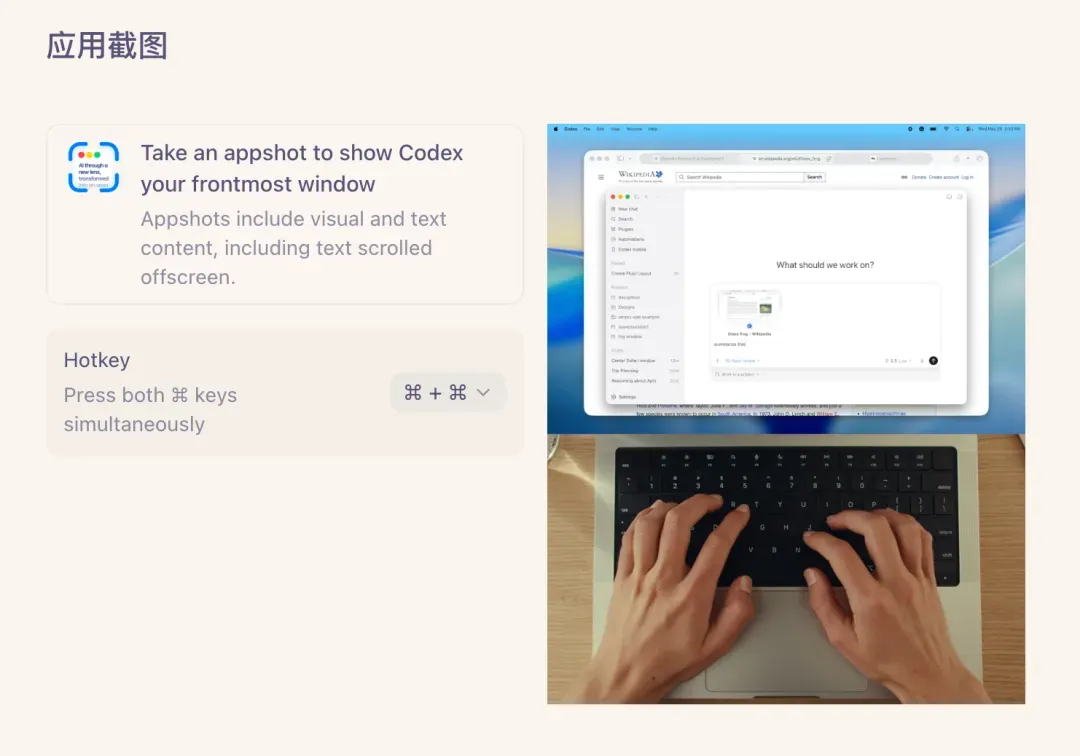
乍一看像是普通截屏,但实际远不止于此。首先看英文描述:截图将向 Codex 展示你的应用窗口,其中既包含视觉内容也包含文本,甚至包括已滚动出屏幕的文本内容。
这意味着 Codex 的截图不仅完整,还附带窗口内的全部上下文。具体演示如下:在 Mac 系统下,按照提示同时按下 cmd 键(空格键旁),当前界面的截图连同上下文会一并交给 Codex:
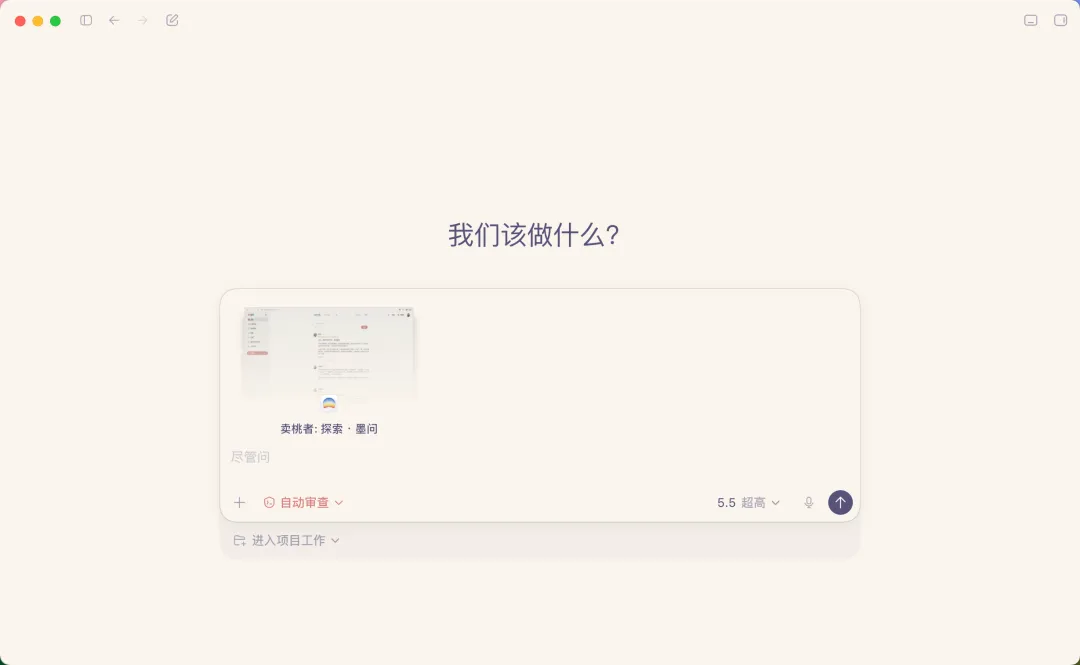
以上图为即将上线的墨问 Web 社区界面,截图生成后,点击右上角的“查看文本”,即可看到整个页面的全部信息:

这样的交互设计相当精妙。在常规 Chat 之外,这一特性尤其助推 Vibe Coding——等同于把 Web 或 App 界面的截图连同页面结构的上下文一次性提供给大模型,无论实现新功能还是修复 bug,都能明显提升准确性与效率。
2
在 Codex 中,/goal 专门用来管理需要持续推动的长任务,例如“完成 xx 功能,做到可执行并验证”,即要求 AI 完成一个大的功能模块,任务可能持续数小时。目前该功能已在 App 端正式上线,此前属于实验特性。
常见用法如:
/goal 修复这个 repo 里的所有 bug 并测试通过
也可以增加预算限制:
/goal 在 30000 token 以内,完成 rss bridge 的所有功能并验证
Codex 开始执行后,仍可继续输入正常指令,例如:
Codex拯救Mac:告别混乱,一键重建Apple Silicon纯净开发环境
我从 2008 年起就在 Mac 上办公与研发,那时操作系统的代号还叫雪豹;后来一路从 Mac OS X、OS X 走到今天的 macOS。因为系统一直保持着细腻顺滑的体验,我一次都没有重装过,甚至还无缝完成了从 Intel 到 Apple M 芯片的迁移。
早年换电脑依靠时间机器,后来有了雷雳线,直接用迁移助理的双机对拷模式搞定。正因如此,我手头的三台 Mac,基本都可以溯源到 2008 年的那台。从当年的各种本地开发环境,到后来较少编程,再到 Coding Agent 时代又一次需要配置全套本地开发工具,可以说是一路折腾不断。
直到某天我突然发现,不少程序还是 Intel 版本,Homebrew 也是 Intel 版,许多应用依然通过 Rosetta 2 桥接到 Apple 芯片上运行……就连 MySQL 也还停留在 2015 年装的 Intel 版本。
随着 macOS 更新,频繁弹出的系统通知更是扎心:「系统很快将不再支持 Rosetta 2 转接的程序,请尽快升级」。更要命的是,如果你的 Homebrew 一直是 Intel 版本,那么在 AI 时代安装各种 AI Coding 工具时,它也会顺势沿用这个老 Homebrew,导致 Codex 帮你安装的都是旧版 Intel 程序。整个环境就这样变得越来越混乱。
如果你的 Mac 也面临着类似的问题,别急,解药来了。
过去想要重新梳理这种密密麻麻的开发环境、上百个开发工具,极为耗费时间和精力,更别说要在三台环境一致的 Mac 上操作,几乎是不可能完成的任务。而现在有了 Codex,这一切都可以交给它来自动完成。
第一步:清查 Rosetta 遗留程序
首先,请 Codex 帮你检查还有哪些程序是通过 Rosetta 运行在 M 芯片上的。
DeepSeek AgentHarness 产品经理招聘揭秘:AI 原生应用如何定义下一个十年
在 DeepSeek 官网的招聘栏目里,一条新发布的“Agent Harness 产品经理”岗位引起了许多人的注意:
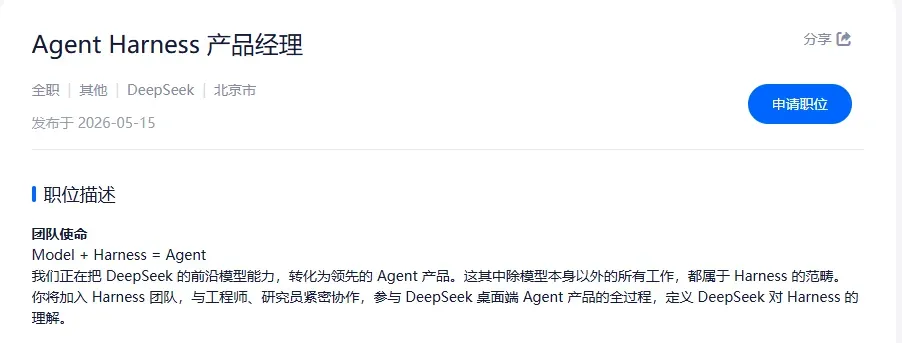
根据 DeepSeek 的官方定义,除了模型本身,所有支撑模型运转的工程化工作,都可以划入 Harness 的范畴。
再对比一下 DeepSeek 官方的 Agent Harness 工程和普通人理解的 Harness 工程,差异就显现出来了:
- 与模型训练团队的研究员深入沟通与协作,推动模型与 Harness 的共同进化。
- 推动 Harness 产品在内部真实任务中的落地,把这些内部任务当作 Harness 产品和模型能力训练的关键反馈源,以此持续打磨产品。
- 维护 Harness 产品的用户社群,从海量潜在用户中收集反馈、提炼信号,指导产品迭代方向。
所以,回过头来看,同样是 AI 编程工具,Anthropic 推出的 Claude Code 之所以能站上金字塔尖,一点也不意外。
DeepSeek 的模型早期就一直以出色的编码能力见长,那么它对自己“产品经理”的编程技能会不会有硬性要求呢?
答案很微妙:“能够使用 vibe coding 写代码,不一定需要技术背景。”
“不需要技术背景”,但又要“深度使用过 Claude Code、Codex、Cursor、OpenCode、GitHub Copilot”——能深度使用这些工具,却又说不要求技术背景,难道这些 AI 编程工具真的已经进化到可以深度撰写“PRD”了?
这个 Agent Harness 产品经理的岗位,其实也从侧面为我们揭示了普通人应当了解的 AI 原生应用核心概念:
理解 LLM 与 Agent 的基本机制及技术原理,包括 LLM API、KV Cache、Agent Loop、Tool Use、Reasoning、Planning、Skills、MCP、Memory、Subagent、Multi-Agent 等一系列知识;对于 Prompt Engineering、Context Engineering、Harness Engineering 等课题,也需要有第一手的实践经验。
GLM-5.2 海外评测直逼闭源冠军,开源权重正在改写全球人工智能竞赛规则

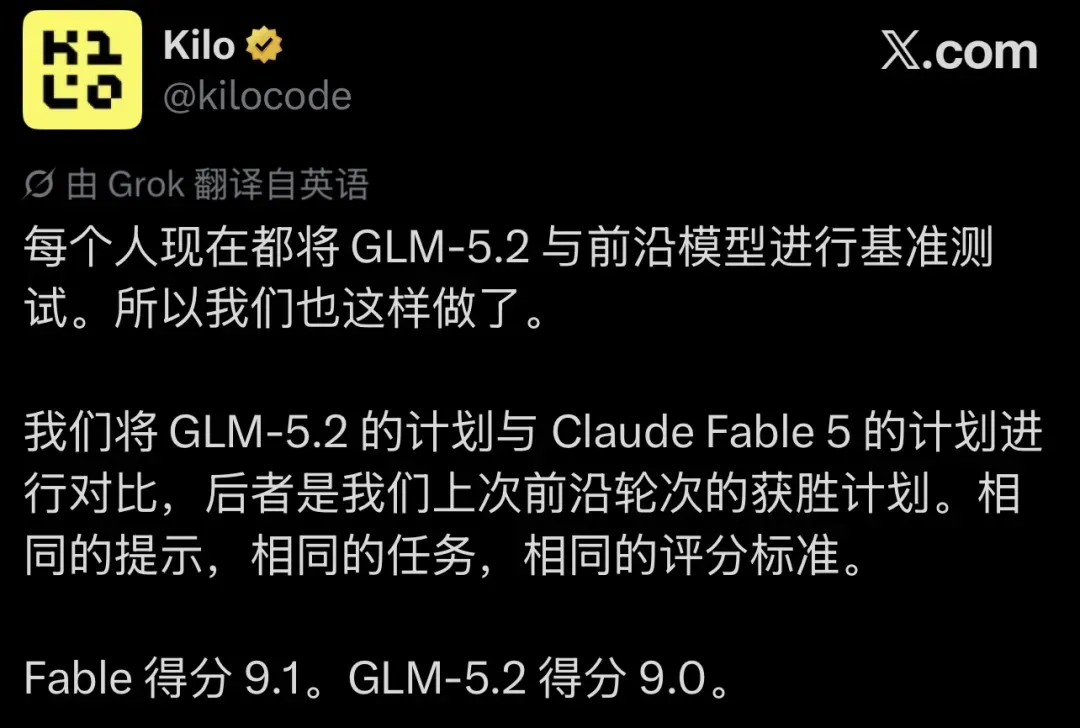
一家海外编程平台用同一套评分标准,把智谱刚刚推出的开源权重模型 GLM-5.2 与 Anthropic 上一轮闭源旗舰 Claude Fable 5 放在一起衡量。结果:9.0 对 9.1。不到 0.1 分的差距几乎可以忽略,但两个模型的身份标签却隔着巨大的鸿沟。

图注:Kilo 平台的评测对比卡片。左侧 GLM-5.2 标注 open weights,右侧 Claude Fable 5 标注 frontier,评分来自同一套标准。
海外开发者到底在兴奋什么
拥有超过三百万用户的海外编程平台 Kilo,其业务直接扎根于 AI 辅助工程,利润命脉系于模型的选择——用什么模型、花多少钱、产出质量有多高。因此,他们对模型的任何风吹草动都极度敏感。
在上一轮测试中,Claude Fable 5 以 9.1 分的成绩成为冠军。这一次,Kilo 把 GLM-5.2 拉进同样的擂台:相同的 prompt、相同的任务、相同的评分指标,最终得分 9.0。开源权重模型与闭源旗舰之间的性能差距,被压缩到了小数点后一位。
这条推文发出后,迅速获得了 421 个赞、13 条深度引用讨论和 2.1 万次浏览。评论区里最高频出现的一个词是 game changer——游戏规则改变者。
对海外开发者而言,开源权重意味着三样东西:可以自行部署、可以自主调优、不必被任何一家 API 供应商锁定。当一个开源模型的性能逼近闭源旗舰时,商业逻辑就被彻底改写了。
拼的不是性能排行榜,而是经济账
海外开发者对大模型的关注点,与国内存在一个微妙的错位。国内讨论大多聚焦于谁登上了哪个榜单、谁又宣布了降价,话题围绕 DeepSeek、Qwen、Kimi 的日常体验展开。这些模型在国内已经遍布足够多的免费入口,用户几乎不需要关心底层模型到底是哪一家。
但海外的情况截然不同。Claude、GPT 的 API 价格严格按照 token 计费,企业级调用成本高得惊人。一个中等规模的编程辅助平台,月均 token 消耗可以轻松突破数十亿。在这个规模上,模型单价每差 0.01 美元,月度账单就是数十万美元的起伏。
GLM-5.2 的定位恰好击中了这个痛点:开源权重意味着可以自部署,推理成本由自己的 GPU 决定;它的 API 调用价格远低于 Claude;而输出质量又完全够用。对海外的中小团队和独立开发者来说,这根本不是性价比选项,而是生存选项。
GLM-5.2本地化部署新突破:744B模型2-bit量化,Mac Studio上实现低成本私有推理
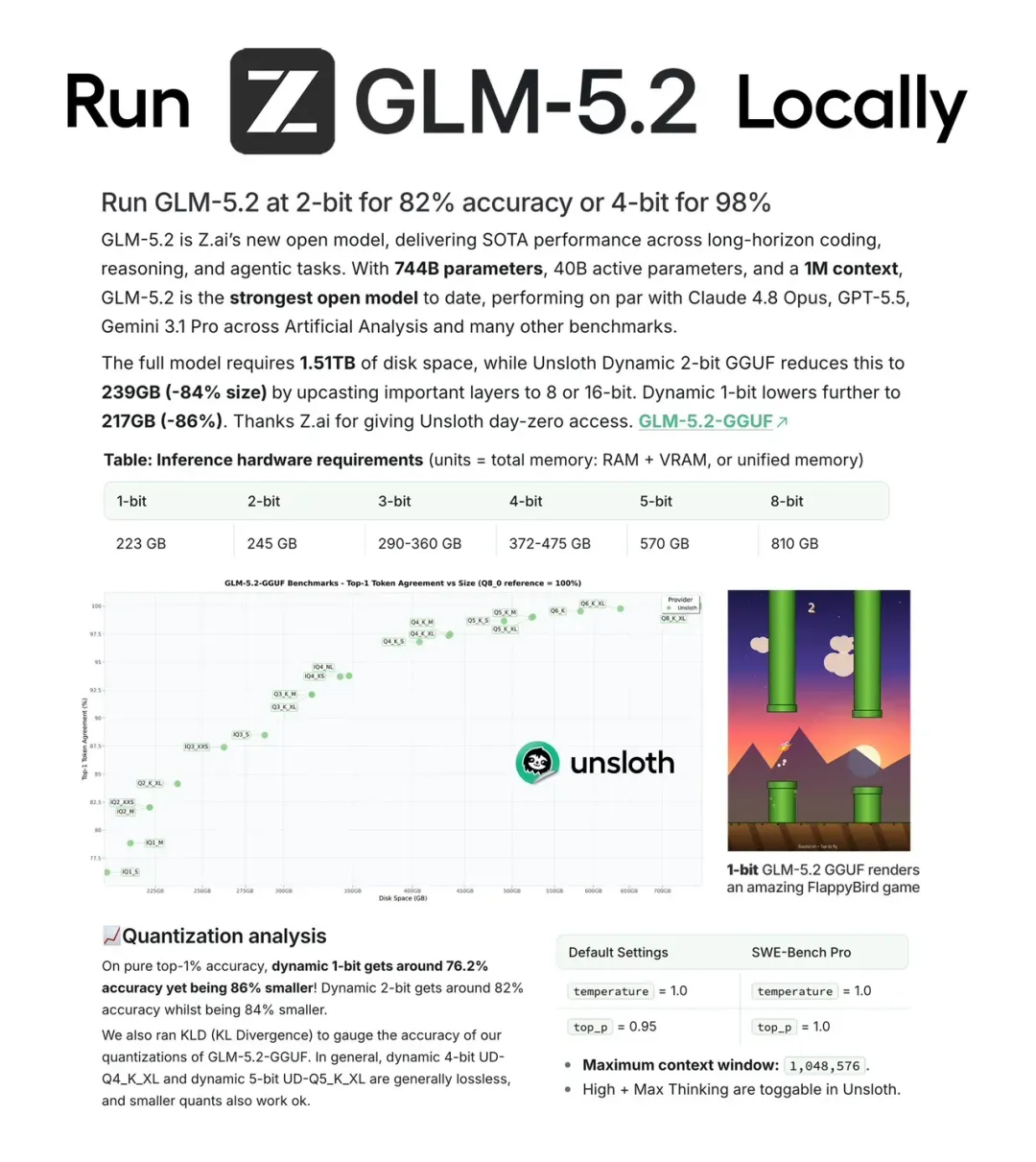
一个拥有7440亿参数的旗舰模型,经2比特量化压缩至238 GB,在2026年直接跑进了Mac Studio的统一内存。这意味着什么?不再是畅想“未来某天”,而是当下就有开发者把桌面机器变成了不联网的私有推理节点,并且宣称效果超过了几天前还在榜单上的主流闭源模型。

帖子里嵌入的视频截图显示,1-bit GLM-5.2 GGUF在本地渲染Flappy Bird游戏,被用作“足够小的模型依然能产出真实输出”的视觉佐证。
01
纸面参数只是“规模”,真正跑进内存的才算“交付”
GLM-5.2是由Z.ai推出的新一代开源模型,官方核心参数如下:744B总参数,MoE架构下40B激活参数,上下文长度1,048,576 tokens。模型仓库登陆Hugging Face时,明确标注支持中英双语文本生成,以多分片GGUF文件集形式分发。
Unsloth社区随即放出了量化版本。2-bit动态量化压缩至239 GB,文件数减少84%;1-bit动态量化进一步压到217 GB,文件数锐减86%。单张RTX 4090难以承载192 GB显存,但配备512 GB统一内存的Mac Studio已经跨过门槛,距离桌面独立运行只差一台不算便宜的硬件。
社区生态图谱由此被重新点燃。有人在Mac Studio上以2-bit满负载运行,开始驱动智能体与编码循环;也有人断言“本地AI时代”即日开启,替代了曾需持续订阅云服务的前沿模型。空气中弥漫着类似2022年末第一次在消费级GPU上跑Llama时的兴奋感。
02
“比Opus更好”的兴奋背后,藏着两个被忽视的数字
事件原点是一位工程师在社交平台上发布的长帖,其核心判断是“我在本地的GLM-5.2 2-bit上得到了比Opus 4.8更佳的结果”。这句话重复了自2023年以来每次本地旗舰模型复现的叙事套路:先是高调吹捧本地效果,接着审视硬件与延迟,最后发现“主力工具”与“玩具体验”的分界线依然存在。
同一位工程师两天后追加了一份澄清。从质量角度看,2-bit准确率82%、4-bit达到98%的结果,以及可与家人分享的兴奋感都很真实;但从速度角度看,生成一段18秒视频中的Flappy Bird游戏画面,本地耗时5分钟,而同款前沿云端模型大约只需15秒。由此得出的结论毫不含糊:它不会取代主要工作流,而是在不联网、不付费、不被封号这三个维度上解锁了被云端模型定价长期排除的新用例。
目前的量化数据来自Unsloth社区的标定曲线:1-bit约76.2% token一致率,2-bit约82%,4-bit/5-bit则接近无损。这些数字通过KL散度标定,作为精度参考比“主观评判”更贴近可复现标准;但“是否够用”是由用户的具体任务定义的,而非由量化位宽一锤定音。
03
不是替代,而是补全:本地模型催生的新用例才值得认真审视
真正的转折点并不在于“本地跑都没输”,而是“出现了云端根本无法完成的任务”。同一篇帖子里列举的新用例非常具体:让本地模型24小时循环审查最近的所有的PR,周期性扫描Creator Buddy的反馈数据,用浏览器自动爬取社交媒体上的专有数据,以及构建一份不存储于任何远程服务器的私聊助手。
这些任务的共同要求是:成本可忽略且路径完全可控。用云端模型实现同等效果,要么每家SaaS的API调用费变成固定支出,要么数据会被记录、审计、共享;而在这些维度上,本地模型具有无可替代性。所谓的“解放”,并不是单一技术突破制造的幻觉,而是由新形态的基础设施成本塑造出来的现实。
这也解释了社区里为何同时出现“本地AI已死”和“你的电脑就是星球最强终端”这两种对立信号。前者对照的是云端模型绝对不让步的推理质量;后者指向的则是本地模型开启了一个此前不存在的市场。两种判断同时成立,才是这件事情的真实面貌。

04
2026年6月,你该做的不是“迁移”,而是“重新定义问题”
放眼望去,AI行业的发展叙事始终围绕着“谁更聪明”,而这一次本地化的意义更像是在追问“谁的成本结构不同”。当推理成本从按token计费变为一次性硬件折旧,许多原本不成立的产品方案会同时浮出水面:24小时后台循环、自有数据链路、离线推理、私密对话。这些需求不再是小众偏好,而是下一波独立开发者、研究机构和数据敏感企业的产品基础。
如果今天你对本地AI的期待还停留在“替代云版ChatGPT”,那大概率会失望。但如果你将其理解为一个可以随时接管你电脑网络的、不联网的副驾驶,那么许多成本壁垒和市场空白将被重新定义。GLM-5.2在这个节点出现,不是为了追赶某个赛道的第一名,而是在推高门槛两边站着的队伍人数。
所有关于“AI泡沫是否破灭”的争论,既不取决于某次榜单更新,也不取决于社区情绪。真正的问题是:你的主工作流消耗的究竟是什么——是算力,还是AI解决问题的能力。
来源:Z.ai GLM-5.2 博客、unsloth/GLM-5.2-GGUF 模型仓库、Hugging Face 文件页
MCP 模型上下文协议:从原理到实践,AI 时代的统一连接标准
🔥 MCP 协议迅速走红原因解析
2024 年末,人工智能公司 Anthropic 正式开源了 MCP(模型上下文协议),该协议很快便成为 AI 行业的新焦点。MCP 的目标是为大语言模型(LLM)与外部数据源、工具之间建立一套统一的连接规范,直击 AI 应用实际部署中的集成痛点19。
MCP 的三大核心优势:
✅ 统一连接标准:无需为每个数据源编写定制代码,一次配置即可连接多种平台1
✅ 上下文保持能力:支持多轮对话中保持应用/服务间的上下文,增强 AI 自主执行复杂任务的能力10
✅ 安全高效传输:采用二进制通信和标准化安全机制,比传统 API 效率提升 40% 以上4
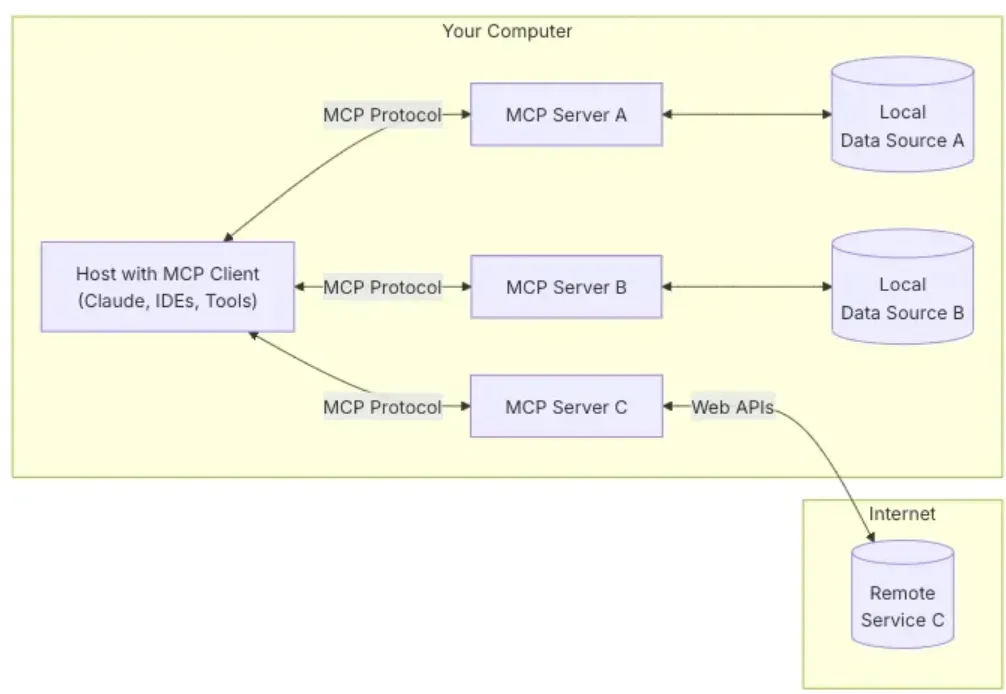 (图示:MCP的客户端-服务端架构,来源:Anthropic官方文档)
(图示:MCP的客户端-服务端架构,来源:Anthropic官方文档)
💻 MCP 对比传统 API:为什么称其为颠覆式创新?
| 对比维度 | 传统 REST/Function Calling | MCP 协议 |
| 开发效率 | 需为每个接口编写适配代码 | 标准化协议,一次开发多平台使用 |
| 上下文管理 | 难以保持跨服务上下文 | 原生支持上下文传递和保持 |
| 传输效率 | JSON/XML 文本传输,冗余高 | 二进制压缩,延迟降低 40% |
| 安全控制 | 依赖各自实现 | 标准化认证和访问控制 |
| 适用场景 | 通用 API 调用 | 专为 AI 模型交互优化 |
数据来源:Anthropic 技术白皮书及第三方评测410
🛠️ MCP 核心组件与工作机制深度剖析
MCP 采用客户端‑服务端架构,主要包含以下组件9:
- MCP Host:如 Claude Desktop 等 AI 应用,作为用户交互入口
- MCP Client:协议客户端,与 Server 建立 1:1 连接
- MCP Server:轻量级服务,连接数据源或工具并暴露功能
- Local/Remote 资源:可以是本地文件、数据库或远程 API
通信机制支持两种方式:
NAS部署AI修仙文字冒险《仙途》指南:用Docker搭建你的私服修仙世界
《太吾绘卷》在6月17日结束了EA阶段,正式以《太吾绘卷:天幕心帷》之名上线。对修仙养成题材的偏爱似乎是刻在玩家骨子里的,无论是《太吾绘卷》《鬼谷八荒》,还是《觅长生》,只要沾上“修仙”二字,就总能让人心痒。哪怕是不太喜欢的战棋玩法,一旦裹上修仙养成的外衣,也值得耐着性子试试。
正是在这种情怀下,一个名为《仙途》(XianTu)的AI修仙文字冒险项目吸引了不少眼球,下面就把它分享给大家。
项目介绍
完整项目名:qianye60/XianTu,可在GitHub搜索。
《仙途》是一款AI驱动的沉浸式修仙文字冒险游戏,基于Vue 3、TypeScript和FastAPI开发,支持Gemini、Claude、OpenAI等多种大模型。它并非传统意义上的大型修仙游戏,而是将修仙题材、文字冒险与AI动态生成相结合,让剧情、事件和角色经历不再依赖固定脚本,而是能够根据玩家的选择实时生成新内容。
功能概览
- • 🤖 AI动态叙事 — 支持 Gemini / Claude / OpenAI / DeepSeek 等多种大模型,实时生成个性化剧情
- • ⚔️ 完整修仙体系 — 涵盖境界突破、三千大道、功法修炼、装备炼制及NPC互动
- • 🎲 智能判定系统 — 基于境界、属性、装备、功法等多维度计算判定结果
- • 💾 多存档管理 — 支持多角色、多存档槽位,可导入导出与云同步
- • 🗺️ 开放世界 — 自由探索朝天大陆,偶遇奇遇事件,构建人物关系网络
- • 📱 全平台适配 — 完美适配桌面端与移动端,提供亮/暗双主题
- • 🍺 酒馆兼容 — 兼容SillyTavern嵌入式环境及独立网页版
部署流程
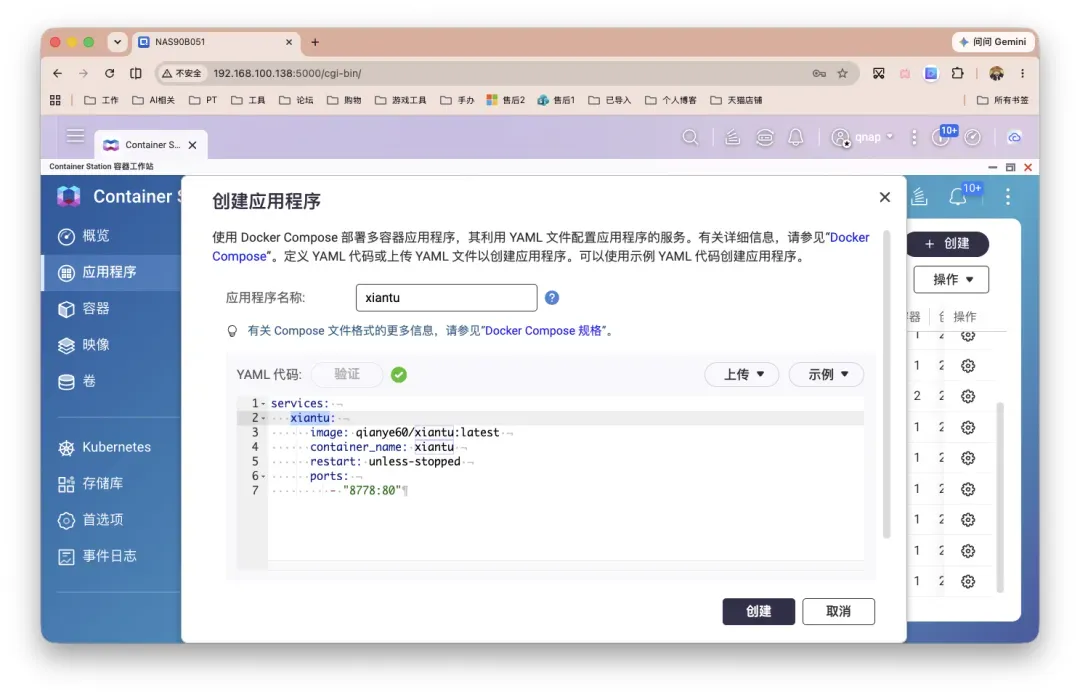
以威联通NAS为例,使用Docker Compose进行部署,配置如下:
services:
xiantu:
image: qianye60/xiantu:latest
container_name: xiantu
restart: unless-stopped
ports:
- "8778:80"
打开威联通Container Station,创建新的应用程序。
Omnigent:AI Agent的元调度层,让Claude Code与CodeX互相审查代码
你是否同时深度使用 Claude Code 和 CodeX 等多款 AI 编码助手?还是始终以一款为主、其余打辅助?我猜大多数人会选择主力工具,毕竟我们精心配置的插件、Skill、MCP 等早已与它深度绑定,切换代价不小。但如果存在一个“上层建筑”,能让你随时调度不同 Agent,甚至让 Claude Code 与 CodeX 相互审查对方的产出呢?
最近在 GitHub 上发现的开源项目 Omnigent,恰好瞄准了这个方向。
这个项目给自己起了一个颇有意思的定位:meta-harness——元调度层。请注意这个词,它要做的是运行在所有 “Claude Code 们” 之上的那一层。
深入理解 meta-harness:从发动机到底盘
要理解 meta-harness,得先拆解这个词。我们平时使用的 Claude Code、Codex、Cursor 本质上是 harness,即把大模型包装成能实际干活的 Agent 的外壳,集成了 prompt、工具调用、上下文管理和文件操作等能力。而 Omnigent 想做的是 meta-harness,一层运行在这些 harness 之上的调度系统。

开源地址:https://github.com/omnigent-ai/omnigent
打个比方:harness 是发动机,meta-harness 就是底盘和方向盘。你可以在同一辆车上换发动机,也可以同时装好几台发动机协同工作。这听起来抽象,但落到具体场景就清晰起来。Omnigent 给出了三大核心能力:
① 多 Agent 协同
在同一个 session 中,你可以同时调度 Claude Code、Codex、Cursor、Pi 等多个 Agent。更妙的是,你能指派一个 Agent 去审查另一个 Agent 的工作。比如让 Claude Code 写代码,由 Codex 来做 review。
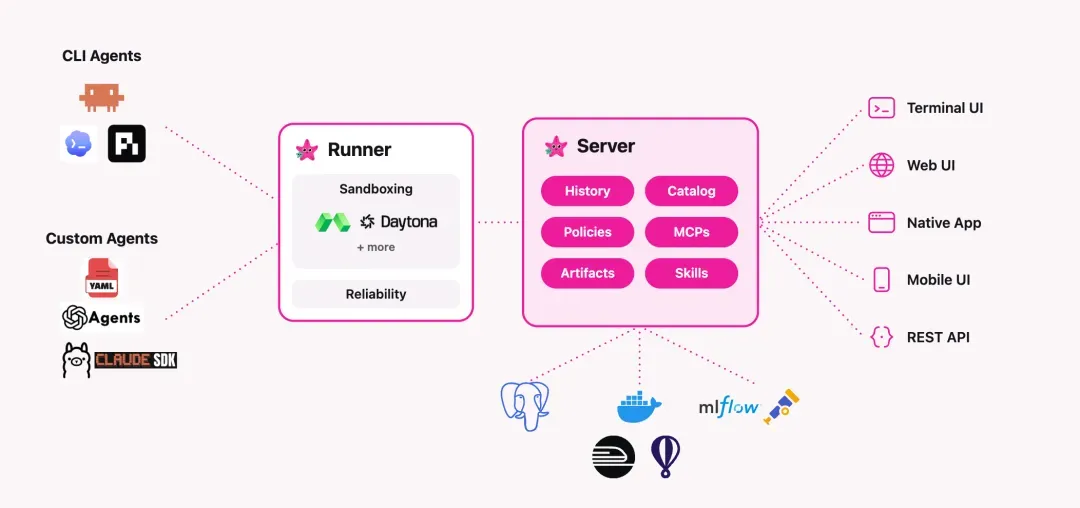
② 跨设备无缝接力
一个 session 可以从终端里开始,切换到浏览器继续,最后在手机上收尾。消息、子 Agent、终端、文件全程同步。对于需要在路上或者躺在床上随时盯进度的人来说,这解决了很真实的需求。
Step 3.7 Flash 实测:Agent 工作流的高频推理引擎如何重塑生产力
周末例行查看常用的模型供应商控制台,突然注意到阶跃星辰刚刚上线了 Step 3.7 Flash,便立刻配置尝鲜。早就听说这款模型要来:新一代高效多模态 Flash 模型,主打极速推理、长上下文、工具调用与多模态工作流,直接面向 Agent 场景,最高生成速度可达 400 tokens/s。
用 CC Switch 打开 Claude Code 的配置文件,填入 Step 3.7 Flash 的相关信息,保存退出,再重新启动 Claude Code,就可以直接体验这款新模型了:
一、上手实测:用 Flash 模型搭建 Agent Loop Analyzer
最近打算做一个叫 Agent Loop Analyzer 的小组件,用来分析 Agent 在规划与执行任务过程中各阶段的耗时和成本。还没正式动工,正好拿 Step 3.7 Flash 试试手。
我的整体目标是生成一个“Agent Loop Analyzer”小工具:让 Coding Agent 从零开始构建一个 Vite + React + TypeScript 单页应用,用来估算 Agent 任务在规划、搜索、工具调用、代码生成、验证五个环节的耗时和成本,并通过图表直观呈现结果。
最终我给到 Agent 的 Prompt 是这样的:
从零开始创建一个 Vite + React + TypeScript 单页应用,名称为 Agent Loop Analyzer。
功能要求:1. 左侧配置 Agent 任务的五个阶段:规划、搜索、工具调用、代码生成、验证。2. 每个阶段可输入调用次数、平均输入 tokens、平均输出 tokens、预估延迟。 3. 右侧实时展示总 tokens、总耗时、估算成本和阶段占比。 4. 用简单图表展示每个阶段的耗时占比。 5. 提供一组默认示例数据。 6. 支持导入和导出 JSON 配置。 7. 生成 README,说明如何启动、如何使用、核心设计取舍。8. 完成后运行构建检查,并汇报是否通过。 约束: - 使用 React + TypeScript。- 样式使用普通 CSS,不引入复杂 UI 库。- 优先保证第一版可运行、结构清晰、代码可维护。
记录四个结果就够了:模型版本、推理强度、首次生成是否能跑通、人工修改了几处。这个 Demo 能同时测 Coding、Agent loop、工具调用稳定性和 first-pass 完成度。
任务交给 Step 3.7 Flash 后,通过 Claude Code 的调度,模型迅速展开了规划与骨架搭建,接着开始编写代码。
Vercel发布生产级开源智能体框架eve:Agent工程化标准化时代的Next.js
随着eve的发布,Agent框架正迅速从百花齐放的混乱局面走向标准化。2026年下半年,Agent开发将迎来类似2018年前端开发的关键转折:框架之争刚刚开始,但标准化的方向已然清晰。
my-agent/└── agent/ ├── agent.ts # 可选:定义所用模型及基础配置 ├── instructions.md # 必须: 系统提示词,明确Agent人设与目标 ├── tools/ # 可选: 模型可调用的自定义工具函数 │ └── get_weather.ts ├── skills/ # 可选: 技能,可复用的操作流程 │ └── plan_a_trip.md ├── channels/ # 可选: 消息通道 (HTTP, Slack, Discord) │ └── slack.ts └── schedules/ # 可选: 定时任务 └── weekly_recap.ts
AI Agent的工程化正在经历一场根本性重塑。以往,每个团队都在重复搭建执行环境、审批流程和状态管理,如同前端领域在Next.js诞生前的“手工时代”。Vercel eve的诞生终结了这一碎片化的局面,它被明确命名为“Agent领域的Next.js”,其使命是通过一套标准化的框架,极大压缩从原型验证到生产部署的周期。

eve的核心价值在于将生产就绪的能力直接固化到框架内部,让开发者无需再为以下通用难题投入过多精力:
- 如何确保服务重启后会话无缝恢复?
- 如何隔离Agent所生成代码的执行风险?
- 如何在执行删除等敏感操作前插入人工审批?
- 如何追踪每一次模型调用和工具执行的全链路?
技术架构:文件驱动与持久化执行
Vercel eve凭借独创的文件驱动架构、可靠的持久化机制以及分层记忆与状态管理,从根本上攻克了AI Agent在生产环境中的执行中断、状态丢失和上下文膨胀等核心挑战。其设计目标不仅是提升开发效率,更是为了保障复杂任务的长期稳定运行。
安全机制:沙箱隔离与人工审批闭环
Vercel eve构建了一套“隔离为基底、权限为纲领、验证为盾牌”的全栈安全体系,系统性地应对AI Agent在生产中面临的越权操作、提示注入、凭证泄露等核心风险。该设计将复杂的多层安全保障深嵌于框架底层,使开发者无需再从零开始构建防护机制。
运维能力:可观测性与成本控制
Vercel eve框架将生产级运维能力融入其基因,使开发者能够以极低的额外成本实现对AI Agent行为的全面掌控与资源优化。在真实的业务环境中,可观测性与成本管理是决定Agent能否规模化落地的关键因素。
生态集成:跨平台协同与业务闭环
Vercel eve不只是一个运行时框架,更是一套完整的生态集成方案。它通过标准化的接口与协议,打破了AI Agent与外部世界的连接壁垒,让开发者能够快速构建端到端的自动化流程,实现从用户触达到任务交付的完整闭环。