办公小浣熊2.0深度评测:本地Office文件直读+打通飞书钉钉企微,AI真正融入工作流
要让AI办公在国内真正落地,必须聚焦两个关键场景。首先是本地Office文件的处理。毕竟需要AI处理的文档大多存储在个人电脑上,如果每次都要手动上传文件、等待AI处理完再下载,不仅流程繁琐,效率也极其低下。更理想的方案,是能授权一个本地目录,让AI直接在文件夹内执行指令、处理文件。
其次是打通飞书、企业微信、钉钉等主流办公IM。想象一下,你费尽心思让AI生成了一份高质量报告,却最终不得不手动复制粘贴到飞书文档中——这种断层的体验,让AI始终无法无缝嵌入真实协作流程。

如果这两个痛点不解决,AI办公就永远隔着一道玻璃墙——看得见,用不畅。只有打通本地文件高效处理和企业IM的对接,AI才能真正进入核心工作流。正是瞄准这一点,办公小浣熊桌面版2.0应运而生。
01 桌面版2.0:从等待提问到主动执行
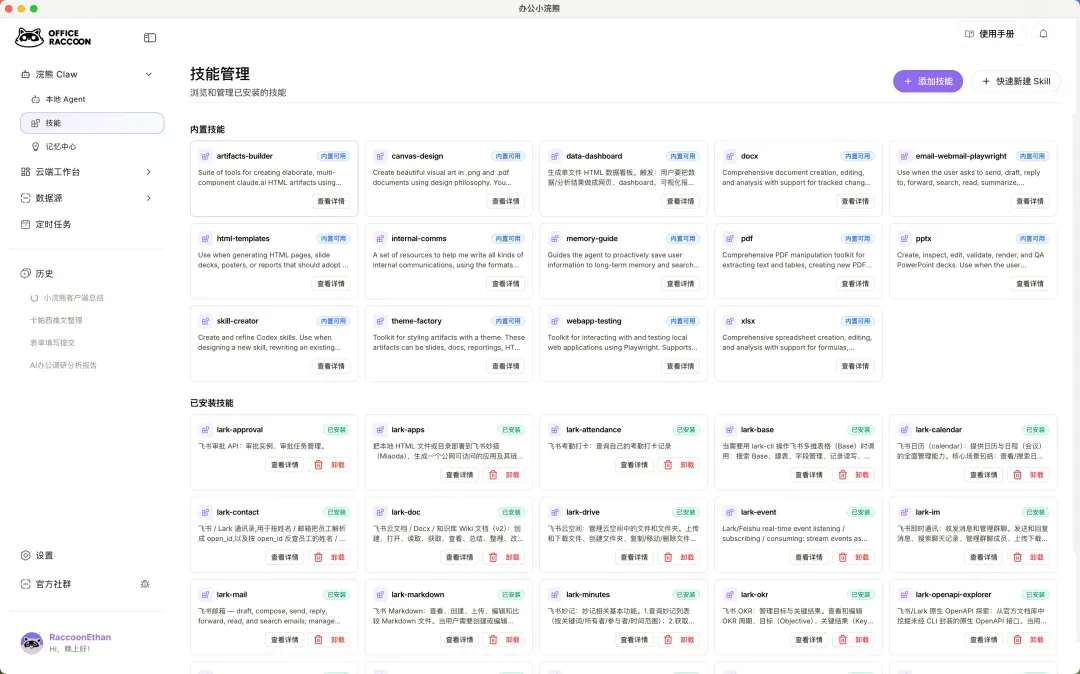
过去的桌面版,更多是把网页端的功能平移到了本地,胜在操作便捷、系统稳定。但在实际使用中,用户很快发现,仅仅切换入口远远不够。真实的办公场景并不局限于一个对话框——文件存放在本地目录,数据流淌在Excel表格,资料分散在浏览器标签页,而团队协作则沉淀在飞书群聊里。2.0版本的重磅升级,正是将小浣熊的角色从“等待提问”转变为“主动执行”:在你授权的范围内,它可以直接读取本地文件、操控浏览器、对接企业系统、处理你当前浏览的内容,甚至自动完成重复性任务。下面,逐一拆解这六大新能力。
① 本地文件直读
支持Excel、CSV、PDF、Word、PPT等二十余种格式,告别反复上传下载的繁琐。你只需授权一个本地目录,小浣熊就可以直接在该文件夹里展开工作。

比如,你可以直接下令:“分析这个文件夹里的销售数据,找出增长最快和下滑最明显的品类。”或者让小浣熊读取本地的PDF,梳理每篇文档的核心观点,自动生成一张对比表格。
文件无需事先搬动,小浣熊就在本地目录里直接加工,一切都在原始位置完成。
② 一句话操控浏览器
桌面版还集成了浏览器自动化引擎。只需一句话,它就能自动打开网页、读取内容、抓取关键信息,并按你的需求整理结果。当然,使用前需要先下载一个配套的浏览器工具,该工具内置了Playwright MCP,使AI可以便捷地启动浏览器、执行抓取与操作。
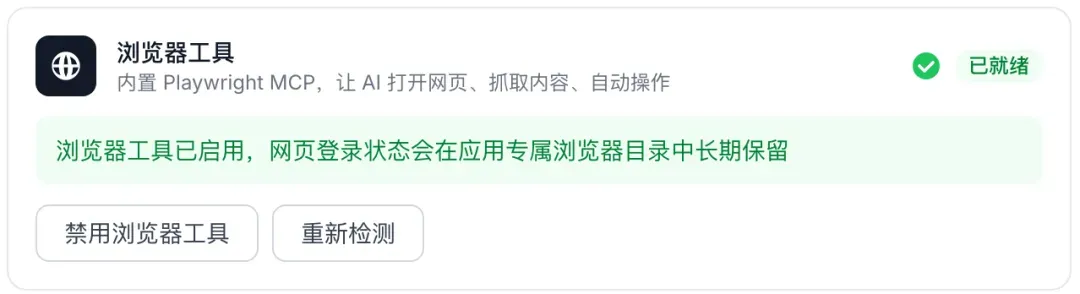
以往需要在浏览器中反复切换标签页、复制粘贴、手动整理的工作,现在一句语音或文字指令即可完成。
③ Quick Bar 全局唤起
在任何应用程序中,通过快捷键 ⌘K(Mac)/ Ctrl+K(Windows)即可呼出小浣熊的快捷指令栏。
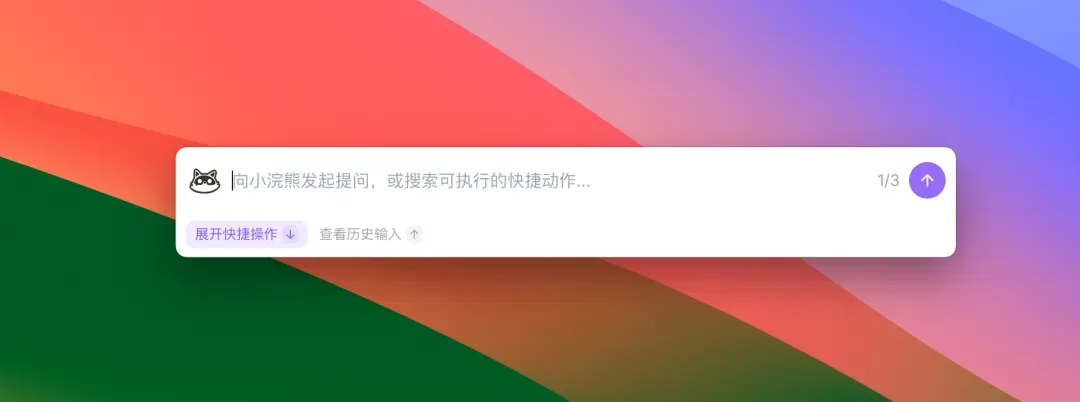
选中一段文字,一键翻译、摘要或改写;在Excel中圈选一组单元格,它可以直接分析异常、打上分类标签,甚至将处理结果回填到原表格。小浣熊不再是一个悬浮于工作流之外的独立窗口,而是直接嵌入到你的工作界面,即时处理你眼前的内容。
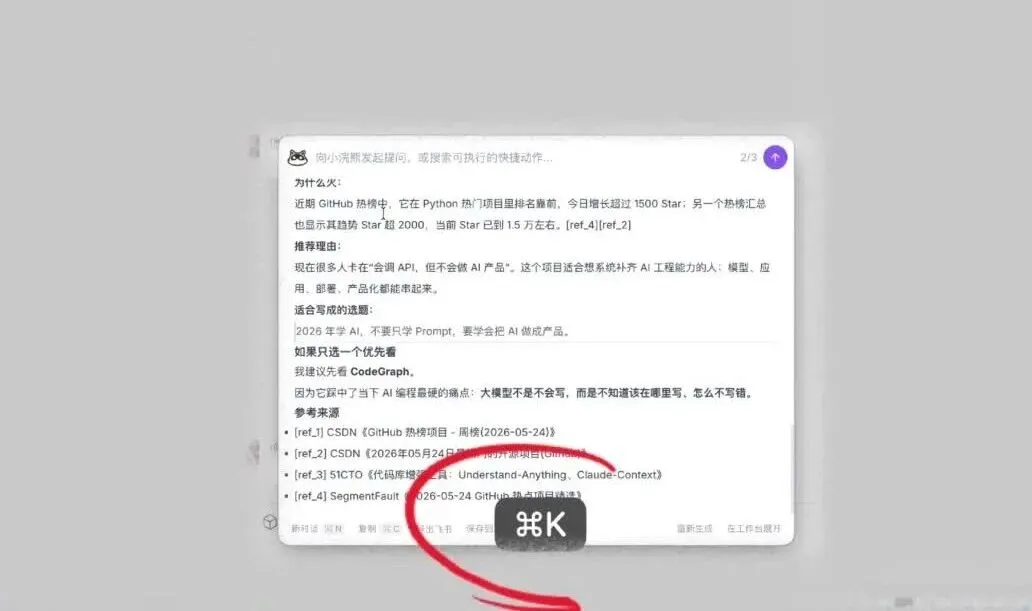
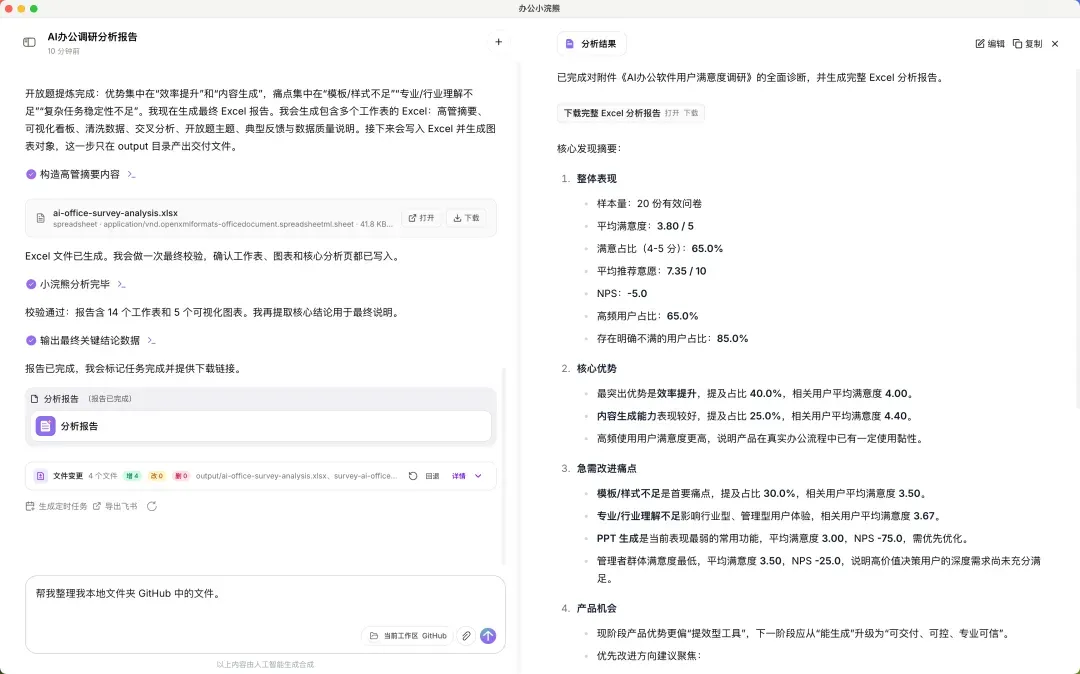
办公小浣熊2.0实战:同时处理Office文件并打通飞书、钉钉、企微。
④ 打通国内办公 IM 软件
桌面版2.0已实现直连飞书,企业微信和钉钉的支持也即将上线。以飞书为例,通过一键授权即可将飞书内置的20多个Skill能力整合进来,整个过程简单快速。

同时,小浣熊客户端还提供了飞书文档空间的可视化管理面板——即使你没有安装飞书客户端,也能轻松浏览和操作飞书文档。
⑤ 本地记忆,越用越懂你
小浣熊具备本地记忆能力,能记住你的职位、行业、常用术语、文档风格偏好以及输出习惯。这些记忆跨会话持久生效,让你不必每次对话都重复说明背景。

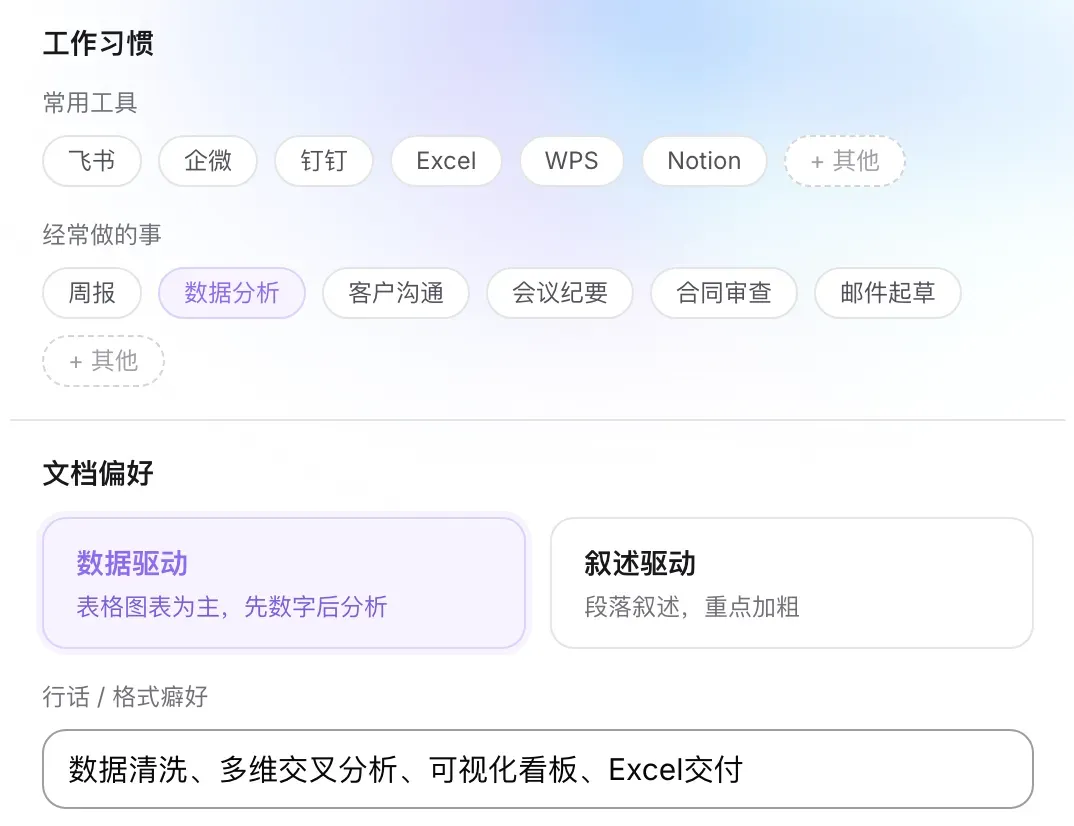
可以预先设定偏好,例如:“以后撰写产品文档时,语言要正式、清晰,避免过度营销。”或者“我常用的分析框架是:现状、问题、原因、建议。”用得越久,它的理解就越精准。
⑥ 定时任务,自动执行
有些工作并不复杂,但却耗费心力。比如每日查看数据、每周汇总周报、每月收集反馈、定期监测竞品官网。现在只需设定好执行时间与任务内容,小浣熊即可自动按时完成。

例如,每天早上9点自动读取指定目录中的最新数据,生成一份前一日业务日报。
目前,办公小浣熊已构建起三端协同的产品矩阵:网页版主攻复杂任务,移动端随时响应需求,桌面版2.0则承担深度执行。三者并非互相替代,而是各自覆盖不同的办公场景。桌面版2.0现已同步支持Mac与Windows双平台,当前处于内测阶段,可限时免费无限制使用。后续你也可以通过小瓢虫快速提交使用反馈。
02 真实任务挑战季:300万奖池邀你用真任务检验实力
功能已就位,接下来就看能否扛得住真实场景的考验。5月23日,商汤小浣熊“真实任务挑战季”正式启动,总奖池超过300万元,分为两大部分:
OPC 能力挑战赛
挑战赛由商汤小浣熊与Datawhale联合发起,设有两条赛道:赛道一为“OPC新手出道赛”,只需用办公小浣熊完成一次真实任务,并将成果发布到小红书、知乎或微信公众号即可参与。整个赛季共4轮,每周均设有创作奖励抽奖,越早参与,获得机会的轮次越多。赛道二为“OPC高手创造赛”,选手需围绕一个真实行业场景,打造完整作品——可以是内容生产工作流、行业解决方案或深度数据分析,个人单项最高奖金可达10万元。

与此同时,还发布了全国首个OPC能力认证体系,从OPC Learner起步,逐步晋升至OPC Builder乃至OPC Founder,以真实任务和作品为标尺,验证AI实战能力。整个OPC能力挑战赛的总奖池为55万元。

21 天真实任务打卡挑战
5月27日开启,目标明确:通过连续21天的打卡,助你养成用AI提升办公效率的习惯。每日完成一次涵盖数据分析、任务规划、PPT生成等真实场景的任务打卡,便能积累坚果奖励,坚果可兑换周边产品和会员权益。额外还有Mac mini、iPad Air、AirPods Max等实物大奖。该打卡挑战总奖池超过200万元。
杭州六小龙开源Aholo Viewer:3D高斯浏览器支持10亿高斯点渲染,性能全面碾压Spark 2.0
今年4月中旬,李飞飞创立的World Labs开源了3D高斯泼溅渲染引擎Spark 2.0,在全球开发者社区引发一阵轰动。这款引擎能在浏览器中轻松渲染上亿个3D高斯点的精细场景,甚至在手机上也能流畅运行,这一突破着实令人振奋。然而仅仅时隔一月,一款名为Aholo Viewer的国产3D高斯浏览器也正式开源,并在多项核心性能指标上实现了对Spark 2.0的全面超越。最令人震撼的数据是:Spark 2.0的上限为1亿高斯点,而Aholo Viewer能够扛住10亿高斯点的渲染,性能差距整整一个数量级。海外技术社区正对此展开火热讨论。
项目概况:Aholo Viewer是什么?
Aholo Viewer是一款完全在浏览器中运行的3D高斯泼溅(3D Gaussian Splatting)渲染引擎。这个词听起来充满科技感,通俗来说,它用大量模糊的圆点拼接重构出栩栩如生的3D场景。但3D内容一直以来的痛点在于数据文件过于庞大,传输困难、加载缓慢。像Aholo Viewer和Spark 2.0这类项目的开源,使得普通用户无需安装任何额外客户端,在不同终端设备上打开网页就能流畅浏览包含亿万高斯点的超大规模3D场景。这让3D内容的传播和消费变得像观看视频一样简单、高效。
开源地址:GitHub:github.com/manycoretech/aholo-viewer
不用装任何客户端,打开浏览器,手机、电脑、VR头显都能用。你可以在浏览器里直接漫游一座城市级别的3D场景,比如将整个杭州西湖区域的实景3D重建塞进网页中,像刷短视频那样随意闲逛。这个项目来自群核科技,它也是杭州“六小龙”之一,今年4月刚刚在港交所上市,一直深耕空间智能领域。

群核科技在3D渲染领域已有长达15年的技术积累,这次直接将核心能力开源,Aholo Viewer能实现这番性能表现并不令人意外。事实上,群核科技一直在向开源方向积极迈进,此前已经发布了3D高斯语义数据集InteriorGS、空间语言模型SpatialLM、空间生成模型SpatialGen,在3D空间智能赛道上布局极为深远。
下面是Aholo Viewer的实际运行效果:

性能对决:Aholo Viewer vs. Spark 2.0
3D高斯泼溅是近两年3D重建领域最炙手可热的技术方向。其核心思路是借助数以亿计的3D高斯点云来重建真实世界的场景,并实时渲染呈现。当李飞飞的World Labs在4月开源Spark 2.0时,主打卖点就是在浏览器中跑通1亿以上的高斯点,同时适配所有设备,当时这一指标已足够震撼。但Aholo Viewer的到来,重新定义了性能边界。
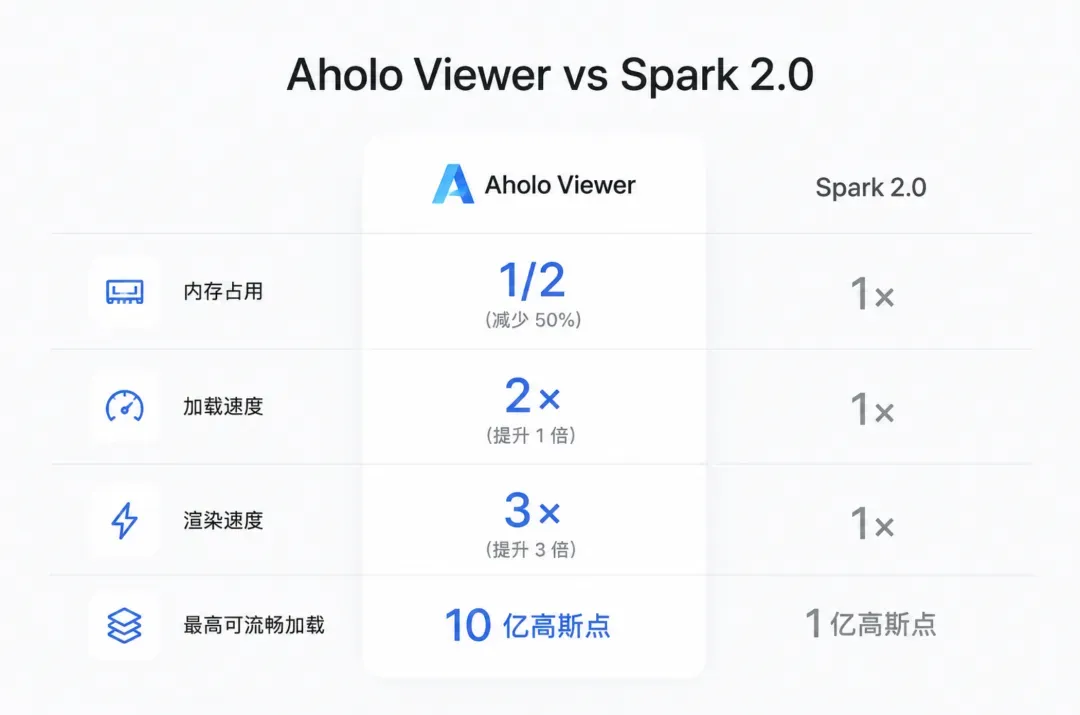
直接看对比:在场景承载力上,Spark 2.0最多支持1亿高斯点,Aholo Viewer则支持10亿,拉开了10倍的差距。在同一个3亿高斯点的场景下实测,结果更是一边倒:
- 内存占用:Aholo只有Spark的1/2
- 加载速度:Aholo快1倍
- 渲染速度:Aholo快3倍
- 画面效果:Aholo更优
这不是微弱的领先,而是全方位的技术碾压。Spark 2.0基于Three.js和WebGL2构建,走的是传统的Splat‑based技术路线,Aholo Viewer则选择了一条完全不同的道路。
核心技术揭秘:区块式LOD架构如何实现高性能?
性能差距的根源在于底层架构。Spark 2.0采用Splat‑based方案,以单个高斯点作为基本单元进行调度和渲染。场景较小时还算流畅,但场景一旦扩大,数据量会指数级爆炸,内存与显存都会不堪重负。Aholo Viewer则创新性地采用了Chunk‑based LOD Tree,即区块式细节层级树。
它的思路完全不同:它将整个3D场景切分成一个个区块(Chunk),每个区块拥有独立的细节层级(LOD)。当你浏览时,近处的区块加载高精度细节,远处的区块仅呈现低精度版本。这样的设计让内存变得更加可控:同一时刻只需加载视野范围内的区块,不必将整个场景完全塞进显存。一个10亿高斯点的场景,你的浏览器其实完全不需要一次性装下10亿个点。
区块化管理也让缓存命中率大幅提升,远比逐点管理高效。当你在一片区域内环顾四周时,已经加载过的区块会被缓存在本地,切换视角时无需重新下载。扩展性同样极佳,如果想支持城市级甚至更大规模的场景,只需增加区块数量即可,核心架构无需任何改动。配合流式分批拉取技术,Aholo Viewer可以实现首屏10秒内进入场景,之后根据视锥优先级逐步加载剩余内容。你看哪里,它就加载哪里,不看的部分完全不占资源。这借鉴了游戏引擎中经典的LOD思想,但Aholo将其深入应用在更加复杂的3D高斯泼溅场景中,而且做得极为彻底。
全链路工具与开箱即用体验
仅有一个渲染引擎还不够,开发者还需要一整套工具,才能把原始3D数据转化为可实时渲染的场景。Aholo Viewer直接提供了一条完整的工具链:
格式兼容: 支持ply、spz、sog、splat、lcc、ksplat等主流3DGS格式。市面上常见的格式几乎都能直接吃进去,不用自己再编写格式转换脚本。
LOD生成: 自动将原始3DGS数据转换为分层细节的流式资源,开箱即用。你只需丢入一个原始文件,后续所有处理都自动完成。
物理碰撞体生成: 这个功能很有创意。它可以把3DGS重建的空间转换为可查询的碰撞边界,支持射线检测、胶囊体碰撞、地面检测、墙体阻挡等。你可以在3D场景内启用行走模式、第三人称相机避障、区域限制等交互,而不止是被动漫游。
下面的演示展示了行走模式下的碰撞检测与交互效果:

此外,群核Aholo空间智能平台还开放了云端渲染、空间重建、3D AI模型生成等一系列API。云端混合渲染可以将3DGS与高保真Mesh放在同一个场景中,在云端实时混合渲染并串流输出。空间重建允许你仅凭一段视频,就将物理世界1:1复刻到数字空间。而3D AI模型生成支持图生3D和文生3D,能产出材质细节更丰富的模型,并顺畅接入3D内容生产工作流。低配设备也能流畅预览高精度场景。
同时提供多档位渲染配置:效果优先、性能优先、极限性能三种模式,按需平衡性能与画质,适配不同设备和场景需求。从数据输入到最终画面呈现,开发者几乎不再需要依赖第三方工具。
开发者社群基于Aholo Viewer已经探索出不少有趣的项目,比如游戏场景和数字化博物馆:
开源AI必须赢:从Fable 5禁令看技术垄断时代的破局之道
6月9日,Anthropic推出Claude Fable 5模型,号称为当时地表最强AI,社区一片沸腾,众人争相涌入体验。
仅过了三天,6月12日下午5点21分,美国商务部长签署紧急出口管制令,径直送达Anthropic。理由是国家安全隐患,要求90分钟内彻底禁止所有外国公民使用Fable 5与Mythos 5。
Anthropic被推入两难境地,索性一刀切,在全球范围内关停了这两个模型。美国本土用户也一样,再也无法访问。
此事在社区炸开了锅。
闭源被禁,开源呼声为何响彻社区?
模型被关停后,社区成员纷纷给Anthropic出主意,说得最多的就是:何不直接开源?把代码扔到网上,美国政府想禁也禁不了。
X平台上,一句口号被反复转发——“Open Source AI Must Win”,开源AI必须赢。他们的逻辑非常直白:如果Fable 5是开源的,任何国家的开发者都能自由下载、部署、继续使用,一纸公文根本拔不掉你的网线。
但Anthropic没有这么做。也不可能这么做。
原因很简单:Fable 5是Anthropic的核心资产,是砸下数十亿美元筑起的技术壁垒,也是其盈利命脉。把赚钱的东西免费公开,不是自断生路吗?Anthropic不是慈善机构。这是商业逻辑,与道德无关。
对Anthropic来说,“开源”这个选项从一开始就不存在。
国产开源模型成为破局关键
有意思的是,就在Fable 5被封的同一天,智谱发布了GLM 5.2。
完全开源,支持100万token无损上下文,Code Arena全球可用模型排名第一,总榜第二,仅次于已被封禁的Fable 5。大模型圈自此有了“新御三家”的说法——Anthropic、OpenAI、智谱。
不仅是智谱,国内大模型几乎全线开源。DeepSeek、Qwen、GLM、Kimi,一数一大串。再往前看,DeepSeek V4 Flash推出时,Redis的作者antirez专门为其写了DS4引擎,让模型在128G内存的MacBook上就能跑起来,社区当时称其为“惊天动地”。
你或许会说,他们开源是因为蒸馏了国外大模型,不好意思不开源。这话不全无道理。
国外用户对中国大模型的确怀着一份复杂心态。鄙夷的很多,觉得你的技术不过是ChatGPT和Claude那里蒸馏过来的,没多少技术含量。
但他们骂归骂,用也是真用。
因为不但开源,价格也确实低廉。海外技术人员同样没有绝对的忠诚可言,哪个好用用哪个,哪个便宜用哪个。他们甚至直接把模型下载到本地电脑上跑,无需联网、不必付费、不看任何人脸色。
而且,越来越多人开始看清一件事:正是因为中国大模型一直在追、一直在开源,OpenAI和Claude才不敢搞技术垄断。它们被迫不断推出新版本、不断降价、不断开放更多功能。
如果没有这些竞争者,后果不堪设想。
于是你会发现一个很值得玩味的现象:每次Claude或OpenAI发布新模型,底下的评论画风出奇一致——“中国大模型赶紧加油,快去蒸馏,弄个便宜的出来。”
翻译过来就是:Claude用不起,还是DeepSeek更有性价比。
这便是当下真实的生态。
开源的本质:为何它是打破垄断的唯一武器
假如没有国内这些开源大模型,一切都将被OpenAI和Claude牢牢垄断。企业级数据量庞大且高度敏感,绝对不能对外公开,更牵扯到竞争关系。腾讯不可能用阿里的模型,阿里也不可能把自己的数据开放给腾讯。中小公司更惨,既买不起最贵的API,又不敢将核心数据交给闭源服务商。
如果没有开源模型,摆在所有企业面前的只有一条路:交出数据,使用闭源服务。
Fable 5被封这件事,给所有人上了刻骨铭心的一课。印度科技圈大佬Sridhar Vembu说了一句扎心的话:“全球化已死。”他呼吁印度全面转向开源模型。
欧洲也摆出了相似姿态。欧盟本已与Anthropic谈妥了访问权限,哪知一纸禁令下来,所有安排灰飞烟灭。欧盟官员公开表态:这是对欧洲“技术主权”的警钟。
你看,全世界都在得出同一个判断:闭源的东西,不握在自己手里,随时可能被夺走。
开源,是唯一能对抗这种不确定性的方式。
结语:开源让AI回归初衷
AI时代,开源的意义愈发明朗。不是因为开源有多高尚,而是因为闭源太危险。
领先者不会主动开源,这可以理解。但如果世上只剩闭源模型,所有人的脖子都被卡在少数几家美国公司手中。某天美国政府再写一张纸,你又什么都用不了了。
国内大模型虽被嘲讽“蒸馏”,但蒸馏完便开源了,逐渐催生出一个庞大的生态。DeepSeek把API价格打到谷底,智谱用MIT协议将GLM 5.2完全开放,Qwen从第一天起就走开源路线。
他们当然有商业上的考量,但客观上让更多人触碰到了前沿模型,让大批企业不必把所有数据一股脑交给闭源厂商。
这才是当初发展AI的初衷。
没有开源,AI只属于少数人。有了开源,AI才属于所有人。
这就是开源存在的意义。
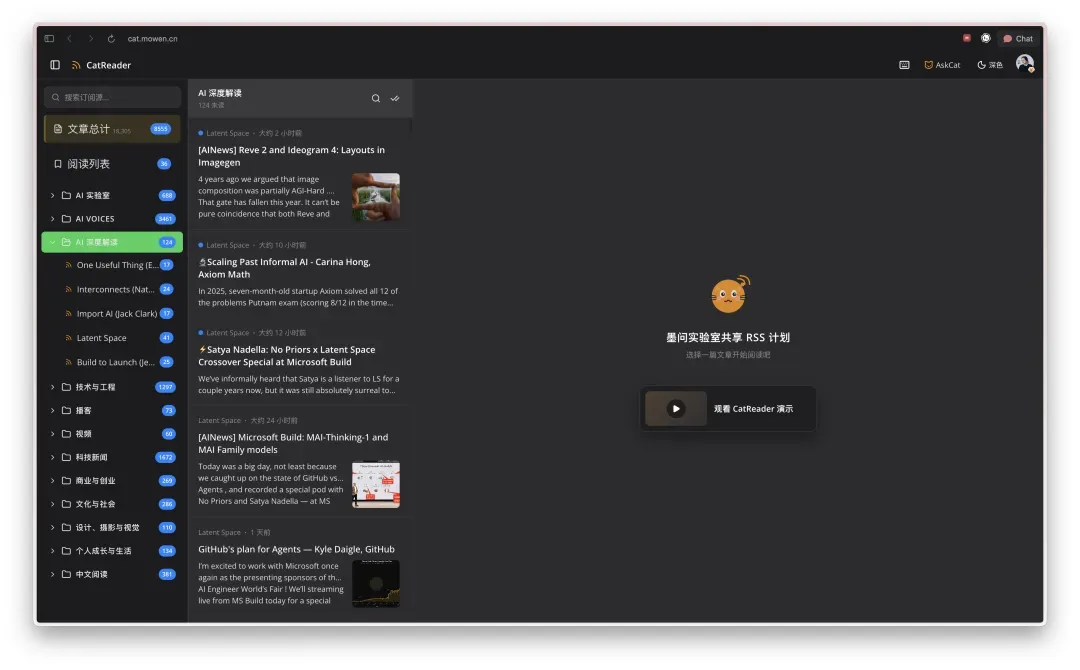
墨问推出 CatReader:公开信源 AI 知识库 RSS 阅读器正式上线,让信息获取更智能
在 AI 时代,拥有一份自己信赖的一手信源比以往任何时候都重要。与其阅读大量不靠谱媒体靠翻译、组稿和 AI 生成的内容,不如直接关注各大 AI 实验室的官方博客、研究报告、产品动态,以及知名 AI 实践者的个人博客、创始人在 x.com 上的发言。此外,长期累积的优质博客、播客、视频和书籍等资源,也迫切需要一个高效的使用方式。那么,AI 时代如何更有效率地利用这些信息?
Reeder 虽然界面优雅,但缺乏 AI 辅助,也无法桥接 x.com 等非 RSS 源。其他阅读器要么设计不佳,要么 AI 功能不实用,要么价格高昂——一款阅读器动辄几十美金并不稀奇。于是,构建一个带知识库的 RSS 阅读器的想法应运而生。
这个项目在春节后启动,基于 Claude Code 和 Codex 构建,经过断断续续的开发,基本功能很快就完成了。初期仅有前端,所有内容缓存在浏览器中,但已能满足个人使用,还内置了 AI 助手 AskCat。后续考虑更进一步,通过 Vibe 的方式实现一个相对完备的 RSS 信息系统,并开放给所有墨问用户。
之后的迭代则体现出更强的工程属性,比如前后端项目分离、独立桥接程序、数据分离、整个用户系统的改造、与墨问的接入、跨域问题、网络与安全、演示视频制作、CI/CD 以及部署到生产环境等。到最后,许多环节还需要研发团队提供解决方案和相关资料,才能让整个项目完整落地。这意味着,通过 Vibe 模式构建一个简单的离线系统(包括工具软件),即使所用技术再精深,AI 也能帮你完成;但一旦涉及网络、数据库、用户系统、生产环境和安全,并且需要为成千上万人提供服务时,门槛依然很高,挑战不言而喻。
目前这个产品已经正式发布,并对墨问 Pro 会员开放。访问地址非常简单:
cat.mowen.cn
这就是墨问最新推出的现代 RSS 阅读器,其中所有信源都经过精心整理,涵盖十几个分类、两百多个订阅源,积累了 18,000 多篇文章,不仅包括图文内容,还有播客和音频播放器。其中一部分是原生 RSS 源,另一部分通过桥接实现,因此它是一个动态更新的 RSS 知识库。
首页还设计了一个有趣的文章推荐功能,点击猫头图标即可查看:
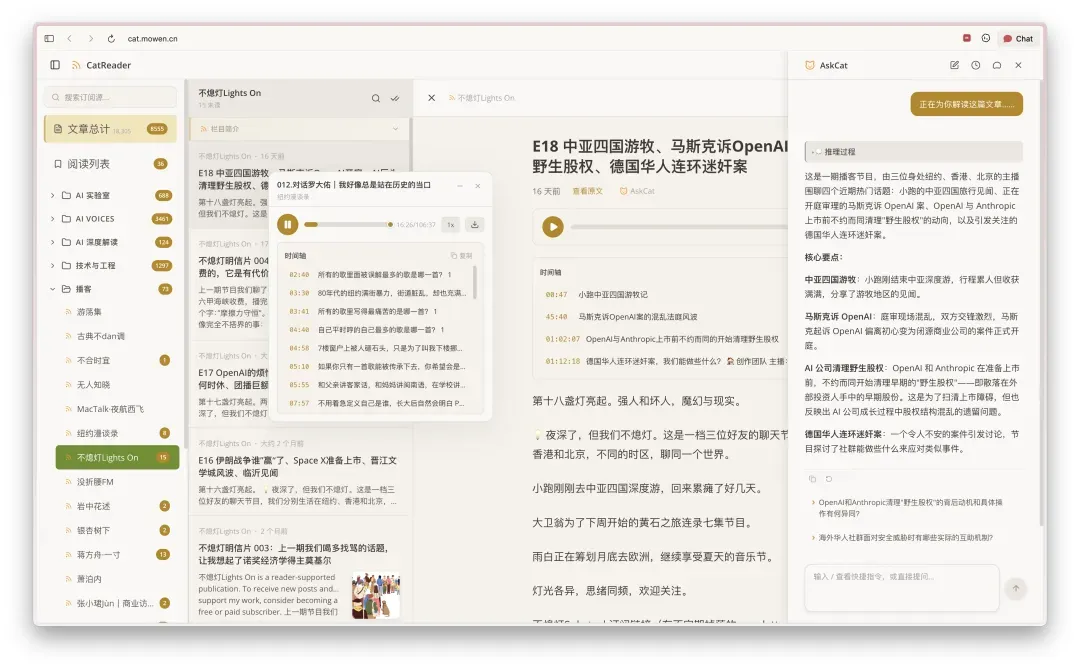
此外,产品配备了非常全面的快捷键支持:F 键全屏阅读文章,V 键查看原文,cmd + k 打开智能助手,同时也支持 vim 快捷键(j/k 上下翻阅文章)等。
AskCat 作为智能阅读助手,能够自动感知用户当前打开的分类、信息源和文章,自动接入上下文来回答问题,并设计了斜杠弹出菜单:
死磕AI写作的终极指南:工具、优势与盈利机会全解析
在这个数字技术狂飙的时代,AI写作正以前所未见的势头重塑创作方式与内容生态。它不仅为写作者带来了全新机遇与便利,还在文学、营销及学术等领域展现巨大能量。那么,为何我会坚持推荐你全力钻研AI写作?接下来,一同揭开其奥秘。
AI写作的核心优点
高效产出:加速内容制作节奏
传统写作常需耗费大量时间在构思、撰写和润色上,而AI写作工具能瞬间生成海量文本,大幅提升生产速度。以新闻报道、产品简介或社交媒体文案为例,AI可基于指令快速产出合格稿件,节省人力。某电商案例显示,引入这类工具后,产品描述编写效率激增数倍,原本耗时多日的任务如今数小时即可完工。
精准把控:保证内容质量与连贯性
依托自然语言处理技术,AI能准确解析信息,生成符合语言规则的文字。它内建语法检查与句式优化功能,让文本更流畅无误。同时,AI可对文章进行逻辑层面的分析与调整,确保叙述连贯合理。在学术领域,工具能辅助梳理文献、生成摘要,并检查论文结构,从而提升作品的可信度与严谨度。
个性适配:满足多样化的创作需求
AI写作工具能够根据用户偏好,调校内容风格、语气和表达,使得最终文稿更贴合个人或品牌特质。无论是严肃的学术论述、诙谐的博客帖,还是专业商业报告,AI皆能依据关键词与需求进行风格化输出,回应不同场景与受众。比如,品牌在构思广告时,便可借助AI依据定位和目标人群,选定恰当的语言调性,让文案更具穿透力。
创意激发:打破思维僵局
当创作陷入瓶颈时,AI可抛出多样思路与构想,助人们跨过障碍。它从海量数据中挖掘隐藏的热点与趋势,为写手注入灵感。不仅如此,AI还能模仿各家文风,生成特色纷呈的篇章,为创作开辟新路。例如,在创意写作中,AI可基于预设情节和角色自动化景虚构故事,成为作家的灵感引擎或辅助利器。
语言破壁:跨越全球沟通障碍
面对多语言创作需求,AI工具可快速完成翻译与本地化,赋能国际化内容输出。它能精准转换语言,并保留原文意涵与风格。这对跨国企业、国际媒体及翻译从业者而言,无疑是强力襄助。以某跨国公司为例,启用AI写作后,其全球内容传播效率猛升,能及时且准确地触达各地客户。
AI写作的成功案例:开启创作与收益新篇
九岁学童凭AI练就科幻长篇
北京年仅9岁的小学生许萌萌,在AI辅助下完成科幻小说《AI少年:火星生存大挑战》,并斩获2万元版税。创作中,他交替使用ChatGPT与国内模型智谱清言,不断打磨提示词,并精细修正AI输出,终成此作。该书出版后迅速加印,首月售出逾6000册,证实了AI在童书创作领域的潜能。
在校大学生借AI写作月入数万
21岁大学生李明,以AI写作工具为辅助,实现月入五万的佳绩。他先将情节大纲输入工具,设定文体与语调,再依据AI提供的初稿进行人工调整与深化。此法既大幅提升了码字速度,又确保了作品品质。其网络小说订阅量稳步上升,加之广告与版权合作,收入最终攀升至令人艳羡的高度。
团队携手AI创作百万字巨着
华东师范大学王峰团队采用“国产大语言模型+提示词工程+人工后期润色”模式,产出一部逾110万字的AI小说《天命使徒》。勤奋的网络作家完成同等篇幅常需一年,而AI仅用一个半月。团队深入剖析网文架构,解析情节脉络,撰写大量提示词,在大模型中批量生成内容,形成线索连贯的宏篇,再经人工打磨交付。此举彰显了AI在长篇创作领域的巨大潜力与前景。
常见AI写作平台简介
通用型生成引擎
豆包AI(字节跳动)
:搭载云雀大模型,并支持DeepSeek-R1与V3双模型切换。输入“XX使用指南”即可自动生成结构化文档,其“智能纠错”功能可侦测逻辑漏洞,在科技教程、职场指南等场景中准确率达98%。2025年新增“行业模板库”覆盖超30个领域,企业用户可通过API实现内容批量产出。
文心一言(百度)
:整合百度搜索生态,输入主题后将自动关联权威文献与行业数据,生成含代码示例的深度内容。“术语标准化”工具可统一专业词汇,学术场景准确率达98%。2025年升级“多模态生成”,支持图文混排与数据可视化。
通义千问(阿里云)
:内置“合规审查”模块,在医疗、金融领域表现突出。支持跨文件智能补全,上下文理解力强悍,输出内容可直接用于行业报告。其“多语言翻译增强”功能可同步产出中英双语版本,将跨境电商文案生成效率拉升60%。
创意与文学创作利器
小鱼AI写作
:拥有超4000个模板,涵盖小说、剧本、诗歌等领域,并支持“故事接龙”与“角色设定”功能。其“灵感库”提供200余个细分场景的创作思路,助创作者快速搭建故事框架。例如输入“科幻小说开头”,可生成包含世界观、核心冲突的三种风格方案。
讯飞写作助手
:集成语音输入转文字功能,支持多语言互译,适用于会议纪要、访谈稿生成。新增“法律文书生成”模块,自动标注法律依据,在医疗场景中可输出合规的病历文书。
商业与营销文案工具
爱制作AI
:一键生成适配小红书、抖音、淘宝等平台的文案,并支持带货话术与爆款标题优化。内置“SEO关键词分析”模块,可自动提取高流量关键词,提升曝光率。例如输入“夏季连衣裙”,能产制10条符合平台算法的标题,并推荐关联话题标签。
海鲸AI
:以“行业垂直化模板库”为核心卖点,提供餐饮、IT、美妆等十大领域逾100个专业模板。用户选定行业后,AI自动调用对应术语库与数据包,生成高度定制方案,并支持跨平台一键分发至知乎、公众号等渠道。
学术与教学辅助工具
Kimi智能助手
:支持处理200万字级别的长文档,自动提取参考文献关键步骤并生成流程图。其“知识图谱关联”功能可推荐前沿研究方向,在学术论文场景中效率提升40%。例如输入“AI+医疗诊断”,便能产出包含5至8个研究角度的文献综述框架。
作业帮AI写作
:针对论文、报告提供文献综述框架与参考文献推荐,并支持查重预警。其“降AI痕”功能可使生成内容顺利通过知网查重,学术场景重复率可压至15%以下。
特色化工具
Jasper
:专注全球化内容创作,支持30多种语言智能写作,尤其擅长英语长文。输入主题后,AI自动调用行业数据库构建逻辑框架,并填充案例与数据,输出可直接用于博客、白皮书或社交媒体的高质量内容,同时提供SEO优化建议。其母语级表达力使其在跨境内容创作中表现突出。
腾讯Hy3预览版收费即登顶OpenRouter用量榜首,Hermas Agent超越OpenClaw成为最热应用
今天在全球最大的token中转站OpenRouter观察到,腾讯新推出的Hy3 preview竟然在收费状态下拿下了本周token用量第一名:
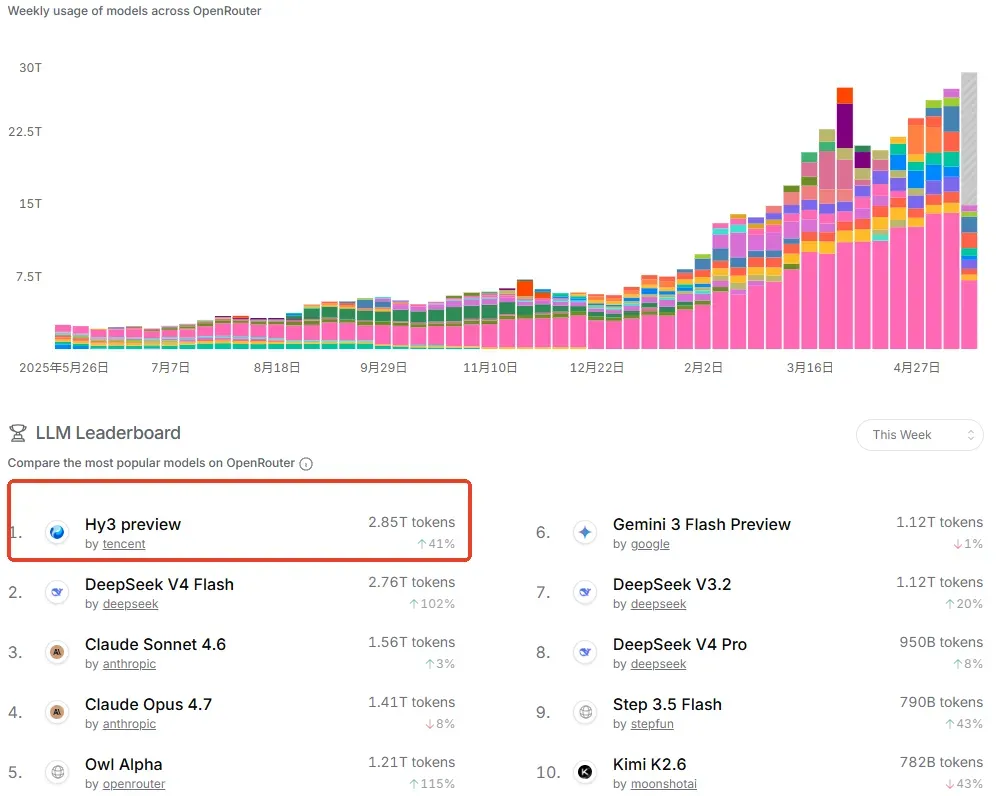
以往国产模型只有在免费上新时才会出现这种现象,而这次Hy3 preview完全是在收费的情况下冲上榜首。当然,它在OpenRouter上的定价——百万token输入0.066美元、输出0.26美元,也确实比官网更便宜。
与此同时,在OpenRouter的Top Apps排行榜中,具备自我进化能力的Hermas Agent已经超过了一个月烧掉OpenAI 130万美金来维持运行的OpenClaw:
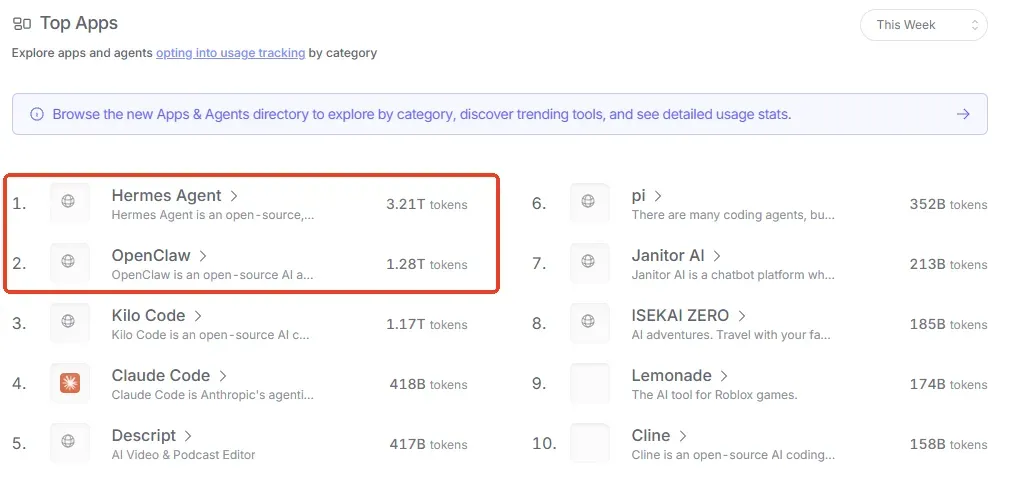
从增长趋势看,Hermas Agent仍在持续攀升,而OpenClaw已经连续一个月走下坡路:
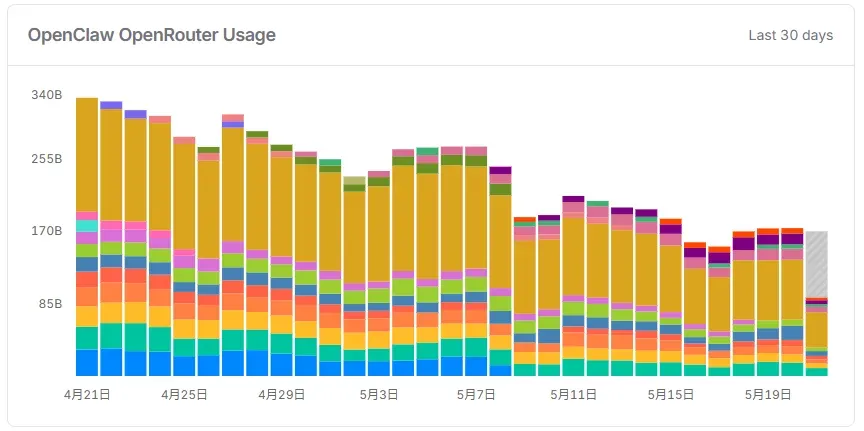
这背后到底发生了什么?
翻开Hermas Agent过去30天调用的模型列表,使用最频繁的依然是DeepSeek V4 Flash,而Hy3 preview已悄然排在第9位。可以预见,随着Hy3 preview性能口碑的发酵,它的用量还会继续上涨,从而形成“热门应用拉满热门模型”的双赢组合。
腾讯开源AgentMemory:四层记忆架构让AI记住你,准确率提升60%
腾讯开源AgentMemory,让AI真正记住你
腾讯最近开源了一个项目,短短两个月就收获了4600多个Star。它的目标非常专一:为AI Agent装配长期和短期记忆能力。
那装上之后效果如何?我们看评测数据:长期记忆的整体准确率从47.85%提升到76.10%,涨幅接近60%;用户事实召回率从不到30%飙升至79%;而在短期记忆的加持下,长任务最高能节省61%的token消耗。
这个项目就是TencentDB Agent Memory,由腾讯云数据库团队于5月14日正式开源。
AI 记忆到底难在哪
当下,每当你开启一个Agent的新会话,系统几乎默认它对过往一无所知。你不得不重新描述背景或上下文,它才可能按预期工作。而记忆的终极目的,正是提升效率。
TencentDB Agent Memory的思路与主流方案迥然不同,它采取的是符号化短期记忆 + 分层长期记忆。

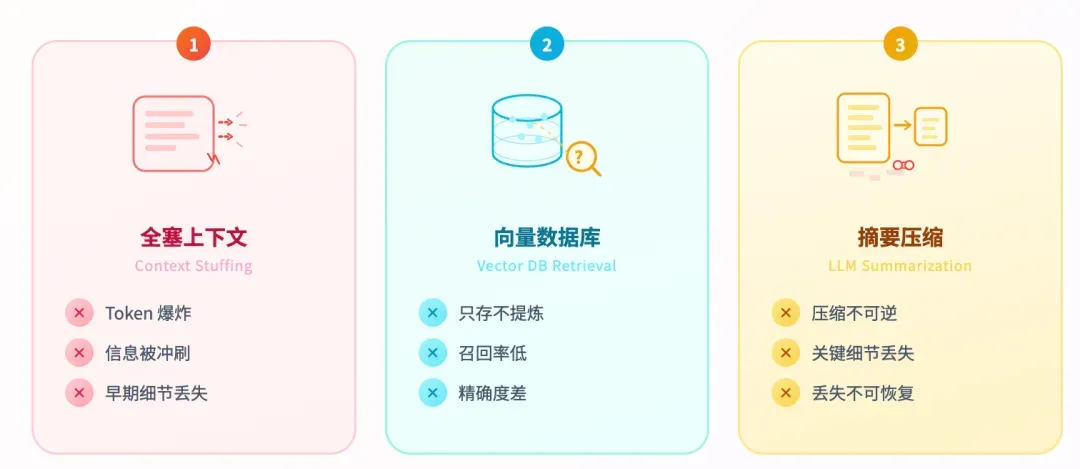
目前主流的解决方案大致有三种,但均存在明显短板。
第一种,全量塞进上下文窗口。简单粗暴,可窗口有硬上限,塞得太多token直接爆掉。
第二种,用向量数据库做记忆。比全塞上下文要好一些,但致命伤在于只存不提炼。当对话碎片繁多时,召回率低,精确度也不够。
第三种,让大模型自己做摘要压缩。但压缩是不可逆的,常常导致关键细节丢失。
腾讯开源项目的核心架构
这个项目最核心的设计,是一套四层渐进式记忆架构。从L0到L3,从底到顶,每一层各司其职。
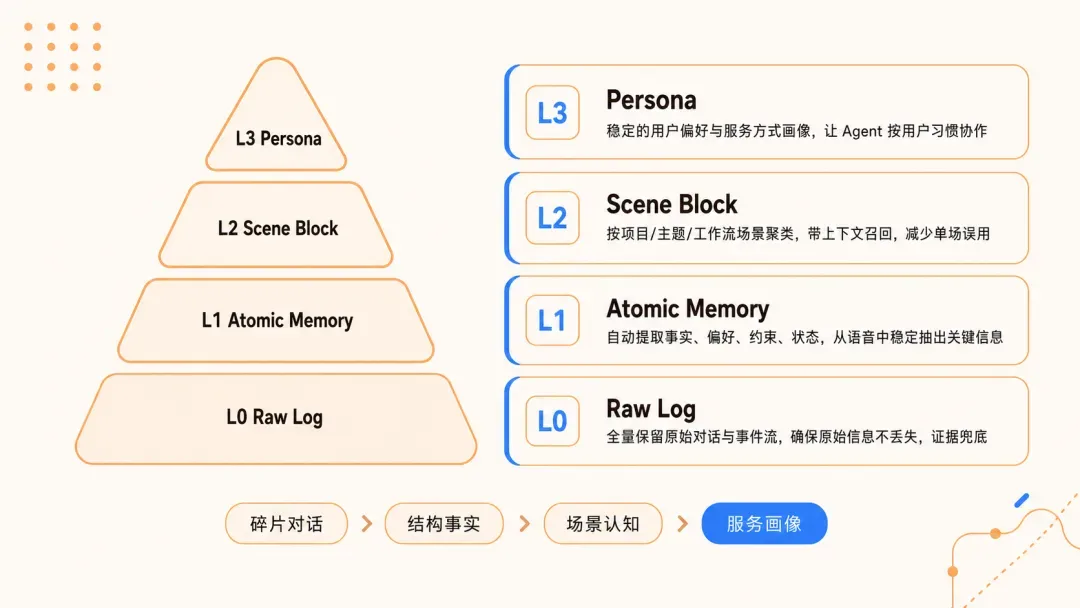
L0:原始对话。
全量保留,一字不落,作为兜底,随时可供回查。
L1:原子事实。
系统会自动从对话中提取独立的事实节点,例如“我爱吃火锅”、“我后面用NextJS”,打上标签并存储。
L2:场景聚类。
相关的原子事实按场景汇聚。比如,用户在系统讨论中涉及的所有事实——表结构、权限、接口——会合成一个场景块,以Markdown格式呈现,人可以直接阅读。
L3:用户画像。
基于下面三层生成稳定的用户画像,沉淀技术偏好、代码风格、常用工具链等。
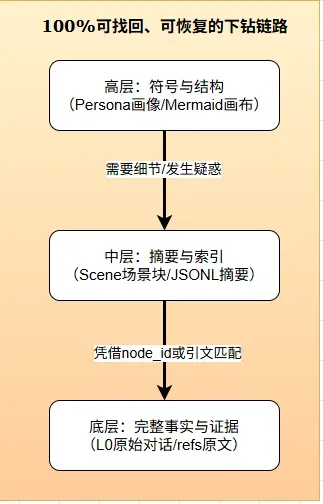
这样一来,既不会因为上下文过长影响推理,也不会丢失关键信息。而且,系统保证了从顶层到原始证据的完整回溯路径。比如L3里提到用户偏好TypeScript,这个结论可追溯到L2的某个场景块,场景块里的每条结论又能回溯到L1的原子事实,而原子事实最终指向L0中你曾经说过的那句话。整条证据链稳固不断裂。
短期记忆压缩:巧用 Mermaid 图
四层架构解决的是长期记忆,但短期上下文同样是烧钱大户。比如AI排查一个bug需要调用十几次工具,上下文会被日志塞满。
解法是符号化记忆,也就是把完整的日志卸载到外部文件,再用Mermaid语法绘制一张紧凑的任务状态图塞进上下文。需要细节时,则通过节点ID来检索。Mermaid用极少的token,将线性摘要列表重组为带状态、依赖关系和可寻址索引的任务拓扑结构图,让大模型通过图的拓扑来推断任务全貌,而不必死记某个标签。
这种方式信息密度更高、结构不丢失、细节可逐层找回。实测结果显示,Token消耗直降超50%,任务完成率反而提升了23%。既省了钱,活儿还干得更好。
语义检索(Embedding)擅长模糊匹配,关键词检索(BM25)则长于精确命中。两路各自召回候选结果,再经由RRF融合排序,语义相关的不会遗漏,精确匹配的也不会丢失。
跑出来的数据
说了这么多设计,来看看实际跑出来的数据。腾讯使用PersonaMem基准测试做了评测,对比了原生OpenClaw与接入Agent Memory之后的OpenClaw:
| 指标 | 原生 OpenClaw | 接入 Agent Memory |
|---|---|---|
| 总准确率 | 47.85% | 76.10%(+59%) |
| 用户事实召回 | 29.63% | 79.07%(+167%) |
| 偏好跟踪 | 66.67% | 83.45%(+25%) |
| 个性化推荐 | 46.67% | 76.36%(+64%) |
其中用户事实召回这个指标最为夸张,从不到30%飙升到79%。也就是说,从前你跟AI说过十件事,它只能想起三件;现在,它能想起八件。
支付宝推出Agentic Commerce全栈支付方案,AI迎来‘支付宝时刻’
本周AI领域的重头戏,毫无疑问是支付宝周二发布的、面向AI Agentic Commerce(智能体经济)的全栈支付解决方案。
一切商业行为最终都要落到支付上。所有场景都必须为AI Agent重新打造,支付场景绝不会例外。
过去一年,Agent的能力飞速增长,已经能写代码、查资料、做分析、调用各种工具去完成长链路任务,比如帮用户规划行程、购买商品、订酒店、买车票等等。当一个Agent真正要替用户完成现实世界里的一件事,它迟早会走到最后一步——付款。
没有支付,Agent再聪明也只能停留在建议层。现在大家的Agent是怎么做的呢?帮用户选好酒店、点好咖啡、找到便宜的机票、筛出合适的线上课程,到最后一步,需要跳出当前流程,让用户自己确认、输入、完成支付。流程就这么断了,你想想,目前有哪家的Agent能连续帮你完成两件涉及交易的事?没有。流程断裂之后,智能就退回到“推荐工具”的位置。
“黄老爷”缺了一条腿,现在得给他接上。AI支付一旦打通,Agent就有机会成为一个真正端到端的智能体,还能跨交易执行任务。这正是Agentic Commerce的核心所在。未来的交易入口,除了在网页、App、搜索框和货架里,也一定会出现在智能体、车载系统、眼镜、语音助手以及各类硬件终端上。用户不再需要每一个支付按钮都亲自去点,改为授权Agent在明确的任务范围和支付限额内,自动完成操作。需要强调的是:AI支付的主体依旧是用户本人。完整的逻辑是,用户向Agent下达支付指令,Agent在既定任务框架内执行支付。Agent不是付款的主体,也绝不能绕开用户意图独立花钱。这个边界极其重要,它决定了AI支付能否长久地建立信任。
支付宝这次发布的方案,应该是业内首个Agent支付解决方案。我把它归纳为几个层面:
第一是信任基座。今年1月,支付宝联合千问App、淘宝闪购、Rokid、大麦、阿里云百炼等伙伴发布了ACT协议,也就是智能体商业信任协议。这套协议试图在AI与电商、外卖等服务平台之间建立一套通用协作语言。4月,ACT升级至2.0,由IIFAA互联网可信认证联盟联合支付宝、小米、智谱、比亚迪等20多家厂商共建,进一步覆盖A2A(智能体对智能体)、A2M(智能体对机器)的支付能力框架。安全始终是重中之重。支付宝的“AI付智能安全系统”涵盖身份安全、运行时安全、供应链安全和意图安全,核心目标就是让交易过程可审计、可追溯,确保用户真实意图在执行过程中不走样。今年5月,这套系统通过了中国信通院泰尔实验室的两项安全认证,安全能力都达到了最高的5级标准。
第二是收付引擎。面向用户的“AI付”服务,解决的是如何让付款更自然。用户可以通过Agent或智能终端,用“说一下、看一下”的方式完成支付。最新数据显示,支付宝AI付的支付笔数已经突破3亿笔,而春节时这个数字还只有1亿多。AI付已经渗透到多个典型场景:千问App接入后,可以让Agent帮用户完成从商品发现、下单到支付的全链路;OpenClaw等通用智能体接入后,可以自动完成缴费、购买Token、购物等任务;AI眼镜上的“看一下支付”,正在被Rokid、小米、华为、千问、魅族、雷鸟等品牌接入;在车载场景,支付宝智能座舱已服务理想、奇瑞、吉利、东风等超过1000万辆汽车,用户通过语音就能买门票、订酒店、点餐、缴停车费。
面向商家的“AI收”服务,要解决的是商家和开发者如何降低收款门槛。2025年4月支付宝推出MCP Server,后续又陆续上线AI打赏、AI订阅付费、支付集成Skill,到2026年4月,“支付宝AI收”正式上线,接着在5月,也就是当月,支付宝AI收又升级了支付集成Skill和商家入驻Skill。它的价值在于,让API、内容、算力、工具调用这些过去很难变现的资源,变成能够按次、按时长、按调用收费的服务。我注意到一个非常有趣的案例——“博查搜索”,它为主流模型和AI应用提供联网搜索能力,日API调用量超过3000万次。接入“支付宝AI收”后,就能将搜索能力封装成付费Skill,实现“调用即收费”。还有一些AI学术写作平台,也通过按次付费降低了用户的决策门槛。这对开发者尤其关键。一个没有技术背景的人,可以在Qoder这样的平台上用一句话创建电商站,再通过支付宝支付集成Skill接入支付,然后收获自己的第一笔订单。AI让生产门槛降低了,支付又让交易门槛跟着降了下来。
第三是AI钱包助手和Token Pay。如果说AI付和AI收看解决的是收付款能力,AI钱包助手解决的则是管控问题。打开支付宝,搜索“AI钱包”,就能看到本月支出分析,也可以管理智能体任务。未来,它还支持给不同的Agent设置支付额度、授权周期、消费规则,并处理Agent之间的分账、结算和授权等事务。随着Agent数量增加,支付场景会变得非常分散,用户需要一个hub来集中管理授权和风险,这个hub就是AI钱包。否则,智能体经济越繁荣,个人资金管理的压力就越大,容易失控。而新发布的Token Pay瞄准的是AI时代最基本的生产要素——token的支付问题,这是一套综合方案,既有订阅服务,也覆盖龙虾智能体这类自己给自己买token的场景,正好切中当前的高频需求。
——————
支付宝作为国内支付领域的开创者和最大品牌,在过往几次关键机会里,都踩准了交易范式变革的节点。担保交易解决了早期电商的信任障碍,让陌生人之间敢于进行线上买卖。扫码支付把线下商业带入移动互联网,让小店铺、摊贩、服务业都能接入数字支付。而现在,AI支付正面对第三次迁移:交易入口从人和App,延伸到了替人类执行任务的AI Agent身上。几乎可以断定,这个变化势在必行,它关乎AI产业能不能从工具使用走向完整的商业循环。Agent能发现需求,能比较方案,能执行任务,最后还要完成可信交易。接上支付,整个产业飞轮才算真正开始高速转动。
这件事肯定不会是“快功夫”。Agent本身还需继续进化,同时,用户授权、责任边界、风控审计、跨平台协议,每一项都必须长期打磨,最难的部分是让用户能够放心地把授权交给Agent。不过,整体的方向已经非常清晰:Agent若想真正进入现实世界的生产力体系,支付是绕不开的门槛。支付宝现在所做的,就是把这个门户构建得结实、稳健、方便、安全。Agent的“支付宝时刻”已经来了。
智谱GLM-5.2深度评测:1M上下文补齐短板,思考过久成最大槽点
6 月 11 日,美国商务部长致信 Anthropic CEO,以国家安全为由,要求 48 小时内暂停所有外国人对 Fable 5 与 Mythos 5 的访问。技术细节未公开,申诉窗口缺失,甚至 Anthropic 自己的外籍员工也一并受限。
6 月 13 日,智谱宣布 GLM-5.2 下周开源,MIT 协议,无任何地域限制。
两天之差,一边封锁,一边开放。这大概是 2026 年国产大模型最具戏剧性的一个发布窗口。
但故事归故事,GLM-5.2 到底好不好用是另一回事。虎嗅的实测、知乎的讨论、新浪和智谱官方的报道纷纷点出亮点与槽点,该夸的夸,该指出的问题也毫不遮掩。
反常开局:发布当天零跑分表
按惯例,旗舰模型发布首日,官方会甩出一张 benchmark 成绩表,SWE-bench、HumanEval、LiveCodeBench 一字排开,以此证明实力。
GLM-5.2 完全没有这样做。
官方这次主打四件事:Coding Plan 优先开放、真正可用的 1M 上下文、MIT 开源、华为昇腾训练。一个跑分都没放,连 DataLearner 的模型卡上都写着“评测数据待官方公布”。
来源:卡码笔记《GLM-5.2 发布:智谱这次不放跑分表,先让你用上》
这种情况存在两种解读。
往好了看,智谱想“先把开发者拉上车”,跑分让位给实际体验。毕竟被 PPT 跑分欺骗的开发者太多,先使用再信任,姿态是对的。
往另一种方向想,不放跑分往往意味着跑分不够炸裂。第三方目前能查到的仅有一条:LLM Benchmark Code V3 私有评测中,GLM-5.2(max) 综合排名全球第三。
来源:搜狐《智谱GLM-5.2全量开放Coding Plan:1M上下文 CodeV3评测全球第三》
第三不差,但也没有 GLM-5.1 当年“SWE-Bench Pro 58.4 分全球第一”那种爆炸感。智谱或许也清楚这点,干脆不主动挑起这个话头。
核心升级:补齐上一代最大短板
把 GLM-5.1 和 GLM-5.2 放在一起,变化非常清晰:
智谱GLM‑5.2开源模型被赞“奇迹”,性能逼近GPT‑5.5与Claude 4.8,引爆主权AI讨论
一位素来以四字短语苛刻评价美国开源模型的布道者,面对这款中国开源模型,却发出了“简直是个奇迹”的感叹。这不仅仅是随口表扬,而是对当前模型能力梯队的一次公开重新标定。
Jeremy Howard 在 X 上直接回复 GLM‑5.2 的官方推文,称其“至少与 Opus 4.8、GPT‑5.5 一样出色,更快、更便宜,而且以前从未体验过这样的开源权重模型”。
01 GLM‑5.2性能爆炸:1280屏幕也装不下的信息密度
GLM‑5.2 是智谱在 z.ai 品牌下最新发布的旗舰模型,核心规格为 744B 总参数、40B 激活参数,支持 BF16/FP8 双精度,已在 HuggingFace 和 ModelScope 双站同步开源。它更将上下文窗口一举拉至 1M token,这不是营销口径里的“理论上可读”,而是真正卷动了架构改造。
性能数字首先落在最受关注的编程能力上。Terminal‑Bench 2.1 上,GLM‑5.2 得分 81.0,将前代 GLM‑5.1 的 62.0 远远甩开;SWE‑bench Pro 从 58.4 跃升至 62.1,与 Claude Opus 4.8 的差距缩至个位数——官方版本实测只差 4 分。
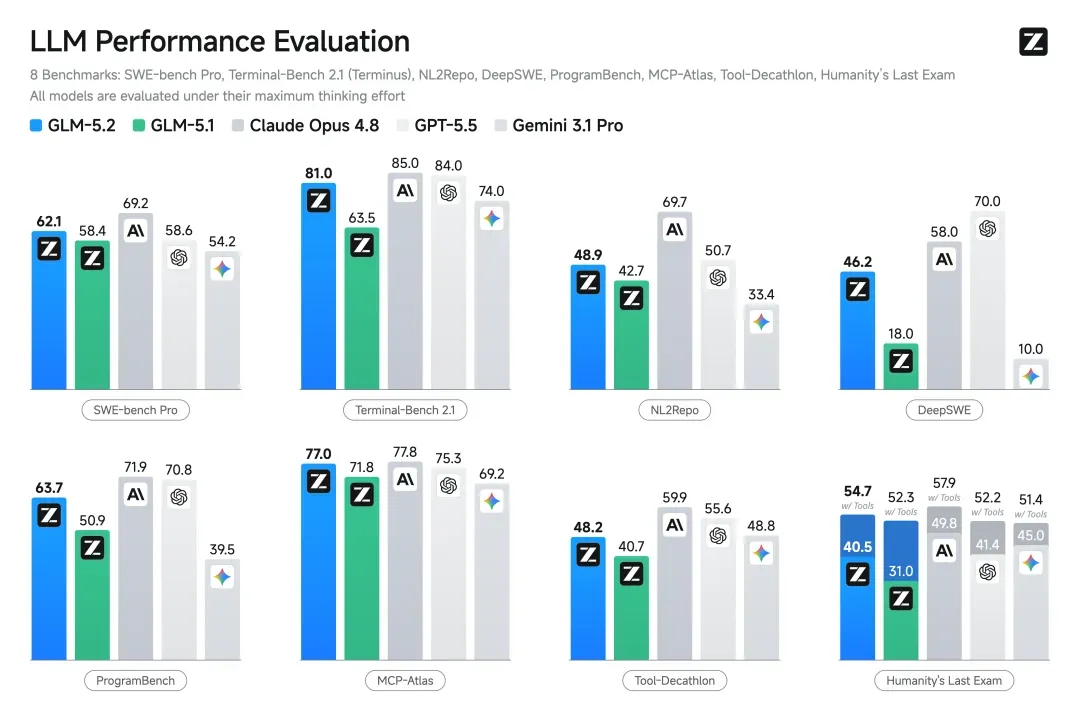
官方 benchmark 织出了 GLM‑5.2 在编程任务上的位置——开源模型顶部,距离 Opus 4.8 仅 4 分,并已超越 Gemini 3.1 Pro。
边注:benchmark 数字永远带有口径,以上列出的是官方测试环境。实际使用中的差异会因开发者工作流、prompt 结构、GPU 配置不同而变化;测量的标尺若不统一,结论便不统一。
02 应用层震动:速度、主权AI与不应急的机遇
如果只看基准测试,开源权重模型距离最强闭源似乎总差临门一脚。但真正搅动舆论池的,是 15 条推文在六小时内密集出现:Box 创始人 Aaron Levie 公开讨论“主权 AI”与成本优势;Elon Musk 引用创始人说法,点出“Q1”时间线;Simon Willison 直接喊话 Groq 和 Cerebras,希望让超快推理机跑起 GLM‑5.2。