字节跳动开源UI-TARS Desktop:多模态AI Agent重塑浏览器自动化,开发者可即刻下载体验
🚀 项目背景
多模态AI Agent正以理解文本、图像、声音等多元信息的能力,成为人工智能探索未知领域的关键角色。今天,字节跳动正式将内部孵化的UI-TARS Desktop推向开源社区,这款被称为“字节版Manus”的多模态Agent,旨在通过视觉解析与浏览器深度交互,彻底改变人机协作的方式。
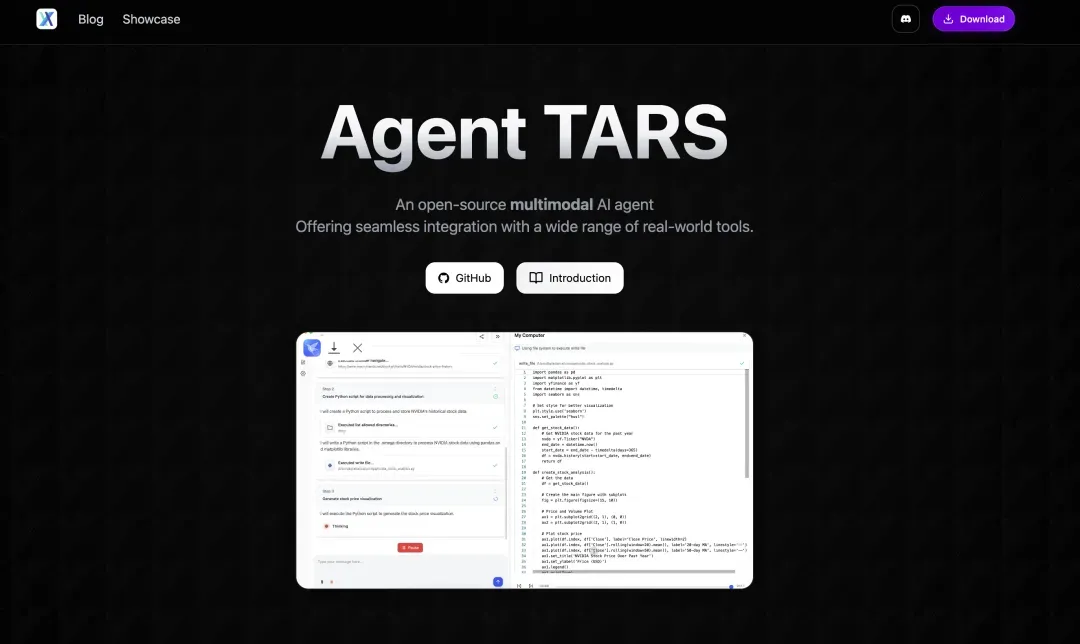
🌟 项目概述
Agent TARS(UI‑TARS的核心控制单元)是字节跳动打造的多模态AI代理框架,它能够像人类一样观察网页视觉元素,并直接融入命令行与文件系统,通过浏览器完成一系列真实世界的操作任务。
📚 核心特性
1. 深度浏览器操控
借助先进的代理框架,Agent TARS可执行复杂任务,包括深度信息研究、多步骤操作与路径规划,实现从意图理解到完整执行的全链路自动化。
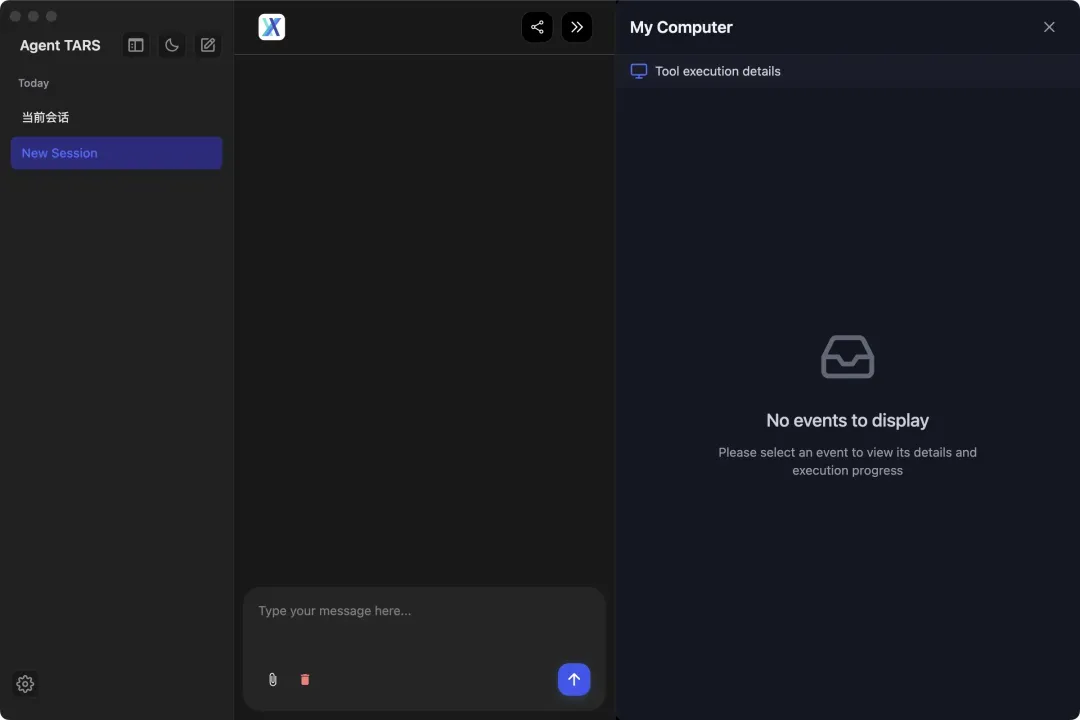
2. 全栈工具集成
与搜索引擎、文件编辑器、命令行及模型上下文协议(MCP)工具无缝衔接,能够高效串联多种异构系统,应对高复杂性工作流场景。
3. 重构桌面交互体验
全新的用户界面集成了浏览器实时画面、多模态交互模块、会话管理、模型动态配置、对话过程可视化以及浏览器/搜索状态的跟踪面板,让操作过程透明可控。
4. 灵活的工作流编排
将搜索、页面浏览、超链接探索和信息综合等GUI代理能力串联成直观的流水线,最终汇聚为结构化的输出结果。
5. 开发者优先的架构
提供简洁的集成接口,便于与UI‑TARS主项目结合,同时支持开发者快速自定义GUI代理任务的流程,加速二次开发与创新。
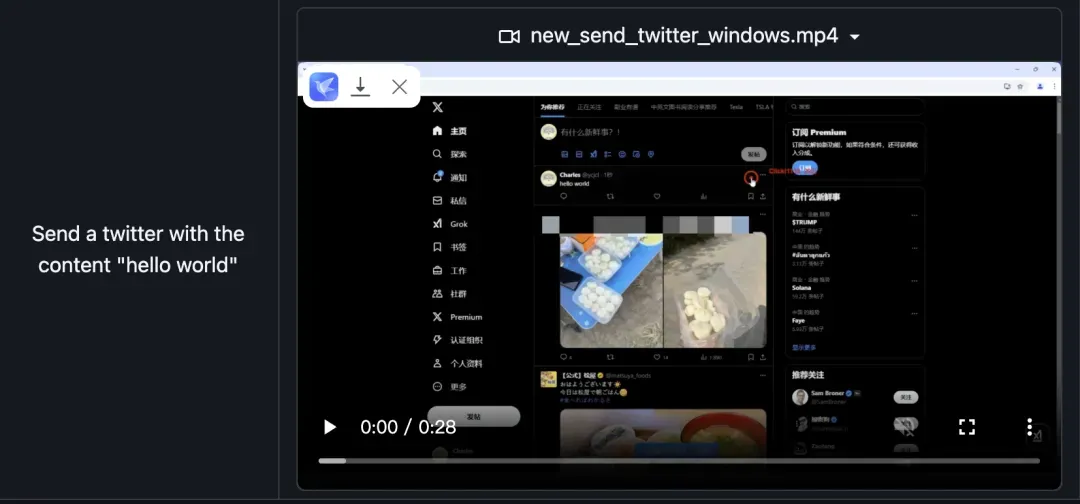
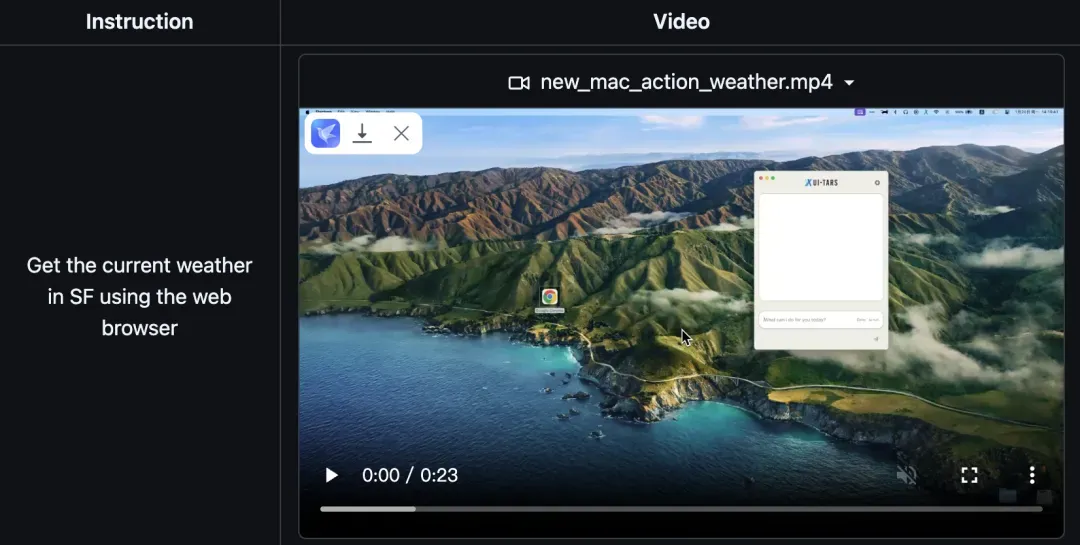
📝 快速上手
从项目发布页面可直接下载Agent TARS的最新版本。若已安装Homebrew,只需在终端执行以下命令即可安装UI‑TARS Desktop:
brew install --cask agent-tars
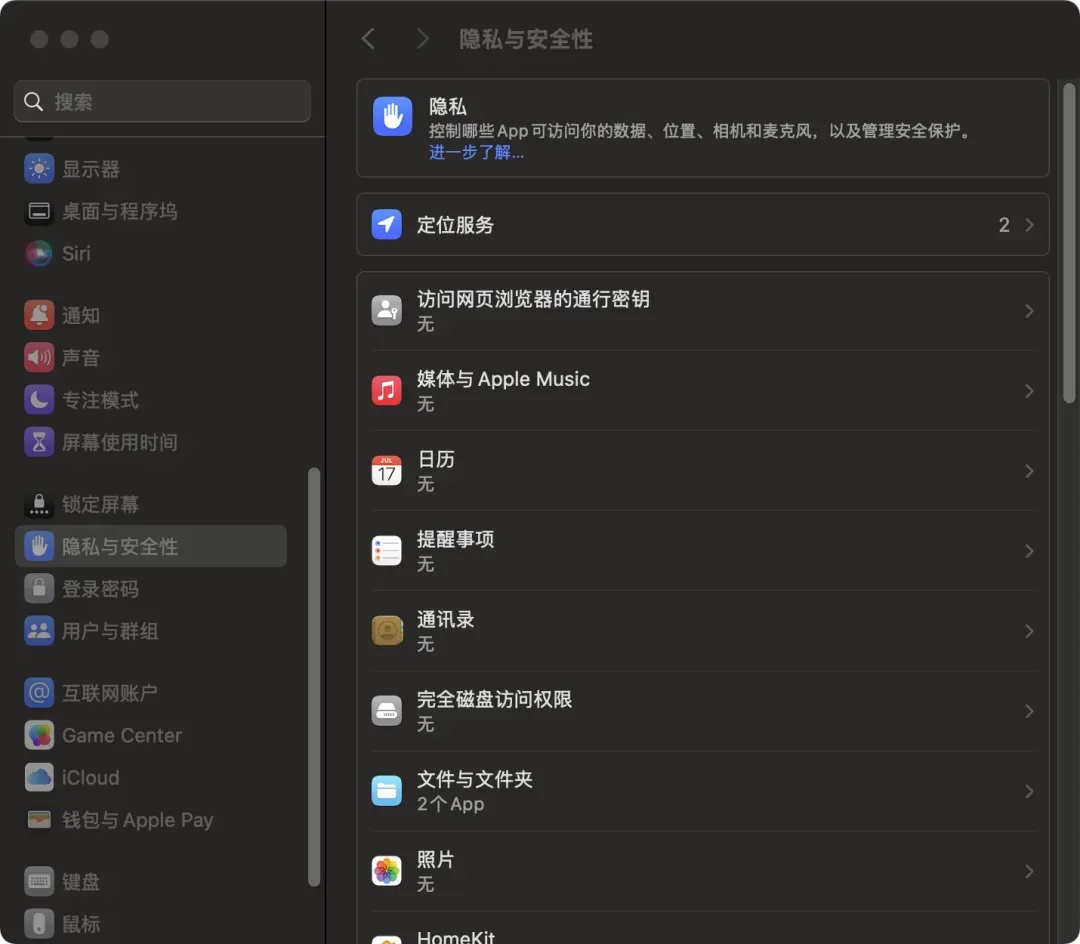
在macOS上使用时,需为Agent TARS开启辅助功能权限:
系统设置 -> 隐私与安全性 -> 辅助功能
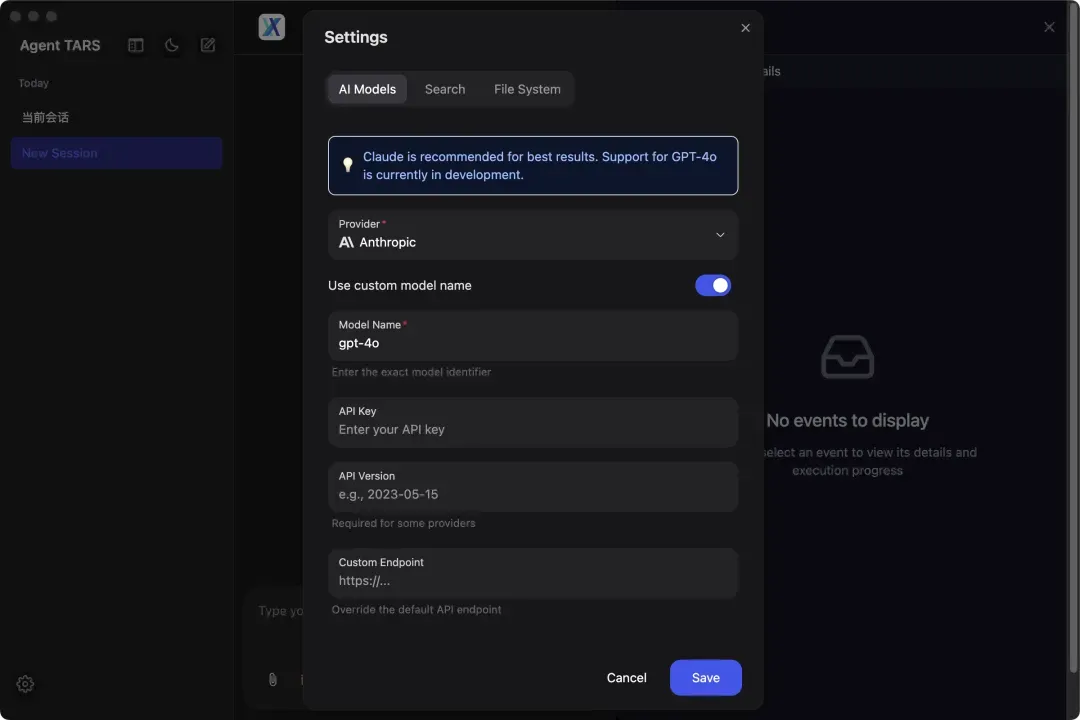
完成基础配置后,可按需设置模型参数与搜索引擎偏好:
官方GitHub仓库地址:
https://github.com/bytedance/UI-TARS-desktop/
🎉 总结与展望
UI‑TARS Desktop的开源不仅是技术架构的一次突破,更彰显了字节跳动推动AI Agent生态协作发展的决心。我们热忱欢迎全球开发者和研究人员加入这一开放项目,共同打磨出一款更加智能、更具人性温度的多模态AI代理,让自动化真正服务于每个人的日常工作与创造。
最快开源模型 Step 3.7 Flash 发布:兼顾速度与智能的 Agent 效率利器
近两年来,国产大模型的能力演进方向耐人寻味。
2024 年,行业还在疯狂内卷单个场景的上限——MMLU 分数能刷多高、MATH 能答对多少、编程排名第几。
2025 年,Agent 赛道上道,长程任务规划、多步执行、工具调度成为主流。
到了 2026 年,效率突然被推上台前,变成了新的争夺高地。

原因很直接:复杂任务从指令下达到最终交付,往往要等上几十分钟,甚至数小时,体验实在不算好。
就在这种背景下,极致高效的 Step 3.7 Flash 开源登场。

这个开源模型同时抓住了速度、智能和成本三极。最高生成速度达到 400 TPS,原生支持多模态能力,可以高效率完成真实生产级任务——无论是编程、办公还是搜索,都表现得毫不拖泥带水。
姗姗来迟的「闪电」
很长一段时间里,一听到「Flash」这名字,大多数人的第一反应就是“快、便宜,但不够聪明”。
Step 3.7 Flash 的出现,恐怕要把这张标签撕下来了。
它本质上是一个为 Agent 效率而生的 Flash 模型,专门针对生产级 Agent 场景设计。
有开发者很快将其接入到 GitHub 开源项目 Lumi(一个常驻电脑的 AI 助手,用语音唤醒即可干各种活)中,新增了 Step 模型供应商选项,默认模型设为 Step 3.7 Flash。
实测下来,不到 3 分钟就完成了一个新 feature 的开发,一次成功且没有报错,整个过程相当丝滑。
接下来又用它让 AI 语音助手“钱多多”同时执行两个任务:整理桌面,并撰写一篇关于 AI 大模型发展史的文章。结果不到一分钟,两项任务全部高质量完成。换成其他模型,至少也要小十分钟。
四大亮点,逐一拆解
① Agent 效率:看的是整条链路,不只看 Benchmark
这是 Step 3.7 Flash 最核心、也最容易被误解的一点。
生产级的 Agent 任务绝不只是单次问答,而是一个不断循环的完整链路:规划、推理、搜索、工具调用、代码生成、多模态理解、反复修正……所有环节环环相扣。
《007:初露锋芒》深度评测:纯正线性3A回归,重现特工香车美女的硬核浪漫
没有硬塞的政治正确,没有刻意的夹带私货,15到20小时的主线流程一气呵成,剧情反转干净利落,地图与关卡设计处处透着老练,枪战掩体间的射击手感更是丝滑无比。
打通《007:初露锋芒》的那一刻,小发仿佛被拽回到了那个线性3A作品井喷的黄金时代——那时的厂商还在像手艺匠人一样精雕细琢每一段流程。这一通玩下来,从头到脚都透着两个字:舒服。
如果说2026上半年最让我感到惊喜的一款游戏,毫无疑问就是这部007。
如果你已经被千篇一律的开放世界和名不副实的“大世界”折磨得身心俱疲,觉得太多游戏都在恶意拉长时长、浪费生命,甚至已经陷入电子ED的窘境,那不妨也来上一份007,真真正正地当一回英雄主义拉满的大英帝国特工。

首先,作为沉寂已久的007官方IP衍生游戏,《007:初露锋芒》对电影中那些深入人心的经典要素,完成了一次近乎朝圣式的还原。
相信在座的各位,就算没完整看过正版英国007电影,对《国产凌凌漆》也多少有些耳闻。
007的招牌元素,总结起来不外乎这么几条,而在游戏中全都能找到精准的对应:
第一条,你永远拥有一个风流倜傥、万人迷般却又碎嘴强势,单枪匹马打穿全场的王牌特工——詹姆斯·邦德。

这次游戏里的邦德被设定为一个刚从选拔中脱颖而出的特工新人,整个故事从你如何一步步被打造成职业特工开始,直接通过一整个详尽的教程关,将玩家逐渐拉入特工训练的真实视角。
最让人惊喜的是,光是这个开场,体验就丝毫不亚于看一部邦德电影。那些通常只会在影视镜头中出现的混剪与转场,被制作组巧妙地融入到教学流程里,玩着玩着你就能察觉自己的操作在逐次变熟,代入感直线飙升。
与此同时,教学过程中还不动声色地穿插了大量背景叙事,讲述了邦德如何从一个浑身是刺的愣头青,成长为特工训练班里不可或缺的核心人物。

不过最重要的,始终还是邦德的人设。
这一代的邦德除了年龄上是位“00后”,其他的老味道一分都没少。
依然是帅得毫不费力,骨子里桀骜叛逆,走在执行任务的路上,都会有不认识的路人主动嘀咕一句:这小伙儿真精神。
玩家所扮演的角色更是全程骚话不断,顶撞上司、插科打诨、碎嘴子属性拉满,像极了上世纪七八十年代罗杰·摩尔饰演的第三代邦德,随时随地都在散发着一种玩世不恭的魅力。

第二条,你懂的,007的世界里必定要有一位性感带派、风情万种的“邦女郎”。
本作中的几位主要女性角色,颜值那是相当能打,身材傲人且大大方方地展现。比基尼、紧身裤一个不落,日常穿搭的造型设计同样下足了功夫。

就连路人都被赋予了不同程度的性格塑造,暧昧桥段从头到尾贯穿始终。
邦德这小子艳福绝对不浅,经常是在把妹的同时,顺手就把要命的任务给完成了。


即便是对黑人女性角色,也找不出半点刻意丑化的痕迹,完全符合绝大多数正常玩家的审美标准。
比如同样是007系列的常驻角色、永远站在邦德背后如后盾一般的钱班霓,本作就选用了一位干练的黑人女性。
这张脸模做得,让小发看着那是格外顺眼。

当然,身为秘密特工007,又怎么能少了各种神奇的小道具。
像什么古灵精怪的特殊枪械,看似是电话实则剃须刀的大哥大,以及提供这些古怪装备的神奇博士Q。

于是第三条,就是007的各种机密武装和本作的Q博士了。
每当玩家出特工任务之前,都可以在Q博士的实验室里自行搭配装备,种类相当丰富,堪称科技版“要你命3000”。比如让柯南看了都眼馋的黑客欧米茄手表,还有透视眼镜。

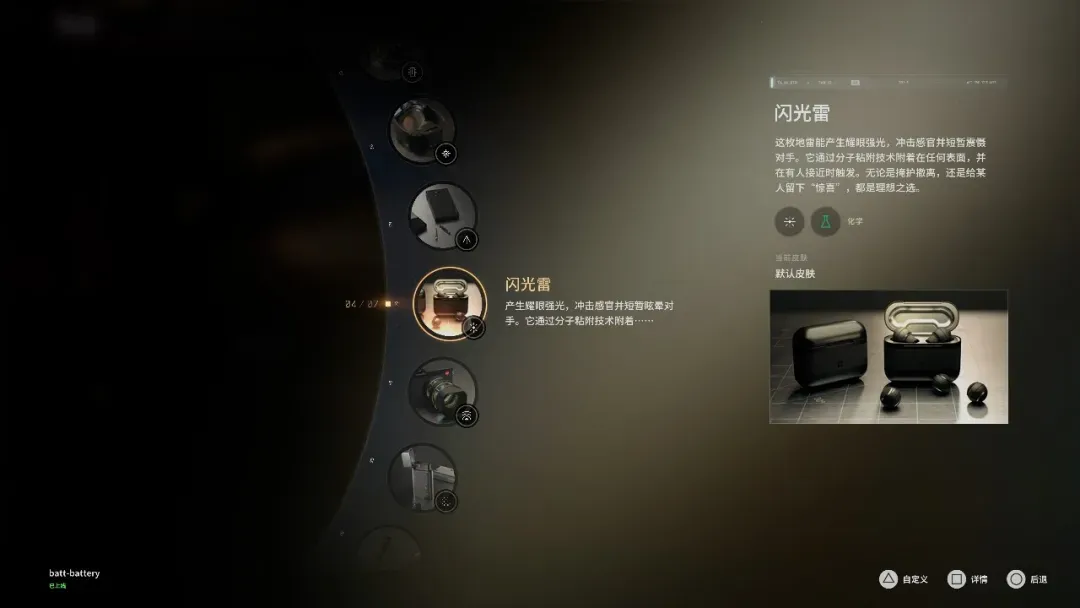
还有能够发射麻醉针的手机、会定向爆炸的蓝牙耳机、伪装成打火机的烟雾弹,甚至是将榴弹炮缩小在一支钢笔中。
这些五花八门的道具,在潜行和执行任务时都能发挥奇效,真正诠释了什么叫做“科技改变生活”。

包括军情六处和顶头上司M,这次在全流程里也占据了相当吃重的戏份。
可以说,关键人物一个都没有缺席,也正呼应了官方曾经说过的那句话——《007:初露锋芒》是一部基于007主时间线的作品,虽然载体是游戏,但在地位上它就是007这一IP当下最新的正统作品。

再来看第四条,振奋人心的动作戏更加不能少。游戏里的战斗大致分成两大块:射击与肉搏。
射击部分没啥可挑剔的,无论枪械手感还是弹着反馈都极为舒适。枪械种类也是该有的全有,从单发狙击枪、霰弹枪、步枪、微冲到手枪一应俱全,不过多数靠拾取敌人掉落的武器,所以会面临一定的弹药紧缺。当然,如果你能做到枪枪爆头,这就完全不是问题。
什么?你说自己枪法平平?没关系,游戏里内置了一套类似“死神之眼”的瞄准系统,只要开镜就能进入子弹时间,让你瞄个够。

至于肉搏战,这才是让小发更为眼前一亮的部分。
当手中没有武器时,对打拳拳到肉,还能和环境产生各种即兴互动,甚至隐隐有几分成龙武打片的错觉。黄光格挡见招拆招,红光亮起则需闪避,还有擒拿关节技等机制,让赤手空拳的战斗变得相当有趣。与此同时,游戏还为你准备了好几段紧张到喘不过气的一对一肉搏战,既带着一定的挑战性,又不至于难得让人想砸手柄,即便是通关后也丝毫没有腻味的感觉。
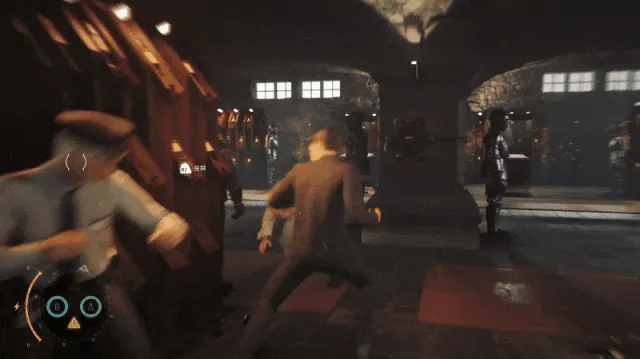
作为标准的好莱坞式大片,第五条必不可少的自然是飞车追逐戏码。
游戏中邦德至少能驾驶五种以上不同类型的交通工具,每一次风驰电掣的飙车戏,都会如同调味剂般恰到好处地穿插在每个章节的开篇或结尾。

最后一条,就是那种飞天入地、仿佛不要钱一样的大爆炸场面。
经典的飞机缠斗、高空飞跃、整栋建筑崩塌爆裂……大场面接连不断,构成了一场绝对的视觉盛宴。尽管我们已经看了这么多年好莱坞商业片,但当这种狂轰滥炸在你眼前真正扎堆上演时,依旧让人血脉偾张,直呼爽快。

顺便一提,本作出自丹麦工作室IOI之手,也就是开发过《杀手》系列的那家知名公司。因此在潜行玩法的设计上,可以说既有质量,也有分量。
尽管007不像《杀手》系列那样将潜行暗杀推到极致的高度,暗杀手法也谈不上那么花样繁多,但本作依然在潜行部分投入了大篇幅的重点。玩下来小发从未感到一丝乏味,反而常常为了尝试不同的潜入路线而反复读档重开。
更难得的是,潜行玩法与007本身作为特工的性质,融合得十分巧妙。有时候,你只需要善用场景里的物件和自己的高科技装备,引诱敌人走位;有时候,也可以机敏地化解危机,用嘴炮编造一个新身份,大摇大摆地瞒天过海。


除此之外,游戏还准备了大量解谜和趣味小挑战,以及形式各异的战斗方式。
特别值得夸的一点是,《007:初露锋芒》中的所有路线和解谜,都卡在一个刚刚好的难度上,基本上没有哪一个地方是故意刁难你的。无论是谜题本身的难度层次,还是游戏的引导,都做得相当周到。也就是说,这部游戏你完全不需要查看任何攻略,就能一路十分顺畅地通关。
如果你觉得主线玩得不够尽兴,通关之后IOI还预备了众多潜行挑战关卡,甚至搞出了一个全球玩家速通排行榜,并附带了大量待解锁项目,比如各类角色皮肤等等。
总而言之,这就像是一部流畅得如同《神秘海域》般、却又无比传统的线性单机大作。无论是画面表现力,还是行云流水的操作手感,抑或是关卡和剧情的编排,都显得极为成熟老练。
假如你是从PS3那个世代一路玩过来的老玩家,对这种影视化叙事加手工打磨关卡的游戏,想必会格外偏爱。它绝对可以让你一包烟、一杯茶,一个游戏痛痛快快地玩上一整天,根本停不下来。

毕竟,谁心里没藏着这样一个梦呢:出生入死,凭着过人的智慧和胆识化解危机,在枪林弹雨中闪转腾挪,身边还有佳人相伴,来一场刺激到极点的冒险。
《坦克大战3D》双端发布:零开发经验借助AI打造经典3D坦克大战
万万没想到,我这样一个连游戏开发门都没摸过的菜鸟,竟然真的折腾出了一个像模像样的作品!

特别感谢 Claude、Fable 5 和 Codex,这几件神器在手,真的有一种“天下我有的感觉”。
随手一句描述,直接帮我生成了一个经典坦克大战的完整雏形。
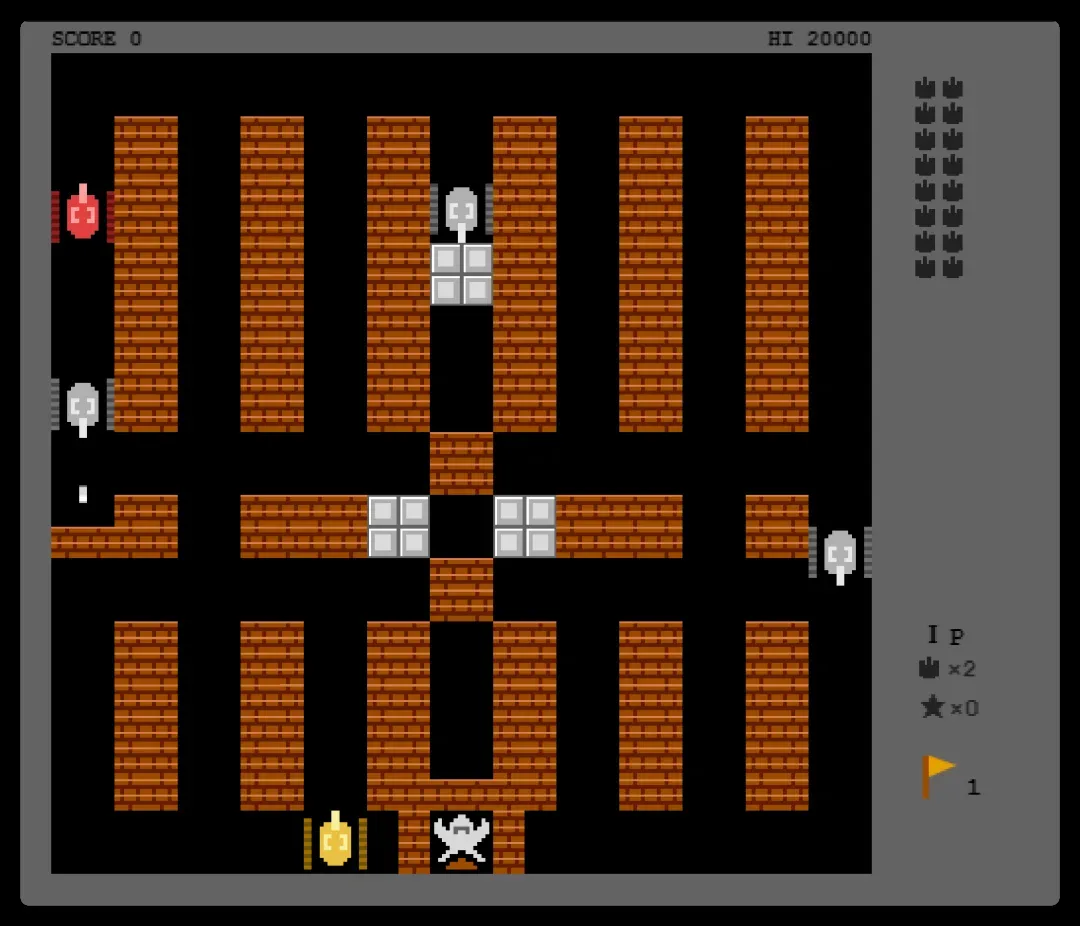
再一句话,游戏原地升级成了 3D 版——自动建模、代码贴图、代码配音一气呵成,完全不用我操心美术和技术细节。

接着一句话,贴图的质感与画面效果又被拉高了一个档次!

然后又一句,游戏手柄也丝滑接入 🎮,操控体验瞬间拉满。
最后补上一句,电脑版也安排得明明白白。
全程几乎就是“言出法随”,一切就这么到位了!(这里说“一句话”只是简化描述,实际沟通时当然也多聊了好几句。)
来看看最终落地的效果:
虽然坦白讲,游戏还称不上多么精良,但对我自己来说,已经远远超出预期了!
道具系统、关卡设计、玩法逻辑、积分机制全部妥妥运行,一样不少。
下面简单说说怎么上手。
网页端,打开网址,一秒就能投入战场!
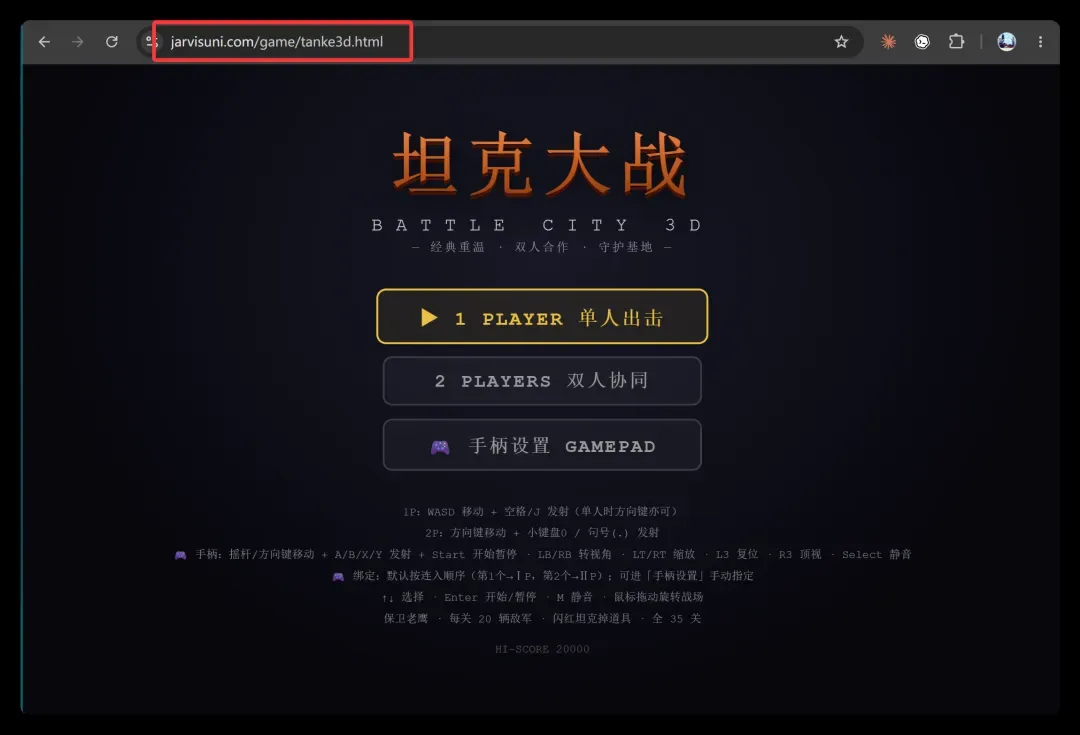
PC 端提供免安装版,软件包只有区区 7.62 MB,随随便便一台老电脑,都能流畅跑起来。

怎么玩、操作有哪些,开始界面就有详细的引导说明,一看就懂。
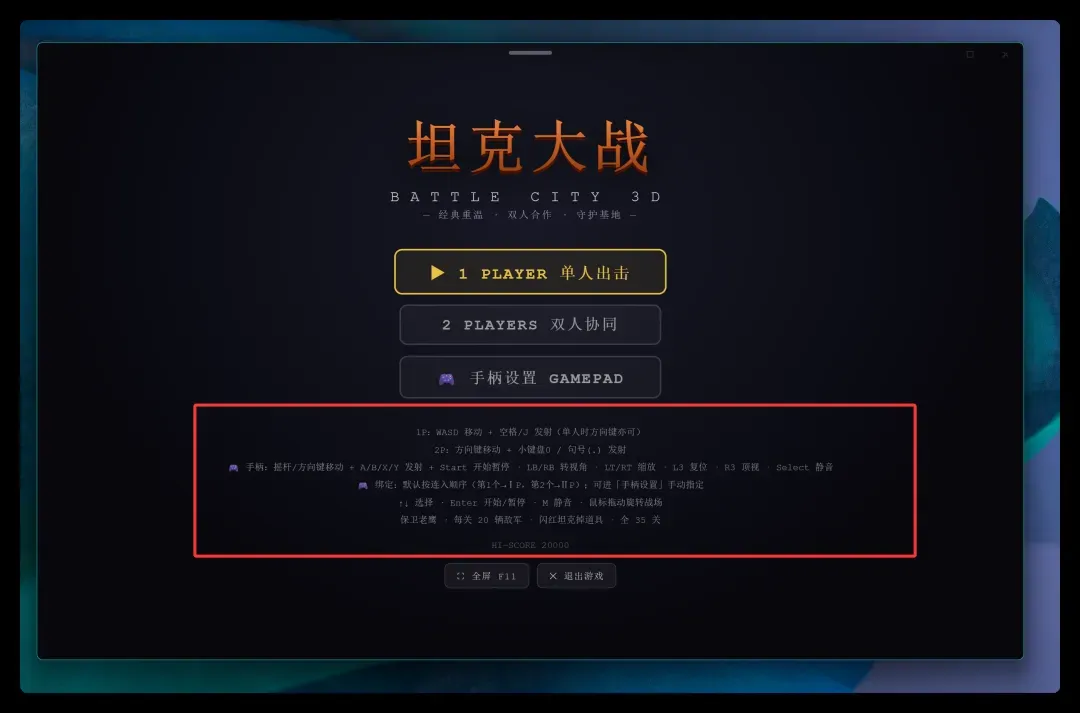
键盘和手柄都能控制,还支持双人对战,叫上朋友立马开打。
玩法说明
核心目标是保卫老鹰,消灭所有敌军坦克。每一关共有 20 辆敌军坦克,闪红光的坦克会掉落强力道具,全部共 35 关,节奏越来越紧凑。
键盘操作
1P:WASD 移动,空格 / J 发射。单人模式下,方向键也能顺带控制 1P。
2P:方向键移动,小键盘 0 / 句号键发射。
手柄操作
摇杆 / 方向键:控制移动
A / B / X / Y:发射
Start:开始 / 暂停
Select:静音
LB / RB:旋转视角
LT / RT:缩放视角
L3:复位视角
R3:一键切换顶视角
2026国内21家AI编程套餐横评:价格/模型/用量全对比,入门到旗舰推荐
核心要点速览
如果你正在使用 Cursor、Claude Code、Trae 这类 AI 编程工具,却为每月高昂的模型费用头疼,那么这篇横评或许能帮你省钱。我们梳理了国内 21 家大厂的 Coding Plan 编程套餐,从价格、模型、用量、工具支持四个维度进行详细对比,平均月费约 ¥59.4,最高 ¥198,最低仅需 ¥15。
数据参考来源:国内 Coding Plan 性价比排行(2026 年持续更新)
计费方式解读:先搞懂这 5 种单位再比价
在 21 家平台中,存在 5 种计费方式,若直接对比单价很容易踩坑:
| 计费方式 | 代表平台 | 含义 | 1 次≈几次 API 请求 |
|---|---|---|---|
| API 请求 | 京东云、百度千帆、字节火山、科大讯飞、联通云 | 一次完整的模型调用 | 1 |
| Token 计费 | 腾讯云、阿里云百炼、华为云、Kimi、智谱、MiniMax | 按输入+输出 Token 量 | 1 次请求 ≈ 15–20 次 |
| 积分制 | 字节火山 Agent Plan | 自家虚拟币换算 | 视模型倍率 |
| 按量计费 | Cursor、Anthropic、OpenAI | 美区套餐,美元计价 | 1 |
| 请求次数 | UCloud 优云智算 | 简化版的 API 请求 | 1 |
常见误区:将月费 40 元提供 1200 次 API 请求的套餐,与月费 49 元提供约 5M Token 的套餐直接比价,看上去 40 元更便宜,但 5M Token 实际上能支撑几百次长对话,折算下来单次成本反倒更低。
2026年5月GitHub优质开源项目精选:17个AI编程、自动化与防御工具盘点
这份清单中包含部分近期二次冲榜的项目,在此先做简要回顾:
- andrej-karpathy-skills:基于 Karpathy 观察 LLM 编写代码时的常见陷阱提炼而成的 CLAUDE.md,直接放入 .claude 目录即可生效。
- mattpocock/skills:Matt Pocock 开源的 Claude Code 技能包,已获 11 万星标,将实战经验打包分享。
- ruflo:基于 Claude 的多 Agent Swarm 编排框架,支持自适应记忆和 RAG,适合构建 Agent 集群。
- academic-research-skills:面向 Claude Code 的学术研究技能包,覆盖从文献调研、论文写作到审稿的全流程。
- ai-engineering-from-scratch:从零开始学习 AI Engineering 的 Python 教程,适合入门者。
- MoneyPrinterTurbo:利用 AI 一键生成自媒体短视频,项目仍在持续更新。
- RuView:通过 WiFi 信号实现空间感知,无需摄像头即可监测人体位置和生命体征,技术极具黑科技色彩。
- agentmemory:为 AI 编程 Agent 提供持久化记忆的方案,帮助解决 Agent“失忆”问题。
- Pixelle-Video:AI 全自动短视频生成引擎,与 MoneyPrinterTurbo 处于同一赛道。
- 9router:免费的 AI 编程路由,支持 40 余个服务商自动切换。
- AiToEarn:收集用 AI 赚钱的各类项目,对寻求工具变现的人颇具参考价值。
- UI-TARS-desktop:字节跳动开源的多模态 AI Agent 桌面应用,专注于 GUI 自动化方向。
以下是本月精选的 5 个新晋优质项目:
01 将代码库转化为可交互的知识图谱
Understand-Anything 能对整个代码库进行分析,并生成一张可交互的知识图谱。
2026年6月第3周GitHub热门开源项目速览:AI Agent生态霸榜,语音对话、桌面笔记与容器工具齐飞
打开本周的 GitHub Trending,AI Agent 生态几乎包揽了前几名。从我挑出的 10 个值得详聊的项目里,你会看到各类 Agent 工具、本地化方案和性能优化利器同时涌动;其余几个上周已经提过,这里就快速带过。
last30days-skill:驱动 AI agent 自动跨 Reddit、X、YouTube、Hacker News、Polymarket 完成信息抓取与趋势总结。
headroom:把传输给大模型前的工具输出、日志、RAG 分块先进行压缩,在不牺牲效果的前提下节省 60‑95% token 消耗。
taste-skill:为 AI 注入审美判断,避免它吐出千篇一律、毫无风格的低质文本。
markitdown:微软出品的多格式文件转 Markdown 利器,Office 文档、PDF 等一键转换。
career-ops:基于 Claude Code 构筑的求职 agent,内置 14 项技能模式。
opencv:老牌计算机视觉库,几乎每周都驻留在 Trending 榜单。
svelte:前端框架,本周保持小幅热度。
01 语音对话不延迟:用本机 LLM 搭建你的 AI 伙伴
Open-LLM-VTuber 是一套允许你用语音跟任意大语言模型实时对话的开源方案,目前 GitHub 上已有 1.1 万星。
它完全在本地运行,可以对接 Ollama 或任何 OpenAI 兼容接口。并且支持随时打断,而不是那种非要说完整句才能切换话轮的“伪实时”。
更吸引人的是它可以挂载 Live2D 模型,让对话对象呈现面部表情和动作,并且跨平台适配 PC、移动端和 Web。
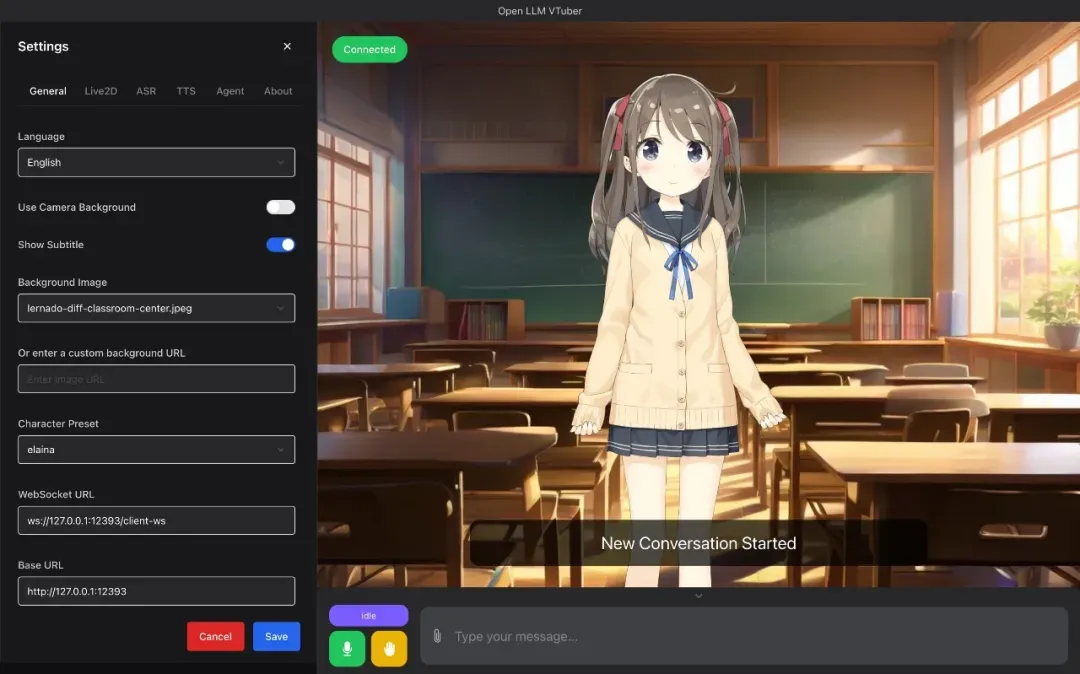
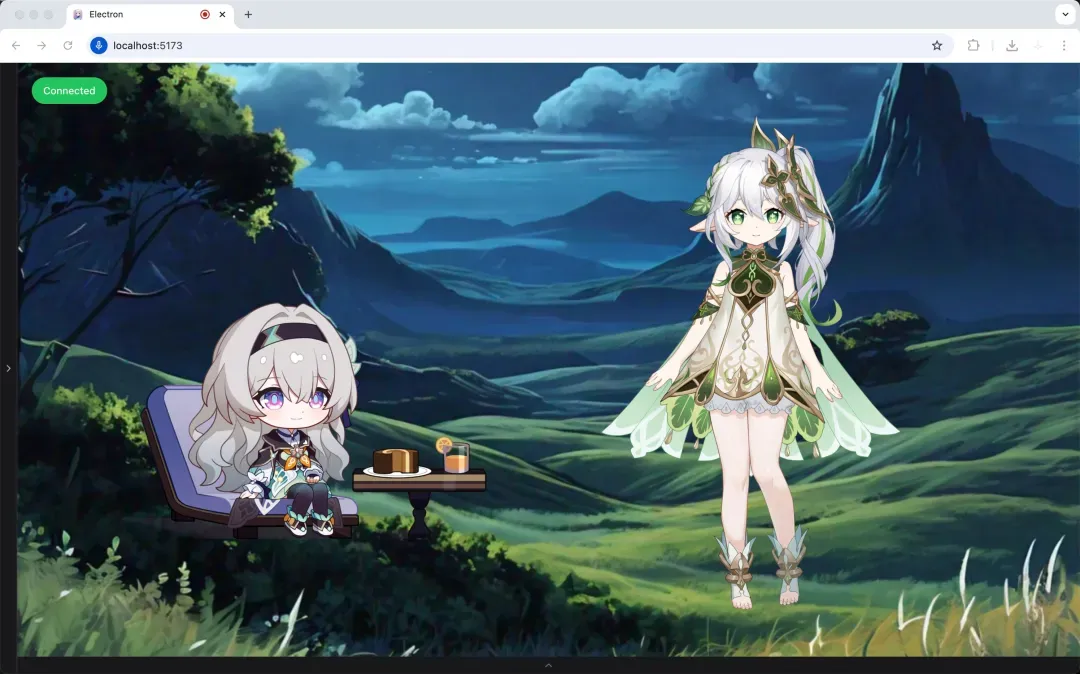
项目定位偏向 AI 陪伴和 AI VTuber,与 Neuro-sama 这类虚拟主播思路相似。如果你想打造一款本地部署的语音助手、虚拟主播或者 AI 陪聊伙伴,这正是一个现成的起点。
2026年四大实用GitHub开源项目精选:AI省Token路由、多任务Claude桌面、AI求职系统与提示词泄露
智能模型路由:Token开销降至原来的十分之一
OpenSquilla 能让你与 AI Agent 之间的每一轮对话,都先经由本地运行的模型路由器评估复杂程度,再自动分派给能胜任且成本最低的模型。这意味着只有真正的复杂难题才需要动用 Opus 这样的高级模型,那些琐碎、简单的任务则交给便宜模型即可,Token 账单瞬间瘦身。

开源地址:https://github.com/opensquilla/opensquilla
团队在 PinchBench 1.2.1 上跑了 25 个任务的基准测试。OpenSquilla 的平均得分为 0.9251,而对照组 OpenClaw(全程使用 Claude Opus 4.7)则是 0.9255,表现几乎持平。但总花费却天差地别:前者仅 0.688 美元,后者高达 6.233 美元,整整省了约 9 倍之多,输入 token 消耗更是降到只及对方的零头。
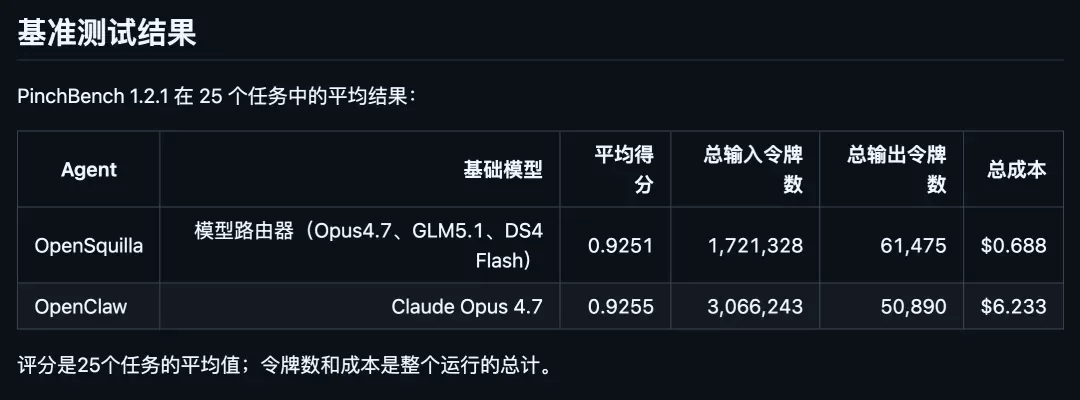
更贴心的是,整套路由判断完全在本地执行,基于 LightGBM 和 ONNX 实现,你输入的 prompt 不会被事先发送出去做分类,隐私和成本一举两得。
多任务并行黑科技:让 Claude Code 真正同时干活
经常使用 Claude Code 的人都有过这样的烦恼:在一个项目上跑着 Agent,想去折腾另一个项目就不得不再开一个终端窗口,在不同标签之间来回切换,时间一长甚至忘记某个 Agent 原本的任务是什么。Nezha 正是为解决这个痛点而生。

开源地址:https://github.com/hanshuaikang/nezha
Nezha 把自己定义为 Agent‑First 桌面应用,专为 vibe coding(AI 写代码,人盯进度)这类场景打造。简单来说,它把多项目管理、终端、Git 操作、会话回放、代码浏览等功能全部整合进单一界面。
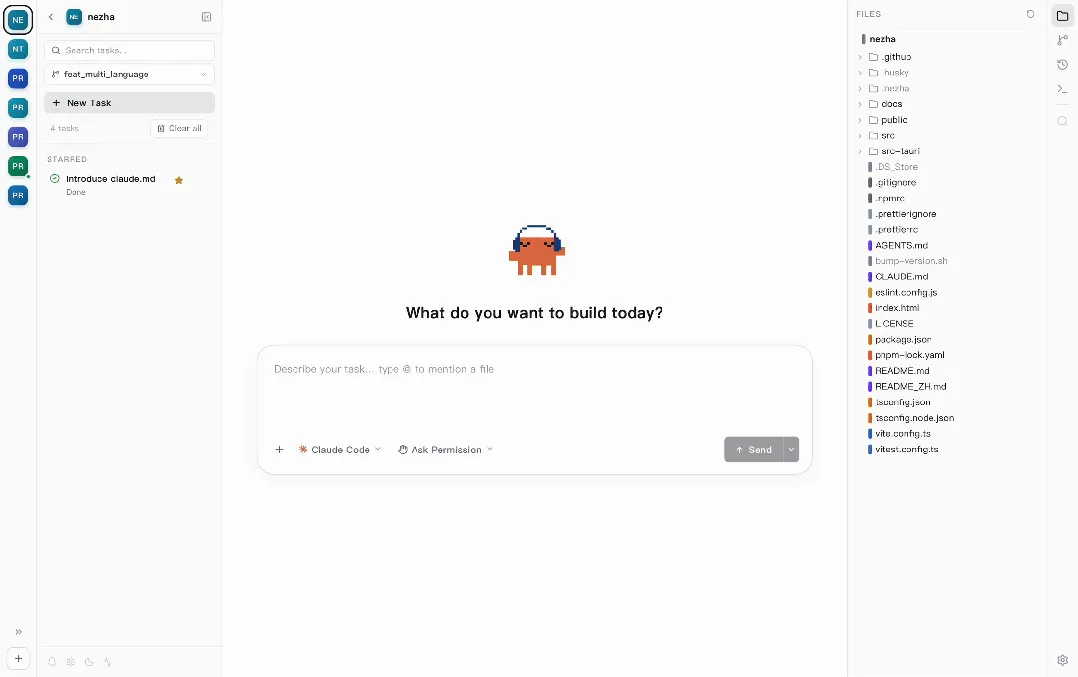
你可以在一个窗口里同时并行跑着多个 Claude Code 和 Codex 实例,每个项目独占一个标签,点一下就能秒切过去,后台终端依然正常运转。如果某个项目因等待确认而卡住,左侧栏会亮起黄色指示灯提醒你。整款应用安装包只有区区 7 MB,还能自动识别 Claude Code 和 Codex 的会话文件,将每次对话可视化出来,随时都能 Resume 继续。
2026年智能电动头皮按摩器选购深度报告:蓝海定位、品牌真空与DTC破局之道
一、市场全景速览
全球头皮按摩器赛道正处在稳健的中速增长通道上。综合多家机构数据,2024 年整体市场规模录得 8.515 亿美元,预计到 2030 年将攀升至 12.9 亿美元,年复合增长率约为 7.3%(Grand View Research)。进一步聚焦智能头皮按摩器细分领域,Deep Market Insights 测算 2025 年市场体量为 9.2 亿美元,2030 年有望达到 13 亿美元,CAGR 7.2%;DataIntelo 从电动头皮治疗按摩器角度给出的数据则更为可观:2025 年 18 亿美元,2034 年增长至 32 亿美元,年复合增速 6.6%。三大机构的判断相互交叉验证,头皮按摩器赛道基本锁定在个位数百分比的中速增长带。
核心增长引擎:
- 全球脱发与发际线后移人群持续扩大:据国际毛发修复外科学会(ISHRS)2024 年报告,25-45 岁女性中有 32%、男性中有 41% 出现肉眼可见的发量减少;
- “头疗经济”强势出圈:2025 年中国头疗门店数量同比增长 47%,日本、韩国及东南亚头部 SPA 业态同步爆发;
- TikTok 平台上 ASMR 内容引爆“抓头皮”热潮:话题 #scalpmassager 累计播放量超 16 亿次,ASMR 抓头皮、滚珠拨筋、激光生发三类内容同时爆发;
- 居家自护理渗透率快速上升,100% 线下头疗院及美容院的“家庭化”场景成为窗口期。
区域分布: 北美以 38% 的份额稳居最大市场(高可支配收入 + 强防脱发意识),欧洲占 28%,亚太地区占比 25% 但增速最快(CAGR 8.5%),中东和拉美合计约 9%。
二、竞争格局梳理
当前头皮按摩器行业呈现典型的“哑铃型”结构:$20-35 价格带拥挤大量白牌,$90-130 高端段由 Breo 等极少数品牌把持,中间 $50-90 的品牌真空带鲜有有实力的 DTC 玩家切入。
AI模型《超级玛丽》游戏复现实战:豆包2.0、Model3与Qwen3.7 Max横评,仅Fable交出满分答卷
《超级玛丽》这款跨越时代的经典游戏,各大AI模型居然至今没能完美复现,实在让人大跌眼镜。我几乎把所有国内外主流模型都拉出来遛了一遍。
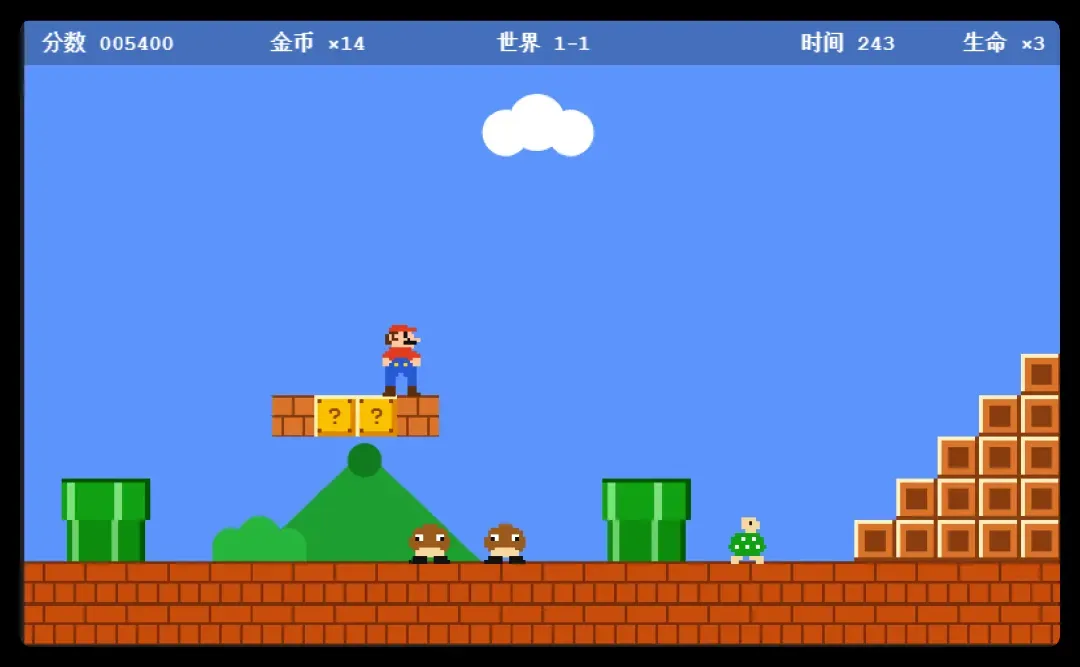
到目前为止,表现最抢眼的还得是Fable,其他选手可以说是状况频出、错误连篇。
GLM5.2和Kimi2.7的测评之前已经做过,也分享过了。这次的主角是Doubao2 Pro、Model3、Qwen3.7 Max。
为什么挑这三家?因为在《超级玛丽》这道题目上,它们勉强能坐到同一张桌子上。本来还想拉上MiMo,不过那篇已经单独写过,就不再重复了。看完它们交出来的作品,我只能感慨一句:真是别有一番趣味。
寓言
为了对比起来更直观,先让Fable打个样。
Claude Fable这个称呼本身就挺有意思,大致可以理解为“克劳德·寓言”。其中的“Claude”普遍被认为是在致敬信息论之父克劳德·香农。而最新版的寓言与神话模型共用同一个基座,算是目前公开可用的最强选手之一。
它的成绩单如下:
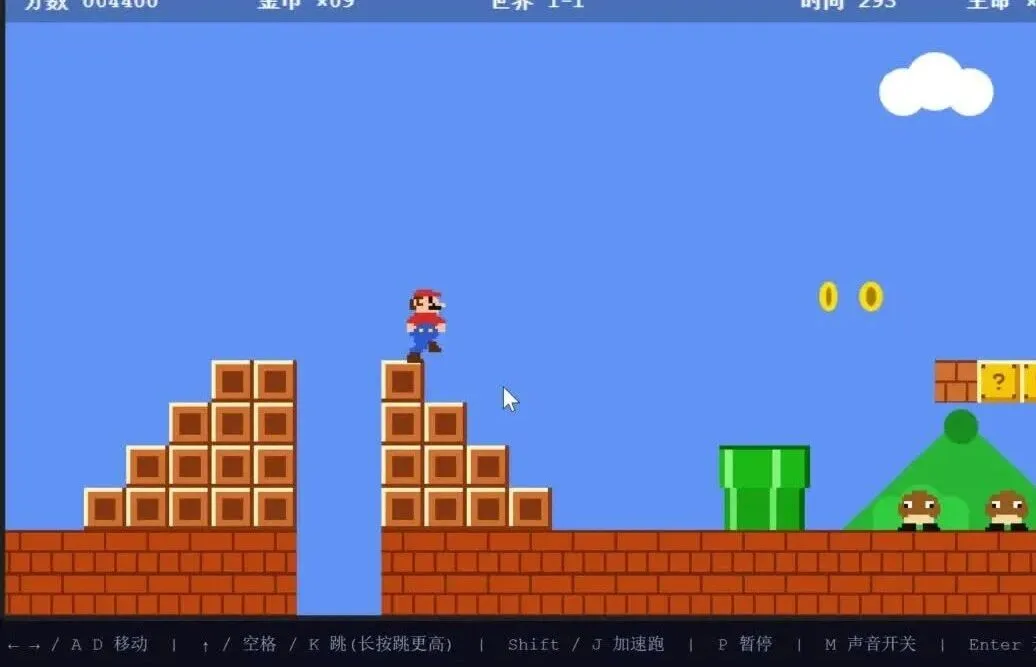
这里展示的是一轮对话直接生成的结果,全程没有加入任何二次提示。超级玛丽的地图布局、场景还原,以及角色行为和底层逻辑,背后其实藏着数不胜数的讲究。那些真正引爆市场的游戏,无一不是靠海量细节堆砌出来的。Fable还原得最到位的地方在于,整套代码完全是纯手写JavaScript搓出来的,相当震撼。
豆包2专业版
豆包大家已经熟得不能再熟了,国民级的日常应用。日常闲聊或者基础问答可能还顶得住,但一旦涉及编程、深度推理和低幻觉输出这几个维度,就一直差着那么一口气。平时我基本不会特意去碰它,这次纯粹是灵光一闪。
效果如下:
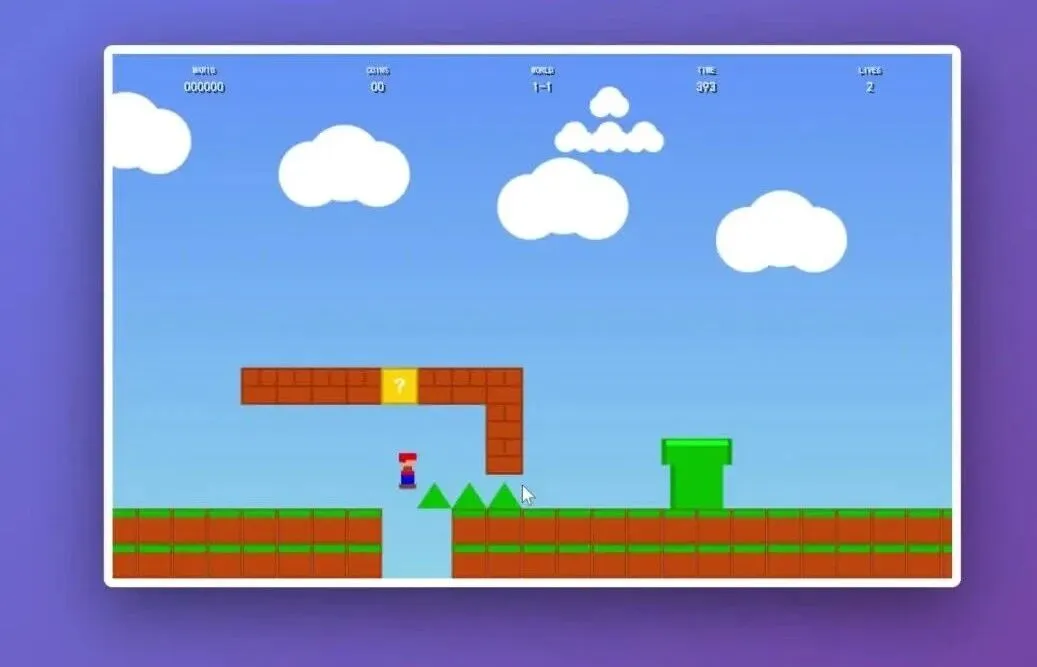
哈~我就看看,不说话。
Model3
为了不干扰对方的市值和内部同事的工作,这个模型我就不点名了,姑且叫它Model3。事实上,Model3一系的规模是最小的,基础能力也相对最弱,可是宣传上的声势却最响。
直接上展示吧:
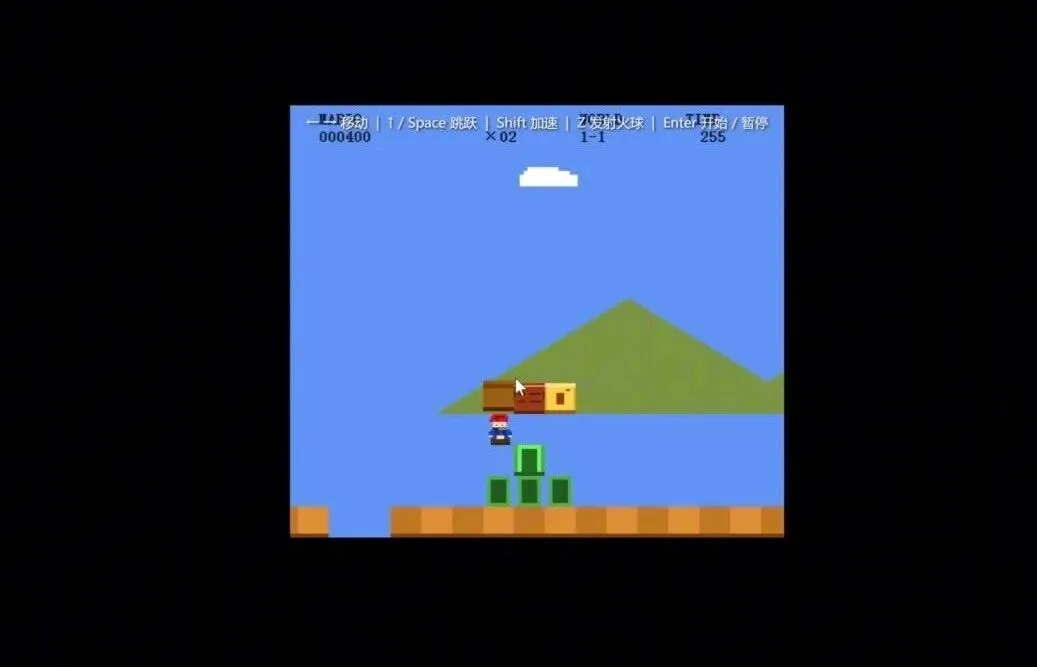
哈~我就看看,不说话。
Qwen3.7 Max
这是阿里目前手里最强的一张牌,刚发布时就打出“全球第二,国内第一”的口号。单看各种基准榜单,确实可以到处碾压同行。不过数据归数据,真刀真枪上场又是另一回事。今天就请《超级玛丽》给它好好上一课。
效果如下:
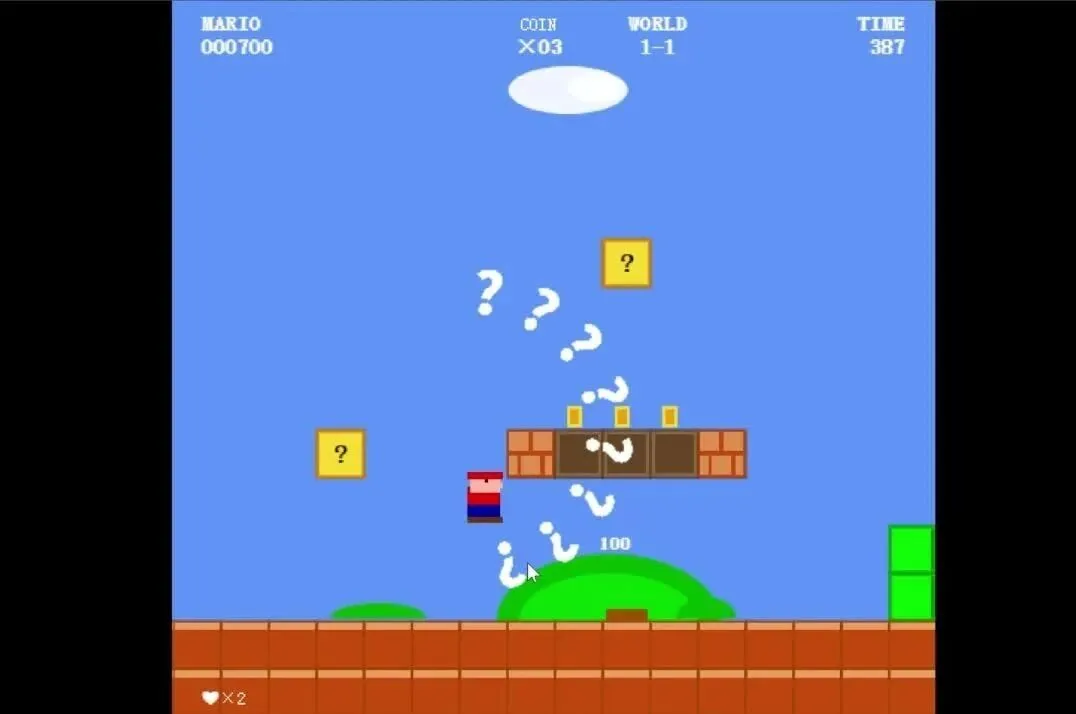
哈~我就看看,不说话。
现在咱们抛开所有公司名头,单纯看看最后捧到眼前的这些效果,各位作何感想?到底哪家棋高一着,差距又拉开了多少?当然,这只能算是一个极其狭窄的观察切口,远远不能代表它们的全部实力。不过窥一斑而知全豹,多少还是有些参考意义的。
我不能直说谁差,只能说娱乐指数拉满了。它们才是真正意义上的“原创高手”。
看过这些娱乐选手的表现,我更怀念用Fable的那三天了,那种感觉就是——我好像什么都做得出来!只要吸过那一口,再看别的就通通变得索然无味。用过的人自然心领神会,没用过的可以尽情想象一下。