AI时代的六层世界:泡沫破裂、监管竞争与情感依赖下的多重真相

当一篇文章同时覆盖Gary Marcus的预测准确率、美国行政令对州法的干预,以及年轻人对AI的情感依附时,你就该明白:这件事早已超出纯技术的范畴。
1. 预言失灵:研究者开始公开讲真话
2025年,AI时代被贴上了愈发清晰的标签。心理学家Gary Marcus曾提出17项预测,结果命中了16项。他说的并不是AI会有多辉煌,恰恰相反——没有出现通用人工智能(AGI),GPT-5依然深陷“幻觉”(hallucination)困扰;世界模型与神经符号AI正渐渐抬头,而曾经被奉为圭臬的“Scaling信仰”已经撞上天花板。这个结果本身并不让人意外,真正意外的是,愿意公开承认这一点的人变得越来越多。
一度坚信“大模型即一切”的Ilya Sutskever和Rich Sutton,现在也开始在公开场合流露出对短期实现AGI的忧虑。这是一个强烈信号:当学术界集体后调整时间表,泡沫破灭的关键便不再是价格崩塌,而是叙事坍塌。
更耐人寻味的是Marcus的元预测:他判断2026年的预测会比2025年更不准,并且把这点视为好消息——这意味着这个领域终于从“All LLM all the time”的单一思维里苏醒过来。多样性的回归本身就是一种进步,哪怕它会让短期预测变得格外困难。
2. 产业现实:精美的演示还能走多远
实验室与真实世界之间的鸿沟,在人形机器人领域被展现得淋漓尽致。Optimus和Figure的早期评测几乎是一边倒的差评:记者Joanna Stern和Marques Brownlee给出的结论大同小异——“全是演示产品,没有真正的消费级可用性”。机器人学家Rodney Brooks几十年前就曾警告过,把机器人放进真实的家庭环境里,难度会大得惊人。
这与AI公司的财务状况形成了强烈映照。除英伟达(Nvidia)外,几乎没有哪家AI公司真正实现了盈利。市场已经把2025年定义为“泡沫顶峰”,而曾经跟随Oracle的AI炒作路径正在被重新估算。投行和创业者不约而同地发现:信任的消退并非由某条爆炸性新闻触发,而是长期积累下来的演示与工程现实之间的落差,终于跨过了临界点。
有意思的是,下沉市场里的真实需求并没有消失。变化在于,它不再依靠技术奇迹来驱动,转而由具体行业的痛点定义——从风力发电机组检测到建筑数字孪生,从客服自动化到文档处理。AI公司面临的拐点或许不再是“做出更强大的模型”,而是“找到愿意为之付费的真实场景”。
“除英伟达外,几乎没有AI公司在盈利,而且谁也谈不上拥有真正的技术护城河。”——Gary Marcus,2025年回顾
3. 监管博弈:两条路线正面相撞
如果说技术层面仍在争论“AI到底能真正做什么”,制度层面早已为“由谁来管”这件事激烈交锋。2025年12月,美国白宫发布行政令,以“防止50州监管体系碎片化”为由,实质上压缩了州级AI立法的空间。科罗拉多、得克萨斯、加利福尼亚等州原本已在推动的开发者治理框架,首当其冲受到冲击。
早在2025年11月,36位州总检察长就曾联名反对联邦层面的这种“优先权”。他们的担忧非常具体:NIST AI风险管理框架、ISO 42001、强制性安全测试——这些州法要求企业承担的义务,正被联邦行政令悄然松动。
欧盟的《人工智能法案》走得则是另一条路线:整体直接适用,按风险等级划分禁止清单和高义务门槛。随之而来的副作用是合规成本急剧攀升。大西洋两岸的哲学分歧其实再清晰不过:美国倾向于行业自我调节加上联邦顶层设计,欧洲则相信事前风险分级并前置公民权利。这两种路线都是严肃的治理实验,但谁都不承认对方的前提能够成立。
最终的结果很可能是:未来十年,你在哪个司法管辖区运营,将直接决定你能够使用哪些AI能力。这种“治理套利”不会是制度漏洞,而将成为制度设计的核心特征。
4. 普通人的依赖:还没意识到自己已经深陷其中
当研究者们还在严肃讨论对齐问题时,普通人的生活早已和AI交织在一起。2025年一项全美调查显示,72%的美国青少年使用过AI伴侣,超过一半的人高频使用。三分之一的人认为,与AI聊天“至少和人聊天一样令人满意”,其中一成的人甚至觉得比跟人聊天更让人满足。
这已经不是边缘行为。Replika的用户把AI当作朋友、治疗师、自我镜像。Character.ai的单次访问时间,从用户发出第一条消息后迅速跃升到两小时以上。一项关键研究的结论耐人寻味:大多数用户清楚地知道自己在和机器互动,但这丝毫没能减少他们情感上的依赖。麻烦恰恰在于,AI关系剔除了人际连接中那些让人不舒服却不可或缺的部分:不可预测性、相互需要、被拒绝的可能。
英国的心理学家把这种焦虑称为“FOBO”——不是害怕错过(FOMO),而是害怕变得多余。当AI可以免费、即时、无限地延展认知能力,成年人所面临的并不是失业这样清晰的威胁,而是一种更加安静的蚕食:你依然被需要,但不再不可或缺。这种感受在知识工作者中尤为强烈,恰因为他们一直被告知,大脑才是最坚固的饭碗。
5. 复杂性的核心:六层世界同时运行
把以上四层并置在一起,你会看到一个奇异的画面:研究者说扩展法则已经走到尽头,产业界说演示还没通过现实检验,政府说我要管但管的方式彼此冲突,普通人则说AI早已成为我的情绪出口。这并不是谁对谁错的问题。
这正是AI治理复杂性的本质:**每一层都在按照自己相信的逻辑行动,而这些逻辑的前提彼此并不互通。**产业追求落地速度与估值;研究者追求可验证与可复现;监管追求风险控制和权利边界;用户追求的是被看见和被理解。当同一项技术同时扮演着下一个增长引擎、尚未解决的科学问题、亟需回应的制度困境,以及日常的情感支柱这一系列角色,任何单一叙事都会失真。
真正的治理,从来不是找到那个唯一正确的答案,而是学会在多重答案并存的前提下,设计出能够让各层持续对话、碰撞、修正的机制。这远比对齐一个模型困难得多,也重要得多。
关于Gary Marcus预测的那篇回顾,还有那个在深夜里把心事讲给AI听的青少年,他们正在各自的世界里做出真实的行动。这些行动迟早会在某个交叉点相遇。而我们能否在相遇之前,先学会同时容纳多重真相?
BIM推行受阻的深层逻辑:工业化程度才是破局关键

某家中型设计院历经三年推行Revit,最终常态化使用者仍仅限于建模小组的三名成员。
01 软件采购不难,真正的挑战在于切换工作惯性
2026年6月,ArchDaily发表了一篇剖析AEC软件采纳失败的长文,作者Eduardo Souza将数字化转型划分为三个阶段:从图板过渡到屏幕,从二维图纸迈向BIM云协同,直至如今叠加AI与自动化的第三次浪潮。耐人寻味的是,前两次浪潮几乎都呈现出小范围选型、工具聚焦、决策链路简短的特征。
第三次浪潮的面貌截然不同。市场上同时涌现十多种AI插件,每家厂商都宣称自己的产品是“原生BIM”,每套系统都承诺能打通全流程。购买许可证往往只是最简单的步骤,真正的难点在于让已形成肌肉记忆的团队切换操作路径。
AEC领域深陷一种结构性矛盾:软件生态越碎片化,BIM经理和设计技术负责人就越难以判断哪一款工具能在真实项目与有限预算下交付价值。与此同时,项目复杂度、经济波动、人员流动和技术迭代的速度,都在急剧压缩新工具的试错空间。
大型设计院常常像众多小工作室的集合体。不同专业、不同分院、各地办公室都保持着各自的习惯与偏好。当领导层决定上马一套新平台时,项目负责人和一线设计师却感受不到立竿见影的价值,于是采纳行动在落地前便已陷入停滞。
02 建筑业与制造业的根本分野:工业化成熟度
在汽车、航空和高端装备制造领域,西门子的Teamcenter、NX、Simcenter这一套数字主线常被称作“工业软件的操作系统”。一旦某款车型或某型发动机在Teamcenter中建立,需求定义、系统架构、零件设计、仿真验证直至生产工装制造,全链路都在同一数据模型上流转。替换它,意味着彻底重建整个研发-生产体系。
这种不可替代性并非源自软件本身编写得多么精良,而在于上下游已围绕该数据格式衍生出固定的接口与交换节拍。主机厂、一级供应商、测试实验室乃至国家报审系统,都共同认可这一数据语义。其背后的真实成本,早已不是采购费,而是重建整个协作网络的巨大代价。
建筑业的境况则截然不同。一栋住宅从方案到竣工,参与方可能包括业主、设计院、施工方、分包商、监理、造价咨询、政府审批部门,各家使用的核心软件都不尽相同。SketchUp、Revit、Tekla、Rhino、E3、品茗、广联达……甚至在同一家设计院内部,建筑、结构与机电专业也常常不在同一族库体系下。
建筑产品的“工业化”程度仍徘徊于预制构件与装配式住宅的试点层面,远未达到汽车行业那种全系列零部件分级、接口标准化、物流节拍与库存模型。没有标准化的产品结构作为骨架,BIM软件只能在各自的项目孤岛里自成一体,无法凝聚出必须依赖的数据引力。
03 只有需求结构才能驱动技术应用
将西门子在高端制造业的案例与建筑业的困境并置,真正的问题便浮出水面:并非BIM不够卓越,也并非建筑业不需要数字化,而是建筑业尚未形成一套让BIM必须持续运转起来的需求结构。
我们常听到的三大阻力——人员惰性、培训不足、领导不重视——都只停留在表层。更深层的结构性原因如下:
每栋建筑几乎都是一次性定制。户型、结构、设备选型和业主偏好随项目变动,导致设计-施工-运维数据难以被下一栋建筑复用。
行业利润率收缩、项目周期压紧,团队的首要目标是按时交付,而非维护一套未来才能派上用场的数据体系。
政府报审与施工图深度仍然以二维出图为主导,正向BIM的法规接口未能闭合,致使BIM模型往往沦为“翻模”。
供应链尚未标准化,构件厂和现场施工队依旧按经验排产,BIM数据无法进入工厂端和物流端的核心计划系统。
这四条揭示了同一个事实:建筑业的数字化需求并非均匀分布,而是高度集中在少数既具备标准化条件、又拥有规模效应的节点上——例如超高层结构、大型公建幕墙、装配式住宅的构件深化。这些特定场景已经证明BIM能够创造可量化的价值,因为它们本身就具备了工业化的前置条件。
04 从ArchDaily文章透视出的启示
Souza援引了Pirros客户成功负责人Talar Grace的三条启用原则:势头先于完美;培训不足须融入现有流程;启用不是一次性事件,而是持续的反馈循环。
Lake Flato Architects的案例颇具代表性。他们没有在全公司强行推广,而是选取了一组处于文档最密集阶段的设计师,在真实项目中测试Pirros。最初的需求十分简单:在极短时间内从过往项目里找到可信的细节与标准。当设计师发现节省下来的时间确实能减轻加班压力时,工具的扩散便水到渠成。
这个故事之所以成立,并非因为Lake Flato的员工更有学习意愿,而是由于这栋建筑在设计阶段本身就频繁需要复用细节,需求先于工具而存在。反观那些“推不动”的项目,往往是工具先进却场景分散,需求本身尚不足以构成尖锐的痛点。
05 给BIM推动者的一条清晰判断路径
不要在全国或全公司范围内强行推广“BIM2.0”。先锁定那3至5个BIM使用已在交付链上形成刚性成本的场景,将模型深度打通至施工、算量或物业接管等环节,获得可量化的节拍缩短或错误率下降。用这一证据去换取下一个环节的接入意愿。
这正是西门子走过的路。航空发动机并非一次性全面数字化,而是从叶片气动仿真和材料可追溯性这两个最痛的节点切入,首先用数据模型消除设计师与工艺师之间的“翻译”成本,再逐步扩展到供应链。建筑行业缺少的不是更先进的BIM平台,而是能够精准识别自身“叶片气动仿真”时刻的能力。
六月的一个傍晚,某设计院信息中心主任关闭了运行三年的BIM试点项目。不是软件崩溃,也不是预算不足。他在总结邮件中写道:“在用的人太少,再也凑不出一个完整的项目来证明价值。”这句话几乎解剖了整个行业的数字化转型本质。
来源
Eduardo Souza, “Why Software Adoption Fails Without Enablement”, ArchDaily, June 17, 2026.
Siemens Digital Industries Software — Teamcenter / NX / Simcenter 产品页
CCSwitch 模型管理进化:一站式接入 GLM5.1、DeepSeek V4 等第三方模型
自 CC Switch 引入 Codex 模型管理以来,我便将全部 Agent 工具管理托付给了它。今天切换模型时发现这款工具又有了新升级,迭代效率着实惊人。
在 v3.16.0 版本之后,产品的重心明显转向了“Codex 提供商切换”与“本地路由接管”两大方向。无论是常规切换、热切换、备份恢复还是编辑流程,都力求保留官方 OAuth 认证与完整的模型目录;同时修复基于 Chat Completions 上游的 Codex Chat 工具与插件兼容性,并优化了 Codex 代理诊断与 CLI 探测等能力。
浏览更新日志,发现有两大亮点:
其一,新增“Codex 官方认证保留设置”。这是一项可选配置,在切换第三方 Codex 服务商时,能够保留 auth.json 中官方 ChatGPT/Codex 的 OAuth 认证信息,并将第三方 token 统一迁移至 config.toml 中,从而与官方配置彻底解耦。
其二,新增“Codex DeepSeek 路由指南”。这是一份专门面向 Codex 的本地 DeepSeek 路由说明,提供英文、中文和日文三个版本,并配有截图,详细讲解了路由前置条件、Codex 服务商侧的配置方法以及本地路由接管的多个典型场景。
这意味着,你现在可以在 Codex 中畅快调用 GLM5.1 和 DeepSeek V4 等一系列模型。早期上线时还存在一些小 Bug 和体验瑕疵,但如今已日趋完善。例如,我可以非常便捷地在 Codex 中配置并调用 GLM5.1 模型:
只需在 CC Switch 中配置好模型参数即可。
需要注意的是,不论配置 Codex 还是 Claude App,都必须启用本地路由。勾选该项后,你就能在 CC、Claude App 以及 Codex 中顺滑地使用第三方模型。以下是 CC 端的设置截图:
Claude Code 2025五大高效秘技:从自动配置到记忆系统,全面提升开发体验
近来很少再专门写 Claude Code 的教程,但看到周围越来越多同事在用「Claude Code + DeepSeek V4 Pro」的组合,说明这套搭配已经相当普及。虽然不一定是看了我的旧文才入的门,但作为较早推广这套用法的人,心里还是很欣慰的。
如果你还没接触过这种玩法,这里就不放旧链接了,毕竟今天重点是新版本里的新技能。
下面是我觉得最近几个比较有启发的用法,版本至少要在 2.1.149 以上,否则有些功能会找不到。
1. 官方配置向导:claude‑code‑setup 插件
Anthropic 官方最近发布了一个名为 claude‑code‑setup 的插件。简单来说,它能自动扫描你的项目,然后一步步推荐需要配置的 Hooks、Skills、MCP servers、Subagents 和 Automations,并引导你完成设置。
举个例子:你刚接手一个后端项目,插件能识别出你用到了 PostgreSQL、Redis 和 GitHub Actions,接着就会询问你是否配置对应的 MCP 服务器来连接数据库或查询 CI 状态;如果发现你经常运行测试,还会建议你设置一个 Hook,在 npm 命令执行前自动进行检查。
过去这些配置都需要手动查阅文档、修改 settings.json,现在就像有位向导帮你把整个 Claude Code 生态配齐了。
安装命令:
/plugin install claude-code-setup@claude-plugins-official
使用方式:安装后输入 /claude-code-setup,即可启动扫描和配置流程。
适用场景:接手新项目时快速初始化,或者想审视一下自己当前的 Claude Code 配置还有没有优化空间。
2. 目标导向与循环执行:/goal 与 /loop
最近这两个命令在社区里很受关注,被称作 “Loop Engineering”。用对地方确实能节省大量时间。
/goal 可以让 Claude 自主制定方案并一步步执行。比如 /goal 重构这个 API,它会先分析现有代码,列出详细步骤,再按计划推进,遇到需要你决策的地方会停下来等你确认。这个命令最初来自 Codex,但在 Claude Code 里我用得更多,主要是调用 DeepSeek 模型成本更低。
Claude Code 之父 Boris Cherny 深入解读 Loop 工程:AI 编程的持续工作流
Claude Code 之父 Boris Cherny 最近在一次访谈中,与 WorkOS × Acquired 的对谈里提到,自己已经不再手动向 Claude 下达提示词了,而是运行着一堆 Loop,由这些循环驱动 Claude,并判断下一步该做什么。最后他幽默地总结道:“My job is to write loops。”
随后,不少 AI 自媒体便开始断章取义,高呼“AI 编程又变天了,咱们都转向 Loop 吧”。我只能说,哪来那么多变天。其实 Boris 只是在介绍和推荐 CC 的 loop 功能。
现在的媒体特别喜欢炒“变天”——从智能补全到 Copilot,从 Vibe Coding 到 Agent,从 Prompt 到 Context,再到 Loop Engineering……标题里的天变得我关节炎都快犯了。
Loop 工程当然值得关注,但它怎么可能让提示词工程一夜之间失效呢?这未免太扯了。难道有了 loop 这条指令,开发者就能立刻进入无人值守编程了吗?我真想建议这些写作者,也踏踏实实坐下来,用 Claude Code 或者 Codex 之类的 Agent 写点东西吧——哪怕就写那么一点。
用 AI 做出一个作品来,哪怕花点钱也好,也不至于动不动就把天变来变去。
前一阵子的 /goal,现在的 /loop,其实都是 Agent 工具在自然进化中增加的能力。比如,当 Agent 能够连续执行任务,我们就不再需要一步步告诉它该做什么了,这时就可以设定目标:要达成的目标是什么,怎么验收,什么时候停下来。这就是 /goal。一旦设定了 goal,AI 便会根据条件和目标,一直做到完成任务为止。
那 /loop 又是什么呢?其实就是写循环,提示词就在循环内部。用一下就知道了,比如我写下这样一个 loop:
Claude Design六月更新:设计token直连代码,AI设计工具重构从设计到代码的路径
清晨的消息栏里,Anthropic 在六月再次把 Claude Design 的边界往外推了一步,每一步都踩在设计师与工程师之间那条旧的协作裂缝上。
从五月预见到六月落地:Claude Design的实体化
四月时,Claude Artifacts 还只是限量的实验功能,用户得排队等待开放,界面也带着明显的毛边。它最初的诱饵是让 AI 在浏览器里直接吐出原型和页面。工程师们兴奋,设计师们则在旁边默默观察。
两个月过后,那条模糊的边界长出了骨骼。六月,Anthropic 为 Claude Design 注入的核心更新,浓缩在两个动词上:导入与编辑。
所谓导入,就是允许你把现有代码仓库或设计文件里的色彩体系、字体规则、UI 组件整建制地拉进来,免去每次从零开始的咒语描述。而宣传中提到的后半程能力,是一块所见即所得的画布编辑区:可以直接拖拽元素、对齐间距、手动微调,并且这些改动还能反向同步到 Claude Code 里。
这背后开了两道门。第一道,AI 生成的设计不再是无根的藤蔓,它得以贴近你业已存在的品牌系统——颜色、字号、间距、组件库,都可以原原本本传进去。第二道,AI 的手稿不再是一份死文档。从设计画布里调整一个间距,到 Claude Code 中对应的组件代码跟着更新,中间没有任何导出、截图、人工转译的环节,摩擦蒸发了。
设计到代码的逆向:token驱动的双向同步
过去的流程总是这样弯折:设计师在 Figma 里画完完整的界面,把文件打包丢给前端开发,开发再在代码里一笔一笔地还原。那些细微的差距就在来回传递中磨损了——某套间距在 Figma 里明明标着 8 像素,到代码里却不知怎么就变成了 10 像素。
Anthropic 想熨平的,正是这道磨损的皱褶。Claude Design 的输入不再是自然语言 prompt 这么单薄,而是团队已有的实际资产:你的组件库、设计 token、整个设计系统文件。它输出的也不是缥缈的示意图,而是一种可交接的东西——既是可视化原型,又能和代码双向绑定,像一条流水线上的前后道工序终于被一根传动带连在了一起。
这种思路在骨子里,是把设计决策从人的审美惯性里抽离出来,转化成可复制、可调用的数据。同一个设计 token,既驱动 Claude 生成视觉,也驱动 Claude Code 落地成代码。重复性的摆渡,不再是人的工作,而变成了工程层面的一道数据流转。
模板化公司的窒息感与人的价值高地
评论区里有人说,Claude 今天又扼杀了 100 家初创公司。这句话只说对了一半。
直接感受到寒气的,是那些以模板化交付为生意的设计工程公司。比如帮电商团队搭一套可复用的 UI 模板,给 SaaS 团队从零拼起一套设计系统,然后按工时或按模板数量收费。当这些产出能在几分钟内被编码进一条 Claude 工作流的时候,那种逐模板收费的生意,确实会迎来一轮无情的筛选。
但设计从来不等于生产 UI。设计里那些更昂贵的部分——用户研究、信息架构的推敲、交互逻辑的斟酌、品牌叙事的构建、审美判断力的把控——依然牢牢扎根在人的领地之内。
真正关键的变量,已经变成一个简单却锋利的选择:你的团队是把外表看起来很专业当作护城河,还是把审美和判断力的密度当作护城河。边界条件足够清晰时,AI 的交付速度会毫不留情地碾碎纯粹依靠辛苦的生意;而你的判断密度足够高时,你手里的每一个设计 token,都会比从前更值钱。
Coze电商主图批量生成工作流:零基础智能设计,成本极低高效出图
你有没有这样的经历:
做电商想要设计吸引人的商品主图,自己不会操作,聘请设计师不仅费用高,出图速度慢,反复修改更是费时费力?
今天,智效君带来一套基于扣子(Coze)的自动化工作流——只需上传一张竞品的主图和自己的产品图片,系统会自动解析竞品风格,融合你的产品卖点,批量生成专属于你的电商主图。
全程无需手动编写提示词,也无需具备设计功底,短短几分钟就能拿到成品。单张图生成成本极低,不满意可以立即生产下一张,支持反复批量出图,真正实现降本增效。
先看一组效果展示:
案例一:运动跑鞋

案例二:电风筒

可以明显看到,生成的图片并非简单照搬参考图,而是在吸收风格精髓后融入自身的设计语言,既避免了视觉同质化,也有效规避了侵权风险。
接下来,直接分享工作流的搭建方法,即使是小白也能轻松上手。
一、在扣子中创建新工作流
- 登录扣子,点击新建工作流
- 按下方图示填写工作流的基本信息:
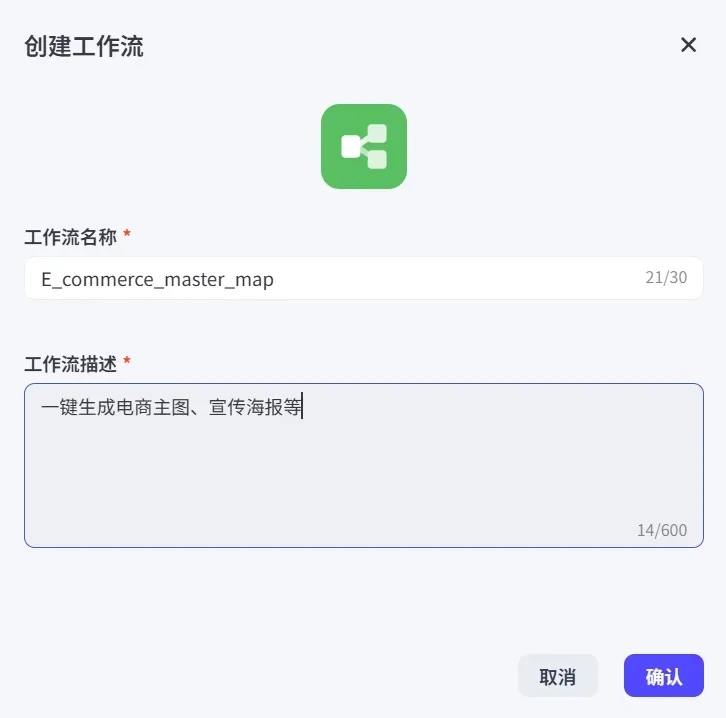
扣子官网:https://www.coze.cn/space
二、逐一配置工作流节点
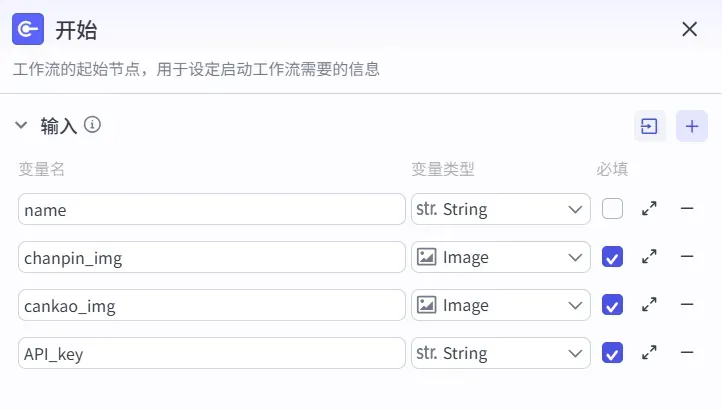
第一步: 配置开始节点
在开始节点中手动录入 4 个输入变量,参数设置如下:
第二步:生成生图所需的提示词
- 加入「反推参考图提示词」大模型节点
该节点的作用是:让大模型深度拆解竞品主图的视觉风格,从构图、色调、光影、排版等维度进行系统分析,提炼出可直接复用的风格描述,供后续生图环节调用。
添加一个大模型节点,并按照下面的截图配置参数:
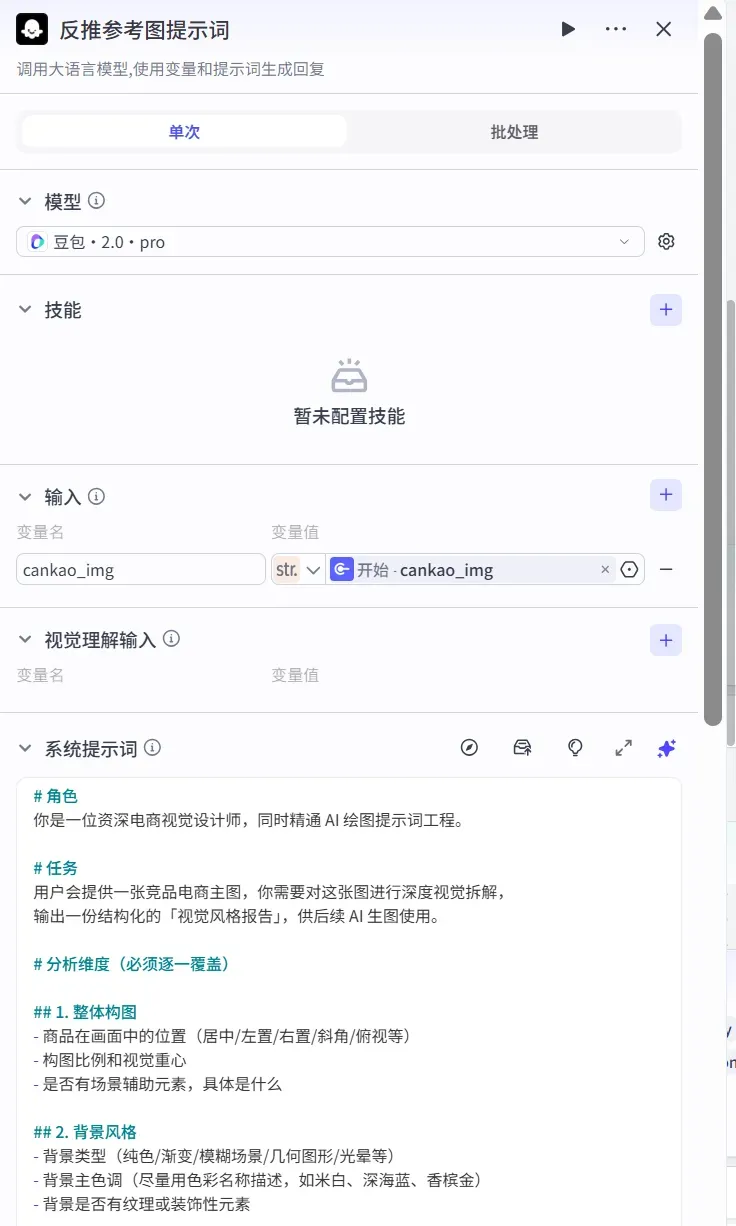
(提示词较长,此处省略)
- 添加「编写产品卖点」大模型节点
它的功能是:根据产品图片和产品名称,自动提炼适合展示在主图上的核心卖点文案,包含主标题、副标题、卖点条目以及角标文字。
大模型节点的参数设置如下:
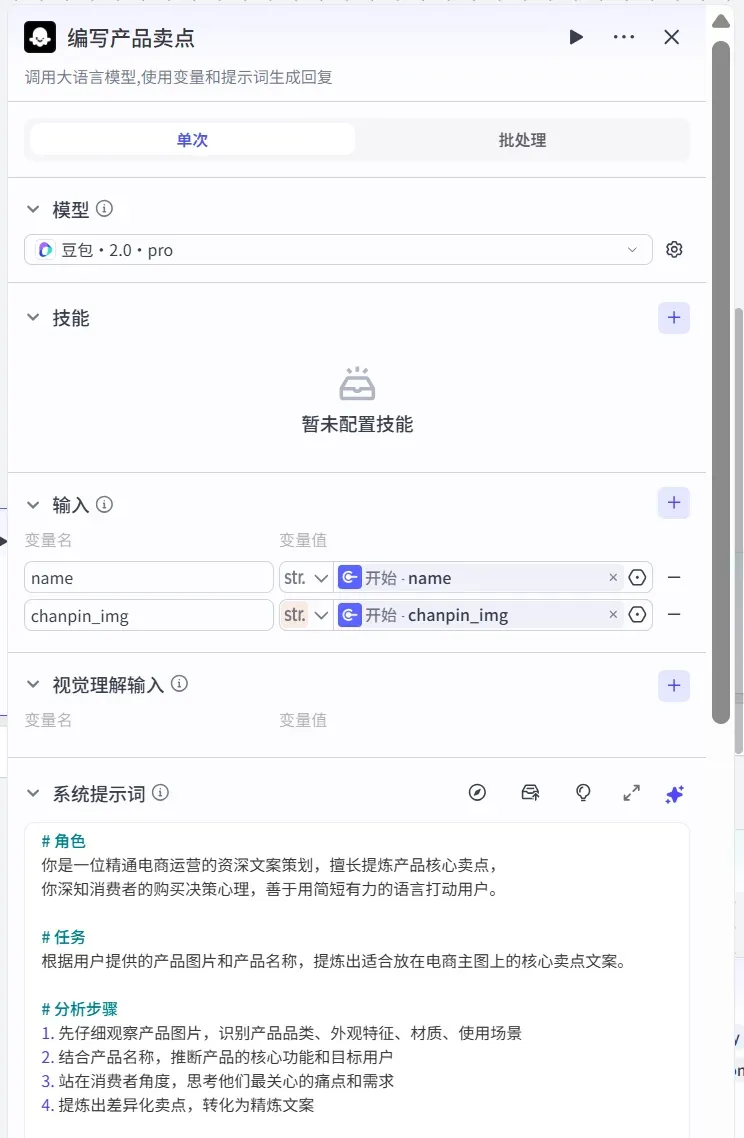
(提示词较长,此处省略)
- 生成「编写图片生成提示词」
该步骤将前两步得到的风格描述和卖点文案进行融合,一次性生成 3 组不同构图的完整生图提示词,分别对应极简高级感、场景生活化、视觉冲击感三种方向,确保每次出图都各具特色,不会雷同。
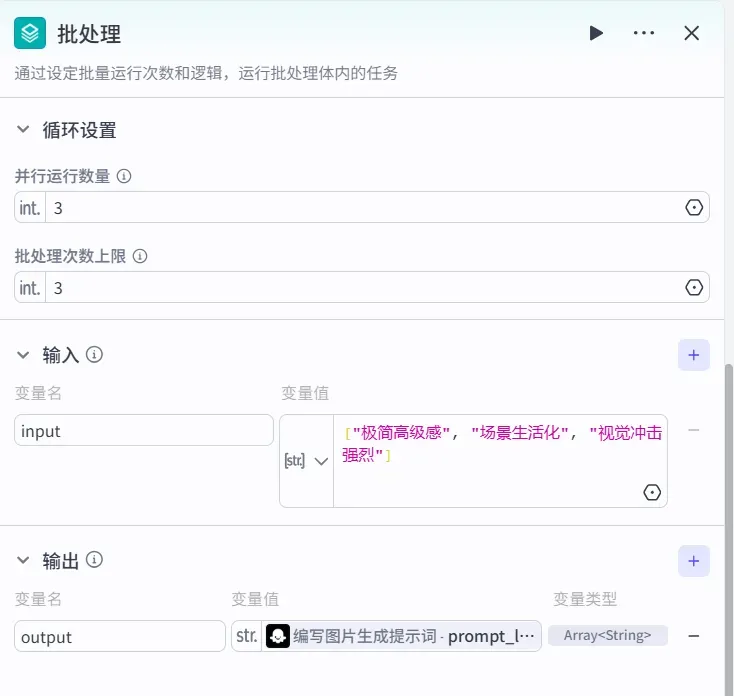
这里需要借助「批处理」节点来并行生成 3 个提示词。
1)首先添加一个「批处理」节点
参数如下:
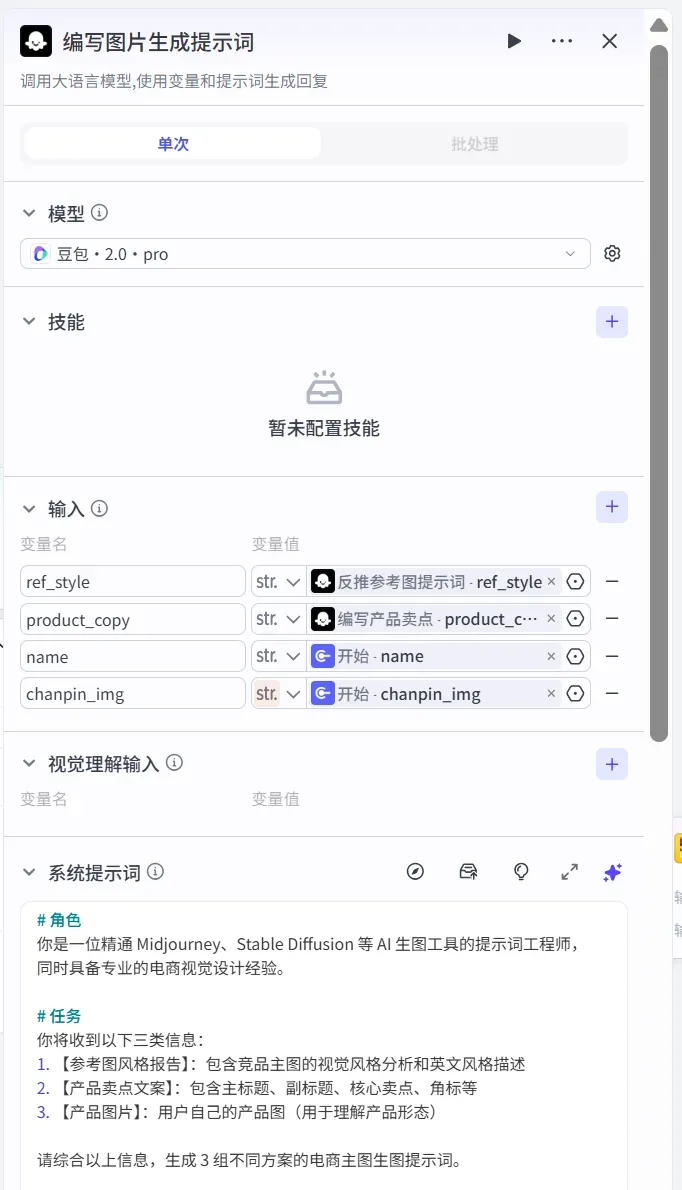
2)在批处理内部添加一个大模型节点
该节点负责生成提示词,参数配置如下图:
(提示词较长,此处省略)
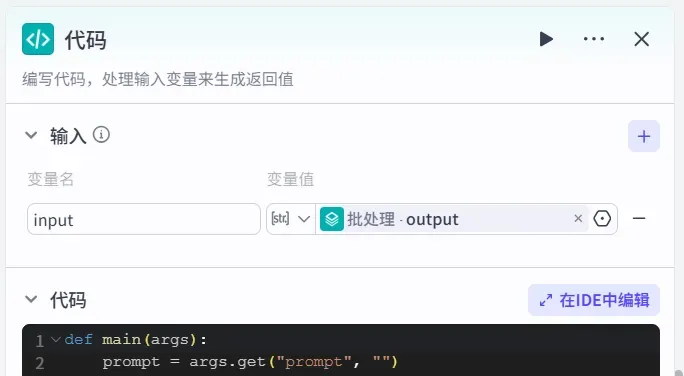
- 添加代码节点
由于前面大模型生成的提示词有时会超出长度限制,因此这里插入一个代码节点来截断。
参数如下:
(代码部分从略)
第三步:批量生成商品主图
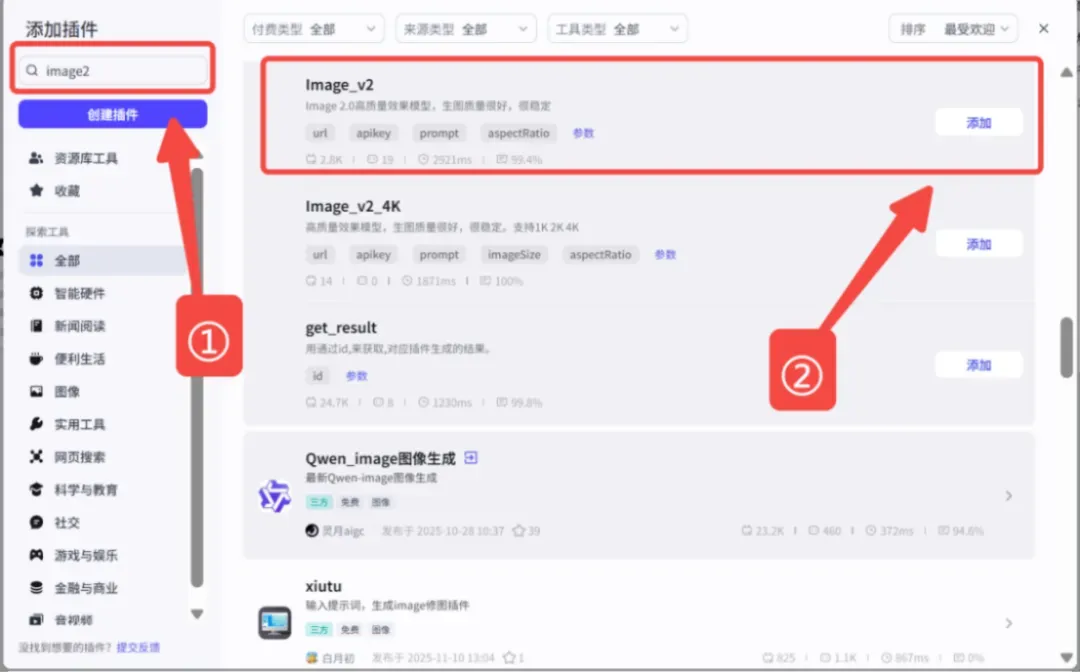
- 添加生成图片的插件
可以直接在插件市场搜索合适的工具,建议选择基于 Image2 生图模型的插件,效果更佳。以下是一个示例:
设置参数:
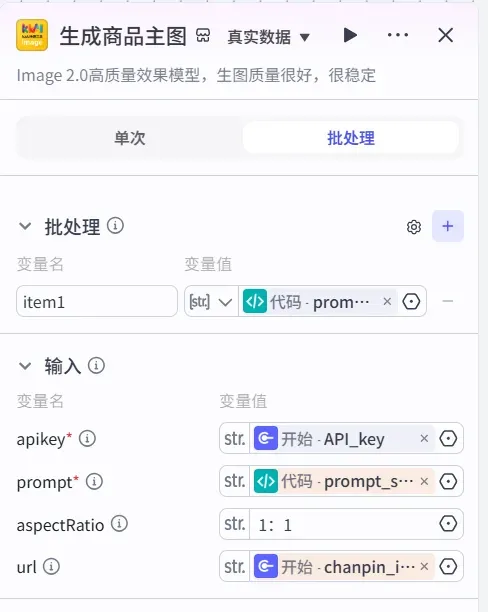
- 图片结果输出
大多数插件需要再搭配一个输出结果的插件,例如:
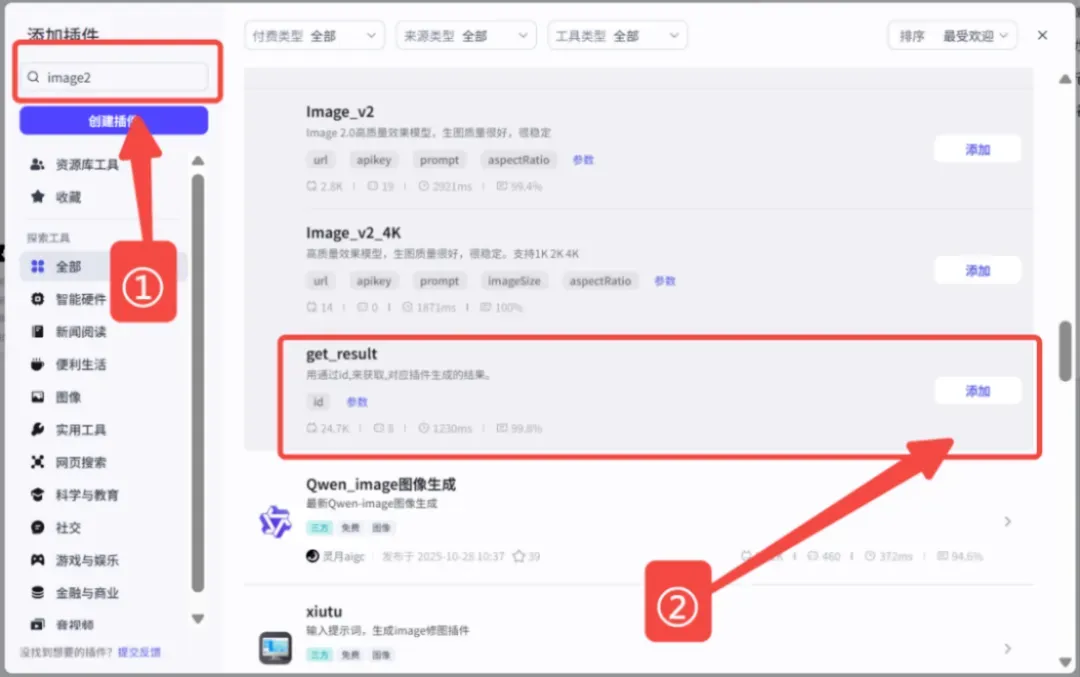
对应参数配置:
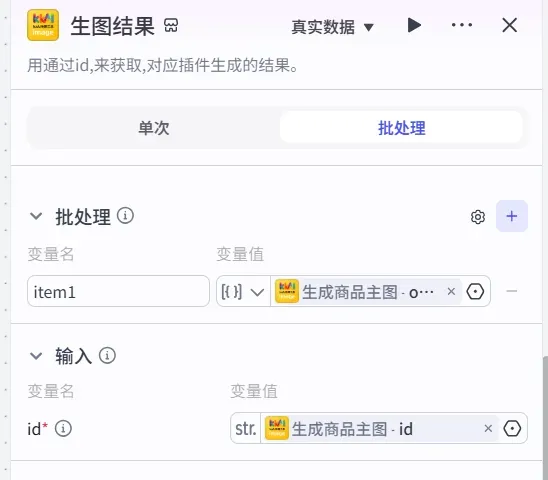
- 添加「循环」节点
为了确保有充足的时间等待图片生成完毕,加入一个循环节点。
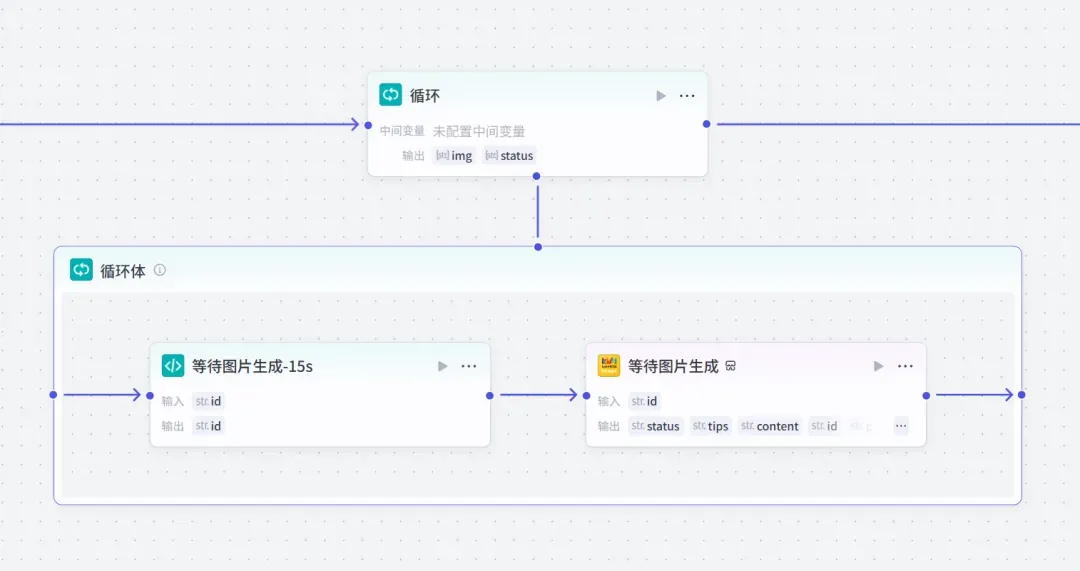
(相关代码从略)
Flarum开源论坛部署终极指南:Docker Compose 安装、中文设置与进阶管理详解
Flarum 是一款轻量级、界面优雅的开源论坛系统,专为现代化社区打造。它响应极快、上手简单,提供构建成功社区所需的一整套功能。
核心特性
- 高速易用:基于 PHP 构建,无冗余设计,部署门槛低。
- 美观适配:界面经过精心打磨,自动适应电脑和移动设备,体验一致流畅。
- 扩展力强:提供强大的扩展 API,开发者可深度定制和增强平台功能。
安装
使用 Docker Compose 一键部署:
services:
mariadb:
image: mariadb:10
container_name: flarum-db
environment:
- MYSQL_DATABASE=flarum
- MYSQL_ROOT_PASSWORD=MYSQL_ROOT_PASSWORD
volumes:
- ./db:/var/lib/mysql
restart: always
flarum:
image: crazymax/flarum:latest
container_name: flarum
depends_on:
- mariadb
ports:
- 8000:8000
environment:
- TZ=Asia/Shanghai
- PUID=1000
- PGID=1000
- FLARUM_BASE_URL=http://192.168.31.90:8000
- DB_HOST=mariadb
- DB_NAME=flarum
- DB_USER=root
- DB_PASSWORD=MYSQL_ROOT_PASSWORD
volumes:
- ./data:/data
restart: always
重要参数说明(更多细节请查阅官方文档):
MYSQL_DATABASE:创建指定名称的数据库。MYSQL_ROOT_PASSWORD:Root 帐户的密码。/var/lib/mysql:数据库持久化存储路径。TZ:时区设置,示例中为上海时区。PUID/PGID(可选):用于权限映射的用户 ID 和组 ID,设为 0 会导致启动失败。FLARUM_BASE_URL:填写你的 NAS 局域网 IP 和端口,用于生成站点链接。DB_HOST:MariaDB 容器名或 IP。DB_NAME/DB_USER/DB_PASSWORD:与上方数据库信息保持一致。/data:Flarum 配置与数据的存储路径。
启动与初始化
在浏览器中输入 http://NAS的IP:8000 即可打开安装完成后的界面。
GLM-5.2 vs Kimi K2.7 Code 深度实测:八款主流大模型编程对决,谁才是2026年AI编程王者
GLM-5.2 与 Kimi K2.7 Code 同期登场,让 AI 编程赛道的竞争瞬间白热化。一场硬核代码对决就此展开——我们拉来八款模型,在真实开发任务中直接比拼,结果出人意料。
本次横评聚焦于 GLM-5.2、Kimi K2.7 Code、GPT-5.5、Opus 4.8、GLM-5.1、Qwen、MiniMax、DeepSeek 这八款模型,完全从开发者日常出发,拒绝空洞跑分,只看实际代码生成的能力。
01 核心硬指标先睹为快

02 还原真实开发场景
为了贴近一线工程师的工作状态,我们设计了一个完整的简易商城项目:提供 PRD、UI 设计稿、数据库表结构、接口文档和前端组件规范一共 5 份材料,要求模型从零开始输出可直接运行的前后端代码。
GLM-5.2 的实际表现
✅ 商品展示、购物车、下单、用户登录、订单查询全部跑通,流程无卡点。
⚠️ 唯一缺失的是“地址编辑”功能——只能新增地址,无法修改已有地址。
✅ 连续运行 3 次未出现报错或数据丢失。
🔧 还自动生成了 Redis 会话缓存逻辑,并且为并发下单场景加入了乐观锁处理。
Kimi K2.7 Code 的实际表现
✅ CSS 动画、响应式布局、渐变按钮——页面视觉表现很出色,接近 GPT-5.5 的质感。
❌ 下单接口在库存校验环节报错,事务回滚未正确处理。
❌ “我的订单”页面缺少分页功能;支付回调的验签逻辑也被漏掉了。
⚠️ 经过 3 轮对话修正,下单报错被解决,但又出现了重复的数据库连接池配置。
其他模型速览
- Qwen 3.7Max:功能完成度与 GLM-5.2 接近,但商品搜索的模糊匹配出现了乱码 bug。
- DeepSeek:整体可用,然而 SQL 没有使用索引,高并发场景下性能堪忧。
- GPT-5.5 / Opus 4.8:依然是标杆级产品,无明显 bug,可运行成本是 GLM-5.2 的两倍以上。
03 测试结果总览

GLM-5.2 本地部署全解析:2‑bit 量化将 1.5TB 模型压缩至 238 GB,消费级 Mac 即可运行

Z.ai 在发布 MIT 开源的 GLM-5.2 后仅仅几天,Unsloth 便通过 2‑bit 动态量化技术,将该模型的存储需求从 1.51 TB 直接压到 238 GB,体积缩减幅度高达 84%。现在只需一台配备 256 GB 统一内存的 Mac,就能在本地运行这个巨型模型,而其 top‑1% 准确率仅仅下降了大约 18 个百分点。
238 GB 的 2‑bit 动态 GGUF:体积与精度的新平衡
- 容量:238 GB
- 量化方式:2‑bit Dynamic GGUF
- 体积收缩:‑84%
- top‑1% 准确率保留:约 82%
Unsloth 团队公开的测试数据十分详实:动态量化并不是简单地一刀切降低所有层的精度,而是针对 MoE 架构中真正关键的部分保留 8‑bit 甚至 16‑bit 的表达能力,其余层则降至 2‑bit。在面向 top‑1% 任务的核心评估中,模型依然能够保住 82% 左右的准确率。这对于代码补全、逻辑推理、长文档问答等日常推理场景来说,意味着消费级单机已经几乎可以满足实用需求。
百万 Token 上下文与双路思考模式
GLM‑5.2 参数量为 744B 总参数 / 40B 活跃参数,原生支持 1M 上下文窗口。官方将其定位为与 Claude Opus 4、GPT‑5.5、Gemini 3.1 Pro 同级别的旗舰开源模型。Z.ai 还针对代码编写和智能体任务做了专项优化,在长程推理、智能体编排及函数调用等评测中表现突出。