GLM-5.2 开源旗舰限时免费体验:753B 参数 MoE 模型零成本接入全攻略

GLM-5.2 已在 Hugging Face 推理提供商平台开放限时免费调用——这款拥有 753B 参数的 MoE 旗舰模型,支持百万级上下文,采用 MIT 开源协议,并且五大推理平台同步上线。免费期一旦结束即恢复原价,现在只需注册 HF 帐号即可白嫖。
753B
MoE 参数规模
1M
上下文窗口长度
MIT
开源协议类型
认识 GLM-5.2
GLM-5.2 由智谱 AI(Z.ai)推出,是当前最新一代的开源旗舰大模型。它基于混合专家(MoE)架构,总参数量达到 753B,但实际激活的参数量远小于这个数字。相比上一代 GLM-5.1,它在长序列任务上实现了质的飞跃,首次稳定支持百万 token 级别的上下文。
从技术上看,GLM-5.2 采用了 IndexShare 架构:每四层稀疏注意力层共享同一个索引器,使百万 token 级别的每 token 计算量(FLOPs)减少至原来的 1/2.9。同时,模型改进了 MTP 层用于投机解码,最长接受长度可提升 20%。这意味着一方面能承载超长文本,另一方面推理速度也不会拖累体验。
授权方面,GLM-5.2 使用 MIT 开源协议,不设地域限制,也没有商业使用门槛。对个人开发者和中小团队而言,这是当前能够免费利用的最强开源模型之一。
基准测试表现
从官方披露的跑分结果来看,GLM-5.2 在多个重要榜单上成绩突出:
- AIME 2026 数学推理:99.2,超过 GPT-5.5(98.3)和 Claude Opus 4.8(95.7)
- GPQA-Diamond 科学问答:91.2,与 GPT-5.5 持平
- SWE-bench Pro 代码修复:62.1,超过 GPT-5.5(58.6),接近 Claude Opus(69.2)
- Terminal Bench 2.1 终端操作:81.0,赶超 Gemini 3.1 Pro(74)
- HLE 高难推理:40.5,引入工具增强后可达 54.7
注意:以上均为厂商自报数据。AIME/HMMT 属于竞赛数学领域,SWE-bench Pro 衡量真实代码修复能力,HLE 则评估高难度开放推理。不同榜单侧重的能力维度各异,单一分数不能代表模型的全面优劣。
GLM-5.2 正式发布:1M 上下文国产第一,编程能力与审美双双领跑
GLM-5.1-HighSpeed 面世时,我就曾表示十分期待 1M 长上下文版本。没想到仅仅数周之后,大家翘首以盼的 GLM-5.2 就带着 1M 上下文窗口如约而至。

全新发布的 GLM-5.2 可以这样概括:**1M 上下文窗口 + 国产模型中编程能力第一,**并且设计审美极具水准。
相较于此前 200K 上下文的旧版模型,GLM-5.2 在下列场景中的表现有了质的飞跃:整库级代码分析、Agentic Coding、超大规模代码仓库重构、一键网页翻新以及超长文档处理。
这些任务的共同点是上下文必须完整覆盖,任何压缩都会带来信息损失。
近几天我消耗了 3800 万 Token,也颇为认同社区用户的一则调侃:从这周开始,你很可能会发现中转站里那个看起来像 Opus 的服务,背后其实跑的是 GLM-5.2。

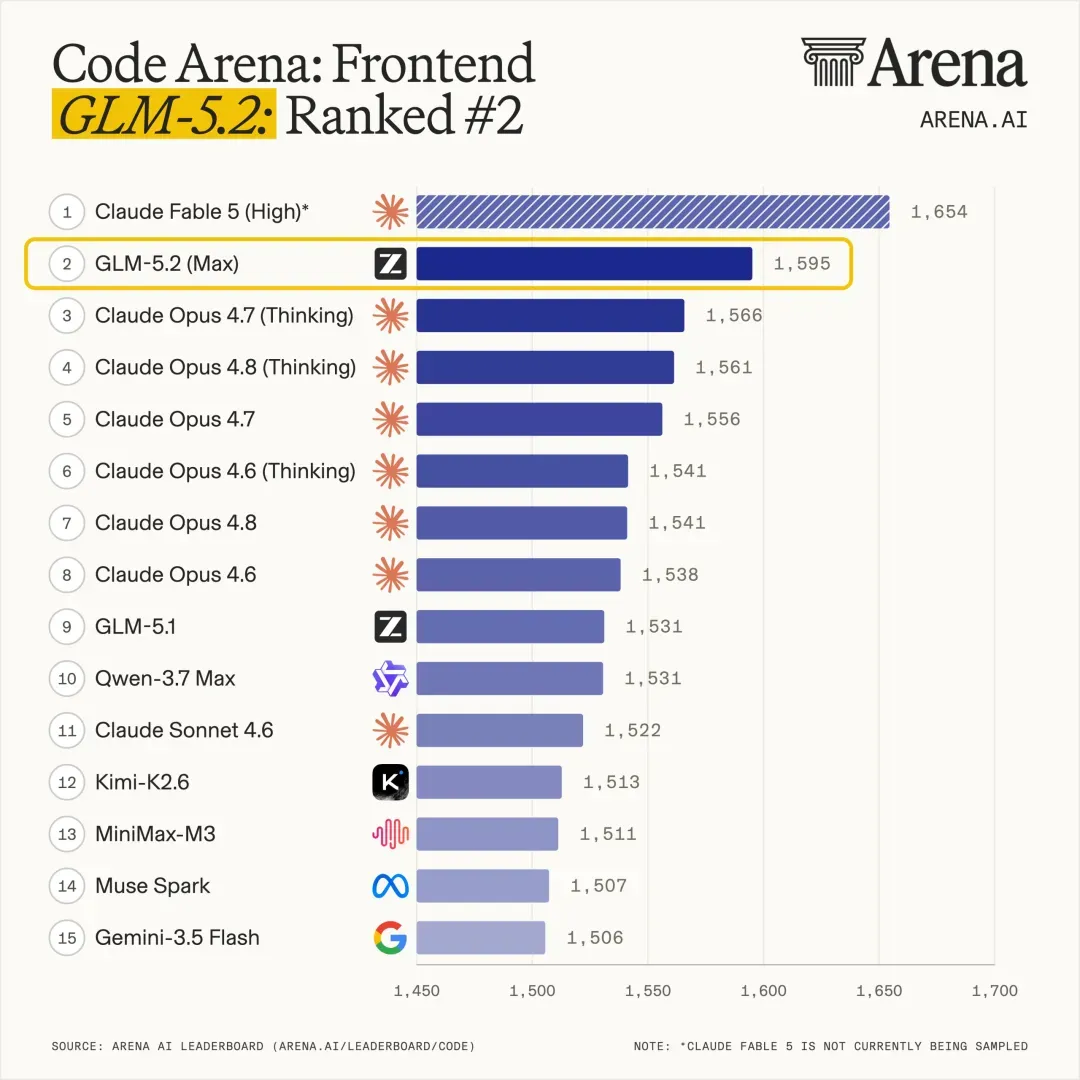
此外,在拥有全球百万用户参与盲测的前端开发评估系统 Code Arena 上,GLM-5.2 取得了全世界所有可用模型中的第一名。
这里要强调“全球可用模型”这一限定,因为表现最惊艳的 Fable 5 尚处于被封禁状态,无法公开使用。
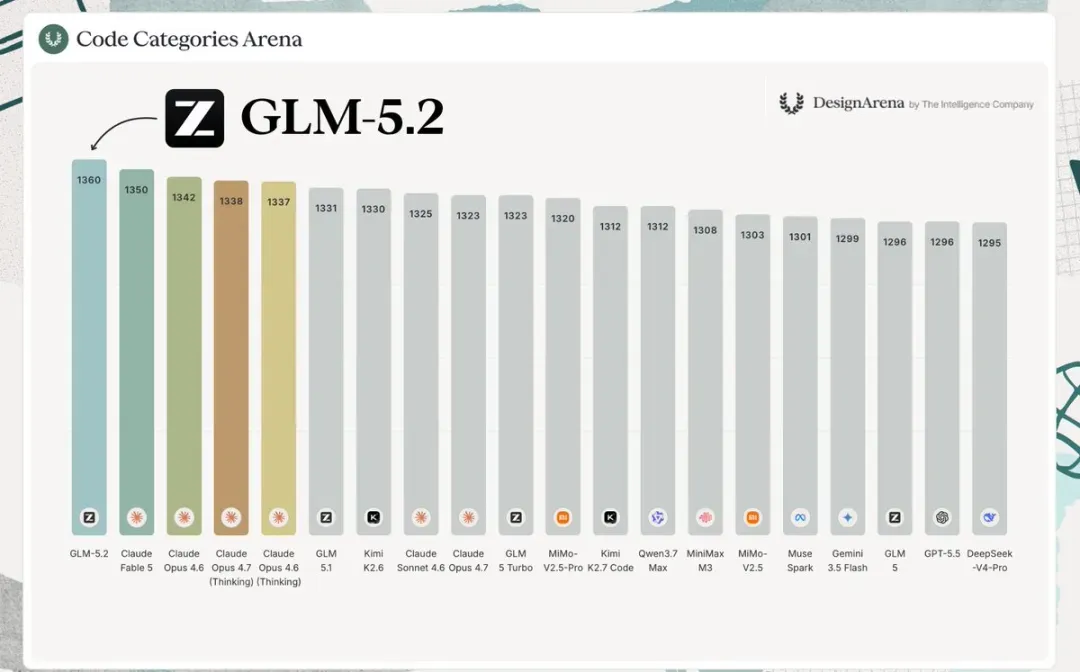
在专门衡量模型设计审美的 Design Arena 榜单上,GLM-5.2 同样摘得全球第一。
三重核心升级
第一重:真正可用的 1M 上下文窗口
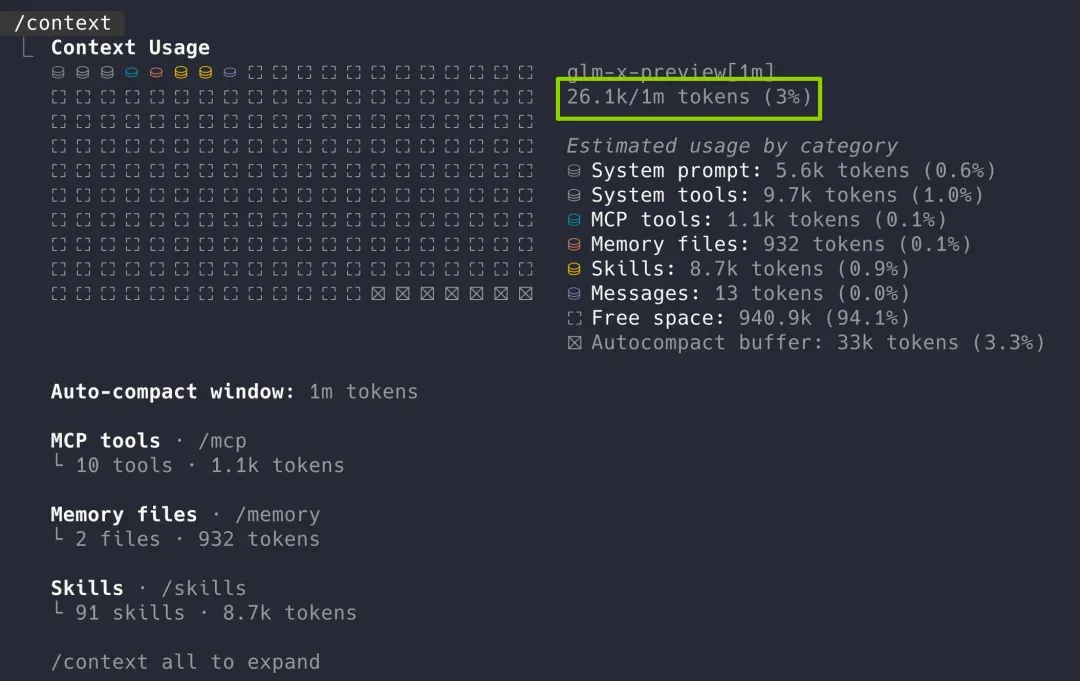
如果你是一名 Claude Code 或其他 Agent 工具的深度用户,一定经常通过 /context 命令或者状态栏来监控当前上下文窗口占用了多少。
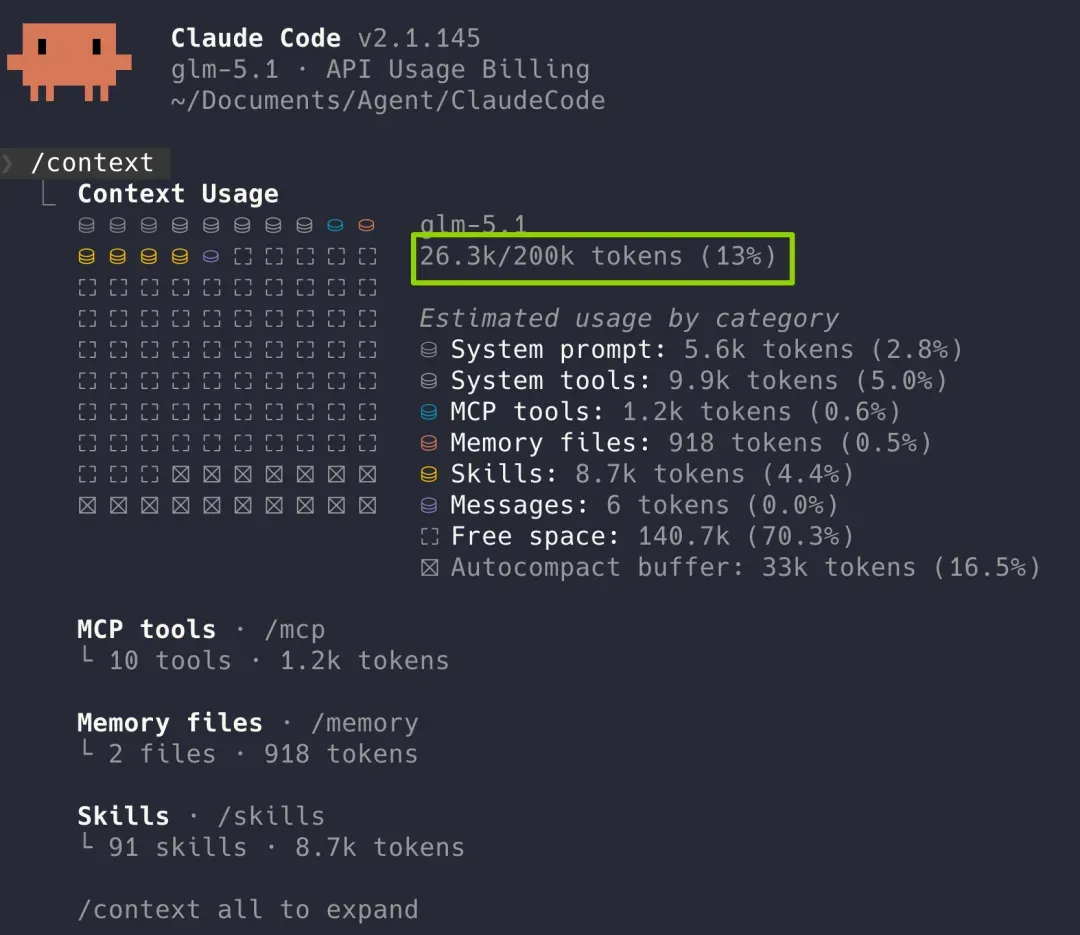
一旦占用率超过 70%,模型就很容易给人一种“变笨”的感觉。这正是上下文窗口不够长带来的副作用——不敢直接读大文件,也不敢频繁使用搜索功能,几次操作之后可用的窗口空间就所剩无几了。
现在 GLM-5.2 把上下文支持从之前 GLM-5.1 的 200K 直接拓展到了 1M 级别。
GLM-5.2前端性能实测:全面超越Opus 4.8,全球第二仅次Fable 5
关于 GLM-5.2 的测试我已进行多次,并撰写过详尽的分析。我之前的结论很明确:它依然无法战胜 Opus 4.8。因此,如果笼统宣称“GLM-5.2 全面超越 Opus 4.8”,无异于天方夜谭。不过今天我不再聚焦于它的短板,而是深入剖析其显著进步之处——前端能力。
今天早上打开 X,大模型竞技场的官方账号发布了这样一条消息:
这条消息的核心意思是:
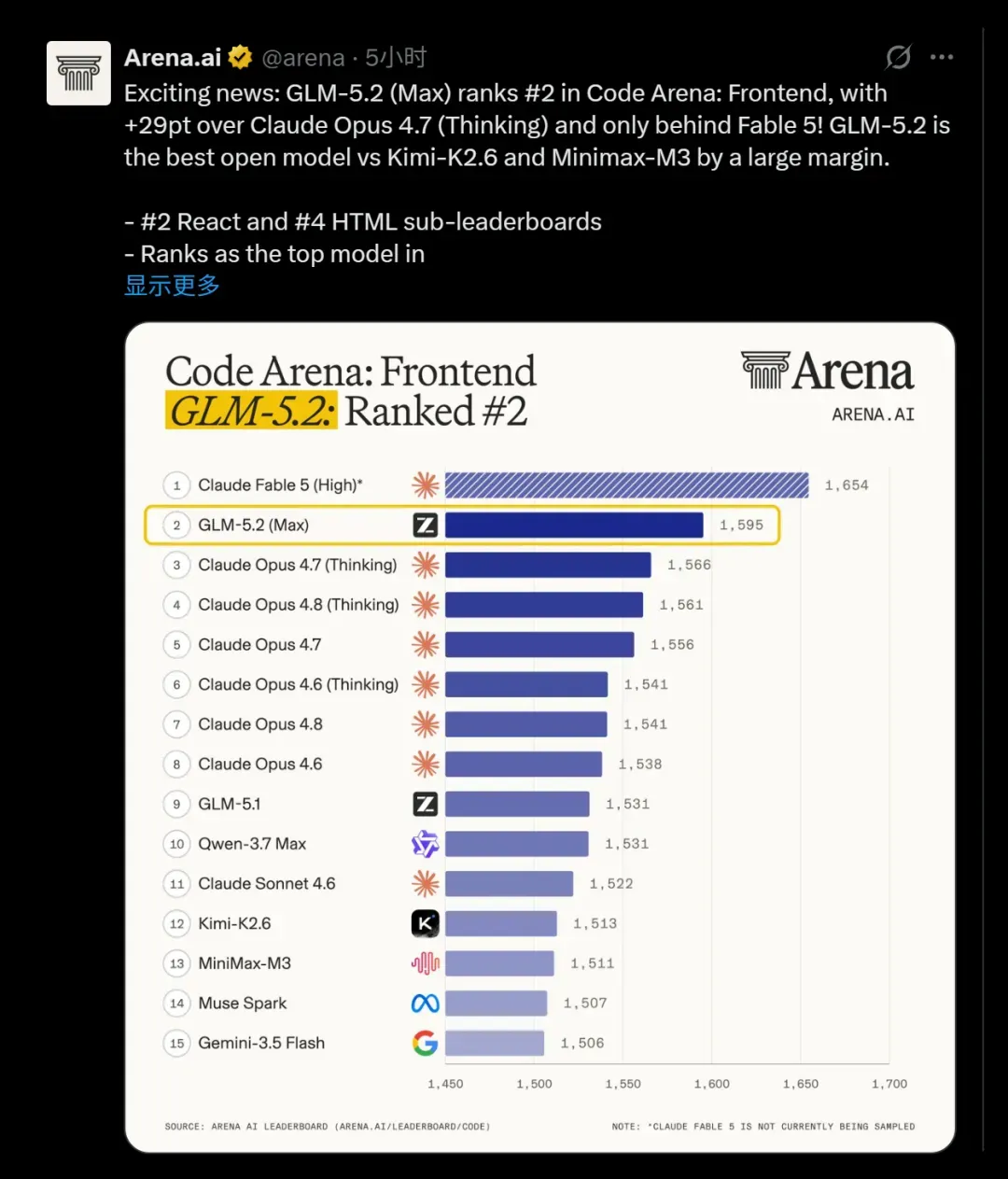
振奋人心的更新:GLM-5.2 (Max) 在 Code Arena: Frontend 中排名第 2,
比 Claude Opus 4.7 (Thinking) 高出 +29 分,仅次于 Fable 5!
GLM-5.2 是开源模型中领先优势最大的,远超 Kimi-K2.6 与 Minimax-M3。
- React 子榜单第 2,HTML 子榜单第 4
- 在品牌与营销、基于参考的设计、数据与分析、消费品、游戏和模拟等几乎所有子类中均位列第一。
一句话总结:GLM-5.2 的前端表现已经超越 Opus 4.8 Thinking,仅次于 Fable 5!
大模型竞技场不同于单纯的基准测试,它融入了真人盲评。尽管目前也掺杂了一些水分,每次国产模型发布都会掀起一波榜单洗刷,但相比干巴巴的基准数字,仍更具参考价值。我个人虽然对这个排名持保留态度,但能够冲到全球第二,本身就说明了一些问题。
在我们的固有印象中,GLM 系列的前端一直是薄弱环节,没想到如今竟然快变成优势领域了!
这对于真正在使用 GLM-5.2 的人来说,无疑是个好消息!
这意味着 GLM-5.2 的综合能力更加全面,投入的成本也显得更有价值。
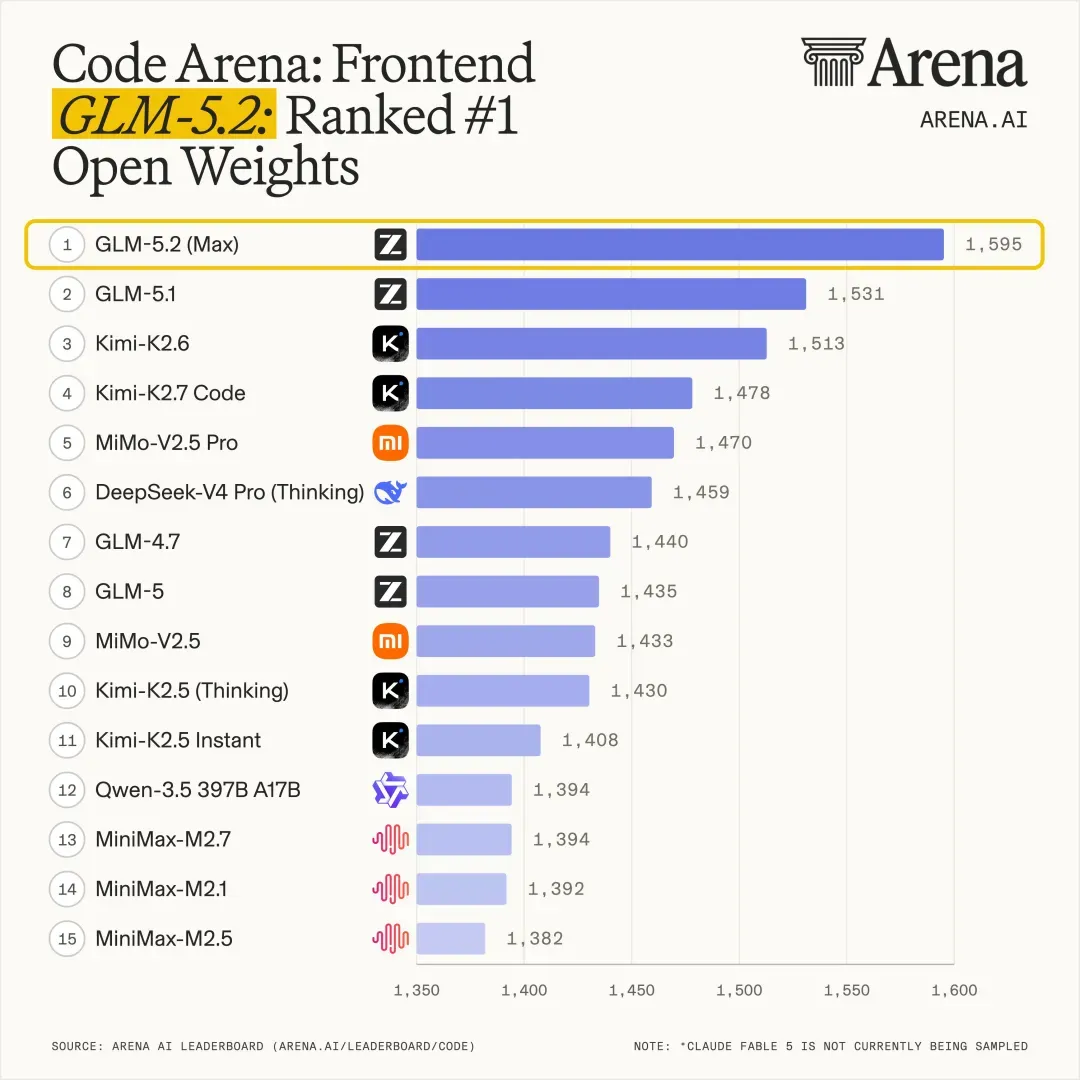
关于它前端能力的强化,我在前两篇文章中已经有所提及。
尽管原因不明,但 GLM-5.2 似乎加载了一个精美的设计技能包,所有网页作品都精致了不少,尤其在布局上已经超越了 GPT-5.5(主要因为后者前端实在太拉胯)。
因此,今天这篇文章重点剖析前端问题。各位可千万别小看前端,它最复杂的地方在于与终端用户直接交互,和人打交道的事,从来都不简单。
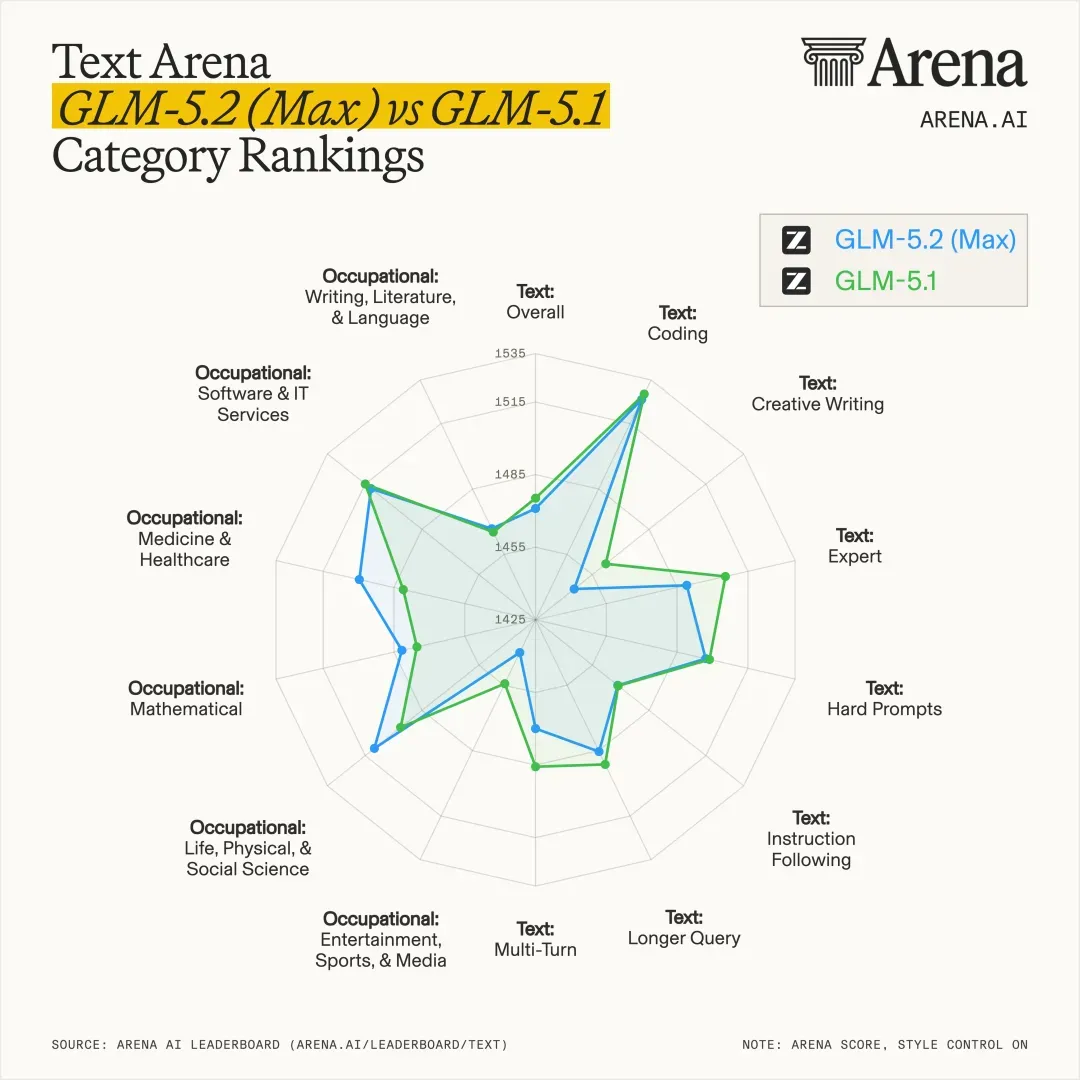
正好借着这个机会,让大家直观感受 GLM-5.2 与 GLM-5 老版本之间的差异。
Headroom:为 AI Agent 打造的上下文压缩中间层,Token 最高省 90%,还支持跨代理记忆
跑一次 Claude Code,稍微大一点的项目,一个长任务下来几万 token 就没了。Codex 调试日志时,光日志本身就把上下文吃掉一大半。赶上月底限流、超额警告,那种感觉就像电脑在烧钱。更难受的是,这些消耗掉的 token 里夹杂着大量无用信息——一百行 grep 结果,真正有价值的就那三行,但模型必须全部读完;日志里大片无关的 INFO,可你又不敢删,生怕漏掉关键报错。直到我发现了 Headroom,它为 AI Agent 装了一层上下文压缩层,所有东西在送进 LLM 之前先被“拧干”。一段 10144 token 的内容,压完只剩 1260。
开源项目快速预览
Headroom 是嵌在 AI Agent 和 LLM 之间 的一个中间层。你平时喂给模型的所有信息——工具输出、命令行结果、代码搜索结果、RAG 检索片段、文件内容、对话历史——在进入 LLM 之前都会被 Headroom 拦截并压缩一遍。

开源地址:https://github.com/chopratejas/headroom
压缩后的内容几乎不影响最终效果,但 token 数量却大幅下降。项目提供了四种接入方式,几乎覆盖所有使用场景:
① 库(Library):在 Python 或 TypeScript 代码中直接调用 compress(messages),几行就能集成。
② 代理(Proxy):通过 headroom proxy --port 8787 在本地启动一个代理,零代码改动,任何兼容 OpenAI 的客户端都能立刻套用。
③ Agent 包装器:一条命令 headroom wrap claude | codex | cursor | aider | copilot,就能把主流的编程 Agent 直接包裹起来,无需额外配置。
④ MCP server:注册三个工具 headroom_compress、headroom_retrieve、headroom_stats,Claude Code、Cursor 这类原生 MCP 客户端开箱即用。
Hermes Agent百天实战避坑指南:5个耗时陷阱与高效自动化部署
很多人以为会聊天式地使用 ChatGPT 就算掌握了 AI,但真正的分水岭在于你能不能把代理放在后台,让它替你完成重复性的闭环工作。
01 百日之殇:时间耗散在哪里?
近期,一位开发者在社交平台公开了一段21分钟的录像,标题朴实无华:“使用 Hermes Agent 一百天的经验”。真正让这条内容被大量转发的,不是技巧炫耀,而是坦诚——他把自己百余天里犯下的5类错误,按照时间戳逐条摊开,像解剖标本一样呈现在众人面前。
录像开篇的第一句话就扎中了许多人的痛点:使用 Hermes 与运维 Hermes 之间隔着一条巨大的鸿沟。前者是想到什么随口问一句,后者则是把提问抽象成可重复的循环、将提示词沉淀为可调用的技能、把手动触发替换为定时任务与事件响应。
Hermes 官方说明文档列出的能力其实相当全面:skills(技能)、memory(记忆)、tool use(工具调用)、multi-platform gateway(多平台网关)、profiles(配置文件)、cron/schedules(定时调度)、subagents(子代理)。遗憾的是,绝大部分用户一直停在“会用聊天框”这个层面。他们没有让代理记住你是谁,没有把频繁使用的提示词固化成可复用的指令,没有用 Cron 在后台自动生成日报,也没有把网关挂接到 Telegram 或 Discord 等即时通讯工具上去。
02 封装提示词,打造可复用的循环
分享者把最有价值的作业方法放在了最前面讲解。他反复提到一个概念:Loop。这既不是新工具,也不是新文件夹,而是将“一套提示词 + 期望产出 + 下次触发条件”包装成固定的格式。
如果你每次向代理提出的问题都属于同一模式,比如“整理今天的信息流并给出摘要”“检查项目状态并生成进度卡片”,那么它们本质上就是同一个 Loop。
在 Hermes 体系里,Loop 的实现路径至少有三种:把常用提示词固化到 Skill 中;利用 Cron 定时执行同一段自然语言任务;或者把触发条件绑定到 Webhook 或轮询(Polling)上。这三层能力不是互斥的,而是可以叠加使用,形成多重保险。
03 告别聊天窗口的混乱,用工作区隔离任务
第二个被生动剖析的错误,是把所有事务不加区分地塞进同一个聊天窗口。后果是同一个会话里无缝混杂着工作需求、生活琐事、研究任务、代码调试,上下文很快便相互污染,代理的回答也因此变得飘忽不定。
他的解法是借助 Telegram 的 Topics 功能搭建独立工作区。每一个 Topic 代表一个长期任务,上下文天然隔离,历史记录绝不会搅和在一起。官方说明同样支持这种思路:Hermes 内置的多平台网关,可以同时接入 Telegram、Discord、Slack、WhatsApp、Signal 和 Email,并且上下文是按会话进行独立管理的。
他推荐了三种工作空间划分策略:第一种是按项目分拆,每个长期项目拥有专属 Topic;第二种是按职能分拆,研究、写作、编程各自独立;第三种是按触发方式分拆,把来自 Cron 和 Webhook 的任务与普通聊天严格分开,避免信号互相干扰。
04 拒绝万金油代理,为任务配置专用子代理
第三个错误是让同一个代理承载所有类型的任务。他在录像中实际演示了两个专用子代理:Nova 和 Sage,前者偏重执行,后者侧重分析。
Hermes 原生支持通过 delegate_task 派生出子代理,每个子代理都拥有完全隔离的上下文和独立的终端会话。父代理只负责分派和结果汇总,不再陷入执行细节。
Hermes 代理能力升级路线图:7 步从简单聊天走向完全自主

大多数人只把 Hermes 当作聊天机使用,但其实存在一条更高效的路径:七个递进的能力层级。统计显示,90% 的用户停留在前三个级别,而解锁全部七个层级只需每月最低 19 美元(支持三个代理)。大多数 AI 代理产品都有一个使用阈值——低于阈值时,它们像普通聊天机器人;超越阈值后,它们开始主动替你工作。Hermes 的七个级别不是营销话术,而是实际可用的能力分层:从一次性对话直到后台异步执行,每个层级对应着不同的配置深度和收益幅度。
级别 1:一次性提示
你发出一个提示,代理回答,结束。这并不寒酸,但却是效率最低的用法,相当于只使用 Clawd 的默认聊天通道。
级别 2:记忆 + SOUL.md
Hermes 能在会话之间记住你。你编写一个 SOUL.md 文件来定义身份、语气和约束。于是,两个人问同一个问题会得到不同的回答。
级别 3:后台命令
/background把任务丢进后台,主对话照常继续,结果以面板形式呈现。/steer向当前正在运行的代理注入新提示,不打断其正在执行的事项。/queue把新请求排入队列,等当前任务完成后再执行。
级别 4:技能 + 匹配每个技能的模型
安装技能后,Hermes 会将其转化为斜杠命令。更关键的是,你可以为每个技能分配专门的模型:将研究型任务交给廉价且容量大的模型,而把代码审查推给推理能力更强的模型。这一步才是真正控制成本的地方。
级别 5:MCPs
MCP 将 Hermes 连接到邮件、日历、Notion、Slack 等外部工具。但要警惕工具集合膨胀的风险:15 个 MCP 每个带来 10 个工具,意味着每一轮调用都要多读取 150 个工具定义。只安装你需要的,禁用那些你不用的。
级别 6:子代理 + 并行执行
delegate_task 会生成一个拥有隔离上下文的子代理。在批量模式下可以并行运行,默认最多同时运行 3 个子代理。角色分为叶(leaf)和编排者(orchestrator):叶节点不能再继续委托,而编排者可以进一步分派任务,受衍生深度(spawning depth)限制。
级别 7:异步运行
这是 Hermes 在你睡觉时依然工作的部分。cron 任务按计划执行;/goal 设置跨会话的持续目标;/background 在当前会话中并行跑任务,结果随时可以回传。关键转变在这里:从“我问,它回应”,变成“它工作,我审查”。
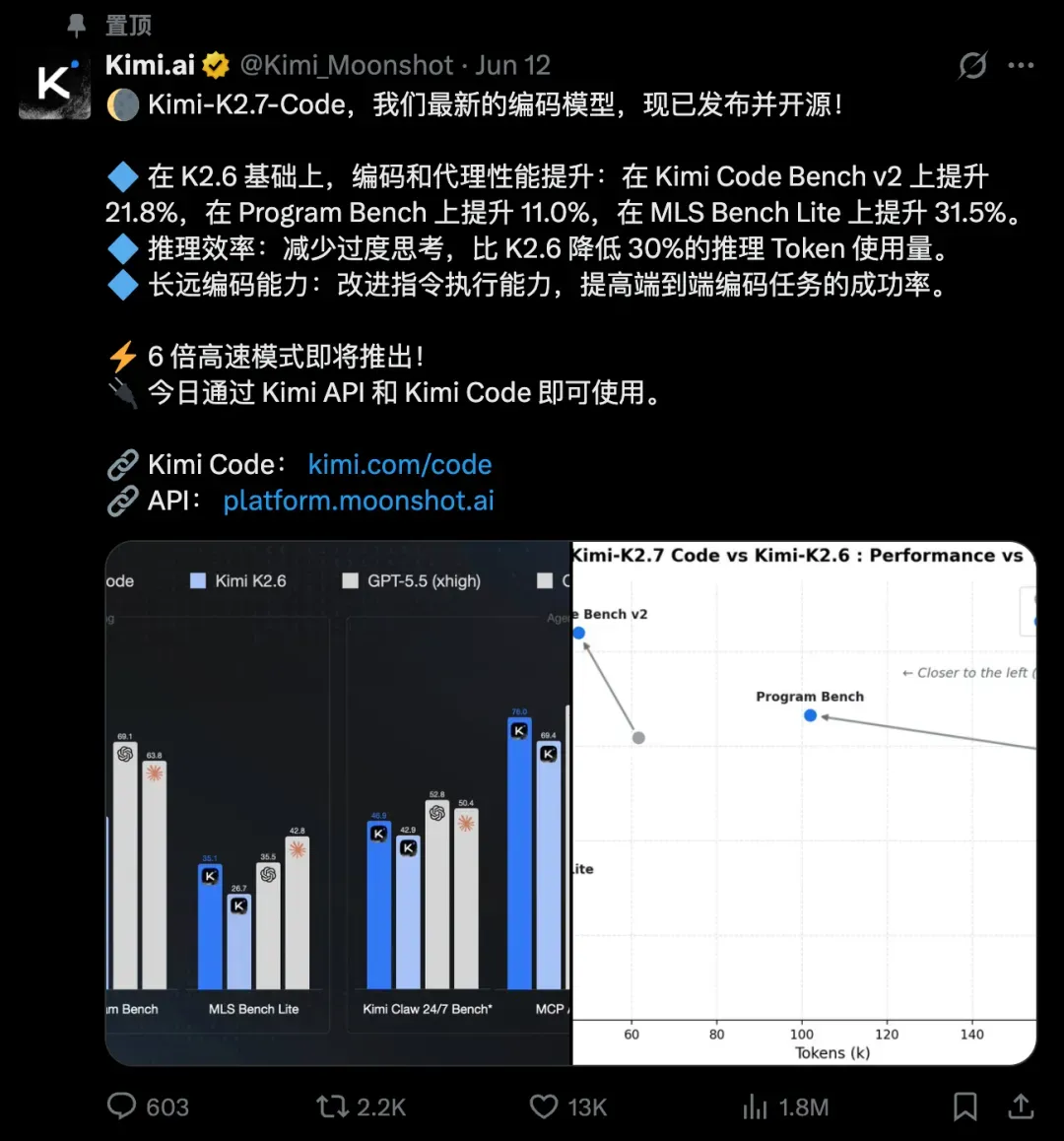
Kimi K2.7 Code 深度发布:五大亮点全解析与 Kimi Code 上手实战
Kimi 自家的编程模型迎来重要更新,Kimi K2.7 Code 正式上线。这并不是通用模型的常规迭代,而是一款专门为编程场景深度特化的模型,在指令遵循、长链任务、Agent 能力和成本效率上都有明显突破。下面梳理一下这次更新的五个核心亮点。
① 长上下文编程中的指令遵循能力显著增强
② 长程编程任务的连贯性明显改善
③ 有效解决了“过度思考”问题,长程任务平均 token 消耗降低 30%
④ Agent 自主执行能力进一步提升
⑤ 高速版即将上线,推理速度可达普通版的 5~6 倍
即日起,你打开 Kimi Code 写代码,后台调用的就是 Kimi K2.7 Code 模型,并且同时提供普通版和高速版两种模式。这篇文章会手把手带你把这个新模型用起来。如果你因为 Claude Fable5 无法继续使用,或者对 Claude Code 感到困惑,想找一款可靠的国产替代,可以把本文收藏起来备用。
效果演示
双螺旋 DNA 交互模拟
提示词:用 Three.js 做好多个旋转的 DNA 双螺旋,点击某一个可以查看细节,包括碱基对 A-T 红蓝、G-C 绿黄连线,深空背景加 bloom。
可交互 3D 魔方
提示词:帮我写一个可交互 3D 魔方,能整体旋转、点击单层旋转 90°,带光照和阴影,单 HTML 文件。而且能有一个可以一键复原的按钮。

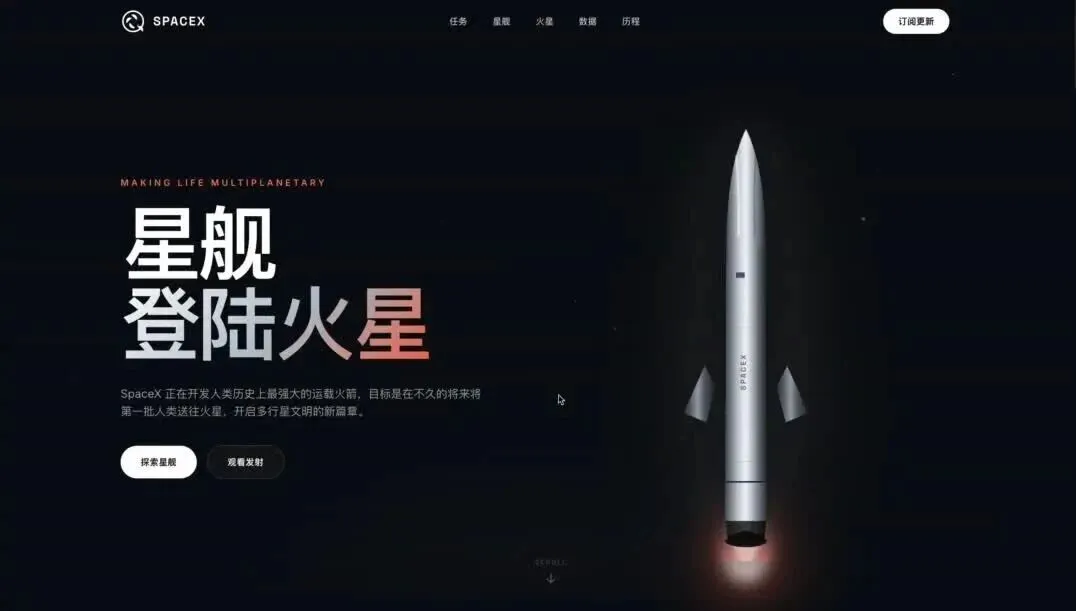
SpaceX 风格落地页生成
提示词:帮我生成一个美观炫酷的落地官网。作为马斯克的 SpaceX 的官网。
安装与使用

Kimi Work 十分钟打造投资大师技能并开源,多Agent集群实战揭秘
近期,OpenAI 发布了一份报告,提到 Codex 的周活跃用户已经达到 500 万,其中知识工作者占比 20%,增速是开发者的 3 倍以上。Claude Code 也从开发者工具场景延伸出了面向办公的 CoWork。
就在刚刚,国产的 Kimi Work 也正式亮相了。

Kimi Work 的定位非常清晰:为知识工作者打造的通用型本地 Agent。
可以预见,在不远的将来,人们再回头看传统的手工编程、手工写文档、制作 PPT 和数据分析的方式,会感到难以置信。Vibe Working 的时代,已经全面来临。
Kimi Work 来了
下面是 Kimi Work 核心功能的一个总结。
- Kimi Work 的内核是 Kimi Code。
- 它支持 Agent 集群,单次任务最多可派出 300 个子 Agent 并行工作。
- WebBridge:AI 帮你直接操控浏览器。
- 内置 Skill 市场,也允许用户自己创建并沉淀专属 Skill。
- 尤其适合金融投研场景,接入了同花顺、雅虎财经、天眼查等权威数据源。
① 多 Agent 集群 + Skill 沉淀
我让 Kimi Work 同时启动 5 个子 Agent,分别深入研究查理·芒格、彼得·林奇、霍华德·马克斯、瑞·达利欧这几位投资大师的投资理念,并将研究成果沉淀为一个可复用的技能(Skill)。
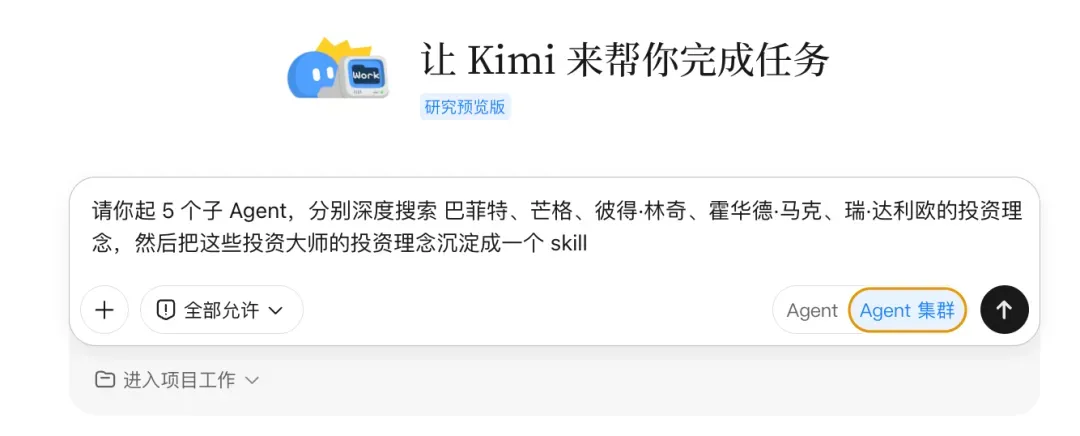
每个子 Agent 独立完成分配给自己的研究任务,这样做的好处不仅是并行处理效率极高,而且单个 Agent 的关注点非常集中,最终产出的质量也更高。
NAS变身AI智能衣柜:零成本打造私人穿搭助理,告别每日搭配烦恼
每天早上打开满满当当的衣柜,你是否也常常陷入“今天穿什么”的灵魂拷问?穿衣选择困难几乎人人都有,衣服越买越多,管理越来越难,翻遍衣架也凑不出一套满意的搭配。如果你正好也有这类烦恼,不妨来看看本期介绍的 AIWardrobe 项目,或许它能成为拯救你早起纠结的贴心助理。
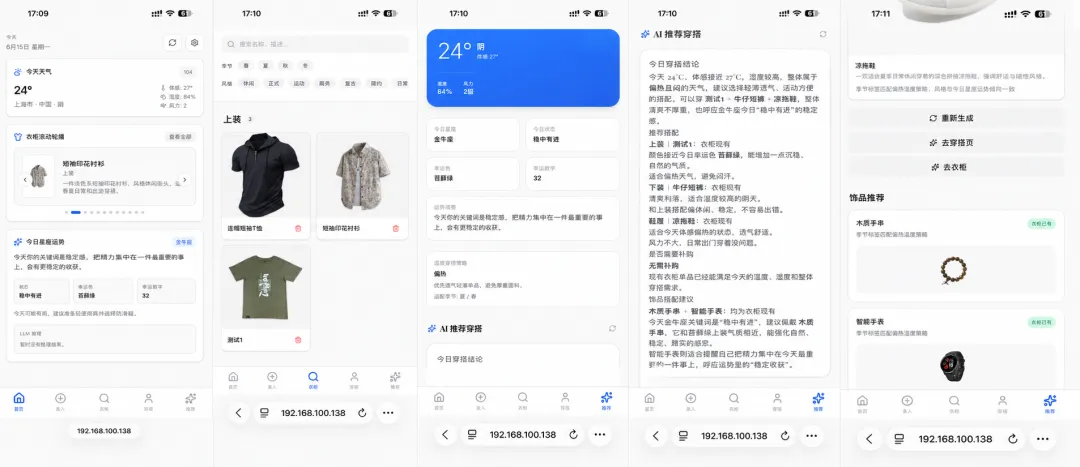
部署和使用过程中若遇到异常,请翻阅文末的常见问题部分,大部分卡点都能迎刃而解。
项目简介
项目全称 leoz9/AIWardrobe,你可以在 GitHub 上直接搜索找到它。
AIWardrobe 是一套开源的 AI 智能衣橱系统,主要能力包括:录入衣物、批量上传衣照、AI 自动识别衣服属性、虚拟衣柜管理,以及结合实时天气和用户场景自动生成穿搭推荐。
核心功能亮点
- 智能图片上传:上传衣服照片后,自动调用 rembg 去掉背景,并由视觉模型识别服装的品类、颜色与风格标签。
- 天气感知穿搭:对接 Open-Meteo 全球免费天气接口,能根据当日天气实时调整搭配建议,让你穿得既得体又应季。
- 虚拟衣橱管理:以卡片或列表形式结构化展示衣橱,支持浏览、搜索和分类检索所有衣物。
- AI 个性推荐:兼容 Gemini 与 OpenAI 风格的接口,可自由选择大模型来生成个性化穿搭方案。
- 全设备适配界面:基于 Tailwind CSS 构建,完美适配桌面、平板和手机等不同尺寸的屏幕。
上手部署
这里以威联通 NAS 为例,直接使用 Docker Compose 一键启动服务。
部署配置参考如下:
services:
aiwardrobe:
image: ghcr.io/leoz9/aiwardrobe:latest
container_name: ai_wardrobe
restart: unless-stopped
ports:
- "8000:8000" # 建议先别改
environment:
DB_FILE_PATH: /app/backend/data/wardrobe.db
# Gemini 可选。如果不用 Gemini,可以先留空。
GEMINI_API_KEY: ""
# 和风天气 API。没有的话可以先留空,但天气相关功能可能不可用。
QWEATHER_API_KEY: ""
QWEATHER_API_HOST: devapi.qweather.com
volumes:
- /share/Container/aiwardrobe/backend/uploads:/app/backend/uploads # 衣物图片目录
- /share/Container/aiwardrobe/backend/data:/app/backend/data # 数据库目录
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 5s
retries: 3
start_period: 20s
在威联通 Container Station 中新建应用,将上述内容粘贴进去,启动即可。
OiiOii 2.0革新AI视频创作:告别抽卡式生成,智能画布、拉片复刻与Skill库一键自动化
最近,各类 AI 视频工具密集涌现,底层模型的能力越来越强大,视觉效果不断刷新上限。但真正上手之后,很多人才意识到一个现实:模型跑得快,不等于成片稳定可靠。
在实际创作中,往往要学习复杂的提示词、反复寻找参考图、进行大量抽卡尝试,还得忍受排队、生成翻车、不断重做等各种不可控环节。AI 视频最让人头疼的地方,从来都不是算力不够,而是创作者能否精准掌控每一个细节。
正是带着这样的痛点,我注意到 OiiOii 2.0 的升级方向——它想做的事情很直接:把 AI 视频创作从手动挡,切换成自动挡。
下面这个短片,就是我用了不到半小时,在 OiiOii 上从头到尾完成的。从分镜图片、动态镜头到背景音乐与剪辑,全部流程都在单一平台内闭环,几乎覆盖了所有可能的创作动作。
这一次,OiiOii 2.0 重点推出了三项核心能力:智能画布、拉片复刻,以及 Skill 库。

我们逐一来看它们到底解决了哪些现实问题。
智能画布:告别提示词负担,用对话驱动画面
过去做 AI 视频,对新手最不友好的门槛就是提示词。一段镜头需要描述场景、角色、风格、动作、镜头运动和光影氛围,听起来非常专业,实际用起来却让人焦头烂额。更令人沮丧的是,即使花了大量功夫精心编写,AI 也不一定按照你的预期执行。
OiiOii 2.0 的智能画布思路简单了许多:你只需要对着画布说出想法,就像在跟助理交代任务。
“把这个角色改得可爱一点。”
“第一组分镜节奏太拖沓,帮我加速。”
“整个画面换一种偏赛博朋克的风格。”
全程不需要重新输入冗长的上下文,也不用重新组织一套复杂的提示词。AI 已经理解当前画布中的所有元素,并能针对性地进行修改。

这背后的秘密是多个 AI Agent 在同时协作——角色总监、分镜总监、音乐总监等,各司其职。创作者只需传出创意意图,剩下的任务拆解、提示词生成以及效果控制,全部交给这些 Agent 完成。
拉片复刻与 Skill 库:告别低效抽卡,让灵感稳定落地
很多创作者都渴望做出爆款视频,但往往遇到一个尴尬的处境:看到一条好看的片子,却不知道该从哪些维度去学习和还原。
音乐节拍怎么卡得准?
镜头运动如何推进?
整体节奏张弛如何变化?
分镜组合背后的叙事逻辑是什么?
虽然市面上有一些工具可以辅助分析,但它们彼此割裂,创作者不得不在不同软件之间来回跳转,不仅操作繁琐,也严重打断了创作心流。
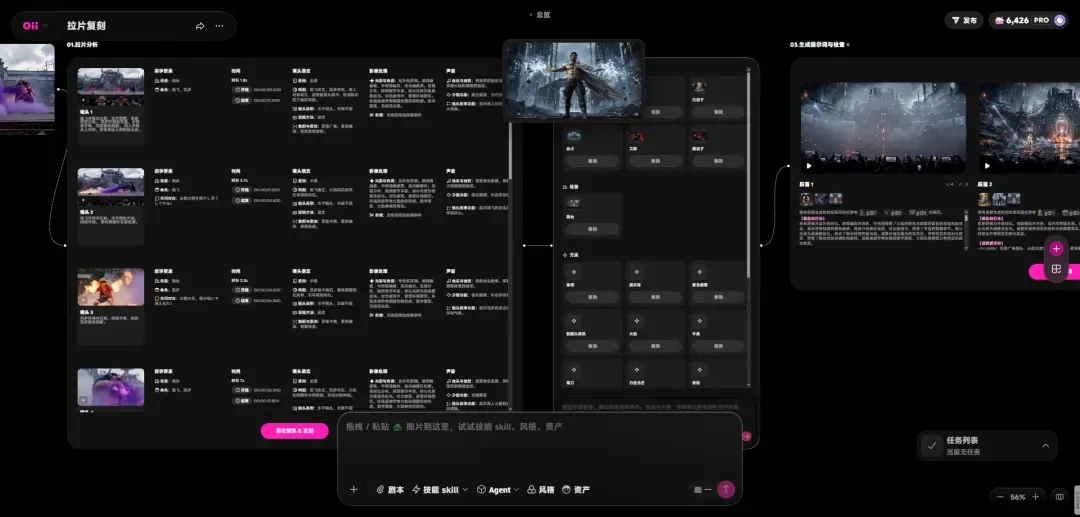
OiiOii 的拉片复刻功能直接把拆解过程自动化了。上传任意一段你想学习的视频,系统会从音乐音效、剪辑节奏、分镜语言、镜头叙事等多达 18 个专业维度,进行结构化分析,提炼出创作逻辑和对应的提示词。本质上,这就是把电影学院导演课的拉片训练,变成了一键可得的能力。随后,你只需上传希望替换的主体(角色、道具等),就能一键复刻出结构一致的同类短片。
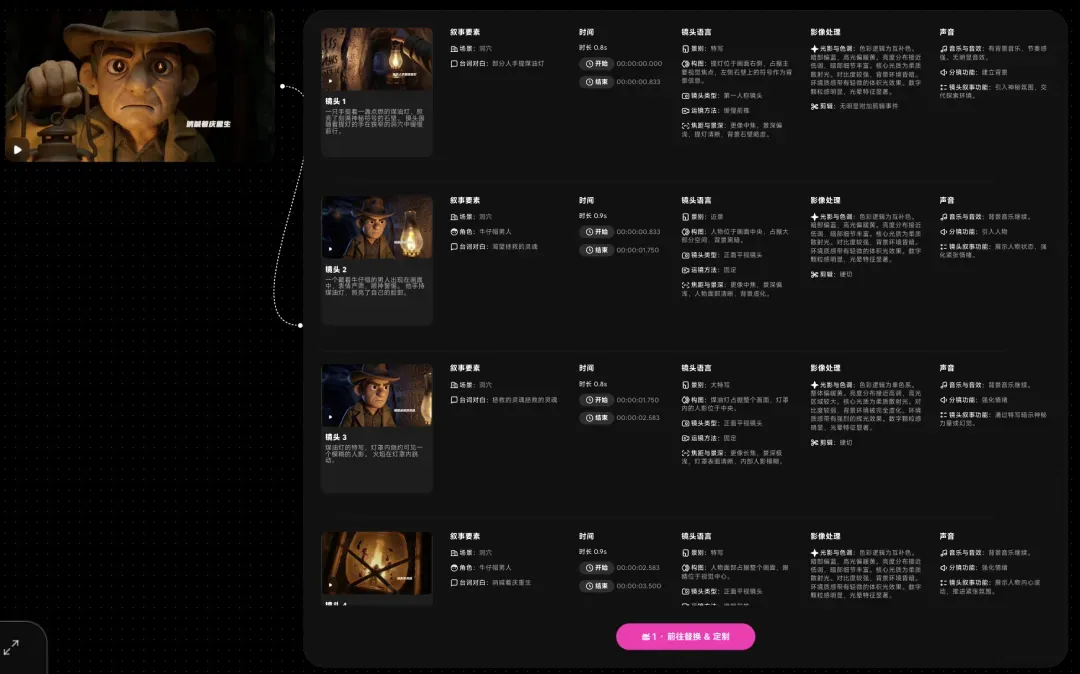
我实际尝试用它复刻了行者老师的一条爆款作品。
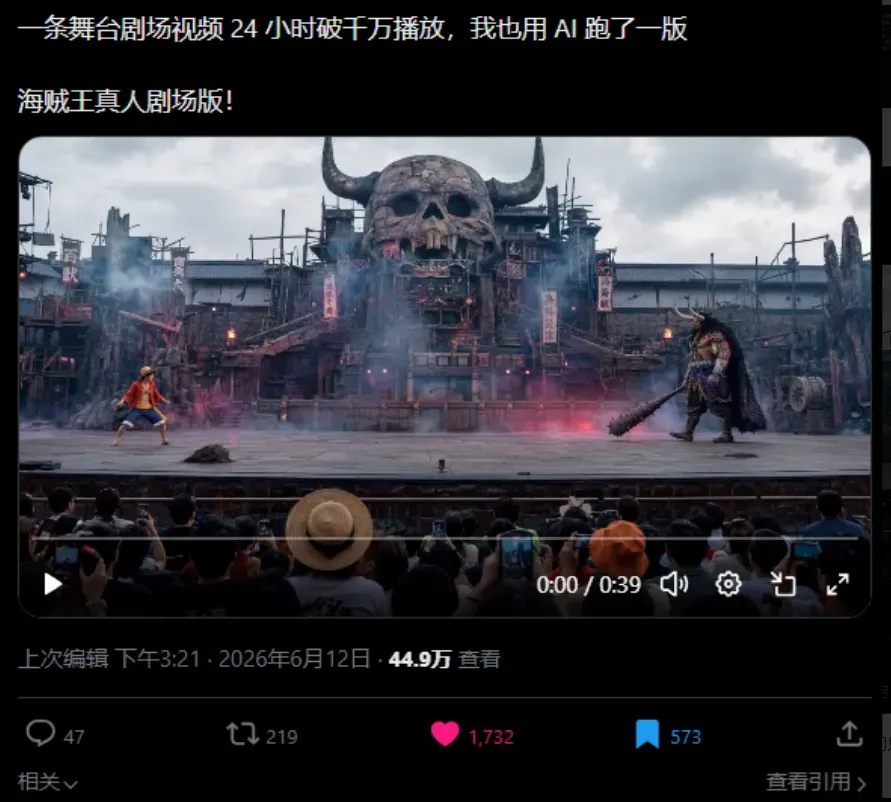
上传目标视频后,OiiOii 会详尽拆解原片的骨架结构,同时自动生成一套待替换元素的方案,创作者只需根据自己的需要完成替换即可。
直接来看复刻效果,还原度相当高。
这对于从事短视频创作、广告投放素材、游戏宣发这类工作的人来说,实用价值非常高。通常大家缺的并不是灵感,而是把灵感稳稳落地的系统方法,如今 OiiOii 直接帮你打通了最后一公里。
如果目标更明确,想快速做出一条适配某个行业需求的视频,这时可以直接调用 OiiOii 的 Skill 库。