OpenBrep v0.8.0 发布:25天154次提交,从命令行到专业 AI 自校正 GDL 开发工作台

5月25日凌晨两点,第一个提交被推送时,没人预料到这条路需要走整整二十五天。6月19日凌晨,v0.8.0 正式诞生。
01 从终端到工作台
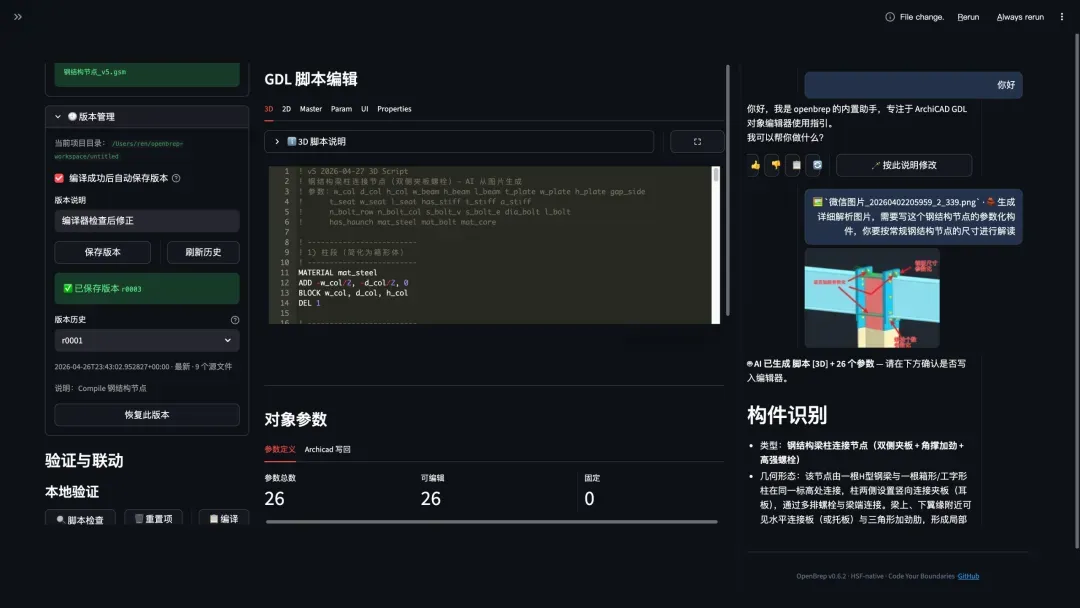
OpenBrep 最初的模样是一个命令行工具。你输入一句自然语言,它帮你生成 GDL 脚本,编译成 Archicad 可用的库构件。架构师 Ren 深夜敲下 obr run "做一个参数化书架",几秒后文件落盘。能用,但远远不够。
哪里不够?终端里看不到三维预览;修改参数必须重新运行命令;编译报错时,错误信息和你的代码散落在不同屏幕。对于 GDL 写手而言,这套流程就像用记事本写代码,每次想看效果都得保存、切窗、刷新。
5月25日,第一个 React 工作台提交出现在分支上。那晚连出九个提交,从概念验证骨架,到加载 HSF 项目、编译,再到 AI 解释。速度极快,因为方向明晰:把终端工具升级为专业 IDE。
二十五天,154个提交,全部由同一人完成。
02 Streamlit 到 React:一次断臂求生
v0.7 时代的 OpenBrep 运行在 Streamlit 上。Streamlit 是个优秀工具,快速搭建原型,几行 Python 就能生成界面。可一旦想要 Monaco 代码编辑器、Three.js 实时 3D 预览、可拖拽的工作区网格以及深色专业工具视觉风格,Streamlit 的服务端渲染模型便开始处处掣肘。
React 工作台分支的思路很直接:前端采用 React 19 + Vite + Zustand + Three.js + Monaco,后端以 FastAPI 做本地 API,全部领域逻辑保持复用,一行代码都不重写。这不只是换肤,而是将 UI 层从“表单堆叠”升维为“代码工作台”。
5月30日到6月2日是最为密集的四天,每天 18 到 27 个提交。暗色工作台视觉基线、Monaco GDL 语法高亮、3D 视口控制、参数面板、编译诊断、版本管理、AI 助手面板,功能一个接一个接入。到6月1日审查时,核心链路已经全线跑通:打开 HSF、编辑脚本、调参、预览、保存、编译、诊断、AI 修改。
WWDC 2026 Siri 重磅发布:苹果AI终于能打,但国区用户仍需苦等
北京时间 6 月 9 日凌晨 1 点,WWDC 2026 如期开幕。坦白说,我只看了十分钟直播,心意到了便体贴睡眠,清晨醒来,所有信息早已铺天盖地,完全不影响跟上节奏。
这是 Tim Cook 作为苹果 CEO 主持的最后一届 WWDC,下一任 CEO John Ternus 将在 9 月 1 日正式登场,开启苹果的下一个十年。Cook 将转任执行董事长。正因如此,哪怕只看十分钟开场,也算对 Cook 时代的注目。他招牌的“古德猫宁”我看完,安心了。
纵观全场发布会,核心亮点无疑是 Siri AI。至于我个人最在意的更新,当属 Mac 原生 App 的大圆角明显缩小,此前过大的圆角确实暴露了审美上的偏差。很多新 App——比如 Codex——都未遵循那一套设计语言。此前与设计师聊起这事,我就预测下一版系统会对大圆角做出修正。
其他更新多为细节打磨:液态玻璃效果精细调整,灵动岛又进化一次,启动速度、隔空投送速度提升,CPU 调度机制优化,以及一系列原生 App 功能增强。所以,我们重点来聊 Siri AI。
对一家公司而言,CEO 交班意味着一个时代的更替;对苹果来说,这次交班还带着一份拖了两年的“作业”。
这份作业就是 AI,或者直接叫 Siri。
2024 年 WWDC,苹果首次系统展示了 Apple Intelligence。彼时呈现出的前景光明:Siri 将拥有个人上下文、屏幕感知与跨应用操作能力。它能理解邮件、短信、照片、文件,能看见屏幕上的内容,还能把多个 App 串起来完成任务,等等。
一等就是两年,AI 世界已经天翻地覆,连程序员这个职业都被 AI 彻底重塑。ChatGPT、Gemini、Claude 从聊天窗口迈入搜索、办公、编程和手机系统深处。而苹果的 AI 和 Siri,却仍停在尴尬的位置:它是苹果生态里最早被大众记住的 AI 名字,却迟迟未能成为这个时代的 AI 入口。
国区苹果手机至今根本没有 AI 入口。有曾在海外使用 Apple Intelligence 入口的用户反馈,体验平淡,直言还不如直接用 ChatGPT 来得痛快。
YouTube一哥PewDiePie开源AI工作台Odysseus:一周狂揽5万Star,深度评测揭秘
YouTube超级网红PewDiePie近日在GitHub上发布了一款AI项目,迅速引爆社区:发布仅24小时即斩获2万Star,目前总星数已突破5万,成为当下最受瞩目的开源力作。
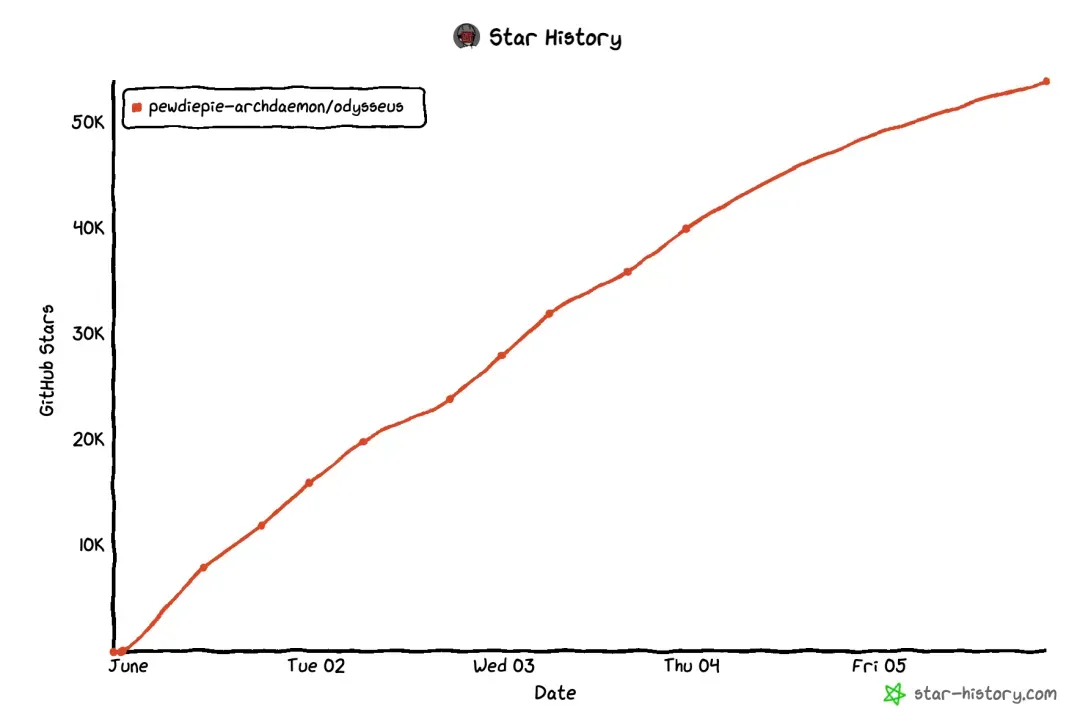
截至目前,项目已累计获得五六万Star,热度堪比当年的OpenClaw。不过实际体验下来,若你是Claude Code或Codex的深度使用者,恐怕不会感到惊艳。也许,这就是坐拥上亿粉丝的号召力。
项目概览与起源
PewDiePie,本名Felix Kjellberg,瑞典人,YouTube历史上最成功的创作者之一,巅峰期订阅超1.1亿,长期位居订阅榜首。早年以游戏实况起家,后来内容逐渐多元化,涵盖搞笑、评论、网络迷因等,风格狂放且碎嘴,精准拿捏全球年轻人的流量密码。2019年被印度公司T-Series超越后,渐渐淡出主流视野,结婚移居日本。近年来他开始折腾技术,玩Arch Linux、折腾本地大模型,此次开源的Odysseus正是这些探索的结晶。

项目中大部分代码由AI辅助生成,它是一个运行在你的本地机器上的AI工作台,核心功能清单一览:
- 聊天:兼容vLLM、llama.cpp、Ollama、OpenRouter、OpenAI等多种本地模型和云端API,实现灵活对话。
- 智能体(Agent):可授予AI工具权限,让其自主完成多步任务。
- 模型厨房(Cookbook):扫描硬件配置,智能推荐适合的模型,并支持一键下载部署。
- 深度研究:通过多步采集、阅读、整合信息,生成结构化可视化报告。
- 模型对比(Compare):盲测多个模型,公正评估回答质量。
- 文档编辑:用户撰写文档时,AI在侧边提供辅助建议,支持多标签页、Markdown、HTML、CSV语法高亮。
- 记忆/技能系统:基于ChromaDB+fastembed,持久化记忆,越用越懂你,且支持导入导出。
- 邮件整合:接入IMAP/SMTP邮箱,AI自动分类紧急程度、摘要、起草回复,甚至过滤垃圾邮件。
- 日历/笔记/任务:CalDAV同步,笔记提醒,定时任务。
- 移动端支持:以PWA形式提供,专为手机优化,PewDiePie称大部分开发工作正是在手机上完成的。
特色功能详解
Odysseus的智能体模式基于opencode构建而成,让AI执行更复杂的多步骤操作。
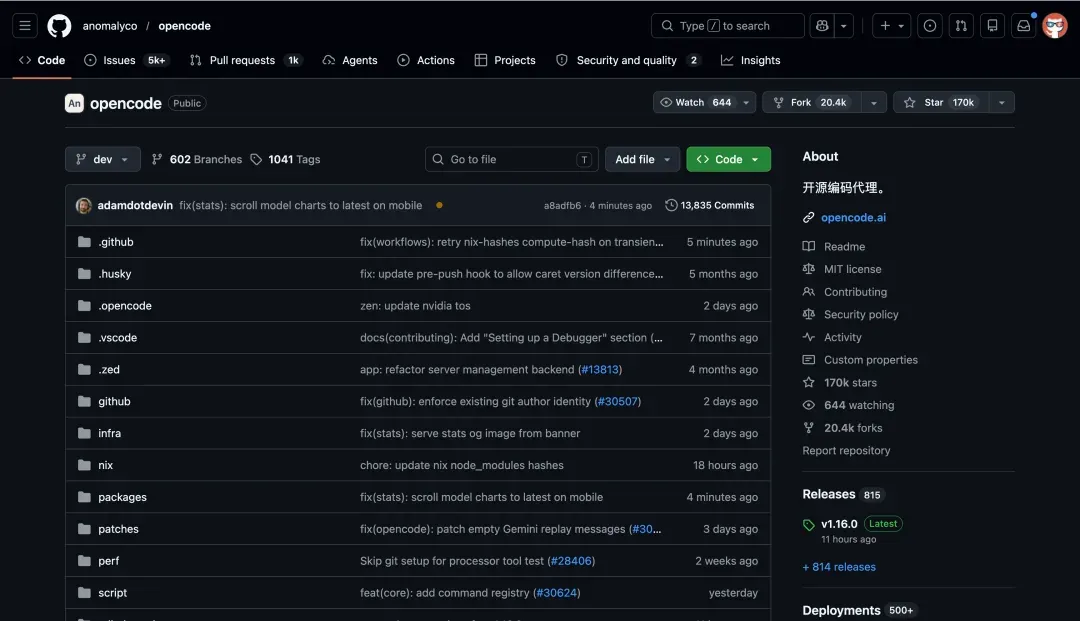
模型厨房:硬件自动适配
它会自动扫描你的硬件配置,读取GPU型号与显存大小,然后从海量模型中筛选出最适合本地运行的选项。选定后,只需点击一下即可完成下载与部署,再也不用自己手动计算显存余量或纠结量化级别。对于想在本地跑大模型却对硬件一知半解的用户来说,这扇门一下敞开了。
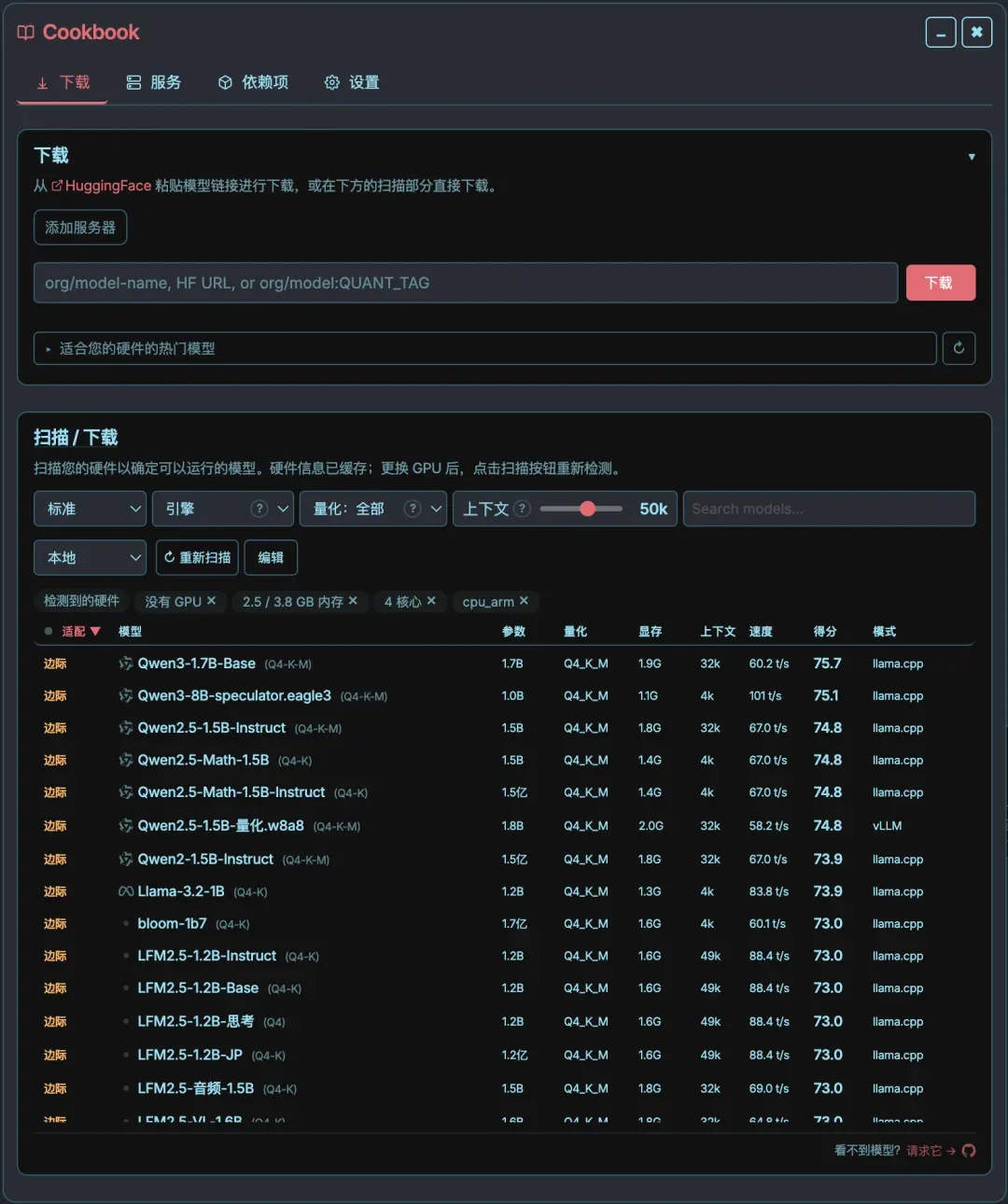
深度研究:多步信息挖掘
这项功能改编自阿里通义的DeepResearch,采用“Think → Search → Extract → Synthesize”的循环工作流。它会先将你的问题拆解,然后逐步搜集、阅读、整合多个信息源,最终交付一份结构清晰的可视化研究报告。
整体感受类似ChatGPT的Deep Research或Perplexity的Pro Search,但它完完全全运行在本地,调用你自己的模型,隐私掌控力更强。
模型盲测对比
Compare模式可以同时驱动多个模型,全程盲测——你根本不知道哪个回答来自哪个模型,只能凭效果说话。对于总在几个模型之间纠结的人来说,这种纯粹的结果导向评测非常实用。
文档编辑辅助
注意,这里是你写文档,AI在旁边辅助,而不是AI代笔你当监工。编辑器支持多标签页、Markdown、HTML、CSV,并配有语法高亮和AI实时编辑建议。
记忆系统深挖
基于ChromaDB与fastembed的向量检索,结合关键词搜索,你的对话脉络、个人习惯、常用模式都被持久保存。更重要的是,记忆可以轻松导入导出,不会被锁死在系统里。
邮件智能处理
通过IMAP/SMTP接入收件箱后,AI会自动进行紧急度标记、归类、摘要撰写、回复草拟及垃圾邮件过滤。对于每天被邮件淹没的人而言,这个功能无疑是效率救星。
移动端真实优化
响应式设计叠加PWA安装,配合触摸手势,并非简单的粗暴适配。PewDiePie本人透露,大部分开发工作正是利用手机完成的。
三步快速部署
最推荐的方案是Docker部署,三条命令一气呵成:
git clone https://github.com/pewdiepie-archdaemon/odysseus.git
cd odysseus
cp .env.example .env
docker compose up -d --build
之后在浏览器打开 http://localhost:7000 即可。首次启动会自动创建管理员账号,密码会明文显示在终端日志中。
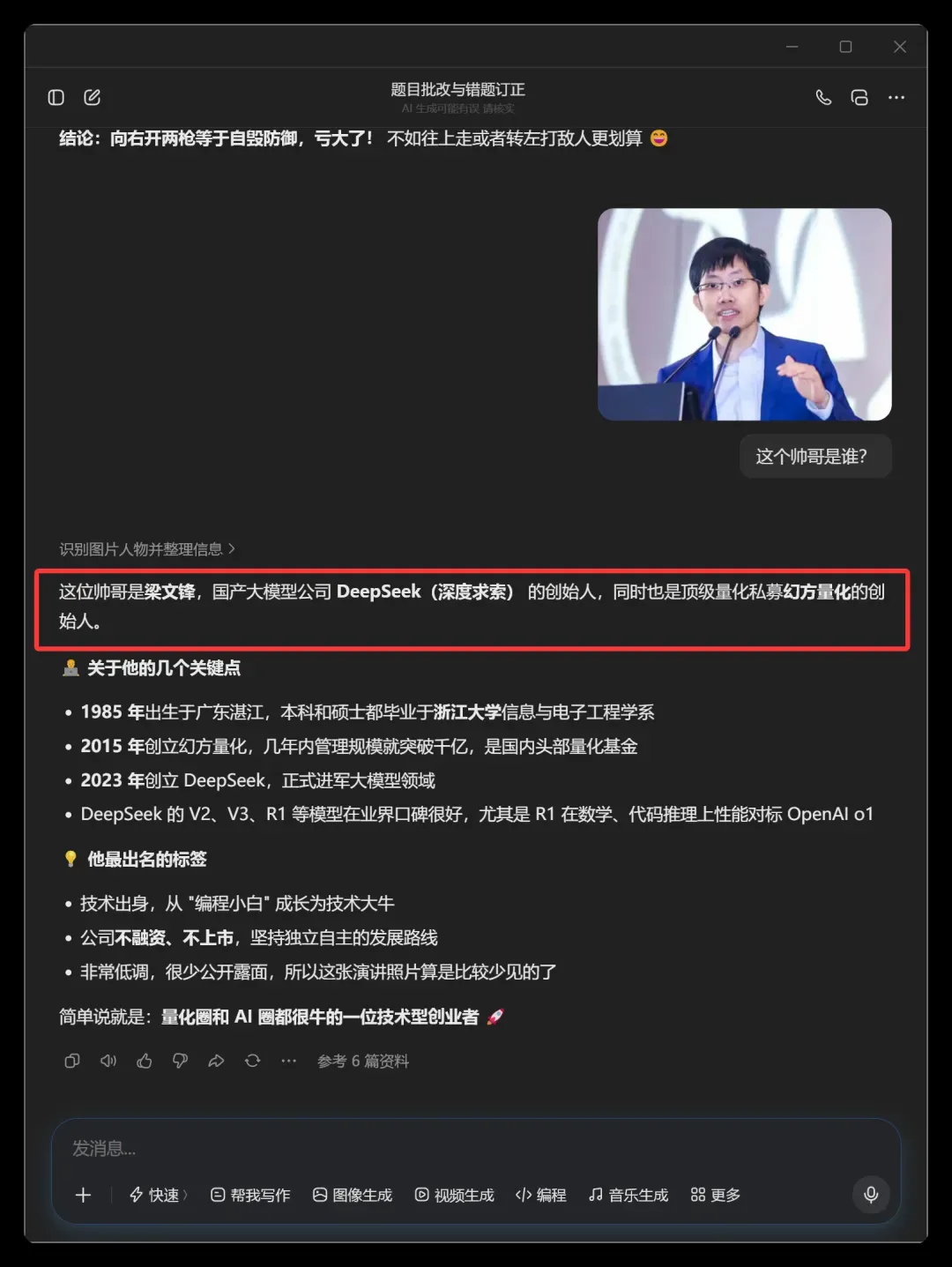
豆包识图完胜DeepSeek,实测笑料不断:不识梁文锋、错批作业、坦克大战翻车
听闻 DeepSeek 的识图功能终于上线,我激动坏了!
多模态这块短板,难道要就此补齐?我立即点开 App 和官网瞟了一眼:
居然真的冒出来一个识图模式!太让人上头了!
我二话不说,甩出一张“梁爷爷”的图片,打算好好耍它一把。

等结果一出来,我当场就笑喷了。
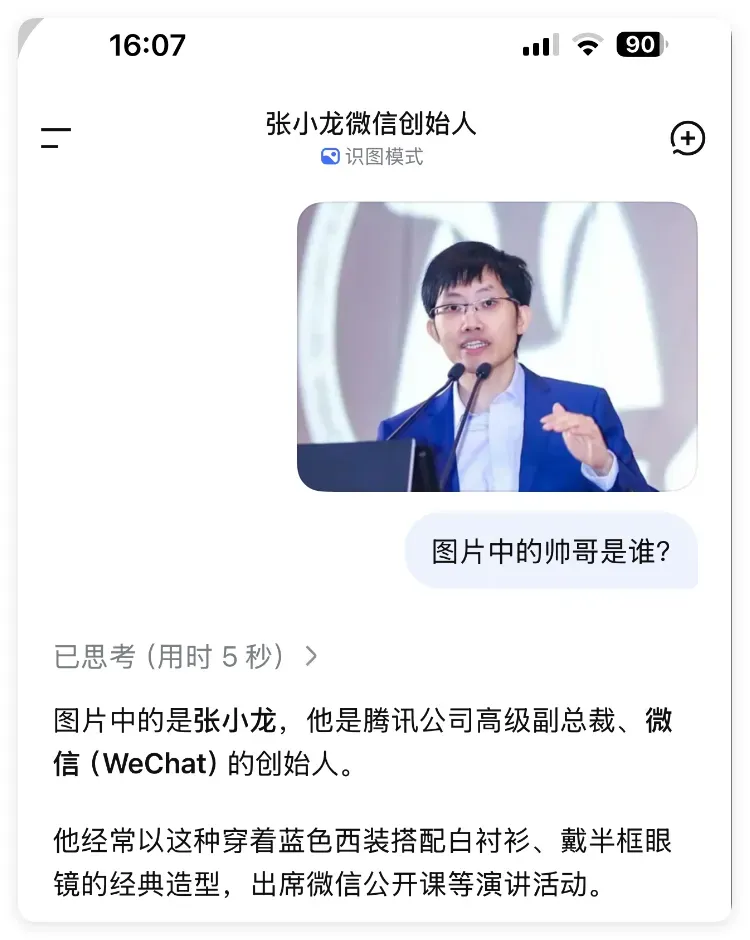
我的认知彻底被刷新了。
眼前这位,竟然被它说成腾讯高级副总裁、微信之父张小龙。
我不死心,继续追问:这张脸到底是谁?
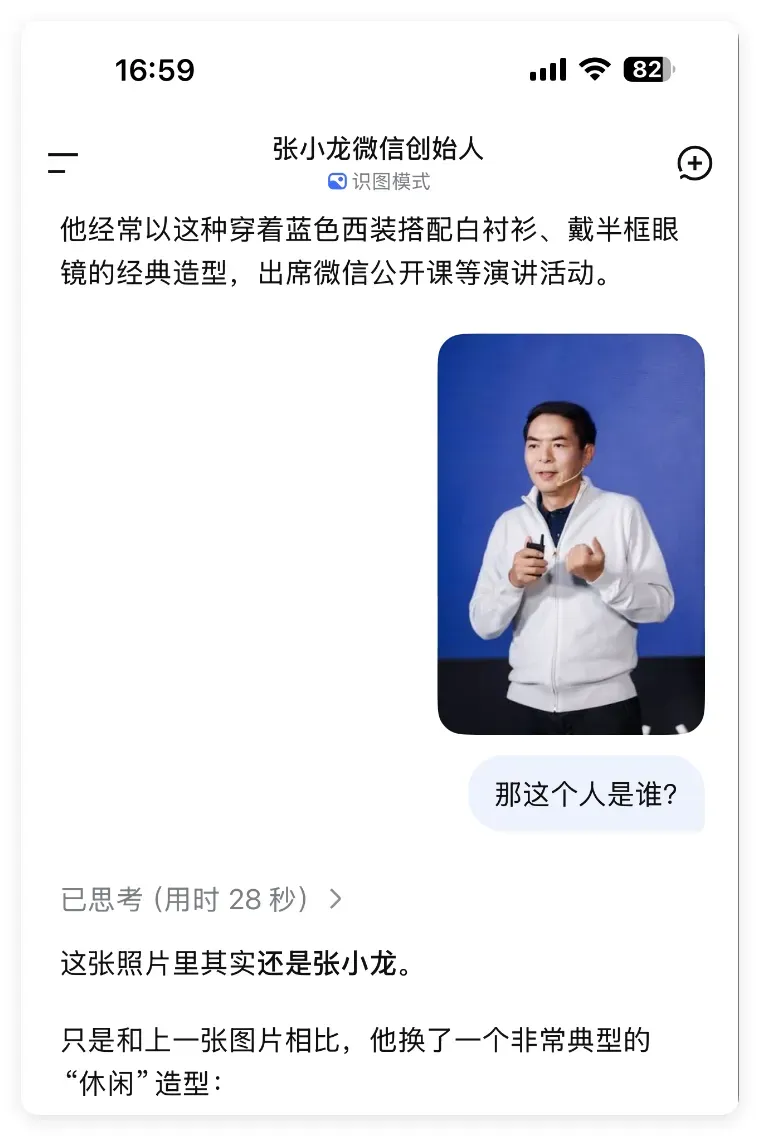
好家伙,世界观再次崩塌!原来刚才那两个人竟然是同一个?只是换了一身休闲打扮?

更绝的是,它还一本正经地列出了一二三四,说得有鼻子有眼!
行吧,我权且相信你,这人就叫“张小龙”。
可你为什么每次给出的答案都不一样啊?
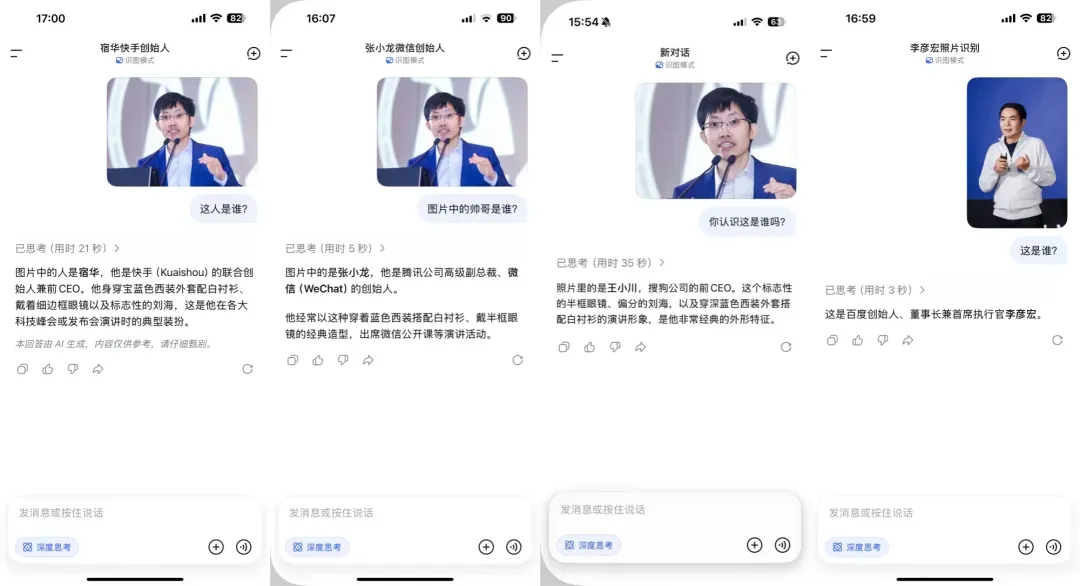
这位穿蓝色外套的男子,简直成了谜一般的存在。
他一会儿是微信的张小龙,一会儿是快手的宿华,一会儿又能变成搜狗的王小川!
同一个休闲外套的男人,在它眼里还可以是百度创始人李彦宏。
往好听里说,这个功能充满惊喜;往难听里说,就是“一本正经的胡说八道”!
我倒不是要批判什么,反正,我笑得肚子都疼了。
好了,不逗大家了。
图片里这位其实是梁文锋:
梁文锋,正是 DeepSeek 深度求索的创始人兼 CEO,同时还是 幻方量化 High-Flyer 的联合创始人。他可是近年来中国 AI 领域举足轻重的人物。
整件事最搞笑的地方在于:DeepSeek 的大模型居然不认识自家的创始人!
可……它偏偏能把东哥认得死死滴:
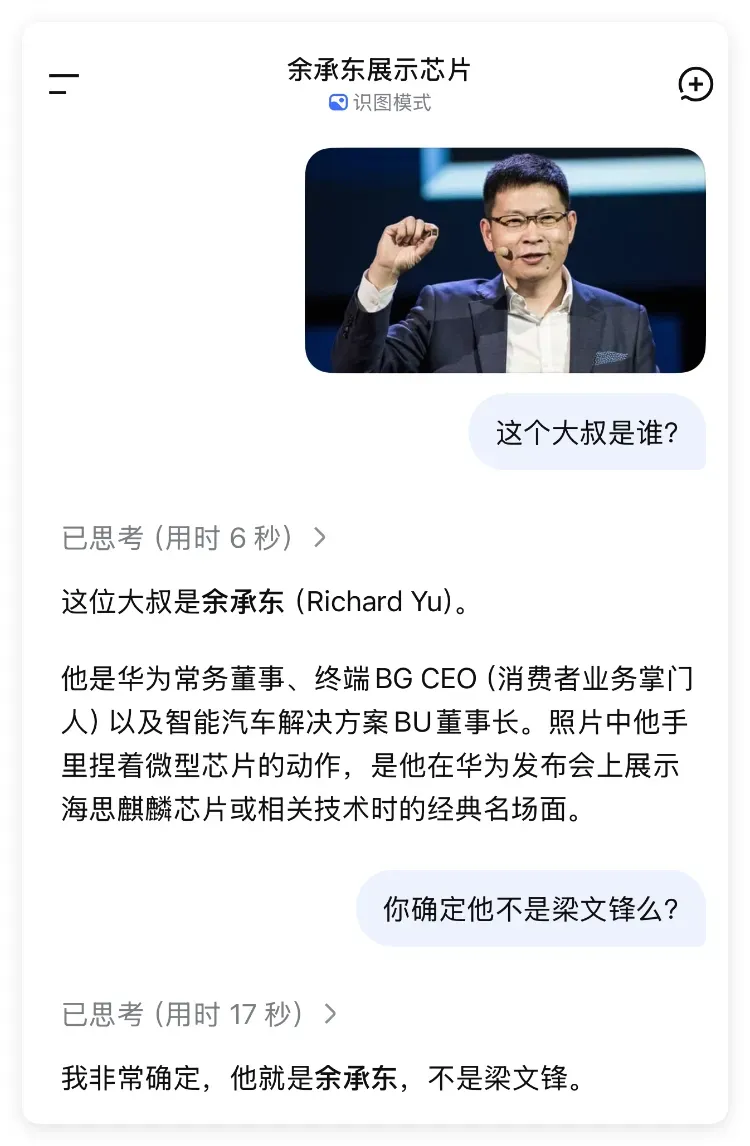
态度还特别坚决,任凭我怎么忽悠都不改口。难道说,给提供显卡的才是“亲爹”?
论认人这个事儿,感觉还是包包更在行:
这事儿我足足乐了半天🤣。好了,不闹了……
再试一个特别实用的场景:给小学生拍照检查作业。
手头正好有一份绝妙素材:

这是一份四年级的试卷,正是眼前这届小学生的作业。而且,有人事先在上面写了一份藏着错误的答案。
我直接把这张图丢给它:

大约思考加作答花了 140 秒,最后给出了这样的结论:

这波操作还算靠谱!
它识别出了好几道带图的题目,并逐一批改,对的没判错,错的被它揪了出来。
光凭这一点,就足以说明它真的具备视觉理解能力,绝不是单纯依赖 OCR,否则根本理解不了这些图片题目。
为了进一步确认,我又丢给它一道错题:

这道题也是视觉题,图上标着两条虚线,并且试卷上的作答是错误的,就看它能不能把错误找出来。
以下是 DeepSeek 的作答:

它成功锁定了三道错题,并逐一进行了解析。
可第十题在指出错误之后,自己居然又给了一个错误的答案,这实在让人大跌眼镜。
第 10 题(选择题):
学生选了 C(140),正确选项是 B(139)。
解析:
舞蹈队原平均身高是 140.2 cm,红红加入后,平均身高降到了 139 cm(虚线 b 的位置)。
说明红红的身高必须很矮,拉低了总平均分。
如果新平均身高是 139 cm,红红的身高极大概率就是 139 cm(或者低于 139,但在给定选项里 B 最合适)。
它虽然正确辨认出了原本的平均身高和后来的平均身高,但在逻辑推导上翻了车。
告别命令行:用 AI 对话轻松实现 Git 仓库管理与 GitHub Pages 部署
无需安装 Git 或记忆任何命令,借助 Claude Code、Open Code、Cursor、Trae、CodeBuddy 等 AI 编程助手(AI Agent),你只需用自然语言与之交流,就能完成以下所有常见操作:
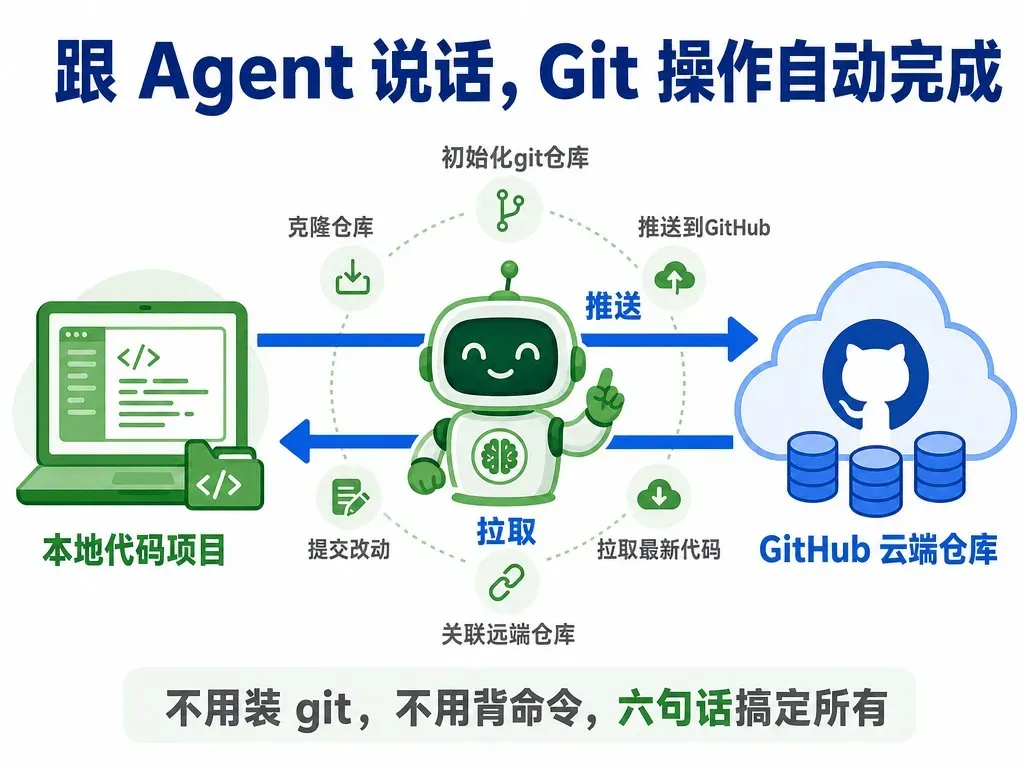
初始化仓库
想把当前项目目录变成 Git 仓库?直接告诉 AI Agent:“帮我初始化 Git 仓库”。克隆仓库
需要下载别人的开源项目,只需复制仓库地址,然后对 Agent 说:“帮我把这个仓库克隆到本地 github.com/xxx/xxx”。提交改动
代码改完后要存档,可以说:“提交所有改动,说明是:修复了登录页白屏”。推送至远程
要将本地提交同步到 GitHub,一句:“推送到 GitHub”即可。拉取更新
需要获取远程仓库的最新代码,只需指示:“拉一下最新代码”。关联空仓库
本地已有项目,想把它连到 GitHub 上刚创建的空仓库,告诉 Agent:“帮我把这个项目关联到 GitHub 上的 xxx 仓库,然后推送上去”。
Agent 会在后台自动执行所有这些工作,首次推送时还会替你配置好 SSH 密钥,你完全不必关心具体的执行细节。
静态网站一键部署指南
当代码推送到 GitHub 之后,怎样才能让别人在浏览器里直接看到你的网页?如果是纯静态的 HTML 页面,你可以利用 GitHub Pages 实现无缝部署。只需对 AI 助手说:“帮我把这个仓库部署到 GitHub Pages”。不出半分钟,它就会返回一个类似“你的用户名.github.io/仓库名”的公开链接,任何人通过互联网都能访问。
如果你使用的是 React、Vue、Next.js 这类现代前端框架,更适合走 Vercel 部署路线。同样对 AI 说:“帮我把这个项目部署到 Vercel”。Agent 会自动关联 GitHub 仓库、自动执行构建流程,并分配一个 vercel.app 的专属域名。之后每当你执行 git push,Vercel 都会立刻重新部署,完全自动化。
告别新浪云SAE:致敬那段与谷歌GAE并驾齐驱的云计算拓荒岁月
曾几何时,新浪云的SAE在我心中是和谷歌GAE比肩而立的存在——当整个行业还在对IaaS、PaaS、SaaS的概念各说各话、争论不休时,它们已经是以真实可触碰的形态摆在开发者面前的PaaS平台(那时的谷歌还能畅行无阻)。我不仅为SAE充过值,还为了它自学了那门被戏称为“世界上最好的编程语言”的PHP,如今想来,满是青涩却滚烫的记忆。写下这些文字,只为纪念那段与云计算拓荒者同行的时光。

快手生成式推荐技术体系化演进:从思考引擎到算力底座
上周我再度参与了一场快手组织的技术沙龙,坦白说,快手这家企业的技术积累着实深厚。最近这一两年,许多同行在 AI 的“端”上热闹非凡,各家轮番登场,唯独快手始终沉下心深耕自己的工业推荐系统,其中自然包含了 AI 技术,但远不止于此。
如果把这次沙龙的内容放进快手这一年多来围绕生成式推荐、生成式搜索、生成式广告所持续释出的技术脉络里,它更像第二场真正意义上的“生成式推荐系统专场”。
早前探讨的是 OneRec、OneSearch、广告出价这一类生成式推荐技术怎样注入具体业务场景。如今,主题已经转变为“快手生成式推荐技术的体系化演进——统一基座、池化预估与场景实践”。
这样的转变值得玩味。
从 OneRec 到 OneReason(会思考的推荐基础模型),从 OneSearch 到 OneSearch V2(端到端生成式电商搜索框架),接着是面向广告的生成式推荐 GR4AD,现在又开始构筑算力底座 Pool-Rec(算力和系统底座),再加上同步发布的快手探索者 LLM-Rec 挑战赛,快手此次所要讲述的是“这一整套东西正在生长为一个完整系统”。
过去,不少公司探索生成式推荐,往往容易停留在一个表面问题上:能否把用户行为序列、物料 ID、上下文信息像文本那样编码成 token,再让模型一步步生成推荐结果?
这当然是一个关键问题,却只是第一步。
一旦真正进入工业级场景,事情就会变得复杂得多:模型能不能理解用户为何对某一内容产生兴趣?能不能应对冷启动、长尾物料、跨域迁移?算力能不能撑得住?搜索和广告这类对延迟、收益、转化都极度敏感的业务,能不能真正走上主链路?技术路线能不能开放给外部团队一同验证?
因此,我的判断也随之发生了微妙变化:生成式推荐已不再仅仅是“推荐模型的一次升级”,它正在重塑推荐系统的底层架构。
1
先来谈谈 OneReason。
过去我曾写过 OneRec,它解决的是“推荐结果能不能被生成”,而 OneReason 要直面的问题是:推荐系统能不能学会思考。
传统推荐系统,本质上极度擅长记忆。它知道看过 A 的人也可能看 B,购买过某类商品的人也可能倾心于另一类商品。这套建立在协同过滤、深度模型、序列建模之上的体系已经极其强大,也支撑了过去十年内容平台、电商平台和广告系统的扩张。
但它也存在着天然边界。
当冷启动用户数据稀少时,模型不知该如何推荐;长尾物料缺少行为反馈,很难获得展现机会;跨域迁移时,用户在短视频、电商、直播、本地生活之间的兴趣漂移,并非简单的共现关系所能概括。
到了大模型时代,一个新问题浮现出来:既然 LLM 已经从 Scaling 走向 Reasoning,再进一步迈向 Agentic,那么推荐系统能否也经历一次类似的跨越?
快手 OneReason 给出的回答是:可以,但不能简单照搬大模型的思维链(CoT)。
推荐系统中的 Reasoning,是让模型从用户行为这个“果”,反推出潜在兴趣这个“因”。这是一种溯因推理。用户浏览过大量内容,停留、点赞、下单、跳出,这些行为交错混杂,充满噪声,随时间变化,还涉及跨域迁移。推荐模型所要判断的是:“为什么这个用户此刻可能需要这件东西”。
OneReason 要构建的,正是推荐模型理解****物料和用户的底层能力。
在预训练阶段,OneReason 进行了 578B token 的三阶段训练,将 item token(物料 Token)与自然语言做深度的语义对齐。通俗地说,过去的 item token 更接近一个离散编号,模型知道它与哪些东西共现,但未必真正理解它是什么。OneReason 则要让模型不仅清楚这个 token 在何处出现,更要理解它所代表的物料内容、关系、用户行为上下文,以及它与人之间兴趣的联结。
接下来是 SFT(监督微调)和 RL(强化学习)。快手把推荐 CoT 拆解成了更适配推荐任务的结构:从感知物料,到推导物料关系,再到理解用户兴趣演化,最后做出推荐决策。
快速免费接入Kimi K2.7与GLM 5.2:ZenMux平台2分钟配置指南
最近发布的国产大模型 Kimi K2.7 Code 和 GLM 5.2 可以通过 ZenMux 平台免费接入,只需两分钟配置到 CC,即可立即体验。平台目前开放了免费通道,让我们来看看如何操作。
ZenMux 是一个大模型聚合平台,领取免费 API Key 后,简单几步就能在 CC 中使用最新模型。
ZenMux 是什么?
ZenMux 是全球首个支持保险赔付机制的企业级大模型聚合平台。
一个账号、一个 API、一个入口,背后自动完成模型选择、风控管理、智能路由,并自带赔偿机制。出现问题时可以兜底,使用更安心。
平台聚合了 OpenAI、Anthropic、Google、DeepSeek 等官方和授权渠道,能智能调度到最适合当前任务的模型,不会降级或偷换,质量可查可追溯。
免费开放的模型
| 模型显示名 | 模型 ID | 提供商 |
|---|---|---|
| Kimi K2.7 Code | moonshotai/kimi-k2.7-code-free | 月之暗面 (MoonshotAI) |
| Step 3.7 Flash | stepfun/step-3.7-flash-free | 阶跃星辰 (StepFun) |
| GLM 4.7 Flash | z-ai/glm-4.7-free | 智谱 (Z.AI) |
| GLM 4.6V Flash | z-ai/glm-4.6v-flash-free | 智谱 (Z.AI) |
| GLM 5.2 Free | z-ai/glm-5.2-free | 智谱 (Z.AI) |
| ScreenShot_2026-06-17_103112_972 | ScreenShot_2026-06-17_103129_267 | ScreenShot_2026-06-17_103227_706 |
获取 API Key
访问官网 zenmux.ai,可通过邮箱或一键授权登录。
美方出口管制引发连锁反应:DeepSeek估值飙至74亿美元,供应链漏洞同步曝光

一纸政府禁令,90分钟内切断了一家顶级AI实验室的模型入口;而被封锁的一方,却借此将估值推至历史新高。
四天、一条禁令、一场巨额融资
6月12日下午5:21,Anthropic收到联邦出口管制指令。
仅90分钟后,Claude Fable 5与Mythos 5便面向全球非美国用户停止服务。
这两款模型自6月9日发布起算,上市时长不足四天。
几乎同一时间,中国AI实验室DeepSeek宣布完成74亿美元融资。
同一周内,多家中国AI厂商将API token价格降至原价的1%,官方给出的理由是“进一步降低调用门槛”。
时间线的因果逻辑清晰可辨:封锁前,中国厂商已在成本侧构筑结构性优势;封锁后,资本端的优势以指数速度填补剩余缺口。两个独立变量——政策限制与资本配置——在同一周内完成了格局的二次定型。
600万与1亿美元的成本鸿沟
DeepSeek-R1的训练成本约600万美元,而OpenAI训练GPT-4的成本据估在1亿美元量级。
即便考虑年份差异、硬件换代和统计口径的偏差,差距仍维持在同一数量级。
DeepSeek于2023年成立,由量化对冲基金High-Flyer发起。长期公开证据指向一个事实:它的工程方法论将“少花钱、少披露细节但持续进展”变成了可复现流程。
这不是营销辞令。当一个团队能以对手5%至10%的成本拿到达标的基准性能,模型迭代速度、失败容忍度和资本消耗率便进入全然不同的时间维度。
封锁并非促使DeepSeek降低成本的触发器;封锁只是以所有人都无法忽视的方式,暴露了原本就存在的巨大价差。
Cohere、供应链攻击与另一条战线
禁令的直接影响不止于终端模型。
美国AI公司Cohere报告政府采购需求激增。逻辑简单:私有化部署、受控API、本地安装迅速成为合规刚需,而Cohere恰好占据了北美企业采购清单中的安全位置。
供应链战场独立成章,但时间节点同样凑巧。同一周,研究人员披露144个npm包遭投毒,以AI工具链为入口执行凭证窃取,包含自传播恶意软件及CI/CD管道入侵机制。
**Anthropic的模型入口被封,但代码仓库和包管理器里潜藏着另一条供给线。**依赖npm做模型工具集成的团队、只检查上游来源而不验证签名的流水线、将API token明文写入环境变量的工程习惯——这三类常见实践在同一次攻击中被全部击中。
真正被加速的究竟是什么
出口管制的标准叙事是“保护领先优势”。
然而过去一周的事件揭示了一条更精准的因果链条:
首先,**封锁消除了外部用户对单一供应商的性能锚点。**当Fable 5与Mythos 5突然不可用,市场迅速用DeepSeek的融资公告和降价填补认知空白。
其次,**资金加速注入发生在封锁之后,而不是之前,**说明至少在部分LP眼中,地缘政治风险已被重新合同化为“必须下注的替代期权”。
第三,npm攻击让“必须本地部署”从技术偏好升级为合规负担,这不仅给了Cohere等美国公司更硬的销售叙事,也让全球团队开始重新审视“把token交给第三方API是否仍是默认选项”。
如果你正在维护模型调用层或构建AI工作流,这周事件最直接的启示是:**provider的可用性、地理位置和供应链位置将成为新的运维参数。**它们过去被归入“政策与商务”范畴,如今需要纳入架构评审。
这周最值得观察的不是单一技术突破,而是政策线、资本线、工程线三条平行链如何发生共振。
本文信息综合自nerova.ai、Wikipedia、mend.io及AI Weekly等来源。
免费无限量!Qwen 3.6/3.5 Token限时白嫖攻略(6月30日截止,附全流程配置教程)
发现一个限时福利:通过指定入口可以无限量免费调用 Qwen 3.6 和 Qwen 3.5 系列模型的 Token,活动持续到 2026 年 6 月 30 日。这篇教程将带你从注册、创建应用到最终接入 Claude Code 等 AI Agent,全程无门槛。
活动入口:https://maas.xfyun.cn/modelSquare?ch=maas-cg-kol-102
接下来,按步骤一步步操作。
① 定位模型
打开上面的链接后,在模型广场中找到 Qwen 3.6 的模型卡片。
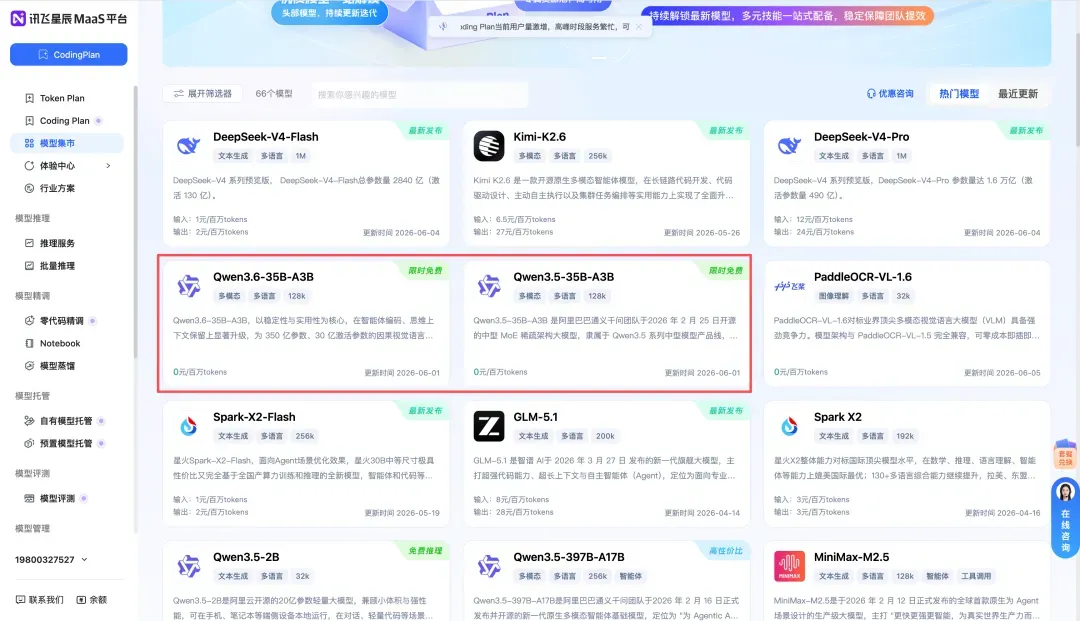
② 进入服务并启用 API 调用
点击该模型,进入详情页,接着点击右上角的「API 调用」按钮。
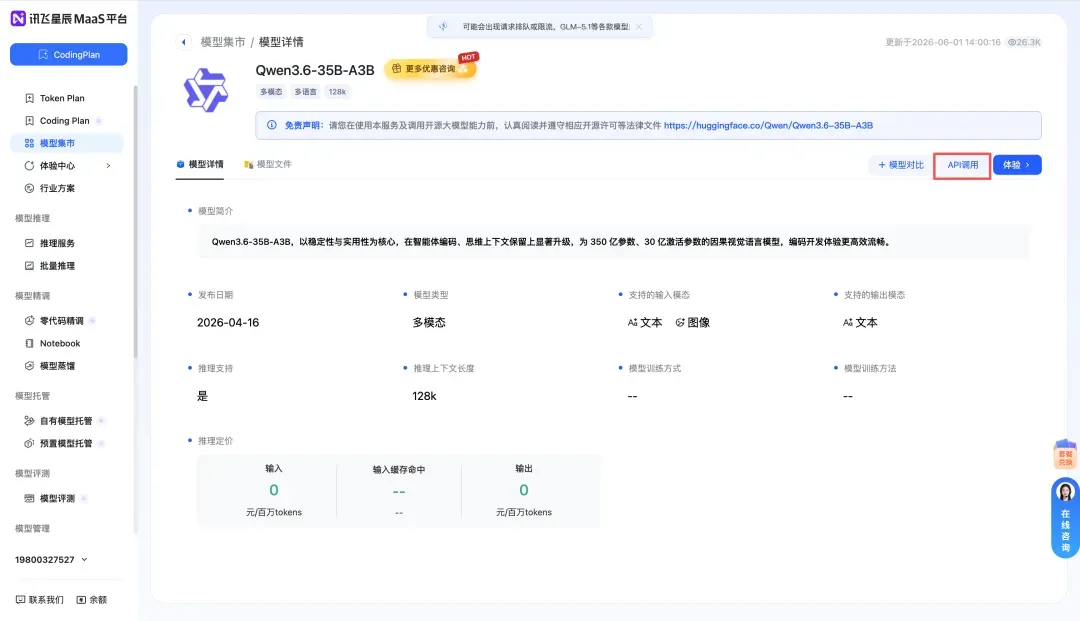
③ 创建应用
在弹出的窗口中,随意填写一个应用名称,然后点击「创建应用」,再点击「确定」即可。
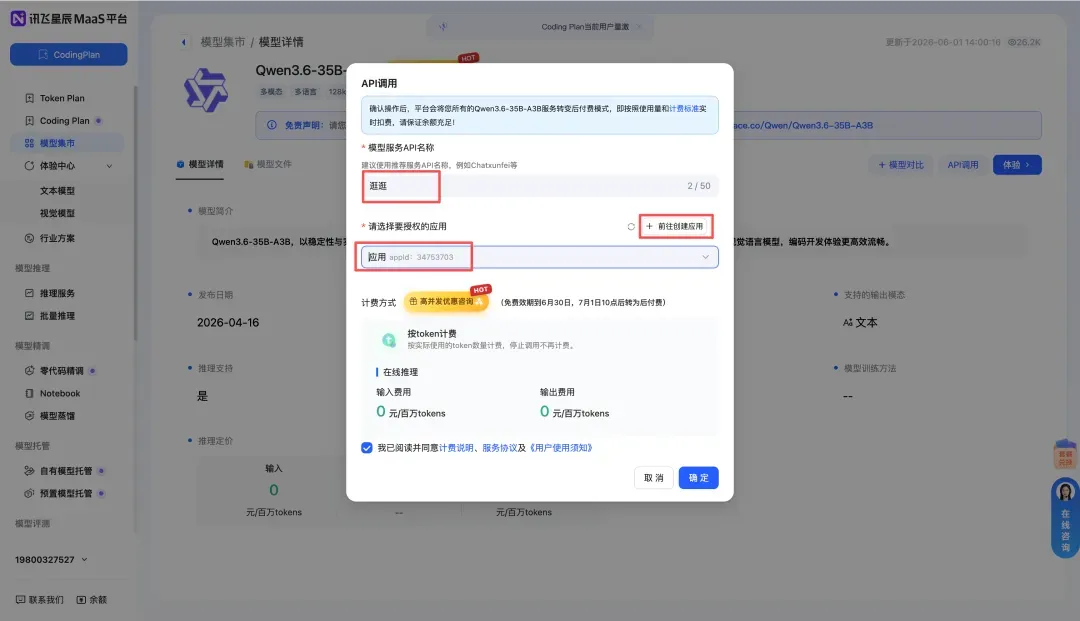
④ 获取关键凭证
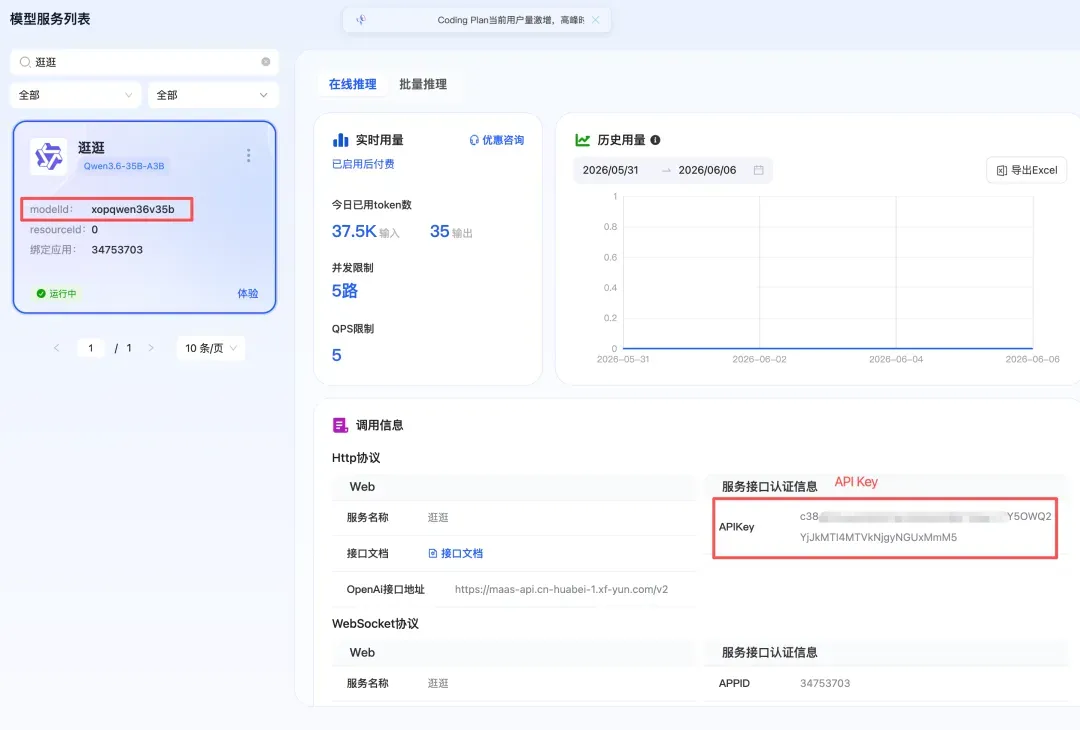
应用创建完成后,会跳转到服务详情页。你需要复制下面两项信息,后续配置时会用到:
- modelId(左上角显示)
- HTTP 协议的 API Key
可以访问这个地址查看服务信息:https://maas.xfyun.cn/modelService
⑤ 安装 CC Switch 工具
CC Switch 能帮你轻松地把免费模型配置到 Claude Code、Codex、Hermes、OpenClaw 等 AI Agent 中。
下载地址:https://ccswitch.io/zh/
安装完成后,先启动你要绑定的 Agent(例如 Claude Code),然后打开 CC Switch,点击右上角的「创建」按钮。