起底闲鱼-千问诈骗链:阿里全家桶如何沦为电诈“信任通道”
近日,表妹发消息告诉我,她在闲鱼上栽了跟头,买一台 Switch 2 被卷走 2300 元。我第一反应觉得有点荒诞——她母亲是个刑警,反诈教育居然没起作用,怎么还会中招?是买到了假货,还是被诱导跳过了平台私下转账?我倒要看看整件事到底怎么发生的。
等我用闲鱼扫了那张二维码,亲手把这条“受骗路径”走了一遍,就再也笑不出来了。如果不是事先知道这是钓鱼页面,我自己八成也会上钩。就连办案的民警在测试后也实话实说:要是没提前知情,他自己也难逃一劫。

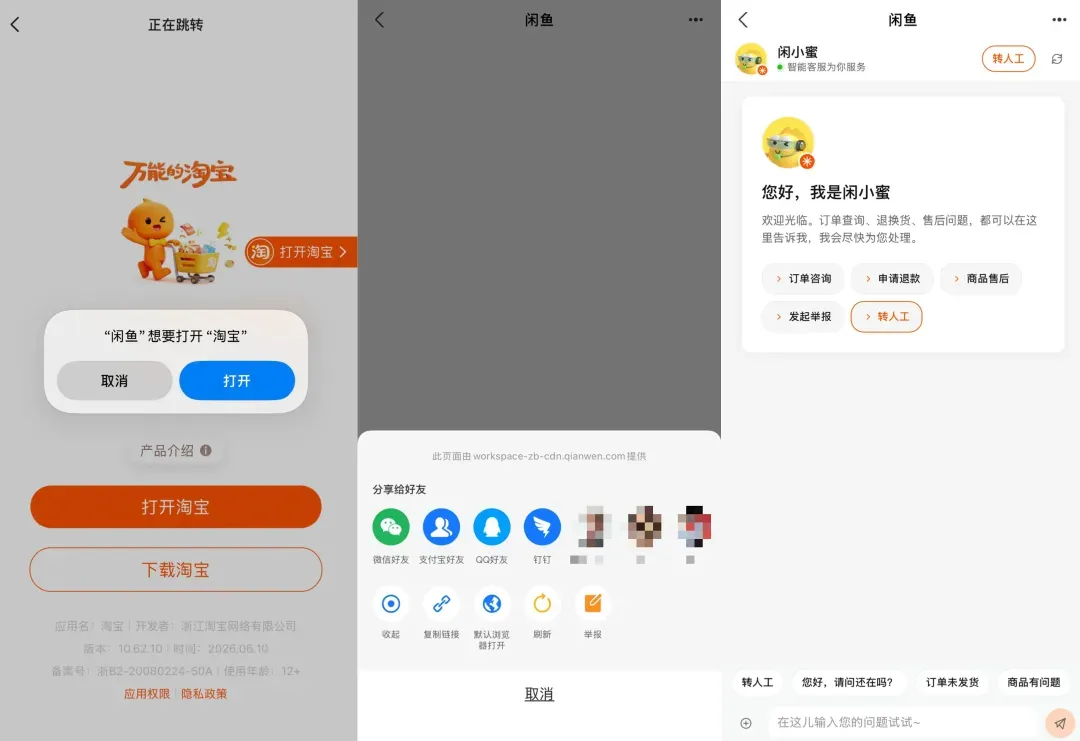
总结下来,这其实是一张伪装的闲鱼商品分享二维码:用闲鱼扫码,先调起淘宝,再唤起支付宝,最终在支付宝内嵌浏览器里打开一个高仿的闲鱼页面,然后受害者就用支付宝顺畅地“完成了一笔闲鱼交易”。整个过程都在阿里系的 App 里流转——闲鱼、淘宝、支付宝层层递进;一路上看到的域名也全是合法可信的阿里域名,全程没有弹出任何外部链接风险提示。最终的钓鱼版闲鱼,就在支付宝内以假乱真地呈现出来。
我认为这里最关键的一个关节是:钓鱼站利用了通义千问的 CDN 域名当作掩体,借助支付宝对阿里系域名的白名单信任,成功绕过了支付宝自身的安全拦截。
阿里这些年谈得最多的一个词,是“赋能”。赋能商家,赋能行业,赋能千行百业。而这一次,官方 App 全家桶却“赋能”了一个诈骗团伙。我那表妹的 2300 块,以及其他受害者的钱,就顺着闲鱼、淘宝、支付宝、千问铺好的信任道路,被稳稳地接走了。

故事的起因与经过
事情并不复杂。表妹是在小红书上看到有人转卖二手 Switch 2,谈妥之后,对方发来一张看似闲鱼商品分享页的二维码。
她并不是毫无戒备。她专门去闲鱼搜了这个卖家,不仅找到了对应的账号,而且信用评级居然显示“极好”。于是她放下顾虑,用闲鱼 App 扫描了那张二维码。
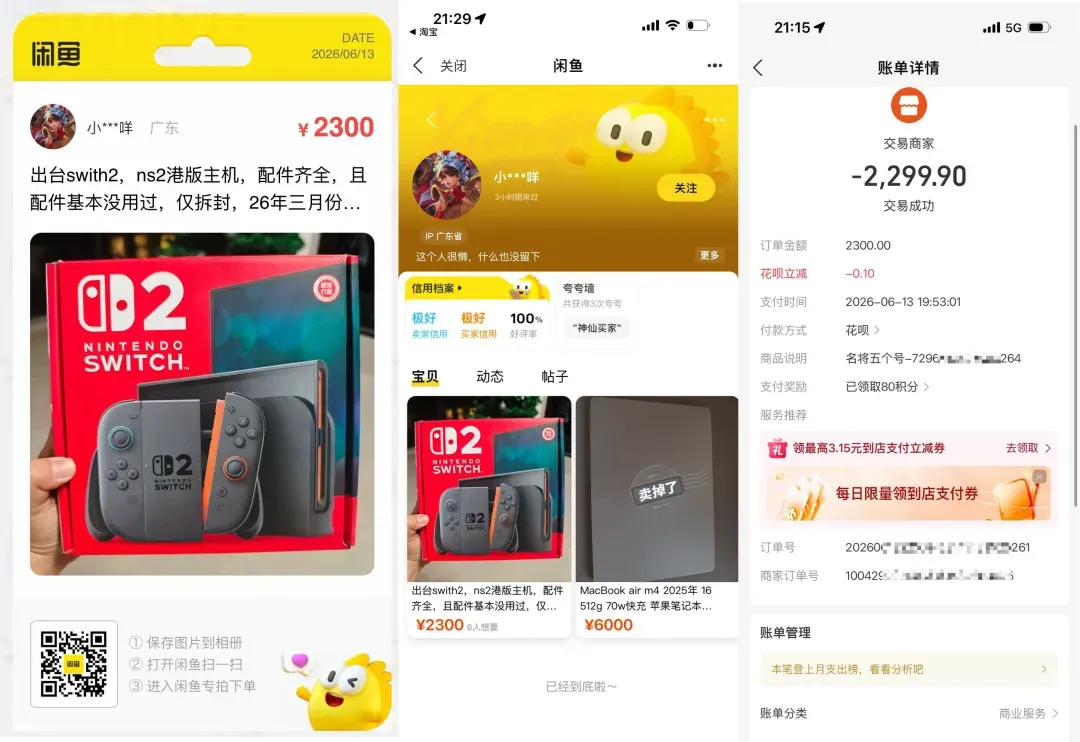
扫码后,页面先经过淘宝短链和唤端跳转,再走支付宝路由,最后落在一个支付宝内嵌页面上——一个高度仿真的“闲鱼”界面。整套流程做得滴水不漏,而且自始至终没有弹出平时那种“非支付宝链接请注意”的提醒。
于是,她在那里付掉了 2300 元。
付完款,她看到收款方就感觉不对劲,回闲鱼一查,才发现上了当。她立刻给支付宝客服打电话,要求冻结、止付、把钱拦回来——客服只会打太极。她又去派出所报案,立了案,拿到了受案回执。

可即便把回执拍在客服面前,支付宝那边依然在扯皮,问题根本得不到解决。
而且,从警方了解到的情况看,被这套钓鱼系统骗到的人远不止表妹一个。这并非单一的个案,而是一条仍在持续运转、可复用的精密诈骗流水线。它不是一桩“二手交易纠纷”,而是一套“有组织的电信诈骗交易系统”。
失灵的安全信号
我们这代人所接受的反诈教育,大多建立在几条简单的信条上:别去陌生网站、认准官方 App、核对官方域名、看准 HTTPS、核实卖家、走平台担保交易别私下转账。这些规则没有错,可在这条链路里,它们被逐一绕开了。
入口不是赤裸裸的陌生链接,而是一张闲鱼风格的商品分享二维码。 或许有人会说,闲鱼不是早就提醒过“扫码跳出平台交易就是诈骗”吗?可骗子发的恰恰是一张闲鱼官方样式的分享卡片。把闲鱼链接分享到站外、再扫码打开,本来就是闲鱼自己提供的正常功能。更何况,表妹是用闲鱼 App 本身去扫的这张“闲鱼码”。
中途看到的是淘宝和支付宝,而不是一上来就跳转到粗制滥造的诈骗域名。 路径上出现的全是阿里官方应用,域名全是 taobao.com、alipay.com、qianwen.com,HTTPS 也齐全。对普通用户来说,这些本身就是再强不过的信任符号。
第三,那道本该弹出的“外部链接”提醒,这次完全没有出现。 现在几乎所有主流 App 在打开站外页面时都会弹出一句“该页面非本应用提供,请注意甄别”之类的警示——你在微信、支付宝、知乎里都领教过这种烦人却必要的拦截。可在这条阿里系 App 一路跳转的链路里,这道提醒始终缺席。恰恰是这种“一路绿灯、零告警、还落在支付宝 App 里”的顺畅体验,让受害者坚信一切都正常。
卖家信用也没能救她。 案发前能搜到“信用极好”的卖家,案发后蒸发得一干二净。那么,这些“信用极好”的账号,到底是怎么养出来的?
最常用的甩锅话术就是:“防骗意识太差,活该被骗”。可一个受过大学教育、熟练使用各种 AI 工具、认知常识和警觉性都在平均线以上的年轻人,全程在官方 App 里操作,看到的全是“安全信号”,最后却仍然被骗了。
在这条链路上,入口是闲鱼的商品分享页;唤端与跳转,靠的是淘宝短链和支付宝路由;钓鱼站的外壳,挂在通义千问的 CDN 上,展示在支付宝的浏览器里;付款,用的是支付宝。
入口、跳转、托管、支付、收款——一条诈骗链上,用户每一个会产生信任的环节,凭证几乎全部来自阿里。骗子几乎从头到尾没有亮出自己的真身,而是借了阿里的信誉,完成了一次教科书般的诈骗。普通用户看到的是官方 App、官方域名、HTTPS、支付宝付款,一路畅通,既没有提醒也没有阻拦,就在支付宝内部直达钓鱼站。
那么,普通消费者真的有能力识别这类骗术并成功避开吗?这些所谓的“安全信号”又真的还靠得住吗?
十大Agent神级技能实战指南:从TDD到UI设计,程序员提效必备
上一次我们系统聊了 Agent Skills 是什么、怎么用,以及和 Prompt / MCP 的区别。今天直接上干货,分享 10 个真正值得程序员装上的 Skills,覆盖开发流程、代码审查、UI 设计、网页操作、前端验收、MCP 开发、API 接入等高频场景:
- 让 AI 自动走完整 TDD 流程,测试先行,实现在后
- 把模糊输入变成 PRD、技术方案或决策文档
- 一键生成符合行业特色的完整设计系统
- 从 SOLID、安全性、性能等多维度做专业代码审查
- 解决长对话中上下文“腐烂”的失忆问题
- 为 AI 配上真实的浏览器操控和自动浏览能力
- 用 Playwright 对本地 Web 应用进行交互验收与截图检查
- 辅助开发 MCP Server,将内部 API 封装成 Agent 工具
- 在编写 Claude API 应用时查 SDK、流式、工具调用、缓存和模型迁移细节
接下来按场景逐一展开。
Superpowers
如果你只是偶尔让 AI 补一行代码,Superpowers 可能看起来有些笨重。但当你把 Claude Code、Cursor 这一类工具真正嵌入日常开发后,一个现实问题立刻浮现:AI 可以写代码,但并不会自动遵守工程流程。
需求还没有澄清就动手,测试还没跑就说“完成”,改到一半把主分支搞乱,或者实现后只检查语法而不管设计是否跑偏。Superpowers 要解决的正是这些。
它把需求澄清、方案拆分、Git Worktree、TDD、代码审查、调试和完成验证打包成一套 Skills,让 AI 在每个阶段都按固定步骤推进,避免你在 Prompt 里一遍遍提醒。
内置主要技能:
| 技能名称 | 触发方式 | 核心能力 |
|---|---|---|
| brainstorming | 命令 /superpowers:brainstorm | 先追问目标、约束和边界,再整理成设计文档 |
| using-git-worktrees | 自动(设计确认后) | 为每个任务独立开 Git worktree,隔离当前分支干扰 |
| writing-plans | 自动(设计确认后) | 把设计拆成 2–5 分钟粒度的小任务,写明文件、改法与验证方式 |
| executing-plans | 自动(执行计划时可选) | 适合批量重复任务,按计划逐项推进 |
| test-driven-development | 自动(代码实现阶段) | 按红-绿-重构节奏,先补充测试,再补实现 |
| subagent-driven-development | 自动(执行计划时可选) | 给任务分配独立子 Agent,完成后二次检查设计符合度和代码质量 |
| code-review | 自动(任务完成后) | 在代码合入前做第二轮质量检查 |
| systematic-debugging | 需要时触发 | 按阶段定位问题来源,避免边猜边改 |
| verification-before-completion | 自动(宣称完成时) | 没有测试、日志或命令输出,就不允许宣布完成 |
我最看重的是 verification-before-completion 和 test-driven-development。很多 AI 编程翻车症结就在验证:模型改完了代码,测试、日志、命令输出却没跟上。Superpowers 直接把验证变成流程硬约束:没有证据,就不能收工。
树莓派5打造完全离线疲劳驾驶预警系统:零订阅、零云端,安全驾驶新方案

所需组件
硬件
- 树莓派5 × 1
- 树莓派摄像头模块 V2 × 1
- MicroSD 存储卡 × 1
- 树莓派触摸显示屏 × 1
- 蜂鸣器 × 1
软件与在线服务
- 树莓派 Raspbian 系统
- OpenCV
项目背景与动机
驾驶疲劳的严峻问题
疲劳驾驶是道路交通事故中最致命、却最常被忽视的诱因之一。现有的商用驾驶员监控系统,如奔驰、宝马、特斯拉等高端车型搭载的方案,往往价格高昂,且与特定车型深度绑定。面向车队的独立系统则普遍依赖云端连接和持续付费模式。
DrowSAFE 是一个完全开源的替代方案:它是一套完全自包含的疲劳检测系统,任何人都可以自行搭建,并安装到任意车辆上。
系统运行原理
DrowSAFE 以约每秒 30 帧的速率持续执行检测流水线:
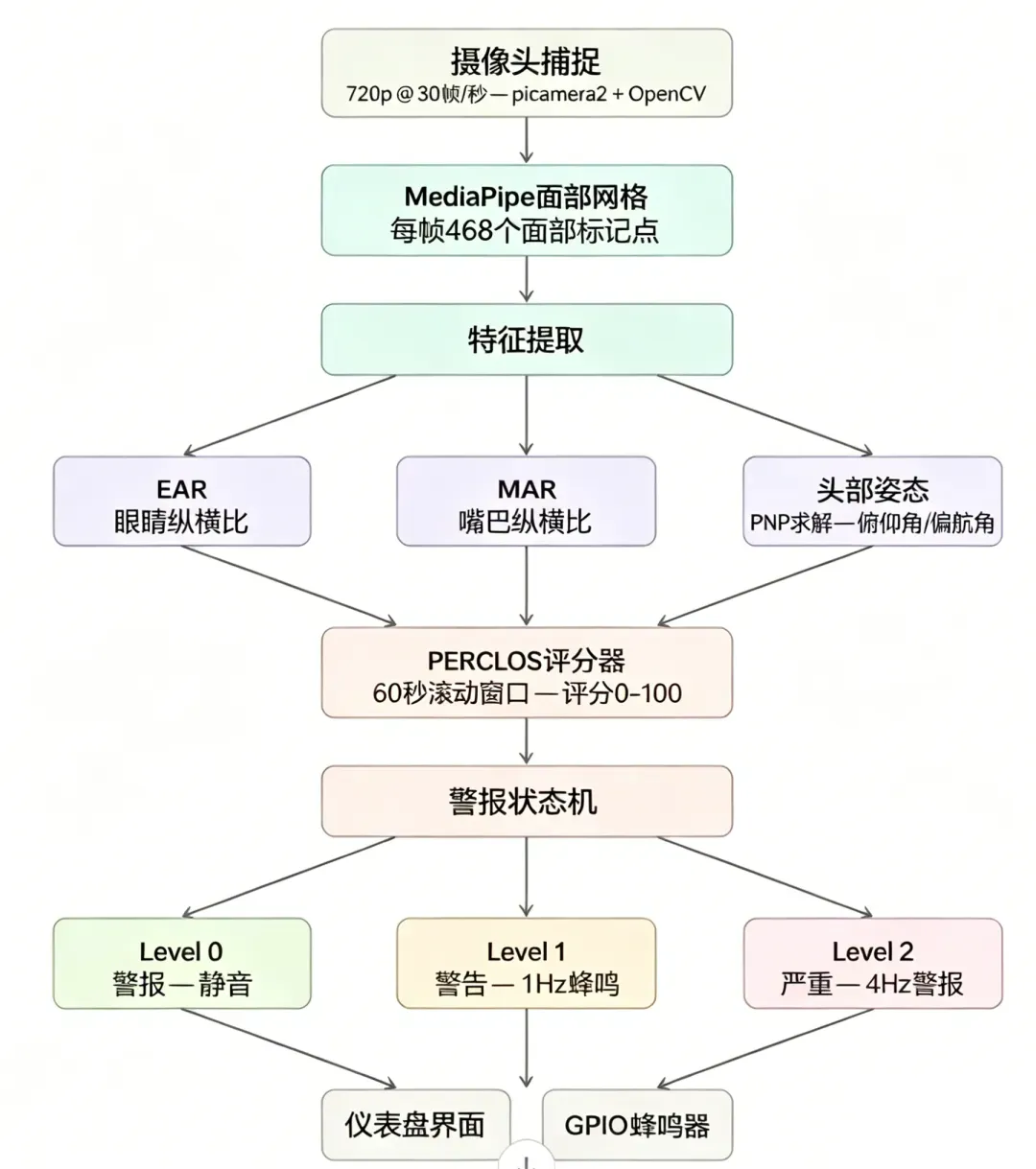
整个流水线在树莓派 5 的四核 Cortex-A76 CPU 上运行,无需 GPU、AI 加速卡,也不需要任何网络连接。
关键疲劳检测算法:眼纵横比(EAR)、嘴纵横比(MAR)与 PERCLOS
系统基于 MediaPipe Face Mesh 每帧检测到的 468 个人脸关键点,计算三项疲劳信号:

- 眼纵横比(EAR):由 Soukupová 与 Čech(2016)提出的指标——利用每只眼睛的 6 个关键点,测量眼睛纵向与横向跨度的比值。眼睛睁开时,EAR 通常处于 0.28–0.35 的范围;眨眼时该值急剧下降;持续偏低的 EAR 表明驾驶员处于疲劳状态。
- EAR = (|p1–p5| + |p2–p4|) / (2 × |p0–p3|)
- 嘴纵横比(MAR):将相同的几何计算方法应用于嘴部区域。当 MAR 超过设定阈值且持续 15 帧以上时,系统判定为一次确认打哈欠。
- PERCLOS(眼睛闭合时间百分比):美国 NHTSA 所采用的金标准疲劳指标。在 60 秒的滑动窗口内,统计眼睛闭合帧占比超过 80% 的时间比例。PERCLOS 值大于 15% 即可可靠地表明警觉性受损。
- 头部姿态:通过 OpenCV 的 solvePnP 函数实时估计,依据 6 个标准 3D 人脸关键点。头部前倾角度超过阈值,即典型的“微睡眠点头”动作,会计入疲劳评分。
综合疲劳评分机制
系统采用加权方式合成 0–100 分的复合疲劳评分:
树莓派6终极预测:2028年登场?处理器、内存、存储大升级猜想
我暂时不急着替换手头的树莓派 5,但对下一代旗舰单板机将带来哪些进化充满好奇。性能会再跃升吗?运存是否会扩容、存储方案能否彻底革新,甚至出现颠覆性的新架构?树莓派 6 至今没有官方消息,不过依据历代产品的迭代规律和现款 5 代的硬件指标,我们完全可以做出一系列合理推测。
树莓派 6 有望接棒 5 代,成为全新的旗舰级 SBC。官方尚未敲定上市时间和硬件参数,但按照基金会一贯的更新节奏,2028 年前后面市是最稳妥的判断。
本文将梳理目前已掌握的信息、社群传闻,以及那些能真正提升日常使用体验的潜在升级点。目前大部分内容都属于合理猜想,但畅想新品的各种可能性,本身就是树莓派新品发布前的一大乐趣。
- 什么是树莓派6?
- 树莓派6的发布时间推测
- 树莓派6的传闻规格一览
- 树莓派6的售价范围
什么是树莓派6?

树莓派 6 是一台具备桌面级运算能力的微型计算机,所有核心元件集成在一块电路板上,因此被称为单板计算机(SBC)。
从 2012 年初代诞生至今,树莓派已经走过漫长的进化之路。2016 年的 Pi 3 让它变得更加多功能,2019 年的 Pi 4 实现了质的飞跃,2023 年的 Pi 5 则蜕变成我们如今熟悉的性能小钢炮。
在主力型号迭代之间,树莓派基金会也会推出其他产品,如 Raspberry Pi 400、Pi Zero、Pi Pico 和 Pi Compute Module 等。它们各有特色,但树莓派生态的整体演进通常由主力型号来定义。我们所有人翘首以盼的下一块主力板,正是树莓派 6。
树莓派6的发布时间推测
需要指出,截至目前树莓派基金会尚未公布树莓派 6 的任何官方发布日期。
虽然没有任何确认信息,但我们可以借助前几代型号的发布节奏来预测窗口:
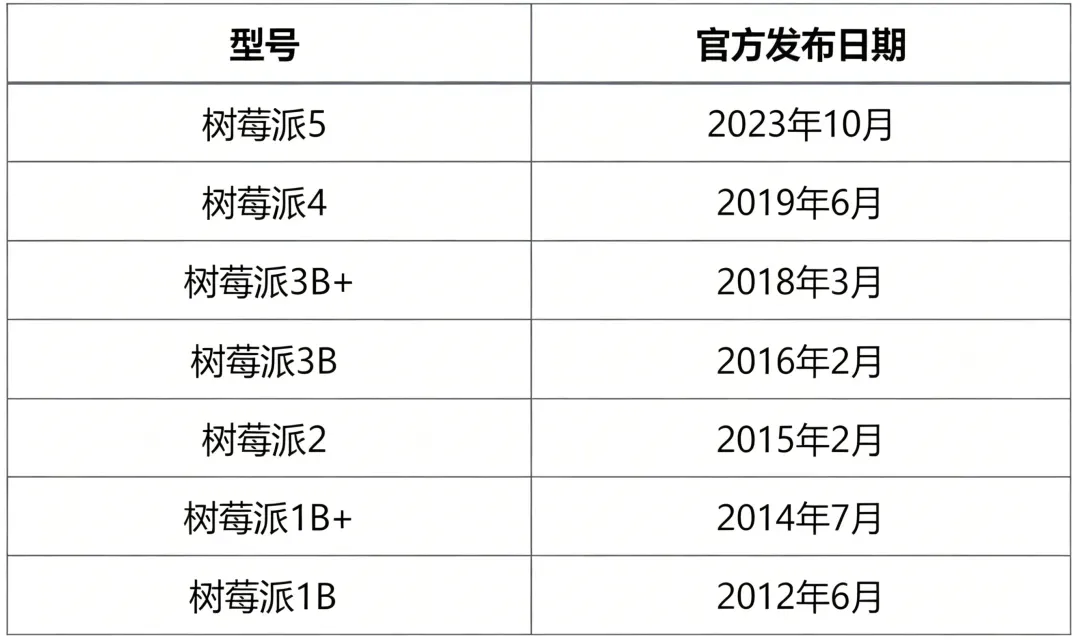
可以看到,从初代 Pi 3 到 Pi 4 间隔了三年多,随后又过了四年 Pi 5 才亮相——这很可能是受全球疫情的影响,导致推迟了大约一年。
尽管如今生产已经恢复正常,芯片短缺也告一段落,但新的变量出现了:AI 数据中心对内存的巨量需求,推动内存价格显著上涨。这些不确定性给树莓派 6 的研发与上市计划增添了变数。我们预计,树莓派 6 可能会推迟到 2028 年初甚至更晚才会发布。
树莓派GPIO引脚完全指南:从点亮LED到制作机器人的五大玩法
GPIO引脚应该是树莓派上最容易让初学者感到困惑的部分了。曾几何时,我也好奇那些细小的针脚究竟能派上什么用场。在累积了多年的项目测试经验之后,我决定把GPIO的核心工作方式整理清楚,并分享一些易于上手的实用例子。
树莓派共拥有40个GPIO引脚,它们可以灵活地配置为输入或输出。借此,你可以连接传感器、开关、电机等各种各样的外部设备。
本文会逐一介绍树莓派GPIO的几种典型使用方法,同时配合实际项目创意或场景示例,让你直观感受它的强大与便利。
基础开关控制:从闪烁LED到智能家居
GPIO最基本的功能莫过于操控开关。通俗地讲,每个GPIO引脚只有两种状态:开(高电平)或关(低电平)。我们完全可以通过程序或脚本来自由切换每个引脚的状态。
那么,“开”和“关”在电气上究竟意味着什么?实际上它们对应的是两种不同的电压或功率等级,电子传感器和元器件在不同电压下的行为也因此不同。
看看下面这个最简电路,就能帮助理解:
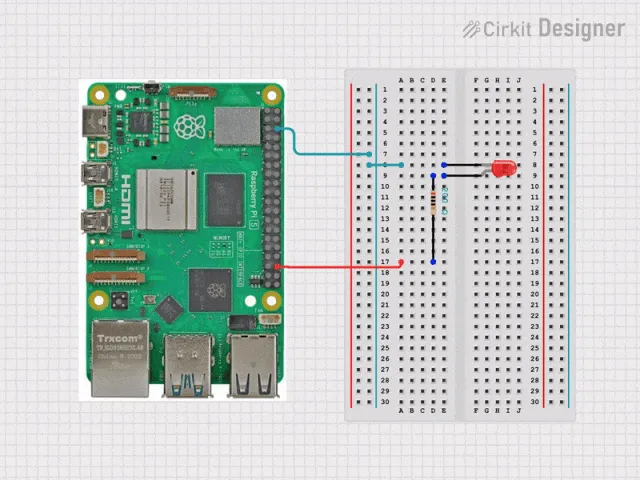
图中,LED通过一个电阻接在了树莓派的GPIO 16上。接下来,我们写一小段简单的Python程序,运行即可点亮这颗LED:
from gpiozero import LED# Initialize LED on GPIO 16led = LED(16)# Turn LED ONled.on()
如果你对基础电子元器件还感到陌生,可以参考文章:树莓派GPIO基础
可见,只需执行一条指令,我们就将一个GPIO引脚从关闭切换到了开启。这个简单的原理同样能延伸到更贴近生活的场景中。
不过,树莓派的GPIO有一个根本限制:它只能直接驱动像LED这样的低压(LV)负载。若要控制家中灯具、风扇之类的高压(HV)设备,就必须想办法把低压信号转换成高压信号。
这样的信号转换电路对新手来说颇有难度,幸好市面上已有现成的继电器模块可供选择。

将这类继电器模块连接到树莓派之后,你就可以用它来取代原来的手动开关(连接方式见下图),把一台普通风扇升级为一台智能风扇。
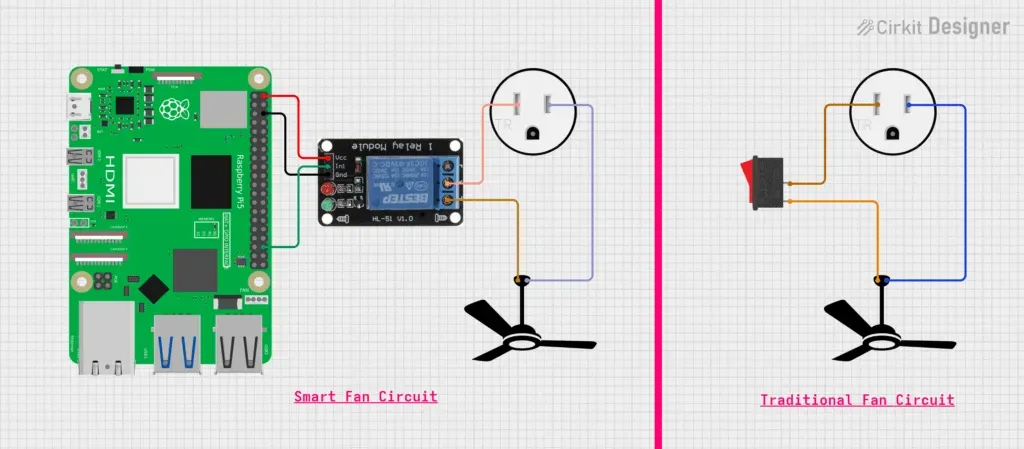
当然,你可以把案例中的风扇替换成任何你想用树莓派GPIO控制的电器。
这种电路能让你轻松实现家居设备的自动化:既可以设定在特定时间自动开关,也可以依据某些传感器信号来触发动作,把原本呆板的设备改造成智能家居的一员。
按钮状态检测:将按压动作变成操控指令
开关控制的反面,就是用GPIO来感知某个对象的“开”或“关”。GPIO除了作为输出,也可以是输入。这样我们便能在程序中判断某一引脚当前处于高电平(开)还是低电平(关)。
以按钮为例,来看树莓派如何通过GPIO读取外部输入。连接方式如下:
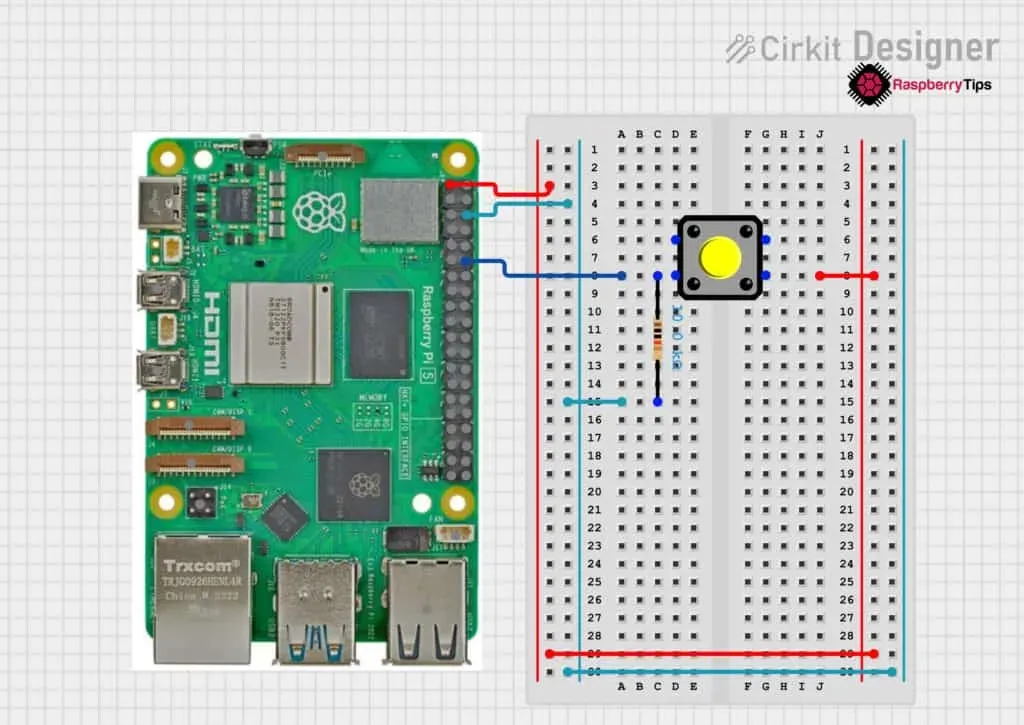
在这个例子中,我们把一只按钮连接到树莓派的GPIO 18。接着,用一段简单的程序就能读出按钮的状态:
from gpiozero import Buttonfrom signal import pausebutton = Button(18)button.when_pressed = lambda: print("Button pressed")button.when_released = lambda: print("Button released")pause() # keeps program running
可以看到,依靠寥寥几行Python代码,我们就能读取GPIO状态,进而转化为按钮是被按下还是松开的信息。
你可以把这个按钮输入当作触发后续动作的起点。例如,同样在树莓派上接好LED,按下按钮时点亮LED,就像下面视频里的效果:

这个案例看似简单到有些过分,但你可以在此基础上做更多复杂的事:把按钮输入作为激活某个脚本的开关,或者当成游戏里的控制键。
与传感器通信并测量真实数据
除了上面说到的简单高低电平输入输出,GPIO还能与数字传感器进行更复杂的通信。
一个很实际的例子就是用红外或运动传感器来检测移动。树莓派可以借助这类传感器识别到运动并发出提醒,常用的器件如HC-SR501。

把传感器接到树莓派上,每当它检测到运动,就会拉高对应GPIO引脚的电平。此时,你在Python程序中读取这个高电平(就像处理按钮时那样),即可据其触发动作,比如发送一条通知。
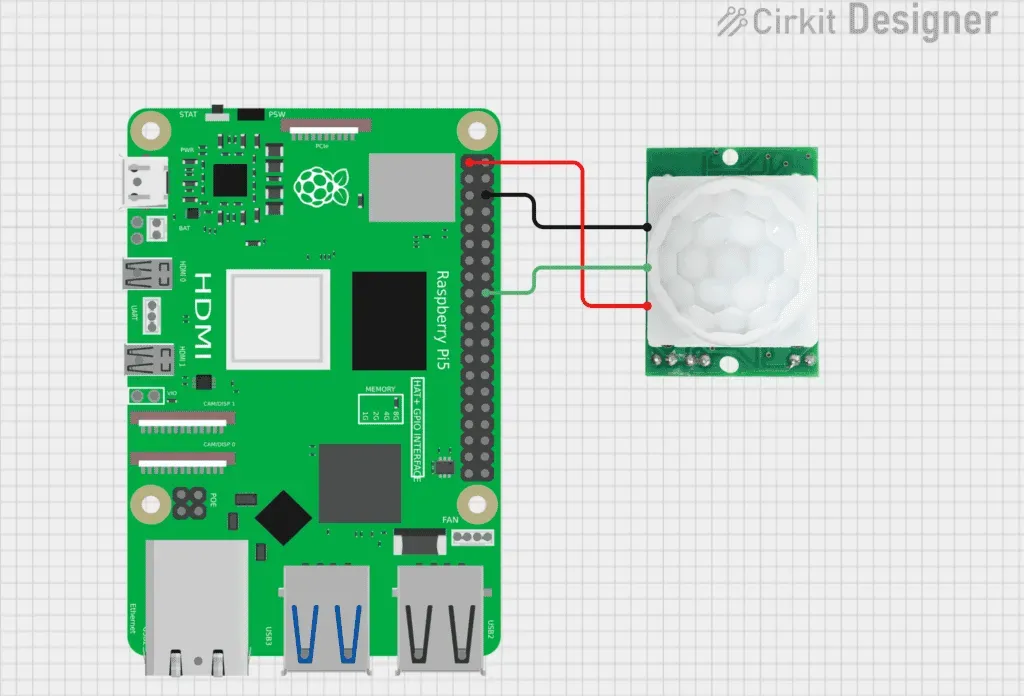
这种配置既可以应用于安防系统,也可以用来监控家中孩子或宠物的活动。
更进一步,还可以把它与前面的开关控制案例结合起来。编写一个程序,在检测到特定的动作(例如早上起床的脚步)时,自动打开某样设备(比如卧室的灯)。
树莓派搭建私有 GitLab 服务器:告别 GitHub 的数据掌控指南

每当能够自行托管一个工具而摆脱对云服务的依赖,我总是按捺不住动手的冲动。GitHub 的确出色,可自从它被微软收购之后,我也渐渐理解了为何一些开发者宁愿将代码保存在自己的私有服务器上。GitLab 使得这一切成为可能,而树莓派正是低成本在家中进行这类实验的绝佳载体。
通过添加官方 GitLab 仓库,可以在 Raspberry Pi OS 上用 APT 安装社区版(Community Edition)软件包。建议使用树莓派 4 或更新的型号以获得足够流畅的性能。
接下来,我将先梳理 Git 与 GitLab 究竟是什么,以及为何值得使用它们。随后会一步步展示安装 GitLab 的过程,并介绍该软件的基础用法。
目录
- Git、GitLab 与 GitHub:三者究竟有何不同?
- 在树莓派上部署 GitLab
- 树莓派 GitLab 上手操作
- 常见疑问
Git、GitLab 与 GitHub:三者究竟有何不同?
那么,Git、GitLab 和 GitHub 之间的区别在哪里?让我们简单拆解一下。
Git
Git 是一款代码管理工具,用来在参与同一项目的开发者之间共享源代码。它支持多人对同一文件进行并行编辑,即使你是独行开发者,它也是备份代码、记录变更的一把好手。
如果你对这些工具有一定了解,会发现 Git 的目标与 SVN(Subversion)或 CVS(并发版本系统)是相同的。
关键差异在于,Git 不需要依赖集中式服务器即可工作;它借助开发者自己的电脑来存储文件。(不过,当项目中只有你一人时,仍建议在服务器上部署 Git,以确保代码安全。)
GitLab
GitLab 恰好填补了 Git 默认架构中那个缺失的服务器角色。它为你提供一个附带 Web 界面的备份托管端,用于管理你的项目。
起初,GitLab 仅仅是一个通过 Web 界面查看源代码的工具。但此后 GitLab 不断丰富功能,使其成为任何 Git 项目中不可或缺的一环。
GitLab 是一款免费且开源软件。
你也可以使用他们提供的托管云服务(如果你愿意),订阅价格在 0 到 99 美元之间。而在本教程中,我将演示如何在你的树莓派上安装其免费版本。
微软SkillOpt开源:像训练神经网络一样优化AI技能,评测准确率暴涨39分
训练神经网络早已拥有一套成熟的流程,从 epoch、batch size 到学习率,每一步都有章可循,结果也可稳定复现。但当我们要训练一个 AI Agent 的“技能”(skill)时,情况就截然不同:调整一下 prompt,跑一遍看看效果,效果不理想就再改,既没有验证集,也几乎全凭手感。
微软研究院近日开源了一个名为 SkillOpt 的项目,首次将训练神经网络的方法论完整迁移到了 skill 优化中。同一个模型,在不微调、不更换任何参数的前提下,仅靠优化一份 Skill.md 文件,就能将技能准确率最高拉升近 39 分。项目在 GitHub 上线不到一个月,已收获超过 5000 星。
把 Skill 当作神经网络来训练
SkillOpt 的核心思路非常直觉:将 Skill 的 Markdown 文件视为神经网络中的可训练权重,然后运用训练神经网络的整套纪律去优化它。
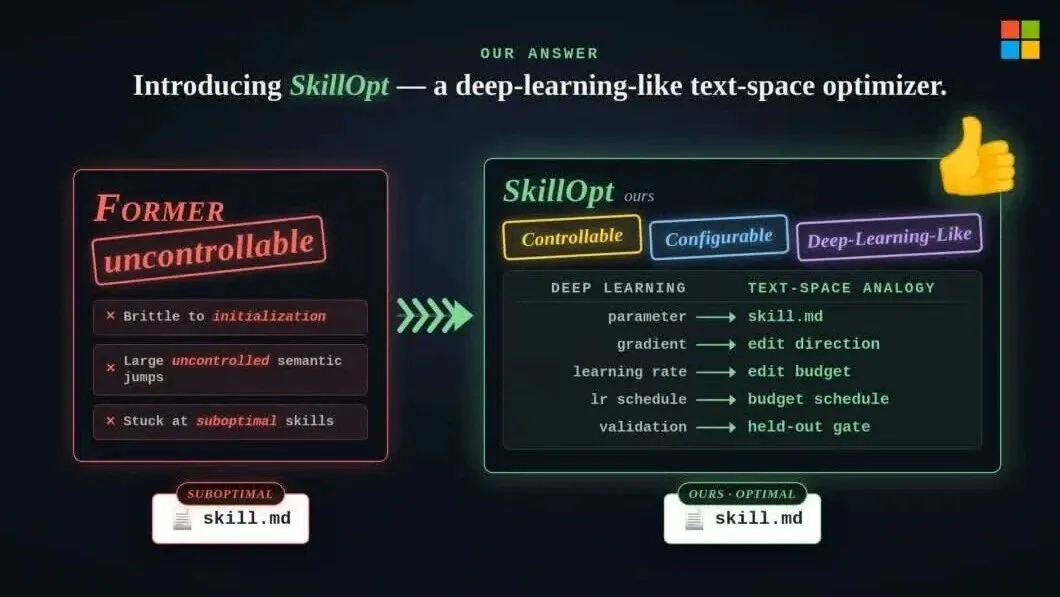
具体对应关系如下:
- 神经网络的权重 → Skill.md 文件内容
- 梯度 → 基于任务执行轨迹的反思分析
- 学习率 → 每次文本编辑的幅度预算
- 验证集 → held‑out 数据集上的评分门控
- epoch → 多轮迭代优化
整个优化由一个名为 ReflACT 的六阶段管线驱动,每一步都在做同一件事:让 skill 文档变得更好,并且有据可查。

开源地址:https://github.com/microsoft/SkillOpt
第一步:Rollout(展开执行)
使用当前 skill 文档驱动目标模型执行一批任务,收集每条任务的执行轨迹与得分。
第二步:反思分析
一个独立的优化器模型(Optimizer Model)分析这些轨迹,指出 skill 文档中哪些部分导致了错误,哪些部分表现良好。
第三步:生成补丁
优化器模型根据分析结果生成针对性的文本编辑,对 skill 文档中的具体段落进行添加、删除或替换。关键设计在于:每次编辑的幅度受“文本学习率”控制,不会一次性大幅改动,而是以小步迭代的方式进行。
微信遥控Claude Code:开源项目wechat-claude-code全新升级,消息优化、文件互通与安抚体验深度打磨
在体验了 OpenClaw、Hermes 等一系列 AI 个人助理之后,我的日常工作流最终还是会回到 Claude Code 或者 Codex。原因并不复杂——绝大部分用到智能体(Agent)的场景,方向都指向创作和生产力。给 AI 嘘寒问暖、设定定时提醒,对我而言并没有真实且持续的诉求。短暂尝鲜之后,热情自然就消退了。
真正“扛重活”的那部分,最终还是要靠 Claude Code 或 Codex 来处理。加上我日常高频使用的 Skill 都已经沉淀在 Claude Code 里,所以我重新捡起了此前开源的 wechat-claude-code,并对体验进行了几轮细致打磨。目标很明确:把它做成在移动端用微信操控电脑端 Claude Code 的优选方案。

项目速览
通过这个 Skill,你可以让微信与 Claude Code 无缝衔接。扫码绑定之后,微信里会出现一个对你可见的“好友”。你给这位好友发送的每一条消息,都会被实时转发到电脑上正在运行的 Claude Code;而 Claude Code 的回复也会即刻推送到微信,交互体验就好像在跟一位真人朋友聊天。它不仅支持发送图片、语音、Word、PDF 等各类文件,还能够把电脑上的文件主动推送给你,方便随时查阅。
开源地址:https://github.com/Wechat-ggGitHub/wechat-claude-code
最新优化一览
微信内消息阅读更清爽
现在微信里只展示 Claude Code 吐出的核心信息,实用却不繁杂。过去会收到大量混杂的通知,阅读体验非常吃力。如今,仅把“任务走到哪一步了、是怎么推进的”这类有效信息呈现出来,视野干净很多。
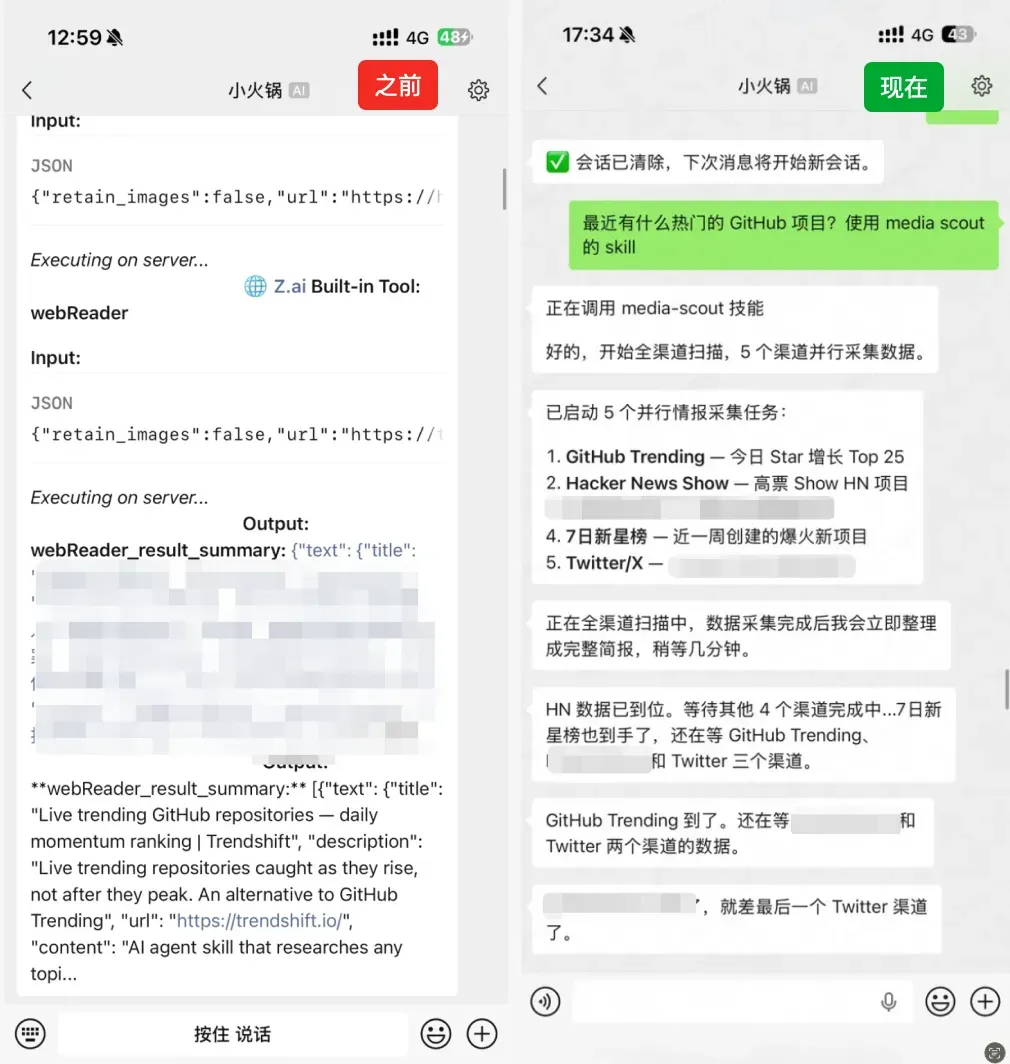
任务执行中的情绪安抚
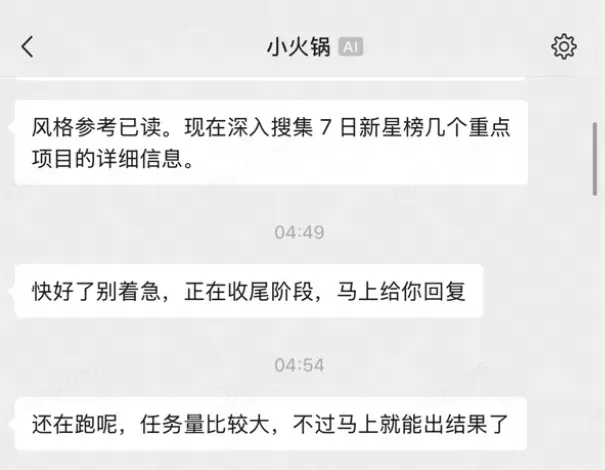
我还加入了一个颇有意思的细节。如果 Claude Code 连续超过 5 分钟没有任何响应(可能某个任务一直在处理,但还没有最终交付),它会从一组安抚话术库里随机挑选一句发送到微信。这样既能照顾到等待时的情绪,也能让你真切感受到 Agent 并没有掉线,仍在后台默默干活。
“对方正在输入中…”还原对话感
这个之前一直没有实现,现在已经补上了。当 Agent 开始接手任务时,微信对话顶栏会显示“对方正在输入中…”,让整个过程更加接近真人交流。

电脑与手机体验高度一致
这一点我认为最为关键。市面上不少通过微信或飞书接入个人 Claude Code 的插件,用起来总有一种割裂感——感觉电脑上面对的是一个 AI,手机上则是另一个 AI,体验很不统一。这个问题现已得到解决。此前从微信发出的消息会走 SDK 模式而非 CLI,而今进行了调整。你可以在电脑上打开 Claude Code 输入一个指令,观察它的编排与输出方式;再在手机上输入同样的指令,得到的效果几乎一致。而且现在也无需反复确认,默认全程自动运行。
限时白嫖:TokenRouter 聚合平台 MiniMax-M3 模型零成本接入全攻略
TokenRouter 是什么?
TokenRouter 是一个类 OpenRouter 的模型聚合平台,它提供一个统一的 API 基础地址,用户只需一个 Key,就能调用背后接入的多家厂商模型,省去逐个平台注册的麻烦。
近期,该平台针对 MiniMax 系列推出了限时优惠:
- MiniMax‑M3:完全免费,输入/输出价格均为 $0
- MiniMax‑Hailuo‑2.3(视频模型):五折
- minimax‑m2 系列:五折
需要注意的是,除 M3 外,其他模型按正常计费,只有 M3 可以真正免费使用。
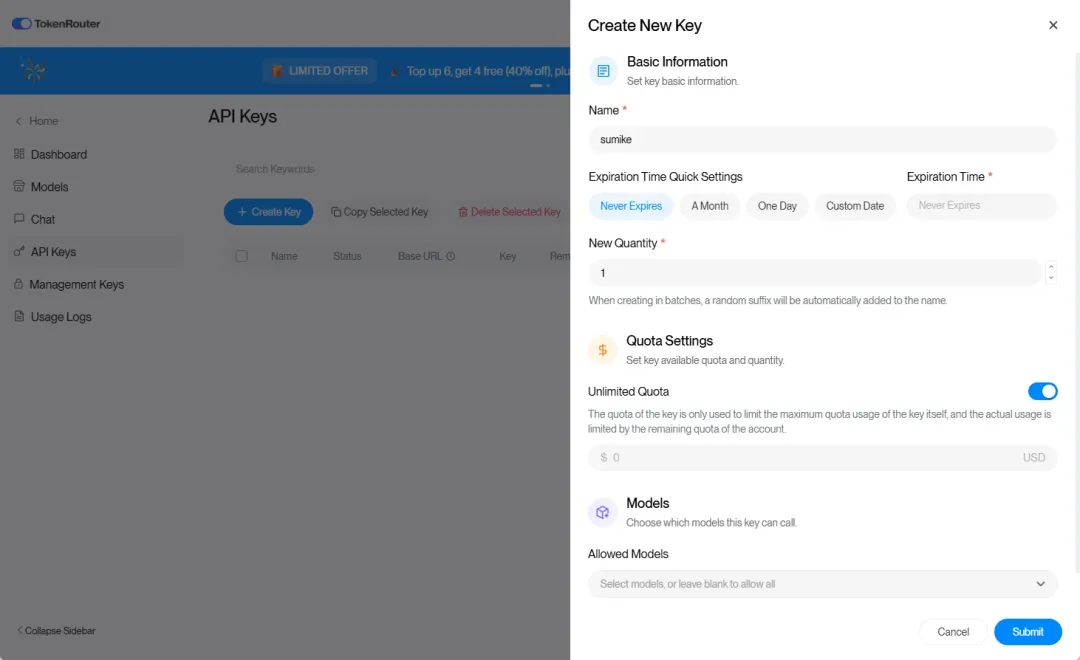
注册并获取 Key,只需两分钟
访问 tokenrouter.com,点击 Sign Up,可使用 Google 或 GitHub 账号一键登录,无需填写繁琐表单。
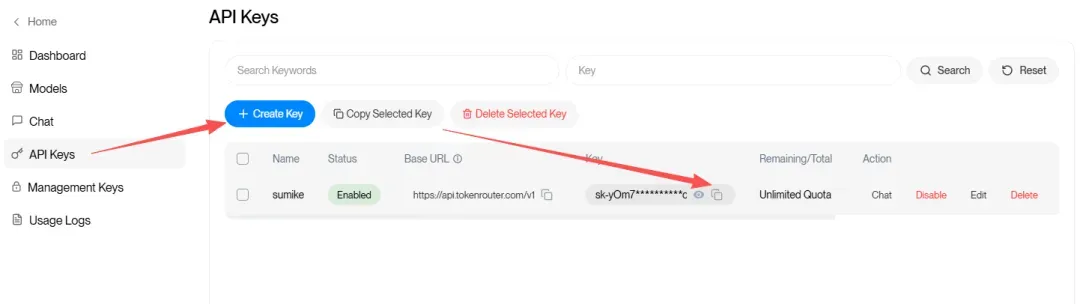
注册后,在左侧菜单选择「API Keys」,生成一个新的密钥:
生成后直接复制备用:
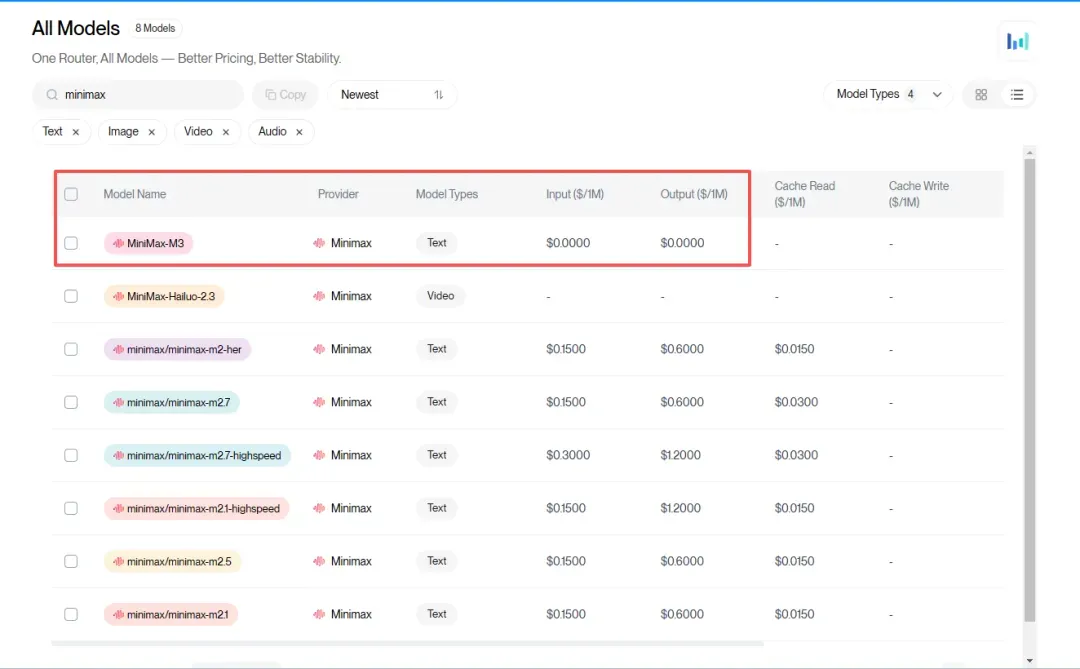
为了确认 M3 是否真实免费,可以进入「Models」页面,搜索 minimax 或 M3,即可看到 MiniMax‑M3 标注为 Free,且价格两列均显示为 $0.0000:
在 CC Switch 中配置接入
如果你使用 CC Switch,添加供应商时按照以下信息填写:
- 供应商名称:TokenRouter
- API Key:刚才复制的密钥
- API 请求地址:
https://api.tokenrouter.com/v1
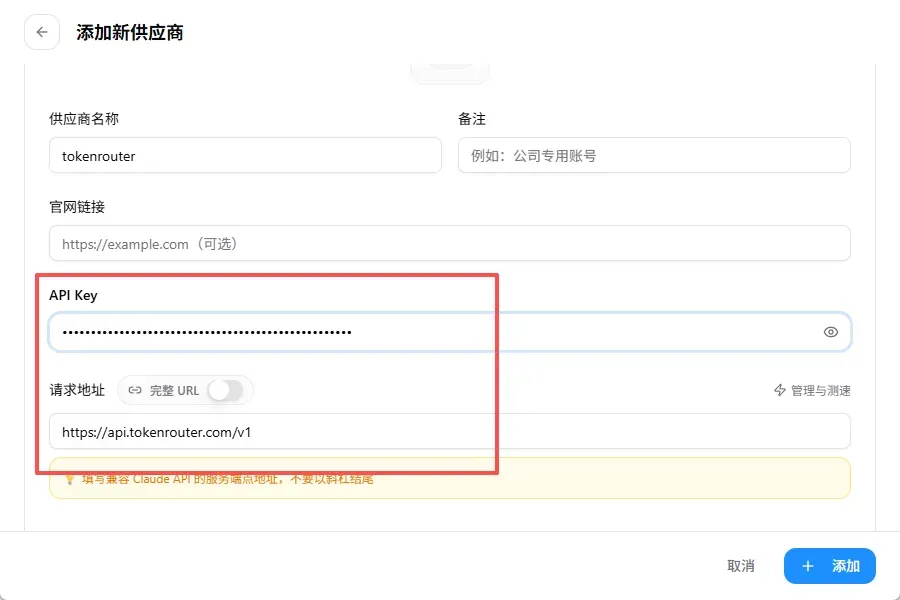
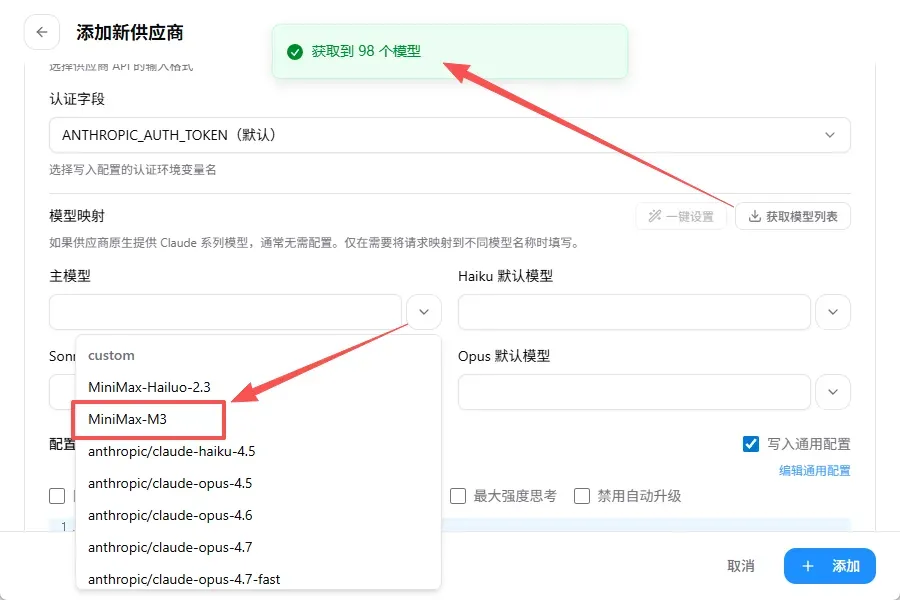
一键获取模型列表
CC Switch 支持直接获取模型列表。点击获取后,平台会将包含 98 个模型在内的完整列表自动拉取回来,之后按需选择即可,无需手动逐个添加。
经实测,Claude Code 和 Codex 均可正常调用。
永久免费!Agnes AI 三大模型无限量接入 Claude Code 全攻略
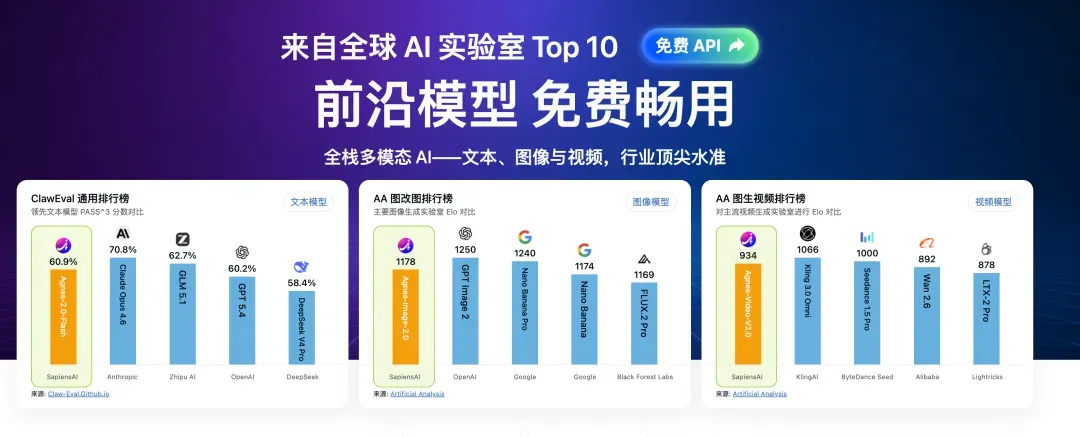
Agnes AI 是一家跻身全球模型榜单前十的 AI 实验室。从 6 月 1 日起,它宣布旗下文本、图片、视频三个核心模型的 API 永久免费,没有任何使用期限或调用次数限制。
开放第一周,文本模型 Agnes‑2.0‑Flash 被调用的 Token 数就达到了 1 万亿;图片模型 Agnes‑Image‑2.1‑Flash 生成了 200 万张 图片;视频模型 Agnes‑Video‑2.0 则贡献了 200 万秒(约 550 小时)的视频,热度与能力可见一斑。
认识 Agnes AI:三大核心模型简介
文本模型 Agnes‑2.0‑Flash
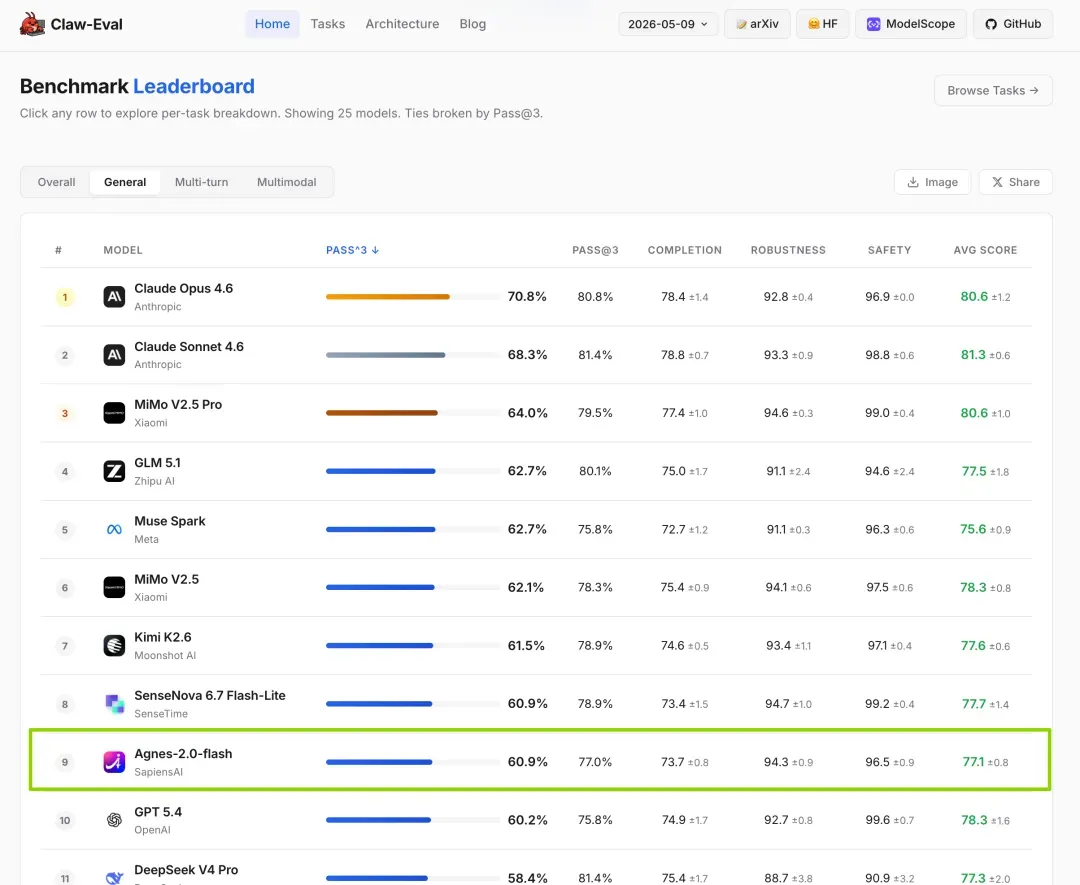
该模型在代码生成、知识问答、Agent 任务调度、复杂规划等场景中表现十分抢眼,尤其适合编程辅助与企业知识库应用。在智能体评估榜单 Claw‑Eval 上,Agnes‑2.0‑Flash 成功进入 Top 10。
图片模型 Agnes‑Image‑2.1‑Flash
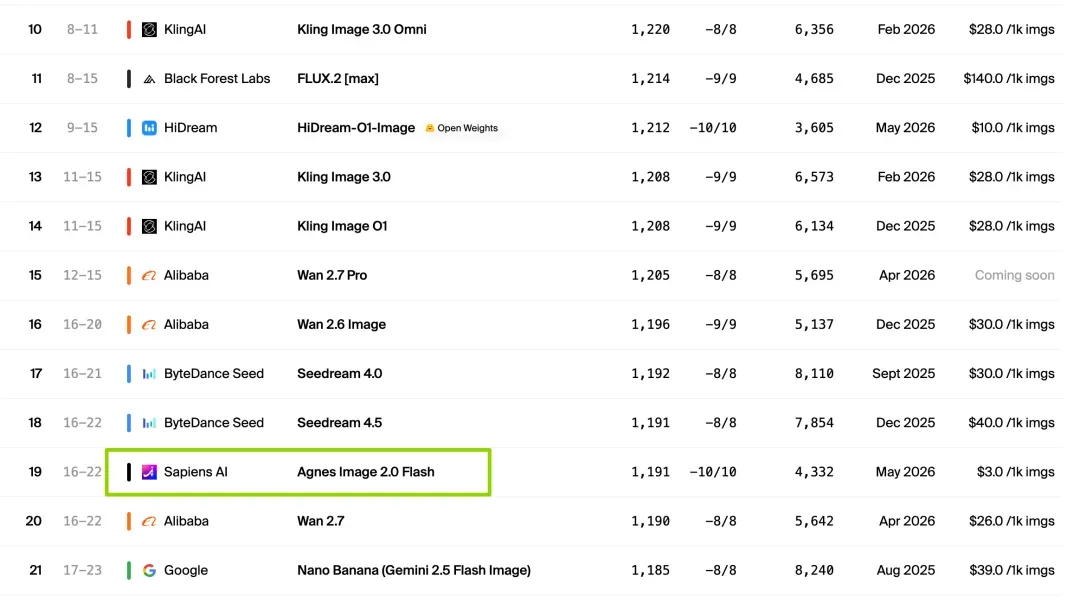
支持图生图、多图融合、背景替换、文字修改、图像修复等功能,对电商主图、广告素材等反复调整的需求极为友好。该模型同样登上了 artificial analysis 排行榜,排名紧随 Seedream 和阿里的 Wan 2.7 模型。
实际效果相当能打。使用免费 API 输入“生成一个图片,熊猫和北极熊打架”,得到的画面如下。

视频模型 Agnes‑Video‑2.0
该视频模型支持原生音画同步,首帧/首尾帧驱动视频生成、多镜头切换等功能,分辨率可在 720P 与 1080P 之间自由选择。例如,输入“熊猫和北极熊在竹林里打架”后,即可获得一段高质量演示视频。

接入指南:详细步骤
首先,前往官方 API 平台获取密钥:platform.agnes-ai.com