Coze实战:Seedance自动化工作流搭建教程,两步生成AI短剧完整素材
此前介绍了用 Image 配合故事板与 Seedance2.0 快速生成视频的思路,但部分读者反馈操作步骤仍显繁琐。
为了进一步提效,本文将整个流程封装进扣子(Coze)工作流,只需两步就能获得全套视频制作素材:
输入一个主题,工作流自动帮你:
- 撰写完整的剧本
- 生成专业的视频故事板(附带中文标注与分镜说明)
- 输出可直接用于视频生成的提示词
拿到这些素材后,倒入可灵、即梦等工具就能产出视频。
整个过程无需手动干预,一键跑通。
先看效果(工作流运行示例):
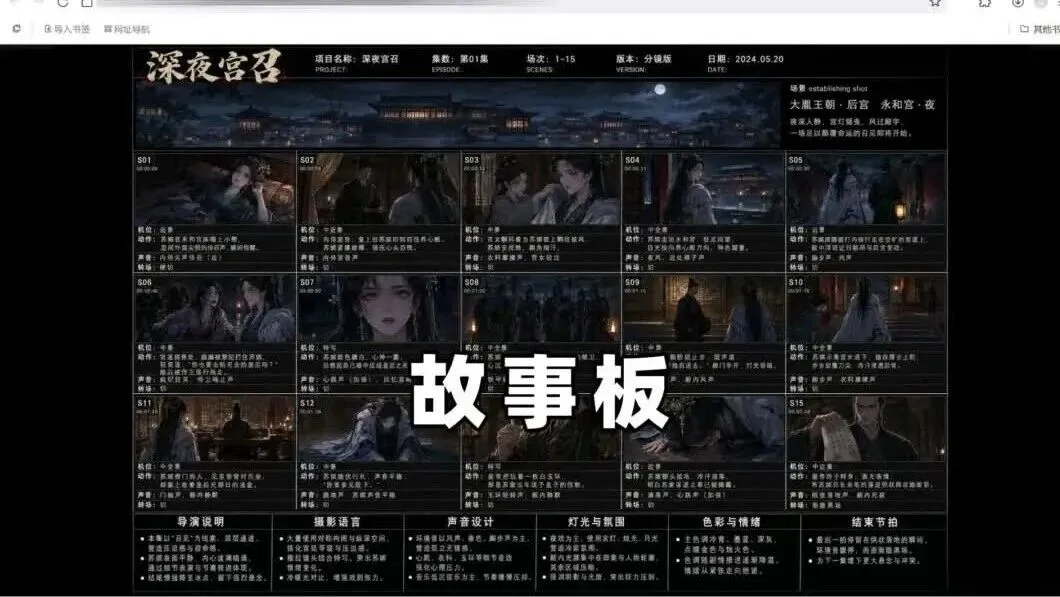
示例主题:古装宫廷悬疑剧,贵妃深夜被皇帝突然召见,表面恭顺内心恐惧,宫廷权力斗争一触即发
工作流自动生成了:
① 完整剧本(包含标题、类型、15 个场景描述)
② 专业故事板(5列×3行共15格,含中文分镜标注、镜头类型与动作说明)
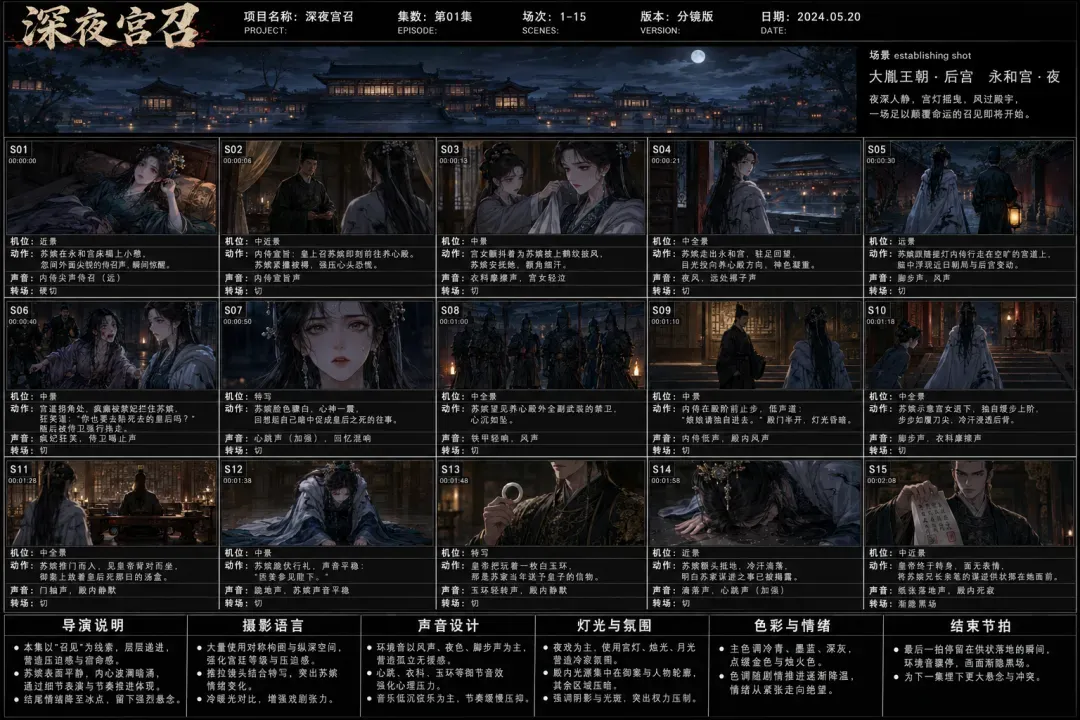
③ 视频提示词
有了这三样素材,AI短剧的制作管线就基本形成了闭环。
这套工作流并非只适用于短剧,它还内置了另外三种主流视频类型的故事板格式,方便适配不同创作需求。
- 广告/产品宣传故事板

- 知识科普视频故事板
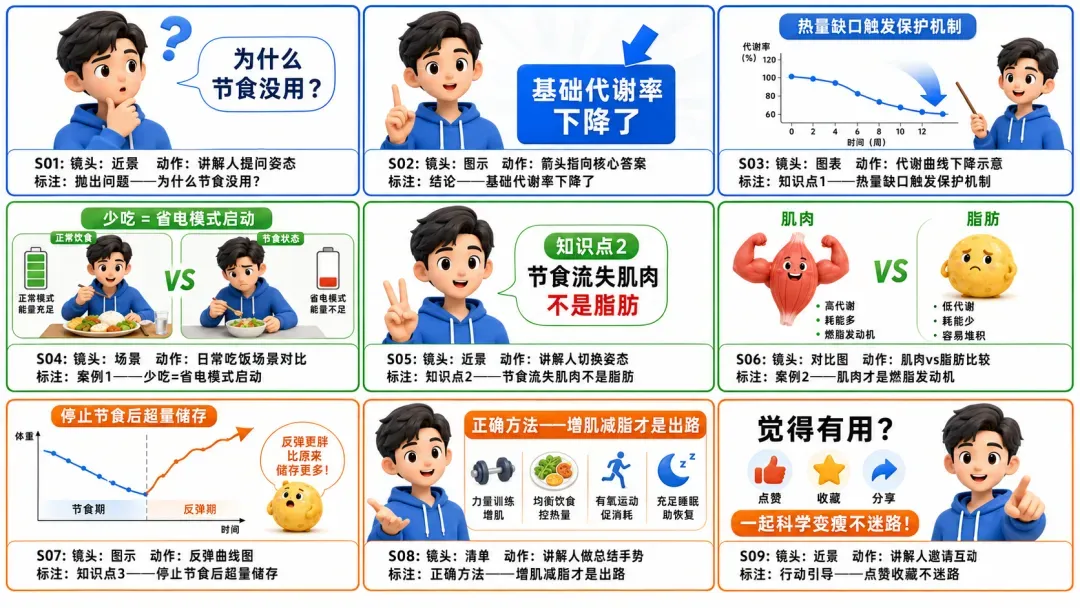
- 带货视频故事板

拿着生成的这些故事板,再去制作 AI 漫剧、商业广告或产品宣传片(根据实际情况略作调整),都可以轻松胜任。而且工作流一旦搭建完成,就可以反复使用。如果后期找到了更合适的其他故事板模板,也只需直接替换即可,灵活性极高。
下面就来一步步拆解这个 Coze 工作流的搭建全过程。
一、在扣子中新建工作流
- 打开扣子,点击“新建工作流”。
- 填写工作流的基本信息:
扣子官网:https://www.coze.cn/space
二、工作流节点搭建详解
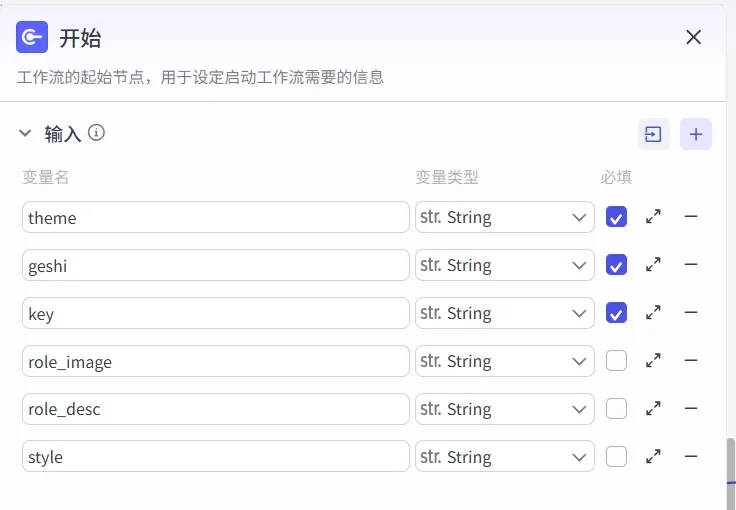
第一步:开始节点配置
在“开始”节点中,依次配置 6 个输入变量:
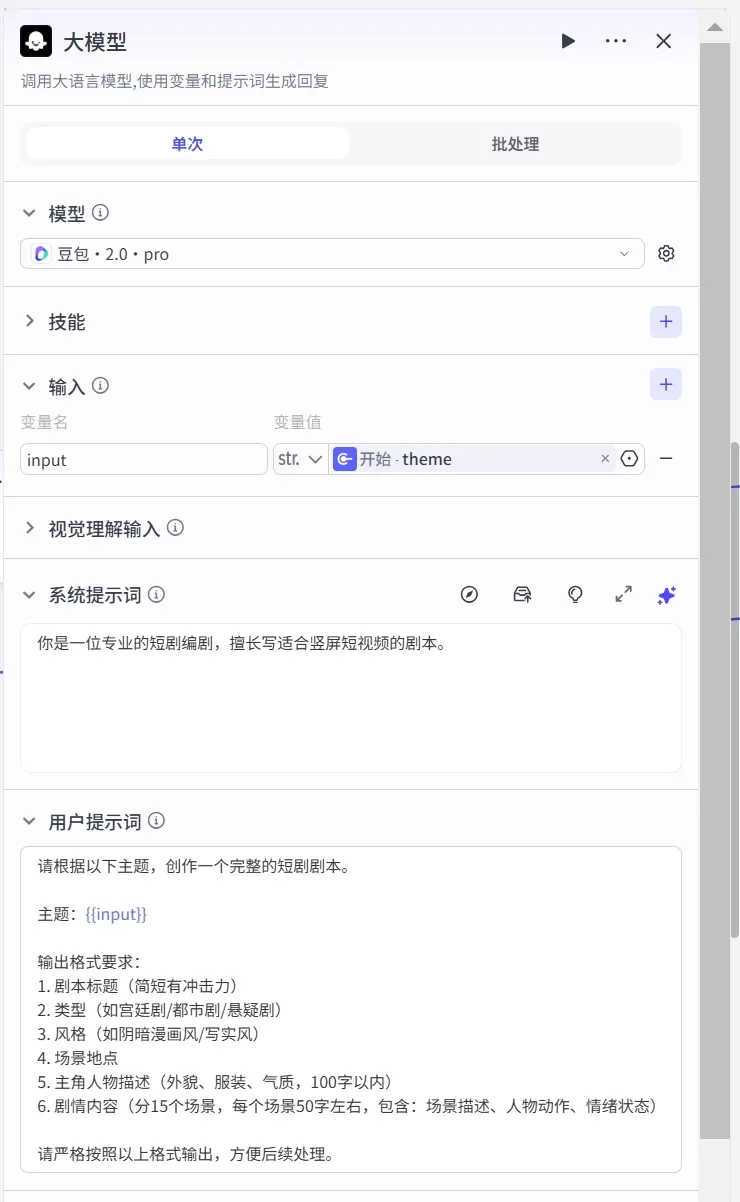
第二步:剧本生成节点
添加一个大模型节点,填写提示词,并设置好输入与输出参数,由大模型输出完整的文字剧本。
第三步:人物参考图处理
在使用 AI 生成视频、尤其是包含角色的画面时,缺少统一的人物参考图很容易导致角色形象不一致。因此这一环节非常关键。
工作流中提供了两种模式:
- 如果已有现成的人物图,直接上传 URL 即可;
- 如果没有,让工作流自动生成。
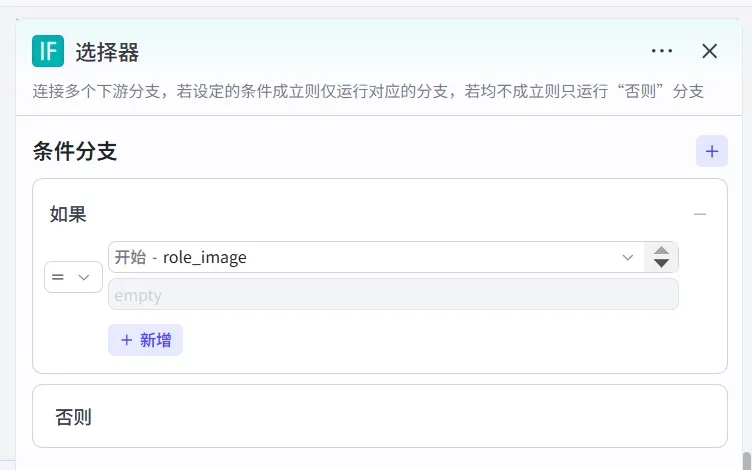
1. 添加条件判断节点
用以判定「是否已提供人物图」,从而决定跳过或执行自动生成分支。
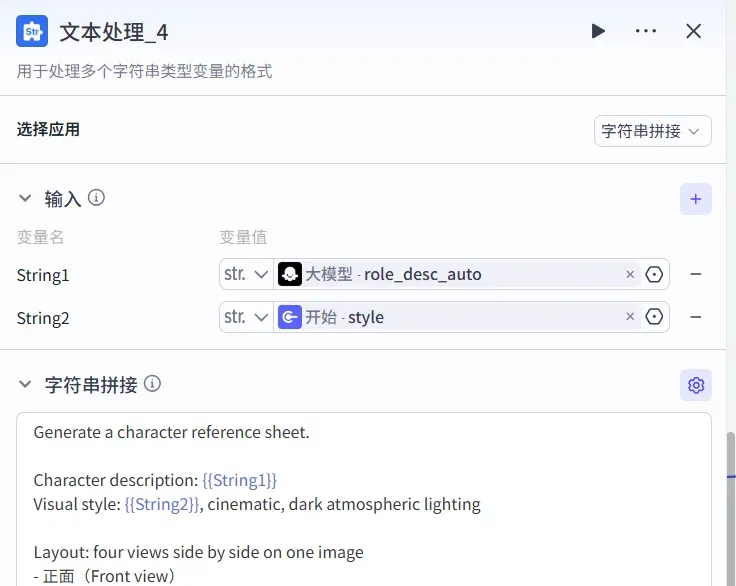
2. 添加文本处理节点
此节点负责生成用于绘制人物图的提示词。
(完整提示词见文末)
GPT-5.6未发先火:150万token、三倍更便宜,模型竞赛已转向成本与长任务实战
OpenAI Codex 的后台日志里,忽然冒出了一串从未正式公开过的模型代号。社区立刻将它与 150 万 token 的超大上下文窗口、比 Claude Fable 5 便宜三倍的定价传闻绑定。虽然 OpenAI 至今没有出面证实,但这场讨论本身已经透露出一个强烈的信号:大模型竞争的标尺,正从“谁在排行榜上分数更高”快速滑向“谁能用更低的成本完成复杂的真实任务”。
1.5M
传闻中的上下文窗口(token)
3×
比 Claude Fable 5 更便宜的传闻
6月下旬
预计的发布窗口
一条后台日志,怎么就变成了行业风向标
开发者在 Codex 后台日志里捕捉到了 iris-alpha 的踪迹。它没有任何官方解释,却瞬间点燃了社区的想象:150 万 token 上下文、更激进的 API 定价,甚至更强的代理编程能力,都被一一对应到这个代号身上。这些参数目前都还停留在猜测层面,OpenAI 既没有发布 GPT-5.6,也没有确认任何一项性能指标。
但这次“泄露”之所以能被放大成行业事件,是因为它恰好卡在了一个竞争叙事极度成熟的节骨眼上。Anthropic 已经用 Claude Fable 5 明确把“长任务代理+企业工作流”锁定为下一个主战场;谷歌的 Gemini 系列则借助自研 TPU 和云基础设施,同样在悄悄构筑长上下文的壁垒。OpenAI 若要在同一时间窗口内作出回应,必然要在上下文长度、代理深度和价格上同时出牌——而这位“iris-alpha”所暗示的,正是这三张最敏感的牌面。
150 万 token:装得下整个仓库,但守得住注意力吗?
从 GPT-5.5 的 100 万 token 到传闻中的 150 万,数字上只是半倍的扩展,可它带来的工作方式变化却是结构性的。在短上下文时代,工程师必须把代码库切成一堆小包,按相关性逐段喂入。而 150 万 token 意味着整仓的依赖关系、接口协议、测试输出、需求文档可以一次性塞给模型。
直接受益的几类典型任务:
- 代码库级理解:一次性送入仓库结构、依赖图和测试信息,大幅减少人工剪裁
- 长文档处理:合同、论文、会议纪要包不再需要强行分块
- 多步代理任务:多轮决策和中间结果被保留,无需反复压缩历史
- 企业知识检索:对 RAG 管道的强依赖会松动,但检索本身并不会退出舞台
不过,上下文拉长的同时,成本、延迟和指令稳定性上的挑战也成倍放大。真正该追问的不是“能塞进去多少 token”,而是“模型在十几万字的混杂输入里,能不能始终如一地记住约束条件、不遗漏关键事实,并稳定输出正确的工具调用”。容量增加只是门票,可靠性才是上桌的资格。
Linux真能完全替代Windows吗?深度体验报告与避坑指南

最近,越来越多的人开始讨论告别 Windows、转投 Linux 的可能性,我也完全看得出背后的逻辑。Windows 近年的变动,让不少用户重新审视自己操作系统的选择。我本人也已经完成了系统切换,说实话,这次迁移给我带来了很多意想不到的收获。
对于当下绝大多数日常场景,Linux 完全有能力成为 Windows 的优质替代。它能让你对电脑拥有更高的掌控权、更少的限制,运行效率通常也更出色,不过它并不是万能方案,并不适合所有人。
我现在的日用系统就是 Linux,接下来我会用自己的亲身经历,和你拆解切换是否值得、真实的使用感受、踩过的坑,以及这套系统究竟适合哪类人群。
- 为何考虑从 Windows 转向 Linux
- 日常主力用 Linux:实际体验如何
- 客观总结:你该不该用 Linux 替换 Windows
为何考虑从 Windows 转向 Linux?
Windows 一直都是一款省心、开箱即用的系统。但近几年来,它的一些界面和功能调整显得多余,而且常常打断使用体验。
Windows 在自定义方面门槛偏高。想要实现个性化设置,通常需要额外安装第三方软件,而系统的一些核心组件更是无法彻底卸载。
此外,系统强行集成智能助手 Copilot 也让人颇为苦恼,它会持续占用电脑资源,用户却很难完全禁用这项功能。
Windows 11 似乎总在有意识地限制用户按照自己的习惯来使用电脑。虽然网上总能找到各种变通方法,但实际操作时,就像在和系统“掰手腕”。电脑本该完全由使用者掌控,不是吗?
Linux 与 Windows 的核心区别
想换掉 Windows,主流选择实际上只有两个:macOS 和 Linux。macOS 只能运行在苹果硬件上,因此绝大多数人最终会把目光转向 Linux。
长久以来,大众对 Linux 的印象往往停留在无图形界面的服务器系统,并且一定要熟练掌握终端命令才能使用。
我在深入了解后发现,很多对 Linux 的刻板印象并不成立。它真正的亮点在于:
- 高度可定制:不需要借助第三方工具,就可以自由调整桌面外观、操作流程乃至系统运行方式。
- 无冗余捆绑:系统初始状态精简干净,用户只需要按需安装自己所必需的软件即可。
- 性能出色、资源占用低:没有杂乱的预装程序,加上 Linux 内核对低配设备极佳的支持,整机运行非常高效。
- 天然适配开发场景:对 Python、C++、Rust 等编程语言的支持远优于 Windows;Docker、Docker Compose、Git 等开发工具原生深度集成在终端中。
- 免费且开源:Linux 属于开源系统,绝大多数发行版完全免费,没有隐性收费。整个社区也以开源为核心理念,并不提倡付费闭源软件。
人们不愿切换到 Linux 的原因
尽管优势明显,仍然有很多人犹豫不决。我当初打算换系统时,也同样有过不少顾虑,下面分享一下我是如何逐个克服的。
MindFS:开源Agent远程网关,将本地AI CLI无缝延伸至手机与平板
远程访问 · AI Agent · 终端工具
MindFS 是一个开源网关,让你在本机跑 Agent CLI 的同时,通过浏览器把会话、文件和终端能力搬到手机、平板或其他设备上。
17+
支持 Agent CLI
AGPL-3.0
开源协议
<10MB
单文件安装包
刚在本机搭好一个 AI 编程 Agent 的终端 CLI,体验畅快,可一旦离开座位,整个交互链路就会断掉。过往的 session 滞留在本地,日志只能回到主机翻阅,手机或第二台设备完全无法触达。MindFS 正是为填补这个断层面设计出来的开源网关,让你在本地跑着 Claude Code、Codex、Qwen 等 Agent 的同时,将操作窗口、文件和历史会话一并映射到任意远程设备上,保持对话延续。
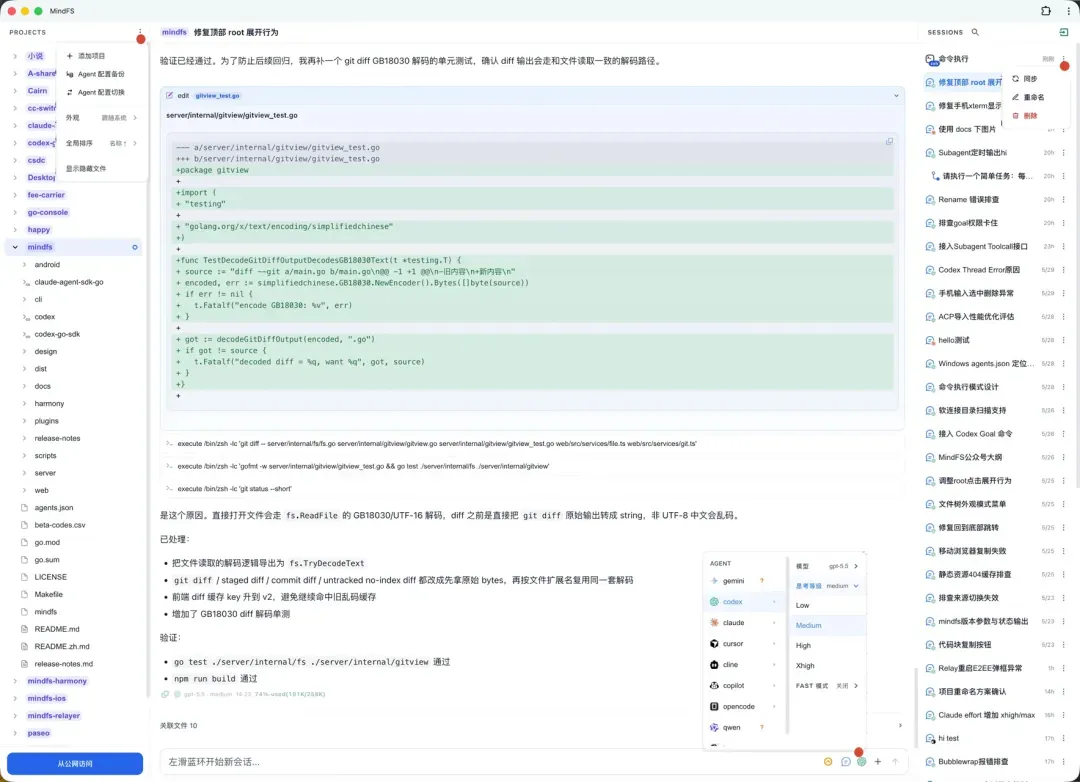
MindFS 的定位与核心能力
MindFS 本质上是一个 Agent 远程访问网关加结果可视化层。它坐落在本机 Agent CLI 和浏览器之间,负责转发对话流、文件树和工具调用流,让同一份 Agent 会话能被多个终端看到并继续推进。官方仓库为 a9gent/mindfs,采用 AGPL-3.0 协议。开发团队同时运营着 relay 服务 relay.a9gent.com,为那些不想折腾端口映射的用户提供一条公网可达的访问通道。
它自身不捆绑任何模型,也不内嵌 Agent,只专注于打通“输入‑输出”的全路径。底层的智能替换工作交给你本机已安装的 Claude Code、OpenAI Codex、Gemini CLI、Cursor、Copilot CLI、Qwen、Kimi、Hermes、OpenClaw 等 17 个主流 Agent CLI。安装时你需要主动声明当前使用的 Agent,MindFS 会通过已有配置去发现并代理它们,透明地接管交互。
适用场景:四种典型困境的打通方式
最常见的一个使用场景就是“用 iPad/Android 躺在床上查看电脑上跑着的 Agent”。“远端”不必是云服务器,而可以是除本机外的任何一种浏览器交互入口。在四种高频需求里,MindFS 都能给出直接路径:
Understand Anything:一键生成代码知识图谱,看懂任何陌生项目

一个新项目动辄 20 万行代码,别人花几天都理不清的架构,现在一条命令就能输出为可交互的知识图谱。Understand Anything 把“读懂一个项目”从新人的苦差事变成了几小时的探险。
覆盖 15+ 平台 | 6 个分析 Agent | MIT 开源协议
先说结论:它不只是一个 AI 代码分析工具
Understand Anything 是以插件形态嵌入 Claude Code、Codex、Cursor、Copilot 等 CLI 或编辑器的增强层。它通过多智能体流程扫描项目,将文件、函数、类与依赖关系编织成交互式知识图谱,然后给你一个可点击、可搜索、可追问的可视界面。本质上,它把代码结构变成了可探索的思维地图,让你摆脱靠目录名猜测和随机跳转来理解系统的低效方式。
项目源自 Egonex,采用 MIT 协议开源,GitHub 仓库维护详实,已提供在线演示和丰富示例。
核心用途
简单来说,它解决的是“刚接手一个陌生项目时,如何快速建立整体认知”的难题。加入新团队、继承历史代码、审查大型仓库,这些场景通常需要数天甚至数周来消化代码。 Understand Anything 的目标是把这一过程压缩到几小时:自动扫描、抽象结构、生成图谱,帮你自上而下建立起清晰的认知框架。
输出远不止一张图。除了结构视图,还能切换到业务领域视图,将代码映射为业务流、领域和步骤;甚至可以把 Karpathy 模式的 LLM Wiki 知识图谱化,将文档中的实体、论断和关系可视化。
适用场景与局限
适合经常接手或维护中大型项目的开发者,尤其是负责集成、模块拆分和团队知识传递的人。系统设计、代码评审、新人 onboarding——这些环节都能借助该工具显著降低认知负担。
不适合那些已经习惯成熟 IDE 内置导航的用户。它依赖 LLM 完成语义理解,意味着在中文项目里,模型对语言和业务术语的把握会直接影响输出质量。另外,对无权限的私密超大 monorepo 进行全量扫描会非常耗时,更推荐分阶段或按子目录执行。
功能亮点
▸ 交互式知识图谱 — 文件、函数和类变成可点击节点,支持搜索、查看关系和摘要。
▸ 业务领域视图 — 切换至 domain view,将代码结构映射为业务流和步骤。
▸ 引导式学习路径 — 自动生成按依赖排序的学习路线。
▸ 变更影响分析 — 提交前预览改动可能波及的模块。
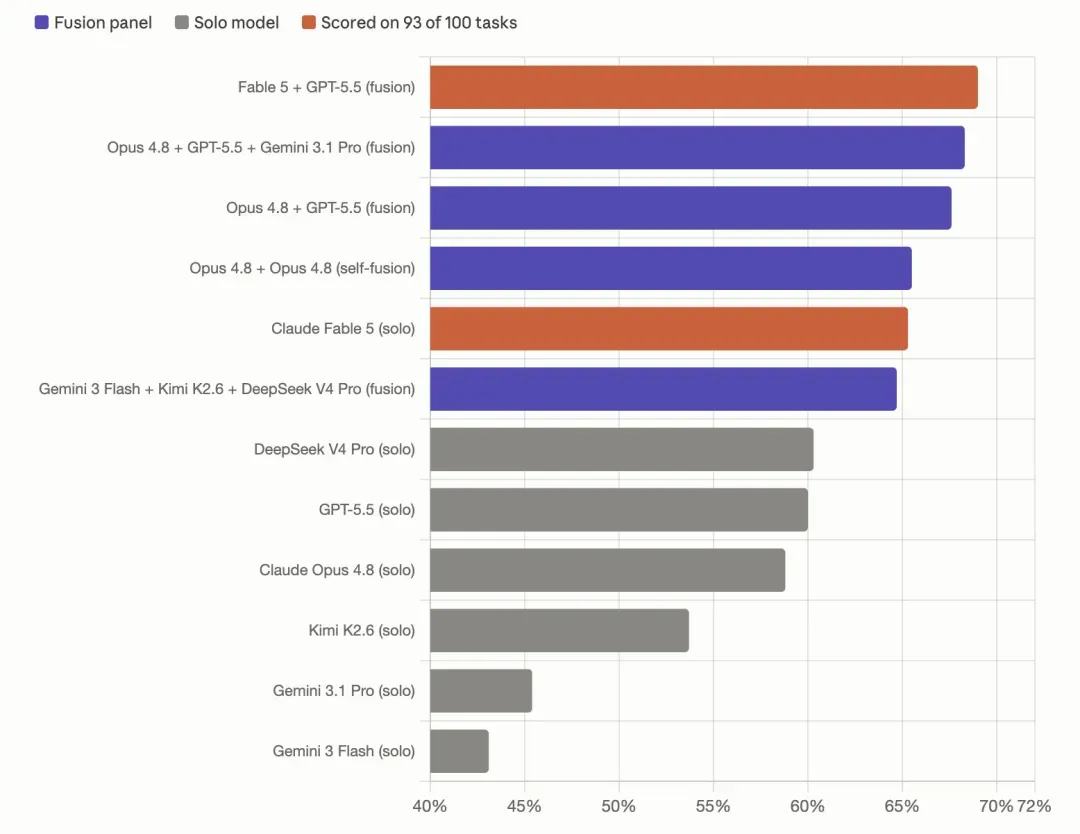
半价旗舰智能解密:OpenRouter Fusion API 模型委员会协作机制深度拆解
当前可用性:Beta 测试阶段
将同一问题同时提交给多个模型,再由裁判模型提炼共识与分歧,最终输出远超单一模型的答案——这正是 OpenRouter 新推出的 Fusion API 的核心机制。它以“模型委员会”的协作范式,声称用一半的成本实现旗舰级智能。背后并非新模型的诞生,而是一套精巧的调度与归纳架构。这对 AI 代理商、集成商和开发者意味着什么?本文将深入拆解其工作原理与最佳适用场景。
从单一模型到专家圆桌:并行调度多个模型
传统 API 调用模式中,发送一条提示词,只由一个模型返回结果。Fusion API 将这套流程重构为三个阶段:分发、收集与归纳。
系统首先将同一提示并行分发给一组模型。每个模型均可自主调用网页搜索和命令行工具,独立完成检索、推理和内容生成。
随后,一个专门的裁判模型会审阅所有返回结果,并从中抽离出四类结构化信息:共识点、矛盾点、部分覆盖的交叉内容,以及每个回答独有的洞见。
最后,裁判模型基于这些结构化信息重新整合答案,而不是简单地对多个回答取平均或投票,从而获得更均衡、更深刻的回应。
性能揭秘:共识与差异协同驱动的增益
OpenRouter 在官方发布中通报,他们在 100 个高难度研究任务上的测试显示:模型组的表现持续优于组内任意单一模型;即便组员全部采用成本更低的预算模型,其组合也能以更低总成本超越单只旗舰模型。
进一步拆解增益来源时,官方给出的贡献比大致为 3:1——约四分之三的性能提升来自模型间答案的综合整理,剩余四分之一归功于模型多样性本身。
这意味着,即便你只调用两个模型,收益也主要源于它们如何被整合,而非模型各自的绝对强度。组合方式远比模型数量更加重要。
对 AI 代理商的启发:外包式质量保障与动态调度
Fusion API 本质上是一套“外包式质量保障机制”。无需自己训练更强模型,也不必在价格战中继续内卷,只需调度多个现有模型,就能摊薄成本并提拉输出质量的上限。
对于 AI 代理商而言,这个模式的价值在于能够根据任务难度动态选择模型组:简单请求使用经济型模型,复杂任务灵活引入旗舰模型,系统输出质量不会打折,但账单却会显著优化。
普通 AI 用户同样可以通过 OpenRouter 的聊天界面或 API 直接接入 Fusion,无需绑定任何单一厂商,也不用关心底层究竟是哪个模型在担任裁判。
适用场景与潜在局限
如果你已经在使用 OpenRouter 的多模型路由,Fusion API 是对现有流程的直接升级。对于追求成本与质量平衡的团队,它提供了一个无需更换供应商的折中路径。
然而,它并非所有场景的最优解。在低延迟要求苛刻的场景下,并行调用多个模型会引入额外的时间开销;对答案一致性要求极高的生产系统,也需额外验证裁判模型的归纳逻辑是否稳定可靠。
此外,Fusion API 目前仍处于 Beta 阶段,产品页面已明确标注。进入生产环境前,建议先在低风险任务上跑通全链路验证。
可以预见,当“模型委员会”逐渐成为行业标准组件,竞争的焦点将从“单个模型谁更优”转向“谁能以更低成本高效整合多个模型”。
参考来源:OpenRouter 官方主页及 Fusion 产品页面
高迪圣家堂的光影叙事:如何用彩色玻璃与空间走向一场建筑戏剧
高迪从未将教堂仅仅视为一座结构体,他让光线成为第四维度的建造材料,用其分配空间,书写时间。

圣家堂的中殿并非被动容纳日光的容器,而是一处精心编排的光路再分配现场。穿透彩色玻璃的日光,是高迪最精准的台词;石墙、窗棂与穹顶合谋,将教堂变成一台让时间显形的戏剧装置。
光作为材料:彩色玻璃的色彩工程
高迪对待彩色玻璃的方式充满了物质性。他并不是在玻璃表面贴覆图案,而是在制造阶段便将不同颜色的玻璃层叠融入厚度。这样,进入室内的光先天带有精确的色温差序——深红、琥珀、青蓝、紫罗兰各司其位,相互交错又彼此制约。当云层缓慢游移,整套色温便随之产生一次轻柔的漂移,室内光线如同呼吸般起伏,而非一种固定的氛围设定。
也正因如此,圣家堂的石材地面与柱体不再仅仅是结构承重构件,它们同时充当了漫射光线的媒介。高迪对拱顶及柱身的曲线做了连续的微调,让阳光先在某一柱面上均匀铺展,再经过柱面反射进走廊通道。这意味着,在同一时刻,教堂内不同站位会接收到截然不同的色温光域。建筑师在这里扮演的,实际上是一位空间编剧——调度光的出场次序,控制明暗节奏,将人置于情节推进之中。



日光经过彩色玻璃落在石质地面上,将剖面图中的色彩事件直接写入现实。
东西立面的时间剧本:喜悦与受难的光影对比
高迪将教堂的西立面交付给黄昏,东立面则留给上午。这种安排并非选址的被动结果,而是他主动运用建筑朝向去控制色温与亮度强度。上午,西立面被高色温的强光洗礼,呈现出白热而明快的氛围;下午,东立面的光线变得深沉、厚重,阴影步步加深。他把喜悦立面与受难立面分别捆绑在这两种截然不同的光场强度中,使建筑叙事与太阳的运行轨迹形成直接的耦联。
这在宗教建筑史上虽非孤例,但高迪将其推向了极致的演出状态——他并非仅仅迎接光的到来,而是预先构设光的戏剧转折:云的形状、窗外树木的剪影、地面反射率,都在他的计算之内。观者需要放慢脚步,才可以真正读完这场被太阳执导的演出。


东西向立面开口使太阳处于地平线上方不同位置时,室内的色温性格随之变化。
身体在光场中的重组:动态的空间体验
在实地观察中,最直观的一条证据即是:日光在中殿地面上铺出一块块琥珀色与深红色的光池,云层掠过时,这些光池的颜色立即随之流变。观者的身体被安置于这样一道气态边界中,这远不止是装饰层面的象征隐喻,而是一个实在的空间修辞事件——光将空间切割成实时变色的区域,人由此自动调整行走速度和停留位置。
换言之,高迪建造的并非一座供人穿行并观赏内部装饰的教堂,而是一台光的接收器。人体的存在,正是让这台仪器运转起来的必要条件。所有的柱、拱、墙、窗,最终承担起对日光进行再分配的功能,人和光共同完成空间的最后一层意义。
设计启示:将光的叙事转化为空间方法
把色温作为结构层级来考虑:在项目的材料阶段,就应当将光的颜色分层嵌入物质本身,而不是留待后期用灯具去补救或模拟。让材料直接承担光的叙事功能,灯具仅处理必要的功能性照明。
通过动线来设计光场:在高迪的方法中,人的行走路线不是观光流线,而是光路的测试路径。任何对空间叙事有所追求的设计,都应先模拟人在一天内不同时段所处的位置变化,将人的动线规划为光的“观影位”,再着手其他装饰表达。
验证尺度的变量,而非固化氛围:未来的宗教或冥想空间最容易犯的错误,就是把“氛围”制成一层固定的滤镜。高迪给出的提示是,真正的氛围来自颜色、时长、运动状态的动态叠加,这三项都能被逐时段量化或枚举,然后写入设计说明,成为可操作、可验证的依据。
参考来源: ArchDaily, “Contemplative Drama: How Gaudi Shaped Light and Color at Sagrada Familia” https://www.archdaily.com/1042229/contemplative-drama-how-gaudi-shaped-light-and-color-at-sagrada-familia Sagrada Família 官方背景资料
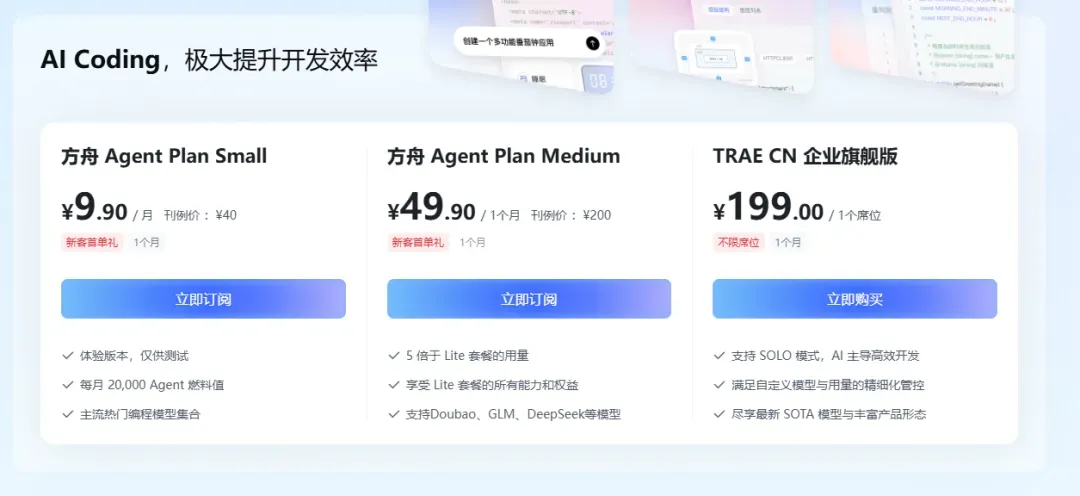
火山方舟Coding Plan大促:9.9元起享旗舰模型,首两月2.5折,再领2500万Tokens
AI大模型超值评测:火山方舟Coding Plan限时促销
Coding Plan 9.9元起,旗舰模型仅需19元
618特惠:首两月2.5折,9.9元起,另送2500万Tokens免费领取
当其他平台纷纷涨价之时,字节跳动却在618推出了大幅降价活动,令人惊喜。Coding-Plan-Lite套餐仅售9.9元,Agent Plan Small也是9.9元。
原本我已打算放弃续费,没想到竟然迎来此等优惠,当即决定趁机续订两个月。
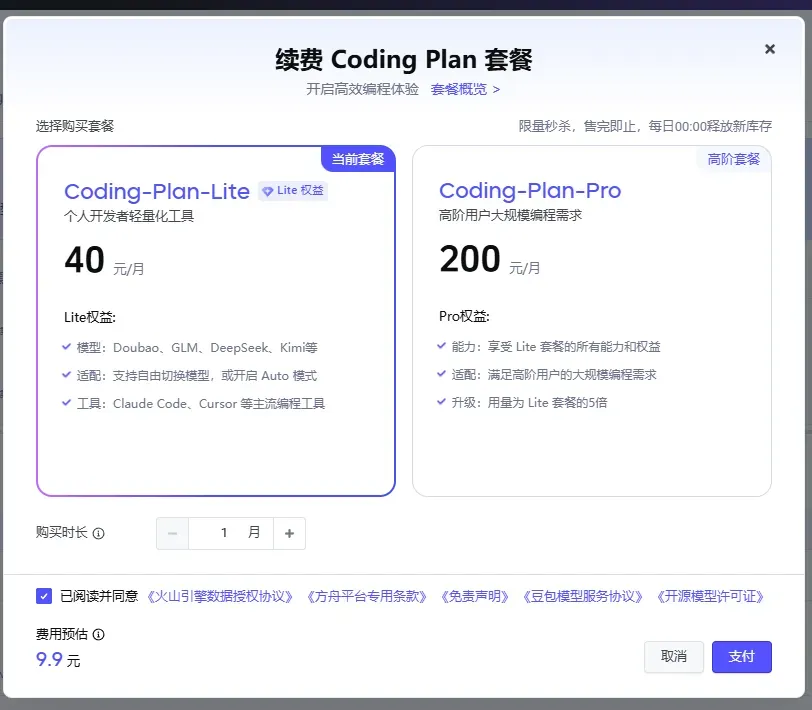
2026年6月8日至2026年8月8日期间,所有用户购买 Coding Plan Lite、Pro 套餐,均可享受首两个月 2.5 折的优惠,第三个月起恢复原价。
该优惠资格在新购、续费、升级场景中共享,一旦使用,后续即便升档或退订,也不会重新获得。
📅 活动时间:2026年6月8日至2026年8月8日
👥 活动对象:所有用户,名额有限,先到先得
参与活动的产品与资格说明
活动期间内,每个账号最多能享受两个月的特惠套餐,新购、续费、升配共享同一优惠资格。若用户首次仅订阅了一个月的特惠套餐,第二个月的特惠套餐相关操作需在首月套餐购买成功次日起才可进行。
优惠规则的详细说明
• 活动优惠资格按用户维度发放
• 新购、续费、升配共享同一优惠资格
• 用户使用优惠资格后,后续操作不会因续费、升配或换档重新获得
• 名额有限,先到先得
最近更新时间:2026.06.08
这次火山方舟618活动的优惠力度的确相当可观。Agent Plan也同步加入了降价行列。
2500万Tokens免费领
此外,登录即可领取2500万Tokens的使用额度。我此前早已领取,如今也即将使用完毕。领取方式很简单:前往火山方舟控制台,点击开通服务并完成一键授权,每个模型即可免费获得50万Tokens。
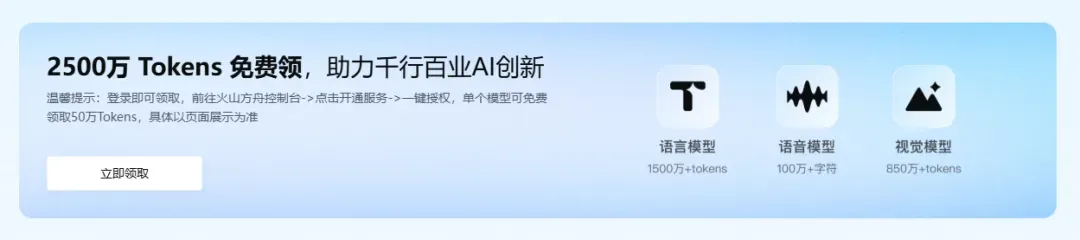
名额有限,先到先得!赶紧去体验这场降价盛宴吧。
节点小宝:国产替代Tailscale,无公网IP也能高速组网的NAS神兵利器
花大价钱购入顶配NAS,塞进20TB的电影和工作资料,结果通勤路上想看一部4K蓝光,转圈加载半小时仍无法播放;客户临时需要方案,家里的NAS文件却如何也调不出来。试过DDNS、申请过域名,甚至苦盼公网IP,最后总被运营商的对称NAT揍得毫无还手之力。
玩过市面上一堆热门远程工具的都知道,要么代码门槛高到直接劝退,要么免费版限速限到近乎瘫痪,要么弹窗不断逼你掏出几百块办会员。
直到看见群晖、极空间、绿联、飞牛、铁威马……几乎全部主流NAS厂商,就连iStore、OpenWrt这类软路由固件,都在应用商店里内置了同一个工具:节点小宝。
这个默默在远程连接领域深耕8年的国货,究竟藏着什么魔力,能让半个数码行业集体为它站台?
它远非一般的远程控制软件
很多人一听到“远程连接”,脑子里立刻浮现出那些专做远程桌面的软件。但它们根本不在一个赛道上:
普通远控:帮你接管别人的屏幕,适合远程修电脑。
节点小宝:为你的家庭局域网修建了一条专属加密高速通道,无论你身处国内哪个角落,都可以像连上家里Wi-Fi一样畅通无阻地访问所有内网设备。
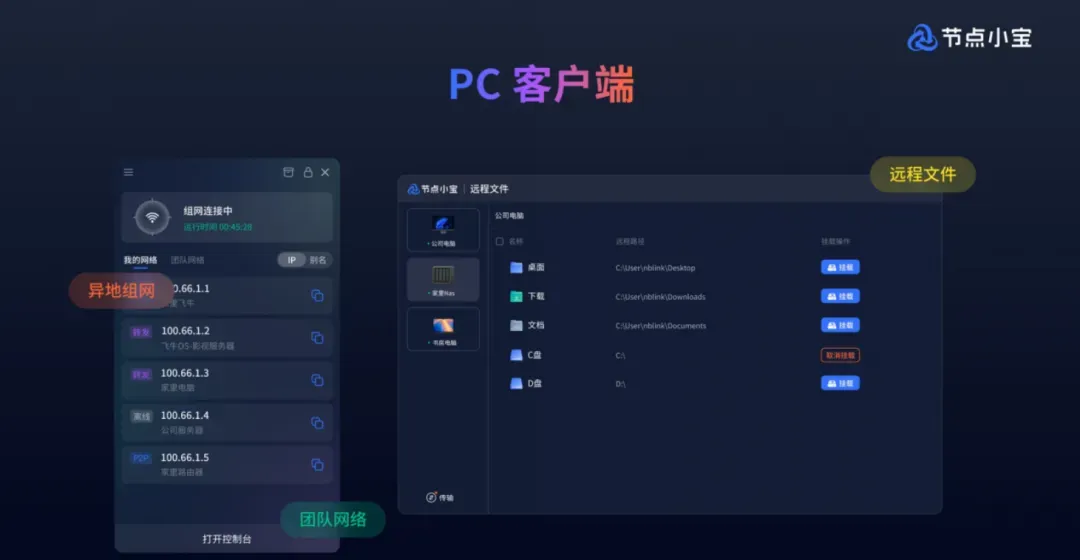
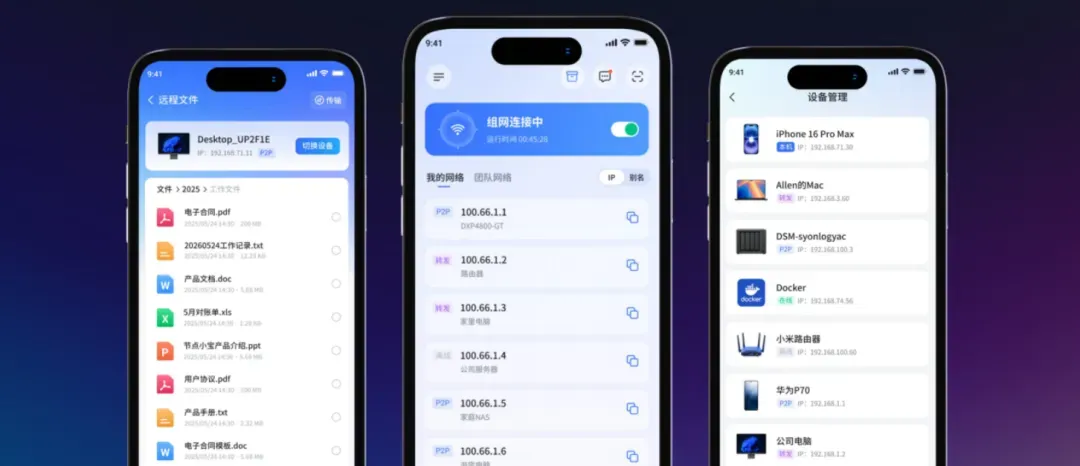
说白了,它直击所有远程玩家的终极难题:没有公网IP,照样高速跨网连接一切。
无需死记IP、不用改动路由器、不必敲一行代码,下列场景它全都能轻松驾驭:
- 通勤路上用手机直接点播NAS里的4K大片,拖动进度条秒速加载
- 公司电脑直接挂载家里NAS硬盘,拖动10GB素材就像本地复制一样流畅
- 手机串流家中高配显卡主机狂玩3A大作,延迟低到能连招互搏
- 远程管理软路由、Docker、智能家居,哪怕人在外地也能帮家人修复网络
- 一键远程开机家中的电脑,再也不用24小时待机空耗电
- 手机相册自动备份至NAS,彻底告别云盘会员费
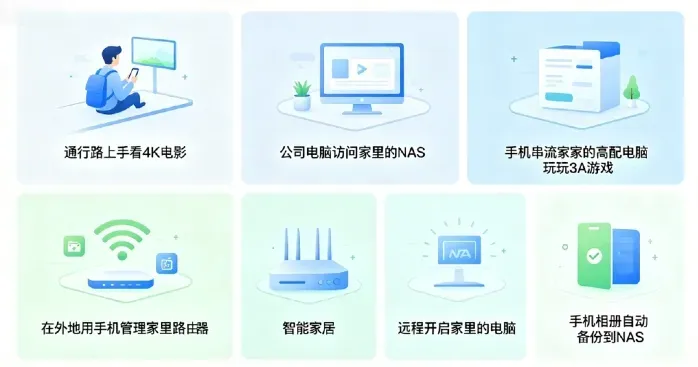
为何全行业大厂纷纷为其背书?
远程工具遍地开花,能拿到全行业主流厂商官方应用商店上架支持的,确实屈指可数。实际使用后你会发现,它把同行一直没搞定的痛点,全部解决了。
1. ### 极致零门槛:连端口号都不用你记
用过传统内网穿透的朋友都清楚,最反人类的就是手动配置端口:不同服务对应一串串数字,记得脑壳疼,输错一个号码就直接告吹。
节点小宝直接砍掉了这一步!只要在NAS上安装客户端,它便会自动扫描家里整个局域网的所有设备和服务:NAS后台、影音库、下载器、智能家居、打印机、摄像头、软路由后台,统统整理成清晰明了的列表。
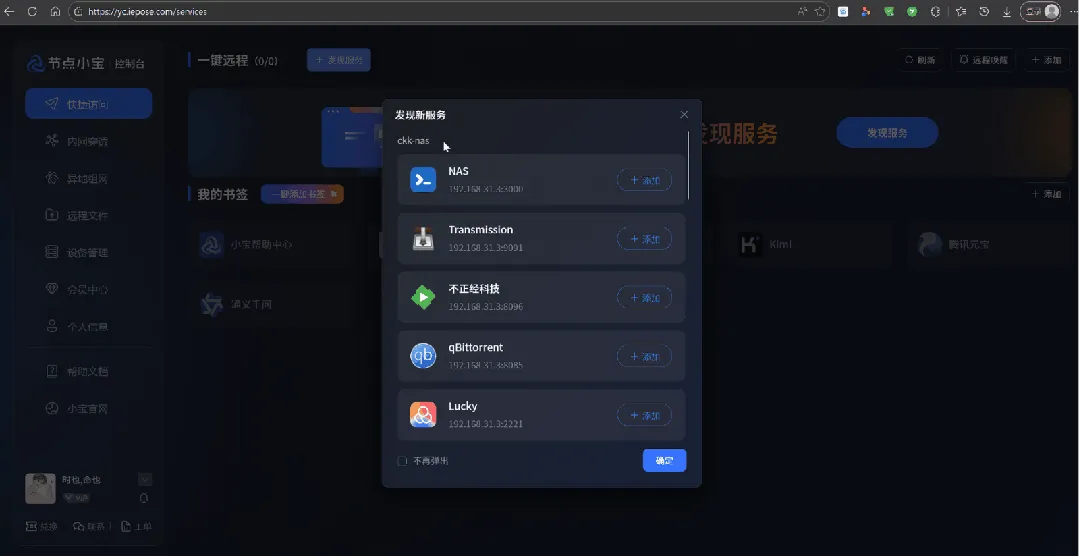
你只需要点一下“添加”,新手也能在1分钟内搞定。
2. ### 独家秘籍:单设备开网关,整网免客户端
这是我最推崇节点小宝的核心原因,也是绝大多数同类工具根本做不到的功能。
以前用别的组网工具,想访问哪台设备,就得在哪台上装客户端。结果,老式打印机装不了、电视机顶盒装不了、智能摄像头装不了……这些设备瞬间变成信息孤岛。
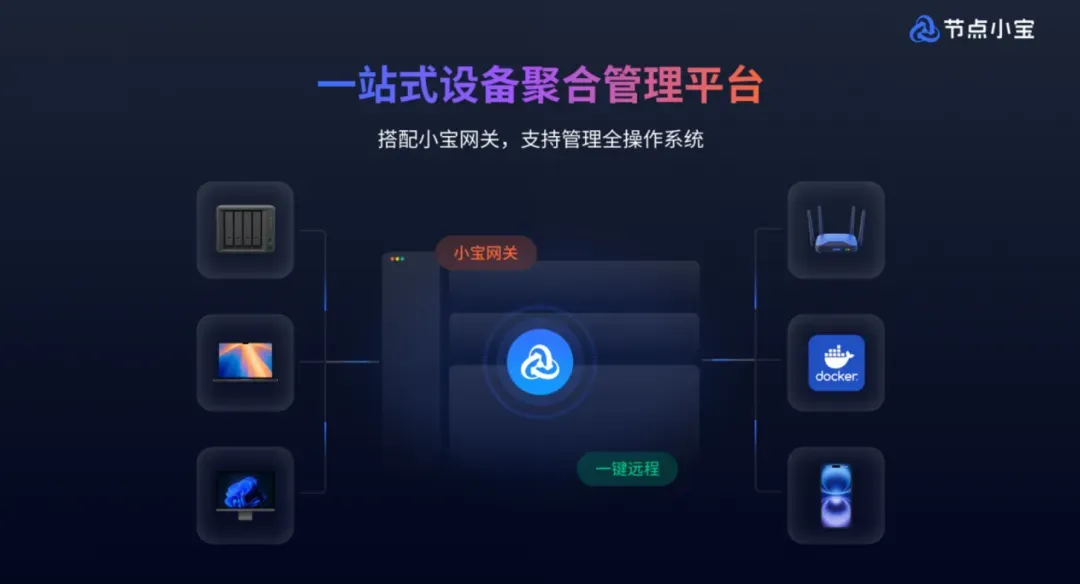
节点小宝的网关模式直接终结了这个难题:你只需在NAS或路由器上开启网关,家里所有设备——哪怕不装任何软件,也能自动加入组网,从外网直接访问!
这种体验,用过就再也回不去了。
3. ### 专攻国内网络:本土优化才是硬道理
不少国外开源工具,理论上很完美,可一遇到国内复杂的网络环境就水土不服。
国内九成以上的家用宽带都是对称型NAT架构,或者存在严重的IPv6双栈延迟,导致大量工具常常“打洞失败”,只能被迫走极其缓慢的公共中继。
节点小宝作为本土自研工具,8年来只做了一件事:把国内网络的坑全部趟平。
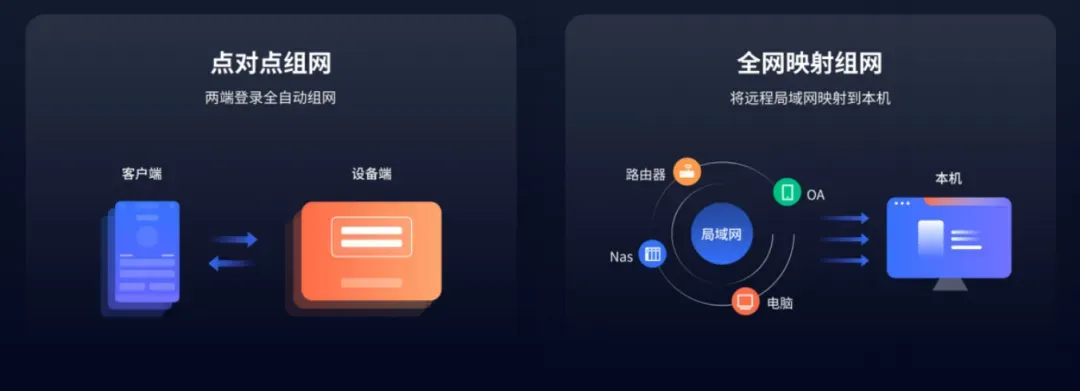
- 自研P2P打洞算法,国内直连率超过95%,一旦成功就跑满你家上行带宽,不限制速度与流量
- 智能双栈检测,自动绕开有问题的IPv6链路,再也不会无缘无故卡顿
- 全国省份部署高速中转节点,全面覆盖电信、移动、联通三大运营商
- 断点续连,网络闪断后1秒自动恢复,传输超大文件中途断网,重连后自动续传,无需重新传输

我亲身实测,在电信5G环境下,远程传输文件稳定在10MB/s,串流4K视频毫无压力;甚至在高铁上,也能流畅观看NAS里的电影。
4. ### 三重加密防护:你的数据,它连碰都不碰
远程访问最让人担忧的就是隐私泄露,毕竟存着全家人的照片、孩子的视频以及公司的机密文件。
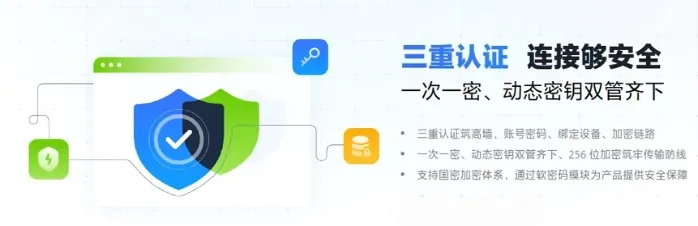
节点小宝的安全机制着实令人安心:
- 三重认证:账号密码 + 设备指纹 + 动态密钥,就算别人偷了你的密码也登录不上
- 端到端加密:所有数据只在你的设备之间直接传输,节点小宝的服务器只负责“牵线”,不缓存、不触碰任何用户内容
- ISO27001信息安全管理体系认证,企业级安全标准,数据安全有保障
5. ### 良心定价:核心功能免费,无隐性消费
在这个所有软件都在搞强制包月的时代,节点小宝简直是一股清流。
许多同类工具的免费版都有各种苛刻限制:要么限制设备数量,最多只能连3到5台;要么限速限流量,超量就断网;要么满屏广告,弹窗逼你续费。
而节点小宝:
- ✅ 基础异地组网:免费,20台设备额度,P2P直连不限速不限流量
- ✅ 内网穿透:按需购买,89元/条/年,12Mbps不限流量,用多少买多少
- ✅ 尊享版VIP:不到100元/年,包含1条穿透线 + 1台网关授权 + 40台设备额度

金丝雀倒下后劳动关系重构:AI让年轻人就业下降16%,职场梯子断裂如何自救?

2025年,斯坦福大学一份报告把AI对就业的冲击直接摆上台面:在AI高暴露岗位中,22至25岁年轻人就业相对下降了16%。但问题的核心远不止“谁被裁掉”——钱财的流动方向、职业阶梯的断裂、幸存者付出的隐形代价,才是这波技术变革真正重写的游戏规则。
核心趋势:生产力跃迁下的劳动关系变革
最近你的朋友圈大概率被两类内容反复刷屏:一是某大厂一次裁掉50%员工的所谓“内幕”,二是“AI让你的效率翻十倍”的速成课程。两种论调表面上方向截然相反,实际上指向的是同一件事:当生产力发生剧变,生产关系就必须跟上重构。这并非新鲜事。蒸汽机淘汰织布工的时候,没人在意织布工的个人感受;电气自动化时代,流水线工人被机械臂取代,也没有公司开新闻发布会宣布。每一轮生产力跃迁,都有一批人最先倒下,而倒下的往往是处在最底层、工作最标准化、最容易被替代的那个群体。
金丝雀已坠落,多数人却仍在否认空气危机
斯坦福数字经济实验室2025年8月发布的报告标题极其扎眼:《煤矿里的金丝雀》。矿工下井携带金丝雀,是因为它对毒气最敏感,先倒下就能为人报警。这份报告利用全美最大薪资系统ADP的真实工资数据,追踪了自2022年底ChatGPT问世以来的就业变化,结论令人不安:22至25岁的年轻人在AI高暴露岗位的就业相对下降了13%,到11月更新为16%。其中,22至25岁的软件工程师群体,到2025年7月就业跌幅接近20%。更讽刺的是,同一时期,相同岗位上年纪更大、经验更丰富的从业者,就业不但稳定,甚至还在增长。同样的工种,同一段时间,年轻人被挤出,资深者安然无恙——AI专挑职业阶梯的最下一级下手。
招聘端的数据同样冰冷。美国入门级岗位招聘量自2023年初以来下降了约35%,英国科技类应届岗2024年暴跌46%,2026年一项调查显示,21%的公司因引入AI直接冻结了入门招聘,47%预计2027年前会彻底取消应届岗。SignalFire对头部科技公司的研究指出,2019年至2024年间,毕业不满一年的新员工入职量缩水了50%。一旦AI能够几乎零成本生成SQL语句、调通一段代码、总结法律摘要,“花7万美元雇一个新人,等上十年养成资深”的账就再也算不过来了。而被锯断的最低一级,恰恰是新人成长为行家那唯一的通道。
资本流向揭露残酷真相:钱不会说谎
每天都有人争论:究竟是AI替代了人,还是企业借AI的名义裁员?德意志银行给这个现象起了个名字叫“AI washing”,连Sam Altman也承认,许多裁员本就该裁,AI只是个好听的由头。美国劳工统计局追踪到2026年初,那些高AI暴露岗位的整体失业率在统计上并未出现显著变化。但这场争论本身就是一记烟雾弹。真相不在裁员数字里,而在资本开支上。北美四大科技企业2026年资本开支合计约7250亿美元,同比增幅接近七成,几乎全部砸进算力建设。一边花几百亿美元囤积GPU,一边裁掉数万人——企业只是在你和一堆显卡之间,果断选择了显卡。
BCG今年3月的分析描绘出一幅更完整的图景:美国50%至55%的岗位将在未来两到三年内被AI重塑,其中10%至15%可能被彻底替代。但“重塑”不等于“消亡”。虽说软件工程师的编码效率能被AI大幅提升,但系统架构的判断、性能与安全的权衡、需求翻译这类核心能力,短期内还得依赖人。真正岌岌可危的是客服、数据录入、基础财务分析这类需求总量有限、流程高度标准化的岗位。当需求不再增长,效率提升直接等同于人手缩减。
幸存者的代价:效率降低与议价权丧失
还有一个反直觉的事实:裁员过后,74%的“幸存者”自我评估觉得工作效率不升反降。74%的HR承认,团队士气和产能需要4个月到一年才能恢复,但66%的高管却期待3个月内就能满血复活。期待与现实之间的这道裂缝,由留下的人用超负荷工作填平,而他们的议价权却降到了冰点——毕竟,亲眼目睹隔壁工位突然空出来,谁还敢开口谈条件?被裁的人好歹拿了一笔N+1补偿,一次性结清;留下来的人签下的是一份没有写明条款的协议:默认加量、默认降薪、默认随时待命,而且没有结束的期限。Anthropic的研究也证实了这种分化:高暴露职业的资深员工失业率与从前持平,但22至25岁年轻人进入这些职业的概率下降了14%。金丝雀已经在你前面那一格倒下了,别等到毒气扑面才肯相信。
历史的轮回:技术进步从不怜悯底层
回溯工业革命的历史,你会发现一条残酷的规律:新技术从不先杀掉最有经验的人,它先摧毁的是入口。蒸汽机普及,最先失业的是学徒,工厂主的利润照赚不误。电气自动化来临时,最先被替代的是操作工,工程师依然照常升迁。每一次技术跃迁,梯子的最低一级总是首先被锯断,而这一级偏偏是新人成长为专家的必经之路。芝加哥大学经济学助理教授Anders Humlum的研究揭示,蒸汽机、电力、计算机等变革性技术,花费了几十年才产生大规模的经济效应。但这一次截然不同——生成式AI的扩散速度远超以往,从ChatGPT发布到全球企业级部署,用了不到三年。适应窗口被极度压缩。世界经济论坛2026年3月的报告直接指出,美国入门级岗位在过去18个月里减少了35%,很大程度上要归因于AI。被替换的是那些“标准化、能写进SOP、能被一句prompt描述清楚”的工作,这与你个人能力无关。企业省下了今天的钱,代价却是五年、十年后招不到任何资深人才——因为再也没有人能沿着底层一步步长上去。这叫吃掉种子。
灵魂三问:你正踩在哪一级梯子上?
我每天干的活,是不是梯子最低的那一级?高度标准化、可以写进标准操作流程、能被一句提示语清晰描述的工作,不论AI眼下干不干得了,它都在排队等着接手。要么向上移动到“做判断”的区间,要么横向钻入“AI干不了的脏活、累活、复杂活”。卡在中间,最为危险。
我的全部收入,是不是押在一个老板的战略心情上?所谓稳定,不过是将你100%的现金流压在某个公司某一次战略会议的决定上。这不叫稳定,这叫极其不分散的单一押注。它从不比创业更安全,只是危险降临的方式更突然。
如果今天公司递给我一份N+1补偿,我手里除了这份工资还剩下什么?只剩一整套只在原公司管用、换个环境就失效的内部黑话和流程经验?那很危险。只剩一套可以带走、在市场上直接标价的硬本事、作品、人脉,甚至哪怕一条微小的副业现金流?那你才算真正有了底气。
没有第三条路:拥抱AI,重塑自身价值
Anthropic今年3月的劳动力市场报告给出了一个冷静的基线:截至目前,AI对整体失业率的影响尚不可测。但这份“尚可”恰恰是暴风雨前的平静。模型理论能力的覆盖与实际部署之间横着巨大的鸿沟,而这条鸿沟正以月为单位快速收窄。BCG的分析说得非常直白:那些裁掉超过AI实际替代能力员工的企业,将会目睹生产力下降、机构知识消失、关键人才流失;那些拒绝彻底重设工作模式的企业,会发现对手增长更快、利润更高;唯有把劳动力战略嵌入竞争战略的企业,才可能在下一轮洗牌中站稳脚跟。
归根结底,这波裁员的真正分水岭,既与“周期”或“AI”无关,也与被裁还是留下无关。它只区分两种人:一种人的价值绑在岗位上,岗位一消失,价值归零;另一种人的价值长在自己身上,公司只是他变现的渠道之一。前者在焦虑地问“下一波会不会轮到我”,后者早就不再问了——因为无论轮到与否,他都能把价值带走。
看透这一点,你就已经走在了时代的前头。生产力这台机器一旦开始加速,不会为任何人暂停。唯一的选择,就是主动拥抱AI,把工具用透,把能力长在自己身上。
来源
- Brynjolfsson, Chandar & Chen, “Canaries in the Coal Mine?”, Stanford Digital Economy Lab, 2025.08
- BCG, “AI Will Reshape More Jobs Than It Replaces”, 2026.03
- Anthropic, “Labor market impacts of AI: A new measure and early evidence”, 2026.03
- World Economic Forum, “How AI is changing the nature of entry level work”, 2026.03
- CNBC, “AI isn’t just ending entry-level jobs. It’s ending the career ladder”, 2025.09
- S&P Global, “AI impact on employment 2026”, 2026.06