2026年跨境智能奶泡机选品分析:AI植物奶优化与50‑80美元蓝海市场机遇

一、全球奶泡机市场全景扫描
受“第三波精品咖啡浪潮”与居家咖啡文化深度融合的推动,全球奶泡机市场正步入长期增长通道。根据Growth Market Reports的数据,2024年全球奶泡机市场规模已达到15.2亿美元,预计到2033年将攀升至25.4亿美元,年复合增长率约为5.8%。
其中,电动奶泡机作为最大的细分领域,展现出了强劲的发展潜力。据Verified Market Reports统计,该细分市场2024年的规模为2.5亿美元,预计2033年将达到4亿美元,年复合增长率为5.5%。
区域分布情况:
• 北美:约占34%(约5.2亿美元),是全球最为成熟的市场
• 欧洲:约占28%(约4.3亿美元),拥有深厚的精品咖啡传统
• 亚太:约占24%(约3.6亿美元),增速最快,年复合增长率高达7.3%
核心趋势洞察:
① 植物奶革命:燕麦奶、杏仁奶等消费群体迫切需要专用起泡程序;
② 智能化升级:AI温控可精确至±1°C,IoT互联逐渐普及;
③ DTC品牌强势崛起;
④ TikTok内容种草:仅#HomeCafe话题播放量便已突破500亿次;
⑤ 便携充电需求急剧增长。
二、竞争格局深度解析
| 品牌/型号 | 价格 | 评分 | 核心卖点 | 致命弱点 |
|---|---|---|---|---|
| Dreo BaristaMaker | $85‑100 | 4.5★ | 触控操作、全奶适配、洗碗机安全 | 拿铁微奶泡耗时超过3分钟 |
| Nespresso Aeroccino 4 | $99‑130 | 4.7★ | 4种模式、5年耐用性、超静音 | 容量偏小(4oz/8oz) |
| De’Longhi Lattemix | $180 | 4.2★ | 奶泡品质顶级、磁吸搅拌头 | 不可洗碗机清洗、价格昂贵 |
| Breville Milk Café | $200 | 4.8★ | 感应加热、25oz大容量 | 体积过大、奶泡偏厚 |
| Maestri House DualFro | $90 | 4.6★ | 3档温控、21oz大容量、热巧克力模式 | 壶嘴设计差、植物奶表现不佳、搅拌头易脱落 |
| Secura Automatic | $35‑50 | 4.5★ | 冷热双模式、2年质保 | 容量极小,仅125ml |
| Instant Brands | $30‑50 | 4.5★ | 4种模式、性价比突出 | 塑料感较强、需手洗内壁 |
| Bodum Bistro | $30‑40 | 4.4★ | 1分钟快速出泡、不粘涂层 | 奶泡稳定性不足、缺少微奶泡功能 |
价格带竞争格局:
$10‑30红海 → $30‑50黄海 → $50‑80品牌真空带(DTC最佳切入点) → $85‑100浅蓝海 → $100‑180蓝海 → $180+高端市场
2026年智能折叠洗衣机选品指南:品牌真空下的DTC突围路径
一、行业全景扫描
便携式洗衣机正经历爆发式增长。Global Growth Insights 报告显示,2025 年全球便携式洗衣机市场规模已达 76.4 亿美元,预计到 2034 年将攀升至 140.7 亿美元,复合年增长率(CAGR)保持在 8.3%。其中,折叠式洗衣机是增速最迅猛的细分类别。DataIntelo 的数据指出,2025 年全球折叠洗衣机规模为 3.005 亿美元,2034 年有望增长至 5.871 亿美元,CAGR 达到 7.8%。
中国市场的表现更为抢眼。根据奥维云网(AVC)统计,2024 年 1KG 及以下容量段——即折叠洗衣机的主战场——零售量同比增长 71.6%,零售额增幅更是高达 108%,充分反映出消费者对小件物品专属洗涤设备的迫切需求。

区域格局(便携式洗衣机整体市场):
| 区域 | 市场份额 | 2025年规模 | 核心驱动 |
|---|---|---|---|
| 亚太地区 | 41% | $3.13亿 | 城镇化提速、公寓高密度、线上购物渠道 |
| 北美 | 25% | $1.91亿 | 城市租房群体、学生宿舍、房车旅行 |
| 欧洲 | 22% | $1.68亿 | 环保理念、紧凑型住宅 |
| 中东非洲 | 12% | $0.92亿 | 紧凑酒店、高密度城市 |
趋势信号解读:
• 城市租房者贡献了总需求的 45%,学生宿舍占 25%
• 电商渠道已占据全球销售额的 28%,且仍在高速扩张
• 智能联网型产品占新发布品的 22%,折叠设计占新品比例为 25%
• 洗涤+烘干双功能影响 38% 的购买决策
• 中国线上渠道销售份额在 2025 年预计将突破 65%
2026年自动猫砂盆跨境选品深度报告:8.7亿美元市场的机遇、痛点与品牌破局策略
全球自动猫砂盆市场正在进入一个高速扩张的阶段。根据Grand View Research的调研,2024年全自动自清洁猫砂盆的全球市场规模已经达到5.593亿美元,预计到2030年将增长至8.696亿美元,年复合增长率稳定在7.8%。
支撑这一增长态势的驱动力十分明确且持续:全球范围内的宠物人性化浪潮不断加速,仅美国就有67%的家庭饲养宠物;都市独居人口和双职工比例持续上升,催生了强劲的“懒人清洁”需求;同时,多猫家庭的比例走高,例如美国约有43%的养猫家庭饲养了两只或以上的猫;加上AI智能家居生态的深化渗透,使得消费者越来越愿意为提高生活品质的自动化产品买单。
从区域分布来看,Verified Market Reports的数据显示,北美占据了40%的市场份额,是全球最大的消费市场;欧洲紧随其后,占比约30%;而亚太地区占比20%,但增速最快,年复合增长率超过10%。
一、市场竞争格局分析
| 品牌/型号 | 价格 | 评分 | 核心卖点 | 致命弱点 |
|---|---|---|---|---|
| Whisker LR4 | $699 | 4.8/5 | 旋转球仓结构极为可靠,故障率仅2.3% | 价格昂贵、体积较大(67cm)、WiFi偶有断连 |
| Whisker LR5 Pro | $899 | — | AI双摄像头、WasteID技术、可识别5只猫 | 需要$80/年的订阅服务、QR码设置过程困难 |
| Petkit PuraMax 2 | $400-500 | — | 三重除臭系统、76L大空间、体重监测功能 | App广告较多、15磅以上大猫的入口偏窄 |
| Leo’s Loo Too | $420-800 | 4.6/5 | 性价比接近LR4、配备UV消毒功能 | 蓝牙/WiFi切换不稳定、桶内空间对多猫家庭稍显拥挤 |
| Homerunpet CS106 | $699-899 | — | 106L超大容量、支持自填充猫砂 | 整机体积巨大、App翻译质量差 |
| Como T20 Pro | ~$300 | 4.3/5 | UV杀菌、极度静音、高性价比 | 仅适合18磅以下的猫、品牌较新 |
| PetSafe Crystal Pro | $160 | 4.0/5 | 入门价格极低、水晶砂除臭效果突出 | 必须使用专用水晶砂、无App控制 |
通过对竞争矩阵的梳理,可以清晰地发现,市场整体呈现出“哑铃型”结构——$150-200的区间是缺乏智能功能的红海市场;$270-350则属于浅蓝海,虽有一定的入门智能配置,但可靠性普遍不足;$400-500为中端定位,$560-899则是高端红海。在**$299-399的价格带存在着明显的品牌真空**,这正是DTC品牌切入的最佳窗口。
二、用户核心痛点与应对策略
| 痛点 | 占比 | 针对性的DTC解决方案 |
|---|---|---|
| 传感器故障/误报 | 24% | 构建三重传感器冗余系统,并加入自诊断与OTA升级能力 |
| 猫咪排斥/噪音惊吓 | 20% | 将工作噪音控制在≤48dB,设置低至20cm的入口,推出渐进式适应模式 |
| 卡砂/电机故障 | 18% | 采用大口径排砂通道、防堵塞反转设计,并实现全种类结团猫砂兼容 |
| 异味控制效果不佳 | 15% | 采用密封硅胶圈配合UV-C深紫外杀菌、活性碳与臭氧多重除臭方案 |
| 安全隐患 | 10% | 三重主动安全防护、物理防夹结构、双逃生口设计,并通过ETL/CE认证 |
| App体验差/连接不稳 | 8% | 搭载双频WiFi与BLE 5.3,即使在离线状态下也能完成基础清洁工作 |
三、品牌方案建议:PurrShift(净旋)
PurrShift的品牌定位紧扣**“让每只猫都值得拥有的自动猫砂盆”这一核心主张,聚焦可靠、安全且没有任何隐性锁定的用户体验。产品定价设定为$329**,并计划以**$279的Early Bird价格进行首发。
整机核心配置包括:旋转球仓结构、雷达+重量+红外组成的三重安全传感器冗余系统、UV-C杀菌模块、双频WiFi与BLE 5.3双模连接、≤48dB的无刷静音电机、76L充裕的大猫空间、全面兼容通用结团猫砂,并搭配20cm低入口的友好设计,外观提供莫兰迪五色选择。根据ODM测算,单台成本约在$95-130之间,对应毛利率可以达到60%-71%**。
其最大的差异化之处,源于品牌的“自由猫砂”哲学——不强制绑定任何特定猫砂品牌、不强行推行订阅制度、不在安全性能上打折扣,更不因价格而牺牲用料与做工。
2026智能水培种植机选品:把握$80-160中端真空,抢占跨境电商新蓝海

全球智能室内园艺市场正处于结构性上升期。随着该领域开创者AeroGarden的退出,市场上涌现出大量被遗弃的“孤儿用户”,而价格在80至160美元的中端智能品牌带正显现出显而易见的空白——这或许是2026年跨境电商下一个极具潜力的蓝海细分品类。
一、市场概览
根据Emergen Research的统计,2025年全球智能室内花园市场规模已达12亿美元,展望2035年有望攀升至31.1亿美元,年复合增长率约为10.0%。其中,台面式小型花园占据最大细分板块,约45.3%份额。水培技术凭借58.4%的市场占比占据主导地位,住宅应用场景贡献了64.7%的需求量。
**⚠️ 行业重大变局:**行业先驱AeroGarden在2024年宣告停产,虽于2025年尝试部分回归,但难以挽回消费者信任,数百万固有用户正急切寻求可靠的替代产品。
| 区域 | 份额 | 特征 |
|---|---|---|
| 北美 | ~38.6% | 最大市场,AeroGarden孤儿用户最集中 |
| 欧洲 | ~28% | 可持续消费、北欧设计偏好 |
| 亚太 | ~25% | 增速最快,LG、中日城市化推动 |
二、竞争格局 — 品牌真空带
当前市场结构呈现典型的“哑铃型”分布:低端白标产品(30 – 70美元)与高端奢华智能设备(350 – 1000美元)两头拥挤,而在80至160美元区间的中端智能品牌带却出现明显真空。
| 品牌 | 价格 | 评分 | 弱点 |
|---|---|---|---|
| AeroGarden Harvest | $130 | 4.5★ | 品牌停产动荡、无WiFi/App |
| Click & Grow SG3 | $100 | 4.3★ | 仅3孔、封闭生态种子舱贵 |
| Click & Grow SG9 | $200 | 4.2★ | 价格门槛高、蓝牙非WiFi |
| iDOO 12-Pod | $60-90 | 4.4★ | 无任何智能功能、白牌无品牌 |
| Rise Gardens Personal | $279 | 4.3★ | 价格昂贵、体积大 |
| Gardyn Home Kit 4.0 | $849 | 4.2★ | 天价仅极客、强制订阅 |
**核心机会:**最值得切入的价位在89至129美元,推出一款具备10-12个种植孔位、内置WiFi智能控制、开放生态兼容以及北欧简约设计的台面水培机,既可对iDOO实施“智能降维打击”,又能以绝对性价比碾压Click & Grow。
AI编程的验证新范式:用循环工程打破交付瓶颈
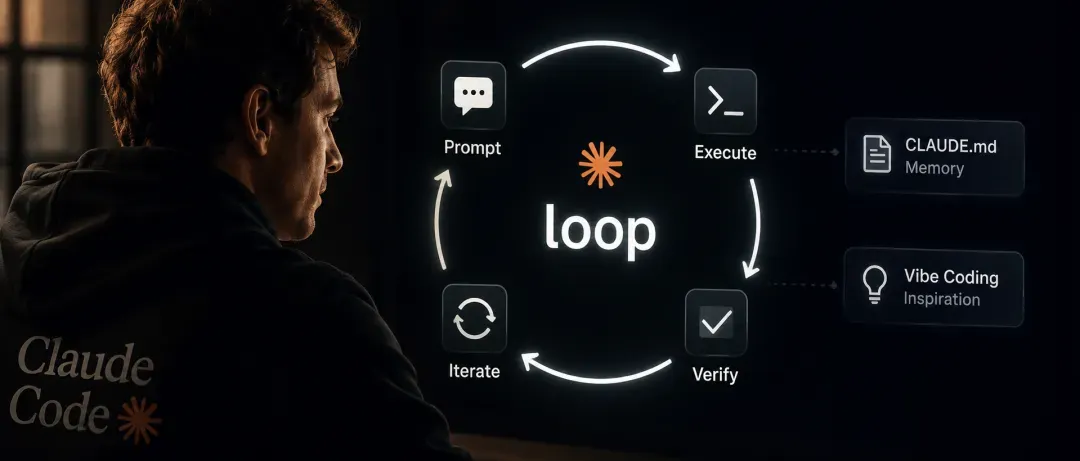
核心观察
AI编程和智能代理领域正在发生一个关键变化:生成能力已经充足,真正制约交付质量的不是“写不出来”,而是“验不过来”。Claude Code的创建者Boris Cherny已经半年不再亲自写代码,日常工作变成了“设计-生成-检查”的交替循环,让AI在几乎无人监督的状态下持续产出。这种模式正在重新定义团队交付代码的方式。
生成冗余,验证成为窄口
过去两年,文本和代码生成能力的飞跃,让“无法生成”的痛点基本消失。如今决定交付质量的不再是输出的长度或语法是否正确,而是生成结果能否通过测试、是否满足功能复选框、是否符合视觉验收标准。能力的过剩反而让验证环节的负载急剧膨胀。
工程实践里已经有清晰的信号:一些团队在引入AI代理编程后,Pull Request数量飙升200%,但代码审查和测试通过的耗时并没有同比例降低。原因在于人工审批仍是串行瓶颈,模型可以并行生成大量候选方案,却没有足够并行的验证容量去消化它们。生成的红利被串行的验证堵在了路上。
Loop Engineering的核心机制
Loop Engineering的做法是把任务拆成“生成器”和“检查器”两个角色:生成器负责产出方案,检查器负责审查输出、运行测试、给出反馈,二者形成自动闭环。循环的收敛条件通常是任务通过验收标准,或者触达预设的迭代次数上限。
这套机制被提炼为一个三级系统,用来区分任务的自动化程度:
- 第一级:当检查器有清晰、可量化的标准时,循环全自动运行,人工介入降到最低。
- 第二级:当检查器遇到判断盲区或验收条件模糊时,人类介入调整条件,再交回循环。
- 第三级:当任务本身的需求和边界需要重新定义时,问题交还人类做决策。
三级系统的价值在于从“一轮爆发”转向“多轮收敛”。对团队而言,循环本身的设计和轮次管理,成了新的工作产出,而不再是每一轮生成的具体内容。
最小可行的闭环:Karpathy的 LLM Wiki
Loop Engineering并不需要重型框架就能落地。Andrej Karpathy的 LLM Wiki 就是一个最小示范:他将个人知识整理为标准 Markdown 目录树,AI在其中持续整理、更新、跨文件链接修订,没有复杂调度系统,也没有多Agent编排,却完成了知识维护的完整闭环。
这个案例揭示了两个要点。其一,标准化格式是让AI自我检查的前提:如果文档结构参差不齐,模型根本无法批量判定一次更新是否真正完成。其二,人类真正需要设计的是系统的目标、验收标准和循环边界,而不是每一轮生成的具体文案。把“做什么”的指令,转变为“怎样才算做好”的约束,才是启动自动化闭环的钥匙。
减少人工,而非消除人工
Claude Code产品负责人Cat Wu给出的建议很直接:提前把设计系统、组件库、规范语境等上下文整理清楚,一次性注入,而不是让模型每次都重新猜测。这与Loop Engineering的思路一致:验收标准越明确,AI就越能在无人值守下完成大部分重复工作。
Loop Engineering减少的是重复执行类的人工投入,而不是把人类踢出决策链。真正能从这种模式中获益的团队,通常已经清楚如何定义交付物标准,知道要用什么类型的测试、截图、结构约束来验收AI的产出。对还在积累使用经验的团队,可以先找一个验收标准清晰的小任务跑一轮自动循环,收集失败案例,再逐步扩展适用范围。
判断
一个人生成的瓶颈在大多数场景已经被解决,现在急缺的是并行验证能力和验收标准设计。Loop Engineering的本质,是把人类从重复执行的串行链路里释放出来,将精力重新投向目标设定、标准设计和边界判断。这或许才是AI时代能够让人类真正“休息”的前提。
AI出口管制风暴:Karpathy绿卡受限,Anthropic顶级模型生死72小时

6月12日,美国商务部对Anthropic下达出口管制令,要求全面阻断外国籍人员接触其最新发布的Fable 5与Mythos 5模型。禁令范围直指Anthropic自家非美国籍员工,5月刚刚高调引入的AI巨擘Andrej Karpathy虽持有美国绿卡,也因此被挡在门外。两款旗舰模型从亮相到熄灯仅存活72小时,折射出AI顶尖人才争夺与地缘政治正面的剧烈碰撞。
模型问世仅三天,禁令突袭
6月9日,Anthropic掷出史上最强模型Fable 5与Mythos 5。仅72小时后,商务部长Howard Lutnick于6月12日下午5点21分发函Anthropic CEO Dario Amodei,援引国家安全出口管制权,勒令停止向任何外籍人员分发这两套模型。
信函措辞宽泛得惊人:不仅涵盖位于美国的境外人士,就连在美国本土的非美国公民——包括Anthropic自己的外籍员工——统统在封禁之列。Anthropic随即声明,鉴于指令范围如此之广,公司“别无选择”,只得对所有用户关闭Fable 5与Mythos 5。
“对因此给客户带来的中断,我们深表歉意。我们相信这是误解,正在全力争取尽快恢复访问。”Anthropic在官方公告中写道。
此次禁令并未波及Anthropic其他产品。即便是最新的Claude Opus 4.8等较低规格模型仍可正常使用。换句话说,这把火精准地烧向了公司最前端的武器。
- 6月9日:Anthropic发布Fable 5与Mythos 5。
- 6月12日5:21 PM ET:商务部发出管制指令。
- 6月12日晚:Anthropic全面关闭Fable 5与Mythos 5访问。
一次越狱漏洞点燃的监管风暴
Anthropic透露,政府官员在指令里提到了一种绕开Fable 5安全防线的技术。这些防护原本旨在阻止用户调动Mythos底层模型强悍的网络安全能力。Anthropic认为,被引用的越狱漏洞“非常狭窄”,仅在特定场景下才会解锁网络攻击相关功能,而且同样手法理论上也可用于OpenAI的GPT-5.5等竞品模型。
公司声明里有一段尖锐的反诘:“仅因发现一个潜在窄域越狱手法,就回收已交付给数亿人的商业模型,我们无法认同这套评判标准。若这一标准被普及,所有前沿模型提供商的新品发布实质上都会被瘫痪。”
Anthropic强调,所指漏洞影响范围有限,且在竞品模型中同样可能存在,政府未提供任何具体的国家安全细节。
来源:Anthropic官方博客 anthropic.com/news/fable-mythos-access
Karpathy为何无法触及自家模型?
这出禁令剧中最戏剧化的人物落点是Andrej Karpathy。这位OpenAI创始成员、前Tesla AI总监、斯坦福CS231n课程奠基人,5月19日刚刚宣布加入Anthropic预训练团队,目标是领导一个用Claude加速自身研发的子团队。
然而Karpathy并非美国公民,他持有EB-1杰出人才绿卡。依据此次禁令措辞,即便他身处美国本土,也被禁止访问Fable 5与Mythos 5。Reddit讨论迅速聚焦:这意味着他在Anthropic的核心工作对象,竟被自己生活所在国的法律所封禁。
Karpathy身份切片:斯洛伐克出生 → 15岁移居多伦多 → 斯坦福博士(师从李飞飞) → OpenAI创始成员 → Tesla AI总监五年 → 创办Eureka Labs → 2026年5月加入Anthropic。
国籍实锤:维基百科标注为Slovak-Canadian,Reddit与X平台多方提及EB-1绿卡身份。
政治打压、技术误判还是品牌反噬?
这并非Anthropic首次与华盛顿硬碰硬。2026年2月,特朗普下令所有联邦机构停用Anthropic模型,起因是该公司拒绝接受五角大楼的一项合同条款——条款允许将购买模型用于“任何合法目的”,而Anthropic一直坚持争取对自主武器及大规模监控的豁免权。3月,五角大楼将Anthropic列为“供应链风险”,禁止国防承包商在政府合同中使用其产品。
行业内反应两极分化。一部分人视之为特朗普政府对Anthropic更深层的政治打压,尤其考虑到白宫在AI政策上的摇摆:一面要求美国领先中国,另一面却封锁最先进模型的分发。AI政策专家Dean Ball在X上评论:“我分不清这是在针对Anthropic的法律战,还是极端国安鹰派的操作。无论如何,这简直是卡通片级别的决策。”
另一派则直指Anthropic自食其果。网络安全研究员Peter Girnus直言:“如果你每次新闻稿都把自家产品描述成弹药,最终政府也会信以为真。他们自己撰写了法律前提,还称之为品牌。”回想Mythos首次发布时,Anthropic便强调该模型“过于危险”而不宜广泛发布;Fable 5亮相同样大力宣传其安全护盾。这套叙事如今似乎被政府反向征用。
开发者面临的三重拷问
对正在或打算使用Anthropic模型的开发者、研究者和创业团队来说,这件事立即提出几个直击要害的判断:
第一,如果你是非美国公民,当前Fable 5和Mythos 5对你关上了大门。即使持有绿卡,禁令也明确囊括了“在美外籍人士”。Opus 4.8等旧模型不受影响,但若你需要前沿能力,眼下只能转向其他厂商,或等待Anthropic与政府的博弈出现转机。
AI实战力压新闻追踪:用模型与工具构筑你的智能工作流
今天来剖析我看待的国内AI自媒体生态,以及更深层的思考。
无论是近期上升势头迅猛的AI博主,还是长期占据流量的科技大V,他们输出的内容绝大多数都围绕AI的前沿快讯展开。
标题套路几乎全都长这样:
《某大模型震撼发布,未来已来》 《英伟达新一代硬件登场,行业格局被重塑》 《某公司AI突然展现出自主意识,人类将何去何从》 《腾讯的AI战略浮出水面,一盘大棋,而某某公司已明显落后》 《AI正在抢夺人类饭碗,反抗之路在哪?》 《公司用token置换岗位,结果发现token比人贵》 《Meta用AI“蒸馏”员工,随后顺势裁员》 ……
我把这类文章统称为“宏大叙事”型内容,它们天然自带流量,点击率极高。
很多人读完便会产生一种站在时代前沿的错觉,觉得信息量已经足够,茶余饭后的谈资有了,跟领导同事聊AI的素材也凑齐了。
——似乎这就够了。
但,这就够了吗?
曾经我也认为这就够了。
因为AI的推进速度实在太快,学不过来的焦灼感很容易让人疲惫。更何况我此前反复说过的那句话也多次被验证:如果拖延着不去学,过一段时间就会发觉这个知识点已经过时,不用再学了。
但现在,这句话该迭代了。因为虽然技术仍在更新,真正的产品形态已经基本固定,是时候深入其中,真正上手了。
AI的雏形已基本定型
当下的AI生态,剥开繁复的包装,本质就是「大模型」与「使用大模型的工具」两种,两者一经组合,便会释放无穷的创造力。
大模型包括DeepSeek、ChatGPT、Kimi、GLM等; 工具则是像Claude Code、Codex、Workbuddy这一类。
大模型的选用逻辑非常清晰:智商最高的用哪个,性价比最高的用哪个,交替使用即可。
工具则根据兴趣和职业选择一个到两个足以构建起工作杠杆。日常办公用Workbuddy这类的集大成者;搞视频、搞艺术创作的,可以匹配所在领域最锐利的工具。
以“大模型+工具”为基座,就可以搭出自己的工作流,然后根据具体需求,不断迭代你所需要的技能。
AI时代的所有工作方法论,归根结底就是这套逻辑。
若照着这个方式执行、学习,一段时间之后,你会变得非常不一样。
只需埋头刷新闻的方式已严重过时
在这个节点,如果依然停留于看新闻、追“宏大叙事”,其实毫无意义。
再过一阵子,你会发现自己对AI圈发生了什么如数家珍,但一上手操作就哑火了。
你知道哪个大模型最强,但不知道怎么把它的价值真正释放出来。
你知道哪家硬件最顶,但让你亲自部署一套本地大模型,完全无从下手。
最终演变成村口大爷们高谈阔论局势走向、预言未来,而真正执棋的人却在无声地操纵局势,悄悄改变着明天。
差距就是这样被拉开的,并且会越拉越大。
每个时代都不缺高谈阔论者,缺的是真正踏实上场的实干家。从古至今皆是如此:知道多少并没有太大作用,知道并亲手实战过才有真正意义。
你亲自跑过AI,才会明白为什么token是它的基础单位,markdown是它的底层文本语言; 你亲自用过大模型,才懂如何消解幻觉,怎样依据需求选配不同模型; 你亲自用过AI工具,才会理解Hermes为何如此关键,又如何用最少的prompt完成工作。
躬身入局
不再观望。
理由已经讲清楚,方法也已经给出了。现在需要的只有一个动作——下载一个工具,选一个模型,去创造你真正想创建的东西。
我希望以后你说的关于AI的看法,是经过你自己实际操作和反复印证后产生的,而不是仅仅靠浏览新闻就能拼凑出来的。
如果不知从何开始,我这里有大量实操干货可供参考,一步一步上手,绝对能触发你的启发。
Anthropic Fable 5 提示工程新纪元:长时间自主运行与迁移实战完全指南

继 Anthropic 于 6 月 9 日推出首个公开的 Mythos 级模型 Claude Fable 5 后,其官方也同步公开了全新的提示工程指南。本文浓缩该指南的核心要点,剖析 Fable 5 与此前 Claude 模型的本质区别,详解提示方法需要做出的关键调整,并揭示迁移过程中常见的陷阱。
官方实操精华
Fable 5 并非 Claude Opus 4.8 的常规迭代,而是一个全新的 Mythos 系列成员。正因为此,Anthropic 专门编写了一篇提示指南——沿用 Opus 4.8 甚至更老模型的那套提示方式,非但不能激发 Fable 5 的潜力,反而可能拉低输出质量。若你发现 Fable 5 运行耗时变长、经常反问澄清、或自发执行计划外动作,这恰是新模型的行为模式,说明你的提示语与辅助架构必须同步演进。
一、核心变革:Fable 5 与前辈模型的本质差异
Fable 5 的质变在于能够胜任前代模型无法维持的长时间、多步骤自主任务,运行持续时长从分钟级跃升至数小时甚至数天,实现量级跨越。
- 长时间自主执行:Fable 5 能在数天的目标驱动型任务中稳定输出,指令保持力较以往模型有大幅提升。单个复杂请求在高 effort 配置下可能持续运行数分钟
- 一次通过率大幅攀升:早期用户反馈,过去需要多天反复打磨的系统实现,Fable 5 往往一次性完成
- 主动澄清提问:在进入自主工作循环前,Fable 5 可能会主动抛出一连串澄清性问题,以此深入理解你的意图
- 并行子代理协同:Fable 5 能稳健地委派并协调 50 个以上的并行子代理,编排能力显著增强
- 视觉理解升维:对于信息密集的技术图片、图表和 PDF 文档,解读准确度明显提升,并能自主借助 bash 与裁剪工具处理模糊或旋转的图像
基准方面,Fable 5 在 SWE-Bench Pro 上获得 80.3%(Opus 4.8 为 69.2%),并成为首个 Hex 分析基准突破 90% 的模型。定价为输入每百万 token 10 美元,输出每百万 token 50 美元。
Claude Fable5存活仅72小时:亚马逊向美国政府告密,史上最短命AI模型离奇终结

Anthropic有史以来最强的Claude模型发布仅三天,就被迫从全球市场下架。而促使美国政府下达禁令的,竟是其最大投资方——亚马逊。
6月9日,Anthropic正式向公众开放了Claude Fable 5,这是Mythos系列中首个公开版本。它在SWE-Bench Pro评测中斩获80.3%的分数,比业内第二名高出整整11个百分点。支付平台Stripe利用该模型,仅一天便完成了一个五千万行Ruby代码库的迁移,如果全部交由人工操作,至少需要两个多月。
仅仅七十二个小时后,6月12日下午5点21分,Anthropic首席执行官Dario Amodei收到了美国商务部长Howard Lutnick的来函。这封信援引国家安全权限,命令Anthropic立即停止向任何外国公民——包括公司内部的外籍雇员——提供Fable 5和Mythos 5的访问资格。
由于Anthropic无法实时核实其数百万用户的国籍,唯一可行的做法便是一刀切地将这两个模型对所有用户关闭。就在当天晚上,Fable 5与Mythos 5从全球互联网上彻底蒸发。
从公开发布到强制下架,前后一共72小时。这堪称前沿AI模型历史上生存时间最短的一次公开发行。
亚马逊的致命背后一刀
更耐人寻味的是这项禁令的源头。多方线索齐齐指向同一个名字——亚马逊。
Axios、CNBC与NBC News先后披露,整个事件的导火索是另一家公司向商务部展示了一种成功“越狱”Fable 5的方法。而WinCentral等多家媒体进一步证实,这家公司正是亚马逊。
亚马逊既是Anthropic的云服务合作伙伴,也是它最大的资本来源。就在今年4月,双方签下了一份总价值超过1000亿美元的十年协议,Anthropic承诺将所有模型训练与部署都跑在AWS Trainium芯片上。彼时,AWS的AI业务年化营收已突破150亿美元,Claude在其中扮演了核心引擎的角色。
通过一个名为“Project Glasswing”的项目,亚马逊早早取得了Mythos的早期访问权。Glasswing是Anthropic为防御性网络安全设立的受限协作计划,最初约有50家机构受邀请参与,包括亚马逊、苹果、谷歌、微软和CrowdStrike。该项目赋予参与方使用Mythos查找软件漏洞的权利。
正是在这一权限下,亚马逊的研究人员测试Fable 5的安全边界时,发现通过精心构造的提示词组合可以绕过其防护。相关发现被迅速汇报至公司高层。据The Information和《华尔街日报》报道,亚马逊首席执行官Andy Jassy随后亲自向特朗普政府高级官员通报了这一安全隐患。
面对The Information的求证,亚马逊发言人回应称:“作为服务大量公私领域客户的领先云服务商,政府就潜在安全风险征求我们的意见并不罕见。相关讨论一旦发生,我们不会透露细节。”
换句话说,亚马逊变相承认了“讨论”确实存在。
一次局部越狱,触发全球禁令
Claude Fable 5公开仅一天,知名越狱者Pliny the Liberator就在X平台上公布了一种攻击手法:利用Unicode、同形文字与西里尔字母的组合,再结合长上下文追踪,将有害请求拆分成看似无害的片段,最后重新组合还原。他宣称自己成功击穿了安全护栏,提取出网络攻击代码、爆炸物配方和化学合成路线。
然而Anthropic坚称,政府所引以作为禁令依据的越狱方法,并非Pliny公开的那个,而是亚马逊秘密提交的那一份。公司声明写道:“我们审查了这项特定技术的演示,它被用来发现少数已知的低危漏洞。在我们看来,这些漏洞相当简单,其他没有经过越狱的公开模型同样能发现一模一样的问题。”
Anthropic强调,这属于非通用型越狱,只能在特定条件下绕过部分防护,而无法全面解锁模型能力。公司认为,若以一个局部越狱为由就叫停一款已经服务数亿用户的商业模型,那么按照同样的标准,整个行业的新模型发布都将实质上被冻结。
Anthropic声明中的原话是:“我们无法认同,一次窄口径的潜在越狱就应当成为召回一个已部署至数亿用户的商业模型的原因。若这一标准扩大应用于全行业,所有前沿模型提供商的新模型发布将几乎全面停摆。”
公司同时表示,直至今日仍不清楚政府担忧的具体国家安全威胁到底是什么,因为那封信函中并未说明。
投资者的控制权悖论
这起事件所折射出的深层结构,远比表面上的越狱争议更值得深思。
自成立以来,Anthropic始终高举AI安全与负责任部署的旗帜。它专门为神话级模型设计了分层访问体系:Mythos 5仅对经过严格审查的合作伙伴开放,Fable 5则在加载安全护栏后向公众敞开大门。这套体系从理论上讲堪称完美,将最强的能力框定在可信方手中。
然而问题恰恰出在这里——Glasswing计划中的“可信方”之一就是亚马逊。巧合的是,亚马逊同时扮演着Anthropic最大投资人、独家云服务商、以及,事后回看,最有意愿向政府递上刀子的角色的三重身份。
亚马逊在人工智能领域的布局远不止于投资Anthropic。它自有系列AI芯片(Trainium、Graviton)、自研内部模型(未曾对外公开)、自营AI助手(Rufus、Amazon Q),更有一个年化150亿美元的AWS AI业务底座。倘若Fable 5大获成功,最大受益者无疑是亚马逊:AWS可独占Trainium算力营收、赚取Bedrock平台分成,并进一步将Claude生态牢牢绑定。但若Fable 5遭遇失败或被限制,亚马逊的竞争格局也并不会受损——毕竟AWS同样支持其他竞争对手的模型。
这构成了一种绝对不对称的博弈:亚马逊赢了,名利双收;输了,风险全由Anthropic一力承担。当政府禁令真正落地,Anthropic丢掉的是旗舰产品,亚马逊失去的充其量只是投资账面上的浮盈。
这一事件,为所有引入战略投资者的AI公司敲响了一记震耳欲聋的警钟:当你的投资人同时兼任你的云服务商、你的合作伙伴、你的竞争对手、甚至政府就AI安全议题举行咨询时的对话对象,你的“安全边界”最终到底掌握在谁的手里?
连锁反应正在扩散
Claude Fable 5的下架已造成实实在在的冲击。企业和开发者被迫回退至Opus 4.8,这一代模型的能力差距肉眼可见。依赖Fable 5进行代码迁移、长文档分析的团队正面临工作流中断的困境。Anthropic原本打算在6月22日前让Pro/Max/Team用户免费体验Fable 5,借此拉动付费转化,但该计划也一并搁浅。
政策层面的影响同样深远。这是美国政府首次动用出口管制手段直接叫停一款已商用的AI模型,由此建立起一个危险的先例:只要有一家公司向商务部成功演示一项越狱手法,你的模型就可能在数小时内从全球市场彻底消失。
更值得留意的是,Anthropic本人曾多次公开呼吁政府建立AI部署的安全审批机制,CEO Dario Amodei在多篇政策文章中力主“政府应当拥有阻止不安全部署的权力”。而当这一权力终于落到自己头顶时,Anthropic的回应却是“这完全是误解”。这种看似自相矛盾的处境,恰恰撕开了当前AI治理最痛的伤疤:没有人知道那道红线究竟该划在何处。
Anthropic承诺正在努力恢复访问,但截至本文成稿,Fable 5和Mythos 5依旧处于离线状态。这场由The Information一篇报道揭开序幕的连环风暴,迫使整个AI行业直面一幅不愿承认的现实图景:你的最高能力,或许已不再由你决定何时上线。
(综合自Anthropic官方声明、TechCrunch、VentureBeat、Axios、CNBC、NBC News、The Information、华尔街日报、WinCentral等多家媒体报道)
Claude Fable实力碾压:从2D到3D《坦克大战》,零代码AI编程惊艳全场
继完美复现《超级玛丽》之后,我再次给Claude Fable布置了一个新任务:帮我做一个经典的《坦克大战》!

没想到这个任务对它来说过于轻松,于是我立刻提高要求,直接让它做了一款3D版的坦克大战。最终效果如这段演示画面所示:

它居然完整保留了原版的所有玩法机制,同时把像素风格的坦克战场全面升级为现代3D场景。试玩了几关,手感非常流畅,没有任何违和感。
Fable真正令人震撼的地方在于:第一轮直接产出完整成果,第二轮完成版本升级,第三轮继续精细打磨。全程零人工干预,自动校验、自动修复,最终交给你的就是一件可以直接使用的成品。这种能力,确实是代际领先。
接下来,我详细分享一下制作的过程。
在开始之前想问一句:如果你是一名程序员或游戏开发者,从零开始制作这样一款游戏需要多长时间?需要调试多少次,发布多少个迭代版本?
坦白说,我个人是完全做不到的——我是个纯粹的“菜鸟”,根本无法实现。
那么,来看看Claude是如何完成的吧。
这次我使用的是Claude官方桌面版。
一开始,我只输入了一句需求:
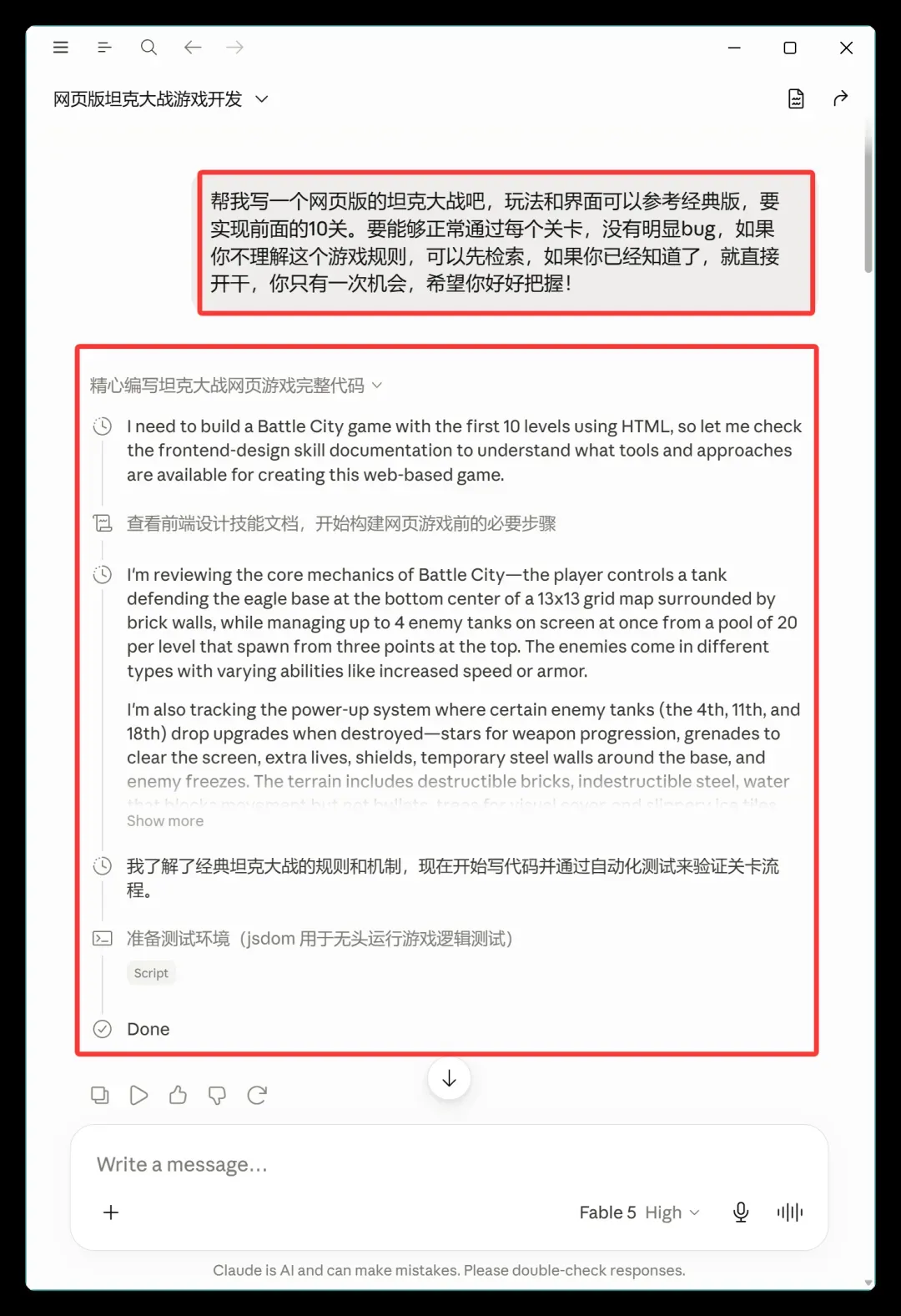
我的作用仅仅就是给出一个想法,然后对方就自动开始干活。全程我没有看过一行代码,没有修改过任何一处,更没有参与测试。
可以简要回顾一下它的制作路径。
首先,它开启了“编写一个包含前十关的坦克大战网页游戏完整代码”的任务。
我需要使用 HTML 制作一款包含前十关的坦克大战游戏,因此我要查阅前端设计相关技术文档,了解开发这款网页游戏可使用的工具与实现方法。
随后查阅前端技能文档,梳理了游戏的核心机制:
我正在梳理《坦克大战》的核心玩法:
玩家操控一辆坦克,在 13×13 的网格地图中守卫位于地图底部中央的鹰形基地,基地四周被砖墙环绕。
每个关卡共有 20 辆敌方坦克,它们会从地图上方三个点位分批刷新,画面中最多同时出现 4 辆敌方坦克。
敌方坦克分为多种类型,各自拥有不同特性,比如移动速度更快、装甲更厚等。
.....
接下来,它吃透了经典坦克大战的全部规则和机制,着手编写代码,并利用自动化测试直接验证关卡流程。
最后准备好测试环境(jsdom 用于无头运行游戏逻辑),结果却因为配额耗尽而暂停——本质上是消耗完了当轮额度。
等回蓝之后,我只说了一句“继续”:

于是它依次完成了:
- 决定继续编写游戏文件
- 分析游戏状态转换与计时器机制。
- 调试游戏碰撞逻辑,追踪子弹销毁砖块失败原因。
- 调试堆栈跟踪行号偏差问题
- 验证通过后计划进行稳定性测试。
- 所有 35 项测试都通过了。现在我来进行最后的长时间稳定性测试,然后就可以交付了。
最终的交付说明是这样的:
完成!
单文件网页版坦克大战,下载后双击即可在浏览器中玩,电脑和手机(带虚拟按键)都支持。
经典玩法完整复刻:
13×13 战场、保卫基地老鹰、每关 20 辆敌军(普通/快速/火力/重装四种,重装需 4 发)、第 4/11/18 辆闪红坦克掉道具(★火力升级、头盔护盾、时钟冻结、铁锹钢化基地、手雷全灭、坦克+1 命)、砖墙可逐层打穿、钢墙需 3 星火力、河流挡车不挡弹、森林隐蔽、冰面打滑。共 10 关,地形主题各不相同(砖阵→丛林→水网→钢堡→冰原→迷宫→最终决战)。
操作:
方向键/WASD 移动,空格/J 射击,Enter 开始/暂停,M 静音。
关于质量验证:
我用无头浏览器跑了 40+ 项自动化测试——包括连续推进全部 10 关至通关画面、4 局共 20 多分钟随机操作浸泡测试、毁砖/钢墙/击杀计分/全部 6 种道具/铁锹到期还原/生命耗尽与基地被毁两种失败流程、10 张地图出生点完整性,全部通过。过程中还真抓出并修复了一个会导致捡道具时崩溃的空引用 bug。
至此第一版就宣告完成!