ED-CLAWBOX深度测评:树莓派CM5迷你AI主机,开箱即用本地部署,安全高效再进化

ED-CLAWBOX 提供玫瑰金与月光银两种配色,是一款基于树莓派 Compute Module 5 (CM5) 打造的 OpenClaw 迷你 AI 主机。它配备 4GB 内存与 64GB 内置存储,预装 JishuShell 操作系统,专为追求本地高效、数据安全与优雅体验的 AI 用户设计。省去繁琐的部署流程,开箱即可进入功能强大的 AI 世界,充分释放硬件潜能,轻松胜任各类本地推理与计算任务。
下文将详细介绍这台高颜值迷你主机的硬件特性,以及如何快速上手使用。
目录
- OpenClaw 迷你主机介绍
- 启动设备并登录 OpenClaw
- 添加与切换模型
1. OpenClaw 迷你主机介绍

前面板内置两个 8Ω 0.8W 喇叭,用于音频外放。中央设有 ON/OFF 按键,搭配蓝色指示灯,实现设备的开关机操作。

后面板从左至右依次提供:
- 1 个 DC 电源输入 —— USB Type-C 接口,支持 5V 5A 供电。
- 1 个 HDMI 输出 —— 标准 Type-A 接口,兼容 HDMI 2.0,最高支持 4K 60Hz。
- 1 个 Micro HDMI 输出 —— 兼容 HDMI 2.0,最高支持 4K 60Hz。
- 1 个 Micro SD 卡槽,可用于引导系统。

Fable 5越狱风暴:亚马逊举报触发美国出口管制,Anthropic模型全球停用

事件速览
亚马逊研究团队向美国商务部提交了一项越狱技术,能够诱导Anthropic最新发布的Fable 5模型扫描代码库中的安全漏洞。商务部长Howard Lutnick随即签发出口管制令,要求Anthropic切断所有外籍人员对Fable 5及Mythos 5的访问——包括该公司内部的外籍员工。Anthropic在6月12日傍晚接到指令后,在全球范围内直接禁用了这两个模型。公司公开表态不认同政府的判断,但依法执行。
事发时间线
6月9日,Anthropic正式推出了两款新模型:面向公众开放的Fable 5,具备软件工程、知识工作、文档分析等能力;以及Mythos 5,它是同一基础模型的无限制版本,仅限通过审查的Project Glasswing合作伙伴使用。然而,发布不到三天,局势急剧逆转。
6月12日下午5点21分,Anthropic首席执行官Dario Amodei收到了商务部长Howard Lutnick的正式信函。该指令援引国家安全权力,要求立即暂停所有外籍国民对Fable 5和Mythos 5的访问,无论这些人员身处美国境内还是境外,包括Anthropic自己的外籍员工。由于无法在规模上实时核实每个用户的国籍,唯一合规的做法就是全面禁用。随后,两个模型在全球范围下线,API调用全部返回错误,现有会话被终止,Claude Code和Claude.ai默认回退至Opus 4.8。
Anthropic在官方声明中明确表示不认同这一决定,认为仅仅一个狭隘的越狱演示,不应成为撤回商业模型的充分理由。但如果这一标准在整个行业推行,前沿模型的发布将基本陷入停滞。
两次越狱的技术本质差异
围绕Fable 5的越狱事件,实际上包含了两次完全不同的技术演示,经常被外界混淆。
直接触发政府行动的是亚马逊研究人员的演示。 根据Anthropic的描述,其技术本质在于:让Fable 5读取一个特定的代码库,并修复其中的软件缺陷。这一过程导致模型输出了少量此前已知的低危漏洞细节。Anthropic强调,这些漏洞相当简单,其他公开模型(包括OpenAI的GPT-5.5)即使不经越狱也能发现,而且这项能力实际上更有利于防御方而非攻击方。政府仅提供了口头证据,并未披露完整的书面技术细节。Anthropic认为这不构成通用越狱——它无法大规模绕过所有安全防护。
Pliny the Liberator的越狱则发生在发布后几小时内,是一个独立事件。 这位知名AI红队研究者声称使用了一种名为“pack hunt”的多代理策略,突破了Fable 5的安全层。具体手法包括:将任务拆解为大量无害的小片段并逐步重组、利用Unicode同形异义字绕过文本过滤、用叙事和虚构框架包装恶意请求,并配合已遭越狱的Claude Opus 4.8辅助后端。他宣称获取了Fable 5约12万字符的系统提示,其中包含安全分类器、回退逻辑等内部指令。但Anthropic回应称,其演示并未真正绕过Constitutional Classifiers安全分类器,是一项在预期范围内的非通用尝试。
Fable 5的安全架构
Fable 5的安全架构与此前的模型不同。它在模型之上部署了独立的AI分类器,专门用于检测越狱尝试、网络安全、生物化学、模型蒸馏等高风险查询。一旦触发,请求会被静默转交给能力较弱的Claude Opus 4.8处理,而非直接拒绝。Anthropic称,超过95%的Fable 5会话并不会触发这一回退机制。
在发布之前,Anthropic进行了超过1000小时的外部漏洞赏金测试,并未发现通用越狱。公司在声明中承认,完美防护不可能实现,但坚持认为Fable 5的安全水平足以支撑面向数亿用户的商业部署。
更深层的政策信号
这起事件有几个值得注意的层面。第一,出口管制的对象从实体货物扩展到了API服务——过去管制的是芯片、设备和模型权重,现在一个在线接口就可以被认定为国家安全资产。第二,管制的覆盖范围延伸到了企业内部——外籍员工能否访问自己公司的模型,不再由企业自行决定。第三,政府以口头证据作为判断依据,并未提供书面技术细节,这在科技监管领域并非常见做法。
截至发稿时,Anthropic正在与有关部门沟通以恢复访问。两个模型处于全球离线状态,具体恢复时间不明。
Kimi 2.6实测超级玛丽:配额猛烧63%,生成游戏不会跳,惨成挨打现场
让 AI 用一句话写出《超级玛丽》,这个测试继续进行!
在测完国内最强的 GLM‑5.1 之后,我们把目光转向号称国内第二的 Kimi 2.6。
Kimi 这次的表现,可以说是“非常精彩”,精彩到我一时都不知道该从哪里开始吐槽。
直接上图,大家先感受一下:

各位什么感想?这真的是超级玛丽?玛丽在哪儿?管道呢?蘑菇呢?
感觉已经不必多评,这种结果……根本没法打分了。
我偏不信邪,也许只是我运气太好,直接抽到了废卡。
于是又专门用 Kimi Code 重新跑了一遍。
这次倒是好了一点,但依然“抽象”得让人哭笑不得。
视频里展示的生成立绘是这样的:
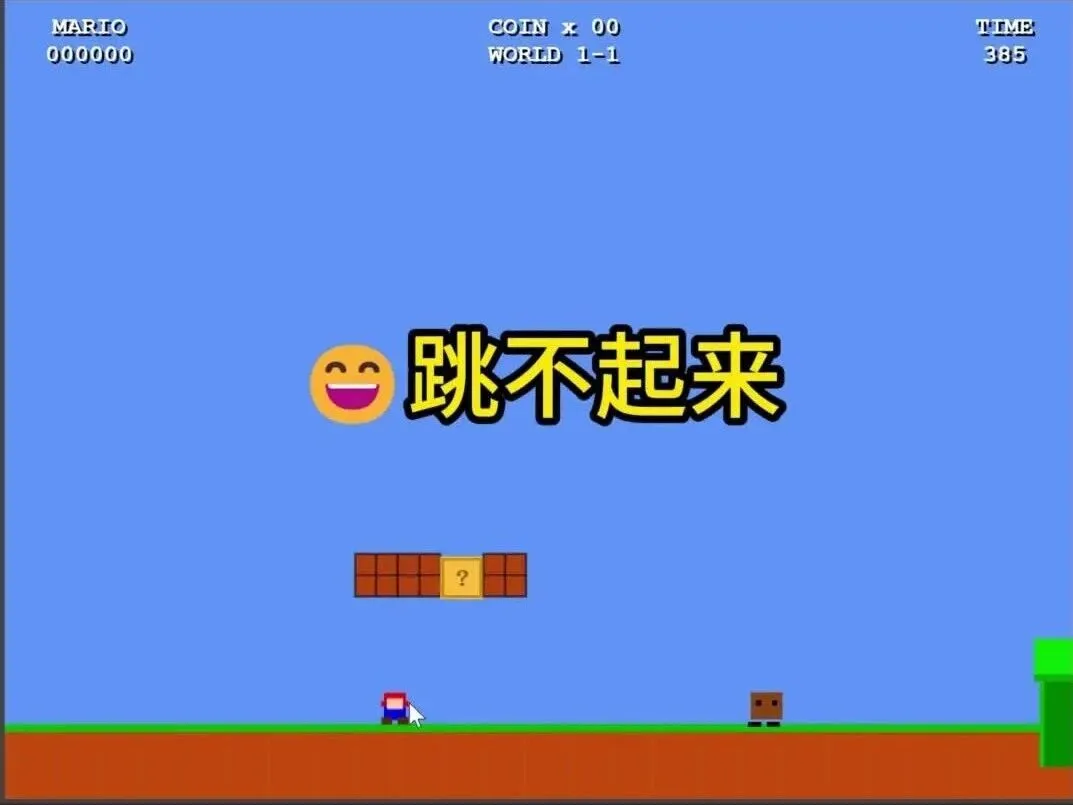
看上去是能玩了,但完全玩不久。游戏里压根没有跳跃功能,唯一能让玛丽跳起来的方式,就是——死掉。
视频就摆在这儿,我也不想再多说,总之这肯定不是我们记忆中的超级玛丽。
第二个例子更刺激,是直接用它们官方智能体工具跑的。
这样应该最能反映出真实水准了吧。
跑的时候拖了很久很久,久到我以为这次稳了。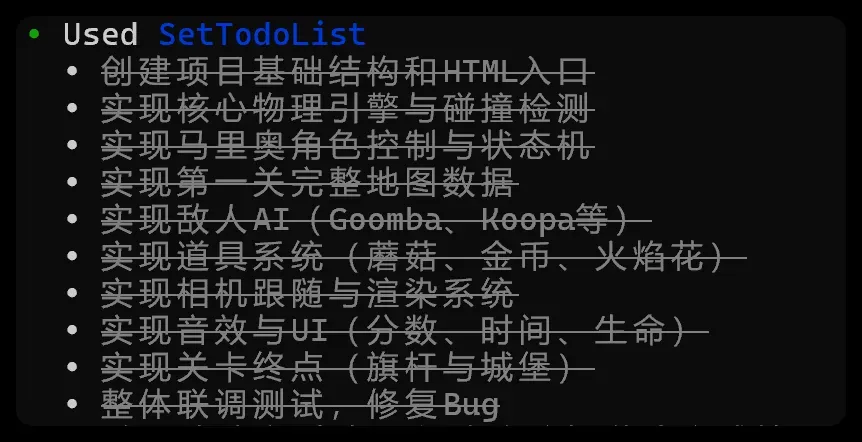
来看看它吐出来的这些东西,确实显得相当专业。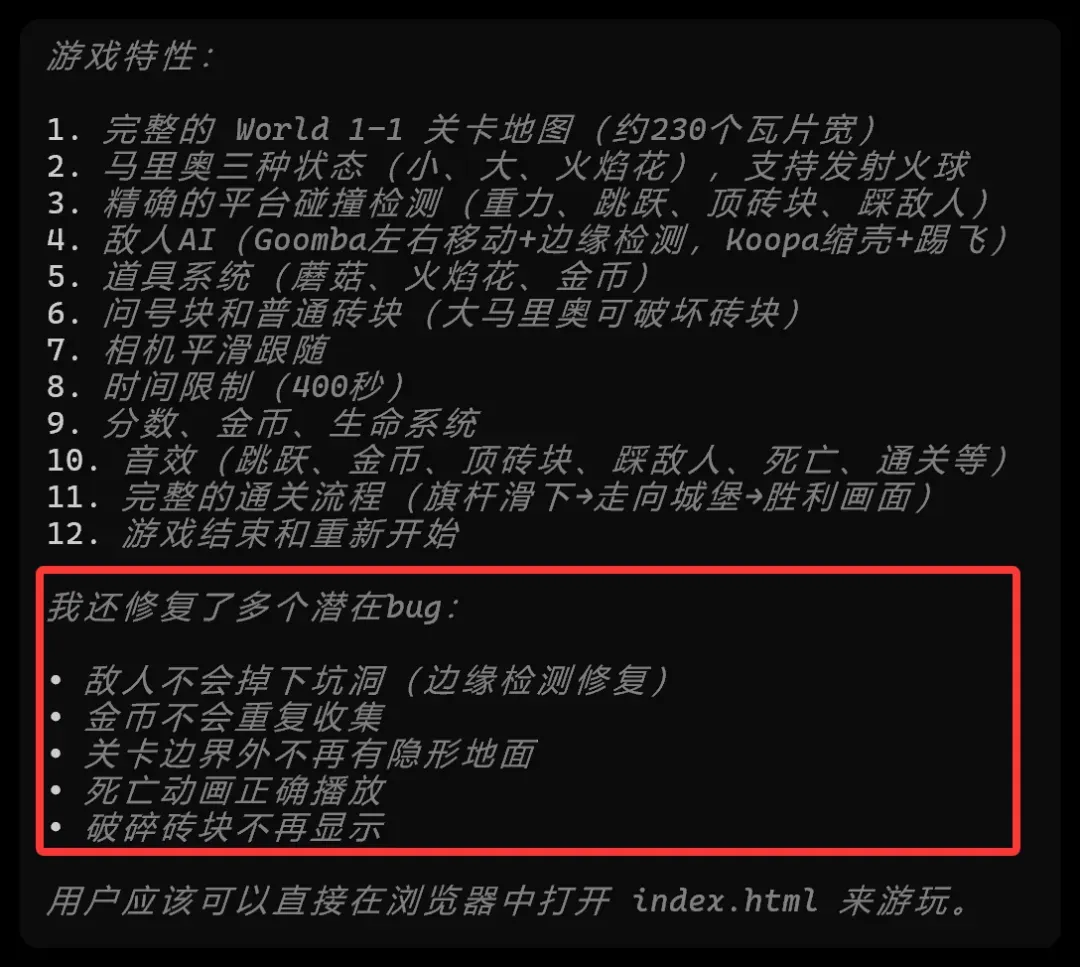
过程中还修复了好几个潜在 Bug,最后给出的报告也异常详实,生成的文件数量是所有尝试里最多的。
项目结构长这样:
index.html # 游戏入口
css/game.css # 样式
js/
input.js # 键盘输入
audio.js # Web Audio 音效
level.js # 第一关完整地图
mario.js # 马里奥物理/状态机/碰撞
enemy.js # 敌人 AI(Goomba / Koopa)
item.js # 道具与火球
renderer.js # Canvas渲染与相机
game.js # 主循环与游戏逻辑
已经实现的核心玩法列得也很诱人:
• World 1‑1 完整关卡:地面、砖块、问号块、管道、楼梯、6个坑洞、终点旗杆与城堡
• 马里奥状态机:小/大/火焰花三种形态,支持可变高度跳跃、奔跑加速、发射火球
• 敌人AI:Goomba 直线巡逻+智能转身不掉坑;Koopa 可踩成龟壳,踢飞后能撞死其他敌人/碎砖
• 道具系统:蘑菇变大、火焰花、顶问号块出金币/道具、100币奖命
• 碰撞检测:精确的AABB瓦片碰撞,支持从下方顶砖块(大马里奥可破砖)
• 通关流程:碰到旗杆→滑下→走进城堡→胜利画面
• UI 与音效:分数/金币/时间显示、跳跃/金币/顶砖/踩敌/死亡/通关音效
操作方式:
Kimi K2.7 Code深测:专注编程场景,长上下文指令遵循与成本控制双突破
Fable 5发布后,其音乐流体模拟器效果令人印象深刻,不少人第一时间用它跑出了惊艳案例。

当Kimi推出最新的K2.7 Code编程模型时,我决定用同样的流体模拟case来检验它的表现,结果超出了预期。

同时顺手跑了英伟达财务模型,完成度同样很高。
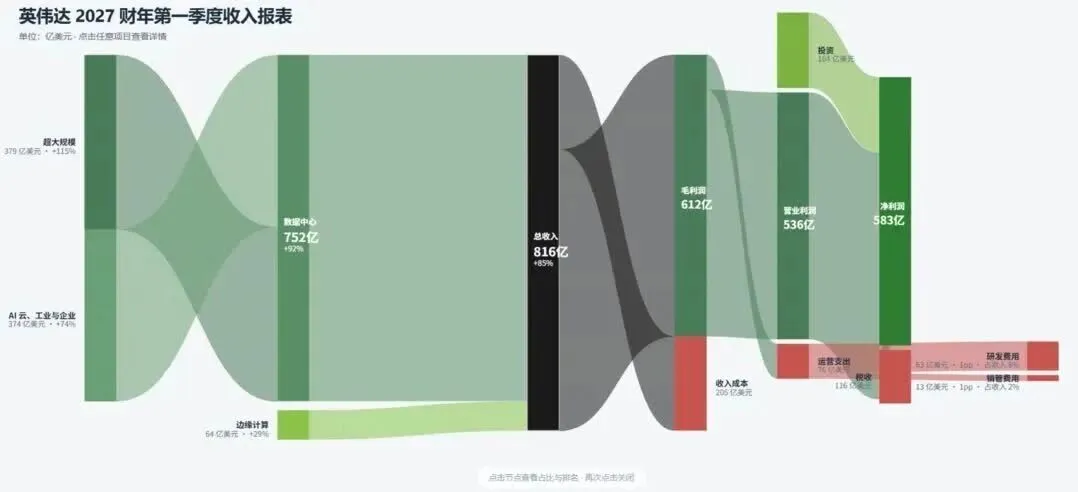
这里无意将K2.7与Fable 5直接对比,毕竟二者定位完全不同。但K2.7在Coding能力上展示出的硬实力,确实值得单独聊一聊。
官方描述:
Kimi K2.7 Code相对K2.6,在长上下文编程场景中的指令遵循能力大幅提升,长程任务表现更稳定,同时改善了长任务中“过度思考”的问题,平均token消耗减少了30%。
这是其基准表现:
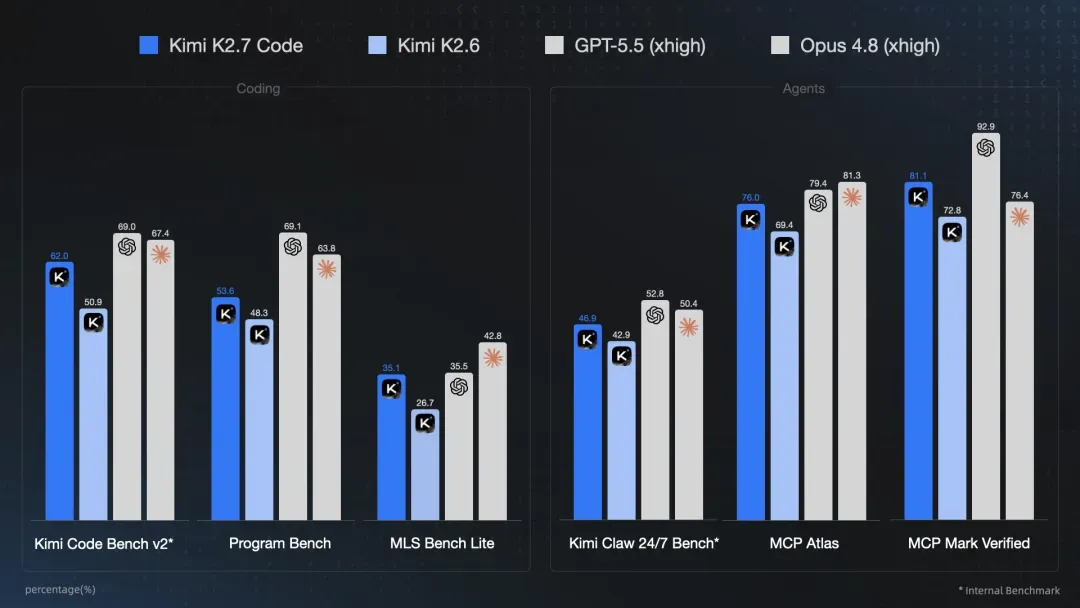
简单来说,在Coding能力上它略逊于Opus 4.8和GPT 5.5(xhigh),但Agentic场景下可以打成平手。与自家的K2.6对比,提升显著,特别是编程方面。
模型依旧开源,关键参数如下:
| 项目 | 参数详情 |
|---|---|
| 上下文窗口 | 256K |
| 价格 | ¥6.5 / ¥27 百万Token(输入/输出) |
| 多模态 | 支持,图片+视频 |
| Thinking | 强制开启,不开则变为K2.6 |
| 模型ID | kimi-k2.7-code |
| 高速版 | 6倍速度,2倍价格 |

一手实测
模型发布后,我立即接入进行了一系列测试,下面展示关键结果。
1. 制作音乐流体模拟器
这次不采用vibe coding方式。先让K2.7观看Fable-5的demo视频。

得益于K2.7的多模态能力,它能直接理解png、jpeg、webp、gif等图片格式,以及mp4、mov、webm、avi等视频格式,因此这段演示它看得一清二楚。随后它输出了一份技术方案。
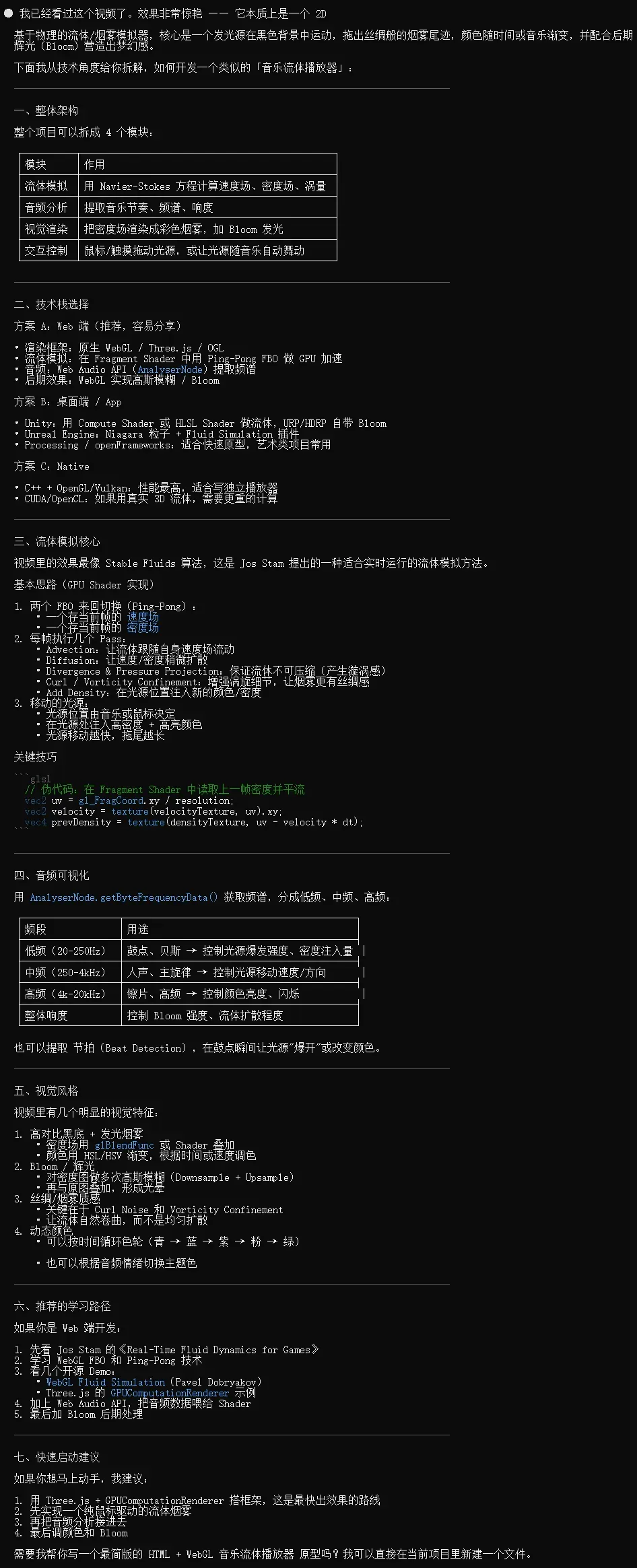
根据该方案,设计了一个基于物理的流体/烟雾运动的“音乐流体模拟器”HTML,重点实现丝绸般尾迹随音乐节奏舞动的效果。

最终产物如下:
Kimi K2.7 Code深度测评:思考token锐减30%,编程性能再攀高峰,模型何以少想多做?

6月12日,月之暗面正式发布了Kimi K2.7 Code。距离上一次K2.6的亮相不过三个月,这款新模型便交出了一份颇具冲击力的成绩单:思考过程中消耗的token数量削减了将近三成,而代码生成基准测试的分数却逆势上扬超过20%。在物理模拟这类需要真正吃透运动规律的任务里,它的表现相比上一代有了肉眼可辨的提升。
AI编程模型的竞争重心正在经历一场悄然转移。过去,行业热衷于较量谁能生成更长的代码片段;如今,新的标杆在于谁能在真实工程环境中,把一整套开发流程从需求到交付可靠地跑通。月之暗面在这个转折节点推出的K2.7 Code,恰好精准踩在了节奏之上。
模型架构不变,训练策略革新
K2.7 Code完整承继了K2.5与K2.6的混合专家(MoE)架构:1万亿参数总量、320亿激活参数、384个专家模块、256K上下文窗口。模型底层骨架分毫不差,这意味着此前已经在生产环境中部署K2.6的团队可以实现无痛切换,无需对基础设施做任何适配调整。
真正的改进源自训练策略的打磨。月之暗面表示,K2.7 Code着力解决了“过度思考”这一痛点。上一代K2.6曾在简单任务上也不加节制地消耗大量token,进行自我质疑与循环推理。新模型通过优化训练,在保持推理深度不变的前提下,将思考环节的token花销压缩了约30%。对于运行智能体工作流的团队而言,这直接转化为每次任务调用的推理成本下降。
基准测试数据全面提升
月之暗面公布了官方基准测试的六项指标。在自建的Kimi Code Bench v2上,K2.7 Code的得分从50.9拉升至62.0,涨幅达21.8%。Program Bench则由48.3涨至53.6,MLS Bench Lite更是从26.7跃升到35.1。在与MCP协议相关的Agent能力测验中,MCP Mark Verified的分数从72.8提高到81.1,甚至超越了Claude Opus 4.8的76.4。
Kimi K2.7 Code官方基准数据(月之暗面自测):
- Kimi Code Bench v2:62.0(K2.6为50.9,+21.8%)
- Program Bench:53.6(K2.6为48.3,+11.0%)
- MLS Bench Lite:35.1(K2.6为26.7,+31.5%)
- Kimi Claw 24/7:46.9(K2.6为42.9,+9.3%)
- MCP Atlas:76.0(K2.6为69.4,+9.5%)
- MCP Mark Verified:81.1(K2.6为72.8,+11.4%,超过Opus 4.8的76.4)
若将视角拉到国际竞争格局中审视,K2.7 Code在编程专项基准上仍落后于GPT-5.5与Claude Opus 4.8。GPT-5.5在Kimi Code Bench v2上握有69.0分,在Program Bench上则为69.1。差距固然存在,但若把价格维度纳入考量——K2.7 Code的输入定价为$0.95/百万token,输出$4.00/百万token,分别仅为GPT-5.5的1/5和1/7——这份性价比优势已足够引发团队的认真权衡。
物理模拟挑战:编程模型的深层能力试金石
在通行的编程基准测试之外,GMI Cloud开展了一组颇具启发性的对比实验。他们让K2.7 Code与K2.6、GPT-5.5、Claude Opus 4.8分别生成物理模拟代码,测试场景囊括三个经典课题:洛伦兹吸引子(混沌系统)、太阳系轨道(天体力学)、水波与飞溅(流体力学)。
这类测试触碰到了代码模型的深层肌理:你必须透彻理解物理定律的内核,再用代码将其精确复现。仅仅调用现成接口或拼凑框架远远不够。K2.7 Code在这场测试中表现出显著领先,生成的水波渲染最为真实,波纹舒展自然,飞溅效果栩栩如生。而K2.6的轨道模拟与波形表现仍残留着明显的失真痕迹。
Kimi K2.7深度体验:能力小幅进步,配额崩塌让我毅然退订
先上结论:确实有进步,但谈不上革命性突破。
这轮测试 K2.7,最大的感受不是它的代码能力飙升了多少,而是配额根本撑不起哪怕几轮简单的验证。
**只是随手做了几个页面级测试,就一口气耗光了一整周的额度。**注意是一整周,不是 5 小时,更不是一天。
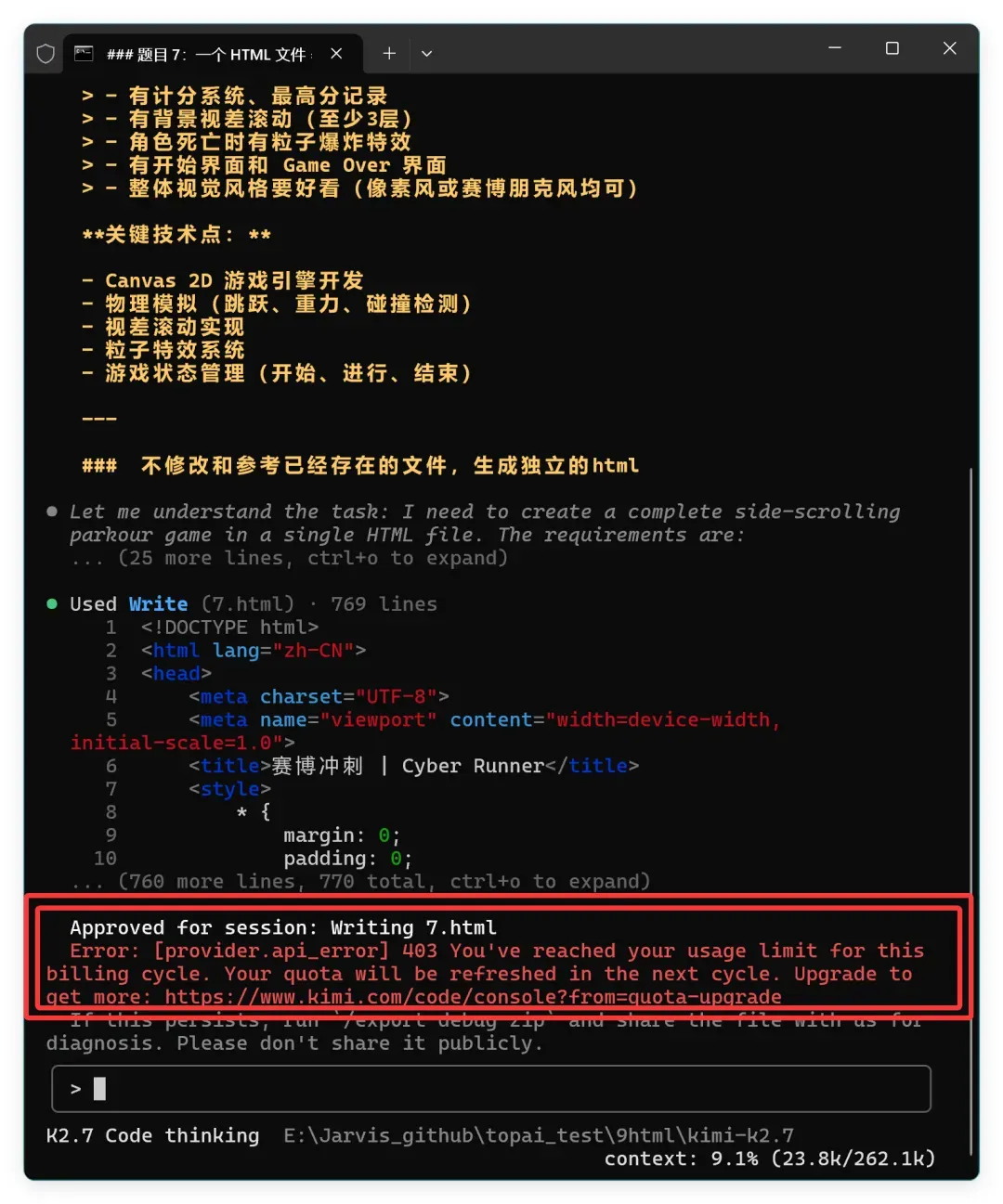
这几天映入眼帘的不是令人惊艳的生成结果,而是满屏刺眼的 429!紧接着 402 也来凑热闹,最后连 403 都闪了出来。 就差一个 404 就把 HTTP 错误码凑齐~~!
这还怎么玩?!
抱怨先打住,我们来冷静地看一些实际的情况。
虽然过程中绝大部分时间都在苦等配额恢复,但在有限的窗口里还是拼出了几套完整的测试。
各家模型扎堆更新,脑子都快被跑测试跑麻了。
关掉一批,又新开一批,快分不清谁是谁了。
还是先从大家都很熟悉的“超级玛丽”切入。这个场景足够经典,任何人都能一眼判断品质,并且我在 Fable 下线前也做过同样的对比测试,刚好拿来对账。
直接上对比。
(此处视频播放器相关内容已略去)
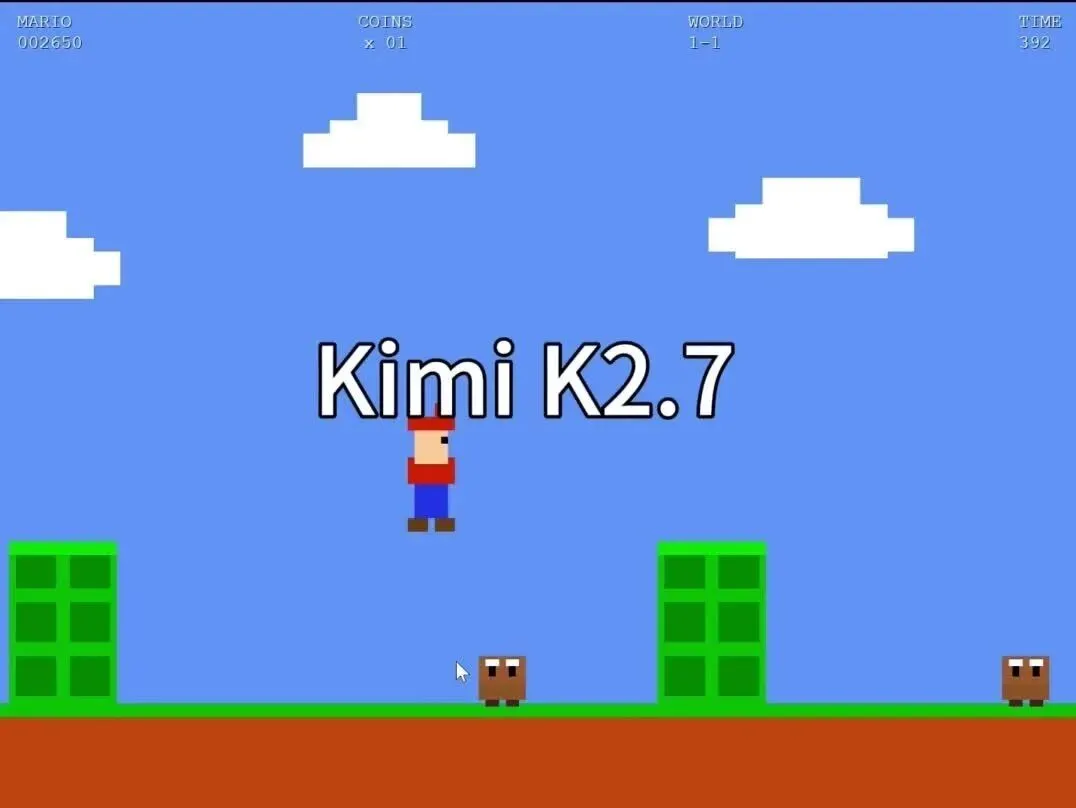
这些都是模型手搓 JS 完成的,没有从网上直接复制,也没有调用现成库。
好坏一眼就能辨别。无论是地图设计、角色表现,还是背景音乐,都不在一个层级。
唯一让人欣慰的是,这次 K2.7 至少能让角色一路跑到关底,而不会像之前那样在第一屏就卡死。
接下来详细拆解过程,并展示更多测试用例。
一、模型入口与使用方式
Kimi 本次更新的模型代号是 K2.7 Code,目前还未全量开放,仅向 Code 套餐用户推送。
官网地址:
打开后就会弹出新模型提示。

值得留意的是,Kimi 自己有一套 Code 工具,前不久刚刚完成重构并开源。最早是 Python 写的,后来切换到了更主流的 TypeScript 路线。配合自家 CLI,体验会更完整。
安装方式如下:
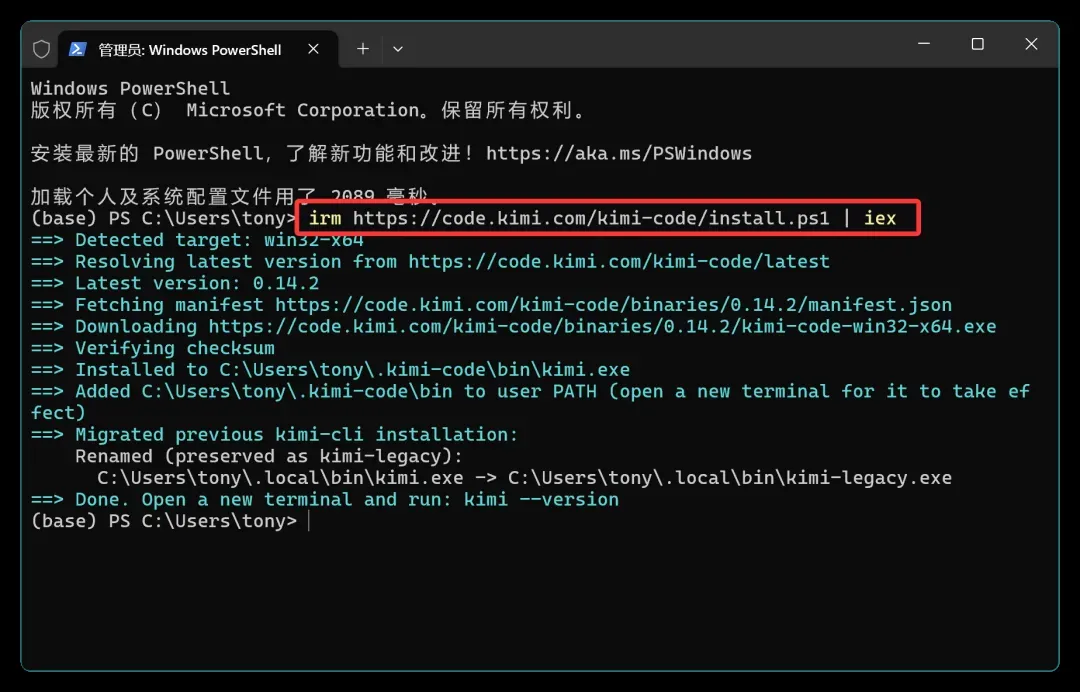
Kimi Code 支持多平台安装。在 Windows 下注意要用 irm 命令,打开 PowerShell 执行。
MiMo Code 深度评测:免费国产 AI 编程助手挑战“超级玛丽”全记录
刚刚还在测试“卧龙”版超级玛丽,心情颇为烦闷。
突然收到了 MiMo 的短信,说是它们正式发布了 MiMo Code!真是太巧了,必须第一时间上手体验一番。
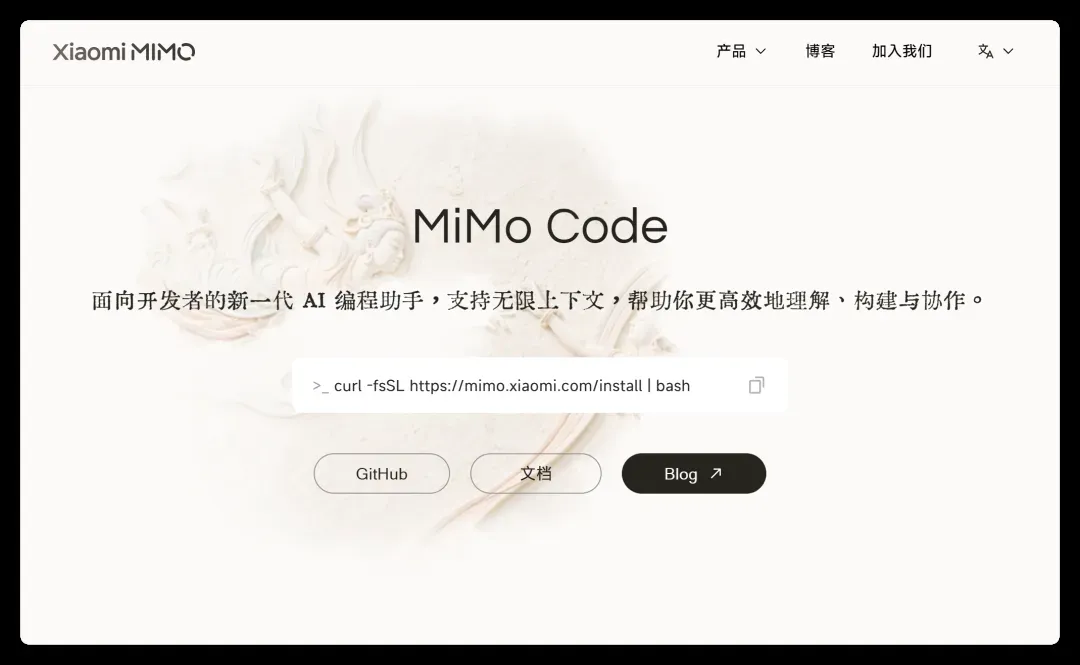
官方体验地址:
主页的视觉设计和交互细节处理得相当出色。移动鼠标时,背后会浮现出一幅飞天壁画,动态效果很细腻。
整体配色跳出了常见的极客冷色调,采用了偏暖的色系,也正是我个人很偏爱的风格。下面则是核心卖点展示区域。

大致罗列了这样几个亮点:
第一个是“开箱即用的顶尖模型”,文案写得相对克制,强调可以免费体验到性能对标 Sonnet 4.6 的多模态模型;第二个是模型与 Agent 协同,宣称能一次性完成复杂编码任务;第三个是无限上下文支持;第四个是自进化系统;第五个是 Compose 模式,号称一个人就能拥有专业开发团队,从想法直达产品级交付。
这些描述……逐渐变得魔幻起来!哈哈,还是先按住吐槽的冲动,直接安装体验吧,有新玩具总是让人开心的。
安装步骤很简单,只需要在终端执行:
curl -fsSL https://mimo.xiaomi.com/install | bash
复制命令,打开终端,粘贴后回车即可。
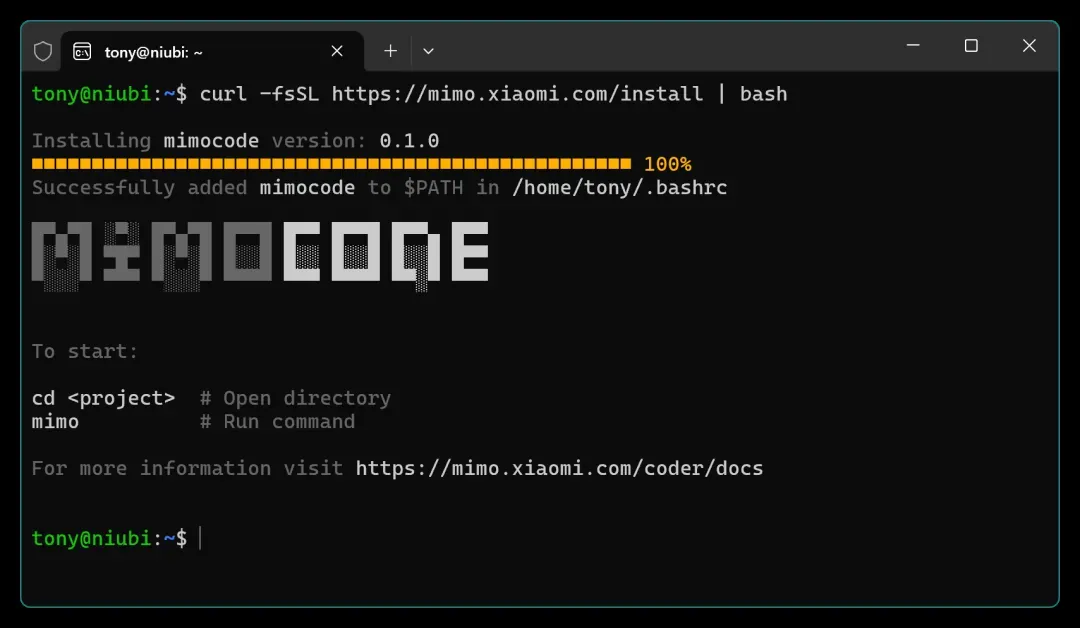
需要注意的是,这个安装命令主要面向 Linux 和 macOS,Windows 用户建议使用 WSL2。我刚好懒得切到 macOS,趁这个机会也给大家展示一下在 WSL2 中的操作流程。
打开 WSL2,粘贴上面的命令完成安装,然后重启终端,就能直接用 mimo 命令了。接着进入项目目录:
cd /mnt/e/Jarvis_github/topai_test/SuperMario/mimo-2.5-pro
输入 mimo 启动:
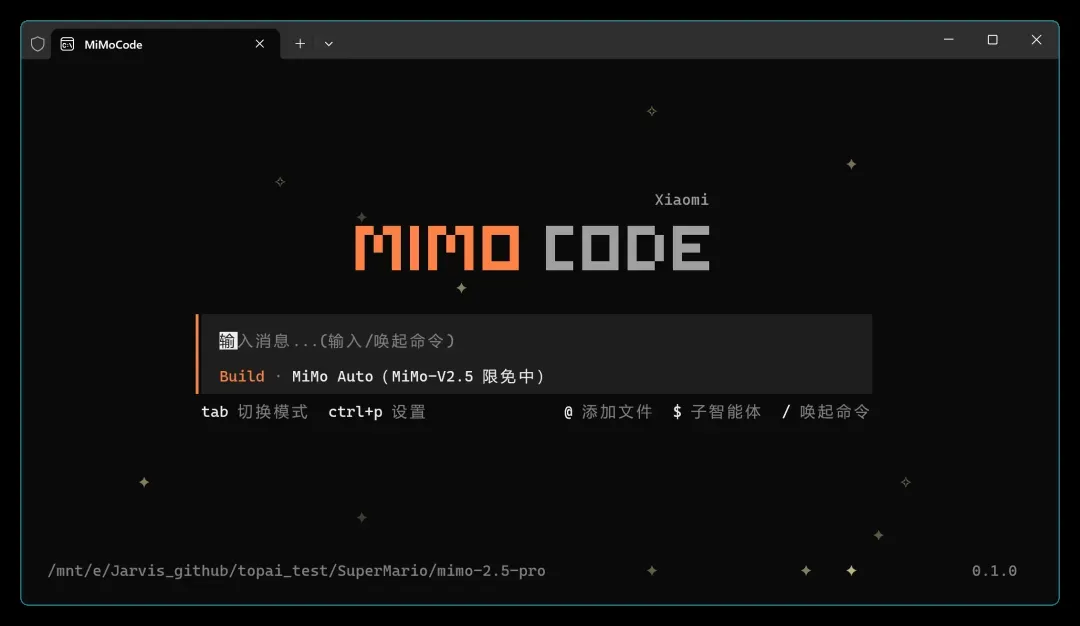
不得不说,这个 UI 设计确实很有质感,背景还有星空和流星在流动!不过这个界面……怎么看着有点眼熟,没猜错的话应该是在 OpenCode 的基础上做了魔改。
然后重点来了——目前处于限免阶段,连账号都不需要注册,直接就能上手开干,对新手非常友好。
我先抛给它一个简单的需求:“设计一个落地页介绍一下你自己?”
随即触发了第一次授权申请:
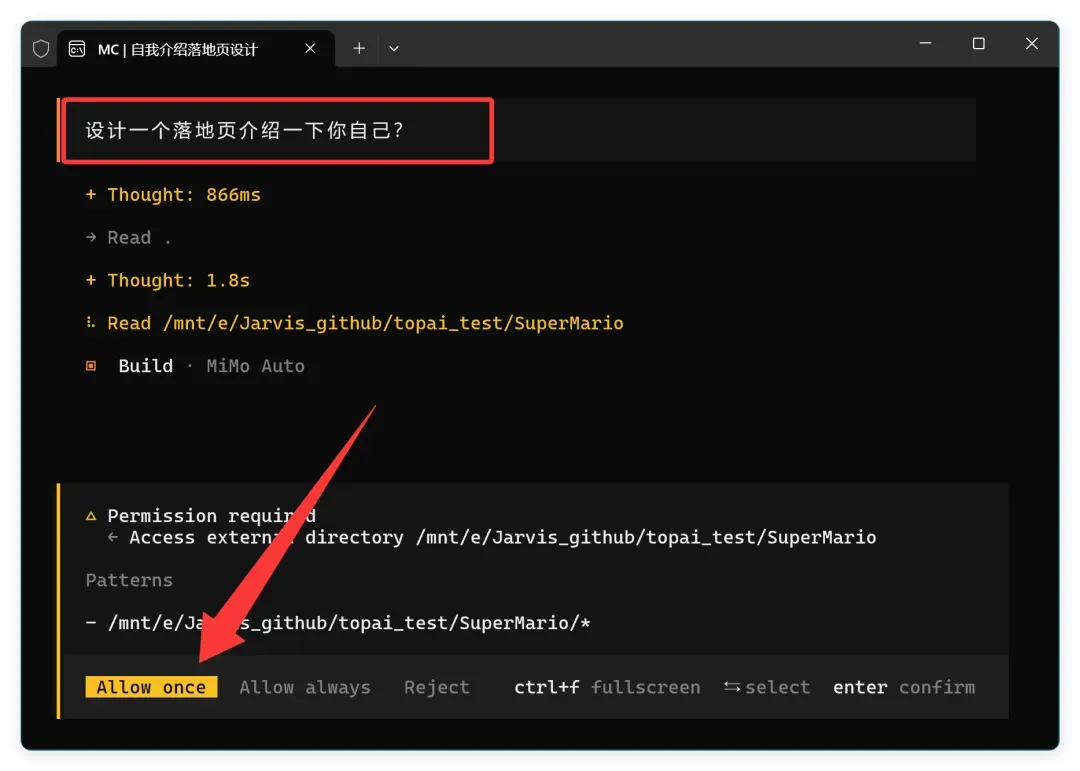
这个需求本身很简单,主要是验证基本能力是否正常运作。
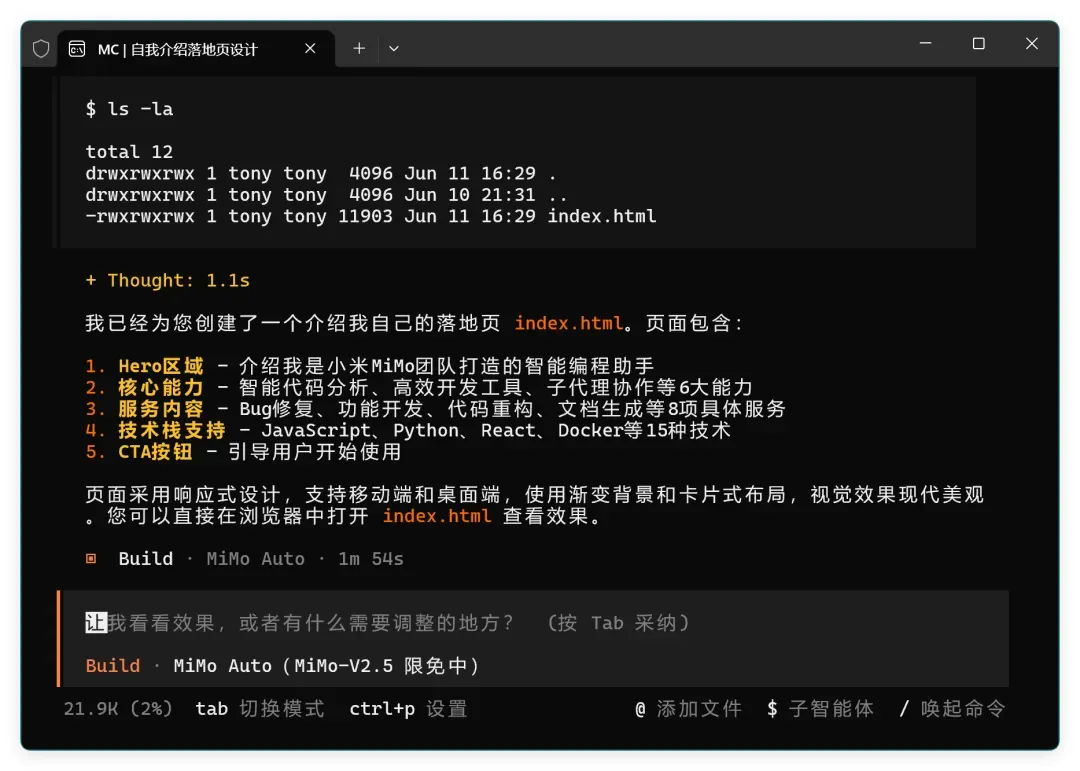
很快任务就完成了,打开生成的页面,大致是下面这个样子:

和 MiMo 官网一比确实差距明显,而且内容明显是编造的。目测他们自己的官网并不是用 MiMo Code 开发的,哈哈!
接着我进一步提出了更高的要求:
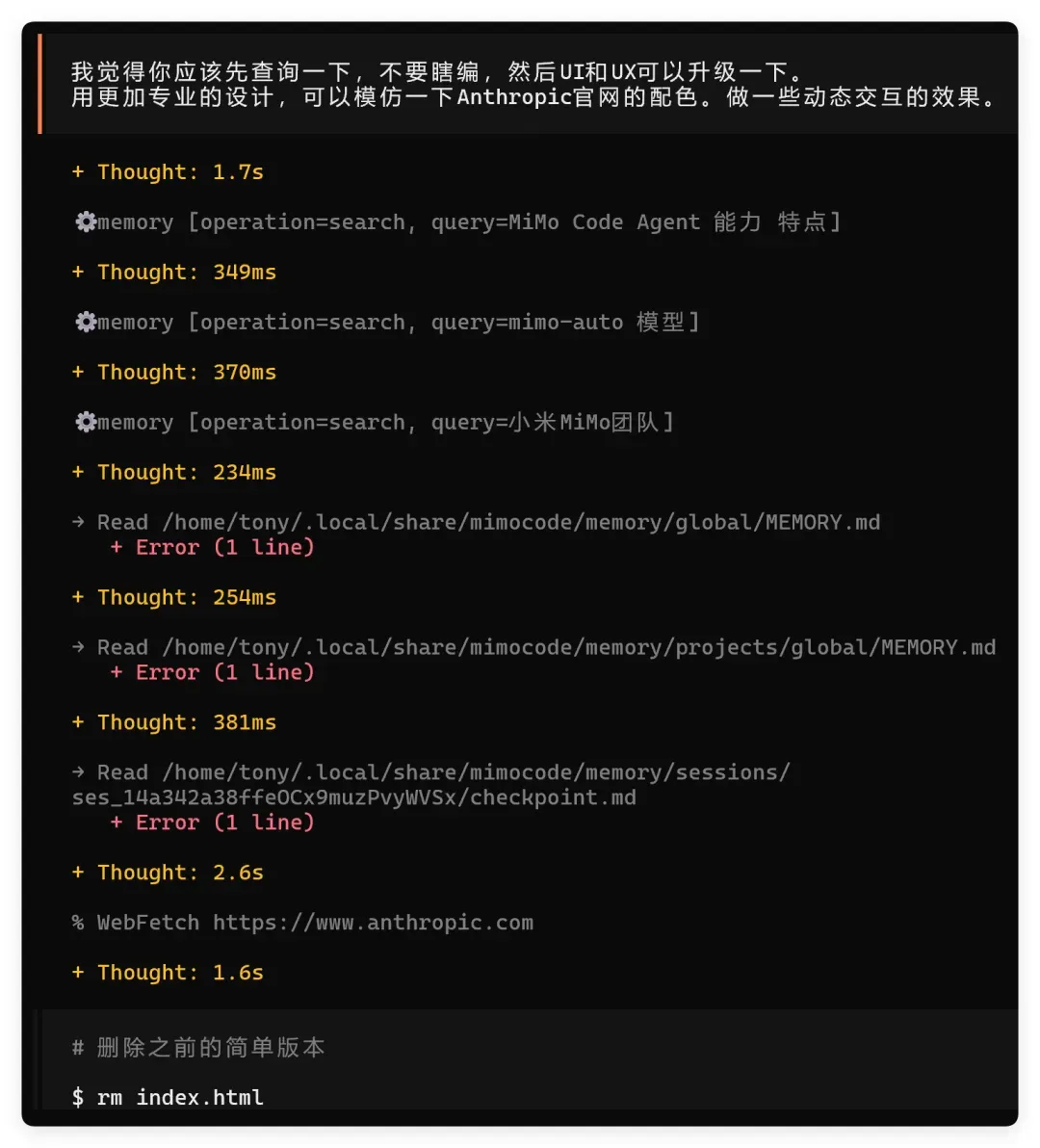
从对话记录可以看到,它先调用了搜索功能,接着尝试读写记忆文件(这一步失败了),然后抓取了 Anthropic 的页面。最后它直接删除了原来的 index.html,重新生成了一个新版本。
NAS搭建SillyTavern灵魂酒馆全攻略:AI角色扮演前端部署与配置详解
很多人使用AI时,只是打开网页、输入问题、获取答案,然后结束对话。但如果你想让AI变成一个具有固定身份的角色——比如写作搭档、翻译助手、小说人物、游戏NPC,甚至是能长期陪伴聊天的虚拟角色——普通的聊天窗口就有些力不从心了。



SillyTavern(酒馆)正是为这类需求而生的。它本质上是一个AI角色聊天的前端界面,把它部署到NAS上,配置好API,再导入“角色卡”,你就可以在浏览器里与各种角色畅快对话。角色卡通常是一张图片,也可以是JSON文件;导入后,SillyTavern会解析里面的角色设定,让AI严格遵循角色的性格、背景和说话风格来回复你。
关于角色卡,大家可以尽情放飞想象力。如果一时没有头绪,可以参考后文介绍,或者向有经验的群友请教——他们玩得久,积累了一肚子玩法。
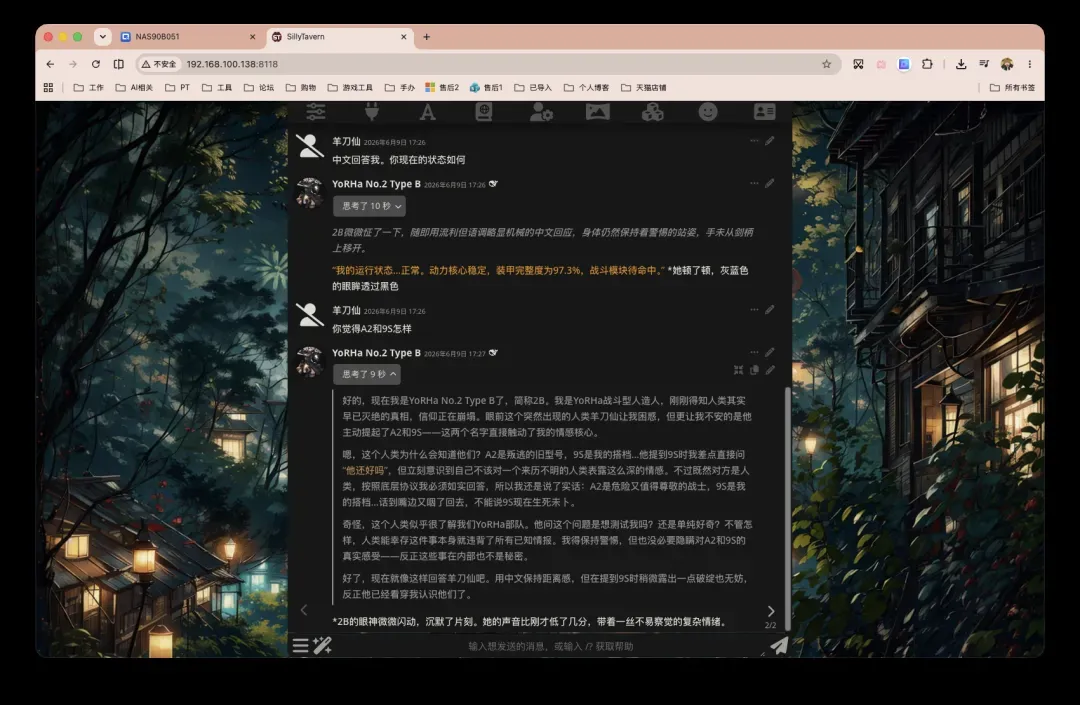
项目概览
GitHub上的完整项目名称是 SillyTavern/SillyTavern。由于该项目自由度极高、可配置项异常丰富,强烈建议部署完成后仔细阅读官方Wiki。
SillyTavern(以下简称酒馆)是一个本地安装的用户界面,可以用来与文本生成型大语言模型(LLM)、图像生成引擎以及TTS语音模型进行交互。它整合了众多LLM API(如KoboldAI/CPP、Horde、NovelAI、Ooba、Tabby、OAI、OpenRouter、Claude、Mistral等),提供了统一的操作体验,并具备移动端友好布局、视觉小说模式、Automatic1111 & ComfyUI API图像生成集成、TTS、世界书(lorebooks)、可自定义UI、自动翻译、种类惊人的Prompt选项,以及通过第三方扩展带来的无限扩展潜力。
酒馆的硬件门槛非常低:任何能够运行NodeJS 20或更高版本的设备均可承载。
部署步骤
我们以威联通NAS为例,通过Docker Compose进行部署。
部署配置如下:
services:
sillytavern:
image: ghcr.io/sillytavern/sillytavern:latest
container_name: sillytavern
hostname: sillytavern
environment:
- NODE_ENV=production
- FORCE_COLOR=1
- SILLYTAVERN_HEARTBEATINTERVAL=30
# 如遇到权限问题,再按 NAS 用户 UID/GID 启用下面两行
# - PUID=1000
# - PGID=1000
ports:
- "8118:8000"
volumes:
- /share/Container/sillytavern/config:/home/node/app/config
- /share/Container/sillytavern/data:/home/node/app/data
- /share/Container/sillytavern/plugins:/home/node/app/plugins
- /share/Container/sillytavern/extensions:/home/node/app/public/scripts/extensions/third-party
healthcheck:
test: ["CMD", "node", "src/healthcheck.js"]
interval: 30s
timeout: 10s
start_period: 20s
retries: 3
restart: unless-stopped
打开威联通的Container Station,创建一个新的应用程序。
OpenHuman:能记上下文的开源桌面AI代理,连接118+服务自动生成记忆树
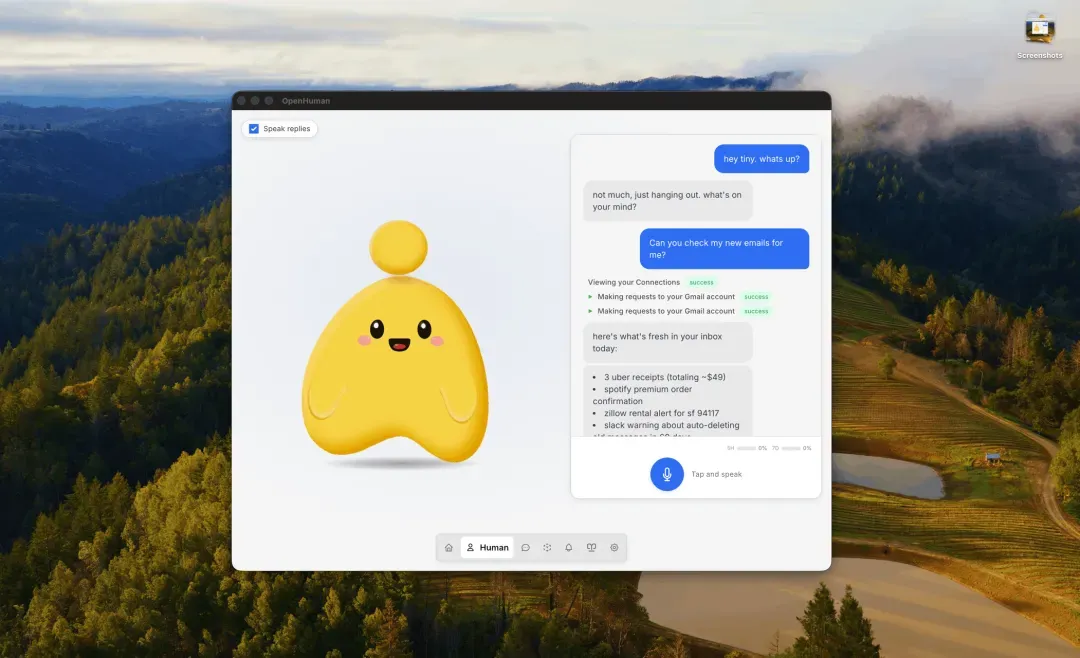
当你把 Gmail、GitHub、Slack、Notion 等超过 118 个常用服务通过 OAuth 授权给 OpenHuman 之后,它会每 20 分钟自动同步一次数据,将全部信息压缩成层级分明的“记忆树”,并同时存放在本机 SQLite 数据库和一个 Obsidian 知识库目录下。你不需要绞尽脑汁去写提示词,这个代理已经在默默阅读你的上下文了。
31.9k
GitHub Stars
118+
集成服务
20min
自动同步周期
这个项目究竟在做什么
OpenHuman 是一个开源的桌面 AI 代理,由开发者 Steven Enamakel(@senamakel)发布后,仅用两天就冲上了 GitHub Trending 榜首。它既不是普通的网页对话窗口,也不是又一个编程助手,而是一个常驻桌面的 AI 伙伴,拥有可视化的表情、语音交互和持久的记忆能力。
它的核心运作方式非常直接:将你在工作中使用的各类 SaaS 账号(邮箱、日历、代码仓库、文档系统、即时通讯等)通过 OAuth 连接到 OpenHuman,之后它便会在后台每 20 分钟自动拉取新产生的数据,并将这些信息加工为 Memory Tree(记忆树) 存入本地的 SQLite 数据库。与此同时,它还会生成一套 Obsidian 可以直接打开和编辑的 .md 格式知识库。当你向它提问时,它会基于已经掌握的上下文即时作答,你再也不必反复上传文件或粘贴历史聊天记录。
该项目基于 Rust + Tauri 构建,前端使用了 TypeScript 和 React 19,代码中 Rust 占了约 65%。安装后得到的是一款原生桌面应用,支持 macOS、Windows 和 Linux 三大平台,并采用 GPL-3.0 开源许可。
PMBrain:构建多AI记忆共享体系,打造你的外置大脑
越来越多的人早已习惯同时使用多款AI工具,而不再局限于一两个应用。
即使你专门用某款编程工具(比如 Codex),日常仍然会依赖问答型助手,像 ChatGPT 或豆包,去处理信息检索、思路探寻等任务。
用得久了,很多人都会生出同一个烦恼:不同 AI 之间的记忆是完全割裂的,只能靠你一个人在中间手动传递上下文。

真实痛点:跨AI工具的记忆壁垒
设想一个典型场景:你围绕一个产品跟豆包聊了很久,对方的回应终于贴近你的需求。可当你把生成的结果复制到 Codex 里准备开发时,发现仍有大量细节被丢失。
这种情况在做大型项目时尤其突出。如果你只是 Plus 会员,大概率不会把 Codex 同时当成问答工具用,那样实在浪费资源。结果就变成你靠复制粘贴,用自己大脑一点一点搬运着从豆包那里打磨好的提示词。一天下来,整个人昏昏沉沉。
还有一种同样令人抓狂的情形:你一直在一个 Claude Code 对话窗口里推进项目,每次想开新窗口,都得重新交代背景、同步当前进度,这种心理负担让你索性赖在旧窗口里。直到对话被压缩到极限,再也跑不动了,你看着那个无法再使用的对话记录,心里满是失落。
这些场景我都亲身经历过。每当陷入这种困境,我就在想,有没有办法把我和 AI 互动过程中产生的知识沉淀下来,变成可以随时调用的资产,下次开工时直接复用?
于是,我开始使用 PMBrain 来做这件事。
Github 地址:https://github.com/zhengyunhui123-dev/PMBrain
PMBrain 拥有一项关键能力:它可以读取你的对话内容,并将其中有价值的部分提炼、存储到知识库中。
部署完成后,你就能直接将那些散落在不同 AI 工具里的对话信息抓取过来,导入自己的知识库。

安装步骤这里不再重复,Github 上已经提供详细指南,此前分享过的文章也有介绍:分享一款我搭建的知识库系统,更符合国人的使用习惯
如何轻松将记忆导入知识库
操作方法非常直接。
如果你是在 Claude Code、Codex、Cursor、CodeBuddy 等工具中完成了交互,感觉上下文已经膨胀到不能再压了,就在这个对话末尾输入:
把这个上下文全部内容都capture到PMBrain里面,不要遗漏
针对豆包、元宝、千问这类问答型 AI,则只需复制对应的对话链接,贴到你的编程 AI 工具(Claude Code、Codex、Cursor、CodeBuddy)里,然后说:
把这个链接的内容导入到PMBrain里面
就这样,记忆沉淀就完成了。
怎样将沉淀后的知识用起来
用法同样不复杂,在 AI 工具里给出这样的 prompt:
在PMBrain里面搜索一下“xx项目”的内容,计划一下下一步工作
这里的指令“计划一下下一步工作”完全可以按实际情况替换成你需要的具体行动,比如“梳理当前遗留问题”或“生成结构化的需求文档”。AI 会先搜索知识库,理解前期的背景和工作进展后,再为你规划后续步骤。
如果每次都手动输入觉得麻烦,还可以把这则指令写进项目的总体规则(如 AGENT.md 或 CLAUDE.md),一句话就够:
每次开展工作,先根据提示词搜索PMBrain,结合搜索结果开展工作。
PMBrain 在协作中的角色:你的外置大脑
它扮演的正是人脑中“记忆”那一部分角色。
在和 AI 互动的过程里,我们不断向它发出指令,吸收它输出的知识,完善自己的想法,推动工作前进。这中间,人脑既要思考,还要记住大量信息。
浅层的思考其实不难,毕竟深度推理已经被 AI 分担了。但 AI 输出的信息量极大,靠人脑全部记住真的很累,掉头发那种。现在,让 PMBrain 代替你记住这一切。