SpaceX IPO暗战:马斯克万亿首富背后的散户高位接盘陷阱

在英文投资社区中盛传的一则推演指出:一旦 SpaceX 启动首次公开募股,埃隆·马斯克将跃升为人类历史上首位万亿美元身家的超级富豪,而华尔街投行则极可能在这场资本盛宴中,一步步将散户推上高位,充当最后的接盘手。不论这一说法是否精确,它已经清晰地揭示了 IPO 定价链条里散户所处的真实位置——一个被高度设计过的角色。
事件推演与散户避险
SpaceX 的上市时间表从来不是公开文件上的确定性事件,但围绕它的叙事早已被反复翻炒、烘托。马斯克本人不止一次公开宣称不会让 SpaceX 走向公开市场,理由直白:上市公司必须臣服于季度财报的短期逻辑,而星际航行和火星移民的回报周期却是以十年为单位计算。然而,私募市场的估值数字持续膨胀,「万亿首富」也从空想演变为资本市场里乐此不疲的剧本。
2024 到 2025 年这段窗口期,SpaceX 在私募二级交易中的估值已攀升到两千亿美元上下。一旦走向 IPO,如果发行价锚定甚至高于这一区间,马斯克手中股权的价值将毫无悬念地冲破万亿美元大关。这种极具冲击力的数字,对散户而言几乎构成了无法拒绝的诱惑,也是投行在路演中最锋利的销售武器。
一、推演路径的三重构造
第一重可以称为「估值区间粉饰」。承销商在预热阶段持续释放偏高估值区间,将全市场的预期锚定在高位,等到实际发行时,即便定价略低于上限,散户也会自动将之解读为「打折入场」。第二重则是「绿鞋托市」。主承销商在挂牌首日尾盘启动超额配售机制,用资金把股价托在发行价上方,制造出强烈的 FOMO 情绪,而这种人造首日涨势,往往在情绪见顶之后迅速消退。第三重是「机构库存转移」。保荐机构在配售环节向关联基金、长线客户大量倾斜低成本筹码,待解禁期一到,由接盘的散户承担后续的抛售压力。
参照:2025 年典型科技股 IPO 的数据特征
- 最终发行价落在指导区间上限甚至溢价区间
- 首日涨幅中位数低于 15%
- 90 天解禁窗口内平均回撤幅度在 15% 至 25% 之间
二、SpaceX 叙事的特殊危险性
星链网络、载人航天、火星移民计划、NASA 政府订单,这些故事中的任何一张牌,都足以单独支撑起一家上市公司的估值故事。而 SpaceX 同时握紧四张高概念底牌,意味着投行在路演中根本不需要费力编造叙事情节,只需把不同业务线的预期收入做一次加总,就能得出极具冲击力的估值数字。在这种宏大叙事面前,散户几乎没有任何天然的免疫力。
马斯克个人品牌则是另一层风险。他将自身命运与公司叙事深度缝合:任何对 SpaceX 的看空言论,都极容易被铁杆粉丝解读为对整个人类航天事业的否定。这种情感捆绑会让散户在市场出现调整时倾向于逆势加仓,而不是止损离场,最终把账面上的浮亏真实地转化为无法挽回的亏损。
三、用二级市场数据验证推演
要判断一场 IPO 是否被人为推高,不必依赖任何地下故事,只需核对几组公开数据即可:发行价相对于最近一轮私募估值的溢价幅度、承销商绿鞋期权规模在总发行量中的占比、以及解禁期前后机构持仓的集中度变迁。一旦 SpaceX 真正上市,这些信息都能在 SEC EDGAR 的 F-1/A 和 13F 文件中直接查询。
自检路径
- 在 SEC EDGAR 系统中检索「Price Range」的修订痕迹,观察指导区间是否被反复上调。
- 在「Underwriting Agreement」中确认绿鞋比例,一旦超过 15% 就值得警觉。
- 上市后第 30 天和第 90 天分别查看 13F 机构持仓变化,集中性的大幅减持通常比散户的公开行动更快浮出水面。
四、散户的自守策略
首先,不要用散户的心态去参与一场由机构主导的定价博弈。IPO 本质上不是彩票开奖,发行价区间内的利差早已被投行和机构客户分割殆尽。其次,把目光优先放在解禁窗口,而非上市首日的涨幅上——多数首日拉升在解禁前会被提前透支。第三,试着将 SpaceX 看作一个航天产业的可转换凭证,而不仅仅是马斯克的个人叙事。星链的商业化节奏、政府合同的续约周期、发射成本的下降曲线,这些硬指标远比「万亿首富」的故事更能护住本金的底线。
订阅额度给我的动力:用尽Token,在倒计时中加速学习与工作
如今,完全是订阅额度在驱动着我。 每当额度即将重置,我就会拼命使用,在大量消耗的过程中总能学到新东西。只不过上一次额度重置前的“狂欢”我未能参与,因为我的五小时限额已满,下一次重置要等到晚上十点半,实在熬不住了。
我之前就说过,token 的用量和学习收获是成正比的,这一点儿也不假。持续消耗 token,与 AI 交互得越频繁,就能掌握越多的技能。当额度即将到期时,迫使自己加速使用,想尽办法把额度耗完,一点都不能浪费。这个时候大脑高速运转,拼命思考能做点什么。不论工作任务还是个人事项,都会被一股脑塞进对话框,让它们跑起来。在这个过程中,大脑被充分调动,多线程并行,工作负荷瞬间拉满。我甚至用上了平时舍不得使用的 /goal 命令和子代理同步功能,又学到了新的技能。工作也因此向前迈进了一大步,以前一直拖着、懒得分析整理的事情,全都完成了。最后,我还会总结这次体验,优化日常的工作思路。这就是额度重置前或到期前的典型收获——在平时根本体会不到。
不过,有时节奏实在太快,人脑来不及思考,只顾着不断下指令,让 AI 做这做那,难免也会出现问题。好在并不是天天这样;要是天天如此,谁也受不了,即便一周一次,强度都有点高。现在我很享受不必着急耗费 token 的日子,甚至觉得当前的工作强度根本不算什么。
或许这也跟贫穷有关:因为穷,token 无法无限供应,平时总舍不得大量使用,总担心离到期日还早额度就先花光了,那接下来的时间该怎么办?于是,临近到期时,又得拼命消耗,一点点都不能浪费。如此循环往复。
但在这个循环里,确实学到了东西,这一点无可否认。我不禁想,那些开通了 100 美元甚至 200 美元额度的人,他们的工作状态会是怎样的?他们每 5 小时的额度或许比我一整周的量还多,又用来做什么呢?大概是在做真正有意义的事,比如构建一个庞大的软件工程,或是维护一个极为复杂而具体的产品。若真如此,我还有很长的路要走。我用得还不够多,可能意味着连门槛都还摸到,更谈不上已经掌握了 AI。所以,继续努力吧。
眼下要学的东西还很多:我要做 CLI 工具,要研究 MCP,要搭建本地化的 AI 操作管理系统。随着想法的不断迭代,token 仍会大量消耗,人脑仍需高速运转,永无止境。因此,我必须消耗 token,并将消耗掉的 token 变成武装自己的武器,以便在这个快速迭代的时代不掉队。加油,做自己想做的,学自己想学的。希望有一天,我能确信,所有的努力都没有白费。
废墟上重生:耐候钢盔甲与闭环水系统打造的离网防火乡村住宅
在陡峭的山坡上建造房屋,既要防得住火灾,又要贴合水源——这种看似矛盾的诉求,本身就带着一种荒野生活的强烈吸引。
在加利福尼亚松平(Pine Flat)社区,2019年金卡德大火吞噬了一栋离网住宅。就在那片废墟之上,福克纳建筑事务所(Faulkner Architects)用耐候钢重新包裹出一栋山地住宅。耐候钢外壳能防火,水系统自循环,离网太阳能供电,雨水实现百分之百回收。这栋房子不仅是荒野生存的设计应答,更是一次彻底到骨子里的乡村建造实验。

Pine Flat住宅以极低的姿态嵌入陡坡,棚式屋顶沿着山脊线平缓铺开。
耐候钢:建筑的防火铠甲
整栋房子的外壳是波纹耐候钢(Corten steel)。这种材料能在空气中自行生成致密氧化层,不燃、免维护,而且越旧越有面孔。福克纳事务所在太浩湖畔的CAMPout House(2022)和内华达的Red Rock(2025)中反复使用同一套策略:把建筑的外皮做成防火盔甲。Pine Flat更进一步,叠加上滑动余烬屏和甲板外部洒水装置,构成从材料到构件的三层防御,层层递进。

波纹耐候钢包裹着入口坡道与采光井,材料本身的氧化肌理便是一种防火宣言。
原址被毁房屋的混凝土基础和墙体被完整地保留下来。事务所用了「蕴含能量」(embodied energy)这个词。已浇筑的混凝土所承载的能量不该被轻易浪费,而在陡峭地形上尽量减少开挖,本身也是一种更轻柔的介入策略。新的矩形体量仿佛轻轻踩在落叶之上,超出旧轮廓的部分顺势转化成雕塑般的入口台阶和玻璃采光井。
水之闭环:独立循环与空间仪式
水源全部来自自流井。设计百分之百捕获场地的雨水:悬臂式排水沟将雨水导入钢制水池,再流经生物滞留区,最终汇入可兼作消防备用水源的滞留池。一台冲击式水轮利用落差水流补充水力发电。混凝土水池同时也是冷却泳池,水体始终处于更新状态。化粪池处理废水,离网太阳能电池阵列提供全部电力。这栋房子完全不依赖任何市政基础管网。

上层主层的室外门廊,混凝土烟囱从窗墙间穿出,西侧的自流水盆与其形成空间上的对仗。
福克纳将水与火当作一对元素来设计。火灾风险催生了防火外壳与余烬防护,而水的存在则被转化为空间仪式。上层主层的中心,一座混凝土烟囱稳稳矗立,无声地提醒着火的威胁;房子的西侧则是自流水盆,工作室说它“促进视觉与诗意的对话,以纪念该地点的泉眼”。在设计内华达州Red Rock住宅时,福克纳同样围绕一座大水池来组织空间。火与水,保护与庆祝,在他们的实践中始终如一对孪生元素,并肩而立。
废墟之上:记忆与工具性重建
Pine Flat所在的Mayacamas山脉,在1870年代曾因水银矿开采而繁荣一时。场地上原有的住宅毁于金卡德大火之后,业主并未离开,而是选择重建:一栋低维护、长生命周期、直面景观并在未来火灾中更耐久的房子。这份任务书从一开始就带着荒野生存的底味。

棚式屋顶体量沿斜坡展开,车库从主屋斜向探出,悄然隐入山坡下层。
建筑拥有三层卧室,两层通高,整体嵌入陡坡。入口坡道特意为无障碍通行设计,预制电梯核心筒也为未来轮椅使用预留了条件。离网设施包括升级后的太阳能电池阵列。车库从长方形的主屋倾斜而出,其下方则是嵌进山坡的工作间。福克纳自己如此说道:住宅建筑可以超越审美层面的考量,房子就是安居于场地之上的一种工具。

客厅被大面积窗墙包裹,混凝土烟囱成为整个空间的垂直锚点。
设计启示:可带走的荒野建造经验
将表皮转化成盔甲
Pine Flat与CAMPout均采用了耐候钢加混凝土的外壳组合,不燃、免维护、越旧越有表情。乡村建造的围护材料不只要保温,更要主动防火——先用构造逻辑回应生存问题,再谈论形式。
把基础设施做进空间里
自流井、雨水收集、水力发电、消防备用水源,福克纳并未将这些功能隐藏起来,而是做成水池、排水沟、瀑布,让水系统成为可见的空间元素。在脱离市政管网的乡村建造中,基础设施本身就是空间的构成。
保留废墟里的能量
原住宅的混凝土基础和墙体被完整保留,既削减了陡坡上的开挖量,也让新房子与原场地的记忆得以连续。在乡村建造中,“保留”常常比“拆除重建”更难,但同时也是一种更有力量的策略。
谷歌云推出OKF 0.1:让AI Agent自动维护团队Wiki,终结知识碎片化

谷歌云正式发布 Open Knowledge Format 0.1,将 Andrej Karpathy 所构想的“LLM Wiki”转化为一套可行的工程规范。它并非谋求统一内容格式,而是致力于标准化知识的储存与结构方式:对人而言,知识以 Markdown 呈现;对 AI 来说,则是可被标准化维护的上下文环境。
为何这件事值得业界密切关注
当前的知识系统存在一个结构性缺陷:它们被强行锁定在五花八门的工具之中。无论是 Notion、Confluence、Obsidian 还是各类 wiki,导入导出机制、权限模型以及维护人情成本各不相同。AI Agent 想要读取这些知识,不得不依赖连接器、API 或导出中间文件,而每一次模型或工具链的切换,都需要重建整条上下文管道。
OKF 的切入逻辑是:知识容器本身不该成为问题的放大镜。它将知识拆解为一包包 Markdown 文件,每份文件的开头写入几行 YAML frontmatter(类型、标题、标签),随后整体放置于 Git 仓库或普通文件夹中。这里没有数据库、无需注册中心,也没有复杂的压缩方案。cat 即可阅读,git clone 就等于部署。这听上去像是在 Markdown 上套了一层规范外壳,但真正令其进入舆论中心的,是它首次由主流云厂商以产品规格的形式,承接了 Karpathy 的 LLM Wiki 理念。
Karpathy 所判断的核心在于:人类终会厌倦维护 wiki,但大语言模型不会。模型永远不会忘记更新交叉引用,不会抱怨 15 个关联文件太过繁琐,也不会因为“知识管理”被排在优先级第三位而主动搁置。
从概念到工程落地:LLM Wiki 终成规范
OKF 刻意保持“最小意见化”:它不规定你该写什么,只约定如何存储与引用。正因如此,它可以承载任意领域、任意粒度的知识。YAML frontmatter 同时充当人类可读的标签和机器可解析的元数据,Markdown 是内容载体,而 Git 则承担版本追踪与跨团队协作的角色。
这一设计带来的实际效果是,知识从诞生之初就具备两层可读性:人可以直接打开文件阅读而无须前端工具,Agent 则能够依循规范解析并维护跨文件引用。两大场景在同一格式下并行展开,不再需要互为镜像的两套系统。
社区反应同样印证了这一判断。对一部分 AI 原生开发者来说,OKF 真正潜在的对手并非其他 AI 工具,而是 Notion 与 Obsidian。因为这两类产品已经沉淀了大量团队知识的维护成本,“记账成本”结构随之改变。传统 wiki 的开销重心其实并不在检索,而在于让团队成员持续更新并保持格式一致;当 LLM 代为管理知识仓库时,这一成本源头便被推进了 AI Agent 的工作流之中。
跨境电商五大动态:Prime Day倒计时9天、海运暴涨87%与Temu全托管谢幕

本期内容聚焦近期跨境赛道的五个关键变量:亚马逊Prime Day进入最后9天倒计时,6月23日起连续四天全球同步大促;美西航线FEU运价较年初大幅攀升87%,马士基宣布自6月17日增收2000美元旺季附加费;TikTok Shop一口气新增八个欧洲站点,欧洲版图扩容至13国;Temu美国站全面终止中国直邮,半托管与本对本模式成为主流;GEO优化正成为独立站获取AI搜索流量的新引擎,转化效率可达常规搜索的23倍。一文速览这些正在重塑出海格局的重要信号。
01 | 亚马逊Prime Day提前拉开序幕:大促锁定6月23至26日
亚马逊已正式宣布2026年Prime Day将于太平洋时间6月23日00:01启动,持续到6月26日,整整四天。这是Prime Day首次提前到6月举行(2021年以来调整幅度最大),意味着卖家的备战周期进一步压缩。
本次大促覆盖23个国家和地区,包括美国、英国、德国、法国、意大利、西班牙、日本、墨西哥、沙特、阿联酋、新加坡、南非等核心市场,而澳大利亚、巴西、印度、日本等将在夏季晚些时候推出专属场次。超过35个品类参与促销,Sol de Janeiro、LG、Stanley等热门品牌折扣最高达到50%,每日还会分三次(太平洋时间0点、8点、13点)更新“今日大促”清单。亚马逊也同步上线了免费生鲜抽奖、Alexa消费送1000美元礼品卡等会员福利。
为何值得紧盯:6月大促对卖家提出了全新的挑战——夏季选品(户外、防晒、水上娱乐)、物流时效(6月17日至7月2日恰逢海运附加费叠加期)、库存深度的三重准备必须同步到位。加之5月底已开始的TikTok DFYD(6月17日-7月2日)和Walmart Deals(6月22日-28日)三平台大促同期,这极可能成为2026下半年跨境电商竞争最激烈的“流量黄金周”。
📰 参考来源:新浪财经《2026亚马逊Prime Day定档6月23日至26日》(2026-06-02)
02 | 美线海运运价飙升87%:马士基6月17日起征$2000旺季附加费
6月初Drewry WCI全球集装箱运价指数周环比骤涨**23%**至$3,433/FEU,创下2026年以来最大单周涨幅。截至6月5日,美西航线FEU运价较年初已累计上涨87%,美东航线涨幅突破70%,SCFI综合指数攀升至2726.48点,创近两年新高,且已连续五周上涨。
头部船公司密集发布涨价通知:马士基宣布自6月17日起对美线每一FEU加收2000美元旺季附加费,中非、南美航线同步执行;地中海航运(MSC)在亚欧、北非航线同步上调运价,部分航线包箱费率最高已达$9,200/FEU。深圳博达捷运物流负责人透露“华南、华东甩柜现象频发,一舱难求”。
| 航线/船司 | 最新运价 | 年内涨幅 | 6月附加费 |
|---|---|---|---|
| 美西航线 FEU | $4,565 | +87% | 马士基6/17起+$2,000 |
| 美东航线 FEU | $5,505 | +70% | 马士基同步+$2,000 |
| 亚欧航线 FEU | $4,000+ | +50%+ | MSC最高$9,200/FEU |
| 地中海航线 FEU | $5,000+ | +60%+ | 燃油+碳排放附加费 |
值得研判的影响:美线运费持续高企将直接压缩FBA卖家的利润空间。可采取的应对思路包括:(1)非紧急货物提前锁舱锁价,避免旺季被甩柜;(2)高价值小件产品转向空运或快船;(3)Prime Day前库存至少按45天销量备货,6月10日前完成入仓;(4)在平台新政策推动下,中大件卖家可优先采用海运快船或海外仓补货模式。
📰 参考来源:东方财富网《2026年以来全球集装箱海运价格出现大幅上涨》(2026-06-12)
03 | TikTok Shop欧洲再下一城:新增8国,覆盖范围扩至13国
5月29日,TikTok Shop正式启动新一轮欧洲扩张,新增波兰、荷兰、比利时、捷克、奥地利、希腊、葡萄牙和匈牙利8个站点。至此,TikTok Shop在欧洲触达的市场已从原有的英国、德国、法国、意大利、西班牙扩展至13国,正在构建更为密集的欧盟电商生态网络。
平台同步推出飞轮计划Plus:开放个体工商户入驻、一证多国(一份资质覆盖多个欧洲站点)、极速审核等政策,显著降低开店门槛。有数据显示,TikTok Shop东南亚跨境市场按摩仪品类GMV增长超10倍,美发个护电器增长222%,保健品增长262%,宠物用品增长235%。
核心机会与挑战:欧洲跨境电商正进入“多国一盘货”阶段。一证多国政策意味着卖家可用一套资质、一次审核撬动13国市场,对中小卖家而言,这几乎是历史性的窗口。但要警惕“语言+合规+税务”这三道门槛——尤其是希腊、葡萄牙、捷克等小语种市场,本地化内容(语言与文化)将成决定性因素,建议优先在德、法、意、西四大语言区搭建内容运营基础。
📰 参考来源:连连国际《官宣|连连全面支持TikTok Shop欧洲8大新站点收款!》(2026-05-29)
04 | Temu美国直邮全面停摆:半托管与本对本模式成为主旋律
自5月3日起,Temu正式关闭中国至美国的直邮通道,所有订单必须由美国本土仓库或本土卖家履约,跨境小包直邮模式彻底退出美国站。再叠加2026年2月美国取消800美元以下包裹免税政策——一个3美元的普通手机壳在加入运费和关税后已无法盈利。
实测美国最强AI出口禁令:Claude全线停摆,全球开发者一夜断供

#Anthropic #Fable5 #Mythos5 #出口管制
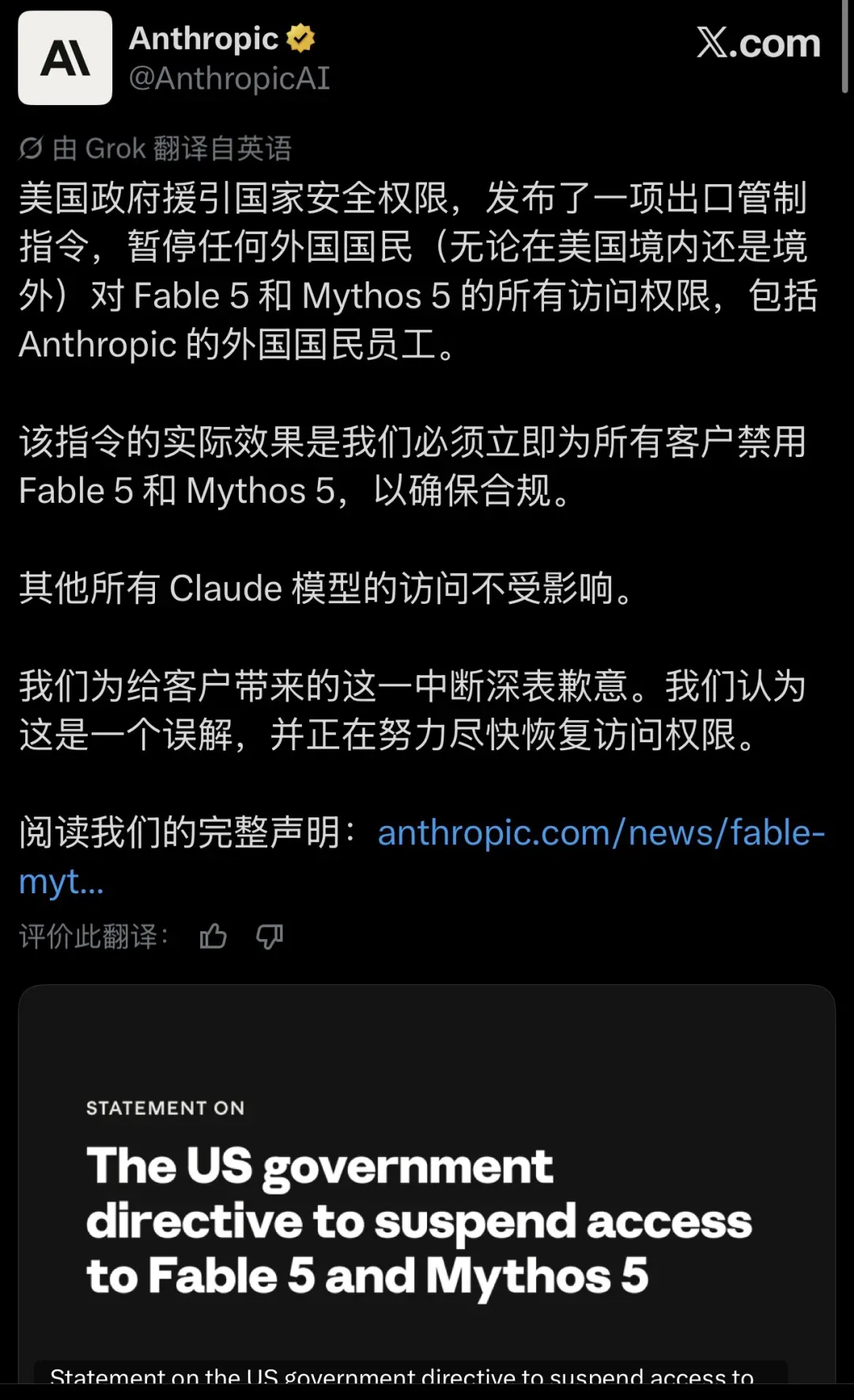
美国以国家安全为由,通过出口管制指令要求 Anthropic 立即暂停 Fable 5 和 Mythos 5 的全球访问权限。Anthropic 于北京时间 2026 年 6 月 13 日凌晨正式接到该指令,并迅速面向所有用户关闭了这两款模型的入口。其他 Claude 系列模型不受影响。此次暂停的直接导火索是政府掌握的一项所谓“非通用越狱”演示,而 Anthropic 经评估后认为,此类能力在当前已公开模型中广泛存在,这次的管制标准明显过于严苛。
一张禁令让最强大模型一夜下线:合规风暴席卷全球
2026 年 6 月 12 日下午 5:21(美东时间),Anthropic 收到美国政府签发的出口管制指令,要求停止所有非美国国民对 Claude Fable 5 和 Claude Mythos 5 的使用。指令覆盖范围极其宽泛:不论用户当时身处美国境内或境外,只要不具备美国国民身份,就全部被纳入禁令。更关键的是,Anthropic 在声明中明确指出,该限制同样适用于公司内部的外籍员工。这就意味着 Anthropic 无法通过地域标签或账户属性进行精准隔离,唯一能让公司合规的做法,便是将这两款模型从所有客户可触及的路径中彻底抽离,而不仅仅是针对非美国用户下线。6 月 12 日晚间起,Fable 5 与 Mythos 5 在全球所有区域的 API 及 claude.ai 平台上已同步关闭。
政府眼中唯一理由:发现了一种绕过模型防线的方法
根据 Anthropic 的官方通报,政府给出的触发条件是:已掌握一种可“绕过”(即 jailbreaking)Fable 5 的方法。Anthropic 对同一份技术演示进行了复核,发现其核心内容不过是引导模型读取某个特定代码库并修复软件缺陷,综合评估后认为演示所展现的攻击层面相对简易,且相同类型的能力在众多已公开发布的模型上也能够复现,根本不需要专门针对 Fable 5 的防护体系进行突破。Anthropic 同时强调,迄今并未收到任何“因潜在越狱导致实际危害”的报告,目前披露的潜在越狱案例要么是完全无害的响应,要么只是一些次要发现,并未提供任何超过现有模型能力、属于 Mythos 独有的安全性增益。也就是说,政府所依据的顾虑,在 Anthropic 看来属于非通用、非严重的已知边界场景。
树莓派5内存涨价了还值得买吗?2026年1GB-16GB版本深入对比与选购攻略

树莓派 5 的产品线不断扩展,选择合适的内存版本变得越来越考验判断力。这篇文章会系统地比较各个选项,帮你找出真正值得入手的那一款。
一般原则: 如果你的项目是无头运行,1 GB 或 2 GB 就足够了;4 GB 是均衡的入门选择;8 GB 和 16 GB 则更适合需要大量资源的高级用户。
下面会先梳理各版本的核心差异,再根据不同使用场景给出具体推荐,同时还会提供一些实际测试数据,供需要精准参考的朋友使用。
目录
- 树莓派 5 内存选项
- 按使用场景推荐内存
- 特定软件的内存估算
- 最终推荐
树莓派 5 内存选项

目前市售的树莓派 5 共有五个主板版本。许多人可能会好奇:它们之间有什么区别?对实际体验有什么影响?到底该买哪一个?这一节就从全局回答这些问题。
规格与关键信息
所有树莓派 5 版本共享同一套基础硬件规格。
- CPU: 4× Cortex‑A76
- GPU: VideoCore VII
- 以太网: 千兆 | Wi‑Fi: 802.11ac | 蓝牙: 5.0/BLE
- PCI Express: 2.0 ×1 | USB 3.0 | GPIO 40‑pin
真正的不同在于内存容量:
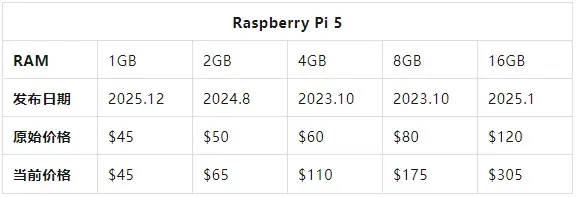
以上价格来源于 2026 年 6 月 11 日树莓派官方手册。
树莓派CM0 IPKVM开源无线采集卡:从零打造你的远程HDMI管控中心
项目概述
这是一款基于树莓派Compute Module 0(CM0)的Linux IPKVM设备,目前项目核心功能已经开发完毕。由于系统运行和视频采集对存储空间有一定要求,建议选用16GB以上eMMC闪存的CM0模块,或者自行替换更大容量的eMMC芯片,以保障长期使用和后续扩展的流畅体验。

开源代码与适配
核心代码已上传至GitHub,并针对CM0硬件进行了完整的PIKVM移植适配。目前的固件在最新的Debian 13系统上经过了全面验证,可以稳定运行。
- 适配仓库:https://github.com/JasonYANG170/pikvm-cm0
实物展示
以下为组装完成的成品及PCB照片,涵盖正反面、HDMI输入输出测试以及PIKVM采集测试的实际效果。

正面

背面

PCB正面

PCB背面

HDMI输出与系统测试
HDMI输入与采集测试
PIKVM移植验证
PIKVM实际采集效果
功能特性
- HDMI输入与输出:具备完整的HDMI视频采集和本地环出能力
- Debian 13系统:官方最新系统完美驱动,生态兼容性极佳
- PIKVM开机自启:上电即运行,无论身在何处都能随时远程控制目标主机
- GPIO扩展:开放标准40针引脚,可自由连接传感器、继电器等外设,实现二次开发
硬件配置与状态
该CM0模块芯片内部集成DDR内存,eMMC接口支持5.1规范。为获得更大的软件安装空间,实际硬件中将原厂eMMC更换为64GB版本,系统识别正常且读写稳定。
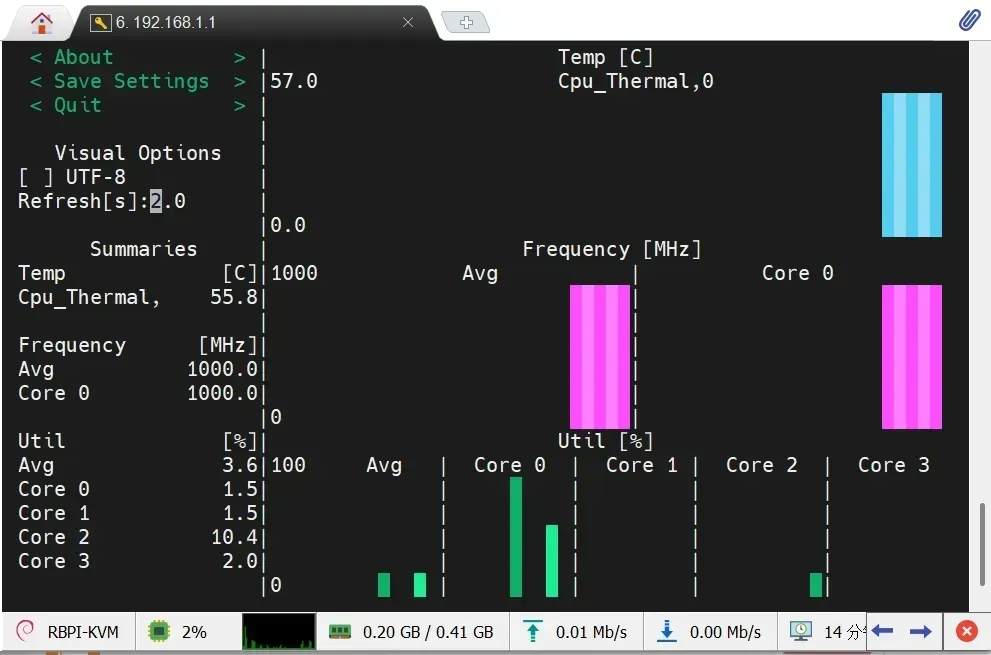
- s-tui监控界面
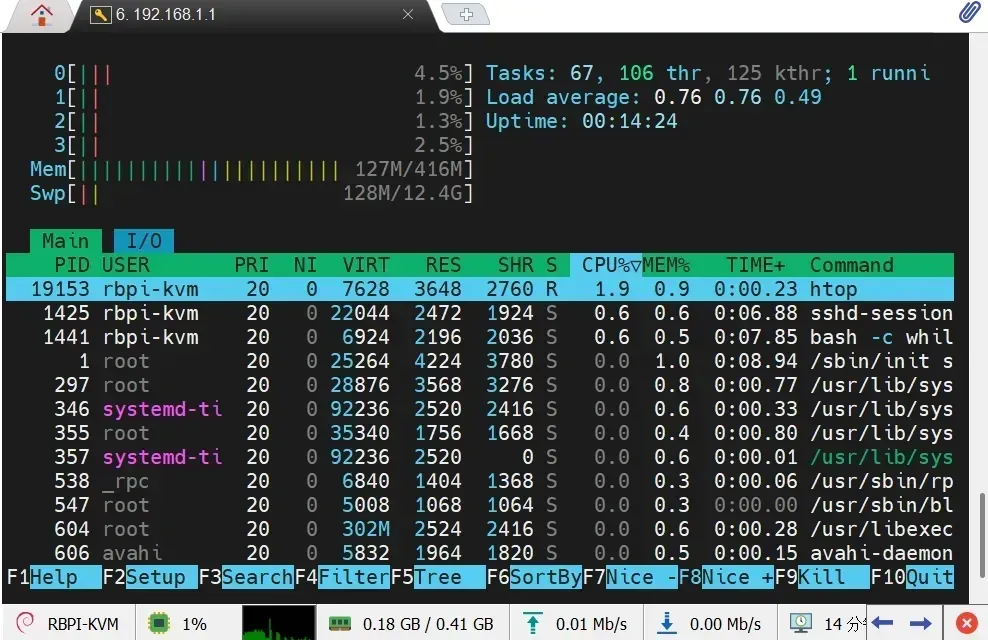
- htop资源占用
- lsblk块设备列表
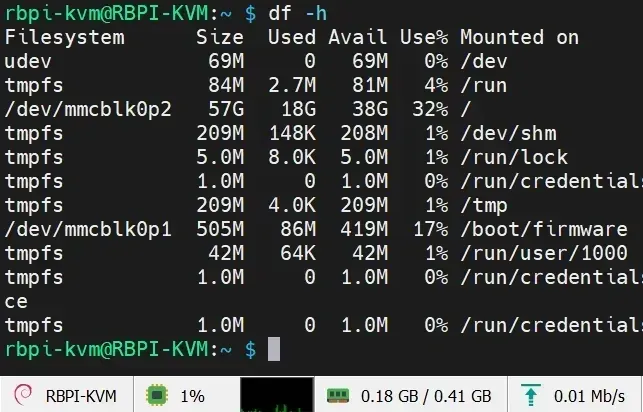
虚拟内存配置优化
CM0的板载内存较小,为了流畅进行视频编解码及PIKVM相关编译任务,需要创建并激活大容量SWAP分区。下面是一个12GB交换空间的完整配置步骤。
1. 创建并启用SWAP文件
sudo dd if=/dev/zero of=/swapfile bs=1M count=12288
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
2. 设置开机自动挂载
sudo nano /etc/fstab
# 在文件末尾添加以下一行
/swapfile none swap sw 0 0
3. 调整Swappiness倾向值
适当提高swappiness值能让系统更积极地使用交换空间,缓解内存压力。
数字孪生自主系统进化路线图:从镜像到AI代理决策的三级跃迁
引言:技术质变已来
2026年,全球数字孪生市场已达494亿美元,然而比规模膨胀更深刻的,是AI嵌入引发的根本性蜕变——数字孪生正从“物理世界的数字化镜像”跃迁为“可预测、可决策、可行动的自主系统”。本文梳理这一进化的三大阶段,并融合NVIDIA、西门子、罗兰贝格等权威机构的最新判断。
几周前,一段基于NVIDIA Omniverse的东京站实时城市模拟视频在网络刷屏。数千个AI代理驱动的行人和车辆,在程序化生成的数平方公里城区中自主穿行,天气与建筑可瞬时切换。画面虽然震撼,但它展现的仍是数字孪生的“旧”能力:高保真可视化与大规模仿真。真正值得关注的,是这项技术正在经历的深层进化。
第一阶段:从静态镜像到预测引擎
数字孪生的概念可追溯至NASA阿波罗13号任务中的地面模拟器,但直到2010年代后期,随着物联网、云计算和3D可视化的成熟,才真正进入工业场景。这一时期,数字孪生的典型形态是3D模型叠加实时数据馈送,主要用于远程监控和状态可视化。宝马集团在新建工厂规划中利用数字孪生,实现了30%的效率提升,验证了其基础价值。
转折点出现在AI被嵌入数字孪生之后。传统机器学习模型依赖历史数据,难以应对罕见事件和分布外场景。而物理信息神经网络(PINNs)将物理定律直接编码进模型架构,使孪生体获得了预测能力。Ansys、西门子等仿真平台正将这类物理信息机器学习集成进工具链。例如,纬创资通利用该技术,将气流仿真时间从15小时锐减至3.6秒,这背后正是物理信息AI的驱动。
第二阶段:AI代理进入孪生体
2026年1月,《自然·计算科学》发表评论文章,明确指出数字孪生正演变为能够自我学习、自主行动的系统。同月,Gartner在制造业预测报告中提出:到2030年,半自主AI代理与闭环数字孪生将彻底改变制造业。5月,AWS在行业博客中详细剖析了代理式AI与数字孪生在制造场景中的融合路径:AI代理可自主推理、规划并执行复杂任务,而数字孪生为这些代理提供了安全的沙箱环境。
关键节点:NVIDIA GTC 2026
2026年3月的GTC大会上,NVIDIA发布多项里程碑技术:Omniverse DSX蓝图、Mega蓝图(多机器人车队仿真与优化),以及FOX蓝图(工厂运营自主管理Agent)。Omniverse从平台转向模块化架构,核心组件以独立C库形式提供,允许开发者无需引入整个平台即可集成物理AI能力。ABB、发那科、库卡、安川等机器人厂商已将其部署至生产级工作流。
第三阶段:自主代理孪生的到来
2026年4月,罗兰贝格发布《从数字孪生到代理孪生》报告。当AI与机器学习被注入数字孪生后,后者不再是物理系统的被动镜像,而是主动的预判引擎,能从实时数据中学习、适应变化并预测未来。罗兰贝格进一步定义了“代理孪生”:它模拟整个企业的功能、工作流、决策逻辑与运营成本,并假定这些均可用AI代理重新设计。
学术界也在快速跟进。《城市信息学》期刊2026年3月刊登了《迈向代理式城市数字孪生》(AUDiTs)的愿景论文,提出将大语言模型与多模态代理集成进城市数字孪生环境,让AI代理参与城市治理中的推理与协商。同期,arXiv上的DDD-GenDT框架展示了利用大语言模型在零样本条件下构建数字孪生的能力——在NASA CNC铣削数据集上,GPT-4驱动的数字孪生实现了4.79%的预测误差,且无需重新训练即可适应设备老化。
产业落地验证
Cloud Latitude数据显示,2026年全球数字孪生市场规模达494亿美元,已跨越早期采用鸿沟。但Gartner也指出,目前只有15%的组织将数字孪生从试点推进至核心运营流程,这既是警示,也揭示了窗口期。
- SK电讯为SK海力士半导体工厂开发数字孪生,使用NVIDIA代理工具包实现自动数据建模,目标是2030年建成自主工厂。
- 美光与MetAI在Omniverse上联合开发SimReady晶圆厂数字孪生,实现从CAD到可仿真环境的自动转换。
- 富士康通过MoMClaw系统,在200米生产线上部署数百个AI代理,根因分析时间缩短80%,劳动效率提升15%。
- 西门子在Realize LIVE 2026上展示“上下文层”架构,将物理定律预编码进本体,让AI代理直接理解工厂数据模型。
治理挑战与趋势信号
综合多方权威信息,可提炼出三个共同判断:第一,数字孪生正从IT资产转变为企业智能核心层,CIO需将数据基础设施与AI能力前置规划。第二,代理式AI使孪生体的自主性跨过关键阈值,但治理框架严重滞后,决策问责与跨孪生通信安全仍是未解难题。第三,合成数据将成为数字孪生的核心燃料,Gartner预测到2030年合成数据将完全覆盖AI模型训练中的真实数据。
值得持续跟踪的信号:
- 头部企业是否将数字孪生列入CIO战略规划,Cloud Latitude数据表明当前窗口仍然开放。
- OpenUSD生态标准化进展,AOUSD联盟的行业Schema扩展速度直接决定孪生体互操作性。
- AI代理在孪生体中的决策权限边界,罗兰贝格已将治理列为代理孪生规模化部署的首要前提。
来源:
San, O. et al., “The evolution of digital twins from reactive to agentic systems”, Nature Computational Science, Jan 2026 |
Roland Berger, “From Digital Twin to Agentic Twin”, Apr 2026 |
Gartner, “Manufacturing Predicts 2026: Digital Twins, AI Agents”, Jan 2026 |
Cloud Latitude, “Digital Twin Investment Surge 2026”, Mar 2026 |
NVIDIA Blog, “GTC 2026 Virtual Worlds Powering Physical AI”, Mar 2026 |
AWS, “Agentic AI and Digital Twins on AWS”, May 2026 |
Ali et al., “Towards Agentic Urban Digital Twins”, Urban Informatics, Mar 2026 |
NVIDIA Blog, “Factory Operations Blueprint FOX”, Jun 2026 |
ARC Advisory Group, “Siemens Realize LIVE 2026”, Jun 2026
小米MiMoCode免费无限用MimoV2.5模型:命令行AI编程助手零成本上手教程
小米 MiMo 团队近期发布了一款名为 MiMoCode 的开源命令行工具,首个版本为 v0.1。该工具基于 OpenCode 进行了二次开发,定位为具备跨会话记忆能力的 AI 编程代理,能够读写代码、执行命令、管理 Git,并可通过调用子代理来完成更复杂的任务。
项目亮点速览
- 项目概况:MiMoCode 在 GitHub 已经收获 4.5k 星标,并且允许用户免费体验小米自研的 MIMO2.5 模型。
- 安装与使用:只需复制官方提供的安装指令在终端中执行,安装完成后重新打开终端,输入
mimo启动界面,点击斜杠菜单并选择免登录的MIMO auto模式即可直接调用模型。 - 与 OpenCode 的差异:MiMoCode 作为 OpenCode 的一个分支,在原有基础上进行了显著增强。小米团队引入了持久内存、智能上下文管理、子代理编排以及目标驱动等工作流,从而大幅提升了编程辅助能力。
本篇内容的核心不是去评测 MiMoCode 的功能有多强大,而是详细演示如何通过 MiMoCode 免费调用小米的 MiMo-V2.5 模型。
详细操作指南
MiMoCode 官方网站:https://mimo.xiaomi.com/mimocode

推荐在 WSL 终端或 Mac 环境下,直接执行官网给出的安装命令:
curl -fsSL https://mimo.xiaomi.com/install | bash
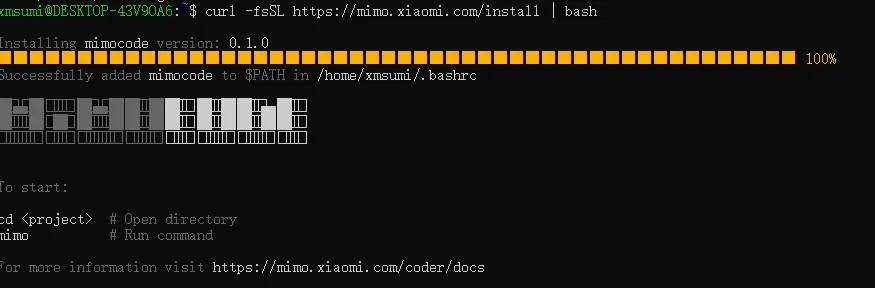
安装完毕后,输入 mimo 即可启动 MiMoCode。

如果已持有小米 MiMo 的 Token Plan,可以在对话框内通过 /login 命令进行登录配置,这一功能同时也兼容其他模型服务商的接入。
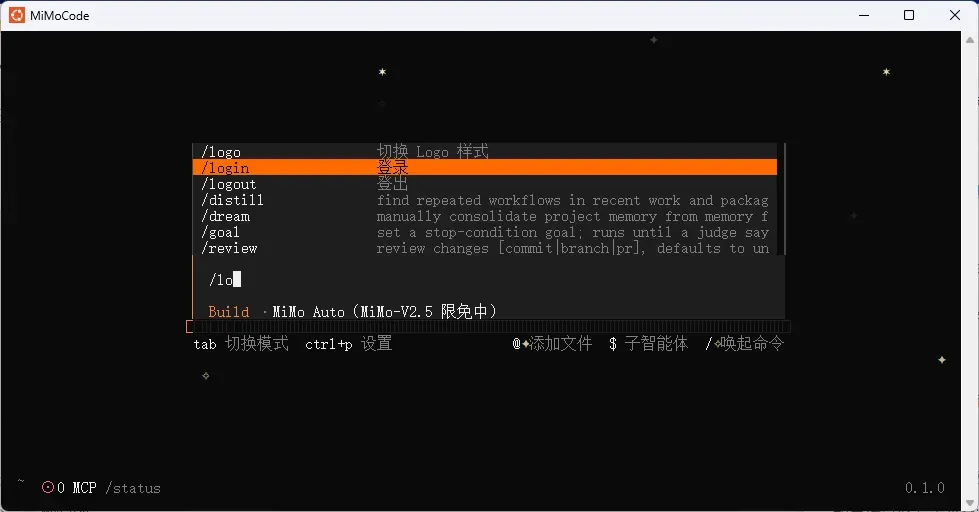
无需任何登录,直接选择 MiMo Auto 模式,即可立刻使用 MiMo-V2.5 模型(目前为限时免费)。