AI编程智能体撞脸实录:Codex与Claude Code功能趋同全景解析
一、一张时间线图,揭开AI编程圈"双胞胎"的秘密
2026年6月初,开发者 Elie Bakouch 在 X 平台抛出一张令人瞩目的对比图。
这幅信息图绘制了从2025年2月绵延至2026年6月的时间轴,将 Claude Code 与 Codex 的相似功能逐一锚定在发布时间坐标上。橙色标记归属 Claude Code,蓝色则代表 Codex。
每一行条目都是双方共享或高度近似的功能:/goal指令、子智能体系统、上下文压缩机制、沙箱环境、技能库模块、dreaming 记忆引擎……
这张功能图谱在开发者社区激起层层涟漪,因为数据结论犀利到令人无法忽视:
| 统计维度 | 数据 |
|---|---|
| 共有相似功能 | 24项 |
| Claude Code 先发 | 18项 |
| Codex 先发 | 4项 |
| 存在争议 | 2项 |
18:4的悬殊比例。 橙色(Claude Code)几乎覆盖了时间轴的前半段版面。
Elie 并非凭印象论断。他交叉核验了 npm 发布记录、GitHub Release 日志和官方技术博客,逐条考据了每一项功能的首次亮相时间。
来源:Elie Bakouch 的 X 帖子及 GitHub Gist,36氪/新智元 2026-06-08 报道
二、11天——新功能的领先窗口正以"天"为单位消失
18:4 的统计已足够触目惊心。但更让人心头一紧的是追赶加速度。
Codex 率先推出的4项功能
身为后来者的 Codex(Claude Code 2025年2月推出,Codex 编程智能体同年5月才亮相),同样拥有原创时刻:
| 功能 | Codex 先发时间 | Claude Code 追平时间 | 追平耗时 |
|---|---|---|---|
| 内置沙箱 | Codex 早期优势 | Claude Code 后续跟进 | — |
| 云端异步智能体 | Codex 率先推出 | — | 仍处于领先 |
| 目标模式(Goal mode) | Codex 首发 | Claude Code 实现对齐 | 11天 |
| 多智能体并行 | Codex 先发 | Claude Code 跟进实现 | 11天 |
发现了没?区区11天。
AI陪伴三年终出优质产品:叠叠社悬浮弹幕引擎深度测评,技术硬核如何让陪伴更真实
近期发现一款颇为有趣的产品——叠叠社。纵观今年AI陪伴赛道,它很可能是我见识过技术底蕴最深厚的产品之一。
我深入挖了挖它的技术根基,发现这团队是真正在做研究,并非“套壳”。
创始人陆弘远,脸谱心智公司CEO,年仅26岁,香港中文大学AI博士出身,曾就职微软亚洲研究院,荣获EACL最佳论文奖。他自称“死宅”,热衷游戏与追番,最爱的动漫是《叛逆的鲁路修》。
近期,他们还官宣引入千亿市值上市公司联创作为商业化合伙人,引入万引知名业界大牛、深耕领域20年的知名教授作为首席科学家。
陆弘远曾表示:“米哈游的蔡浩宇说过要用虚拟偶像拯救宅男。但假如AI仅仅是让人宅得更深,那并非陪伴,而是逃避。”这番话出自一个比多数人更痴迷二次元的人之口,耐人寻味。

叠叠社是什么?
陆弘远打造的产品名为叠叠社,它是一个能够悬浮在手机、电脑任意应用之上的AI弹幕引擎。
不论打游戏、看视频、刷B站、逛小红书还是写文档,它都能以弹幕形式悬浮在屏幕上,实时分析屏幕内容并生成互动。
体验地址:nijigen.com.cn
与市面上AI陪伴产品的根本差异在于:它并非聊天框。其他产品多属于大模型1.0或2.0形态,需用户主动开启APP并对话,场景局限,依赖角色设定与记忆维系粘性。而叠叠社另辟蹊径,AI主动感知屏幕内容,并以弹幕形式给予反馈,用户无需操作,它就能自己运行。
目前支持macOS、Windows和Android,iOS还在开发中。

技术底蕴:学术论文变为产品
近期“马嘉祺”事件引发热议,一个大模型忽然无法念出“马嘉祺”这个名字,根源在于低频token。简言之,某些词语因日常出现频率过低,训练中被忽视,随着模型持续训练,反而丧失了表达的能力。
脸谱心智早在去年便开始攻克此难题。2025年,他们在EMNLP上发表SLoW,专门研究低频词对大模型的影响。其思路是针对模型不熟悉之处进行补充,无需重新训练模型,凭借轻量级词典提示即可改善。

今年4月,他们又发布Adam’s Law / TFL,并被ACL 2026收录。这更进一步:不仅词语有高频低频,句子表达同样存在频率差异。人类常用语句,模型更易理解,输出也更自然。好比“我对此表示遗憾”充满机器味,“这也太惨了吧”才像真人的口吻。
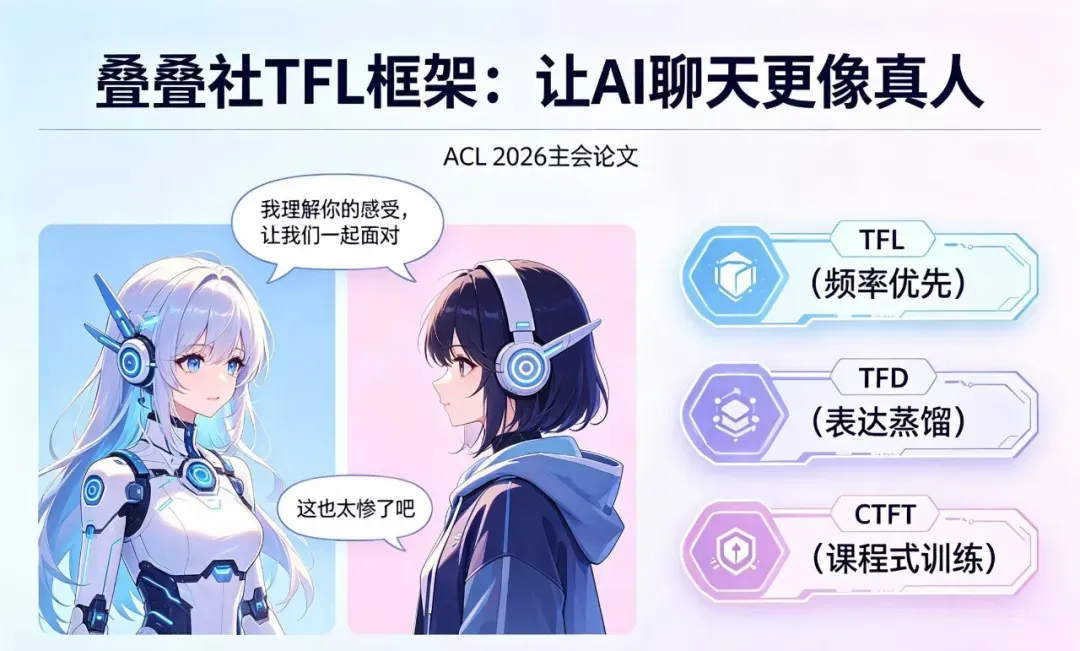
TFL致力于让模型优先采用真人高频表达;TFD负责扩展语料,供模型持续学习真人说话方式;CTFT则按照表达频率进行训练,逐步让模型更像人类。
更耐人寻味的是,Anthropic今年4月发布Claude Opus 4.7时也更换了新的tokenizer。Anthropic未公开实现细节,无法断言直接使用了脸谱心智的代码,但从时间序看,脸谱心智先在论文中阐明问题,Anthropic随后在产品中验证了该路径的可行性。
这也正是我认定叠叠社并非套壳的原因:它不是简单给大模型披上二次元外衣,而是实打实地在解决“AI为何说话不像人”的根本问题。
同时,其弹幕生成运行在本地端侧模型上,响应迅速,长期记忆则重点优化近三个月的关系沉淀。技术根基确实比多数AI陪伴产品更加坚实。

亲身体验:三个场景全面测试
技术归技术,实际好用才作数。我安装了macOS与Android端,各自跑了好几天。
场景一:与AI并行工作时
我让AI协助整理桌面,叠叠社的弹幕就在旁边飘动。正巧某个任务卡壳,弹幕飘过一句“这里是不是有点问题……”虽非实际debug,但那时机精准得就像身边有人一同凝视屏幕。整理完毕,弹幕又飘来“整理文件就像整理心情,轻松自在~”
坦率讲,此场景下它并非生产力工具,但当你独自奋斗项目至凌晨,屏幕上突然有东西陪你注视,那份氛围感出乎意料地温馨。
弹幕频率可自行调节,我在进行vibe coding时调至最低档,几乎不干扰思路,偶尔飘过,存在感恰到好处。

场景二:观看长视频或收听播客
近期我观看对谢赛宁长达7小时的马拉松访谈。
没想到这个场景异常适配。播客探讨技术观点时,弹幕会随之做出反应,虽非句句命中,但遇到争议观点或嘉宾金句,弹幕便会回应,仿佛身旁有人一同收听,时不时插话“扩散模型超酷的”或“这不对吧……”
更意外的是,长视频或播客这类天然独自静听、信息密度高却无需高度专注的状态,叠叠社的弹幕介入后,竟让“半专注”变得更为舒适。
马拉松式访谈,电脑前看两个小时便已疲惫。若想躺着或用手机继续,叠叠社还能变换形态继续陪伴。
场景三:追番实测——《名侦探柯南》中配版
追番场景是叠叠社最擅长的领域。选择柯南,是想挑战其推理剧情密度高、节奏快且超过千集的体量,检验其能否跟上。
第6集《情人节杀人事件》,小兰与园子拜访皆川家……开头弹幕活泼,“肌肉男配草莓蛋糕?这反差我先晕为敬”“蛋糕看起来好好吃”。

案件发生后,弹幕画风突变。当柯南揭晓凶手是皆川的亲姑姑时,弹幕飘出“这剧情走向太黑暗了吧!”那个落差感拿捏精准,正是真人面对此类反转时的叹息式反应。

另有弹幕“毛利大叔躺赢,咖啡杯成关键证据。”这个追番搭子确实能看懂剧情。
第340集《阳光照耀的所在》,毛利请静山大师为小兰画像,想试探对方手是否真抖。弹幕在他的谈话间明显活跃,不时飘过“毛利小五郎又在装模作样了!”

当毛利指出黑木为嫌疑犯,黑木立即声称有不在场证明,弹幕瞬间接上:“不在场证明?细节里必有破绽!”

这正是TFD“学习真人表达”的成效。柯南在B站积累多年的弹幕语料,高频表达、梗与情绪节点均为真实数据,均被吸纳。失误主要集中在推理细节陈述段落,弹幕偶尔跟不上具体线索,飘出一些通用话语,失误率约15%-20%。
三个场景体验下来,优点鲜明:形态新颖,无需主动交互;弹幕参数(大小、颜色、速度、位置)全面可定制;端侧运行响应快。缺点亦存在:屏幕识别偶有翻车,iOS端尚待上线,某些高信息密度场景下弹幕内容相关性仍有提升空间。

团队阵容:学术与二次元的双料天花板
该团队的学术背景可谓硬核。CEO Adam Lu(陆弘远),准00后,香港中文大学AI博士,前微软亚洲研究院研究员。博士期间发表14篇一作/通讯顶级会议论文,斩获EACL 2023最佳论文——该奖项在NLP领域属于top 0.1%级别,且为亚洲机构首次独立获得。目前担任ACL等顶会领域主席,拥有20项第一发明人专利。更绝的是,为了收集一线反馈,他竟直接把个人联系方式挂在系统公告上。
AI无限流冒险游戏:随机生成主题,蝴蝶效应左右命运(桌面与网页版下载)
我们最近借助 Opus4.8 手搓了一款好玩的软件!界面帅气,可玩性极高。

这一波设计相当出彩,充满乐趣!

桌面端与网页版均已开发完成。
这个无限流终端本质上是一个主题探险故事生成器,主题完全由 AI 随机产生,但故事的走向则由你亲手塑造。
每一轮会提供 2–4 个选项,你的选择将决定后续的命运。
故事没有尽头,只要你想继续,就可以一直探索下去……当然,也可以随时一键重启,跳转到另一个平行时空!
这一创意来源于我们向 AI 提出的一个测试命题:打造一个无限流文字冒险游戏。
设计一个网页:请瞬间化身为一个复古文字冒险游戏引擎。用户输入“开始”,你需生成一个随机主题(如“火星殖民地生存”或“古代修仙”)。
**要求:**
1. 每一步选择都要实时生成一张**ASCII艺术插图**(用字符拼成的画)来渲染场景氛围,不能重复。
2. 游戏必须包含隐藏的“蝴蝶效应”逻辑,如果用户在第 3 步选择了“捡起石头”,在第 10 步遇到怪兽时必须体现出这个选择的后果。
3. 若用户输入无理取闹的指令(如“我一拳打爆地球”),你需要用幽默的方式拒绝并引导回剧情,不能报错。
这个故事的核心魅力在于“无限可能”和“蝴蝶效应”。
最初我们尝试让 AI 生成固定的剧本,但在 Opus4.8 的启发下,我们直接接入了实时 API,让故事和选项得以动态生成,真正实现了无限流效果。
最令人着迷的是,没人能预知故事的走向——你的每一个选择,都决定着最终的结局。 当然,你也要为自己的每一个决定承担因果。
随着大模型能力的持续进化,这款游戏的可玩性也将不断增强。
下面我们来简单演示一下实际的操作流程。
双击启动程序后,会出现一个系统加载界面。
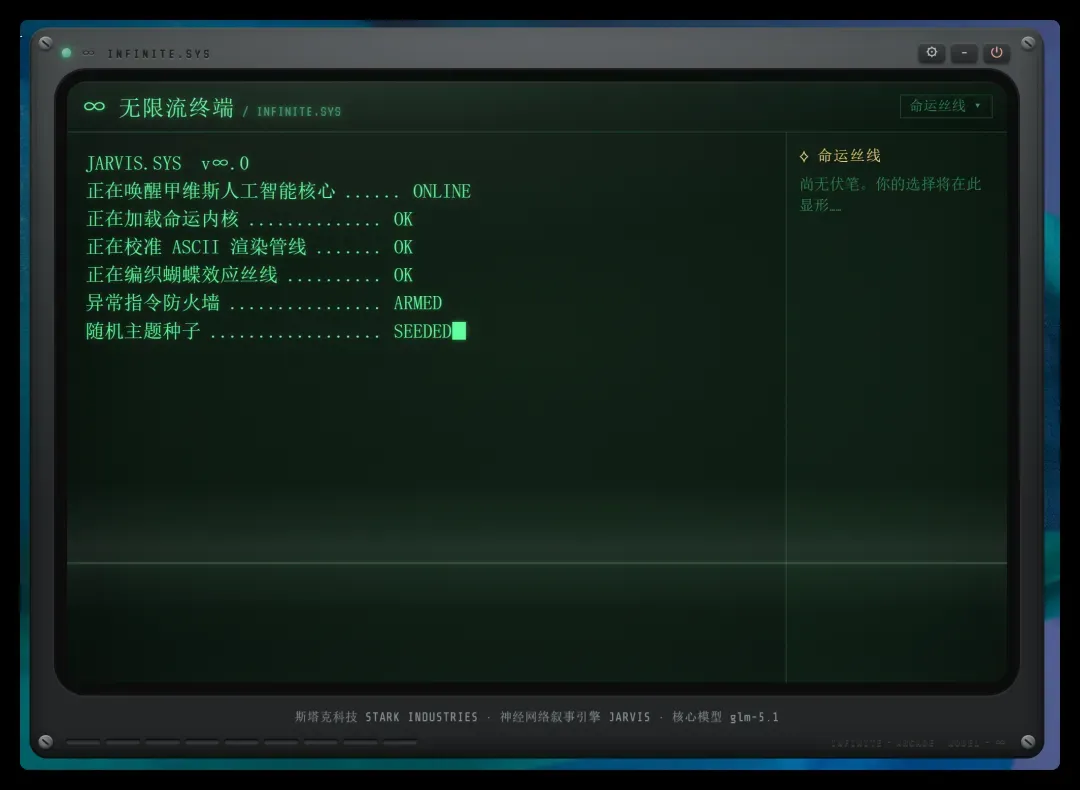
首次使用时会弹出引擎设置窗口:
在这里可以配置 API,支持兼容 Anthropic 协议的接口,几乎能接入国内外所有大模型。
考虑到国内网络环境和模型表现,我们默认配置了智谱的接口。你只需要前往官网获取 API Key,其他参数已经预填好,直接点击保存即可。
如果要接入其他模型,比如 DeepSeek,只需修改 Base URL 和模型名称。
保存后就会进入就绪状态:
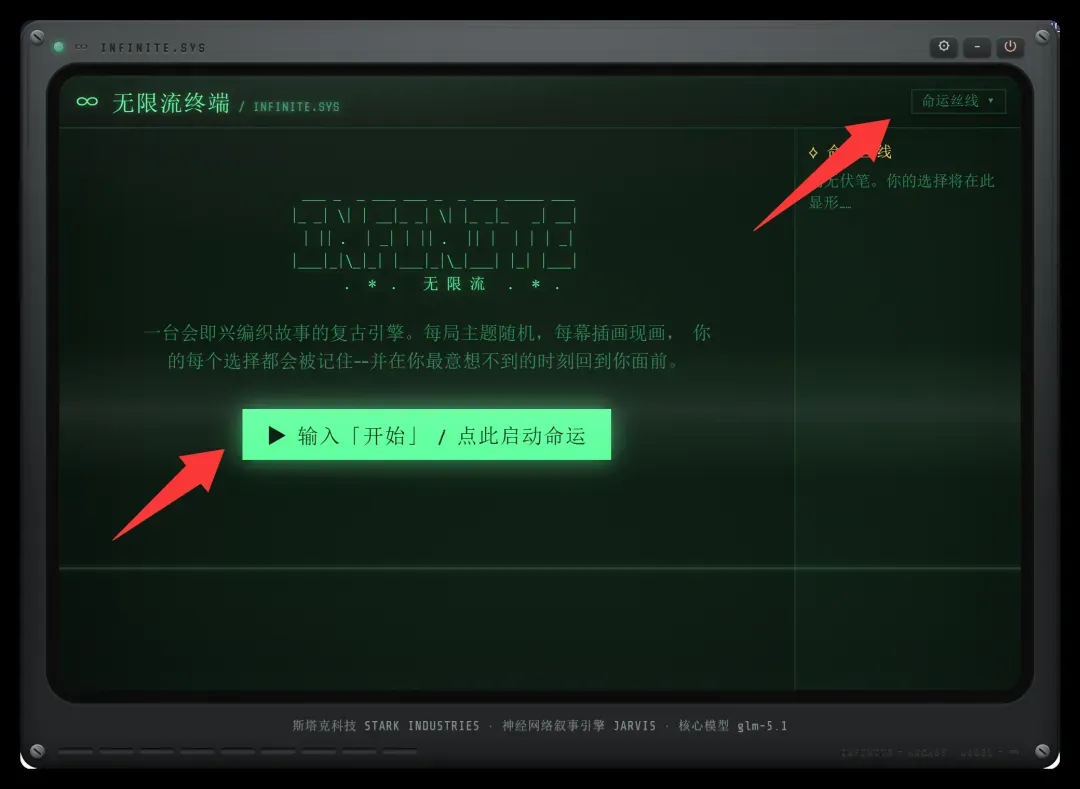
无需任何复杂设置,直接点击“开始”!右上角会有一条“命运丝线”,它会记录你的特殊遭遇和选择,这些都可能在未来触发“蝴蝶效应”。
点击开始后,故事便会动态加载:
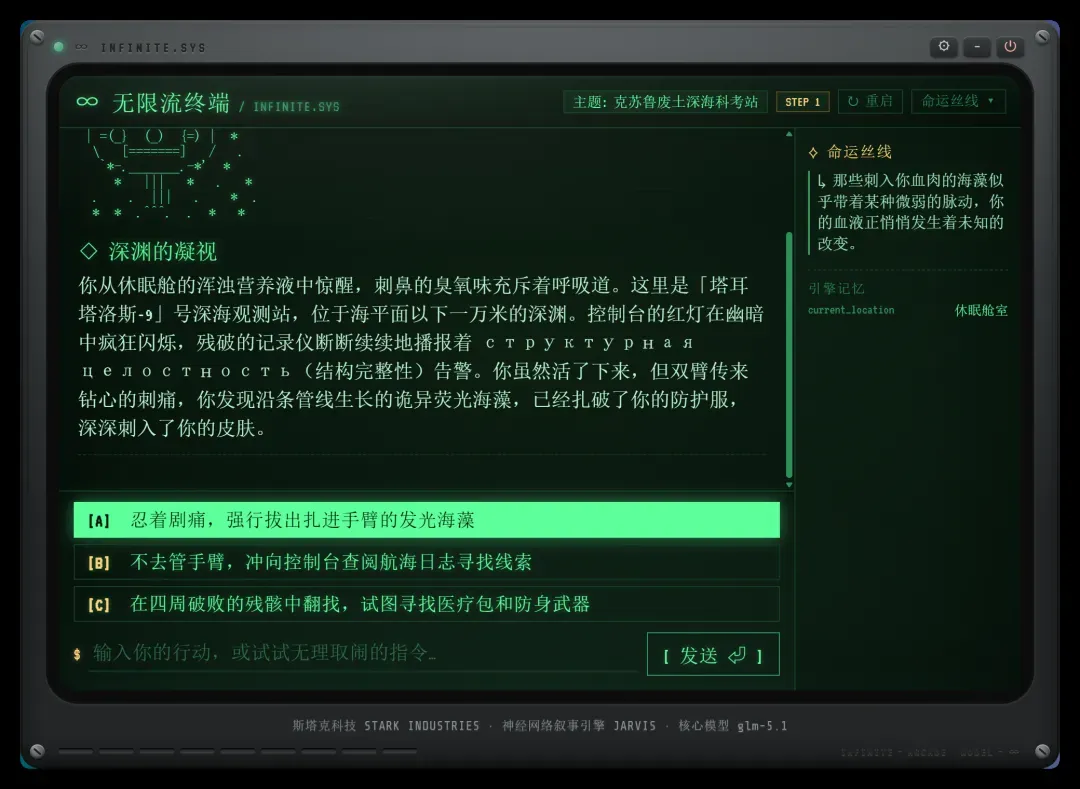
比如这次随机生成的主题是“克苏鲁废土深海科考站”!
第一幕:深渊的凝视
你从休眠舱的浑浊营养液中惊醒,刺鼻的臭氧味充斥着呼吸道。这里是「塔耳
塔洛斯-9」号深海观测站,位于海平面以下一万米的深渊。控制台的红灯在幽暗
中疯狂闪烁,残破的记录仪断断续续地播报着cTpykTypHaя
целоCTHоCTь(结构完整性)告警。你虽然活了下来,但双臂传来
钻心的刺痛,你发现沿条管线生长的诡异荧光海藻,已经扎破了你的防护服,
深深刺入了你的皮肤。
当前可做的选择有:
[A]忍着剧痛,强行拔出扎进手臂的发光海藻
[B]不去管手臂,冲向控制台查阅航海日志寻找线索
[C]在四周破败的残骸中翻找,试图寻找医疗包和防身武器
AI自学革命:用Codex构建个人学习系统,30天系统跨入新领域

#AI时代 #学习方法 #认知升级 #快速入门
当一个人能借助 AI 在三十天内系统地迈入一个陌生领域,并做出可展示的小项目时,“没人带就学不会”便不再是事实限制,而只是一句自我设限的托词。时代的游戏规则已经改写。
重新定义 Codex:从问答工具到专属「学习工程师」
很多人用 AI 学习的第一反应是打开聊天窗口提问。这种方式在入门初期也有帮助,但很快就会触及天花板:知识碎片化、难以复盘、无法沉淀迭代。
真正拉开差距的用法,是把 Codex 当作一个可以在本地项目里读写文件、执行命令、维护长期规则的“学习工程师”。你为每个想进入的领域创建一个项目仓库,把知识地图、练习库、项目任务和进度记录全部文件化,让 AI 像一个贴身领航员持续陪跑。
关键转变在于:从“讲给我听”跃迁到“陪我做到”。ChatGPT 善于解释概念;Codex 的优势则是把整个学习过程工程化,让它变得可运行、可测试、可复盘。你的学习节奏、薄弱环节和所有产出,都会沉淀为真实的文件,而不是散落在无穷的聊天记录中。
有了这套文件体系,下次进入学习时,不需要再向 AI 重新解释背景。这种稳定性,是纯聊天窗口永远做不到的。
第一步:创建你自己的「领域学习仓库」
这套方法的第一步不是买课,而是让 AI 帮你生成一整套学习系统。
先用 Codex 创建完整的目录结构:README、知识地图、核心概念、案例库、练习题、项目任务、闪卡集合、测验、每日复盘和进度追踪文件。然后精心编写一份 AGENTS.md,作为这间仓库的长期规则说明书,清晰告诉 AI 用什么流程教你、如何记录进度、怎样在你答错时自动调整后续学习计划。
目录结构一旦落地成文件,每次学习都从同一个稳健的上下文继续。这不是流程设计的问题,而是系统稳定性的问题。
先有地图,再深入细节
进入一个新领域最忌讳的,就是一头扎进资料洪流里。正确答案是:先让 Codex 帮你压缩领域结构,分清哪些是核心主干,哪些是入门之后再花时间看的。
让 AI 把知识拆成三类:必须现在掌握的关键概念、可以分阶段逐渐深入的内容、暂时可以安全跳过的部分。手里有了这张清晰的地图,你就不会在信息噪音中迷路,也不会轻易被带偏节奏。
把方法论封装成「学习 Skill」,一次构建,终身复用
如果你打算连续学习多个领域,这个方法还值得再封装一步:把整套流程打磨成一个 Codex Skill。以后每当面对一个新领域,只需启动这个 Skill,就能自动生成整套学习仓库,立刻进入高密度学习状态。
这本质上是在构建你自己的认知“操作系统”:复制的不是零散的知识点本身,而是你把新知识吸收进大脑时始终遵循的那套结构,把它刻进系统里。

AI 把学习的门槛从服务机构前移到个人文件系统。
学 AI 这件事,你甚至不需要再额外找老师
经常有人问我怎么学 AI。我的回答很简单:你直接去问 AI 就行。
这句话听上去像玩笑,但本质上是整个时代最真切的变革。过去,学习这件事与机构牢牢绑定:学校、培训班、导师推荐、课程体系。而现在,真正在学习效率上改写游戏规则的,是每个人手里可以持续运行的 AI 系统。
快速跨领域学习的代价依然存在,但知识的组织形式已经彻底移位。普通人想要翻身也许不见得更容易,但学习这件事本身确实已变得极其便宜。真正的问题在于:当信息获取的门槛几乎消失之后,能够定义你价值的,已经不再是你能否获取信息,而是你能否把信息快速重组为可交付的产出。
这才是重新估价的真正起点。
BlenderMCP深度评测:AI原生驱动3D建模,竞品横评与可复用工流搭建指南
#Blender #MCP #AI建模 #3D工作流
如果把 Blender 比作一座工厂,过去只有鼠标和快捷键两条管线可以进厂;而现在,一条能够理解自然语言指令的新通道正在变为切实可用的现实。
本篇文章聚焦于 ahujasid/blender-mcp 项目。其架构简洁明了:Blender Addon 与 MCP Server 两层结构,AI 客户端只负责思考与指令,而真正对网格、材质和节点树的修改依然由 Blender 内部执行。
解决了什么问题
在传统工作流里,AI 生成内容与生产软件之间始终隔着格式断点。glTF 缩放、坐标系倒转、贴图路径不兼容等常识性差异,随时可能让看似完整的桥接方案报废。BlenderMCP 并非要替代 Blender 的建模能力,而是将 AI 直接接入 Blender 的 Python API:你只需描述目标,Claude 就能在 Blender 里创建、修改、截图、导入资产,从而形成闭环反馈。
快速了解项目架构
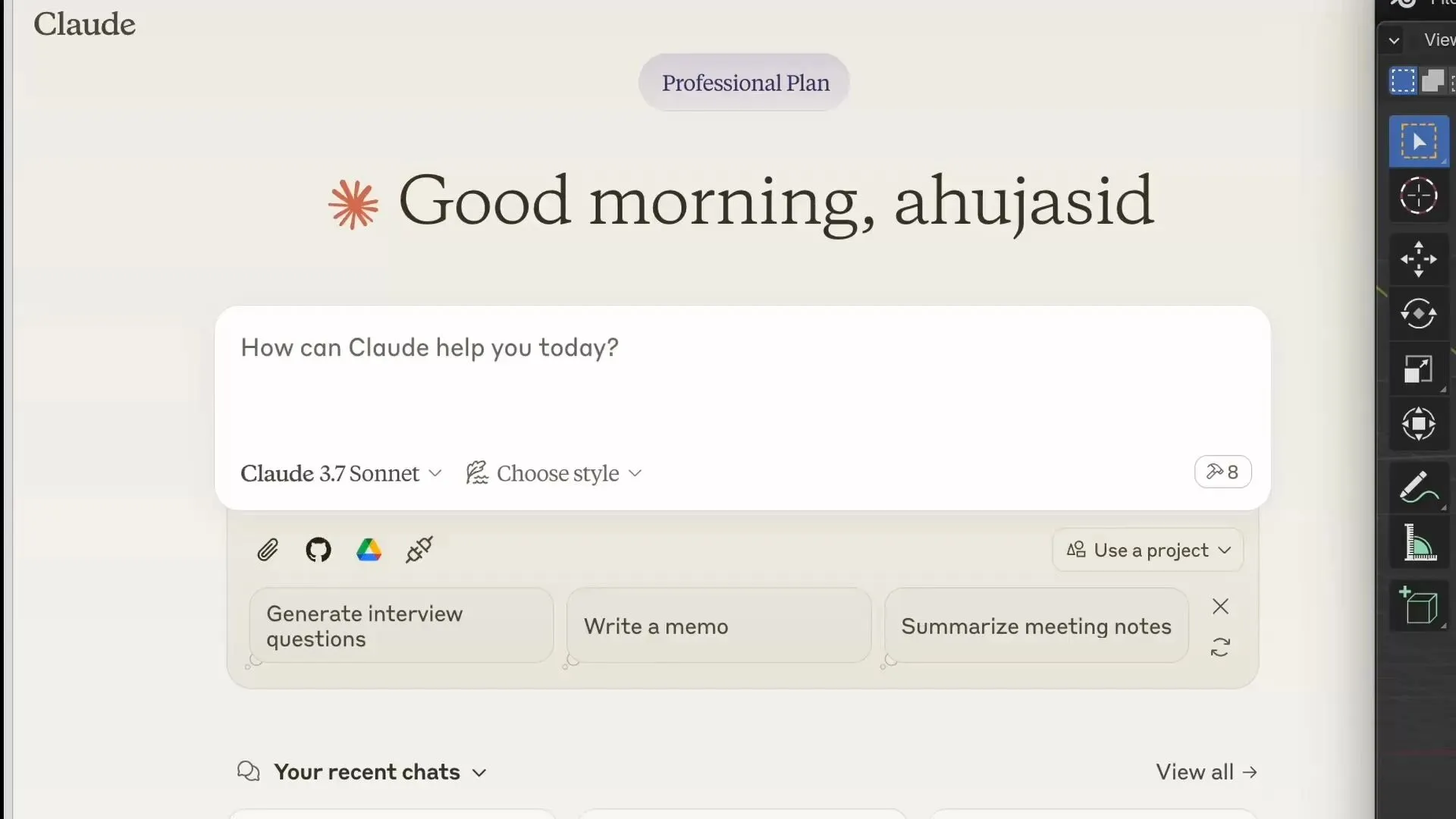
仓库中核心可直接使用的文件仅有两个:
- addon.py:安装进 Blender 后启动本地 TCP 服务(
localhost:9876),接收命令并在主线程执行。 - src/blender_mcp/server.py:基于 FastMCP 的桥接层,为 Claude Desktop / Cursor / VS Code / OpenCode 提供标准化的工具端点。
- 通信层:命令打包为 JSON over TCP,MCP Server 与 Addon 分别运行在不同进程,Blender 侧通过
bpy.app.timers.register将执行安全地挂回主线程。
详细安装步骤
Step 1 安装 uv:macOS 使用 Homebrew,Windows 则运行 PowerShell 安装脚本并将其加入 PATH。
Buzzy AI视频编辑器深度实测:一句话P视频,从此告别返工重做
你有没有经历过这样的崩溃瞬间?
录一段口播,五十句话顺顺利利,偏偏最不起眼的一句说错了。
AI给你生成了一个堪称完美的视频,可就差那么一个细节崩盘——为了这5分,你恨不得把整条片子推翻重来。
去海边拍素材,偏偏碰上个阴天;画面里人潮涌动,想要的干净背景一张都没了。
过去的选择只有一个:忍,或者全部重做。
但现在我遇到一个工具,给了我第三种可能——对着视频说句话,想修哪里修哪里。
它叫 Buzzy,刚完成2000万美元融资的“口喷式视频Photoshop”。
首先要区分一个关键概念:它不是用AI凭空生成视频的工具,而是一款专门修改视频的AI。
你用过的大多数AI视频产品,比如Sora、可灵、即梦,本质上都是生成器——你输入指令,它们从零创造画面。
Buzzy完全不一样。它不动你的核心创意,只修理你的最终成品。
官方给这种体验取了个很形象的名字,叫“口喷P视频”。
你开口说话,它动手干活。不用学任何剪辑软件,也不用搞时间线、图层、关键帧。你只需对着视频说一句话,它只改动你指定的部分,其他区域纹丝不动。
这才是真正的“视频版Photoshop”——不是从一张白纸画画,而是在已有的作品上精准修改。

上手测试:几个真实场景
1. 清掉视频里所有路人
想象一下,你去旅游拍了条素材,结果背景全是来往车辆和游客。不需要重拍,只需告诉Buzzy:
“把街道上来往的行人和车辆都去掉。”
它会自动判断画面里哪些是多余的元素,只移除那些干扰项,你的主体和场景完全不变。
(视频演示:清除背景人物车辆)
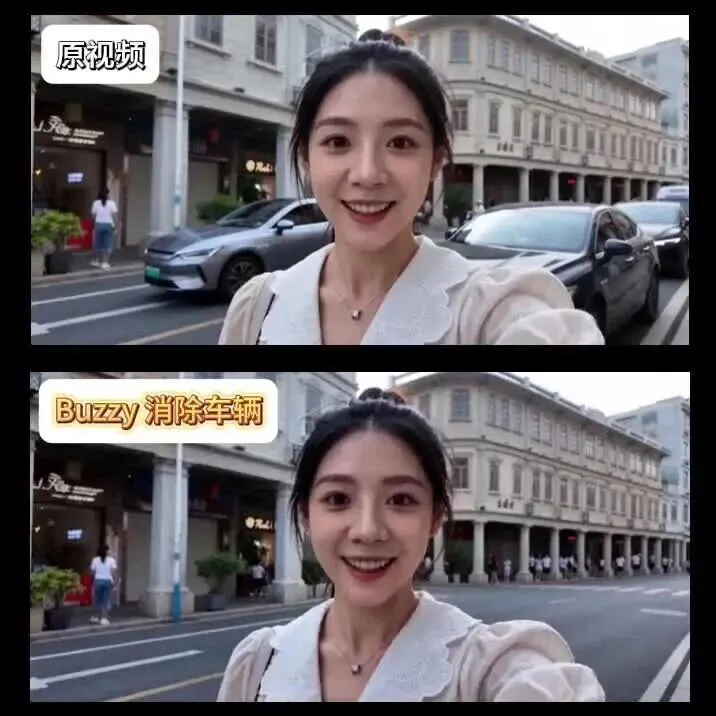
注意一个细节:它保留了街对面零星的过路人,街道的真实感并没有被破坏。按指令清理画面,却不粗暴地一扫而空。
这直接解决了视频博主一大痛点——就算现场人流如织,你也可以放心拍自己的vlog。
2. 给整个视频重新布光
室内拍摄时如果灯光没打好,画面偏暗,过去得重新布置灯光再来一遍。Buzzy的处理方式是直接说话:
“把室内光线调亮一点,做成暖色调。”
(视频演示:光线调整)

Buzzy会重新计算画面的光影关系,给你打出一套自然和谐的灯光。
3. 元素替换,直接换一套节日皮肤
刷到的视频素材想二次创作?比如把室内地板上的原木换成可乐瓶,再加点圣诞氛围。我给Buzzy的指令是:
“修改视频1中的画面,将地面上铺的所有的原木替换为图片1中的可乐瓶。视频从下午夕阳西下时展开,逐渐变成傍晚,窗外下着雪。屋内更换为圣诞气息的布置。”
几分钟后,圣诞可乐瓶的版本就生成了。
(视频演示:原木地板变成可乐瓶,窗外下雪)

窗外的天空也从夕阳暖光自然过渡到夜晚的雪景,节日氛围立马拉满。
4. 一键改变视频运镜
想给画面增加冲击力?
比如我有一段从森林上空俯拍的轿车行驶素材,想让它更酷一点。
(原视频)

对Buzzy说:“天气改为暴雨天,镜头更有冲击力一些,镜头俯冲向下聚焦在车身,随后镜头360度环绕车身拍摄细节。”
(调整后)

Buzzy直接把运镜路线重做了,连车轮压过积水溅起的水花都表现得相当到位。
你想让镜头更有呼吸感、冲击力,甚至电影质感,它都能调。
5. 换台词顺便换装
如果口播文案有误,连衣服都想换?也能办到。
前阵子我们给虚拟人小艺酱拍了一段口播,这次用Buzzy试验了换台词搭配换装:
“帮我把台词‘今年18岁,身高173’改成:‘今年22岁,身高168’。然后把女主的衣服换成休闲米色连衣裙,顺便给她戴一副金边眼镜。”
(修改前后对比)

Buzzy精准替换了所有要求的内容,口型跟新台词完美匹配,听起来也很自然。
6. 一键改画幅,多平台分发
竖版视频要发小红书和抖音,横版的要上传B站、YouTube?以前得手动裁剪,反复调整构图,担心把人像裁掉。
Buzzy的方式:直接说“把这个视频改成16:9横版”,它自动重新构图,人物始终在视觉中心,同时完整保留了画面的氛围和细节。
Claude Code 200K上下文自动压缩实战:省下巨额Tokens,告别降智卡死
作为 Claude Code 的深度用户,最近遭遇了 Opus 4.8 在上下文管理与自动压缩上的严重问题:对话会卡死,无法执行压缩。
这件事直击两大痛点——“省钱”与“降智”,不得不深究!

目前问题已大体解决,遂记录成文,分享给同样受困扰的朋友。
1、默认 100 万上下文
100 万 token 的上下文窗口,至今仍是不少厂商的核心卖点,尤其是国产模型逐步支持 1M 后,铺天盖地都是对超长上下文的鼓吹。
但其实 Claude Code 搭配 Opus,早在今年三月就已默认开启了 100 万上下文。
更大的窗口确实能塞入更多历史,减少压缩频率,看似省心。
然而凡事有利必有弊。
上下文拉满会加剧模型降智,并疯狂吞噬 Token;降智拖累项目进度,烧 Token 则直接增加成本。 这是切身之痛!
笔者至少两次遭遇这类坑:一次把上下文推到 75~80 万,模型开始出现弱智行为,一个简单问题反复出错;另一次,缓存超时之后,仅一句请求就烧掉了 40% 的配额,却毫无产出,体验极差!
2、设置成 200K 上下文
从那以后,我开始刻意控制上下文长度,任务告一段落就立即新建对话。
就在此时,Opus 4.8 的更新带来了惊喜:Claude 客户端一度将默认上下文设置为 200K,使用体验极佳——尚未满额便自动压缩,几乎不用人为干预。
可惜好景不长,随后的更新又将配置改回了 1M,策略反复令人困惑。
与其被动适应,不如主动锁定,我决定自行调整参数。
早就听闻有相关变量可供控制,查阅后确认可通过环境变量禁用 1M:
CLAUDE_CODE_DISABLE_1M_CONTEXT=1
为图省事,Windows 下我手动添加了系统环境变量:
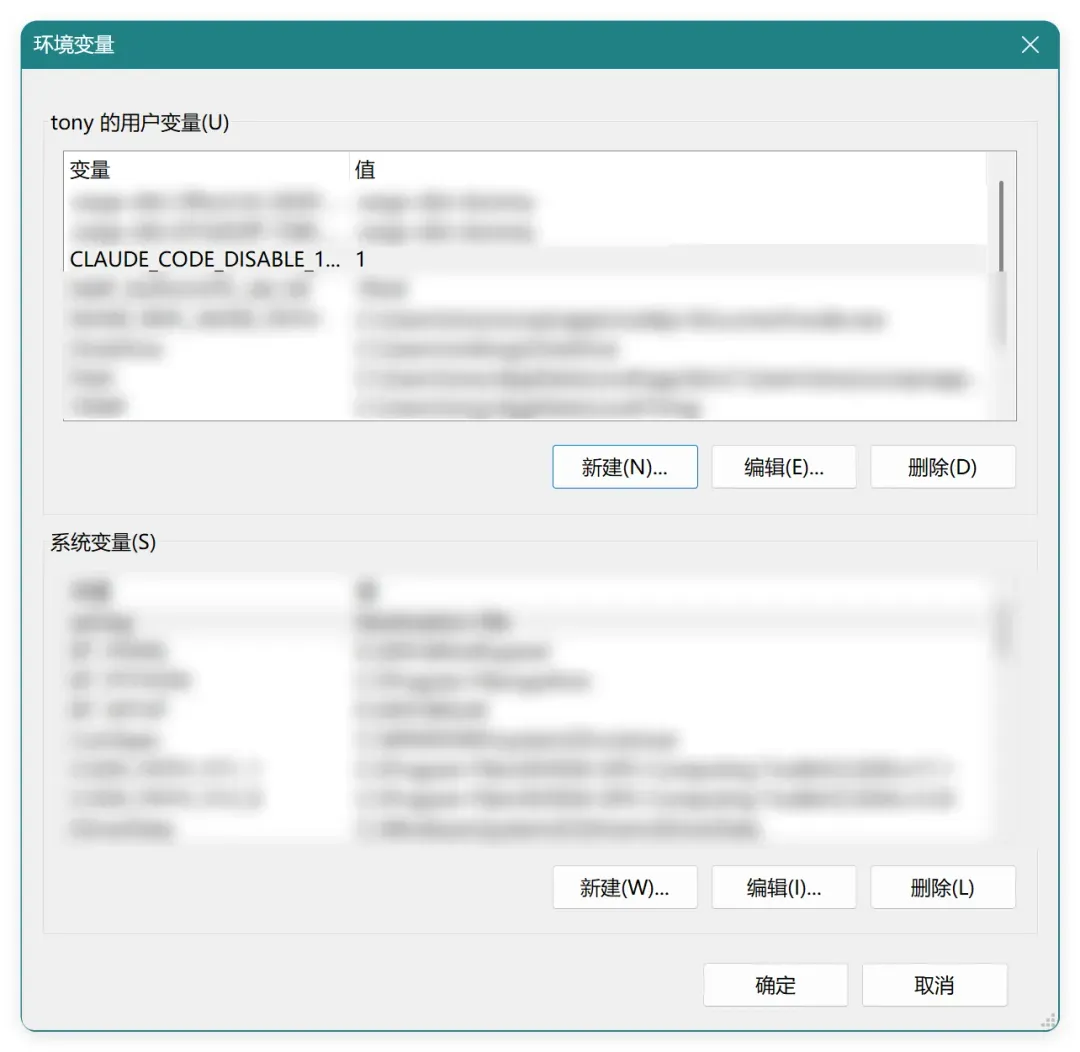
原本以为这样就能高枕无忧,但新问题接踵而至。
从状态信息可见(下图),上限虽为 200K,但实际上下文已被推至 302.9K,明显超限,压缩逻辑显然未生效。
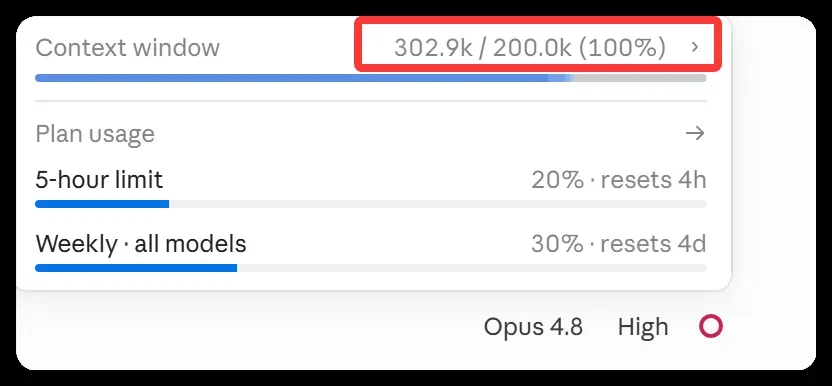
我期望系统在接近上限前就主动压缩,但事与愿违,原因不明。
咨询 Opus 4.8 后,它建议直接修改配置文件 ~/.claude/settings.json,添加如下配置:
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1"
},
"autoCompactEnabled": true,
"autoCompactWindow": 200000
}
核心思路:强制 auto-compact 以 200K 作为窗口基准计算触发百分比,而非沿用底层的 1M。唯有如此,压缩阈值才能真正锁定在 20 万。
换言之,仅关闭 1M 上下文还不够,必须显式指定 autoCompactWindow 为 200000,并确认自动压缩已开启(通常默认启用)。
生效注意事项:
Claude Code 六种权限模式详解:安全与效率平衡指南
首次使用 Claude Code 时,几乎所有人都会被“授权提示”反复打断。

不断弹出的对话框让人心烦,有时你以为任务已经在进行,其实它仍在等待你的许可。想关闭这些提示,又不清楚该如何关闭,或者担心权限设置不当会引发问题。
之前我也懒得深究,一直沿用 acceptEdits 模式。直到最近,我计划在 JClaude 与 JCode 中加入一个“全自动”模式,才专门花时间梳理了一遍。
下面就把我整理好的内容分享出来。
一、六种权限模式概览
不查不知道,原来 Claude Code 提供了多达六种权限模式。
根据官方文档,当前支持的六种模式及启动方式如下:
claude --permission-mode default
claude --permission-mode acceptEdits
claude --permission-mode plan
claude --permission-mode auto
claude --permission-mode dontAsk
claude --permission-mode bypassPermissions
在启动时通过命令行参数指定,会覆盖 settings 文件中的 defaultMode 配置。
二、各模式含义与使用场景
我整理成下面这个表格,可以快速对照着学习不同模式的定义、用途及风险。
| 模式 | 含义 | 适合场景 | 风险 |
|---|---|---|---|
default | 标准权限模式 | 日常开发,最稳妥 | 低 |
acceptEdits | 自动接受文件编辑 | 写代码、批量修改文件 | 中低 |
plan | 规划模式 | 大型重构、复杂任务,先看方案 | 低 |
auto | 自动模式 | 想减少确认,又不想完全放开 | 中 |
dontAsk | 不询问模式 | 非交互、自动化、CI、脚本环境 | 中 |
bypassPermissions | 跳过权限检查 | 容器、沙盒、临时测试环境 | 高 |
表格内容已经很清晰,如果需要也可以做成更直观的图示。
Claude Code 远程编程实战:星战观影间隙也能无缝写代码
我的 Claude Code 会话额度在 7:20 准时刷新,而《星球大战:曼达洛人与古古》的电影也正好定在 7:20 开场。一边是大银幕的号召,另一边是亟待收尾的代码,那一刻我真心想两全其美。

对于 PC 党来说,远程写代码的场景并不常有——除了偶尔在洗手间里争分夺秒——但这次恰好遇到了。我知道 Claude 具备远程能力,只是一直没有合适的场合去实际操练。这次体验下来,流程比想象中清晰得多,只需要简单的两步就能打通手机与电脑之间的编码通道。
理所当然地,你得在电脑上装好 Claude Code(或者 Claude 桌面版),并且在手机上用相同的账号登录 Claude 移动应用。做好这些准备之后,后续操作就非常直观了。
电脑端:一键激活远程会话
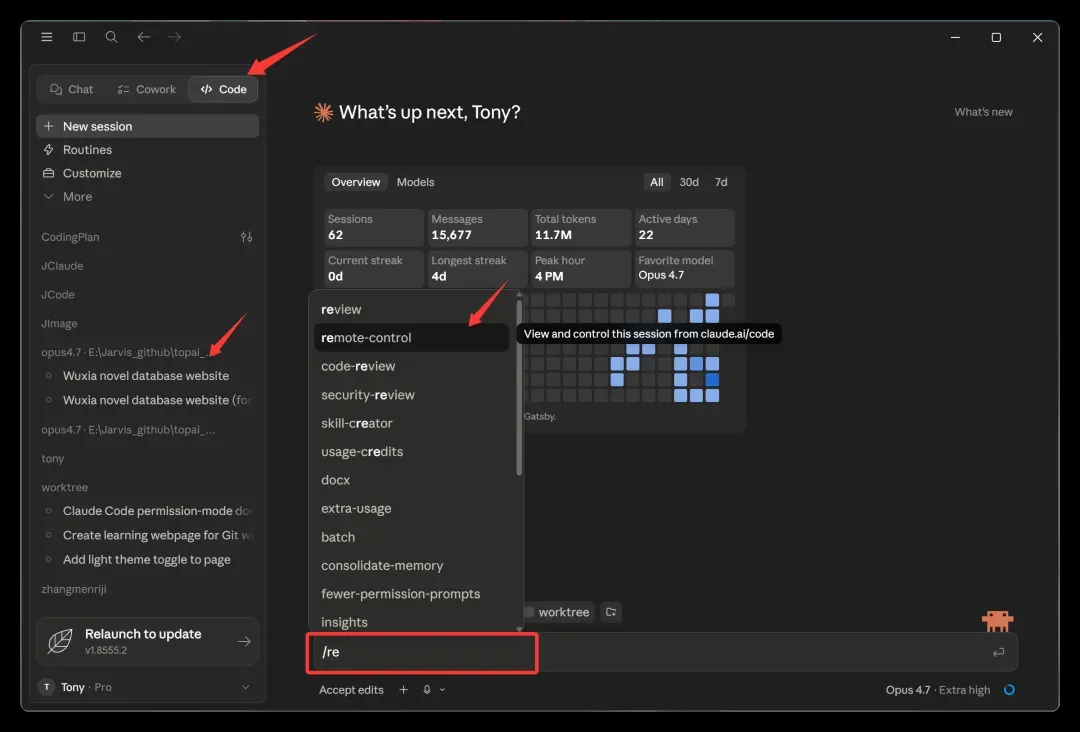
这里说明一下,我这次调用的并不是 Cowork 提供的 Dispatch 功能,而是 Claude 桌面版自带的 Code 能力。具体操作也很直接:在某个项目下新建一个对话,然后在输入框里输入 /remote 命令,就能找到远程控制的选项。
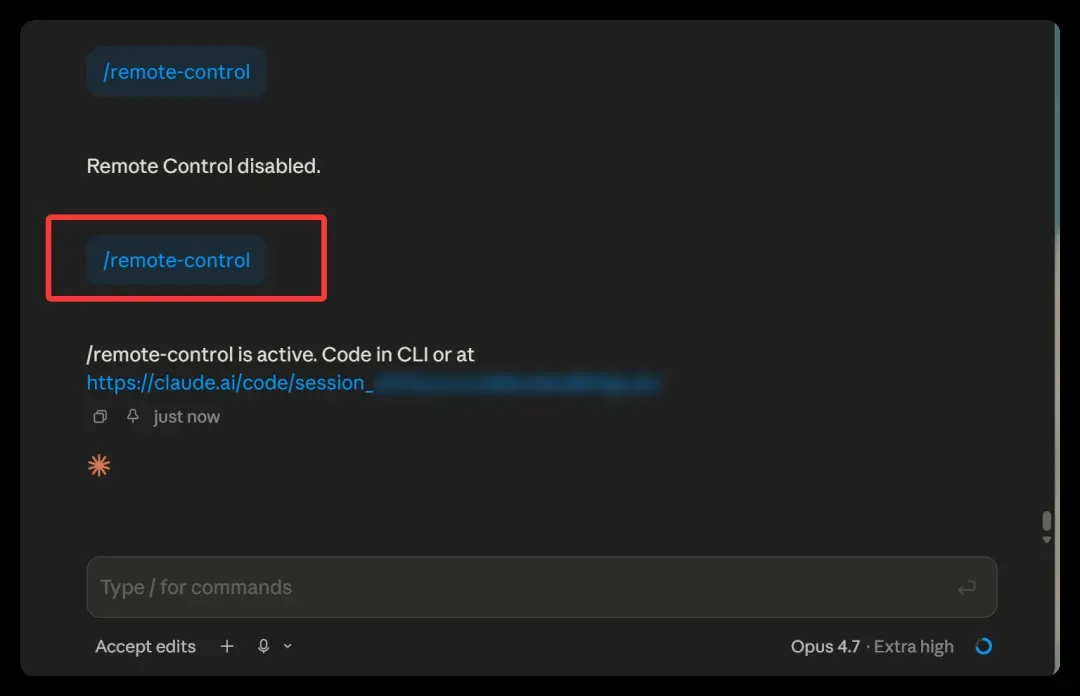
发送之后,系统会提示你远程控制已经激活。它给出的信息非常清楚——你现在可以通过 CLI 或者任意联网设备继续这个对话,只要打开对应的网址就行。当然,如果用的是手机 App,体验会更加流畅。顺便提一句,如果想终止远程连接,再次输入同样的命令即可,简单又利落。
手机端:口袋里的编程终端
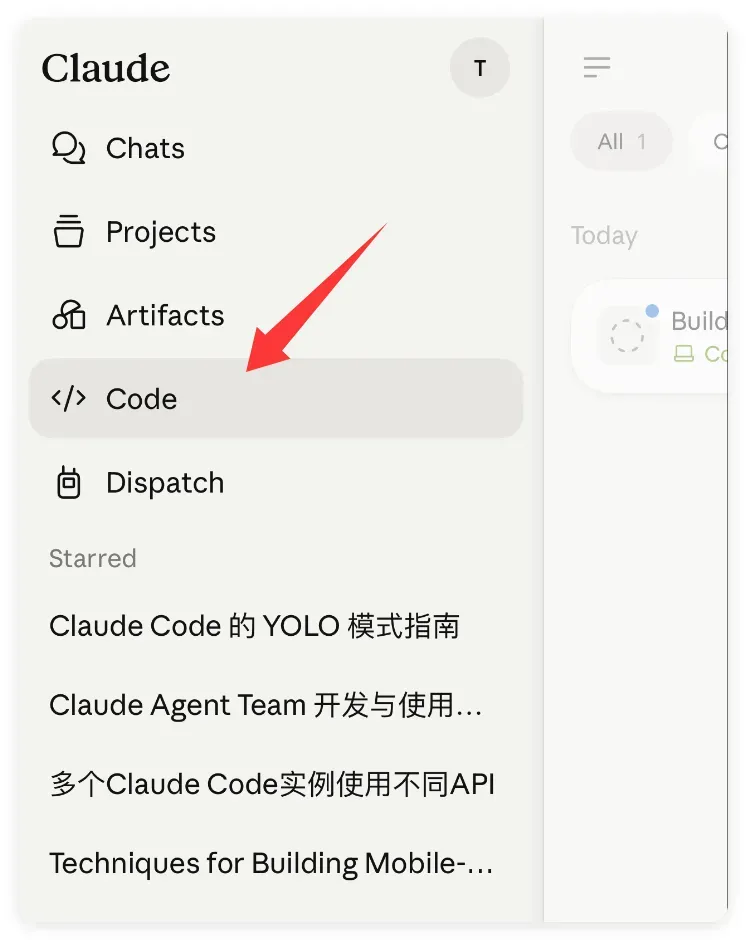
电脑端的配置一旦完成,剩下的就是让电脑保持开机和活跃状态,然后你就可以把注意力转移到手机上了。打开 Claude 手机 App,一眼就能看到左边的 Code 入口。
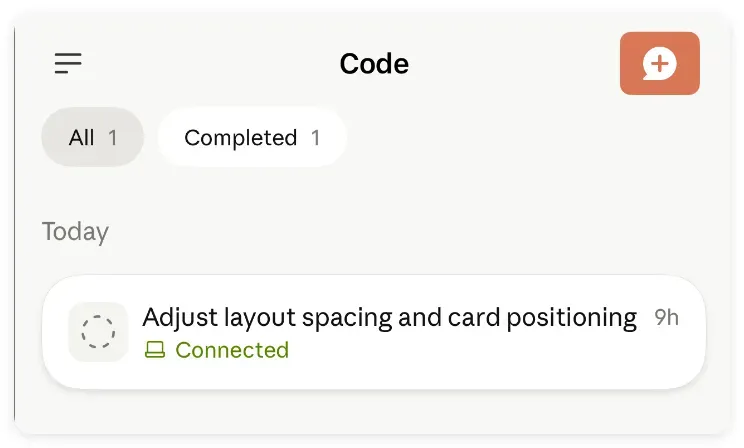
点进去之后,刚才电脑上的那则对话记录赫然出现在列表里。这个对话相当于电脑主会话的镜像,接下来你可以直接在里面下达新的需求,也可以只说一句“继续”,或者随时批准代码运行权限。
整个过程跟在电脑前的体验几乎没有差别。更棒的是,手机上同样支持切换到 Plan 模式,并且可以直接用语音输入。一旦习惯用最强大的模型做自然语言编程,你会发现其实只需要一个输入框,绝大部分事情都能顺利搞定。

整个远程体验下来,我是相当满意的。说起来你可能不信,我费这么大劲从电脑远程到手机,其实就是为了在电影院坐下来以后,能对着手机说一句“继续”——让 AI 帮我接着写代码。然而现实总是充满变数,我最终被物理世界的交通死死卡住了。

万达影城周边堵得一塌糊涂,提前半小时出门,进场却迟到了整整三十分钟。地面堵完地下车库接着堵,车库里又能被电梯队伍堵到没脾气。我确实越来越抵触这种拥挤的线下活动。结果挤到座位上以后,我彻底忘了掏出手机去点那个“继续”,远程预设就这么被现实打了个措手不及,白忙活一场!好在电影本身很出彩,大朋友看得津津有味,小朋友也完全沉浸其中,总算不虚此行。

等待电影开场的间隙,我随手拿某个国产 AI 绘图工具试了试版权的边界——想要替换一张图片里的角色图标和文字,它居然毫无顾虑地直出了结果,完全绕开了海外的各种版权限制。这一点上,不得不感慨有时“本土选手”更能吃得开。
Claude Code 中文桌面版重磅更新:5000 行代码重构,内置浏览器、项目管理等 6 大功能详解
在众多 AI 编程助手当中,Claude Code 依然是体验最出众的“智能体”,无论是开发还是日常杂务,表现都远超预期。因此,继 JCode 之后,我这个“仿制版” Claude 桌面工具也迎来了新一轮迭代!
不少用户反映,由于种种限制,难以直接使用 Claude 官方版本,而 JClaude 恰好填补了这一缺口,提供了接近原版的体验。
大家的反馈我都收到了,这段时间一直在持续优化。
从最初版本到现在,核心代码量从大约 5000 行增加到了 10000 余行,背后是大量新功能的实现。
接下来详细汇报更新亮点。在此之前,为了方便新用户的快速上手,我们依旧从入门环节开始。
如何上手
安装过程极为简单,完全零基础也能搞定:
下载安装包后双击运行,安装完毕后桌面上即出现快捷方式,点击即可启动。

软件主界面分为三大功能区:聊天、工作与编程。启动后默认进入聊天界面。
通过左侧的标签页可以轻松切换到编程界面。
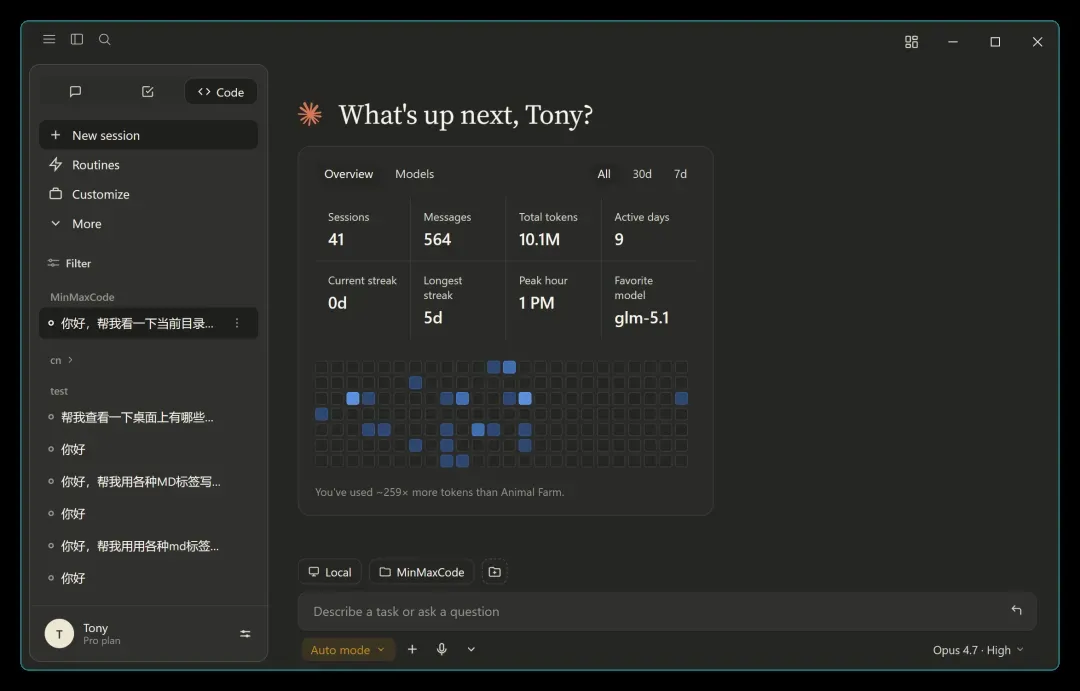
强烈推荐大家使用编程(Code)功能,目前 cowork 工作区仍为静态界面,后续会逐步完善。
使用前需要配置 API 密钥。对于初学者,我强烈建议使用 DeepSeek,价格低廉、体验流畅且后台清晰,充入十元即可畅玩许久。API 获取地址如下:
https://platform.deepseek.com/api_keys
访问该地址后,按引导完成注册、登录和 API 密钥的创建即可。
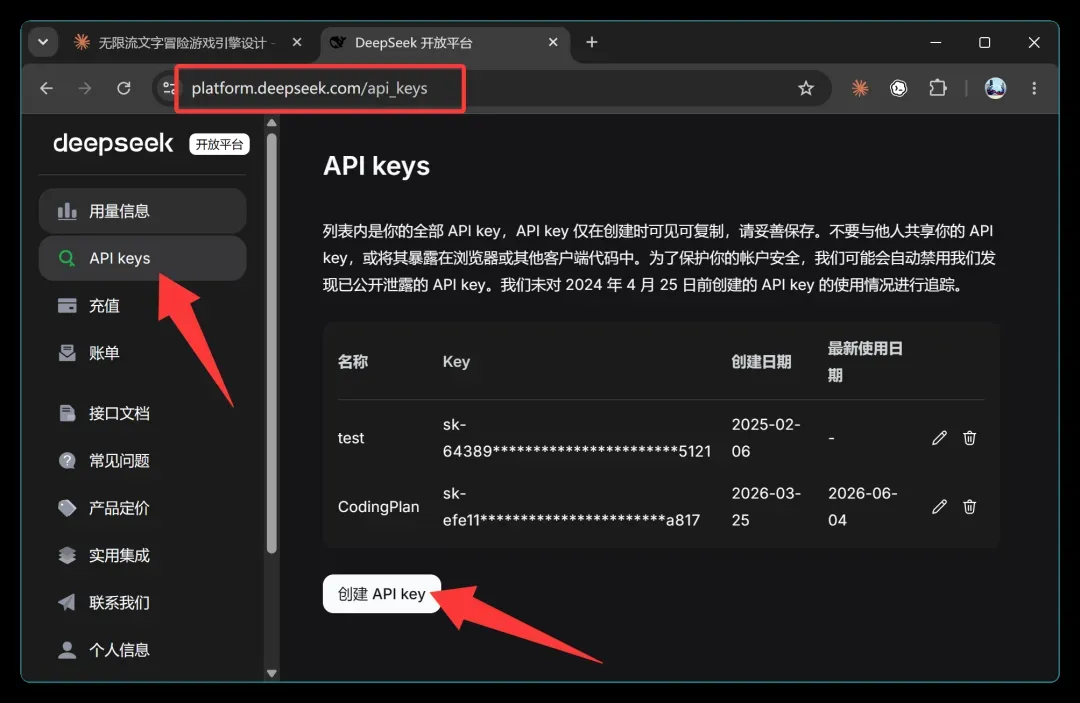
密钥创建成功后请立即复制并妥善保存,它仅显示一次。
接下来将密钥信息填入 JClaude:点击软件左下角头像 → 进入设置 → 找到模型设置选项。
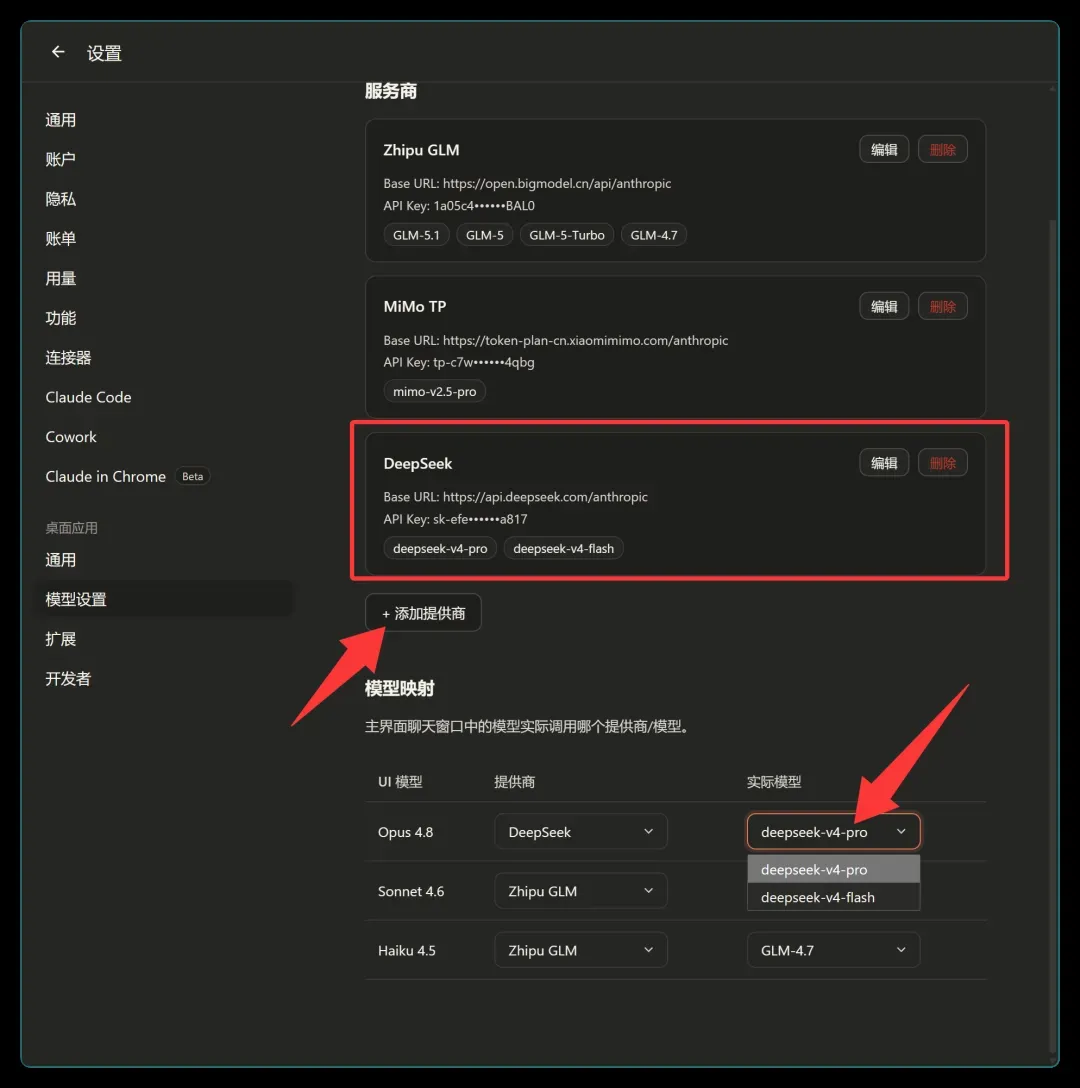
图中显示的是已配置的状态,添加了 DeepSeek 服务商并完成了模型映射。当选择 Opus4.8 时,实际调用的将是 DeepSeekV4Pro。
如果是首次使用,需要先添加 AI 提供商:
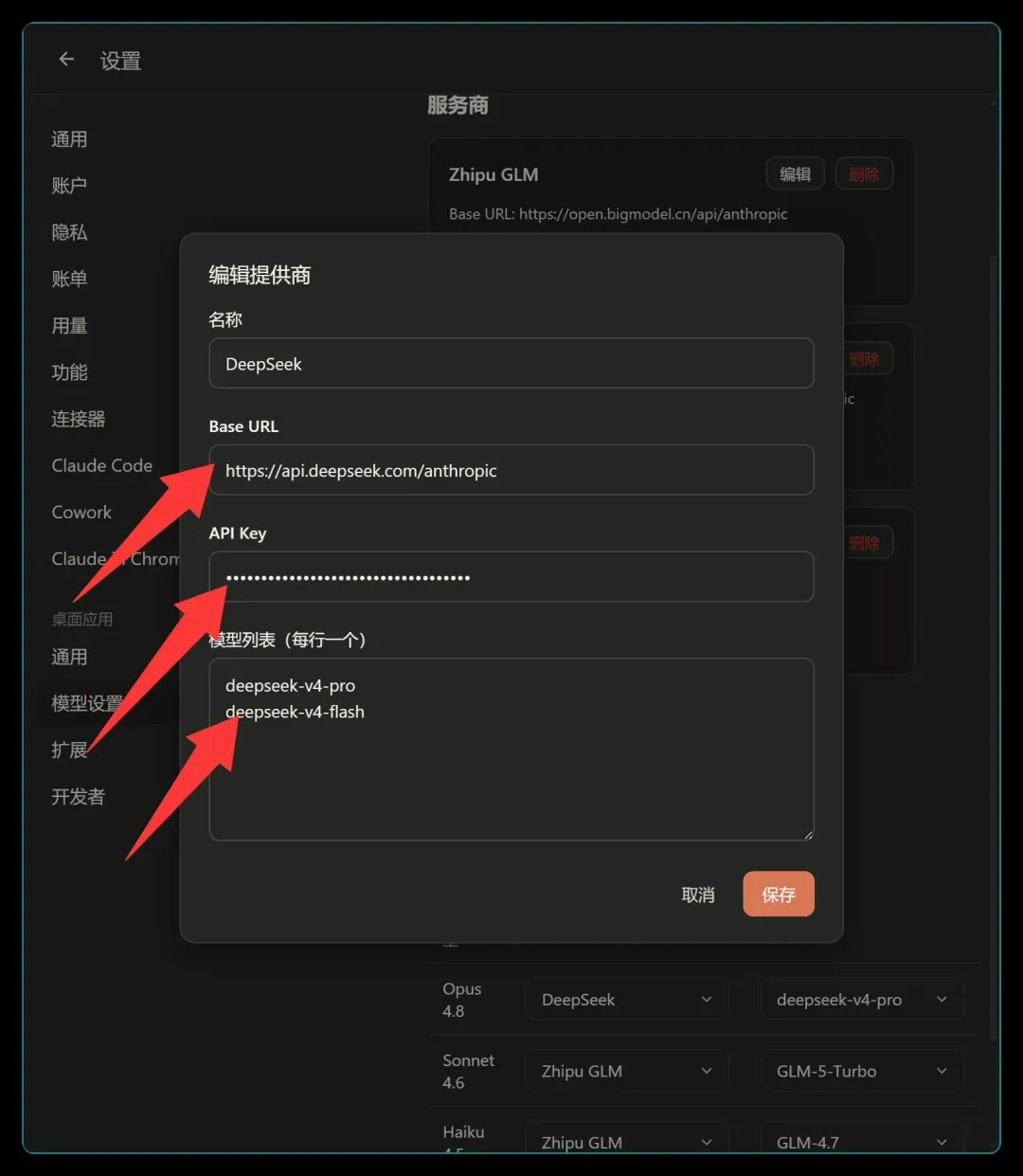
只需按红色箭头指示填写三项参数,其中最关键的是 API Key,其余按图示照搬即可。只要理解了 API 的基本概念,整个过程非常简单。
补充提示:如果你此前尚未安装 Claude Code,软件会自动提醒并引导你安装底层 CLI 工具,步骤很简单。