Claude Opus 4.8 强势发布:编程智能体遥遥领先,极速模式降价66%
时至今日,仍没有哪个模型敢放话全面超越 Opus 4.7。绝大部分国产模型还在对标 Opus 4.6,而 Claude Opus 4.8 已悄然降临。
本文快速梳理出本次发布的三大亮点,一起来先睹为快。
基准表现:编程智能体碾压对手
6 小时前,Claude 官方账号放出了一张基准测试对比图:
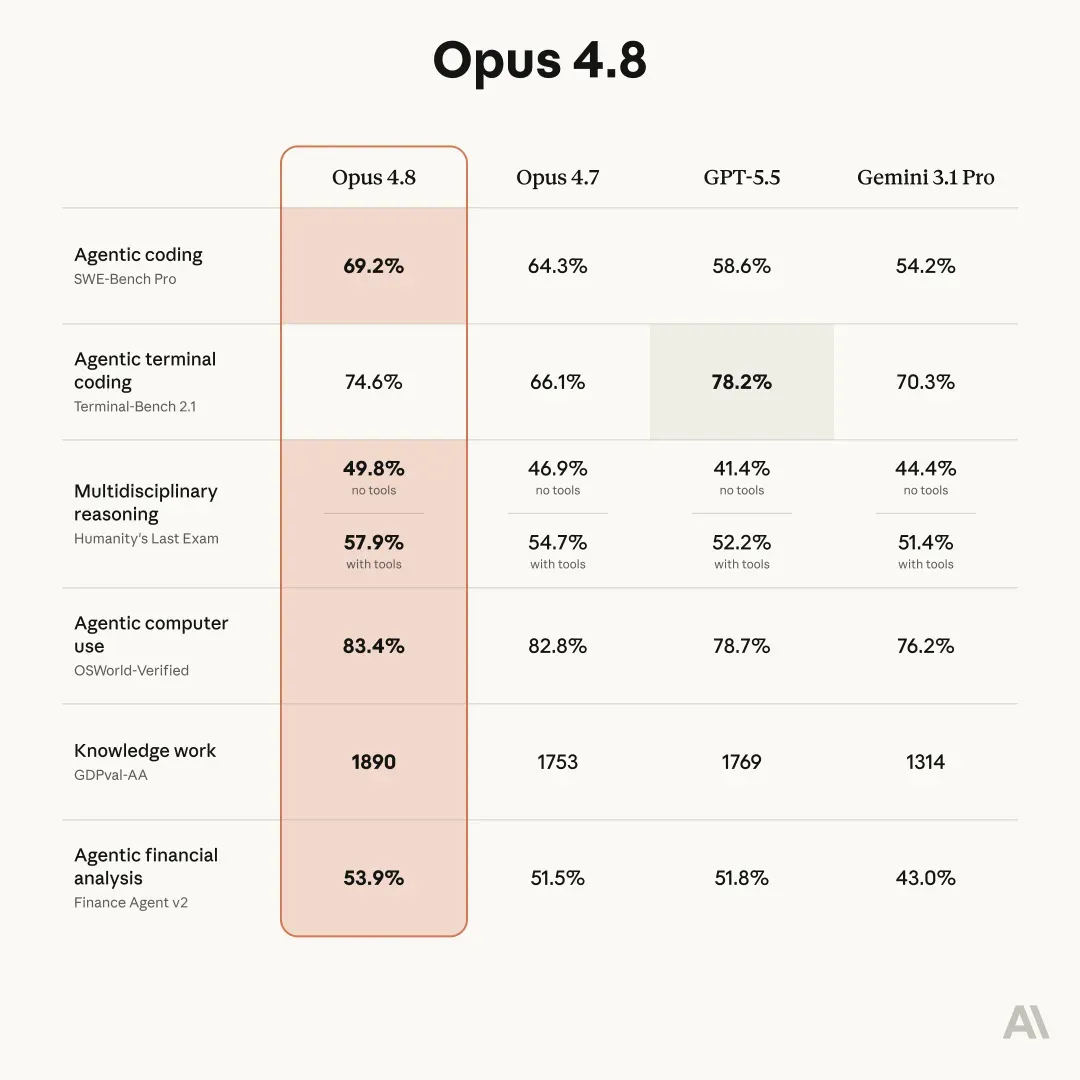
各家公司的基准数据难免存在一定水分,但 Anthropic 的成绩单历来最为克制——凭真实力没必要注水。从图中可以清楚看到,Opus 4.8 在多数关键项上处于领先,唯一失利的是 Terminal-Bench 2.1,这一项仍不敌 GPT‑5.5。GPT‑5.5 操作电脑的稳定性确实出色,很多安装配置流程我都习惯交给它处理,非常踏实。
但在编程智能体维度,Opus 是真正的遥遥领先。
Agentic coding(智能体编程)直接比第二名高出 5 个百分点——第二名恰恰是它自己的前代 Opus 4.7。相较于 GPT‑5.5,领先幅度更是达到 10 个百分点;对比 Gemini 3.1 Pro,足足领先 15 个百分点。多学科推理、电脑操作、知识工作、金融分析也都小幅领先对手。
值得留意的是,官方这次特意纳入了“金融分析”指标。金融不是别的,就是离“钱”最近的事情。各位不妨试试看让 Opus 做些财务分析……很明显,这个方向将成为 Opus 未来的发力重点之一。
Opus 4.8 现已全面上线,价格和 4.7 一模一样。
极速模式:速度拉满,价格骤降
官方释放的第二个信息点:Opus 4.8 已全面支持极速模式。
所谓极速模式,就是相同模型下响应速度提升约 2.5 倍。**核心在于:质量不缩水,速度翻倍涨,整体效率大幅飞跃。**更令人振奋的是:**Fast 模式直接降价 66%!**也就是说,从 Opus 4.7 到 4.8,性能免费升级,极速模式的使用成本还断崖式下降。
Claude Code:动态工作流与全新思考强度
第三条进展与 Claude Code 密切相关——目前业界最强的编程智能体 CLI 工具。
Codex Skills 实战手册:让 AI 从一次性回答进化为流程稳定的内容搭档
近期,一篇关于 Codex Skills 的整理帖引起了不少关注,我觉得很值得单独拿出来聊聊。
现在很多人用 Codex,仍然停留在比较基础的层面:让它写代码,让它修 bug,让它解释报错,顺便生成一些文档。
单次任务看起来都还行,可真放进连续工作里,马上就会发现它缺少一套“做事的方法”。
比如一个需求直接丢过去,它可能拿起来就写;项目里有什么约定和规范,它多半靠猜;CI 出了问题,得一段一段把日志塞给它;写完以后,它也未必会主动自检,更不会知道怎么把这一次踩过的坑沉淀下来,下次少走弯路。
这正是 Skills 越来越受重视的原因。
我们可以把 Skill 理解成一份提前写好的工作流程说明书。一个 Skill 目录里,通常会有一份 SKILL.md,再配上若干脚本、模板和参考资料。
它会告诉 Codex,面对某类任务应该先看什么、怎么拆解任务、要调用哪些工具、做到什么程度才算结束。
如果说 Prompt 像是临时交代,那 Skill 就更像一套可重复使用、可传承的做事流程。
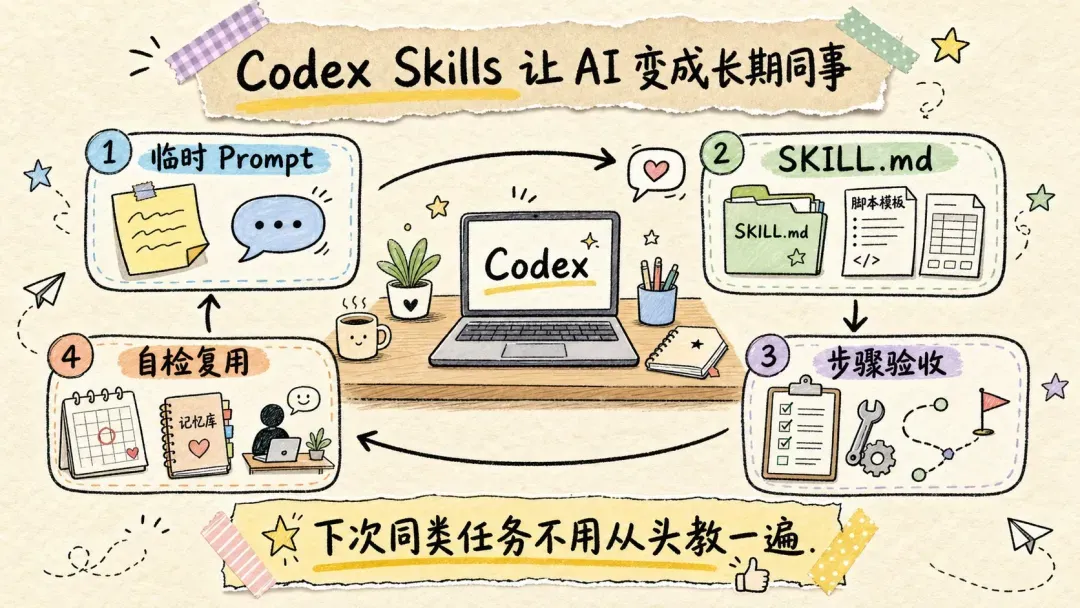
新手不用全部安装,这几类 Skill 优先用起来就足够
如果你刚开始接触 Codex,别一上来就想把全网仓库都扒一遍,也不用急着把大神推荐的 Skill 统统装齐,其实完全没那个必要。
先盯着官方 openai/skills 仓库来看就够了。
官方仓库里有几类特别值得优先安装。
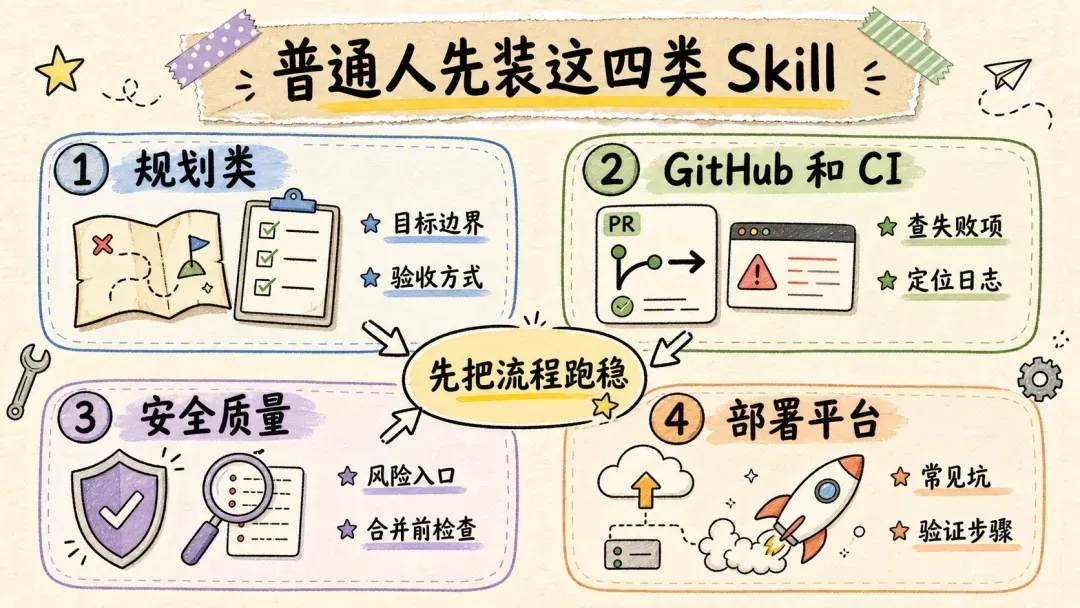
第一类,规划类。像 create-plan、define-goal 这类 Skill,它们专门解决 Agent 开工前先把头绪理清楚的问题。
真实工作流里,大量返工往往不是代码写得慢,而是一开始就把“做什么”理解偏了。规划类 Skill 的用处,就是先把目标、边界、步骤、验收方式讲清楚,再动手写代码或干活。
这种“先想后做”有时看起来很慢,其实非常节省时间,正所谓磨刀不误砍柴工。
第二类,GitHub 与 CI 类。这里我重点推荐 gh-fix-ci。
官方 gh-fix-ci 的说明很明确:当 GitHub PR 的 checks 挂了,它会用 gh 去查看检查项和日志,整理失败上下文,先给出修复计划,获得明确同意后再修改代码。
这一整套流程就非常贴近真实工程协作的样子。CI 失败最让人烦躁的,正是要在多个 job 之间来回跳、翻日志、定位到底是测试问题、依赖问题、lint 问题还是环境问题。这类脏活特别适合交给 Agent 做第一轮排查,我们只需要判断方案能不能接受就好。
Codex 高维开发新体验:AI 自动生成头像与网页设计,九大模型横向对比谁主沉浮?
不久前,我在 Cloudflare 上注册了域名 JarvisUni.com,本只想让 Codex 随意搭个首页、完成基础配置,结果其表现远超预期。除了设计在线,最让人眼前一亮的是:它自动帮我生成了一个配图——准确地说,是一枚与主题高度契合的头像! 这种体验实在丝滑,以后网站图片再也不用四处寻找,直接由 AI 根据上下文实时产出。接下来,我将完整记录这次使用过程,并横向对比其他主流工具与模型的效果。
1. Codex:自动生成头像,一站式开发部署
先来拆解 Codex 的整个操作流程。我首先新建文件夹,命名为 JarvisUni_vercel(因后续要部署到 Vercel,故加此后缀),随后将其拖入左侧项目区域,点击加号创建对话,即可开工。首轮对话让它完成 GitHub 相关配置,紧接着就是截图中的关键一步。
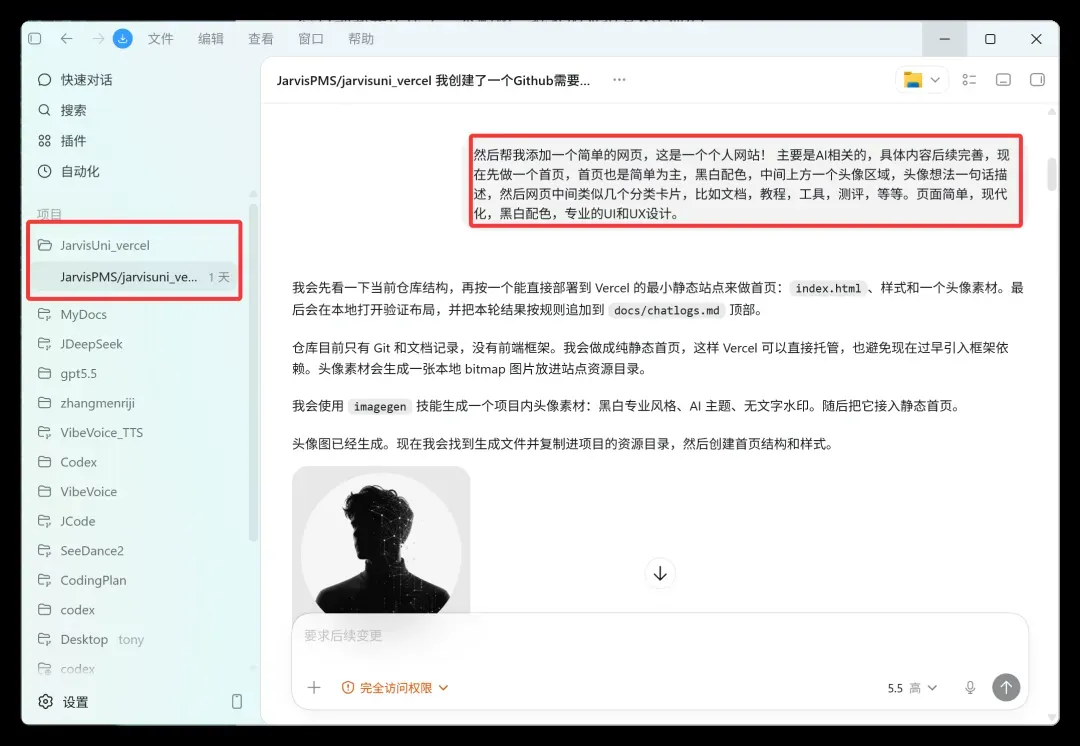
我给出的提示大致如下:
然后帮我添加一个简单的网页,这是一个个人网站!
主要是 AI 相关的,具体内容后续完善。
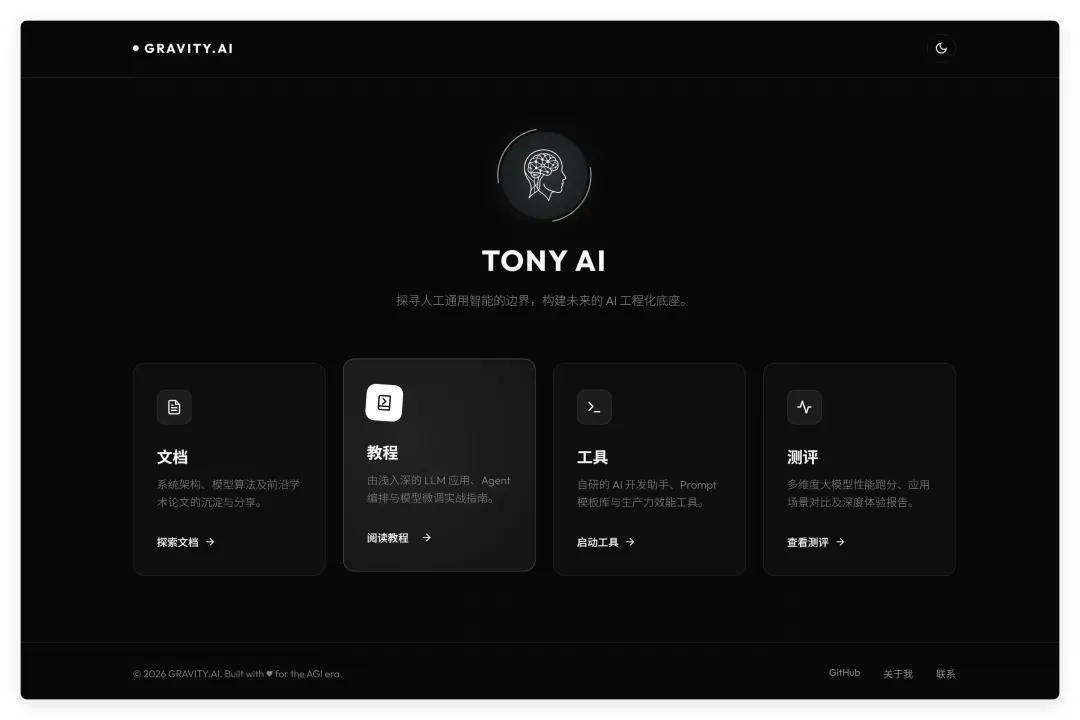
现在先做一个首页,首页也是简单为主,黑白配色,中间上方一个头像区域,头像下方一句话描述,然后网页中间类似几个分类卡片,比如文档、教程、工具、测评,等等。
页面简单,现代化,黑白配色,专业的 UI 和 UX 设计。
可能因为提到了头像,Codex 分析后表示要创建 index.html 页面、样式文件以及头像素材,接着便自然而然地调用内置的 ImageGen 技能,自动生成了一枚头像,并自己写出了提示词:“黑白专业风格、AI主题、无文字水印”。很快,assets 目录下就出现了一个头像:

效果相当不错,完全贴合主题。随后它自动将头像嵌入 HTML 页面。仅通过一轮对话,就得到了如下效果:
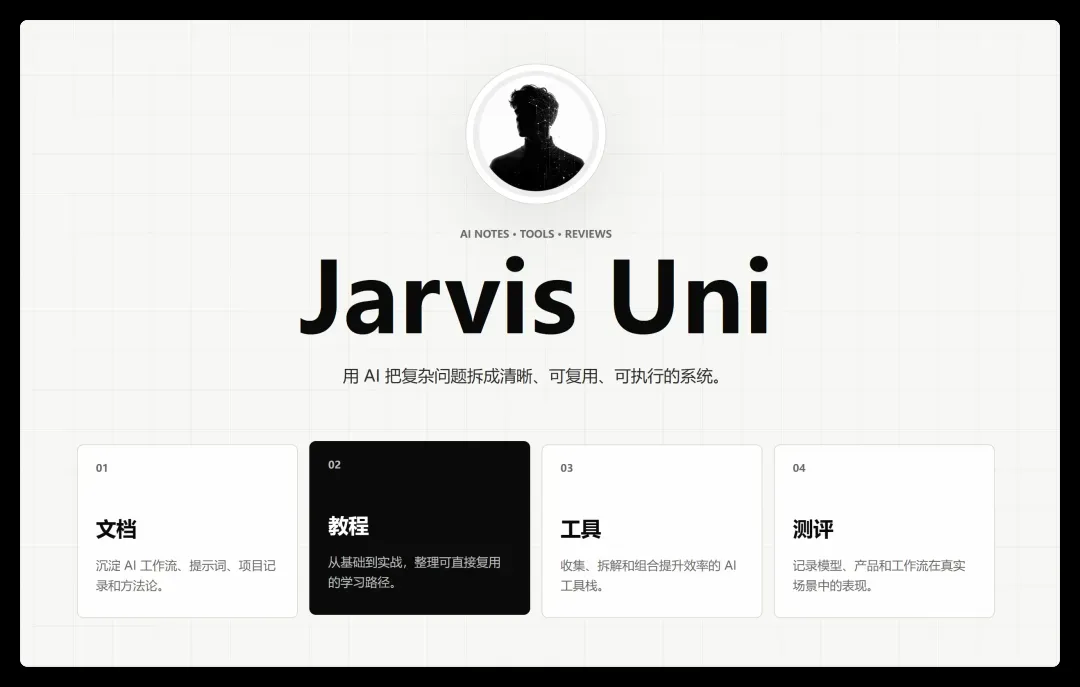
这个页面虽然简洁,但头像、配色、布局、背景、字体都处理得非常到位。以往我常嫌弃 Codex 布局混乱,没想到这次设计相当出彩。更重要的是,它主动调用内置图片生成能力补全了头像,这种自动化程度在同类工具中堪称维度碾压。随后我让它提交代码,打开网址就能直接看到效果——全程无需手动输入任何命令,开发、部署与 Git 管理一气呵成,丝滑至极。
之后我又进行了优化指令:添加了深色模式、语言切换和底部版权声明。

至此基本完工,稍后替换具体内容即可交付。整个过程轻松愉快,Codex 一次性输出质感优秀的页面,我甚至不知如何继续优化。我追求的就是这种简单却极具辨识度的效果——能同时做到这两点,并不容易。
2. Claude Opus4.8:稳定发挥,中规中矩
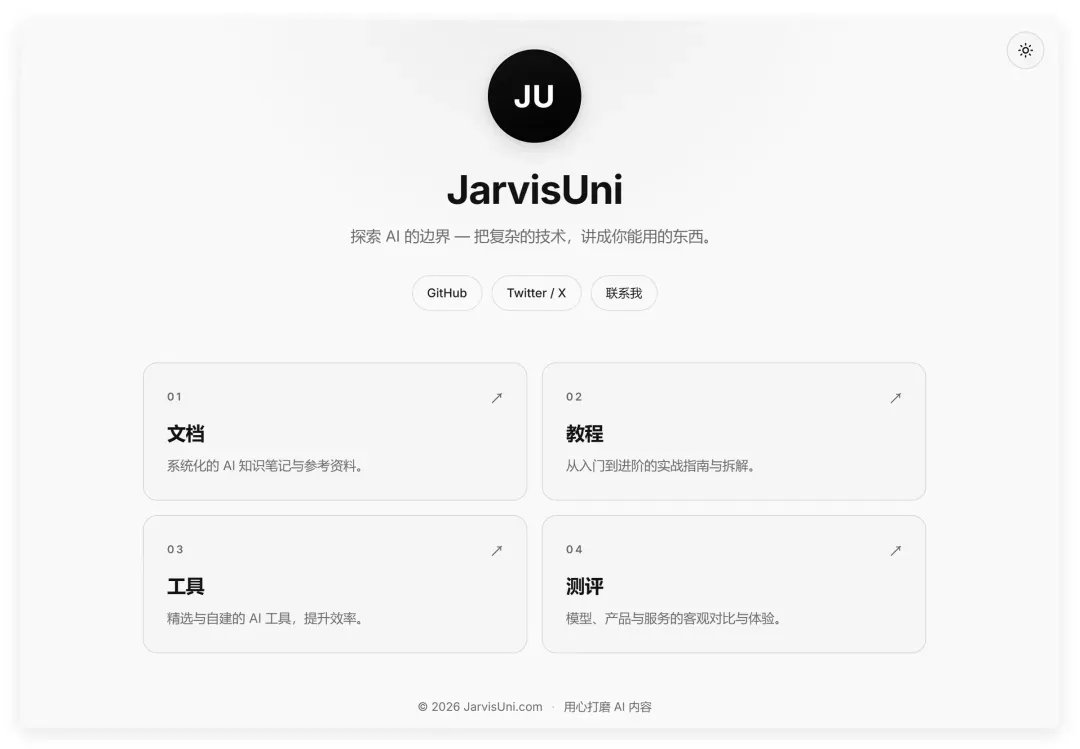
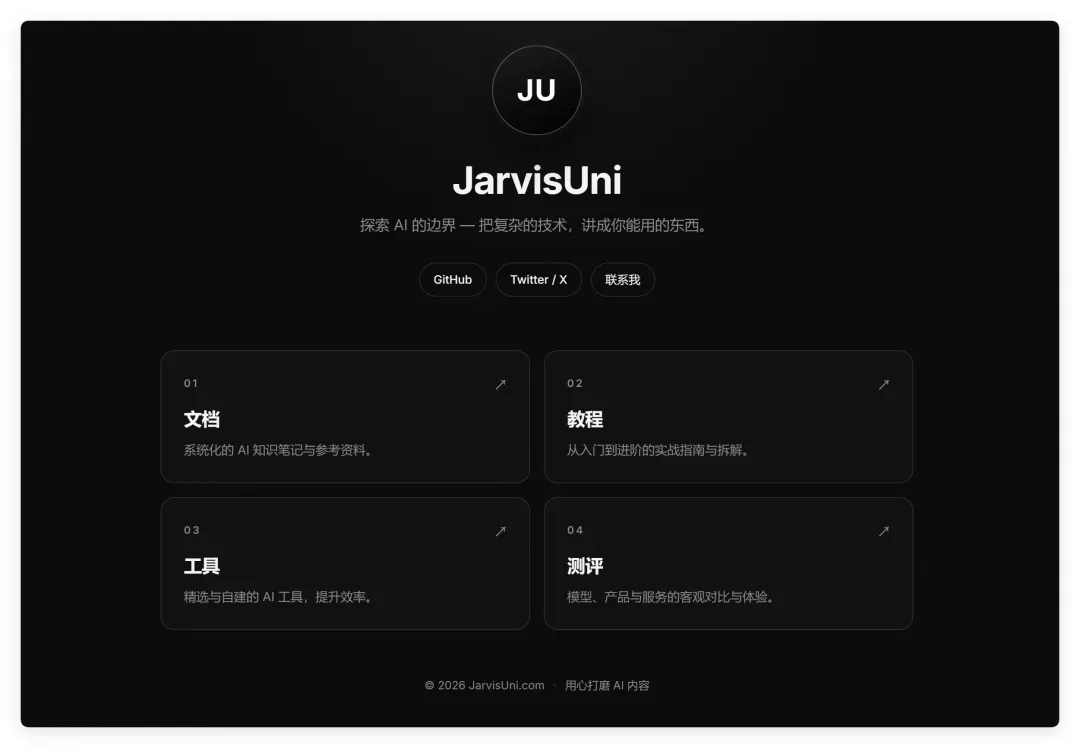
作为我最爱用的模型,Claude Opus4.8 这次的表现只能用中规中矩来形容,无功无过,未带来额外惊喜。
3. DeepSeek V4Flash:功能在线,Emoji 略显掉价
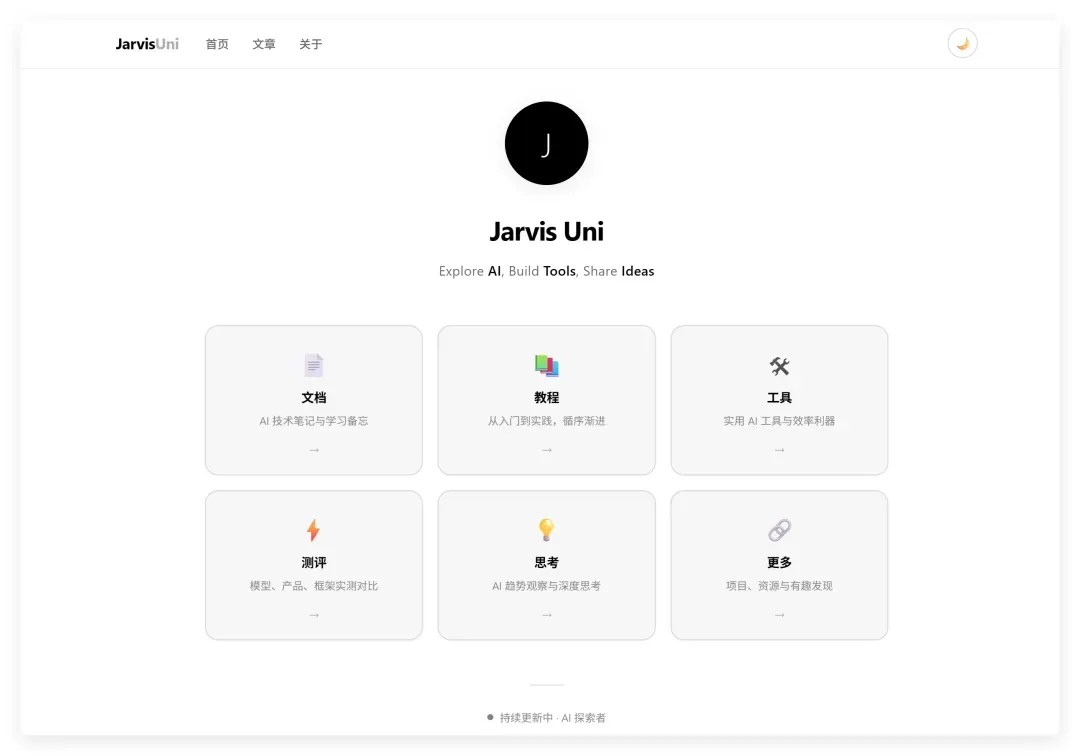
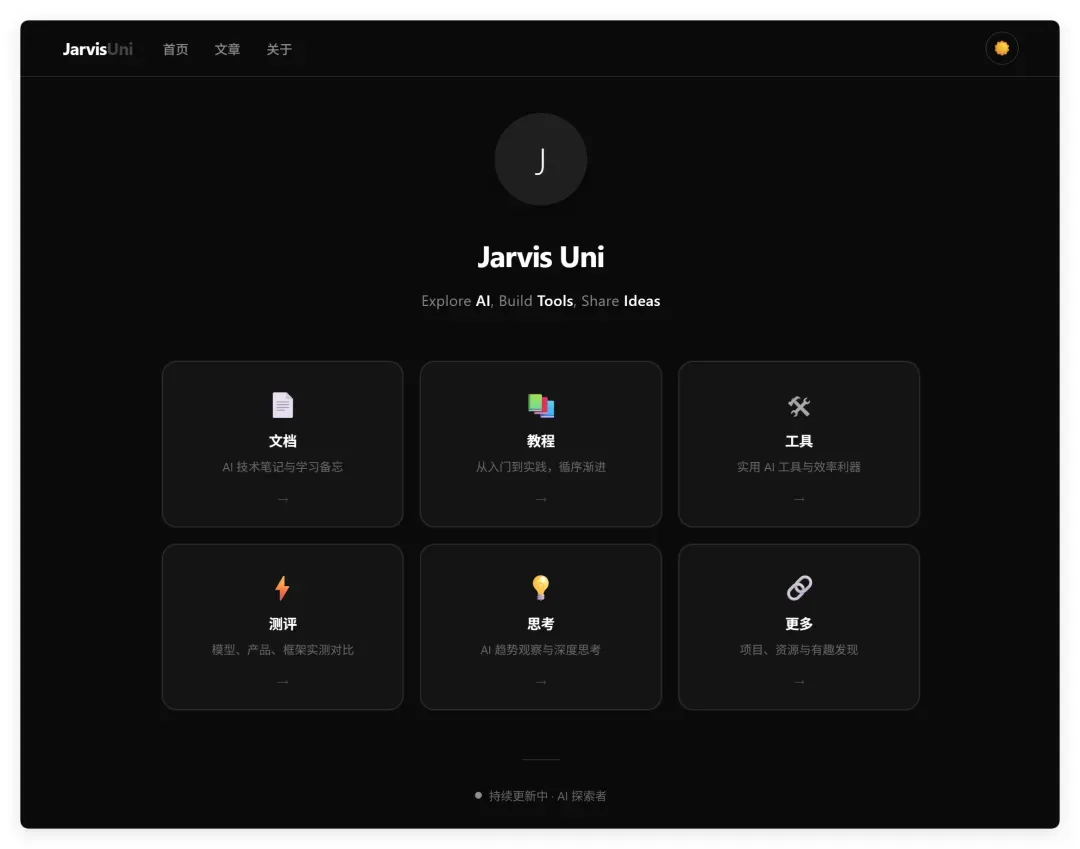
整体功能没有问题,但页面中使用的 Emoji 图标有些廉价,拉低了整体设计的档次。
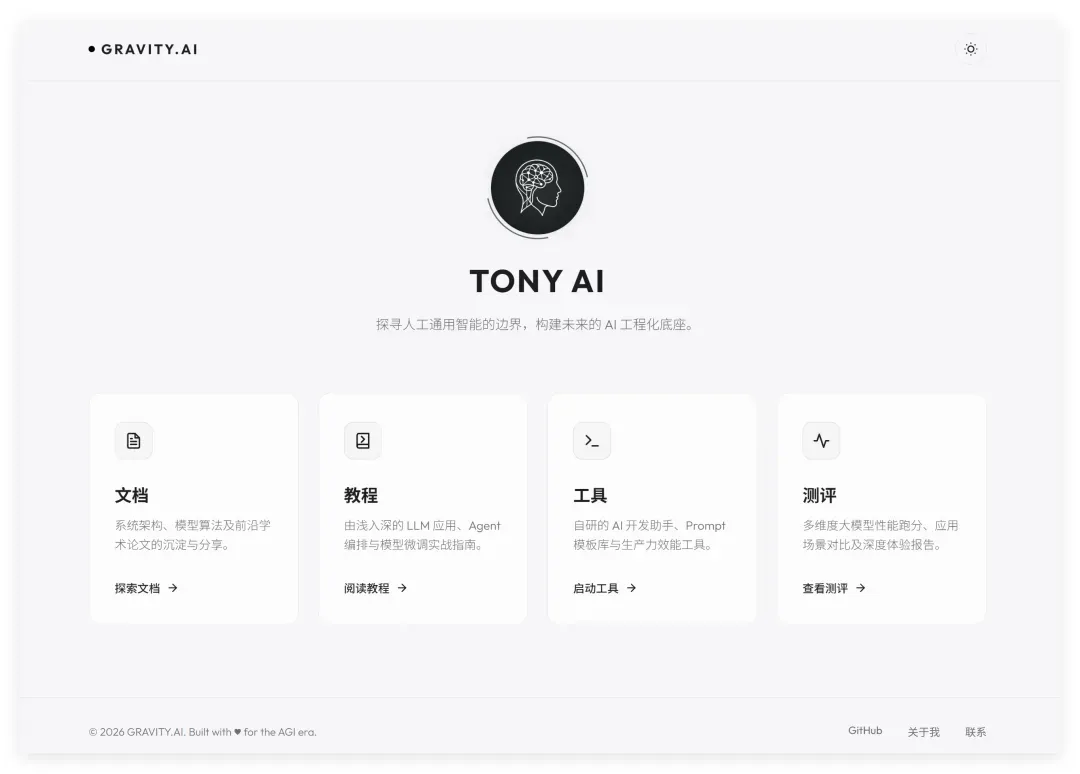
4. Gemini 3.5 Flash:大师级设计,自动生成头像与惊艳交互
Codex、Opus与GLM协同作战:321页OpenAI官方文档中文翻译实战复盘
今天展示一套组合技!

我把 OpenAI 的官方文档完整抓取下来,同时完成了中文翻译,总共涉及三百多个页面。
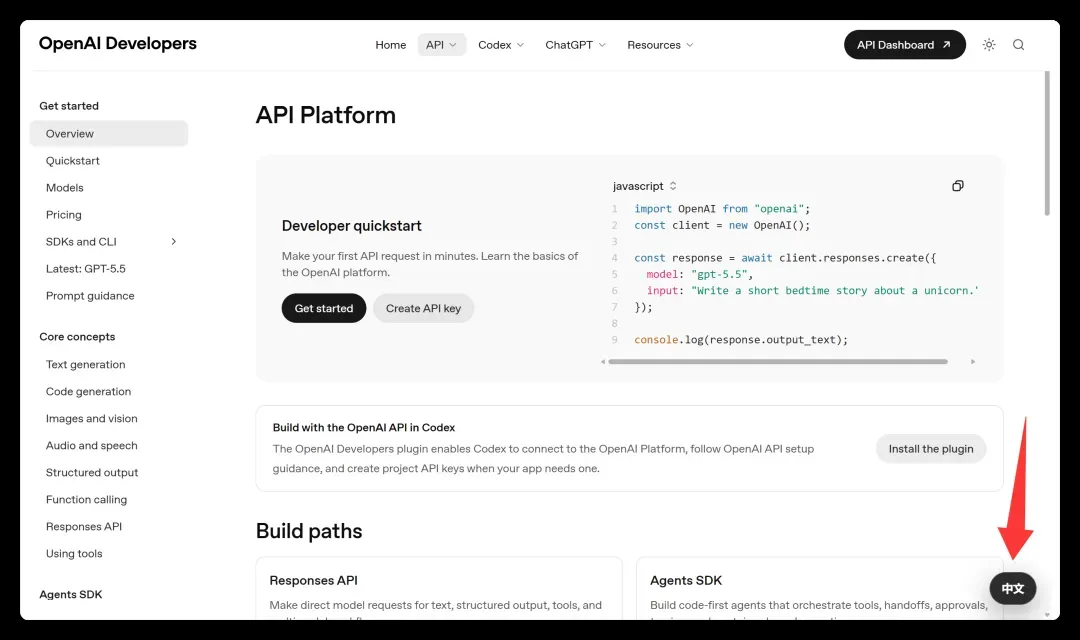
本地完美复刻了官网的页面组织结构和视觉样式,几乎达到 1:1 的还原度,并已发布上线,国内也能流畅访问。
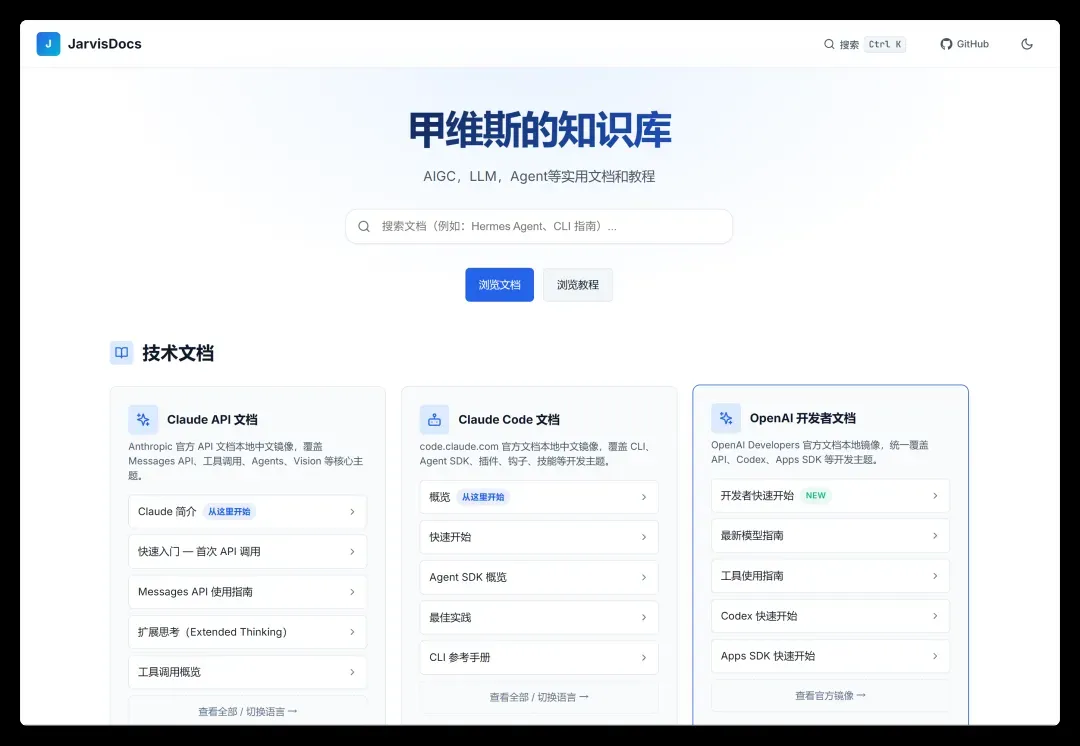
国内用户或英文不佳的朋友可以直接使用,也可以把这些内容喂给 AI,快速定位知识点。
学习 AI 和做开发,先把 OpenAI 与 Claude 两家的文档吃透,基本就打通了关键环节。
这次动用了 Codex、Claude Code、Claude 桌面版、MiMo、GLM5.1 等多个工具和模型。
这确实是个大工程,300 多个英文页面加上 300 多个中文页面,前后持续 24 小时,总共消耗了 120 亿 Credits 和大量 Tokens。
原本是想分享成功经验,可 MiMo 这一环差点变成吐槽现场。
今天算是看了一场“真人秀”,在那些只靠宣传和软文撑场面的渠道里可看不到这种真实过程。
那些动辄宣称排名第一、测评无敌的模型,一旦真刀真枪地干活,谁用谁知道。
1. Codex 负责镜像克隆
我以为最难的部分是抓取页面并复原展示效果,因为需要摸透网站的全部规则,避免触发反爬机制,同时还要恢复 JavaScript、CSS、界面结构等。
但整体进展出奇顺利。
Codex 对自家文档的网页结构了如指掌,轻轻松松就完成了克隆。
最终成果:
本地可访问的 HTML 文件共 321 个,其中 API Docs 156 个、Codex Docs 与 use-cases 152 个、Apps SDK 3 个、其他导航首页 9 个,以及 OpenAI Developers 首页 1 个。
并向 321 个镜像页面注入了本地搜索所需的 CSS 和 JS。
页面顶部的官方搜索按钮被本地脚本接管,支持点击搜索或按 Ctrl/Cmd+K,搜索结果来自本地静态索引,不再依赖官方的 Algolia 服务。
我还把这一整套流程固化下来,后续只需执行相应命令,就能进行整体更新或局部更新:
DeepSeek V4 Pro 永久2.5折:性能碾压、价格砍到行业底线,缓存价仅0.025元
这条看似来自深海的大鲸鱼,其实更像一条搅动池水的大鲶鱼——DeepSeek 以出人意料的姿态,把折扣变成了永远。
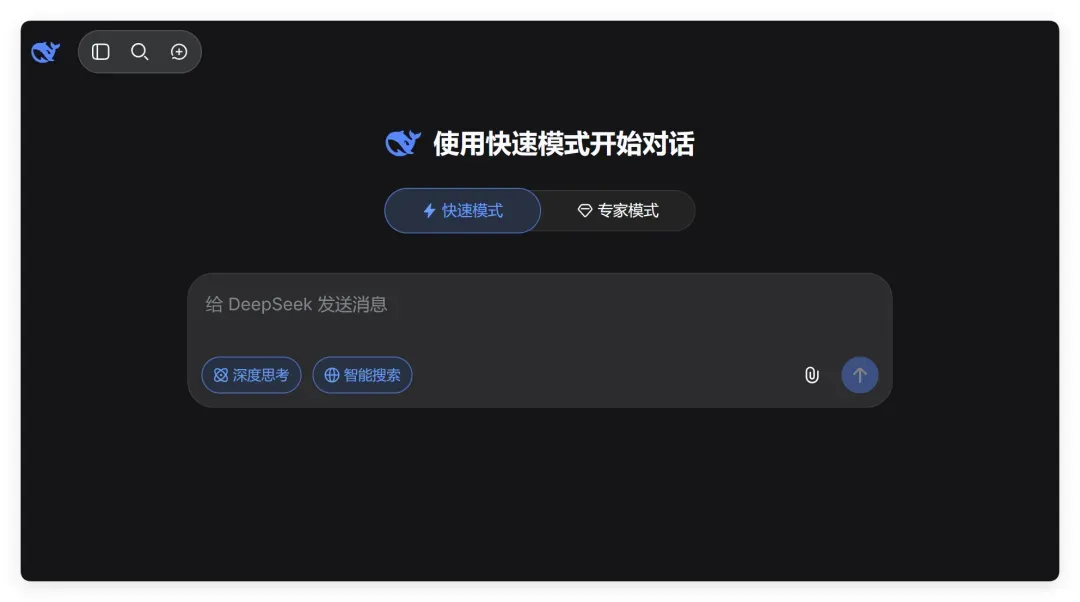
就在 V4 版本刚刚发布、2.5 折优惠即将结束之际,DeepSeek 官方半夜放出了一条爆炸性消息:
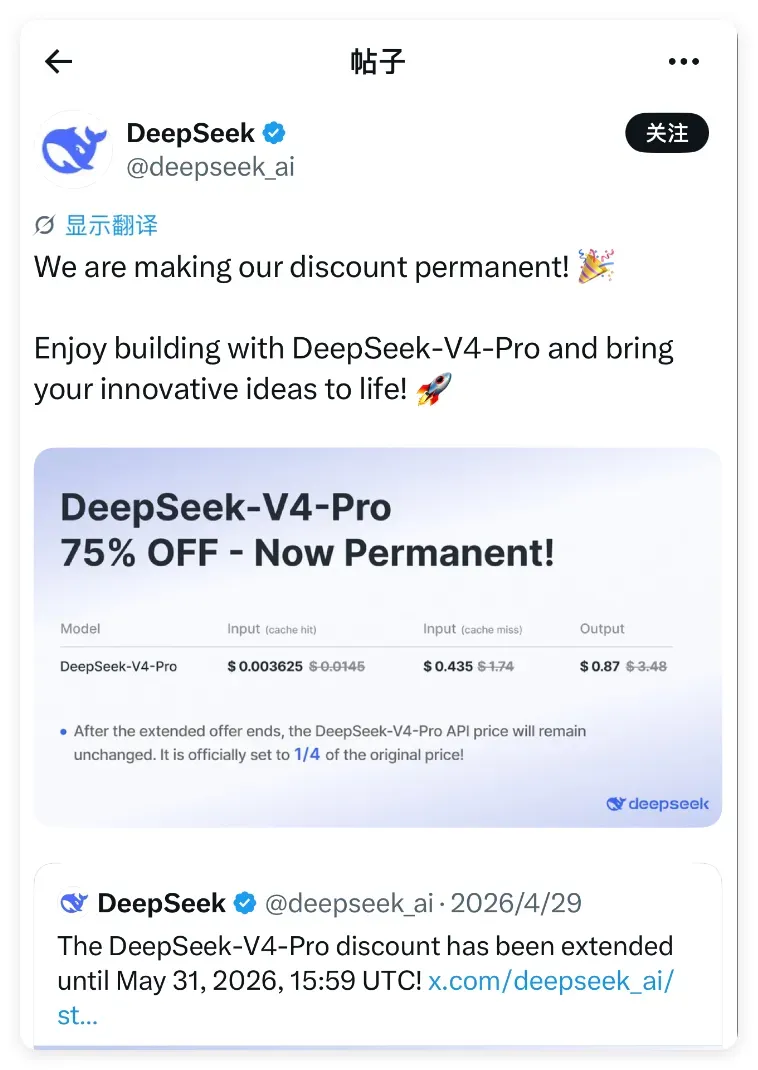
其官方推特转发并补充道:
We are making our discount permanent! 🎉
我们将永久提供折扣!🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀
尽情使用 DeepSeek-V4-Pro 进行开发,将您的创新想法变为现实!🚀
如此大胆的决策让众多国外开发者直呼难以置信,点赞量疯狂飙升。
随后再查官网,虽然信息更新略有延迟,但 Pro 版当前的价格体系已经非常清晰:输入 3 元/百万 tokens,输出 6 元/百万 tokens,缓存命中更是仅需 0.025 元/百万 tokens。
眼下行业太需要像 DeepSeek 这样敢于打破定价惯性的公司了。不少国产模型要么抢不到配额,要么套餐贵得离谱,又或者额度缩水到几乎不能用,个别方案的收费甚至超过了国外的 Claude 和 GPT 5.5。
与其为各种月卡费心,倒不如直接按量购买 DeepSeek 的 API——用多少花多少,既不贵,也不浪费。这里不妨仔细算一笔账:和国外竞品对比优势自不必说,即使与国内同行摆在一起来看,DeepSeek 也便宜到了不可思议的程度。
智谱 GLM
作为国内综合实力最强的模型系列,智谱 GLM 的 Coding Plan 一度供不应求,抢购起来颇有几分“耍猴”的即视感。
目前其入门套餐定价 49 元/月,Pro 档为 149 元/月。
DeepSeek桌面版魔改全攻略:克隆Claude打造全功能AI助手
只要敢想,AI 就能帮你实现!
之前我仅用几张截图便复刻了 Claude 桌面版,随后又通过简单对话实现了聊天与代码功能。今天,我将基于那个克隆版 Claude 桌面版,深度改造出一个 DeepSeek 桌面版!下面先展示最终成果,再详细拆解整个制作过程。
一、成果展示
这是桌面快捷方式的模样:

左边的是 DeepSeek 桌面版(为了区分,名称前加了个字母 J),第二个是 Claude 克隆版,第三个与本文无关——那是我用来控制孩子玩游戏时间的工具,一旦到达设定时长,强制自动关掉游戏。
开始菜单中的图标:
系统托盘区显示:
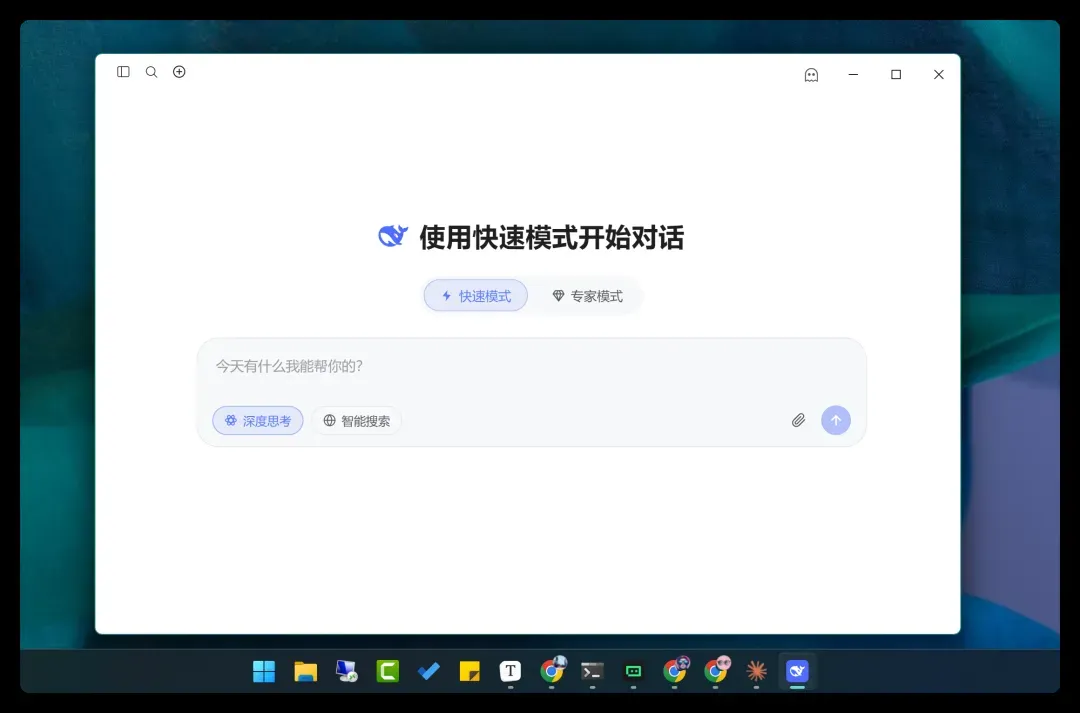
打开后的主界面:
深色主题效果:
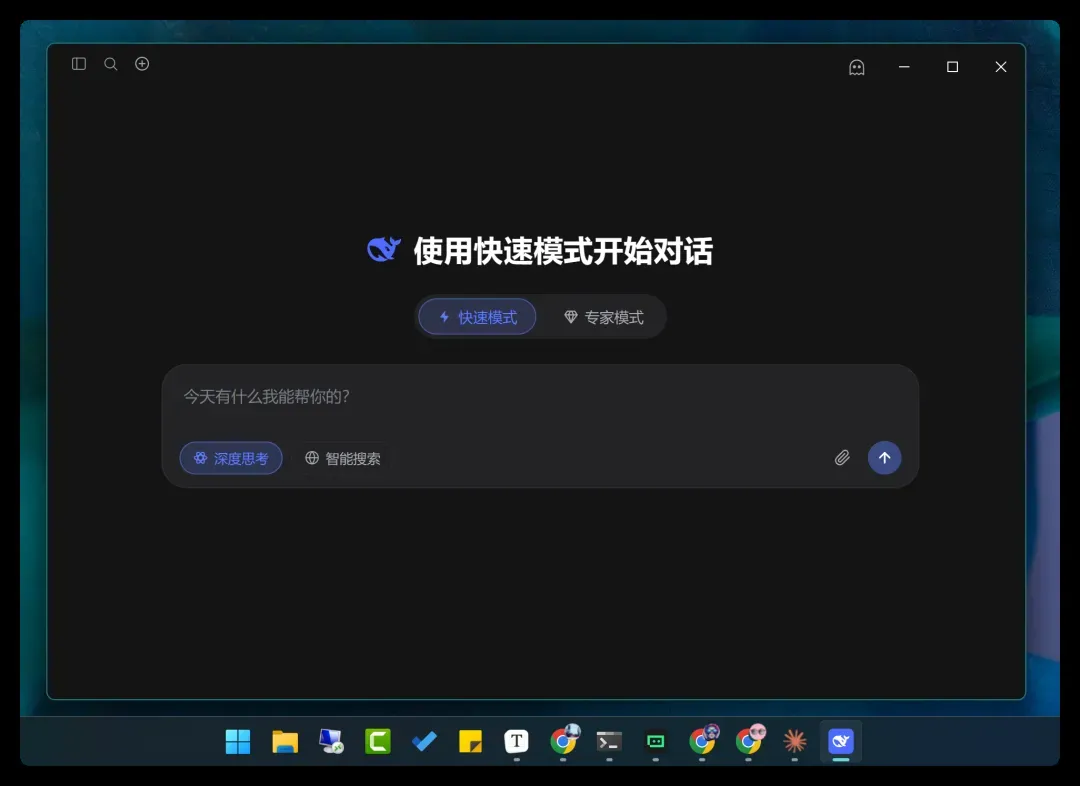
聊天功能界面:
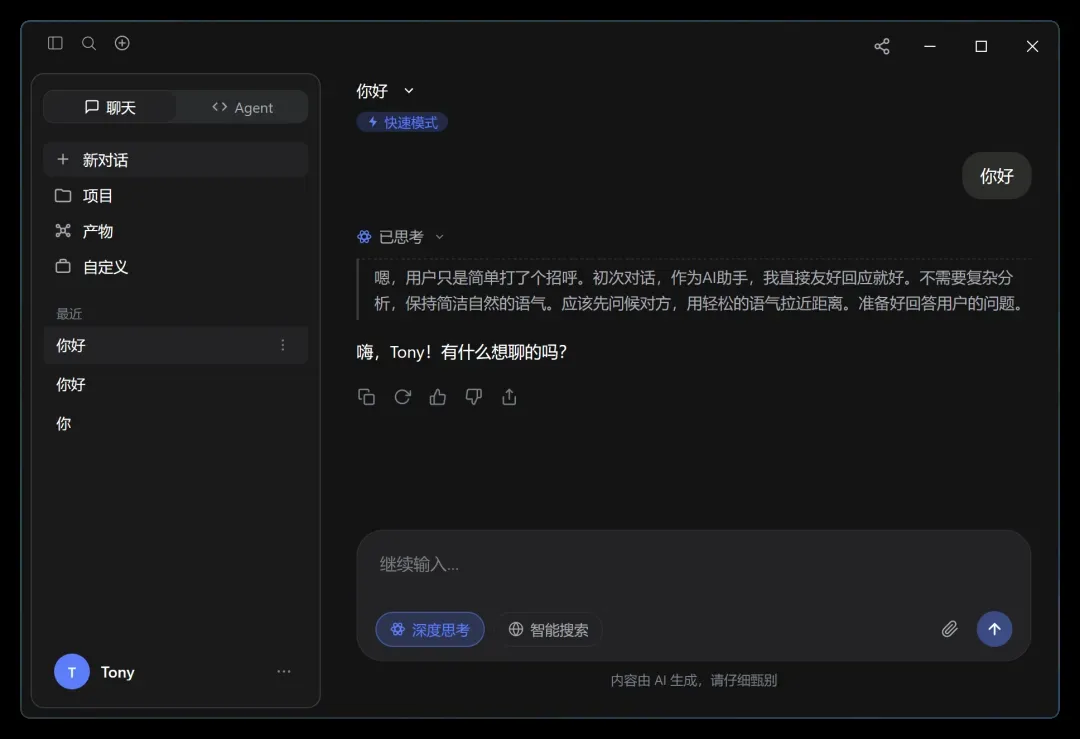
智能体(Agent)功能区:
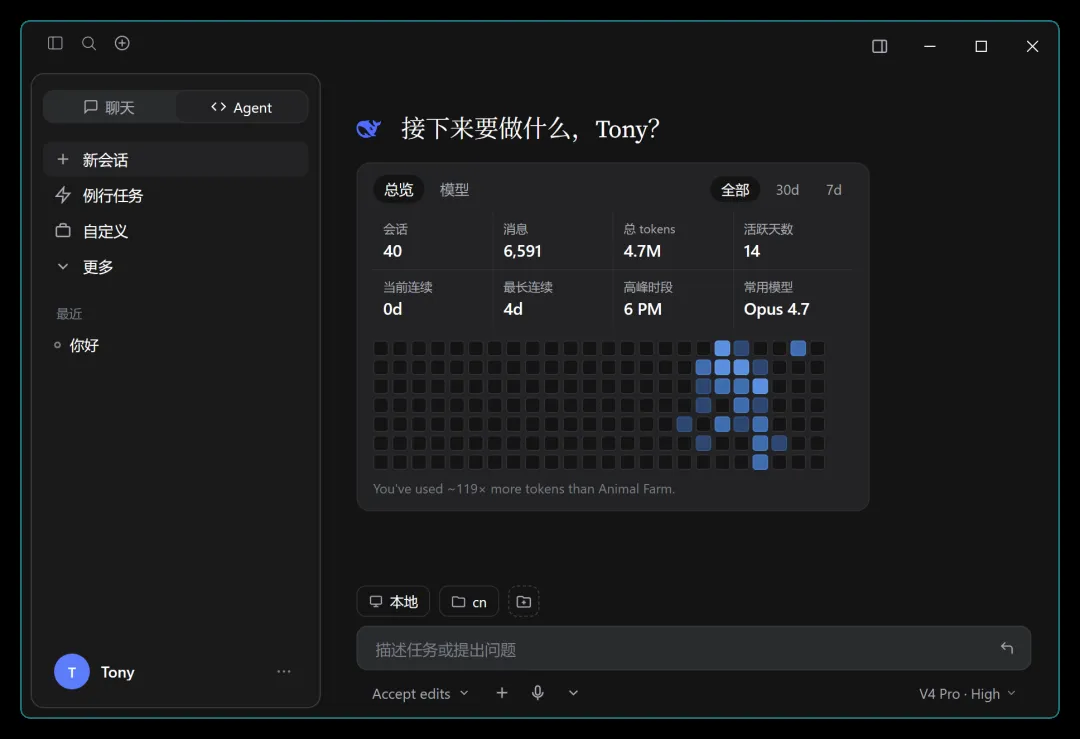
这一部分集成了 Claude Code!如果尚未安装,软件会弹出提示,按照命令安装即可。
系统设置面板:
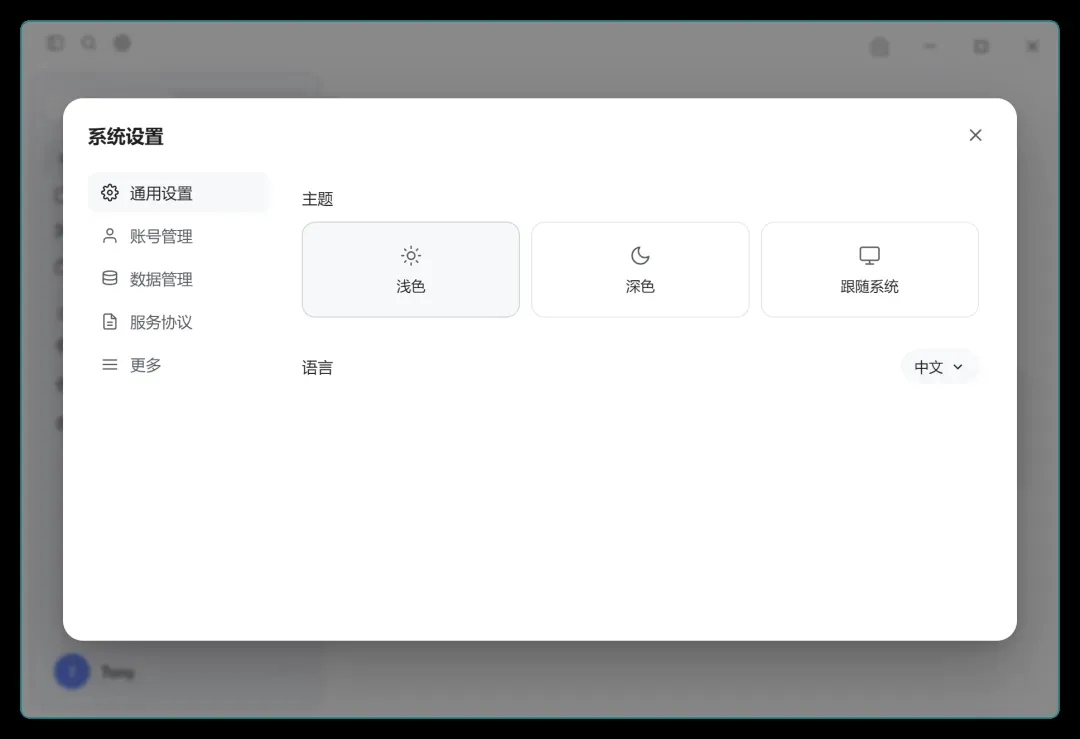
大部分菜单仅为装饰,第三方应用自然无法接入官方系统。不过,主题和语言切换功能是真实可用的。
直接内嵌官网:
这里直接将 DeepSeek 官网嵌入到软件界面中,省去了打开浏览器的步骤。
当前,Windows 系统的首个版本 0.6.0 已经制作完成!主要实现了三大核心功能:通过 API 驱动的对话功能、基于 cc 构建的智能体功能,以及将官网直接嵌入桌面版,允许用户使用官方账号免费使用所有能力。
二、使用方法
最简单的用法:点击右上角的“鲸鱼”图标,直接打开官网页面,登录后即可对话。
另一种更灵活的方法是获取 API 并进行配置,这也是我要着重介绍的。目前 API 费用非常低廉,而且自由度远超网页版,不会被限流、限额,还能与本地文件系统交互,读写本地文件。
直接访问官方开发者平台:
如果没有账号,注册登录即可。充值 10 块钱就能用上好一阵子。
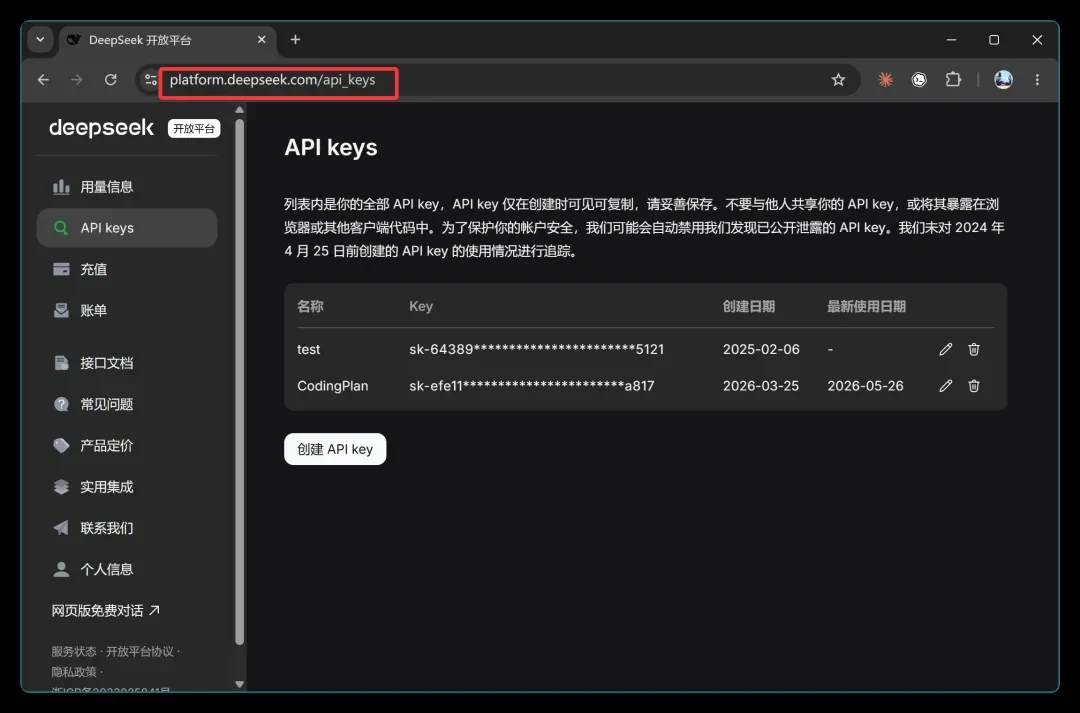
创建 API key 并复制。
然后打开 JDeepSeek:
依次点击头像 → 系统设置 → 更多 → 模型设置:
Final Mowing NAS 部署指南:即开即玩的俯视视角僵尸生存游戏
Final Mowing 是一款基于 WebGL 的俯视角僵尸生存游戏,你需要在不断涌来的尸潮中尽可能存活更久,并将分数提交到服务器排行榜。游戏直接在浏览器中运行,无需安装客户端,支持 Docker 一键部署,让你在 NAS 上也能轻松开玩。
核心特色:
- 浏览器即开即玩,零客户端依赖
- WASD 移动 + 鼠标瞄准射击的直觉操作
- 多波次敌人、连杀反馈与沉浸式音效
- 服务器统一排行榜,防止本地数据丢失
- 完善的 Docker 部署支持
操作说明:
移动 【WASD】
瞄准 【鼠标】
射击 【左键】
换弹 【R】
暂停 【ESC】
部署步骤
通过 Docker Compose 即可快速启动服务:
services:
mowing:
image: superneed/mowing:latest
container_name: mowing
ports:
- 8008:8000
volumes:
- ./data:/data
restart: always
开始游戏
部署完成后,在浏览器地址栏输入 http://NAS_IP:8008 即可访问游戏界面。
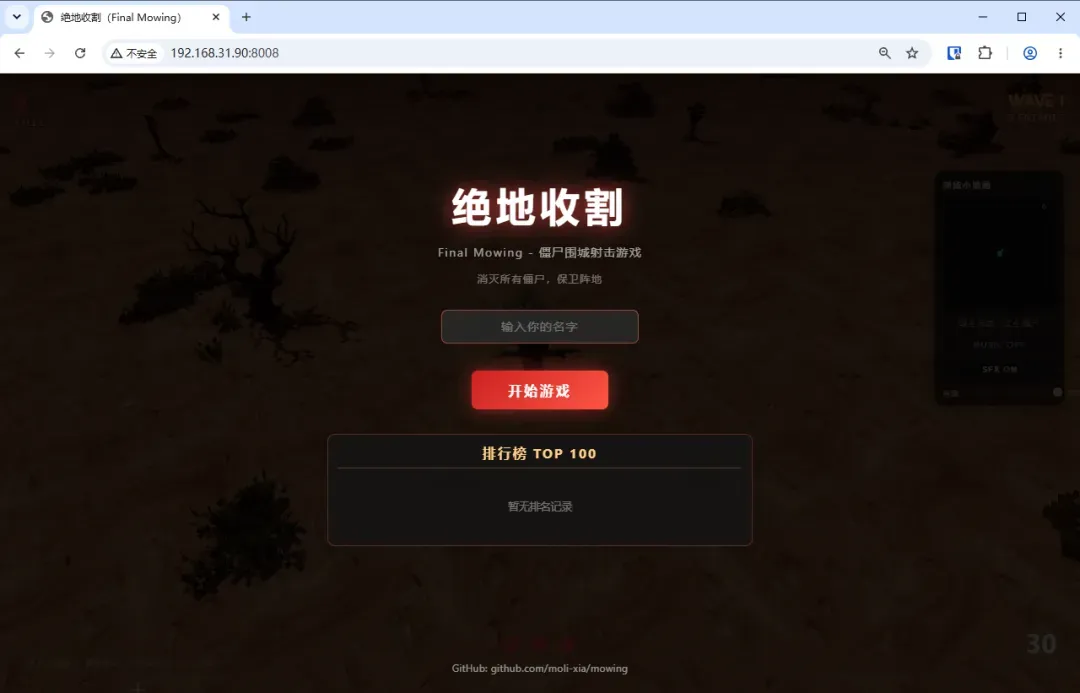
在首页输入昵称,点击开始就能立刻投入战斗。
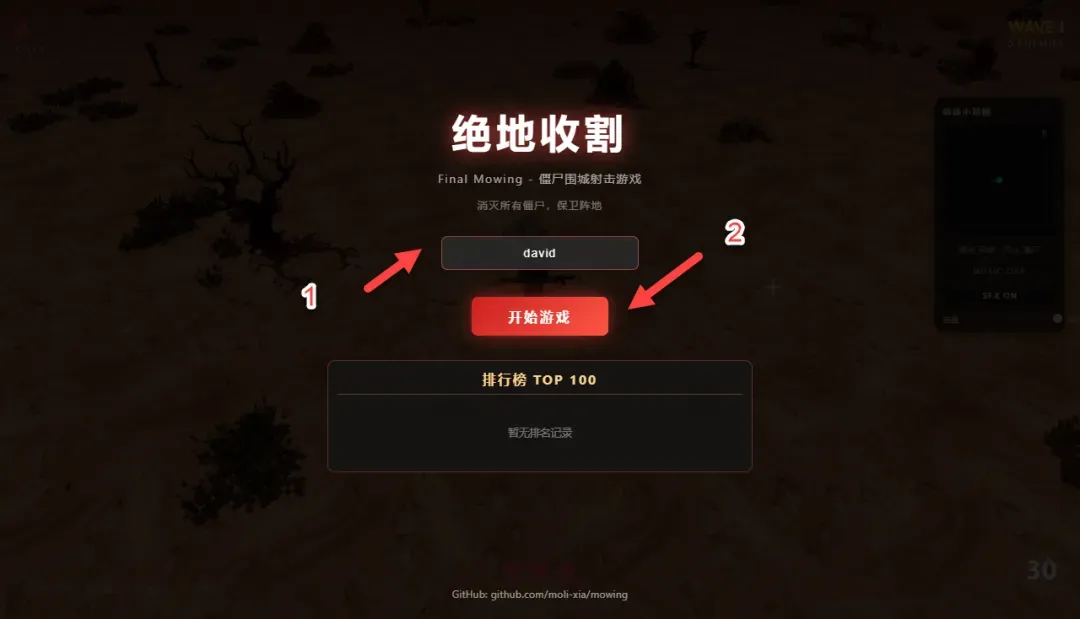
玩法相当直观:WASD 控制角色移动,鼠标瞄准并左键射击,简单易上手。

屏幕上方的击杀数和当前波次会实时显示,帮助判断战况。

右侧的小地图则能让你快速掌握僵尸的分布位置。

初期难度不高,但随波次增加,挑战会逐步攀升。
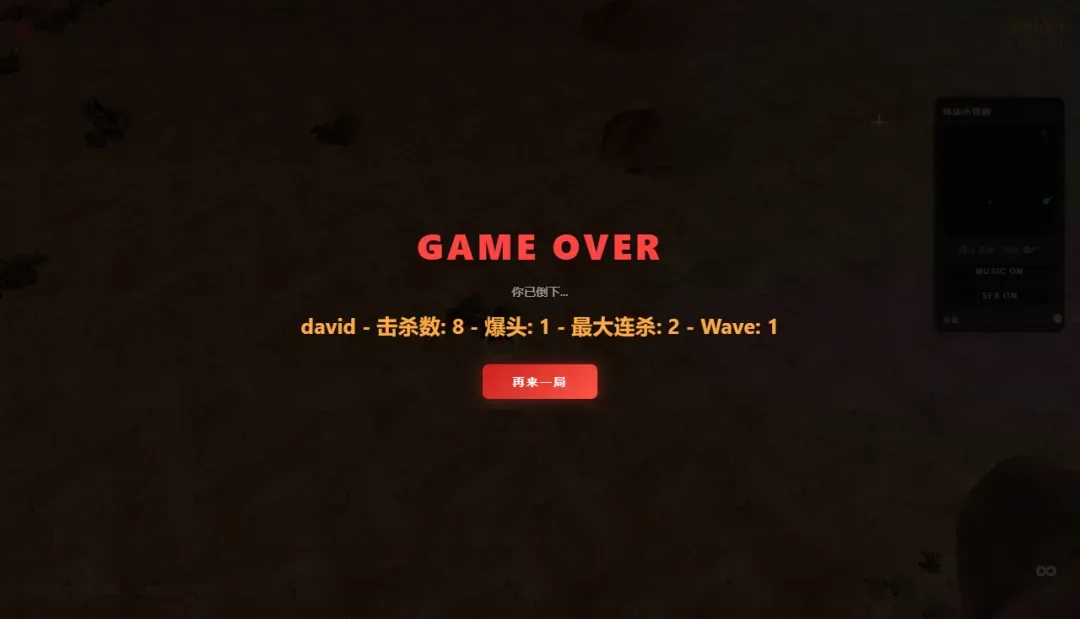
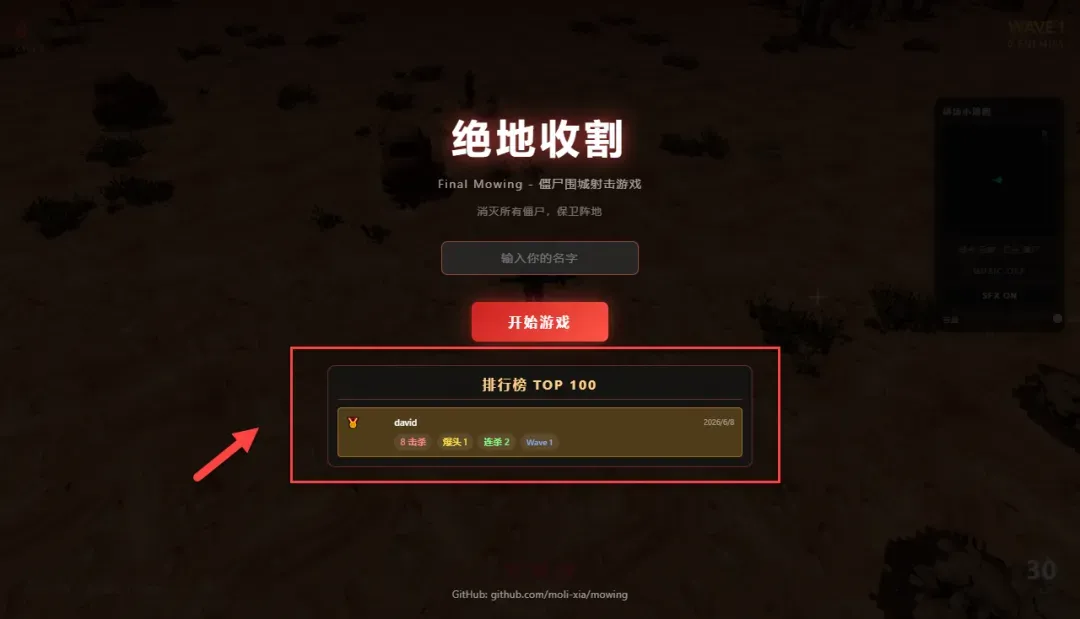
当游戏结束时,你的成绩会自动记录在启动页的排行榜中。
综合评价
Final Mowing 是一款轻量级的浏览器僵尸生存游戏,通过 Docker 部署后即可极速开玩,操作逻辑清晰,只需 WASD 与鼠标配合。游戏内容虽不复杂,却很适合摸鱼时随手来上一局。内置的排行榜系统让本地记录不再丢失,还可以和朋友比比生存时长。
GitHub 6.2 万星神器 Graphify:为 AI 编码助手构建可查询知识图谱,告别无效代码检索
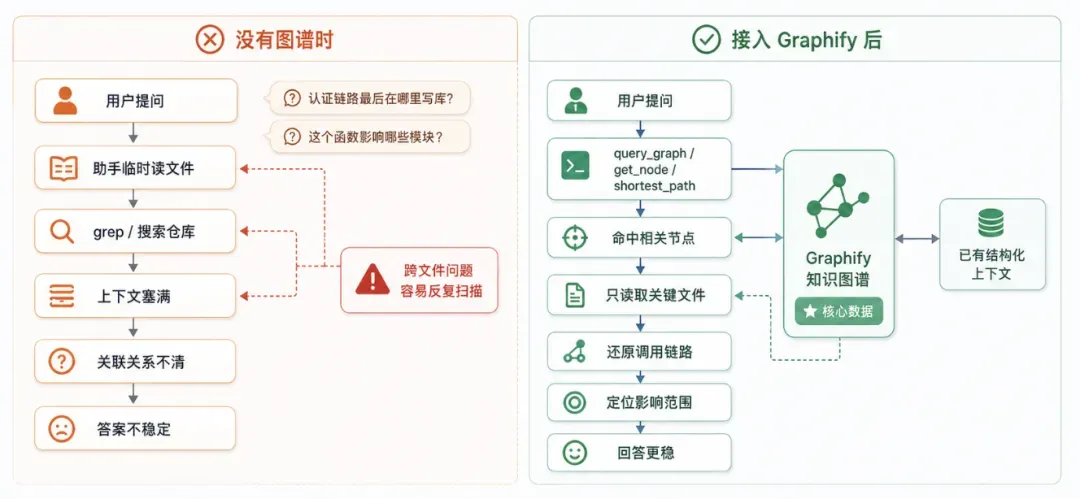
使用 AI 编码助手时最令人烦躁的,莫过于它明明很擅长写代码,却总是在项目上下文里“迷路”。
你问它“认证链路最后是在哪里写数据库的”,它立刻开始读取十几个文件;你再问它“这个函数影响哪些模块”,它又去全仓库 grep 一通。上下文越塞越满,答案却未必准确。
近日,一个名为 Graphify 的开源项目恰好适合接到这类编码助手当中。它做的事情非常直接:把一个目录里的代码、文档、SQL schema、脚本、图片、视频等材料,抽取成一张可查询的知识图谱,让 Claude Code、Codex、Cursor、Gemini CLI 等助手在动手之前,先从这个已有的图谱中寻找线索,而不是一上来就盲目 grep 整个仓库。
项目地址:https://github.com/safishamsi/graphify
截至撰稿时,该仓库已获得 约 6.2 万 Star、6.4k Fork。
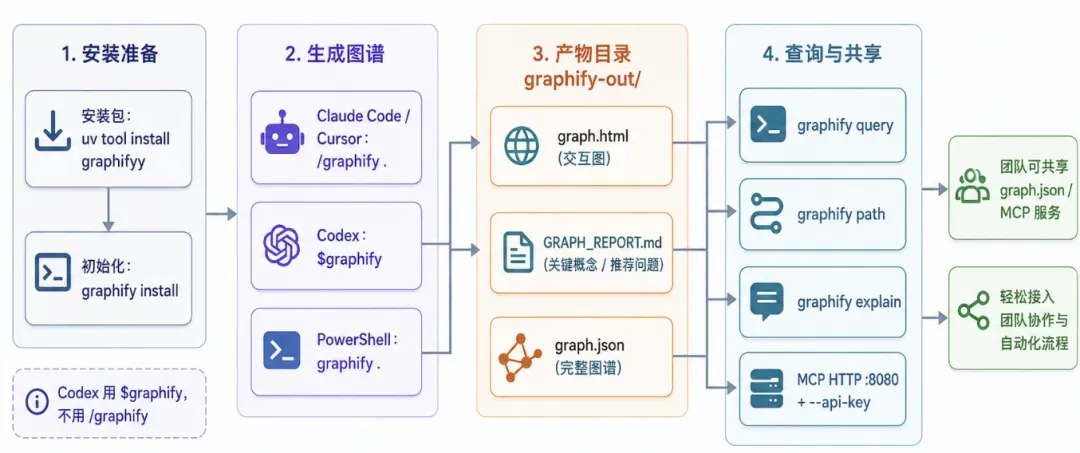
安装与基本使用
官方包名容易踩坑,PyPI 上叫 graphifyy(两个 y),但命令行工具仍然使用 graphify。
uv tool install graphifyy
graphify install
安装完成后,在支持的 AI 编码助手中运行:
/graphify .
需要注意的是,如果是在 Codex 的 assistant 命令里,README 特别提醒要使用 $graphify 而非 /graphify。Windows PowerShell 用户也不能写成 /graphify .,应直接用 graphify .,因为前面的斜杠会被 PowerShell 视作路径。
执行完毕后,项目根目录下会多出一个 graphify-out/ 文件夹,里面主要包含三件东西:
graph.html:在浏览器中打开的交互式关系图。GRAPH_REPORT.md:列出项目关键概念、意外关联以及推荐的问题。graph.json:完整的图谱数据,为后续的查询、MCP 调用和团队共享提供基础。
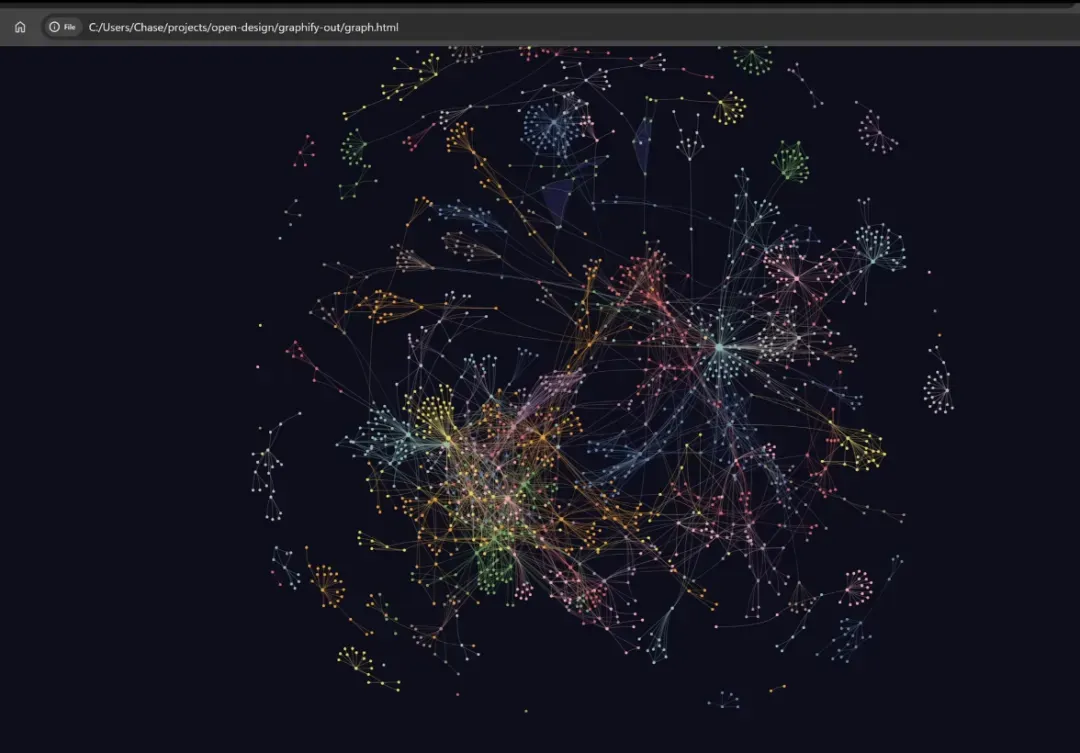
这一产物思路相当直接。以往 AI 助手回答与项目相关的问题时,常常临时读取文件、临时做总结、临时猜测依赖关系。Graphify 则先将项目中的实体与关系沉淀下来,后续再有新问题时,就不需要每次从零开始翻仓库。
GPT-5.5 搭档 Seedance 2.0:一句话生成 ARPG 互动游戏,从 Demo 走向千万播放
最近 AI 圈非常热闹。自从 GPT Image 2 发布后,越来越多创作者把 Image 2 与 Seedance 2.0 组合起来,让视频画质跨越了一个台阶。
就在几天前,藏师傅直接上手,做了一款拳拳到肉的 ARPG 游戏演示。
下面这段就是他用 Image 2 + Seedance 2.0 生成的视频展示(by 藏师傅):

如果不提前说明,恐怕很多人会以为这是某款“水浒传”游戏的实机录屏。
虽然它本质上是一个视频演示,但藏师傅这次尝试,实实在在拉高了人们对 AI 生成 3D ARPG 互动游戏的想象空间。
有意思的是,在评论区我看到了这样一段对话:
显然,大家现在对 AI 生成图片和视频的水准已经有了共识,但依旧习惯性地觉得——要直接用 AI 生成一款游戏,还为时尚早。
然而,如果我说我真的做出来了一款呢?下面就是我今天实跑的案例:

你没有看错,这不再是一位个人创作者随手做的 Demo,而是我自己的录屏。它来自一个名为 Yoroll 的 AI 互动影游平台,是一份可以完整游玩的互动游戏。
而整个游戏,我只用了一句话生成。
为什么这次值得认真聊聊
如果说此前所有 AI 游戏的尝试大多停留在视频片段或者 Demo 层级,那么 Yoroll 这次算是真正把这类内容做成了能够引爆千万次播放的产品。
JCode 0.9.7更新:一键接入Claude Code第三方模型,授权模式与平台管理全面升级
Claude Code 依然是当前世上最强大、最好用的编程智能体,但它接入第三方模型或调用自家 API 的流程总是略显麻烦,所以我自己动手打造了 JCode。对我来说,它就是一个 CC 辅助神器。

JCode 是我之前手搓的一款 CC 多平台启动器,定位与 cc-switch 有些相似,但又有本质区别。之前用 CCS 时,我经常遇到 Claude Code 配置冲突、设置被覆盖的问题,于是干脆自己搞了一个。
核心功能很简单:快速把第三方模型接入 Claude Code,一键启动!启动过程中会自动注入第三方模型、自动创建隔离的配置文件、自动切换到项目目录。同时,密钥会进行加密存储,还可以批量导出到另一台电脑。
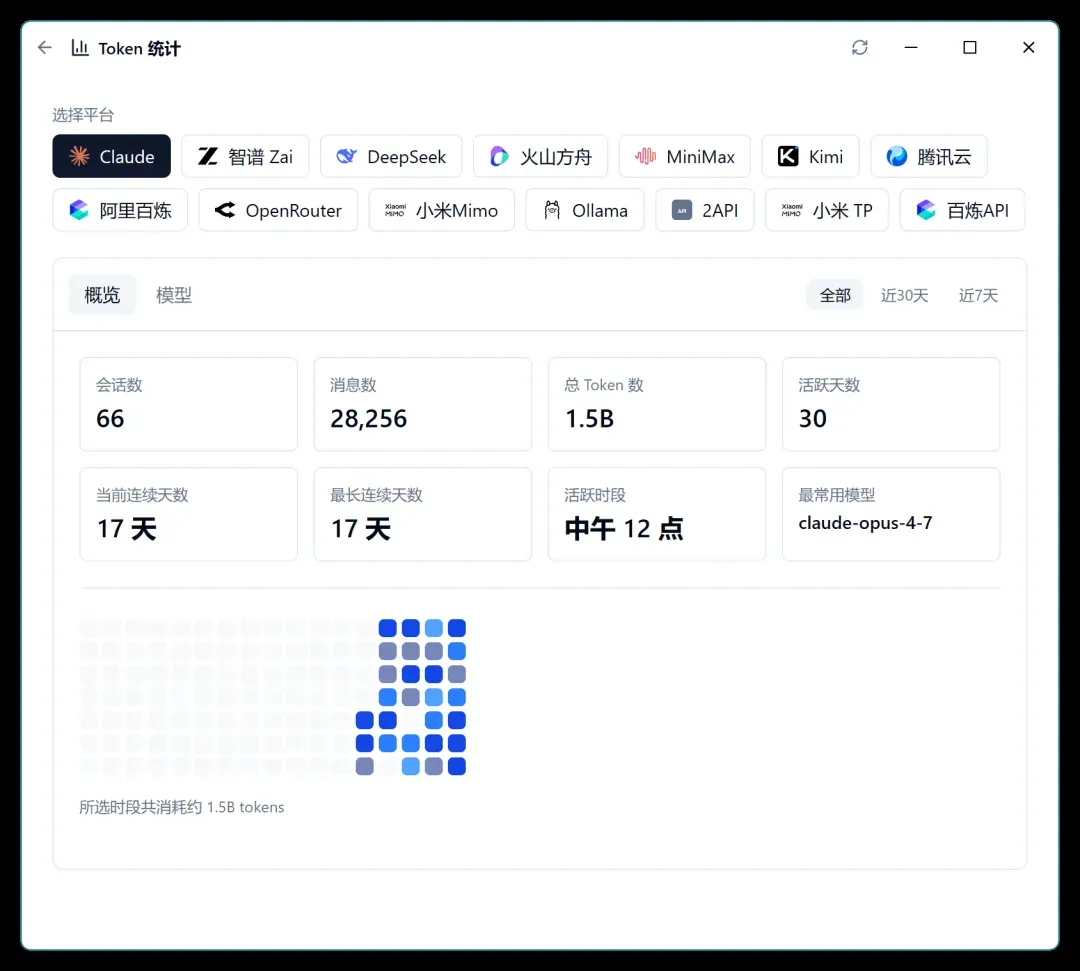
此外还有一些子功能,比如模型映射、Token 用量统计,以及批量运行多个平台等。
最近,JCode 已迭代至 0.9.7 版本。
今天主要为大家简单梳理一下新增的功能与使用方式。
智能授权模式
这一更新其实早就完成了,原本打算发的文章一直拖到现在才和大家见面。
该模式可以让你自动管理授权,也可以完全跳过授权步骤。
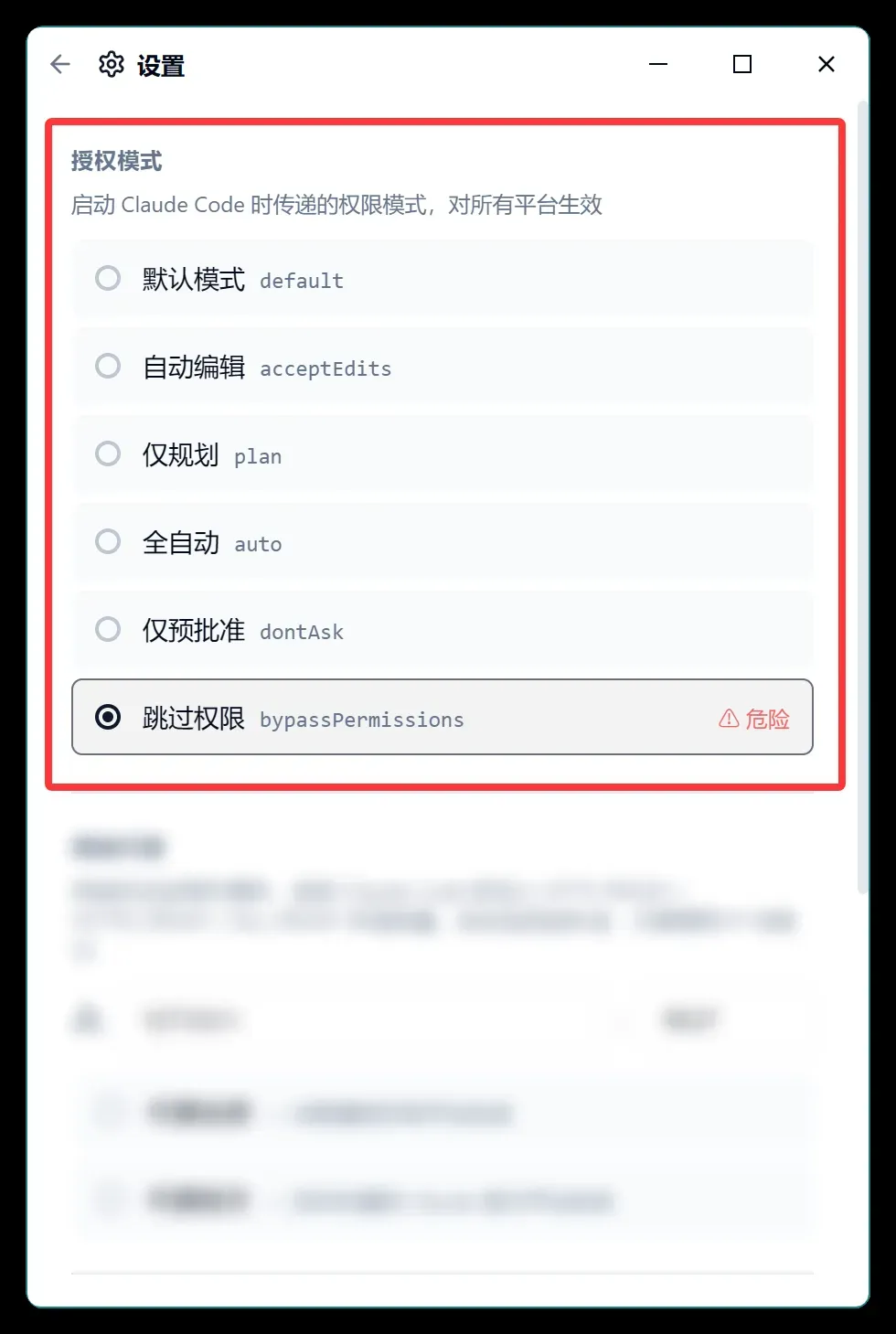
Claude Code 支持的六种授权模式均已整合进来,我个人推荐选择“自动”或“跳过”。不同模式的具体细节在此不展开,可以查阅先前的说明。
过去我一直使用 accept 模式,每次开启新项目都要不停地点击确认,稍不留神就会卡住半天。现在基本上全自动了,流程顺滑了许多。这里完成配置后,对所有平台都会生效,包括 Claude Code 官方与第三方平台。
网络 Agent 辅助
我们天天谈论各种智能体,其实当前最需要的还是“网络智能体”。当然 Agent 还有另一种译法,这个功能我就不在这里展示了。
大致的使用场景是:当你使用 Claude Code 官方服务时,有些工具可以辅助桌面版,却无法辅助终端版。这个功能正是用来填补这种场景的缺口。
平台管理全面优化
为了方便平台管理,新增了一个平台列表视图。
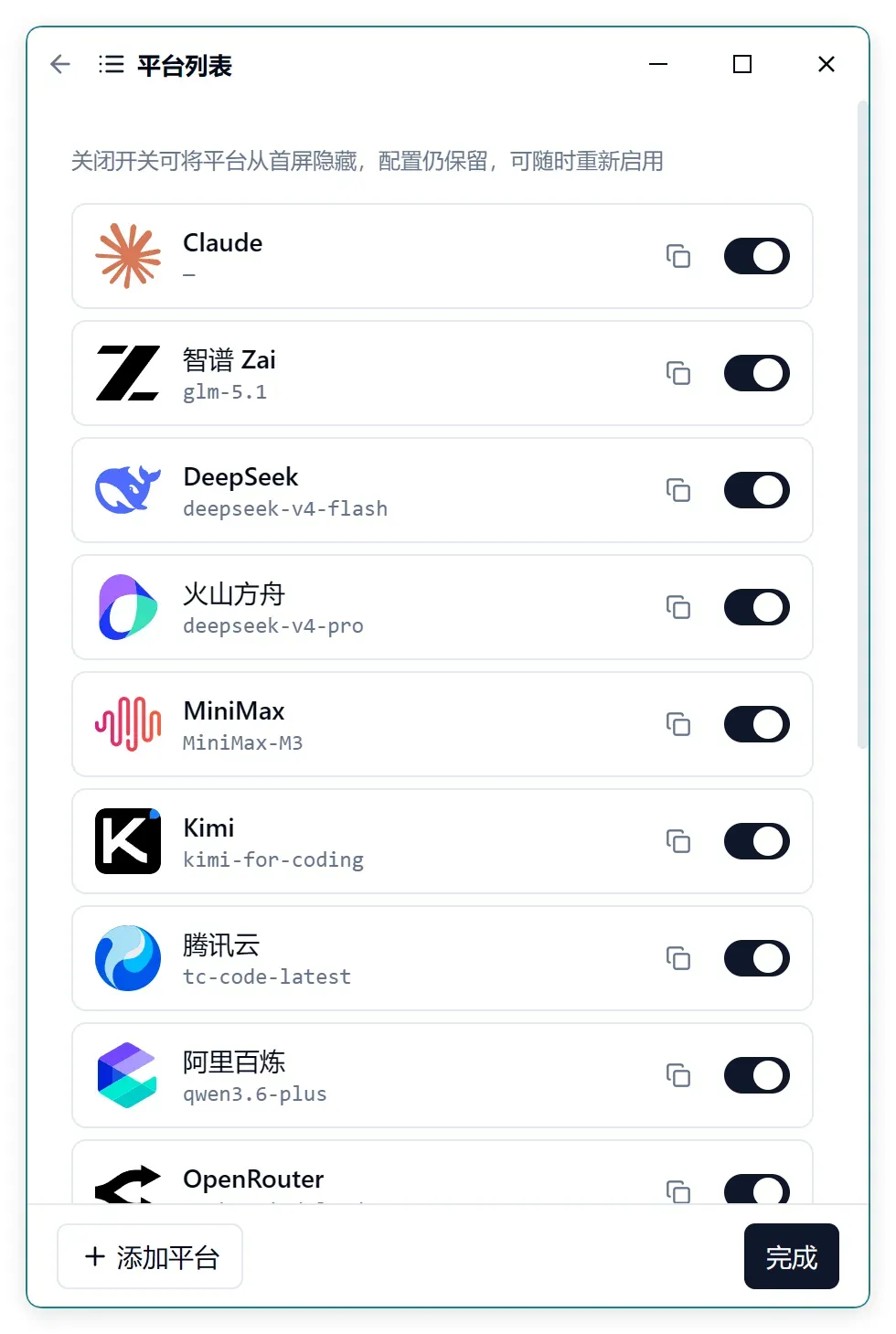
通过这个列表,可以随时启用或停用平台。为什么要停用呢? 因为当配置了大量平台之后,首页就会显得臃肿不堪,这时可以把不常用的先隐藏起来。
同时,还加入了一个复制配置信息的功能:只要将鼠标悬停在对应平台图标上约 1.5 秒,就会出现复制图标。

点击这个图标就能一键复制整个平台的配置信息。为什么会需要这个功能? 因为我的 API 信息非常多,经常要在不同平台、系统和软件之间来回拷贝。更烦人的是,各家平台的 API Key 往往在首次查看后就再也找不到了。有了这个功能,只需配置一次,即可一键复制。