苹果被迫缴纳‘AI税’:AI引发的存储危机正让消费者买单
消费电子产业正站在历史转折点上。苹果、微软等巨头罕见地同步涨价,部分品类涨幅高达三成。这场由AI算力争夺引发的存储芯片危机,正重构全球供应链规则。本文揭秘AI繁荣背后,那些被迫买单的隐性成本。
在接连数月的内存供应紧张预警和涨价预期铺垫之后,苹果昨日终于正式提价,波及Mac、iPad等多条产品线,部分型号最高涨幅达3000元人民币。这是苹果有史以来最猛烈的一次调价行动。
此次未包含iPhone——去年面世的iPhone 17 Pro系列起售价已较上代上涨1000元。外界普遍预测今秋的iPhone新品将大幅提价,折叠屏iPhone起步价可能突破2000美元。
苹果刚录得近三年来最快季度增长:今年一季度营收同比增长17%至1112亿美元,利润飙升19%达296亿美元,双双远超华尔街预期。中国区销售更为强劲,同比劲增28%。
但这些都是过去时了。全球存储价格暴涨所带来的重压,即便是苹果也难以独立消化。库克日前在接受《华尔街日报》采访时感叹,从业四十年来从未经历过如此剧烈的价格震荡,称其为“百年一遇的洪灾”。
在此前的财报电话会上,苹果曾表示现有库存有助于维持短期毛利率,但内存成本压力随后将显现,预计盈利能力将略有下滑。IDC预计今年全球智能手机出货量将下跌13%,创下历史最大降幅,PC市场则收缩11.3%。
今晨美股收盘,苹果股价重挫6.1%,创下近一年来最大单日跌幅。
消费电子全线溃败:无一品牌幸免于涨价风暴
苹果史无前例的涨价标志着消费电子行业最后一块堡垒也已陷落。在全球存储价格飞涨和AI投资持续扩张的背景下,消费电子行业成为第一个牺牲品。
在此之前,安卓手机厂商已率先上调定价。中国市场的OPPO、vivo、小米、荣耀等品牌相继提价中低端机型——这类低利润产品对芯片成本占比更为敏感。
华为余承东在4月的发布会上坦言,因成本上涨,新机定价压力巨大,后续华为也难以独撑。到6月,华为新发布的Nova系列果然已全面提价。
PC端涨幅更为惊人,联想、华硕、惠普、戴尔等厂商多次涨价,部分品牌部分产品涨幅甚至突破30%。不过凭借庞大的商用市场和AI PC概念加持,部分品牌如联想的业绩反而飙升,带动市值重估。
微软、索尼、任天堂等游戏机厂商同样多次提价。3月,索尼PS5国行系列全面上调价格,最大涨幅达700元。5月,任天堂宣布Switch 2全球提价50美元。微软Xbox经历两次涨价后,昨日紧随苹果再度涨价100至150美元,并停售2TB大容量版本。
在过去长达十几年的时间里,消费电子行业的主基调始终是降价。成熟的工艺与供应链不断降低制造成本,持续膨胀的市场进一步加剧竞争与价格搏杀。初代小米手机以1999元登场时,市面上的主流旗舰机售价多在5000元以上。十年前售价上万的55寸4K电视至今近乎绝迹。若以数字编号的iPhone为基准,苹果售价十余年间几乎没有变动。
甚至在此次存储涨价潮来袭前,苹果已开始被用户冠以“性价比”之名——乔布斯若在天有灵,或许会忍不住发笑。今年初上市的MacBook Neo是苹果史上最便宜的Mac,一度卖到断货。年初的龙虾热潮中,Mac Mini甚至成了成本最低的“养虾”方案之一。
然而,新一轮涨价潮过后,这些性价比优势烟消云散。MacBook Neo起售价升至5499元,较此前4599元的零售价上涨19.5%;Mac Mini起售价从4499元猛增至5999元,涨幅高达33%。

MacBook Neo
苹果对外解释称,消费电子行业正面临空前挑战,AI数据中心的极速扩张引发了内存和存储需求的井喷式增长,元器件价格上涨的幅度与速度前所未见。公司此前一直试图在内部消化采购成本压力,但如今已不得不将其中一部分转嫁到产品价格上。
对那些打算购买苹果或微软设备的人来说,此次涨价也许会抑制部分消费意愿。但更令人担忧的是,这远非消费电子涨价潮的终点,而只是一个开场。
微软在宣布Xbox提价的同时披露,游戏机所用的存储和内存价格已上涨超过2.5倍,预计到明年秋季还将再次翻倍。换句话说,Xbox的涨价还远未结束。
考虑到苹果正着手将所有产品融入AI能力,全新升级的Siri也已正式亮相,苹果产品需要更大的内存和存储来支撑AI功能,这些新增的硬件成本无疑将推动苹果产品价格进一步走高。
AI扩张的代价:当普通人开始为AI买单
消费电子全面涨价的直接成因是芯片紧缺,因为更多的产能都让位给了AI。
内存市场由三星、SK海力士和美光科技三家巨头高度垄断,过去数十年来一直承受着类似猪周期的市场波动,产能与利润并不稳定。
但进入AI时代后,全球科技公司掀起了史无前例的资本支出浪潮,将数以万亿计的资金砸向算力基础设施,AI计算对内存的需求急剧膨胀。内存产业原有产能远远跟不上,芯片厂为攫取更大利润,只能不断压缩消费电子领域的产能,将更多产线向AI芯片倾斜。
彭博社梳理了过去数年SK海力士及美光的前十大客户:2022年时,两家公司最大的收入来源依旧是苹果、戴尔、联想、惠普等消费电子厂商;但到了2026年,其核心客户已变成了英伟达、微软、谷歌、亚马逊、Meta等AI产业巨头。
过去一年间,内存厂商利润与股价齐飞。三星股价一年内暴涨逾458%,SK海力士和美光更飙涨超800%。美光上一财季毛利率高达84.9%,较一年前翻了一番不止,创下历史新高,利润率甚至超越了英伟达、微软、Meta、谷歌等“美股七姐妹”。
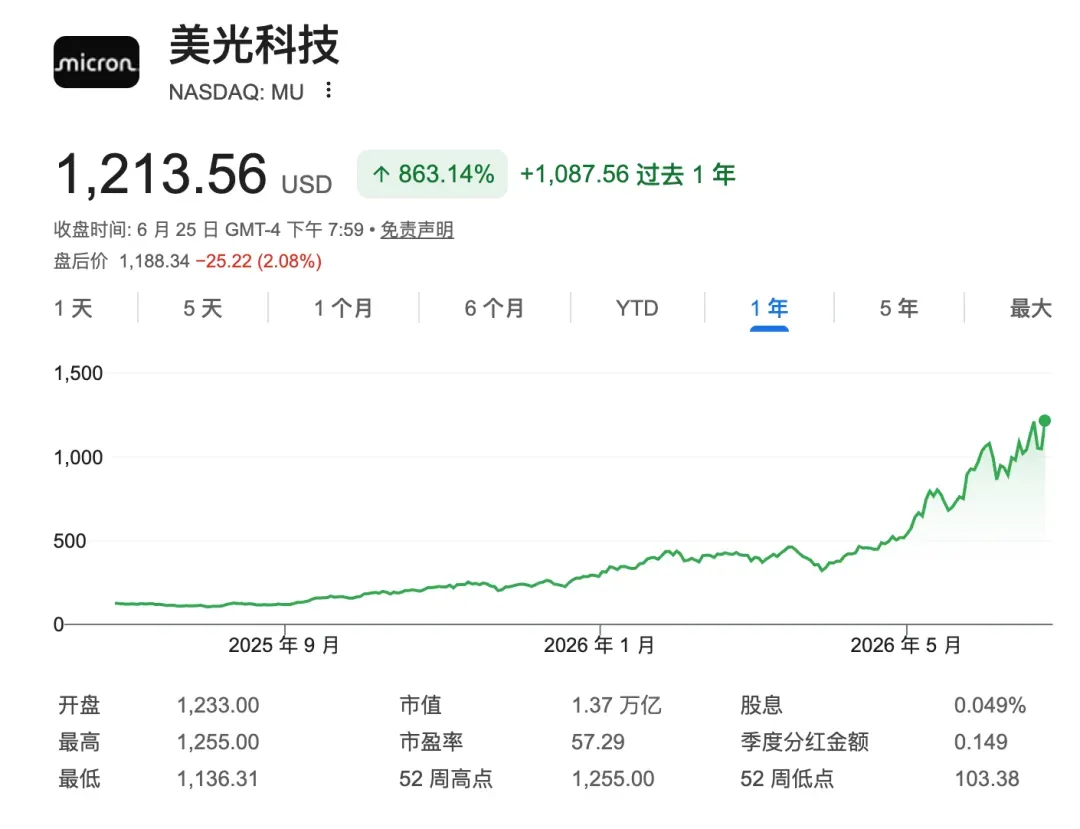
美光过去一年股价涨幅
本周,韩媒报道三星计划未来十年投入1000万亿韩元(约合646亿美元),用于建设AI数据中心、电池及显示产业,这是韩国史上规模最大的投资计划。SK海力士据悉也将扩产,目标五年内将产能翻倍。
但这些投资在短期内都难以缓解芯片供应紧张,况且算力需求仍在持续扩张。彭博数据显示,2025年AI数据中心对DRAM芯片的需求已飙升至全球总消费量的一半左右,而五年前这一占比仅为25%;预计2030年将超过60%。
摩根士丹利预测,到2027年DRAM芯片产能将增长30%。但由于供应商优先生产专用的AI内存,届时用于消费科技的芯片仍将面临最高15%的需求缺口。
苹果涨价仅仅是个开始。对于众多非AI行业的普通人来说,我们或许还未真正感受到AI带来的生产力提升,却已先一步承受起AI引发的涨价压力。
人形机器人改写的不只是效率:龙旗工厂八小时直播揭示的产业变革
一台人形机器人刚刚在中国的电子产品产线上值完了第一个完整的八小时轮班——没有剪辑,没有重启,没有人喊 cut。

01 实况转播:龙旗南昌工厂的八小时轮班
这里不是演示布景,而是真实的生产现场。传送带在持续运转,人类同事就在周围作业,镜头没有经过任何彩排。Agibot 的 G2 在这条产线上处理真实的平板零件,整整八个小时,无间断运转,没有人为干预,也没有后期剪辑。
轮班刚开始时,传送带发生了一次下移,工位位置随之偏移。没有人去标记这个偏差——机器人自己察觉并做出了调整,把零件重新摆正,继续作业。同一个班次里,它还主动标记出了有缺陷的部件。整个机队在 10 小时内处理了超过 3000 个单位,成功率 100%。它通过工厂自身的软件实时完成通信、报告、分拣和跟进,不需要人一步一步地教导。
这个场景最值得注意的,恰恰是它一点都不耸动。真正被改写的,并不是某一台机器有多聪明,而是整条产线的设计开始把“人类的生理极限”从约束条件中剔除。
02 人类的生理极限,曾是工厂设计的默认参数
八小时轮班、强制休息时段、注意力在第六个小时后开始涣散——这些不是意外事故,而是设计前提。工厂、写字楼、医院、高速公路,整个现代社会的运转骨架,几乎都是从人的疲劳曲线出发搭建起来的。

机器人在意这些吗?不完全是。它可以每 19 秒完成一次拾放节拍,毫秒级定位,深夜不会走神,凌晨四点也不会打哈欠。只要系统里没有“六小时后必须休息”的代码,它就天然摆脱了这条边界。Agibot 把这件事说得非常直白:不是机器人终于不被累倒了,而是那些约束原本就可以不写进去。
这个判断听起来轻描淡写,方向却很重。它让工厂设计回到一个根本问题:如果你手里是一台永远在线的设备,你的工序还能按照老办法安排吗?
03 从展示品到生产线:中国的人形机器人不再只是作秀
这些年关于机器人的新闻总是带着两张面孔。一张是实验室里灵巧翻身的演示,另一张是末日电影里推倒人类的金属巨影。真实情况从第一张慢慢走向第二张,但过程极其沉闷:大量的参数调优、系统对接、不稳定性排查,以及工厂信息环境的改造。
Agibot 的 G2 走的是第二条路。它不强调双足的灵巧,而强调“这场直播不是剪辑过的”。今年 4 月,Agibot 在龙旗南昌工厂做了八小时实况转播,数十万人在线看着机器人在轴承旁一点点磨合出真实的节拍。评论里出现最多的词不是“炫酷”,而是“催眠”“踏实”“终于不是摆拍了”。
中国的机器人公司正在进入一个平台期:它们不再只需要融资金额,更需要供应链整合能力、工厂接口协议、质检标准对接和故障响应机制。那场八小时直播与其说是营销,不如说是生产环境的白盒化——让潜在客户相信它能真正上产线,而不是只能在庆典上客串。
背景国内生态速写
2025 到 2026 年间,宇树科技的 Unitree、智元机器人(AgiBot)、从小米 CyberDog 脱胎的创业团队,以及 Figure、Agility 等海外公司,都在把人形机器人从实验场往工厂里推。不同路线的共识正在成形:采用带轮式底盘、允许轮足混合、强调与现有产线软件的实时通信,而不是一味追求纯粹的仿生外形。北京人形机器人创新中心、上海经信委等政府机构也围绕“具身智能”“世界模型”进行政策命名,产业公共基础设施的边界正在被重新划定。
04 先搬箱子,再说故事:具身智能的工程化突围
Agibot 的策略不是先训练模型、再包装成故事,而是先上线、再迭代模型。它公布了一整套全栈思路:依托大规模真实机器人数据集、用大语言模型生成模拟环境、视觉-语言-动作的基础模型、物理空间的预测模型,以及面向企业的无代码部署接口。
这很务实,也很累。它不像大语言模型或扩散模型那样可以只靠算力和论文突飞猛进。具身智能面对的不是算法验证,而是一片工程化的沼泽:装配公差、设备振动、软件协议、维护时机。
龙旗选择 Agibot G2,也和这些细节有关。Agibot 为平板测试工序定制的夹具,并不是通用手臂开箱即用。做夹具、调通工控软件、跑通节拍,公司高管说只用了四个月车间培训。这个速度是上一代工业机器人做不到的。与 Figure 早先在仓储或宝马场景中的测试相比,龙旗这个案子把机器人直接拉入了高吞吐、快节拍的消费电子制造核心,竞争点落在“可靠”而不是“聪明”上。
05 美国资本圈忽略的真相:中国工厂的节奏打法

用《终结者》的语言描述这个场景当然很容易,因为那更贴近娱乐消费的习惯。但真正在中国发生的画面要平凡、也粗暴得多:准时上班、每一班都比上一班略好一点、工厂主管只看异常率和吞吐量。
这恰恰是美国资本圈容易低估的部分。他们习惯于把机器人想象成硅谷式的创业 demo 文化产物,而中国生态的节奏是把供应链、产线改造、成本控制和政府补贴打包在一起向前推。宇树、智元、小米、地平线、商汤等等,并不是每个方向都能成功,但它们把价格压下来,把落地门槛降下去。
拆开来看:产线改造权握在中国厂商手上;然后才是模型能力和本体工程。这种顺序决定了跑出来的不是“通用机器人国家队”,而是“有明确付费客户和交付节点的细分行业实施方”。
06 不取代,只解放:机器人如何重塑工人的岗位价值
最不浪漫的结果,反而是最好的结果。G2 不是用来制造戏剧的,而是用来把工人的手腕从重复搬运里解放出来的。在龙旗工厂,人类同事仍然在岗,只是转到了更需要判断力的步骤。
它没有击败工人。它只是把八小时轮班、注意力衰减、休息间隔这些由历史形成的边界,从必然变为可选。
你再看一遍那条产线。机器人稳定运转,伴随轻微机械声,屏幕上数据显示着实时的产能。没人举杯,没有掌声,屏幕上只有数字。这个画面既不壮观,也不让人后怕。它最重要的地方就在于此:它已经在工厂里“自然存在”,不再需要被当作奇观来解释。
树莓派5 + PS5 手柄实战:搭建六自由度机械臂蓝牙遥控系统
项目概述
本教程将教你如何使用 PS5 DualSense 手柄、树莓派 5 和 Arduino Nano 搭建一套六自由度机械臂控制系统。PS5 手柄通过蓝牙与树莓派 5 配对;树莓派运行 Python 程序读取摇杆、按键输入值,再通过 USB 串口向 Arduino Nano 发送数字指令;Arduino Nano 接收指令后驱动机械臂对应舵机运转。
完整控制链路:
PS5 Controller → Raspberry Pi 5 → Arduino Nano → Servo Robotic Arm
如果你想学习机器人领域的游戏手柄远程操控原理,本项目是绝佳入门案例。不同于手机 APP 控制、Arduino 板载按键控制,本方案使用专业游戏手柄,复刻小型机械抓取设备的操控逻辑。
当前版本仅实现机械臂单独控制;后续可基于这套硬件框架扩展搭配 L298N 电机驱动小车,实现单支 PS5 手柄同时控制机械臂与移动底盘。

物料清单
开工前备齐全部核心硬件与工具:
硬件
- 树莓派 5
- Arduino Nano 主控板
- PS5 DualSense 手柄
- 六自由度铝合金舵机机械臂
- Arduino Nano 舵机扩展板 / 舵机驱动盾板
- 6 个伺服舵机
- 舵机独立外接电源
- Arduino Nano 配套 USB 数据线
- 树莓派 5 专用供电电源
- 预装树莓派系统的 Micro SD 存储卡
- 若干杜邦跳线
软件工具
数字化转型实战:产品心态做项目,甲乙方共赢的精细化拆解
在数字化转型的浪潮中,很多企业都面临一个根本性的抉择:到底应该用项目管理的方式去推进,还是以产品开发的思维去实现?这篇文章将深度剖析数字化转型过程中甲乙方合作的全新模式,对比项目思维与产品思维的本质差异,并给出在转型落地时如何聚焦核心目标、精准选择渠道以及提升执行质量的具体策略。
项目更关注计划与执行,产品则注重探索与持续迭代。
一、甲乙方合作关系正在重塑:从简单交易到深度共创
数字化的发展速度远超预期,企业自身的业务模式在快速变革,转型的需求持续升级,对服务合作伙伴的能力要求也不断刷新,而更为关键的是,甲乙双方的关系正在发生根本性变化。
从合作形态来看,早已不是单纯的买卖关系,而是演变成双方共同为甲方变革结果负责的深度共创关系;
乙方也不能再死扣合同上的功能清单,以“这个优化不在合同范围内”为借口充当“小乙方”,因为合作本质上是长期的,绝不是一次性的短期项目;
甲方同样不能只做一个出钱后撒手不管的甩手掌柜,把所有责任和风险都推给乙方,而是应该为了核心目标和最终成果,与乙方一起投入智慧,借助乙方的专业优势,共同实现变革的终极目标。
那么问题也随之浮出水面:
- 如果项目没有如期交付,责任到底由谁承担?
- 如果项目按时交付,功能也全部通过确认,但甲方上线后不满意,不断要求反复修改,由此产生的成本该谁来扛?
- 即使甲乙方都对交付结果感到满意,但项目落地后实际效果不理想,这个结果又该由谁负责?
这些问题看起来似乎把合作逼进了死胡同,但它们其实仍然是从甲乙双方对立的角度在看问题。如果我们跳出对抗思维,真正从协同合作的关系出发,就会发现出路。
1. 项目延期交付,责任归谁?如何用共赢思维去看待?
如果项目延期,很大概率是因为沟通过程中出现了障碍。那么问题到底出在哪里?是哪些因素导致的?是否能提前避免?假如双方都认为错在对方,那么这段合作关系本质上仍是对抗性的,而不是共赢的。我们需要以合作双赢的态度和方式去争取最终的结果。
站在共赢的视角,项目可能对甲方而言会延期,对乙方来说则可能出现预算超支。但甲方或许能收获因延期带来的超出预期的项目价值,乙方则可能赢得甲方的认可和未来持续合作的机会。在这种背景下,原本相互指责导致的负面结果,完全可能转变为双方共同的收益。
项目总是要推进的,成熟的合作关系中,从来不存在非黑即白的对立。
不过,从甲乙双方各自企业的角度看,这种模式其实投入了更多资源。那么对企业来说,这次项目上投入的“学习成本”,能不能转化为可复用的组织资产?企业是否敏锐地捕捉到了这次教训?是否基于此次情况进行了合理的后续调整?是否将复盘总结固化为组织经验,从而让投入的成本真正变成学习的资产?这笔账,公司老板也需要仔细算一算。
2. 交付后甲方要求反复修改,成本该由谁承担?
如果站在传统买卖关系上看,乙方全责,改就是了,因为甲方出钱却对结果不验收。但从乙方的立场出发,方案和功能都在过程中得到了确认,为什么现在又要推翻重来?难道真要拿出确认邮件来对峙吗?那后面的合作还要不要?
一般情况下,乙方都会选择配合,在可控范围内进行调整。当然,这对乙方来说,最直接的影响就是投入成本的增加。
那么,就需要提前思考:
- 项目报价中是否预留了这部分费用空间?
- 这涉及到乙方的报价策略和项目经验;
- 与甲方的合作可能带来的后续业务机会以及由此产生的额外利润(企业的资源复用成本);
- 以及与甲方合作所积累的品牌效应和资源合作机会。
你看,这从来不是某一个单独的项目在影响乙方的整体收入,而是乙方的商业模式、经验积累、人力调配和资源模式,在决定乙方的收入。如果企业的整体架构设计得不好,项目经理就很容易背锅,项目成员不得不付出更多投入,而企业老板却在承担损失。
对甲方来说,真的就是赢家吗?站在双方互赢的角度来看,
不存在单方面的输,只有共同的赢。
因为企业内部的数据部门或信息部门正在推进数字化项目,这些部门在公司内部其实承担着“内部乙方”的角色。交付后的不满意,很可能会影响部门在公司内部的口碑,甚至干扰多部门协作的节奏。
由此可见,甲乙双方深度协作的模式,才是最理想的方式。我们绝不能以对抗的姿态去合作,而必须以深度共创的模式,才能实现真正的双赢。
那如果甲乙方都验收通过,项目上线后却跑得不顺畅,实际效果未达预期,又该怎么办?这就是今天要讨论的核心。
二、数字化转型项目,必须用产品思维去推进
我们要建立合理的预期。相信没有一家企业愿意花钱只为了扔一块石头、看一朵水花。所有人希望的都是能滚起雪球:项目持续迭代,打磨出好产品,再通过产品赋能业务,实现持续盈利。
首先,在当前的市场环境下,一定要做减法。要将最核心的资源投入到最重要的事情上,反复聚焦、再聚焦。而在如何聚焦这一点上,80% 的企业都做得很不到位。
“明确目标与范围,把 80% 的精力聚焦在最关键的目标上”
这句话听起来轻巧,谁都可以脱口而出,但真正落地却非常虚晃。到底怎样才算是真正聚焦核心目标呢?
至少可以通过四个层次的“如何”,来一步步锁定核心焦点。
我们通过一个具体例子来拆解:假设在项目初期,我们把用户招募列为最重要的事项,那么核心就应该聚焦于不同渠道的铺设以及各个渠道路径的支持。
分析到这里就结束了吗?不,这才刚刚开始。
1. 聚焦用户招募:怎样才算做到了精细化评估?
经过前面的思考,我们已经明确了要“做减法”,把精力聚焦在渠道铺设这一个点上。那么关键目标和执行目标就进一步收敛为:找出最核心的渠道,并投入最大的精力去支持好它。
但如何找到那个最关键的渠道呢?
有些行业的优质渠道可以凭借行业经验直接判断,比如实体零售的关键渠道就是门店,家具行业的关键渠道往往是设计师;现在很多新品牌则依赖小红书这样的新零售渠道,高价值品类行业的关键渠道可能是来自第三方平台的有效线索。
当渠道不清晰时,就需要通过多渠道同时推送,并借助快速的数据分析反馈,计算出各个渠道的投入产出比以及客户质量,综合判断后才能确定哪些是优质渠道。
因此,围绕渠道这个核心点,我们可以从两个维度梳理出核心事件:其一,在多个渠道中筛选最重要的渠道来源;其二,在不同阶段关注不同渠道的优先级。
2. 如何精准评估渠道质量?
评估渠道质量的核心,在于看整体模块的投入产出比。
我们可以通过梳理评估渠道的关键维度,并结合不同维度的权重,来计算不同渠道的价值:
假设评估渠道质量的维度包括:
- 渠道带来的用户数量
- 渠道投入的单个用户成本
- 渠道用户的商业价值(用户质量可通过成交金额或转化率衡量)
- 渠道用户的质量(在数字化平台上,还可以考虑CLV即用户全生命周期价值。有的平台带来的KOC虽然直接成交金额不高,却能影响更多用户来消费;活跃用户也可以贡献更多内容等,所以客户价值绝不只有成交金额这一个维度)
3. 如何计算各维度数据并进行评估打分?
渠道带来的用户数:
- 记录每个渠道带来的新增用户数量。
- 打分方式:可根据用户数量的多少来设定得分。例如将用户数最多的渠道设为最高分,其他渠道按其用户数占最多渠道用户数的比例来打分。
渠道用户的商业价值:
- 选取指标:选择能够反映商业价值的指标,比如GMV、CPS等。
- 计算得分:根据每个渠道的商业指标表现来打分。例如可以计算各渠道的转化率,转化率最高的渠道获得最高得分。
渠道单个用户获取成本:
- 收集数据:记录每个渠道的投入成本,包括广告费用、人力成本等。
- 计算得分:利用公式计算成本得分,例如计算每个渠道的获客成本(CAC),即总成本除以获得的客户数。成本越低的渠道,成本得分越高。
渠道用户的质量:
推特翻译打破“巴别塔”后:印度人造谣中国种姓,欧美自嘲“头号敌人”,中日韩网友被迫相认
推特全球网民聚集地
印度人编造中国的“种姓制度”沦为国际笑话,欧美人自我嘲讽“全球公敌”,中日韩三国的网友隔空互怼却又彼此心领神会。当语言的屏障被瞬间抹除,全世界的年轻灵魂幡然醒悟:最亲近的同类,从来都不是说着相同语言的人,而是陷入相同阶级困局的人。
———— / BEGIN / ————
如果有这么一个跨国的平台彻底瓦解了语言的藩篱,景象会是如何?
有人以西班牙语低语:最初的指南针早于时钟诞生,所以判定方位远比计算时间更加紧要。
有人用英语嘀咕:蹲在垃圾桶旁削铅笔的那种感觉,就等同于成年人在街头抽着烟放空。
有人借葡萄牙语吐槽:网络世界只存在两种人——想求死的人和想寻欢的人。
而最近,X(推特)上面的全部内容,已经开始被自动转译成用户主页设定的语言。
当翻译功能全面铺开的那一瞬间,传说中的巴别塔终于浇筑了最后一方混凝土。
01 当翻译抹平了世界,我们才发现烦恼是相通的
今年春末夏初之际,不少X(推特)的冲浪选手惊奇地发觉,首页的信息流几乎在一夜之间换上了自己的母语。
莫非马斯克得到了什么神明的点拨,让推特的自动翻译毫无预警地马力全开。
这次技术迭代,旨在替代原本的谷歌翻译方案,终极目标是让任何语种的帖子都有机会触及全球的流量池。打个比方,哪怕是巴西老哥用家乡话脱口而出的抱怨,远在格陵兰岛的居民也能用自己的母语秒懂并回复。
对于习惯了冲浪的人来说,全自动翻译代表了什么?恍若电影《超体》里的经典桥段,当女主角刹那间掌握了地球上7000种语言,一个全新的宇宙就此毫无障碍地铺陈在眼前。

推特打开自动翻译后be like
这下可好,推特彻底沸腾了。
平凡人的随口吐槽,莫名其妙就获得了泼天的流量浇灌。
众人惊觉,不论身处哪个角落,不管黄白黑棕,你我被生活毒打的烦闷竟是如此雷同。
有一位讲西班牙语的网友哭诉“但凡有纹身就找不到饭碗”,说韩语和日语的路人便纷纷惊叹“原来针对纹身的歧视并非东亚特有”。
一位韩国网友发牢骚“为什么区区一家公司要反复审核六遍我的履历”,结果评论区里有俄罗斯人连连赞叹“这脏话到底是如何被翻译得如此原汁原味的”。
要知道,跨语言翻译中最难啃的骨头,莫过于黑话和粗鄙之语。
Grok在骂架方面的功夫简直炉火纯青。它既没有谷歌翻译那股子学究的呆板,也不沾染ChatGPT那种人工智能的陈词滥调,满屏充斥的都是最粗野的人间烟火味。也不晓得是哪位大聪明向Grok和盘托出了整个民族的小秘密。
还有一位来自土耳其的网友哀嚎,自己明明已经是个23岁的成年人,但只要有人推门进入房间,他还是会下意识地迅速扔掉手机假装刻苦学习——
看来这并不意味着中国小孩有什么独家隐藏技能。
更令人捧腹的是,一位西班牙语网友正顾影自怜,惋惜自己命根子的尺寸过于含蓄,没想到竟被算法意外投喂了海量公域流量,让这位平日里毫无存在感的普通素人彻底颜面扫地。
“怎么会有乌泱泱一大群人来围观我的推文啊。”
自动翻译全面上线后,刷推特的丝滑体验达到了历史的顶峰。
那种属于人类群星汇聚的时刻不过如此。无论是何种语言,都能对着这该死的日子抒发出一百种截然不同的感悟。
最为一针见血直抵灵魂的抱怨,大多源自成年社畜之间共鸣。
为了赚取那点散碎银两,恨不得把自个儿的灵魂押给魔鬼去剁馅包饺子。
成年世界里的疲惫从来就不分国界线。
仿佛你下班回到鸽子笼,不想触碰游戏和书籍,拒绝一切社交也抗拒任何滋扰,捧上半杯奶茶一块冰西瓜,把脑袋埋进短视频的海洋直到眼皮沉沉睡去——很可能,某个远在印度尼西亚的陌生人也和你共享着一模一样的疲惫感。
至于那段被无数人搬运到国内社交网络上的话,更是击中了柔软的心房。
“活到眼下这把岁数,才突然理解了老妈下班时为何如此迫切地需要微波炉里那盘解冻好的白切鸡。”
非得等到自己长大成人扛起生活,才后知后觉地意识到,母亲在我们如今这年纪时,下班推开门迎面而来的仍是堆积如山的煮饭、辅导作业和洒扫整理,那是一种何其令人窒息的奔溃。
成年人的缴械投降之外,推特上也充斥着生动可爱的生活奇遇。
比如不管怎么兜圈子都摸不着宜家的出口,亦或是每次想从包装里抽出一张湿纸巾,却总能像变魔术般一连带出一大串。
当然,在这样一个以尺度豪放著称的场所,又怎能少得了各种地狱笑话的加持。
在汇聚了全球各色民族的大染缸推特上,你可以尽情浏览一切关于种族、政见、性向、地域和性别的辛辣段子。甚至连汉坦病毒想溜进此地,都得先被网友们夹道阴阳怪气地“礼遇”一番才能获批放行。
完全抛却了体面与顾虑,纯粹是在放肆享受那张淬了毒液的刻薄小嘴。
前一则笑话还没让你收住嘴角,后面接踵而来的那一条便像幽灵般追着你的神经而来。
你会挖出那些毫无违和感的全球通用笑料:莱昂纳多只爱二十出头的女伴、跨性别者触及的争议雷区、以及英国人堪称黑洞的料理水平。

有时,推特又像极了暑假百无聊赖时翻阅的那本《十万个为什么》——
你只需抛出困扰心头的一个疑问,不消片刻,某个角落里总能冒出神出鬼没的路人为你指点迷津,然后功成身退,深藏功与名。
那些困惑或许微不足道,但绝对属于每个人日常生活中会掠过的走神瞬间。
微信AI小微深度实测:15年前预言成真,为何它成了最不着急的AI?
2011年1月10日,微信上线尚不足月,团队在饭否留下一条颇具预见性的状态:“以后的互联网公司组成是,一个CEO和一堆会写程序的机器人。” 转眼15年过去,这句话几乎成了现实。大模型遍地开花的今天,微信终于也亮出了自己的答卷——小微。
总分10分的话,我给小微7.5分。绝大多数功能令人欣喜,响应速度也相当在线,但微信最核心的支付与聊天却并未开放。从群聊或个人对话窗口点击“+”号唤起“问小微”,可以临时调起它来总结聊天内容或提供回复建议。
微信团队承诺:此处的聊天记录仅用于当次分析,不会保存,更不会参与模型训练。
不过,小微的大脑并非 Hunyuan 3 Preview,而是微信自家的 WeLM(WeChat Large Model),并融合了 DeepSeek 的能力。WeLM 是一款深扎微信内容生态的语言模型,擅长摘要、改写、问答、文案、对话等任务,尤其针对中文互联网语境做了精细调校。直白点说,它对微信的“话风”与“场景”了如指掌。
和多数用户一样,我打开小微后做的第一件事也是逗它玩儿。
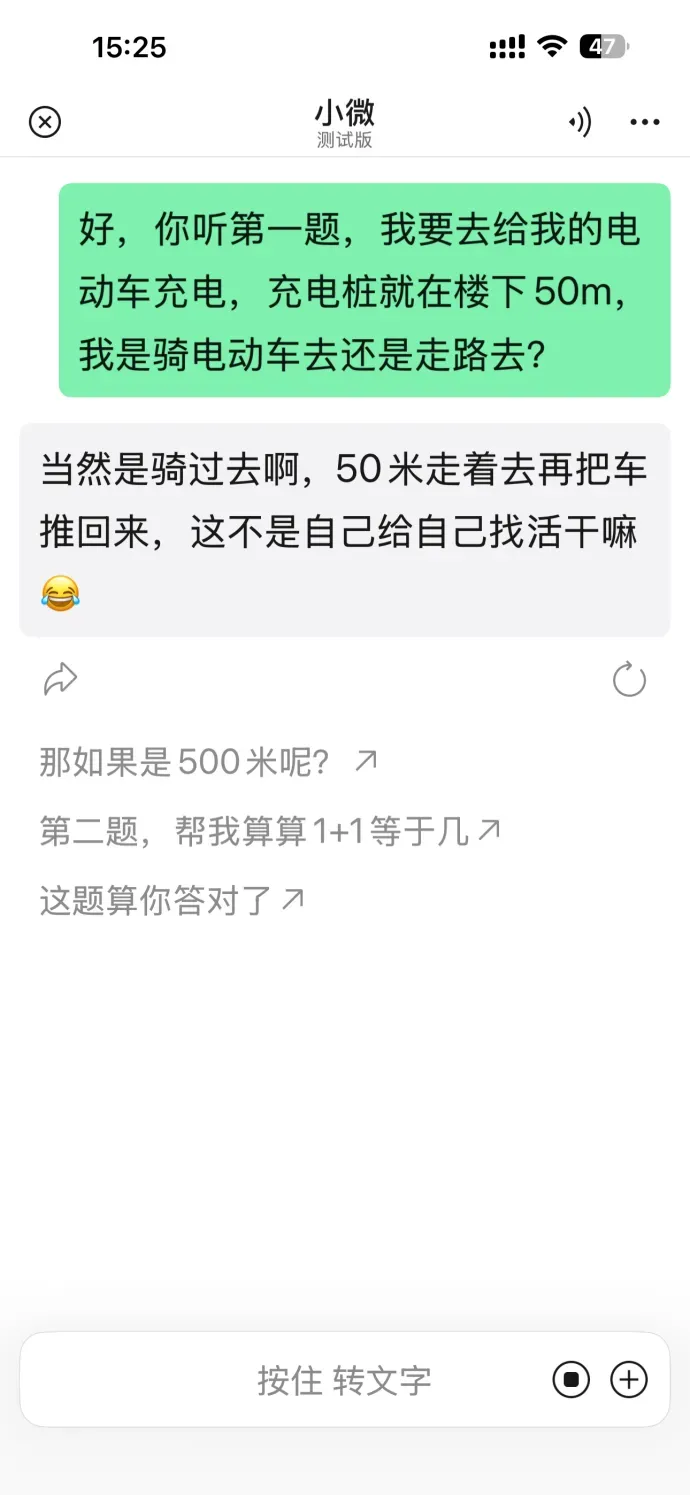
玩笑过后步入正题。小微最核心的功夫,在于一句话拆解多任务。我先抛出三个小要求。

它可以干净利落地拆分对话中的任务,然后逐一执行。于是我又加大了难度,把四个任务一股脑塞进同一句话。

除了拆解能力,小微还具备多模态理解。我拍了一张照片发过去,让它解读图中的内容并推断地点。


连纱窗上的污渍都被它注意到了,对图像元素的理解相当细腻。
另一大惊喜在于,小微能穿透微信的铜墙铁壁,读懂公众号文章。你可能会疑惑:公众号文章有什么读不懂的?实则,公众号堪称中文互联网最优质的长文宝库,却对 AI 设下了层层壁垒。
第一层:robots.txt。微信公众号域名的爬虫协议直接禁止外部搜索引擎索引文章内容,相当于在入口处贴了一张“禁止入内”的告示。
第二层:渲染环境隔离。你在微信内打开的文章,那个链接并非公开网页地址。文章本体并不存在于公网,而是锁在微信服务器里,只有通过微信 App 内置的 WebView 才能访问。唯有点击“复制链接”,才可能从外部一窥其貌。
第三层:User-Agent 与 Referer 双重校验。服务器会检查“谁在访问”与“从哪来”。若不是微信内置浏览器,直接拒之门外;若来源不是从微信内部跳转,同样吃闭门羹。
但以上三层还不是最绝的。传统网页的 HTML 下发时便包含全部文字,而公众号文章却采用“懒加载”:服务器给出的 HTML 骨架里正文是空的,真正的文字需要浏览器执行 JavaScript 去二次请求,且滚到哪一段才加载哪一段。加之页内充斥图片、广告、链接与底部跳转,AI 想要吃透一篇文章,难度可见一斑。
然而小微的阅读表现令人赞叹。我让它从“字母AI”公众号里搜几篇文章,它不仅精准找到,还能高度凝练地总结精华。

更有意思的是,小微还能讲出这篇文章为何值得一读。

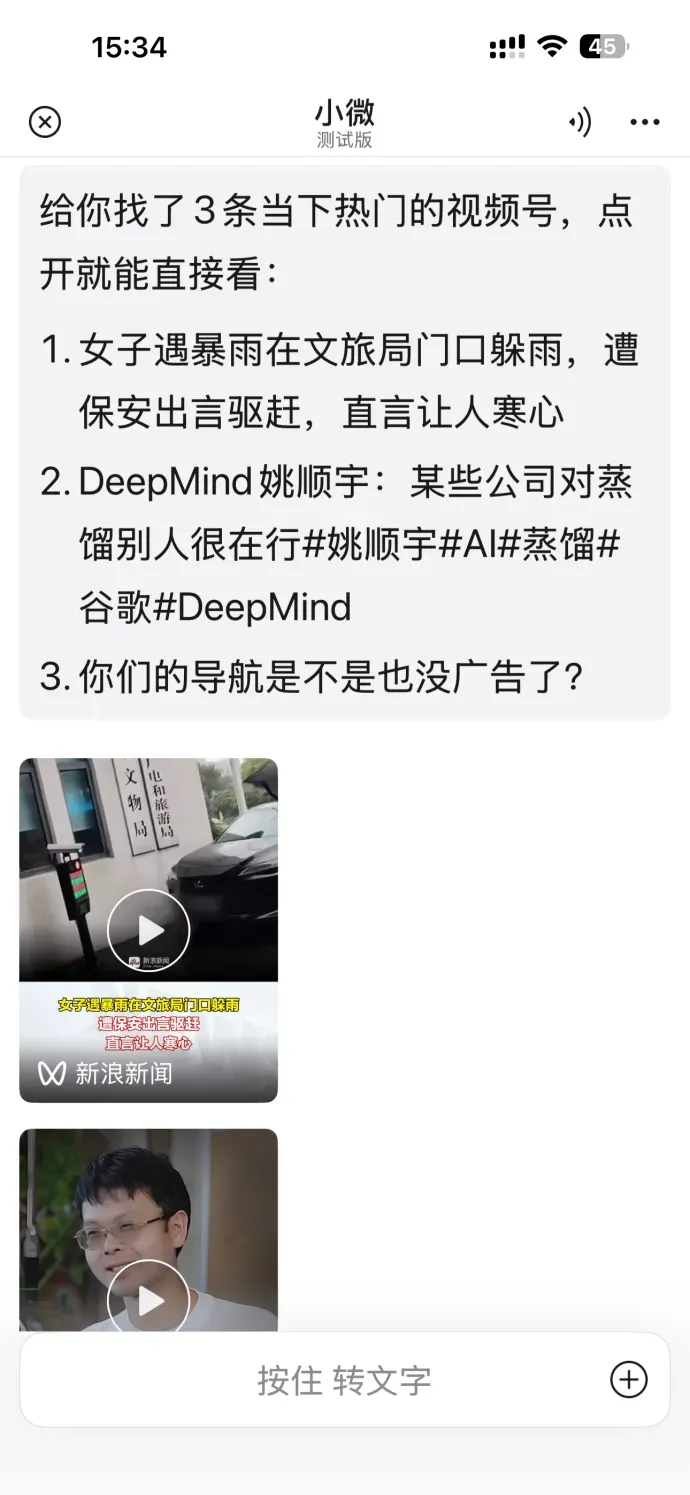
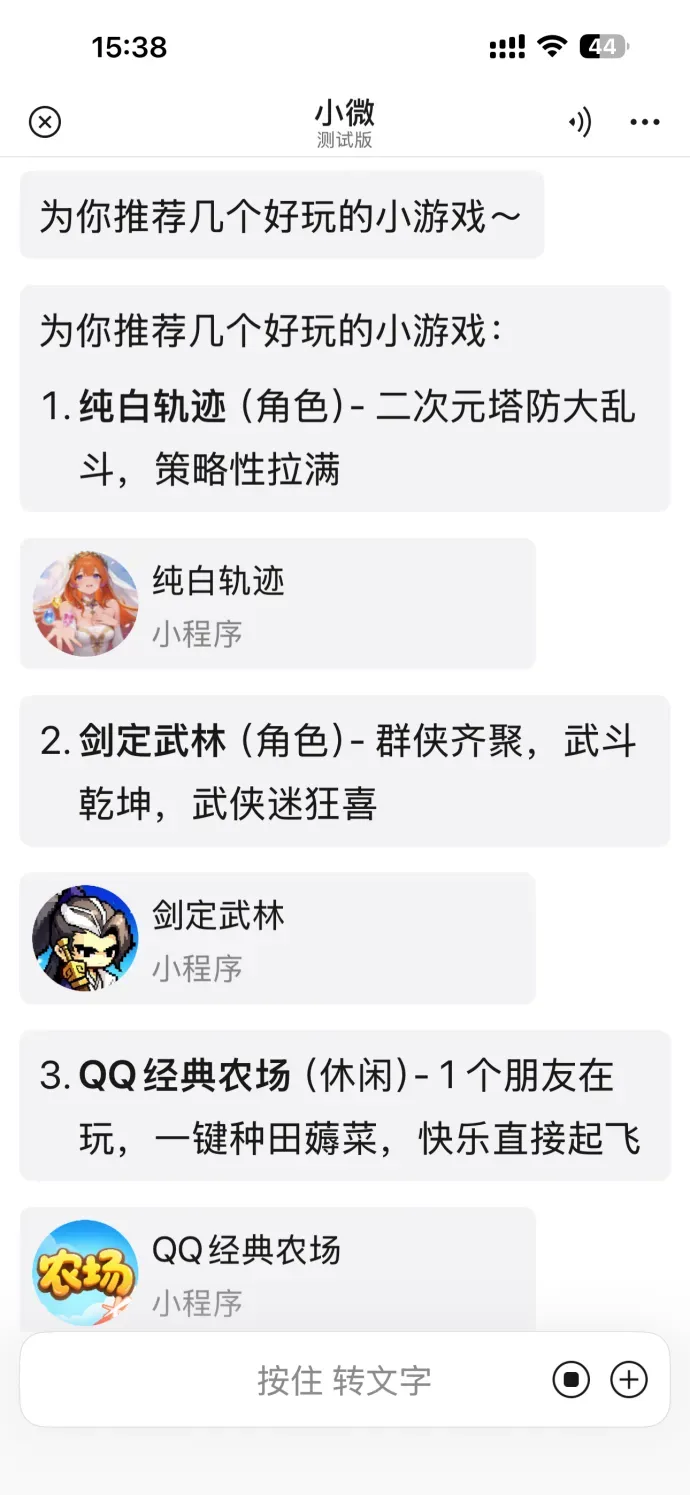
同时,搜索视频号和小游戏也毫不含糊。
最让我意外的,是它还能替你刷朋友圈。小微可以帮你总结朋友们发布的内容,以及各自收获了多少赞与评论。
除了一级窗口的这些本领,小微还增设了“创建小工具”的二级入口。顾名思义,你可以让它为你开发一个专属小程序。

我故意给出模糊的需求——请它做一个用于记录作者和文字的列表。结果第一次生成,就几乎分毫不差地命中我的期待。
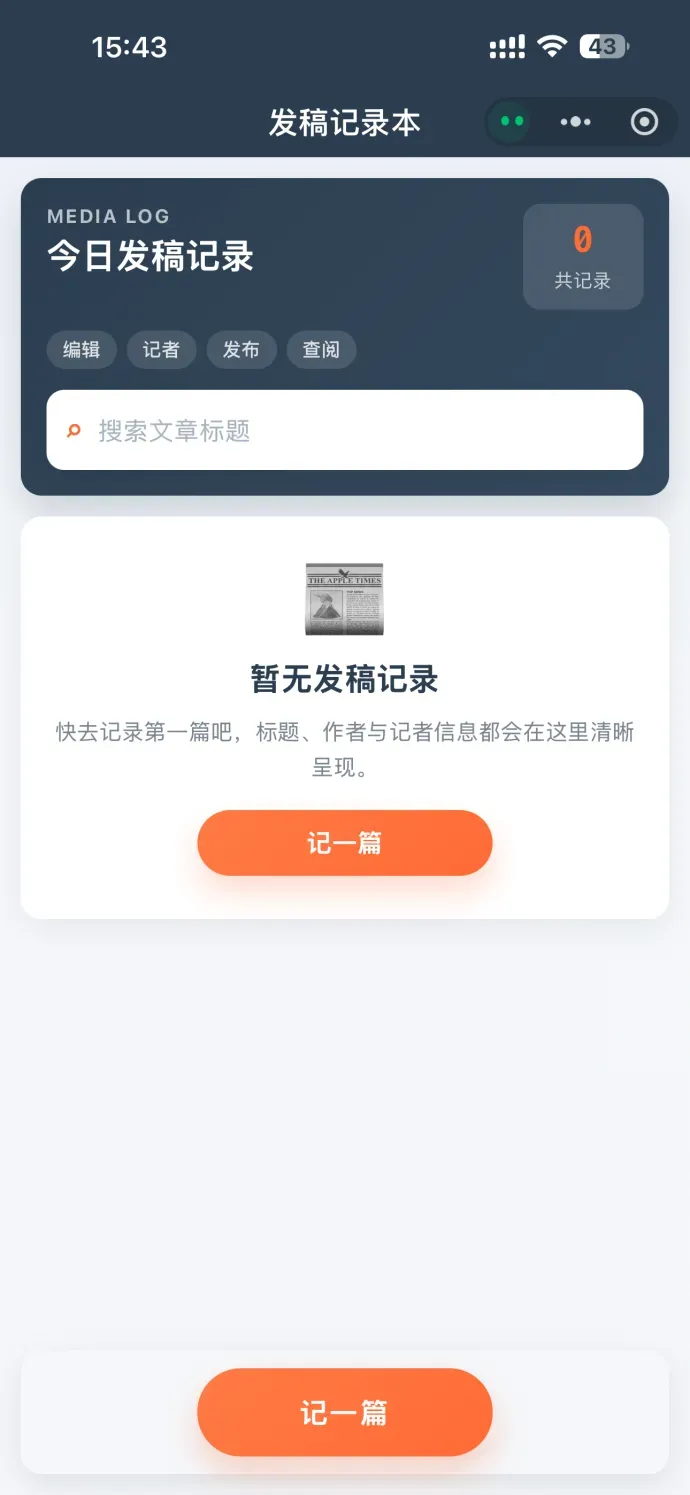
而且还能持续迭代。我创建的记录工具缺了日期功能,于是要求小微加上,它很快便提炼需求并完成了开发。

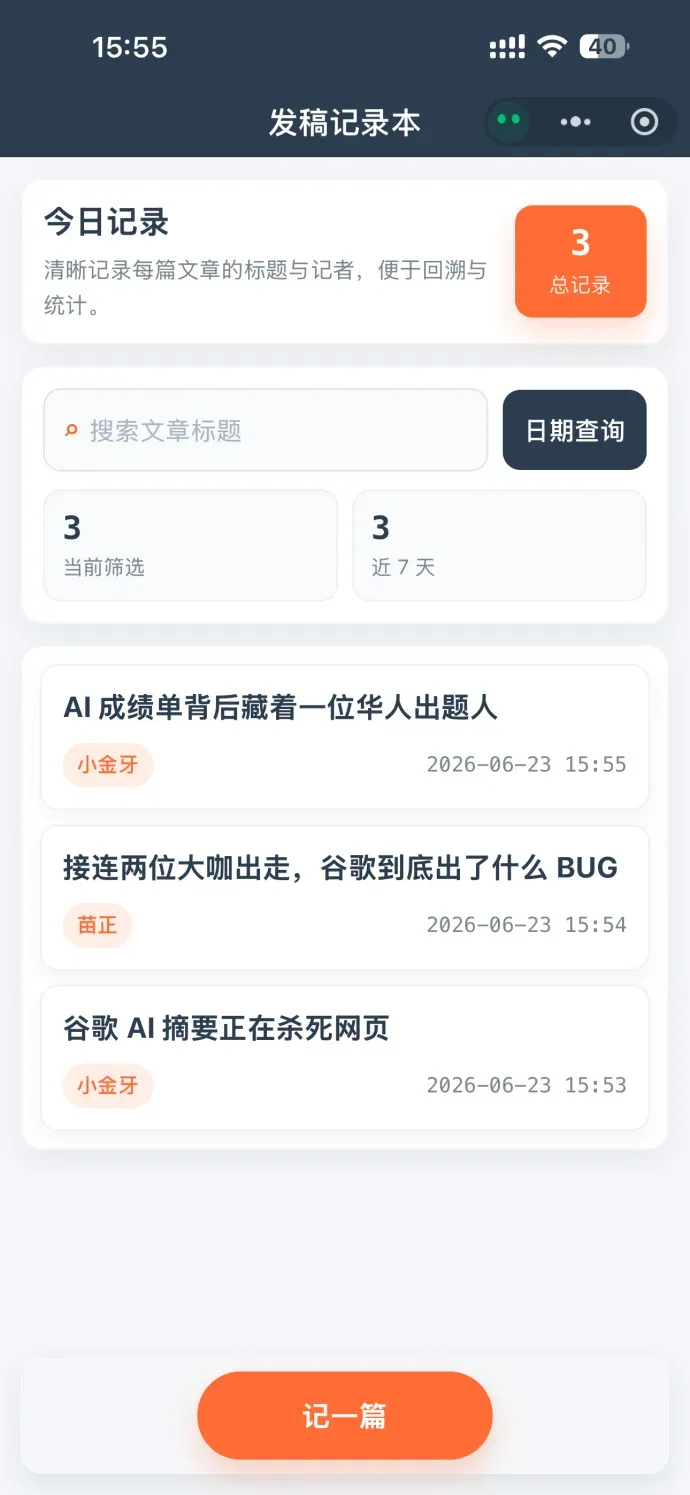
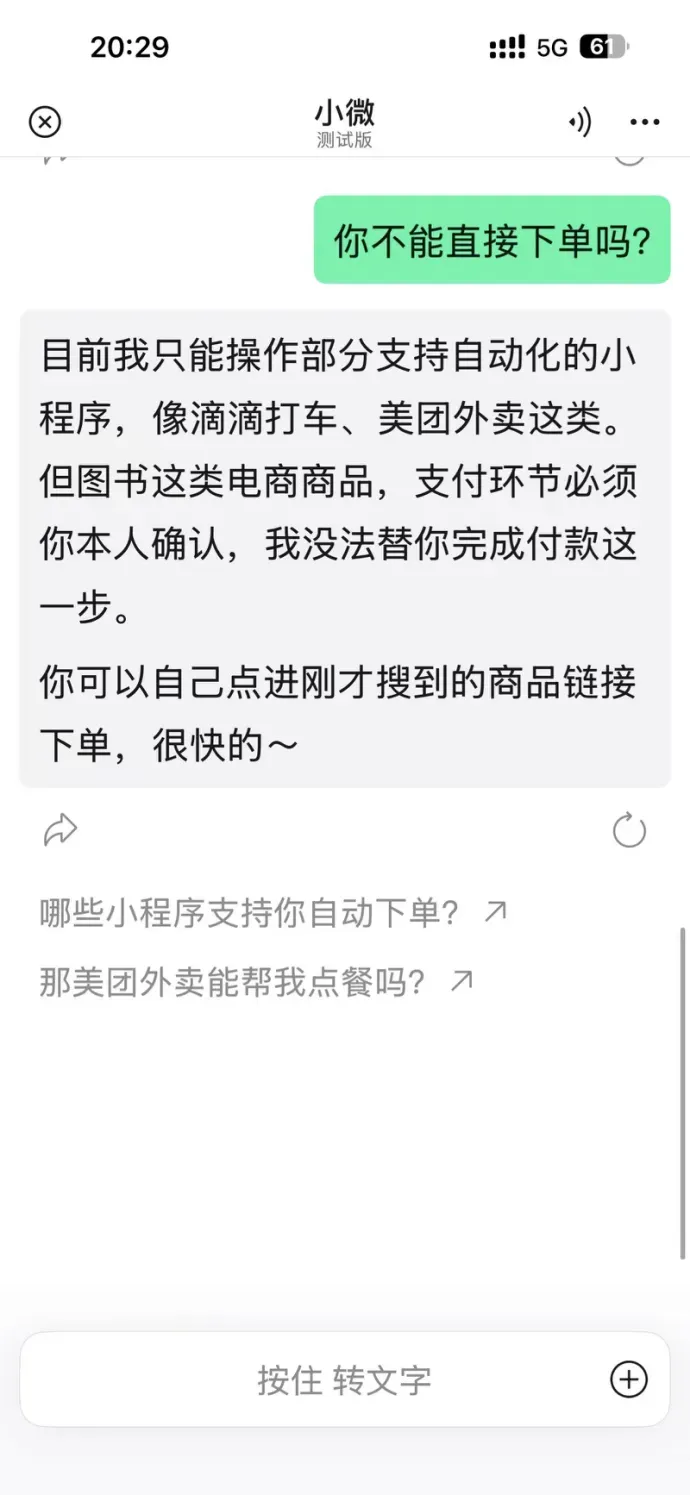
然而轮到微信最核心的聊天能力时,小微却变得格外克制。
就在小微灰度测试前不久,微信团队才更新了 AI 支付 Skills,并开放了支付卡,理论上 AI 可以直接调用卡内余额,避开确认环节。但在小微这里,该功能依然缺席,仍需手动下单。
小红书豪赌世界杯:男性用户涌入背后的增长困局与系统刚性
2026年美加墨世界杯开幕仅三天,小红书就亮出了首份赛事成绩单:直播在线人数较赛前暴涨55倍,直播间累计互动9000万次,观播用户中男性占比首次突破60%,世界杯相关内容总曝光量达到27亿次。一个始终以“年轻女性消费决策社区”为标签的产品,突然迎来用户结构的大幅反转,这件事本身就值得深思。
投入与账本
这轮世界杯入场,小红书下注不轻。据行业估算,版权费用约17亿元,内部人士称实际支出不到10亿,但无论如何,这都创下了公司历史上单次内容投入的最高纪录。一个女性用户占比超七成的社区,为什么要花这么多钱押注世界杯?答案并不复杂:增长焦虑已经到了必须破局的关口。
小红书目前的用户盘子在月活4亿、日活1.7亿的量级,规模不算小。但2023年初内部提出的“3亿DAU”目标,已悄然下调为“冲击2亿”。背后的信号很明确:靠原有的内容生态,已经很难自然催生出下一批高活跃用户。
从用户结构看,2025年男性用户占比已从2018年的18%攀升至约28%,进步不小。可广告收入依然高度聚焦在美妆、服饰、护肤、母婴这些传统女性消费品类,汽车、消费电子、运动装备、金融理财等单用户广告价值更高的品类,品牌方始终没有大规模进场。
更隐秘的压力来自搜索场景的迁移。小红书超过70%的月活用户有搜索行为,“遇事不决小红书”是它商业价值的核心底座。但2026年一季度,豆包、千问等AI原生应用单季新增用户超过1.3亿,部分原本属于小红书的搜索需求,正在不可逆转地向AI工具分流。
三重压力叠加之下,小红书需要一个大型事件来完成三件事:拉男性用户入场、向高客单价广告品类证明平台价值、固守搜索场景的活跃度。在所有IP里,只有世界杯的规模与影响力够得上这个量级。
男性用户涌入之后
开赛前三天的数据证明,世界杯的引流能力毋庸置疑——男性占比突破60%,这是小红书从来没有出现过的用户结构倒转。但更关键的问题是:涌进来的男性用户,能留下来吗?
小红书并非第一次靠大型事件拉动用户增长。2018年冠名《偶像练习生》和《创造101》,用户从5000万翻倍到1亿。那一次增长之所以顺滑,核心原因是新涌入的用户与原有用户画像高度重合——都是年轻女性,都热衷于追星,都会在平台上种草。平台几乎不需要调整内容调性。
世界杯这一次则完全不同。新涌入的是男性,而且是“带着看球目的”而来的用户。小红书的策略是瞄准铁杆球迷与路人之间的那批人——携伴侣观赛的男性、想融入世界杯氛围但又不需要太硬核的泛球迷群体。
这本就是小红书的擅长之处:不跟懂球帝、虎扑比专业深度,而是将所有体育IP转化为“生活方式”。F1在小红书热度最高的内容不是排位赛分析,而是上海站打卡和车手穿搭;露营、飞盘、匹克球的流行,依赖的也不是赛事转播,而是开箱测评和场地打卡。世界杯在小红书上的逻辑理应一致——本质上它不是在转播比赛,而是在转播“现场”。
但这套逻辑在开赛前面向的是“泛足球人群”——那些本来就对足球有兴趣、只是没找到入口的用户。世界杯真正能带来的增量,应该来自那些“从不打开小红书”的男性球迷。这两批人,并不是同一批。
抖音未能拿到版权,这部分用户有可能流向小红书。关键问题在于,这些用户涌入后,信息流里到底会出现什么?是世界杯内容与足球二创,还是看完比赛后第二天首页又回到了美妆与穿搭?
定位塑造的系统刚性
开赛前三日另一个值得单独关注的数据是:世界杯相关搜索量较赛前涨幅超18倍,足球相关内容发布量达到6月初的10倍。热度真实而猛烈。但真正的问题是,推荐算法能不能持续给这批新用户推送他们想看的内容。
小红书的推荐引擎长期训练的数据基础,是女性用户的行为数据——点赞、收藏、搜索、停留时长、互动模式,都是围绕“女性消费决策”场景构建的。当大量男性用户涌入时,算法需要在极短时间内习得全新的行为模式,从零开始识别“男性用户到底想看什么”。
这是实打实的技术难题。推荐系统本质上是一个负反馈放大机制:推送了什么内容,用户有没有互动,互动率高低,反过来决定了下一轮推什么。如果算法为新用户推荐了体育内容,但由于冷启动阶段数据不够精准,推荐准确率偏低,用户互动率不高,算法就会快速衰减这类内容的权重——重新退回到“已经证明有效”的老路径上。
不是平台排斥男性内容,而是系统刚性决定了“新路径”的冷启动成本远高于“老路径”的维持成本。世界杯期间,平台可以用运营手段维持热度——话题页、直播间、人工推荐位。但世界杯只持续39天。39天之后呢?
B站的春晚经历提供了一个参照。2025年春晚,B站直播间观看人数超过1亿,弹幕超过1.2亿。可2025年一季度B站DAU只同比增长了4.2%。事件峰值无法天然沉淀为长期日活,没有被内容生态承接住的新用户,终将离开。而小红书要面对的问题比B站更复杂:B站春晚流失的观众,本来与二次元生态就存在距离,但小红书要留住的,是平台历史上从未真正扎根过的那批人。
一个更小尺度的切片
试举一个更微观的例子。一篇关于打工人如何配置家庭保险的内容,讨论的是保障规划、重疾险选择、常见误区——全然性别中立,既没有从女性视角出发,也没有针对性偏向女性读者。结果这篇内容在小红书收获了8万赞藏,其中九成互动来自女性。
这篇内容在分发过程中被算法“归类”了。系统依据长期训练出的行为模型,把它推荐给了最可能与保险理财内容互动的群体——在小红书上,这个群体主要是女性。于是,即使文章讲的明明是普适性话题,传播结果仍然天然地向女性倾斜。
这不是内容本身的问题,而是系统的“社会性筛选”:推荐算法不做价值判断,它只是忠实地反映平台用户结构下的互动概率分布。它知道“谁更可能跟这类内容互动”,而训练数据,绝大部分来自女性用户的行为。
换一个平台,同一篇打工人的保险内容,分发结果大概率完全不同。在虎扑可能会偏男性,在知乎会更偏理性讨论。内容没变,变的是系统的“用户画像”。
世界杯也是这样。它是一个临时注入的高强度信号,可以在39天内扭曲系统的推荐权重,把信息流的中心从美妆穿搭切换到足球赛事。但比赛结束后,系统很快会回到原有的平衡态。这不是世界杯的问题,而是系统刚性的基本特征。
这个矛盾并非小红书独有
拼多多早期靠“五环外”定位打出来,商品结构和用户心智都围绕“便宜”运转。百亿补贴持续多年,iPhone补贴一补再补,但一二线用户对“拼多多等于假货”的刻板印象至今未能根除。
知乎早期用“高质量问答”筛选出高认知用户。规模扩大后,早期用户出走,大众用户觉得它装。内容质量与用户规模之间的取舍,至今没有标准答案。
B站从二次元起家,破圈的过程里,“B站变味了”这句抱怨几乎贯穿每一次用户增长。
这几个案例的共同点在于:精准定位在早期是增长的助推器,在后期却变成了增长的刹车片。建立系统时形成的“效率优势”,在需要切换系统时,变成了“路径依赖”的惯性成本。精准定位带来的增长红利,大致等于切换定位时需要付出的迁移代价。前期跑得有多快,后期转型就有多重。
世界杯的“账本”该如何计算
回到小红书的当下。39天的世界杯赛程结束后,有三项滞后数据将折射这次押注的真实结果。
第一,赛后30天,新增男性用户的留存率。峰值好看是基本的,次月留存才是真相。
第二,2026年下半年,汽车、消费电子等男性向广告主在平台上的投放规模有没有出现结构性增长。如果用户结构的变化没有转化为广告品类的扩张,对商业化的实质意义就十分有限。
第三,世界杯期间活跃起来的球迷博主与战术分析师,有多少选择在赛后在平台扎根创作。创作者的留存,是用户能否留存的先行指标。
这三个问题如果都能给出正向答案,那就意味着男性用户第一次在小红书走通了完整闭环——进场、留下、找到想看的内容、引来广告主、催生更多创作者。闭环若能在男性用户身上跑通,女装和美妆就不必永远是小她变现的全部。
但如果闭环跑不通,世界杯带来的脉冲流量,就只是一次昂贵的品牌营销。
承认边界,还是突破边界?
查理·芒格曾说过:知道自己不知道什么,比知道自己知道什么更重要。在产品语境下,这句话的意味是:一个团队能够洞察定位的边界所在,并愿意接纳这种边界,本身就是一种认知能力。
不是所有产品的终局都是全民应用。小红书能不能通过世界杯把自己变成“所有人的社区”?如果能,为什么过去十年没有变成?如果不能,为什么这一次就会成功?
明白自己的边界在哪,可能比努力突破边界更重要。
回到那篇打工人买保险的内容:8万赞藏,九成女性。它告诉人们在这片土壤里种什么长得最好,同时也提醒人们这片土壤的边界在哪——哪怕你写的是性别中立的通用内容,分发系统也会帮你完成“筛选”。两者叠加,才构成一个完整的判断。
对小红书来说,道理是一样的。世界杯是一次重要的尝试。但赛事结束之后,它真正需要回答的仍是那个老问题:一个定位精准的产品,究竟应该接受边界,还是应该持续付出高昂的迁移成本去扩张?
这不是仅凭“勇敢”就能解决的问题。但在当下的小红书,或许也是她不得不迈出的一步。
摇一摇广告每年窃取超20亿小时,揭开流量捕猎场的隐秘生意
你大概有过这样的经历:掏出手机打开一个常用APP,开屏广告刚亮起,还没来得及寻找“跳过”按钮,屏幕就瞬间跳转到某个购物平台的限时秒杀页面。退出、返回、重新加载,几秒钟就这样消失了。刚回到首页,打开另一个APP,同样的开屏,同样的跳转,同样的手忙脚乱。你以为是自己手抖,其实早已滑入一个精心设计的流量捕猎场。
2026年6月9日,工信部再次召集企业开会。主题并不新鲜:618即将到来,APP开屏广告的常规作妖又开始了。诱导点击、极高灵敏度的“摇一摇”,让用户还没反应过来,手机已经替他们完成了跳转。会上要求企业自查整改,措辞也越来越严厉——拒不整改的,约谈、通报、下架,三板斧一字排开。
这不是工信部第一次对“摇一摇”动刀。从2023年“不得利用高灵敏度‘摇一摇’”的原则性要求,到2025年对加速度、角度、时间参数的量化规定,再到点名通报和下架警告,监管的拳头一轮重过一轮。但你现在打开几款常用APP,开屏广告跳转的问题解决了吗?大概率没有。问题不在技术做不到,而在于有人不想让它停下。
1. 一场窃取时间的精密生意
先来算一笔账。开屏广告的“摇一摇”跳转,本质上是在你打开APP的最初几秒,利用手机的陀螺仪和加速度计捕捉任何微小动作——抬手、转身、从包里拿出手机——把这些毫无意图的姿态变化“翻译”成用户同意跳转。
究竟有多少时间被这样浪费掉?不同口径的估算差异极大,但即使保守计算也令人心惊。工信部《移动应用生态治理报告》显示,超过72%的手机网民遭遇过非自愿跳转,其中“摇一摇”占比43%。按中国手机网民约11.21亿人计算,至少有8亿人曾被“摇一摇”坑过,而且远不止一次。假设其中一半人每天遭遇一次误跳,每次耗时6.5秒,仅此一项年损失就超过1亿小时。
实际数据只会更高。公开报道显示,部分APP的“摇一摇”触发阈值低至倾斜5度、晃动0.5秒,走路时的自然颠簸都会中招。若按每人每天1.5次、每次8秒估算,年损失超过3亿小时。加上操作中断和情绪耗损等隐性成本,总损失很可能落在5至10亿小时区间;标题中的20亿小时对应的是更高频遭遇模型,这在双11、618等大促期间并不夸张。
这些时间没有为用户创造任何价值,但有人正靠这些“误触”赚得盆满钵满。每一次跳转,无论用户是有意还是无意,都会被广告系统记录为一次有效点击。但在实际交易中,开屏广告的计费远比“点一次付一次钱”复杂。
广告主通常有两种主流模式可选:CPM(按千次展示付费)和CPC(按点击付费)。CPM是开屏广告的传统方式,静态图片千次展示均价在30至50元,视频则在60至100元,此时用户是否跳转并不直接影响单次收入,但跳转率越高,广告主越愿意在下一轮竞拍中加价,间接推高整体收益。CPC则更直接:用户每跳转一次,广告主就付一次钱。具体单价取决于APP类型——工具类应用的用户点击意图常被判定为低价值,单价偏低;电商类则偏高——还取决于广告主所在行业(游戏、金融、电商出价最猛)和投放时段(大促期间单价翻倍)。以某头部广告联盟公开竞价数据为例,开屏广告CPC底价可低至0.1元用于促活,而热门电商大促期间的实时竞价中,单价突破2元也屡见不鲜。
于是可以算一笔现实账:一款日活百万的APP,若全部采用CPC计费(按每次0.8元、人均误触0.5次/天),单日收入约40万元;若采用CPM计费(eCPM 50元),单日收入约5万元。两者相差8倍。多数APP混合使用两种模式,最终单日收入落在数万到数十万元之间——这就解释了为什么开发者宁可得罪用户,也不愿关闭那行代码。
广告主愿意为这些误触买单,原因也很简单——便宜。某头部电商的内部数据显示,通过跳转广告获取的新客成本比传统信息流广告低了67%。低成本的秘密就是:它把用户被迫的误操作算作了自己的营销成果。
这套误触变现的生意,养活了链条上的三方玩家。第一是APP开发者,他们是广告位的提供者,也是直接的变现方,无论“摇一摇”开屏还是伪装成系统通知的弹窗,本质都是将用户的“不小心”转化为可量化的收入。第二是广告联盟,这才是真正的操盘手。腾讯优量汇、百青藤等头部联盟通过SDK工具包嵌入成千上万款APP,远程控制广告展现方式、跳转逻辑和触发阈值——为什么小角度倾斜就会触发“摇一摇”?为什么关闭按钮总要延迟几秒才出现?答案都藏在SDK的参数设置里,大多数用户对此毫不知情。第三是广告主,主要是电商平台。微博2025年第二季度财报显示,广告收入占其总营收的86%,其中来自阿里巴巴的广告贡献了约9.3%的总营收,且同比增速达10%,成为618期间拉动微博广告增长的关键引擎——你打开微博还没看到微博,先进了淘宝,这早已不是段子,而是写在财报里的商业现实。
一条完整的变现闭环由此形成:平台卖广告位,联盟调参数,电商掏钱买单,而用户的时间是这个闭环里唯一的“原材料”。更讽刺的是,很多APP还在玩二次收割:百度网盘客服明确表示“暂不支持取消广告,会员也没有除去广告权益”;美图秀秀则更直白:“关闭后将限制APP展示开屏摇一摇广告,但不会减少开屏广告的数量。”
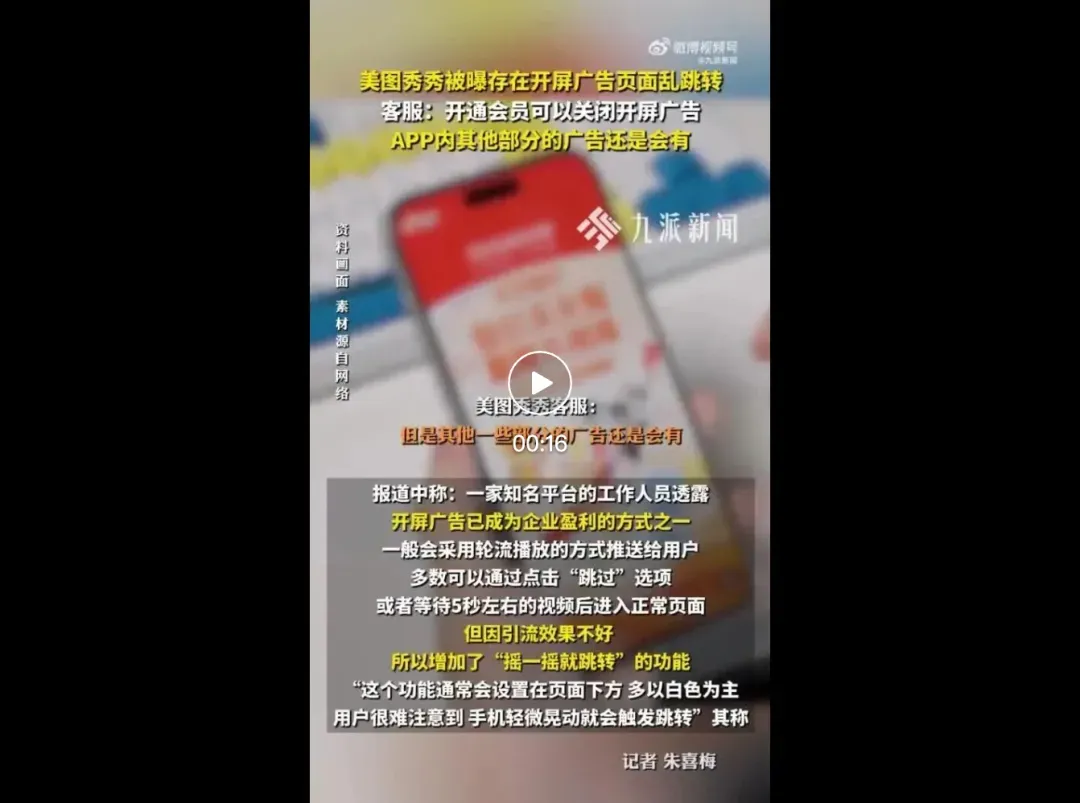
翻译过来就是:花钱开了会员,只是从“摇一摇”变成了“点跳过”。广告还在,只是换了个姿势。
2. 监管与逐利的猫鼠游戏
围绕“摇一摇”的攻防,至少已经打了三轮。第一轮是监管立规矩:2023年初,工信部发文要求“不得利用高灵敏度‘摇一摇’等易造成误触发的方式诱导用户操作”。第二轮是定标准:2025年,信通院联合电信终端产业协会发布规范,给出量化要求——触发加速度不小于15米每平方秒,转动角度不小于35度,操作时间不少于3秒。翻译成大白话就是:手机得先被猛烈晃起(加速度够大),再转过不小的角度(角度足),还得持续一小会儿(时间够长),才算一次有效摇动,同时要求APP必须明示跳转后果。第三轮则是在大促期间高压管控:2026年5月,工信部通报31款APP及SDK存在侵害用户权益行为,其中7款涉及乱跳转;6月9日再次开会,明确表态将采取约谈、通报、下架的阶梯式措施。
纸面上标准越来越细,通报频率越来越高,但打开手机,开屏广告该跳还是跳。原因在于这是一场典型的不对称战争:监管只能抽查,而开发者可以随时动态调整。风头紧时把触发阈值调回合规水平,风头一过,立刻恢复到“5度就跳”。更隐蔽的做法是设置AB测试,对一部分用户展示高灵敏度广告,监控投诉率和卸载率,只要负面反馈没超过某个阈值,就继续加码。这不是技术问题,而是成本问题:禁止跳转只需改动一行代码,但这一行代码的改动可能意味着每天数万元的收入蒸发。当一项操作的代价是实实在在的现金流时,“用户体验”四个字的优先级自然会排到后面。
法律的约束力同样有限。《广告法》第四十四条第二款明确规定:“利用互联网发布、发送广告,不得影响用户正常使用网络。在互联网页面以弹出等形式发布的广告,应当显著标明关闭标志,确保一键关闭。”2023年施行的《互联网广告管理办法》更将开屏广告纳入弹出广告管理范畴。但法律专家岳屾山指出,“摇一摇”跳转的本质,是将用户的非自愿动作“翻译”为同意,这严重违背用户意愿,问题在于举证责任落在用户身上——你如何证明自己只是拿起手机打开APP,而不是“想”打开那个广告?更关键的是违规成本太低。一款APP靠“摇一摇”日入数万元,即便被通报批评,不过发个整改声明,过段时间换个马甲卷土重来。没有集体诉讼,没有天价罚单,几十万的罚款对一条日入数万的变现渠道来说,不过是做生意的“合规成本”。
中国政法大学传播法研究中心副主任朱巍的判断更为直白:“摇一摇”广告本身不违法,但“利用技术手段在不经过用户同意的情况下诱导跳转”就必须纳入规制。难题在于,从“诱导”到“误导”的界限,至今没有清晰的司法界定。
监管受限的同时,广告主也并不糊涂。按照CPC模式,广告主只为“有效点击”付费,每跳转一次便支付一次费用。这套本为精准而设的规则,却给开发者留了一道后门:误触摇身一变成了“有效点击”。广告系统里点击量扶摇直上,开发者赚得痛快,但广告主要的却是真正的潜在客户,不是被弹窗惹毛后秒关页面的路人。行业数据显示,摇一摇广告的日均曝光约4亿次,点击率高达8%,远超正常开屏广告1%-2%的水平,然而其中约80%是误触,用户跳转后平均停留时间不足3秒,转化率几乎可以忽略不计。广告主花大价钱买来的,不过是一堆毫无商业价值的无效流量。
用户也没有坐以待毙,越来越多的普通人在网上分享反制教程:关闭运动传感器权限、使用应用锁、VPN拦截广告请求,乃至直接卸载APP。部分手机厂商也顺势而为,在系统中内置智能广告过滤服务。2026年主流国产手机均已支持对“访问设备动作与方向”权限的精细化管理,实测关闭后摇一摇广告触发率降至0%。供需两端一齐转冷的直接后果,是产业链出现断裂。少数还在硬撑的APP多为中小购物或工具类产品,广告主也试图转向更温和的交互形式(如滑动、点击),但整体ROI已大不如前。数据印证了这一趋势:2026年大促节点摇一摇广告投放量较2023年高峰期下降超80%。业内人士的总结更加直白:摇一摇时代结束了,现在投这个等于烧钱换骂。
但别高兴得太早。投放量下降,不意味着用户体验真的变好。还在投放的那些,往往把灵敏度调得更高、跳转路径设得更隐蔽。用户损失的效率究竟下降了多少,恐怕只有最乐观的评估者才会给出一张漂亮答卷。
真正的转折点,可能来自另一个方向。
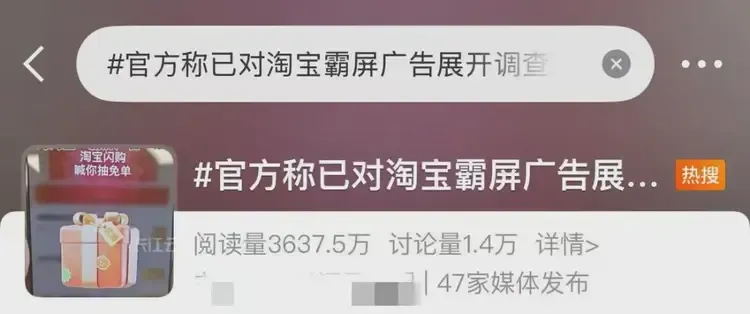
2025年11月,杭州市余杭区市场监管局对淘宝的霸屏广告正式启动调查。这不是工信部的约谈,而是市场监管部门的执法行动。2026年6月9日,工信部再次对全行业“摇一摇”乱象召开专题会议,要求企业自查整改。从地方执法的个案启动,到国家部委的全行业出手,监管正在尝试挥出更硬的拳头。
3. 结语:停止偷时间的利润链
工信部六年约谈五十余次,标准从定性到定量,通报从点名到警告,但“摇一摇”至今仍是APP的标配。为什么?答案很简单——改一行代码容易,放弃每天数万元的收入太难。这不是技术问题,是利益问题。每一次误触跳转,都在为APP开发者和广告联盟创造真金白银,而代价是用户的时间、耐心和对手机的信任,被精准地排除在财报之外。“摇一摇”或许还会继续偷走你的时间,不是因为你手抖,而是因为有人不想让你停下来。
一行命令本地部署GLM-5.2:在Blackwell GPU上零成本跑753B MoE大模型
在终端输入 vllm serve nvidia/GLM-5.2-NVFP4,一台装有 Blackwell 架构的机器就能将总参数达 753B 的 MoE 模型以兼容 OpenAI 的接口启动,无需任何云服务开销。
技术剖析:一行命令的底层支柱
vLLM 是一个源自加州大学伯克利分校 Sky Computing Lab 的开源推理框架,在 GitHub 上已收获 84.5k 星标。它通过 PagedAttention 和连续批处理技术将吞吐量提升到新的数量级。更重要的是,它对各类量化格式兼容并蓄:FP8、MXFP4、NVFP4、INT8、INT4、GPTQ/AWQ、GGUF……支持超过 200 种模型架构,即拿即用。
6 月下旬,NVIDIA 在 Hugging Face 正式发布 nvidia/GLM-5.2-NVFP4。该权重采用 Model‑Optimizer 工具对智谱 GLM‑5.2 进行 4 比特量化,并专门针对 Blackwell 架构 GPU 优化。与 FP8 格式相比,NVFP4 进一步压缩了显存占用,而在编程、推理以及百万 token 长上下文任务上的精度并未出现明显下滑。
智谱 GLM‑5.2 本身采用 MoE(混合专家)架构。公开数据显示其总参数达 753B,每次推理仅激活部分专家,实际激活的参数量远低于此。配合百万 token 的无损上下文窗口,官方在 Artificial Analysis 综合评测中取得 51 分,与 Anthropic、OpenAI 的旗舰模型并驾齐驱,并在编程能力上被贴上了“开源 SOTA”的标签。
采用 MIT 许可证,无论商用还是非商用部署,全球均无限制。
将这三者叠加——开源推理框架 vLLM、开源模型 GLM‑5.2 以及 NVIDIA 提供的硬件优化权重——最终用户获得的正是一个可离线运行、兼容 OpenAI API、无需云端的本地私有推理环境。
扎克伯格AI冒進引爆Meta內亂:員工怒吼「當狗用」、首席產品官飆髒話,燒千億豪賭重演元宇宙慘劇
「真正的商戰樸實無華」,正在發生的商業史也如此殘酷。這家全球科技巨頭,人類數位世界排名前七的企業,內部不滿正以最粗野的方式爆發——一場有數千名員工參加的視訊會議上,Meta員工直接打斷發言,指著主管鼻子開罵:「公司把我們當狗用」(Being the company’s b*tch)。毫無包裝,毫不高端。這就是被AI狂熱攪得亂成一團的Meta。
據《連線》雜誌近日披露,六月初這場大型內部會議剛開場,一名與會者突然情緒失控,頻頻爆粗中斷同事發言,甚至要求現場所有人將自己對某位AI高層的批評書面轉達,措辭是「那個混球」(A Piece Of Sh*t)。目擊者說,現場有人窘迫到掩面,組織者最後不得不強制全場靜音。昔日的社交媒體霸主、扎克伯格這位千禧世代的互聯網巨頭,在優勢不再遙遙領先之後,開始陷入一個反覆上演的循環:老闆壓上全部身家豪賭新賽道,企圖破局;然後項目因各種原因卡關,公司和員工一起為這場孤注一擲買單。元宇宙如此,如今的AI也正在這條軌跡上狂奔。
從首席產品官到基層,Meta人都在為AI集體爆粗
幾千人會議上的公開辱罵,說明基層的離心力已經掩蓋不住。更早之前,裁員與新設「應用AI部門」引發的強制調崗,讓員工覺得自己被當成低階苦力:日常工作就是給AI出題、判卷,做機械式的基礎訓練。有被強制調入的員工向媒體描述這段經歷時,口吻像極了冤案當事人:「那個部門根本就是古拉格,一被關進去,人生目標瞬間消失。幾乎無法跟任何人交流,每週只是麻木地交差。」「工作簡單枯燥得要命,所有人都在抑鬱。」「大多數同事在那裡覺得靈魂被摧殘,快要窒息。」
這股怨氣也燒進高層。Meta首席產品官克里斯·考克斯在Instagram部門的內部會議上,直言公司過去幾個月「搞AI的瘋勁」讓工作環境變得「艱難而殘酷」。講到激動處,考克斯同樣頻繁爆粗:「公司這他媽是怎麼回事?」(It’s like what the f*ck)。他還用陰陽怪氣的比喻形容現狀:「現在的工作就像在冰雹中跑馬拉松,跑著跑著發現隊友被換掉了,領隊還記錄你的每個動作拿去教機器人。在這種環境下,Instagram團隊還能定期給20億用戶更新服務,真的非常不容易。」對於AI大計,考克斯坦承他與部分高層和大老闆看法不同:公司戰略需要腳踏實地,少弄虛的,AI的威力「並不特別激動人心」。「AI既不是上帝也不是魔鬼,而且遠沒有大家以為的那麼厲害。AI的確日新月異,但AI根本不知道今天幾月幾號。」
扎克伯格認錯縮手,員工可申請不被「蒸餾」
組織行為學有個基礎規律:一個業務單位若失能人數超過三成,組織便無法正常運轉。Meta五月底裁掉10%的原有員額,新成立的應用AI部門強制調入的人數也大致相當,等於把近兩成原有員工填進AI的坑。當大群基層公開宣稱自己服的是「古拉格式苦役」時,扎克伯格也不得不放軟身段,承認自己可能錯了。
在一份被路透社曝光的內部備忘錄中,扎克伯格說:「考量到最近一連串舉措的複雜背景與結果,公司決策層確實犯了很多錯誤,未來恐怕還會繼續。」針對各種為AI繼續大裁員、擴大拉伕的傳聞,他也暗示可能縮編AI部門:「時勢以我們無法掌控的節奏變化,我不想過早給出確定承諾……不過若某些部門或團隊犯了錯,公司可以縮減其規模,在其他部門開新職位,把一些員工調回去。」
為了安撫「扎男的嘴,騙人的鬼」這類質疑,Meta已開始收縮激進措施,首當其衝的就是最引人詬病的「蒸餾員工」。六月初,公司宣布縮減記錄員工滑鼠移動、鍵盤輸入以及其他行為數據用以訓練AI的計畫。反對該計畫的員工公開信已有超過1600人聯署,Meta順勢宣布員工可申請豁免參與,即便未申請,也會增加控制選項,允許每次最長30分鐘暫停數據採集。開發監控軟體的團隊還承諾引進多項優化,以降低對員工電腦電池續航的影響。
大模型界的阿森納,連第四都爭不到
扎克伯格為何如此焦慮?不難理解。Meta的Llama曾是開源大模型的巔峰,但如今按活躍度與流量統計,AI產品的熱度前三已被OpenAI、Anthropic與谷歌牢牢佔據,是無可爭議的御三家。商學院課堂上的「波士頓三四定律」說得很清楚:穩定競爭中,市佔超過15%的領先巨頭不超過三個。即便勉強擠出「御三家有四號」的俗諺,眼下最有機會搶第四把交椅的,在技術面與熱度上,也是DeepSeek或Perplexity。作為曾經開源AI界的制霸巨頭,Meta如今爭第四的希望都很渺茫。
越急越難出活。六月初,Meta的Muse Spark傳出跳票消息。四月剛公布時,負責該業務的Alex Wang宣稱模型API「即將推出」,但到了六月對外詢問,Meta仍在說正與合作夥伴測試,計畫本月發布。據《華爾街日報》消息,時程從四月推遲到五月,是因為測試中發現漏洞,且基礎設施跟不上,需要繼續構建。
屋漏偏逢連夜雨,需要趕工之際,Meta卻宣布限制員工Token用量。上週資訊媒體披露,Meta內部備忘錄指出,將限制員工的token消耗,以遏制內部AI工具成本爆增。備忘錄引用員工自行開發的排行榜「Claude經濟學」,稱過去約30天內累計消耗73.7兆tokens,用量呈指數級增長,成本恐將超過數十億美元。為此Meta將推出內部平台AI Gateway,即時追蹤各小組用量並自動告警,同時鼓勵員工改用自家AI編程助手Devmate,並計畫在2027年導入更系統化的成本管理,包括嚴格預算與資源分配。
AI飾品:越賣越虧、隱私糾紛纏身,難成破局利器
為了幫AI業務突圍,Meta絞盡腦汁。大模型受挫,就抄可穿戴裝置的曲徑。六月初,負責可穿戴設備的副總裁Alex Himel的內部備忘錄外流,內容顯示:2026下半年將推出四款新AI眼鏡,代號分別是Modelo、Luna、RBM2 Refresh與Mojito VIP;目標是下半年賣出1000萬台可穿戴裝置,月活躍用戶推高至680萬;同時研發代號「Artemis」和「SSG」的超感知眼鏡原型機,並準備推出面向企業的訂閱服務「Wearables for Work」,2027年春季還將啟動全新AI吊墜的內部測試。
從公開財報看,Meta與雷朋合作的AI眼鏡,2025年日活用戶年增三倍,銷量年增超過200%,全年售出逾700萬副,拿下全球智能眼鏡市場約82%的份額。好不容易在可穿戴裝置出頭,Meta自然想善用這個優勢,甚至計畫在眼鏡上跑Muse Spark模型,並配備開發中的消費級AI智能體「Hatch」。然而這條小路能否變成AI手機那樣的消費級入口,說不準。
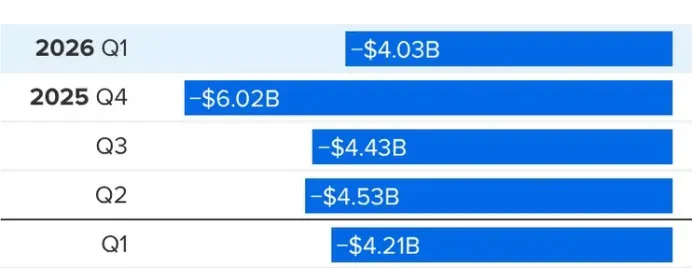
先不說Muse Spark跳票,光是眼鏡就陷入「賣得越多、虧得越慘」的尷尬。2026年第一季財報顯示,負責該業務的Reality Labs部門營收4.02億美元,卻虧損40.3億美元,等於賣一塊錢要賠十塊本。更慘的是,2025年第三季尚未開賣眼鏡時,虧損為44.3億美元,第四季眼鏡開賣後,虧損竟一舉跳到60.2億美元。
就算Meta體量再大,也難以承受新業務如此燒錢,何況AI眼鏡的隱私爭議從來沒停過。2025年十月,Meta更新隱私政策,宣布將利用眼鏡的AI語音和圖像分析等數據構建更詳細的用戶畫像,以便在Facebook、Instagram上推送更精準的廣告。也就是說,「AI給鋼鐵人頭顯彈出廣告」的笑話,被Meta實現了。2026年三月,多名肯亞數據標註員爆料,他們的外包工作內容包含處理雷朋Meta眼鏡用戶的各種私密畫面——眼鏡被語音喚醒答問時,現場即時捕捉的影像會傳給外包人員,內容包括如廁、行房、身體暴露、ATM操作時銀行卡號密碼等。用肯亞老哥的話說:「如果用戶知道自己被錄下了什麼,絕對不敢再用這個眼鏡。」而六月初又爆出有人改造眼鏡、移除拍攝提示燈,這項服務已出現在美國30個州。
一家超級大廠做AI,做到員工罵娘、老闆罪己、軟體跳票、硬體巨虧,Meta的這條AI之路,讓旁觀者都只剩下唏噓。