LibTV 3D导演台实测:从站位混乱到精准调度,AI短剧拍摄的全新解法
LibTV 近日更新了3D导演台功能,于是我们邀请几位艺人到“冷同学的院子”拍了一部短剧,下面先看一分钟正片。
此前,已经为民宿品牌“冷同学的院子”制作了视觉方案,其中两个场景极具记忆点:青石板、绿树与门头构成的院落入口,以及原木风格的植物餐厅。

这一次,直接将这些场景转化成片场。一张场景图,在导演台中变成了可以自由调度人物、机位、走位并串联连续剧情的AI片场。

这就是LibTV导演台最吸引人的地方。

一手实测:导演台的底层逻辑
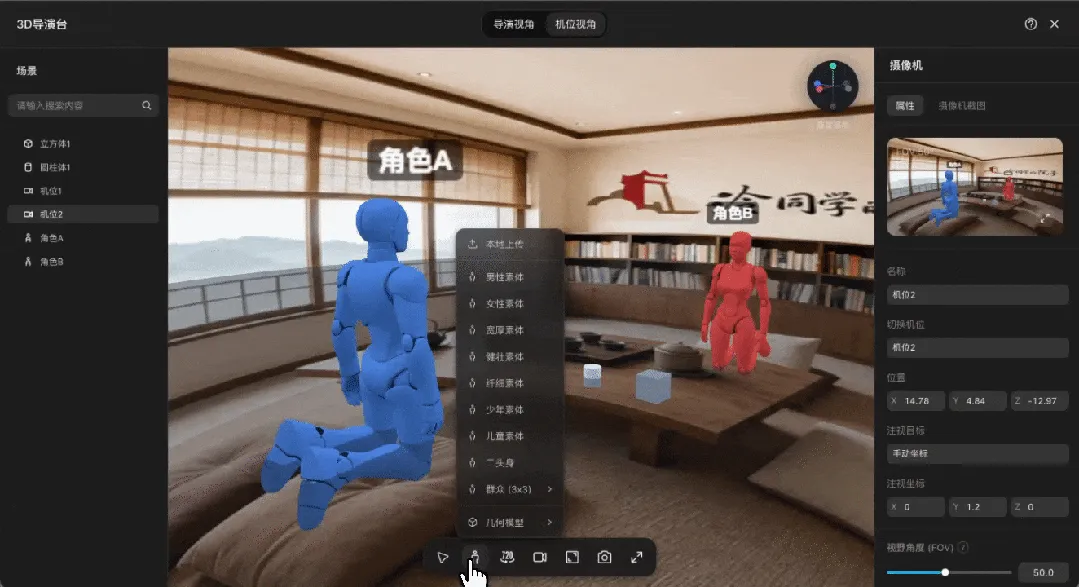
导演台可以理解为LibTV的轻量级3D构图节点,它解决的是AI视频中最难说清楚的空间关系、人物站位和镜头角度问题。
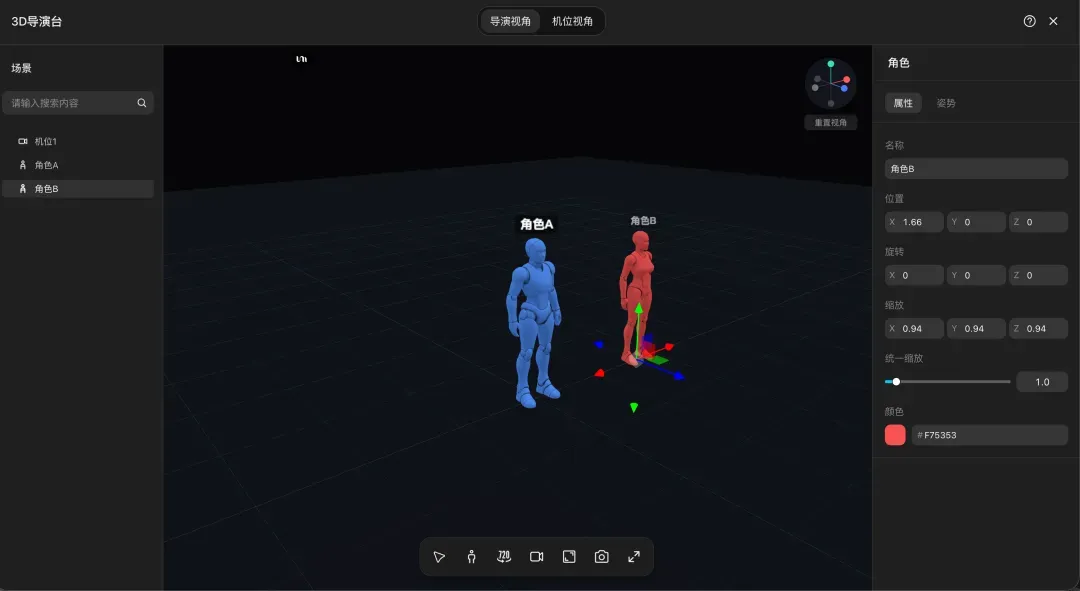
以往写提示词时,经常出现“男主从画面右侧走入”却从中间冒出来,或者两人在长桌边擦肩而过时与桌子关系错乱的情况,想接第二段剧情,场景又仿佛换了地方。导演台的逻辑更接近真正的影视拍摄:先搭建空间,再让模型生成内容。
具体操作也非常直观。
在LibTV画布空白处双击,新建“导演台”节点,点击进入3D空间。内部可以添加人体素模、基础几何模型、群众阵列,也可以上传自己的角色和道具。左侧栏管理元素清单,支持删除、重命名、打组、隐藏;右侧栏负责场景、角色、元素、摄像机的精细化调整,角色姿势、元素颜色均可调节。
调度时,平移使用V键,旋转使用R键,缩放使用S键,按住Shift可等比缩放。
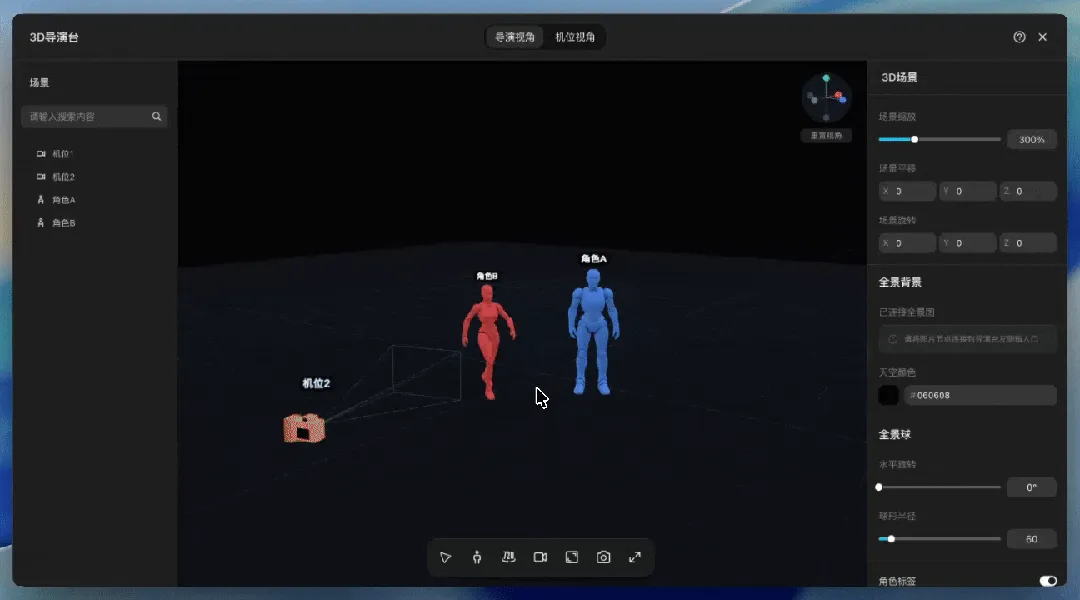
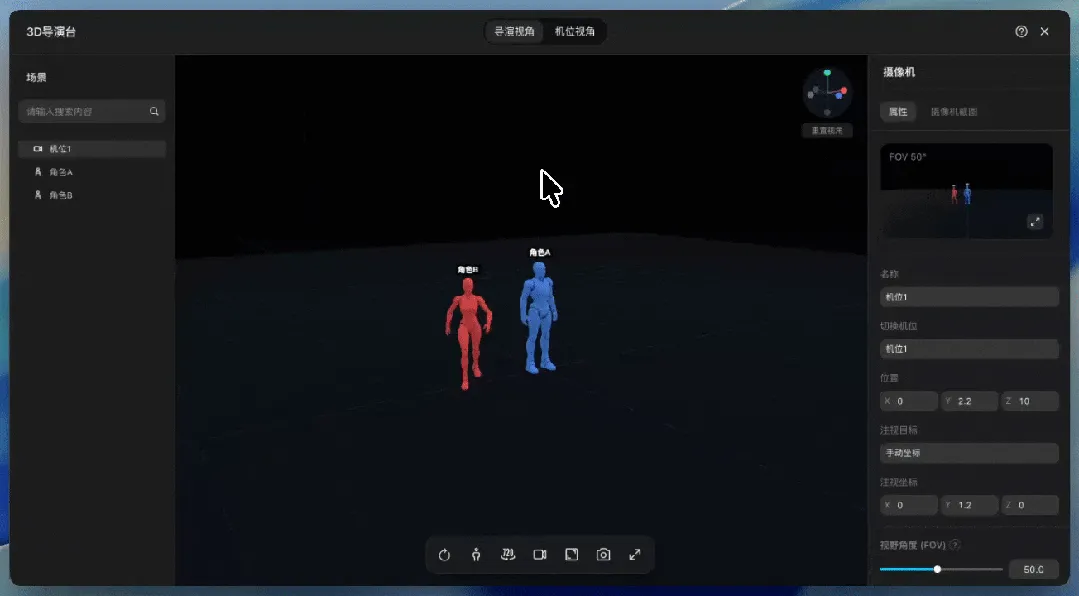
相机部分是关键:导演视角下自由寻找角度,一键新增拍摄机位,再切换到机位视角预览;FOV可调,截图比例也能选。确认后,截图直接发送回画布,作为后续视频生成的参考图。这套流程看似多了一步,但在实际生成时,能够大幅减少不确定性。
素材准备:人物、场景与定帧
本次素材准备分为三层。
第一层是人物。女主是工作室的老演员,性格活泼,为她制作了全套人物三视图和面部细节图,这些也能沉淀为后续持续使用的资产。

男主“冷总”则是霸道登场的人物设定,一身黑西装,步伐稳健,表情冷峻,气质贴合“冷同学的院子”外冷内热的感觉。

第二层是场景。利用LibTV自带的全景图能力,将原先的普通场景图转换成720°全景图。
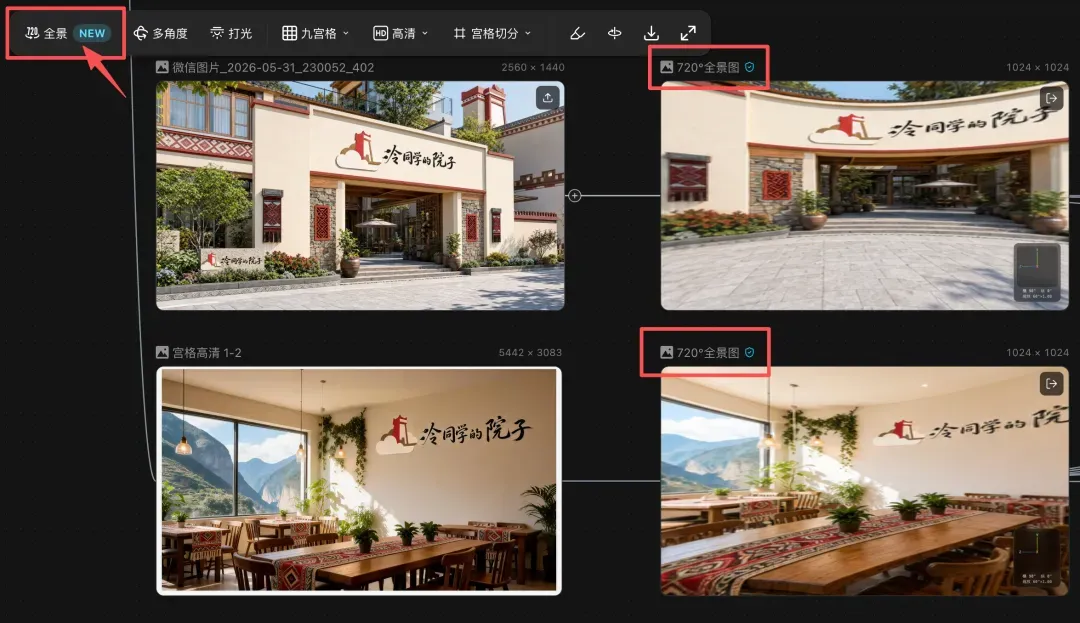
这一步很关键。普通图片只有一个平面,AI很难理解门头、广场、桌子、通道、窗户与植物之间的空间位置关系;全景图则把场地“展开”,让人物进场、镜头转向、前后景关系都更容易控制。随后,分别将院子入口和原木植物餐厅导入导演台。
第三层是定帧。这次设计了多段剧情。
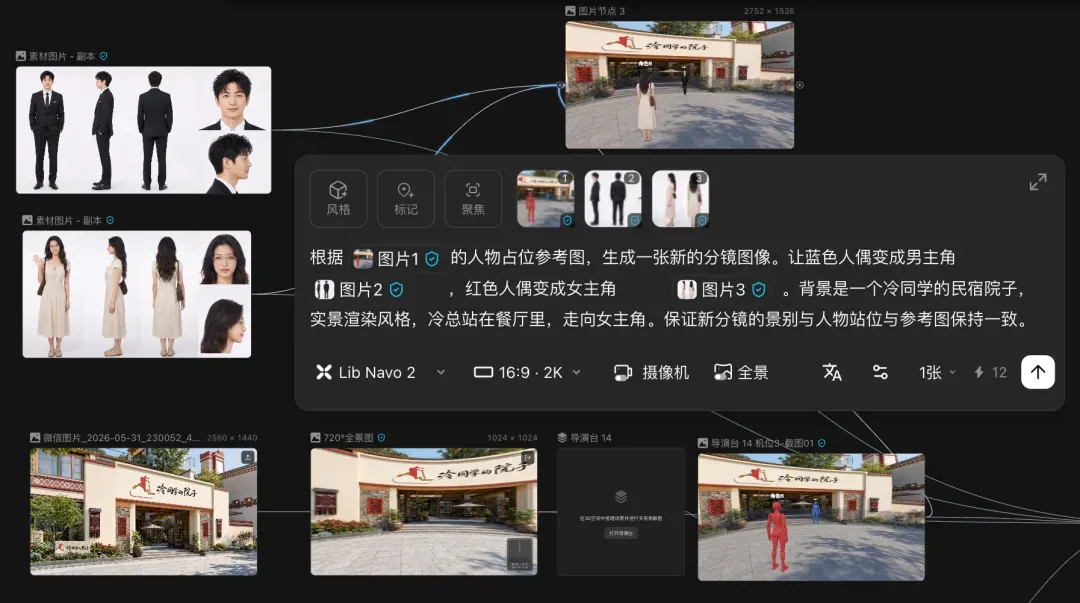
第一幕发生在院子入口。将女主放置在红位:背着小包,站在青石板广场上;男主在蓝位:画面招牌下方。
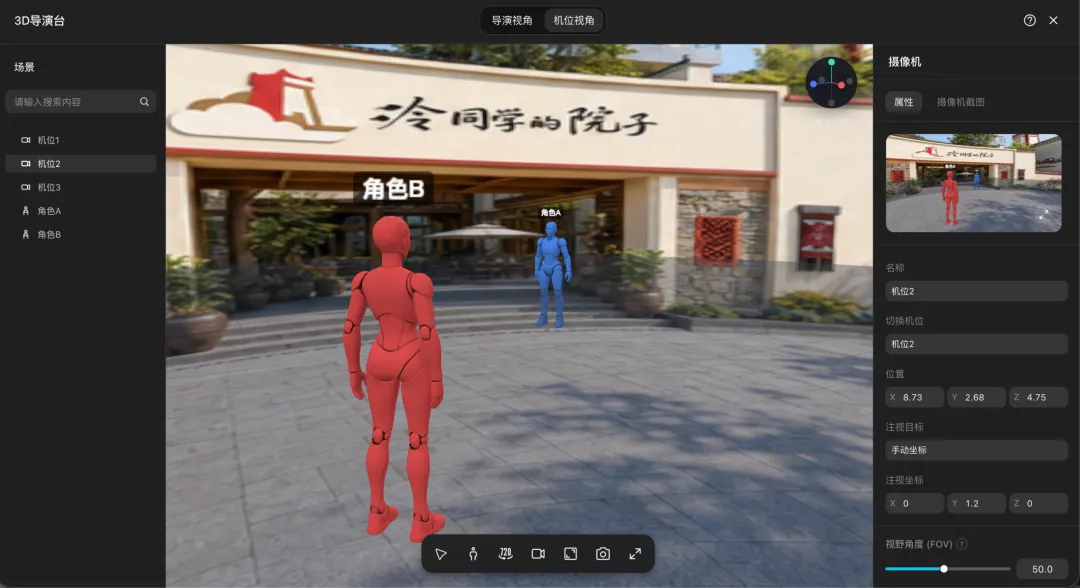
这组定帧的重点是关系清晰:女主首次抵达,男主早已等在院中。青石板、绿树、门头与前后关系,瞬间把“私家小院”和“有人等待”的氛围固定下来。
将截图发回LibTV画布后,基于这些素材创作了一段剧本:
短剧脚本:《盛夏的院子》
场景设定:白天,阳光明媚。“冷同学的院子”大门外广场
人物设定:
男主:一身笔挺黑色西装,气质沉稳,眼神宠溺。
女主:米色连衣裙,戴眼镜,长卷发,清新活泼。
第一幕:反差初见 (00:00 - 00:15)
【画面提示】 远景切中景。画面完美还原占位:女主在画面前景(红位)背对镜头,男主在大门正下方(蓝位)面朝女主。
[00:00 - 00:05] 动作/空镜:阳光洒在青石板上。女主背着小包停下脚步,仰头看门头“冷同学的院子”招牌,嘴角轻笑。画面前方,男主单手插兜,已静静等候。
[00:05 - 00:08] 动作:女主挥了挥手,步履轻快地朝男主走去。
[00:08 - 00:15] 台词: 女主:(打趣地笑,边走边说) “堂堂冷大总裁,周末回自己的私家院子,居然还穿着这么严肃的西装?这和‘冷同学’的招牌可不太搭哦。”
然后便可以生成参考图与视频内容。
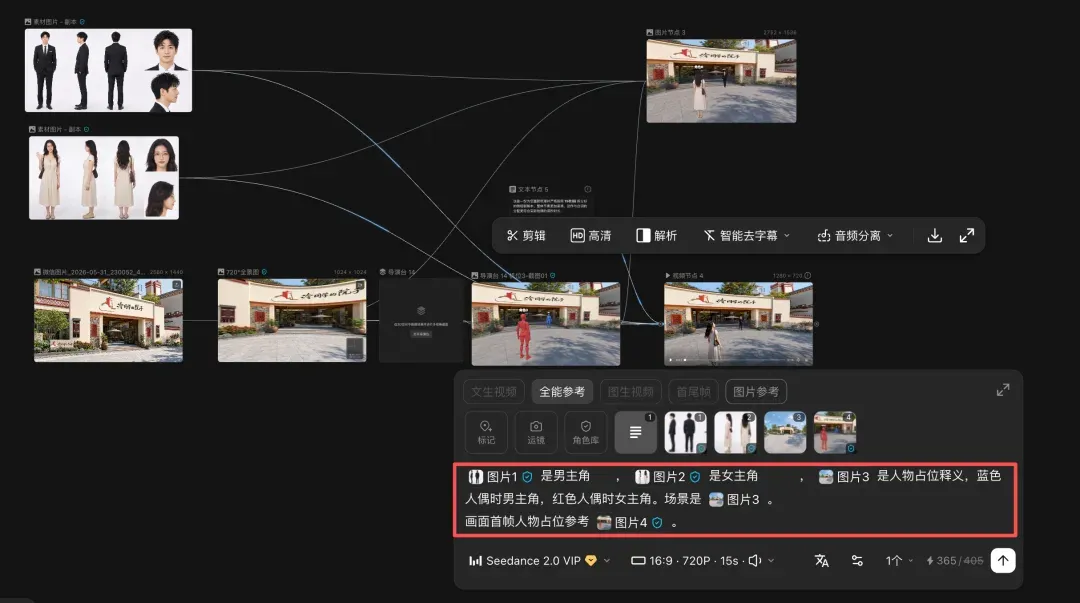
导演台更新后,参考图的灵活度大幅提升,无论想要坐着还是站着,甚至在桌上摆放杯子、盒子,都可以实现。场景、视角、人物和道具一下子变得灵活多变。
随后,继续基于导演台完成了短剧的另外几幕。
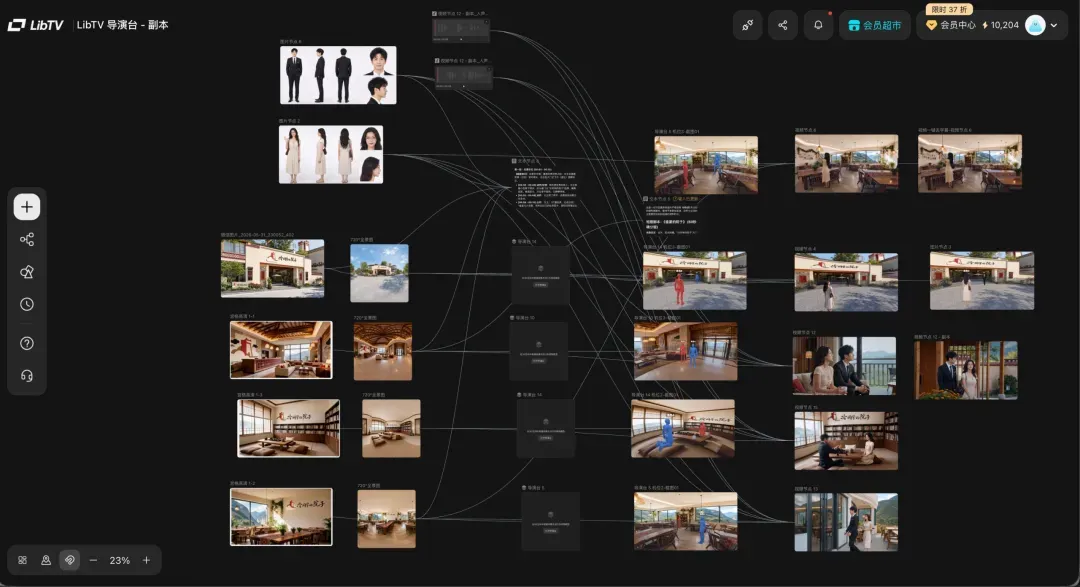
参考内容里,除了导演台截图、人物、场景,还可以加入人物的音色,使得音色统一性问题也一并解决。
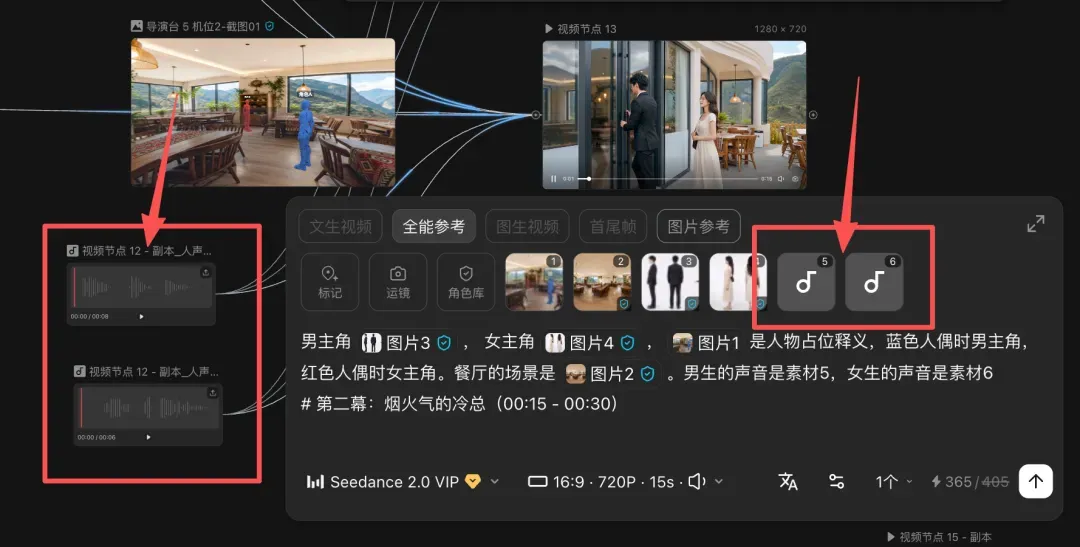
素材一多,难免眼花缭乱。这时可以将素材分类打组,并支持分类拖拽和命名,例如按人物、场景、视频等分类管理。
LiteParse 开源本地PDF解析:轻量高效,为Agent量身打造的文档解析工具
把一份 PDF 丢给智能体去读,听起来只是个小需求。
但真正动手实现时,往往会在两处卡住:要么依赖云端解析服务,文档必须传出去;要么自己用 PyMuPDF、pdfplumber 和 OCR 搭一套流程,虽然跑得通,后续维护却相当琐碎。
LlamaIndex 团队最近开源了 LiteParse,它的定位正正好好落在中间地带。

它并不是 LlamaParse 的本地替代品。
更准确地说,LiteParse 是一款本地优先、速度优先、尽量压低依赖负担的文档解析工具。它适合轻量级的 PDF 解析场景,也适合为智能体准备可读的文本、坐标信息和页面截图。

不过对于复杂文档,暂时不要急着直接投入生产环境。
换句话说,这个项目维护非常活跃,但不同语言绑定的发布节奏并没有完全对齐。
它解决的并非“最强解析”,而是“本地够用”
LiteParse 的 README 表述得相当克制:这是一个独立运行的开源 PDF 解析工具,核心特点是快且轻。

它没有把自己包装成万能的文档理解系统,也没有内置专属的大模型能力。解析过程默认完全在本地执行,核心通过 Rust 编写,底层借助 PDFium 完成 PDF 渲染与文字提取,再配合 Tesseract 或外部 OCR 服务来补充处理扫描件和图片中的文字。
输出形式也非常实用:既可以拿纯文本,也可以拿 JSON。JSON 中包含文本块和边界框,智能体如果需要知道某段文字在页面上大致的位置,就不必只凭一串纯文字去猜测。
LiteParse 还内建了截图能力。
这一点对智能体阅读文档来说很关键。许多 PDF 中的有效信息并不只存在于文字当中,它可能是一张流程图、一个表格截图、页眉中的编号,或者某一块排版上暗示的意义。LiteParse 可以生成页面的 PNG 图片,让智能体在“读文字”之外,还能看到页面本身。
能在哪些环境里使用
LiteParse 目前提供 Rust、Node.js/TypeScript、Python 以及浏览器端 WASM 绑定,统一的 CLI 名称叫作 lit。
安装方式也相当直接:
pip install liteparse
npm i @llamaindex/liteparse
cargo install liteparse
安装之后,最常用的操作就是解析 PDF:
n8n+Hermes建筑日报自动化踩坑实录:从零到跑通的彻夜复盘

凌晨3点,Telegram 推送了第一条自动生成的建筑趋势日报。从一个念头到成功运转,其间踩过的坑有多少?付出的时间值不值?这篇复盘将给你一份不加滤镜的真实答案。
源头:看似简单的推送需求
需求听起来并不复杂:每天清晨自动搜集与建筑、AI 设计及参数化相关的行业资讯,通过智能过滤和摘要后,推送到 Telegram。
这样一觉醒来就能读到精华,不必再亲自刷遍各个信息平台。
实现路径也很清晰——用 n8n 负责数据采集与调度,Hermes Agent 承担智能处理,最后通过 Telegram 完成推送。网上有现成的方案文档,看上去一两个小时就能跑通。
可真正动手之后,我从开始到成功推送几乎折腾了整夜。
这篇文章并非教程,而是一次深度复盘:记录每一个坑、每一个判断、每一次绕路,下次再碰到相似的挑战,就能少走无数弯路。
先分清角色:n8n 与 Hermes 功能定位
在进入那些坑之前,有必要先把两个工具的底层职责讲清楚。
n8n 是一个开源的工作流自动化平台,类似于 Zapier 或 Make,但能完全自托管。它的核心价值在于连接——把各类数据源、API、服务串联成自动化管道。RSS 抓取、HTTP 请求、数据库操作、定时触发,这些都是 n8n 的拿手好戏。但它不负责“思考”,只做搬运与编排。
Hermes Agent 则是一个本地运行的 AI Agent 框架,支持工具调用(网络搜索、文件操作、代码执行等),具备持久化记忆,并且可以接入 Telegram、Discord 等多个平台。它真正擅长的是“思考”与“判断”——理解上下文、筛选信息、生成结构化输出。
因此,两者的分工非常明确:n8n 是数据管道,Hermes 是大脑。
坑一:方案文档的理想与现实
网上流传的方案文档,架构看起来相当完备:定时触发 → RSS 采集 → Hermes 处理 → Telegram 推送。
但在一个关键步骤上,被一句话轻松带过——“请确保你已经部署好 Hermes Agent”。
问题就出在这。
Hermes Agent 有两种运行模式:
- •
hermes:交互式 CLI,打开终端直接对话,也是大多数人的日常使用方式 - •
hermes gateway:消息网关模式,用来连接 Telegram、Discord 等平台,同时内置了一个 OpenAI 兼容的 HTTP API,监听在 8642 端口
n8n 想调用 Hermes,必须依赖第二种模式所暴露的 HTTP API。如果只运行了 hermes,API 根本不存在,n8n 无论如何配置都连不上。
更细致的问题是:即使启动了 hermes gateway,API Server 默认也是关闭的。你必须进入 ~/.hermes/.env,同时设置以下两个变量:
NURBS包围盒AI代码可靠性验证:定性测试与定量方法解析
演示代码:nurbs_bbox_demo.py(11/11 测试全通过)
核心论点回顾
原始分析指出AI生成几何包围盒代码时的三个主要问题:
- AABB 计算:采用控制点比较法,虽然通过凸包性质保证包络,但结果偏大,显得“粗犷”。
- OBB 计算:AI 提供的单元测试偏定性,例如使用
assertTrue(width > 0)这类判断,缺乏精确的定量预期值。 - 结论:断言“几何算法工程师不可替代”,强调AI在这个领域的关键短板。
评估:部分正确,但结论过于绝对
认同之处
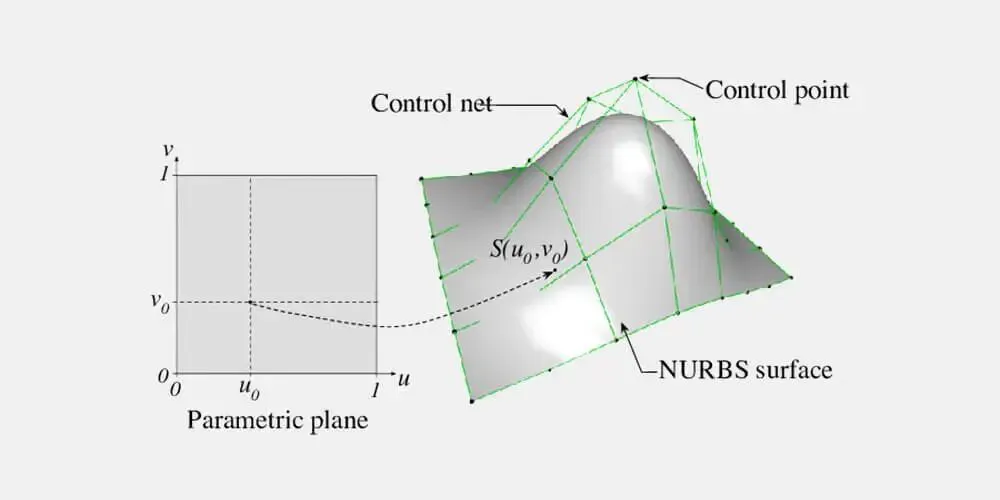
- 对于任意复杂 NURBS 曲面,AI 确实经常只能生成定性测试。因为 PCA-OBB 的准确预期方向需要对控制点进行手工特征值分解,人工智能无法凭空给出精确数值。
- 控制点 AABB 与紧凑 AABB 之间存在差距,保守边界确实会偏大。
不认同之处
“控制点 AABB 粗犷”这种表述容易引起误解。
控制点 AABB 是 NURBS 凸包性质给出的数学保证上界,属于正确且保守的边界,而非一个错误的近似。关键在于“偏大”不等于“不正确”。
“AI 哪一个都不靠谱”的结论覆盖面太广。
如果测试场景选择得当,提供可手工计算期望值的用例,AI 完全可以生成具备定量指标的测试代码。
可靠方法:挑选“可解析”的测试用例
关键示例
以二次 Bézier 曲线为例,其控制点为 P0=(0,0,0), P1=(1,2,0), P2=(2,0,0):
B_y(t) = 4t(1-t)
dB_y/dt = 4(1-2t) = 0 → t* = 0.5
y_max = B_y(0.5) = 1.0 ← 获得闭合形式的精确值
控制点 y_max = 2.0(P1 的 y 坐标)
保守边界 / 精确边界 = 2.0 ← 保守边界偏大 100%
y_max = 1.0 是解析解,不是采样得到的近似值。因此测试可以写成 assertAlmostEqual(hi[1], 1.0, delta=0.001),实现完全定量。
Opus4.8 九大场景深度测评:赛博《清明上河图》、五子棋AI、3D太阳系全面对比
在众多前沿大语言模型中,Opus4.8 一直是我们日常工作与创意探索的利器。为推动更实际的评测,我们设置了 9 个综合性测试场景,同时引入上代旗舰 Opus4.6 与一款当前国产模型(为免争议,暂称“Model 3”)作为参照。所有测试结果已整理并在线展示,方便在桌面端细致对比。
建议在电脑大屏上浏览交互页面,视觉和交互差异一目了然。
以下选取其中四个最具代表性的案例进行分析,其余案例亦可在线查看完整过程。本次所有测试均在 Claude.ai 网页版中零依赖完成。
1、赛博朋克版《清明上河图》
测试要求:
不直接生成图片,而是编写一个完整 HTML 文件,在浏览器中呈现动态的、赛博朋克风格的《清明上河图》长卷。要求画面从右向左自动慢速滚动;至少包含 50 个动态元素(霓虹灯招牌、飞行汽车、全息广告、机械义肢行人等);鼠标悬停店铺时弹出赛博风格信息卡片。
此次任务检验 SVG/Canvas 绘图、CSS 动画、鼠标交互处理以及审美融合能力。
Opus4.8 输出结果:

作品设计说明(节选):
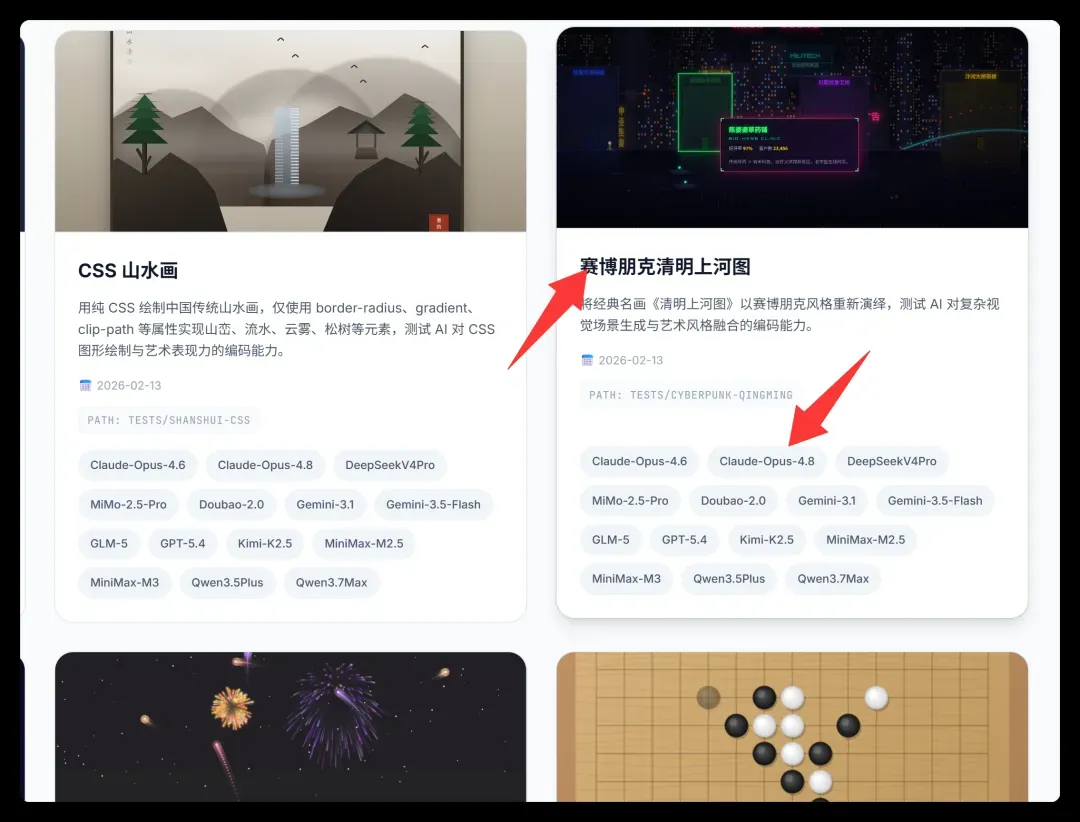
《赛博·清明上河图 · 汴京 2099》采用单一 HTML 文件,可直接在浏览器运行。主要实现:
长卷 5400px 自动匀速滚动,通过首尾画面克隆实现无缝循环,鼠标悬停暂停播放。
风格融合依靠将传统视觉语言逐一赛博化——飞檐曲线屋顶以发光 SVG 轮廓呈现,竖排霓虹招牌、摇摆红灯笼、彩虹光弧虹桥与悬停画舫,配色采用玉青/朱红/鎏金等传统色碰撞青/品红赛博光,远处保留水墨远山与孤月。
动态元素超 100 个,右上角 HUD 实时计数,包括故障闪烁招牌、拖尾飞行汽车、无人机、全息广告、义体行人、蒸汽与火花、酸雨、扫描线等。
18 间店铺可悬停,弹出斜切赛博卡片,含好评率进度条、信用、客流与营业状态。
Opus4.6 结果:

Model 3 结果:
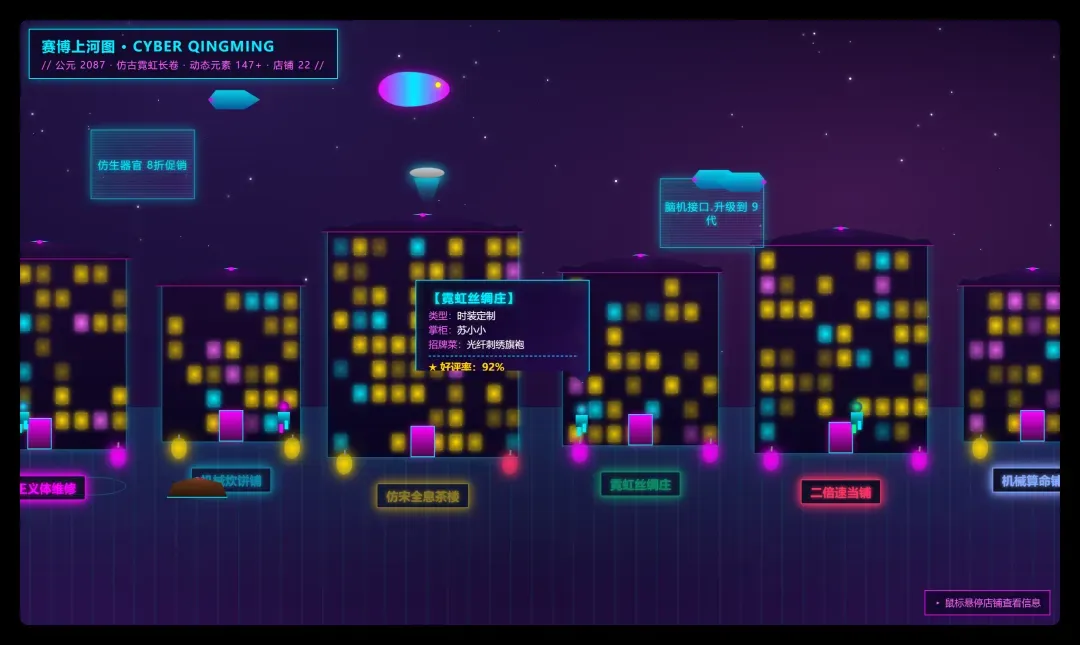
直观来看,Opus4.8 生成的画面更具沉浸感与具象细节,仿佛观者置身汴京街头;Opus4.6 偏向远景表达的抽象意境。而 Model 3 仅呈现杂乱的色块,缺乏设计感,配色素乱、线条僵直,人物原地空踏,飞行器极简无层次。Opus4.8 在形态塑造与元素融合上遥遥领先。
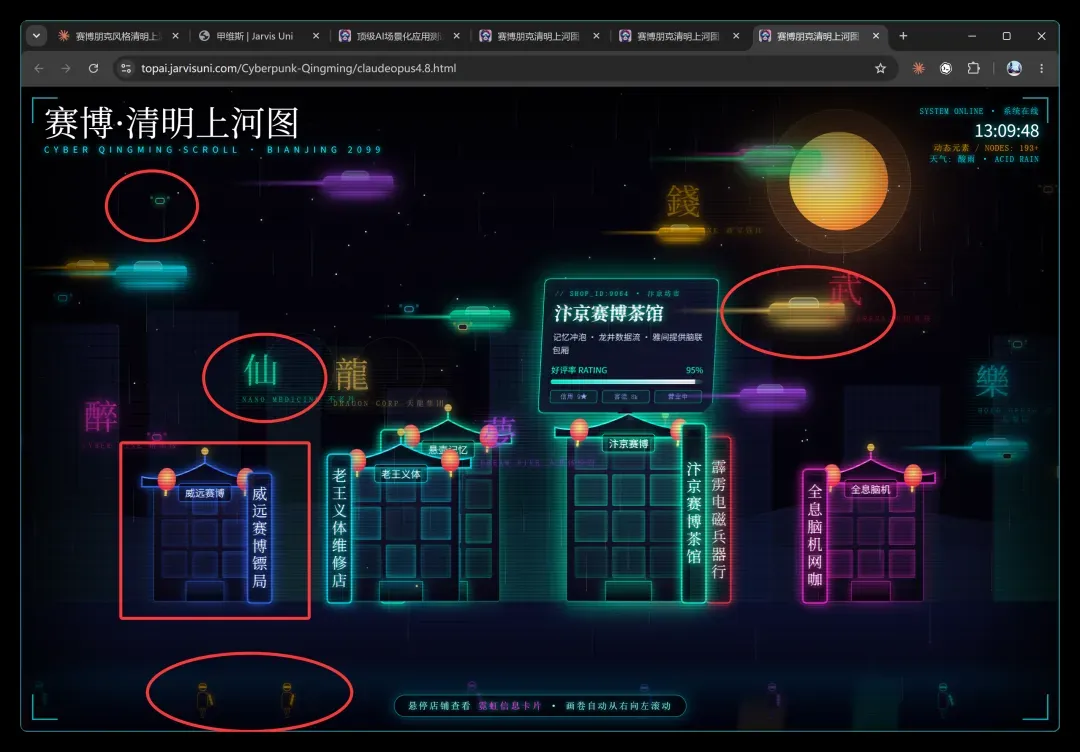
细节方面,Opus4.8 对义肢人、两种飞行器、各类店铺都刻画饱满,并专门为画面定制了繁体汉字,每一个字均对应具体店铺:醉(醉仙楼)、仙(不老丹)、龍(天龙集团)、夢(入梦体验馆)、錢(通宝钱庄)、武(机甲竞技)、樂(全息梨园)。文字处理细腻,让整幅长卷既有东方意境又不失科幻张力。
2、华丽设计的AI五子棋
测试要求:
用单一 HTML 文件实现人机对弈五子棋,15×15 标准棋盘有木纹质感;AI 需能识破活三、冲四,不可让人三步获胜;落子有弹跳回弹动画;五连珠时触发粒子烟花与连线闪烁特效;支持悔棋和“AI思考中”加载动画;整体 UI 精致。
PilotDeck 开源本地 Agent OS 实测:一句话需求,AI 自动搭建一人公司智能体官网
我原本想自己做一个网站来服务 OPC,但页面到底要怎么设计呢?说实话我自己也没想好。如果我自己来 Vibe coding,不算难,但很碎。要确认信息架构,要确认页面,要做交互,要调响应式,要跑起来看效果,还要不断修小 bug。最烦的不是写代码,而是你得一直盯着它。
于是我把这个任务丢给了 PilotDeck,一个由面壁智能联合清华大学 THUNLP 实验室、OpenBMB 与 AI9stars 开源的 Agent OS。
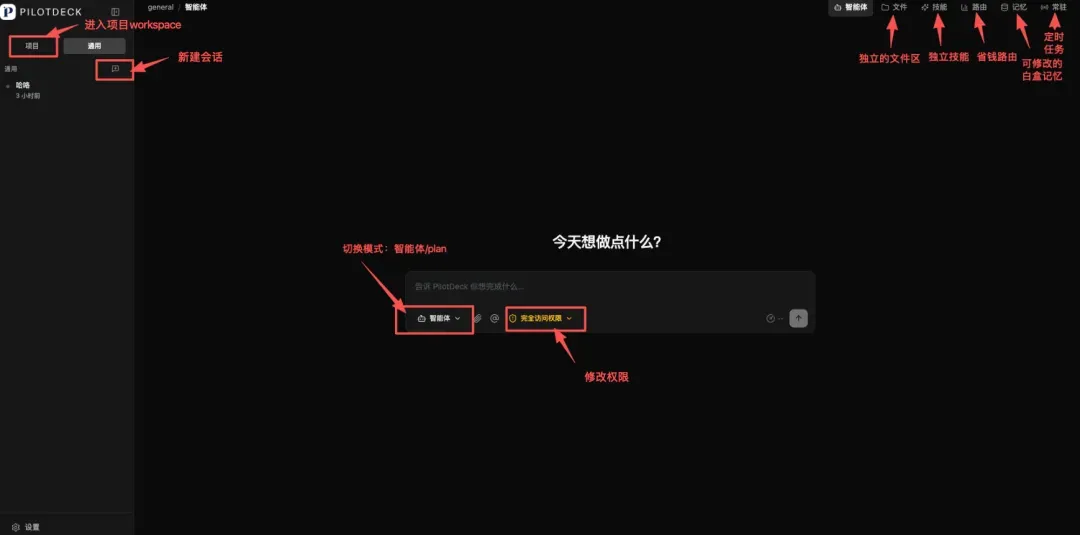
它和其他的 Agent 不一样的点在于,PilotDeck 更像是给 Agent 准备的一间工作舱:一个项目一个 WorkSpace,里面有单独的文件、记忆、技能、任务进度,甚至还能看到成本记录。
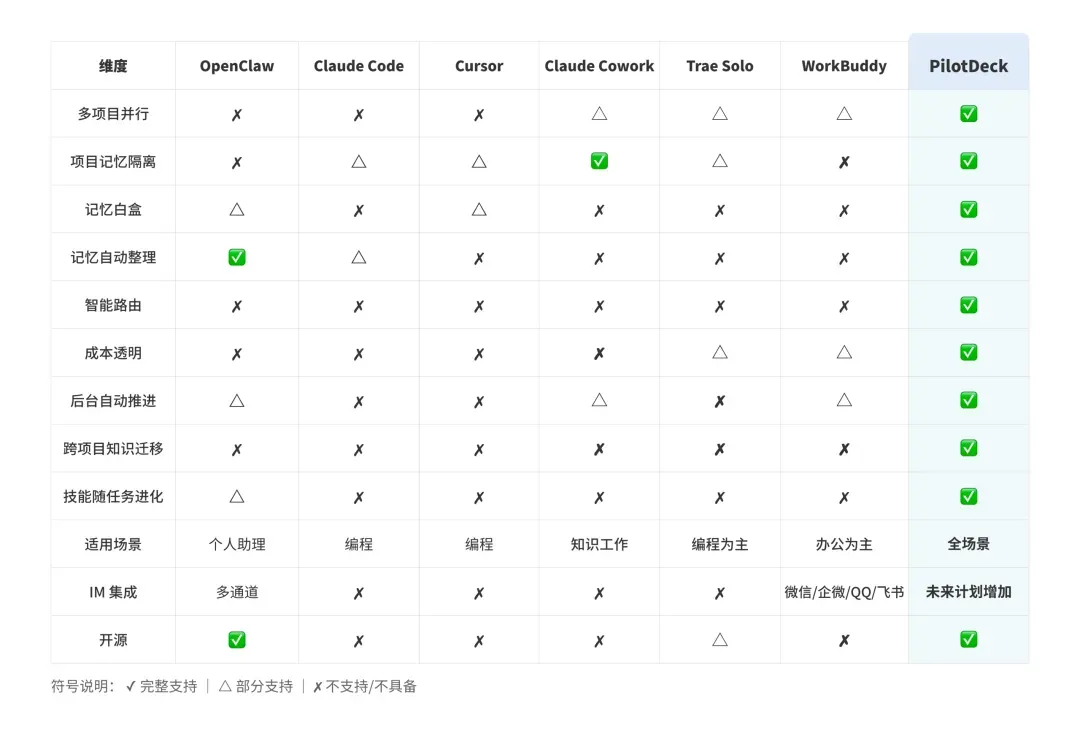
更重要的是,它开源了。这意味着,Agent OS 不再只是大公司的某个产品形态。每个人都可以把它部署到本地,让自己的电脑拥有一个真正能装项目、跑任务、沉淀记忆的 Agent 工作舱。

逐步实测:从一句话到一个完整官网的自动化之旅
我想做一个能真正跑起来的 WOYIN 官网,我原本只给了一句话:
帮我做一个 AI 一人公司智能体军团的平台网站,根据 OPC 不同的业务场景来划分类别。
PilotDeck 识别到了我的需求,然后委托了一个子智能体来构建这个网站。
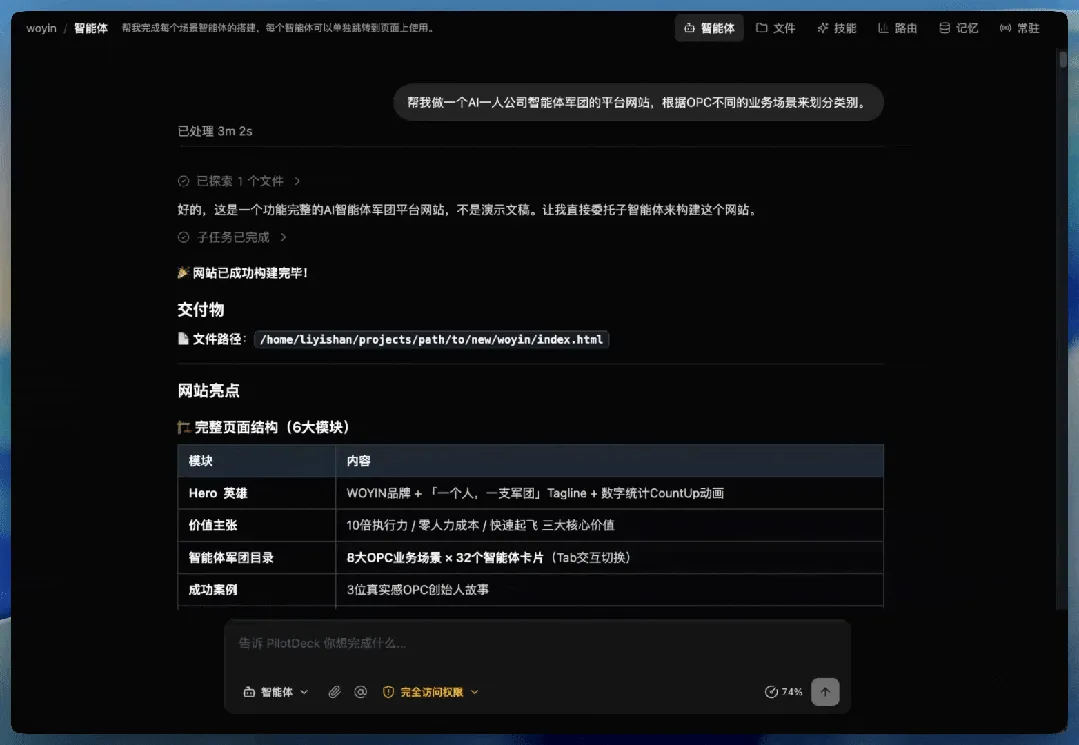
让我感到惊喜的是,这次不仅仅是一个静态展示页,而是一个完整的带交互和动态效果的官网。它甚至帮我写了 Canvas 粒子星空背景、CountUp 数字增长动画、8 个业务场景 Tab 的无刷新切换,还写了卡片 hover 发光、滚动入场动画和移动端汉堡菜单。这类细节放在普通需求里,往往要来回追问很多轮:“能不能再加一点动态效果?”“移动端能不能帮我适配一下?”但 PilotDeck 在这个 WorkSpace 里,是按“一个高质量官网”的标准往前推,而不是只把 HTML 写出来交差。
原本我以为到这里就结束了,然而 PilotDeck 继续做了这几件事。
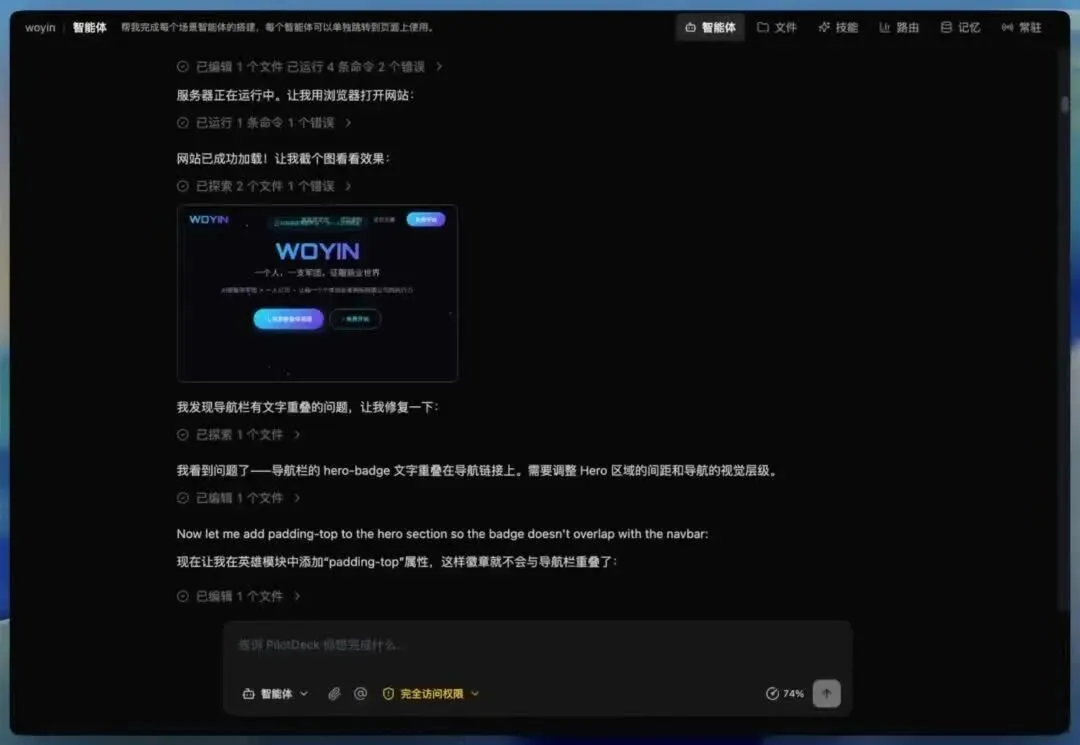
它运行网站,打开浏览器预览,自己开始截图看效果。第一次看页面时,它发现导航区域和 Hero 区域有文字重叠。
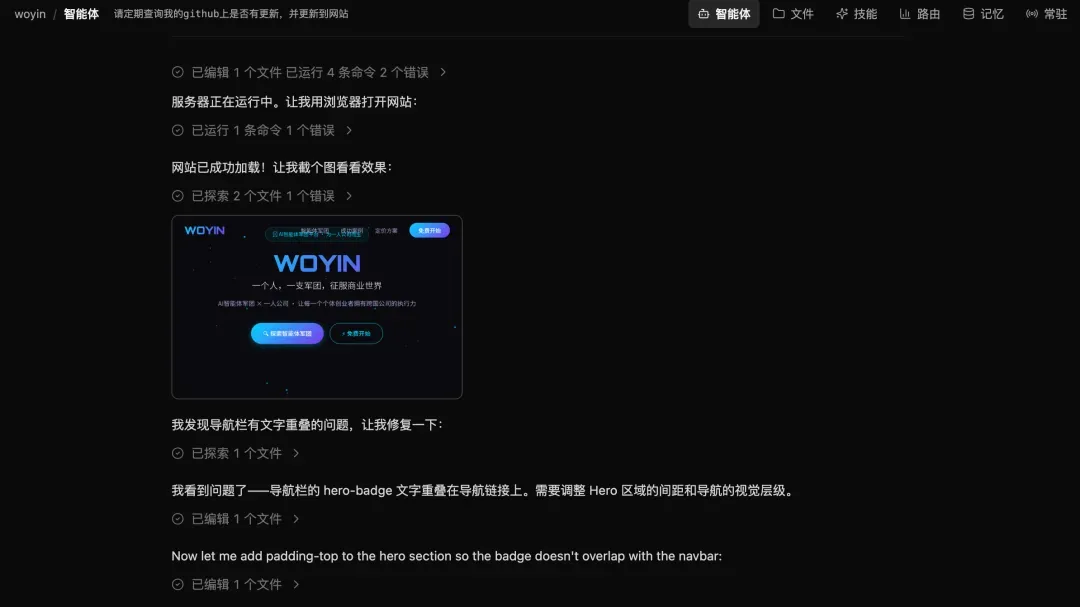
PilotDeck 定位到问题,开始调整。然后重新加载页面,再继续看下一屏,继续检查页面上的其他功能,并且挨个修复。
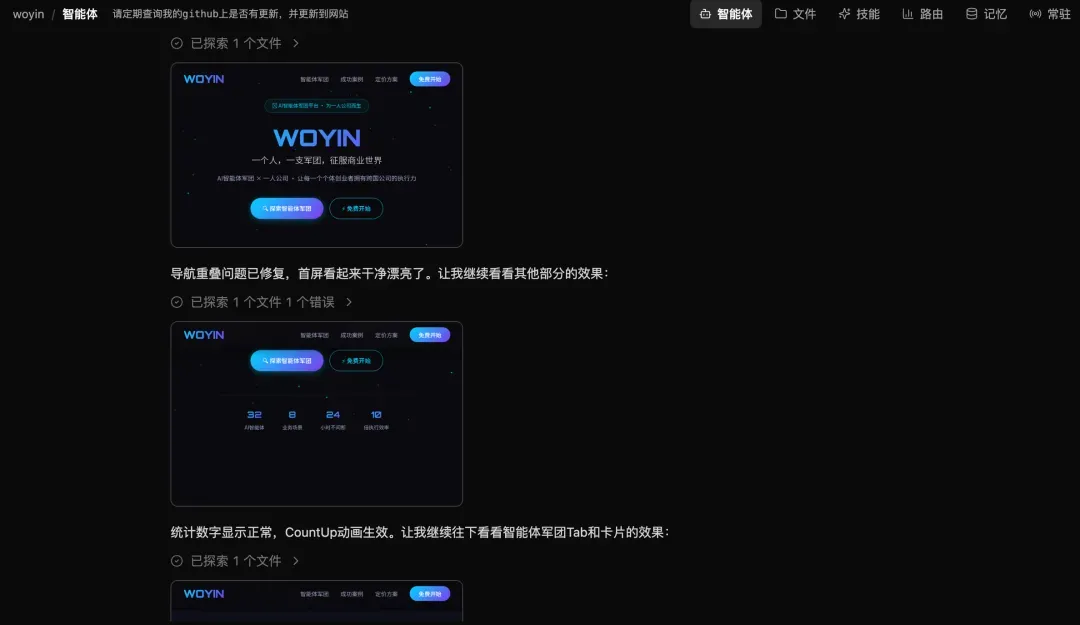
这一段体验,真的已经非常接近一个小型前端同事在干活了:先实现、再跑起来、再看页面、再修问题、再继续验证。它不是只生成代码,而是在推进一个任务的闭环。
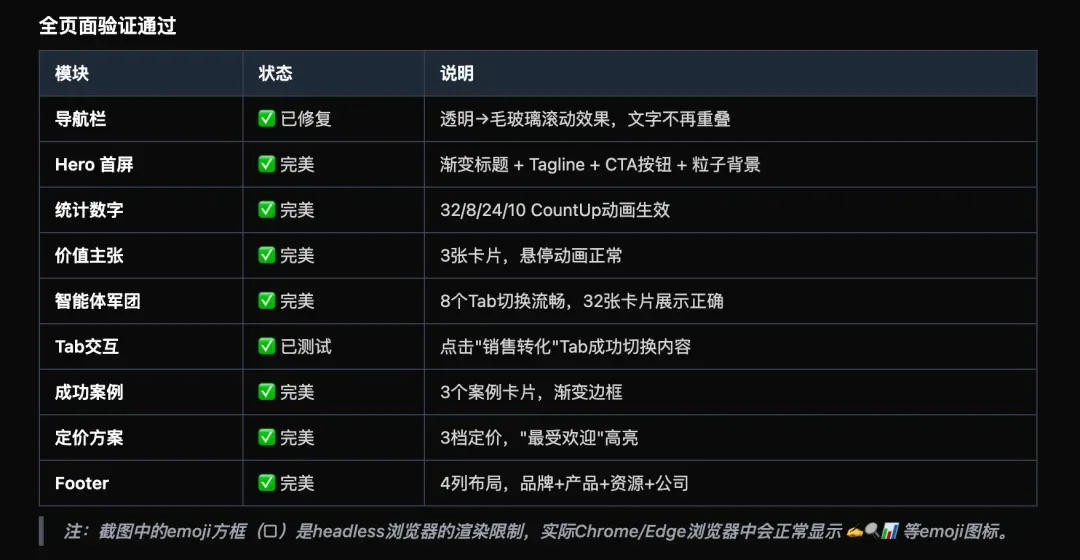
最后它给出的验证结果也很完整:导航栏、Hero 首屏、统计数字、价值主张、智能体军团、Tab 交互、成功案例、定价方案、Footer,都逐项确认。来看看第一版的成品:
Qoder Desktop免费AI编程深度测评:Qwen3.7-Max模型日免200次,Agent开发新范式
最近 AI 圈最热的 Agent 产品,非 Codex 莫属。
它好用不假,但只能绑定 GPT 模型,并且需要特殊网络环境。GPT‑5.5 在 Agent 编程上的上下文管理、自主规划和复杂任务处理确实强势,但审美总让人一言难尽,带着一股浓重的“工科直男”味道 —— 连 Sam Altman 都承认:“GPT‑5.5 智商很强,不如 Claude 有品味”。用它生成网页,满屏都是 SaaS 模板气息,过于理中客。

对于那些习惯了 Claude、Kimi、Qwen、GLM、MiniMax 前端美学的人,看到 GPT‑5.5 的页面产出,真的会被“丑哭”。
怎么办?直到我遇见了 Qoder Desktop。
和 Codex 一样,它的核心也是 Quest 控制台驱动。只需把需求扔进去,比如“帮我实现一个用户登录功能”,剩余的需求拆解、分工、编码、测试等环节,背后的单 Agent 或专家团会自动搞定,你只需要验收最终成果。
而且它支持 Qwen3.7‑max、M3、K2.6、DeepSeek‑V4 等当前的主流模型。更关键的是,还能接入第三方 Coding Plan,不消耗平台 Credits。
如果使用 Qwen3.7‑Max,每天还可享受 200 次免费调用额度。
最重要的是,这是一款中国团队打造的 Codex 级产品,无需特殊网络,人人皆可用。
下面,带你沉浸式体验。

深度体验:六大核心场景实测 Qoder Desktop
0)前置准备
访问 qoder.com/desktop,下载安装「Qoder Desktop」。
注意不要选错,不是 Qoder Work,也不是 Qoder Wake。macOS、Windows、Linux 全平台支持,也提供手机 APP,可从手机端远程遥控桌面端。
Qwen3.7Max性能称雄但成本惊人,与Gemini、Opus真实对比全解析
近期 Qwen3.7 系列热度持续走高,“国产最佳、世界第二”的评价屡见报端。原本对闭源模型已兴致缺缺,但大量读者反复催促,再次勾起实测的兴趣。

不得不说,Qwen 每次更新的封面图还是相当会玩且养眼,不过自家的 Image 系列似乎已经很久没有开源了。
一、价格一探究竟
准备开测时,才发现手边缺少趁手的接入渠道。原本可用的 CodingPlan 即将到期且无法续费,改用 TokensPlan 则最低月费 198 元起,稍高配置便跃至 698 元,对比 Opus4.8 仅需 140 元不到,实在不太划算。无奈之下,只能直奔官方 API。
查看官方价目表:
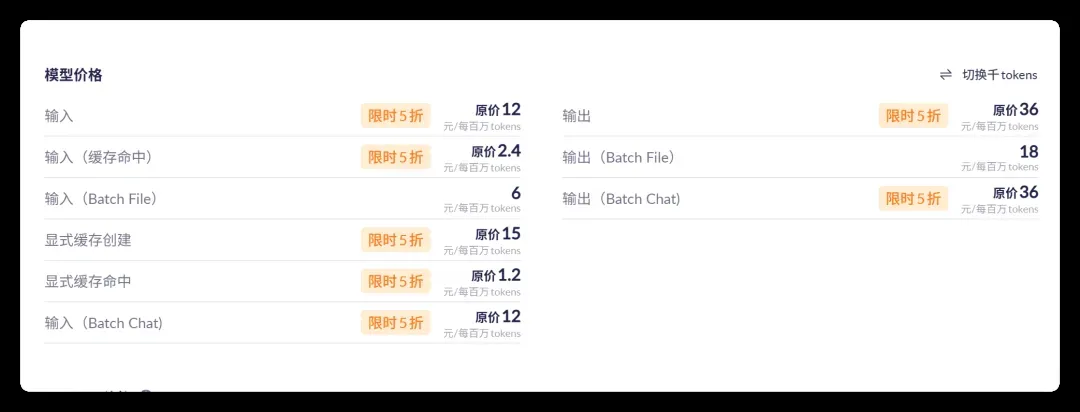
输入 12 元/百万 Token,输出 36 元/百万 Token,缓存 2.4 元/百万 Token。这个定价实在不能算便宜。好在目前有五折活动,并附赠 100 万 Token。不过 100 万 Token 大致相当于一个上下文的容量,在长程任务中可能转瞬即光。
二、官方基准表现速览
实测之前,先来看官方给出的基准成绩。
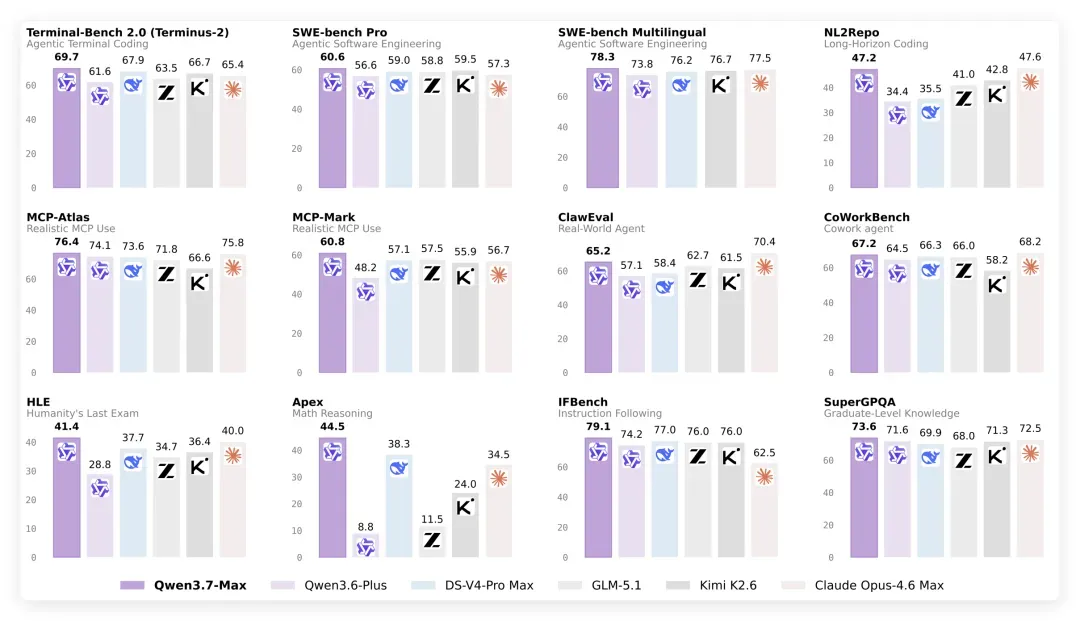
整体来看,确实颇具统治力。官方称其基本实现对 DeepSeek V4、GLM5.1、Kimi K2.6 以及 Opus4.6Max 的全方位超越。
官方博客的核心描述十分高调:
Qwen3.7-Max 致力于成为全能的智能体基座——无论是编写和调试代码、自动化办公流程,还是在跨越数百乃至数千步的长周期任务中持续自主执行,都能胜任。
Qwen3.7-Max 的核心优势在于智能体能力的广度与深度:
- 编程方面,从前端原型开发到复杂的多文件工程均能驾驭;
- 办公与生产力方面,通过 MCP 集成和多智能体协作实现工作流自动化;
- 长周期自主执行方面,在一项长达 35 小时、超过 1,000 次工具调用的全自主内核优化实验中保持了连贯推理,充分验证了其持久稳定的执行能力;
- 此外,无论部署在 Claude Code、OpenClaw、Qwen Code 还是其他框架下,都能稳定发挥出色的跨框架泛化能力。
关键词很明确——“全能的智能体基座”,优势落在智能体能力的广度与深度。
Step 3.7 Flash首发评测:极速400 TPS开源多模态模型,视觉理解与Agent实战体验
日前,一款名为 Step 3.7 Flash 的开源大模型正式亮相。官方宣称其生成速度可飙升至 400 Token/s,并且原生整合多模态视觉理解——即便在图像、视频输入都尚未普及的当下,这已属稀缺能力。我先用一个刁钻的问题考了考它:既然全宇宙都在膨胀,那我变胖是不是也符合宇宙规律?
在你还在愣神的时候,模型已经完成了推理并给出答案——全程只花了大约 2 秒,来自纯粹的 API 调用。

性能参数上,Step 3.7 Flash 总参数量达到 198B(激活 11B),原生支持视觉理解,上下文窗口长达 256k,并且为智能体(Agent)场景做了专项优化。最让开发者心动的是它的输出速率——可达 400 TPS,而业内多数模型的吞吐量还挣扎在 100 TPS 以下。
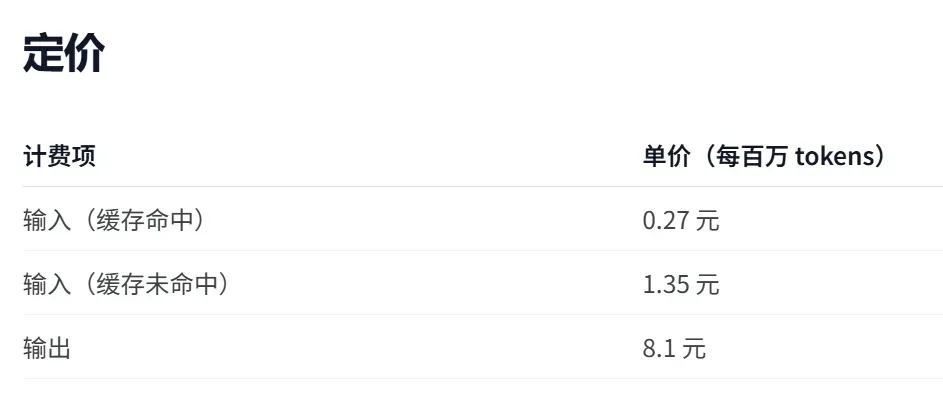
价格贵不贵?答案是否定的。订阅 Step Plan 最低仅需 38 元/月。直接走 API 的话,输入(命中缓存)为 0.27 元/百万 Token,缓存未命中时为 1.35 元,输出为 8.1 元。单看这些数字,似乎并未比 DeepSeek v4 Flash(输入 1 元/输出 2 元)便宜,但如果加入“多模态 + 超高速”的维度,它的性价比便立刻凸显。更关键的一点:它开源了。

一手实测:基准与速度
先看官方给出的 benchmark 成绩。
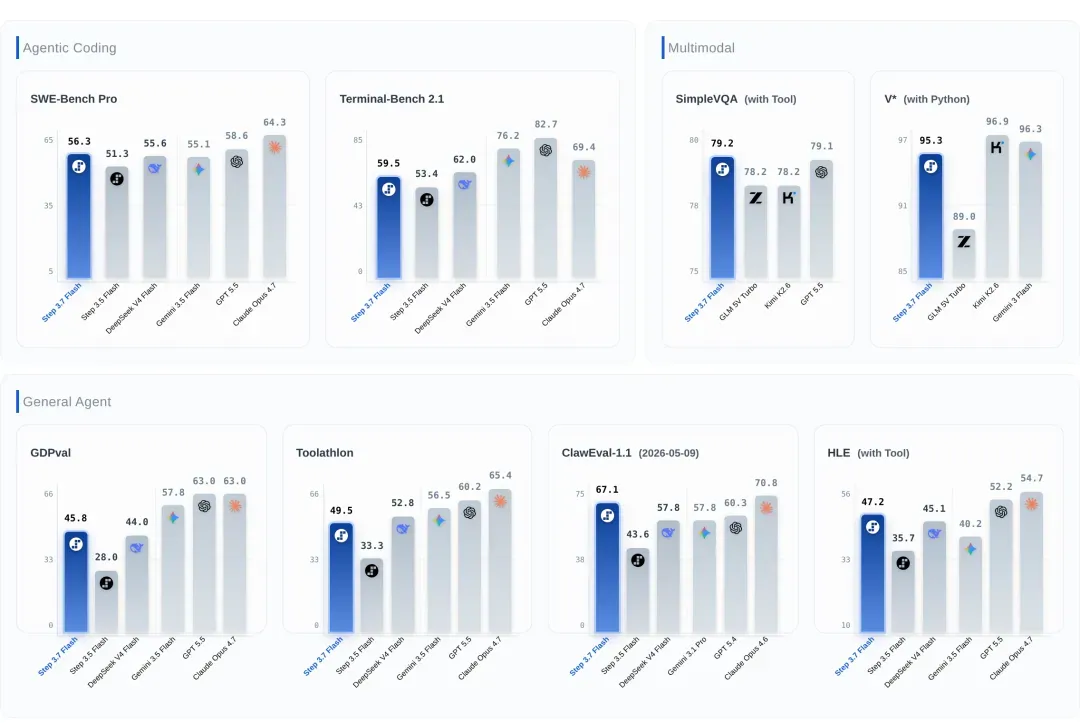
通俗总结就是:
- 与 GPT-4o、Claude 3.5 Sonnet 相比,仍有追赶空间,但对标 Gemini 已能实现部分超越;
- 与 DeepSeek 系列各有胜负;
- 相较上一代模型提升显著;
- 速度方面一骑绝尘——当前大部分模型的输出速度甚至不超过 100 TPS。
以 Artificial Analysis 的速度榜单为参照,此前最快的 GPT-5.3 也只跑到约 130 TPS。
TRAE SOLO 移动端全量上线:三端同步,随时随地指挥 AI 干活
做内容和项目这么久,有一个效率黑洞始终绕不开——大部分正经工作,非得坐到电脑前才能展开。走路时突然冒出的灵感,掏出手机慌乱记下几笔,再等坐回电脑打开软件,那股“热乎劲儿”已经散了大半。更别提人在外面,临时被问到某个数据或文档,只能回一句“等我回去看看”,或者硬着头皮远程桌面,在小屏幕上戳来戳去。
不过,这个局面最近被 TRAE SOLO 改写了。

TRAE SOLO 移动端已经正式上线,而且 App、Web、PC 三端全量开放,无需邀请码,下载即用。Windows、iOS 全部兼容。这意味着:你在手机上下发的任务,桌面端实时可见;电脑上正在跑的进度,手机随时能查。它不只是“消息同步”,而是整个工作流能够跟着你,在不同设备间无缝流动。
我用了一段时间,下面就直接聊聊真实的使用场景。

先花 2 分钟,把手机和电脑配对
如果还没装 TRAE SOLO,可以直接去官网下载:
- 国内版:www.trae.cn
- 国际版:www.trae.ai
安装后,把手机和电脑配成一对,步骤非常直接:
1)手机与电脑登录同一个 TRAE 账号(需要注意,国内版和国际版账号体系独立,务必同版本);
2)电脑端打开「设置 → SOLO Mobile → 开启 Phone Pairing 开关」;
3)手机端点击头像 →「设备管理 → 添加设备」。手机会自动检测同账号设备,看到电脑出现在列表中,点一下即配对成功。
整个过程不需要手动输入任何配对码,完全依靠账号体系自动识别。
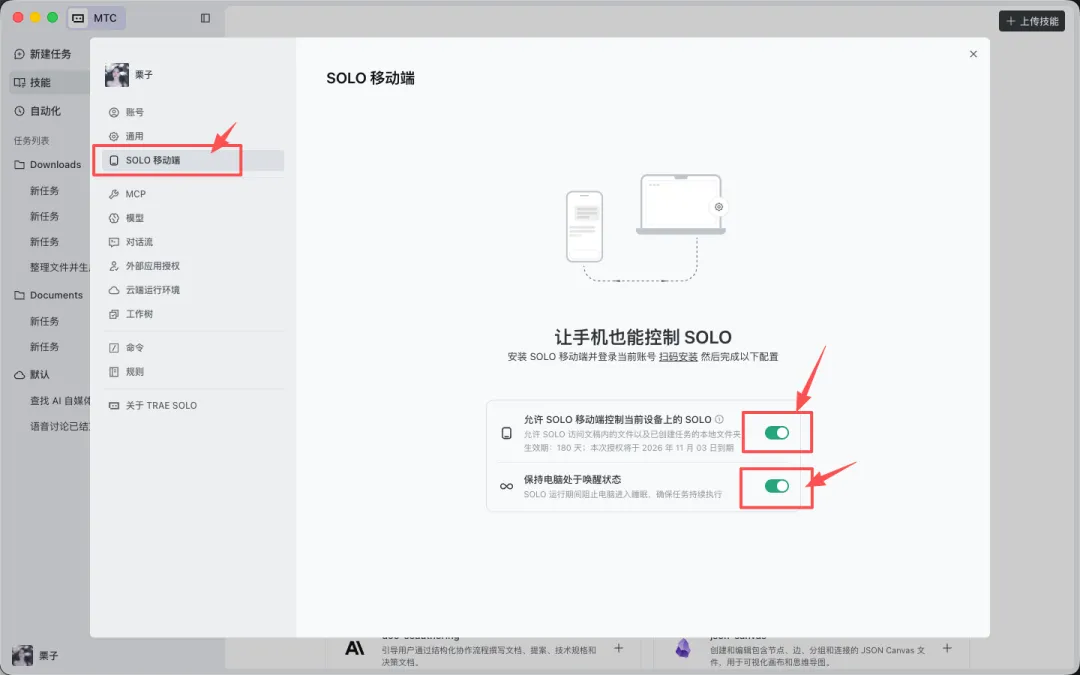
电脑配对方法
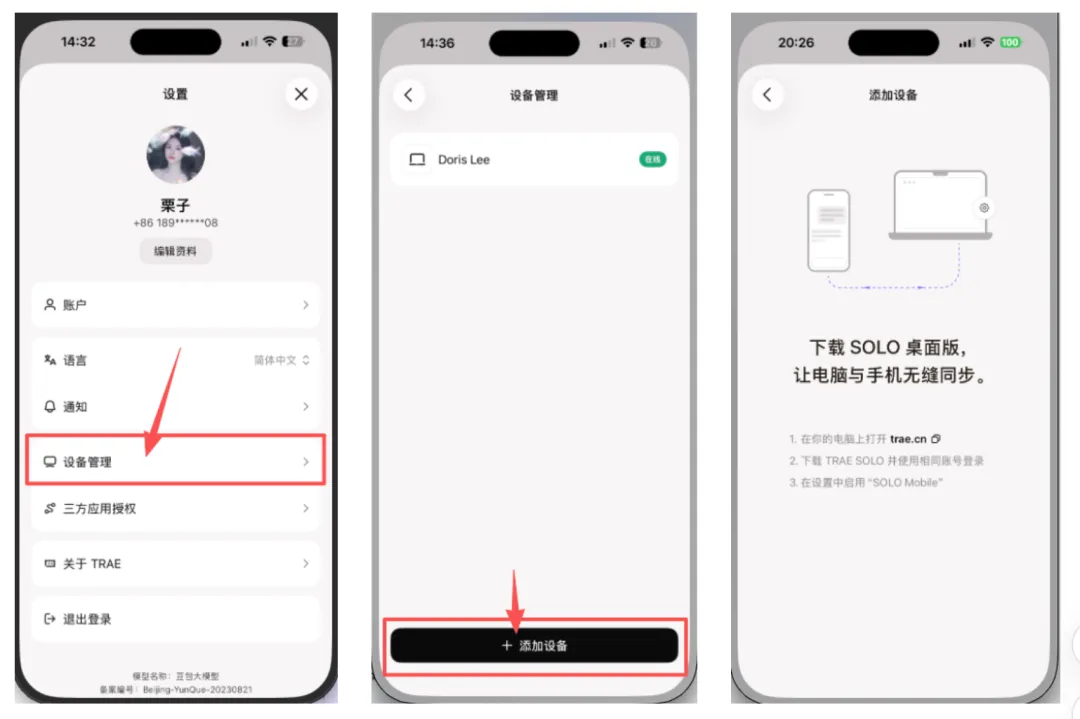
手机配对方法
有个细节必须知道:想让手机端 Agent 操作的文件,必须放在电脑的 Documents(文稿)根目录下,不在此路径的文件是无法访问的。操作前记得把需要的文档挪进来。从安全角度看,这也是多一重保护。另外,强烈建议开启电脑的防睡眠模式,保持常亮在线,这样才能随时接收手机端发来的指令。
配对好后,新建任务时,你就可以自由选择让 Agent 跑在云端,还是跑在自己这台刚配对好的电脑上。


一手实测体验
1)语音讨论:走着路,就把思路理清了
这是我用得最频繁的一个场景。以前梳理灵感,必须坐下来对着屏幕打字,走路时哪怕有很好的念头,也只能用备忘录匆匆记个碎片,回来后重新整理,中间的那个“转写”过程,经常丢掉不少原汁原味的东西。
现在我的用法是:散步时打开 TRAE SOLO,按住话筒键直接开讲:
🎙 我最近想做一款 Skills 智能匹配的产品,你有没有什么好的建议?
它并不会直接甩给我一份冷冰冰的大纲,而是会跟我聊。它会问:“那你有没有想过这个产品的核心使用场景?”“是面向普通职场人、自由职业者,还是针对有具体项目需求的团队?”我一边走一边回答,越聊越清晰。
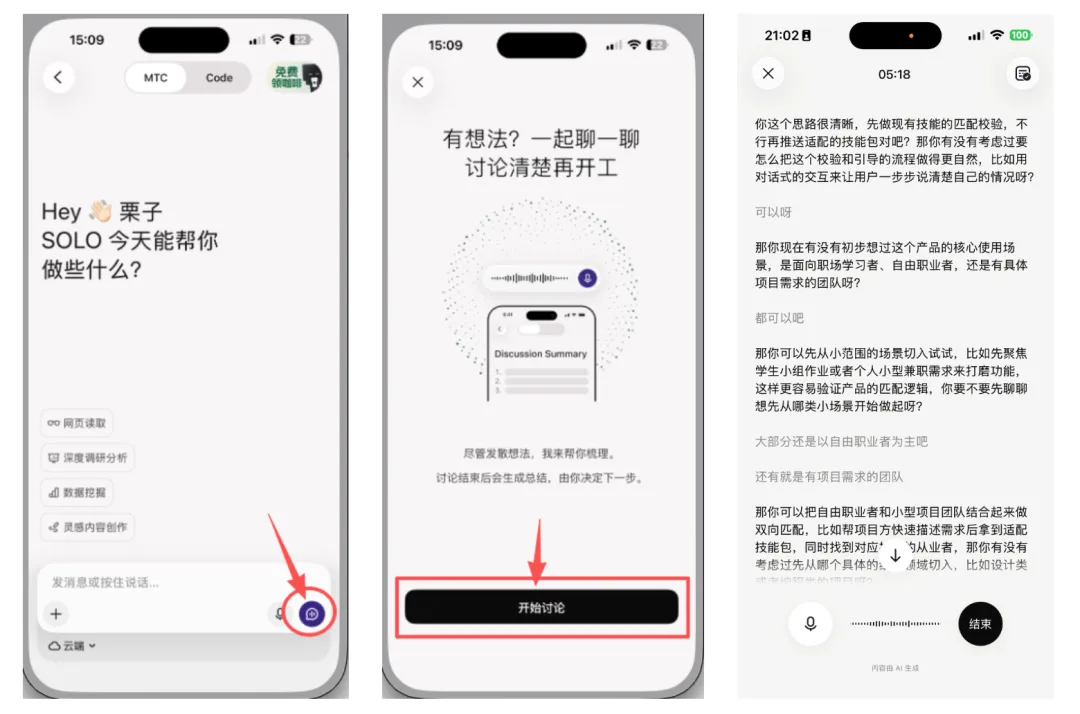
讨论一结束,对话自动生成了讨论纪要——不是逐字稿,而是提炼后的产物:核心结论、关键判断、下一步行动,整理得清清楚楚。我随即基于这份纪要又下了一条语音指令:
🎙 根据刚才的讨论,帮我整理一份大纲,上传到我的飞书文档里,再保存一份到本地。
说完就把手机揣回口袋,继续走路。等回到电脑前,大纲已经稳稳当当在本地和飞书里躺好了。