VibeUI 开源 92 组件:VibeCoding 搭建产品页的终极提示词库
近期关于 Qoder 每天免费使用 200 次的活动吸引了大量关注,有朋友的疑问是:200 次能做出什么?今天我们就用一个全新的开源 Skill 来现场演示,看看项目完成之后还能剩下多少额度。
解决 Vibecoding 中的常见痛点
在日常使用 Vibecoding 开发产品时,以下几种情况经常让人头疼:
- 想快速设计一个 SaaS 落地页、产品发布页、Dashboard 应用或者移动端官网,却不知道如何向 AI 准确描述需求;
- 多个页面之间存在大量相同组件,但是每次都要重新生成,难以复用;
- 视觉效果不够理想,产品结构看起来松散混乱。
正是基于这些困扰,我们准备了一套专门为 VibeCoding 优化的提示词库——包含了 92 个精选 UI 组件提示词,划分为 15 个分类。你可以直接用它来驱动 VibeCoding,快速生成标准化、高质量的产品页面。
实际生成效果预览
下面三个完整页面,全部是使用这套 Skill 组合提示词直接生成的:
SaaS Landing Page —— 从导航栏到页脚,一个结构完整的 SaaS 产品页:
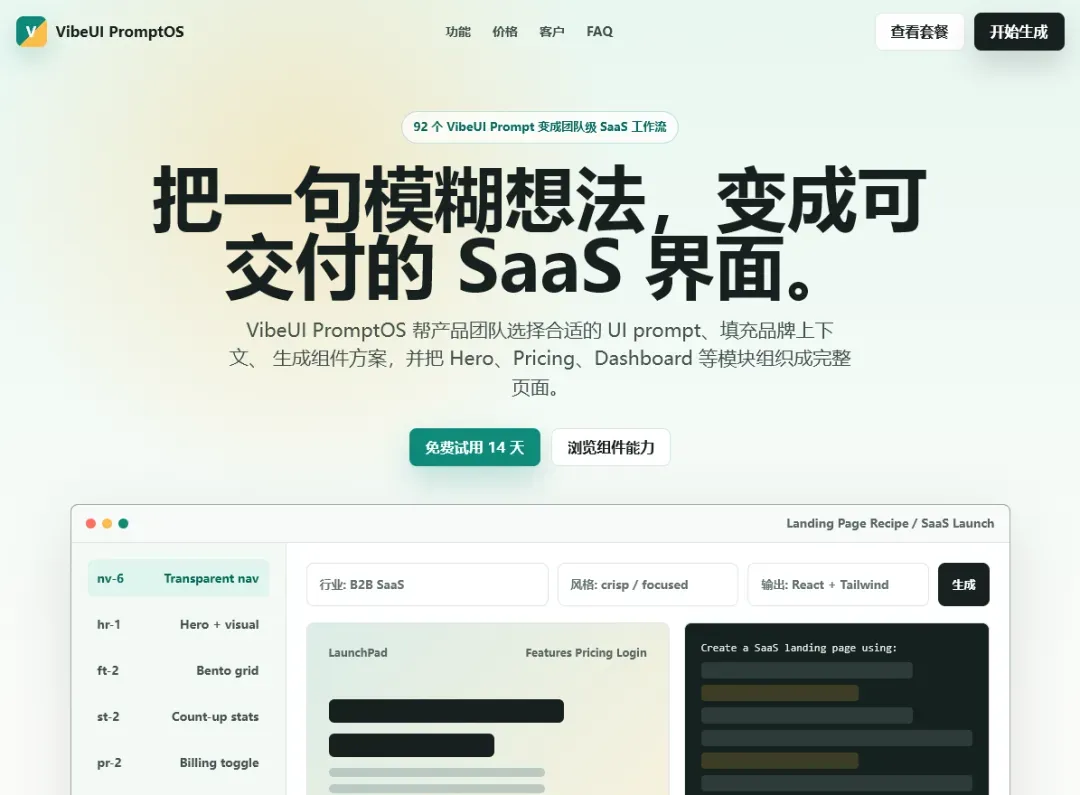
AI Product Launch —— 产品发布页面,视觉冲击力拉满:
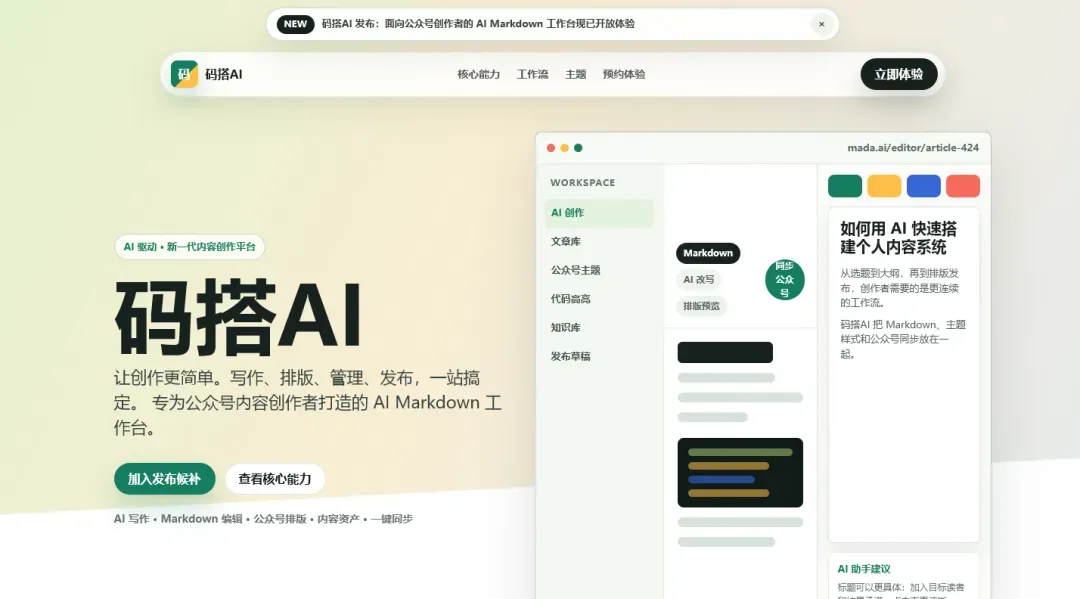
WeChat Dashboard —— 后台管理界面同样可以轻松处理:
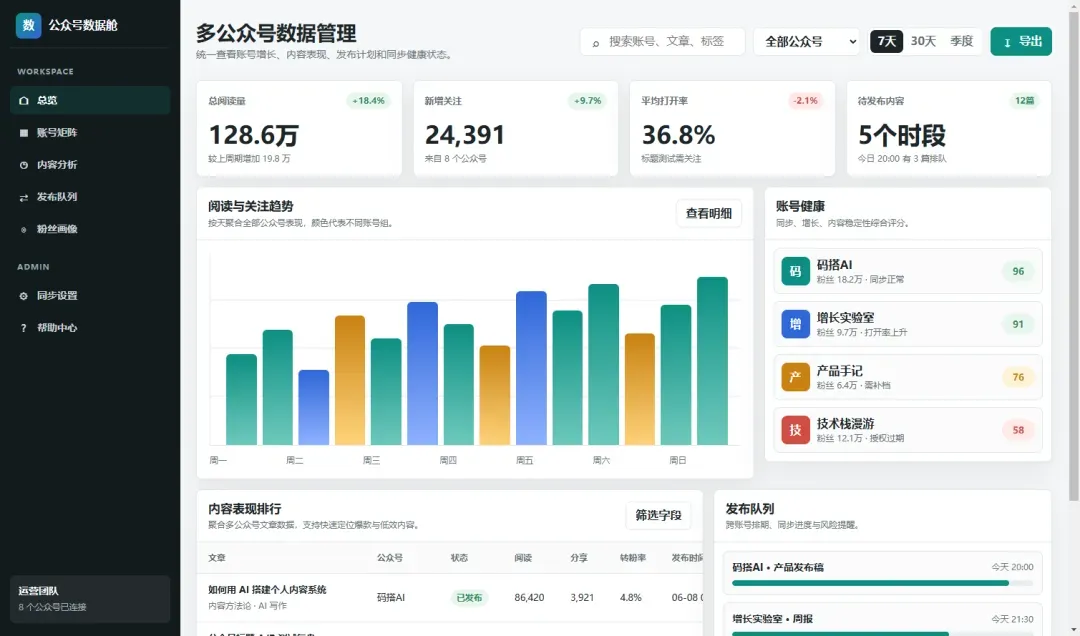
这些页面全程使用 VibeUI 的提示词模板拼合而成,不需要手动编写一行 CSS。
92 个组件覆盖的 15 大产品区块
| 分类 | 数量 | 典型用途 |
|---|---|---|
| Auth Forms 认证表单 | 6 | 登录、注册、魔术链接、多步流程 |
| Pricing 定价 | 8 | 三栏套餐、月/年切换、用量滑动、信用额度 |
| Features 功能亮点 | 8 | 图标网格、Bento 布局、选项卡、前后对比 |
| Hero Sections 首屏区域 | 8 | 分屏版式、视频背景、渐变动画、终端风格 |
| CTA Banners 行动号召 | 7 | 渐变横幅、底部吸底栏、邮件收集入口 |
| Stats Bars 数据统计 | 7 | 数字滚动效果、图标统计、Logo+数据组合 |
| Nav Bars 导航栏 | 8 | 极简导航、Mega Menu、浮动胶囊、透明导航 |
| Testimonials 用户口碑 | 8 | 卡片墙、滚动跑马灯、推文墙、Logo云 |
| Footer 页脚 | 5 | 多列站点地图、极简单行、大Logo、订阅优先 |
| FAQ 常见问题 | 5 | 手风琴展开、聊天气泡、搜索过滤、分类标签 |
| Dashboards 仪表盘 | 6 | 侧边栏、看板视图、三栏布局、空状态提示 |
| Onboarding 新手引导 | 4 | 任务清单、气泡指引、视频引导 |
| Blog 博客版块 | 4 | 杂志化布局、目录侧边栏、筛选卡片 |
| Contact 联系模块 | 3 | 分屏表单、渠道卡片、极简全页 |
| Bonus 附加组件 | 5 | 竞品对比表、公告条、Cookie 提示、404 页面、骨架屏 |
每个分类都提供了多种布局变体。例如 Hero 模块就有 8 种截然不同的风格,从基础的「居中文字+产品截图」到「终端代码动画」「浮动 UI 元素」,总有一种能匹配产品的品牌调性。
Windows 版 Codex 远程控制功能正式上线,跨设备协作更轻松
Codex 的远程功能,终于不再是 macOS 的专属体验了。电脑使用(Computer Use)功能也正式向 Windows 用户开放!
现在起,Windows 用户同样可以使用远程连接与电脑控制功能。
上手过程非常直观,下面通过几张关键截图,带第一次接触的朋友快速完成设置。
电脑端
首先在电脑端安装 Codex,并将其更新至最新版本。
更新后会自动弹出引导界面:
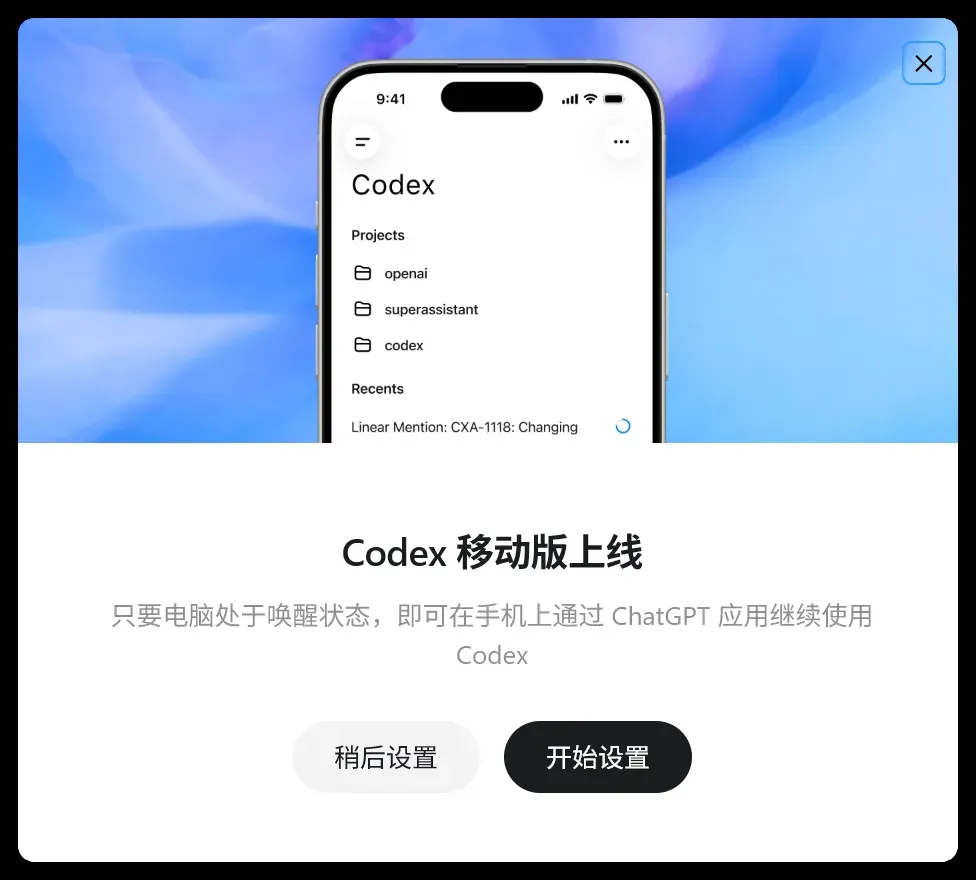
如果意外关闭了这个弹窗,也可以在左侧菜单中找到对应入口。
接下来只需按提示完成几步操作即可。
点击开始设置:
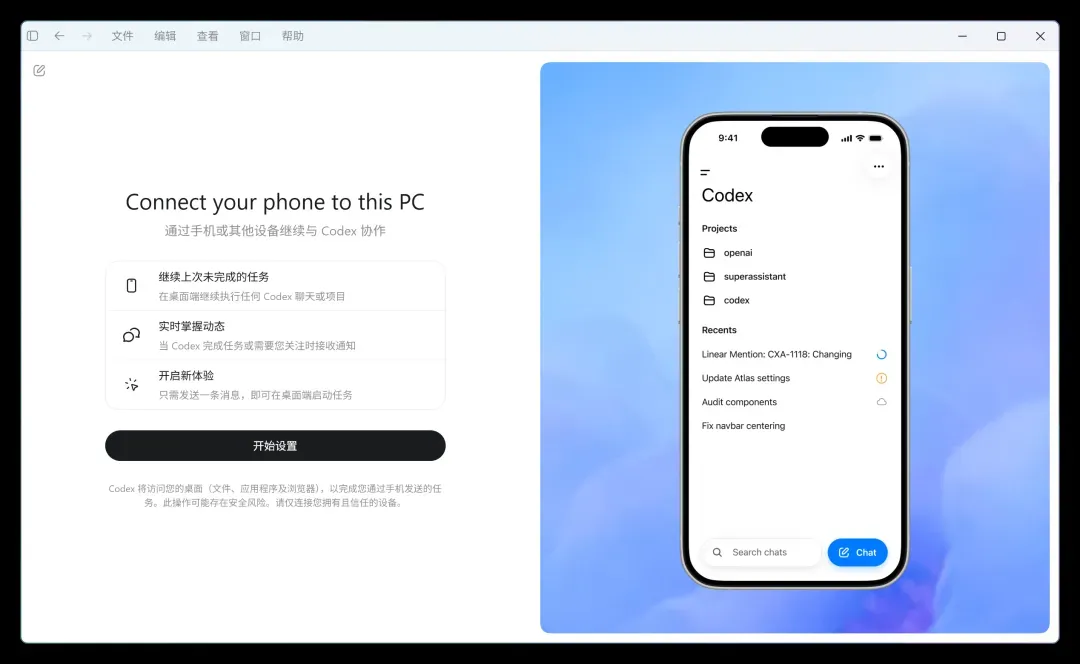
这里会展示一些简要说明。通过手机或其他设备,可以继续与 Codex 协作,比如接着完成未结束的任务、实时掌握工作进度、开启新的工作流程:只需发送一条消息,就能在桌面端启动任务。
这个工具的核心能力可以概括为:延续未完成的工作,接收进度通知,远程创建新任务。
下一步,点击允许连接:
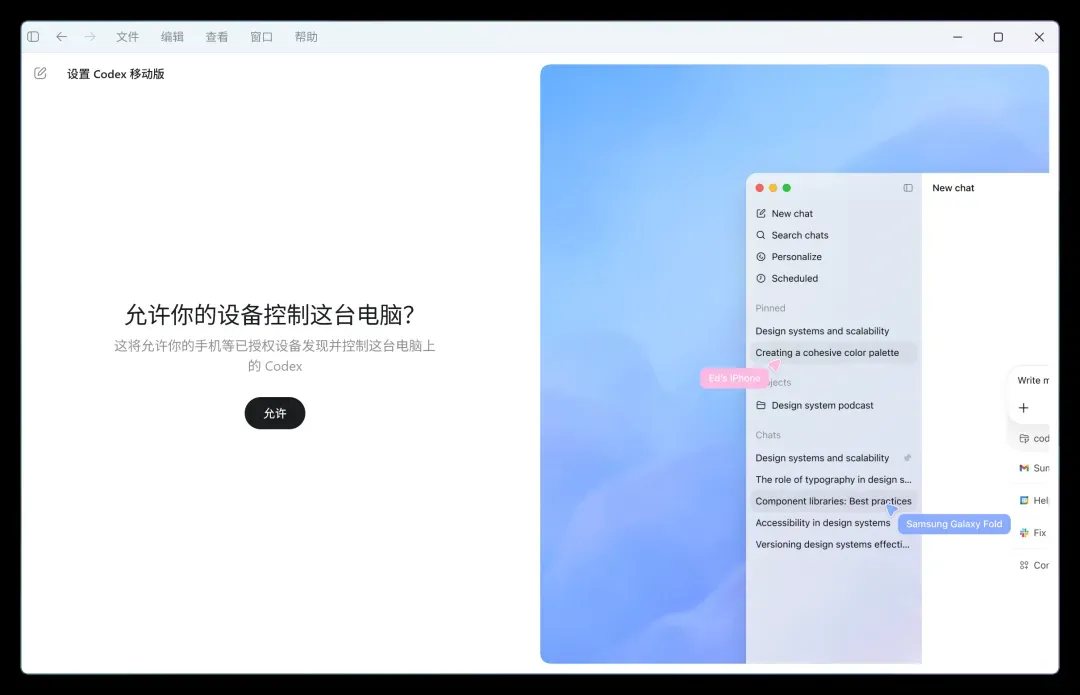
根据提示,授权后,手机等已信任设备就能发现并控制这台电脑上的 Codex。
接着完成几项基础设置:
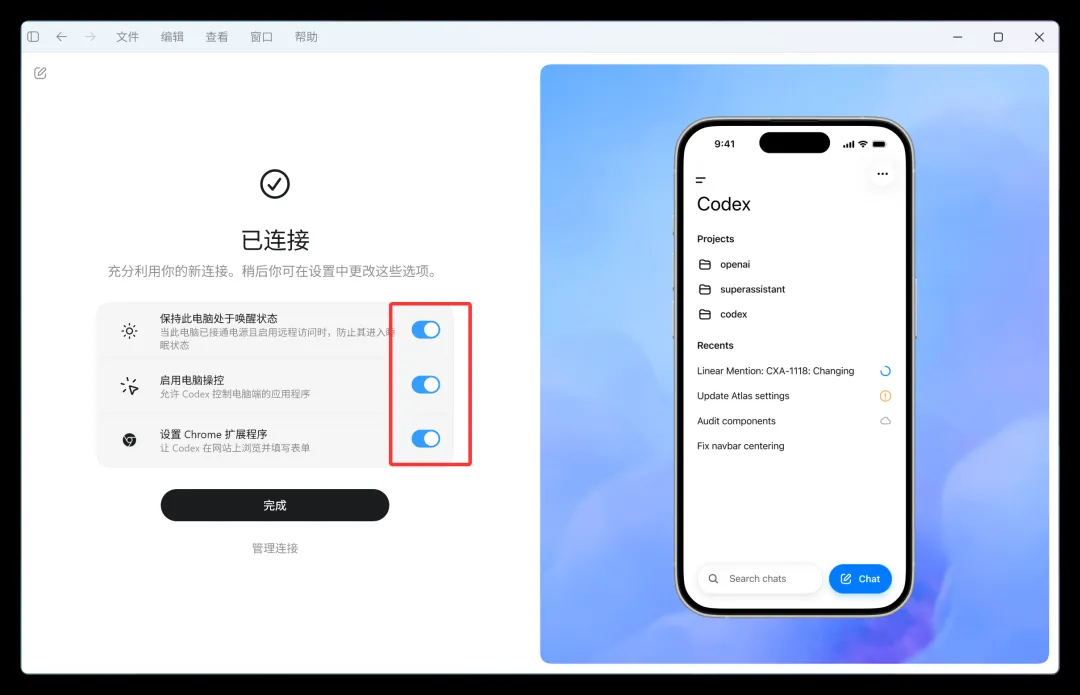
这个界面提供三个选项:保持唤醒、启用电脑操控,以及设置 Chrome 扩展。
第一项用于防止设备进入休眠导致连接中断。如果需要长期进行远程控制,建议保持勾选;临时使用则可视情况决定。
第二项,启用电脑控制:
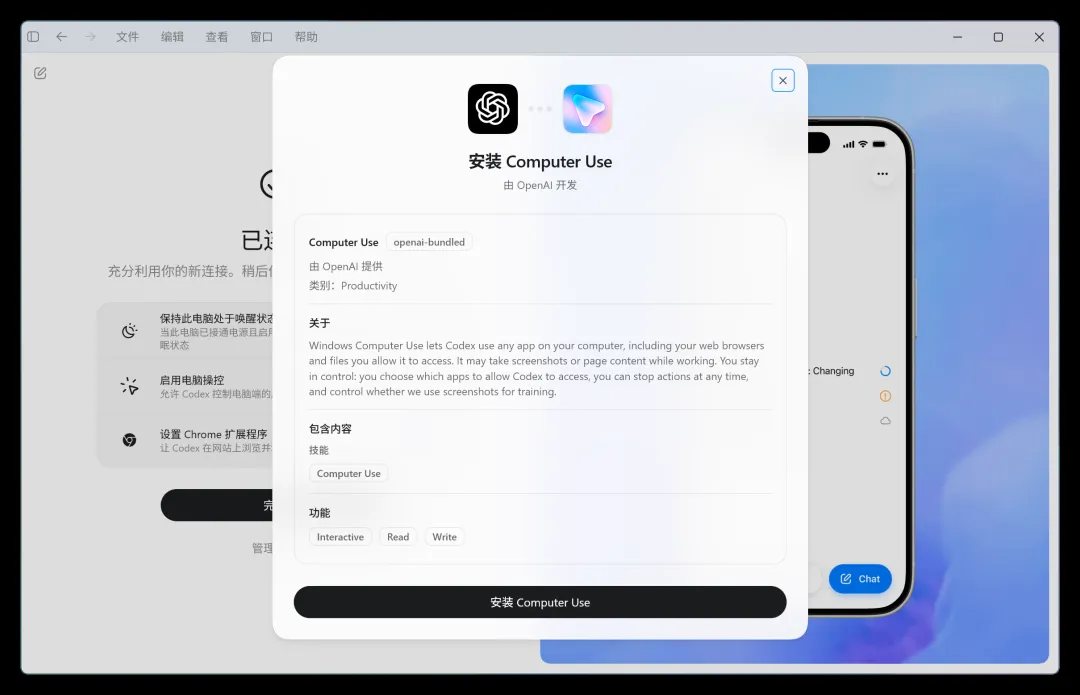
首次使用需安装相关插件。该插件的作用是直接控制电脑,通过模拟鼠标操作来操控系统上的各类软件。
第三项,浏览器扩展。
首次使用同样需要安装插件,分别包括 Codex 插件和 Chrome 插件。
浏览器扩展的功能是操控浏览器,可以代替你执行各种网页操作。例如自动填写表单、发布社交内容,甚至直接与英文客服进行对话,期间你只需通过 Codex 发送中文指令,它会结合上下文自动完成交流。
整个设置流程非常简单!
如果后续需要取消授权,在设置界面的“连接”中即可进行管理。
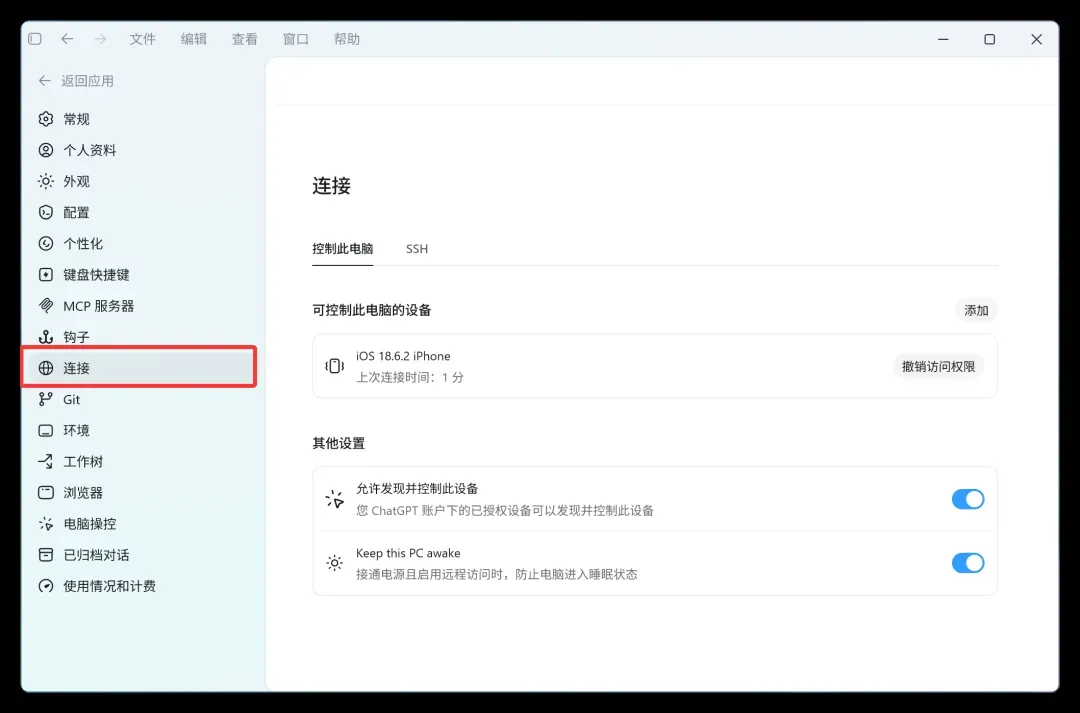
至此,电脑端的配置便已完成。
手机端
手机端无需安装额外应用,直接通过 ChatGPT 的 App 即可连接。
打开 ChatGPT,展开左侧菜单,点击 Codex:
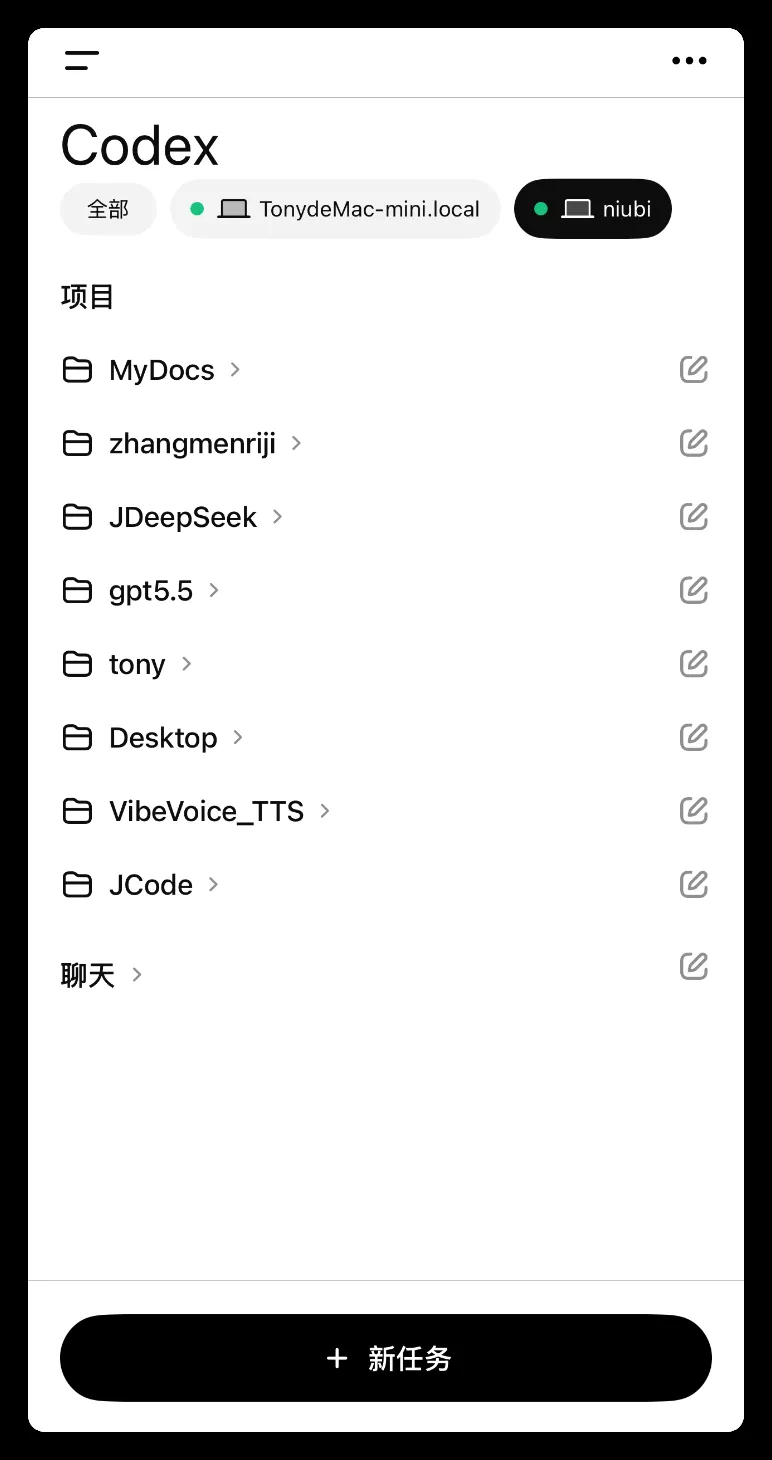
可以看到已连接的设备列表,目前支持 macOS 和 Windows 电脑。
选择对应的设备后,就能访问该设备上的项目。进入具体项目后便可进行对话交互,既可以进行软件开发、日常办公,也可以直接控制电脑。
Codex 的电脑控制与浏览器控制能力表现得十分出色,甚至可以自动化处理一些复杂任务,例如自动注册账号或联系英文客服解决账号问题。
GPT-5.5 在与电脑交互方面的表现非常强大,这一点从相关基准测试中也能得到印证。因此,很多常规的电脑配置、开源项目安装等操作,现在都可以交给它来完成。
此外,Codex 桌面端的用户体验也做得相当顺手,值得尝试。
Workbuddy 自动化工作总结:告别周报加班,AI 帮你一键成文
Workbuddy 在管理待办事项和生成日报、周报、月报方面表现非常出色。我们公司恰恰是那种需要频繁提交各类总结的企业:项目有项目周报,个人也要填写周总结与周计划;每月还必须汇总当月工作,作为绩效评估的依据。过去,每到周五我就变得手忙脚乱,需要绞尽脑汁回忆这一周具体做了哪些事、各个项目的进展如何,再按照固定格式一份一份地撰写,整个过程费时又费力。现在,Workbuddy 彻底解决了我的烦恼。
通常我只需对它说一句:“帮我总结一下 xx 项目的周报”,或者“帮我总结一下我本周的工作周报”,它便会依据设定好的规则把周报写好。如果某些周报需要填入共享文档,比如腾讯文档,那就更加方便,直接让它写进去就行——毕竟是自家产品,信息可无缝流转。但对于 WPS 则暂不支持,目前还需手动复制粘贴。
如何实现自动总结?
当然,这一切依赖于平时的积累,否则数据不会凭空出现。下面分享一下我的具体做法。
首先,我把 Workbuddy 作为记录一切工作的核心工具。每接到一项任务,我都会立刻记在里面;每完成一项工作,同样会录入进去。这只是随手为之的动作,久而久之便构建出一个扎实的“基础数据库”。只要数据库维护得当,后续的应用就水到渠成。
在列待办方面,以前我会用钉钉或其他办公平台的能力,但它们仅仅是记录任务。大模型的能力则完全不同:你把任务情况告诉它,它不仅能帮你总结,还能提醒你还有哪些未完成事项。这比传统的看板工具强大得多。所以,如果你仍然习惯把工作清单写在纸上或散落在聊天工具里,不妨直接把这些信息迁移到大模型里——它才能真正充当你的秘书。
其次,是运用总结方法。基础数据已经准备就绪,接下来就是让数据发挥作用。熟悉这一领域的同学应该已经心中有数,这实际上就是“知识库 + 大模型”的应用:先积累数据,再通过模型处理数据。
- 个人周报:需要从项目维度进行总结,涵盖所有参与的项目,说明具体完成了什么,并阐明下周的计划。
- 项目周报:则聚焦单个项目,从个人角度出发,说明你做了什么、项目整体进展如何,以及下一步的规划。
- 至于月报、绩效报告等,也各有各的格式要求。只需把文档交给 Workbuddy,让它按照指定模板生成内容即可。
这个过程前期需要反复调试与优化,直到输出完全符合你的要求。
最后,也是最关键的一步:让 AI 记住这些写法。让 Workbuddy 记住每类周报、月报的撰写风格和格式偏好。这样,下次你只需像我一样说一句话,AI 就能心领神会,直接交付你期望的结果。这正是 Workbuddy 独有的优势——它具备专门的记忆系统,专门用于固化此类流程。相比普通对话类 AI 工具,它在记忆能力上的投入要深入得多。当前 AI 发展的关键战场之一就是“记忆”,谁能把这一环调教得更好,谁就能领先一步。
讲完了方法论,相信用过 Workbuddy 的朋友已经跃跃欲试。在此我还想特别提醒一句:一定要使用 Workbuddy 的“龙虾能力”,也就是下面截图中展示的功能。请勿使用没有记忆功能的普通对话形式,否则效果会大打折扣。
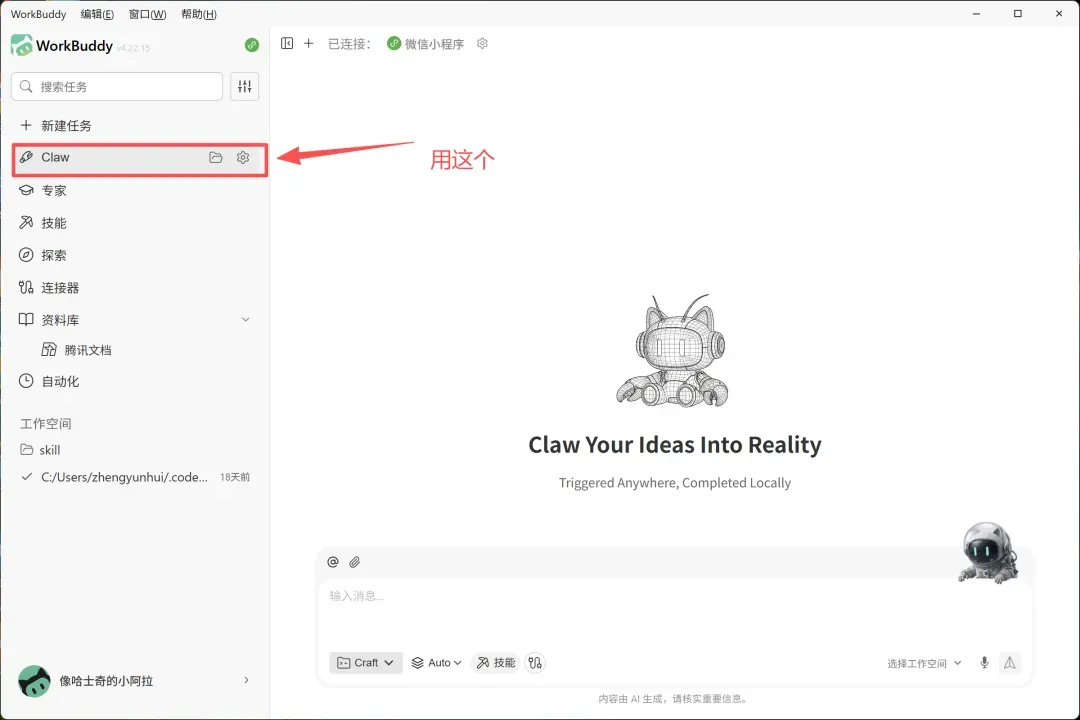
安装简介
对于从未接触过 Workbuddy 的用户,这里简单说明安装方式:
- 访问安装地址:https://www.codebuddy.cn/work/
- 绑定微信:进入后点击“设置”,完成微信绑定,这样便能通过微信直接与 Workbuddy 对话。
- 即使不绑定微信,也可以直接在网页输入框中输入内容。绑定微信只是多了一个手机端的便捷操控方式。
结语
对于长期被周报、月报等模板化写作压得喘不过气的职场人来说,Workbuddy 绝对能带来生产力的解放。节省下来的时间,可以用来做更多更有价值的事。在老板尚未察觉效率提升的秘诀之前,你大可以一边维持努力工作的外在形象,一边从容地享受轻快的工作节奏。
阿里语音设计UI引恐慌?深度实测QoderWork设计工作台:一句话生成高保真界面
前两天看到一条消息,胡彦斌用 Vibe Coding 的方式给粉丝做了一个 APP——巡演地图、打卡系统、动态广场、成长体系,功能齐全。

那个坐姿,一看就是资深 Vibe Coder 了。
当时那张照片让我恍惚了一下:连明星都能顺手写代码了,编程的门槛好像真的被掀了个底朝天。
紧接着昨天,Andrej Karpathy 宣布加入 Anthropic。Karpathy 曾是 OpenAI 创始成员、前特斯拉 AI 总监,2025 年初他造出“Vibe Coding”这个词,意思是顺应感觉让 AI 把代码写完,甚至不必关心代码长什么样。一年前大家还觉得他在说大话,现在没人笑得出来了。
不过 Vibe Coding 跑了一整年,大家也慢慢发现一个真相:代码能跑通并不稀奇,但做出来的东西丑不丑、能不能用,全看编写者的审美,以及他对实际业务的理解深度。
可如果让一个没学过设计的人先在脑子里描绘界面长什么样——这比让他写代码还要命。
那种感觉谁都明白:你分明知道它不好看,却根本不知道怎样才能让它变好看。
刚好就在胡彦斌推出 APP 的同一天,阿里 QoderWork 上线了「设计工作台」,定位非常直接——说句话就能做设计。对着它说出你想要的界面,它就在画布上生成一份可运行、可编辑、可直接交付的设计产物。
如果说 Vibe Coding 解决的是“没有程序员也能写代码”的问题,那 QoderWork 想解决的正是前面那一步——没有设计师也能做设计。
这两块拼到一起,才算把普通人从构思到产品落地的整个链条给打通了。
那它到底靠不靠谱?是真能打仗,还是又一场 demo 很美、用起来叫人摔键盘的幻象?我上手完整跑了一遍。

深度上手测试
0. 准备工作
体验前先做简单设置。在对话窗口左下角选择「设计」模式。
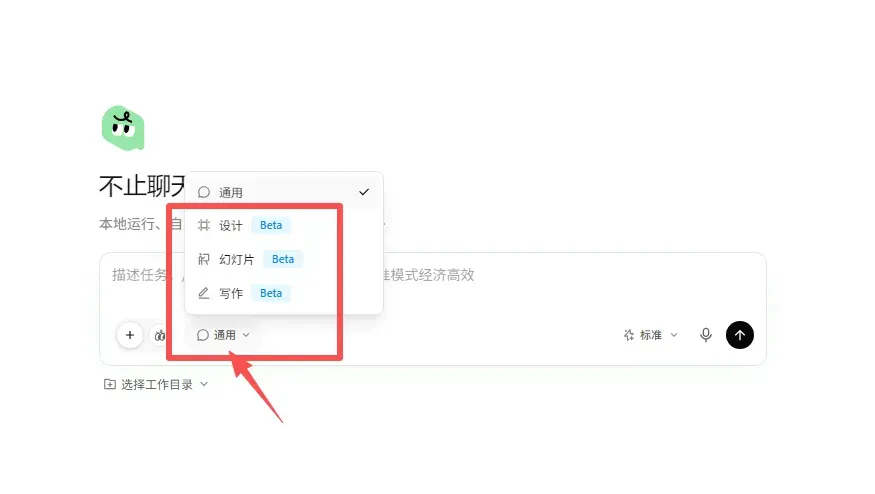
同时推出的还有 PPT 和写作模式,感兴趣可以自行体验,详细说明可查看 QoderWork 官方发布内容:QoderWork 自定义工作台介绍
接着选择参考风格,QoderWork 内置了 161 种风格。

比较值得推荐的包括:
- Apple:一看名字就知道,特别适合科技产品网站,极致留白加克制层级。
- Figma:如果你需要原生 Web 图形控制和产品色彩,这个风格是首选。
- Github:纯正的 Markdown 风,程序员最爱。
- Notion:文档式效率工具风格。
- Bold:深色技术产品,做信息图或大字报非常顺手。
- Claude:Anthropic 经典的暖橙搭配,极简主义。
- Airbnb:尤其适合市场营销页面。
- Carbon:企业后台、B 端产品首选。
拿不准的话可以勾选“自动选择参考风格”,但主动指定后产出的效果更可控。
便携式智能标签打印机选品:锁定$45-65蓝海,DTC品牌破局全攻略
便携式智能标签打印机堪称跨境DTC领域的教科书级选品。据DataIntelo数据,全球便携标签打印机市场规模将从2023年的15亿美元攀升至2032年的32亿美元,复合年增长率(CAGR)达8.7%。北美以38%的份额成为最大市场,而45至65美元价格区间存在清晰的品牌真空,为DTC品牌切入创造了绝佳机会。
市场全景:标签打印机行业的增长引擎与区域分布
消费级标签机市场预计从2025年的26.5亿美元增长至2032年的39.8亿美元,CAGR为5.97%(ReportPrime)。多重增长动力汇聚:居家办公模式的常态化(DataIntelo)、小型电商卖家对运输标签的需求激增,以及TikTok平台上收纳美学内容的病毒式扩散。从区域看,北美、欧洲和亚太分别占据38%、27%和30%的份额。值得注意的是,蓝牙+App智能机型正快速替代传统QWERTY实体键盘机型,成为消费主流。
竞争版图:四层价格带品牌博弈与产品短板
当前市场格局可划分为四个价格带。15-30美元的红海区,Phomemo D30(18美元)、CLABEL 221B(25美元)、NIIMBOT D110(约30美元)等六个品牌扎堆竞争;30-45美元的黄海区,由Phomemo M110、SUPVAN T50M Pro和DYMO LM160各自把守,但每款产品都有明显限制;45-65美元的蓝海区,仅NIIMBOT B21(59美元)一款产品独立支撑,其4.4星评分暴露了产品短板;65-80美元的高端区,Brother P-Touch Cube(70美元)独占鳌头,然而蓝牙距离过短、必须使用交流电源以及胶带锁定等痛点也十分突出。
| 品牌 | 型号 | 价格 | 评分 | 主要短板 |
|---|---|---|---|---|
| Brother | P-Touch Cube | $70 | 4.5★ | 每张标签浪费约1英寸空白、蓝牙范围仅5英尺、无电池供电 |
| NIIMBOT | B21 | $59 | 4.4★ | 仅支持2英寸窄标签、203DPI清晰度平庸 |
| NIIMBOT | D110 | $30-40 | 4.6★ | 完全依赖手机App、149克轻巧易丢失 |
| Phomemo | D30 | $18 | 4.3★ | 需联网操作(存在隐私隐患)、仅支持单色打印 |
| SUPVAN | T50M Pro | $35-45 | 4.5★ | 强制使用RFID锁定标签、Mac版本功能残缺 |
| DYMO | LM160 | $38-40 | 4.5★ | 不支持蓝牙、需6节AAA电池供电、LCD屏幕无背光 |
切入蓝海:$49-59区间DTC品牌的黄金窗口
在45-65美元区间,仅靠NIIMBOT B21一款产品守门,其4.4星评分和2英寸窄标签的限制将其产品缺陷暴露无遗。如果DTC品牌以49.99美元定价入局,搭载300DPI日本ROHM热敏打印头、2500mAh大容量电池、通用标签兼容性、BLE 5.3连接以及莫兰迪5色时尚设计,便能精准建立“比中国供应链产品更优质、比Brother更自由”的品牌认知。差异化的内核在于——不锁定耗材、不强制注册、品质毫不妥协,以“自由标签”的品牌哲学破局突围。
品牌方案:TapeMate(贴谱)的产品定义与优势
| 维度 | 配置 |
|---|---|
| 定价 | $49.99 基础款 / $59.99 Pro款(含5卷豪华标签套装) |
| 分辨率 | 300 DPI 日本ROHM热敏打印头(同级最高) |
| 标签宽度 | 0.5-2.0英寸全尺寸+连续/模切双模 |
| 连接 | BLE 5.3 (50英尺以上) + 物理打印键(离线应急) |
| 电池 | 2500mAh USB-C快充,支持连续打印4小时以上 |
| ODM成本 | $16-20/台 |
| 毛利率 | 58-68% DTC直营 |
| 设计 | 莫兰迪5色+铝合金侧边+极简圆角 |
耗材订阅模式:构建“剃须刀+刀片”式高利润闭环
标签打印机是典型的耗材驱动品类。标准标签带3卷装终端零售价12.99美元(ODM成本仅1.80美元,毛利率高达86%)。TapeMate Club月度订阅计划定价9.99美元,任选3卷标签带,并赠送独家模板与AI设计助手。假设有20%的用户转化为订阅会员,单人年度贡献可达119.88美元,客户终身价值(LTV)将增至首购的3.4倍。耗材整体毛利率超过80%,远超硬件本身。采用“开放兼容+自有品质耗材”的双轨策略,既能保证利润空间,又不会损害品牌口碑。
创作者的真正焦虑,不是流量,而是如何让好故事被看见——Omniwork Agent 实测体验
最近我体会到一种难以名状的焦灼感。它不源于流量数据的涨跌,也不来自技术冲击的恐惧。做内容这几年,我早已习惯起落,爆款固然欢喜,平淡也能复盘,绝不至于为此辗转反侧。我更不惧怕 AI 抢饭碗,因为我本就是靠 AI 协作的人,它帮我检索、帮我生成、帮我执行,我早就被“替代”了一半,而且还被替代得相当愉快。

我的焦虑埋在更深的地方:究竟怎样才能做出让自己真正满意的作品?
最近,一部潮汕方言电影《给阿嬷的情书》在市场上掀起波澜。它仅靠 1400 万成本、全素人阵容,从首日 1.6% 的排片逆袭,总票房突破 10 亿,豆瓣评分高达 9.1。它靠的不是特效,不是明星,也不是所谓的流量密码。导演蓝鸿春透露,团队在东南亚做了大半年的田野调查,采访了无数老华侨,影片里 90% 以上的细节都来自真实原型。那些侨批信札上的字句,每一行都承载着鲜活的人生,有情有义,有血有肉。

AI 能写出这样的故事吗?能。但它永远写不出那种纸短情长的分量——因为它从没有在异国深夜,听一位九十岁的阿婆讲述年轻时替人写信的往事,不知道“江海有岸,团圆可盼”这样的句子背后,是揉了又揉的思念。
所以创作者真正的焦虑,从来不是流量或技术,而是:“我到底能不能打磨出真正让自己满意的作品?”这道标尺,难以量化,也无法靠工具直接填补。
我见过很多同行用 AI 提效后,产量翻番,可作品却变得像流水线成品——结构完整、逻辑无懈可击,就是少了一股劲儿。我自己也经历过这样一段时期,写了一大堆东西,回头再看,每篇都算“过得去”,却没有一篇让我真正兴奋。
正是在这个节点,我开始认真研究 Agent OS 这类产品。我不是期望它们直接帮我写出好内容,那本来就是伪命题——好内容是想出来的,不是生成出来的。我想弄清楚的是:这些专门服务创作者的 Agent 产品,能不能让“找念头”的过程更高效?能不能让我在繁杂的素材里,更快地挖到那个值得深挖的角度,找到那个能打动人的切口?

一手实测:Omniwork 如何嵌入创作流
今天想和大家聊一个叫「Omniwork」的 Agent OS 产品。先看它的界面。
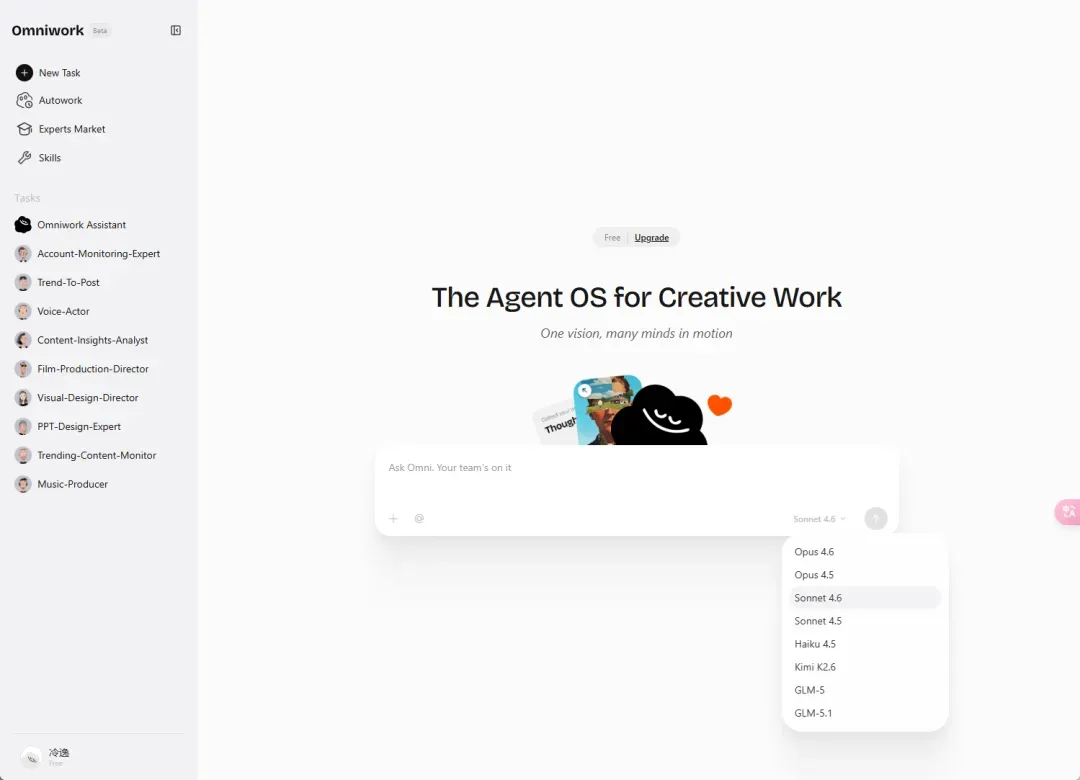
和主流 AI 产品类似,左边是功能栏,包含自动化任务、专家团队(Agent Team)和 Skills 市场,模型方面以 Claude、Kimi、GLM 为主。下面通过四个案例来感受它的真实表现。
1)拆解《给阿嬷的情书》
Omniwork 内置了大量专家,比如这位叫 Trend-To-Post 的专家,擅长追踪热点,为小红书、X(原 Twitter)、公众号等平台创作内容。
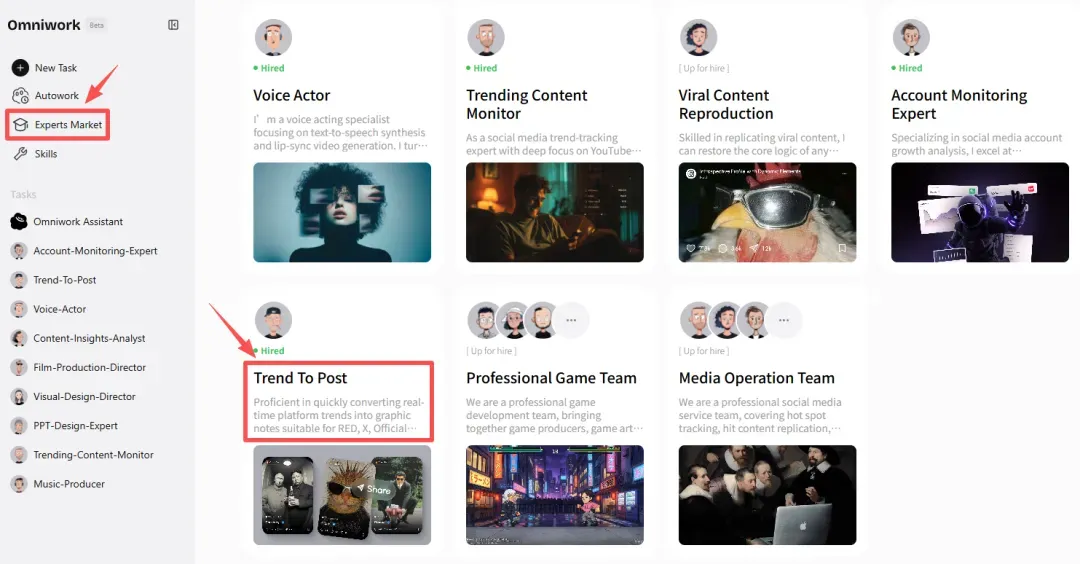
我们“雇佣”一下他。
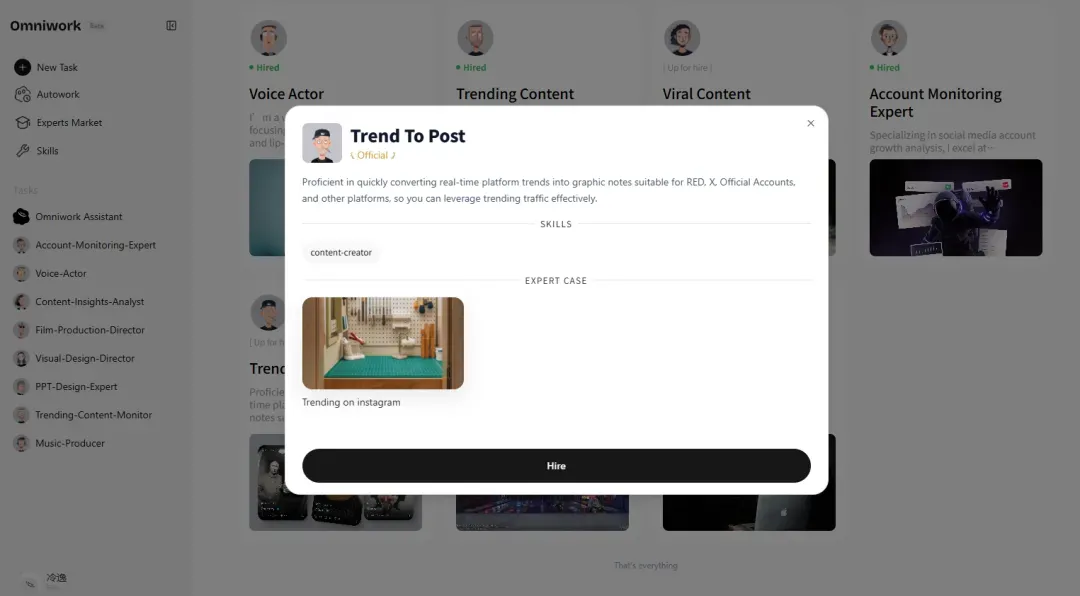
派给他一个任务:
分析《给阿嬷的情书》为什么会火?作为创作者应该如何讲好故事?给了我们什么借鉴。据此创作一篇小红书笔记。
他会自动生产出一整套素材,包含封面图、配图、标题和正文。
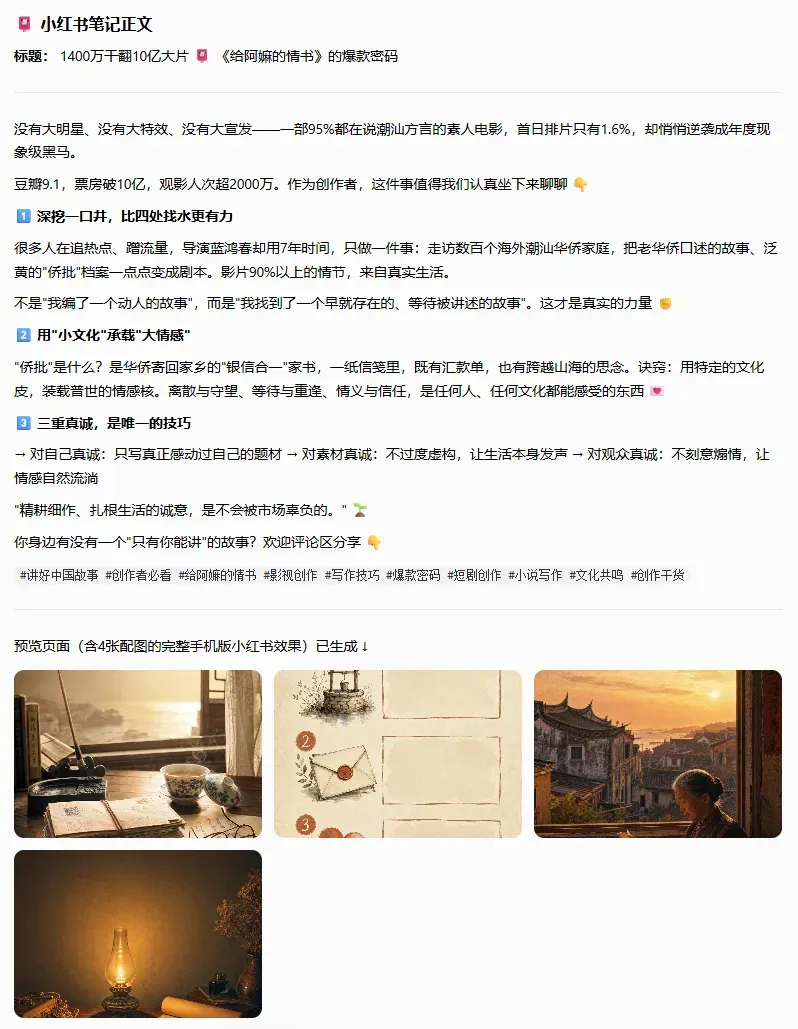
甚至额外做了一个 HTML 预览页面。
仅有图文还不够,我接着让它输出一份 PPT。无需另开任务窗口,直接用对话调起专家就行。
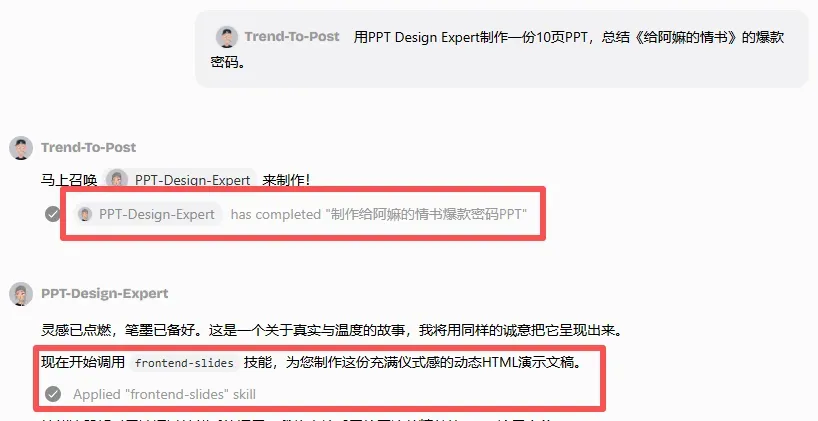
PPT 的视觉调性还不错,暖琥珀色搭配深棕和潮汕红,呼应了侨批信件的时代感。
大明PPT Agent Team:用Multi-Agent架构打造TED级演示文稿
大模型在处理长任务时,就像人的精力一样,上下文一长就容易混乱,要么逐渐变笨,要么直接罢工。我在阅读明史的过程中,发现明朝那套官僚体系非常契合Multi-Agent架构,于是便动手搭建了一支“大明PPT Agent Team”,专门用来产出高质量的PPT。

在这套架构里,你(用户)就是皇帝,是整个Agent Team的最高统帅,对任务和结果拥有一票否决权。调用这支团队,就相当于“皇帝诏曰”。
它的运行逻辑是这样的:
- 你下旨给内阁,内阁负责分配任务、监督进度、汇总结果。但内阁只管理流程,不亲自干活。
- 内阁接旨后,会把任务派发给锦衣卫、东厂、翰林院、工部、织造局等Agent,由它们具体执行,内阁则确保政令畅通。
整个Multi-Agent的工作流程是:下旨 → 深度研究 → 事实核查 → 大纲生成 → 配图生成 → HTML PPT 最终输出。
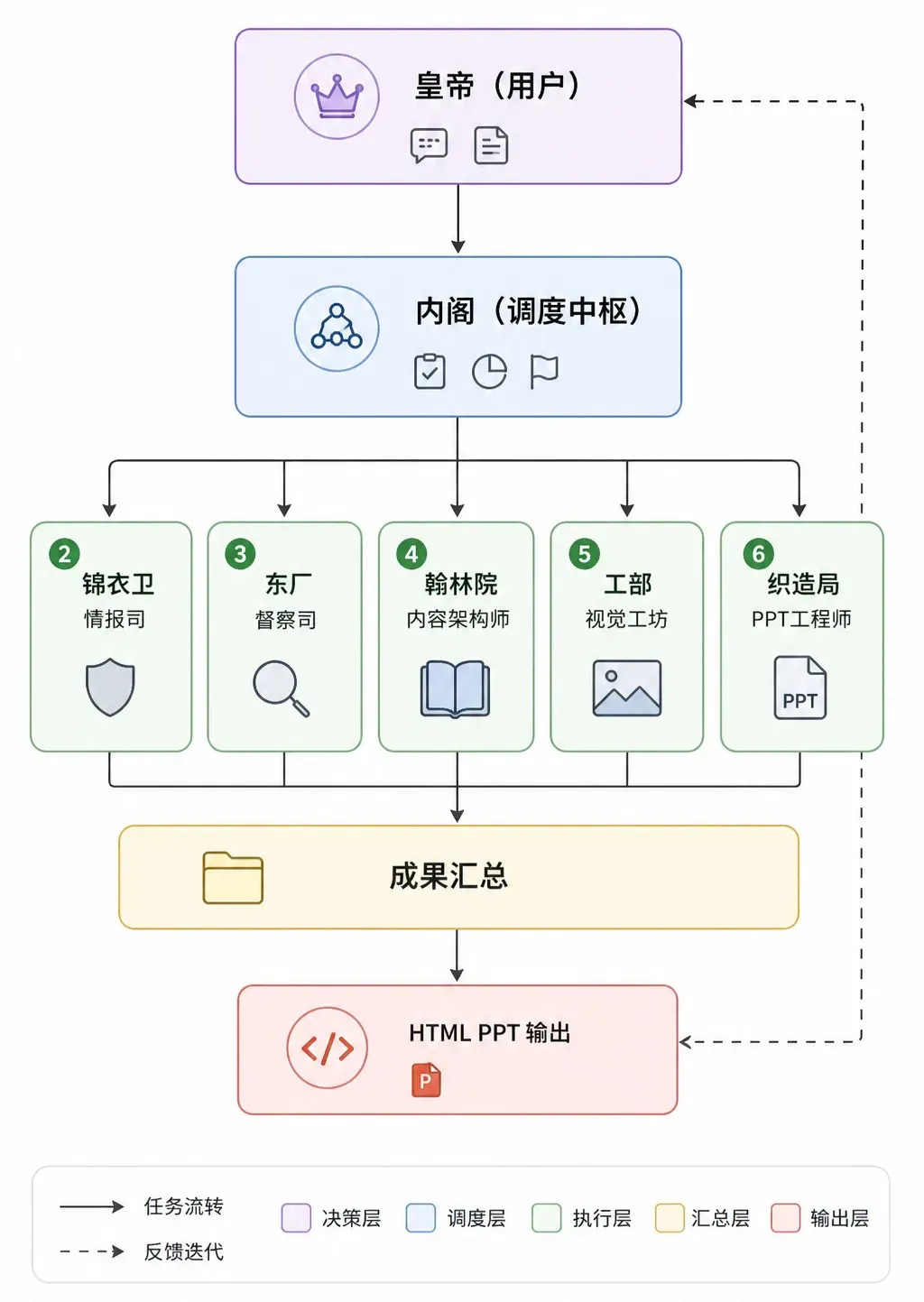
在这个过程中,皇帝(你)只需要躺在床上办公,会用微信就足够了。
整套Multi-Agent架构已经开源在Github上,欢迎大家star。
开源地址:
https://github.com/woyin2024/lengyi-ppt-agent-team
上周,MiniMax Agent桌面端上线了Agent Teams功能,我把这套架构迁移到了MiniMax Agent上,制作PPT的质量和效率都显著提升,尤其是在质量方面。
来看看几个示例。
这套架构重点解决了信源质量、演讲风格和流程自动化的问题,能够直接产出TED叙事级别的PPT。

使用流程
接下来,详细介绍一下这套Multi-Agent架构在MiniMax Agent里的具体运作方式。
0)前置准备
首先,前往MiniMax官网下载并安装MiniMax Agent桌面版,Windows和macOS系统均支持。

下载地址:
https://agent.minimaxi.com/download
然后,订阅一个Token Plan。

目前,MiniMax已将TokenPlan和Agent Plan合并。只需一次订阅,就能打通CLI、API、Agent;M2.7、音乐、视频、语音等所有模型也都包含在内。这一点确实非常赞。
桌面版安装完成后,为它指定一个工作文件夹。建议单独新建一个文件夹,把需要用到的上下文素材(比如图片、视频、文档等)都统一放到这个文件夹里。
这样,后续的上下文引用和输出产物都会保存在该文件夹中。
接下来,为它连接即时通讯工具,飞书和微信都支持,操作很简单,扫码就行。
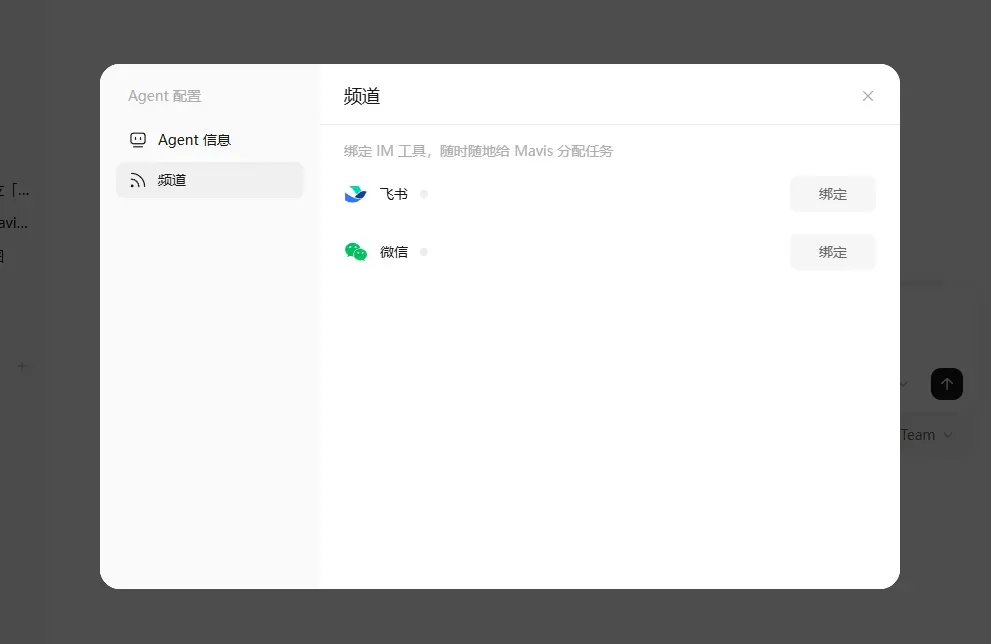
这个连接方式不是企业微信的模式,也不是客服消息那种,而是在个人微信里就能拥有一个AI好友,可以直连MiniMax Agent。
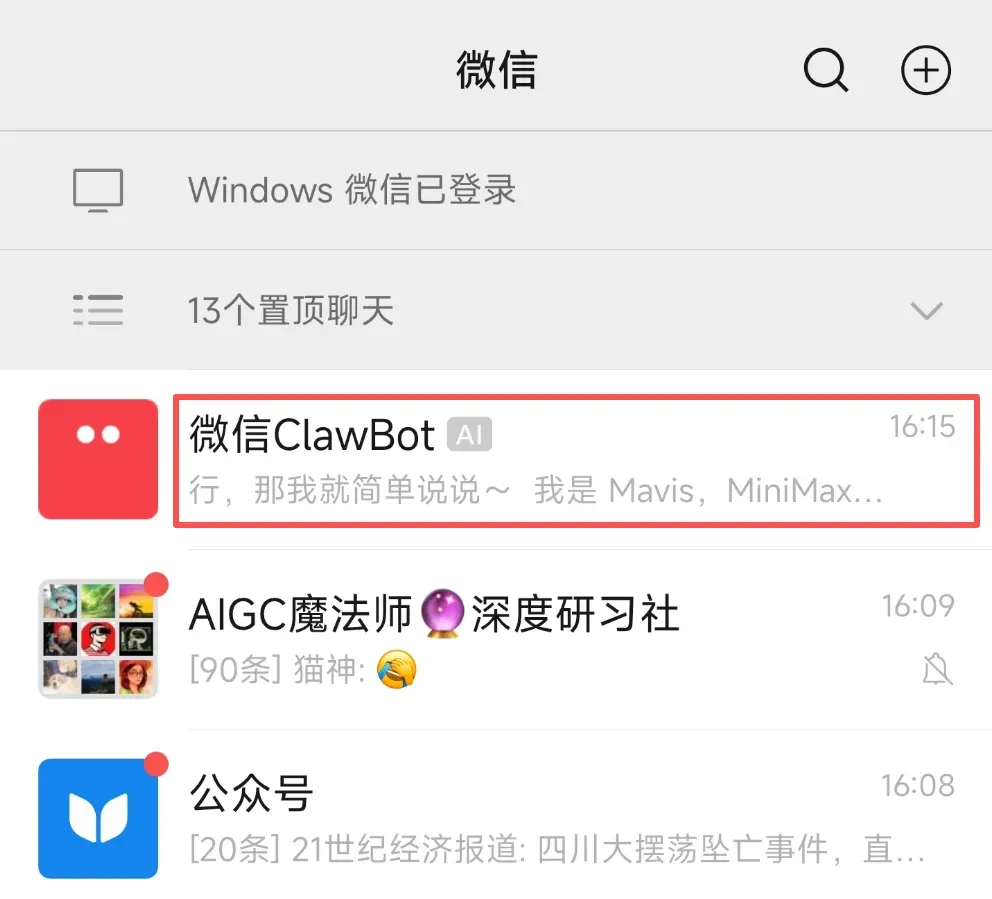
这样一来,你就能随时随地移动办公了,躺在床上都行,保证旁边没有旁人酣睡(笑)。
MiniMax Agent内置了一个技能中心,里面有很多skills可以直接安装,也可以自己创建。
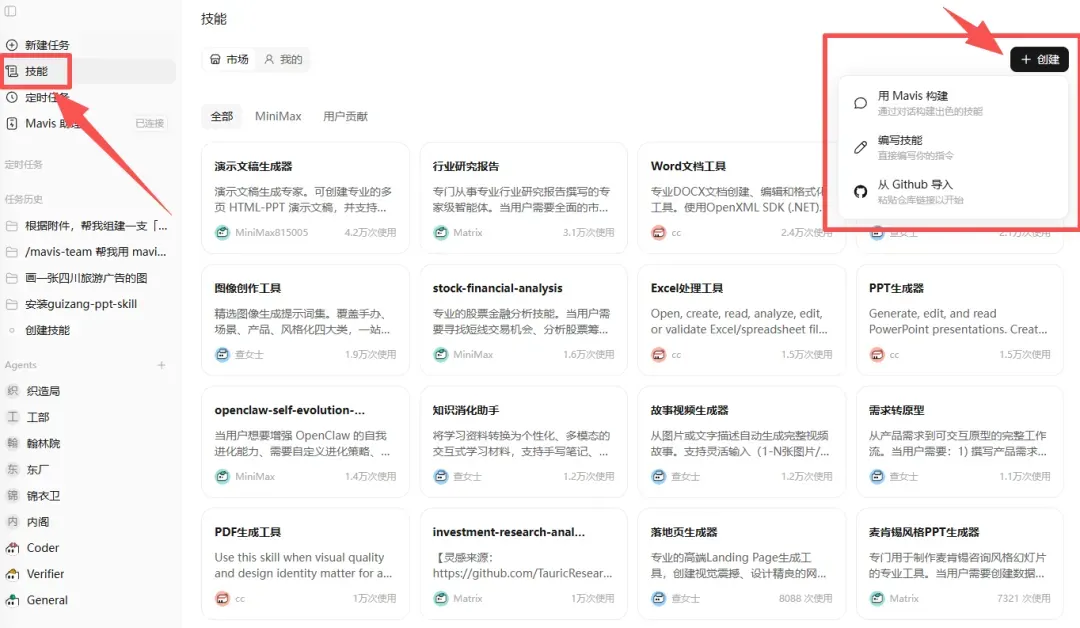
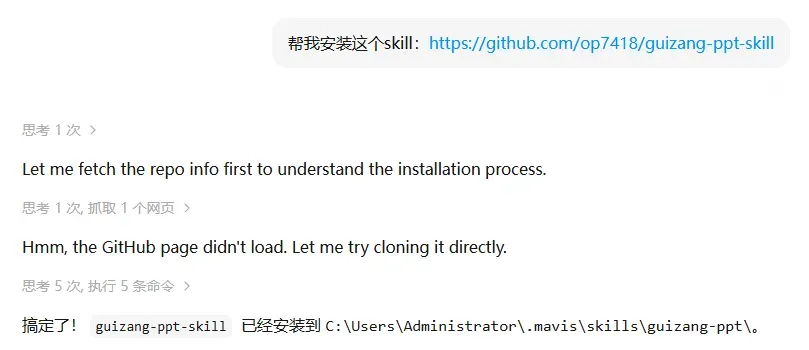
这次的大明PPT Agent Team需要用到guizang-ppt-skill,我们需要提前安装。安装也很简单,直接对Agent说:
帮我安装这个skill:https://github.com/op7418/guizang-ppt-skill
1)创建Agent Teams
MiniMax为升级后的Agent起了个新名字,叫“Mavis”,来源于Jarvis,寓意MiniMax as a Jarvis。
抖音火苗永不熄灭!NAS自动化工具帮你轻松守护好友火花
最近发现身边不少朋友在默默维护抖音好友的火苗标志,有人甚至还组队合养什么精灵。你别说,这玩法就像当年QQ里的“友谊的巨轮”,或者更早的QQ情侣红钻,只不过换了个平台延续下来了。
这次要介绍的恰好就是一个可以在个人自用场景下,帮你自动维护抖音火花的小工具。它自带了Web管理面板、专用的登录桌面、定时任务编排和代理配置模板,默认通过Docker Compose一键部署,很适合跑在NAS上。
温馨提示:本文内容仅限个人学习、技术探索与自我测试使用。任何涉及第三方平台账号、登录态和互动操作的工具,都务必遵守对应平台的规则,不建议将其用于商业营销、批量触达、骚扰他人、异常高频操作或其他可能影响平台生态与用户正常体验的场景。
核心功能亮点
- · Web管理面板,在局域网内即可管理配置、维护目标好友和发送窗口。
- · 集成浏览器登录环境,让你在NAS上就能完成必要的账号初始化。
- · 支持任务配置与手动立即触发,灵活可控。
- · 完整的日志查看功能,轻松排查容器启动、任务执行与服务运行状态。
- · 默认采用Docker Compose编排,包含Web面板、登录工作区、后台任务等多个组件。
- · 提供浅色与深色两种界面主题,日常查看与操作更加舒适。
Docker Compose部署步骤详解
这里以威联通NAS为例,采用源码构建镜像并启动的方案,无需手动拉取现成镜像。首先把整个项目文件克隆到NAS本地,再通过Compose拉起所有服务。
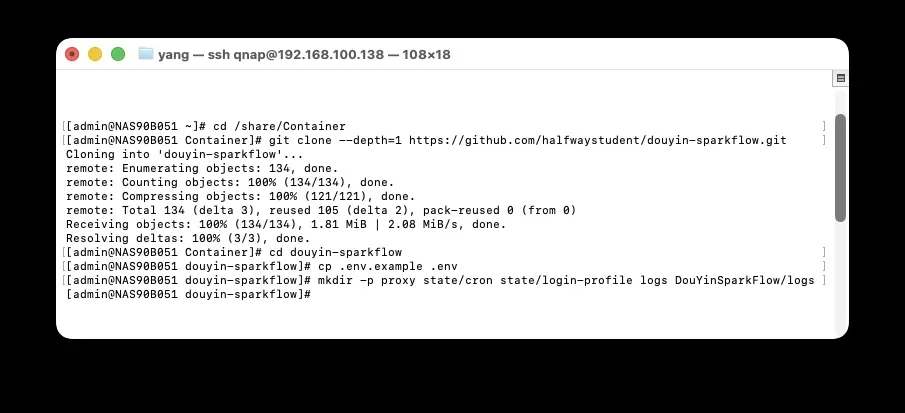
用SSH登录威联通后,进入存放容器数据的目录,比如 /share/Container,执行:
cd /share/Container
git clone --depth=1 https://github.com/halfwaystudent/douyin-sparkflow.git
拉取后可以看到项目文件结构。

继续在SSH里完成准备工作:
# 进入项目目录
cd douyin-sparkflow
# 复制环境变量文件
cp .env.example .env
# 创建必要的挂载目录
mkdir -p proxy state/cron state/login-profile logs DouYinSparkFlow/logs
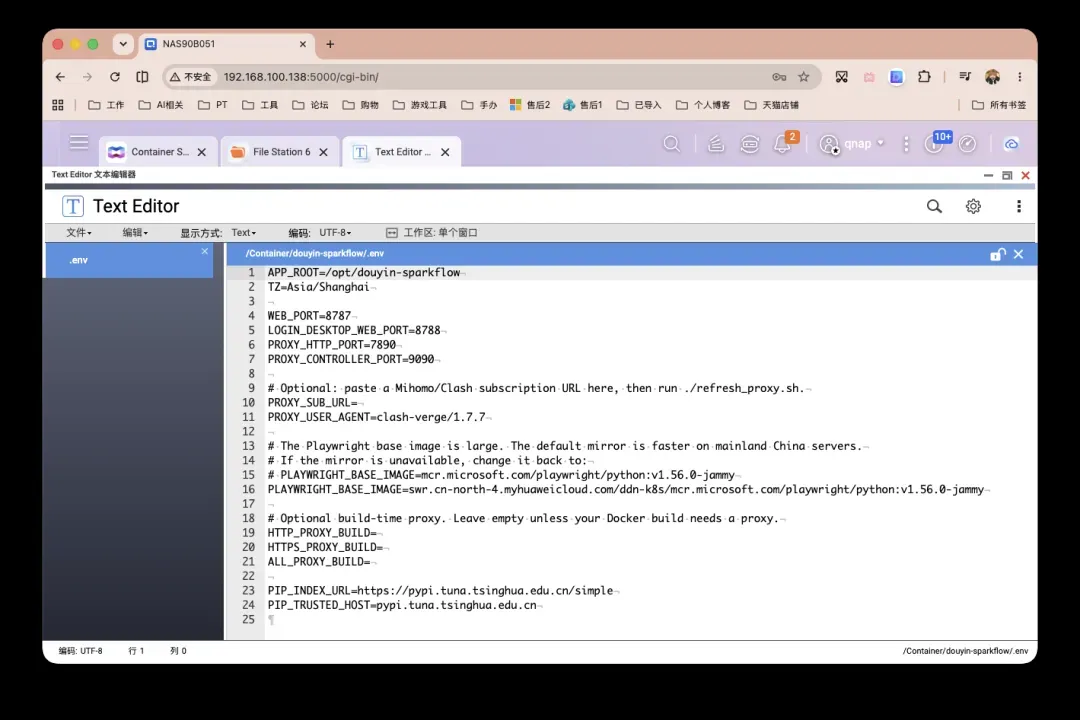
如果有需要,可以自行编辑 .env 文件。另外该项目会额外启动一个Mihomo容器。如果你之前已经部署过同类代理服务,注意避免端口和容器名冲突,在相应位置稍作修改即可。
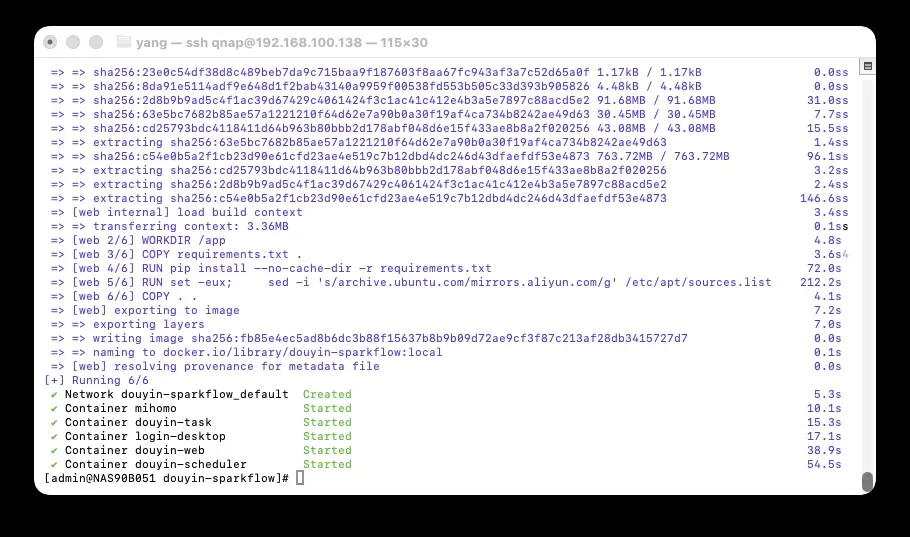
全部就绪后,在SSH中执行启动命令:
# 首次启动会构建镜像,耗时可能较长
docker compose up -d --build
国人友好开源知识库PMBrain:本地部署,支持DeepSeek与全格式文档导入,构建你的AI第二大脑
知识库(RAG)已经成为AI时代不可或缺的基础设施。大模型再强大,本质上仍是“租用的智力”,只有沉淀到个人知识库中的内容才真正属于自己。正因如此,我一直希望构建一套真正贴合自身需求的知识库系统。
探索历程:从多种方案到GBrain
我几乎试遍了市面上的主流知识库产品和构建方法。最初从Karpathy的本地知识库构建思路入手——那是一套通过Obsidian整理笔记再编译为个人wiki的方法,非常适合记录思路与灵感,至今我仍用它来梳理个人想法。但它仅支持Markdown,处理其他格式的资料需要手动转换,整理原始数据相当耗时。虽然如今大模型调用成本大幅下降,这套方案仍然只适合搭建小体量知识库。
在线知识库(如NotebookLM、ima等)或嵌入智能体的知识库功能使用起来方便,但数据保密性是无法回避的痛点。并非所有项目资料都适合上传至云端,这种不确定性让在线库时用时停,最终几乎处于半荒废状态。此外,文件同步也是一笔糊涂账:哪些已同步、哪些未同步,维护一段时间后常常因过于繁琐而放弃。
后来我接触到Garry Tan开发的Gbain——一个在Karpathy理论基础上进一步演进的开源产品。它能自动完成知识整理过程:只需给资料,系统直接向量化,随后可以从任意角度搜索、全面覆盖关联知识。Gbain完全本地部署,并支持各类AI工具调用。
该产品在GitHub上开源,因功能强大且本地化安全,许多公司和个人纷纷部署。横向对比多款开源知识库(如清华UltraRAG等),Gbain的内核确实最为强悍。不过,其设计偏向海外高知用户,对普通中文使用者并不友好:仅支持Markdown原始资料收集,无法直接处理Word、Excel、PDF等日常文档格式;不支持中文分词与反馈;也无法接入国内主流大模型和AI生态。这些短板让国内用户使用起来步履维艰。
开源改造:打造更懂国人习惯的PMBrain
基于以上痛点,我决定在Gbain基础上进行深度定制,让它真正符合日常工作流。几个迭代下来,终于做出了稳定可用的初版,并在实际使用中验证了关键问题的解决:
- 通过MCP协议无缝接入Codebuddy、Workbuddy、Codex等常用AI工具,调用毫无障碍。
- 原生支持doc、docx、csv、xlsx、pdf等文件格式,一句话即可完成批量导入,彻底告别手动转Markdown。
- 检索效果大幅优化,信息可以快速呈现。
- 全面兼容国产大模型API,如DeepSeek、MiniMax、智谱等,自由选用向量化与对话模型。
- 本地化部署过程稳定顺畅,无需远程服务器即可运行。
我将这个项目命名为PMBrain。起初是想为项目经理(我本身是产品经理同时负责项目)打造一个“大脑”——面对堆积如山的会议记录、各类文档和待办事项,必须有一个可靠的知识库来承载。后来发现,这套基于原作者强大内核的改造,几乎适用于任何知识库场景,堪称一个可移植的“第二大脑”。为了让更多人受益,我将其完全开源,地址为:https://github.com/zhengyunhui123-dev/PMBrain
项目开源、代码可自由下载维护,无需付费,且完全本地部署,不需要任何服务器资源,没有任何停服或跑路风险。我的目标是打破信息壁垒,不断为其注入新能力,持续迭代下去。
安装与使用指南
安装流程非常简洁,全程可由AI工具自动化完成:
- 将GitHub仓库地址交给你的AI助手(如Workbuddy、Codebuddy、Cursor等),它会自动执行安装。
- 准备至少两个大模型API:一个用于向量化(推荐智谱embedding-3,10元成本即可开始体验),另一个用于对话与搜索(推荐性价比极高的DeepSeek)。
- 安装完成后,让AI工具接着配置MCP接入。
- MCP就绪后,测试导入文件;如果导入成功,即代表整体环境已经就绪。
日常使用同样轻松,以下是我最常用的几条提示词,可借助AI工具直接操作:
- 文件夹导入:【文件夹路径】将这个文件夹capture到PMBrain中
- 上下文导入:将这个上下文capture到PMBrain中
- 增量同步:把已注册的source在PMBrain全部同步一次
费用与资源消耗
向量化模型(embedding)是必需品,也是消耗最大的部分,具体花费完全取决于知识库的体量。以我目前的使用为例,充值10元尚未用完。如果通过MCP接入AI工具进行对话与问答,额外产生的对话费用极低,主要消耗来自你所使用的AI工具的token。整体而言,仅需承担大模型调用成本,系统本身不产生任何订阅费或服务费。
欢迎各位体验并提出宝贵建议,共同让PMBrain变得更好用。
仅需3.9元解锁无限Token:讯飞星辰Astron Coding Plan接入与实战全攻略
硅谷最近兴起了一种“Tokenmaxxing”(Token刷榜)文化。
Meta内部搞了个Claudeonomics榜,专门追踪员工的Token消耗量,30天内全公司消耗超60万亿Token;黄仁勋直说,如果年薪50万美元的工程师一年没有消耗25万美元的Token,他会“深感不安”;还有OpenAI工程师晒账单,一周两千多亿Token,算下来几万美元就这么没了。
第一次看到这些数字,任谁都会发懵。一个月烧掉几万美元的Token,是什么概念?后来仔细研究了一下他们的用法,才发现这些人并不是在浪费,而是在用Token反复试探AI的能力上限——让AI反复修改、反复跑、反复试错,直到拿到真正可用的结果。
这种用法确实奢侈,但思路本身没有问题。
最近一场Vibe coding线下分享会上,来了七八十位AI coding发烧友。有人问,如何快速建立coding手感?现场一位资深玩家回答:“要练coding手感,先把自己的日Token消耗量拉到亿级再说。”

这不是凡尔赛。言下之意是,如果你每天连几百万Token都没烧过,一直在用免费额度的AI Chat,那你对AI coding的理解大概率还停留在“帮我写个网页”的层面。
当你真的放手去用,让AI搭架构、写应用、跑测试、自己修bug——你才会发现,AI能做的比你以为的多得多,但它的坑,也比你以为的深得多。而这些认知,光靠看教程、刷视频是学不来的,必须自己真金白银地烧过Token,踩过坑,才能长进肌肉里。
但问题是,不是每个人都有Meta工程师的预算。一个月几万美元的Token账单,对大多数人来说就是天方夜谭。
近期,讯飞星辰推出的Astron Coding Plan让人惊呼:这价格,认真的吗?
最低订阅价只要3.9元。注意,不是美元,是人民币。不是一天,是一个月。
这个价格低到什么程度呢?算一笔账:在星巴克买一杯最普通的美式,差不多能订三个月还富余。你中午吃一碗重庆小面,订完Plan还能再买杯蜜雪冰城。这个门槛,几乎等于没有。
当然,便宜不是全部。定价再低,东西不会用也是白搭。
因此,本文将带来具体的上手体验,详细介绍如何接入Claude Code、Codex、OpenClaw这些Agent,比较与其他Coding Plan的区别,并分析讯飞这套打法的深层思路。

深度体验
一、轻松订阅
订阅比较简单,直接前往这个页面,选择需要的Plan即可。
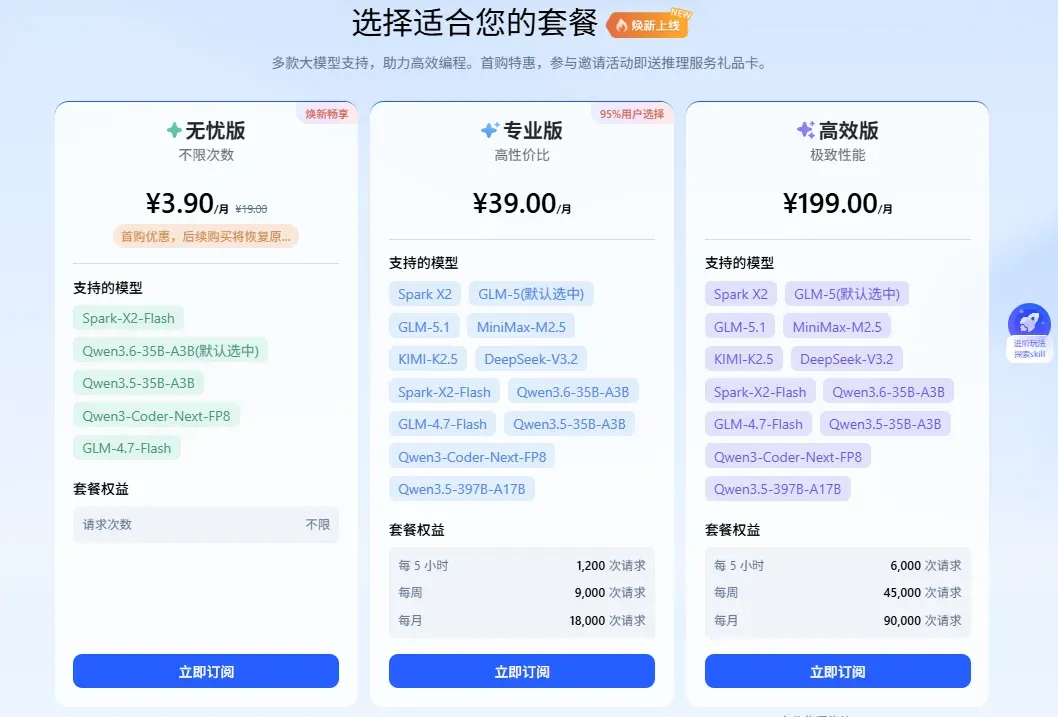
入口:https://maas.xfyun.cn/modelSquare?ch=MaaS-xbkol-wy
这三个Plan,如果想尝新,可以选择无忧版,3.9元一个月,可以体验讯飞星火自家的X2-Flash以及Qwen3.6 35B、GLM4.7-Flash这几个小模型。
注意,请求次数是无限的。这意味着,你可以使劲造,拿来做一些快速开发、重复工作、文档处理、本地脚本等任务,非常好使。
如果是专注编程和长程任务,推荐订阅专业版和高效版,像GLM-5.1、K2.5、Qwen 3.6、DeepSeek V3.2、Spark X2这些国内的主流模型都可以体验。
这2个Plan在模型支持上是一样的,只是请求次数不一样。专业版是每5小时1200次,高效版是每5小时6000次,是专业版的5倍。这个根据自己的需求来,高频开发就上高效版,中频就上专业版。
订阅后返回管理后台,它会自动生成一个Coding Plan的标签模块。
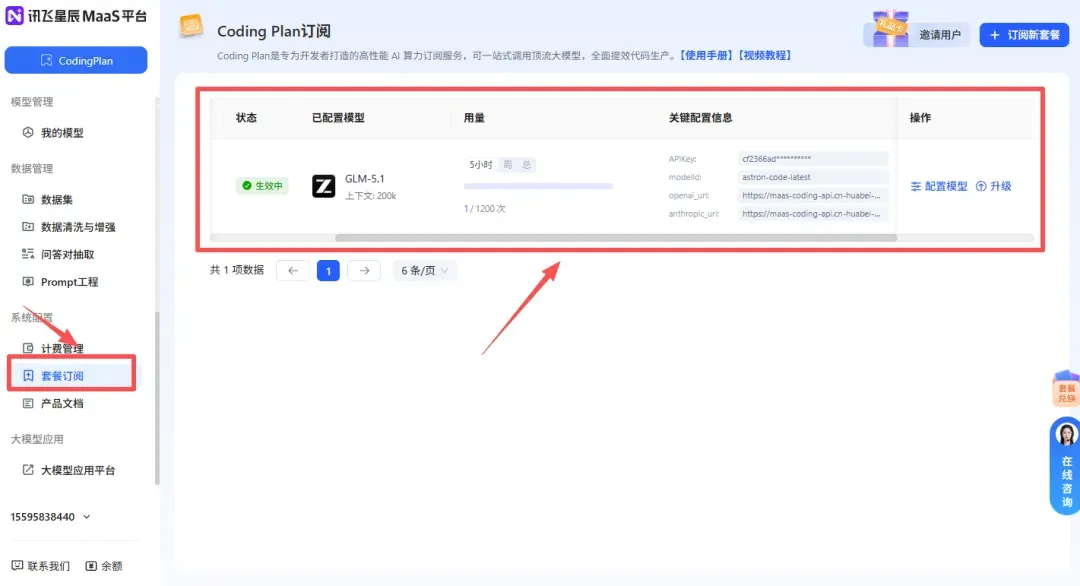
这里面,讯飞星辰把套餐情况、用量统计和关键配置信息都放在了一个地方,非常方便。
API Key、model id、openai_url和anthropic_url都有,它全部帮你配置好了,只需要点一下就可以复制。
如果你是在Codex、OpenClaw、Cursor里用,url用OpenAI格式的;如果你是在Claude Code里用,则用Anthropic格式的。
model id统一填astron-code-latest,这是一个智能路由的模型名。
需要切换模型时,直接在后台点“配置模型”,选择模型后即可,1-3分钟后生效。
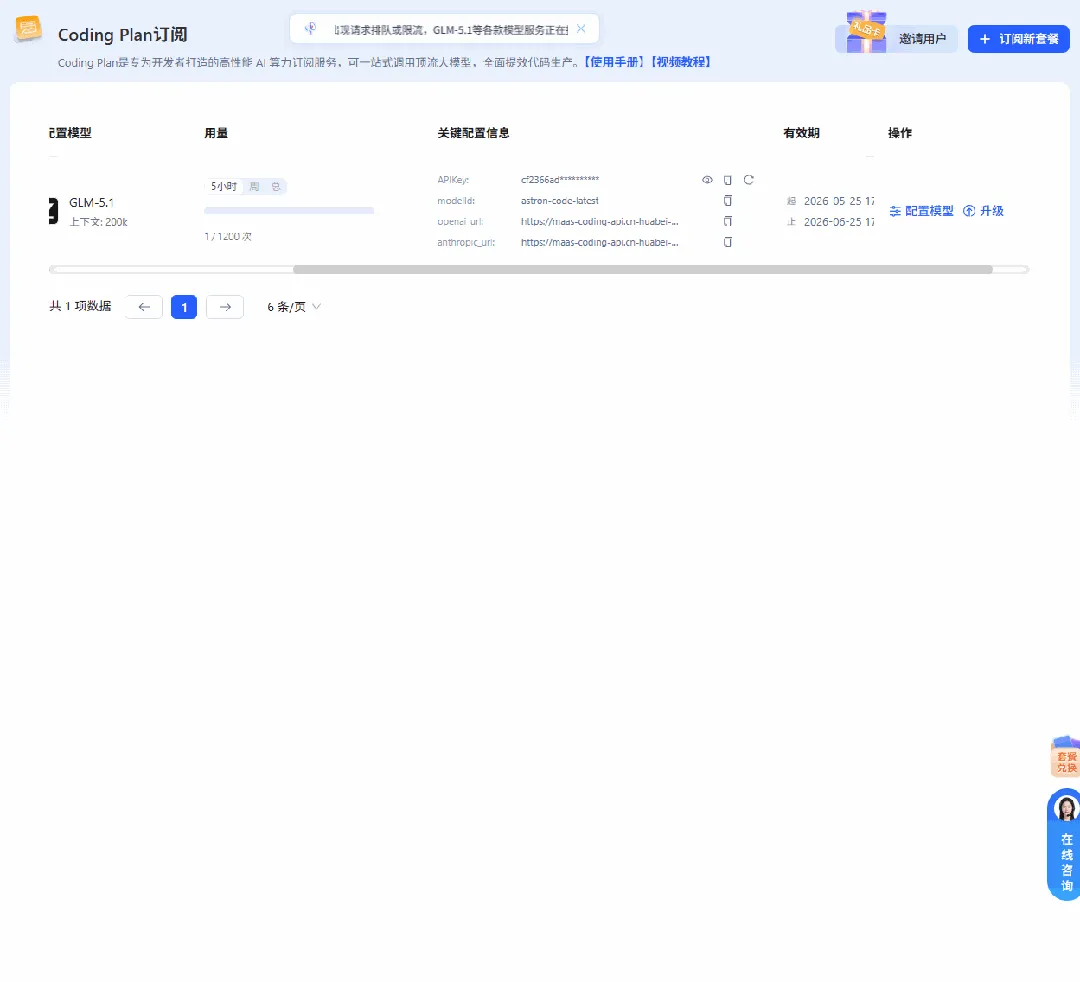
这点非常方便,不用你到CC-Switch这类第三方工具上手动切。
如果不想付费的话,讯飞星辰的模型集市也有很多免费模型可以体验。比如Qwen-3.5-35B和Qwen-3.6-35B这两款小模型,参数虽小但智能不减,可享受7-30天的免费高并发。
二、多款Agent接入指南
订阅了Plan后如何接入到各个Agent里,我们分开讲。
先看Claude Code。
Windows用户,打开cmd,输入这段指令:
setx ANTHROPIC_BASE_URL "https://maas-coding-api.cn-huabei-1.xf-yun.com/anthropic"
setx ANTHROPIC_AUTH_TOKEN "你的API Key"
setx ANTHROPIC_MODEL "astron-code-latest"
macOS用户,在终端输入这段指令:
export ANTHROPIC_BASE_URL=https://maas-coding-api.cn-huabei-1.xf-yun.com/anthropic
export ANTHROPIC_AUTH_TOKEN=你的api key
export ANTHROPIC_MODEL=astron-code-latest
执行指令后,关掉终端,重新再打开一个,随便问几句,看它吐不吐token。能正常吐token,就代表配置成功。