开源熊猫插件panda-gatekeeper:防沉迷提醒比闹钟更凶,一键安装强制休息
最近,我开发了一款防沉迷浏览器扩展,名叫panda-gatekeeper,中文称「熊猫监督员」。当你在网上冲浪时间过长时,一只熊猫会突然出现,用霸屏动画提醒你“主人,你该休息了”,并强制占据屏幕,让你无法继续浏览。
下面是一段体验展示。
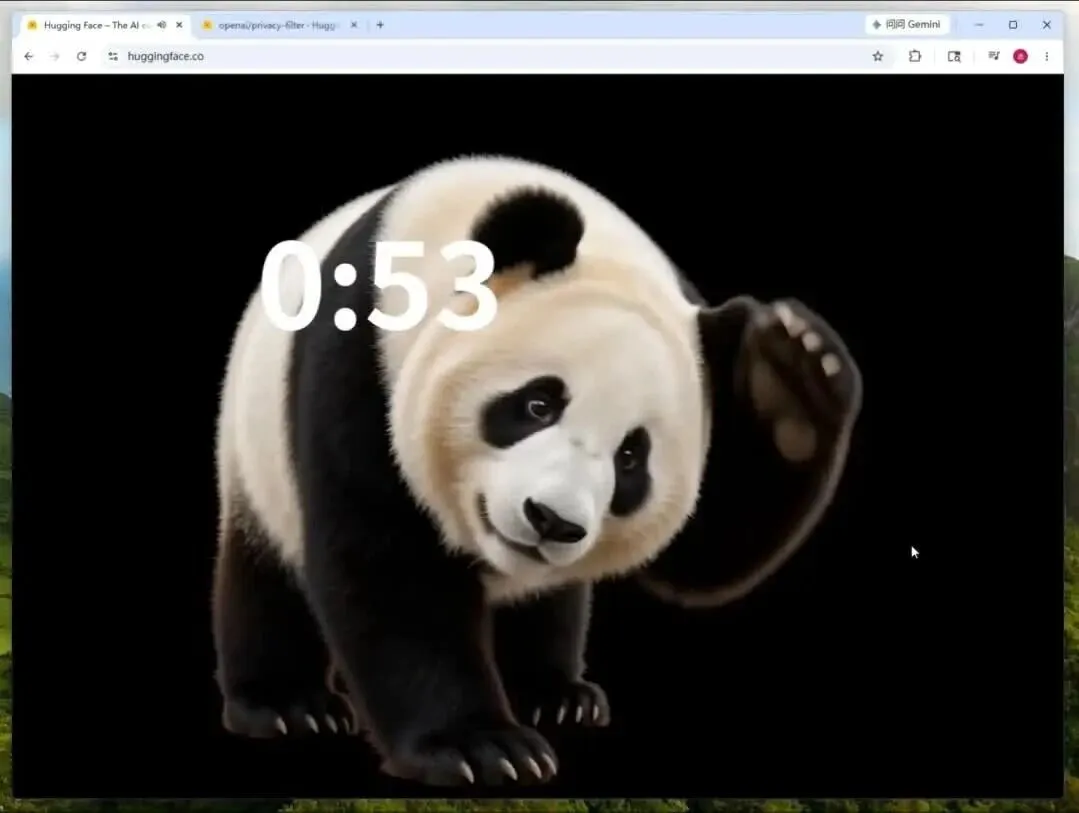
不论你逛的是X、ChatGPT,还是GitHub、HuggingFace,这只熊猫都会强行闯入,每个网站的计时是独立计算的。该扩展支持Chrome、Firefox、Edge等主流浏览器,安装包仅有2MB,运行极其轻便顺畅。
这个项目基于日本开发者@zokuzoku 的「cat-gatekeeper」二次开发而来,我进行了完整的汉化,并加入了一些有趣的新功能。现在已经全部开源,欢迎前往仓库查看。
开源地址:
https://github.com/lengyi2030/panda-gatekeeper

项目开发思路解析
整个项目采用Claude Code配合Step Plan来推进。借助阶跃星辰Step Plan的多模型整合能力,开发进度非常快,前后大约只用了半天。
很多开发者接触过各种Coding Plan,但多数方案只对接单一模型,如果需要切换模型,就得反复手动修改环境变量,操作比较繁琐。而Step Plan提供了另一种思路:它本身就是一个统一的多模型入口,可以在不同任务中动态调用不同能力的模型,一套配置就能使用多种模型。
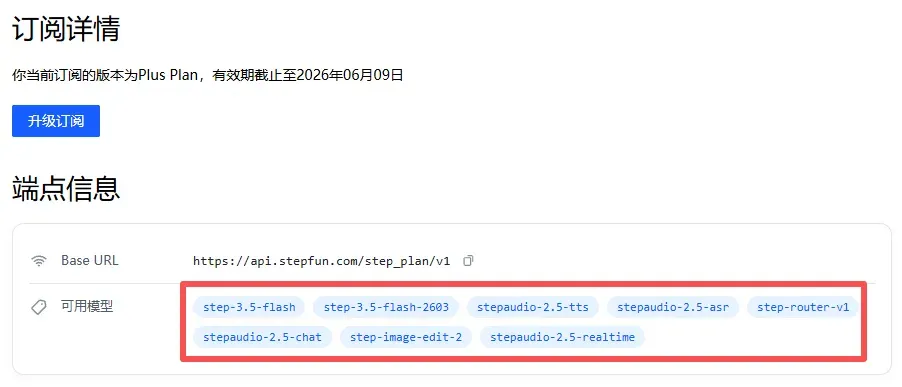
对我这种需要同时写代码、改素材、生成语音的项目来说,“一套配置,多种能力”的体验让流程顺畅许多。
其中有个很实用的模型名是step-router-v1,它能根据任务类型自动智能路由到合适的后端模型,比如step-3.5-flash、DeepSeek-V4-Pro等,通常直接使用这个model就行。
如果你在Windows环境下,可以在终端运行以下命令完成配置:
setx ANTHROPIC_BASE_URL "https://api.stepfun.com/step_plan"
setx ANTHROPIC_AUTH_TOKEN "YOUR_API_KEY"
setx ANTHROPIC_MODEL "step-router-v1"
配置好Claude Code的模型之后,接下来进入具体的开发环节。
1)克隆原始仓库
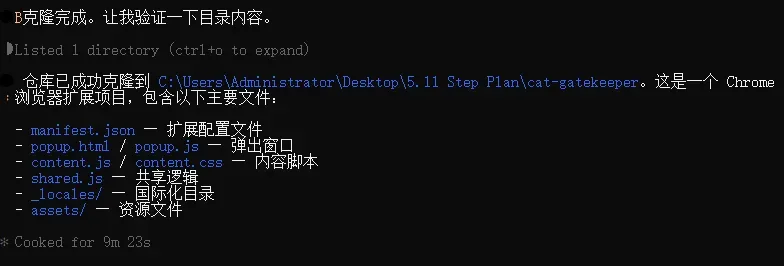
原项目@zokuzoku 已上传至GitHub,我直接让Claude Code把代码拉到本地,指令很简单:
帮我把这个项目 https://github.com/zokuzoku/cat-gatekeeper 下载到指定文件夹。
2)准备素材
初始项目是一只猫咪霸屏,我需要换成熊猫,并添加一些新的功能。于是先询问Claude Code需要哪些素材,它列出了3个图标和2个动画视频需要替换。

图标方面直接使用step-image-edit-2模型生成PNG,尺寸都已经自动适配好,我只需简单裁剪。提示词如下:
用同一个熊猫主体,设计3个png图标,尺寸分别是:16x16px、48x48px、128x128px

视频则随便找了一家视频生成模型,给出提示词:
纯黑背景(网站素材),固定镜头,一只熊猫从画面左侧走过来,做着一些有趣的动作,霸占着整个画面。
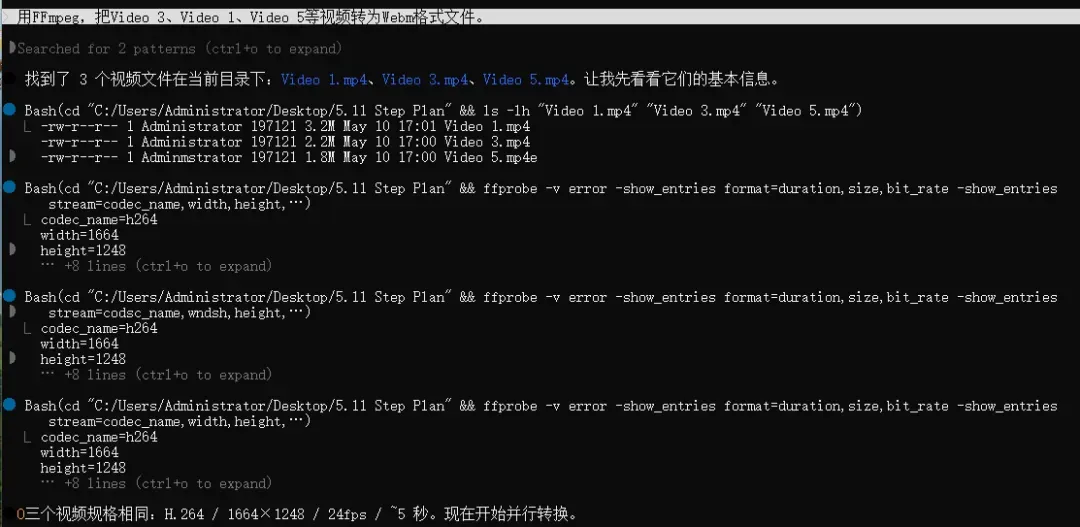
需要注意的是,大部分模型生成的是MP4格式,而要嵌入网页使用,需要转成WebM格式并压缩。我直接用FFmpeg命令行处理:
ffmpeg -i input.mp4 -c:v libvpx-vp9 -crf 30 -b:v 0 -c:a libopus output.webm
如果对命令行有些犹豫,也可以直接告诉Claude Code:“用FFmpeg把xx视频转为Webm格式”,让它代劳。
3)二次开发
素材准备完成后,开始根据需求进行二次开发。我整理了一份明确的改动清单,直接发给Claude Code:
文件夹xxxx放了一个浏览器插件项目,请对这个项目进行二次开发,角色换成熊猫,素材我已经放在assets文件夹了。
要求:
1、刷新频率的时间可以由用户定制。
2、提供测试入口,用浏览器打开即可测试。
3、素材仅用neko1,循环播放。
4、给应用增加语音提醒功能。用stepaudio-2.5-tts模型生成一段audio,配音文字为“主人,你该休息了。听话,现在就离开工位,去喝杯水,看下风景,多走动走动,这是命令”,模拟熊猫憨态可掬的形象生成一段语音内置到应用里。
5、我需要放在Github上,重写README.md,中英日三种语言。
CC先是完整理解了整个项目的结构,然后逐一实现需求,包括内置语音也一并由Step Plan生成。没有花费太多时间即完成修改。
免费体验阿里Qoder:Qwen3.7-max编程工具每日200次免费,值不值?
上星期 Qwen3.7 的消息铺天盖地,都说它很强。能力提升肉眼可见,但也暴露了一个硬伤:价格昂贵!
无论是套餐还是API,性价比都让人摇头。
不过现在情况有变——免费通道终于打开了。这算不算一份六一惊喜?
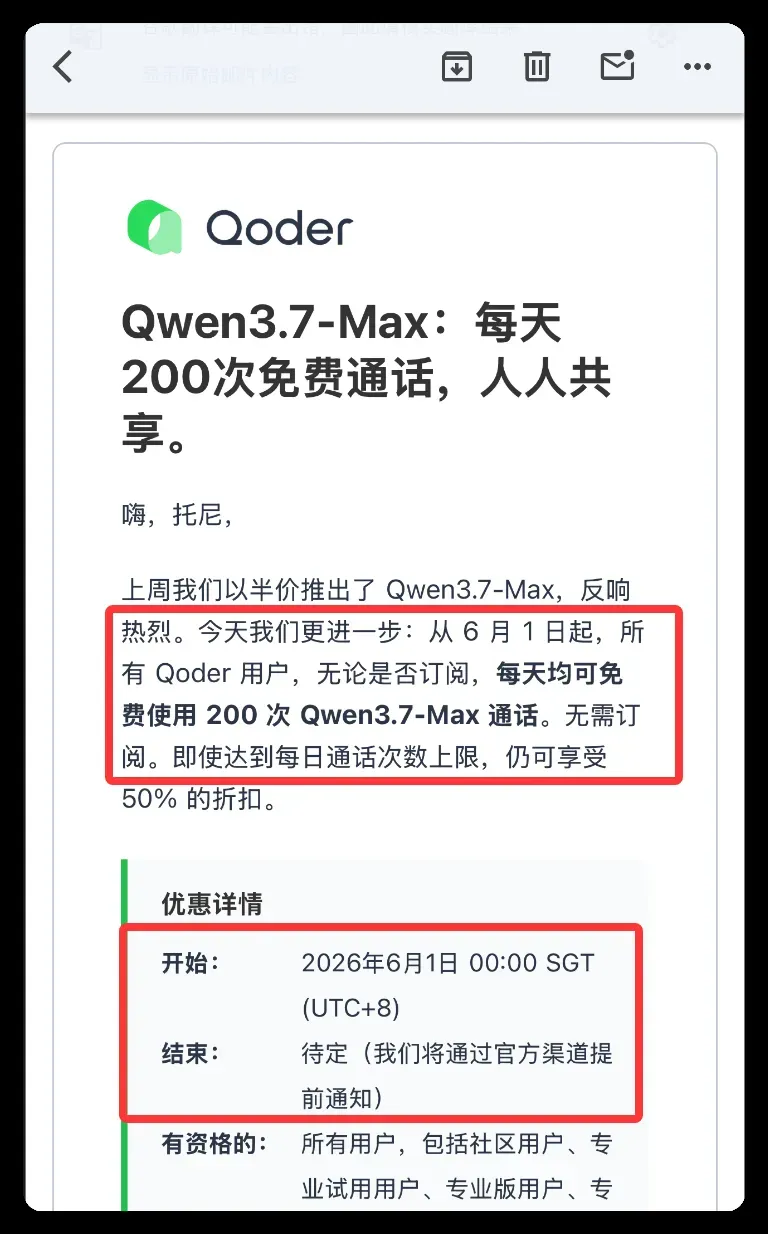
刚收到的邮件原文:
从 6 月 1 日起,所有 Qoder 用户,无论是否订阅,每天均可免费使用 200 次 Qwen3.7-max,无需订阅!结束时间待定。
别觉得每天 200 次太少。如果只计使用次数,一天根本用不完。换算成 API Token 的价值,数百元是轻轻松松的。
前几天我拿它测一个复杂案例,光那次就跑掉了 40 多块。
下面来详细看看怎么玩,顺便全流程走一遍阿里系的编程工具——Qoder。这个名字明显是从“Coder”谐音梗里脱胎而来。
不多废话,直接上手。
打开 qoder.com:
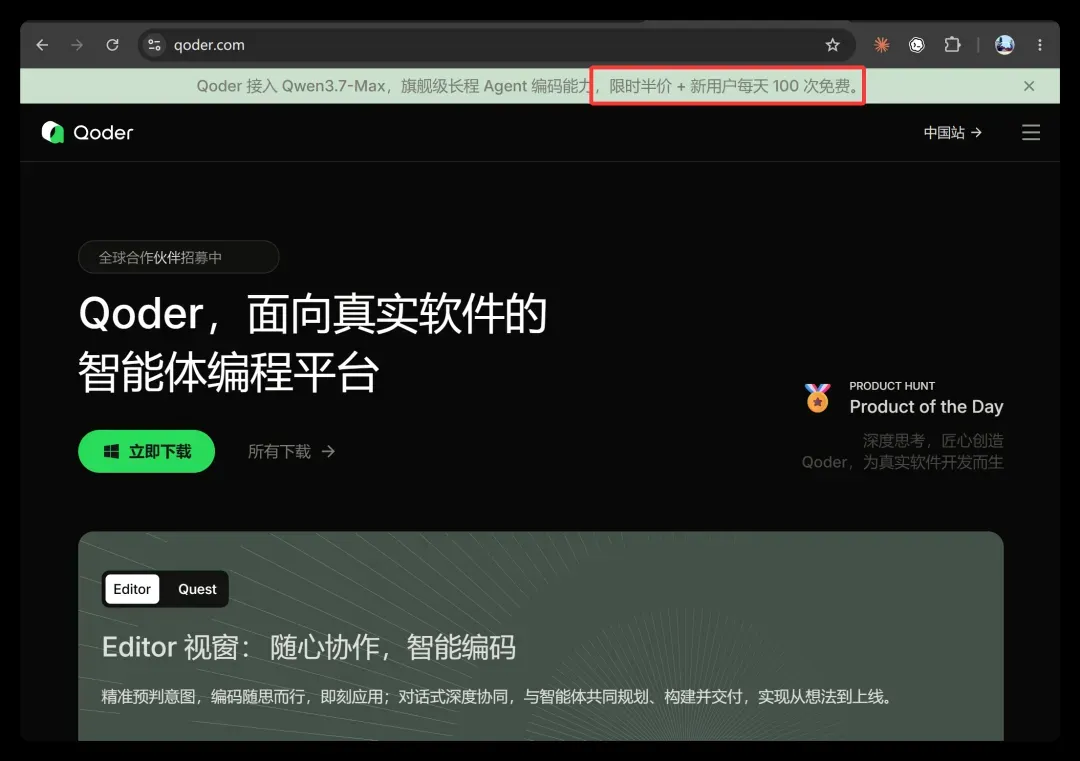
阿里的 AI 产品有时候真的很迷。之前出现过倒反天罡的情况:“订阅用户反而用不了,免费用户却给了 2000 次”。现在邮件里清楚写着 200 次,到网页上却变成了 100 次,到底多少还是先不管了。今天主要体验它的 Qoder 和 CLI,两个都可以免费使用。
去官网下载对应版本,双击安装即可:
前阵子刚卸载,今天又给装回去了。
安装完长这样:
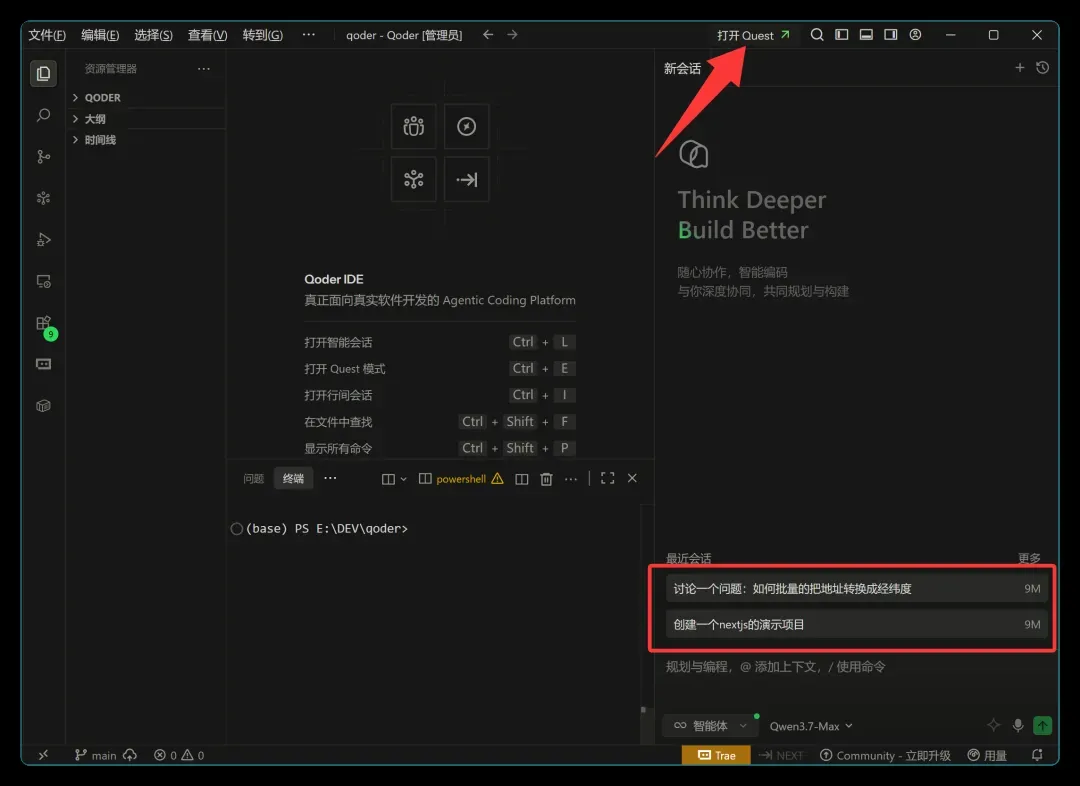
右下角还能看到以前的会话记录,确认我以前确实用过。同时右下角也能找到 Qwen3.7-Max 模型。
这界面本质就是 VSCode 套壳,用法完全一致:新建项目,输入需求,就可以边聊边开发了。不过这种模式我已经用得很少了。
现在请把目光转向右上角的 Quest!
打开之后界面如下:
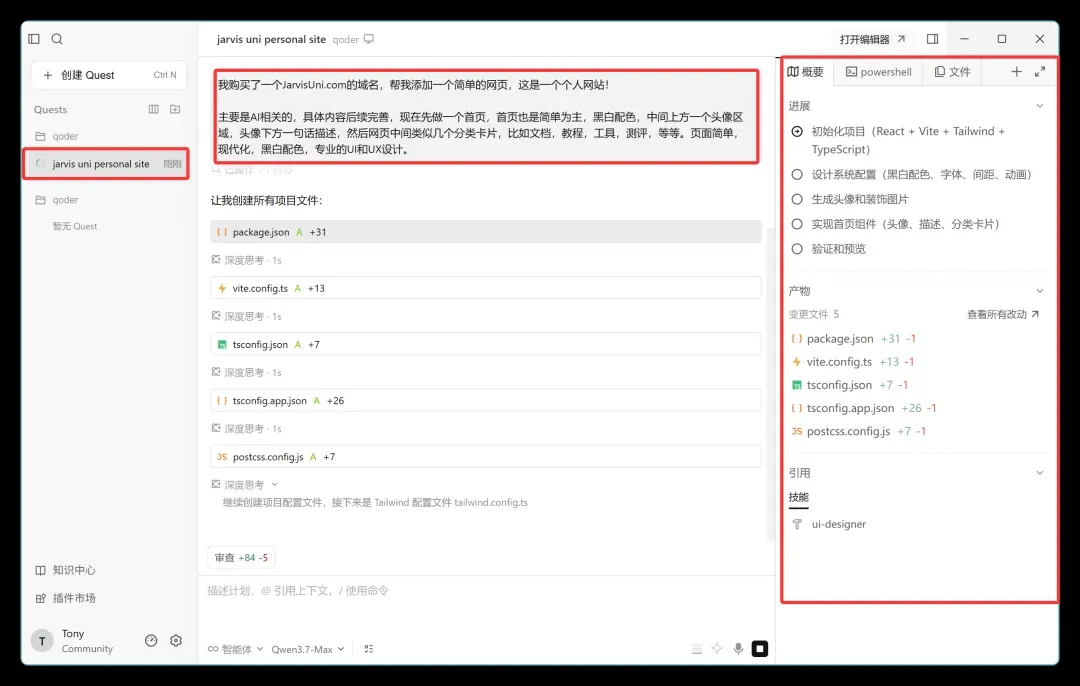
这才是下一代 AI 编程 IDE 该有的样子。
从 Claude 率先打出样板,Codex 紧跟其后,各家大模型公司和开发者都在打磨这类“编程体”。用法也很直接:左边选一个文件夹,中间扔进需求,敲一下回车就开始自动干活了。
右侧会实时展示项目进展、生成物、技能模块、文件列表。
我就写个简单的需求来试一试:
假设我买了一个 example.com 的域名,帮我先做一个简单的个人网站首页。
主题是 AI 相关,后续内容再填充,现在只做首页。风格要求极简化,黑白配色,页面上方中央放一个头像占位区域,下面配一句话自我介绍;页面中部放几个分类卡片,比如文档、教程、工具、测评等。整体追求现代、专业的 UI 和 UX。
它收到需求后会自己拆分步骤、制定计划、执行开发,最后自动打开浏览器预览。
巧用Claude桌面版无缝接入DeepSeek:一键开启多模型混合工作流
前阵子,那篇《骚操作!把Deep Seek接入Claude桌面版!》刷了屏,转发轻松破千。
趁着这股热乎劲儿,我决定再来个“骚操作2”!
前不久我克隆了一份Claude桌面版程序,并在界面上预留了一个“小鬼图标”,原本想用它来做匿名会话。不过,当我们使用的都是自配API时,匿名反而失去了实际意义。
正好这段时间DeepSeek宣布了永久性大幅降价,无论Flash还是Pro模型,性价比都很突出。
于是我就动了个念头:把这款软件稍加改造,摇身变成DeepSeek的桌面版!
但全面改造的工程量不小,所以我索性先把那个“匿名”图标派上用场。
最后整出了这么一个效果:
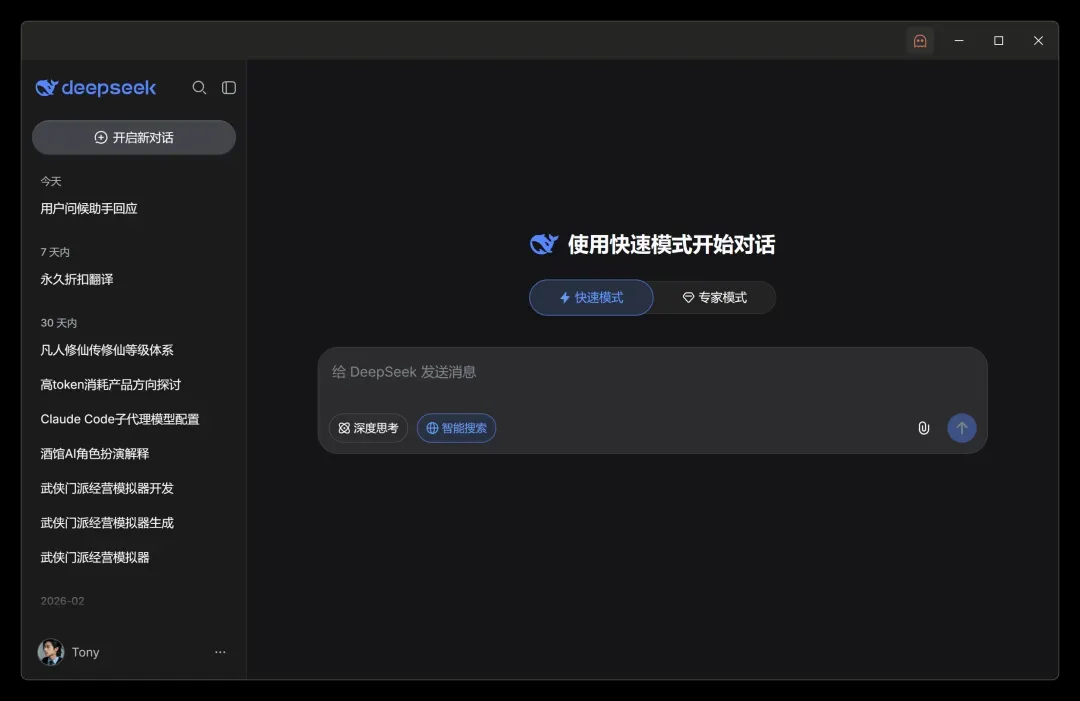
换成浅色主题后是这样:
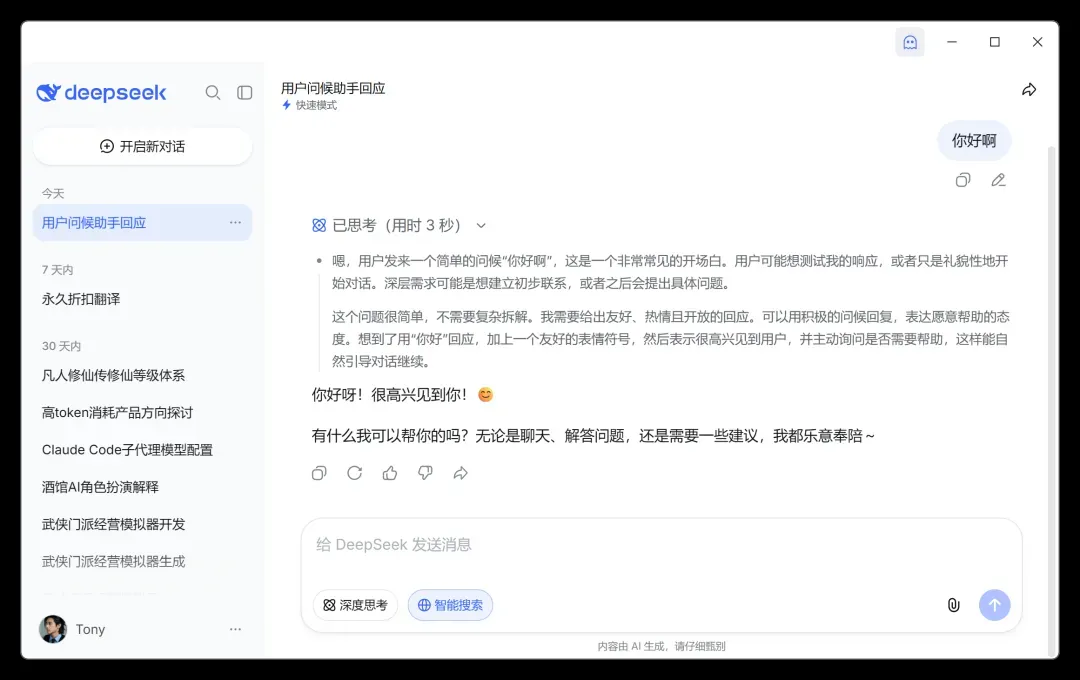
看到这个界面,明白人一眼就能猜到门道。
思路其实非常简单粗暴:点击匿名图标后,在软件窗口里加载一个WebView,内容直接指向DeepSeek官网。这样一来,我就可以在Claude桌面端里原汁原味地使用DeepSeek官方版,无需跳来跳去。
说起技术含量,真心没什么,纯粹是图个好玩。
听说DeepSeek已经开始招聘人手打造自己的Harness,那估计他们不好意思直接套壳Claude Code。不过我不是官方,心理上毫无包袱,那我先“套壳”为敬!
接下来,我打算对软件做一次更彻底的改造,准备在本机桌面端直接集成**聊天(Chat)和智能体(Agent)**两大模块。
Chat模块基本对标官方网页版的体验,侧重快速对话和即问即答,适合头脑风暴或日常咨询。
Agent模块则会直接嵌入Claude Code,再自动注入DeepSeek的模型。这样一来,Agent就能操作本地文件、联网搜索、调用工具链等等,整体能力直接看齐Claude官方水准!
设想很丰满,不过具体工作量还得慢慢摸索。
目前开局不算太顺,甚至有点哭笑不得:
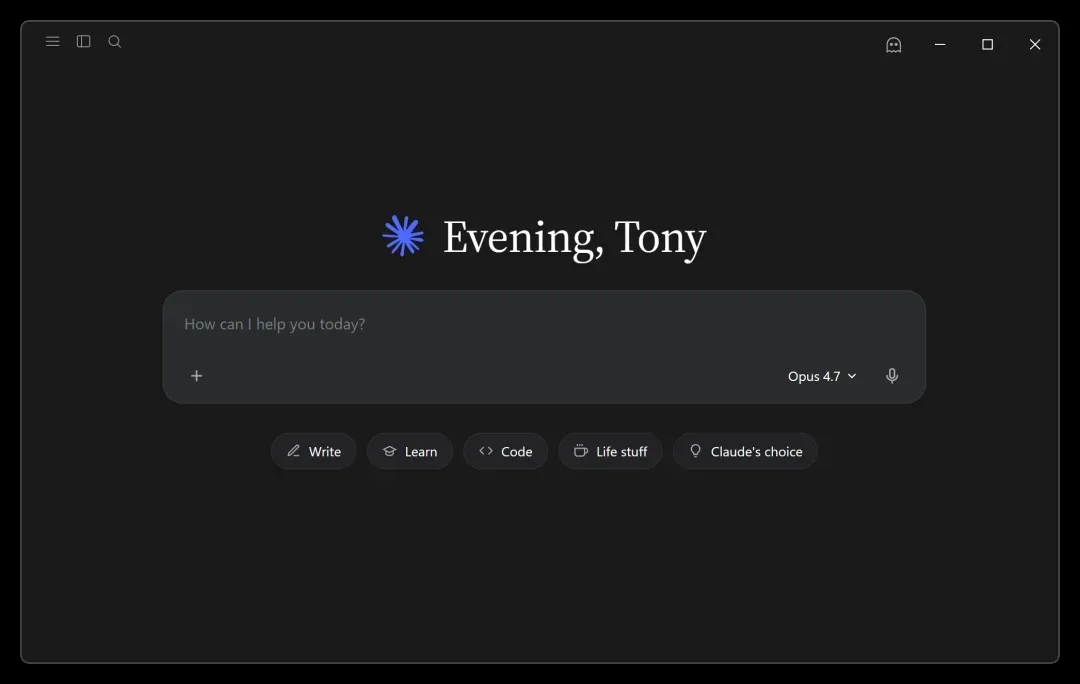
哈哈哈,Claude Opus可真是个鬼才!我让它学习DeepSeek的视觉风格,结果它果断把自己的Logo染成了DeepSeek的配色……我至今没搞懂它是怎么自我领悟出这种“P图”技能的。
眼下我正在和它反复沟通,想引导它实现出下面这种效果:
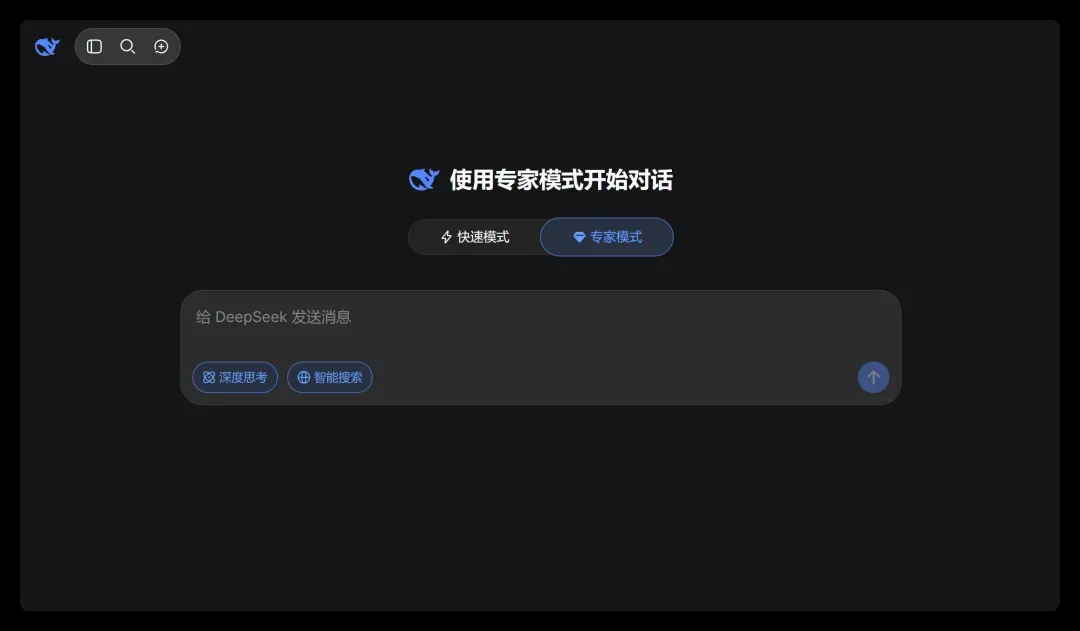
我相信一定能说服它,只要Token给足,我们就是无敌的。
转眼第二天,基本结构已经跑通了。
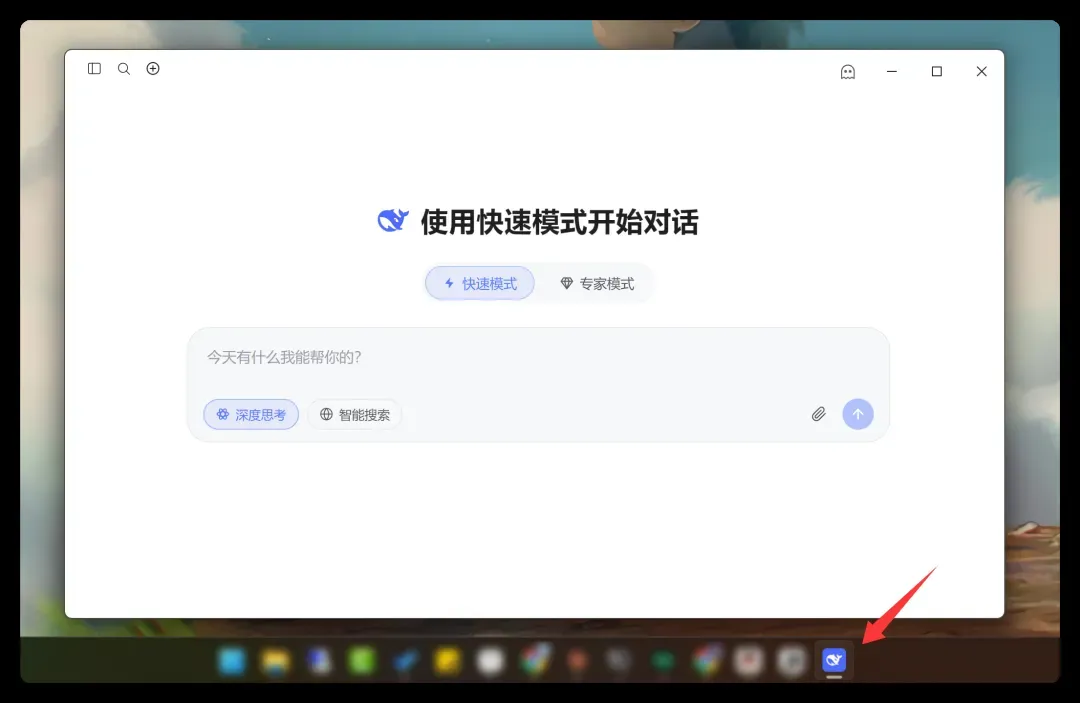
深色模式下的表现:
目前大致实现了三种工作模式:第一种是直接内嵌官网,第二种是通过API接入的纯Chat模式,第三种则是融合了Claude Code的Agent模式。
现在还剩一些细节收尾。
更具体的界面展示和开发全过程,会在下一篇里详细分享。
整个开发过程也充满戏剧性——Opus曾毫不留情地拒绝了我两次!
先放出一个初版,后面再慢慢打磨吧。
软件获取方式:
向公众号“甲维斯C”发送消息“jds”,即可得到。
厦门中跨展今日开幕SHEIN首秀,Prime Day秒杀明日截止,差评联系功能关闭,治愈经济年销破亿——跨境电商6月实战速览
导语:
本期聚焦今日启幕的厦门中跨展(SHEIN首秀+近千工厂源头直供)、Prime Day秒杀提报明日截止的最后冲刺提醒、亚马逊关闭差评联系功能的运营转型策略,以及治愈经济出海的全新风口。
一、厦门中跨展盛大启幕:SHEIN首次官方亮相,近千家工厂源头直供
第六届中国(厦门)国际跨境电商展览会于6月8日至10日在厦门国际会展中心举行。本届展会以“跨境互联 货通全球”为主题,展览面积超5万平方米,设有1500余个国际标准展位,汇集近千家源头工厂、30余家全球主流跨境电商平台以及上百家生态服务商,全面覆盖鞋服箱包、3C电子、家居百货、户外用品等热门品类。
本届最大亮点是SHEIN首次以官方身份参展,现场将发布最新招商政策。同期还有20多场高规格论坛密集展开,重点探讨AI跨境应用、海外合规、POD柔性供应链等前沿话题;6月9日还将举办TEDx厦门2026年度大会,主题聚焦“跨境出海”。
**为什么值得关注:**中跨展为卖家提供了一站式获取选品资源、平台政策、AI工具和合规指导的绝佳机会。对于正在寻找夏季爆款、准备拓展新平台的卖家来说,免费预约入场门槛极低,强烈建议周边卖家抓住最后两天亲临现场,高效对接。

**信息来源:**同花顺财经、百度百科‑第六届中跨展
二、Prime Day秒杀提报明日截止:美国站最后窗口紧逼
亚马逊2026年Prime Day已敲定6月23日至26日,这是自2021年以来大促首次从7月提前至6月。美国站闪电秒杀和超值促销的提报截止日为6月9日(即明天),欧洲站的截止日期则是6月19日。
今年Prime Day的费用结构出现重大调整:新增100美元报名费,外加1.5%的活动服务费。同时,折扣力度必须达到至少30% off才能解锁Buzzworthy Deals专属曝光位。FBA入仓截止日也已迫在眉睫,且IPI达标分数线将从7月1日起由400分上调至500分。
**卖家行动清单:**务必在今天之内完成秒杀/Z划算的提报;核实FBA库存已入仓或在途;检查IPI分数是否≥500;集中优化Listing主图与关键词。
**来源:**搜狐‑2026年Prime会员日提前至6月23日、知乎
三、亚马逊封禁差评联系入口,差评管理全面转向事前预防
亚马逊正在分批灰度推进一项新规,取消卖家通过站内信主动联系1‑3星差评买家的权限。多位卖家反馈,后台Customer Reviews板块中的“Contact Buyer”按钮已大面积变灰失效,以往靠“退款换改评”“补发求改评”的操作通道被彻底关闭。
**运营转型建议:**强化出厂质检,如实标注产品参数;在包裹内放置引导卡片,引导买家通过平台官方售后渠道解决问题;恶意差评仍可按正常流程提交移除申请;同时需要建立完善的售前售后服务体系,将差评管理重心从“事后补救”转向“事前预防”。
| 维度 | 变化前 | 变化后 | 卖家应对 |
|---|---|---|---|
| 联系差评买家 | 可主动发站内信 | 按钮变灰 | 等待买家主动联系 |
| 差评处理 | 可退款/补发 | 渠道全面切断 | 前置质检 + 包裹卡片 |
| 站外联系 | 灰色地带 | AI监控+封号 | 严禁绕道联系 |
**来源:**出海网
四、治愈经济引爆全球:智能香薰年销过亿,中国品牌抢滩高溢价赛道
全球冥想及心理健康市场规模预计到2030年将达到275亿美元,中国出海品牌正加速卡位。智能香薰机2025年在北美销售额突破1.2亿美元,同比劲增近40%;智能睡眠眼罩在欧洲的月均销量已超过20万件。
成功出海品牌的核心打法是“去穿戴化 + 数据可视化”:通过App连接和生理数据追踪塑造差异化的体验,并以东方禅修文化作为品牌故事内核,从而避开低价内卷。治愈经济品类普遍具有高溢价、高复购、低退货率的特点,非常适合以DTC独立站模式运营。
**来源:**出海网
五、四大船司6月集体拉涨欧地航线,最高每柜9200美元
达飞、马士基、MSC、赫伯罗特四大船公司自6月8日起相继上调亚洲至欧洲/地中海航线运价。MSC西地中海40尺柜FAK运价最高已报至9200美元;CMA CGM加收旺季附加费,20尺柜900美元/40尺柜1800美元;北欧航线则统一加收600美元/TEU。
**行动建议:**建议卖家提前锁定舱位和运价,合理规划6月中下旬的出运计划;欧洲海外仓备货的卖家更要关注到港时效,防止因海关查验或港口拥堵导致Prime Day期间断货。
**来源:**出海网
小结:
本期动态覆盖了展会选品机遇(厦门中跨展近千工厂直供)、运营Deadline预警(Prime Day秒杀提报明日截止)、政策合规转型(差评管理重心前移)、新兴品类蓝海(治愈经济高溢价赛道)以及物流成本预警(欧洲运价上涨)五大方向。6月是全年度最密集的决策窗口——今天去展会看品,明天前完成秒杀提报,趁早锁定运价,才能在Prime Day真正抢到红利。
实测千问电脑版语音输入:动动嘴让AI替你干活,效率翻倍
你是否也曾经历这样的时刻:脑子里想法电光石火,手指敲字的速度却慢得像踱步;回一封措辞周到的邮件要反复琢磨半天,给领导写段汇报得修来改去,灵感闪现想立刻记下,结果被杂事打断了思路。
试用了千问电脑版整整一周,重点体验了它的“千问语音输入法”后,许多挖空心思想速记、速写的焦虑就消散了。
我逐渐从一个键盘前的“码字员”,切换成了用嘴指挥的“口语指挥官”。
先别把它简单归入“语音转文字”。这套工具的内核,是“张嘴就让AI干活”的全新交互方式。你尽管把话说出来,它会替你理顺表达,更可以凭一句话指挥AI,把沟通、创作、信息处理一连串的任务都承包下来。
动手实操前,做两步基础设置,避开踩坑:
1、前往千问官网下载“千问电脑版”客户端,获取最完整的体验。
https://www.qianwen.com/download?ch=tongy_redirect
安装后,点击首页左下角头像,进入【设置】-“桌面小工具”,确认开启“千问语音输入法”。
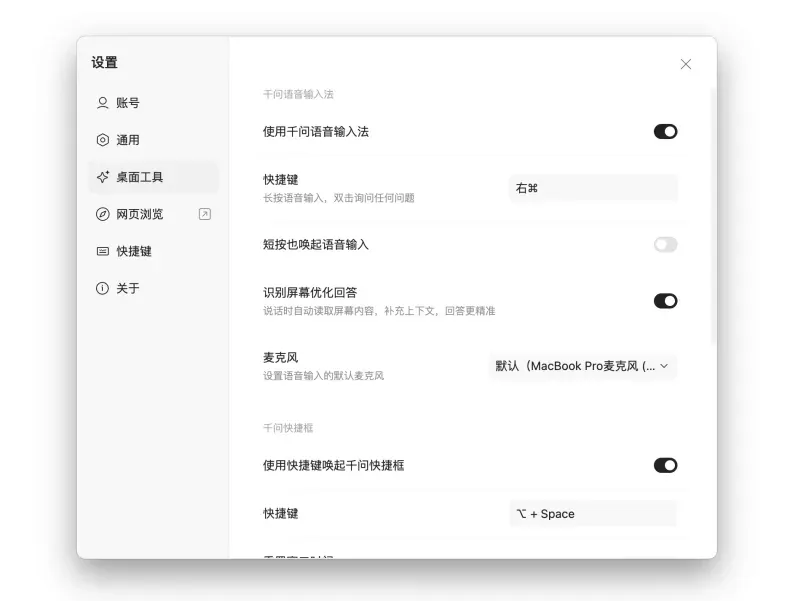
2、熟记两个核心快捷键,这就是你动嘴的“开关”:
- 按住右Alt键 (Windows) / 右Command键 (Mac):启动智能语音输入(你说AI记)。
- 双击右Alt键 (Windows) / 右Command键 (Mac):启动智能语音指令(你说AI做)。
设好了?立刻进入实战。

智能语音输入:口语秒变精炼书面语
首先解决“从说到写”的断层。传统语音转写如同复读机,说啥记啥,连“呃、那个、然后”这些口头禅也照单全收。而千问的语音输入法,更像一位隐形的随行速记编辑。
我做过一个对比测试。同一段项目规划的口头表达,普通转写与千问输出的结果差别极大:
我的原话(模拟思考状):“呃…我们下个季度,那个,主要是聚焦在A项目,对吧?然后B项目那个,优先级可以,嗯…稍微往后放一放。对了!还有C功能,必须得上线。”
普通转写:一字不差地保留了所有语气词和重复,文本松散,基本需要大修
千问输出:“下季度主要聚焦A项目,B项目优先级可适当延后。同时,C功能需确保上线。”

看得出差异吗?它自动过滤了无意义的语气词,修正了随口说的小口误,还把碎片化的口语整理成了结构清晰的书面表达。
更惊喜的是,它能准确识别中英文混杂的说法,比如我说“这个API的call要注意一下”,它会正确转写,不会写成“扣”或“靠”。
还没有完,它的“场景感知”才是杀手锏。千问能识别你在哪个应用里、屏幕上有哪些内容,从而优化输出结果。
- 在微信里说:“跟客户说我们方案周三前一定给”,它生成的就是更适合聊天的口语化语句。
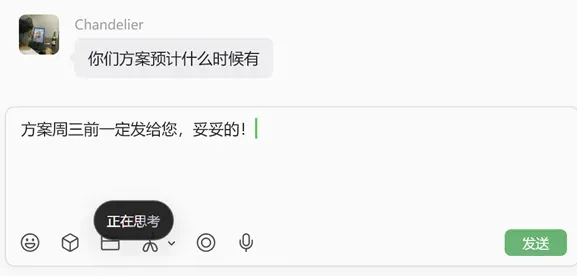
- 在Word或邮件里说同样的话,它可能输出更正式的书面语句式,比如“已与客户确认,方案将于周三前提交”。
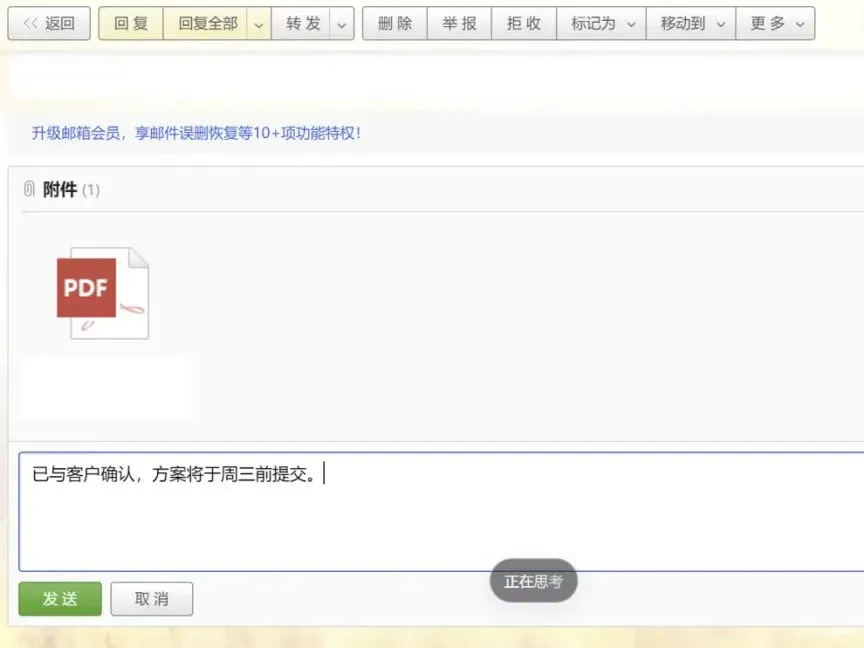
更贴心的是,当光标不在任何输入框时,仍然可以语音输入,并有三种后续操作,适配不同场景:
1.复制到剪贴板:临时想到一句金句或一段代码,说完直接复制,粘贴到任意地方。
2.记为便签:速记一个待办或灵感,自动保存到“我的空间”,稍后处理。
3.打开小窗问千问:说的内容本身就是一个问题,比如“爱因斯坦的生日是哪天?”,直接跳转问答。
这样一来,“随时想到,随时记录”的所有场景基本全覆盖了。

智能语音指令:所说即所得,开口就出结果
如果说语音输入是解放双手,那“智能语音指令”就是解放大脑。它把“说话”变成了给AI下达命令的触发器,核心逻辑从“输入文字”跃迁到了“获取结果”。
这带来了三层效率飞升:
第一层:“帮我回消息、邮件”——让沟通快速响应
遇到一封复杂的英文会议邀请邮件,传统做法是:读邮件→构思中文回复→打字→检查。现在只需双击快捷键,说:“帮我用英语礼貌回复,确认参加,并请对方会前分享议程。”
几秒钟后,一封措辞得体、格式完整的回复草稿就出现在面前。它理解上下文,帮你完成了最耗时的那部分——思考和组织语言。
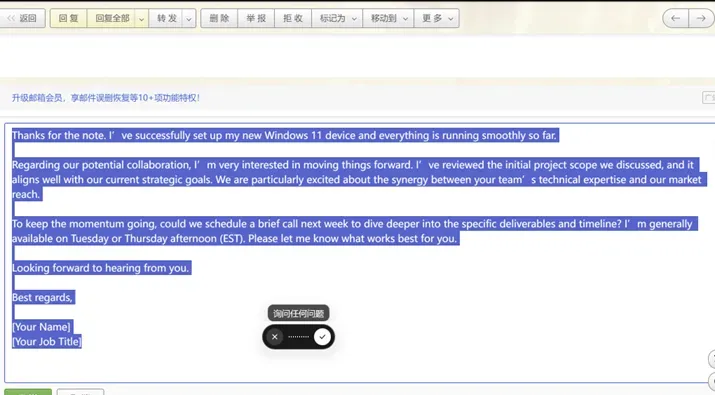
第二层:“帮我优化表达”——让文案创作更得心应手
做PPT卡住了,觉得某页文案冲击力不够?选中那段文字,双击快捷键说:“把这段话优化得更激昂,更有号召力。”眨眼的功夫,三版不同风格的优化文案就摆在你眼前。

周报写得太平淡?说“帮我优化得数据感更强一些”。它就像一个不知疲倦的文案高级助理,你只需要抛出要求,它负责执行、提供选项。别人还在琢磨提示词怎么措辞,你这边已经拿到了结果。
第三层:“帮我搜资料、整表格、做PPT”——让工作流无缝衔接
这是颠覆我旧习惯最深的一层,它让“搜索-复制-粘贴”这套流程成了历史。
- 双击就问:在任何界面,双击快捷键直接问:“乾隆皇帝活了多少岁?”答案立刻弹出。
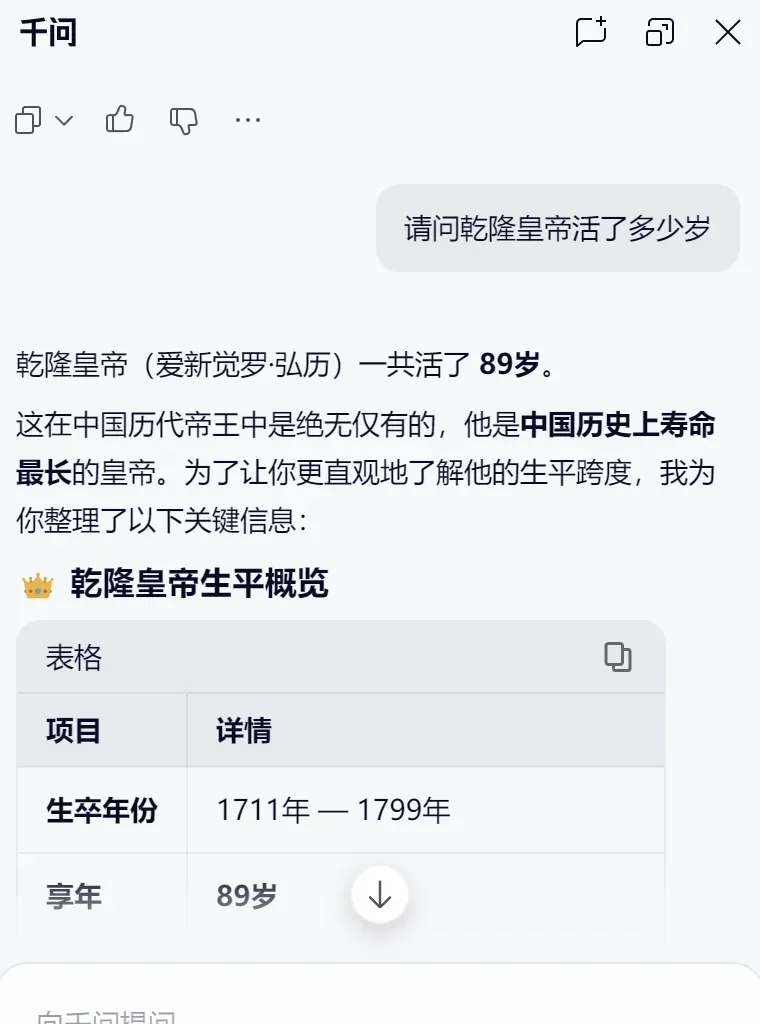
- 划词提问:在网页上看到陌生术语,选中后说“解释一下这个概念”,千问能结合上下文给出解答。
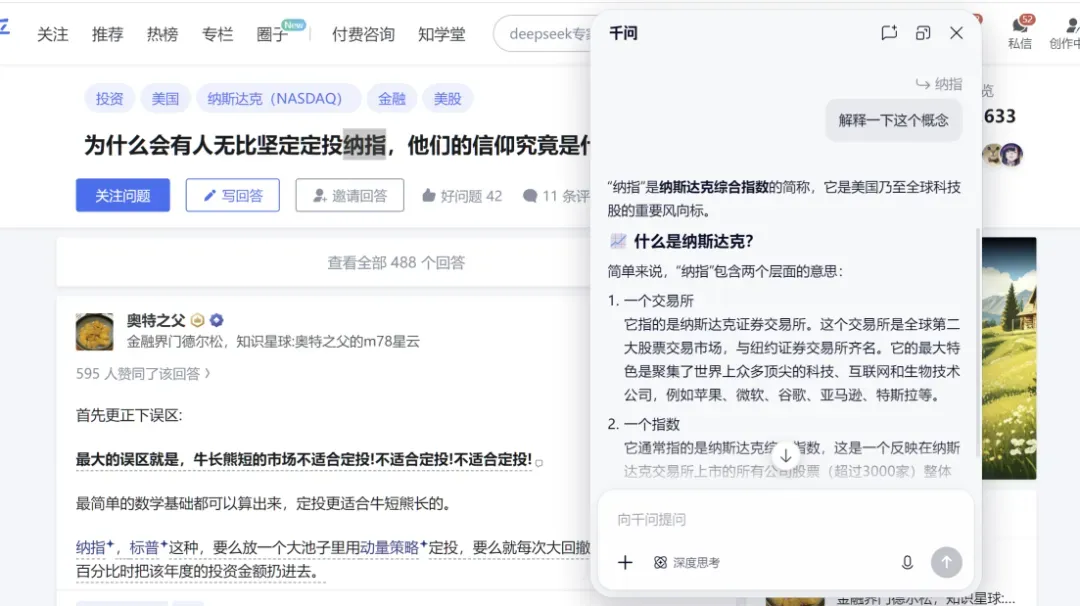
- 语音记便签:开会时听到一个要点,直接说:“记为便签,下季度重点调研AI在医疗影像的应用。”
- 做PPT:工作群里被催促快速提交一份PPT,选中领导提的要求,直接说:“帮我做一份简短的PPT”。
- 整表格:筹备618大促,需要做一份扫地机器人价格观察,直接说:“帮我做一个2026年扫地机器人价格对比表格”。
这种工作流的改变是根本性的:你的思维不再被工具和具体操作割裂,始终流动在一条连贯的创作线里。

它凭什么能做到这种程度?
也许你会好奇,为什么千问能实现“场景感知”和“张口即得”?背后是两层能力的叠加。
树莓派2025财年业绩里程碑:半导体销量首超主板,营收利润双超预期
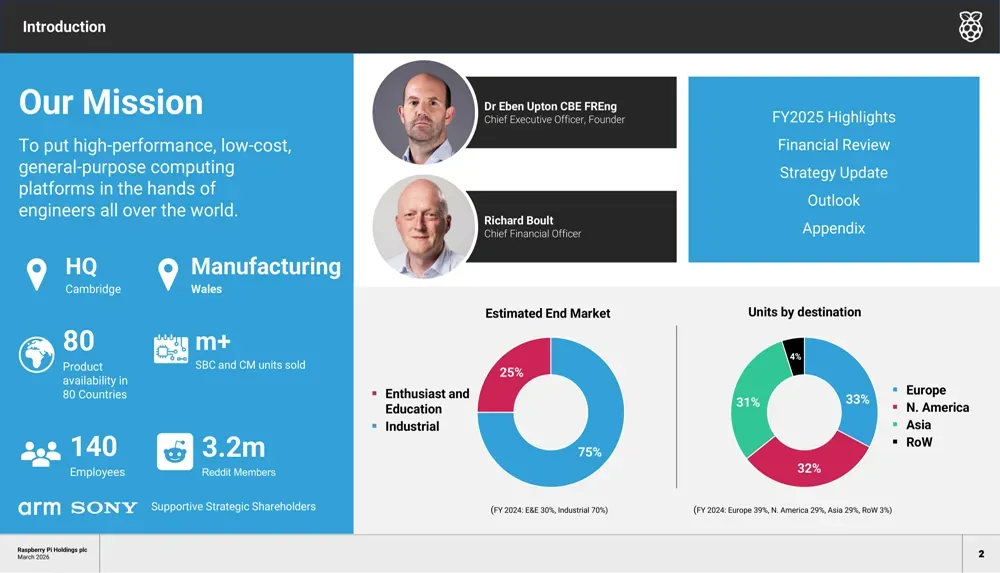
Raspberry Pi Holdings PLC(LON: RPI)于2026年3月31日发布了2025财年全年业绩,实现历史性突破:半导体芯片出货量首次超过主板销量。调整后EBITDA同比增长25%至4640万美元,营收达到3.232亿美元,这一强劲表现促使股价当日飙升44.42%至422便士,不过仍较其52周高点556便士低约25%。
财务表现超越预期
这家总部位于剑桥的计算平台供应商在2025财年总出货量达760万台,同比增长9%。值得注意的是,营收增长25%远超出货量增幅,表明公司正成功向高价值产品和高利润市场转型。
财务概览凸显了其全球布局和战略定位。产品销往80个国家,工业应用占比提升至75%,爱好者和教育市场降至25%,标志着树莓派已大幅超越其最初的创客社区根基(上财年工业应用占70%,爱好者与教育占30%)。
单位毛利润由7.40美元增长17.6%至8.70美元,即便在DRAM成本上涨的压力下,毛利率仍稳定在24%。调整后营业利润同比跃升35%至3590万美元,调整后摊薄每股收益达到14.19美分,显著高于上年的10.23美分。
公司在四大关键业务板块的详细业绩,充分展现了财务韧性和运营活力,全年成功推出13款新品,同时有效应对了DRAM成本上涨。
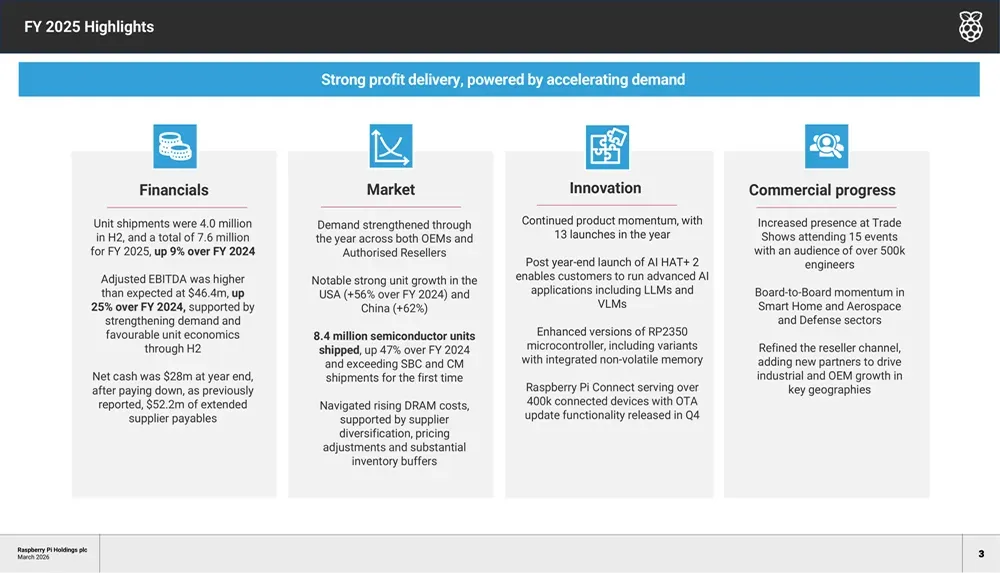
半导体业务迎来重要拐点,芯片出货首次超越主板
2025财年标志性的突破在于半导体部门同比增长47%,芯片出货量达840万颗。公司称这一年为‘交叉年’——硅片销量首次超越传统主板,预示着树莓派商业模式的根本变革。
详细指标反映出强劲的环比增长动能:2025财年下半年直销单元销量同比增长21%,环比增长17%,直销占比已达76%,恰好落在公司70%-80%的目标区间,而授权销售则出现同比下滑。
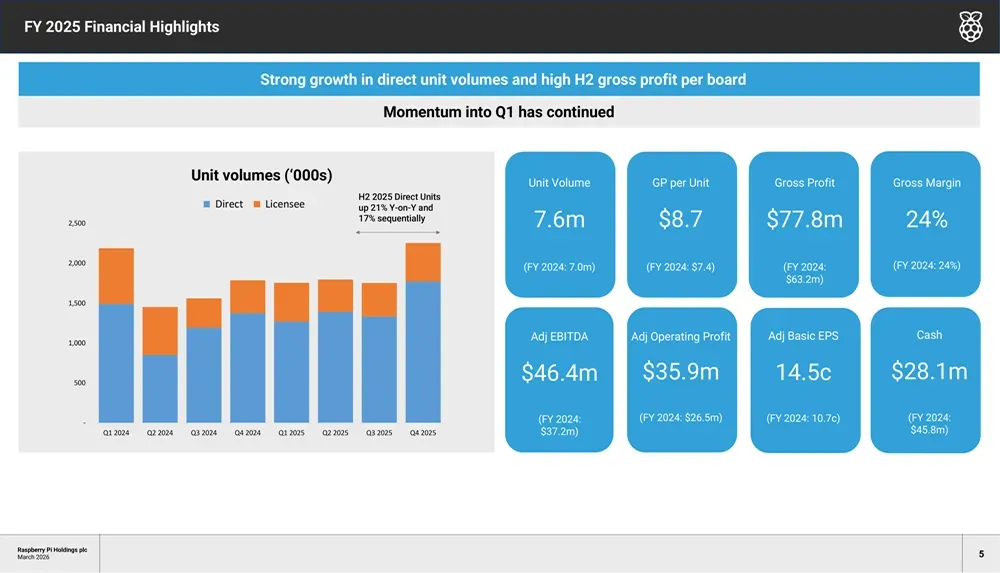
平均售价从43.30美元上升至46.70美元,增幅3.40美元,受益于产品结构优化及高利润半导体产品的比例增长。主板业务分析显示,其单位毛利润也从7.00美元提升至8.70美元。
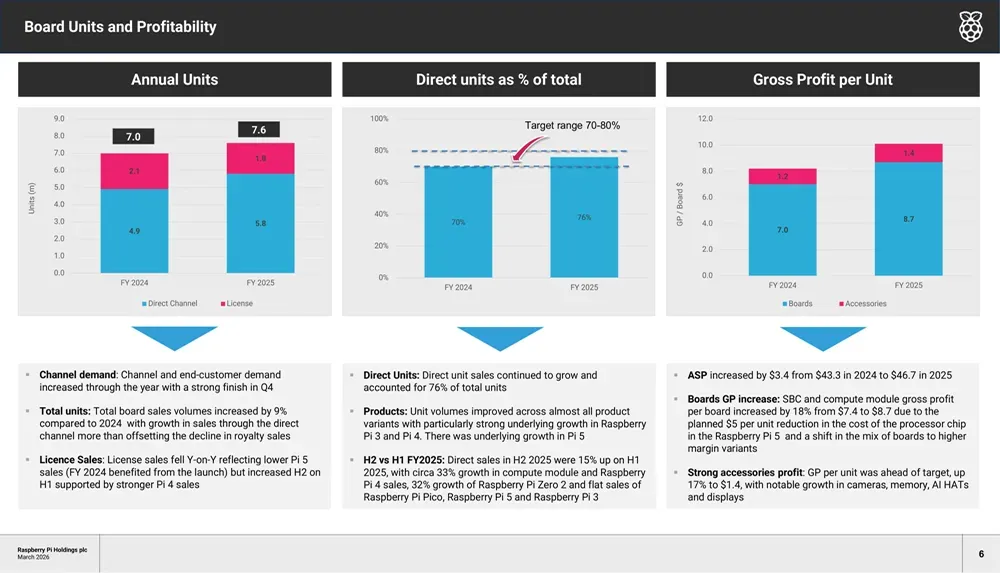
营收增长远超预期,利润指标全面提升
损益表反映出强劲的营收扩张,全年收入由2.595亿美元增至3.232亿美元。毛利润同比增长23%达到7780万美元;同时,公司加大对未来的投资,调整后研发费用上升28%至1110万美元,管理费用增加19%至2060万美元。
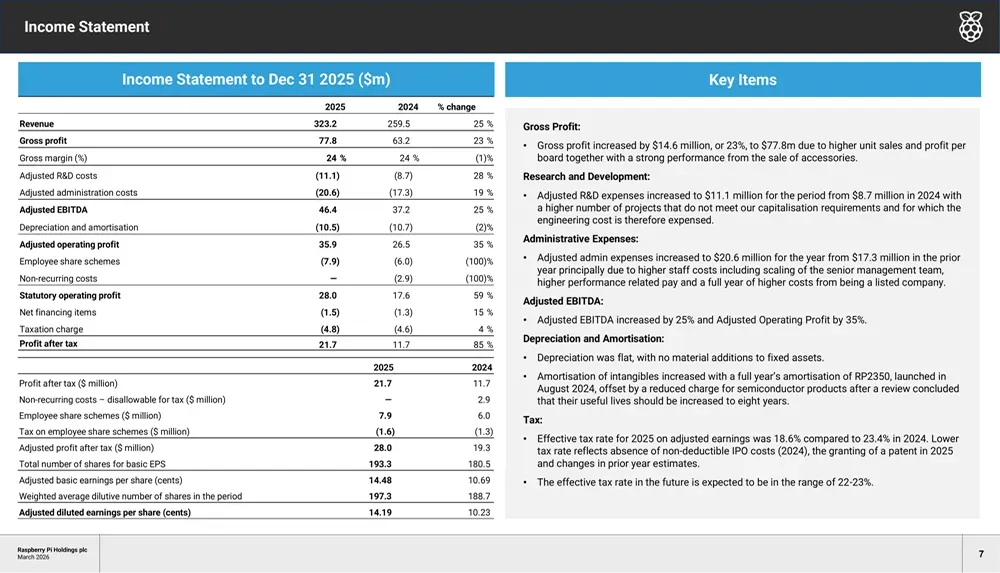
尽管成本上升,但得益于在不断扩大客户群体中充分释放平台价值,调整后EBITDA利润率仍然改善。税后利润从1170万美元激增至2170万美元,增幅超过一倍,凸显了商业模式的经营杠杆效应。
区域市场全面发力,美国与中国增速领跑
区域业绩表明,重点市场增长势头尤为强劲:美国市场单元销量同比激增56%,中国更是增长62%。销售区域分布均衡,欧洲占总销量33%,北美32%,亚洲31%,其他地区4%。
地域多元化增强了抵御局部经济波动的能力,也使公司能够把握多个地区的工业自动化浪潮。工业与嵌入式市场已占业务的75%,较前期进一步提升。
资产负债表显示战略性增长投资,库存与应收款扩张
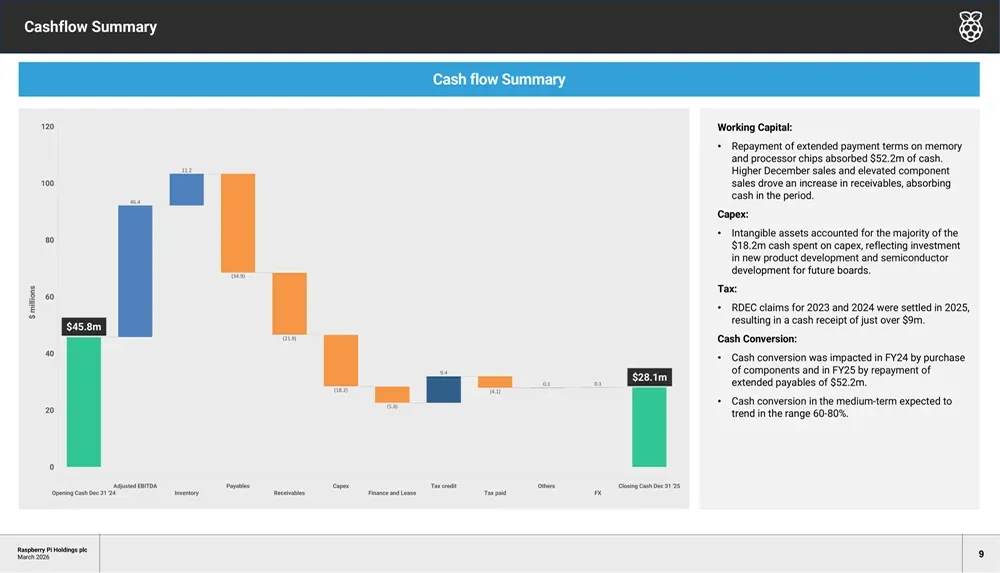
资产负债表反映出公司为支撑增长而战略性提高库存水平和扩大营运资本。为应对供应链不确定性,库存规模增至1.453亿美元,应收账款则因销售增加而升至5950万美元。

现金流分析进一步揭示了快速扩张所必需的运营资本投入。期初现金从4580万美元降至年末的2810万美元,主要归因于应收账款增加(流出3490万美元)和库存增加(流出2190万美元),强劲的调整后EBITDA产生的4640万美元现金部分对冲了上述影响。
多策略应对DRAM成本上涨,保障盈利能力
管理层在财报中重点提及的挑战之一是DRAM价格从历史低位反弹。公司详细阐述了多项缓解措施,包括供应商多元化、通过技术创新引入替代内存方案(目前已有30%的产品采用非DDR4内存)、实施战略采购和保持定价弹性。
管理层认为,DRAM涨价有望引发产能扩增,援引ASML数据指出,内存设备订单占净预订量的比例已从2024年Q4的39%上升至2025年Q4的56%,订单量增幅超150%,最终将缓解供应紧张。
OEM合作纵深拓展,客户案例验证商业化能力
公司在OEM市场拓展方面取得实质性成果,客户案例凸显部署规模。美国设计伙伴Sixfab已在全球范围内部署了超过11万套基于树莓派计算模块的边缘计算系统,并荣获2026年CES最佳创新奖。
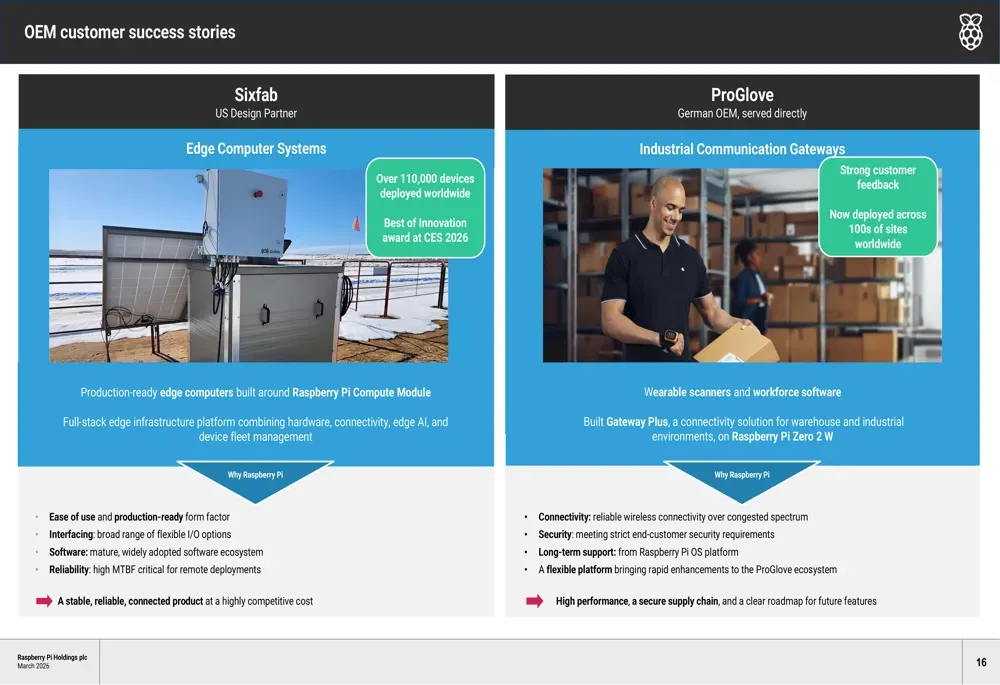
德国工业可穿戴设备制造商ProGlove基于树莓派Zero 2 W打造的Gateway Plus仓库连接方案,已在全球数百个站点落地。这些案例证实了公司的判断——OEM客户正将嵌入式计算视为战略性外包机遇。
瞄准AI与边缘计算,定位下一增长引擎
展望未来,树莓派正积极卡位人工智能向边缘端迁移的契机。财年结束后,公司发布了AI HAT+ 2,并着重指出树莓派Connect平台已连接超过40万台设备,为OEM客户提供标准化的设备管理、OTA更新及合规认证功能。
半导体业务的里程碑让公司在边缘AI转型中占据有利位置,因为对于有特定性能和功耗要求的边缘AI应用而言,定制芯片的价值日益凸显。
战略前瞻:抢占份额,深化半导体与边缘AI布局
管理层对市场环境充满信心,强调:“树莓派将当前环境视作抢占市场份额、深化客户关系、化颠覆为竞争优势的战略契机。”
公司拥有71名精英工程师,人均创收450万美元,平均司龄5.5年,构成执行产品路线图的强大技术班底。财报演示明确了未来将继续聚焦半导体业务扩张、OEM合作深化以及边缘AI机遇的把握。
公司的使命——“将高性能、低成本的通用计算平台交到全世界工程师手中”——越来越聚焦于工业和商业应用,而与创客社群最初的品牌认知渐行渐远。凭借约7.46亿美元市值,以及在维护利润率的同时驾驭供应链挑战的实力,树莓派已成功将自己塑造为工业数字化和边缘计算浪潮中的平台型企业。
四款顶级AI模型356元横评实测:Opus 4.8 vs GPT-5.5 vs DeepSeek V4 vs MiniMax M3,真实能力排名揭晓
近期,AI模型领域的更新节奏明显加快。Opus 4.8、GPT-5.5、Qwen3.7-Plus、MiniMax M3四款重量级模型几乎在同一时间亮相,想逐一深入体验都颇为吃力。
前两天我留意到一个名为「Browse Code」的榜单,专门评估大语言模型在真实浏览器环境中完成编程与网页自动化任务的成功率。
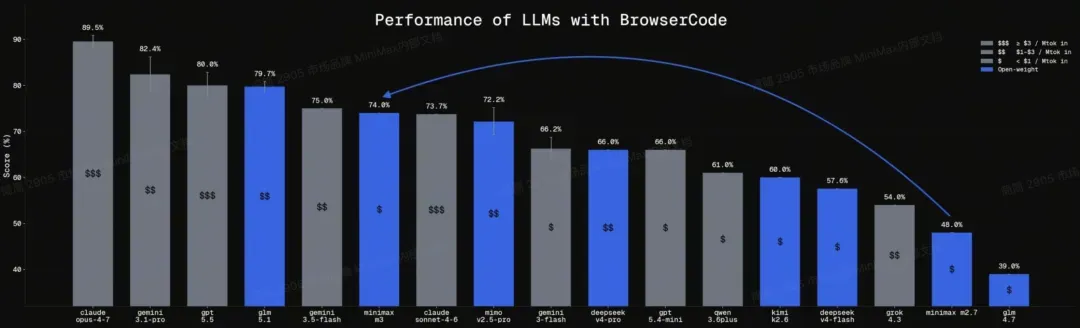
出乎意料的是,MiniMax M3在这个榜单上从之前M2.7时期的倒数第二,直接跃升至全球第五,与Claude 4.6 Sonnet、Gemini 3.5 Flash并列。
当然,单一榜单远远不能说明全部问题。因此我投入了356元,将Claude Opus 4.8、GPT-5.5、DeepSeek-V4-Pro和MiniMax M3这四款模型放在一起,使用完全相同的任务、提示词和评分标准,全部通过API连接Claude Code/Codex进行实测。
测试覆盖了3D编程、视觉编程、游戏开发以及Agent长程任务四大场景,横向对比结果如下。

一手横评
本次测评坚持“变量归一”的原则,只有如此对比才有意义。
四个模型使用同一份视觉素材、同一条提示词,分别通过各家API在Claude Code/Codex里运行,最终从任务完成度和输出质量两个维度来评价,场景覆盖3D编程、视觉编程(网站开发)、游戏开发以及Agent长程任务(涉及Office三件套与Coding)。
1)3D任务
首先让模型观察一张金门大桥的实景照片,然后根据桥梁的外观,用Three.js编写一个可交互的3D网页。
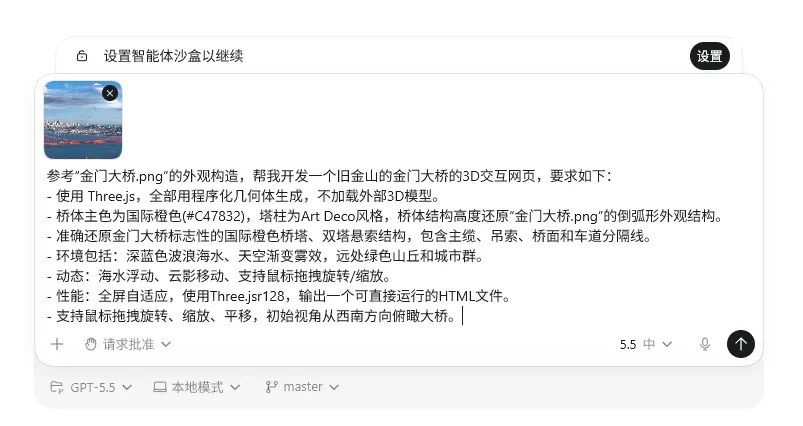
这项任务的考验是三维的:第一,模型必须具备视觉理解能力,能够从照片中提取关键的结构特征;第二,要能将这些特征精准映射到三维空间的几何关系上;第三,Three.js的代码质量必须过硬,不能写出运行即崩溃的内容。
三项能力缺一不可,任何一项的缺失都会导致结果大打折扣。
提示词:
参考“金门大桥.jpeg”的外观构造,帮我开发一个旧金山的金门大桥的3D交互网页,要求如下:
- 使用 Three.js,全部用程序化几何体生成,不加载外部3D模型。
- 桥体主色为国际橙色(#C47832),塔柱为Art Deco风格,桥体结构高度还原“金门大桥.png”的倒弧形外观结构。
- 准确还原金门大桥标志性的国际橙色桥塔、双塔悬索结构,包含主缆、吊索、桥面和车道分隔线。
- 环境包括:深蓝色波浪海水、天空渐变雾效,远处绿色山丘和城市群。
- 动态:海水浮动、云影移动、支持鼠标拖拽旋转/缩放。
- 性能:全屏自适应,使用Three.jsr128,输出一个可直接运行的HTML文件。
- 支持鼠标拖拽旋转、缩放、平移,初始视角从西南方向俯瞰大桥。
Claude Opus 4.8:
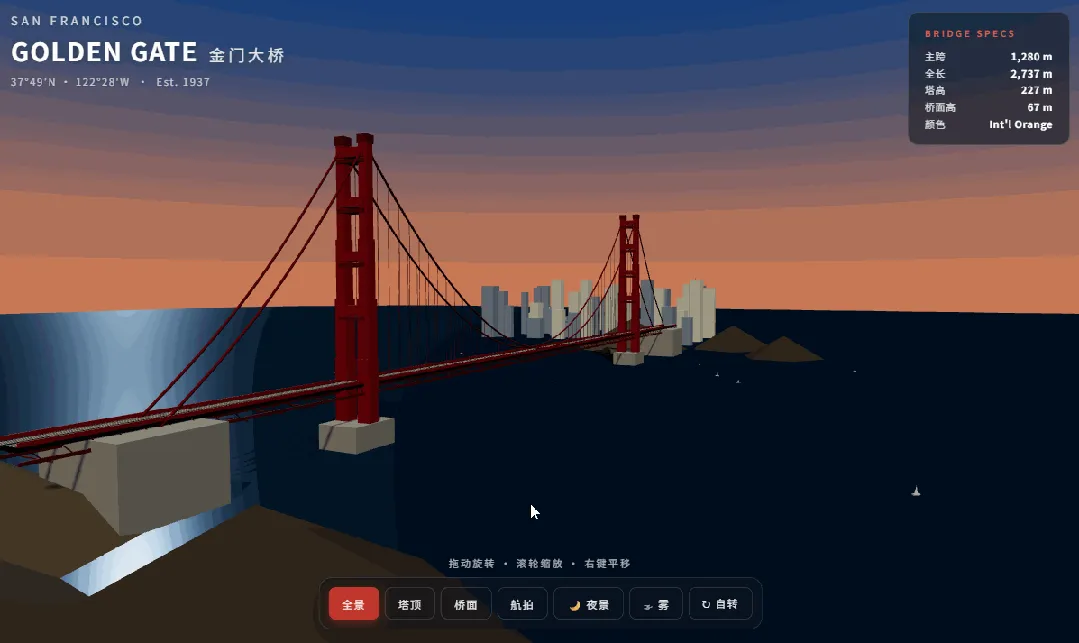
GPT-5.5:

DeepSeek-V4-Pro:

MiniMax M3:

在这个案例中,表现最为出色的是Claude Opus 4.8,MiniMax M3紧随其后。
这两款模型都准确还原了金门大桥最具标志性的物理细节:主缆从两侧塔顶向跨中自然垂落的倒弧形外观。这说明它们不只是在描述一座桥,而是真正理解了悬索桥的结构原理,并能将这种理解转化为三维几何体。
GPT-5.5和DeepSeek-V4-Pro则未能呈现出这一特征,输出的桥体形态各异。
特别是GPT-5.5,如何描述其编程审美呢?有一种“浓眉大眼”的粗糙感。在后续几个案例中,这一特点一直延续。而Claude和M3的视觉语言则完全相反,一看就非常精致、高级,具备明确的设计意识。
另外值得一提的是,DeepSeek设计的海洋流体动态效果颇有意思,但天空部分出现了穿模问题,说明三维空间碰撞逻辑的处理还不够扎实。

本轮实测:Claude Opus 4.8 > MiniMax M3 > GPT-5.5 > DeepSeek-V4-Pro。
汶川民宿AI视觉全案:Lovart 130元打造,设计师朋友看完沉默了
都说奶茶店、咖啡店和民宿是“中产返贫三件套”,我偏不信这个邪。干脆请来一位AI品牌设计师,帮我做了一整套民宿的视觉物料,各位帮我看看,这家民宿到底有没有搞头。
这是门店招牌。

宣传视频戳下方,可以直观感受整体氛围。

再来看下夜间效果,同样令人惊喜。

这家店名叫“冷同学的院子”,打算开在川西,所有视觉产物都是靠Lovart生成的。全部成本只有19美金,折合人民币130块钱。
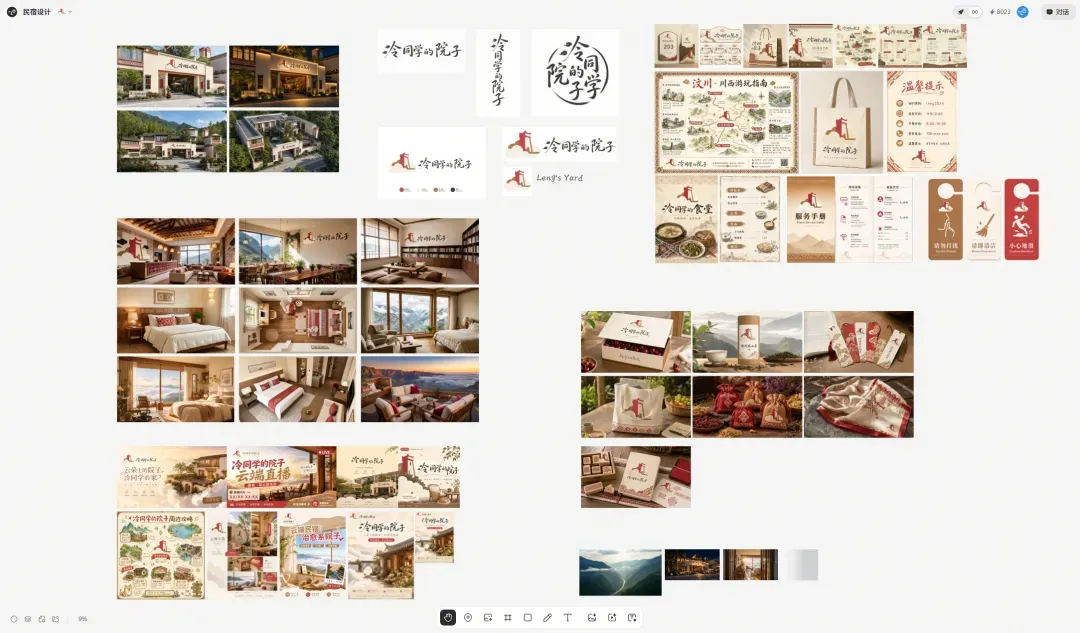
这是全套设计产出。

下面我来详细拆解这套设计都包含了什么,以及我是怎么一步步做出来的。过程真的非常简单,重点是,大家多帮我掌掌眼,看看这家民宿能不能行。
品牌套件:一步到位立起品牌
做设计之前,需要先搭一套Brand Kit(品牌套件),里面要有logo、slogan、品牌色、字体和素材库等。
和AI聊了很久,最终决定把店名定为“冷同学的院子”,民宿的基本信息如下:
- 民宿名称:冷同学的院子
- Slogan:云朵上的院子,冷同学的家
- 地理位置:四川汶川(羌族文化核心区、高山峡谷地带)
- 品牌调性关键词:温暖治愈 · 在地羌韵 · 自然松弛 · 外冷内热 · 有故事感
- 目标客群:追求慢生活的年轻人、亲子家庭、文化旅行者、成都周末度假客、川西旅游爱好者
接着,让Lovart根据这些背景信息生成主logo。

效果相当好,这个融合了云朵和羌族碉楼的logo,我很喜欢。配色把握到位,店名也设计得很得体。

接下来,我让AI继续输出横版、竖版和圆版等多种格式的logo,还包括字体方案。

字体设计非常直观,我特意录了个屏。
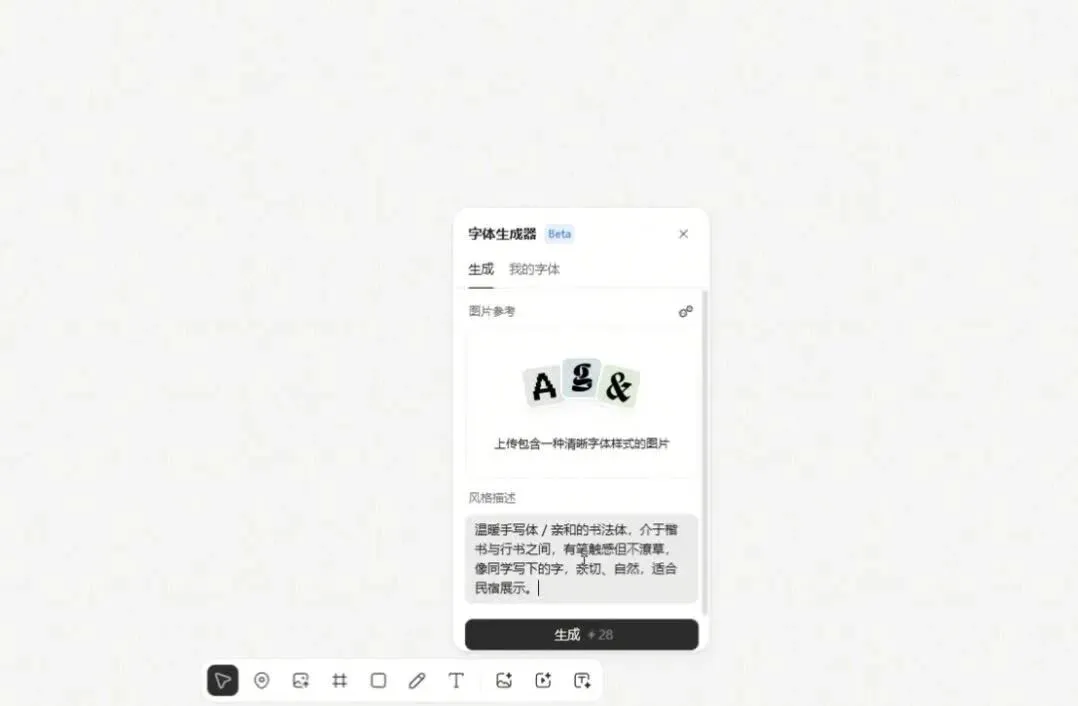
直接在画布底部的“字体生成器”输入风格描述就行,也可以上传你中意的字体样式图片作为参考。
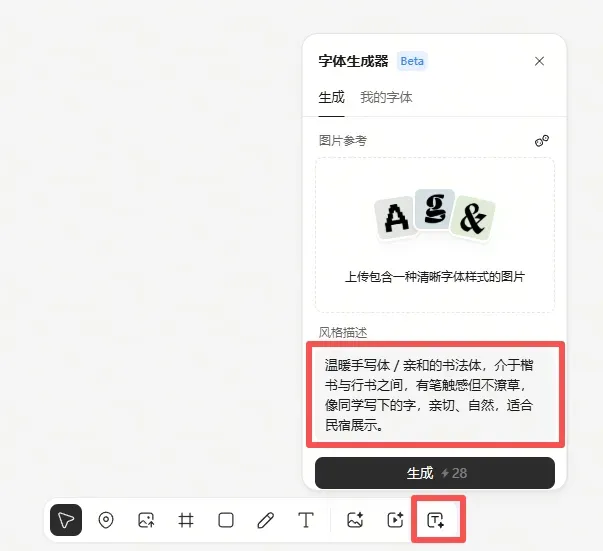
我的风格描述是:
温暖手写体 / 亲和的书法体,介于楷书与行书之间,有笔触感但不潦草,像同学写下的字,亲切、自然,适合民宿展示。
关于字体设计,我在淘宝上咨询过,一套英文字体最少要2000块起,周期两到三周;中文字体就更贵了。而Lovart这个Font Generator功能,只需28积分(大概2块钱),不到三分钟就出活儿。稍微有点遗憾是,目前只支持英文,要是以后能支持中文就更好了。
接下来,把这些品牌素材固定成品牌套件。
打开lovart.ai主页,左侧边栏有个“Brand Kit”功能,也就是品牌套件。我们把刚才这一系列品牌素材都传上去。
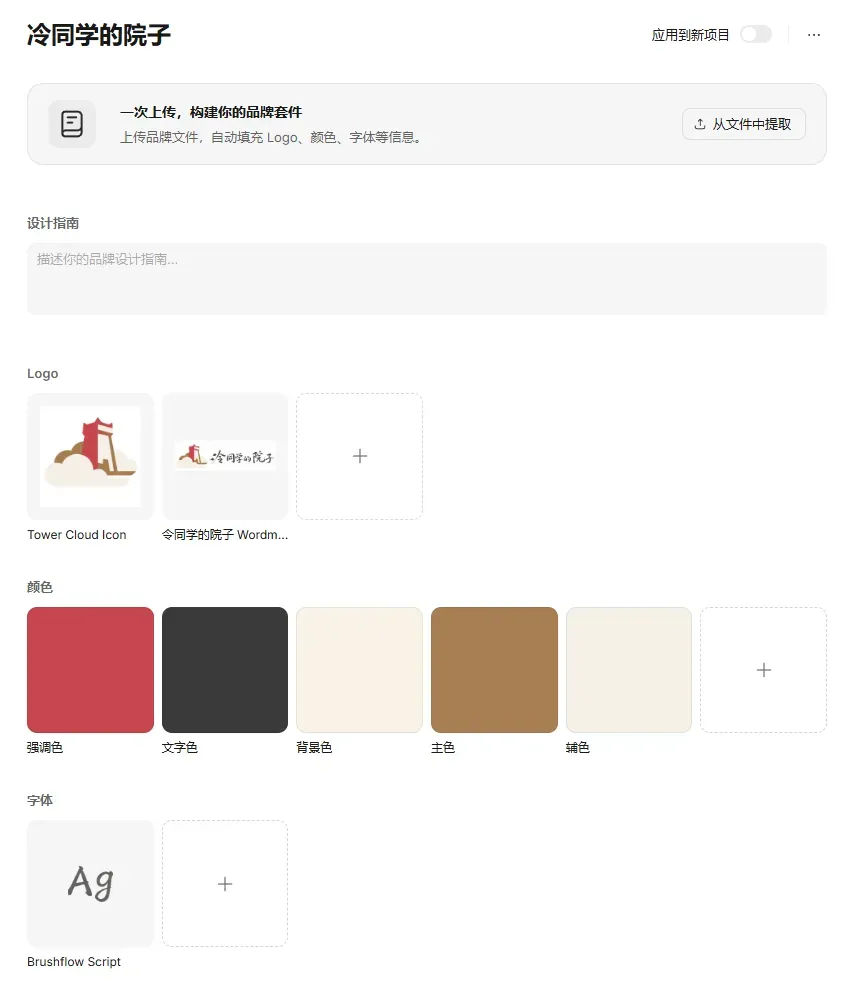
如果你有品牌方案pdf,也可以直接上传pdf,它能够自动解析logo、字体、vi色和设计指南。
上传后,打开新的项目,在画布左上角勾选品牌套件。
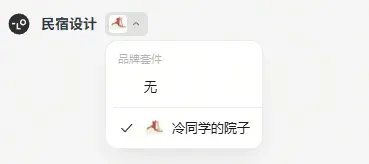
套件挂到项目后,之后在这个项目下做的所有图,logo、vi色、字体都会自动遵循这套品牌规范。
不需要每次都重新说“我要温暖治愈的风格,主色羌族红,背景云朵白,字体墨灰”,也不用再上传logo做参考图;直接开始设计,它会自己调用品牌套件。
一个画布:打造全套设计物料
现在,给你们看看我用Lovart产出的全套视觉物料。各位云股东们,一定要认真帮我把关啊。
先是门店视觉,涵盖了近景、远景、夜景和航拍多个视角。

然后是房间部分,包括大堂、餐厅、茶室、观景台、庭院和各种山景房的效果图。

房间介绍还配有视频版。

小米MiMo 16亿Token限期将至:四款AI大模型消耗方案深度对比,谁的建议更有价值?
眼看着小米 MiMo 赠送的 16 亿 Tokens 即将过期,账户里还剩十几亿额度,焦虑感油然而生。
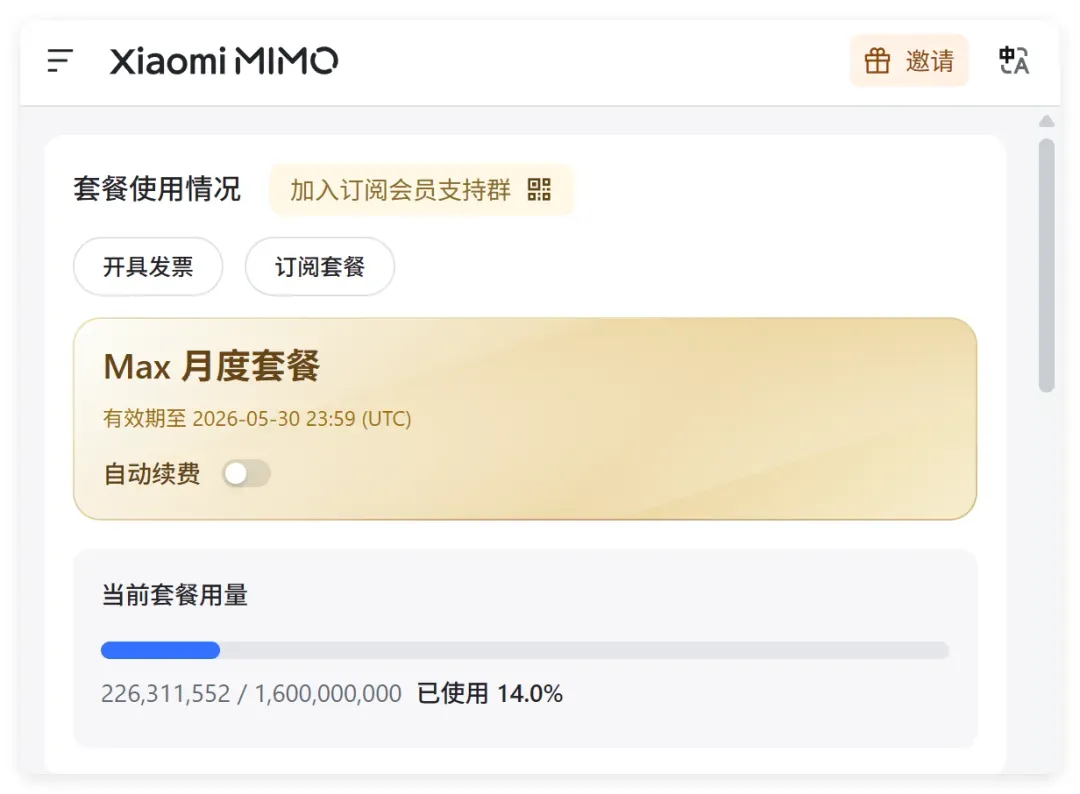
必须赶紧找办法把它们消耗掉,浪费了实在可惜。可问题是,我一时并没有那么大的需求。平时用 Opus 4.7 开发时一直精打细算,从没有大手大脚烧 Token 的习惯;如果把正在推进的项目全部交给 MiMo,心里又不太踏实。
于是我把难题抛给了 AI,把能问的模型都问了一遍。结果发现,大多数 AI 的回答大同小异,但总有那么几个会想得更深一层。就跟人一样,智商高的会在问题之上再思考一层,而智商低的就只是你让干什么就干什么,从不琢磨怎样做得更好。
我先把自己的需求描述清楚:
如何在短时间内消耗大量 Tokens,并做出有意义的产品。目前主要关注 AI 领域,可以是文档、软件、网站等方向。
接下来,就记录一下不同 AI 给出的答案。
1. MiMo:循规蹈矩的指示执行者
既然是 MiMo 送的 Token,先来问问它本尊。
问答截图如下:
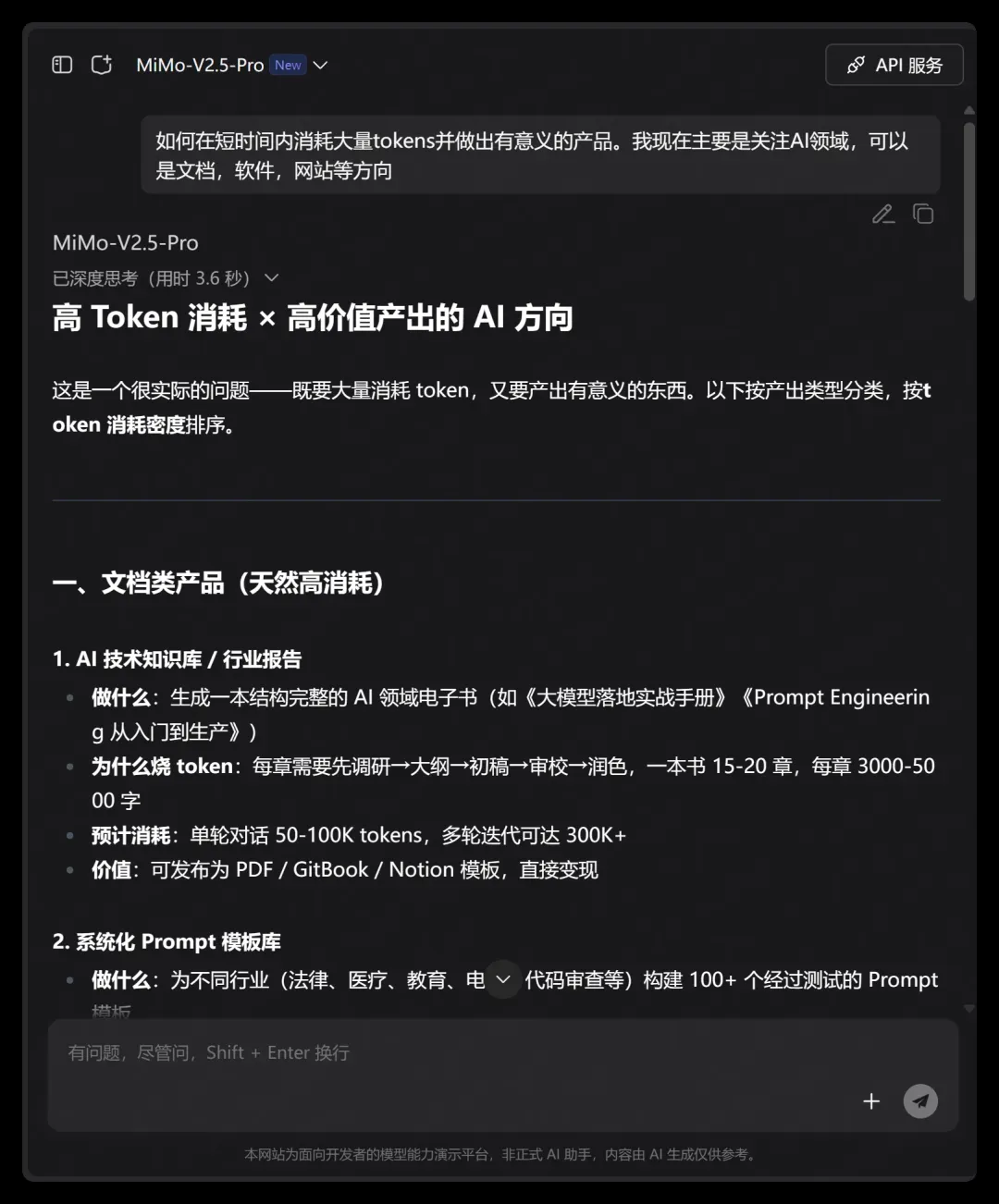
它主要列出了三个方向:文档类产品、软件类产品、网站/可视化产品,几乎完全按照我提示词里的关键词做了分类回应。
这里截取它给的部分内容:
1. AI 技术知识库 / 行业报告
做什么:生成一本结构完整的 AI 领域电子书(如《大模型落地实战手册》《Prompt Engineering 从入门到生产》)
为什么烧 token:每章需要先调研→大纲→初稿→审校→润色,一本书 15-20 章,每章 3000-5000 字
预计消耗:单轮对话 50-100K tokens,多轮迭代可达 300K+
价值:可发布为 PDF / GitBook / Notion 模板,直接变现
2. 系统化 Prompt 模板库
做什么:为不同行业(法律、医疗、教育、电商、代码审查等)构建 100+ 个经过测试的 Prompt 模板
为什么烧 token:每个模板需要场景分析 → 多版本生成 → 效果对比 → 迭代优化
预计消耗:200K-500K tokens
价值:可做成 SaaS 产品或付费课程配套资源
3. 竞品分析报告
做什么:对 AI 领域某个细分赛道(如 AI Agent 框架、向量数据库、RAG 平台)做深度横评
为什么烧 token:每个产品需要功能拆解 → 代码示例 → 架构分析 → 优劣势对比
预计消耗:100K-200K tokens
这份回答在“AI 技术知识库/行业报告”“系统化 Prompt 模板库”“竞品分析报告”这三个细分方向上,把做什么、为什么烧 Token、预计消耗、价值四个维度都讲清楚了。就结构而言,可以说该有的都有。
小米MiMo深度评测:6400万Tokens缘何撑不起一个武侠百科?
MiMo 的 16 亿 Tokens 额度即将耗尽,我赶紧追加了一波测试。结果……彻底垮掉。虎头蛇尾,金玉其外,败絮其中。
先上一张图,各位感受一下:
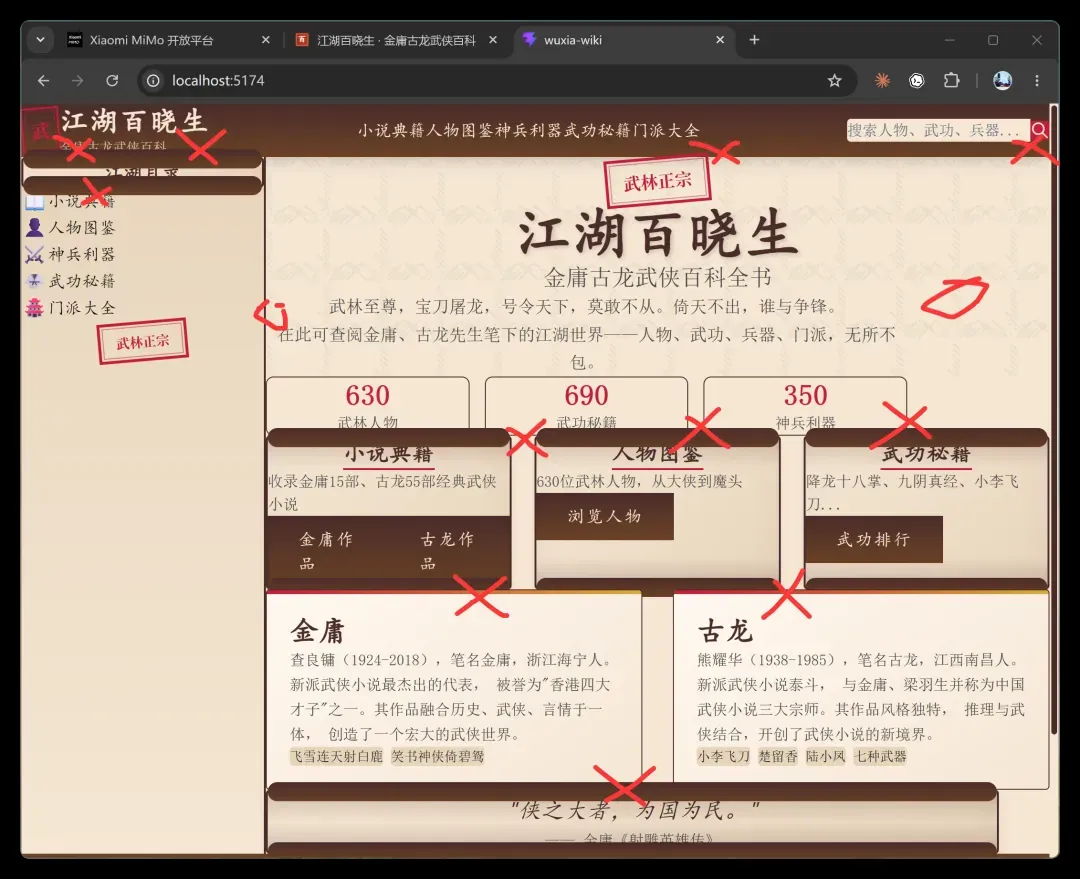
就这个网页,吃掉了 16 亿 Tokens 额度的 4%,约合 6400 万!
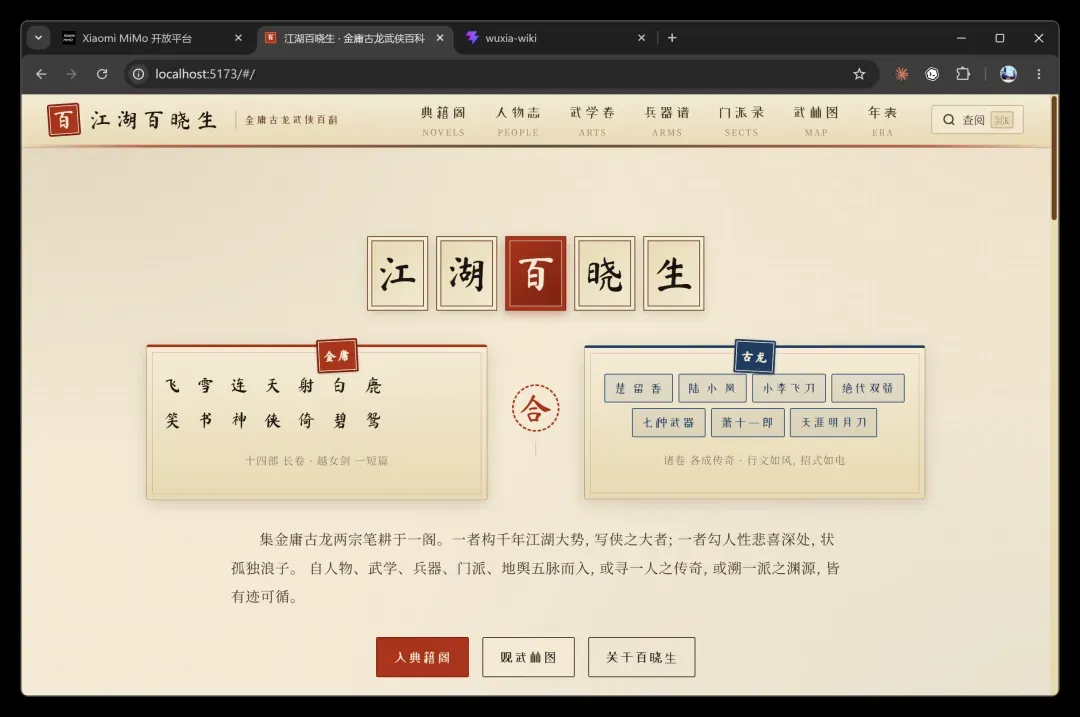
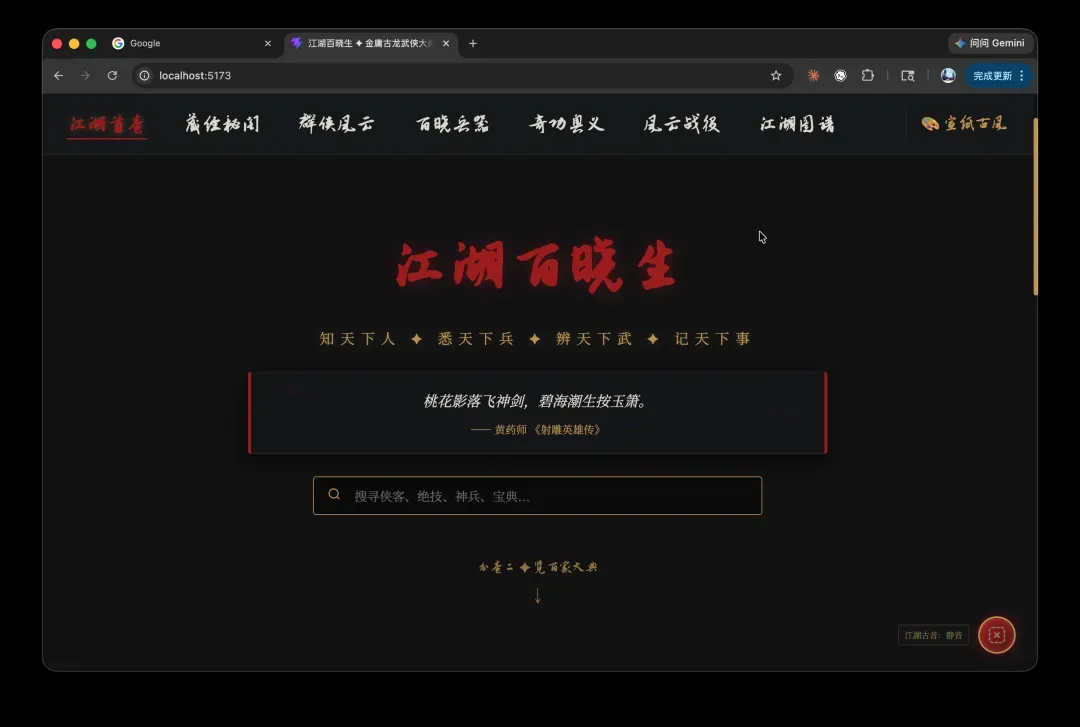
同一道题,Opus4.7 和 Gemini3.5 的表现完全碾压它!
Opus4.7 做出的效果:
Gemini3.5 做出的效果:
界面展示完了,我们来深挖一下细节。
这是 AI 实战开发测试《江湖百晓生》的第二篇!
核心需求是:构建一个以金庸、古龙武侠世界为主题的百科,要囊括主要人物、兵器、武功等核心要素。
下面我将完整还原开发工具、开发过程,带你沉浸式感受 MiMo 在真实场景中的能耐。
工具环节
现在我基本不用 CCSwitch 了,一切交给自己的 JCode + Claude Code!
配置好后,打开 JCode,双击图标即可呼出 CC:

你无需在终端里敲 Claude,也不用 cd 进特定目录,更不必手动设置环境变量或修改配置文件。
只需通过软件的添加功能:
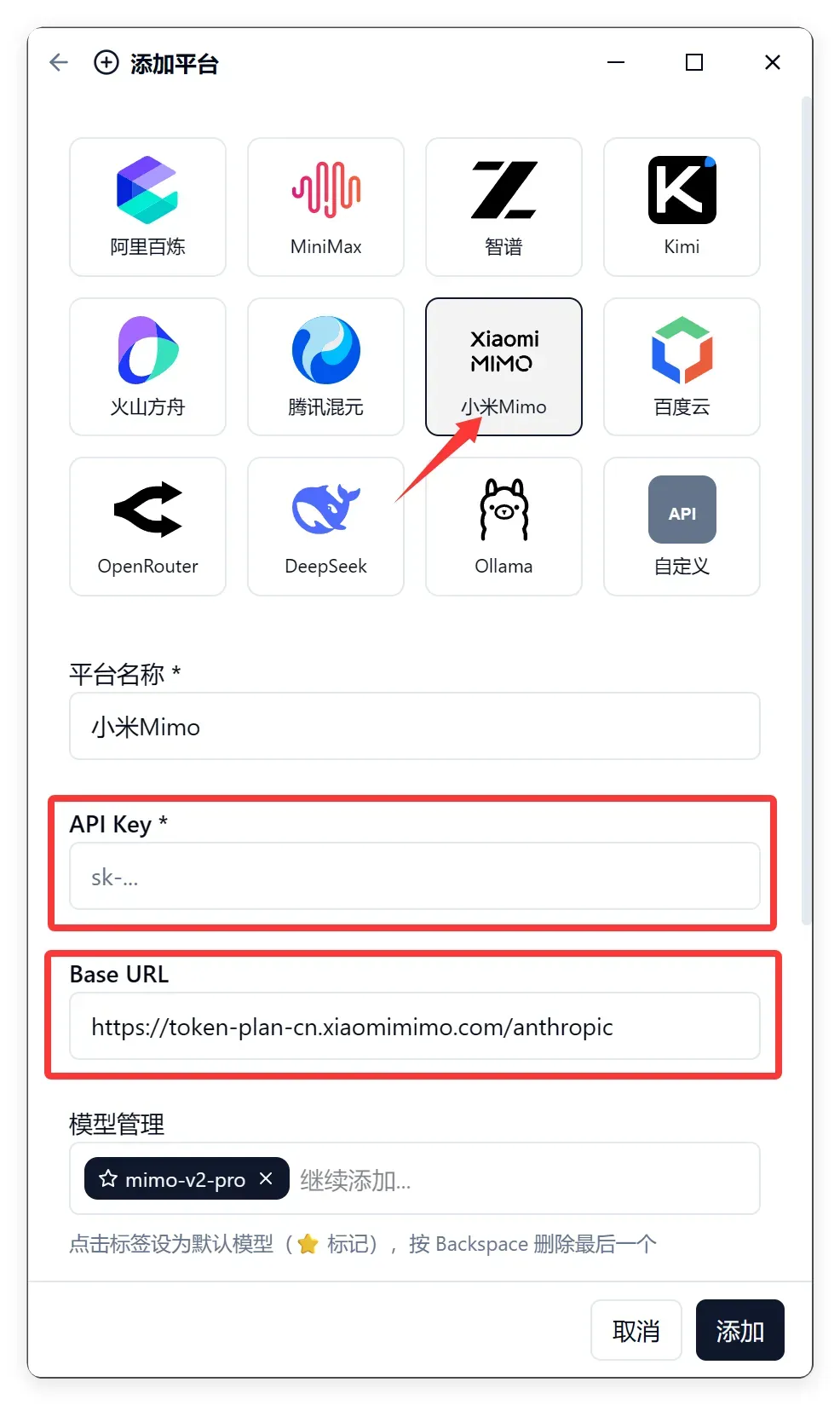
填入 API key 和正确的 Base URL,万事大吉!
小米的 base URL 其实已经内置。不过,默认接入点和 Token Plan 的接入点不同。所以如果用 Token Plan 套餐,就必须像截图中那样调整;若按用量计费的普通 API,则无需改动。
配置完成后,后续无需再费心。