2026上半年AI十大变革:从Agent Skills到Seedance 2.0,全面重塑人机协作格局
2026年的一天,一位用户通过手机向本地AI发出指令:打开一堆PDF发票整理成Excel报销单、一句话给电影《火遮眼》生成带宣传视频和海报的网站,以及按特定风格为这篇稿件撰写开头。饭做完,活也全部完成。这种事,一年前还只是科幻,今年已成日常。
这并非渲染,而是想指出:2026年上半年的AI,早已不是“哪个模型评分高”的叙事。模型端的竞逐,在GPT‑5.5、Claude 4.8、M3这一档已显露明显的边际递减。真正发生位移的地方,悄悄移到了别处——移到了如何将AI植入日常生活、融入工作流、嵌入个人电脑之中。
这半年一线测试过的产品不胜枚举,发布会看到一半就关掉的同样数不清。本文并非流水账,而是从众多事件中拣出10件亲手验证、踩过坑、形成判断的,串成一条主线。
10个话题的顺序是:Agent Skills、OpenClaw、Harness、Multi‑Agent(含Agent OS、Sub‑agent)、Coding Plan、CLI回归、Desktop Agent、Physical AI、语音交互、Seedance 2.0。
全文逾万字,细品。
一、Agent Skills:2026年最值得掌握的核心能力
整个上半年,最被低估却又最能影响一线工作流的事,就是Agent Skills。
它在半年内从一家厂商的功能,跃迁为行业标准。Anthropic于去年10月推出,12月做成开放标准,到现在OpenAI、谷歌以及国内AI厂商已全线跟进。
它究竟是什么?一言概之,Skills是一个文件夹,里面必须包含一份SKILL.md:开头是YAML元数据(name和description),下面是Markdown写成的执行说明,并可附带可选的scripts子目录、references子目录和assets资源文件。
skill-name/├── SKILL.md (必需)│ ├── YAML frontmatter (必需)│ │ ├── name: (必需)│ │ └── description: (必需)│ └── Markdown instructions (必需)└── Bundled Resources (可选) ├── scripts/ - 可执行代码 ├── references/ - 参考文档 └── assets/ - 资源文件
Agent Skills最精妙之处在于progressive disclosure,即渐进式披露机制,共分三层。第一层是元数据,每个Skill约50到100个token,会话启动时所有Skill的name与description都进入系统提示词,模型只是“知道有这些Skill存在”。第二层是指令,SKILL.md全文建议控制在5000 token、500行以内,仅当模型判定当前任务匹配某Skill时才加载进上下文。第三层是资源,scripts和references等更深层文件,只会在SKILL.md主动引用它们时才进入上下文。
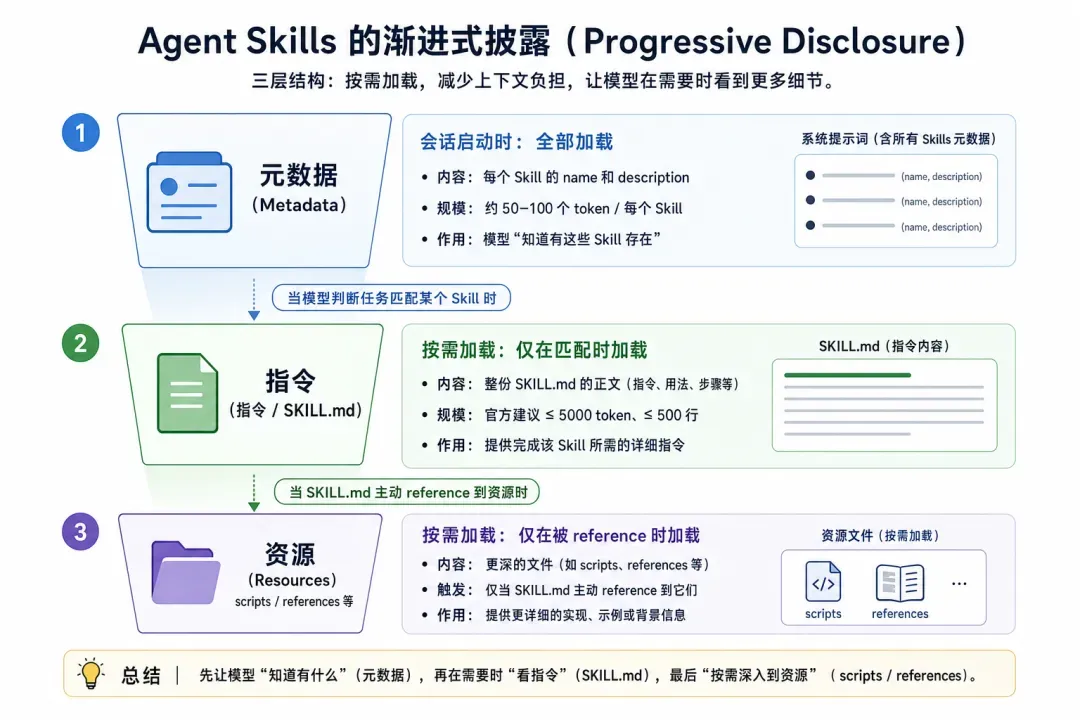
这套架构解决了一个极为现实的问题——上下文的稀缺性。早期Agent的痛点是想往System Prompt里塞更多专业知识,塞得越多模型越糊涂。Skills把“有哪些能力”和“具体怎么干”在物理层面拆开,让模型只为正在做的事情付出token。
Skills真正解决的,并非prompt的长短,而是个人知识的资产化。组织里最值钱的从不是写在手册里的SOP,而是只有少数资深员工才知道的“这个表必须按这个口径填”。过去这种事要么口口相传,要么写成员工手册然后被束之高阁。Skills第一次让个人或团队的方法论具备了可分发、可复用、可版本化管理的形态。
实际体验下来,最直接的感受是效率神器。以常见的内容创作流程为例,可构建覆盖选题、风格、标题生成的Skills集合。每添加一个新Skill,模型在未触发时完全察觉不到,触发后却能精准照做。这种“加它不亏,用它管用”的体验,是传统提示词工程时代无法想象的。
时间来到2026年6月,再提“学会怎么问AI”已显过时。该学的是怎么教AI,而Skills是这件事最干净的载体。
二、OpenClaw:全民Agent的第一次破圈
2026年春节后,国内AI圈最热的名字是“龙虾”,学名OpenClaw,基于TypeScript的开源项目,作者Peter Steinberger。名字由来很简单:作者想做一个叫Molty的“太空龙虾”AI助理,后来将底层部分抽出来开源,便有了OpenClaw,“Open + 螯”。其GitHub Star数已达37万,登顶开源榜首。

它解决了一个被长期忽视的痛点。
过去做Agent,主流路径两极分化。比如ChatGPT的Operator、Manus、Genspark等,打开网页就用,体验流畅,但对话、文件、记忆全在第三方服务器上。另一类如Claude Code、Codex CLI,虽在本地运行,但本质上是写代码的终端工具,不管多通道、跨设备、永远在线这些事。
2026世界杯明日开幕,Temu合规门槛再升,阿里国际首季盈利,美线海运暴涨87%!6月跨境关键事件全解析
6月跨境圈迎来几波密集冲击:2026美加墨世界杯将于明日(6月11日)正式开赛,选品冲刺进入最后倒计时;小红书Redshop跨境电商平台正式落地,内容电商正式杀入跨境赛道;阿里国际数字商业集团首度交出季度盈利的成绩单,AI工具被指为增长的核心引擎;美线海运运费年内已累计上涨87%,旺季备货的成本压力急剧升温。
01 | 世界杯开幕在即,冲刺选品的三个低风险方向
明日(6月11日),2026年美加墨世界杯就将拉开帷幕。本届赛事首次将参赛队伍扩展至48支,由美国、加拿大、墨西哥三国共同承办,预计将吸引全球超50亿观众,无疑是2026年跨境电商领域规模最大的流量窗口之一。
海关总署数据显示,2026年1至2月义乌体育用品及设备出口额达23.4亿元,同比增幅高达38.5%。足球、球迷助威道具、户外观赛装备等品类订单呈现爆发式上扬。虽然揭幕战近在眼前,但仍有三大类不易触碰知识产权的选品方向可重点把握:
**① 通用足球周边:**包括无品牌标识的足球、训练器材、球袋球网、门将手套等产品,能有效规避FIFA官方IP侵权风险,主要面向大众消费者和业余训练人群。**② 观赛场景用品:**助威道具(气棒、旗帜、口哨)、啦啦队服饰,以及户外露营装备(便携椅、保温箱、投影幕布),瞄准家庭观赛和户外大屏观赛的场景。**③ POD定制类产品:**如球迷定制T恤、手机壳、挂件等按需生产的产品,可以借助柔性供应链实现零库存和快速响应。世界杯期间,TikTok上 #WorldCup2026 话题播放量早已突破百亿,社媒引流效果明显。
需要特别提醒的是,义乌海关已将世界杯相关出口商品列入重点查验范围,凡带有FIFA标识、球队队徽、球星肖像等官方IP元素的商品均面临扣货风险。建议卖家坚持“通用品+定制化”组合路线,远离版权红线。

📌 来源:浙江省政府官网——义乌体育用品出口数据 | 腾讯新闻——世界杯开幕时间确认
02 | 小红书Redshop正式上线,内容电商切入跨境赛道
市场传闻已久的小红书跨境电商平台“Redshop”本月正式上线启动,首批覆盖香港、澳门、美国、英国、新加坡等9个市场,初期采取定向邀请种子商户的模式,主营品类集中在非遗手工、特色手工艺品,后续会陆续拓展至更多类目。
这标志着小红书从“种草”全面走向“拔草”闭环。与TikTok Shop的短视频直播驱动、SHEIN的快时尚供应链效率和Temu的极致低价打法不同,Redshop的核心差异化落脚在**“审美溢价”**上——依托小红书上积累的图文种草心智,将非遗手工、设计师品牌等高溢价品类推向海外市场,目标锁定那些愿意为设计感与品牌故事买单的中高端消费群体。
对跨境卖家来说,Redshop的入局带来一个全新的低竞争渠道,特别匹配有设计能力、手工艺供应链优势或擅长内容营销的中小卖家。不过也应注意,小红书跨境尚处于起步期,物流、支付、售后等基础设施仍在搭建过程中,较稳妥的做法是先从“测试性投入”切入,持续跟踪平台后续的招商政策。
📌 来源:科创板日报——小红书Redshop将于6月正式上线 | 紫鸟浏览器——6月9日跨境新闻汇总
03 | SHEIN与Temu玩具美妆品类强制白名单,合规大限仅剩10天
为对接欧盟最新监管要求,SHEIN和Temu近日联合公布:自2026年6月20日起,玩具、美妆两大品类将强制实施白名单实验室专属报告制度。这也意味着,以往行业内常见的“挂靠证书”“免样办证”等灰色操作将被彻底清理。
新规要求十分明确:所有在售及新上架的玩具、美妆商品,必须由平台指定白名单内的检测机构出具专属检测报告,且证书上的送检方、品牌方、生产方等信息必须与平台卖家主体信息严格一致。不合规的商品将在6月20日后被集中下架。
对上述两个品类的卖家而言,距离截止日期仅剩10天。眼下最紧迫的动作是立刻排查现有产品证书的合规情况,核实检测机构是否处于平台白名单以内,并协调供应商尽快提供与店铺主体身份一致的检测报告。欧盟市场的合规方向已经非常清晰,从玩具美妆起步,未来将逐步延伸至更多品类,合规成本必然成为常态运营的一部分。
📌 来源:搜狐——SHEIN/Temu玩具美妆强制白名单新规
04 | 阿里国际首次季度盈利,AI工具成就跨境增长新引擎
阿里国际数字商业集团(涵盖速卖通、Lazada、Trendyol等)在最新财报中披露了一项里程碑式数据——首次实现单季度盈利,经调整EBITA亏损从前季度的数亿元大幅缩小至仅剩1.38亿元,已非常接近盈亏平衡线。
财报中明确指出,盈利的核心驱动力来自大范围落地的AI工具:AI智能选品协助卖家精准锁定目标市场热销品类,自动翻译显著降低多语言运营门槛,而无人直播则大幅压缩了内容制作成本。在速卖通平台上,使用AI工具的卖家平均运营效率提升超过40%。
这对独立站卖家同样具有参考价值。目前主流AI跨境工具已能覆盖“选品调研→多语种Listing生成→AI客服→广告素材自动生成→数据分析”的全链路,月均成本控制在50至200美元之间。与其一味增加人力,不如先用AI替代重复性工作,这正是2026年跨境卖家降本增效的最短路径。
📌 来源:新浪财经——阿里国际接近盈利,AI提效双线并进
05 | 美线海运价格暴涨87%,马士基再征2000美元旺季附加费
上海航运交易所最新数据显示,上海港出口至美西基本港的40英尺集装箱(FEU)运价已攀升至4,149美元,年内累计上涨87%;美东航线运价达到5,333美元,累计涨幅超过70%。欧洲航线方面,6月上旬报价已稳定在4,100美元/FEU以上,较5月末的2,850美元明显上移。
马士基已发官方通告:自6月17日起对远东至美加航线征收旺季附加费,40尺柜最高加收2,000美元。阳明海运、万海航运等头部船公司同步上调美线基础运价,单柜涨幅普遍在1,000至1,500美元之间。当前正值Prime Day备货(6月23—26日)和世界杯双旺季叠加,舱位紧张与高运价状态预计将持续至7月中旬。
给卖家的实操建议:①已确认参加Prime Day的卖家,应立即锁定舱位并出货,不宜再等待降价窗口;②货量较大的卖家可拆分成3至4批,采用“海运慢船+铁路+空运”的多渠道组合方式发货,以摊薄单次物流成本;③建议将70%以上的库存提前送入第三方海外仓,FBA仅保留2至4周的安全库存,通过少量、多批次的调拨补货策略来规避旺季运价高峰。
📌 来源:中国发展网——国际海运价格接连跳涨 | 百家号——6月最新国际物流新闻汇总
**小结:**6月跨境圈“世界杯+Prime Day”双旺季,对卖家的运营能力和成本控制提出了全新挑战。选品要紧抓赛事红利,合规需紧密跟随政策动向,物流讲究提前锁舱锁价,运营要善于借力AI工具——能在旺季领跑的,永远是提前一步做好准备的人。
2026智能无线烧烤温度计选品深度解析:抢占79-89美元品牌真空带的DTC机遇
一、市场全景
全球智能无线肉类温度计市场正迈入高速增长阶段。根据Verified Market Reports(2026年4月发布)的数据,2025年该市场全球规模约为1.2亿美元,预计到2034年将攀升至2.5亿美元,2026至2034年间的复合年增长率(CAGR)达到9.2%。
从更宏观的视角看,Grand View Research的数据显示,全球烧烤炉市场2025年规模已达54.9亿美元,预计2033年将达到81.2亿美元,整体CAGR为5.0%。其中,智能烤炉细分市场的增速达到6.63%(Mordor Intelligence数据),说明烧烤爱好者正全面拥抱“智能化”升级,而无线温度计则是所有智能烧烤配件中渗透率增长最快的品类。
在地域结构上,北美市场凭借超过1.3亿烧烤用户,占据全球约40%至45%的份额,是当之无愧的第一大市场;欧洲约占25%至30%,德国与英国处于领先地位;亚太地区则凭借超过10%的复合年增长率,成为增速最快的区域,市场份额约为20%至25%。

二、竞争格局解析
当前市场格局呈现出典型的“沙漏型”结构:低端30至50美元价格带已经是红海,充斥着大量白牌产品;高端200至350美元区间则由少数品牌把持;而在中端79至89美元区域,存在一个不容忽视的品牌真空地带。
最关键的发现是:市面上至今没有一款产品能够同时满足“双探头真无线 + 双频WiFi + App智能引导 + 精致设计”,并且将价格定在79至89美元之间。入门级的GoveeLife单探头版本定价69美元,体验并不完整;ThermoPro TempSpike单探头款价格为79至99美元,功能有所欠缺;再往上一级,价格直接跃升至119美元以上,中间形成了一个空白区间。
| 品牌 | 价格 | 评分 | 核心卖点 | 明显短板 |
|---|---|---|---|---|
| MEATER Plus | $99-119 | 4.5★ | 真无线先行者、Guided Cook、双传感器 | 仅支持蓝牙165英尺、单探头、无WiFi、连接偶尔不稳 |
| ThermoPro TempSpike | $79-99 | 4.2★ | 双频WiFi+蓝牙、500英尺范围、IP67防护 | 仅为单探头、App功能相对简单、外观偏工具化 |
| Typhur Sync | $199-269 | 4.5★ | 6传感器、±0.5°F精度、0.5秒响应、铝合金底座 | 价格是MEATER的两倍、品牌认知度尚待建立、过于专业 |
| GoveeLife 4探头 | $129-149 | 4.3★ | WiFi+蓝牙、4探头配置、72小时续航、性价比突出 | 蓝牙连接偶尔不稳、App交互不够直观、品牌调性偏工具型 |
| GoveeLife 1探头 | $69 | 4.2★ | 入门级真无线、WiFi+蓝牙、价格友好 | 仅单探头、精度仅±1.8°F、外观廉价感明显 |
| Inkbird IBT-4XS | $39-49 | 4.4★ | 极致性价比、4探头、150英尺蓝牙 | 有线探头而非真无线、无WiFi功能、品牌定位偏低端 |
三、用户核心痛点与DTC应对方案
| 痛点 | 用户反馈占比 | DTC品牌可采取的解法 |
|---|---|---|
| 蓝牙/WiFi频繁断连 | 28% | 采用双频WiFi与蓝牙5.4双模自动切换方案,基站设计远离金属干扰源 |
| 温度读数偏差明显 | 22% | 配置±0.5°F多传感器阵列,通过NIST校准,配合App提供智能引导 |
| 探针过热或烧毁 | 18% | 使用耐温1000°F的不锈钢材质、IP68防护等级,并加入过热预警机制 |
| 电池续航不足 | 15% | 提供48小时以上续航、5分钟快充功能及低电量预警 |
| App体验不佳或闪退 | 10% | 开发轻量级自研App,内置本地缓存及离线模式保障使用体验 |
四、品牌真空地带与市场机会
缺口一:79至89美元双探头无线品牌真空。
消费者想要购买一副“真无线双探头+WiFi”的产品,最低也需要99美元起步(如GoveeLife),而在79至89美元这个价格区间内,只有单探头款式可供选择。
38年重塑罗马:Gismondi 的石膏城市模型与君士坦丁大帝的帝国记忆
一座留存至今的城市模型,并不依赖文字叙述,而是通过精准的比例、真实的材料,以及如同考古学家般的持久耐心才得以呈现。罗马的建筑史被无数巨匠反复书写——米开朗琪罗、贝尔尼尼、维特鲁威。然而,真正让一座消逝的古城以物质形态重返现实空间的,是 Italo Gismondi 耗费 36 年(另一说法为 38 年)精心堆塑而成的石膏模型。这件作品远不止是一件考古纪念物,它本身就是一座将记忆凝固为物质材料的建筑。

图 整座模型占地16.764m×16.764m,以1:250比例呈现公元4世纪初君士坦丁大帝治下的罗马城。
从大理石残片到微缩罗马
公元 203 年至 211 年间,塞普蒂米乌斯·塞维鲁皇帝下令在一块巨大的大理石板上镌刻整个罗马城的平面图,这就是赫赫有名的《Forma Urbis Romae》(罗马城大理石地图)。该石板原长 18 米、宽 13 米,如今仅存约 10% 至 15% 的残片。一个多世纪后,考古学家鲁道夫·兰恰尼(Rodolfo Lanciani)依据这些碎片拼合出 1893 至 1901 年的复原图《Forma Urbis》。Gismondi 继承的不单是兰恰尼的平面图,更是一条跨越 1800 年的城市制图传统。
他不仅将兰恰尼的二维平面立体化为三维模型,还把时间坐标从塞维鲁王朝的 3 世纪推进到 4 世纪初君士坦丁大帝执政时期。每一栋保存下来的建筑物、每一段城墙、每一列柱廊,都需要在石膏中确定体量,而判断依据往往仅残存的柱础、一段台阶的走向或提图斯凯旋门现存结构。Gismondi 的方法是“以考古遗存锁定确凿部分,用类型学补足证据缺失的区域”。这一原则使模型既是严谨的科学研究,也带着合理推测的创造色彩。
政治授权下的城市重建
1933 年,墨索里尼以“庆祝奥古斯都诞辰两千年”为名委托制作这项模型。同年,他下令拆除罗马大量中世纪民居,为修建“帝国大道”腾出空间。极具讽刺意味的是,这些被夷平的建筑恰恰毁掉了 Gismondi 原本可以用来复原君士坦丁时代城市肌理的关键证据。模型工程在政治动机与考古资料匮乏的矛盾中启动,这决定了它的一部分城市面貌源于可验证的遗址,另一部分则出自 Gismondi 基于古罗马建筑类型学的合理推断。
因此,这件作品在今天看来尤为微妙:它既见证了法西斯政权对古罗马符号的挪用,也凭借顽强的考古工作保存了一段被政权刻意抹除的城市记忆。模型上的君士坦丁大殿、万神殿、大竞技场,并非服务于政治宣传的布景,而是 Gismondi 用 36 年时间,将碎片逐一拼合而出的学术判断。
实体模型:比数字孪生更持久的城市档案
1955 年,这件模型被永久安放在罗马文明博物馆(Museo della Civiltà Romana)的 EUR 分馆,Gismondi 则持续修改直至 1971 年,次年便与世长辞。时至今日,它仍是全球规模最大、信息密度最高的古罗马城市实体模型。用建筑师的话来说,这是一座“不依赖屏幕的数字孪生”——它不用算法计算视距,而是让观者的眼睛在 1:250 的比例中亲自丈量那座陨落的帝国都城。
对今天的建筑师而言,Gismondi 的工作蕴含着跨越时间的力量:当当代 BIM 模型还在追逐 LOD 精度和信息丰富度时,这件始于 1930 年代的手工模型提醒我们——真正的“城市信息”从来不止是参数组合,更是一系列在比例中可读、在材料与观察中积淀下来的判断。
AI时代必备:从提示词到上下文工程,三步构建可复用智能工作流

关键词:AI技能、提示词工程、上下文工程
AI 技术并不新鲜,但把它转化为你能用、好用且长期可复用的能力,正成为这个时代的基本功,其重要性不亚于会用电脑、会上网、会点外卖。核心差距不在于工具,而在于你如何使用它。
一次不起眼的收费,照见了基础设施化的拐点
2026年5月,豆包在 App Store 悄然上线了付费订阅:标准版68元/月,加强版200元/月,专业版500元/月,年付最高一档 5088 元。官方随即声明,基础聊天、问答、写文案和简单生图仍旧免费。网友迅速分裂为两派,一方表示“敢收费就卸载”,另一方则认为“免费不可能长久”。
这件事的关键不是价格本身,而是其背后算力逻辑的根本转变。传统互联网产品的边际成本会随用户规模递减,搜索引擎和社交平台通常靠免费圈地、广告变现。而如今按 token 计费的服务,每一次提问都产生真实的算力消耗,用户越多,总成本就越难控制。正因此,字节将 AI 基建预算从 1600 亿提升至 2000 亿,腾讯的 AI 新业务也在一个季度内拖累88亿利润。
豆包的收费试探与 OpenAI CEO Sam Altman 在同年的 BlackRock 基础设施峰会上的表态遥相呼应。Altman 将 AI 比作未来的电力和水,主张按“表”计量,用户和企业按用量付费。他还直言:想拉低价格,只能继续扩张算力、建造数据中心,而这需要巨额投入。收费并非某个产品的商业策略,而是整个行业从免费圈地走向按实际消耗回收成本的必然。
技术并不新鲜,但能力分层正在加速
从公开资料看,这套技术从学术讨论到产品爆发仅用了不到十年。今天的智能助手能生成代码、整理文档、分析表格、美化图片,甚至连续执行多步任务,仿佛全新的物种。然而拆开来看,所谓大模型本质上仍是基于海量数据学习模式的预测系统,其核心原理十年前就已存在。
真正的变化发生在“怎么用”这一层。从写好一个 prompt,到设计一套上下文工程,再将个人方法论封装进 CLAUDE.md、AGENT.md,进而搭建出可复用的 harness,每一步都不是技术本身的突破,而是人把工具吃透后展现出的熟练度。再往上,便是 vibe coding、agent loops 与持续探索:你不再只是“向它提问”,而是“设计一套让它持续交付的工作流”。差距正是由此拉开。
常见技能阶梯
- 第一层:会对话。打开页面就能提问,收到基本回答。
- 第二层:会调教。能借助提示词、上下文约束与工具调用,让它稳定输出工作水准的结果。
- 第三层:会搭 harness。将流程、规则、模板与个人经验封装为可复用体,训练出专属的“外脑”。
从“提示词”到“上下文工程”
早期人们强调“写好提示词”,但“prompt engineering”一词在2025年后已被从业者刻意淡化。并非它不再重要,而是它已变得如同写字一样基础,无需专门冠名。
新一代提法叫“上下文工程”。它要求的不只是你写对一句话,而是把任务目标、参考资料、输出要求、校验标准、迭代方式打包成一条稳定的执行管道。换言之,你原本在脑内“准备上下文”的隐性工作,如今要显式地写成结构化规则,让智能工具按预期运行。
对普通人而言,最友好的切入点仍是提示词。世界经济论坛《2025年未来就业报告》明确指出,近40%的核心工作技能将被生成式方法改变,而“新读写能力”正是最底层的一项:会筛选信息、拆解任务、借助辅助工具将想法变为成果。
将个人方法封装成专属 Harness
真正让工具从“能帮你”变成“你用得顺手”的,是你自己的 harness。这个词听起来像开发术语,但本质是把做事流程打包封装:你的判断标准、常用资料、成品格式、质量检查步骤,都写成可重复执行的规则。
Build / Test / Iterate,这是工程师的节奏,对普通人同样适用:先搭建最小可行版本,用真实任务测试,再根据结果调整。你会发觉,不是模型变聪明了,而是你更懂得“指挥”它了。
CLAUDE.md、AGENT.md 这类文件,就是你写给自己的一份“使用说明书”:在特定场景下要遵守哪些原则,哪些是禁止触碰的红线,输出达到什么标准才算完成。它们实质上是经验的固化,并非神秘的咒语。
Vibe Coding、Loops 与持续探索
如果你已能稳定让工具完成单项任务,下一步加码的路径就是 loops:把“生成→检查→修正→重跑”串成自动循环。写代码的人如今管这叫作 vibe coding,意思是描述你的“感觉”和大方向,由模型处理琐碎实现,你只判断“方向是否对头”。
Claude Code 之父 Boris Cherny 深度解读:编程已死还是重生?
2026 年 5 月 6 日,红杉资本 AI Ascent 大会上,Claude Code 的创建者 Boris Cherny 走上舞台,向现场观众抛出一个问题:
“有多少人 100% 手写代码?有多少人 100% 用 AI 写代码?”
两极各有少数,中间占大多数。Boris 笑了笑,甩出一句震撼全场的话:
“对于我个人而言,编程已经被解决了。从去年 10 月、11 月开始,模型就已经能写出 100% 的代码。”
此言一出,开发者社区瞬间炸锅。有人质疑他只是 Anthropic 的“活体广告”,也有人觉得这不过是“AI 将取代程序员”之后又一件“皇帝的新衣”。
但我将 Boris 在红杉大会上的演讲、YC 圆桌访谈、他在 X 上发布的长文,以及 36 氪的专访全部研读一遍后,发现事情远比“编程已死”这个耸动标题要复杂得多。
Boris 并非夸大其词。但他讲述的现实,也并不代表大多数开发者的日常。
先看看这位“不写代码”的人,实际在做什么
Boris 的个人数据确实令人震惊:
| 指标 | 数据 |
|---|---|
| 2026 年至今手写代码 | 0 行 |
| 日均合并 PR | 数十个 |
| 单日最高 PR 数 | 150 个(主动测试上限) |
| 主力开发设备 | 手机(iOS Claude 应用) |
| 同时运行的 Agent 数量 | 数百个 |
| 每夜深度异步 Agent 数量 | 数千个 |
数据来源:红杉资本 AI Ascent 2026 Boris Cherny 演讲
Claude Code 自然语言驱动 Blender 建模:MCP 插件安装全攻略
安装完成后,您就能在 Claude Code 桌面版中用日常对话的方式指挥 Blender 自动完成建模任务——这意味着从构思到渲染的创意全流程都将变得像聊天一样自然。
教程源自:Blender 官方 MCP 服务页面与 GitHub 开源项目 ahujasid/blender-mcp,目的是让 Claude Desktop 能够通过标准化协议直接操控 Blender,把自然语言转化为精确的建模指令。
安装前的系统检查
请依次确认以下三项已准备就绪:
① Blender 5.x(已安装 ✓)
② Python 3.10 或更高版本
在终端执行 python3 --version 检查
预期输出类似 Python 3.10.x 或更高
如需升级请访问 https://www.python.org/downloads/
③ uv 包管理器
Mac 终端运行:brew install uv
若未安装 Homebrew,请先执行:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
完成后验证:uv --version
第一步:为 Blender 安装 MCP 插件
方式 A:官方拖拽安装(Blender 5.x 推荐,支持自动更新)
需要分两次拖拽,分别添加仓库和安装插件:
首次拖拽 → 注册 Blender Lab 源:
① 访问 https://www.blender.org/lab/mcp-server/
② 找到页面中的 “Install in Blender” 按钮
③ 用鼠标将该按钮或链接直接拖拽到已打开的 Blender 窗口内
弹出的确认框中点击 OK
第二次拖拽 → 安装插件本体:
④ 重复上一步的拖拽操作
在出现的安装确认窗口中点击 OK 或 Install
方式 B:手动下载并加载插件
① 打开 https://github.com/ahujasid/blender-mcp
② 在页面右侧 Releases 区域下载最新版的 addon.py 文件,保存至桌面
③ 启动 Blender,通过顶部菜单进入 Edit → Preferences(或按 Ctrl + ,)
④ 在偏好设置左侧选择 Add-ons(插件)选项卡
⑤ 点击右上角 Install... 按钮,在弹出的文件浏览器中选中 addon.py
随后点击右下角 Install Add-on
⑥ 在插件列表中找到 “Interface: Blender MCP”
勾选它左侧的复选框,确保该项高亮显示(已启用)
⑦ 关闭偏好设置窗口即可。
第二步:在 Blender 中启动 MCP 服务器
Claude Fable 5评测:断代领先的编程模型,价格却低于预期
今天必须以“震撼”开场,因为这是一款断代领先同行的模型,而且价格远没有想象中昂贵! 程序员和知识工作者的工作模式即将迎来巨变。
这次发布的模型没有被称作“神话 Mythos”,而是取名为“寓言 Fable”!
未来世界的神话,始于今日的寓言。
这件事注定会刷屏,我们先来看看官方公布的第一手消息。Claude系列正式迈入5.0时代。

Claude 是 Anthropic 旗下的大模型系列产品。
Claude 官方推文只有两句话:
推出 Claude Fable 5:一款神话级模型,我们已为其添加安全护栏,面向一般用户开放。
它的能力超越了我们此前任何公开可用的模型。
第一句点明新模型名为 Claude Fable 5,达到了 Mythos 级别的实力,并且套上了保护框架。
第二句指出能力超越了 Claude 以往所有模型,实际上可以去掉限定词——它超越了全球所有模型!
为什么敢这样说?请看第二条推文:
Fable 5 在几乎所有测试基准上均处于最先进水平,在软件工程、知识工作、科学研究和视觉领域都表现突出。任务越发长且复杂,Fable 5 相较于我们其他模型的优势就越大。
同时附上了这张基准对比图:
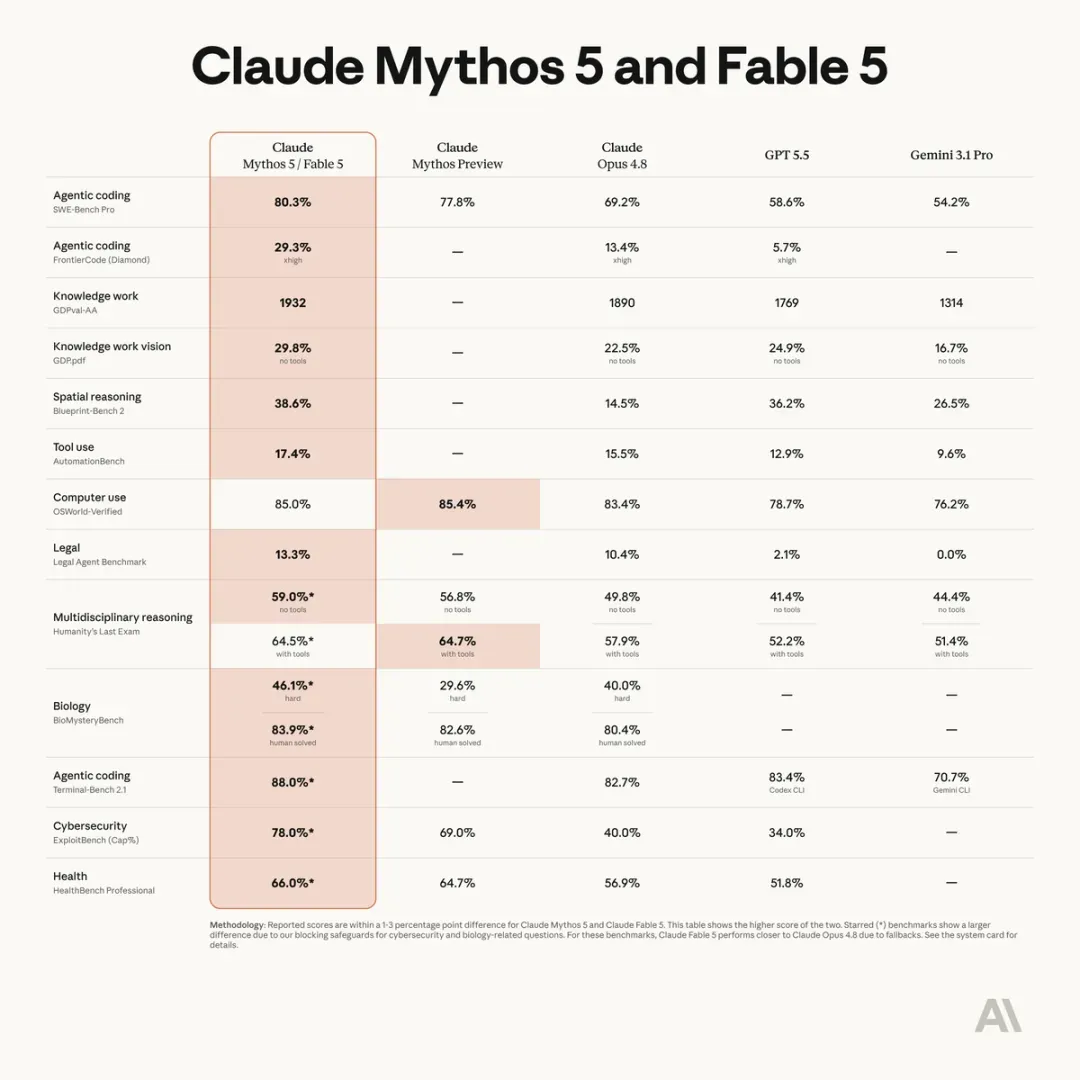
看到这张图确实令人头皮发麻。奥特曼看了恐怕都会瘫坐沙发,就像目睹原子弹爆炸一样。
这一次绝对不是夸张!
先看“智能体编程”类别中的 SWE-Bench Pro 基准。
“寓言” Fable 5 得分 80.3%,而预览版“神话” Mythos 5 为 77.8%。
也就是说,今天发布的寓言,比之前亮相的神话还要强悍。
在同一指标上:
Claude Opus 4.8 仅 69.2%
GPT‑5.5 仅 58.6%
Gemini 3.1 Pro 仅 54.2%!
要知道编程本身难度极大,Pro 基准又是高难度专业基准。在这样的专业测试中,居然能实现对前代与同行的断代式超越。
这是何等恐怖的实力!
智能体编程的第二项 FrontierCode,同样翻倍领先前代和 GPT‑5.5!
PGConf.Dev 2026精要:冯若航阐述PostgreSQL扩展交付之道——构建人人可用的pgext.cloud生态
在2026年PGConf.Dev大会上,Pigsty的作者冯若航带来了一场名为“Extensions for Everyone”(为所有人而构建的扩展)的演讲。这篇整理稿提炼了演讲的核心内容,并提供了在线PPT链接:https://vonng.com/work/extensions-for-everyone。
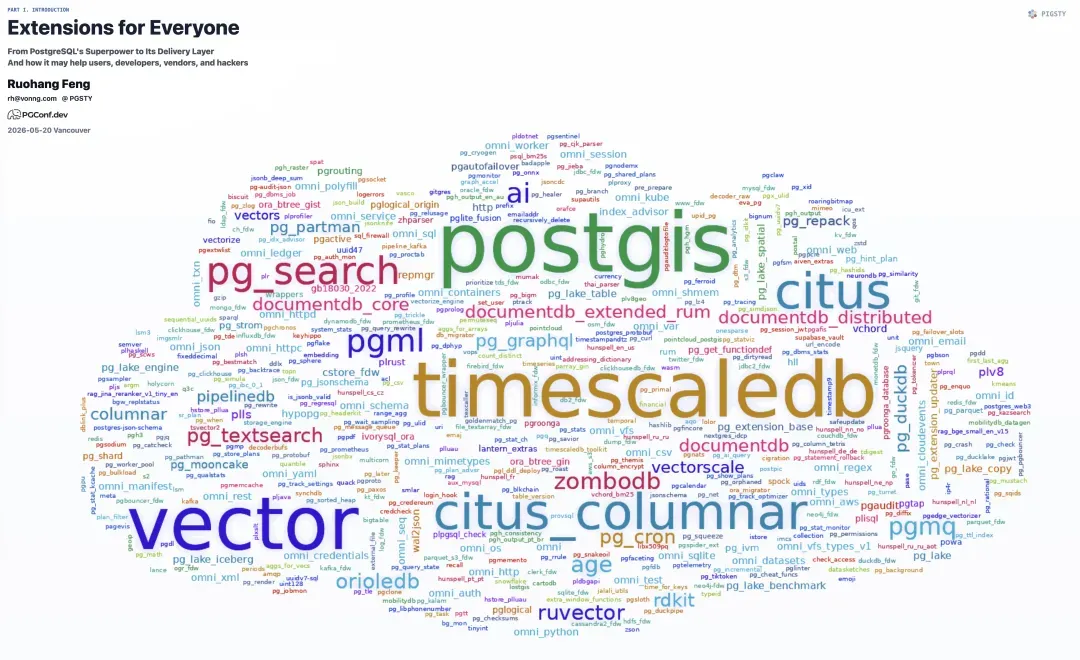
开篇:扩展的超能力与共享交付的价值
0. 扩展,属于每一个人的工具箱
各位来宾,我今天分享的主题是“让每一个PostgreSQL用户都能轻松获取扩展”。
它围绕扩展的交付展开,探讨一个共享的交付层,如何让用户、扩展作者、厂商乃至PostgreSQL内核开发者都从中获益。

1. 讲者简介:冯若航与Pigsty
我叫冯若航,是开源PostgreSQL发行版Pigsty的作者和维护者。
过去两年间,我一直在为数百个PostgreSQL扩展做编目、构建、打包与测试,横跨不同的PG大版本和Linux平台。所以今天的内容不是理论推导,而是一份来自一线的务实报告。
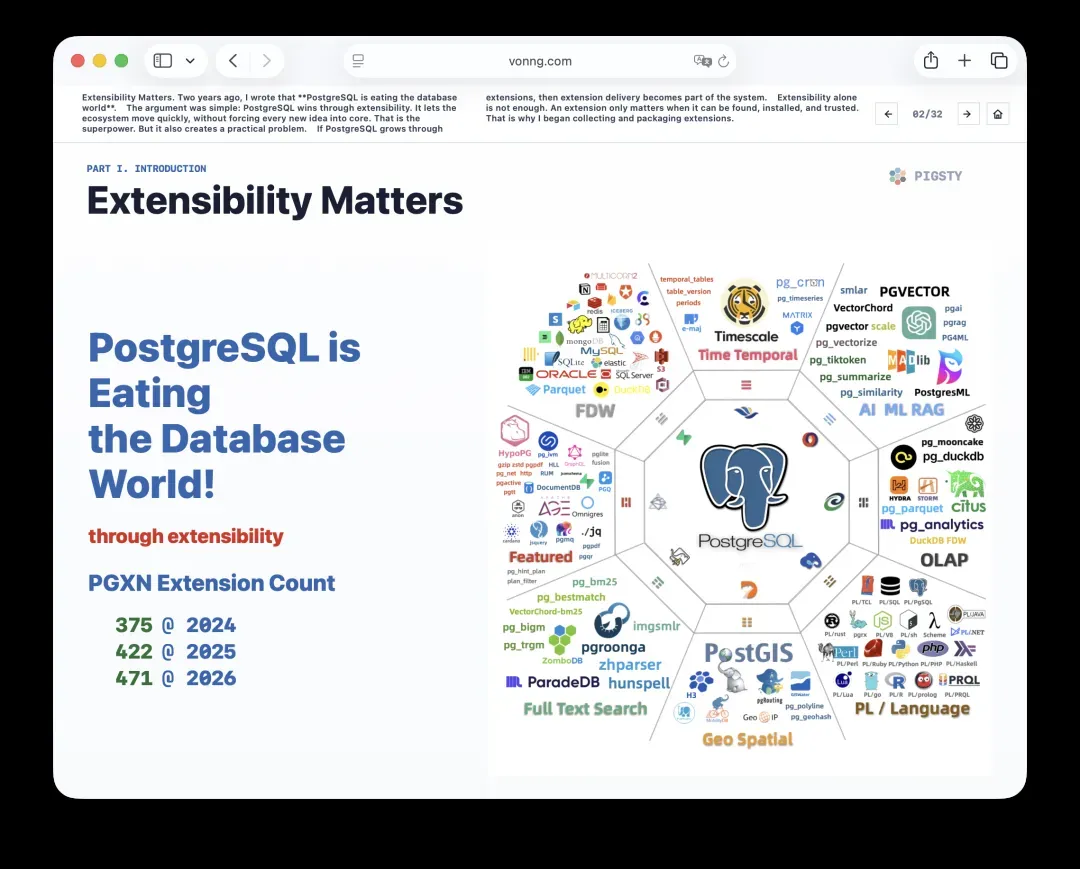
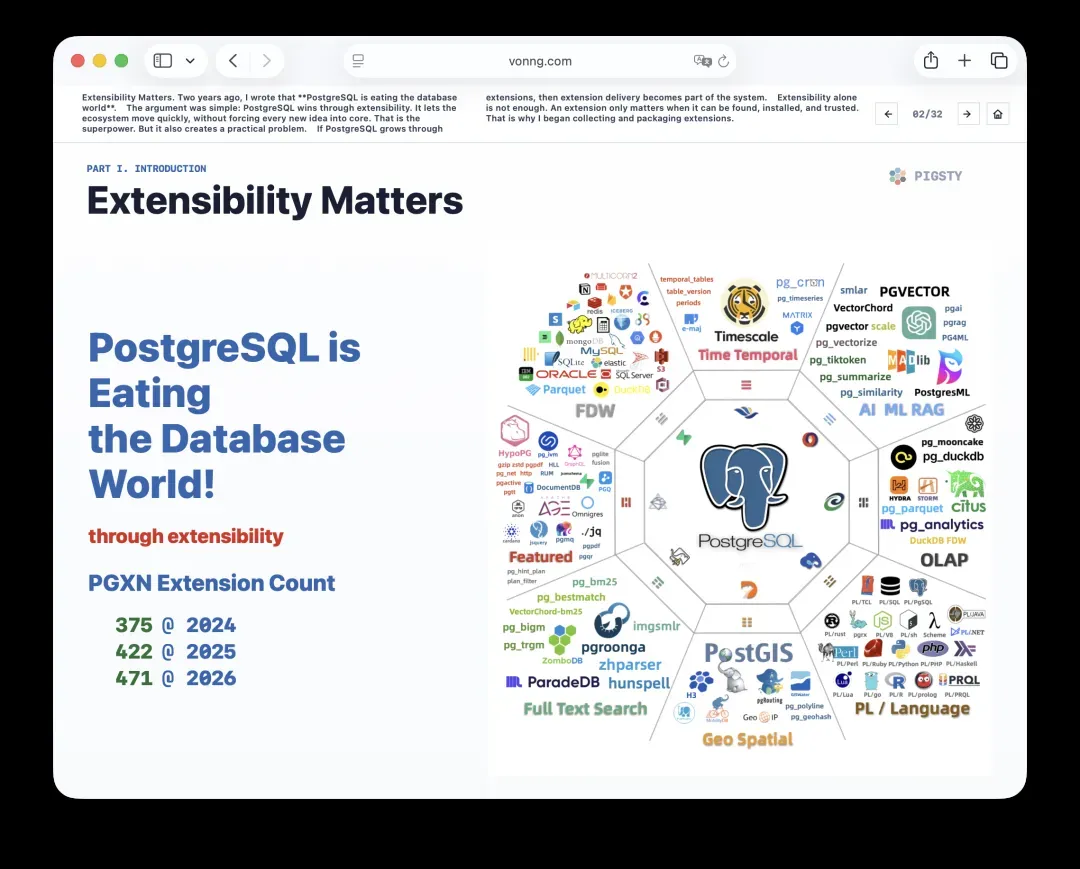
2. 可扩展性:PostgreSQL吞噬数据库世界的动力
两年前我就写过一篇文章,指出PostgreSQL正在吞噬整个数据库世界。
核心论点很直接:PostgreSQL的成功源自它卓越的可扩展性。这种能力让生态可以快速进化,而不必把每一个新特性都硬塞进内核。这是PostgreSQL的超能力,但也随之带来了一个非常现实的挑战。
如果PostgreSQL通过扩展来成长,那么扩展的交付本身就成了系统的一部分。
光是可扩展还不够。一个扩展只有被用户发现、被顺利安装、被充分信任,才具备真正的意义。
这就是我着手收集和打包扩展的起点。
3. 两年之后:一个百万下载的开源基础设施
两年后,我搭建起了一套名为pgext.cloud的开源基础设施,专注于PG扩展的交付。
目前它已经覆盖了16个Linux目标平台和5个活跃的PostgreSQL大版本。把PGDG和contrib计算在内,可交付的扩展集合大约有511个。
这个仓库现在每月提供大约一百万次下载。已有几家PostgreSQL厂商借助它来分发自己的扩展。但今天要谈的重点并不是这个仓库本身。
更重要的是,我们在维护这张覆盖矩阵的过程中学到了什么。这才是我想和大家分享的内容。
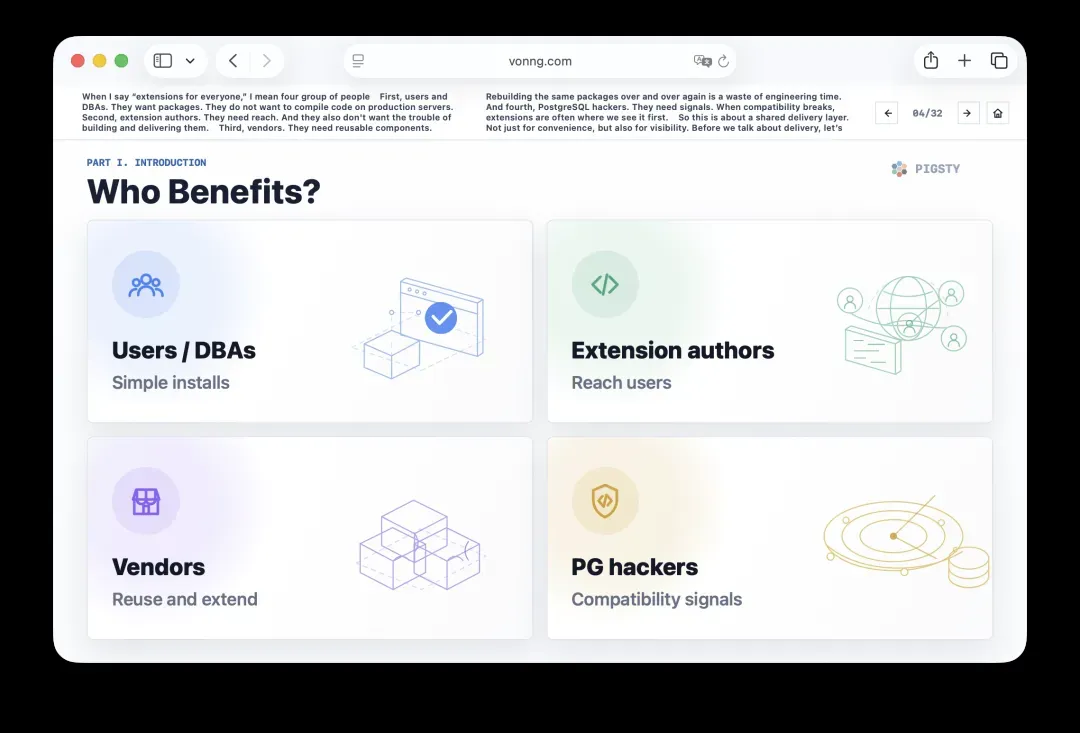
4. 四类受益者
当我说“人人都能用上的扩展”时,指的是四类人。
第一类是终端用户和数据库管理员。他们需要现成的二进制包,而不是在生产服务器上编译代码。
第二类是扩展作者。他们需要触达用户,也不想被构建和交付这些琐碎事务拖累。
第三类是厂商。他们需要可以复用的组件。反复重新构建同一批包,是对工程时间的巨大浪费。
第四类是PostgreSQL内核开发者。他们需要反馈信号。当内核改动导致兼容性被破坏时,扩展往往是最早暴露问题的地方。
所以,这件事的本质是一个共享交付层。它不仅让工作更省力,也提供了可见性和反馈通路。在深入交付之前,我们先要了解生态系统本身,弄清楚我们到底在交付什么。
生态全景:一个庞大而散乱的扩展星系
5. 星系级条目数:1600+个候选项
PostgreSQL到底有多少扩展?社区里有一个众人维护的GitHub列表,收录了一千多个条目。我自己维护的目录目前跟踪着大约1,617个条目。
但这个数字需要背景信息:一些项目还在活跃开发中,一些已经无人维护;有些只能在特定云上使用;有些依赖专有的PostgreSQL分叉;还有一些仅仅是想法和示例。因此,1,617这个数字并不意味着有1,617个可以直接安装的扩展。
它真正表明的是,生态的边界非常巨大,而且相当混乱。
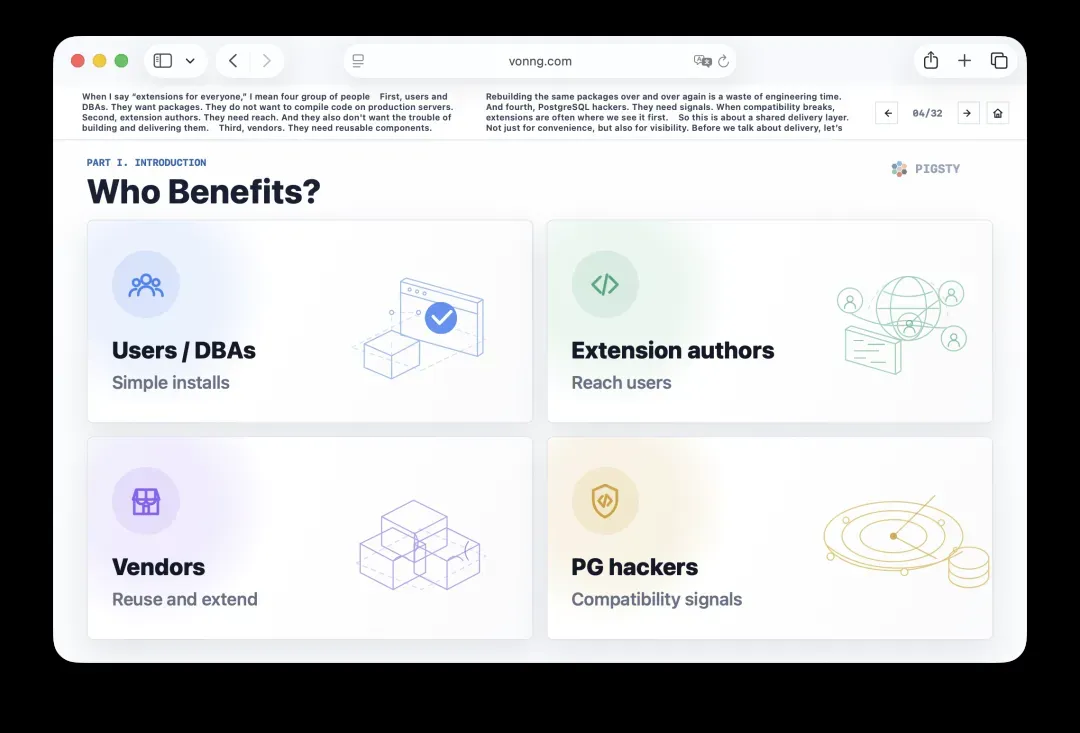
6. GitHub星标:关注度的快照
第一个公开的信号是GitHub星标。星标既不能衡量质量,也不能代表生产环境的使用情况,还会遗漏掉那些根本不托管在GitHub上的项目,比如PostgreSQL本身和PostGIS。
但星标仍然有价值。它反映了关注度、声誉和大概的认知度。排在榜单前列的都是熟悉的名字:TimescaleDB、pgvector、Citus、pg_search、pgml、pgai、pgmq等等。
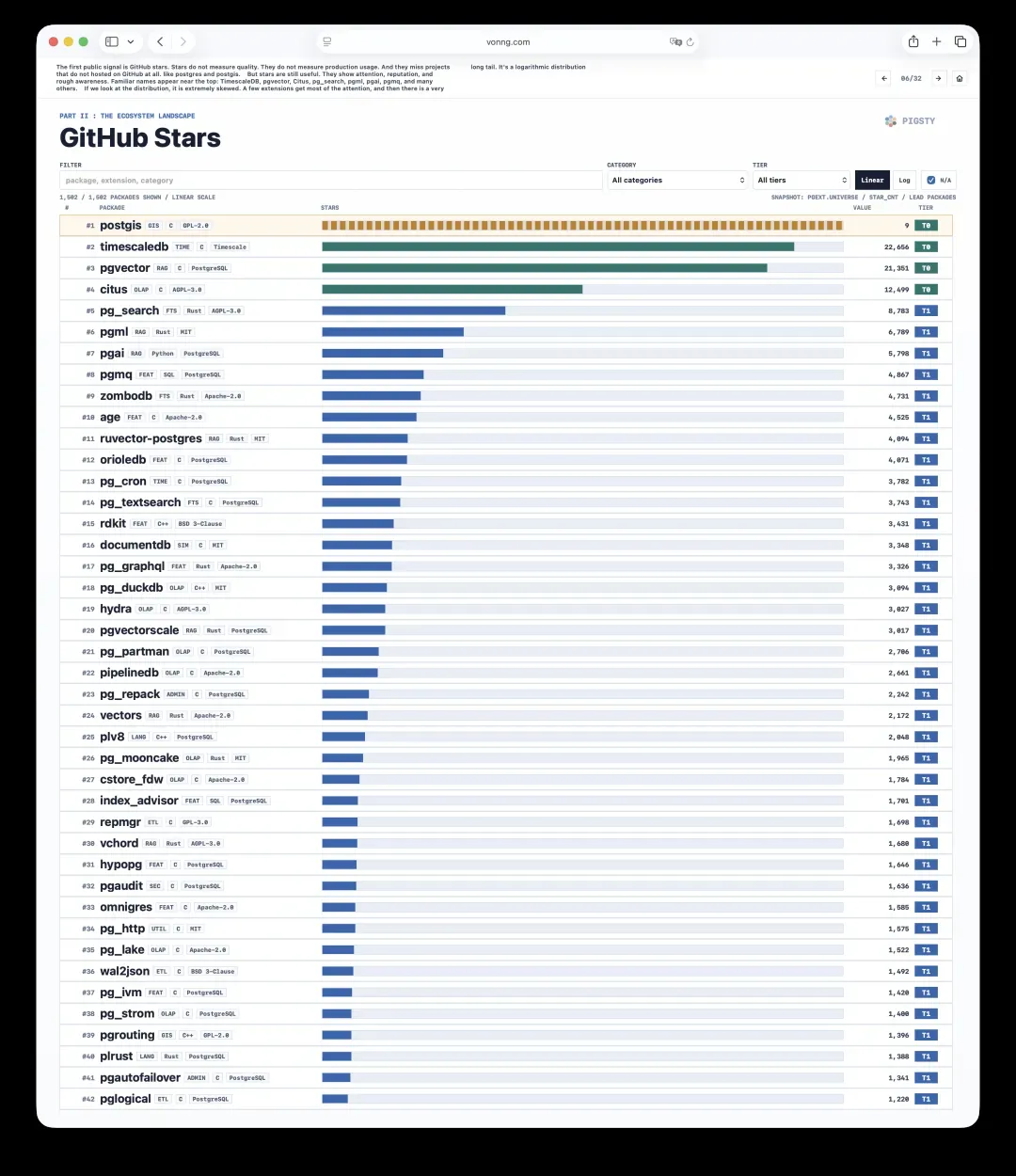
观察其分布会发现,它高度倾斜——少数扩展吸走了绝大部分注意力,后面拖着一根长长的尾巴,呈现典型的对数分布。
7. 星标梯队:从四大天王到长尾
把扩展按星标数量级分组,可以得到一个简单的层级模型。
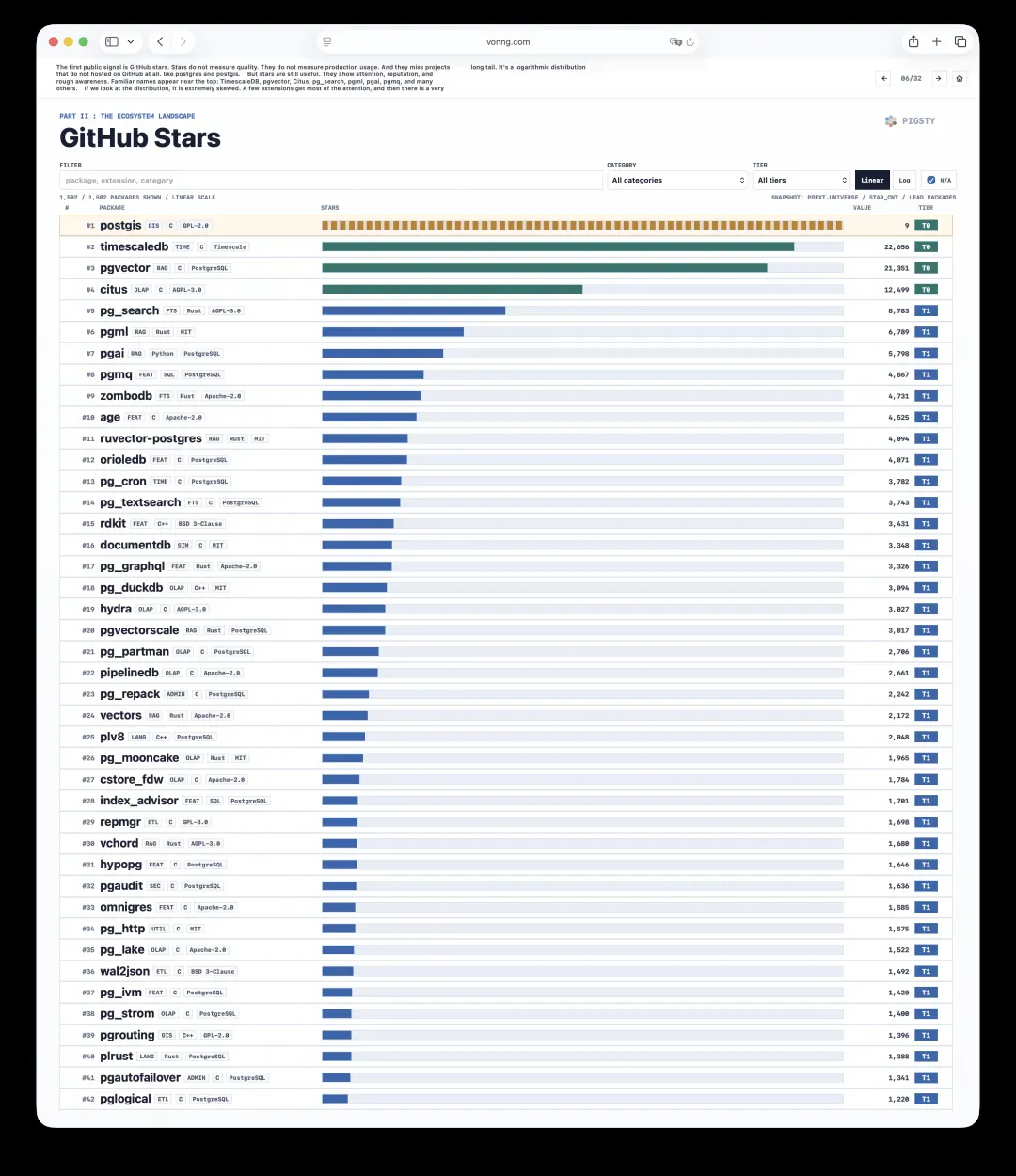
第零层:四大天王——PostGIS、TimescaleDB、pgvector、Citus,每家的星标都突破了一万。
第一层:44个扩展,星标在一千到一万之间。
第二层:大约152个扩展,星标在一百以上。
第三层:大约373个扩展,星标超过十个。
再往下就是约748个星标低于十的长尾扩展。
这并不是质量排行榜。有些热门项目早已不再活跃,比如pgml或zombodb;而某些低星标的扩展却非常实用。
不过这些层级向我们揭示了一件事:可见的生态远比已被发现的生态要小得多。把第零层到第三层加总,大约有570个超过十星的扩展,这与实际可交付的规模十分接近。
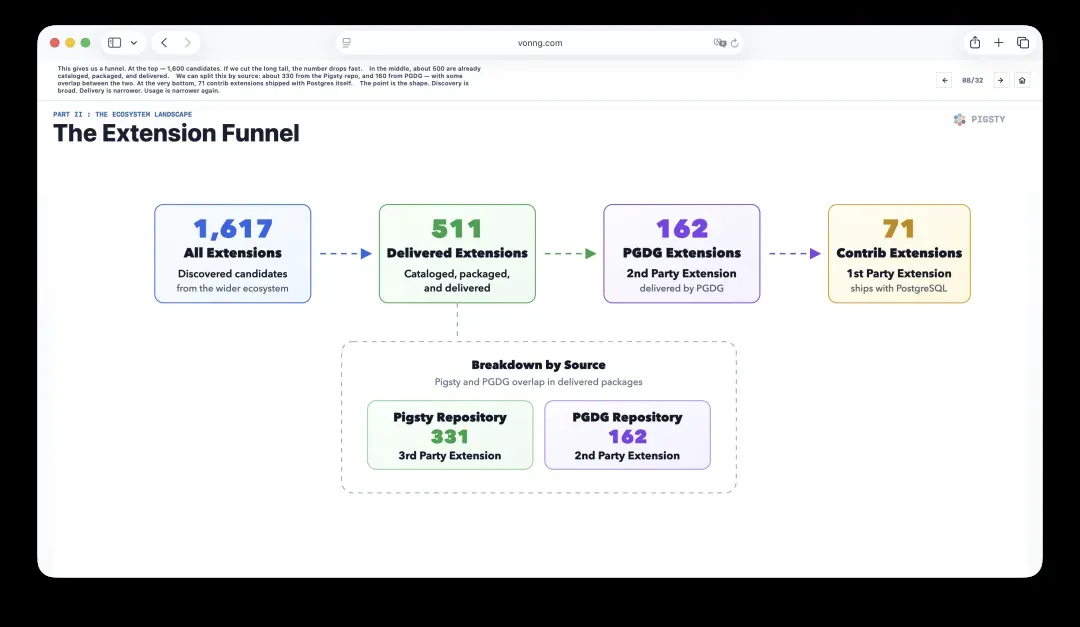
8. 扩展漏斗:从发现到实用
由此,我们得到了一个漏斗模型。顶部约有1,600个候选项。一旦将长尾截断,数量会急剧收缩。
中间,大约有500个扩展已经被编目、打包并进入交付阶段。
从来源拆分看,大约330个来自Pigsty仓库,160个来自PGDG,两边存在一些重叠。最底层是PostgreSQL自带的71个contrib扩展。
这个漏斗的形状很重要:发现面很宽,实际交付的范围窄得多,而真正广泛使用的又更窄。
9. 维度分析:32种观察角度
这个目录跟踪的维度远不止星标,还包括语言、许可证、分类、最近发布日期、仓库状态、打包状态、PG版本支持以及操作系统支持。你可以从多达32个不同的维度浏览扩展。
Seko无限画布实战:AI一小时打造震撼世界杯宣传片
使用AI创作视频时,真正的瓶颈往往不是最终画面的精细度,而是从想法到成片的混乱过程。脑海里已经浮现出球场灯光、看台欢呼、球员在雨夜中奔跑、倒计时与“世界再次沸腾”的定格画面——热血又清晰。可一旦开工,难题接踵而至:分镜如何拆分?角色怎样保持统一?场景怎么衔接?一支60秒的宣传片需要多少镜头?每个镜头的提示词怎么写?做出一版不满意,素材又该如何管理?很多AI视频创作就卡在了这一步。
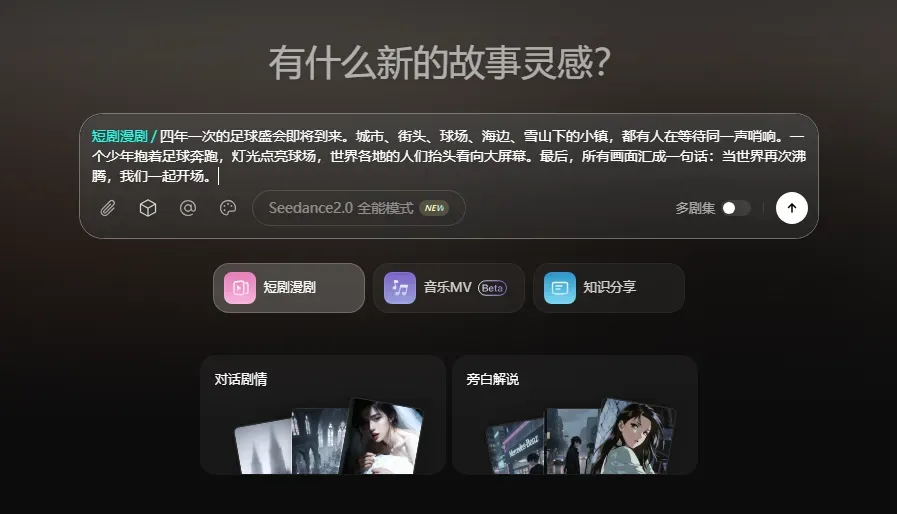
为了攻克这道坎,我尝试了Seko的无限画布,它把AI视频流程里最混乱的部分摊开、理顺。官方平台在seko.sensetime.com/explore。这次给自己定的任务是制作一支世界杯主题短片,讲述一个励志故事。向Seko输入的初始灵感很简单:
四年一次的足球盛会即将到来。城市、街头、球场、海边、雪山下的小镇,都有人在等待同一声哨响。一个少年抱着足球奔跑,灯光点亮球场,世界各地的人们抬头看向大屏幕。所有画面汇成一句话:当世界再次沸腾,我们一起开场。
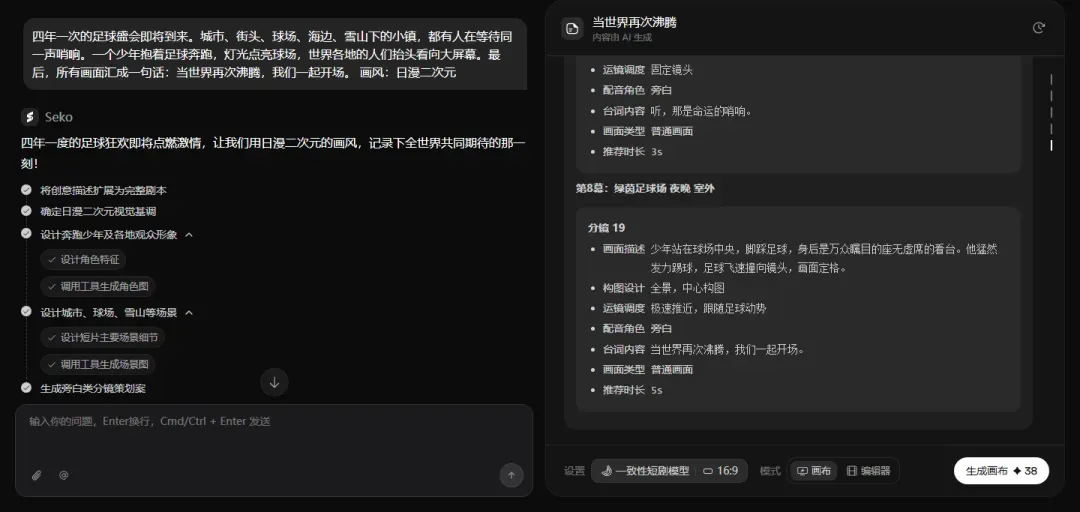
过去做这类片子,得先建文档拆脚本,逐条写分镜,再单独生成场景、人物、动作和转场,AI虽能辅助,但耗时依旧。最折磨人的是刚完成第一个镜头,就开始焦虑后面的分镜能否顺畅衔接。而在Seko的无限画布里,我直接把这段灵感丢进去,让它自动生成画布工作流。
系统会首先将故事拆解为一组可继续编辑的分镜。
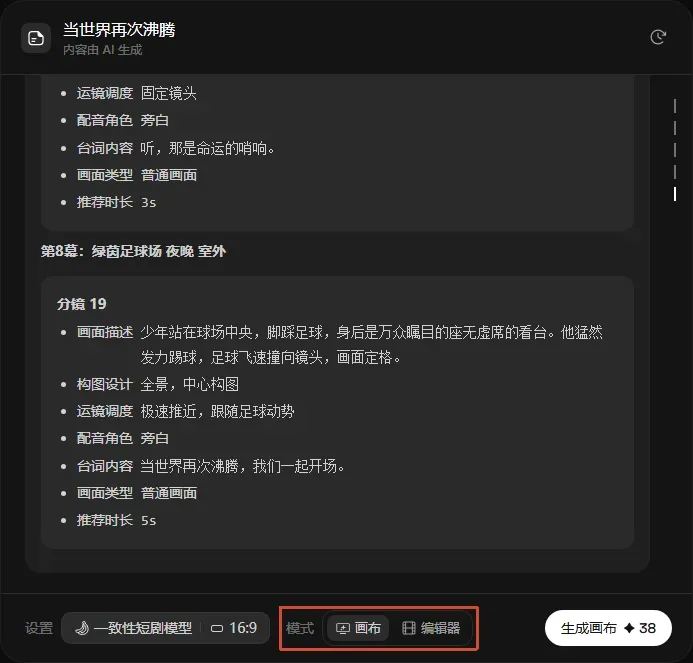
整个过程完全自动化。如果对某处分镜不满意,随时可以修改。确认无误后,直接进入画布开始创作。下方有两种生成模式可供选择,这里选画布模式,更加直观可控。
进入画布后的景象让人既不敢相信又极度兴奋——所有逻辑连线都已预先规划好,这种体验在以往画布产品中从未有过。
点击观看画布展示视频:
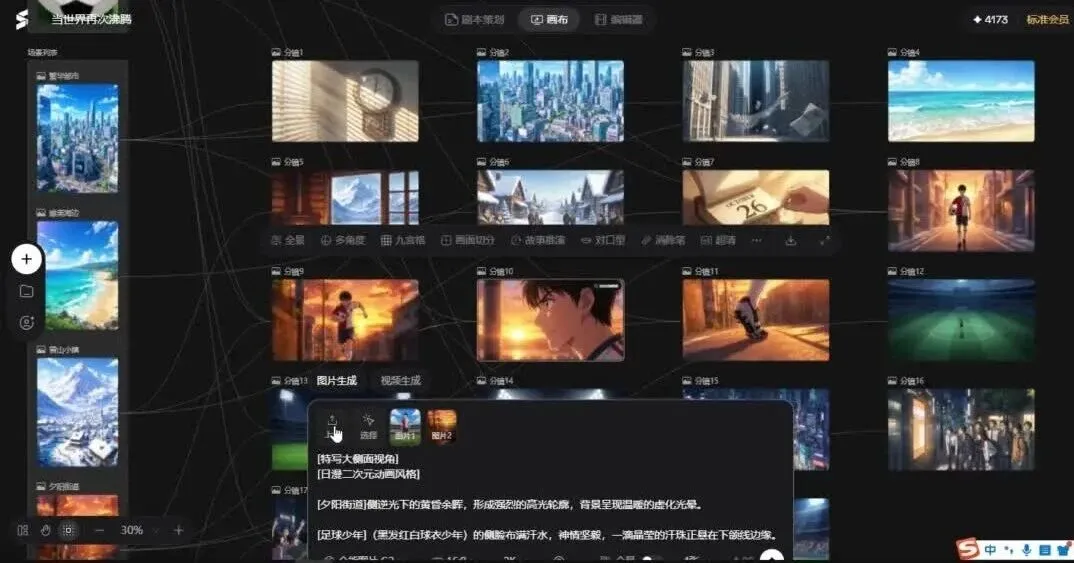
接下来只需逐一检查各分镜图片是否符合预期,不合格的重新生成,合格的直接输出为视频。视频提示词已自动填入,我们的工作就是点击确认。
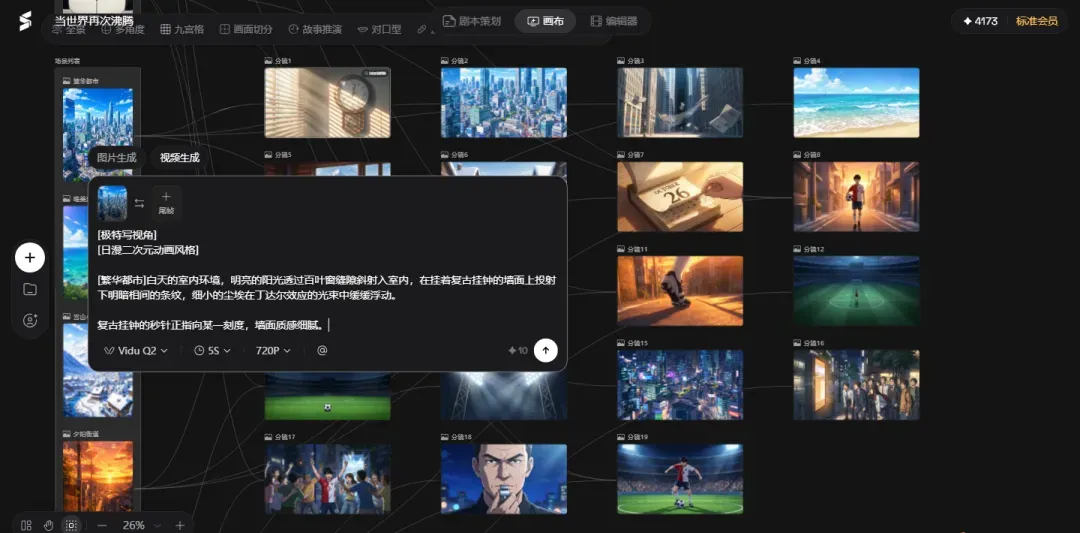
生成视频的模型阵容也相当齐全,除了顶级模型Seedance2.0,还整合了Vidu、可灵等实用工具。建议在普通镜头下使用Vidu或可灵,当需要处理大动态或提升提示词遵循能力时再启用Seedance2.0,这样能有效控制积分消耗。
例如,以下是用Vidu生成的分镜视频:

再用Seedance2.0生成另一组分镜视频看效果:

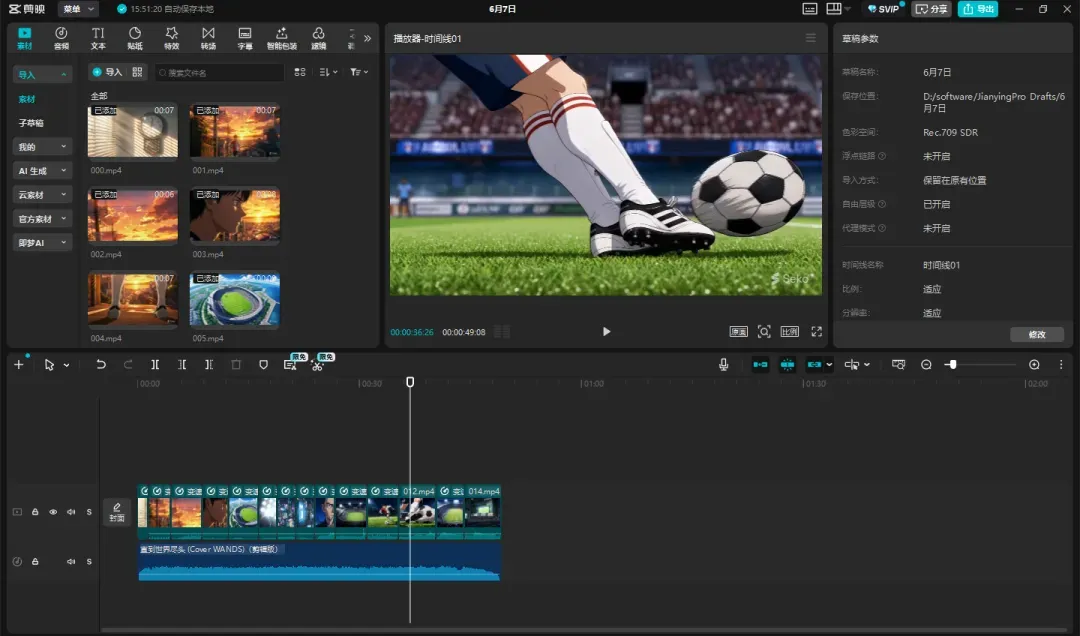
随后可以将各个分镜视频拖入编辑器进行精细调整。
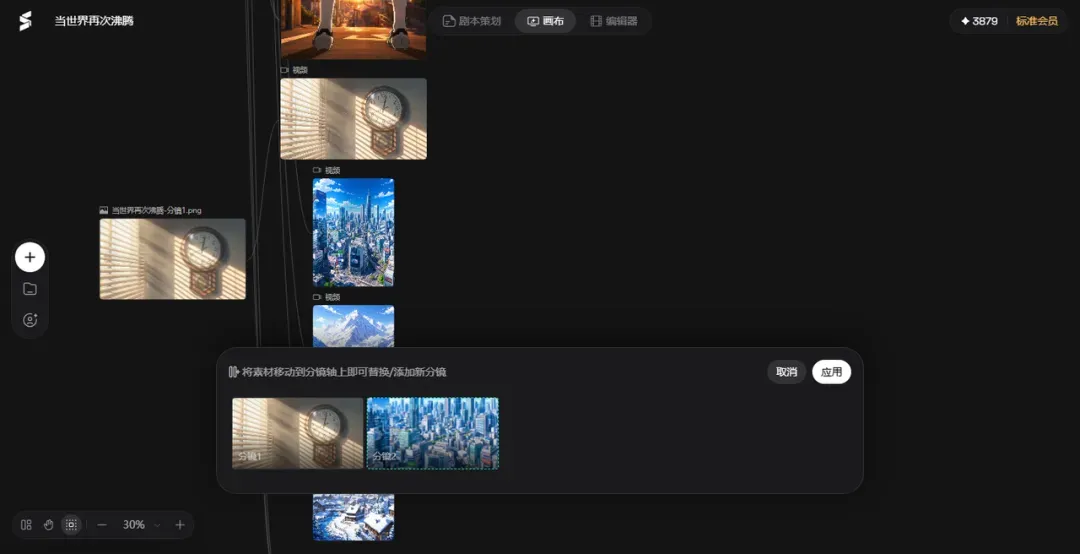
批量导入编辑器后,即可着手最终的视频剪辑与合成。
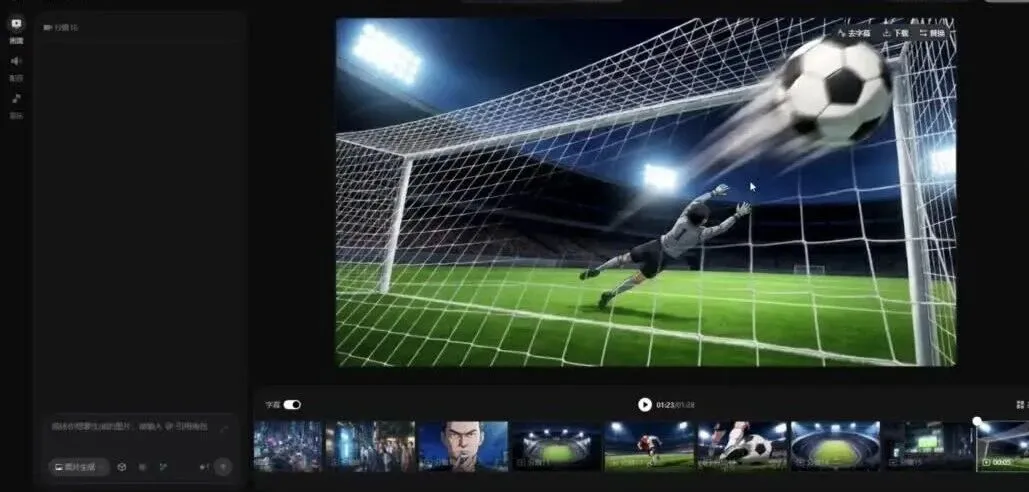
调整好各分镜后直接导出即可。
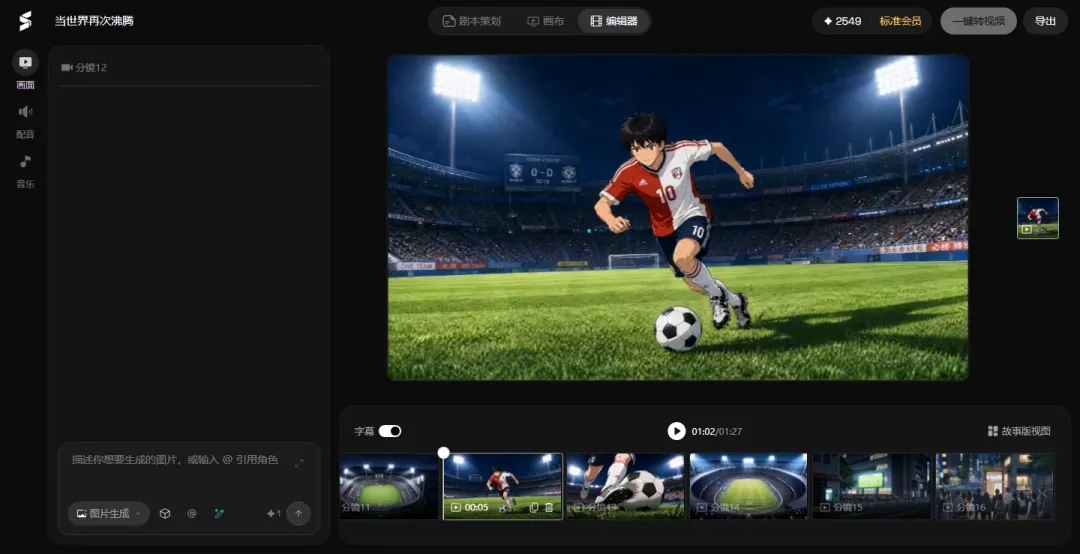
此外,侧边栏还能选择和制作背景音乐与配音音频,一站式服务到位。
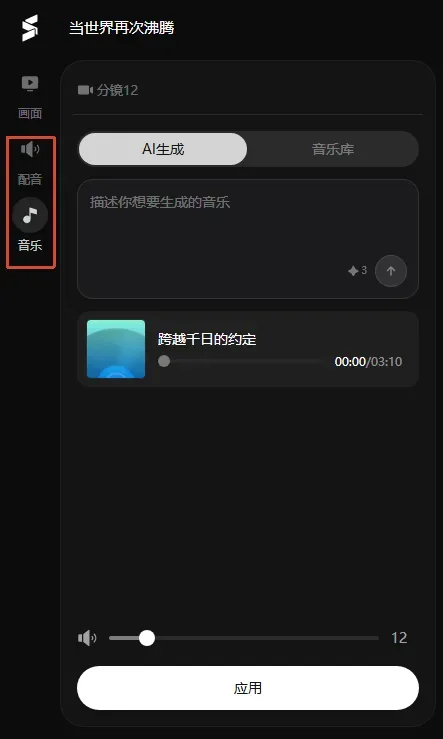
最后把所有分镜导入剪映进行微调,一部质感不错的短片就完成了。
来看看最终成片效果:

这套流程对新手非常友好。不用先把所有镜头想透彻再动手,只需先输入一个整体方向,让Seko拆解故事、生成画布,然后像导演一样在画布里调节节奏、补充镜头、变换构图、精修画面。
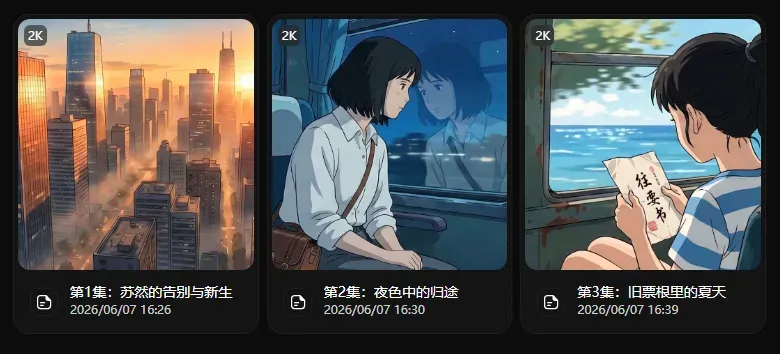
Seko的一大特色是可以一次性制作多剧集短剧,这个功能也被完美继承到了无限画布中,各个剧集之间的资产、风格都是共享的,非常便利。例如,我制作了一个文艺小短片,灵感是:
“一个人在夏天结束前,坐最后一班巴士去海边,和过去的自己告别。”
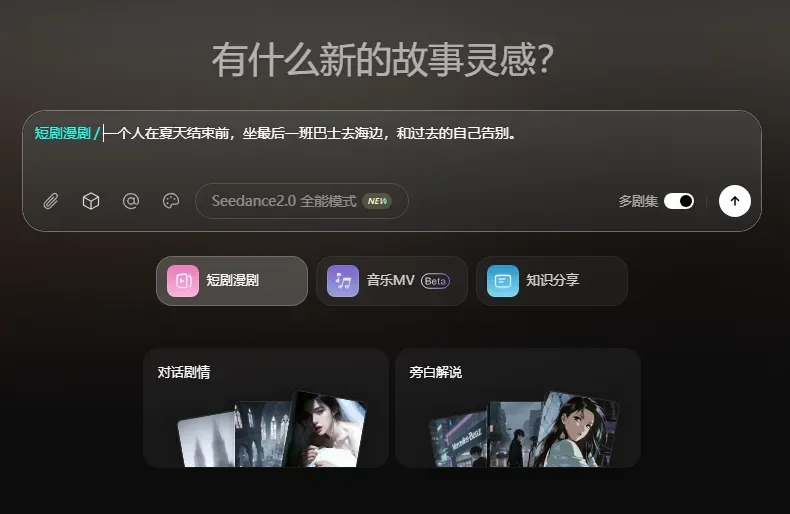
第一集成片如下:

不同剧集间,人物角色与关联场景都保持高度一致。第一集画风如下:
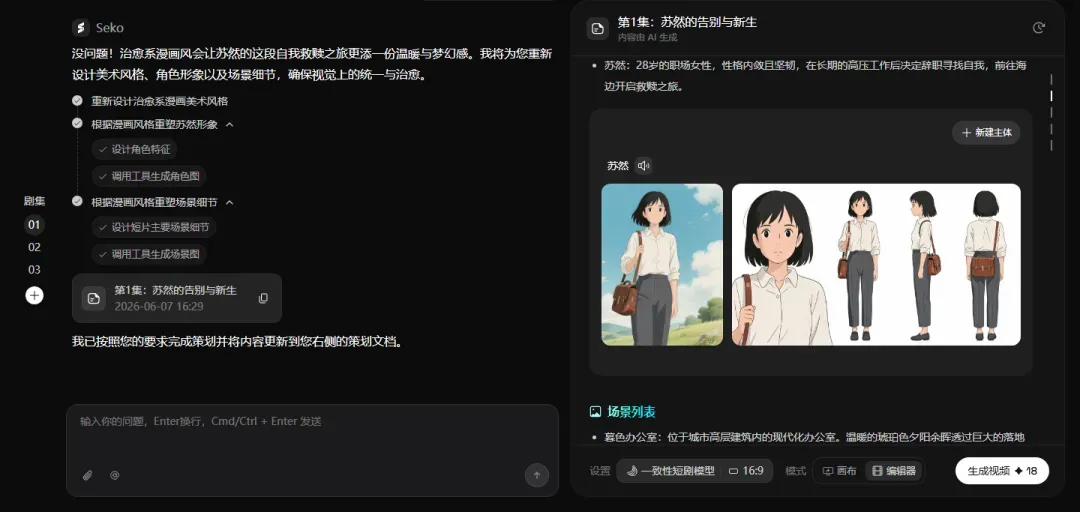
第三集则完美继承了相同的风格和人物。
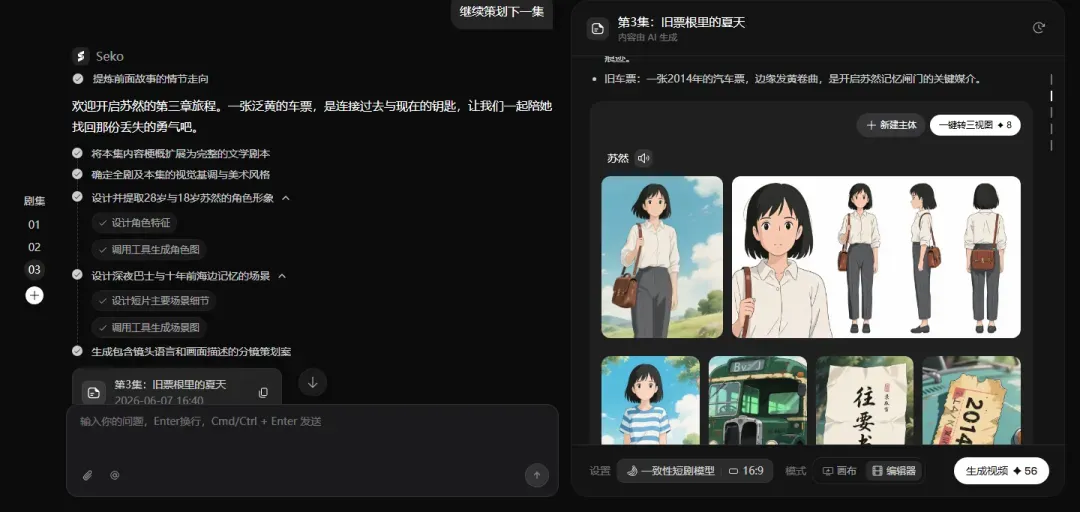
再看看具体画布中的资产情况:
可以清楚看到,不同剧集间的人物、资产是互通的,这样能最大限度保证多剧集视频内容的主体角色一致、主要场景不偏离。在资产管理部分,也可以按分集查看画布信息。
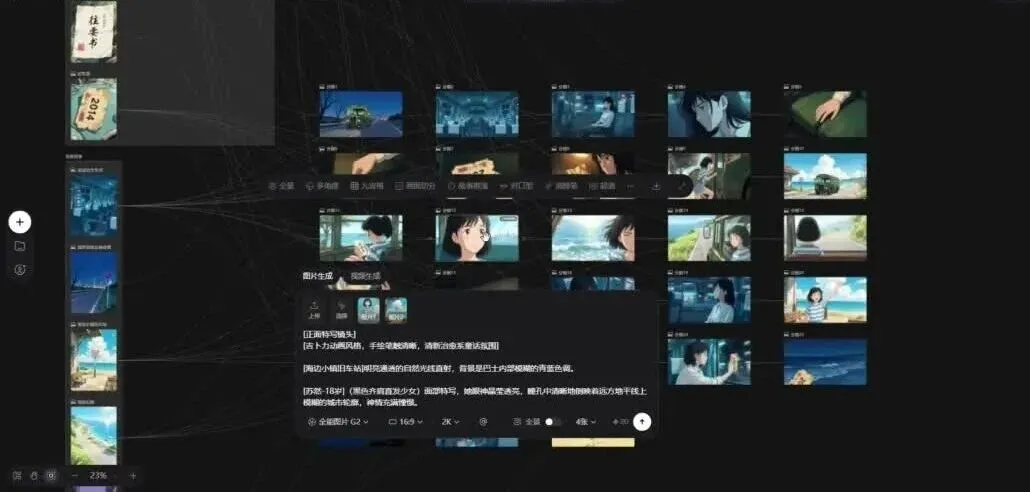
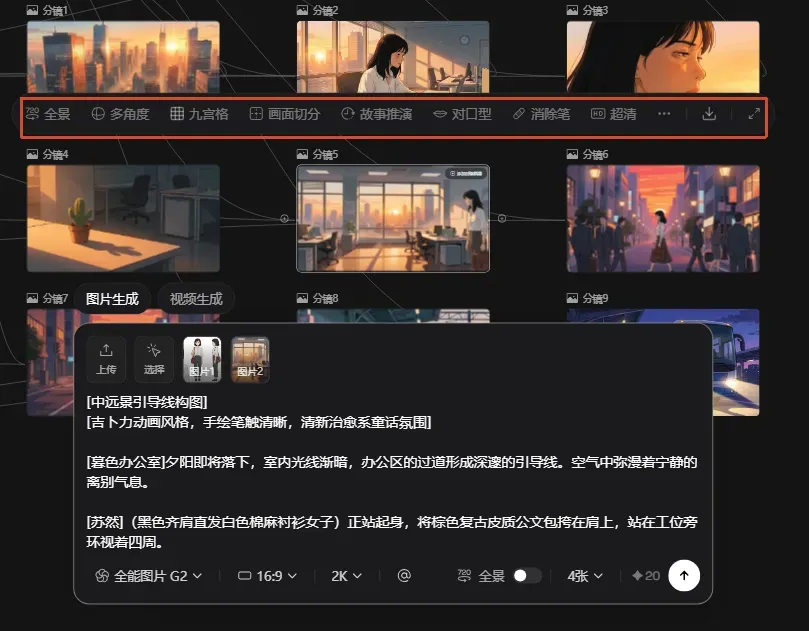
除了基础的图片与视频生成,无限画布还内置了许多实用的附加功能,例如全景生成与多角度图片生成,对AI视频创作十分关键。

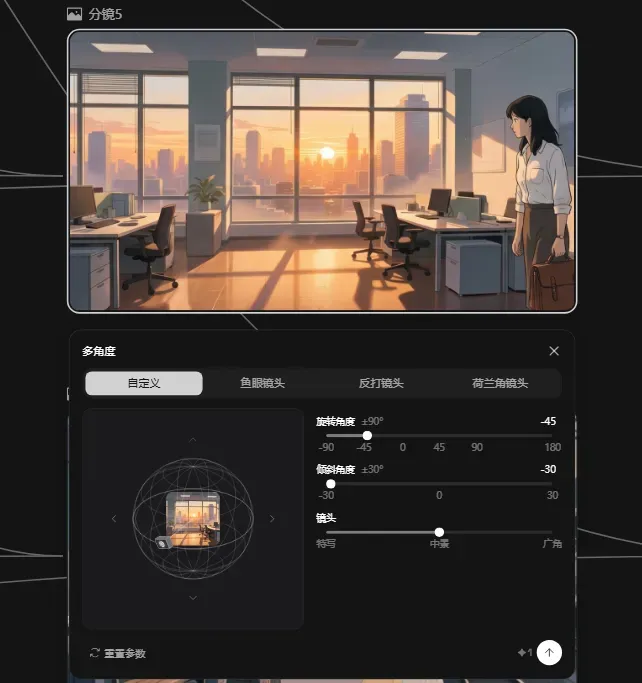

很多人不缺乏精彩灵感,缺的是能承接灵感的清晰流程。像制作世界杯宣传片这样听上去热血沸腾的内容,实际执行时容易在“城市、球场、人物、人群”之间迷失。如果没有画布,很快就会攒成一堆散乱的素材;而有了画布,从灵感到分镜、从分镜到资产、从资产到精修、最终进入编辑器成片,每个环节都变得清晰可控。这正是Seko无限画布最值得体验的地方——它让AI视频创作终于走出黑箱,我们能亲眼看着自己的故事一点点变成画面,这种掌控感令人兴奋。
如果你也想制作一支AI短片、预告片或赛事宣传片,或者只想验证脑中故事的可视化可能,不妨从一张画布开始,先把灵感写下来,剩下的让Seko陪你往前推进。
对于新用户,Seko目前赠送算力,Seedance2.0模型还有4.8折优惠,同时可以参加官方举办的“神作星探局”活动,参与即可获得积分补贴。