Token纯度检测神器开源:TokenPlay大模型批量测试与对战平台
在我过去的模型评测中,经常用到一款叫做 CodingPlan Test 的自研工具,很多读者来问,表示很想上手一试。今天就把最新的软件和源码一块儿开放出来。
项目跑起来非常简单,完全零基础也能轻松玩转。
为什么要做这个平台
初衷很直接:需要一个可以批量检验不同 CodingPlan 真实水平的环境,同时观察它们的响应速度、Token 消耗等硬指标。而平台本身的迭代过程,也成为大模型能力测试的一部分,相关的文章我已经写了几十篇。
经过长时间实测,我越来越肯定一个结论:同样叫 Token,纯度之间的鸿沟远比想象中大得多。 优质的 Token 一口吸进去就再也不想换,劣质的吸一口就想吐。
短期内我可能不再发布评测向的内容,索性把工具完全交出来,方便大家自己动手对比。如果你在用中转站或其他代理服务,也可以拿它来检验一下 Token 的成色。
让我有点意外的是,不过短短几个月,纯粹的 CodingPlan 已经所剩无几,几乎全线变成 TokenPlan,不是贵得离谱,就是抢到崩溃。这就让原来的平台名字有些尴尬。所以我索性给它改了个更直白的名——TokenPlay。一个随便“玩”Token 的地方。
下面就从功能菜单出发,逐一说明有哪些玩法,每个功能都对应着不同的使用场景。
1. 平台配置
这个模块负责统一管理各类大模型供应商,也就是不同平台的接入信息。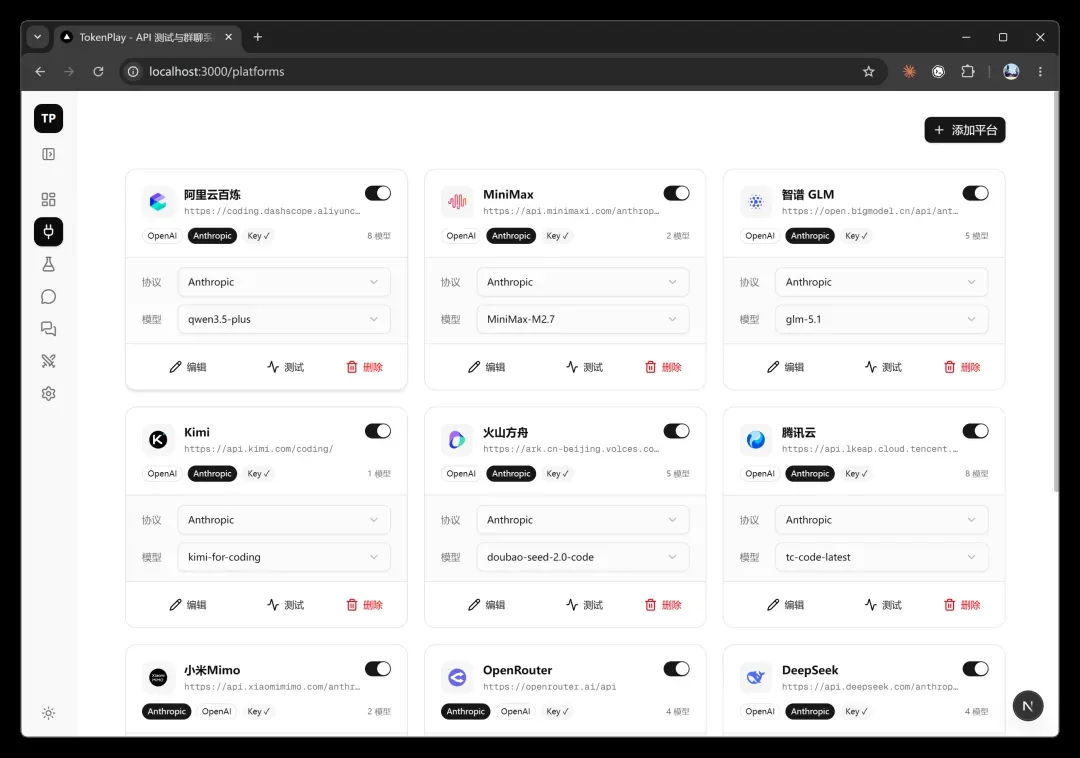
目前内置了 6 个平台,只需要填入 Key,选好协议和模型,立刻就可以调用。
同时提供添加、编辑、测试、删除等基础操作。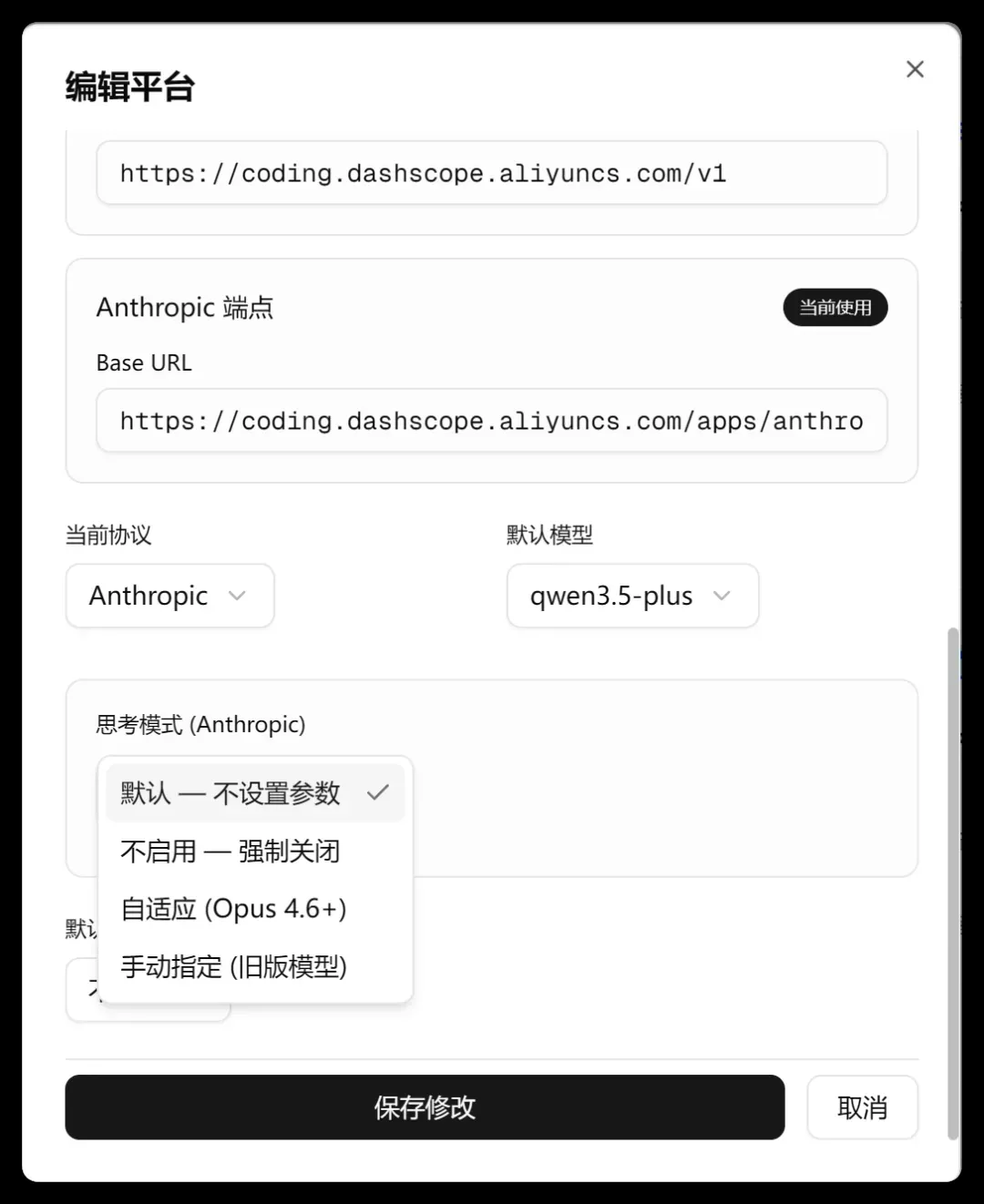
编辑界面可以调整的信息包括:
- 平台名称
- 支持的协议
- 接入点地址
- 模型清单
- 密钥
除此之外,还允许指定思考模式以及默认的系统提示词。
添加模型时,我预先内置了大量常见选项,方便快速录入。目前国内主流模型基本都在预设列表里,海外也整合了 OpenRouter。模型配置完成后,后续所有功能都可以直接调用,还能随时启用或停用某个配置。
2. 批量测试
这个功能支持一键对多个模型进行批量测试,并将结果、速度和 Token 消耗并排展示。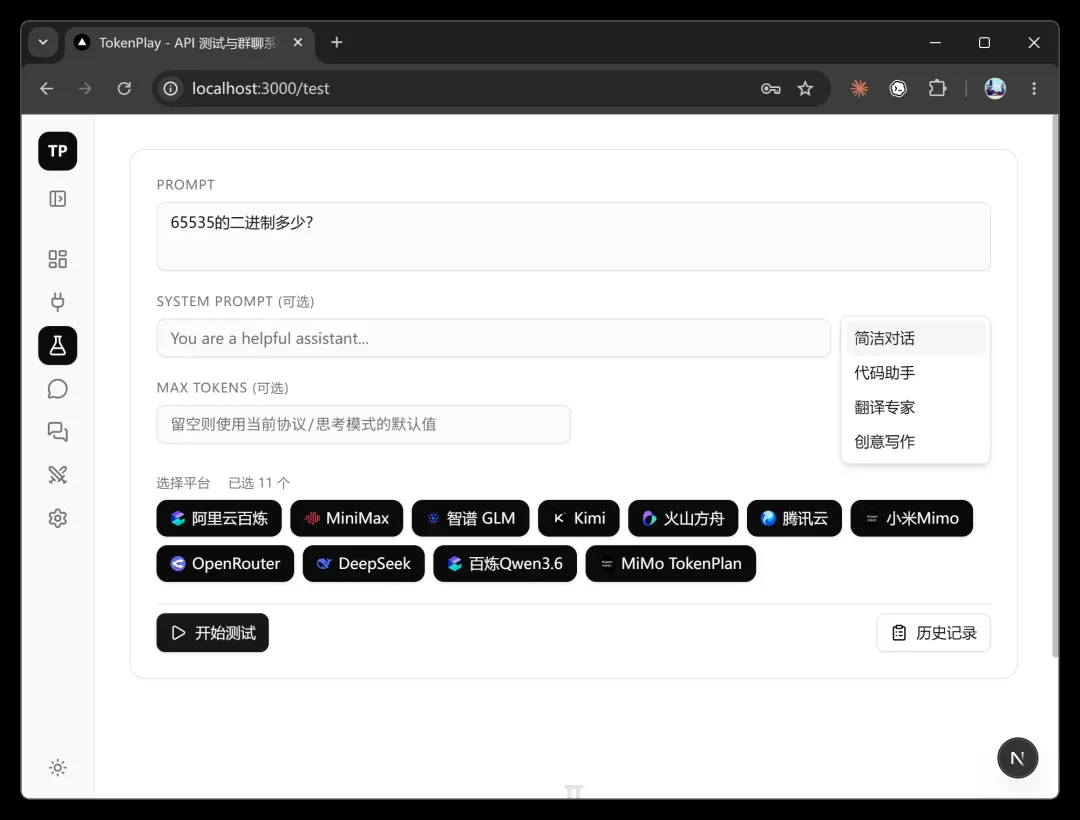
当前可以自定义的参数包括:
- 核心提示词
- 系统提示词
- 最大输出 Token 数
- 具体参与测试的平台
测试结束后会全部自动存档,直接点击“历史记录”即可查看。
响应结果展示界面如下: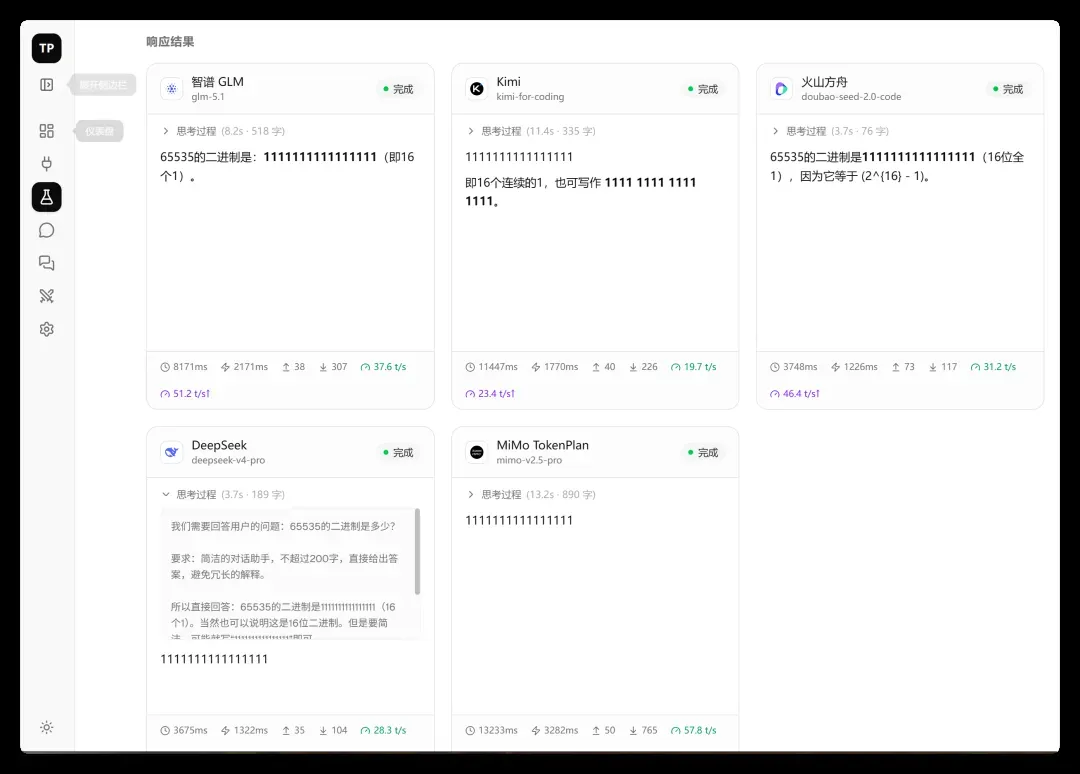
这里会显示所有参与模型的输出、思考过程以及详细的请求数据,内容完美支持 Markdown 格式渲染。
除了文本结果,还有性能数据: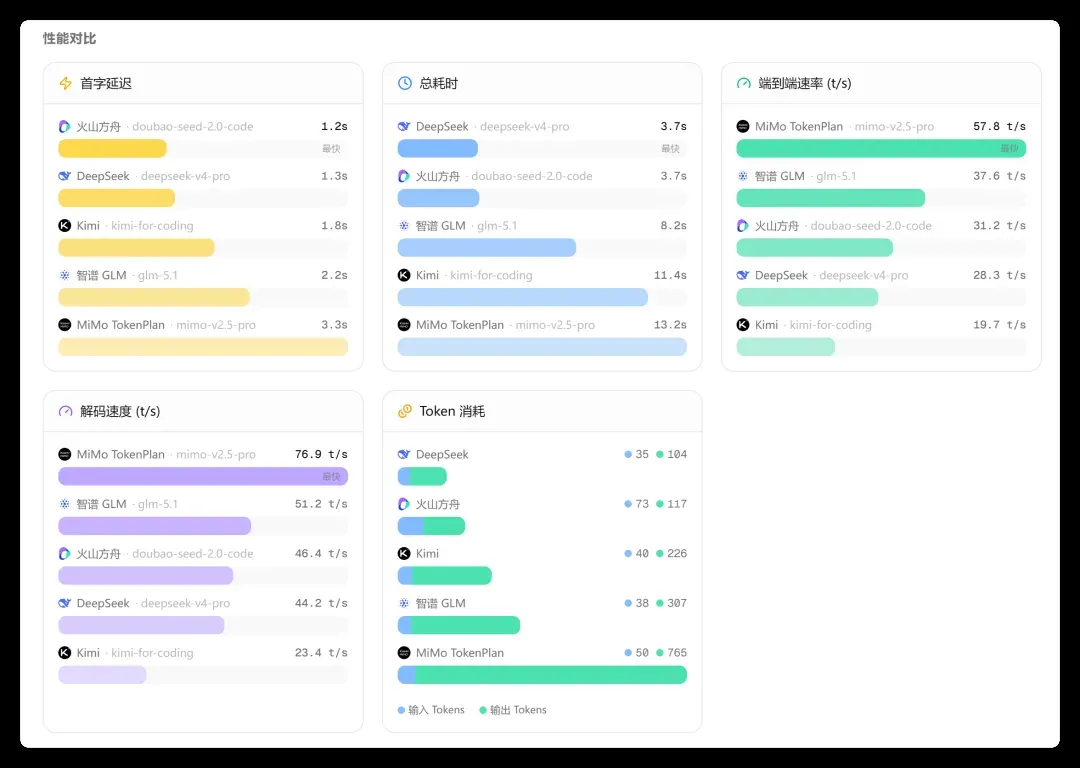
性能指标包含 5 项:
- 首次响应延迟
- 总耗时
- 端到端速度
- 解码速度
- Token 消耗(功耗)
全部用图表呈现,一目了然。这就是 Token 照妖镜——随便抛出一个问题,谁强谁弱、谁快谁慢便一目了然。
从零到上线:Vibe Coding零成本开发微信Markdown编辑器全流程
此前曾分享过微信小程序 Vibe Coding 上线全流程,收到许多关于如何利用 Vibe Coding 开发网站的留言。趁着最近动手搓了一个几乎人人必备的 Markdown 文章编辑器,我将整个零成本开发部署的过程整理出来,供大家参考。
项目缘起
Markdown 文章编辑器如今人人都能通过 Vibe Coding 手工打造,但开发完成之后,“如何部署”往往成为新的问题。
恰好我手头有一个与 Markdown 相关的域名,便顺势开发了一款专门面向公众号内容创作者的 AI Markdown 工作台,命名为「码搭AI」。
核心功能一览
内容库管理
码搭AI 与其他 Markdown 编辑器最大的不同,就是它对“内容库”的深度支持。
很多编辑器只能单篇写作,写完即走,但公众号运营者往往需要同时管理多个账号、多篇文章,缺少的是完整的内容管理方案。
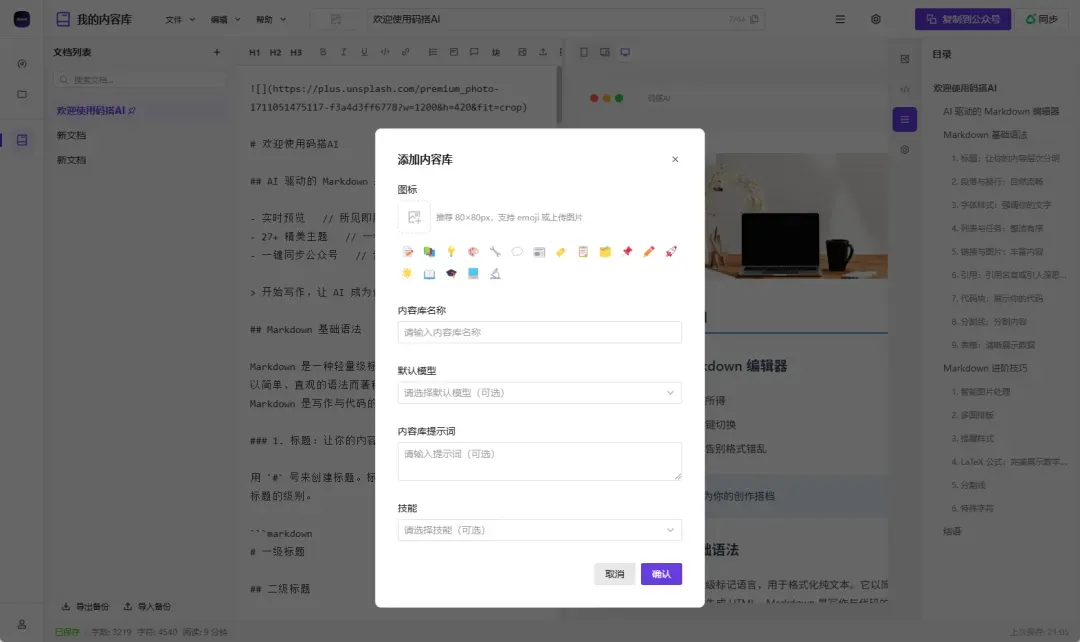
- 多库管理 — 支持创建多个独立的内容库。如果你运营多个公众号,可以按账号分库存放,互不干扰,一键切换。
- 自定义图标 — 每个内容库都可以上传自己的图标或选用 Emoji,让你在侧边栏就能快速辨认并定位。
- 多文档管理 — 每个库内都可以创建、编辑、删除及重命名多篇文档,随时增删改查。
- 文档排序与置顶 — 重要文档一键置顶,也可以通过上下移动灵活调整顺序,写作节奏完全由你把控。
- 侧边栏快捷切换 — 内容库直接展示在侧边栏,单击即切换,无需进入二级页面翻找。
- 本地持久化 — 所有内容自动保存在浏览器本地,刷新页面也不会丢失,打开即用,免登录。
一句话概括:一个编辑器帮你管好所有账号的所有文章。
三步实现零成本部署
整个项目从代码到上线都无需花费一分钱,流程非常简单,主要分为以下三步:
第一步:初始化项目
打开 Claude Code(或其他 AI 编程工具),用下面这样的描述告诉它你想要的功能:
帮我创建一个微信公众号 Markdown 编辑器,使用 Vue 3 + Vite + TDesign,支持实时预览、主题切换、一键复制到公众号。
AI 会自动搭建项目骨架、安装依赖并生成核心代码。
从依赖到自主:降低对Codex过度依赖的三大实战策略
Codex目前每月全球活跃用户数已达500万,这对一款编程工具而言堪称惊人。
在各大社区中,Codex的口碑也超越了Claude Code、Cursor等竞品。业内人士对其赞誉有加,纷纷预测它未来可能发展为像Windows和iOS一样的系统级生态应用。
作为一名普通但深度的Codex用户,我几乎将所有重要工作都交给Codex处理。
原因很简单,交给其他AI工具我实在不放心。
Codex工作极其严谨,每一步过程都会向我说明。我能够清晰了解它的思考路径和工作流程,因此格外安心。
更重要的是,Codex能够直接操控浏览器,甚至控制整个电脑。
再加上Codex生态的全面性,集设计、Office文档编制、网站开发等能力于一身。
可以说,一骑绝尘。国内的工具短时间内确实难以望其项背。用过Codex之后,再回头使用国内AI工具,总会有各种不适应。
对于Codex,我既深深依赖,又怀有隐忧。担心某一天账号突然失效,自己“一夜回到解放前”。
这种担忧并非空穴来风。前段时间,Codex因风控问题曾封禁一批账号,虽然后来证明只是虚惊一场,但足以给所有人敲响警钟。
对于Codex,绝不能过度依赖,谁也不知道它会不会像Claude Code那样,突然对你赶尽杀绝。
以上说的是风险,再来看看使用中遇到的实际问题。
问题主要源于网络不互通。尽管Codex拥有强大的浏览器操作能力,但又有几家公司的内网环境能随意访问外部服务呢?
因此实际场景是,我打开Codex就无法访问工作网站,登录工作网站时又无法使用Codex。
我还是只能手动操作网站进行测试、排查问题。两者无法结合,此时Codex对我的价值就降到了与豆包、元宝差不多的程度。
由于网络频繁切换,我甚至可能两三天都找不到机会使用Codex。在那些忙得焦头烂额的日子里,我格外怀念Codex,偶尔不免抱怨:如果它能帮上忙,我又怎会如此忙碌?
基于以上风险与现实问题,我认为降低对Codex的依赖才是正确的方向。
假若有朝一日Codex离我而去,我也能独自扛起一切。
所以,从现在起,就要为那一天铺路。
第一步:沉淀Codex经验,建立可迁移的知识库
我会将Codex中的每一次对话、每一次解决问题的思路与方法都记录下来,沉淀到我的 PMBrain 知识库中。

借助PMBrain作为中央知识库与工作路由,其他AI工具也能了解我所处理的事务和进度,从而随时接手。
反过来同样有效,我可以把在其他AI工具上失败或难以推进的工作记录进PMBrain,再交由Codex继续完成。
第二步:熟练驾驭一款国产AI助手,作为可靠备选
我选择了Codebuddy作为下位替代,这款工具总不会被禁用。我需要彻底摸熟、摸透它。虽然它不如Codex强大,但基本能力健全,完成大部分基础工作不成问题,万一搞砸了再回头找Codex也不迟。
我也会使用Claude Code + DeepSeek 的组合方案,同样好用且靠谱。只是命令行界面(CLI)的操作我始终不太习惯,觉得有些反人类。但Claude Code的Hermes功能确实强大,如果能适应CLI,其能力远胜Codebuddy。
第三步:解耦工作流,让能力脱离单一工具的束缚
我认为这一步最为关键。许多人依赖Codex,真正难以割舍的是Codex帮你塑造的那套工作方式。
但今天由Codex执行,明天可以换成Codebuddy,换成Claude Code,甚至可以由你手动操作。因此,我会有意识地将一些高效的流程整理成文档、规则或技能(skill)。一旦落地为文,Codex能用,其他工具同样能用。
这就是把能力从工具中解耦出来。工具会变,成熟的流程能一直留存。
结语
走完这三步,Codex不再是唯一的选择。它依然很好用,我依然会继续使用它。但我不会再将所有希望寄托于一身。
写这篇文章,并非要说Codex不好。恰恰相反,正因为我太喜欢Codex,才会担心自己过度依赖。
一个工具越好用,你越容易将自身的能力外包给它。短期来看很爽,长期则暗藏风险。
今后,我会继续用Codex,但绝不能只会用Codex。把知识沉淀下来,把流程解耦出来,把替代工具练熟。
如果它还能用,当然最好;即便某天它真的离你而去,你也不至于在原地手足无措。
工具可以更换,你的思考能力仍在。
建筑软件的未来:从画模型到智能判断设计,五条关键路径全解析
#参数化设计 #建筑软件 #性能化设计
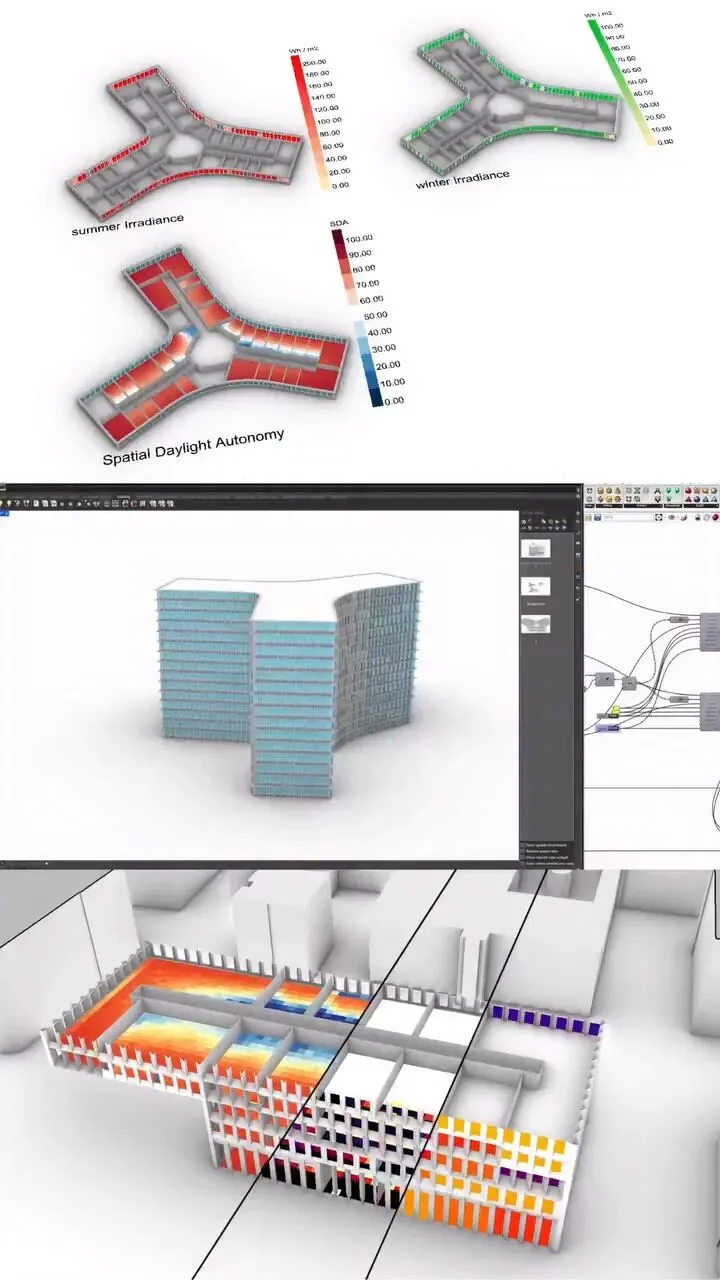
建筑软件的新一轮竞争,表面争的是AI功能、云端平台与实时分析,实质却指向同一个核心——谁能把早期设计中模糊的经验判断,转化为可计算、可追踪并能延续到BIM中的项目证据。将Forma与Opossum并置观察,恰好能看清这一趋势。
AEC趋势判断
近期一个颇具代表性的课程组合进入视野:Autodesk Forma协同Grasshopper中的Opossum,借助早期性能数据、日照模拟、辐照分析、空间日光自主性与多目标优化来推敲方案。表面上看这像是一场参数化工作坊,实质上更像建筑软件演进路径的一张切片。
过去二十年,建筑软件的主战场一直是“表达”:把形体绘制出来,把构件搭建出来,把图纸输出出来。而如今主战场正在向“判断”迁移:一个体量为什么这样摆放,一块立面为什么这样开洞,一个户型组合为什么如此取舍,方案从概念转入Revit时,前期所做的性能假设是否丢失。
我的判断非常明确:未来五年,建筑设计软件不会简单蜕变成“会聊天的CAD”。更可能出现的是一批面向设计决策的工作台:一边承接几何与构件,一边接入气候、碳、成本、规范以及项目知识。
路径一:性能分析前置,拒绝定型后补救
Forma最具代表性的地方,不在于能否替代Revit,也不在于建模功能有多细腻。真正的关键在于,它把环境反馈移到了方案早期。Autodesk在2026年推出Forma Building Design时重点强调的能力,包括场地快速生成、平面与立面自动化、日照与采光潜力评估、碳分析,以及将方案作为附带地理位置的原生Revit模型继续深化。
这背后的软件逻辑十分重要。传统流程里,早期方案靠经验快速推进,性能分析往往后期才补做。补做当然有其价值,但它常常只能告诉你“这个方案哪里出了问题”。当分析被嵌入概念阶段,它便开始改变设计动作本身:你每调整一次朝向、后退红线、体量高度或窗墙比,软件立刻把影响反馈回来。
这正是“性能化设计”从顾问报告走向设计桌面的过程。它的任务并非让建筑师变成能耗工程师,而是让建筑师在最便宜、最可逆的阶段,提前看清关键变量的方向。
但同时必须界定清楚:早期分析提供的只是决策线索,并不等同于施工图深度的模拟结论。把它当作“方向盘”不妨,若当作“审图依据”则危险。
路径二:参数化不再造形,转为方案搜索引擎
Grasshopper长期被很多人理解为“做复杂形体的工具”,这种理解过于狭隘。参数化真正强韧的地方,在于把方案拆解为变量、约束和目标。Opossum的价值恰落在这里:它将注意力从奇特的形态转移到参数搜索上,在一组可变参数中寻找更优解。
Opossum由斯图加特大学ICD相关团队开发,名称源自OPtimizatiOn Solver with SUrrogate Models。它在Grasshopper中提供了RBFOpt、CMA-ES、RBFMOpt、NSGA-II等优化算法。对建筑师而言,不必纠结于算法名称,关键在于理解两类核心能力:一类是在模拟耗时长的情况下,利用代理模型减少真实计算次数;另一类是在能耗、日照、造价、舒适度相互制衡时,给出Pareto取舍方案。
这和传统Galapagos式遗传算法最大的区别,在于它更适应昂贵模拟。建筑性能问题常常无法在一秒内跑完,一次能耗、日照、热舒适或结构响应可能需要较长时间。此时粗放地尝试上千个解根本不现实;让软件先学习问题的大致形态,再把计算预算投向更可能有效的区域,才是更贴近真实项目的策略。
建筑师的职责因此发生转变:少一些凭手感在无穷版本中漫游,多一些对变量、约束和评价指标的定义。谁能把问题定义清楚,谁就能让工具产出有价值的成果。
路径三:BIM数据拆解,走向按需调用
建筑软件真正的变革,不只发生在界面层,也在数据层。Autodesk的AEC Data Model API已经把Revit这类大文件中的元素、参数、版本和属性查询,拆解为云端可访问的颗粒化数据。2025年的几何公开测试更进一步,将Revit geometry、IFC转换、内存网格以及多应用工作流置于同一轨道。
这件事将深刻重塑建筑软件的形态。过去我们围着文件转:谁打开RVT,谁导出IFC,谁发送模型,谁再进行分析。未来,越来越多流程将围着数据接口转:质量检查、房间数据表、材料统计、碳核算、规范筛查、成本预估,都可以直接抓取元素级数据,无需等待某人手动导出一次文件。
开源与开放标准路径也在加速同向演进。buildingSMART的IFC 4.3已作为ISO 16739-1:2024成为正式标准,Speckle也把重点从“模型互通”转向数据驱动流程、实时洞察和自动化。一个清晰的信号是:互操作本身不再是终点,让数据流入分析、协作与自动判断,才是终点。
路径四:AI从渲染工具切入,深入项目上下文
很多人第一次接触建筑中的AI,是通过出图工具。Graphisoft的AI Visualizer 2.0便是典型例子:在Archicad里将草图、模型视图、材质构思转成更容易沟通的视觉成果。这具有现实价值,尤其适用于概念表达、材料试探和客户沟通。
但如果只停留在出图,建筑软件的深层变化就被看浅了。图像工具能帮你表达一个方向,却很难替你承担项目连续性。真正会改变事务所工作方式的AI,不应只停留在“把这个模型渲成某种风格”。更关键的能力,是读取项目数据、理解约束、调用分析、比对版本、指出风险、生成可追踪的交付材料。
这也是为什么云端数据、API、IFC、参数化优化会突然变得如此重要。没有结构化数据,AI只能看图说话;拥有了元素、参数、版本、关系和分析结果,它才可能进入真实的设计流程。
建筑行业不会被“一个万能设计按钮”瞬间改写。它更可能被无数细小而具体的判断环节慢慢重塑:这个窗洞是否加剧过热,这个单元组合是否牺牲了采光,这个方案为何碳值更高,这次修改相比上一版改变了哪些关键指标。
路径判断:建筑师须从操作者转型为流程定义者
从Forma到Opossum,从Revit数据API到IFC 4.3,从Speckle到Archicad的视觉与知识辅助工具,背后共同指向一条路径:建筑软件正从“单机生产工具”走向“连续决策系统”。这一系统包含三个关键部件。
第一,早期模型必须拥有数据密度。 体量不能只是漂亮盒子,至少要带上位置、面积、层数、朝向、开窗、材料假设和基本性能指标。没有数据密度,后续的判断不过是视觉讨论。
第二,参数化模型必须配备评价指标。 不要只会拉动滑块。每个参数都应该回答一个问题:它影响日照、碳、成本、得房率、施工复杂度,还是运营能耗?变量若没有目标,优化便只是随机试错。
第三,BIM必须能够承接早期决策。 早期分析若无法带入后续模型,就会沦为漂亮汇报页。未来的核心竞争力,就在于让概念阶段的性能证据、方案取舍、数据假设持续流入详细设计,避免每换一次软件就得重来一遍。
对事务所而言,最现实的升级顺序并非采购一堆新软件。先选定一个真实项目,将“概念体量、性能分析、参数优化、BIM承接、版本记录”串成一条小流程。跑通一条,再扩展到一类项目。
建筑师的三项行动指南
先把Forma这类工具当作早期判断仪表盘,不要把它视作Revit替代品。用它快速测试场地、日照、噪声、碳和体量方向,目的不是得到最终答案,重点是尽早排除错误方向。
再将Grasshopper/Opossum当作问题定义训练。不要一上来追逐复杂算法,先从三个变量、两个目标起步:例如窗墙比、遮阳深度、体量退台,对应日照、碳或得房率。模型越小,越容易看清优化是否真正有意义。
最后,把数据连续性作为软件选型的硬标准。一个工具再炫,如果只能产出孤立图片或孤立模型,长期价值便非常有限。能不能回到BIM,能不能导出结构化数据,能不能接入IFC或API,能不能被团队复用,才是建筑软件下一阶段的硬指标。
建筑师无需害怕软件越来越聪明。真正需要警惕的是,自己仍停留在“会操作按钮”的层面。未来更有价值的能力,是把设计问题翻译为变量、约束、证据和交付链路。工具会换,软件公司会换,平台会换;能定义流程的人,才不会被每一轮更新牵着走。
来源:Autodesk News, “Autodesk brings design and make intelligence to the built environment with Forma Building Design and deeper cloud connections with Revit” https://adsknews.autodesk.com/en/news/autodesk-design-and-make-intelligence/
Autodesk Forma Blog, “Design Now, Revit Next: Schematic Design with Forma Building Design” https://blogs.autodesk.com/forma/2026/04/07/introduction-to-forma-building-design/
ICD University of Stuttgart, “Opossum” https://www.icd.uni-stuttgart.de/research/research-tools/opossum/
Autodesk Platform Services, “AEC Data Model API” https://aps.autodesk.com/en/docs/aecdatamodel/v1/developers_guide/overview/
buildingSMART Technical, “Industry Foundation Classes” https://technical.buildingsmart.org/standards/ifc/
Speckle, “Speckle’s new era of data-driven workflows” https://speckle.systems/blog/speckles-new-era-of-data-driven-workflows/
Graphisoft, “AI Solutions” https://www.graphisoft.com/en-us/plans-and-products/ai-solutions/
在树莓派上部署Ubuntu Server 26.04完整指南:安装、初始化与桌面扩展
当需要一台接近正统Linux体验、清爽无桌面组件的服务器时,我常选择在树莓派上运行Ubuntu Server。这款系统特别适合搭建家用服务器、小型实验环境或各类常驻后台任务。唯一的小遗憾是启动后直接进入命令行界面;若你习惯了树莓派官方带桌面的系统,初次接触会感到过于简朴。
Ubuntu Server 26.04 已正式适配最新的树莓派硬件。你可以通过Raspberry Pi Imager工具,或直接从Ubuntu官网下载镜像,将系统烧录到SD卡或U盘,整个过程不包含任何桌面环境。
本文首先讲解完整的安装流程,接着分享系统初始化的配置技巧,最后介绍如何按需加装桌面环境。
- 在树莓派上安装 Ubuntu Server 的两种途径
- Ubuntu Server 初次启动与基础配置
- 为 Ubuntu Server 扩充桌面环境
在树莓派上安装 Ubuntu Server 的两种途径
整体安装流程包含以下三步:
- 在个人电脑上下载并安装 Raspberry Pi Imager。
- 使用该工具将 Ubuntu Server 镜像写入 SD 卡。
- 将准备好的 SD 卡插入树莓派并开机启动。
接下来我们会展开每一步,并介绍使用 Balena Etcher 等工具的备选方案。
方法一:通过 Raspberry Pi Imager 快速部署
想要最便捷地在树莓派上运行 Ubuntu Server,首推 Raspberry Pi Imager,可以从官网下载。
安装 Raspberry Pi Imager
打开官网的软件页面。
下载对应你操作系统的版本。它支持 Windows、macOS 和 Linux。如果你正在运行 Raspberry Pi OS,甚至可以直接在树莓派上安装:
sudo apt install rpi-imager
安装完成后,就可以将 Ubuntu 文件写入存储卡。
智能香薰扩散器选品深度洞察:抢占$59-79蓝海,打造开放生态新品牌
一、市场概览
根据Straits Research的统计,2024年全球芳香疗法扩散器市场规模约为20亿美元,预计到2034年将攀升至46.9亿美元,复合年增长率(CAGR)达8.9%。其中,智能与WiFi连接型扩散器已成为增速最快的细分领域,正从传统家用电器蜕变为智能家居生态中不可或缺的节点。从区域格局来看,北美市场占据了44%的份额,欧洲占比30%,而亚太地区以20%的份额和高达9.7%的CAGR成为增速最快的区域。社交端,TikTok平台上的#homescent话题已累计超过50亿次播放,强烈映射出消费者对“居家幸福感”的追求正不断深化(数据参考:Emergen Research、Verified Market Reports)。

二、竞争格局
| 品牌/型号 | 价格 | 评分 | 核心卖点 | 致命弱点 |
|---|---|---|---|---|
| Pura 4 | $44-50 | 4.3 | 250+香氛/双瓶轮换/地理围栏 | 封闭生态/无语音助手 |
| Pura Plus | $79.99 | 4.4 | 大空间/自适应扩香/双控 | 封闭生态/补充装消耗快 |
| Aera Large | $235 | 4.2 | Alexa/冷风微滴/800h续航 | 设备+胶囊双贵/仅55款 |
| Aera Mini | $95 | 4.1 | 便携/600h/无雾低敏 | 胶囊$30/颗/单槽 |
| Vitruvi Cloud | $119-199 | 4.5 | 陶瓷美学/超声波静音 | 弱智能(仅蓝牙)/价高 |
| Moodo | $149 | 4.0 | 4槽混香/WiFi+BLE | 设备贵/品牌小众 |
| ASAKUKI WiFi | $35-40 | 4.3 | 500ml/Tuya Alexa/安全 | 全塑料/设计廉价 |
| GoveeLife Smart | $30-40 | 4.4 | Alexa/Google/IFTTT | 300ml小容量/白色塑料 |
| Meross WiFi | $35-45 | 4.2 | HomeKit原生/纳米雾化 | WiFi不稳定/配对困难 |
从中提炼的核心洞察是:市场整体呈现哑铃型结构——低端$20-$50区间已是全塑料白牌的肉搏红海,高端$95-$250则被Pura、Aera等品牌的封闭生态牢牢锁定。而**$59-$79的价格段,几乎没有出现任何同时具备WiFi智能、开放生态、高端设计与500ml大容量的产品**,正是DTC品牌切入的理想空白地带。
三、用户痛点分析
| 痛点 | 占比 | DTC 解法 |
|---|---|---|
| 漏水/渗水 | 25% | 双密封圈+IPX4防溅+硅胶防滑垫 |
| 霉变/水垢 | 22% | UV-C LED自清洁+抗菌PP+宽口清洗 |
| WiFi/App断连 | 18% | 双频WiFi+BLE备份+本地离线记忆 |
| 雾化片堵塞 | 15% | 可更换模块化雾化片($9.9)+除垢提醒 |
| 设备寿命短 | 10% | 2年质保+可更换核心组件 |
| 香味太弱 | 6% | 双超声波振子+3档雾量+覆盖30㎡ |
| 封闭生态耗材贵 | 4% | 开放生态+可选精油订阅(不强制) |
四、品牌真空带:$59-79最佳切入点
当前市场的哑铃型结构极为分明:
🔴低端$20-50 → ASAKUKI、InnoGear、Urpower等数百个白牌,清一色全塑料、廉价感突出,全部困在价格战中
🟢$59-79 → 品牌绝对真空!至今没有一个品牌能够同时兑现“WiFi智能+开放生态+高端设计+500ml大容量”
🔵高端$95-250 → Pura(封闭)、Aera(封闭)、Vitruvi(弱智能)、Moodo(小众)牢牢占据
💡 Pura $44-50虽低价却将用户锁在封闭系统内,Aera $95+用高价胶囊抬高后续成本,Vitruvi $119+以陶瓷美学为卖点却缺失WiFi——这些玩家的短板恰好拼接成一块“黄金三角”机会,静待新品牌精准切入。
2026跨境广告巨变:Temu强制全域ROAS出价、Shopee转向Views计费及独立站逆袭实操解析
近期跨境电商领域迎来密集调整,本期重点解读三大关键变化:Temu广告模式自6月7日起强制切换至全域ROAS出价,低单价铺货策略失去空间;Shopee在多个站点将广告计费从点击(CPC)转变为浏览(Views)归因,广告投资回报率测算方法需全面重建;同时剖析一个DTC独立站从月亏损6万到月盈利18万的逆袭案例,总结可复制的精细化运营方法。
一、Temu广告系统重大调整:全域ROAS出价即日强制启用
自2026年6月7日起,Temu广告投放体系发生根本性变化:新建的推广计划只能采用全域ROAS出价模式,原有的“目标推广ROAS出价(单品推广出价)”选项已不再支持创建新计划。此前已建立的单品推广计划可沿用至6月30日,之后将全面停用。
新模式的核心机制是:卖家只需为整个店铺设定预期的投产比(ROAS),平台便会自动将商品推广至搜索、推荐及活动页等全域流量位,并配套14天超长退单红包和全店利润核算功能。
| 卖家类型 | 影响分析 |
|---|---|
| 低毛利/价差大卖家 | 利润空间受压缩,流量更多分配给高转化商品 |
| 高毛利/新品测试卖家 | 可用小预算测试全域出价模式,快速积累数据 |
| 多SKU铺货型卖家 | 无法再手动指定爆款,对选品精准度提出更高要求 |
二、Shopee广告计费模式革新:从CPC转为浏览归因
从6月1日开始,Shopee在菲律宾、越南、马来西亚、泰国、新加坡、巴西以及中国台湾这七个市场,对全站推广的商品广告新增了1天浏览归因,正式将计费方式从按点击收费(CPC)转为按浏览计费(Views)。换言之,即使买家未直接点击广告,只要他们浏览过广告展示位置并在1天内完成订单,该交易就会被算作广告带来的转化。同时,部分原本的自然流量转化也可能被归因到广告上,这可能导致广告投资回报率(ROI)被高估。
| 维度 | 旧规则 | 新规则(6/1起) |
|---|---|---|
| 归因方式 | 仅7天点击归因 | 新增1天浏览归因,并保留7天点击归因 |
| 计费方式 | 按点击(CPC) | 按浏览(Views) |
| 覆盖市场 | 所有市场 | 七个市场(菲、越、马、泰、新、巴西、中国台湾) |
三、DTC独立站逆袭案例:从月亏损6万到月盈利18万
EcoVibe是一个由国内卖家运营的环保家居DTC品牌,于2024年底在Shopify上线。早期依赖低价爆款和大规模广告投放,却在2025年上半年累计亏损超过80万元。经过策略转型,到2026年4月,其月营收达到82万元,净利润18万元,净利率达22%。其方法论可划分为四个阶段:
| 阶段 | 核心策略 | 关键数据 |
|---|---|---|
| 止血 | 削减低ROI广告、清理库存、签订年度物流合同 | 月广告支出15万→8万,单件运费$4.2→$2.8 |
| 升级 | 放弃$19.9低价产品,聚焦$65-$120中高端价位 | 客单价$28→$78,毛利率38%→62% |
| 复购 | 搭建邮件及WhatsApp自动化复购系统 | 复购率12%→34%,用户生命周期价值$45→$128 |
| 精细 | 通过Looker Studio与Shopify Analytics数据看板驱动决策 | 库存周转天数120天→45天,月净利18万 |
盈亏平衡ROAS计算公式为:1÷(1-毛利率-退货率-手续费率)。一旦广告ROAS低于该盈亏平衡点,投入越多反而亏损越严重。
四、Shopee马来西亚6.6大促持续进行:流量较平日高出五倍
Shopee马来西亚2026年“6.6生日大促”从6月3日持续至16日,为期14天,涵盖预热、爆发和返场三个阶段。预计主会场流量集中度比平日高出至少5倍,跨境直邮、家居用品、美妆、电子产品等核心类目将迎来订单集中爆发。大促活动仍在进行中,建议重点布局家居日用品、平价美妆和3C配件,提前为广告账户充值以冲刺转化效果,并抓住每天的流量高峰期。
纵观6月跨境电商领域,Temu和Shopee的广告模式几乎同步迎来根本性变革,标志着粗放式铺货运营时代的正式终结。EcoVibe的逆袭之路表明,走精细化运营路线、定位于中高端市场并构建系统化的复购体系,才是当前唯一可持续的增长路径。
2026年便携冲牙器跨境选品深度分析报告:市场机遇、竞争格局与DTC品牌破局策略
一、全球市场生态全景
全球水牙线(又称冲牙器或口腔冲洗器)市场正迎来高速扩容周期。根据 Mordor Intelligence 的行业监测,2025年全球市场规模约 11.5亿美元,到2031年预计攀升至 17亿美元,测算期内复合年增长率(CAGR)约为 6.8%。另一机构 Deep Market Insights 的评估则显示,2024年市场规模约11.9亿美元,至2030年可达23.6亿美元,中长期增长动力强劲。
在细分形态中,便携式无线冲牙器无疑是领跑品类。Mordor Intelligence 指出,2025年无线款已占据整体市场 57.12% 的销售份额,成为新用户入门的绝对首选。QY Research 的数据进一步显示,全球无线便携冲牙器市场2024年估值约 8.79亿美元,2031年预计达到 12.06亿美元,CAGR 4.7%,体量和增速均十分可观。
区域市场分布上,呈现出明显的梯度格局:
北美
以 38.47% 的份额稳居全球第一大市场(Mordor Intelligence)。在美国本土,Waterpik 凭借 40%–45% 的压倒性市占率占据主导地位(Accio 数据)。
亚太
以 7.9% 的 CAGR 成为增长最快的区域,由中国和印度市场共同驱动,2023年收入贡献约占全球的24%。
欧洲
受可回收材料法规驱动产品迭代,市场增长稳健,高端化替换需求持续释放。
核心趋势信号速览:
- 亚马逊平台搜索数据显示,12月受节假日效应拉动出现爆发式跳涨,2月和4月也分别录得 +8.49% 和 +9.18% 的显著搜索增幅,表明多个消费节点存在商机。
- 60% 的英、美消费者愿意以超过80美元的价格购买高端冲牙器(Accio 数据),支付意愿强烈。
- 智能化需求已成主流:76% 的美国受访者和 72% 的英国受访者将蓝牙连接、APP追踪、可调节压力等智能功能视为关键购买因素。
- TikTok 上 #waterflosser 话题持续升温,相关内容的月均增长达32%,社交传播势能显著。
二、竞争格局深度拆解
| 品牌 | 型号 | 价格(美元) | Amazon评分 | 核心卖点 | 致命弱点 |
|---|---|---|---|---|---|
| Waterpik | ION Professional WF-12 | $100 | 4.5★ | 10档水压+770ml超大水箱+4周续航,兼具台式性能和无线设计,ADA认证 | 机身偏厚重,$100价格门槛较高 |
| Waterpik | Cordless Advanced 2.0 | $80 | 4.4★ | 3档水压+210ml水箱+USB磁吸充电,品牌信任度极高,ADA认证 | 水箱容量仅210ml需中途加水,功能传统无智能互联 |
| Philips | Sonicare Power Flosser 3000 | $80 | 4.3★ | Quad Stream四流道技术覆盖面积提升9倍,250ml水箱+ADA认证 | 续航仅14天为行业最短,按键复杂学习成本高 |
| Quip | Cordless Water Flosser | $70 | 4.2★ | 订阅模式($7/季度喷嘴自动配送),8周超长续航,ADA认证 | 水压较弱,深度清洁力不足,仅2种使用模式 |
| BURST | Water Flosser | $70 | 4.1★ | 80天行业最长续航,3种模式,360°旋转喷嘴适合正畸人群 | 水箱仅110ml极小,使用过程易漏水,无ADA认证 |
| COSLUS | C20 | $30 | 4.4★(49004评) | 300ml大水箱+5级水压+30天续航,预算段唯一ADA认证,性价比突出 | 6个月后储水槽密封可能出现松动漏水,设计观感较普通 |
| Nicwell | F5025 | $30 | 4.3★(36827评) | 11档水压调节最为丰富,4种模式+30天续航,功能覆盖最全 | 12–18个月电池衰减显著,品牌知名度低,无ADA认证 |
| Bitvae | C5/C6 | $20 | 4.3★ | $20超低价+40天续航+3种模式5档水压,极致性价比 | 无ADA认证,做工略显粗糙,售后支持几乎为零 |
| AquaSonic | Precision | $40 | 4.3★(20756评) | 5喷嘴包含正畸专用,IPX7防水,Target线下渠道铺货 | 200ml水箱偏小,专用充电线便利性不足,无ADA认证 |
竞争格局总结:
一人公司创业真相:离开业务流,AI只是个昂贵的玩具

过去一年,OPC被塑造成“一个人+AI=自动赚钱”的神话。可多数冲进去的人半年后才发现:不但没赚到钱,反而搭上了时间、社保和工具订阅费。真正的OPC并不是AI创业,而是用AI替换你现有业务中的人力成本。没有业务流程,AI再先进不过是个玩具。
数据照进现实:热闹背后的尴尬
2026年被称为“一人公司元年”,全国已有超过20个城市推出OPC专项扶持政策——广东、浙江、江苏等地政府纷纷砸钱、发放算力、建设社区,竞相争夺AI创业者。但现实数据却并不好看:52.7%的OPC月收入不足7000元,大量创业者在半年内黯然退场。我在多个创业社群里看到的反馈高度一致:OPC被严重高估,AI完全没有想象中那么神奇。
问题出在哪里?不是AI不行,而是多数人从根本上误解了OPC。
一人公司的本质:用AI替换人力,而不是凭空造富
市面上最流行的OPC叙事是:一个人、一台电脑、几个AI工具,等于在家稳赚。这不过是典型的卖课文案,根本不是商业逻辑。
真实的OPC只有一个等式:你原有的业务流程 + AI替代原本需要招人完成的环节 = 一个人干完一队人的活儿。
那些真正跑通的OPC案例,没有一个是从“先学AI再找生意”开始的。月入200万的杭州蔡治郅,做的是工业AI系统——他本身就是工业自动化+AI的老兵,客户是他以前服务过的制造企业。年营收150万的武培文,做AI跨境运营——他的底牌是8年跨境营销经验加Meta硅谷履历。AI对他们而言,是把原先需要5到8个人协作的工作,压缩到一个人就能完成。成本锐减的同时,业务本就一直在那里。
失败者的通病:手握AI武器,却找不到战场
回顾近半年OPC失败者的复盘,模式高度重复:
- 花两周用AI搭了个产品,结果根本没人用;
- 做了三五个工具,每一个都半途而废;
- AI能输出代码、出图、出文案,却不知道究竟该卖给谁;
- 客户提出需求时,才发现对方要的是一套解决方案,而不是一个孤立工具;
- 算力账单甚至比收入还高。
这些人的共性非常明显:没有一个已经跑通的业务。他们以为“有了AI就能自动找到生意”,可AI不负责获客,不负责成交,更不负责售后。AI能帮你把一个流程从5小时压缩到30分钟,但前提是你必须明确那个流程究竟是什么。
**一个真实的反差案例:**西安的刘旦,专做本地商家AI自动化运营。他第一个客户免费做,用心做出结果截图;第二个就敢收3000元;第三个直接报价8000元。三个月后,月均收入稳定在2到4万。他并非技术出身,但他的业务路径极为清晰:先发现需求,再用AI去满足需求。
政策真相:OPC是就业缓冲,而非造富快车
理解OPC的另一条线索藏在政策里。2025年到2026年,中国科技行业经历了大规模裁员,大模型能力的爆发又让大量初级工程师的岗位面临替代风险。那些被裁掉的程序员、产品经理、设计师怎么办?OPC政策本质上正是一个就业缓冲方案。上海浦东给出30万元算力补贴,杭州成立10亿元OPC基金,广东计划到2028年培育1000家标杆OPC。这些措施的目的绝不是批量制造百万富翁,而是把失业的技术人才转化为独立经营者,让他们自己养活自己。
换句话说,OPC是下限兜底机制,而不是上限致富通道。把它理解成“政府帮我创业、AI替我赚钱”的,从一开始就弄错了前提。
能活下来的OPC长什么样
根据多地公开报道与社群反馈,当下能跑通的OPC创业者普遍具备三个特征:
- 业务在前,AI在后:早在创业前就已清楚要服务谁、收什么钱,AI只是替代了原本的交付人力。
- 存量客户转化:第一个客户往往来自前同事、前客户或行业圈子,而不是从零开始获客。
- 业务本身有利润:不会先烧钱再找模式,而是上线第一天就有正向现金流。
OPC生存自检清单
- 你现在的收入来自哪个具体业务?这个业务不用AI时能赚钱吗?
- 你的第一个客户是谁?此刻你能写出三个真实潜在客户的名字吗?
- AI能帮你少招几个人、省下多少钱,而不是凭空变出一个新产品?
- 你的月均算力和工具支出是多少?它低于你月收入的10%吗?
四个问题中只要有一个答不上来,那你很可能还不适合做OPC。
AI是加速器,加速成长也能加速破产
网上流传的一篇OPC相关文章,列举了五位创业者的案例,其中四位失败,一位勉强维持。文章结构工整、案例完整,但观点上却像是AI生成的那种“先有结论再找素材”的操作:先坐实“OPC是坑”,然后找五个符合调性的人填进去。真正的逻辑并非如此。
OPC不是坑,它是一根杠杆。但杠杆只会放大你原本就拥有的东西。你没有业务,AI能放大什么?你没有客户,AI能凭空变出来吗?你没有利润,AI能替你扛住成本吗?
说到底,不赚钱的OPC,还叫OPC吗?没有业务流的OPC,什么都不是。AI的确很好用,但只有介入真实业务流的AI才值钱。还是那句老话:AI是加速器,要么加速成长,要么加速破产。
2026跨境电商新变局:TikTok欧洲13国拓张、美区退货转嫁、Prime Day提前至6月与欧盟免税终结全解读
六月首周,跨境电商赛道密集震荡:TikTok Shop一口气开放八个欧洲国家入驻,欧洲站版图扩张至13国;但美区同步打出退货新规,所有退货运费全部由卖家吸收,重击高退货率品类;亚马逊Prime Day 2026正式定档6月23日至26日,首次提前到6月,让卖家备战时间骤缩;同时欧盟150欧元以下包裹免税政策7月1日终结的倒计时声越来越近,直邮成本即将陡升。本文聚焦平台扩张、政策风险与战斗节奏,帮你抢先一步。
一、TikTok Shop欧洲八国同步开通入驻
6月1日,TikTok Shop跨境电商正式为波兰、荷兰、比利时、捷克、奥地利、希腊、葡萄牙和匈牙利8个国家打开商家注册入口,叠加此前已经运营的英国、德国、法国、西班牙、意大利五国,欧洲站点扩大至13个国家。跨境卖家仅需持有一套海外资质,就可以覆盖欧洲主流消费市场。
新站点开放阶段,平台会配套新商家成长计划、流量倾斜、广告补贴和佣金减免等激励。欧洲整体消费能力强劲,尤其是德国、法国、荷兰等地客单价偏高、品牌意识成熟。越早卡位,越容易咬住第一波流量红利。
二、TikTok Shop美区退货规则巨变
自6月起,TikTok Shop美区退货逻辑迎来划时代调整——所有退货运费统一由卖家全部负担,包括买家因个人原因(如“不再需要”、“尺码不合适”)发起的退货,彻底告别此前的平台、消费者、卖家三方分摊模式。
| 对比维度 | 旧有规则 | 全新规则 |
|---|---|---|
| 平台承担 | 部分基础运费 | 不再承担 |
| 消费者承担 | 按比例支付 | 零成本退货 |
| 卖家承担 | 仅分担尾款运费 | 全部运费+处理费 |
鞋服、3C、饰品等较高退货率的类目冲击最大,行业平均退货率在25%到40%之间。应对方向建议:①全面重新核算综合成本,重塑定价模型;②精细化优化Listing,从源头尽可能压低退货率;③对低货值商品积极协商“退款不退货”方案。
三、Prime Day 2026定档6月23日至26日
亚马逊Prime Day首次提档至6月,将在6月23日到26日全球同步开跑,打造为期四天的超长促销窗口。美国站提报截止时间为6月9日,欧洲站则在6月19日。今年新增每场100美元报名费叠加1.5%活动服务费,让成本压力明显攀升。
选品聚焦方向:消费电子、家居户外、办公用品、季节性服饰等。若折扣力度达到30%以上,可解锁“Buzzworthy Deals”高级曝光位。此外,Alexa for Shopping已经全面落地,Listing必须补齐场景、人群、差异性和评论这四大关键举证。
四、欧盟免税政策7月1日正式终止
依据欧盟(EU)2026/382法案,从7月1日起取消150欧元以下跨境小包裹的免税待遇,一律征收关税和增值税。对中小卖家来说,直邮单件成本预计上涨12%到22%。6月内必须完成IOSS注册并提交、启动海外仓备货、同步更新定价策略。
五、SHEIN美区限制自发货
自6月30日起,SHEIN美区半托管和自运营商家将被限制自发货,只能使用平台合作物流体系。这意味着卖家会失去自主选择物流服务商的灵活性,需要尽快评估平台物流报价与现有配送方案之间的成本差异。
小结:新市场要趁早抢占,老市场必须精细核算成本,合规立于先,利润才能真正为王。