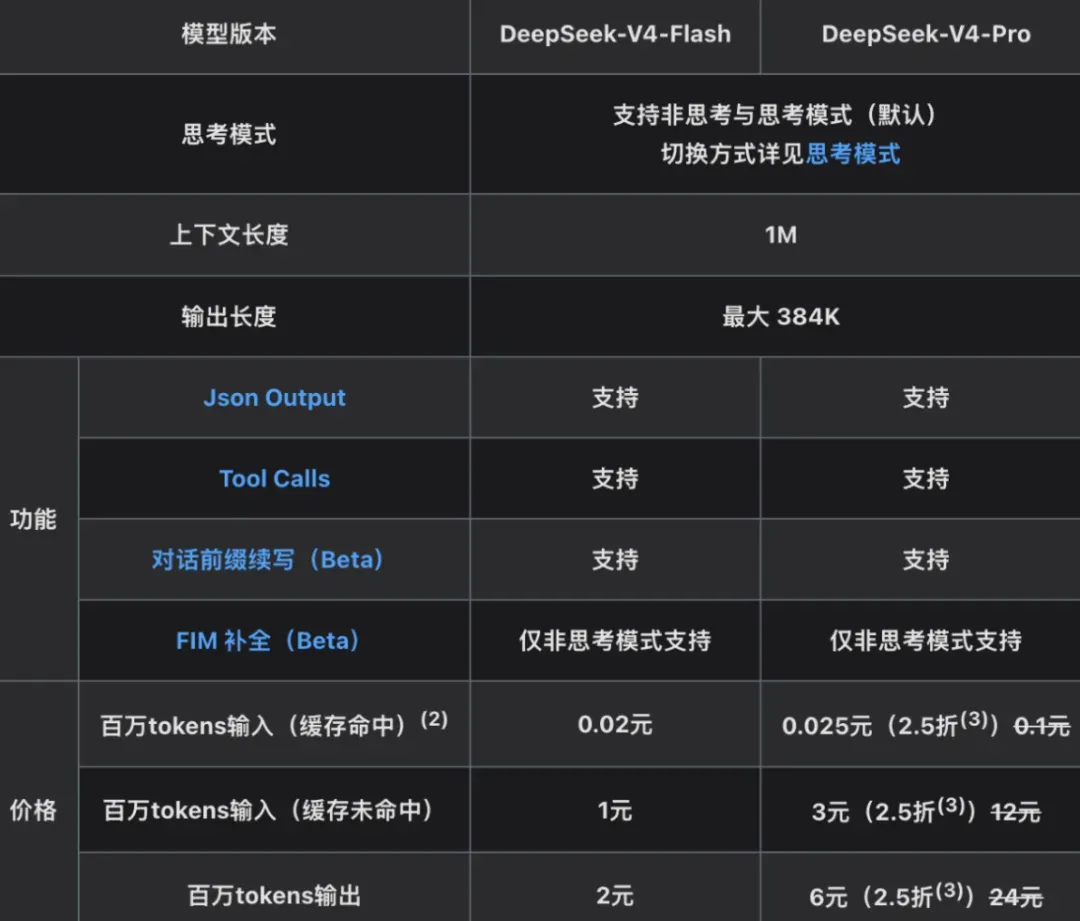
DeepSeek-V4-Pro永久降价至0.025元:Coding Plan彻底没戏,收电费时代已至
DeepSeek-V4-Pro 永久降价,Coding Plan 再无优势
AI 大模型评测
DeepSeek-V4-Pro 宣布永久降价,之前让人兴奋的 Coding Plan 瞬间失去了竞争意义。限时折扣正式转为永久底价,输入(缓存命中)仅需 0.025 元/百万 tokens,官方直言“就是收个电费”。
周末看到降价通知时还没有太在意,直到今天仔细审视,才发现亮点在于 “永久” 二字。大模型价格战打了快两年,各家“限时优惠”套路层出不穷,但这次 DeepSeek 直接反套路:原本的 2.5 折优惠不再是短期噱头,而是直接锚定为永久官方定价。如果说过去是“限时打折”,现在就是“直接腰斩再腰斩,一分钱都不会涨回去”。
算来算去,不如直接上 DeepSeek 官方接口。
先看 DeepSeek 定价
DeepSeek-V4-Pro 原定价为:输入(缓存命中)0.1 元、输入(缓存未命中)12 元、输出 24 元/百万 tokens。2.5 折优惠后,三个档位分别是 0.025 元、3 元、6 元。
5 月 31 日后:优惠活动结束,但价格永久锁定为原定价的 1/4,即 0.025 元、3 元、6 元。

简单说:过去是短暂的狂欢,现在是永久的低价。DeepSeek 直接摊牌,只收个电费,不在乎别的。
DeepSeek 到底有多便宜?
以 100 万 tokens 输入(缓存命中)作为基准,看看各家同级别模型的价格对比:
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 | 便宜多少倍 |
|---|---|---|---|---|
| DeepSeek-V4-Pro | 0.025 元 | 3 元 | 6 元 | — |
| MiniMax M2.7 | ≈0.43 元 | ≈2.1 元 | ≈8.4 元 | 17 倍 |
| Kimi K2.6 | 1.1 元 | 6.5 元 | 27 元 | 44 倍 |
| Qwen3.6-Plus (≤256K) | 2 元 | 2 元 | 12 元 | 80 倍 |
| Qwen3.6-Plus (256K‑1M) | 0.8 元 | 8 元 | 48 元 | 32 倍 |
| GLM-5.1 (≤32K) | 1.3 元 | 6 元 | 24 元 | 52 倍 |
| GLM-5.1 (>32K) | 2 元 | 8 元 | 28 元 | 80 倍 |
表格一摆出来,任何多余的解释都显得苍白。DeepSeek 在低价的极点上,甚至还顺手压低了缓存命中时的成本,让其他厂商的定价看起来像另一条赛道。
DeepSeek-V4接入Claude Code实战:零成本打造自媒体数据分析神器,效果惊人
前几天,有位学习群的朋友私信问道:
“Claude Code 能不能用 DeepSeek 的模型?每次跑任务都要花几十块钱,实在有些心疼。”
确实,在国内的众多模型里,DeepSeek 在性价比方面一直很能打。
顺着这位伙伴的提问,今天这篇文章就来详细分享一下,如何把 DeepSeek-V4 接入 Claude Code。
更有意思的是,在边做教程边实测的过程中,我意外地顺带做出了一个自媒体数据分析工具,实际用下来效果还挺惊喜!
继续观看
我用DeepSeekV4+Claude Code开发了个「自媒体数据分析工具」,效果出奇的好。。。
观看更多
转载
,
我用DeepSeekV4+Claude Code开发了个「自媒体数据分析工具」,效果出奇的好。。。
AI智效坊已关注
Share点赞Wow
Added to Top StoriesEnter comment
而且,开发这么个小工具,一共跑了一万七千多个 Token,用的还是 Pro 模型,算下来也就花了五分钱。
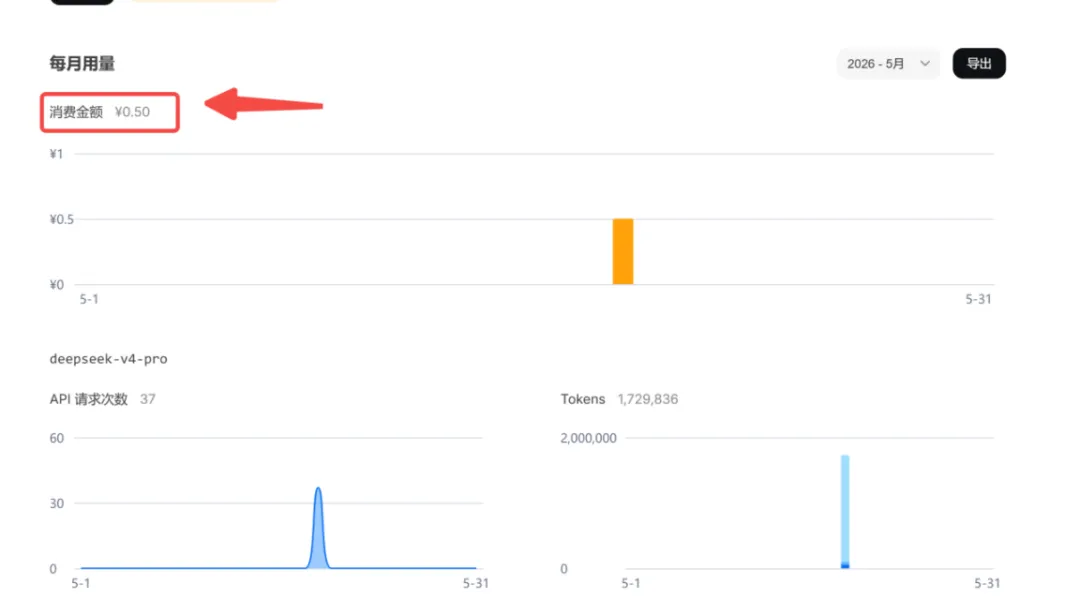
看来账号里充的十块钱真的可以用很久。
话不多说,直接上干货。
01
DeepSeek-V4 接入 Claude Code 的完整流程
接入过程其实很简单,不过前提是你已经安装并部署好了 Claude Code,具体的安装步骤可以参考这篇详细指南(略)。安装完成后,照着下面的步骤就能完成模型连接。
第一步:获取 DeepSeek 的 API Key
打开官网:https://platform.deepseek.com/api_keys
进入页面后,在 API keys 处点击"创建 API key",然后把生成的 key 复制到文本文档里保存好,一会儿会用到。
Docker部署礼记LiJi:打造专属人情账本,送礼收礼一目了然
在中国人的社交哲学里,送礼与随礼从来不只是金钱往来,背后折射的是关系亲疏、情分厚薄和礼尚往来的拿捏。礼物承载心意,礼金刻录人情。随轻了恐有失体面,随重了又怕给对方增加负担;最棘手的莫过于遗忘,等到需要还礼时才靠残存的感觉去揣测。
正因如此,一款专为“人情账”设计的工具显得格外实用。今天要介绍的开源项目礼记 LiJi,恰好能将收礼、送礼、礼簿、人际关系、金额和日期等核心信息系统化整理,只需借助Docker便可快速部署在你的NAS或服务器上。
不只有数字,更有人情温度
与复杂财务软件不同,LiJi瞄准的是最接地气的人情场景:帮你把每一次礼金往来记得明明白白。比如家里乔迁设宴,你可以新建一个礼簿,逐条登记亲友姓名、随礼金额、关系与备注。日后对方遇喜,再也不用纠结“上次他家是不是封了600”,直接打开LiJi便知根底。同样,当你参加婚礼、满月或升学宴时,也能记录自己送出的礼金。实用之处并非功能繁杂,而是将分散在微信转账、支付宝账单、纸质礼簿甚至便签里的碎片信息,集中储存于一处,方便长期归档、随时查阅。
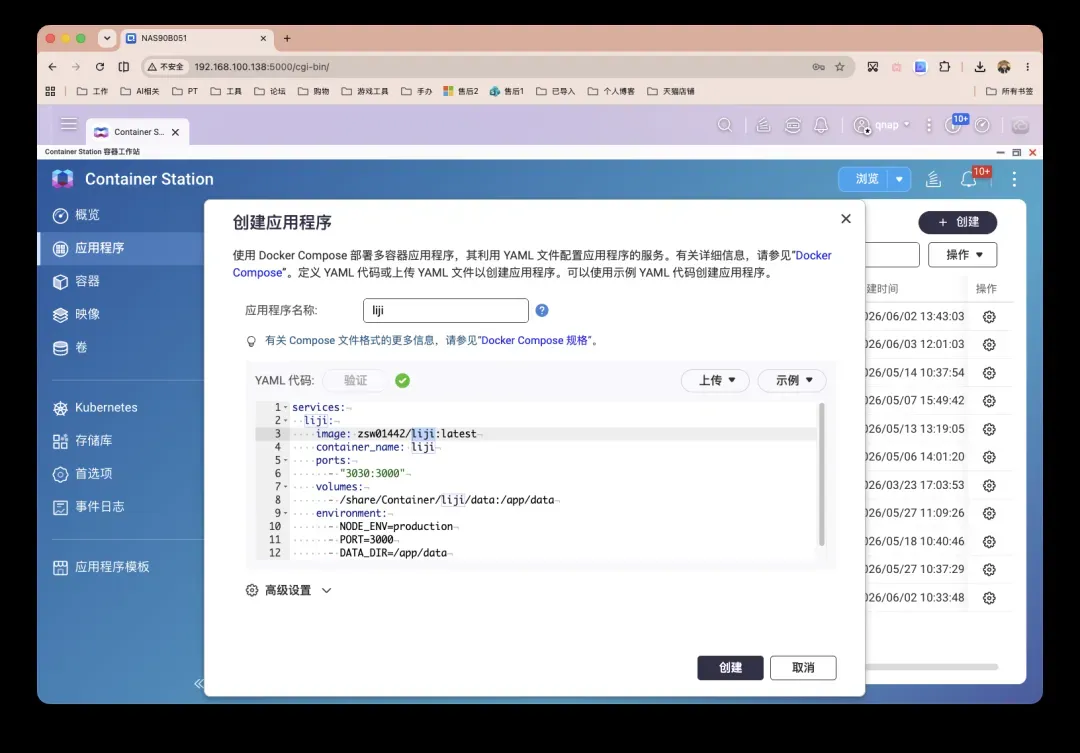
快速部署:用Docker Compose拉起LiJi
以威联通NAS为例,通过Docker Compose的方式进行部署。在Container Station中创建新应用,粘贴以下配置即可:
services:
liji:
image: zsw01442/liji:latest
container_name: liji
ports:
- "3030:3000"
volumes:
- /share/Container/liji/data:/app/data
environment:
- NODE_ENV=production
- PORT=3000
- DATA_DIR=/app/data
restart: unless-stopped
功能详解:从礼簿管理到智能统计
部署成功后,在浏览器输入NAS_IP:3030即可进入LiJi界面。默认登录密码是admin,首页会有提示。首次登录后请立即修改密码以保障安全。
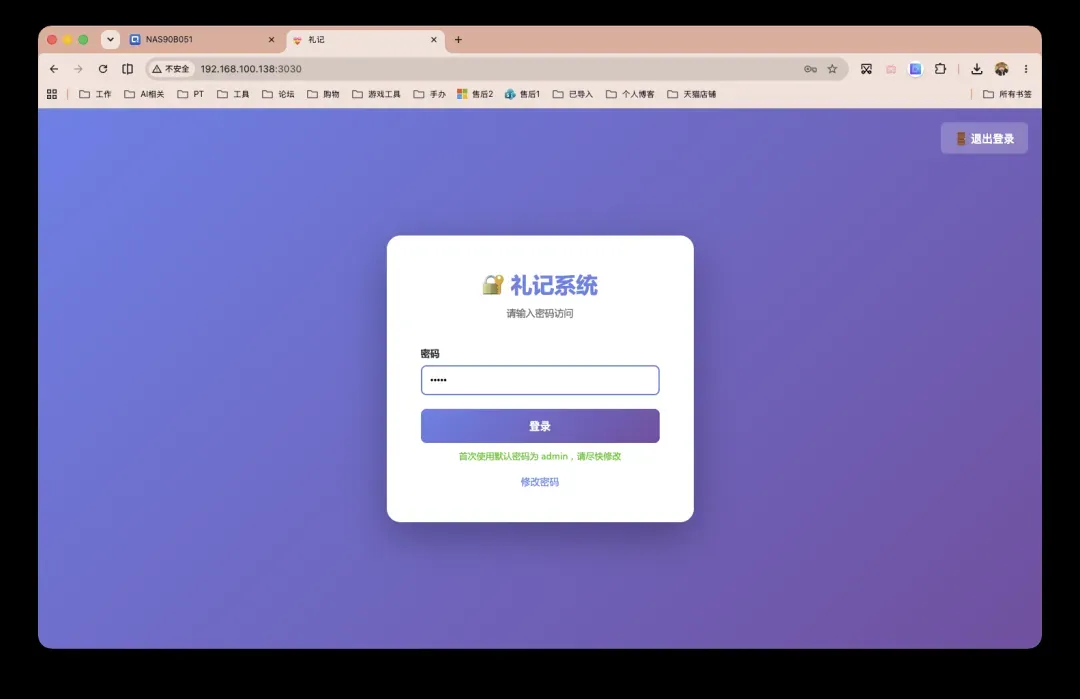
若不小心忘记密码,只需进入挂载的数据目录,删除password.json文件并重启容器,系统便会重置密码为默认值。该目录下的records.json存储所有人情往来记录,giftbooks.json则保存礼簿数据,方便手动备份与迁移。
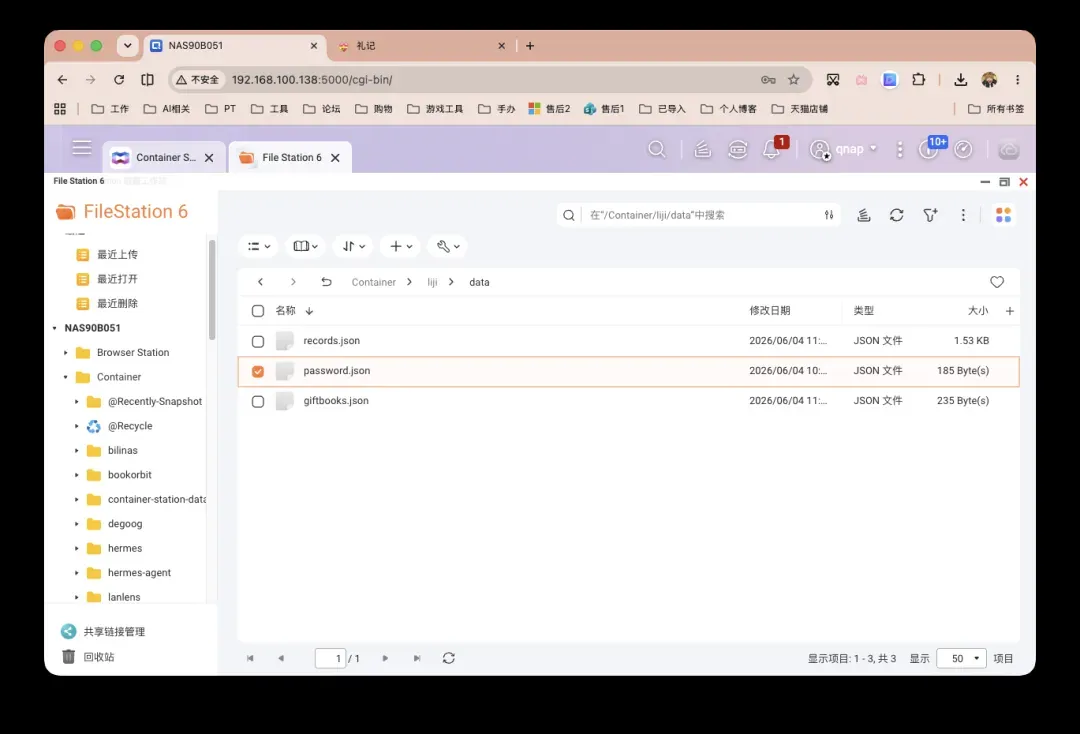
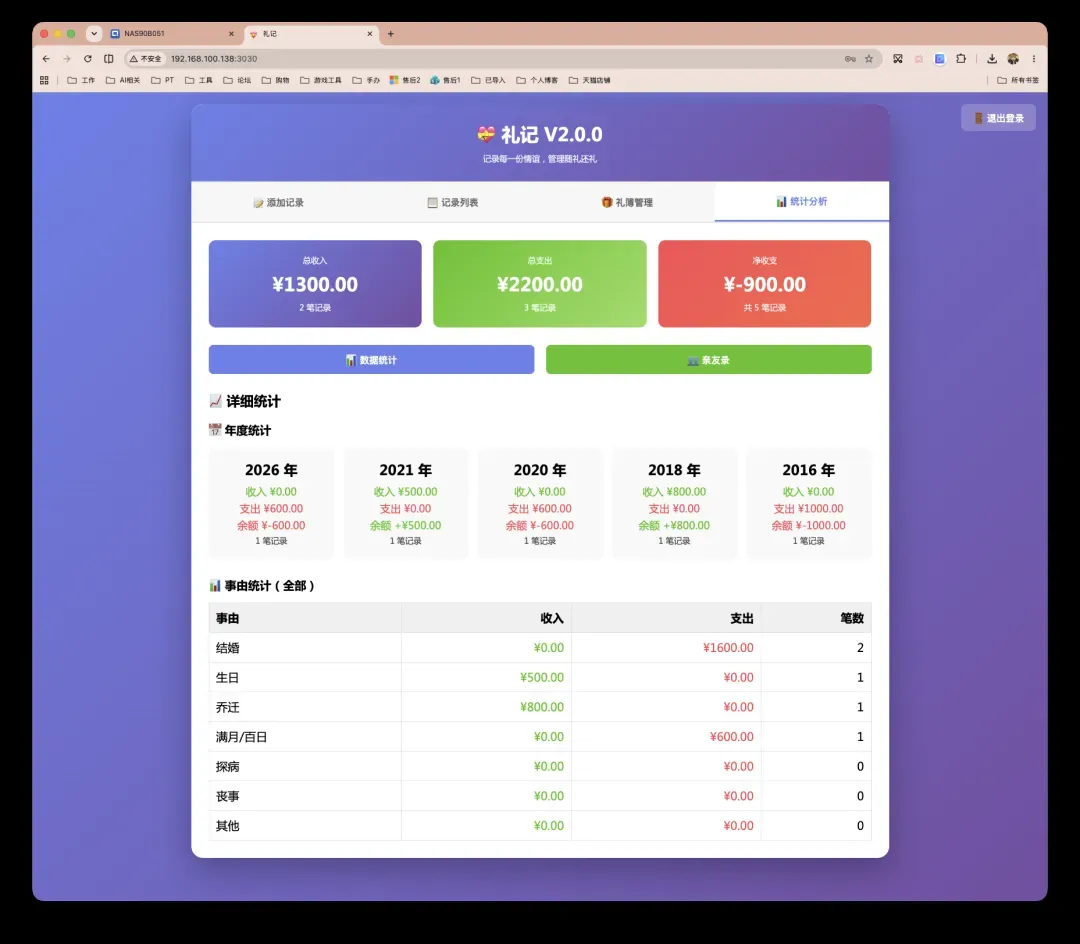
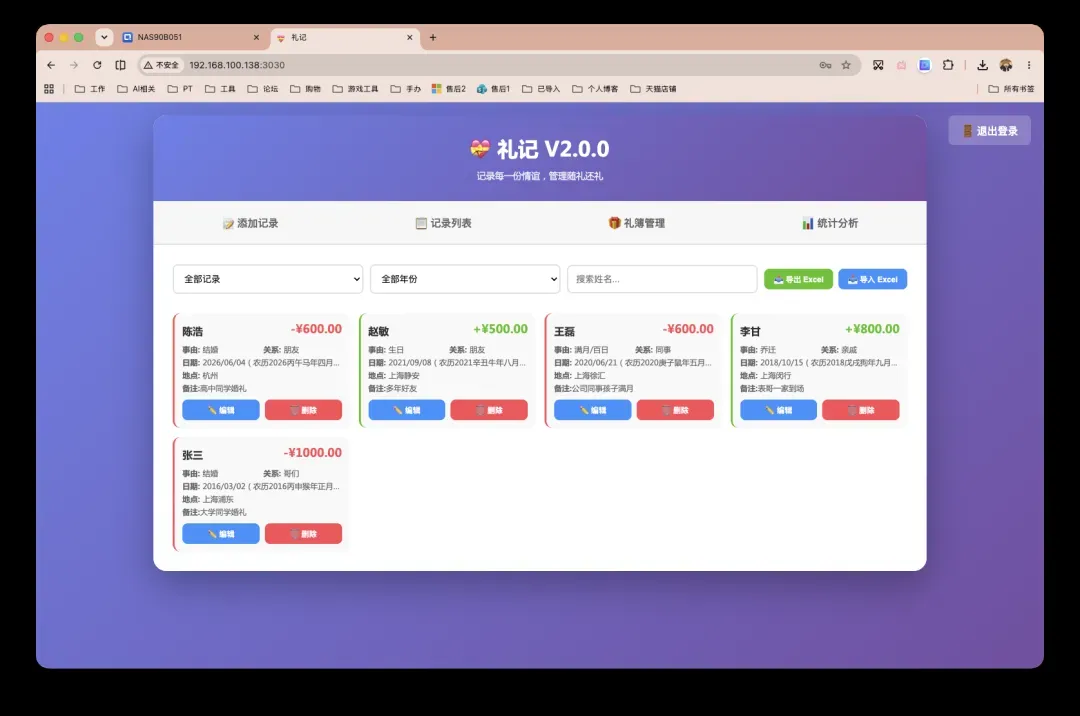
主界面简洁直观,可自由选择“送礼”或“收礼”,并填写姓名、关系、金额、事由、日期、地点与备注。所有记录均保存在你的NAS中,日后的查询与统计分析都十分便捷。
选择“收礼”时,界面会增加“关联礼簿”选项,你可以提前在“礼簿管理”中为各类宴席创建礼簿。
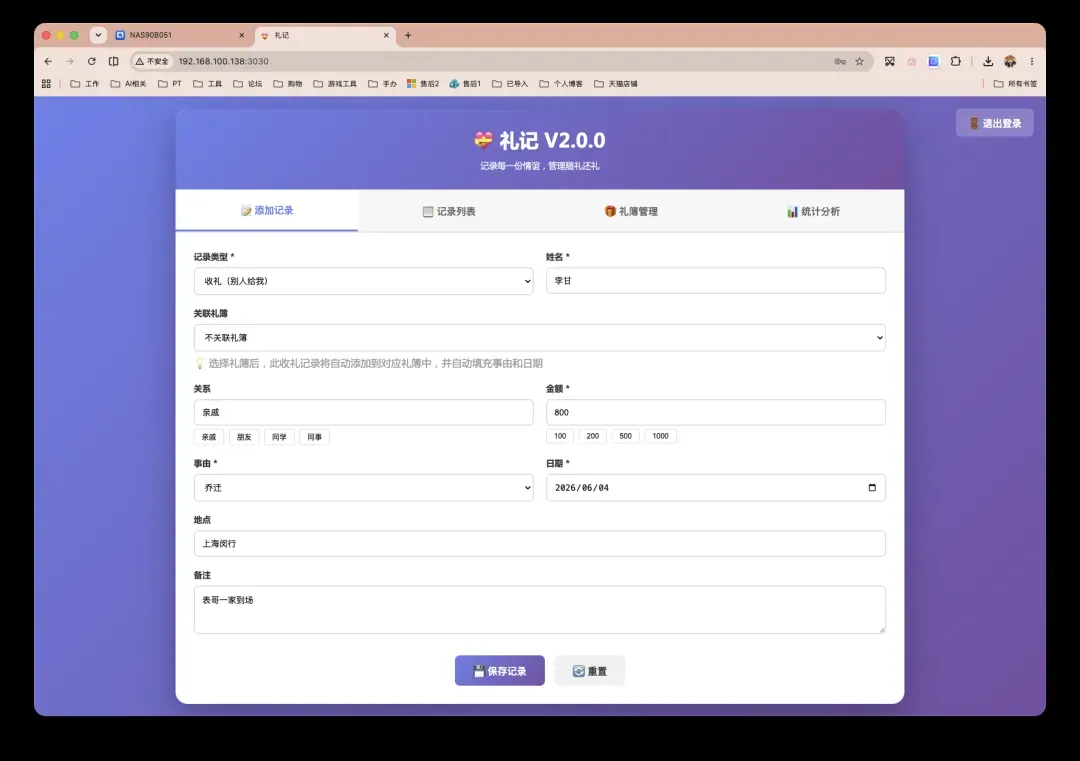
“礼簿管理”允许按事件创建专属礼簿,例如婚宴、乔迁、满月酒等。每个礼簿内可添加宾客,统一登记收礼明细,并支持编辑、导出和删除,是办席时整理礼金清单的利器。
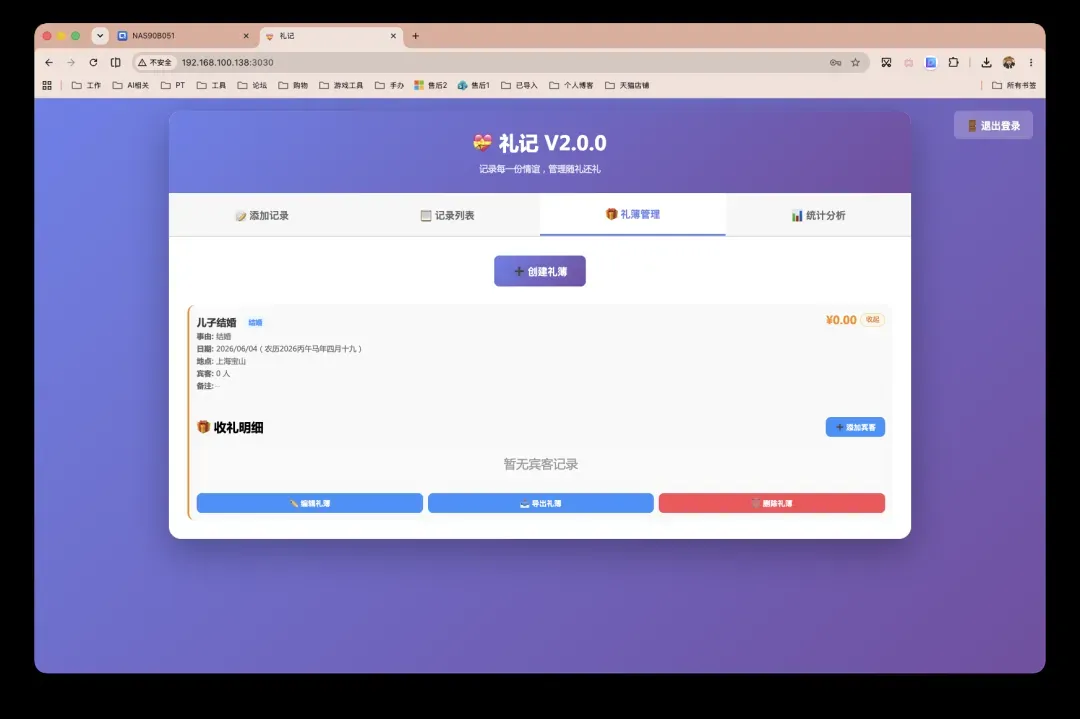
在“记录列表”中,所有的送礼与收礼记录一目了然。可按记录类型、年份及姓名快速筛选,也支持编辑、删除、导出或导入Excel,方便日常维护和数据备份。
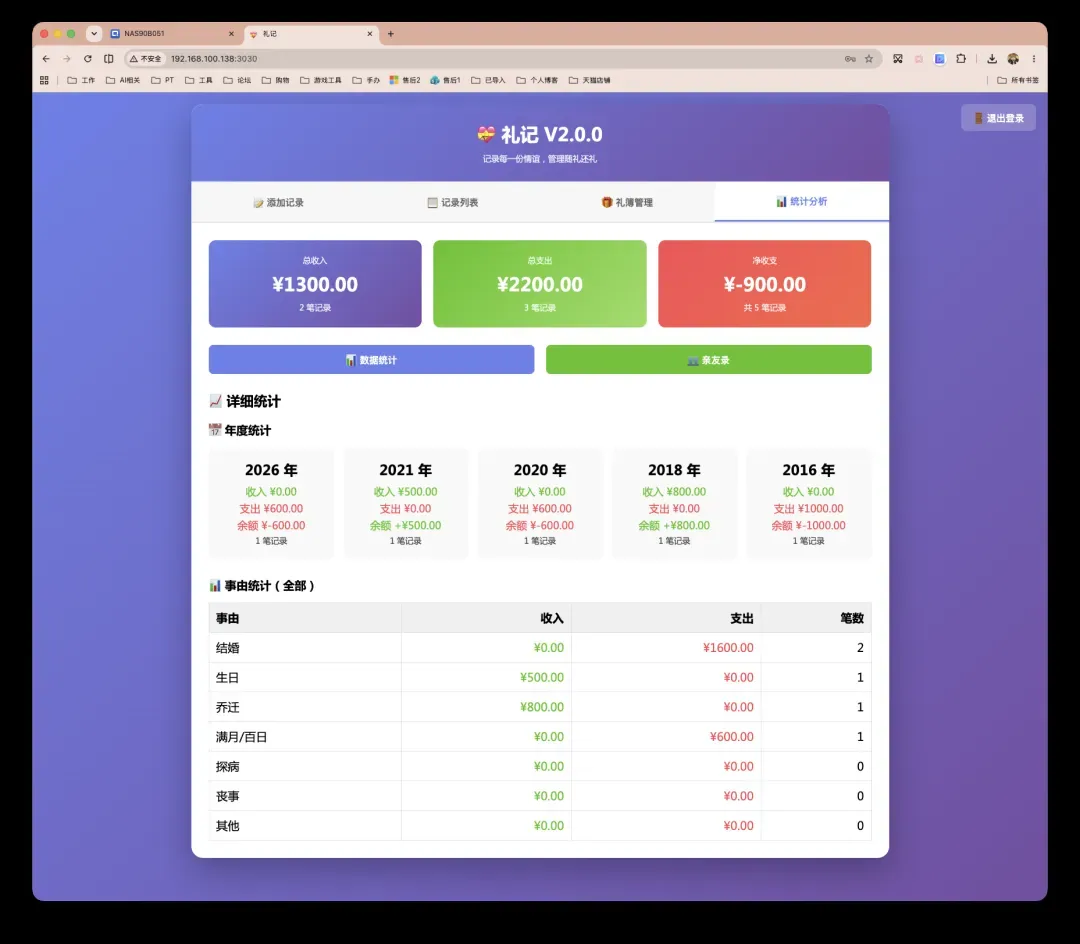
统计面板(与前文截图呼应)会综合呈现总收入、总支出和净收支,按年份、事由等维度分类统计。所有录入的收礼与送礼记录将在此自动聚合,让你一目了然地掌握不同时期、不同场景下的人情收支情况。
结语:让人情往来有温度有记录
礼金可以随出去,但人情记录不能随缘丢失。有了LiJi,每一次心意往来都有迹可循,让情分不因遗忘而减淡。
Free Claude Code 开源代理:用任意模型驱动 Claude Code,告别高价与封号困扰
Claude Code 的体验有口皆碑,这一点无需赘述。尽管 Anthropic 的一些策略时常引发争议,但工具本身依旧值得使用。不过,真正将它作为主力编程助手投入日常开发时,账单往往会变得非常醒目。尤其是那些需要 Agent 反复阅读代码、修改逻辑、跑测试的长时间任务,一个晚上下来,心跳几乎会跟着 API 调用次数的飙升一起加速。
更麻烦的是,Claude 对国内用户并不友好,订阅后封号风险高,很多时候开发者只能退而求其次去使用第三方模型。这两天,一个开源项目突然吸引了大量目光:Free Claude Code。
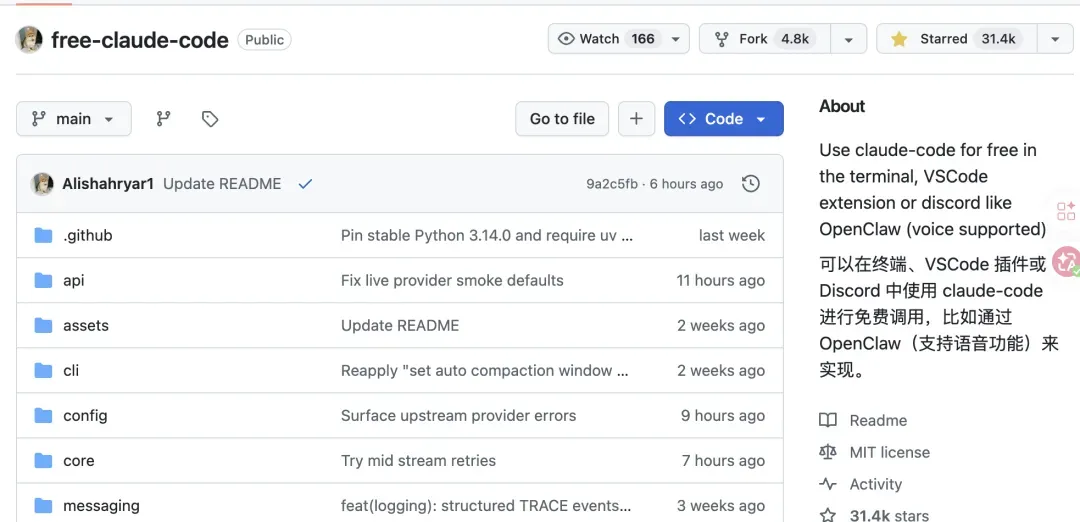
它并不是 Anthropic 官方推出的免费版 Claude Code,更不是破解或盗版。更准确地讲,它是一个本地代理服务,专门负责拦截 Claude Code 发往 Anthropic Messages API 的请求,并将其转发到其他模型服务上。
需要先说明一点:这篇文章不是在教大家白嫖官方 Claude,也不是说它能 100% 复制 Claude Sonnet 或 Opus 的能力。它解决的是一个非常直接的问题:让你继续使用 Claude Code 这个出色的客户端,但模型流量可以灵活地路由到 NVIDIA NIM、OpenRouter、Gemini、DeepSeek、Kimi、Ollama、LM Studio 等各类后端。
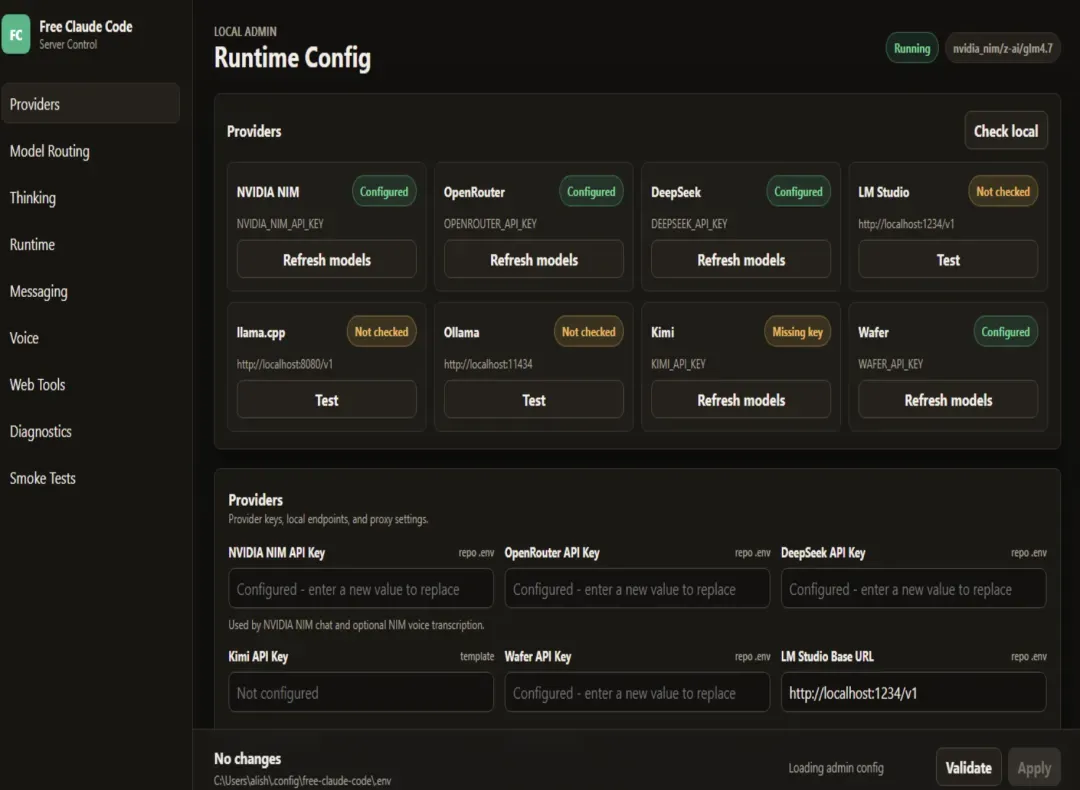
你熟悉的 Claude Code 工作流依然保存完好,而后端的模型则可以随心替换。
它的原理是什么
Free Claude Code 的核心是一个本地搭建的 FastAPI 服务。Claude Code 原本会将请求发给 Anthropic 的 API。而这个项目在你的本机启动一个代理,暴露出 /v1/messages、/v1/messages/count_tokens、/v1/models 这类与 Anthropic 兼容的接口,然后根据你的配置,把收到的请求分发给不同的 provider。
你可以把它理解为一个中间翻译层:
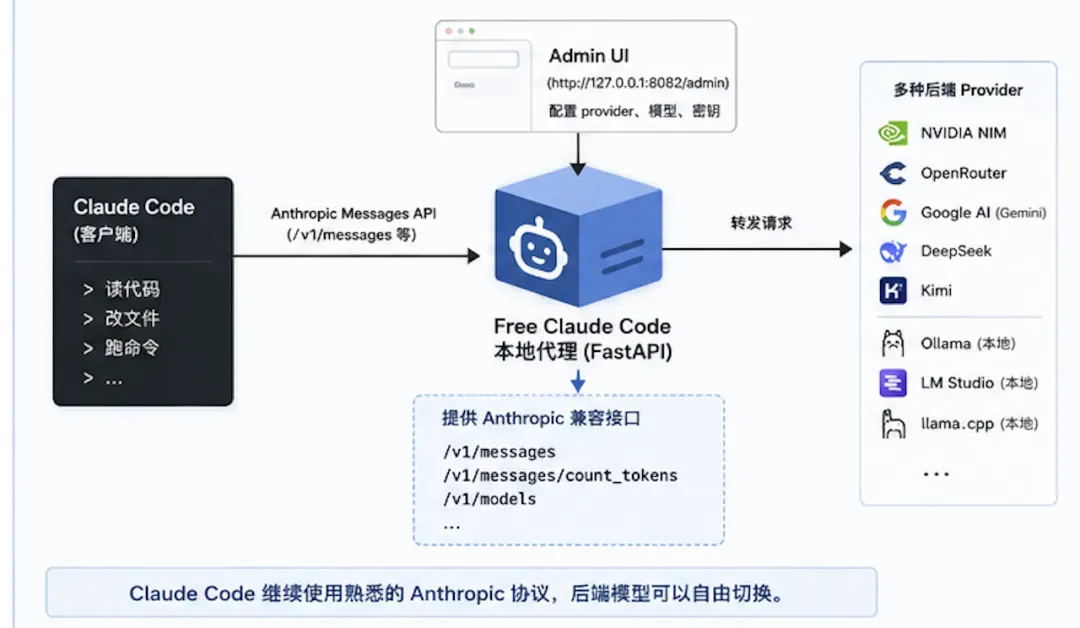
Claude Code 继续使用 Anthropic 的协议进行对话,后端的模型则可以是 OpenAI-compatible 接口、Anthropic Messages 风格接口,也可以是本地的 Ollama、llama.cpp 或 LM Studio。
Gemini Pro 3 免费体验指南:四大入口助你即刻上手最新AI模型
近日,谷歌全新一代大语言模型 Gemini Pro 3 正式亮相,迅速点燃科技圈热情,各大自媒体争相报道。如果你想第一时间亲身感受它的强大能力,却不知从何入手,本文整理了四个切实可用的免费访问渠道,覆盖官方平台、编程集成环境、轻量级对话工具以及流行代码编辑器,无论你是专业开发者还是普通用户,都能找到适合自己的方式。

1、Google AI Studio
**链接:**https://aistudio.google.com
这是谷歌官方出品的 AI 开发与实验平台,集成了丰富的模型调试、Prompt 设计和 API 调用功能。在这里你可以无障碍、无限制地试用 Gemini Pro 3,尤其适合热衷尝鲜的技术爱好者和开发者,全方位探索模型的生成能力。
2、Antigravity
**链接:**https://antigravity.google/
Antigravity 是基于 VS Code 架构深度定制的 AI 编程环境,对于经常与代码打交道的同学来说几乎可以无缝上手。它直接在编辑器内嵌了 Gemini 的交互面板,让你在编写代码的同时随时调取模型进行解释、补全或优化,真正实现“边写边调教”的效率提升。
3、ZenMux
**链接:**https://zenmux.ai/
ZenMux 是一个界面清爽、操作直观的在线 AI 对话平台,当前已接入 Gemini Pro 3 并开放免费体验。它的优势在于轻量化和便捷性,无需复杂配置,打开网页即可开始对话。更值得一提的是,该服务在国内能够正常访问,为不便使用官方入口的用户提供了极佳的替代方案。
4、Cursor
知名智能代码编辑器 Cursor 也同步宣布对 Gemini Pro 3 的支持。更新后,你可以在 Cursor 的模型选择中直接切换至 Gemini Pro 3,无论是撰写代码、查阅文档还是解决编程难题,都能享受到更流畅的辅助体验。对于日常依赖 Cursor 的开发者来说,这无疑是一个不容错过的升级。
不妨从上述入口中选择一个最符合自己使用习惯的平台,亲自上手试试 Gemini Pro 3 的实际表现。如果在体验过程中有任何心得或疑问,也欢迎在评论区分享交流,一起挖掘更多实用玩法。
Hermes Agent 24/7 全自动运行:十个官方指南遗漏的关键配置
本文整理了十个高频被默认安装忽略的配置项。它们既不出现在 README 里,也不在快速入门指引中,但每个都直接决定 Hermes 是只在你手动打开窗口时才工作,还是能持续自主运行、主动提醒并自动归档。读完即可立即调整。
实际工作中,大多数安装 Hermes Agent 的用户大约只激活了它 20% 的能力。不是技术门槛高,而是那些把 Hermes 从单一对话界面转变为全天候自驱系统的设置,藏在记忆持久化、时区校准、输出自动路由、失败容错这些你不太会主动检查的角落。一旦全部对齐,行为会有显著改善:定时任务在你预期的时刻准时触发,失败会自动重试并通知你,产出直接写进你的笔记库。
第一步:打好基础,避免静默故障
持久化记忆与正确时区是最容易被忽视的“静默故障”来源——前者决定了 Hermes 能否真正记住你,后者则让定时任务在你需要时执行。
步骤 1-1:确认记忆存储路径可持久化
使用绝对路径代替相对路径:
MEMORY_BACKEND=sqlite MEMORY_PATH=/Users/yourname/hermes-data/memory.db
验证方法很简单:询问 Hermes “你最老的记忆条目是什么”。若返回零条目,说明存储并未落盘。
步骤 1-2:修正调度时区
默认使用 UTC,但凡时区不是零度经线,都可能误点运行。
SCHEDULER_TIMEZONE=Asia/Shanghai
请根据所在城市填写 IANA 标准时区名,不要使用 EST、GMT+8 这类缩写。
步骤 1-3:为失败配置重试与通知
长期任务难免遇到接口抖动或文件路径错误,提前设置兜底机制。
SKILL_RETRY_ENABLED=true SKILL_RETRY_MAX=3 SKILL_RETRY_DELAY=300
第二步:让记忆与输出产生复利
前四组设置围绕记忆库的深度、检索策略、输出路由和目录监听展开。它们会彻底改变 Hermes 的记忆行为——从“每次新开对话”变为“每轮都站在上一轮的肩膀上”。
技能目录热加载
将 SKILLS_PATH 指向你 Obsidian vault 内的 skills 文件夹,同时开启 SKILLS_WATCH 和 SKILLS_AUTO_RELOAD。此后每次保存或更新 skill 都会即时生效,无需重启。
拆分上下文文件,告别巨型 CLAUDE.md
把 CLAUDE.md、项目状态、本周重点、表达风格、记忆规则拆成五份小文件,通过 CONTEXT_PRELOAD=true 和 CONTEXT_FILES 一次性加载。每次调整只需修改细小的条款,不必翻动整份巨型文档。
提升记忆检索深度
默认只回溯最近 5 条,在做周报或长期分析时几乎起不到作用。将深度上调至 20,策略改为 relevance,让真正相关的历史条目被准确拉取,而不是被时间戳截断。不同 skill 还可以单独覆写这些参数。
Hermes Agent v0.16 桌面版发布:183K Stars 开源 AI 代理迎来原生跨平台应用
从终端跃入桌面:Hermes Agent 的里程碑时刻
Hermes Agent v0.16.0 携“Surface Release”代号正式亮相,最大的变化是首次推出了原生桌面客户端。这个在 GitHub 上斩获 183K Stars 的开源 Agent 项目,从此告别单一终端交互,转变为覆盖 macOS、Windows、Linux 三端的独立应用。
拥有如此高的人气,是因为 Hermes 并非普通的自动化脚本,而是一款定位为可独立运行、持续进化的智能代理框架。它内置记忆系统、工具链、技能市场(Skills Hub),可对接 50+ 模型供应商,并原生支持 Telegram、Discord、微信等消息平台作为交互界面。以前,所有操作都得通过命令行(CLI)或终端界面(TUI)完成,对非技术用户来说门槛极高。这一次,桌面端彻底扫清了这一障碍。
v0.16 “Surface Release”的诞生:一周内狂飙的桌面应用
6 月 5 日发布的 v0.16.0,内部代号“Surface Release”。从 v0.15.2 至今,社区累计完成 874 次提交、542 个 PR 合并、399 个 Issue 关闭,背后有 170 位贡献者的心血。但所有数据都指向一个主角:Hermes Desktop 原生桌面应用。
这款桌面端基于 Electron 打造,其核心开发仅在一周内就通过 100 个 PR 和 159 次提交拼装完成。从此,用户无需再面对枯燥的终端窗口、记忆命令行指令或快捷键——它就是一个标准桌面软件:有专属图标、可调节窗口和完整的菜单栏,安装即用。
桌面端带来的六大体验变革
▸ 真正的原生安装 — 提供 macOS DMG、Windows Setup 以及 Linux 的 DEB/RPM/AppImage 包,内置自动更新,装完即刻就绪。
▸ 拖拽文件直传对话 — 想分享文件?直接拖进聊天区即可;剪贴板中的图片也能粘贴,再也不用折腾文件路径。
▸ 状态栏一键切换模型 — 桌面底栏即可换用不同模型,告别命令输入。
▸ 同一窗口运行多 Profile — 不同配置的 Agent 实例可并行存在,并支持通过 @session 互相引用。
▸ 连接远程 Gateway — 桌面端既能本地运行,又可指向远端的 Hermes 服务器,通过 OAuth 或用户名密码登录,走加密 WebSocket。
▸ 完整简体中文界面 — 桌面 UI 已完整汉化,在设置中一键切换语言。
Hermes Agent 自动化深度实践:10招让你每周省下15小时

数据显示,90%的用户仅停留在启动层进行即时问答,而Hermes Agent真正的价值在于支持全天候后台值守(24/7)和自动化调度,每周能为你节约超过15小时。
- 你的Hermes用法可能只触及表层
很多人对Hermes的使用仅仅停留在“打开对话窗口—输入问题—等待回复—关闭会话”这四个步骤。这样一来,只有模型被直接调用,而那些不太显眼却极具价值的特性——Cron调度、Webhook触发、并行子代理、后台持久会话、状态看板以及技能脚本——全被晾在一旁。真正的分水岭不在于提示词的好坏,而在于运行架构的差异。常见问题包括频繁手动检查导致的人力消耗、信息延迟以及上下文的碎片化。破解之道是充分利用Hermes内置的调度、事件触发、任务隔离和持久化机制,将“人工踩油门”的模式转变为系统自动值守。
- 用 /goal 指令取代孤立提问,驱动自主任务执行
普通提示往往只求一次答案,而 /goal 命令则为任务划定完整边界,推动代理自驱动地完成目标。该命令包含四要素:结果、来源、约束和可交付物。在“结果”中要说清任务完成的标准,防止目标漂移;“来源”应指定工具、文件路径、目录或URL,切勿依赖代理记忆;“约束”可以限定文件格式、调用次数、风格规则或成本上限;“可交付物”则定义最终产出,比如文件名、JSON schema 或提交位置。如果你还不懂如何设计目标结构,可以先让Hermes向你提三个问题,再依据回答生成最强版的 /goal。
- 把重复工作自动化:利用时间触发器实现定时任务
Cron 是 Hermes 在后台释放效率的引擎,用以取代人工定时轮询。你无需记忆繁琐的 crontab 表达式,直接用日常语言描述周期即可。典型场景包括每日早晨汇总简报、每小时检查 GitHub 通知、每周归档线上会议纪要;这些任务全不用点“开始”。要让 Cron 真正见效,需注意两点:任务本身应短小且可中断,输出必须指向固定落点,例如发送到 Telegram、写入文件或推入特定看板列。避免将 Cron 任务设计成巨无霸,否则失败一次就需要从头重跑整个批次。
- 借助 Webhook 将外部事件转化为内部执行流程
Cron 依赖时间推进,而 Webhook 靠事件驱动。无论是 Notion 卡片、GitHub PR、表单提交还是第三方告警,只要它们能在状态变更时发出 HTTP 请求,Hermes 网关就能接收并立即启动 /goal。这特别适合“一旦发生就必须处理”的动作,如产品缺陷自动收集上下文、新 PR 执行检查清单、客户工单自动生成摘要。一个有效的工作模式是:事件触发后,Hermes 先根据卡片或工单的元数据提炼要点,经过格式校验后发送结果。其实质是将人工的“看到再处理”变成系统化的“到达即分流”。
- 用多话题与隔离空间化解并行任务冲突
在同一个会话中塞入过多任务,首当其冲的代价是上下文冲突。Hermes 支持多种隔离手段:Telegram 不同话题、指定目录作为工作区、多组配置文件以及看板列结构。每一条隔离通道都将“外来上下文”拒之门外,防止任务之间相互污染变量、路径或模板。如果你常常并行处理内容策划、代码审查和竞品跟踪,至少应分出两条职责链;每条链内部可再细化,但绝不可共用同一上下文。越早隔离,后续重排、监控与复盘的成本就越低。
- 利用看板将任务推向可追踪状态流
Hermes 内部的每项任务均可映射至看板,经历“待处理”、“进行中”直至“关闭”的状态流转。这样你便无需靠记忆追踪任务状态,也不必翻找聊天记录,只用一个固定视图便能掌握全局。看板尤其适用于多用户协作或自身拥有多个代理实例的场景。它还能帮你揪出两类隐疾:卡了太久的僵尸任务,以及看似未被阻塞却停滞不前的任务。前者需要重新指派,后者则要明确写入预期。
- 启用 Dashboard 与统一设置入口,削减频繁切换的摩擦
Hermes 自带的 Dashboard 能够在一个页面内呈现配置文件、定时任务、技能与看板状态;统一设置入口则通过 OAuth 授权同时接通模型、工具网关与聊天连接。这些集成会省去逐项核查配置的繁琐,也让你在出现故障时能迅速定位是权限、模型还是网关的问题。别小看初期的摩擦:多花十分钟对齐 Dashboard 与 Provider,此后每一次新任务都能避免一个易漏的检查点。
- 用并行子代理分担多源头信息收集
让一个主代理同时啃下多份数据集,结果多半是注意力稀释和上下文负载飙升。此时最佳方案是采用“调度器加工人”架构:将主代理拆分为多条子代理,各自在隔离上下文中搜索、汇总、生成摘要,最后将精简结果回传主线程。常见的例子是:一条子代理抓取社交媒体热度,一条分析历史表现,一条追踪竞品动态,主代理再将三份摘要合成为一份建议。将这种结构固化为模板技能,远比每次重新搭建来得快。
- 把流程固化为可执行 Skills,一次编写到处复用
Skills 是存放在 ~/.hermes/skills/ 下的可执行 SOP。定义好触发词、核心规则与步骤后,只要有同类请求,代理便自动加载执行,你无需每次都重复切分数据、检验格式、写入文件等相同操作。Skills 的好处在于可复现、可审查、可升级。如果团队共享同一个“内容发布 Skill”,风格与质量管控就能一次维护、全员受益。验证闸门、保护区与版本迭代正是 Skills 长期可用的关键。
Hermes+飞书CLI:打造X平台内容自动运营飞轮,AI工作流实战指南
今天参加了飞书举办的线上AI Builder分享会,收获颇丰。最近我一直在探索如何用Hermes与飞书CLI搭建一套专属于X平台的内容运营系统。简而言之,就是让智能助手帮我完成选题挖掘、账号分析、爆款内容整理、改写建议生成,并自动将结果同步到飞书多维表格中。我只需要专注于三件事:审核、调整、发布。跑通这套流程后,我才真正体会到飞书CLI的强悍之处——它能让普通人毫不费力地把AI助手接入自己的日常工作流。
我的飞书CLI实践:三步搭建内容运营流程
目前我将主要精力放在X平台的内容运营上,想看看自己能用多长时间把它做起来。得益于Grok与Hermes的打通,现在通过Agent直接在X上搜索帖子、分析账号、梳理互动策略,都变得非常顺手。
我的常规操作流程只有三步:
- 先用Grok在X平台检索爆款内容和高价值账号。
- 再用Hermes对这些内容进行深度分析。
- 最后通过飞书CLI,将有价值的数据写入飞书多维表格。
这样一套下来,选题方向、目标账号、爆款样本、改写思路、最佳发布时间……这些关键信息全部都能沉淀在表格里。所有内容都有记录,所有判断都有依据,所有复盘都有抓手。
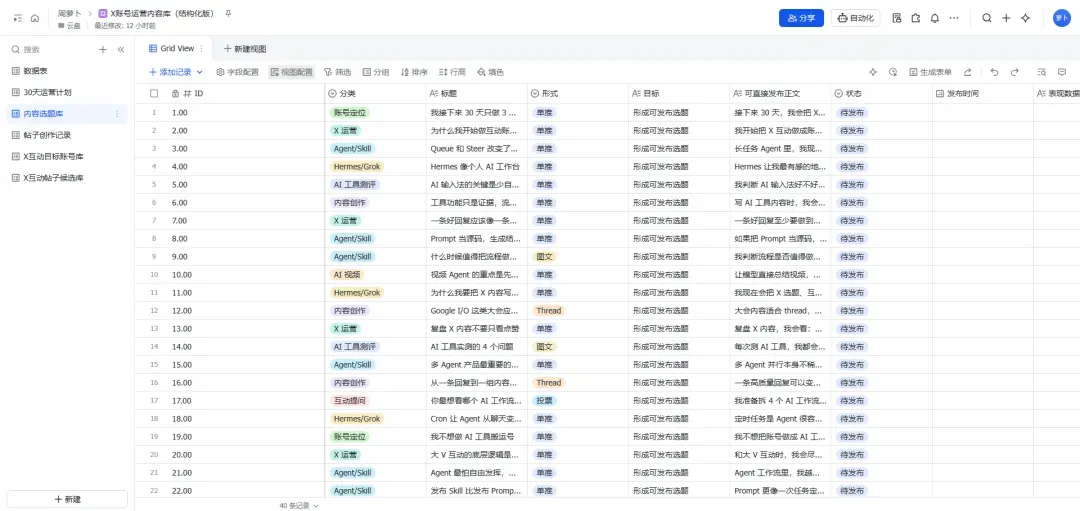
这才是飞书文档真正适合作为内容中台发挥作用的地方。
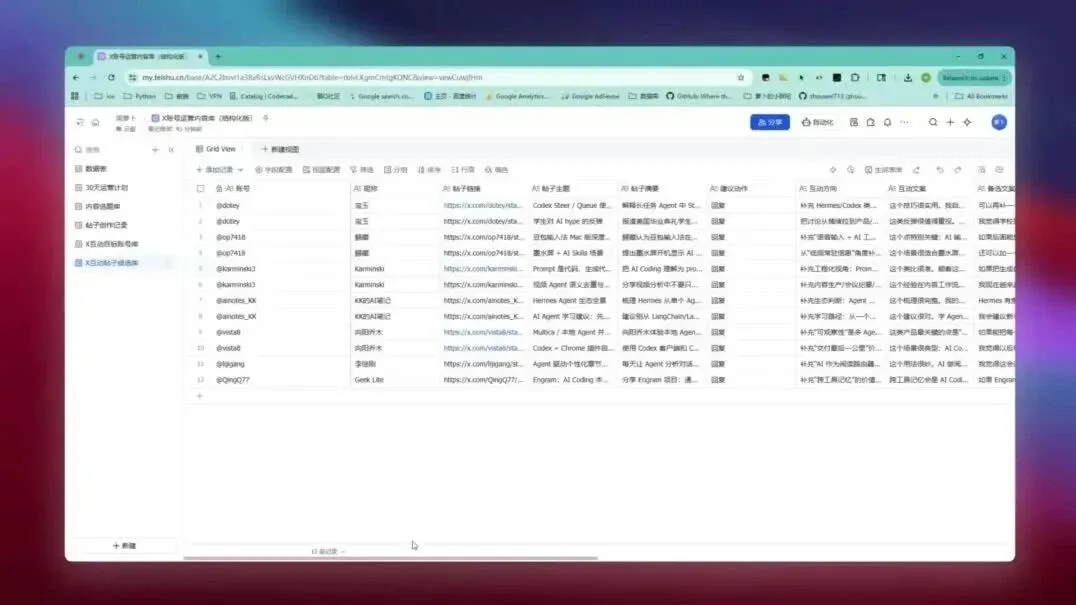
Agent操控飞书文档:复盘自动化与画板可视化
更令人惊喜的是,飞书CLI现在可以让Agent以极顺畅的方式读写飞书文档和多维表格。例如,我可以直接让Hermes分析某个X账号近期的表现,并把结果自动回写到飞书文档里,甚至直接生成一份完整的复盘报告。

我只需要给出一个指令,后面的结构框架、内容总结、数据表格、行动建议,它都可以自动整理出来。这一点实在太实用了。很多时候,我们并不是真的缺数据,而是缺一个能持续复盘的习惯。现在Agent自动把数据拉回来,再生成一份结构化报告,复盘这件事立刻变得轻松了许多。
这次飞书CLI还有一个我特别喜欢的功能——画板。利用画板,Agent可以直接在文档中插入可视化图示,把原本密密麻麻的文字流程瞬间变成清晰的结构图。比如,将整个内容飞轮的运转逻辑用画板呈现出来,就直观多了。
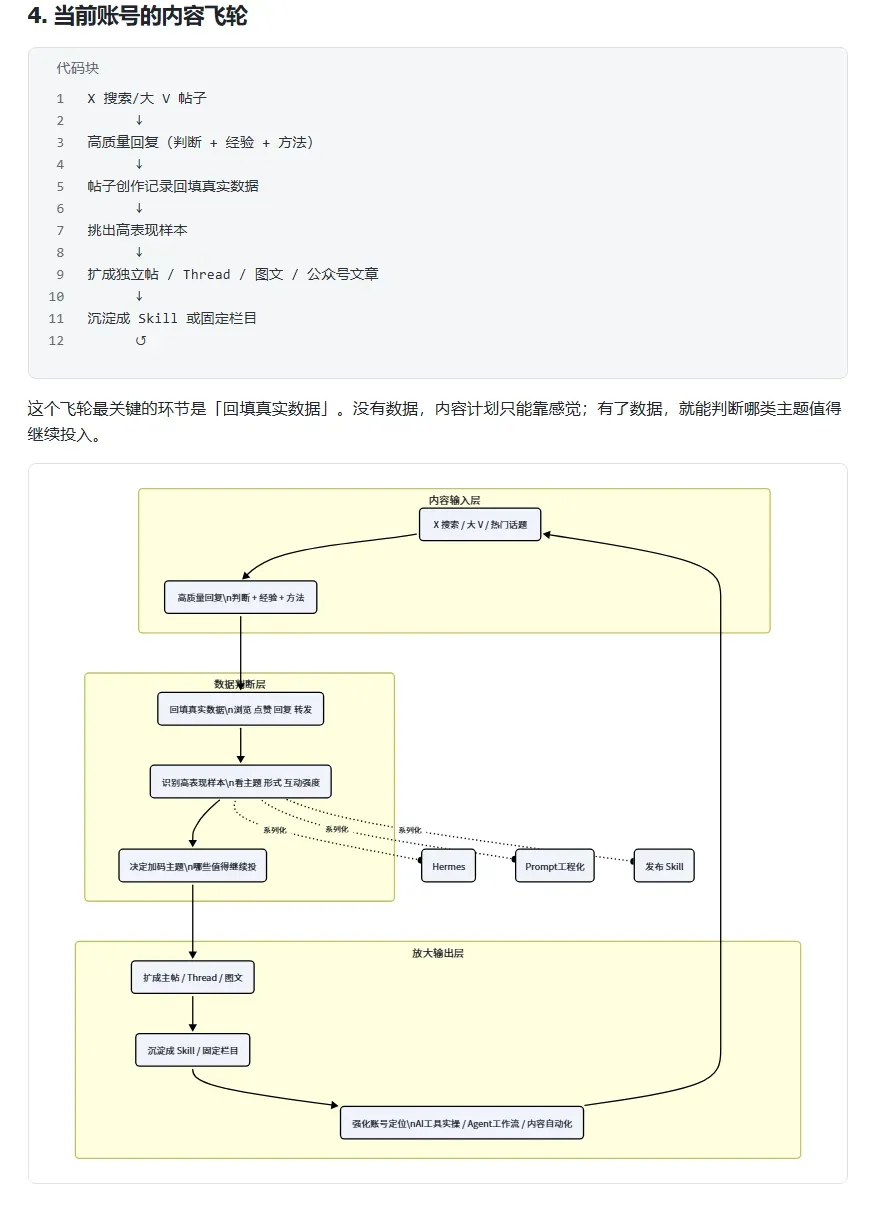
还有内容整改建议,用画板分类展示后,执行起来也更条理分明。
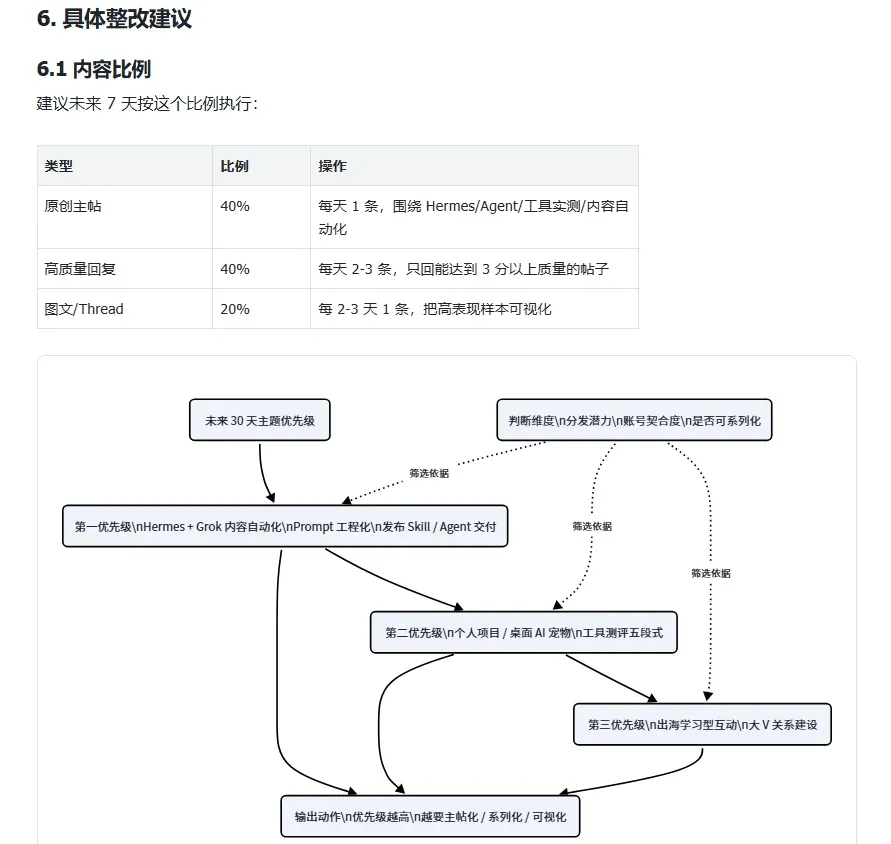
如果只是一堆文字,理解起来难免会绕来绕去,但换成画板之后,整个执行链路一下就通了。画板的核心价值,就是把复杂的流程变成一张任何人一眼就能看懂的图。
Claude Code集成飞书:远程操控AI编程的新姿势
分享会中还有一个让我非常兴奋的项目——张咋啦老师开源了一个能把Claude Code接入飞书的方案。对我而言,日常使用最多的两类AI工具就是Hermes和Claude Code/Codex。Hermes本身自带APP接入渠道,我早已通过飞书机器人进行各种操作,但对于Claude Code,之前仍然得老老实实坐在电脑前才能使用。没想到这次竟然有了意外收获,找到了可以在任何地方指挥Claude Code写代码的方法。
安装过程极其简单,只需一条命令,再绑定一个飞书机器人即可:
npm i -g lark-channel-bridge
安装完成后,执行以下命令启动,会弹出二维码,扫码后根据指引完成配置:
lark-channel-bridge start
然后就可以愉快地通过飞书和Claude Code对话了。

这种躺在床上随手指挥CC干活的感觉,终于我也体验到了。
结语:AI工作流的关键在于稳定承接
过去我们使用Agent,很多时候像是在体验一个新玩具:它会写东西、会查资料、会跑任务,看起来很酷炫。但真正要把它落到日常工作中,还差一个稳定、可靠的承接系统。飞书CLI补上的,恰好就是这一环。
- IM负责接收和分发任务。
- 云文档负责沉淀内容资产。
- 多维表格负责结构化数据管理。
- 画板负责流程可视化。
- Agent负责具体执行与持续优化。
这套组合拳下来,任何一个普通人都可以慢慢搭建起属于自己的AI工作中台。所以我越来越清晰地感受到,接下来真正有价值的能力,不是你会不会用某个AI工具,而是你能不能把它无缝嵌入到自己的工作流里,让它每天稳定地帮你干活。AI的真正终点,从来不是陪你聊两句;真正厉害的AI,是能一步步把你的生活和工作串联起来,稳稳地向前推进。
Horizon开源AI热点抓取工具爆火:4000+ Star,自动生成中英双语日报
每天早上打开 Hacker News,没刷几页就感到倦怠。Reddit 里关注的 subreddit 堆了几十条未读,Telegram 频道的消息更是直奔 99+。信息源不断膨胀,可真正值得细看的内容却越来越难寻。
Horizon就是来解决这个难题的。它是一款用 Python 构建的开源工具,能够从多个信息源自动采集新闻,完成去重、AI 打分与过滤,最终产出结构清晰的中英双语日报。

简单讲:你只需要关注结果,中间的苦活累活都由它包揽。
数据透视:热度惊人
这个项目目前在 GitHub 上已揽获超过 4000 Star、500 多条 Fork。主编程语言为 Python,采用 MIT 开源协议。
覆盖哪些信息源
Horizon 当前支持 7 类信息源,基本包揽了技术人员每日必刷的渠道:
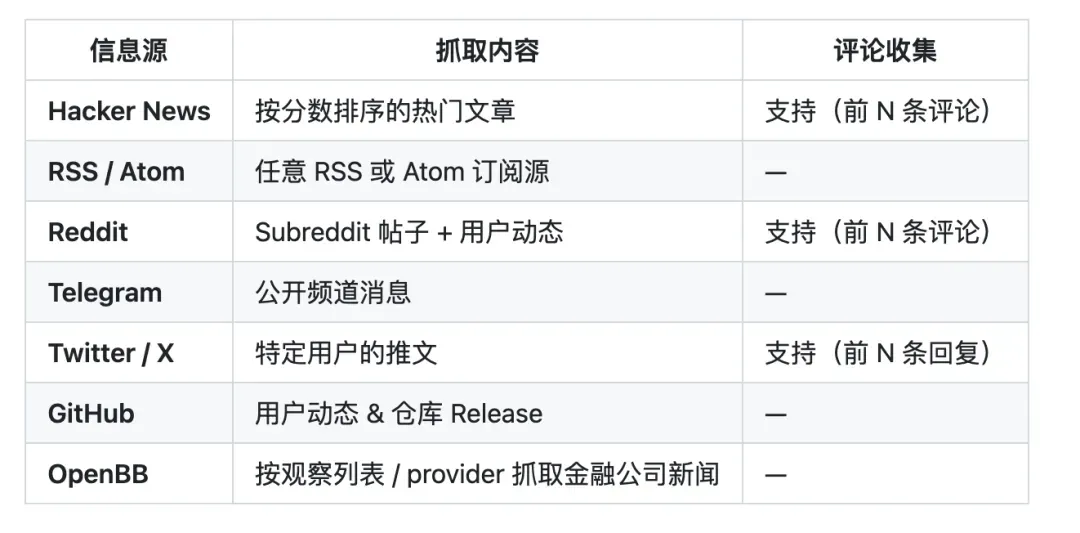
看得出,从技术社区到社交平台再到金融资讯,技术人员“日常必逛”的阵地几乎一网打尽。而且每个信源的抓取范围与评论条数都可以单独设定。
AI 智能评分:从筛选到精华
这正是 Horizon 与普通 RSS 阅读器的本质区别。
采集回来的内容不会一股脑儿全抛给你。Horizon 会依靠你指定的 AI 模型给每条内容打出 0–10 的分数,然后仅保留超过阈值的条目(默认 7.0)。拿到 9 分以上的内容会自动归入“Today’s Highlights”重点板块。
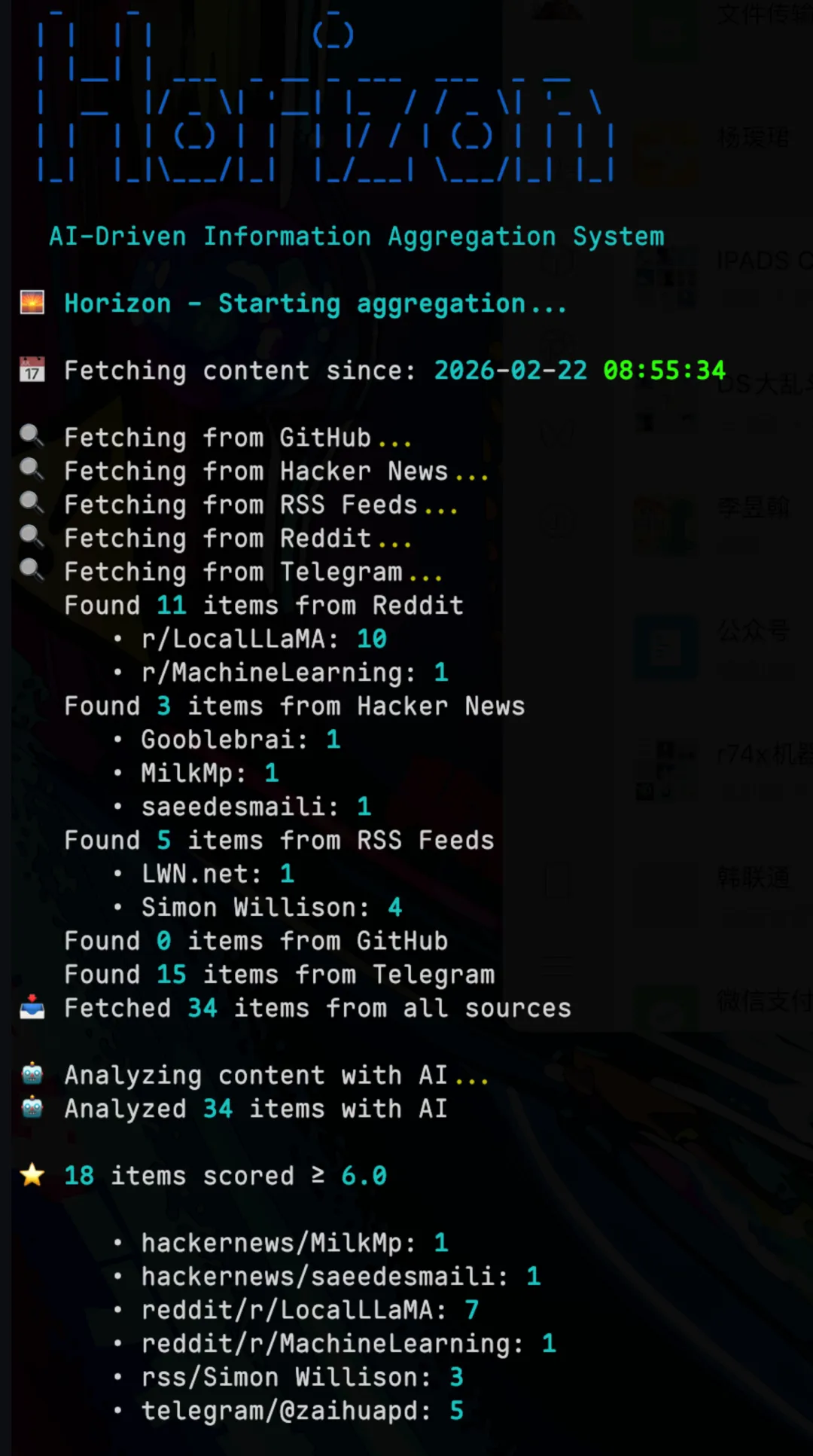
评分不止看标题热度。AI 会综合判断:这是否属于重大突破?有没有技术深度?对某个领域是否真正有价值?还是纯粹噪音与广告推广?

可接入的模型阵容很广:Claude、GPT、Gemini、DeepSeek、豆包、MiniMax,以及任何兼容 OpenAI 的 API。甚至还能自行指定 base_url,接入本地模型。
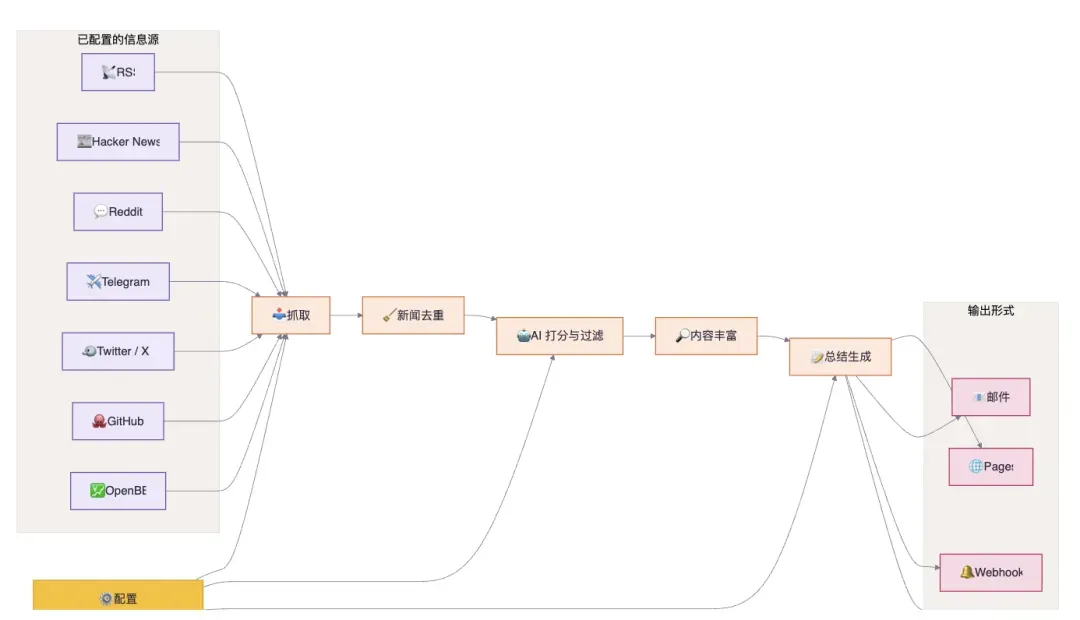
去重与背景加持
不同平台常常重复报道同一件事。在生成日报前,Horizon 会自动将指向同一故事或同一 URL 的内容合并,你不会看到三条重复的“GPT-5 发布”。此外,遇到不熟悉的术语、公司或项目,Horizon 会通过网络搜索补上背景解释。比如某条新闻提到一个冷门开源项目,日报中会自动附上一段“它是什么”的说明。
社区讨论也不落下
对于 Hacker News 和 Reddit 这类带有评论功能的信源,Horizon 不只是抓取正文,还会拉取热门评论并生成摘要。很多时候,一条高赞回复比原文更有价值——如果丢掉这些信息就太可惜了。