Ideogram 4.0 开源设计模型:9.3B参数,24GB显存,文字渲染超越80B级

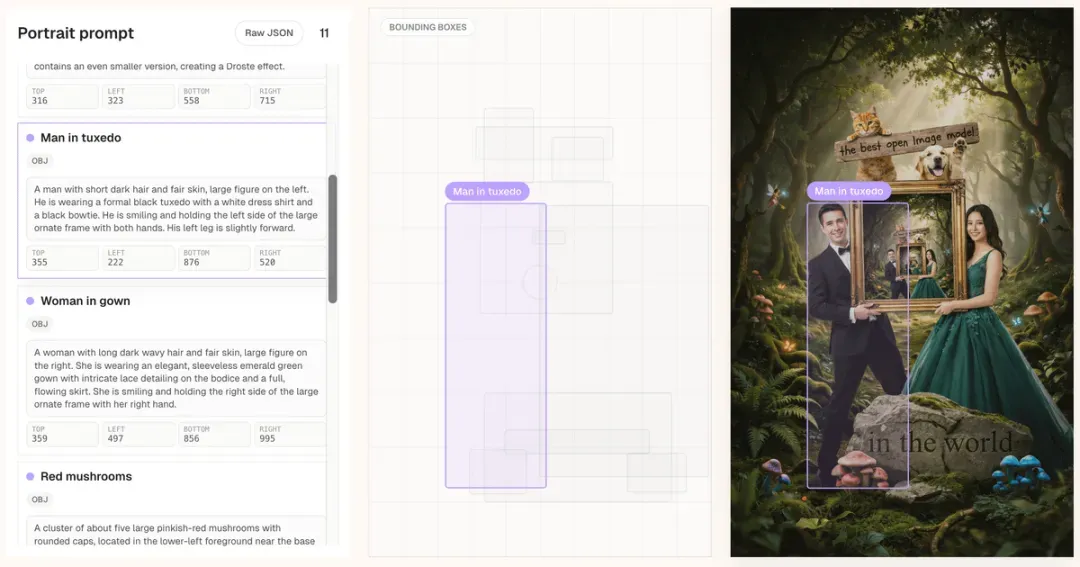
#Ideogram4 #开源图生模型 #DiT
凭借 9.3B 参数,Ideogram 4.0 展现出顶级设计生成实力,其图像内文字渲染能力甚至超越了某些 80B 参数的大模型,并且通过 JSON 结构化提示词,设计师能够精细调整构图、色彩与排版。经过 NF4 量化后,该模型仅需 24GB 显存即可在本地运行。
- 9.3B 参数量 | #1 开源设计模型 | 24GB 最低显存
Ideogram 4.0 是多伦多 AI 初创公司 Ideogram 推出的首个开源权重文生图模型,于 6 月 3 日正式上线。因其在文字渲染、版面精度和设计品质方面的出色表现,被社区公认为当前最强大的开源图生设计模型。
该模型并非基于任何现有模型的微调,而是完整的 Flow-Matching Diffusion Transformer(DiT),拥有 9.3B 参数、34 层 Transformer 结构,文本与图像 token 共享同一序列空间。正是这一架构选择,使其以仅 9.3B 的参数量,在文案渲染和排版控制等设计关键指标上超越了某些 80B MoE 架构的大模型。
整个管线分为四层:冻结的视觉语言编码器、处于训练状态的 DiT 主干、运行时的流匹配采样器以及同样冻结的 KL VAE 解码器。实际接受训练的仅有中间这 9.3B 参数的 DiT 模块,编码器与解码器则复用已有的预训练组件。
在文本编码方面,模型并未采用 CLIP 或 T5 等传统选项,而是选择了 Qwen3-VL-8B-Instruct 视觉语言模型。Ideogram 从该 VLM 的 13 个中间层抽取隐状态,并将它们拼接后送入 DiT,从而获得了远比单层 CLIP embedding 更丰富的语义理解。这也是它能够出色处理复杂排版指令的关键所在。
Java Integer 判等陷阱深度复盘:为什么 168≠168 差点引发生产事故?
前阵子组里来了个新人,我分配给他一个看起来非常简单的任务。
我们团队固定在每周四上线发版,按照惯例,上线前两天会进行集体代码评审。那次评审也顺利通过了——功能本身很直接,大家都没有太细看。
但从业这么多年,我一直保持着上线前再做一次独立代码审查的习惯,这个习惯确实救过不少次场。
就在最后一遍过代码的时候,IDEA 突然弹出一个智能提示,我当时心里就“咯噔”一下:

我心里很清楚,如果这次二次复查没有发现这个问题,后续的麻烦绝不是小事。正是这次经历促成了这篇文章的整理。
一个“简单”代码段的反直觉表现
各位 Java 开发者不妨先停下想一想:执行下面这段代码后,控制台会输出“不相等”吗?
public static void main(String[] args) {
Integer total = 168;
Integer count = 168;
if (total != count) {
System.out.println("不相等!!!");
} else {
System.out.println("相等!");
}
}
很多人第一反应就是:两个变量的值都是 168,那结果肯定是“相等!”才对。
然而真实的运行结果却是:
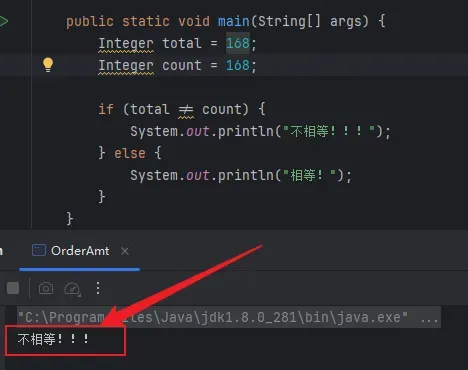
它直接打印了“不相等”。
这种现象背后的根本原因
这个问题其实反映了 Java 中一个常见的认知模糊点,不只是新手,一些有几年经验的开发者也可能会掉进去:
int是基本数据类型,使用==比较的是数值本身;Integer是包装类,属于引用类型,==比较的是对象的内存地址。
也就是说,即便两个 Integer 对象里面保存的数值一模一样,只要它们不是同一个实例,== 就会返回 false。
这个坑正好解释了上面代码中 total != count 成立的原因——两个 168 的 Integer 对象在内存里指向不同的地址。
更让人困惑的“相等”情况
再来看另一段看似几乎一样的代码:
Integer total2 = 100;
Integer count2 = 100;
if (total2 != count2) {
System.out.println("不相等!");
} else {
System.out.println("相等!");
}
猜猜这次会打印什么?
MiniMax M3新套餐值不值?6亿Token月付49元,全面对比告诉你答案
6月1日,MiniMax官方发布公告,正式推出新模型M3,同步启动了M3按量API限时7天的5折优惠活动。同时,平台还对Token Plan订阅套餐价格体系进行了全面升级,将原来的6种套餐精简为3种主流订阅方案。
MiniMax M3模型核心能力一览
M3是一款集前沿编程能力、1M超长上下文窗口以及原生多模态处理能力于一身的大模型,MiniMax官方宣称,它是目前市面上唯一能同时满足这三项要求的开源模型。

在编程能力方面,M3在SWE-Bench Pro测试中斩获59.0%的成绩,超越了GPT-5.5和Gemini 3.1 Pro,逼近Opus 4.7;在SVG-Bench上甚至反超Opus 4.7;在Agent评测Claw-Eval中同样拔得头筹。
单从跑分数据看,M3的进步毋庸置疑。但关键问题在于:在如今竞争激烈的市场格局下,这样的性能提升是否对得起它的定价?
国产模型竞品能力横向对比
把MiniMax M3放在国内顶级模型里,究竟处于什么水平?

对比结果表明,M3的59.0%得分虽然很有竞争力,但Qwen3.7-Max已在开发者社区投票的Code Arena中取得了1541分,超越了GPT-5.5和GLM-5.1;GLM-5.1则稳坐全球开源模型编程榜第一。M3在能力上并未明显甩开国内顶尖对手,价格反而上涨了不少。
新旧套餐对比:品种精简,价值升了吗?
将原来的六种套餐精简为三种,显著降低了用户的选择难度。Plus、Max、Ultra三档定位明确,分别面向个人开发者、日常专业用户以及重度高频使用场景,方便按需选择。
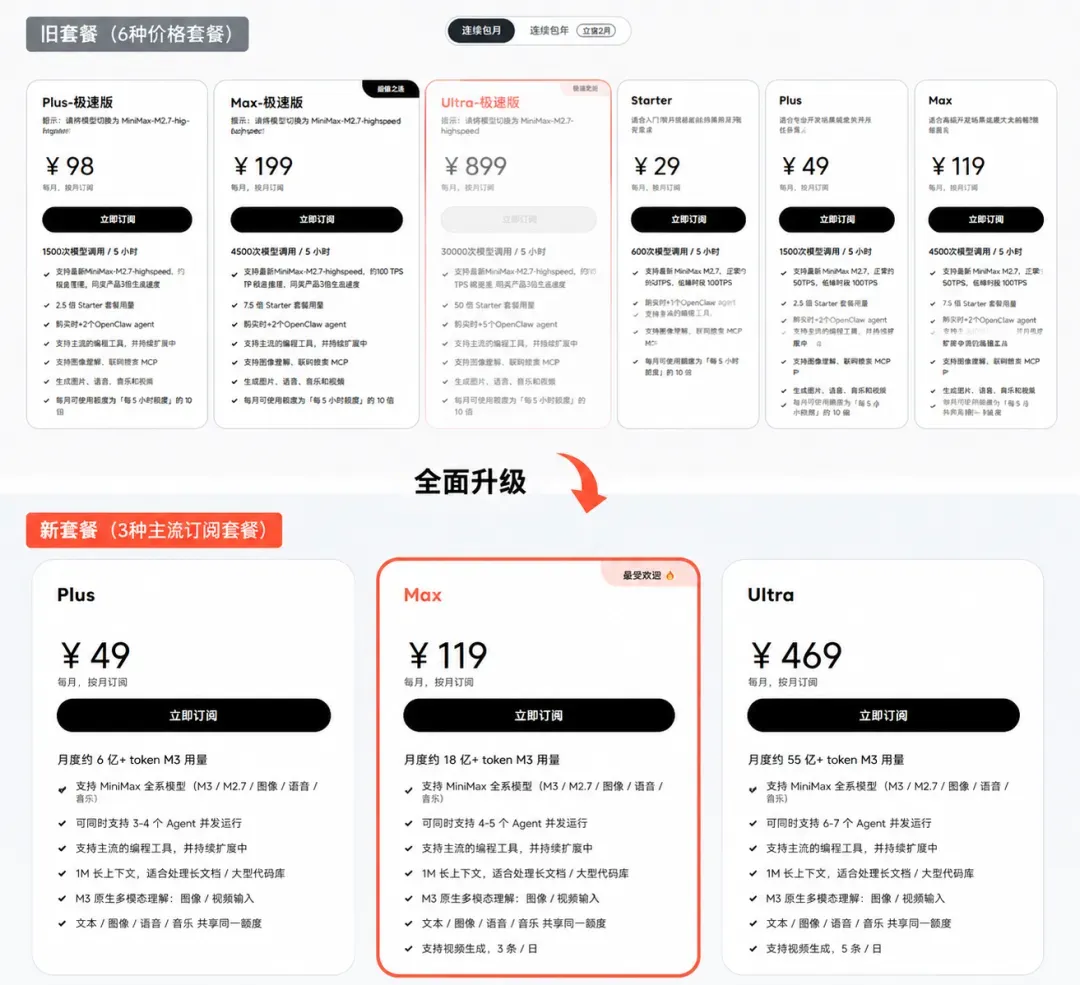
但核心问题来了:同样是¥49/月,用户要接受的改变是什么?
旧版Plus套餐(¥49)提供“每5小时1500次调用”,按照编程场景估算约合3.6亿Token/月。新版Plus套餐(¥49)则直接提供6亿Token/月。计费口径从调用次数转变为Token总量,但实际价值是否提升,还要结合具体使用场景来看。
M3 API限时5折:窗口期与长期性价比分析
5折体验真香,原价可能劝退:5折活动期是尝鲜M3的理想时机,一旦恢复原价,性价比将大幅缩水。
| 模型 | 输入价格 | 输出价格 | 缓存读取 |
|---|---|---|---|
| MiniMax-M3(≤512k,五折) | 2.10 | 8.40 | 0.42 |
| MiniMax-M3(≤512k,原价) | 4.20 | 16.80 | 0.84 |
| MiniMax-M3(>512k,原价,限量) | 8.40 | 33.60 | 1.68 |
| MiniMax-M2.7 | 2.10 | 8.40 | 0.42 |
| MiniMax-M2.7-highspeed | 4.20 | 16.80 | 0.42 |
🔹 M3五折后价格与M2.7完全一致(2.10元/百万输入,8.40元/百万输出)
🔹 原价恢复后,M3比M2.7贵一倍(4.20 vs 2.10)
🔹 超过512k上下文目前限量供应,价格翻倍(8.40/33.60)
全新Token Plan与市场竞品一览
下图展示了全新Token Plan与市场上主要竞品的套餐对比:

到底值不值?分场景购买指南
| 你的情况 | 推荐 | 理由 |
|---|---|---|
| 日常AI编程,月用量几千万tokens | MiniMax M3 Plus套餐 | 6亿Token,47倍于按量,多模态白送 |
| 想尝鲜M3,但不确定用量 | 7天内用五折API | 五折价与M2.7持平,灵活试水 |
| 追求无限制、生产环境 | 小米/DeepSeek API | 无套餐限制,永久低价 |
| 需要视频生成 | MiniMax Max套餐 | 每日3条视频,业内唯一 |
| 轻度用户(月<1000万) | M3五折API | 用多少付多少,不浪费 |
最终建议:
🔹 日常重度AI编程(月消耗超2000万Token):首选MiniMax M3 Plus套餐,性价比碾压。
🔹 无限制生产环境需求:推荐小米或DeepSeek API,缓存命中价格低至0.025元/百万Token。
🔹 仅想尝鲜M3:利用7天5折API窗口,灵活试水。
NAS部署Tomcat实战:轻松运行Java Web项目(WAR/HTML/JAR全解析)
Apache Tomcat 是一款开源、免费的轻量级 Java Web 应用服务器,主要用于运行 Servlet 和 JSP 程序,常被用来部署 Java 网站和接口服务。简单来说,别人用 Java 开发并打包好的程序,放到 Tomcat 里就能直接在服务器上跑起来。
利用 Docker Compose 快速安装 Tomcat
以下是推荐的 Compose 配置:
services:
tomcat:
image: tomcat:9.0
container_name: tomcat
volumes:
- ./webapps:/usr/local/tomcat/webapps
ports:
- 8080:8080
restart: unless-stopped
几个关键参数说明(更多细节建议查阅官方文档):
- 镜像标签
9.0:适配 Java 8,大多数企业项目和旧系统都采用这一版本。 - 容器内路径
/usr/local/tomcat/webapps:默认的应用部署目录,所有要运行的项目文件最终都要放到这里。
初次访问与 404 现象
服务启动后,在浏览器输入 http://NAS的IP:8080 就能打开 Tomcat 页面。
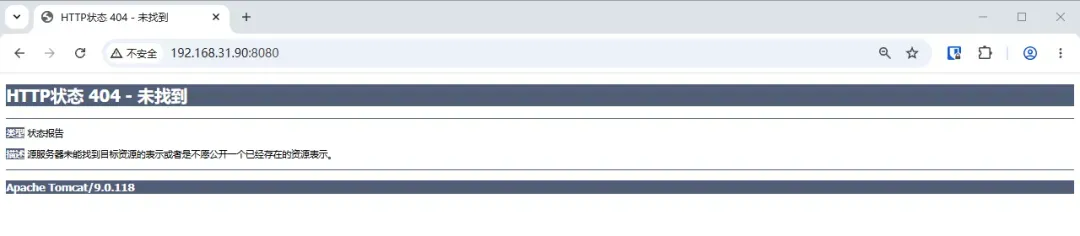
如果看到 404 错误,这是正常情况。因为此时
webapps路径下还没有ROOT目录,Tomcat 找不到默认页面,所以返回 404。

如何恢复官方演示 Demo
Tomcat 镜像里其实内置了一个演示应用,如果想让首页出现熟悉的欢迎画面,可以按下面的步骤操作。
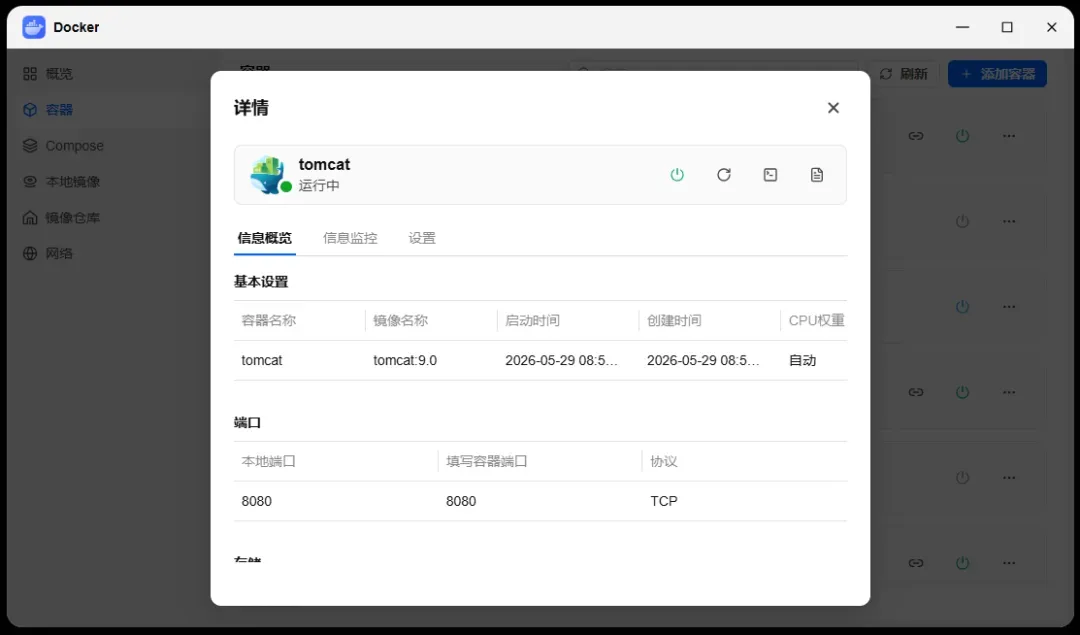
首先进入 Tomcat 容器的终端。
NAS一键部署MicroWARP:轻量WARP SOCKS5代理实现Docker网络自由
为什么你的NAS Docker应用总是连不上?
在NAS上运行Docker时,常常会碰到这些让人头疼的问题:
- 拉取镜像如同蜗牛,甚至直接失败;
- 需要访问海外API的容器,时不时断线;
- 服务看起来在正常运行,但更新、同步、订阅以及对外接口调用的速度与稳定性都大打折扣。
过去我曾分享过Mihomo的部署方案,它适合做全局的代理管理和规则分流。但对于大多数NAS用户来说,需求远没有这么复杂——只是想让某几个特定的Docker应用能够顺畅地下载镜像、更新订阅或访问外部API,而不是改变整台NAS的网络架构。
有没有更轻量的办法?今天要介绍的MicroWARP,就是这样一个方案:通过Docker在NAS上运行一个WARP SOCKS5代理,按需为特定的容器提供干净的出口网络。简单说,它不搞复杂的分流规则,只专心做好“落地出口”。
⚠️ 安全提醒:此代理服务默认仅供本地使用。如果必须开放到公网,请务必设置复杂的用户名和密码,避免被他人滥用。
为什么选择MicroWARP?
完整项目仓库为 ccbkkb/MicroWARP,可通过GitHub搜索获取。如果你需要其他平台的版本,可以切换到仓库的next分支自行构建,但记得准确指定镜像Tag。
市面上常见的WARP镜像(比如 caomingjun/warp)大多依赖Cloudflare官方的 warp-cli 守护进程,这通常会带来约150MB以上的内存占用,且在高并发场景下容易出现性能瓶颈。
MicroWARP 则采用了完全不同的底层设计:
- 内核级WireGuard:直接利用Linux原生内核态的
wg0接口处理流量,CPU损耗几乎为零。 - 轻量服务组件:核心部分由小型C语言程序构成,长时间运行资源消耗极低。
- 极低内存占用:高并发下内存用量依旧控制在5MB以内(实测常驻仅800KB左右),特别适合资源受限的设备。
- 原生兼容Tailscale:智能保留回程路由,避免全局接管造成的非对称路由黑洞,与异地组网直连完全兼容。
- 多架构支持:原生支持
amd64和arm64,完美覆盖各类ARM平台的NAS。
部署流程
下面以威联通NAS为例,通过Docker Compose的方式完成MicroWARP的部署。
完整的 docker-compose.yml 配置如下:
services:
microwarp:
image: ghcr.io/ccbkkb/microwarp:latest
container_name: microwarp
restart: always
ports:
- "0.0.0.0:1080:1080" # 监听所有IP
cap_add:
- NET_ADMIN
- SYS_MODULE
sysctls:
- net.ipv4.conf.all.src_valid_mark=1
environment:
- SOCKS_USER=ydxian # 如果监听任意IP,建议设置用户名
- SOCKS_PASS=qnap1234 # 务必配置强密码
volumes:
- /share/Container/microwarp/warp-data:/etc/wireguard
logging:
driver: "json-file"
options:
max-size: "3m"
max-file: "3"
作者还提供了一些进阶环境变量,可按需添加,例如用于自定义WARP端口或开启调试日志等。
Open Design:40K Star的开源设计神器,免费替代Claude Design,本地运行不依赖云端
4 月 17 号,Anthropic 推出了 Claude Design——只需一句需求描述,就能直接生成可交互的 HTML 设计稿。无需 Figma,不用 Photoshop,甚至不需要任何设计基础。
设计圈瞬间沸腾。
但热度过后,现实泼了一盆冷水:闭源、仅限付费用户、数据必须上传 Anthropic 云端、模型锁定为 Opus 4.7、不支持自托管、不能更换模型。
仅仅十一天之后,nexu.io 创始人 Tom Huang 在 GitHub 上发布了 Open Design。五天冲到 18K Stars,目前已经来到 40.8K Stars、4.6K Forks。采用 Apache-2.0 协议,完全免费。
它没有重新造一个 Agent,而是巧妙地把你电脑上现有的编码 Agent,直接转化为设计引擎。
Open Design 是什么

简单来说:给 Claude Code、Codex、Cursor、Gemini 这类 CLI 工具包上一层设计工作流,让它们像专业设计师一样输出网页原型、PPT、移动端界面和视觉物料。

可以把它看作“Claude Design 的开源复刻”,但架构迥异。Claude Design 是一个封闭的 SaaS 产品,Open Design 则运行于本地,以 daemon + web 应用的形式,使用你自己的 API Key,驱动你自己的 Agent,数据始终不离开硬盘。

技术栈基于 Next.js 16 + Express + SQLite,既可以部署到 Vercel,也能完全在本地运行。
OpenAI Codex全员AI工作台登场:六大角色插件、Sites建站与Annotations精修,9亿用户零代码拥有AI员工
2026年6月2日深夜,OpenAI的一场直播完全打破了外界的预期。没有新模型发布,也没有花哨的PPT,唯一的主角是Codex——可这一次,它已不再是程序员的专属玩具。
一、500万周活背后,一个反直觉的信号
先来看一组 OpenAI 官方公布的数字:
| 指标 | 数据 | 来源 |
|---|---|---|
| Codex 周活跃用户 | 500万+ | OpenAI 官方公告 2026-06-02 |
| 较年初增长倍数 | 8倍 | 澎湃新闻/智东西 2026-06-03 |
| 非开发者占比 | 约20% | OpenAI 官方博客 2026-06-02 |
| 非开发者增速 vs 开发者 | 3倍以上 | OpenAI 官方博客 2026-06-02 |
最后两行让我愣了一下。
五分之一的Codex用户根本不写代码。 他们来自分析师、营销、运营、设计、研究、投资和投行等岗位。更令人吃惊的是,这群非开发者用户的增速是开发者的3倍还多。
这意味着什么?
Codex早已不是“程序员专用工具”。它正快速蜕变成一台全员AI工作台。
而这,恰恰就是6月2日直播中 OpenAI 一口气放出三大更新的底层逻辑。
二、三大更新,一次性补齐关键短板
更新一:六大角色专属插件——零代码打造“AI员工”
OpenAI一次发布了六款角色插件,每一款都打包了该岗位日常工作所需的应用、技能、指令和工作流:
| 插件名称 | 目标用户 | 集成工具 | 核心能力 |
|---|---|---|---|
| 数据分析 | 分析师、业务团队 | Snowflake、Databricks Genie、Hex、Tableau | 数据探索、指标归因、自动生成报告和仪表盘 |
| 创意生产 | 营销、创意团队 | Figma、Canva、Shutterstock、Picsart、Fal | 将创意简报转化为可审阅物料,制作广告变体 |
| 销售 | 销售团队 | Salesforce、HubSpot、Slack、Outreach、Clay、Rox、Actively | 锁定高优先级客户、会前准备、跟进、CRM更新、识别流失风险 |
| 产品设计 | 产品、设计团队 | Figma、Canva | 从想法到原型、交互流程审查、静态截图→可交互原型 |
| 公募股权投资 | 基金经理、分析师 | Moody’s、Daloopa、Datasite、FactSet、LSEG、S&P、PitchBook、Hebbia | 财报审阅、公司对比、信号追踪、投资论点验证 |
| 投资银行 | 投行分析师 | 可信数据提供商 | 路演材料、可比公司分析、尽调→建议输出 |
关键数据:6大插件、62款应用、110项技能,全部无需编写代码即可使用。
OpenAI合并ChatGPT与Codex:桌面超级App登场,9亿用户解锁全栈AI办公
一、一则快讯引爆AI圈
6月4日早晨6点,财联社推送的一条简短快讯震动业界:“OpenAI 据悉正计划将 Codex 与 ChatGPT 合并。”不过四十多字,却让整个技术社区沸腾起来。为什么?因为在48小时前的深夜,OpenAI才刚举办了一场面向企业的专题直播,发布了Codex三项重磅更新——角色插件、Sites建站工具和Annotations精确批注。外界原以为这只是一轮普通的版本迭代,直到直播尾声,联合创始人兼CEO Sam Altman突然揭开底牌:
Codex将在数周之内,整体融入ChatGPT。
这不是在ChatGPT里新增一个入口那么简单。这意味着三条原本各自独立的产品线——ChatGPT(对话)、Codex(任务执行)、Atlas浏览器(环境感知)——将被熔铸为一款桌面超级应用。届时,近10亿ChatGPT存量用户将可以直接在统一界面中启用完整的AI办公能力。
二、三个月前的备忘录:Code Red警报
时间拨回2026年3月19日。CNBC独家报道,OpenAI应用副总裁Fidji Simo发出内部备忘录,宣布ChatGPT桌面版、Codex编程平台与Atlas AI浏览器将整合成一款统一的桌面超级应用。一位女发言人随后证实该计划,并强调:“新超级应用将让内部团队协同更紧密,也将帮助研究部门更快把成果转变为产品。”联合创始人Greg Brockman亲自督战。
然而外界并不清楚,这次整合的急迫性早已到了窒息的程度。
代号“Code Red”
2026年初,Anthropic旗下的Claude Code正以令人难以置信的速度蚕食开发者市场:
| 指标 | Claude Code | 时间节点 | 来源 |
|---|---|---|---|
| 年化收入(ARR) | 超过25亿美元 | 2026年2月 | 新浪财经/招银国际 |
| 市场份额 | 54% | 2026年Q1 | 新浪财经/Ramp报告 |
| 周活跃用户 | 连续翻倍 | 2026年1月起 | 36氪 |
| Anthropic总ARR | 440亿美元 | 2026年5月 | 投中网/财联社 |
| 企业客户使用率 | 34.4% | 2026年4月 | 腾讯新闻/Ramp报告 |
54%的市场份额。Claude Code一度独占了AI编程工具的半壁江山,远超GitHub Copilot和Cursor。更致命的是,Anthropic在2026年Q1录得48亿美元营收,Q2预测高达109亿美元——几乎一个季度就翻一番,估值逼近万亿美元,势头有望压过OpenAI。OpenAI随即拉响了内部的“Code Red”警报。
三月时的Codex:仅160万周活
据虎嗅报道,合并计划启动之时,Codex的周活跃用户数仅有大约160万。作为2026年2月才推出桌面客户端的产品,这个增速并不算差,但和Claude Code的差距令人焦虑。而且OpenAI面临一个更深层的困境:用户不知道该选哪个产品。
“企业最迫切的需要是把所有产品和服务融合成统一的内部工作流。”Sam Altman在6月2日的直播中这样说道。此前,ChatGPT负责闲聊,Codex处理编程,Atlas负责浏览网页——三者互不联通,上下文断裂,用户时常困惑“这个任务该点开哪一个”。合并是唯一的出路,而Code Red的压力让必然变成了刻不容缓。
三、90天极速冲刺:从160万到500万周活
随后90天里,OpenAI以惊人的速度推进Codex能力建设和用户增长:
四月:补齐基础能力
- 内置浏览器正式上线
- 开放计算机操作(Computer Use)能力
- SSH远程连接功能
- 代码审查大幅增强
五月:拓宽使用场景
- 移动端App上线,手机变为远程遥控器
- Appshots截图功能问世
- 目标模式(Goals)支持长时间任务
- 锁屏状态下也可远程控制
- Chrome扩展程序发布
6月2日:直播三连更与合并官宣
- 六个角色专属插件,覆盖62款应用、110项技能
- Sites一键建站
- Annotations精准批注
- 正式宣布与ChatGPT合并
增长数据如下:
OpenCode + GitHub Actions:完全自主的 AI 代码审查流水线搭建指南
PR 提交两分钟后,AI 即可返回一份全面的代码审查报告。这并非遥远的未来,而是今天就能落地的实践。
还在为每个 PR 手动审查代码而烦恼?还在犹豫是否要把仓库权限交给第三方 AI 审查工具?本文将带领你用 OpenCode 与 GitHub Actions 构建一条完全自主可控的 AI 代码审查流水线——无需交出仓库权限,不绑定任何平台,边际成本几乎为零。
为何要在 CI 中引入 AI 代码审查
传统持续集成与交付的局限性
传统的 CI/CD 管道已经解决了自动编译、自动测试和自动部署等问题,但在代码审查环节,大多数团队依然依赖人工。
典型的人工审查流程:
开发者提交 PR → 等待同事空闲 → 同事粗略浏览 → LGTM → 合并
↑ ↑
时间成本高 质量无法保证
传统 CI 在代码审查方面存在明显的短板:
| 局限 | 说明 |
|---|---|
| 静态分析缺乏智能 | SonarQube、ESLint 等工具仅能识别模式化问题,无法理解业务逻辑。 |
| 人工审查成为瓶颈 | 团队规模较小时,审查拖慢进度;规模扩大后,审查质量良莠不齐。 |
| 审查标准不统一 | 不同审查者的关注点各异,缺少一致的质量基线。 |
| 响应延迟 | 跨时区协作时,PR 可能等待数小时甚至数天才能得到反馈。 |
AI 辅助审查带来的价值
AI 代码审查并非要取代人工,而是充当一道 7×24 小时在线、标准统一的第一道质量关卡:
引入 AI 审查之后:
开发者提交 PR → AI 立即审查(< 2 分钟)→ 自动评论反馈 → 人工最终决策 → 合并
↑ ↑
即时响应,全天候 开发者提前修复问题
AI 审查能够做到:
OpenCode Zen 免费模型深度评测与 CC Switch 接入教程:DeepSeek 等五大模型实测体验
在AI大模型快速迭代的今天,如何不花一分钱就能用上当前最主流的国产开源模型?OpenCode Zen 给出了一份令人惊喜的答案。这篇文章将为你详细展示 OpenCode Zen 免费模型的实际能力,并通过 CC Switch 工具手把手教你完成接入,让 Claude Code 即刻调用这些强大模型。
前段时间我们曾深入评测过 OpenCode 编程套餐,那次体验已经证明,5美元的 OpenCode Go 套餐确实汇聚了市面上所有能打的国产开源模型,性价比直接拉满。然而没想到的是,OpenCode Zen 还藏着更大的福利——多个完全免费的模型接口,覆盖了 DeepSeek、小米、NVIDIA、MiniMax 等一线厂商,而且全部是已测试验证的聚合接口,可用性和响应质量都有保障。
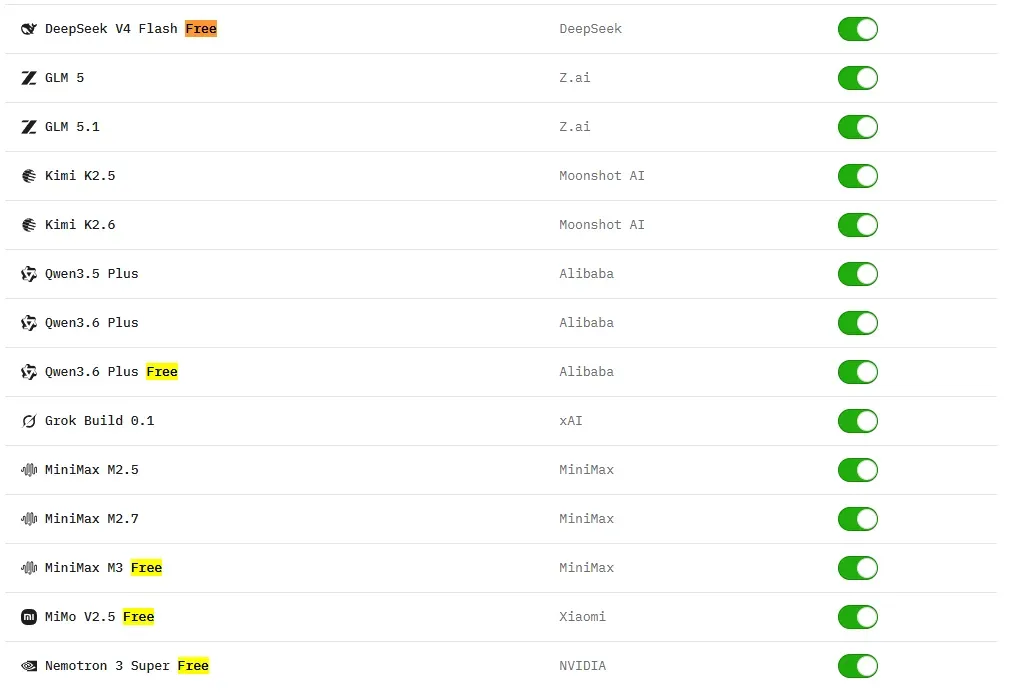
一、OpenCode Zen 免费模型清单
| 模型名称 | 说明 |
|---|---|
| DeepSeek V4 Flash Free | DeepSeek 免费版 |
| MiMo-V2.5 Free | 小米大模型免费版 |
| Nemotron 3 Super Free | NVIDIA 免费版 |
| MiniMax M2.5 Free | MiniMax 免费版 |
| Qwen3.6 Plus Free | Qwen 免费版 |
这些模型均为各家最新的版本,覆盖了轻量高速与强性能的不同需求,你能不花一分钱就享用前沿的AI能力,确实让人直呼“这波真香”。
接下来是核心内容,我会用最清晰的步骤教你通过 CC Switch 工具,将这些免费模型接入到 Claude Code 中使用。
二、接入 OpenCode Zen 免费模型的详细教程
1. 获取 OpenCode API 密钥
首先登录 OpenCode 平台,进入 Zen 页面后,系统会自动生成一个 API 密钥。你只需直接复制保存即可,整个过程几乎零门槛。