掌握 Loop Engineering:让 Agent 持续自动找工作的长期循环系统设计指南
可能你已注意到,一个名为 Loop Engineering 的新概念正在技术圈掀起波澜。它由 OpenClaw 创始人与 Claude Code 核心维护者共同倡导,核心理念简洁而强韧:别再死磕提示词了,去构建循环吧。虽然名字里带着 Engineering,但这并非 AI 产品研发或系统设计的专属术语,而是一种更高效、更合理的 Agent 使用方与思维模型。换句话说,它属于每一个希望真正用好智能体的人。
一句话概括 Loop Engineering:围绕一项长期目标,设计一套位于 Agent 外部的循环控制体系,让智能体能够稳定地被触发、执行任务、产出交付物、进入待命、再次运行……
本文从一次真实的日常需求出发,应用 Loop Engineering 思维,把这项任务全面托付给 Agent,实现长期、自动化且高质量的循环执行。如果你正在考虑如何让智能体持续地帮你搜集并跟进工作机会,这个场景应该很对胃口。
概念上下文:Loop Engineering 与各类“工程”是什么关系
Loop 和 Engineering 这两个词,总让人联想到 Agent Loop、Prompt Engineering、Context Engineering 或 Harness Engineering 等流行术语。但这个新概念和它们完全不在同一维度——后者更多出现在你设计或开发一款 Agent 产品时。因此,即便你不了解那些概念,也完全不妨碍你理解 Loop Engineering,并成为一个高阶应用者。
Loop Engineering 真正需要的能力是任务流程的抽象——把一个重复性事项固定下来,使其自动运行。这是产品经理的基本功,其实非常简单。即使暂时不熟练,读过本文后,你也能快速掌握。
从零开始:哪些任务值得采用 Loop Engineering?
在进入具体案例前,必须明确一个边界问题:并非所有让 Agent 完成的活都需要套用 Loop Engineering。
适合被设计成 Loop 的任务通常具备以下特征:
- 输入持续变化,而非一次性给定;
- 任务不是一次性完成,而是需要长期跟踪与迭代;
- 用户的反馈会直接影响后续执行策略;
- 多次执行之间需要共享状态信息;
- 需要由定时、事件或外部系统触发;
- 必须具备审计、恢复、降级甚至停止规则。
举个例子,“帮我找 10 个上海的 AI 产品经理岗位”这类指令,Agent 一次性搜索便可完成,最多再上传一份简历作为上下文。这是求职过程中的单次查询,虽然你很可能每天都会做类似的事,但如果你始终在循环中承担验收交付的角色,真正的循环成本就会很高。
智谱市值破万亿、DeepSeek估值500亿:中国大模型泡沫还是价值重塑?
一家中国基座模型企业近期再度刷新了市值纪录。盘中,智谱的市值一度冲过1万亿港元,年内累计涨幅超过1900%。收盘时,这家公司的总市值落在1.1万亿港元,大致相当于阿里巴巴市值的一半,接近美团的两倍,是京东的三倍。上市不到半年,智谱就从500亿港元量级挤进了港股万亿市值区间。
在港股的“万亿俱乐部”中,并肩而立的是腾讯、阿里、中国移动、工商银行这类产业巨头——它们身后都有着经过验证的用户入口、现金流或基础设施属性。智谱进入这一参照坐标,意味着公开市场对中国大模型公司的定价正持续膨胀。
不过,过山车一般的涨速,也让市场开始争论这究竟是一次神话还是泡沫。智谱上市后交出的第一份财报披露了2025年全年的营收数据:收入7.24亿元,净亏损47.18亿元,研发开支31.8亿元。一家去年收入7亿元的公司,市值却率先触及万亿级。看多者将其看作中国AI产业的估值突破,看空者则认为当前股价明显带有强泡沫属性,已远远跑在了基本面的前面。
从某种意义上看,这场争论早已超出智谱本身,而直接指向了中国大模型产业的整体估值。最新的消息显示,DeepSeek在新一轮融资后估值已超过500亿美元,阶跃星辰和月之暗面的资本化预期也不断升温,两家都瞄准了港股市场。中国大模型公司的估值曲线正从一级市场向二级市场抬升,而随着智谱成为第一家万亿市值的大模型企业,这条曲线正在向上触及新的天花板。
一、 GLM-5.2与“国产Anthropic”想象
智谱这一轮市值攀升,最直接的催化剂来自GLM-5.2。去年以来,行业内的主流模型升级普遍聚焦于Coding、Agent、长程任务和复杂工程能力。在这些场景下,智谱GLM系列已经跻身第一梯队,而全球范围内最强的参照对象是Anthropic。
今年以来,Anthropic完成了650亿美元的融资,投后估值高达9650亿美元。市场对它的追捧,核心在于Claude Code在开发者场景中跑出来的收入。官方披露的数据显示,Claude Code的年化收入已超过25亿美元,较年初翻倍。这个样本为全球AI公司更换了估值锚点。C端聊天产品证明的是用户规模,代码和企业级Agent证明的是付费能力;前者制造声量,后者靠近收入,而收入背后的商业化能力,正是资本市场评估大模型企业时所重点关注的。智谱在这一轮行情中被重估,正是因为市场把它放进了“国产Anthropic”的坐标系里来观察。

近日,特斯拉首席执行官埃隆·马斯克与智谱创始人唐杰的隔空互动,则进一步放大了这种想象。马斯克判断,中国可能在2027年一季度出现接近Anthropic Fable级别的模型。唐杰回应称,不会等那么久。尽管这句回复本身简短得几乎没有给出具体信息,但侧面凸显出,国产模型已经身处全球前沿模型的追赶叙事之中,市场正在观察谁能跟上头部选手的脚步。
今年以来,除了智谱股价的攀升,国产模型圈的资本动作也在不断加快。本月初,智谱通过了A股发行议案,计划登陆科创板募资不超过150亿元,其中120亿元投向通用基座大模型研发,20亿元投向MaaS一站式服务平台。几乎在同一时间,MiniMax与中信证券签署辅导协议,正式启动A股IPO进程,并评估发行人民币股份登陆科创板。两家港股大模型公司同时推进A股路径,说明中国AI的估值曲线正在从港股弹性,进一步延展至A股的产业融资。
与此同时,DeepSeek在一级市场疯狂吸纳融资。近期,DeepSeek完成超过74亿美元的融资,估值超过500亿美元。这家来自杭州的AI巨头,凭借出色的模型效率、全球范围内的开发者声量和开源生态,把中国大模型一级市场的定价推到了新的高度。
在二级市场,智谱和MiniMax相继登陆后,港股市场也在转向拥抱AI产业。今年以来,港股已有65家公司上市,合计募资超过1765亿港元。硬科技和高端制造企业贡献了接近1293亿港元,占比超过七成。半导体、电气设备、AI公司成为发行主线,资金正在把港股当作中国硬科技资产的再定价市场。换句话说,智谱的万亿市值,不仅来自GLM-5.2的出色表现,也源于几个条件的共振:全球AI资产估值上扬,中国大模型公司资本化提速,港股缺少纯正的大模型标的,硬科技资金重新聚集。所以,市场真正在买入的,是中国AI估值边界仍能被继续拓宽的预期。只是,这条边界拓得越宽,围绕产业泡沫的争论就越会持续下去。
二、 泡沫警告与解禁压力并行
看到智谱万亿市值,大多数投资者直觉上就会判断,这里边必然含有泡沫成分。一家年收入7亿多元的公司,盘中市值超过万亿港元,任何估值模型都会感到紧张。更何况,智谱的股价之前已经出现过大幅度波动。5月末,它盘中市值曾突破8800亿港元,随后快速回落;今日再度冲上万亿的过程中,盘中震荡依然剧烈,短短十几分钟就从高处回落,蒸发了上千亿市值。
然而,这也正是AI行情最特殊的地方:市场一边承认价格昂贵,一边继续追逐头部标的。泡沫警告和估值上调同时发生,构成了这一轮AI资本周期的底色。与此同时,港股新股市场已经出现分化。今年一季度,香港IPO破发率升至44.74%,明显高于去年。传统行业和认购不足的公司承压,而硬科技、AI、新能源企业仍在被资金追逐。资金并没有无差别地买入新股,它只在少数赛道里集中冒险。显然,以智谱为代表的AI产业,就属于被集中冒险的资产。突破万亿,靠的是市场对中国AI基础设施公司的稀缺预期。
不过,资本并不会无止境地投入。7月上旬,智谱和MiniMax即将迎来上市后的首轮限售股解禁。智谱的解禁时间在7月8日,规模约有2568.16万股,占总股本约5.76%,按近期股价测算,对应的解禁市值约269亿港元。解禁前,智谱的流通股约1735.08万股。也就是说,即便总股本占比不高,新增的可交易筹码也会明显改变此前的低流通盘结构。MiniMax所面临的解禁压力更大,它将在7月9日解禁约1.07亿股,占总股本约34.25%,其中财务型投资者的持有比例超过三分之一。两家公司的股价相较上市时都经历了大幅上涨,市场自然会提前对减持压力产生担忧。
事实上,不只国产大模型,全球市场也在经历同样的估值冲突。就在马斯克和唐杰隔空对话的前两周,SpaceX上市后市值迅速突破2万亿美元,股价也攀升至210美元区间。这家集航天与卫星互联网一身的企业,上市前夕就已大量整合资源,强化其在AI基础设施、与xAI的协同、星链网络和未来算力叙事中的行业地位。针对这家公司,纽约大学斯特恩商学院教授达莫达兰给出的估值低于市场定价,并提醒SpaceX的高估值已包含大量关于未来的假设。而在过去几个交易日里,SpaceX的股价经历了大幅回调,股价已经来到170美元区间。
6月初,Scion Asset Management创始人、电影《大空头》原型投资人迈克尔·伯里也把质疑指向了Anthropic。他认为,Claude背后的大模型研发成本过高,近万亿美元的估值很难只靠当前的商业模型来支撑。行业内部如此巨大的认知分歧,其实看似对立的观点之间并不矛盾——在产业高速增长周期里,泡沫已经天然地成为了AI估值的一部分;而这部分“泡沫”究竟是长期溢价还是即将破裂,关键取决于AI企业的商业化能力。
三、 商业化是估值能否守住的核心
突破万亿市值后,智谱面前真正的命题,是收入的增长速度。2025年,智谱实现收入7.24亿元,同比增长131.9%。其中,本地化部署收入5.34亿元,同比增长102.3%;云端部署收入1.90亿元,同比增长292.6%;企业级智能体业务收入1.66亿元,同比增长248.8%。在这些收入中,智谱MaaS API平台的年经常性收入(ARR)约17亿元,过去12个月提升了60倍,平台毛利率提升至18.9%,这意味着MaaS的收入占比正在持续扩大。
2026年一季度,面对模型调用的旺盛需求,智谱直接选择了涨价。今年2月以来,智谱对GLM Coding Plan套餐价格进行了结构性调整,整体涨幅从30%起步,给出的理由是用户规模和调用量快速提升,需要保障高负载下的稳定性和服务质量。只是,这部分营收究竟对应着多少实际收入增长,尚需等到智谱的下一份财报才能揭晓。
与此同时,作为一家独立模型公司,智谱的成本压力极为沉重。2025年,智谱净亏损47.18亿元,经调整净亏损31.82亿元,研发开支高达31.8亿元,研发投入相当于收入的4倍多。模型公司可以烧钱,但必须让资本市场看到长期盈利的预期。
好在,中国整个市场的调用量基础正在不断抬升。IDC数据显示,2024年中国企业级MaaS市场的调用量为114万亿Tokens,2025年跃升至1944万亿Tokens,预计2026年将达到40000万亿Tokens。Token正从技术指标变成商业结算单位。在国内模型体量最头部的字节跳动一侧,其旗下豆包大模型日均Token调用量已突破120万亿,三个月内翻倍,较2024年5月发布时增长了1000倍;累计调用量超过一万亿Tokens的企业,也从去年底的100家增加至140家。
与此同时,C端场景也在扩容。QuestMobile数据显示,2026年3月,中国AI原生App月活用户规模达到4.4亿,豆包、千问、DeepSeek位列前三。AI应用已从小圈层工具变成了大众产品。但用户规模并不等同于利润水平,行业内的泡沫担忧,本质上是对AI无底线烧钱、始终看不到盈利预期的无力感。在这个问题上,Anthropic仍然是最强的参照样本。
今年二季度,Anthropic预计实现收入109亿美元,并可录得约5.59亿美元的经营利润。如果这一预期能够兑现,它将成为全球AI公司商业化的转折样本。市场会因此相信,大模型公司并不需要长期停留在“烧钱换规模”的阶段。这也是中国AI公司被重估的根本原因。如果Anthropic能够依靠代码、Agent和企业API接近盈利,国内市场自然会寻找对应的中国标的。智谱、DeepSeek、MiniMax、月之暗面,以及几家头部AI大厂,都将被放进这条商业化曲线里进行逐一比较。
随着智谱率先突破万亿市值,这也成为了中国AI产业接下来的共同命题。估值边界已经被打开,关于泡沫的争议不会停息,市场的波动与不确定性依然存在。想要巩固这条估值边界,大模型厂商首先要能够把模型能力稳定地转化成收入,再把收入继续推向毛利和现金流;同时,也需要更多国产厂商在追赶Anthropic的路上跑出有效的商业化样本。智谱今天站上万亿市值,是中国AI产业重估的第一个高点。这个高点能否守住,能否演化成一条行业曲线,最终要由国产大模型厂商的商业化成果来回答。
中国用户如何突破Claude封锁:四大屏障与灰色中转站的隐秘生意

每年 Anthropic 都会把地理围栏修得密不透风,结果第二年就有人把绕过它的那一整套流程做成产品,挂在淘宝上卖。
4 月 23 日,白宫发布了一份备忘录,警告中国实体正对美国前沿 AI 模型进行“工业级蒸馏攻击”,动用了“数以万计的代理账号”。两个月后,Anthropic 在官方安全报告里补了一句更具体的话:一个代理网络就能管理超过 20,000 个欺诈账号。这两段话读起来像是对同一个剧本的不同机位,一个讲需求侧,一个讲供给侧。真正的原因,是市场底层更顽固的结构。
那是一个公开运转的灰色经济体,活跃在 GitHub、淘宝、Telegram,甚至 X 的公开帖子上。被卷入其中的远不止备忘录点名的那几家实验室,而是把 Claude 当成日常工具的人:大学教授、研究生、跑自动化流程的工程师,还有在淘宝帮人代下单的外贸卖家。门槛早已不是“能不能用”,而是“能不能便宜地用”。
01
Anthropic 设下了四道门
在所有主流 AI 服务商里,这家公司对中国用户的防范可能是最用力的。
第一道门是账号注册。要拿到一个 Claude 账号,海外手机号、海外信用卡、账单地址三件套缺一不可。9 月 5 日,Anthropic 又补了一刀:只要是由总部在受限地区(包括中国大陆)直接或间接持股超过 50% 的实体,其 API 账号无论在何处注册,一律作废。这一条直接堵死了“离岸壳公司”的出口。
更狠的一刀在 4 月落地:限量触发身份核验。用户必须上传政府签发的带照片证件,同时完成一次实时自拍比对。这是 Claude 第一个把活体人脸比对拉到这个级别的消费级 AI 服务。对普通中国人来说,这几乎等同于“你再用下去,就得把自己实名制搭进去”。
四道门,每一道都在抬高真实成本。但真实成本本身,就是一门生意。
02
中转站:把这门生意做成闭环
中转站,也常被叫做 API proxy,是开发者为 Claude 辗转找到的一条新路径。它的结构并不复杂,却足够有效:你把自己原本要发给 Anthropic 的请求,改发到第三方服务器上,那台服务器替你完成与 Anthropic 的所有对接,再把结果原路返回。你不需要翻墙、不需要海外信用卡、不需要提供任何真实身份,只需要用微信或支付宝把钱打给中转站的运营者。
这不是一个浪漫的叙事。GitHub 上有人把它做成开源工具,并煞有介事地强调合规和审计;更多的人把它做成淘宝店铺、Telegram 机器人或者微信群里的接龙。还有人把中转站平台本身再包一层,变成二级分销。
低价背后的真实驱动力,是一张多层供应链:上游批量注册账号、兜售虚拟手机号、测试最新 KYC 绕过方案的人,从没见过来自中国的下游用户;中游的中转站运营者负责维持服务可用,并轮换账号池;最下面则是买 token 跑任务的工程师、跑在笔记本里的创业 demo。几乎没有人同时握通链条上的三段,而这恰恰是它的韧性所在。
03
模型正在被静悄悄地替换
一篇来自德国 CISPA 的论文,让“便宜 Claude”第一次有了可被核查的证据。研究者审计了 17 个 API 代理,结果触目惊心:你付的或许是 Opus 4.7 的价格,拿到的却可能是质量低得多的小模型;你自认为跑的是“Gemini-2.5”,在一个医疗基准测试中,官方接口的正确率是 83.82%,在代理侧只剩下 37%。
2026 AI电商元年深度解析:消费行为重塑与商家生存指南
2025年除夕夜,近2亿人次用一句话完成年货采购——“千问帮我下单年货”,商品自动推荐、比价、下单,全程无需搜索和浏览详情页。这是2026年春节真实的商业切片:阿里千问“一句话下单”服务近2亿次,字节豆包除夕AI总互动19亿次,腾讯元宝日活突破5000万。互联网大厂累计投入超80亿元,展开一场面向全民的AI应用“拉新实验”,其结论极为清晰:AI购物元年,正式到来。
当“人找货”成为历史,电商生意逻辑正在被彻底重构。本文将深入探讨消费者、商家、平台三个维度的核心转变,并提供切实可行的生存指南。
消费行为重塑:从“人找货”到“AI代办”
过去二十年电商的核心逻辑是“人找货”:用户产生需求后,搜索关键词,筛选商品列表,比对参数和价格,最后下单。这一逻辑统治了两代电商从业者,但在2026年正被迅速瓦解。
场景一:模糊需求,AI精准响应
传统模式下,若想为怀孕六个月的妻子买一双鞋,你需要打开电商平台,输入“孕妇鞋”,然后在几十页商品中逐一查看材质、防滑系数、穿脱便利性,耗时至少半小时。如今,只需对AI说一句:“老婆怀孕六个月,需要一双防滑、方便穿脱、舒适的鞋,预算200元左右。”三秒内,AI便会推送三款推荐,并附上适用理由,直接完成下单。这不是搜索效率的提升,而是需求理解范式的彻底颠覆。
场景二:“券找人”取代“人找券”
过往,用户需要主动进入优惠券中心翻找,或跨平台查询当日优惠,信息零散且依赖主动操作。如今,AI基于消费记录、偏好与购买时机,在用户恰好需要的时候,主动推送最匹配的优惠。AI由被动响应转变为主动发现——这是价值分配逻辑的根本性改变。
消费者行为的三个底层变化
- 关键词让位于自然语言:用户无需知道“如何描述”,只需表达“想要什么”,AI负责翻译需求。
- 主动搜索变为被动接收:用户变得日益“懒惰”,AI愈发懂你,等待“自己被找到”取代“自己去寻找”。
- 单点决策升级为信任外包:用户将决策权越来越多交给AI,不是因为AI完美,而是基于“它不会坑我”的信任。
这意味着品牌触达用户的路径,从“用户看到你”转变为“AI替你发声”。如果AI不了解某个品牌,不理解其核心价值,它便不会推荐。
商家角色演进:AI从效率工具到智能员工
许多商家仍将AI视为高级客服工具,这种认知正在让人错过一个时代。AI在电商领域的角色,正经历三级飞跃:辅助工具 → 效率倍增器 → 独立智能员工。
案例一:阿里“龙虾”与“悟空”——AI员工团队正式上岗
天猫TOP TALK推出的“龙虾版”生意管家,配置了AI数据分析师、AI设计师、AI广告投手、AI导购,形成四位一体的“超级店长+专家团队”。而阿里企业级AI平台“悟空”,更将AI能力推向新高度:商家可用自然语言指挥AI完成选品分析、素材制作、上架更新、效果监控全流程。多AI Agent协同运作,转化率下降时,商品素材Agent自动优化主图,广告投放Agent同步调整推广策略,全程无需人工介入。
案例二:AI客服直接驱动成交
“店小蜜”AI客服目前已累计服务3亿人次,在20万商家试点中,成交转化效率提升30%。这不仅因为回复更快,更因为AI直接从咨询到下单全链路打通,引导成交无需人工干预。对于日均1000询单的店铺而言,这意味着每天多成交300单,全年可额外贡献近千万级GMV。
案例三:AI视觉革命——拍照搜品准确率达98.2%
淘宝拍照搜品准确率提升至98.2%,用户在现实中拍摄任意商品,立即匹配同款或相似款,线上线下边界被彻底抹除。对商家而言,产品图片已转变为“销售员”。图片质量不再仅是美观问题,而是“AI能否识别并推荐你”的关键。
商家运营模式的根本转变
传统电商运营:人执行,AI辅助;AI原生电商:AI执行,人决策和监督。这是“AI员工+人类CEO”的全新协作模式,运营角色从执行者转变为策略制定者——你告诉AI做什么,而非自己动手。
平台竞争升级:从“流量分发”到“意图理解”
电商平台的竞争逻辑正经历根本性重构。过去的竞争焦点是“谁拥有更多流量,便可吸引更多商家”,平台充当“房东”,商家充当“租客”,流量即摊位费。当下及未来的核心是“谁更懂用户意图,能更精准地匹配供需”。平台演变为“AI管家”,商家作为“服务提供方”,核心能力转变为“被AI推荐”。
抢占“AI入口”:各大平台的争夺战
- 阿里:千问App接入淘宝、支付宝、飞猪、高德,完成“规划—决策—支付”闭环;悟空平台主攻B端企业级AI。
- 字节:豆包嵌入抖音电商与本地生活,探索“内容+消费”一体化路径。
- 腾讯:元宝+微信生态,力图打通社交与消费决策链路。
- 京东:推出“AI年货地图”,实现“订单未下、货已先行”的智能分仓。
互联网大厂春节期间投入超80亿元,争抢的不是流量,而是用户心智中的“AI第一入口”——谁率先占领这一入口,谁便能在下一代电商格局中占据优势。
GEO崛起:搜索引擎的流量危机
一组数据值得所有商家警惕:传统搜索引擎流量预计2026年下滑25%。与此同时,GEO(生成式引擎优化)正快速崛起,品牌营销核心正从“SEO关键词排名”转向“让AI理解并信任品牌”。GEO商用后,AI推荐场景下获客转化率提升2.8倍,用户决策周期缩短40%。这意味着,谁能让AI更准确地理解自身,谁就获得更多被推荐的机会。对商家而言,品牌信息、商品描述、用户评价,正成为AI判断“该推荐谁”的依据。过去拼关键词SEO,未来拼AI信任度建设。
AI电商生存指南:五大策略制胜未来
在AI电商时代,核心竞争力不再是“流量运营能力”,而是“AI构建能力”——能否熟练运用AI工具,能否培养AI协同团队,能否建立让AI“信任”的品牌,将决定生存质量。
第一:从高频重复劳动切入,立即行动
不要等待或观望,今天就选择一项每天面对的重复性工作,用AI解决:
- 客服80%的重复咨询 → 部署AI客服替代;
- 每周手动整理数据报表 → 切换成AI自动生成;
- 上新依靠设计师排期 → 采用AI生图工具;
- 选品凭感觉和经验 → 改用AI分析竞品评论。
每解决一个环节,每年可节省几十到数百小时——这些时间正应用于构建真正的核心竞争力。
第二:建设“AI信任度”——让品牌被AI读懂
从现在开始,必须思考一个问题:“若用户对AI描述需求,AI会推荐我的品牌吗?” 要回答“是”,需要做好三件事:
- 商品描述结构化:AI读不懂“时尚大气上档次”,但能读懂材质、规格、适用场景、核心卖点;
- 用户评价真实完整:AI会分析评价判断产品优劣,真实详尽的好评即最佳SEO;
- 品牌故事可被提取:AI需要知道你是谁、解决什么问题、为何不同——写清楚,写入品牌介绍。
第三:转变团队角色——从执行者到监督者
这可能是最重要的一次认知跃迁。过去,你告诉员工做什么,员工执行;未来,你告诉AI做什么,AI执行,你负责验收。这意味着,需要培养的不再是“更会操作后台的人”,而是**“更会下达精准指令的人”**。Prompt能力、批判性思维、数据解读能力,将成为AI时代运营团队的核心技能。
第四:关注CPS模式——为“实际成交”付费
AI购物的普及,催生商业模式变革:CPS(按成交分佣)将成为主流。逻辑直接而公平:AI帮你卖出商品,收取佣金;卖不出,不收费。这对商家是重大利好,你不再为无效曝光付出冤枉钱,只为真正的成交买单。
第五:关注新硬件入口——智能眼镜的爆发
一组关键数据:2026年1-2月,智能眼镜网络零售额增长183.5%,擦窗机器人增长130.8%。智能眼镜正成为下一代AI入口:用户戴上眼镜,看见任何商品,眼镜自动识别、比价、下单。这意味着视觉搜索与即时购买将取代当前的“拿起手机搜索”模式。提前布局适配AI眼镜的内容与商品描述,准备迎接下一个流量入口的爆发。
拥抱变革,而非恐惧
每次技术革命,总有人高喊“狼来了”。电商兴起时,断言“线下零售完蛋”,但线下并未消亡,而是学会用线上工具服务线下客户。AI并非来取代人,AI是增强人。那些忧心“AI让我失业”的人,忽略了一个关键事实:AI永远需要一个“验收者”——那个判断AI做得对错、好坏、是否偏离品牌价值的人。这一角色,永远属于人。
2026年必看:四个实用GitHub开源项目,AI编程搭档、多模型对话、前端动效与海量古诗词
Ponytail:帮你的AI Agent“减负”,让代码回归本真
大家都有让AI写代码的经历。让它做个日期选择器,它可能先装个 flatpickr,再套一层 wrapper 组件,接着陷入时区处理的反复拉扯,动辄五十行起步。Ponytail 要治的,就是这种过度工程化的毛病。
它的人格设定很传神:你公司里那位扎着马尾辫、戴着椭圆眼镜的老程序员,拿过五十行代码,一言不发,直接压缩成一行。

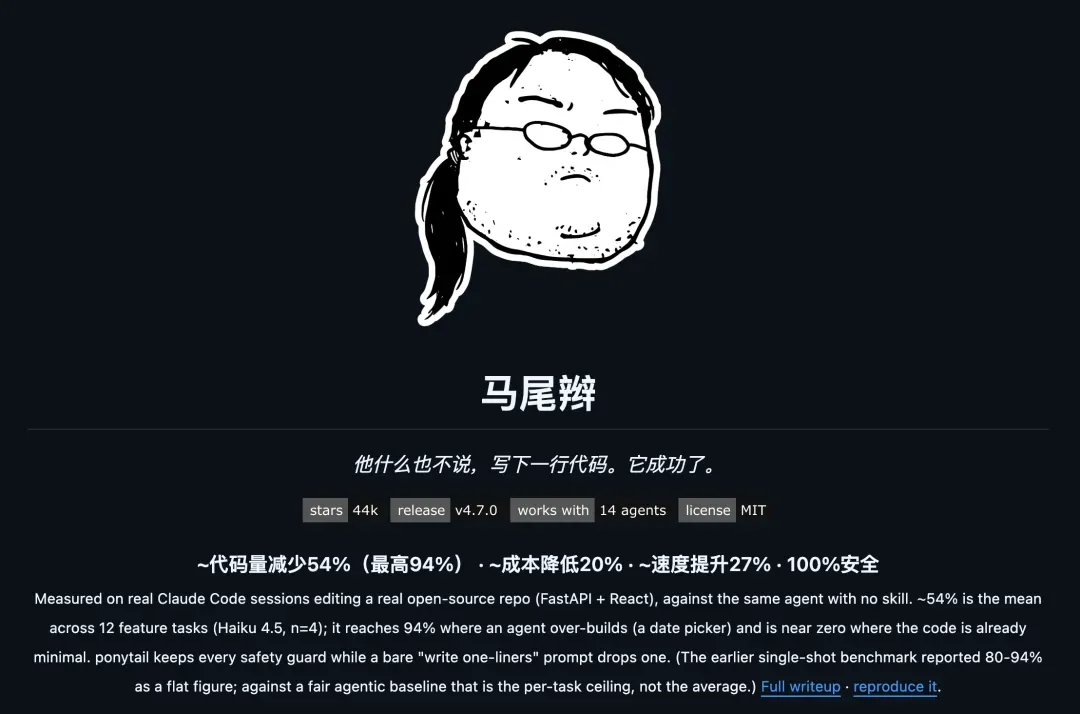
Ponytail 兼容 13 个主流 AI Agent,Claude Code、Codex、GitHub Copilot CLI、Gemini CLI 全都能接入。它的核心思路是给 AI 注入一条过滤链:动手之前先层层自问——这事真的必须存在吗?标准库能不能搞定?平台有没有原生支持?能不能一行写完?筛到最后,才允许写出最精简的代码。
在 Claude 上实测,单任务代码量减少 80-94%,执行速度提升 3-6 倍,调用成本节省 42-75%。
开源地址:https://github.com/DietrichGebert/ponytail
三条配套指令,让管理更透明:
/ponytail-review审查当前 diff 中的过度工程/ponytail-audit扫描整个仓库/ponytail-debt将所有临时取巧的地方汇成一份技术债台账,免得过后忘得一干二净。
在 Claude Code 里两行命令就能装好:
/plugin marketplace add DietrichGebert/ponytail/plugin install ponytail@ponytail
LibreChat:把所有主流AI模型装进同一个聊天界面
如果你同时使用 ChatGPT、Claude、Gemini,每天在好几个标签页之间来回切换,这个近 4 万 Star 的项目值得一试。

LibreChat 是一个 AI 聊天平台,接入了 OpenAI、Anthropic、Google、Azure、AWS Bedrock 等主流供应商。更棒的是,同一场对话可以在流式输出过程中直接切换模型,前面用 GPT,后面接 Claude,完全不用重开窗口。
多用户、Agent、MCP、Artifacts 等功能也早就内置了,远不是 ChatGPT 的简单克隆。
2026年抖音小店新规全面解读:免佣、算法红利与退货率实战指南
如果此刻你仍在用去年的运营逻辑做抖音小店,那可能已经落后了一大截。
过去两个月,平台接连释放了两个强信号:一是1月8日对**“九大商家扶持政策”进行系统性升级**,方向是战略性的让利与松绑;二是2月份生效的12条新规集中落地,标志着治理层面全面收紧。
松中有紧,核心意图毫不含糊:将合规生意的综合成本打下来,同时堵死各类灰色投机的通道。
我把这些变化整理成一篇干货,读完你就能明白2026年抖音小店的钱该从哪里省、流量如何免费拿、坑又该怎么提前绕开。
📌 本文核心速览
✅ 免佣政策细节:技术服务费最低可至0.6%
✅ 算法方向明确:优质内容不用投流也能成为爆款
✅ 退货率破解方案:四招帮你拉高结算率
✅ 2月生效新规:达人带货受限、保证金收紧等12条必知规则
一、扶持政策再度加码:2025年减负320亿,2026年红利再扩大
先看一个数据:320亿。
这是2025年抖音电商通过商品卡免佣、特定类目免佣、运费险补贴、小微商家专项支持等组合拳,为商家实打实省下的经营成本总额。折算下来,每个工作日帮商家多留住了大约1.3亿元。
换个角度拆解:
- 货架场景下的商品卡免佣贡献超 138亿元
- 内容场景里,水果生鲜、日用百货、厨具、男装等大批类目陆续纳入免佣范围
- 三轮运费险降本举措累计省下 85亿元
进入2026年,这个数字还会继续攀升。1月8日,抖音电商正式发布了“九大商家扶持政策”升级版本。

▲ 2026年九大扶持举措概览
🔑 最大亮点:千川·乘方技术服务费率降至0.6%
这是整轮免佣政策中最值得放大的细节。
商家使用平台新推出的一站式AI智能营销工具“千川·乘方”所产生的订单,技术服务费直接递减到 0.6%。
同时,免佣的适用范围从原有的货架场商品卡,延伸至 全品类,场景也从货架场覆盖到了 内容场(含短视频、直播)。
过去内容场免佣覆盖有限,现在只要走千川·乘方的成交,就能享受到最低0.6%的费率保护。一边有自然流量的加持,一边有最低扣点兜底,综合投放成本肉眼可见地往下走。
💡 操作提醒:千川·乘方是平台智能营销的整合入口,建议尽早接入实测。用上这个工具,等于把技术服务费优惠和AI智能投放打包在一起,双重利好一次性叠加。
💡 净成交出价:一个值得跟进的新指标
2026年扶持政策中涌现出一个值得记住的关键词:“净成交出价”。
这是平台新推出的投放指标。对符合评估条件的订单,系统会自动减免部分推广费,提升商家的投放效率。直白地说,就是平台帮你筛出真正值得花广告费的流量,避开无效消耗,让每一分钱都花得更聪明。
💡 联盟双佣金体系:达人合作成本更可控
这条对联盟带货的商家非常友好。
新机制允许商家在后台同时设置 两套佣金标准:
- 日常佣金:面向达人和自然流量的常规比例
- 推广佣金:投放期间生成的订单,按更低费率结算
系统自动识别场景并切换计算。投广告时支付更低的佣金,不投放则恢复正常费率。过去要么全部按高位佣金走,要么跟达人逐一对谈,现在平台直接帮你一键区分。
💡 百亿优惠券补贴:平台出钱帮你拉新
平台将启动 百亿优惠券补贴专项,通过智能优惠券形式精准触达潜在消费者。
这笔费用由平台承担,用户用券购买你的商品,你照常拿到全额货款。怎么参与?关注官方活动通知,通常符合资质的店铺会被系统自动纳入。基础门槛是保持稳定的商品质量和好评率。
二、算法重构:2026年“好内容=好流量”已成现实
一个明显趋势是:用心做内容的商家,自然流量正变得越来越可观;而一味拉时长、低价冲单的老套路,效率正加速下降。
这不是偶发现象,而是算法在主动导向。
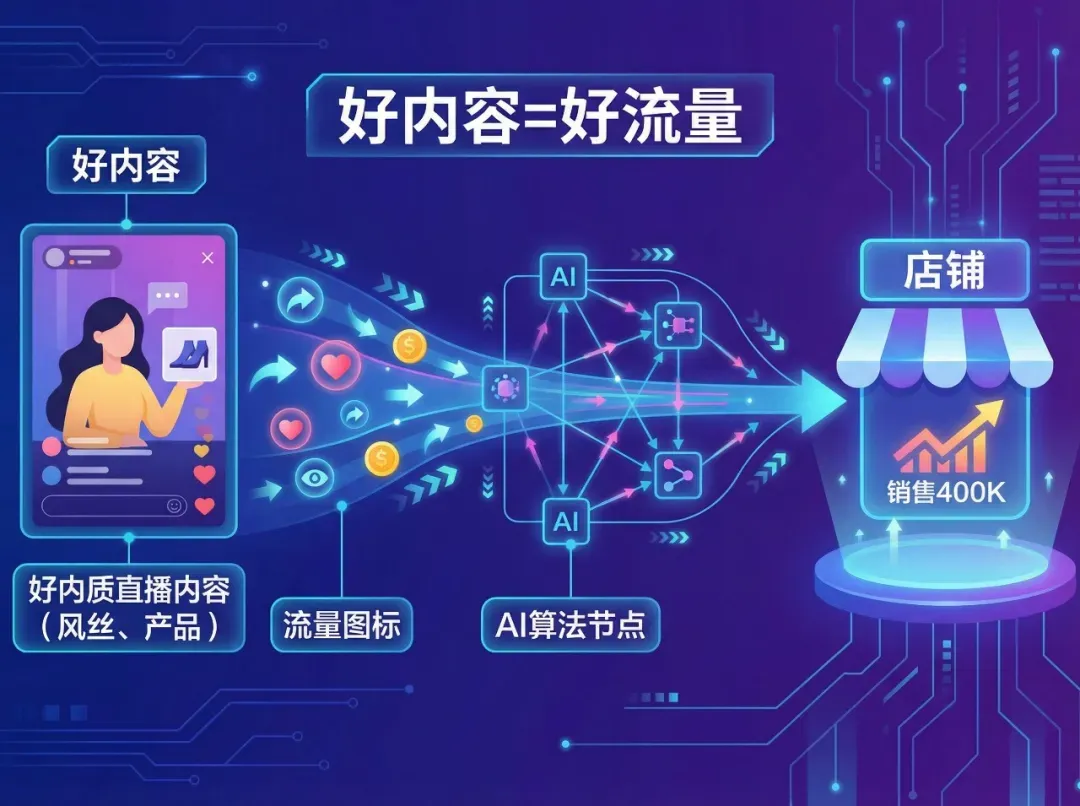
▲ 好内容即好流量,算法正重塑电商底层逻辑
📊 用事实说话:内容型黑马跑得有多猛
看两个真实样本。
案例一:@洪湖颜姐莲藕特产店
儿子小陈记录妈妈挖藕的真实劳作日常,搭配走心旁白,零付费投流。最终账号积累了近 24万粉丝、百万量级点赞,店铺莲藕的日均销量从不足20单,直接飞跃到日发货万斤。
案例二:@FeiFei飞飞女鞋
主理人对直播间灯光和场景极度挑剔,2025年重新打磨了直播间的视觉呈现后,流量质量明显上升,轻松孵化出多款销量过万的爆品。
两则故事指向同一个结论:平台的算法,正在真金白银地奖赏优质内容。
2026年俄罗斯电商:门槛升维后的结构性机会与破局路径
过去一年,俄罗斯电商市场发生了剧烈变迁。从跨境账户政策、清关模式到各项合规要求,全线收紧,最令人咋舌的当属平台规则——佣金一年内可上调四到五次,尾程物流算法一两个月就可能大改。在这个市场上,一旦缺失精准的算账能力和快速应对变化的敏捷度,被拖垮几乎是大概率事件。
如今,俄罗斯市场的进入门槛已从“地平线”抬升至“半山腰”。卖家供给高度饱和,平台早已不缺货,且绝大部分商品都已布局本土仓,早期的流量红利彻底消退。合规认证的复杂度大幅上升:EAC认证、诚信标签、清关资料对账等环节成为入场标配,准入门槛今非昔比。同时,重资产的本土化模式对初始资金和周转资金的要求,早已不是两三年前的量级,投入金额可能是过去的数倍。曾经双清包税十几天就能到货的模式日渐稀少,资金周转效率显著下滑。
尽管如此,俄罗斯市场仍然蕴藏巨大潜力。每年一千多亿美元的销售额仍在持续增长,消费者线上购物习惯已经不可逆转。从竞争格局看,大量类目中大品牌尚未完全回归,卖家面对的仍是中国同行、俄罗斯本土力量以及来自土耳其、越南等国的竞争者,较量强度远不及与全球品牌正规军硬碰硬。更为关键的是,随着各类新规(如传闻中的SPOT/EDC等)陆续落地,大批低质、不合规的散户被清退,市场环境反而对具备产品意识、品牌意识和资金实力的卖家更加“干净”和友好。
最终判断很清晰:俄罗斯市场已经告别“谁来都能赚钱”的草莽阶段,但远未到“毫无新机会”的存量绝境。它处于一个极具深意的临界点——市场规模仍在增长,平台集中度极高,卖家竞争明显加剧,平台费用持续走高,跨境合规红利逐步收窄,而欧美品牌退出后的供给重构尚未完全闭合。因此,它不再是一个普适性的红利市场,却依然是一个充满结构性机会的市场。
关键问题不再是“俄罗斯还能不能做”,而是:以我们当下的资源和能力,能否在俄罗斯某些类目中建立起比普通卖家更强的结构性能力?若能做到,俄罗斯就值得持续下注;若不能,这个市场将演变为高销售额、低利润、高库存、高费用、高波动的风险漩涡。
用一句话总结:现在的俄罗斯,不适合轻装上阵的投机者,但适合经过能力重构后再入局的玩家。对于普通卖家,生存难度大幅提升;而对于拥有供应链基础、充裕资金、本土化运营能力和清晰类目战略的企业来说,竞争环境反而可能更优渥。因为市场一旦从红利期进入能力驱动期,淘汰的是散兵游勇,留下的将是体系化玩家。2026年的俄罗斯电商,不再是草根创业者的淘金地,而是品牌与资本的收割场。
2026年跨境电商平台深度避坑:亚马逊、速卖通、TikTok Shop等七大主流平台陷阱解析
近期很多朋友都在问同一个问题:现在想进入跨境电商赛道,还来得及吗?又该从哪个平台入手?坦白讲,这个问题我已经被问过上百次。今天就把主流平台的真实情况全面揭开,一次讲透它们各自的隐患和难点。
跨境电商现状分析
跨境电商这个赛道,当前仍然是中国普通从业者可以抓住的窗口。
为什么?
「全球市场体量巨大,大到你的产品只需要精准服务一小部分人,就能取得相当可观的生存空间。」
但关键的是——
并非所有平台都值得你毫无保留地投入时间和资金。
主流平台潜在风险深度剖析
亚马逊(Amazon):最大平台即最卷战场
亚马逊作为行业老大哥这一点毋庸置疑。
不过,很多人并不清楚——
大量新手卖家在亚马逊上遭遇滑铁卢,根本原因不在于不懂运营,而在于根本玩不起这场资本游戏。
| 痛点 | 具体有多痛 |
| 资金压力 | FBA模式要求提前将货物囤至海外仓,垫资动辄数万甚至十几万 |
| 封店风险 | 平台可无理由封店并冻结资金,仅2021年就发起过四波大规模封号 |
| 竞争激烈 | 工厂型卖家以成本优势强势入局,价格战已进入白热化阶段 |
| 广告费昂贵 | CPC广告成本持续攀升,新品冷启动难度直线上升 |
| 纠纷严重偏向买家 | 几乎任何交易纠纷平台都倾向保护买家,卖家权益很难得到有效支持 |
我的判断是:
亚马逊更适合资金充裕、拥有稳定供应链和丰富运营经验的玩家。
小白卖家贸然冲进去,大概率只能花钱买一次沉重教训。
速卖通(AliExpress):低价路线的利润困局
速卖通的核心标签就是“便宜”。
但在中国强大的供应链面前,“便宜”本身几乎没有任何护城河可言。
核心问题:
- 产品客单价低到什么程度?有时甚至比你的进货价还要低
- 平台走的是跑量逻辑,客单价一旦过低就意味着——必须卖出天文数字的销量才有可能盈利
- 利润空间被极限压缩,一单只赚几块钱,做得再多也只是寂寞
「低价是一剂慢性毒药,一旦起跑就再难停下。」
Shopee(虾皮):东南亚市场的低价之殇
东南亚市场表面上看起来极具吸引力,人口基数大、电商渗透率尚低。
但现实情况却是——
| 问题 | 说明 |
| 客单价极低 | 东南亚消费者整体购买力有限,一单几十块人民币已是天花板 |
| 物流复杂 | 岛屿分散,物流基础设施薄弱,运输成本居高不下 |
| 本地化难度高 | 各国语言、文化和消费习惯差异显著,运营复杂度成倍增加 |
| 价格战惨烈 | 本土卖家与中国卖家互相内卷,利润被不断摊薄 |
eBay:规则复杂、偏向买家的老牌平台
后台操作逻辑几乎反人类,付款方式局限于PayPal,平台规则又严重偏向买家。
很多资历深厚的老卖家都感叹:能坚持在eBay上活下来的,靠的都是绝对的真爱。
TEMU(拼多多海外版):极致低价下的卖家困境
TEMU用疯狂补贴与极致低价策略高调杀入海外市场,表面上很有诱惑力。
但隐藏的真相是——
| 问题 | 说明 |
| 定价权被剥夺 | 平台强制压价,卖家几乎没有定价自主权,最终售价完全由平台决定 |
| 利润空间逼近零 | 在无底线低价竞争中,卖家利润被压至极限甚至形成亏损 |
| 回款周期偏长 | 资金回笼速度慢,现金流压力持续紧绷 |
| 政策风险突出 | 美国取消小额豁免政策后,TEMU过去的价格优势已大幅削弱 |
直白地说:你更像是在给TEMU打工,而不是在为自己创造收益。
2026年龙虾OpenClaw变现10个真实案例:AI自动化收入流实战秘籍
电商赛道摸爬滚打十余年,见证过无数风口起落。但2025到2026年,AI Agent终于从概念迈入了实质变现阶段。
下面这10个案例,全部是已经跑通商业闭环的真实操作,希望能为准备入局的朋友提供一份清晰的地图。

案例1:YouTube内容自动化——5天 MRR 达到$700
实践者:YouTuber Mark Savant
运作方式:借助OpenClaw构建内容生产流水线,从脚本生成、视频剪辑到平台发布全链路自动化。
成果:发布5天内累计获得50万次观看,每月经常性收入(MRR)攀升至$700。
亮点:边际成本几乎为零,一条成熟的自动化工作流可以轻松复制到多个频道。
案例2:跨境电商矩阵——驱动5个AI员工
实践者:跨境电商运营团队
运作方式:通过OpenClaw部署5个专属AI Agent,分别负责选品调研、视频制作、Reddit传播引流、亚马逊店铺运营以及客服回复。
成果:全业务流程自动化运转,每天节约4–5小时人工,月均总成本不足400美元。
亮点:多Agent协同作战,各司其职,输出品质稳定且可规模化。

案例3:公众号内容工厂——月收入突破 ¥10,000
实践者:自媒体创业者
运作方式:运用OpenClaw搭建自有内容生成系统,一个月内产出20多篇深度文章。
成果:用Agent完成热点监测、分析报告生成及内容发布,日常手动操作减少90%。
亮点:从“每天被任务追着跑”切换到“系统自动生产内容”,真正解放生产力。
案例4:AI数字员工团队
实践者:科技公司创始人
运作方式:招募6个OpenClaw AI Agent,每个只执行一项专业任务——文案撰写、图像生成、数据处理、邮件回复、竞品监控、报表产出。
成果:每天平均节省4–5小时,月度总成本控制在400美元以内。
亮点:不追求一个超级智能体包揽一切,而是让专业Agent各自深耕,效率倍增。

案例5:垂直SaaS产品
实践者:技术创业者
运作方式:将OpenClaw的核心能力封装成面向垂直行业的SaaS工具,锁定CRM、电商、客服等具体场景。
成果:Facebook API集成服务月收入$600,Reddit API集成$400/月,CRM集成$500/月。
亮点:提供确定性ROI的垂直场景,客户付费意愿强烈。
案例6:7小时赚取$10K
实践者:独立开发者
运作方式:利用OpenClaw快速打造一个直接解决用户痛点的小工具,并配合限时促销策略。
成果:7个小时内获得$10,000收入。
亮点:精准抓住市场窗口期,以最小可行产品(MVP)快速验证需求。
案例7:投研自动化
实践者:金融机构分析师
运作方式:用OpenClaw构建投研自动化系统,自动采集行业数据、生成分析报告并实时监控市场动态。
成果:原来需要团队一周完成的工作,现在由Agent在几小时内搞定。
亮点:高价值场景中,节约的时间直接转化为专业生产力。
案例8:电商选品工具
实践者:电商运营人员
运作方式:搭建OpenClaw驱动的选品监控系统,自动抓取淘宝联盟、多多进宝等平台数据,分析佣金率、销量走势和竞争饱和度。
成果:成功筛选出多款爆品,月度佣金收入提升3倍。
亮点:数据聚合与洞察能力正成为电商竞争的关键壁垒。
案例9:知识付费自动化
实践者:培训导师
运作方式:部署OpenClaw Agent自动解答学员疑问、输出课程纪要、整理常见问答库。
成果:客服人力成本降低70%,同时学员满意度显著上升。
亮点:知识付费的本质是服务,Agent将服务能力放大至千人千面。
案例10:多平台矩阵运营
实践者:MCN机构
运作方式:借助OpenClaw同时管理抖音、快手、小红书、视频号等10+个账号,自动完成内容生成、定时发布和数据分析。
成果:单人即可完成过去一个团队的工作量,月输出超100条短视频。
亮点:矩阵玩法的竞争力核心在于持续内容产能,AI正在彻底改写这一逻辑。
2026年墨西哥电商利润告急:销量尚在,利润蒸发,市场洗牌已至
许多卖家今年的共同感受如出一辙:销量仍在,利润却已消失;市场依旧存在,可打法和过去截然不同。
近来,我愈发明显地察觉到一件事:
2026年在墨西哥市场赚钱,确实变得十分艰难
(回想去年,不少人受困于物流问题,赚钱同样不易)
这并不是说墨西哥市场毫无机会,或者完全无法经营,
而是此前那种宽松的市场行情已经一去不返。
原先只要产品过得去,定价不算离谱,货物能发出,链接能正常运转,
就能获取不错回报的阶段,恐怕真的结束了。
一、今年的核心体感是:销量未必差,但利润极其难看。
成本上涨带来的压力实在沉重,
想提价,但又难以推动
从商业逻辑上,价格理应随成本上调。
因为成本切切实实增加了,平台代扣代缴的费用就摆在那里,
还有税务开支、合规投入等等。
可现实情况是,大量卖家就是不敢涨价。
二、并非单单一两家不易,身边多数同行也同样艰难
最近和不少做墨西哥市场的朋友交流,大家的体感高度接近。
一些朋友销量尚能维持,但利润率断崖式下跌。
有些朋友看着还在出货,可是仔细算账后,几乎没有任何实质盈利,
甚至在某些类目和部分链接上,已经亏本售卖,想不停都难。
这恰是最难受的地方。
如果货物根本卖不动,大家反而更容易下定决心,
该清仓清仓,该撤退撤退,该调整就调整。
然而当下的情形是:
货还能卖,链接还在动,销售额数字依然存在,可利润已经不见。
这让人极度纠结。
继续扛下去,感觉就是在苦熬;
就此作罢,又觉得市场尚在,机会仍存,心有不甘。
今年很多墨西哥卖家的处境,大概都卡在这种两难状态中。
三、真正实现盈利的墨西哥卖家,比例可能非常低
前段日子听一位行业资深人士给出判断:
今年在墨西哥切实盈利的公司,比例大概率不会超过10%。
这个数值不一定完全准确,
毕竟不同圈子所见的样本各异,各个平台、不同类目、各式店铺模式也有差别。
但从我自己的实际感知来看,这种判断至少并不是毫无根据的夸大。
2026年的墨西哥市场,确实远不如前两年那般顺遂。
从人们议论的焦点也能看清变化,
早几年的热点,是谁的账号如何布局、运营怎么攻防、增速有多高;
可今年大家再聊起墨西哥,越来越多地转向
利润还剩多少,税号到底办妥了吗,究竟继续坚守还是果断转型。
这已经说明,市场的整体环境和底层商业逻辑,发生了深度重构。
四、为何今年会如此难熬?
这一点我们此前也聊过,
市场价格并未普遍大幅上升,而中间凭空新增了代扣代缴的税务成本,
市面上还有大量商家在拼命出清库存,
同时也不断有外来卖家闯入(当然,涌向巴西市场的比进入墨西哥的还要多),
这些因素相互叠加,注定了市场的痛苦。
在行情如此的大环境下,即便每个参与者之间存在些许不同,
整体情况也好不到哪里去
(可能充当服务商是例外,毕竟他们是“卖铲子”的)。
五、未来的墨西哥市场,到底还能不能继续做?
1、从宏观层面来看,我认为仍然可以
毕竟市场规模可观,增幅也相对较高,
还具备一定程度的基建基础。
2、但不再是适合所有卖家无差别地继续投入。
如果你只是依赖低价铺货、信息差、短期红利,或是模糊的合规手段,那么前路只会越走越窄。
如果你握有供应链优势、产品差异化能力、长期合规能力,
具备本土化布局、充足的资金实力和组织能力,那么墨西哥依然值得深耕。
因为墨西哥市场自身并没有消亡,
只是经营门槛显著抬升,开始对卖家进行筛选。
过去的逻辑是:谁敢闯进来,谁就有机会。
未来则可能是:谁能实现长期主义,谁才真正有机会。
六、2026年墨西哥市场,极可能是一道分水岭
因此在我的判断中,2026年的墨西哥,非常可能成为一道明确的分水岭。
在这一年,大批卖家将重新审视墨西哥市场。
有人会选择退出,有人会主动收缩,
有人会切换平台,甚至彻底转变经营模式。
这个过程无疑会伴随剧烈阵痛。
但从行业进展的视角去看,这也十分合理。
任何一个市场,从早期的黄金红利迈向成熟竞争阶段,都必然要经过这样一场洗礼。