OpenHuman 桌面 AI 助手深度解读:记忆树、118+集成与智能 Token 压缩
OpenHuman 究竟是个怎样的存在?
OpenHuman 是一款开源的智能体助手,它的使命是深度融入你的数字日常——默认以隐私为先,开箱即用,并且威力强大到足以取代一堆零散且互不相通的 AI 工具。截至发文时间,从 2 月中旬上线到 5 月下旬这短短三个月内,OpenHuman 已在 GitHub 上揽获超过 24k stars。
大多数 AI Agent 一启动就要面对“冷开场”——你必须花上几天乃至数周向其灌输数据与上下文,它们才能开始发挥价值。而 OpenHuman 彻底颠覆了这一局面:只需关联你的各类账号,几分钟之内,Agent 就能完整压缩你的收件箱、日历、代码仓库、文档与消息记录。这得益于三大协同运转的架构支柱:Memory Tree 将所有已关联数据浓缩成精炼的 Markdown 文档;Auto-Fetch 以 20 分钟为周期循环同步你的账号信息;TokenJuice 则在任何数据进入大模型之前,先经过压缩层处理。最终的结果是,你从第一句对话开始,它就真正地“认识”你。
官网 / 安装入口:tinyhumans.ai/openhuman
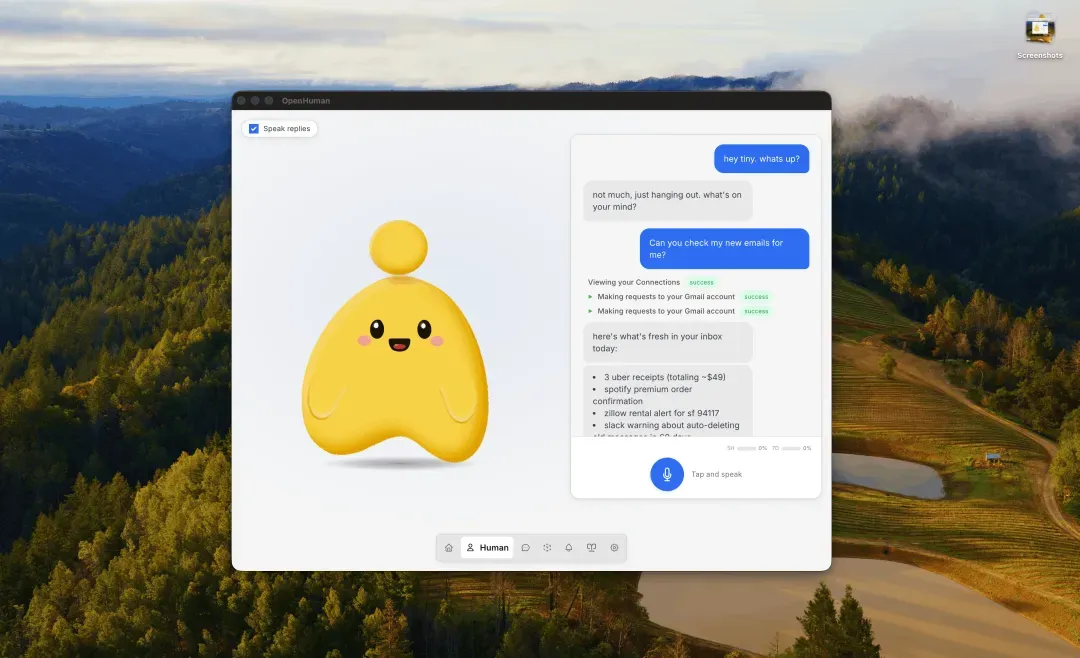
桌面截图
八大核心特色功能
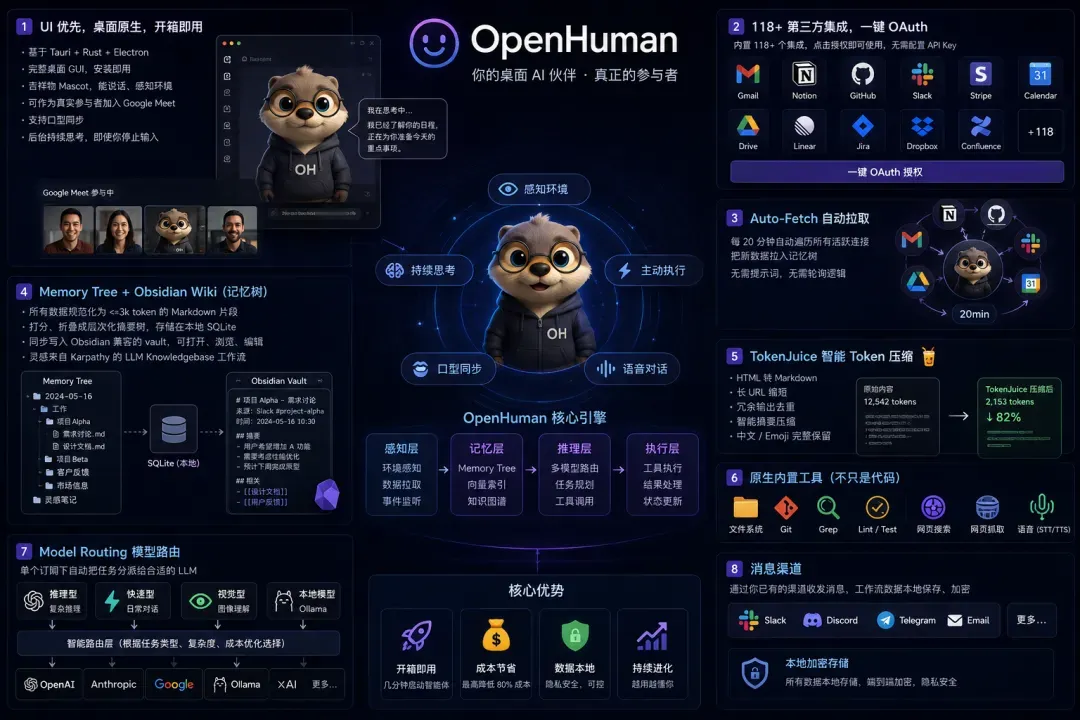
OpenHuman功能概览
1. 桌面优先,原生体验,开箱即用
拥有完整的桌面图形化界面(基于 Tauri + Rust + Electron 技术栈),安装后几分钟内就能跑起一个可用的智能体,完全不需要在终端里配置繁琐的 config。桌面还配有会说话、能感知周边环境的吉祥物,它可作为真实参与者加入 Google Meet 会议,并支持口型同步。即使你停止输入,它也会在后台持续思考。
2. 118+ 第三方集成,一键 OAuth
内置 Gmail、Notion、GitHub、Slack、Stripe、Calendar、Drive、Linear、Jira 等超过 118 个集成项,只需点击 OAuth 授权即可搞定,无需手动去配置 API Key。每一个连接都以类型化工具的形式暴露给 agent。
3. Auto-Fetch 自动拉取
每 20 分钟自治遍历所有活跃连接,将新数据拉入记忆树。你完全不需要写任何提示词或轮询逻辑,每天早上 agent 就已经为你准备好了当天的上下文。
PewDiePie的奥德赛四天5万星:用本地AI工作台走出Agent第二条路线
最近,海外开发者圈子里疯传一个项目——上线仅四天就在GitHub上收割了5万颗星,涨势凶猛得让人想起年初那款席卷全网的现象级工具。
夸张,却真实。
这个项目叫 Odysseus,背后的作者既不是传统人工智能公司,也不是哪家大厂的实验室,而是那个粉丝量级破亿的网红 PewDiePie。
起初,我以为它不过又是一个本地版的ChatGPT。毕竟现在这类项目满地都是,把大模型接过来,套层聊天界面,就推给用户。
然而真正跑起来之后,我才发现它最有意思的地方根本不在对话本身。
它更像是一间运行在你电脑里的AI工作室,或者说,是一个高度个人化的AI操作系统的早期形态。
换个角度去看,甚至可以把这里理解为AI Agent进化的第二条路径。
它把「本地部署大模型」这件事的门槛,压低了整整一个数量级。
怎么理解这一点呢?
太多人并不是不想运行本地模型,而是在第一步就被劝退了。
打开 Hugging Face,迎面而来的是 7B、8B、14B、32B、70B 这样的模型代号;再往下翻,又冒出 GGUF、Q4、Q5、FP8、AWQ 等一系列术语。你还得搞清自己显卡的显存大小、内存够不够用、该选 Ollama 还是 llama.cpp、是否要上 vLLM,模型下载完后该怎么部署,部署好之后又如何接入聊天界面……
明明只是想在自己的电脑上跑一个AI模型,结果还没触碰到真正的功能,就先被一堆黑话暴击了一遍。
Odysseus 最关键的地方,就扎在了这里。
它内建了一个名为 Cookbook 的功能模块,会先对你的硬件环境做一次扫描,看清你的CPU、内存、显卡、显存大概处于什么层级,然后主动推荐适合这台机器安装的模型。
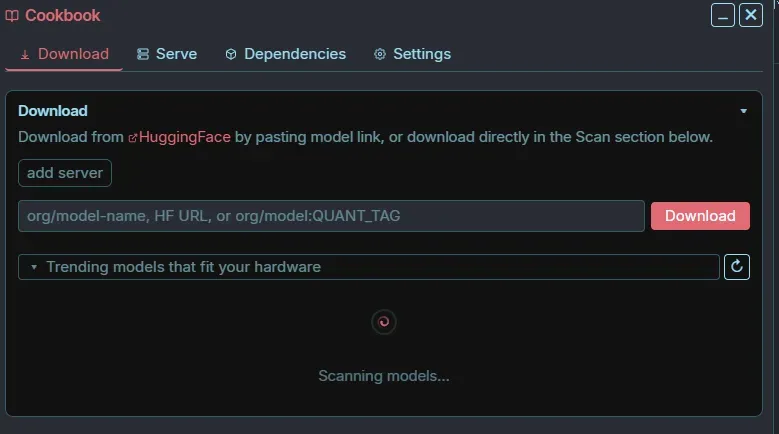
也就是说,它并不指望用户自己去揣测「我的电脑到底跑不跑得动8B」。它先替你过滤一遍:哪些模型比较契合你的配置,哪些模型可能太大拖不动,哪些版本更适合在本地部署。
接下来,你可以直接从Hugging Face 拉取模型,把它们下载到本地,再一键部署起来。
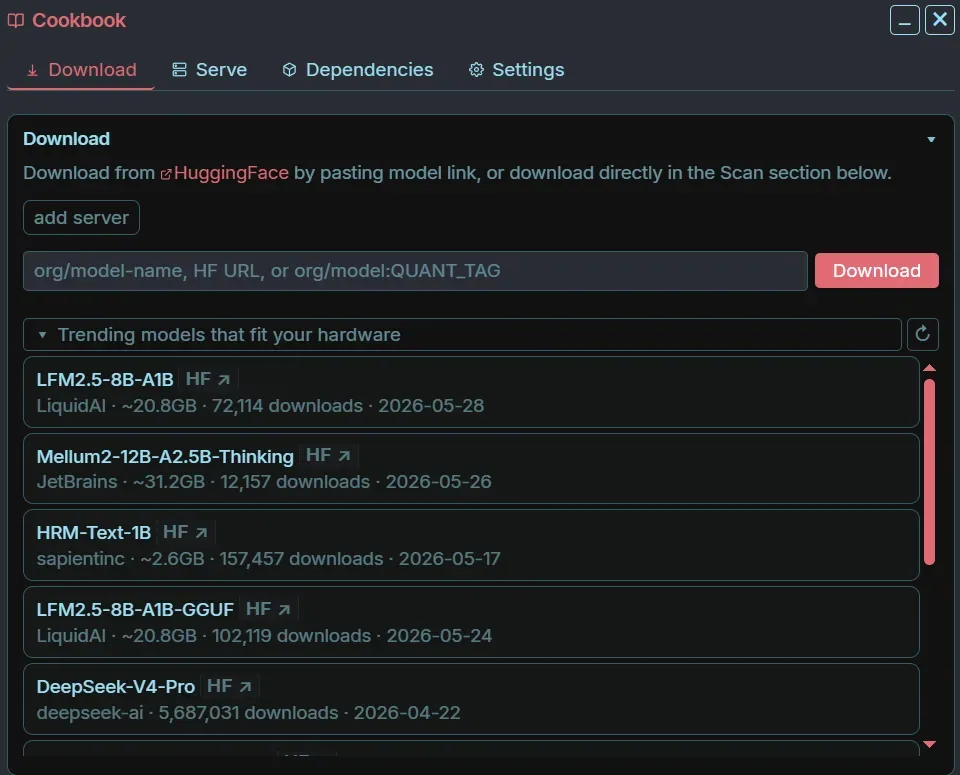
这个环节尤为关键。
因为在以前,本地模型最难的,从来不是「有没有模型」,而是「很多人根本弄不清自己到底能用哪个模型」。看到密密麻麻的参数就退缩的人比比皆是。但Odysseus想要实现的,正是把模型选择、下载、部署和调用这整条链路,都收纳进同一个工作台。
所以,这不单单是递给你一个聊天框,而是先为你推倒本地AI面前最高的那堵墙:你的电脑到底能跑什么。
当然,它也并不只服务于本地模型。
你同样可以接入 OpenAI、OpenRouter、Deepseek 这类云端 API。也就是说,轻量的、涉及隐私的任务,你可以尽量放在本地处理;遇到复杂的、需要更强模型的任务,随时切到云端大模型。
这才触达了它真正的精彩之处:并不是让用户在本地和云端之间做二选一的单选题,而是给你一个统一的AI工作台,由你自己来决定,什么数据留在本地,什么需求交给云端。
看到这一步,肯定有人立刻会问:那为什么不直接用 Codex?
这个问题得讲清楚。
如今的Codex已经进化成龙虾的升级版(注:此处指年初的某爆款项目),它所具备的 Computer use 能力已经能完成大量操作——看屏幕、点按钮、输入文字、调动你电脑上的各类应用。让它打开软件、检查网页、复现界面上的问题,几乎都能通过Computer use来搞定。

所以,如果你只是想要一个强大无比的AI操作员,Codex 当然非常强大。
但 Odysseus 和 Codex 本就是两个完全不同的事物。
Codex 更像是 OpenAI 提供的一位高级AI执行代理。它的强项在于模型能力、任务执行、代码理解、桌面操作和自动化。你把一个目标扔给它,它就能为你完成。
而 Odysseus 更像是一个构筑在你本地的AI中控台。它的关注点不在于能不能替你点鼠标,而是你的模型、你的数据、你的文档、你的记忆、你的工具,是否能尽量保留在你自己的环境里。
这恰恰是两者最根本的区别。
Pi-hole 全屋广告过滤实战:NAS 部署一次,全家上网更清净
眼下上网最让人头疼的未必是带宽不够,而是无处不在的广告和追踪探针。网页刚打开,广告位抢先渲染;点开一个 App,后台就冒出一连串数据上报请求;家中的手机、电脑、平板乃至电视盒子,都可能在你不经意间悄悄访问各类统计、跟踪和广告域名。
这次我们就在 NAS 上搭建一个“广告橡皮擦”——Pi-hole,把冲浪体验变得干净利落。
同类方案中,AdGuard Home 和 OxiDNS 也很出色,界面更现代,部署同样便捷,完全可以根据个人偏好选择。
Pi-hole 简介
项目在 GitHub 上的完整名称是 pi-hole/docker-pi-hole,搜索即可找到。
Pi-hole 是一款开源的网络级广告拦截工具,并非浏览器扩展或手机应用,而是一个部署在局域网内的 DNS 过滤服务。只要把终端设备的 DNS 指向 Pi-hole,从理论上说,局域网内所有设备都能享受到过滤效果。
其工作逻辑大致如下:
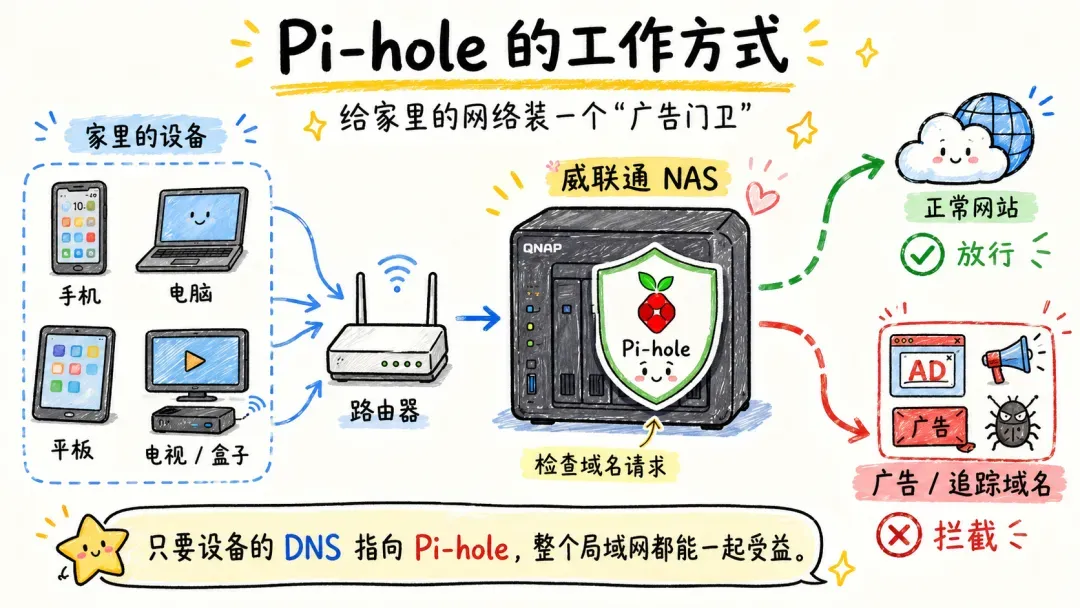
很多人可能会首先想到:这类 DNS 服务是否最好直接装到路由器里?其实,部署在路由器上并非必需。假如你的路由器性能足够、系统开放且支持 Docker,那么放在路由器里当然顺畅。但现实是,大量家用路由器并不具备这些条件。Pi-hole 的资源消耗很低,在 NAS 上运行后,只需让全屋设备将 DNS 指向这台 NAS 上运行的 Pi-hole,所有设备就都能一道受益。
当然,NAS 需要保持 24 小时开机,以确保服务始终在线。
核心特点
- 一次部署,全家受益:只要在路由器上将 DNS 指向 Pi-hole,局域网内所有设备就会统一通过它解析,无需在每台终端上单独设置。
- 新设备“零”配置:部署完成后,只需在路由器的 DHCP 设置中把 DNS 改为 Pi-hole 的 IP,此后新连上 Wi-Fi 的设备都会自动使用该 DNS。
- 图形化管理面板:自带 Web 管理界面,可直观查看拦截记录、每台设备的请求数量、拦截频率等信息。
- Docker 化部署:官方提供 Docker 镜像,部署灵活、资源开销小。
上手部署
本文以威联通 NAS 为例,采用 Docker Compose 方式进行部署。下面给出完整配置,你可以根据自己的环境适当裁剪:
Redis 分布式缓存实战:Java 企业级用户认证与缓存高可用设计
Redis 在分布式锁、限流等场景中的应用大家已经聊得很多了。
今天聚焦另一个高频使用场景——「分布式缓存」,并结合用户登录模块来深入拆解实现细节。
假设公司有一款日活百万的 App,用户登录成功后获得一个 token,后续所有 HTTP 接口访问都需在请求头中携带该 token。
业界标准方案非常简单:登录成功后,直接将用户状态(Token + 核心信息)整体写入 Redis。后续每个请求带着 Token 进来,服务端直接查 Redis 进行校验,毫秒级响应,既快又稳。
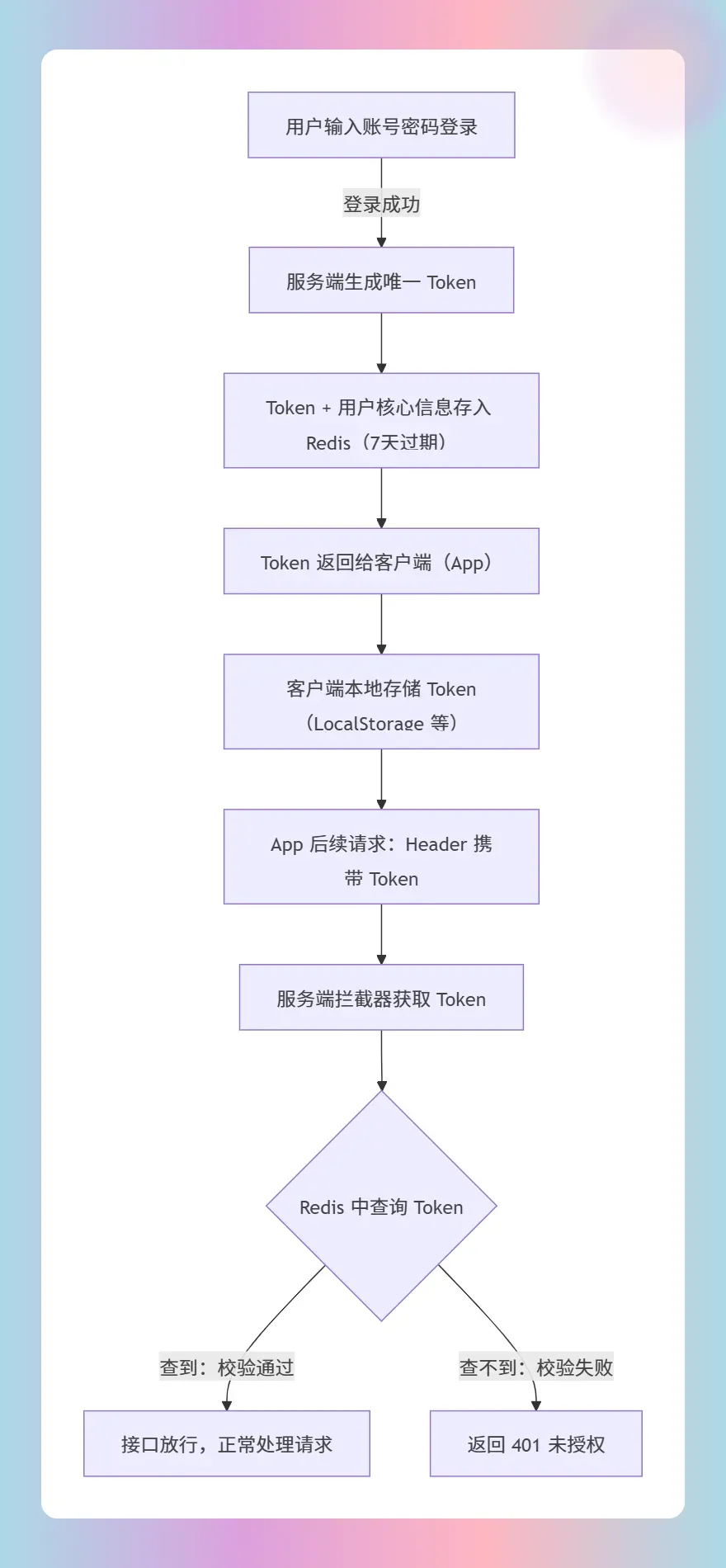
✿一、具体业务流程
- 发放令牌:用户输入账号密码登录成功,服务端现场生成唯一 Token。
- 写入 Redis:将 Token 和对应的用户关键信息存入 Redis,并设置过期时间(此处采用 7 天)。
- 客户端保管:Token 返回给 App,App 自行存储本地(如 LocalStorage 等)。
- 携带令牌访问:App 所有后续接口请求,均在 Header 中带上该 Token。
- 拦截器校验:服务端拦截器获取 Token 后直接查询 Redis。查到则放行,查不到直接返回 401。
✿二、核心代码
技术栈采用 Spring Boot + RedisTemplate。为直观展示,Token 使用 UUID 生成。
实际项目中也可选择 JWT,但注销逻辑仍需借助 Redis 黑名单,各方案都有各自的取舍。
1、登录成功后生成 Token 并写入缓存
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* 认证服务 - 负责发放"通行证"
*/
@Service
public class AuthService {
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Resource
private UserService userService;
public LoginResult login(String phone, String password) {
// 1. 校验用户身份
User user = userService.findByPhone(phone);
if (user == null) {
throw new RuntimeException("用户不存在");
}
// 密码必须使用 BCrypt 算法比对,切忌明文存储或自行编写加密逻辑,这是血的教训
if (!user.getPassword().equals(encryptPassword(password))) {
throw new RuntimeException("密码错误");
}
// 2. 生成 Token,添加 APP_ 前缀便于运维在 Redis 中快速识别
String token = "APP_" + UUID.randomUUID().toString().replace("-", "");
// 3. 构建缓存对象,仅存储最核心信息,越轻量越好
LoginCacheUser cacheUser = new LoginCacheUser();
cacheUser.setUserId(user.getId());
cacheUser.setPhone(user.getPhone());
cacheUser.setNickname(user.getNickname());
// 4. 写入 Redis,Key 命名需规范,便于后续清理与管理
// 格式:app:login:token:{token},有效期 90 天,具体天数可配置到 Apollo
String redisKey = "app:login:token:" + token;
redisTemplate.opsForValue().set(redisKey, cacheUser, 90, TimeUnit.DAYS);
// 5. 返回给前端
LoginResult result = new LoginResult();
result.setToken(token);
result.setUserInfo(new UserVo(user));
return result;
}
}
2、拦截器逻辑
App 端发起请求时,会在 Header 中携带 Token,例如:X-Auth-Token: APP_xxxxxxx。
Redis限流实战:精准保护短信验证码接口,杜绝恶意刷量
一、短信限流背景
在企业业务中,许多场景都依赖短信发送。例如,用户注册或登录流程中,短信验证码是确保安全验证的核心环节。因此,涉及企业成本的关键环节必须全面考虑异常情况,否则可能造成严重经济损失。
短信服务成本较高,必须实施限流措施,防止恶意刷量:
- 恶意攻击者利用脚本高频调用短信接口,导致短信费用急剧上涨。
- 业务安全风险:验证码可能被暴力破解,威胁用户账号安全。
- 服务资源过度消耗:大量无效请求会快速耗尽系统资源。
曾有一家电商平台在上线初期就遭遇此类攻击,当日短信费用飙升至正常水平的10倍以上。

二、核心代码实现
1. 限流配置类
@Component
@ConfigurationProperties(prefix = "sms.rate-limit")
@Data
public class RateLimitConfig {
// 手机号频率限制:60秒内仅1次
private long phoneInterval = 60;
private int phoneMaxAttempts = 1;
// IP总量限制:24小时内不超过100次
private long ipInterval = 24 * 60 * 60;
private int ipMaxAttempts = 100;
}
2. Redis限流服务
整个Service可直接复用,通用性强。
@Service
@Slf4j
public class SmsRateLimitService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private RateLimitConfig rateLimitConfig;
private static final String PHONE_PREFIX = "sms:phone:";
private static final String IP_PREFIX = "sms:ip:";
private static final String GLOBAL_KEY = "sms:global";
/**
* 检查是否允许发送短信
*/
public RateLimitResult checkRateLimit(String phoneNumber, String clientIp) {
RateLimitResult result = new RateLimitResult();
// 检查手机号频率限制
if (!checkPhoneLimit(phoneNumber)) {
result.setAllowed(false);
result.setMessage("操作过于频繁,请60秒后再试");
return result;
}
// 检查IP总量限制
if (!checkIpLimit(clientIp)) {
result.setAllowed(false);
result.setMessage("今日发送次数已达上限");
return result;
}
result.setAllowed(true);
return result;
}
/**
* 手机号频率限流检查
*/
private boolean checkPhoneLimit(String phoneNumber) {
String key = PHONE_PREFIX + phoneNumber;
return checkAndIncrement(key, rateLimitConfig.getPhoneInterval(),
rateLimitConfig.getPhoneMaxAttempts());
}
/**
* IP总量限流检查
*/
private boolean checkIpLimit(String clientIp) {
String key = IP_PREFIX + clientIp;
return checkAndIncrement(key, rateLimitConfig.getIpInterval(),
rateLimitConfig.getIpMaxAttempts());
}
/**
* 通用的Redis限流检查方法
* 使用Lua脚本保证原子性操作,避免并发问题
*
* @param key Redis键
* @param interval 时间间隔(秒),在此时间窗口内进行限流计数
* @param maxAttempts 最大允许尝试次数,超过次数则触发限流
*/
private boolean checkAndIncrement(String key, long interval, int maxAttempts) {
try {
// 采用Lua脚本确保原子性
String luaScript =
"local current = redis.call('get', KEYS[1]) " +
"if current and tonumber(current) >= tonumber(ARGV[1]) then " +
" return 0 " +
"else " +
" redis.call('incr', KEYS[1]) " +
" if tonumber(current) == 0 then " +
" redis.call('expire', KEYS[1], ARGV[2]) " +
" end " +
" return 1 " +
"end";
RedisScript<Long> script = RedisScript.of(luaScript, Long.class);
Long result = redisTemplate.execute(script,
Collections.singletonList(key),
maxAttempts, interval);
return result != null && result == 1;
} catch (Exception e) {
log.error("Redis限流检查异常, key: {}", key, e);
// Redis异常时,为保障主流程可用,默认放行
return true;
}
}
}
3. 业务服务层
@Service
@Slf4j
public class SmsService {
@Autowired
private SmsRateLimitService rateLimitService;
@Autowired
private SmsProvider smsProvider;
/**
* 发送短信验证码
*/
public SendSmsResult sendVerificationCode(String phoneNumber, String clientIp) {
// 1. 限流检查
RateLimitResult limitResult = rateLimitService.checkRateLimit(phoneNumber, clientIp);
if (!limitResult.isAllowed()) {
log.warn("短信发送被限流, phone: {}, ip: {}, reason: {}",
phoneNumber, clientIp, limitResult.getMessage());
return SendSmsResult.fail(limitResult.getMessage());
}
// 2. 生成验证码
String verificationCode = generateVerificationCode();
try {
// 3. 调用短信服务商API
boolean sendResult = smsProvider.sendSms(phoneNumber,
"您的验证码是:" + verificationCode + ",5分钟内有效");
// 其他业务操作
} catch (Exception e) {
log.error("短信发送异常, phone: {}", phoneNumber, e);
return SendSmsResult.fail("系统异常,请稍后重试");
}
}
private String generateVerificationCode() {
// 生成6位随机数字验证码
Random random = new Random();
return String.format("%06d", random.nextInt(1000000));
}
private void saveVerificationCode(String phoneNumber, String code) {
String key = "sms:code:" + phoneNumber;
redisTemplate.opsForValue().set(key, code, 5, TimeUnit.MINUTES);
}
}
该方案已在多个生产环境稳定运行,日均处理百万级短信发送请求,有力保障了系统的稳定与安全。
Spring Boot 微服务开发实战:OpenCode 智能助手全流程指南
Java 开发者长期受困于效率低下的编程工具——将 Spring Boot 与 OpenCode 结合,开发效率可以获得质的飞跃。在阅读完前 9 篇教程后,你已经全面掌握了 OpenCode 的功能。现在,让我们用一个完整的 Spring Boot 微服务项目,把所有知识串联起来——从项目初始化到 Docker 容器化部署,全程使用 OpenCode 辅助完成。
本章目标
我们将使用 OpenCode 构建一个用户订单管理微服务,包含以下技术栈:Spring Boot 3.3 + JDK 17,JPA 数据持久化(MySQL),RESTful API(CRUD + 分页查询),JWT 认证与权限控制,全局异常处理,以及 Docker 容器化部署。在整个过程中,你会看到如何逐步向 OpenCode 下达指令,并观察它如何辅助完成工作。
一、项目初始化
1.1 创建项目结构
在终端打开工作目录并启动 OpenCode,然后发出指令:
你:请帮我创建一个 Spring Boot 3.3 微服务项目,项目名为 user-order-service,采用 JDK 17 和 Maven 构建。要求生成标准的包结构,包含 controller、service、repository、model、dto、config、security 七个包。
OpenCode 随即生成如下目录结构:
user-order-service/
├── pom.xml
├── src/
│ └── main/
│ ├── java/com/example/userorderservice/
│ │ ├── controller/
│ │ ├── service/
│ │ ├── repository/
│ │ ├── model/
│ │ ├── dto/
│ │ ├── config/
│ │ └── security/
│ └── resources/
│ └── application.yml
1.2 /init 生成 AGENTS.md
你:请运行 /init 为项目生成 AGENTS.md
OpenCode 会分析项目结构并生成 AGENTS.md:
Token 消耗暴降七成!AI 编程新利器 CodeGraph:用代码知识图谱终结「Context Rot」
借助 Claude Code 或 Cursor 写代码,效率确实高到飞起。但真正深入用过一阵子的人,大概率都撞上过同一个痛点:Token 烧得飞快。尤其在中大型项目里,随口问一句“这个登录流程怎么串联起来的”,AI 就会翻遍整个仓库,反复读取几十个文件,一轮查询就能烧掉六位数 Token。
月末打开 API 账单的那一刻,心情可谓五味杂陈。
最近,我在 GitHub 上发现了开源项目 CodeGraph,上线没几天就冲进 Trending 榜,Star 数一路暴涨。
它的定位非常直接:为代码库构建一张知识图谱,让 AI 编程工具不再靠蛮力翻找文件,而是像翻字典一样精准定位。
原理并不难理解。
过去问 AI 一个架构问题,它得先全局搜索关键词,然后依次打开相关文件读完,再判断哪个是入口、哪些是被调用的辅助函数。一套流程走下来,可能动辄几十步。
引入 CodeGraph 之后,AI 直接查询图谱,一次性拿到完整的调用链和符号关系。几十步被压缩到一两步,Token 自然省下来了。

官方在 7 个真实开源项目上,用 Claude Opus 4.7 做了对比测试,每个问题跑 4 次取中位数。
结果相当可观:平均费用降低 35%,Token 消耗减少 59%,响应速度提升 49%,工具调用次数锐减 70%。
具体到某些项目上,差异更为惊人。比如在 VS Code 这种拥有上万文件的项目中,Token 直接减少 73%;而在 Tokio(Rust 异步运行时)上,费用节省了 52%。
这组数据是借助 claude -p 进行无头测试得出的,WITH 和 WITHOUT 两个对照组使用相同的问题、相同的代码,模型自带的 Read/Grep/Bash 能力全部保留,唯一的变量就是是否开启 CodeGraph 的 MCP 服务器。
Token套餐发展图鉴:从限量抢购到按需付费的理性回归
近期两条消息引发热议:电信推出了Token套餐,DeepSeek则把折扣永久化,V4‑Pro价格直降75%,缓存命中每百万token仅需两分五。二者并行出现,让人顿感割裂——一边是运营商亲自下场兜售套餐,一边是直接击穿价格底线。谁在为你的问题提供解法,谁又在解决自己的生意,一目了然。
回看Token套餐这半年多的历程,很值得玩味。
Coding Plan:疯抢背后的虚妄
最早的形态是Coding Plan。去年底到今年初,平台密集上线,智谱、阿里百炼、字节Trae、百度千帆、Kimi,无一缺席。
定价极具诱惑:便宜到每月9.9元,贵一点的200元包月,按调用次数计费。“5小时窗口内1200次请求,月保障18000次”,一看便觉得近乎白送。
于是你加入了抢购大军。每天按时补货、限量发售,售完即止。
不少用户曾蹲守智谱、腾讯的套餐,提前守候页面,倒计时结束立即点击,结果瞬间已无库存。细想之下颇为荒诞:数字产品搞限量抢购,服务器持续运转,稀缺感从何而来?无非是制造紧迫,让人来不及算清账目便匆忙下单。
即便抢到手,坑也不少。一个提示词并不等于一次调用。Agent模式下,后台触发少则5次、多则30次模型交互,号称1200次的额度几十轮对话便耗尽。加上5小时窗口的限制,上午额度用光,下午想继续写代码只能干等。花钱买来的服务,居然还得排队。
更隐蔽的还有消耗倍率。火山引擎的Coding Plan中,不同模型的消耗倍数迥异,有用户实测发现,动不动就被乘以6倍甚至10倍。表面是按次数收费,实际token消耗比直接按量计价更快。知乎上有用户吐槽:“问两个问题,5小时1200次的额度就归零了。”
Token Plan:遇冷背后的逻辑
此后,平台意识到Coding Plan赚不到钱,纷纷下架,转向了Token Plan。
Token Plan按token结算,比如99元买2亿token,看似更透明,用多少扣多少。
然而上线后,再无人抢购。各大平台货架满满,闹钟也彻底失了用武之地。
究其原因,Token Plan揭开了Coding Plan时期被掩盖的种种问题。
第一,月底强制清零。 这是最大的痛点。花99元购入2亿token,当月没用完,次月自动归零,不结转、不累积、不退费。本质上,你购买的是“当月有效消费券”。若出差数日未用,额度蒸发;身体不适几天没写代码,同样作废。掘金有分析文章直言不讳,标题就叫《大模型套餐“月底清零”:消费者权益的灰色地带》。
第二,实际消耗远超预期。 Agent模式下,一个复杂编程任务可能消耗上百万token。2亿看似充裕,真要认真用一个月,支撑不了多久。而且不同模型的token消耗计算各异,事前极难估算。
第三,生态锁定如影随形。 在一个平台充值的token,只能在该平台消耗。想换工具?不行。想换模型?不行。觉得服务质量下滑想离开?余额还困在里面。
于是出现了两难局面:需要高频率使用AI的用户,算下来发现直接调用API反而更省钱;没需求的人,又抗拒为一个会过期的虚拟资产埋单。两边不讨好。
API 接入:按需消费的真正自由
最终,人们将目光转向了API接入。
API是充值使用模式,充多少用多少。最大的好处是充值永久有效,永不过期。你充100元,用一个月或者一年,都不会因为某个月使用量少而被清零。你的钱始终是你的钱。

更灵活的是,你可以同时接入多家服务。DeepSeek便宜就用DeepSeek,kimi效果出色就用kimi,哪家发布新模型就去体验,哪家物美价廉就长期使用。无需被任何单一平台绑定,选择权牢牢握在自己手中。
更重要的是,API接入会促使你主动学会管理token:优化上下文、压缩提示词、提升缓存命中率。这些能力,是Coding Plan永远无法赋予的。当你能追踪每一分钱的去向时,使用反而更加高效。
DeepSeek 成为必备选择的底层逻辑
当其他平台还在组合套餐、设计限量抢购、玩隐藏倍率时,DeepSeek只做了一件简单的事:把价格降到所有人都感到合理的位置,然后不再折腾用户。
不搞抢购,不设清零,没有隐藏倍率。用了多少就付多少,资金始终属于你。
正因如此,它成了每个AI玩家的标配。不是因为功能无人能及,而是因为它不套路你。
Coding Plan和Token Plan都是过渡产物。运营商都开始售卖Token套餐,说明这种模式还能继续内卷一段时间。但最终方向必然指向API接入——价格透明、选择自由、永不过期、不讹不绑。
DeepSeek的这次降价,正是朝着这个方向一次完美的迈进。
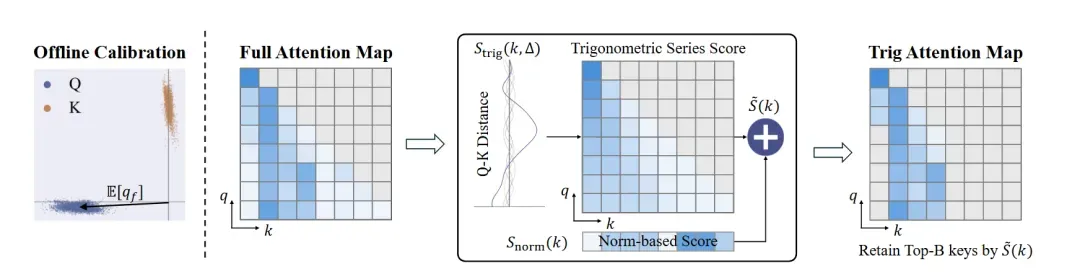
TriAttention:面向长文本推理的高效KV缓存压缩,2.5倍吞吐提升与10.7倍内存缩减
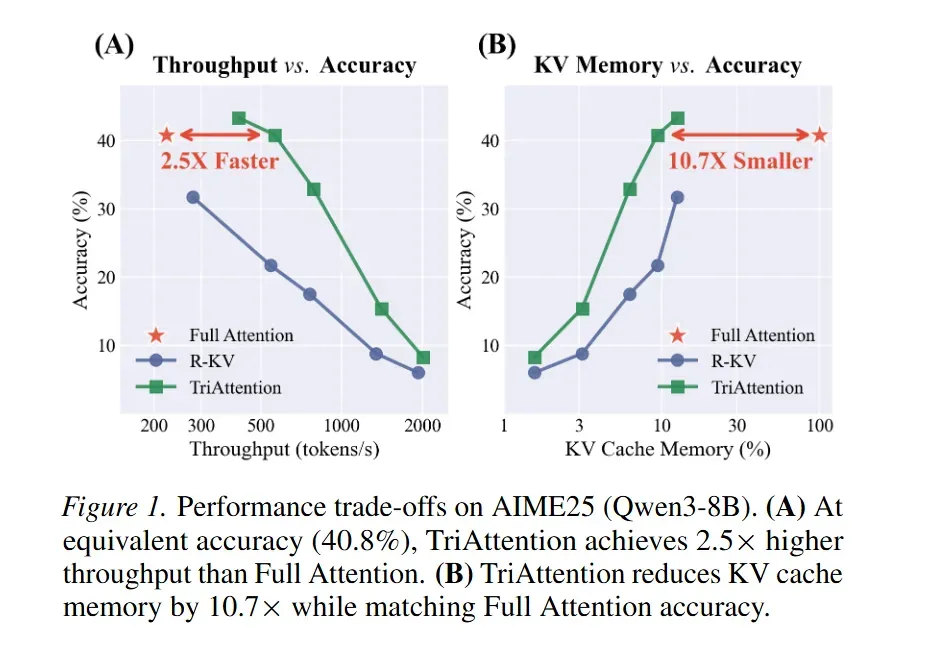
TriAttention 是一项专为大模型长文本推理设计的高效KV 缓存压缩方法,直击传统 Post-RoPE 压缩因查询位置旋转导致的关键键筛选失效、推理不稳定等痛点。该方法发现 Pre-RoPE 空间中 Q/K 向量高度集中于固定非零中心的核心特性,通过三角级数刻画注意力距离偏好,并结合 Q/K 范数自适应加权来筛选关键 KV 对。在 32K token 的 AIME25 任务中,TriAttention 匹配全注意力推理精度,实现2.5 倍吞吐量提升、10.7 倍 KV 内存缩减,显著超越 SnapKV、R-KV 等基线,使单张消费级 GPU 即可部署长推理模型。
论文链接:https://arxiv.org/abs/2604.04921
开源链接:https://github.com/WeianMao/triattention
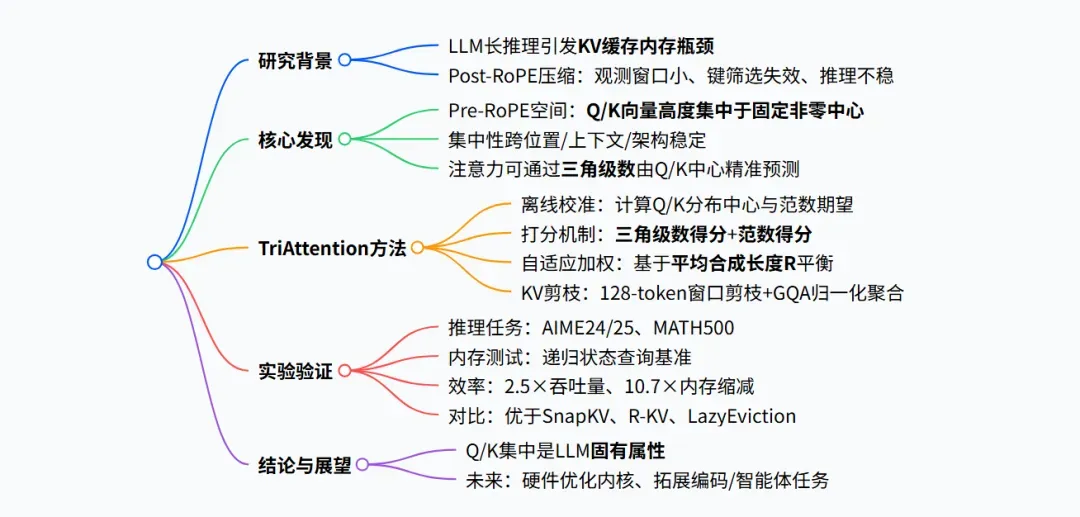
背景:LLM 长推理的 KV 缓存瓶颈与传统方法的不足
- 核心痛点:大语言模型在生成长达数万 token 的序列时,KV 缓存会随序列长度线性膨胀,引发严重的 GPU 显存瓶颈,直接阻碍长推理任务的部署与执行。
- 传统 Post-RoPE 压缩方法的局限:
- 依赖 Post-RoPE 查询计算注意力分数,由于查询经过 RoPE 位置旋转,有效观测窗口仅约 25 个查询,重要键极易被错误移除。
- 范数类方法只利用向量幅值,忽略了方向信息,导致重要性评估不完整。
- 长推理过程中关键 token 的丢失会破坏思维链,造成推理精度断崖式下降。
突破性发现:Pre-RoPE 空间中 Q/K 向量的高度集中特性
- Q/K 集中现象:在 Pre-RoPE 空间中,绝大多数注意力头的 Q/K 向量高度聚集于非零固定中心,这一特性跨位置、上下文乃至不同模型架构均保持稳定。
- 量化指标:使用平均合成长度 R(Mean Resultant Length) 来评估集中程度,R→1 表示完全集中;在 Qwen3-8B 中,约 90% 的注意力头 R 值超过 0.95。
- 注意力预测原理:当 Q/K 高度集中时,注意力 logit 可简化为仅与 Q-K 相对距离相关的三角级数,由此可通过 Q/K 中心精准预测注意力模式,注意力重建的相关系数均值超 0.5,单头最高可达 0.72。
TriAttention 方案设计:双维度打分与自适应 KV 压缩
VibeCoding 大型复杂项目实战:Superpowers + Codex + Claude Code + Kimi 2.6 工具组合全解析
这两年,随着 AI 编程工具功能日趋强大且不断进化,使用门槛已大幅降低。如果你的项目只涉及前端页面,不牵扯后端逻辑和数据库操作,那确实很简单——毕竟主流 AI 编程工具写前端的能力普遍不差。

我身边越来越多非技术背景的朋友也开始用 AI 写代码,从产品经理到设计师,甚至完全不会编程的运营同学,都纷纷尝试用 AI 做出点东西。但问题也随之而来。
很多人试过之后,体验并不好。它远没有网上一些博主渲染得那么简单,尤其是在面对大型复杂项目时。对于没有系统学习过编程、缺少项目经验的非开发者来说,很难真正把控全局。自己玩玩尚可,一旦要直接给用户使用、尤其涉及资金安全,就极容易出问题。

AI 并非万能,它就像一位技术很强但毫无项目经验的新人。你不给它明确方向,它就盲目乱干;不给它清晰流程,它就横冲直撞。
因此,这篇文章我想分享自己在 VibeCoding 中,目前摸索出的最佳工具组合。为什么要强调“目前”?因为 AI 发展实在太快了。 这套组合拳,是我踩过不少坑之后沉淀下来的。
这套组合拳即:Superpowers + Codex + Claude Code + Kimi 2.6

需求梳理与架构设计:Superpowers
不知道你有没有这种感觉:用 AI 开发时,最怕的不是它写不出代码,而是它一上来就直接写。如果你没有把需求表述清楚,AI 大概率会偏离方向,等写了一大堆才发现全不对,只能推倒重来。偏偏清晰表达本身就很困难——有时候我们自己也不完全清楚到底需要什么。
这个问题,我在之前一篇文章里专门讨论过,核心症结在于缺少一套标准的工作流程。而 Superpowers 这个开源项目,正是为此而生。
将近 200k Star,相当惊人。
✅ GitHub 项目地址如下: https://github.com/obra/superpowers
Superpowers 是一套指导 AI Agent 编程的Skill,它会强行在你的开发流程里插入一套结构化链路:先进行头脑风暴,把需求彻底聊透;接着做架构设计,给出多个方案让你选择;然后拆解成 2 到 5 分钟就能完成的小任务;最后才开始写代码。更关键的是,写完还会自动审查——每个小任务要过两道检查,一道核实需求是否完成,一道审视代码质量是否过关。全部结束后,再来一轮全局审查,确保整个系统能顺畅集成。
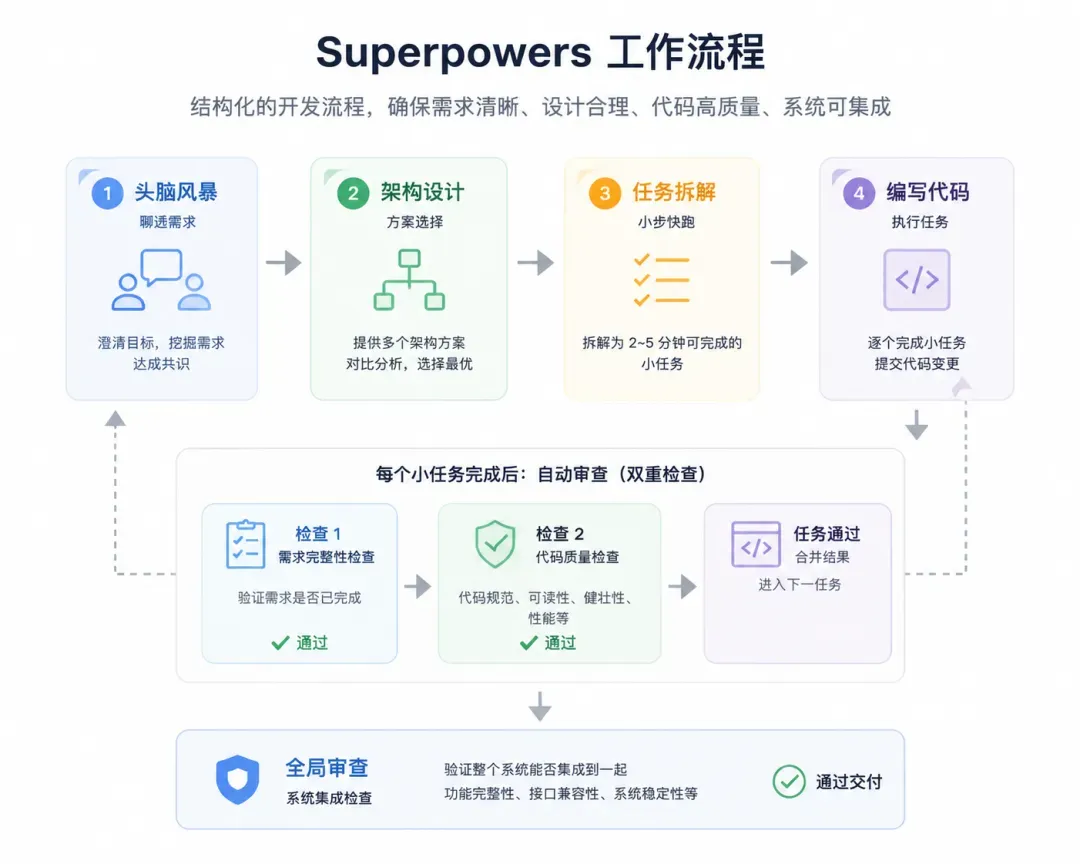
在项目启动之初,先用 Superpowers 把架构和需求理清楚,后面能少走太多弯路。
比如,我想让 AI 帮我做一个 AI Coding 的 Agent。它会主动向我确认方案和功能;中途要加什么或者有疑问,它都会给出建议并让我做选择。对于那些我们不太理解的需求或功能,它也能提供很有见地的方案。
需求确认后,它会生成一份设计文档。
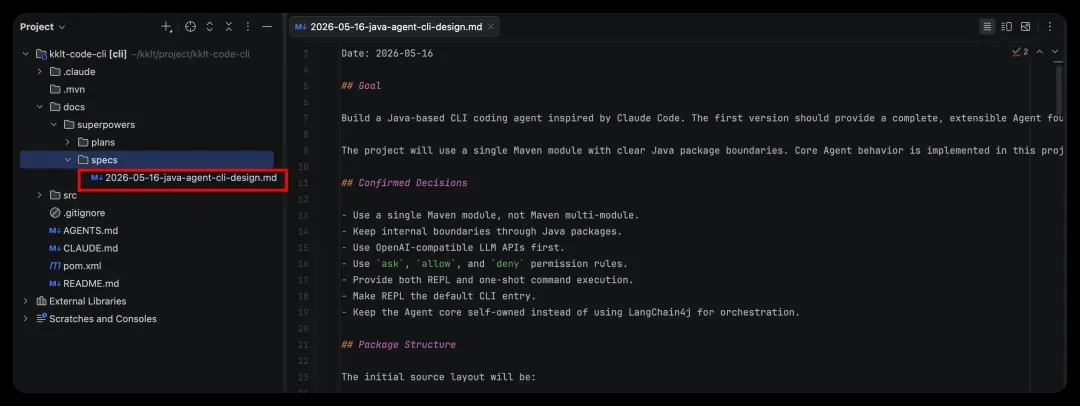
等你确认之后,它会基于这份设计文档,生成一份计划书。