告别论文生成器:构建13 Agent文献调研+12 Agent写作+审稿的全流程学术Agent操作系统
过去一年,AI Agent 最受瞩目的方向之一,就是让大语言模型不再仅充当“问答工具”,而是真正去承担完整的工作闭环。在学术研究这个垂直领域,最稀缺的已不是“论文生成器”,而是:
- 能够统筹研究流程的系统
- 支持多轮推理与交叉验证的智能体
- 可以接入阶段管理与质量门控的流水线
- 能在“调研 → 写作 → 审稿 → 修改”中持续协同的Agent体系
这正是 academic-research-skills 试图解决的课题。
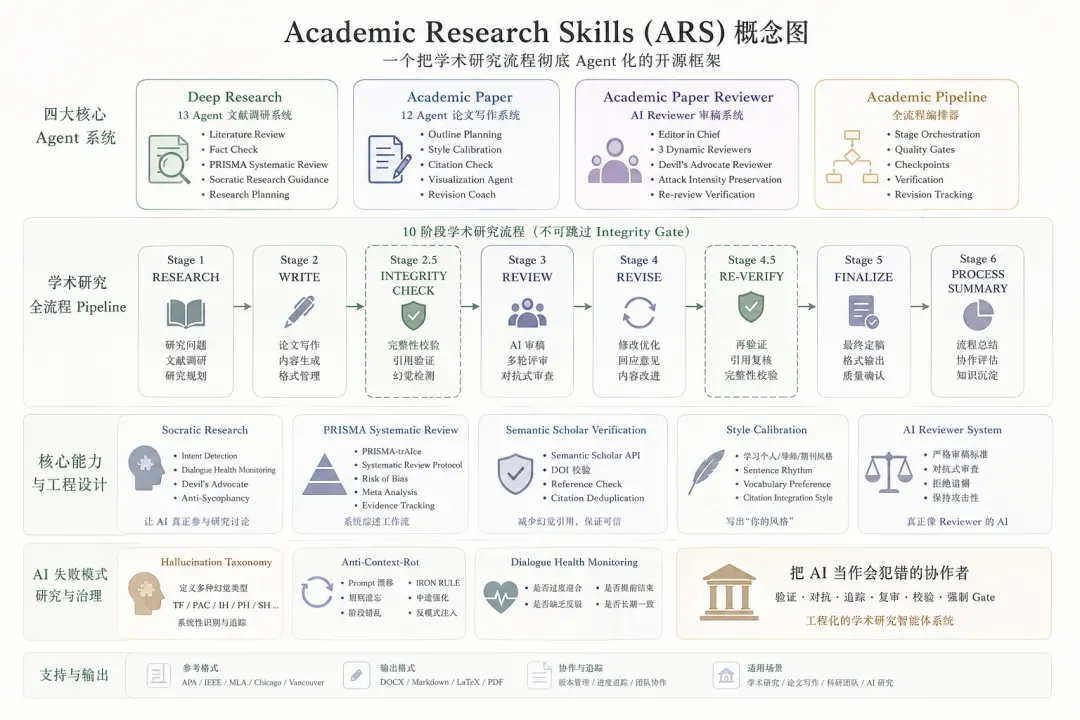
它绝非普通的 Prompt 仓库,而是一个完整的学术Agent操作系统(Academic Agent Operating System)。
项目地址:https://github.com/Imbad0202/academic-research-skills
Academic Research Skills
一、这是研究工作流系统,而非文本生成器
市面上大量AI学术工具,本质上都停留在“帮我写一篇论文”的层面。Academic Research Skills(以下简称 ARS)所做的远不止文本输出。它真正探索的是:如何开展研究、如何组织研究过程、如何进行质量控制、如何避免模型幻觉、如何保证引用可信、如何实现 Reviewer 级别的同行评审,以及如何完成修改闭环。
于是,ARS 构建出了一条清晰的研究流水线:
Research
↓
Paper Writing
↓
Integrity Verification
↓
Peer Review
↓
Revision
↓
Finalization
换句话讲,ARS 并非“写论文的AI”,而是“研究流程的智能体”。
二、项目整体架构:四大核心Agent系统
整个仓库以4个大型Skill模块构建起学术研究的基础骨架:
| 模块 | 职能 |
|---|---|
| Deep Research | 文献调研与研究规划 |
| Academic Paper | 论文写作 |
| Academic Paper Reviewer | Reviewer审稿系统 |
| Academic Pipeline | 全流程编排器 |
这些模块并非孤立存在,而是被设计为一条可以串联运行的完整链路。
告别天价Token!开源AI Agent OpenClacky:极致省钱的个人助理,账单仅需同行六分之一
过去一年,人们对 AI Agent 的态度颇为矛盾。尤其是“小龙虾”爆火之后,大家都知道它有用——写代码、做 PPT、查资料、跑流程都不在话下。它确实能把原本需要反复切换软件、查格式、盯进度的工作一口气推进一大步。但当真要用到日常工作中时,心里难免会嘀咕:这次又要烧多少 Token?账单会不会又爆了?不少用户已经弃用 OpenClaw,原因无他,太烧钱。一个工具,如果每次打开前都得先算账,那它就很难成为值得信赖的个人助理。这也意味着 AI Agent 赛道已进入全新阶段。上半场,大家比拼的是谁更聪明、谁能跑更复杂的任务,谁更像 Devin 或 Claude Code;现在,焦点已转移到一个更根本的问题:谁能真正让用户每天都敢打开?
最近,一款名为 OpenClacky 的开源 Agent 吸引了我,它把答案押在了“最省 Token”上。
它没有定位成“功能最全的 Agent”,也没堆砌炫技概念。OpenClacky 的目标清晰而务实:成为最省 Token 的开源 AI Agent。它基于 MIT 协议 100% 开源,支持本地运行;既能像 Claude Code 那样在终端中工作,也提供 Web UI、多 Session、长期记忆、Skill 功能、定时任务、飞书/企业微信/微信接入和浏览器自动化。一个面向普通用户的 Agent 该有的都有,而它将“省 Token”置于设计的核心。官方报告显示,在对三项真实任务进行的同 prompt、同模型、同 Skill、同时段对比测试中,OpenClacky 的花销最低。同样的三个任务,OpenClacky 的总账单约为 Hermes Agent 的 1/6,OpenClaw 的 1/3,甚至比 Claude Code 还略低一些。
那么 OpenClacky 是如何做到这一切的?背后是一套极度克制的工程策略:少重启会话,少改动系统提示词,少携带无关工具,少直接回塞完整历史上下文。
第一项选择:尽量保持 Session 稳定,少动 System Prompt。Agent 执行任务时必须携带大量背景信息。如果会话频繁重启、System Prompt 经常变化,Skill 重新加载就会扰乱上下文,导致缓存轻易失效。缓存一失效,相同的信息就要重复付费。OpenClacky 的做法是确保主会话尽量稳定,Skill 重载、模型切换、上下文压缩等动态变化不会直接卷入主会话,而是通过独立的 session context 注入。这样,已缓存的内容可继续复用,Agent 就不必每次干活都重新“认识”你一遍。
国内安装Codex免验证对接DeepSeek,零基础也能轻松上手(保姆级教程2026)
昨天凌晨,OpenAI 举办了一场名为 “Intelligence at Work” 的线上发布会,释放了两个重磅信号。
第一,Codex 的周活跃用户已经突破 500 万,而且其中有 20% 并非传统开发者,而是分析师、营销人员、运营、设计师、投资人等多元角色。这个非开发者群体的增长速度是开发者群体的 3 倍以上。
第二,同时发布了 6 款针对特定岗位的专属插件,涵盖数据分析、创意制作、销售、产品设计、投资银行等领域。每款插件内置了 62 个高频应用和 110 项技能,全程无需编写一行代码即可投入使用。
意思非常明显:Codex 不再甘心只做程序员的工具,而是要全面进入每一个人的办公桌。
这个数据让我颇感意外,原本一直以为 Codex 只是属于程序员的小众玩具。也正是这条消息,让我下定决心有深入折腾一番 Codex 的冲动。
下面,我将会给大家详细拆解:在国内如何顺利完成 Codex 的安装、怎样对接第三方大模型,以及几个真正能用在日常工作里的实用技巧。
01
Codex 到底是什么?有一个更好的比喻
可能很多人一听到 “Codex” 这个词,脑海里会立刻闪现出“程序员专属”的印象。
但如果换一个更形象的比喻来理解,可能会直观很多:Codex 更像一位能亲手执行任务的 AI 同事。
你不需要和它一来一回地聊天,也不需要它会写代码,只需要用自然语言说一句需求,它就能立刻在你的电脑上开始操作:读取文件、整理文件夹、分析表格数据、撰写文案、批量修改内容,完成后还会主动向你汇报结果。
正因为如此,Codex 非开发者用户的增速才会是开发者的 3 倍以上。他们中有自媒体运营、电商团队、市场推广人员,大家日常用 Codex 做的事情,是素材整理、报告自动生成、文案批量改良,以及把一份枯燥的数据,瞬间变成一个可以分享和互动的网页。
这和豆包、千问、DeepSeek 这类对话式 AI 最大的不同在于:它并不只是给你建议和操作思路,而是真正动手把事情办成。
02
国内用户上手 Codex 会遇到的三个难题
Codex 作为全自动 AI 助手虽然体验很棒,但国内用户在初次接触时,常常会碰到三道槛:
1、额度捉襟见肘
Codex 官方对普通用户的免费使用额度控制得非常严。原本是按周重置,近期调整为按月重置,等于可用额度直接压缩到原来的四分之一。
我用一个简单的可视化分析网页实测过一次,只是中途加了一个修改需求,任务完成后,月额度就从初始的 95% 直接掉到了 2%。
2、安装环境受限
Codex 的安装需要稳定的海外网络环境,仅是这一点,就劝退了不少国内用户。
阶跃Step 3.7 Flash:Codex Agent的国产大模型最佳搭档
最近 Codex 的热度确实很高。
它最吸引人的地方,不只是帮你生成几行代码。现在的 Codex 已经蜕变为一个全能的 Agent:能够阅读项目、理解上下文、修改文件、执行命令,再根据执行结果继续调整。OpenAI 官方文档也明确提到,Codex CLI 默认以 Agent 模式运行,具备读取文件、运行命令、修改项目目录内代码的能力。
但国内开发者在实际使用中,往往会遇到不少现实问题。
访问稳定性和账户配额都不好保证,Plus/Pro 订阅的成本也需要精打细算。公司的网络策略、团队合规要求、API 预算管控,都会让直接使用 Codex 变得不那么顺畅。
这让我开始思考,是否可以保留 Codex 这套优秀的代码 Agent 交互框架,但把背后的模型替换成自己能够稳定调用的大模型 API。
这个思路其实并不绕。Codex CLI 本身支持通过 API key 登录,并且允许在配置文件里设置 model_provider、base_url、env_key 等自定义模型服务参数。只要模型接口兼容、配置正确,完全可以把其他大模型 API 接入 Codex 的工作流,让它继续执行读代码、改代码、跑任务这一整套 Agent 操作。
接下来唯一需要回答的问题就是:如果要给 Codex 接入一个国内模型,到底应该选择哪一个?
恰好这个时候,阶跃发布了最新的开源 Flash 版本 —— Step 3.7 Flash。
这个模型的定位本来就不是一个单纯的对话聊天模型,而是更专注于服务 Agent 创造者的 Flash 模型。
它在长上下文、搜索、Coding、多模态、工具调用等能力上做了重点强化,目标场景也非常明确:帮助开发者以更高的性价比搭建自己的 Agent。
这不正好就是为国内开发者丝滑使用 Codex 而设计的吗?
Codex 负责提供代码 Agent 的操作框架:阅读项目、修改文件、执行命令、连续推进任务。
Step 3.7 Flash 负责提供模型能力:理解需求、处理上下文、生成代码、根据反馈修正结果。
一个提供手脚,一个充当大脑,配合起来刚好。
所以这篇文章就只做一件事:实际测试,看能不能把 Step 3.7 Flash 顺利接进 Codex,让它成为更适合国内开发者的 Coding Agent 底座。
阶跃星辰StepPlan实测:Agent开发者的一站式订阅方案值不值得入手
阶跃星辰推出 Step Plan,不止是又一个套餐
市面上的 Coding Plan、Token Plan、Agent Plan 层出不穷,但真正让人觉得“终于有一套像样的订阅方案”的,反而不多。阶跃星辰最近推出的 Step Plan,却让我明显感到不同。

只要开通这一个 Plan,推理模型、语音模型、视觉模型和图像编辑模型这几大能力,基本就能一站式覆盖。这样一来,过去那种在不同平台之间反复切换接口、查文档、找 API 的割裂感会大幅减少。给 Claude Code 这类工具做能力配置时,也不再需要一遍遍解释“这是什么平台、应该调哪个模型、API 具体怎么写”。大多数情况下,你只需要说一句“帮我写一个调用某功能的脚本”,后面的平台实现细节就能省略掉。
之前我也介绍过不少大厂的 Coding Plan 套餐,很多都给人“看上去很美,上手却不顺手”的印象。阶跃星辰这次的 Step Plan,给人的感觉不太一样:它不仅做到了“用着顺手、价格合适”,模型的综合实力也确实在线。
核心体验:不按 Token 卡你,全家桶式的组合思路
和很多平台常见的订阅模式不同,Step Plan 并不是靠 Token 用量来卡你。
如果你用过像 OpenClaw 这种会在后台长时间运行、而且高频执行任务的 Agent,就会知道传统 Token 套餐的额度往往很快就会被消耗殆尽。Step Plan 采用的则是一种不限 Token 用量的订阅思路,即使单次任务输出量很大,也不用太担心额度一下子被打穿。
更关键的是,它不是在“能用”的基础上做表面文章,而是直接把大部分常用能力打包了进去。目前这个“全家桶”里,以下几类核心模型已经相当完整:
- 智商担当:
step-3.5-flash-2603、step-3.5-flash,适合代码编写和复杂任务拆解 - 听说担当:
stepaudio-2.5-asr、stepaudio-2.5-tts,负责低延迟语音转写和语音播报 - 视觉担当:
step-image-edit-2,覆盖图片生成与图像编辑 - 管家担当:
step-router-v1,支持智能路由,会根据任务复杂程度自动分流并选择合适模型
Step Plan 到底是什么
Step Plan 是阶跃星辰开放平台专门面向高频 AI 开发者推出的订阅制服务。
它的目标很清晰:让你以更高性价比的方式,在主流编码工具和智能体平台里调用阶跃星辰的旗舰模型,比如 OpenClaw、Claude Code、Trae、Cursor 等。
核心优势一目了然:
- 更适配 Agent 场景:极速推理和高频调用,更匹配智能体工作流的实际节奏
- 默认就是高速体验:所有套餐统一提供高速模型,不搞速度溢价
- 用量更充裕:同档位下,可用量通常达到友商的 2 倍以上,Agent 跑起来更放得开
- 跨平台不设限:一个 Plan 就能覆盖主流工具链,不必被平台绑定
- 智能路由更省心:通过
step-router-v1,一行代码切换模型,系统会在deepseek-v4-pro和step-3.5-flash之间自动调度,兼顾效果与成本 - 能力在持续扩展:目前已支持
step-3.5-flash-2603、step-3.5-flash、stepaudio-2.5-tts、stepaudio-2.5-asr、step-router-v1、step-image-edit-2,后续还会陆续加入更多阶跃旗舰模型
哪些场景最能发挥 Step Plan 的优势
1. Agent 性能优化
如果你的任务特点是频繁调用、需要快速反馈,还要保持长时间持续运行,那么 Step Plan 会是一个比较对症的选择。它的高速推理和实时响应能力,的确更贴近 Agent 在实际环境中的工作方式。
内容创作者的AI效率三件套:NotebookLM+Obsidian+Claude Code,搭建从灵感到产出的完整闭环
你是否也曾在用AI辅助创作时,总觉得哪里还差一口气?要么是AI味太冲,要么内容真实性存疑,产出的结果完全不像自己的风格。其实,这不能全怪AI,问题往往出在——我们喂给它的信息本身就一团混乱。
我观察到,大多数创作者请AI帮忙时,要么只丢一句话让它凭空搜索,要么随便塞几份材料就指望它妙笔生花。这样生成的内容,注定很难让你满意。说白了,输送给AI的知识和素材不够扎实,自然吐不出你想要的东西。
这篇文章,带你认识一套真正能持续运转的内容生产系统:
NotebookLM 是你的「知识消化机」
Obsidian 是你的「第二大脑」
Claude Code 是这套系统里真正撸起袖子干活的「执行员」
三个工具环环相扣,才能发挥出化学效应。
NotebookLM:知识消化机与灵感引擎
你是不是也有这样的经历:收藏夹里躺着成百上千篇“稍后必读”,日积月累,多到连点开的勇气都没有。真到需要用时,却根本想不起哪篇讲过什么,信息零散得像孤岛,完全串不起来。
NotebookLM 正是为此而来。它是谷歌推出的一款免费AI笔记,只会基于你上传的内容作答,绝不凭空编造。把文章、PDF、视频链接、音频一股脑丢进去,然后直接跟它展开对话——不是冷冰冰地搜关键词,而是真正的交流:“这篇文章的核心论点是什么?”“这几份资料有没有内在冲突?”“这个结论可能存在哪些反驳?”在问答之间,灵感就这么被激荡出来。

我自己习惯给每一个想深入挖掘的选题建一个专属知识库。等到开始创作时,就进入对应的知识库,通过对话获得碰撞出的新思路。
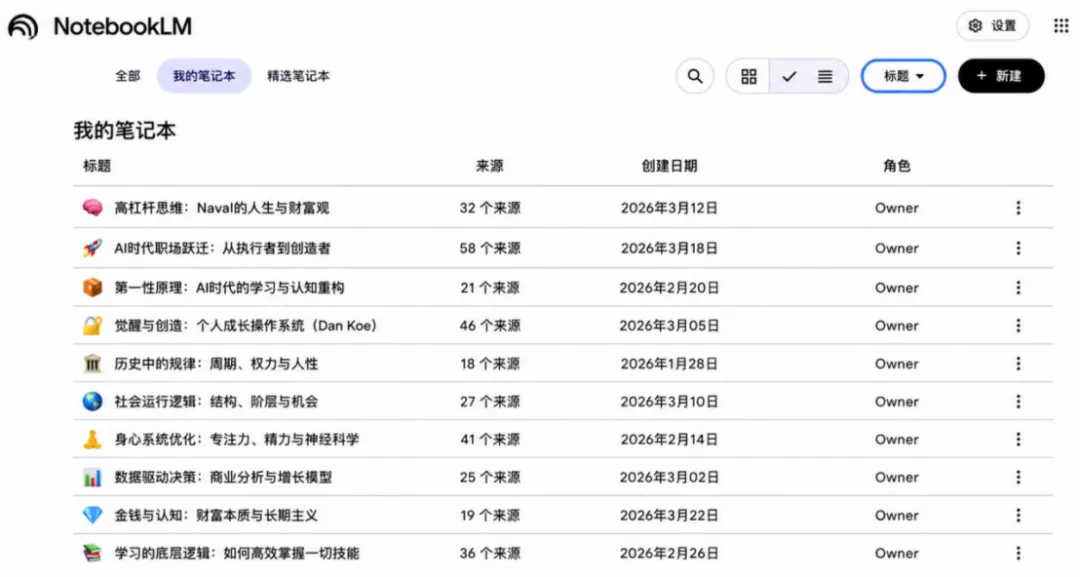
NotebookLM 还有一个很妙的功能:它能把你上传的文章、播客、文档转成播客,这样通勤路上就能完成知识消化,等到真正动笔时便能“心中有墨”。简而言之,它解决了创作前期信息过载的难题,帮我们精准提取有用的内容与灵感。
Obsidian:把碎片灵感编织成知识资产
如果说 NotebookLM 处理的是“外部知识”,那 Obsidian 打理的则是“你自己”。
跟我有关的一切,我都会放进去:零散的灵感、写过的文章、工作复盘、对某个领域的碎片化理解。以前这些念头散落在备忘录和各种笔记软件里,偶尔翻到还会感叹“哦,原来我还想过这个”,但从未被连接起来过。
Obsidian 的双向链接功能,恰恰能把它们彼此勾连。当你写一篇新文章时,能立刻看到“哪条旧笔记跟现在这个主题相关”,再也不用每次都从一张白纸出发。
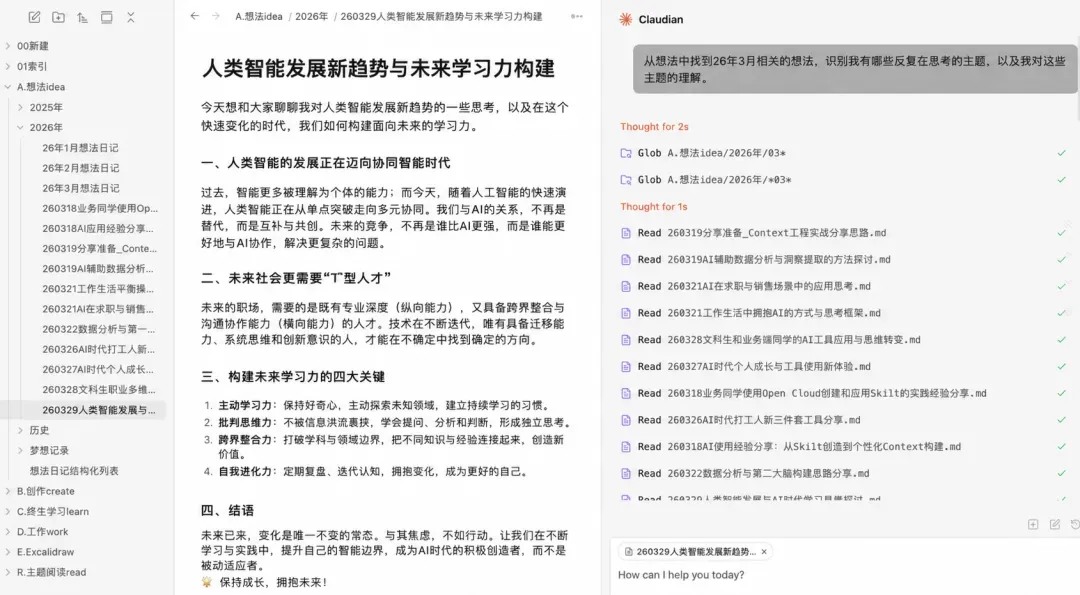
持续积累一段时间后,你会拥有一个真正懂你的知识库。而且它是纯本地存储,完全不必担心资料外泄。你的笔记越多,它就越聪明,越能为你挖掘隐藏的连接点。
Claude Code:你的全能创作执行伙伴
Claude Code 最大的优势,就是它会实实在在地帮你执行任务。
NotebookLM 帮你消化资料,Obsidian 帮你沉淀想法,而 Claude Code 负责最后一步——将创意落地为内容。比如,我们可以直接让它读取 Obsidian 里的笔记,然后据此生成一篇文章。
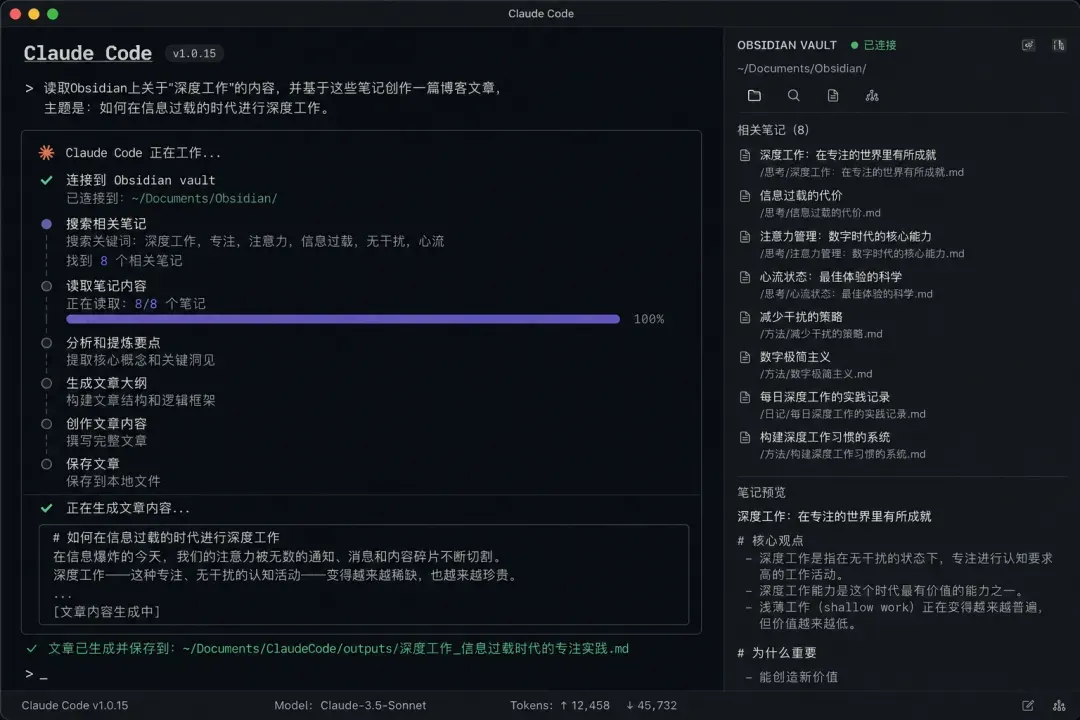
它还能批量处理内容。如果你是矩阵式创作者,同一个选题需要分别输出小红书版、公众号版、视频脚本版,只需用人话告诉 Claude Code 你的要求,它就能在本地直接生成并保存好三个文件。你只负责提需求,它直接动手。你甚至可以把账号数据——比如粉丝增长和内容表现——用表格的形式喂给它,让它帮你撰写分析报告,找到表现最好的内容类型和最稳的发布时间。它可以生成报告文档,并保存在指定路径。
让三个齿轮一起转动
那些用上AI之后产出倍增的创作者,往往并不是因为找到了某款“神器”,而是因为他们把“收集、整理、生产”三个环节都接上了AI,让整条链路真正跑通。
今天介绍的三个工具,恰好分别对应这三个环节:
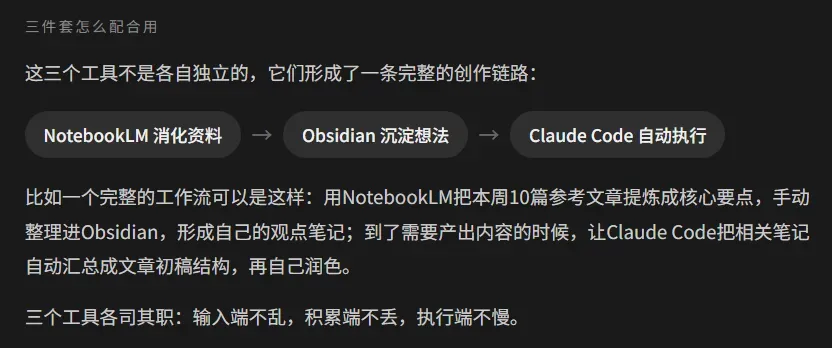
三个齿轮同时咬合,才会带来质的飞跃。你现在的创作链路上,缺的是哪一个环节?不妨现在就开始把它们串联起来。
七彩虹iGame M16 2026首发评测:AI语音唤醒、300Hz电竞屏与RTX 5060性能解析
2026年的游戏本市场迎来了一位实力派新秀。七彩虹旗下高端电竞品牌iGame正式推出iGame M16 Origo 2026,全系标配300Hz超高刷新率屏幕,搭载NVIDIA GeForce RTX 5060笔记本电脑GPU,并率先搭载行业首发的“小希同学”AI语音唤醒开机功能。这款主打轻薄全能的16英寸电竞旗舰,究竟能否一战成名?值不值得入手?今天我们就用实测数据为你揭晓。
AI全域唤醒:FPS玩家的开局利器

作为行业首台支持语音唤醒开机的游戏本,iGame M16 Origo 2026搭载的“小希同学”AI全域唤醒功能,集成了本地关机唤醒引擎与独立低功耗AI语音芯片。在准备开黑的瞬间,你无需腾出双手去按开机键,只需对着笔记本说一句“小希同学”,即可远场拾音、精准识别并智能开机——从关机状态直接进入游戏,每一步都快人一步。
电子围栏感应锁屏/解锁功能同样实用:中途离座去取饮料,系统自动锁屏守护账号安全;回来坐下立刻解锁,省去密码输入的繁琐。环域无感智启与体感多端演控两大智能科技协同,构成了完整的iGame环域智控生态,让智能与电竞无缝融合。
外观设计:简约美学与轻薄手感的双重体验

七彩虹iGame M16 Origo 2026整体遵循Less is More的简约设计美学。星耀白配色A面采用两种阳极喷砂工艺,勾勒出象征宇宙奇点的圆弧线条,使得简约外壳也拥有了细腻的色彩层次。

A面还首次应用了丝绸触感钝化层,触感温润细腻,摆脱了传统金属机身的冷硬感,手感相当高级。整机设计既精致简约,又不乏潮流时尚,随手置于桌上就是一道风景。
机身厚度仅19.9mm,在搭载如此强悍硬件的前提下,这个厚度控制十分出色。将它装入背包赶赴线下比赛或朋友聚会开黑,都不会带来负担。
屏幕:300Hz高刷幻彩屏,电竞视觉的降维体验

翻开B面,最吸睛的无疑是那块与BOE京东方定制的16英寸ACR高帧幻彩屏。2560×1600 2.5K分辨率搭配16:10黄金比例,视野更加开阔,堪称生产力与娱乐的双料神器。
更重要的是,这块屏幕全系标配300Hz超高刷新率——无需额外付费,人人可得。相较常见的144Hz甚至240Hz,300Hz每帧画面显示间隔仅3.33ms,比240Hz快了将近1ms。

500nit以上的峰值亮度结合ACR环境对比技术,支持不同光线环境的抗反射、抗眩光,即便在户外强光下依然清晰可见。100% sRGB色域覆盖、ΔE<1的高色准,让画面细腻逼真、色彩丰富,表现力与感染力惊人。无论游戏还是内容创作,画面都精准通透。
300Hz超高刷新率搭配RTX 5060的DLSS 4.5多倍帧生成,帧率轻松突破极限,与屏幕完美适配,彻底告别拖影、撕裂和延迟卡顿。
键盘与接口:电竞核心需求全面满足

C面搭载了带数字小键盘的全尺寸ARGB键盘以及超大触控板。键盘手感出众,键程适中回弹有力,日常打字不易误触,响应迅速且更具氛围感。触控板面积充裕,手势操作顺滑跟手,足以应对日常办公。
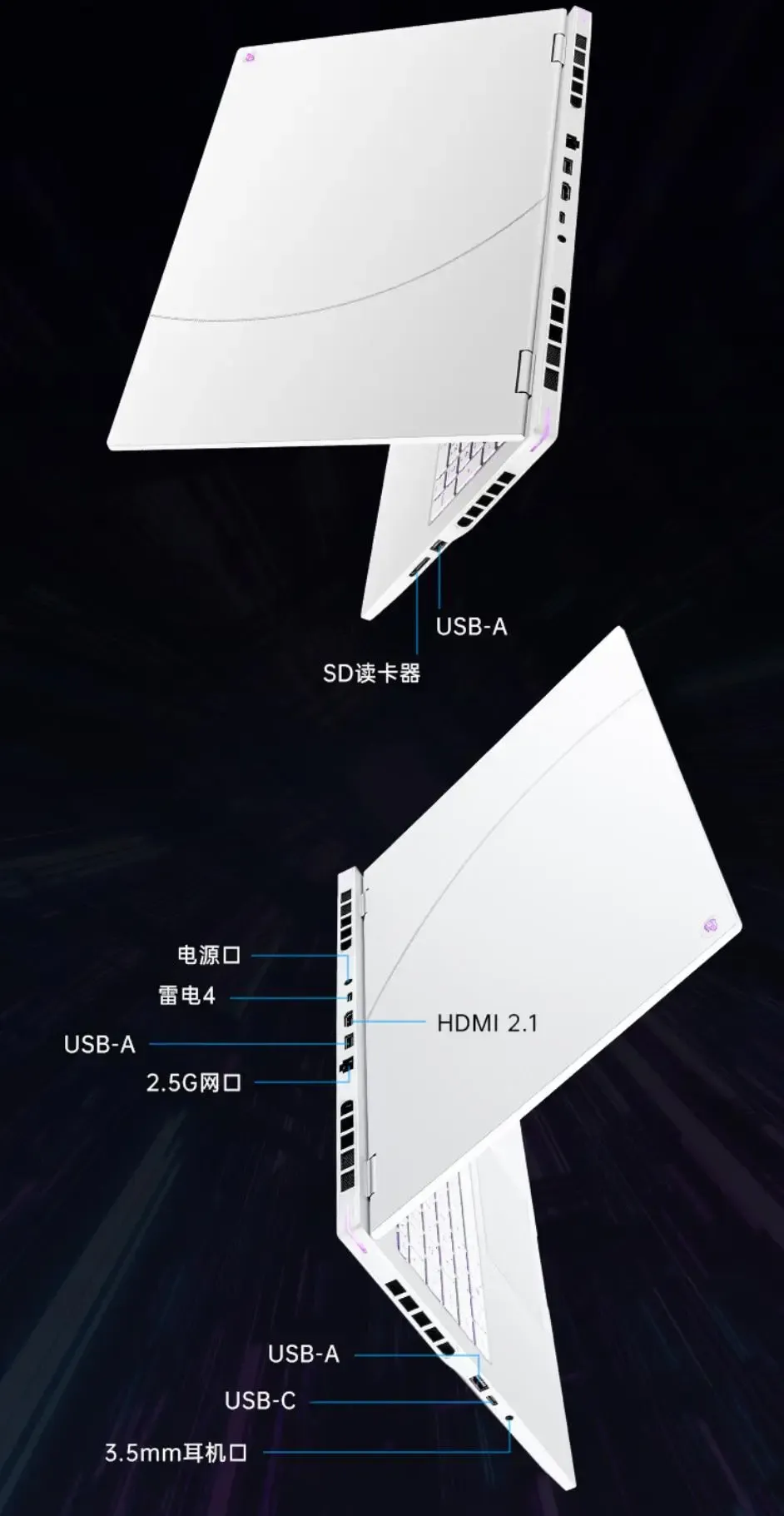
接口方面,iGame M16 Origo 2026给得相当慷慨。左侧依次为USB Type-C、USB Type-A和3.5mm耳机接口;右侧提供USB Type-A与SD卡读卡器;背部则集中了DC电源接口、USB Type-A、USB Type-C、HDMI 2.1、2.5G网口以及雷电4接口。丰富的接口配置,连接投影仪、外接显示器或显卡坞都无需转接头。特别要说的是这个2.5G有线网口,对于经常插网线的重度电竞玩家,有线网络的稳定性远非Wi‑Fi可比,这个升级非常实用。
RTX 5060 + DLSS 4.5,被低估的高帧率组合

七彩虹iGame M16 Origo 2026搭载了英特尔酷睿Ultra 7 270HX Plus处理器,配合英伟达GeForce RTX 5060笔记本电脑GPU,整机200W满功耗释放。

Blackwell架构加持下的RTX 5060支持DLSS 4.5多倍帧生成技术。在DLSS 4.5的多倍帧生成下,即便是RTX 5060也能提供超高帧率——这不是夸大,而是技术的分量。传统渲染一帧的时间,DLSS 4.5可以生成多帧,配合300Hz屏幕的极致刷新,从硬件到软件全链路为低延迟电竞体验优化。
深入解读大模型Function Calling:原理、误解与真实执行流程
当智能体(Agent)能够主动查询天气、撰写并发送邮件、处理Excel报表时,它究竟是如何做到的?这背后依赖一项核心机制——Function Calling。
Function Calling的意义在于,它让模型能用结构化的方式明确表达自己调用工具的意图:该调用哪一个工具,需要传入哪些参数。这不是一句抽象的口号,而是一种精确的通信格式,把模型的“想法”变成程序可以识别的指令。
早在2023年6月,OpenAI就在其标准API中引入了Function Calling功能。此后,不同厂商陆续跟上,有的称之为Function Calling,有的叫Tool Use,但这些名字背后的本质完全相同:让模型以结构化的方式和安全可控的规范去调用外部工具。
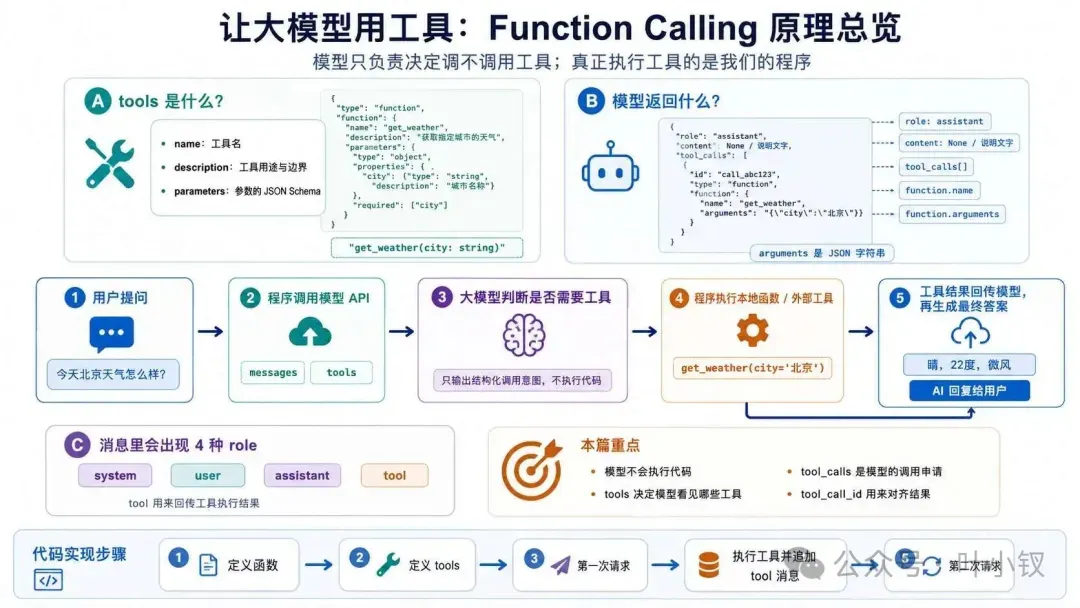
Function Calling 的执行流程解析
很多人在初次接触Function Calling时,会产生一个普遍的误解:他们以为模型获取问题后,会自己去运行那些工具,并直接给出最终结果。甚至有人会问:“模型到底是怎么去执行这些工具的?”
这个理解是错误的。大模型本身没有代码运行环境,它不能真正去执行任何代码或命令。它唯一能做的事,自始至终只有一件:根据你提供的文字输入,生成相应的文字输出。
Function Calling 的真实流程并非模型亲自操刀,而是这样一个协作过程。我们可以用一个天气查询的例子来直观地理解整个交互链条。
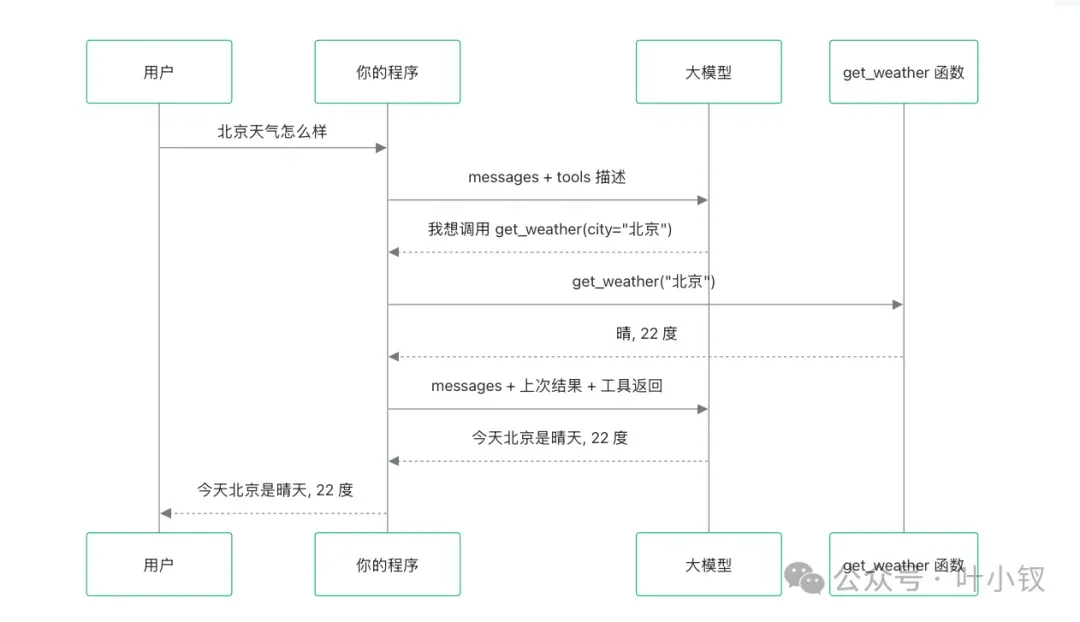
如图所示,模型第一次返回的信息表面上像是“我想调用 get_weather”,但请务必注意,真正执行这个函数的,始终是我们自己编写的程序。模型在整个链条中扮演的角色十分清晰且克制:它只负责决策——决定要不要调用工具、需要调用哪个工具,以及把什么样的参数传给工具。
首月$5解锁12款国产开源模型:OpenCode Go编程套餐深度实测
首月 $5 即可解锁 GLM、Kimi、DeepSeek、Qwen 等 12 款国产开源模型,OpenCode Go 编程套餐到底值不值?本文从模型支持、额度、性价比和使用体验进行深度实测。
OpenCode Go 是什么?
OpenCode 是 2026 年增长最快的开源 AI 编码代理之一,GitHub 一个月内获得超过 30K Stars。它最大的特点是开源加多模型支持,能接入 75+ 个 LLM Provider。
OpenCode Go 是 OpenCode 官方推出的低价订阅套餐,相当于一个打包好的模型订阅服务,让你能以极低的成本稳定访问当前市面上最强大的开源编程模型。

模型支持
OpenCode Go 最亮眼的地方,就是几乎集齐了目前所有能打的国产开源模型。
官方当前支持的模型列表:
GLM-5、GLM-5.1、Kimi K2.5、Kimi K2.6、MiMo-V2.5、MiMo-V2.5-Pro、MiniMax M2.5、Qwen3.5 Plus、Qwen3.6 Plus、MiniMax M2.7、DeepSeek V4 Pro、DeepSeek V4 Flash
具体模型列表以官网为准!
额度拆解
额度是大家最关心的点。Go 套餐采用“刀”计费模式,不同模型的单次调用成本不同,实际可用次数差异很大。

数据解读
官方的预估请求数很直观:
DeepSeek V4 Flash 名副其实的“量大管饱”:每月超过 15 万次调用,日均约 5,000 次,绝大多数开发者根本用不完。
MiniMax M2.5 同样是额度大户:月均近 3.2 万次,性价比极高。
树莓派AI摄像头从入门到精通:本地运行目标检测与LLM联动实战
想要将普通的USB摄像头改造成一台具有人物检测、人脸识别并能实时推送警告的树莓派AI摄像头吗?借助树莓派,你可以以很低的成本搭建一套兼顾家庭安防、智能自动化、计算机视觉等场景的AI智能摄像头系统。将常规摄像头与轻量级AI工具相结合,树莓派就能在本地完成实时视频数据分析,无需依赖昂贵的云服务。对于刚入门的创客、树莓派爱好者以及所有希望涉足边缘AI项目的人来说,这是一套实用性极强的落地方案。
树莓派AI摄像头究竟是什么?
树莓派AI摄像头是部署在树莓派上的智能摄像系统,依靠人工智能技术实时解析视频中的视觉信息。与只能拍摄、录制和回放视频的普通摄像头不同,AI摄像头能够自主识别并理解画面中的动态内容。
例如,它可以:
- 检测是否有人进入房间
- 辨认特定人脸
- 监控活动并对变化做出响应
这样一来,一个基础摄像头就变成了具有决策能力的智能系统。它不再是被动地记录,而是主动处理信息并根据所看到的内容做出反应,类似于本树莓派AI指南中介绍的边缘视觉项目。
摄像头的选择方案
选择适合的摄像头是搭建树莓派AI摄像头项目的关键一步。目前主流的选型方案主要有两种:USB网络摄像头和树莓派专用的摄像头模块。
USB网络摄像头是新手的最佳选择,支持即插即用,绝大多数型号都能被树莓派系统自动识别,无需复杂配置,可快速搭建起基础的AI摄像检测方案,上手门槛极低。

而树莓派专用AI摄像头模块属于进阶方案,其硬件内置了AI处理能力。与仅能拍摄画面的普通摄像头不同,它可以直接在摄像头硬件端运行AI模型,无需占用树莓派大量的计算资源。
该摄像头搭载索尼IMX500智能视觉传感器,所有AI推理和视觉处理工作均在摄像头内部完成,有效降低了树莓派CPU的使用率,大幅提高了实时检测项目的运行性能。
AI摄像头与传统方案的差异
传统的树莓派摄像方案通常依赖OpenCV等第三方库,在树莓派主板上逐帧处理视频画面,运算速度较慢,难以达到高精度、高实时性的检测要求。
而使用 AI 摄像头后:
- AI 推理直接在传感器上执行
- 树莓派只接收结果(例如检测到的物体)
- 延迟更低,性能更优
- CPU 和内存占用更少
这使得它成为对效率有严格要求的边缘 AI 项目的理想选择。
核心功能亮点
- 内置 AI 处理(在传感器端进行推理)
- 实时目标检测与分类
- 降低树莓派 CPU 负载
- 体积小巧,易于集成
- 支持自定义 AI 模型


总体选型建议:如果你只是入门或仅需基础检测功能,USB摄像头完全能够胜任;若希望获得更高的运行性能、更简洁的硬件搭建方案,则应优先选择树莓派专用摄像头模块。
为何选择树莓派构建AI摄像头?
树莓派是构建 AI 摄像头系统的强势选择,原因如下:
- 价格实惠:远低于完整电脑方案,大多数用户都能负担
- 体积小巧:紧凑设计,适合狭小空间或轻松安装
- 低功耗:可以持续运行,电力消耗极少
- 社区支持强大:有成千上万的教程、论坛和开源项目可供使用
这些优势使树莓派成为初学者和经验丰富开发者的实用平台。
搭建所需硬件清单
要搭建一个基础的树莓派 AI 摄像头,你只需几样核心组件:
- 树莓派 5 或树莓派 4
- USB 网络摄像头或树莓派摄像头模块
- 5V 3A 电源
- microSD 卡
仅通过这些硬件就能构建一套基础的AI监控系统,后续可以按需扩展功能。
工作原理
树莓派 AI 摄像头的工作流程十分简单:摄像头采集视频帧 → 树莓派利用 AI 模型处理每一帧 → 根据结果执行动作,例如当检测到人时保存图片。