DeepAgents:一站式复杂AI任务智能体框架,规划、沙盒与子代理开箱即用
Deep Agents 是一套基于 LangChain 和 LangGraph 的智能体基础套件,内建规划、文件系统交互以及子代理动态生成能力,专为应对高复杂度智能体任务而设计。
Deep Agents 提供开箱即用的 Agent 框架,用于搭建能够自主规划、对复杂任务进行推理、管理文件、执行 Shell 命令并将工作委派给专用子代理的 AI 代理——这一切都无需额外拼装提示词、工具和上下文管理逻辑。你拿到手的是一个立即可运行的智能体,同时保留了充分的定制空间。
破解 AI 代理的“浅层”困境
最简形式的 AI 代理仅仅是在循环中让大语言模型调用工具。然而这种架构往往流于表面,难以胜任跨多个回合、步骤繁多的复杂任务。像 Claude Code、Deep Research 和 Manus 这类应用通过融合四个关键要素突破了这一瓶颈:规划工具、子代理、对文件系统的访问以及详尽的系统提示词。Deep Agents 将这四种模式封装为一个可复用的 Python SDK,让你不仅能构建交互式终端,还能为自有应用打造具备深层能力的智能体。
其核心思想是:深度源自架构,而不仅仅来自模型。配备合理的中间件、工具抽象和上下文管理机制的智能体框架,能将能力强大 LLM 变成一套真正可靠的自主系统。
整体架构一览
Deep Agents 以 Python monorepo 的形式组织,包含多个独立版本控制的包。处于核心的是核心 SDK(deepagents),它提供 create_deep_agent() 工厂函数、中间件系统以及可插拔的后端抽象层。围绕核心 SDK 的是 CLI、编辑器集成、评估套件和沙盒合作伙伴等配套包。
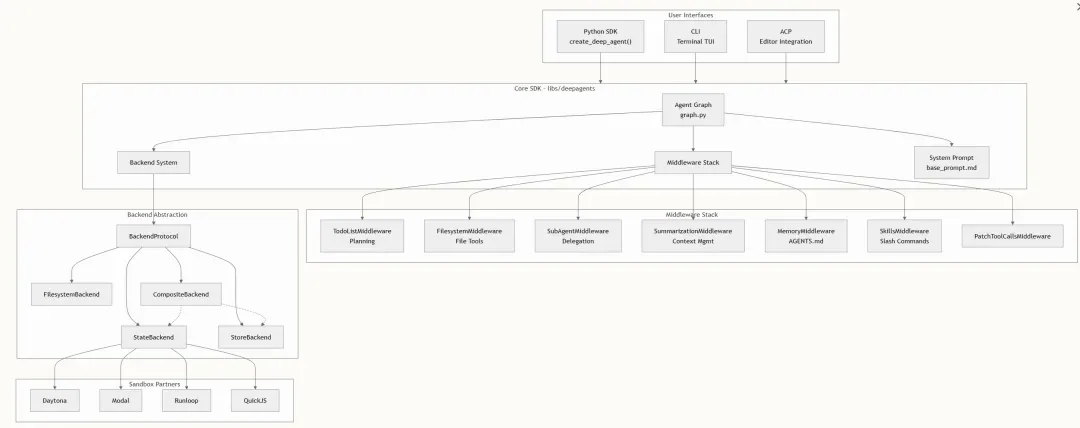
六大内核能力:开箱即用的可组合工具
Deep Agents 附带六大内置能力类别,每一类均以可组合的中间件或后端组件形式实现:
| 能力 | 提供的工具 | 中间件 / 后端 |
|---|---|---|
| 规划 | 用于任务拆分与进度追踪的 write_todos | TodoListMiddleware |
| 文件系统 | read_file、write_file、edit_file、ls、glob、grep | FilesystemMiddleware + BackendProtocol |
| Shell 访问 | 执行命令(沙盒化)的 execute | SandboxBackendProtocol |
| 子代理 | 在隔离上下文中委派任务的 task | SubAgentMiddleware |
| 上下文管理 | 对话变长时的自动摘要 | SummarizationMiddleware |
| 记忆与技能 | 通过 AGENTS.md 持久化记忆,自定义斜杠命令 | MemoryMiddleware、SkillsMiddleware |
系统会自动包含一个名为 general-purpose 的通用子代理,无需额外配置即可提供内置任务委派能力。
DeepSeek TUI 完全指南:从零开始掌握终端原生 Agent 的安装与配置
DeepSeek TUI 是一款由 Rust 打造的终端原生编码代理(Agent),它能直连 DeepSeek V4 模型,为你提供键盘驱动、流式响应的交互界面,可轻松完成文件读取、代码编辑、Shell 命令执行、网络搜索、Git 管理以及子代理编排——全部操作仅需一个 deepseek 命令。该项目包含两个协作的二进制文件:deepseek 调度器 CLI 和 deepseek-tui 伴生运行时,二者共同组成一个流式 Agent 循环,底层由兼容 OpenAI 的聊天补全客户端、类型化工具注册表、会话检查点和基于 ratatui 的终端界面支撑。整个项目以 Cargo workspace 形式组织,包含 14 个 crate,目标平台涵盖 Linux (x64/ARM64)、macOS (x64/ARM64) 和 Windows (x64),并支持通过 npm、Cargo、Homebrew、Scoop、Docker 及直接下载 GitHub Release 二进制文件等多种渠道分发。
项目链接:https://github.com/Hmbown/DeepSeek-TUI
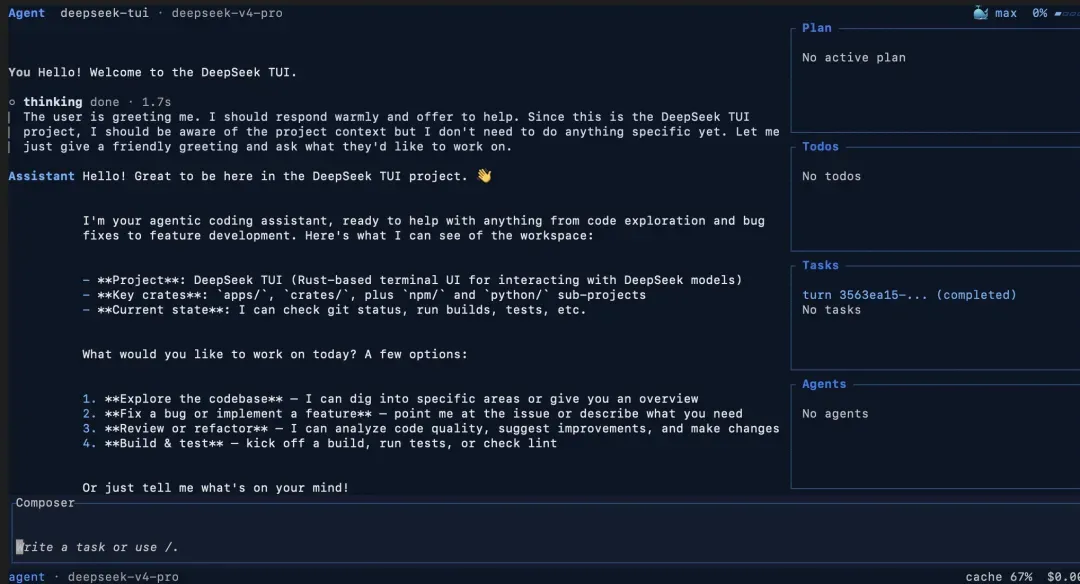
deepseek-tui
核心亮点
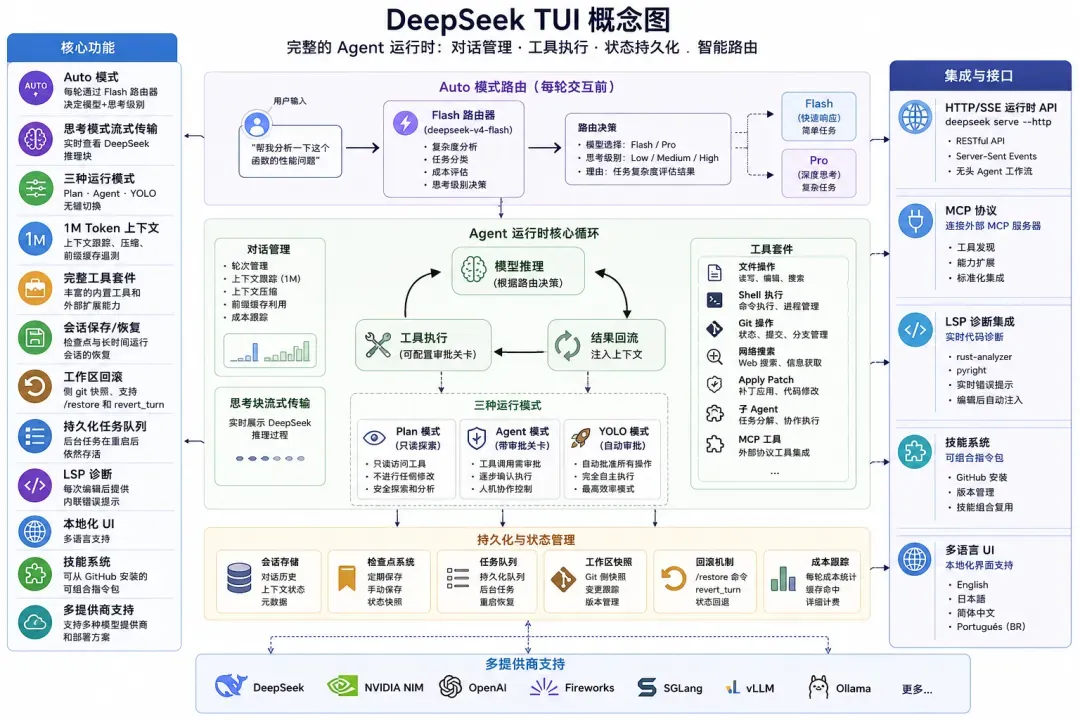
Deepseek整体概览
DeepSeek TUI 远非 API 的简单包装——它是一套完整的 Agent 运行时,负责对话轮次管理、推理块实时流式传输、通过可配置的审批关卡执行工具,并在重启后保持会话状态。三种工作模式(Plan、Agent、YOLO)让你能够从只读探索、带审批的交互式工具使用到完全自主执行之间自由切换。内置的 Auto 模式(--model auto)为每轮交互添加了一个轻量级路由步骤:它会调用一次小型 deepseek-v4-flash 模型,决定实际请求应在 Flash 还是 Pro 上执行,以及应采用何种推理深度,从而避免在简单查询上浪费算力。每个工具的执行结果都会回流到 Agent 循环,编辑后还会注入 LSP 诊断信息,同时成本跟踪会报告每轮交互的缓存命中详情。
| 功能 | 描述 |
|---|---|
| Auto 模式 | 通过 Flash 路由器为每轮对话自动选择模型和推理深度 |
| 思考模式流式传输 | 在模型运行时实时查看 DeepSeek 推理片段 |
| 三种模式 | Plan(只读探索)、Agent(含审批关卡)、YOLO(自动审批) |
| 1M token 上下文 | 上下文跟踪、压缩与前缀缓存遥测 |
| 完整工具套件 | 文件操作、shell、git、网络搜索、apply-patch、子 Agent、MCP 协议 |
| 会话保存/恢复 | 支持检查点和长时间运行会话的恢复 |
| 工作区回滚 | 基于 git 快照的 /restore 和 revert_turn 功能 |
| 持久化任务队列 | 后台任务在重启后仍可存活 |
| HTTP/SSE 运行时 API | 通过 deepseek serve –http 实现无头 Agent 工作流 |
| MCP 协议 | 连接外部模型上下文协议工具服务器 |
| LSP 诊断 | 每次编辑后由 rust-analyzer、pyright 等提供内联错误 |
| 本地化 UI | 支持英语、日语、简体中文、巴西葡萄牙语 |
| 技能系统 | 可从 GitHub 安装的可组合指令包 |
| 多提供商 | 支持 DeepSeek、NVIDIA NIM、OpenAI、Fireworks、SGLang、vLLM、Ollama |
系统架构解析
系统采用分层架构,并界定了严格的数据流边界:TUI 层负责界面渲染和输入捕获;核心引擎层驱动 Agent 循环并处理工具调用;工具与扩展层执行具体操作;LLM 客户端层负责与模型的流式通信。层与层之间通过类型化的通道和事件进行交互——UI 层不会直接调用工具,引擎层也不会直接向屏幕输出。
DeepSeek 首轮融资 450 亿美元:国家队领投,国产 AI 芯片生态迎来决定性转折
彭博社 2026 年 5 月 6 日披露,DeepSeek 正在推进其历史上第一轮外部融资,公司估值高达 450 亿美元(约合 3065 亿元人民币),牵头方正是国家集成电路产业投资基金(大基金三期)。这不仅是 DeepSeek 首次对外吸收资本,也是国家级资金首次直接注资一家中国大模型企业。
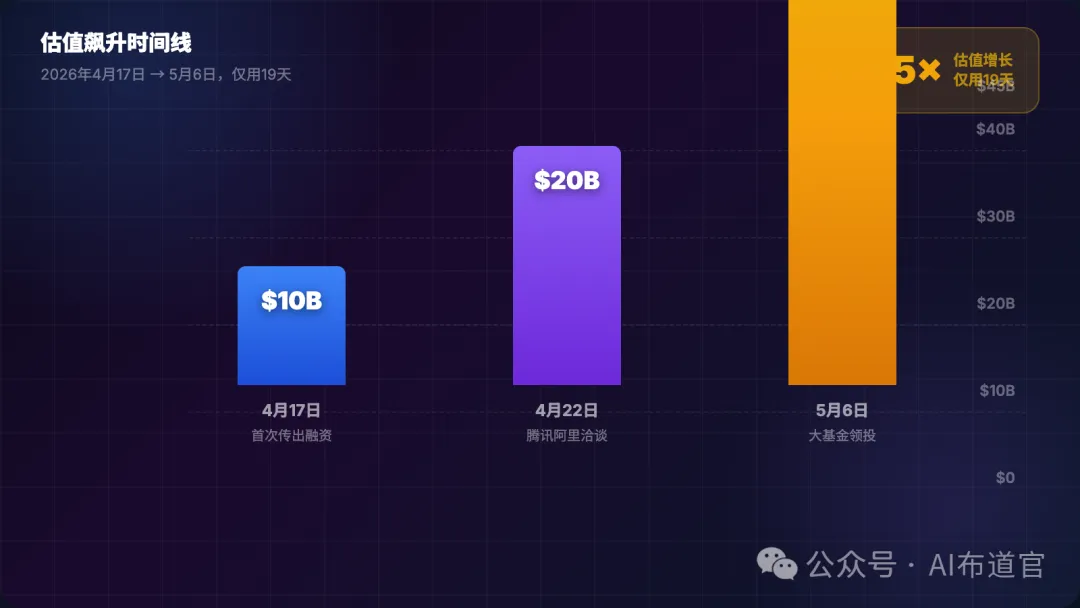
一个月内,估值膨胀 4.5 倍
DeepSeek 的估值轨迹足以成为融资教科书中的经典案例:
| 时间节点 | 估值水平 | 关键事件 | 信源 |
|---|---|---|---|
| 2026 年 4 月 17 日 | ~100 亿美元 | 融资传闻首次浮出水面 | The Information |
| 2026 年 4 月 22 日 | ~200 亿美元 | 腾讯、阿里传出入股意向 | 多家媒体 |
| 2026 年 5 月 6 日 | 450 亿美元 | 大基金三期领投确证 | 彭博社 |
短短一个月,市值/估值直接翻了 4.5 倍。
背后的原因只有一个:市场猛然意识到——
DeepSeek 不只是一家人工智能企业,它已经是中国 AI 产业链条中最核心的连接点。
这轮融资为何值得每个人关注?
你可能会问:“一家公司的融资消息,和我有什么关系?”
实际上,牵一发而动全身。
对开发者而言:DeepSeek 的模型(V3、V4、R1)正逐步演变为国产大模型的事实标准,其 API 定价策略直接决定着你的计算成本。
对投资者而言:450 亿美元的估值意味着 DeepSeek 已超越 MiniMax(港股上市,市值约 298 亿美元),直逼智谱 AI(港股上市,市值约 523 亿美元),稳居中国 AI 公司估值第二的位置。
DeepSeek-TUI:终结Claude Code封号噩梦,用开源与低成本重塑终端智能体
半夜,我那台发烫的拯救者上,Claude Code 正在重构一个 Web 项目。
终端忽然弹出一行刺眼的红字:
This organization has been disabled.
封号。
没错,又一次。这已经是我第三个被干掉的 Claude 账号了。静态独享 IP、海外手机号、环境隔离,所有能做的防御全部拉满,该来的还是来了。
不得不承认,Claude Code 的体验很惊艳。它几乎把“终端就是 Coding Agent 最自然的入口”这件事说透了。但对国内用户而言,它带来了另一种长久折磨:昂贵、难接入、风控严苛。你付了钱,还得时刻提心吊胆。
我本想找朋友吐槽,顺手在 X 上翻了翻。结果看到一个刚更新的开源项目,而且相当离谱。
一位美国开发者,做出了一个专为 DeepSeek 打造的终端 Coding Agent。
DeepSeek-TUI。
真正让我停下来的,不是它发明了什么新范式。Claude Code 已经跑通了终端 Agent 的这条路。DeepSeek-TUI 的有趣之处在于:它把 Claude Code 所代表的那种体验,从封闭产品中重新拆解回开源项目里。
模型接口是 DeepSeek。界面是 TUI。也就是说——一个 DeepSeek 版的 Claude Code。工具调用、权限控制、上下文管理、Skill、MCP、子 Agent,全部摆在明面上。你不再需要等一个海外 SaaS 为你开门,而是在自己的机器上,把 Claude Code 验证过的工作流,用 DeepSeek 重新拼装起来。
所以我不想叫它“国产平替”。“平替”这个词太小了。它更像一次仔细的拆解和重组。
更有意思的是,项目作者是一位美国开发者。GitHub 账号 Hmbown,本名 Hunter Bown。一个美国人,做了一个面向 DeepSeek 的终端 Coding Agent,然后用 DeepSeek 把自己的话润色成中文,跑到中文技术圈里招呼“鲸鱼兄弟们”。
你品。一个美国开发者,用中国大模型写中文,来中国开源圈推广一个 DeepSeek Agent。这个传播链路弯绕得像一碗兰州拉面,但它居然有效。
DeerFlow 2.0深度解析:字节跳动开源的超级Agent框架如何实现复杂多步任务编排
项目地址:https://github.com/bytedance/deer-flow

DeerFlow 2.0 是由字节跳动火山引擎团队倾力打造的开源 超级 Agent 框架。它基于可扩展、渐进式加载的技能体系,能够高效编排子 Agent、内存和沙箱,从而完成复杂的多步任务。框架全称 Deep Exploration and Efficient Research Flow,意为深度探索与高效研究流,折射出其深耕深度研究领域的起源,如今已演变为一个通用 Agent 运行时,不仅能构建数据处理流水线,还支持幻灯片生成、仪表盘启动、内容工作流自动化等丰富场景。

2026 年 2 月 28 日,DeerFlow 2.0 正式发布,一经推出便迅速登上 GitHub Trending 榜首。该版本完全从头重写,与 v1 没有任何代码复用,全新的架构为其带来了更强的灵活性和性能。
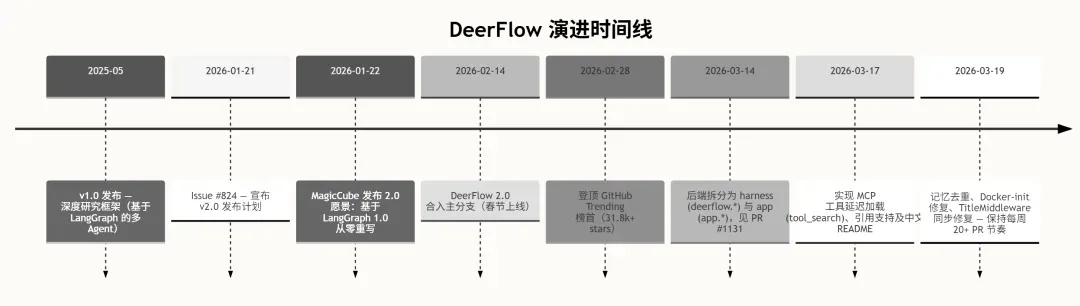
核心特性与功能
DeerFlow 与传统聊天机器人框架的分野在于,它为 Agent 提供了一个完整的 执行环境——不仅仅是简单的工具访问权限,更涵盖了完整的沙箱文件系统、并行子 Agent、持久化记忆,以及通过渐进式加载保持上下文窗口精简的技能引擎。
技能与工具
技能被组织成结构化的 Markdown 文件,其中定义了工作流、最佳实践和资源引用。这些技能 仅在需要时加载,即便是使用对 Token 用量敏感的模型,也能保障上下文窗口始终高效运转。DeerFlow 内置了 17 项技能,覆盖深度研究、数据分析、图表可视化、PPT/播客/视频生成、前端设计等诸多领域。工具遵循同样的设计理念:提供一套核心内置工具集(包括网页搜索、网页抓取、文件操作、Bash 执行),并通过 MCP 服务器和自定义 Python 函数进行灵活扩展。
子 Agent
主导 Agent 能够动态生成 并行子 Agent——每个子 Agent 都拥有隔离的上下文、专用工具和独立的终止条件。一项研究任务可以拆解成十几个从不同视角探索的子 Agent,最终汇聚成报告、网站或幻灯片。这种任务分解机制让 DeerFlow 具备处理耗时数分钟乃至数小时长链路任务的能力。
沙箱执行
每一个任务都在具备完整文件系统的 隔离 Docker 容器 中运行,其内部包含技能、工作区、上传和输出目录。Agent 可以读取、写入、编辑文件,执行 Bash 命令,查看图像——所有这些操作均在沙箱中完成,完全可审计,且会话之间零污染。系统支持三种执行模式:本地执行(适用于开发环境)、Docker 容器(推荐方案)以及通过配置器启动的 Kubernetes Pod(高级用法)。
Hermes Agent:开源闭环进化智能体,跨平台自我改进引擎

Hermes Agent 是 Nous Research 打造的一款持续自我进化的 AI 智能体。它通过闭环学习机制区别于其他智能体框架——该智能体能够从经验中提炼技能,在使用过程中不断改进这些技能,检索自身的历史对话,并逐步构建关于用户的深度模型。不论你是在终端中直接对话、通过 Telegram 发消息,还是集成到 IDE 中使用,Hermes 在所有交互入口都运行着同一个核心智能体引擎。
项目链接:https://github.com/nousresearch/hermes-agent
Hermes 的独特优势
绝大多数 AI 智能体都只是无状态的“请求-响应”流水线——每一次对话都从零开始。而 Hermes 从设计之初就定位为有状态且能自我改进的系统。它会记住已经完成的操作,将这些知识组织成可以复用的技能,并在每次交互中利用这些技能不断提升表现。
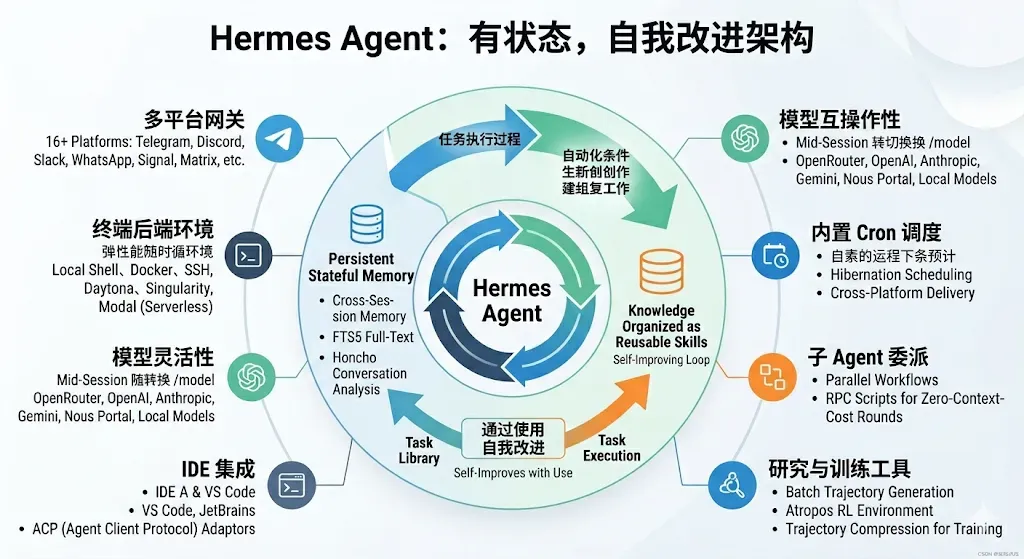
下表将 Hermes 与常见的智能体框架进行了直观对比:
| 能力 | 典型智能体框架 | Hermes Agent |
|---|---|---|
| 记忆持久化 | 仅限单次会话 | 跨会话 FTS5 搜索、Honcho 对话分析、持久化记忆提供者 |
| 技能创建 | 需要手动设计提示词 | 智能体在完成复杂任务后自动生成技能,并在使用中自行优化 |
| 模型灵活性 | 绑定单一供应商 | 在对话中通过 /model 随时切换供应商——OpenRouter、OpenAI、Anthropic、Gemini、Nous Portal、本地模型 |
| 消息平台 | CLI 或单一平台 | 单一的网关进程同时接入 16+ 个平台(Telegram、Discord、Slack、WhatsApp、Signal、Matrix 等) |
| 终端后端 | 仅限本地 Shell | 本地、Docker、SSH、Daytona、Singularity、Modal——包括无服务器休眠 |
| 定时自动化 | 依赖外部 cron 或缺失 | 内置 cron 调度器,支持自然语言定义任务,并可跨平台投递 |
| 子智能体委派 | 极少支持 | 用于并行工作流的隔离子智能体,通过 RPC 脚本实现零上下文成本轮次 |
| IDE 集成 | 不支持或需付费 | 基于 ACP(Agent Client Protocol)适配器,可接入 VS Code、JetBrains 及任何兼容 ACP 的客户端 |
| 研究工具 | 重点关注不足 | 批量轨迹生成、Atropos RL 环境、用于训练的轨迹压缩 |
整体架构设计
Hermes 围绕同一个智能体引擎构建,并通过多种前端界面提供服务。无论是 CLI(cli.py)还是消息网关(gateway/run.py),都会将数据送入 run_agent.py 内统一的对话循环,由该循环负责编排 LLM 调用、工具执行、记忆检索以及技能管理。此外,ACP 适配器(acp_adapter/server.py)作为第三种前端,利用标准化的 Agent Client Protocol 实现 IDE 集成。
HTML取代Markdown?Claude Code工程师深度解析AI输出格式新趋势
2026年5月8日,Anthropic Claude Code团队的工程师Thariq Shihipar在X上抛出一句断言:
“HTML就是新的Markdown。我已经彻底停止编写Markdown文件了。”
说这话的若不是他,或许只会被当成一种个人习惯。可他偏偏是打造AI编程工具的核心开发者。随推文发布的博文《HTML不合理的有效性》(The Unreasonable Effectiveness of HTML)里附带了20个他用HTML生成的输出案例。不出两天,凭借对LLM玩法先知先觉的Simon Willison转发并评论“我把默认设置改了”,连Karpathy也公开表示HTML的信息密度确实优于Markdown。
评论区随即炸开。Hacker News涌出三百多条讨论,Reddit上唇枪舌剑,中文技术圈同样跟进热烈。有声音直斥“开历史倒车”,有人拍手“早该如此”,也有人提醒“别被带偏了节奏”。
在通读Thariq的原文、Simon Willison的深度分析以及社区正反意见之后,会发现这件事远比第一眼看到的更值得玩味。
厘清概念:他究竟想表达什么?
不少读者看到标题便急了——“Markdown要死了?Claude团队背叛开发者?”
别急。Thariq说的并不是“Markdown这个格式将被淘汰”,而是:AI Agent输出结果时,HTML比Markdown更合适。 两者完全不同。
不妨回想日常的工作流:让Claude Code帮忙review一个PR,它产出一份200行的Markdown文档。你打开,扫了15行便关掉。三天后又让它review一次,因为你已经想不起上次的内容。Thariq指出的正是这个痛点:在AI输出场景下,Markdown的信息密度过低。
在他的描述里有一个扎心的细节:为了让Markdown显示颜色,Claude Code竟用Unicode方块字符来模拟。一个2026年的AI工具,却要用上世纪的方法在终端里呈现彩色文本——格式本身成了瓶颈。
HTML的独特优势:Markdown无法企及的功能
光讲概念不够,直接看实例。
1. PR Review变成交互式报告
以往让Claude Code审查PR,得到的是一大段Markdown:
## Code Review
### Issue 1: Streaming Logic (High Severity)
The backpressure handling in line 42 might cause...
Thariq的办法是让Claude直接生成HTML:
Help me review this PR by creating an HTML artifact that
describes it. Render the actual diff with inline margin
annotations, color-code findings by severity.
产出的效果:代码差异在页面内嵌渲染,严重程度按红/黄/绿区分,每一行批注紧挨着代码,点击即可展开详细说明。这不再是一篇文档,而是一个小型工具。
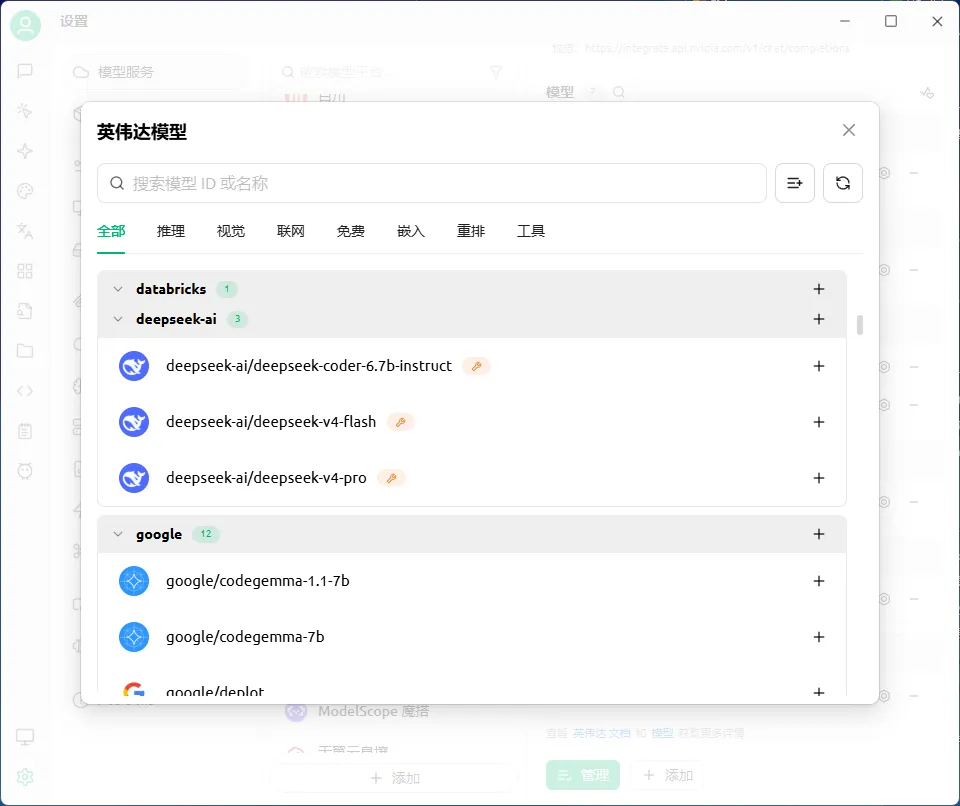
NVIDIA免费开放80+大模型API:零成本接入DeepSeek/Kimi/Llama 3.1全攻略
大模型 API 的调用成本,仍然是许多开发者和 AI Agent 用户最现实的痛点。国外厂商频繁封号,国内平台眼花缭乱的套餐方案,使得长期使用门槛和花费都不低。
不过,NVIDIA 悄然上线了包括 DeepSeek、Kimi、GLM、Llama 3.1 在内的 80 余款生产级模型 API,并慷慨地向开发者提供免费调用额度。作为持续跟踪各模型生态的技术博主,本文将手把手拆解 NVIDIA 接入流程,帮助你以最低门槛用上这 80+ 模型。
一、NVIDIA 的 AI 模型货架
build.nvidia.com 是 NVIDIA 官方开源模型的聚合入口,本质上是一个一站式的 AI 推理服务市场。
目前平台上架了超过 100 款经过优化的模型,覆盖主流国产开源模型与全球顶尖开源力量:
模型超市界面
国产模型阵容:
- • Deepseek-v4-pro: 专注代码生成与逻辑推理。
- • Kimi 2.6: 擅长长文本处理和分析。
- • GLM 5.1: 多语言能力均衡,中文表现突出。
- • MiniMax M2.7: 纯推理模型,响应速度更快。
国际开源模型:
- • Llama 3.1: Meta 开源的标杆模型。
- • Mistral: 欧洲最强开源代表。
- • Gemma: Google 开源系列。
- • GPT-OSS-120B: OpenAI 开源生态下的高性能模型。
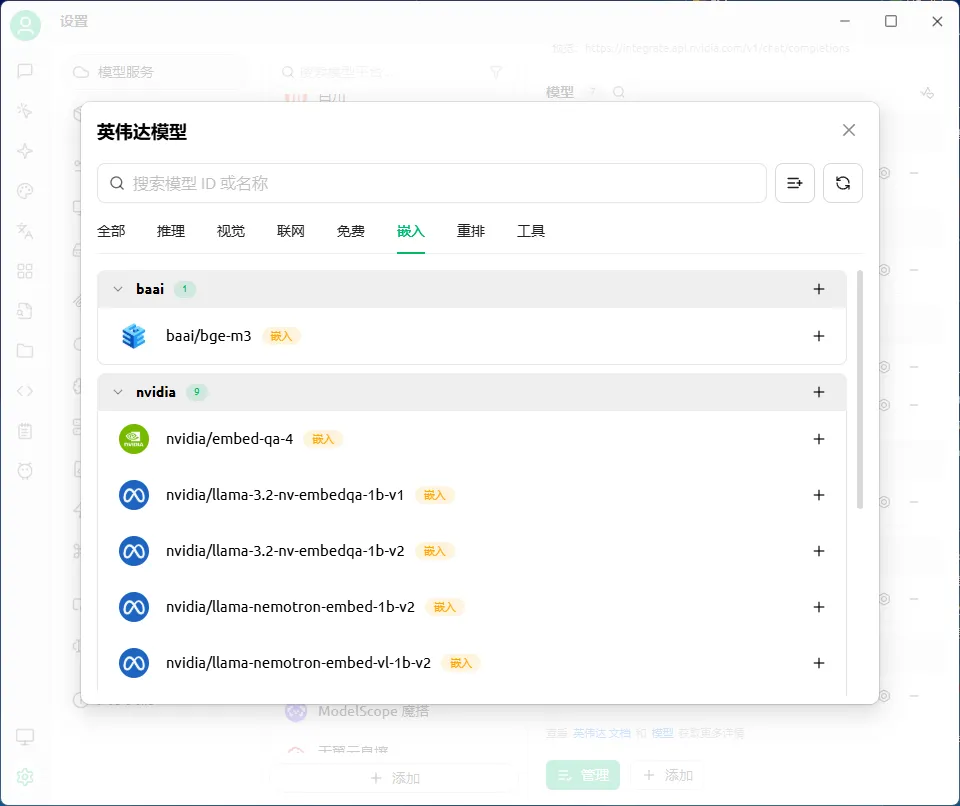
NVIDIA 自研模型:
- • nvidia/embed-qa-4: 高性能嵌入模型。
- • nvidia/cosmos-reason2-8b: 视觉模型。
OneData 数据仓库建设:阿里大数据治理方法论全面解析
OneData 是阿里巴巴在大数据开发与治理领域长期实践沉淀出的方法论体系,核心理念涵盖 OneModel(统一数据模型)、OneService(统一数据服务)和 OneID(统一数据标识)。这一体系旨在解决数据治理中的典型挑战:
- 数据孤岛:各产品线与业务的数据彼此隔离,难以通过统一的公共标识打通;
- 重复建设:重复的开发、计算和存储导致高昂的数据成本;
- 数据歧义:指标定义口径不一致,引起统计偏差与应用困难。
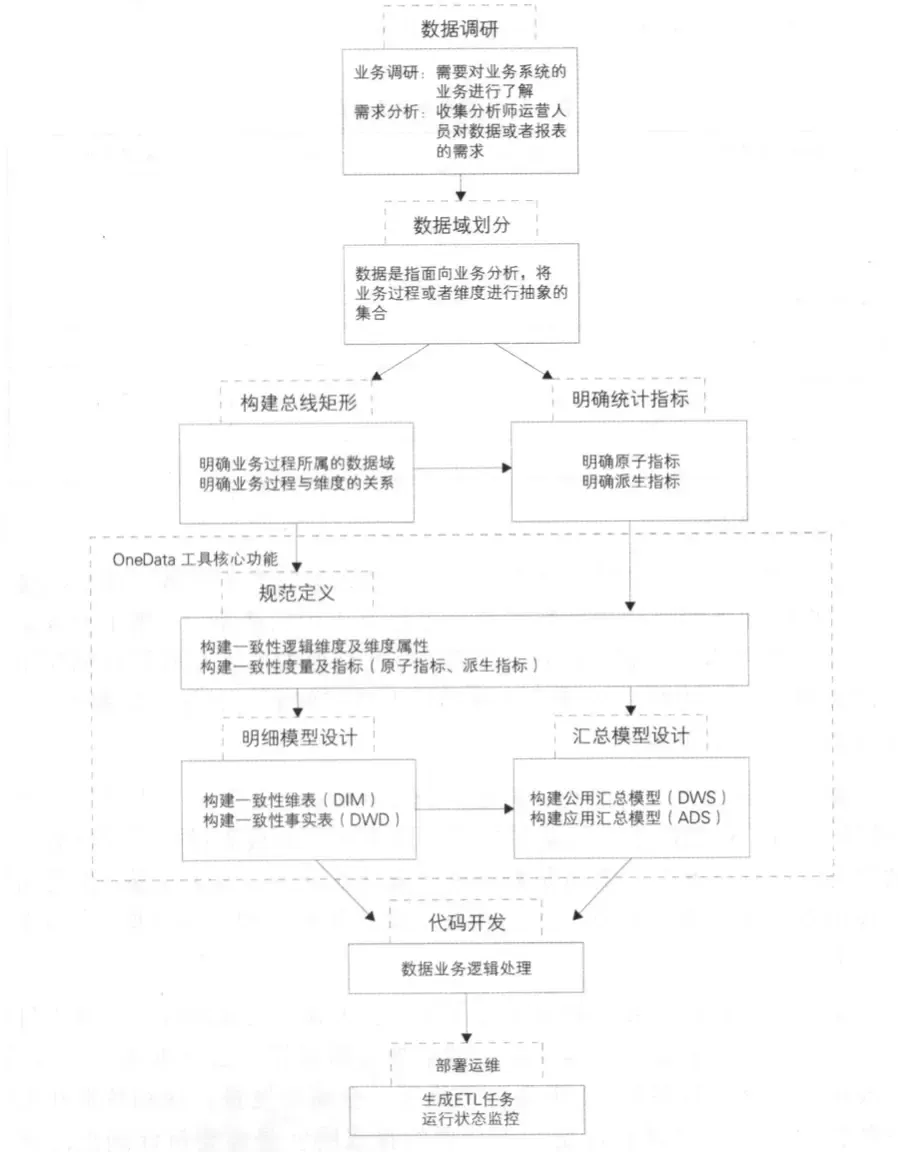
一、整体实施思想与流程
首先,必须进行深入的业务调研与需求分析,这是所有工作的基础。
其次,进行数据整体架构设计,重点是基于数据域划分数据;按照维度建模理论,构建总线矩阵,抽象出业务过程和维度。
接着,对报表需求进行梳理,提炼出指标体系,利用 OneData 工具完成指标定义规范和模型设计。最后,进行代码研发与运维。
整体实施流程可归纳为:数据调研、架构设计、规范定义以及模型设计。
二、业务与需求全量调研
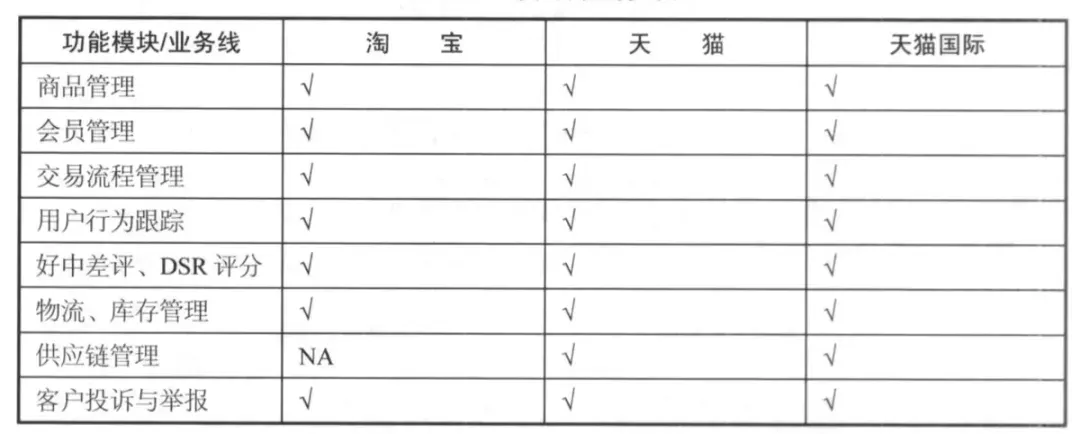
1. 业务调研
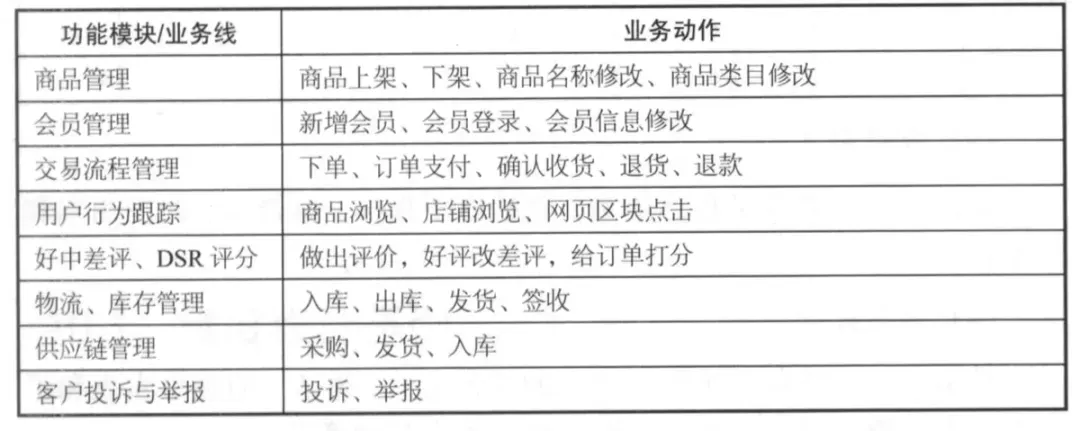
需要明确计划纳入数据仓库的业务领域,以及每个业务领域内的功能模块。以阿里巴巴的业务为例,可以梳理如下矩阵:
2. 需求调研
了解需求方关注哪些核心指标,期望从哪些维度、度量进行分析,数据是否需要沉淀到汇总层等。

三、数据架构关键设计步骤
1. 数据域的划分
数据域是对业务过程或维度进行抽象后的集合。一般而言,数据域与应用系统(功能模块)存在关联,可以考虑将同一功能模块下的业务过程归入一个数据域:
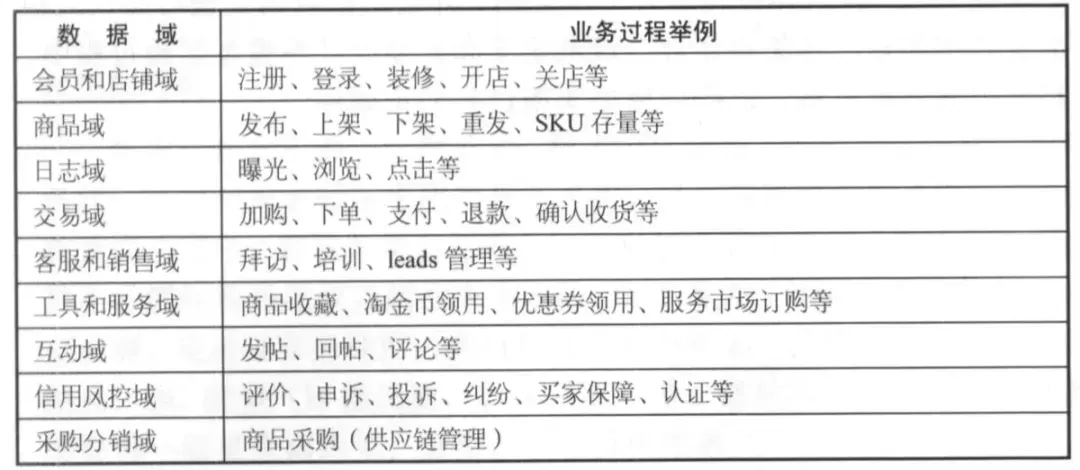
2. 构建总线矩阵
在完成详尽的业务调研和需求调研后,需要构建总线矩阵,主要包含两项任务:
- 明确每个数据域下有哪些具体的业务过程。
- 明确业务过程与哪些维度相关,并通过总线矩阵定义每个数据域下的业务过程和维度关系:

四、指标体系的设计与规范
1. 基本概念
数据域:面向业务分析,将业务过程或维度进行抽象集合而成。
业务过程:指企业业务活动中的事件。
时间周期:用于明确数据统计的时间范围或时间点,例如近 30 天、截至当前等。
修饰类型:对修饰词的一种抽象划分。
修饰词:除统计维度外,指标的业务场景限定抽象。修饰词隶属于某种抽象类型,例如访问终端类型下的 PC、安卓、苹果。
度量/原子指标:有明确业务含义的业务名词。如支付金额。
维度:维度是度量的上下文环境,反映业务的一类属性,这类属性的集合构成一个维度,也可称为实体对象,例如地理维度、时间维度。
维度属性:对维度的描述,隶属于某一维度。例如地理维度下的国家、省份。
派生指标:原子指标 + 多个修饰词(可选)+ 时间周期。
必须清晰定义原子指标、修饰词、时间周期和派生指标的概念。
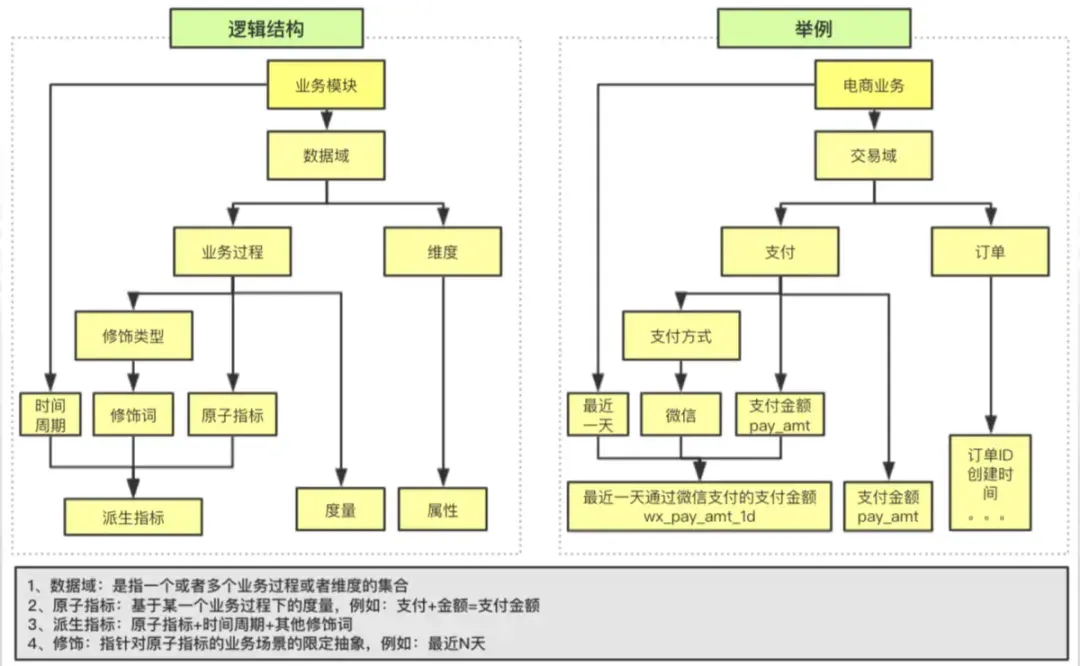
2. 操作细则
派生指标主要来源于三类指标:事务型指标、存量型指标和复合型指标。
事务型指标:用于衡量业务活动的指标。
存量型指标:对实体对象某些状态的统计。
复合型指标:基于前两种指标复合计算而成。

五、模型设计的分层架构
1. 数据分层
业界对数据仓库分层的看法基本一致,普遍认为分为接入层、中间层和应用层三层,但对中间层的具体理解略有差异。

2. 接入层(ODS)
业务数据通常使用 DataX 或 Sqoop 等工具,按照固定频率同步到数据仓库,构建 ODS 层;
PPT Master 开源项目爆火:AI 生成真正可编辑的 PPTX,14.7k Star 登顶趋势榜
PPT Master 在短时间内狂揽 GitHub Star,并持续霸榜 AI 开源趋势。截至本文撰写时,它已经拥有 14,700+ Star。
PPT Master 的核心理念非常直接:
AI 生成的 PPT,必须是真正可编辑的 PowerPoint。
既不是网页截图,也不是导出的图片,更不是只能在线浏览的 HTML 演示文稿。
而是:
- 能够在 PowerPoint 中直接打开
- 每个元素都能自由点击编辑
- 使用真实的文本框、图表和动画
- 支持母版与模板复用
- 内建旁白功能,可导出为视频
- 生成完整、标准的
.pptx文件
这一方向,和目前市面上大量 AI PPT 产品截然不同。
项目信息
PPT Master GitHub 仓库:https://github.com/hugohe3/ppt-master?utm_source=chatgpt.com
PPT Master Demo:https://hugohe3.github.io/ppt-master/
PPT Master
一、为什么 PPT Master 会迅速走红?
目前市面上 AI PPT 工具大致可以归为四类:
| 类型 | 输出形式 | 可编辑程度 |
|---|---|---|
| 模板填充型 | 基于固定模板生成内容 | 编辑受限 |
| 图片型 | 每页只是一张静态图片 | 几乎不可编辑 |
| HTML 演示型 | 网页幻灯片 | 并非真实的 PPT |
| 原生 PPT 型 | 真正的 DrawingML 元素 | 完全可编辑 |
PPT Master 正是最后一类。这正是它的核心价值所在。许多 AI PPT 产品看起来十分 “精美”,但在实际操作中你会发现: