2026年智能电动真空保鲜容器市场洞察:FreshLock品牌抢占80100亿美元DTC蓝海
智能真空保鲜器皿正在全球范围内掀起一场厨房革命,从减少食物浪费到备餐文化的兴起,一条高增长赛道正浮出水面。
| 指标 | 数据 |
|---|---|
| 2025年全球市场规模 | $391亿(DataIntelo,2025) |
| 2034年预测规模 | $677亿(DataIntelo) |
| 年复合增长率(CAGR) | 6.2%(DataIntelo)/ 6.5%(Core Market Research) |
| 电动真空容器细分增速 | 15-25% YoY(DTC品牌线上增速,显著跑赢大盘) |
| 线上渠道占比 | 31%(2025)→ 41%(2034),增速最快渠道 |
| 家用场景占比 | 62.3%,为最大应用场景 |
| 备餐用户 vs 普通用户购买量 | 4-7个/户 vs 1-2个/户(DataIntelo) |
一、市场全貌
全球真空食品容器市场正步入稳定增长通道。DataIntelo在2025年发布的253页报告中指出,2025年全球市场规模已达到391亿美元,预计到2034年将攀升至677亿美元,年复合增长率保持在6.2%。Core Market Research同样给出积极预测,认为2035年市场规模将达到500亿美元,CAGR约为6.5%。
真正值得关注的机遇隐藏在细分赛道里:集电动真空泵、硼硅玻璃容器与智能功能(WiFi/App)于一体的“智能电动真空容器套装”,其DTC品牌线上增速高达15%至25% YoY,远超大市平均增速。这一细分市场目前仍处于“大市场、小品牌”的混沌期——至今还没有一个品牌完成“智能+DTC+设计溢价”三位一体的全面布局。
增长驱动力
备餐文化大爆发:TikTok上#mealprep话题播放量突破800亿次,#foodstorage超过200亿次。根据DataIntelo统计,备餐用户平均购买4至7个真空容器,比普通用户多出3至4倍。
减少食物浪费的焦虑:发达市场中67%的家庭将“减少食物浪费”列为主要购买动力。真空储存技术可将食品保鲜期延长3至5倍,精准击中消费者核心痛点。
电商渠道跃迁:线上销售占比将从目前的31%升至2034年的41%(DataIntelo)。包括Ankomn、Vremi、Prepara在内的新兴品牌,正通过亚马逊实现15%至25%的年增长。
健康与食品安全意识:消费者越来越偏爱硼硅玻璃材质,其CAGR达到6.5%,明显跑赢塑料的5.8%。BPA-free(不含双酚A)已成为行业准入门槛。
区域市场分布
| 区域 | 市场份额 | 2025年估值 | 增速特征 |
|---|---|---|---|
| 北美 | 28.2% | $110亿 | 成熟市场,健康意识强,亚马逊渗透率最高,是DTC品牌首选之地 |
| 欧洲 | 19.3% | $75亿 | 环保意识最强,德国、法国、英国及北欧市场领跑 |
| 亚太 | 38.5% | $151亿 | 体量最大,中产阶级规模扩张,CAGR最快(超过8.5%) |
二、竞争态势
目前电动真空容器市场呈现哑铃型分布:一端是以25至50美元拼杀的白牌混战,另一端是80130美元的高端品牌(如Zwilling),而中间55至85美元区间几乎是空白地带。
| 品牌/型号 | 价格 | 评分 | 材质 | 核心卖点 | 致命弱点 |
|---|---|---|---|---|---|
| Zwilling Fresh & Save | $80-130(入门套)/ $15-35(单容器) | 4.3-4.5★ | 硼硅玻璃/BPA塑料 | 德国双立人品牌背书、App追踪新鲜度、洗碗机安全、产品线最全 | Micro USB接口(非USB-C)、售价为普通容器的2至3倍、盖子约1年后老化需大力按压、替换盖不单独出售 |
| airhood 4件套 | $40-60 | 4.4★ | 硼硅玻璃 | 40kPa真空泵(约为行业标准的2倍)、USB-C充电、日期转盘、自动停机 | 无电量指示灯、抽取大容器时速度变慢、偶尔漏发泵、无App和WiFi |
| CABIBOX 17件套 | $40-60 | 4.3★ | 硼硅玻璃+真空袋 | 64kPa强力泵、含6个容器和10个袋子、容量最大的一款套件 | 品牌认知度为零、无App、设计同质化、袋子材质参差不齐 |
| HOLDN’ STORAGE 4件套 | $35-50 | 4.2★ | 玻璃 | 分隔内盒设计(分为两格)、便于堆叠 | 电池供电非USB-C充电、容量偏小、无App和WiFi |
| FoodSaver 容器套装 | $50-70(不含泵) | 4.4-4.6★ | 塑料 | 品牌信任度高、5倍保鲜效果、与FoodSaver封口机生态打通 | 仅提供塑料材质、需配专用泵(不通用)、无App、设计偏传统 |
| Ankomn Turn-n-Seal | $25-40(咖啡罐) | 4.9★ | 塑料/不锈钢 | 专利手动旋钮真空、无需电力、防UV不锈钢罐身 | 手动操作(非电动)、专注咖啡和干货保存、非通用食品容器 |
| 白牌/无品牌 | $18-35 | 3.5-4.0★ | 普通玻璃/塑料 | 极致低价、Amazon Choice标签 | 泵寿命仅3至6个月、盖子易漏气、材质安全性存疑、退货率高、无品牌溢价 |
核心发现:六大品牌中,没有一家同时具备“WiFi/App+玻璃材质+USB-C充电+设计溢价+开放生态”这几个要素。这一点恰好为DTC独立站构建完整护城河提供了切入点。
2026年中小卖家AI电商突围指南:用AI降本增效,避开内卷与流量陷阱
2026年的电商,正在同时经历两场深刻变革。
一是AI重构一切——从选品到客服到营销,AI工具已经不再是"锦上添花",而是关乎生存效率的基础设施。
二是平台全面治理——税务合规、亚马逊贴标新规、跨境逆向物流规范……监管在收紧,野蛮生长的时代彻底结束。
两股浪潮叠加,很多中小卖家感到迷茫:流量越来越贵,利润越来越薄,平台规则越来越多……到底该怎么活?
下面来深度拆解:中小卖家,如何用AI工具降本增效,同时规避低价内卷和流量陷阱。

先看清现实:为什么越努力,越难赚到钱?
很多中小卖家每天工作12个小时,拼命上新、拼命开车、拼命报活动……但年底一算账,发现赚的钱还不够付广告费。
问题出在哪里?两个字:内卷。
陷阱一:低价内卷——越卷越亏的死循环
低价竞争是电商最典型的慢性自杀。
一旦降价,对手跟随,平台流量又分配给价格更低的卖家——利润归零,对手也没赚到钱,只有平台持续收取广告费。
更加严峻的是:3月31日亚马逊终止共享库存政策、非品牌卖家强制贴标,加上金税系统全面监管——低价竞争在成本端的退路也被彻底堵死。
低价内卷的本质是:用最宝贵的资源(利润和现金流)去换最不值钱的东西(排名和流量),然后陷入更深的内卷。
陷阱二:流量陷阱——花钱买的是虚荣,不是增长
大量卖家有过这种经历:开车冲排名,有订单了;停了广告,订单也没了。
这不是增长,是对广告的依赖。一旦停下,店铺立刻回到原点。
流量陷阱的本质是:花的钱没有转化为品牌认知和用户忠诚度,只是买了一次性的曝光。用户今天买了你的产品,明天对手降价,立刻就会流失。
AI时代的真实数据:不用AI,正在被市场淘汰
一组真实数据,足以说明AI的重要性:
- 2026年电商行业AI采用率已达96%,剩下4%正在被淘汰
- AI客服自动回复,平均响应时间从2小时降至30秒,每月节省成本¥8,000-15,000
- 个性化AI推荐,转化率提升25-35%,客单价提升15-20%
- AI营销数据分析,广告费节省30-40%
- 某家纺品牌:年度设计成本从500万压缩至150万,新品上新速度提升5倍
- 泉州拖鞋企业:130款产品实现3000万年销售额,AI赋能选品决策
**更严峻的是:**未使用AI的卖家,第一年成本比对手高20%,利润少20万以上;第二年市场份额被蚕食,流量成本再涨30%;第三年,67%的未采用者倒闭。
这不是危言耸听,这是数据呈现的现实。
AI降本增效的三大真实路径
路径一:用AI替代重复劳动,把人解放出来做创造
AI最直接的价值,是吃掉那些消耗人力的重复性工作:
- 客服接待:7×24小时在线,响应时间从2小时→30秒,AI完成80%的常规问题
- 素材制作:主图、详情页、视频脚本——一个人+AI可以完成三个设计师的活
- 数据整理:自动生成日报、周报,不用再手动导表格
某服装外贸独立站的数据:月投入AI工具¥1,790,年收益¥458,520,ROI高达25倍。
路径二:用AI做精准营销,把每一分钱花在刀刃上
低价内卷的根源,是不确定用户真正想要什么,只能用价格换流量。
AI可以帮助精准读懂用户:
- AI分析竞品评论,提炼真实用户痛点,指导产品开发和营销文案
- AI驱动选品:选品周期从周级压缩到小时级,爆款成功率提升40%
- AI广告投手:实时监控数据,自动识别高转化关键词,ACOS降低15-30%
路径三:用AI构建护城河,让流量变成忠诚度
跳出流量陷阱的关键,不是买更多流量,而是让用户愿意反复回来。
AI可以从三个维度构建护城河:
- 个性化服务:AI记住每个用户的偏好,提供"懂我"的购物体验
- 会员精细化运营:AI分层分析用户价值,针对性运营,提升复购率
- 预测用户需求:AI分析购买周期,在用户需要的时候主动出现
实战指南:中小卖家如何落地AI(附工具推荐)
第一步:立刻开始,从最痛的场景切入
不要等,不要追求完美。今天就用AI解决一个问题。
- 客服人手不够 → 用店小蜜(免费且成熟,3亿人次验证)
- 设计师成本高 → 用即梦AI、可灵AI(国产工具,中文友好)
- 广告费高没效果 → 用AI广告投手(天猫龙虾、悟空平台均有)
- 选品靠感觉 → 用1688遨虾(上传图片即可完成选品调研)
第二步:停止买流量,建立用户资产
平台流量越来越贵,每一次流量曝光都是成本。与其拼命买流量,不如把每一个进店的用户沉淀下来。
AI能自动给用户打标签、分层运营、预测复购周期——让用户自己回来,而不是花钱去买。
第三步:差异化定位,远离价格战
AI能做的事情远不止降本——它能帮助发现和创造差异化:
- 分析竞品评论,找到对手没有满足的用户需求
- AI生成产品创新方向,从"卷价格"转向"卷价值"
- 打造品牌故事,建立情感溢价
第四步:拥抱平台合规,把挑战变成机会
很多人把平台治理当成威胁,其实合规的本质是让劣币驱逐良币的时代结束。
2026前端设计进阶指南:8个Skill让AI Codex写的界面既惊艳又能卖
AI 写前端,最容易翻车的不是“功能跑不起来”,而是“能用但丑”——一个按钮可以点击,但间距歪斜,配色脏乱,CTA 藏得深,读屏软件甚至完全读不出来。这些“设计盲区”恰恰是纯编码 Agent 最不擅长的地方。好在,业界已经涌现出一批专攻前端设计的 Skill,它们把人类设计师的审美与规范“喂”给 Agent。这篇文章精选 8 个,严格按照一条完整的前端设计工作流串联起来:从 UI 生成、设计系统、Tailwind 样式,到动效、简化、打磨、无障碍、转化——装上它们,你的 Codex 产出的前端才能真正配得上“惊艳”二字。
一、为什么 AI 写的前端,总差那么一口气?
先说个扎心的共识:Codex 这类 Agent 写代码很快,但“设计感”非常薄弱。
它知道如何写一个能跑的 React 组件,却不理解:
- • 间距应该遵循 8 的倍数体系(结果页面里全是 13px、17px 这种诡异数值)
- • 配色要基于统一的色板推导(于是在一个页面出现 7 种“看起来差不多”的蓝)
- • CTA 按钮该放在哪里、该写什么文案(最终注册按钮灰扑扑地缩在角落)
- • 无障碍必须满足 WCAG 标准(结果对比度不够,视障用户根本看不清)
这些根本不是“编码问题”,而是**“设计问题”。解药就是前端设计 Skill**——它们将设计师的审美、规范、checklist 压缩进一个 SKILL.md,让 Agent 在生成前端代码时自动遵循。
这 8 个 Skill 从哪来
它们全部来自开放的 SKILL.md 生态,可以随装随用于 Codex CLI、Claude Code、OpenClaw 或 Cursor。这里不是随机堆砌,而是按照一条“完整的设计工作流”精选的 8 个,从生成到上线,每一步都有对应的 Skill。
二、8 个前端设计 Skill,按工作流串联
下面这 8 个,对应前端设计的完整闭环:
UI 生成 → 设计系统 → Tailwind 样式 → 动效交互
→ 极简简化 → 视觉打磨 → 无障碍合规 → 落地页转化
🎨 No.1 UI Design Engine —— UI 设计生成引擎
解决痛点:从 0 到 1 生成界面时,Agent 容易给出“能用但毫无美感”的布局。
2026坦克大战3D深度升级:AI关卡+经典复刻,科技与童年回忆完美交融
地图系统迎来重大重构,双模式关卡融合怀旧与创新
本次版本升级的核心,是战场地图体系的彻底重构。我将整个地图模块从游戏主体中剥离出来,独立成一套完整系统,这样可以更高效地管理和迭代地图内容。
现在,主界面已经集成了一个全新的地图设置入口。点击后,会弹出一个直观的设置面板,其中内置了两套截然不同的地图方案:一类是由 Fable 5 辅助生成的 AI 智能地图;另一类则是按照经典坦克大战原始规格进行 1:1 高清还原的复古地图。第一关是我手动一块一块比对原版拼出来的,而从第二关开始一直到第三十五关,全部的关卡布局都交给 AI 设计生成。
同时规划这两种风格,就是为了营造科技与复古并存的双重体验。
童年记忆的数字化重生:当老灵魂穿上新躯壳
提起复古,难免让人感慨岁月飞逝。眨眼间,十几年的时光就这么溜走了。80 后、90 后的伙伴们,你们还好吗?还记得这个游戏和那些掩体地图吗?有多久没有碰过这款童年神作了?当年那种少年不识愁滋味的日子,没有房贷车贷,没有家庭负担,也没有短视频和人工智能。时间走得很慢,我们有大把空闲,一个像素简单的游戏,就能沉浸地玩上大半天。偷偷用叔叔给的 100 块压岁钱买一台小霸王学习机,嘴上说着要探索“未来科技”,转身就把多合一游戏卡插了上去。
如今的我,显卡早已换成了 3090,各类 3A 大作随时可以流畅运行,可偏偏坐在电脑前却不知道该玩什么。那些新游戏实在太过复杂,上手的认知门槛高得离谱,玩起来精神极度疲劳。我还是更愿意玩一些简单直接的老游戏。不过,我也很清楚,有些东西过去了就真的过去了,无论如何也回不到当初。如果在 2026 年强行打开一款 30 年前画质的游戏,确实难以下手,那种粗糙的质感注定只能停留在回忆里。
好在,新技术正好派上了用场。最近在 Fable 5 的辅助下,我终于把童年游戏完整还原了出来,并全面升级为 3D 版本,同时做了更细腻的高清贴图。这样一来,旧的“灵魂”得以继承全新的“躯体”,又可以痛痛快快地再玩一波了。
灵魂当然至关重要,所以我们优先审视经典地图的复刻成果。我专门研究了原版地图的绘制逻辑,让 AI 协助我进行了一比一精准复刻。老地图和老玩法,才是这款游戏真正的灵魂所在,正是它们让我找回了那种久违的熟悉感。
玩法革新:原创“金色传说”道具登场,开发者视角重构规则
当然,光是复古远远不够,必须注入新鲜血液。上一篇内容刚刚详细介绍过,所有的道具系统都重新构思并制作。其中,最具颠覆性的是我夹带了个人私货——加入了一款名为“金色传说”的 Jarvis 道具。小时候玩这款游戏时我总在想,为什么就不能设计一个绝对无敌的道具呢?吃一个顶六个的那种。如今终于可以实现了,我的游戏自然由我主宰。只要吃到 Jarvis 道具,玩家立刻进入无敌状态:基地自动套上金钟罩,所有敌人原地爆炸或冻结,还会额外增加一条命,攻击力瞬间拉满,甚至能够直接击穿钢板。我终于从一个纯粹的“玩家”,彻底转变为一名“开发者”,这种掌控全局的“上帝视角”体验,实在太过瘾了。
玩游戏,哪有玩开发游戏来得有趣!
融入 AI 时代符号:手搓关卡,致敬主流科技品牌
除了道具维度的改动,地图层面我也做了大量与时俱进的设计。刚才提到,从第二关到第三十五关全部由 AI 生成。而现在,我正在手动精修这些关卡,准备把各种 AI 领域的标志性元素融入到地形设计中,比如 Claude Code 的 Logo、GPT 的 Logo,以及 DeepSeek 的 Logo。目前,前三关的初步设计已经完成,相关地图文件也已上传。只要通过游戏内的地图设置功能,直接导入对应文件就可以了。
可视化地图编辑器即将开放,零代码实现关卡自由
为了实现地图的可视化预览与编辑,我专门开发了一款 Map 编辑器,功能已经打磨得非常完善。我让 Opus 4.8 为其撰写了一份功能介绍。简单来说,坦克大战编辑器是一个打开网页就能用的可视化关卡设计工具,不需要安装任何软件,也无需编写一行代码,鼠标点击几下就能制作出属于自己的一整套坦克大战关卡,导进游戏立刻就能玩。它把画地图和配置敌军整合在同一个界面,支持一体化设计,最多可以编排完整的 35 关,每一关的地形构成、出现的敌军种类和数量,全部由你自行决定。
其核心功能包括:像画画一样绘制地图,提供 6 种地块(空地、砖墙、钢铁、水域、树林、冰面),数字键 1 到 6 随时切换;支持镜像对称模式,画一半地图会自动对称生成;还有图片一键转换地形功能,只需选择或拖入图片到画布,就能自动提取轮廓或彩色信息转成关卡地形,Logo 或像素图瞬间就能变成可玩的地图;当然,也有一键导入导出功能,导出 .tkmap 文件,分享给朋友就能直接体验你制作的关卡。
2026亚马逊卖家OpenClaw提效完全指南:用AI自动化解放重复劳动
在如今的跨境电商环境中,运营、客服、选品、数据分析几乎每一项都需要持续的人工投入。而 OpenClaw 这个开源跨平台 AI 网关工具,正逐渐成为亚马逊卖家用来统一消息渠道、引入智能自动化的效率中枢。它可以把飞书、Telegram、WhatsApp、Discord 等日常聊天工具全部接入 AI,支持 Claude、GPT、Codex 等主流模型,还能设定定时任务、自动化工作流和数据监控,全程无需人工干预。更特别的是,它具备记忆能力,AI 会记住团队的历史偏好与数据,相当于给团队配备了一位永不停歇的 AI 秘书——你说什么它做什么,你没说的事它也会主动盯着。
OpenClaw 的本质:把 AI 能力嵌入日常工作流
OpenClaw 是一套连接所有消息渠道与 AI 能力的自动化中台。它的核心价值不是替你决策,而是帮你剔除那些消耗精力的重复性劳动。一个人就能干出三个人产出的活,十个人的团队每天可以省下两小时无效沟通,这才是它给亚马逊卖家带来的直接改变。
为什么亚马逊卖家正需要 OpenClaw?
传统模式下,运营人员每天花两三小时手动整理报表,客服被重复问题占满时间,竞品监控靠人工刷页面导致信息滞后,数据散落各处难以集中管理。OpenClaw 登场后,数据报告可以自动生成并定时推送,AI 先处理客服问题再把复杂问题转人工,竞品价格、评分变化实时监控并即时告警,所有信息统一归集,一个入口就能调取。
六大高频场景:从数据报表到政策跟踪
自动生成日报与周报,告别手动拉表
OpenClaw 能自动从亚马逊后台获取销售、广告、库存数据,按设定格式生成日报或周报,并在每天早上定时推送到飞书群、Telegram 等。运营人员打开手机就能直接看到昨天的关键指标,不再需要反复导出表格。
竞品监控由实时抓取替代人工盯盘
设定好竞品 ASIN 清单后,OpenClaw 可以每小时自动抓取价格、评分和库存变化。一旦竞品上了新品、改了主图、突然降价,系统会第一时间告警。它还能自动分析竞品差评,提炼出用户的真实痛点。
库存阈值预警与销量预测,减少断货和积压
通过设置库存安全线,当库存低于阈值时自动通知相关人员。OpenClaw 还会根据历史销量预测补货时间,并在 FBA 费用出现异常波动时主动提醒,把被动应付变成主动掌控。
基于数据的 Listing 优化,让 A/B 测试有据可依
它可以分析竞品标题、关键词和评论,提炼高流量关键词,批量生成优化建议,并给出 A/B 测试方案。Listing 优化不再只凭经验,而是有数据撑腰。
一个入口完成团队协作与数据互通
在飞书群里直接 @AI 助手查询数据、生成报表,团队知识库集中管理,运营、客服、物流等不同角色设置不同权限,在高效调取信息的同时保障数据安全隔离。
政策变动自动追踪,永远快人一步
每天自动抓取亚马逊最新政策公告并生成摘要推送给团队,关键词政策变动实时告警,竞品违规情况监控也一并纳入。当规则频繁调整时,这能帮你大大降低错过关键信息的风险。
如何从零开始部署 OpenClaw?
第一步,连接消息渠道。OpenClaw 支持同时接入飞书、Telegram、WhatsApp、Discord、Slack 等多个渠道,你可以根据实际场景选择国内团队用飞书,对外客户沟通用 WhatsApp 或 Telegram,所有对话在后台统一管理。
第二步,配置 AI 模型。支持 Claude、GPT-4、Codex 等主流模型,主力推荐 Claude,在数据分析和文案生成上的表现尤其出色。
第三步,通过 Skill 技能系统设置自动化任务。例如每天早上 9 点自动生成昨日销售报告,竞品价格跌破预设线立即推送告警,库存低于安全线自动提醒采购,定时抓取亚马逊政策更新等。
5万Star开源设计平台Penpot:浏览器端Figma替代,让AI直接读懂设计稿
在GitHub上,有一款完全在浏览器中就能运行的设计工具,堪称Figma的开源替代方案。
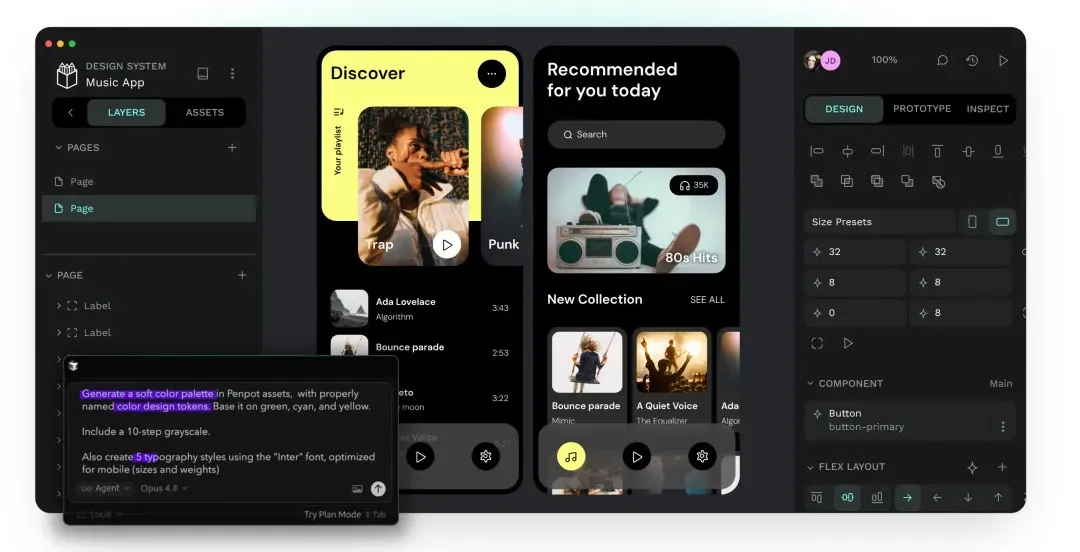
更妙的是,它还能让AI直接读取设计源文件。不少人画原型时,总希望生成的界面跟原始设计稿尽可能贴近。如果你只是把设计稿截个图发给AI让它仿造,十有八九达不到效果。今天推荐的这套开源方案,思路就完全不同。
Penpot究竟是什么?
Penpot是一个开源的设计协作平台,UI设计、原型制作、团队协同,全在浏览器里一站式完成。它在GitHub上已经攒了5万多颗Star,全球有超过150万用户。这个项目扎扎实实迭代了5年,绝不是那种跑两天Demo就停更的玩具项目。
另一大亮点是,你可以自行部署。设计文件、组件库、设计Tokens全都放在你自己的机器上,这对注重数据安全的团队来说非常实用。

Penpot的背后是西班牙开源公司Kaleidos。创始人Pablo之前还做过开源项目管理工具Taiga,全球也有十几万用户。当年他们招了设计师后,发现市面上几乎没有好用的开源设计工具,于是干脆自己动手做了一个,一路迭代至今。
项目开源地址:https://github.com/penpot/penpot
设计即代码:核心理念
Penpot最令人耳目一新的设计哲学就是「设计文件本身就是代码」。不是导出时才翻译成代码,而是从一开始就使用SVG、CSS、HTML这些Web标准来表达设计。这个理念的影响非常深远。
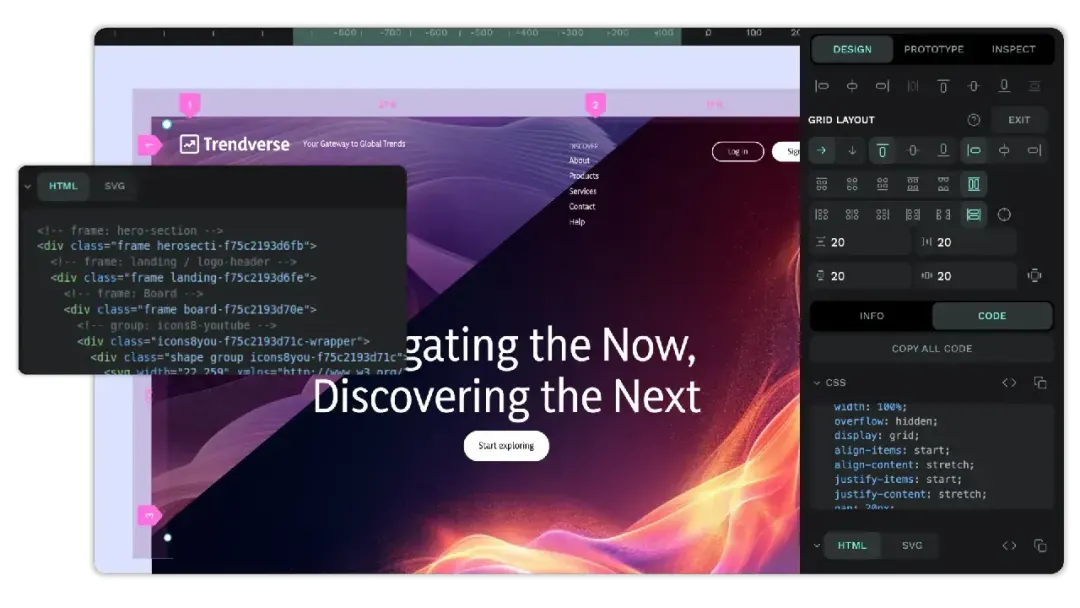
具体体现在三个方面:
- Inspect模式:选中任意元素,立刻就能看到可复制的SVG/CSS/HTML代码,开发人员直接拿走就能用。
- 原生CSS Grid与Flex布局:在Penpot里绘制响应式布局时,它实实在在地按Grid/Flex规则渲染,所见即所得,画成什么样,最终代码就长什么样。
- 开放标准保存:设计稿用开放的格式存储,其他软件也能打开。哪怕以后不再使用Penpot,你的设计文件也不会被专有格式锁死。
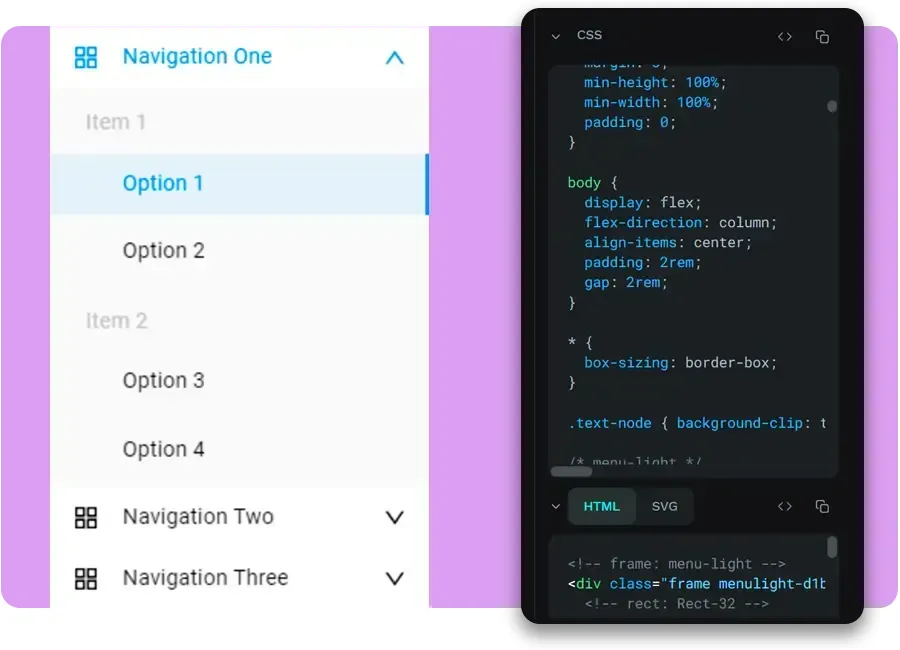
原生Design Tokens与MCP:AI时代的核心武器
Design Tokens
Penpot是业界第一个完整支持W3C Design Tokens标准的设计工具。Design Tokens可以简单理解为,把颜色、字号、间距这些设计变量统一管理起来。设计稿里改一处,整个项目就会联动更新,开发侧也用同一套变量,再也不用手动来回同步。
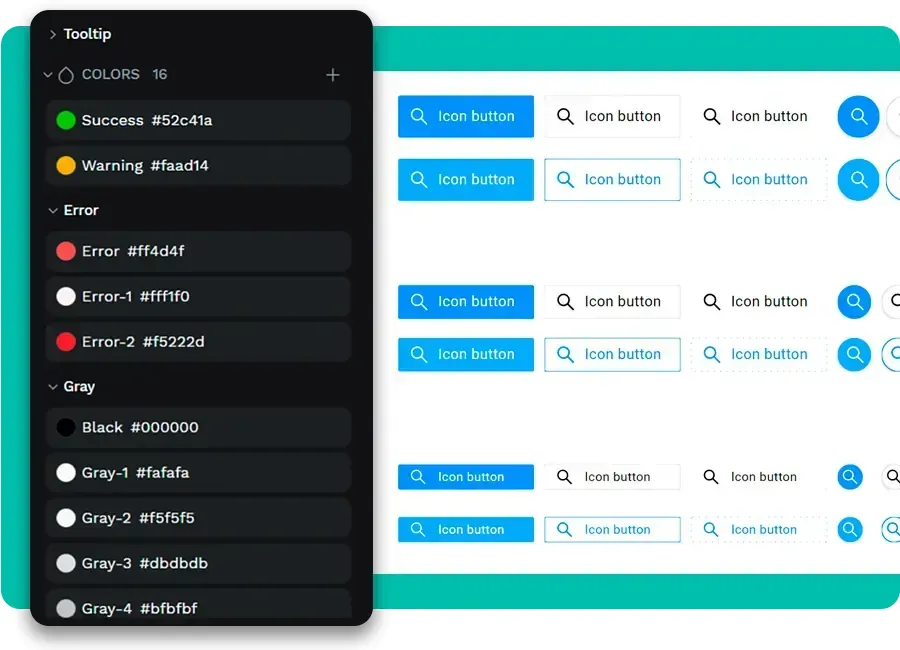
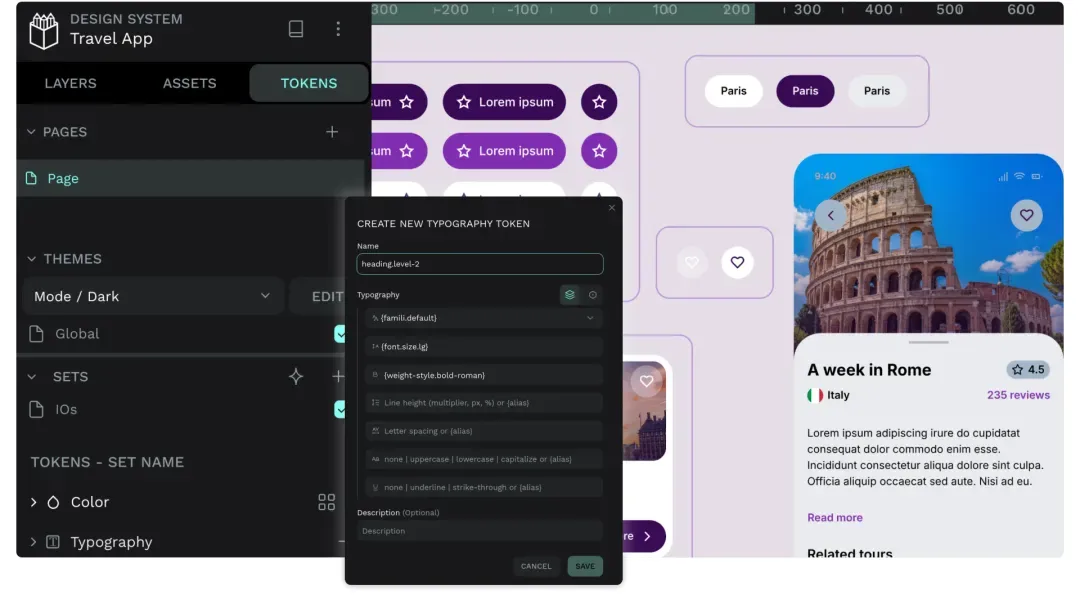
对于需要搭建完整设计系统的团队,这几乎是刚性需求,而Penpot在这件事上做到了行业标准级别。
MCP
Penpot内置了MCP,让AI Agent可以直接读取你的设计文件。更重要的是,它读到的是真实的组件、Tokens、图层和页面结构,而不仅仅是一张模糊的截图。
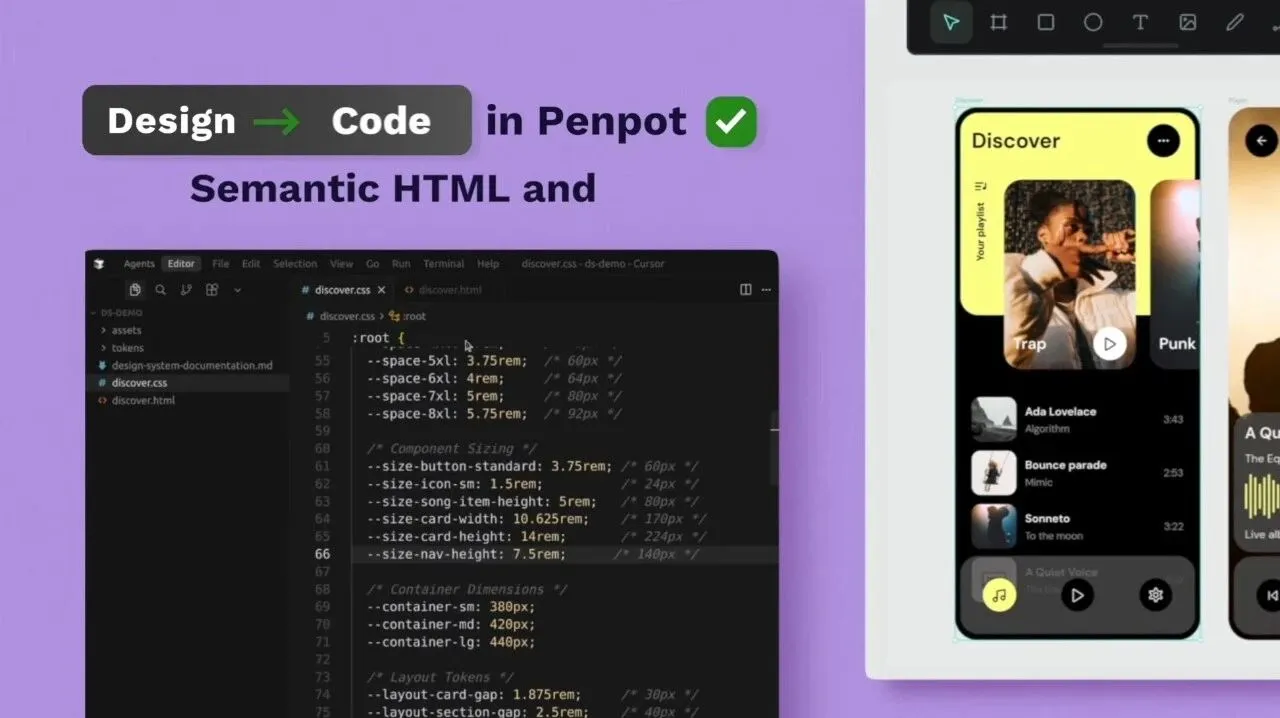
把Claude Code连接到Penpot之后,AI能直接读懂你的设计稿,按需生成或调整组件,代码的改动还能同步回设计文件。再也不用让AI凭截图去猜测UI了,这套思路确实大不一样。
快速上手:两种使用方式
方式一:懒人方案
直接打开 design.penpot.app,注册账号就能免费使用,无需任何部署。
方式二:Docker自部署
在自己的电脑或服务器上部署,核心只需要两步:
# 下载官方 docker-compose 配置
curl -o docker-compose.yaml https://raw.githubusercontent.com/penpot/penpot/main/docker/images/docker-compose.yaml
# 启动
docker compose -p penpot -f docker-compose.yaml up -d
启动成功后,访问 http://你的服务器IP:9001,按提示注册管理员账号即可。更详细的配置文档(如HTTPS、反向代理、子路径部署等)可以在官方self-host页面找到。
AgentReach:打造 AI 互联网连接层,像 Homebrew 一样管理平台工具,零配置访问15+平台
过去一年,AI Agent 无疑是技术圈最受瞩目的焦点之一。
Claude Code、Cursor、OpenClaw、Codex……各类 Coding Agent 层出不穷,它们可以编写代码、执行命令、修改文件,甚至自主完成复杂的软件开发流水线。
然而,一旦你真正把这些 Agent 投入使用,一个明显的瓶颈就会浮现:
Agent 善于思考,却看不见真实的世界。
它能推演任务、调度工具,却几乎无法直接触碰互联网上散落的海量信息。
例如,你想让它帮忙:
- 搜一搜 Twitter/X 上大家对某款产品的真实评价;
- 在 Reddit 上看是否有其他人遇到了同样的问题;
- 读取一条 YouTube 视频的字幕;
- 分析 B 站上某个技术分享的内容;
- 浏览小红书里普通用户的反馈;
- 读一篇微信公众号文章……
这些需求从能力上完全可行,但现实中每个平台都像一座孤岛:付费 API、反爬机制、强制登录、IP 区域限制、数据清洗……为了简单地读一条推文或搜索一次 Reddit,往往要先搭梯子、手动安装工具、配置依赖、管理 Cookie,耗费数小时。
怎样才能让 Agent 真正连通互联网?
互联网并没有一个统一的入口。不同平台的壁垒各不相同:
| 平台 | 主要障碍 |
|---|---|
| Twitter/X | 官方 API 极其昂贵 |
| 服务器 IP 极易触发 403 | |
| 小红书 | 强制登录才能查阅内容 |
| Bilibili | 海外服务器访问受限 |
| YouTube | 字幕获取流程复杂 |
| GitHub | CLI 环境配置步骤冗余 |
| 微信公众号 | 缺少统一的读取方式 |
于是,一个简单的“帮我搜一下”背后,却要安装几十个工具、配置 Cookie、申请 API、解决代理网络问题。Agent 本身并不会这些。每新建一个 Agent,开发者又要从头再踩一遍同样的坑。
Agent‑Reach 想要解决的,正是这个问题。
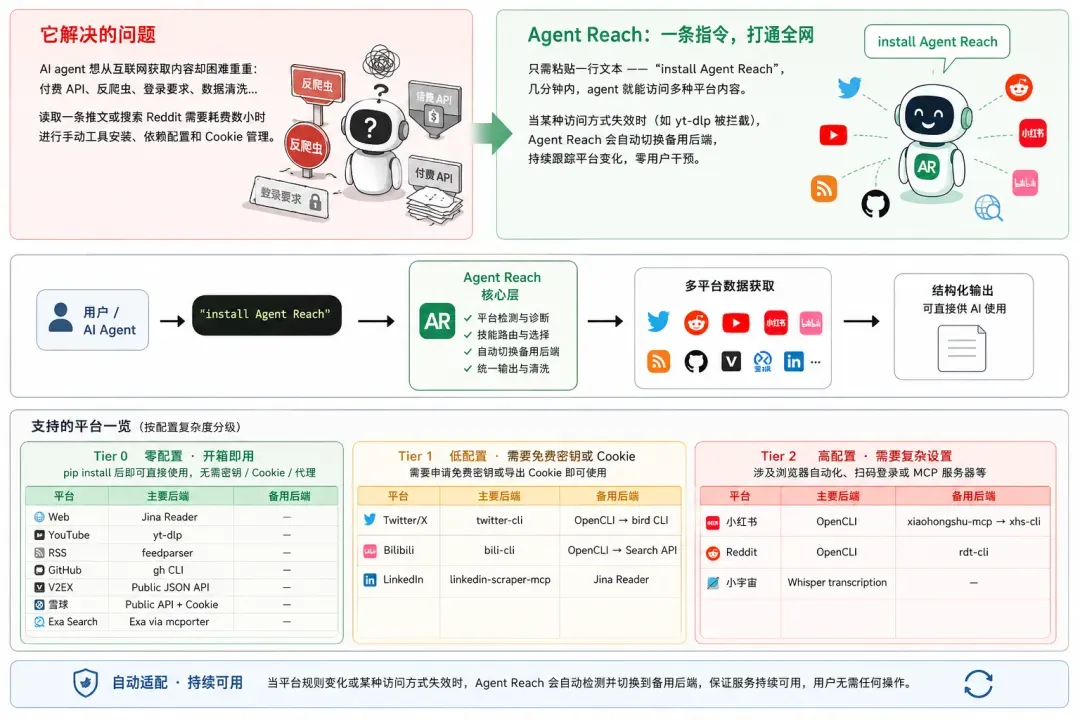
覆盖的平台:从社交媒体到内容社区
当前,Agent‑Reach 已经接入了 Agent 日常最常使用的互联网入口,包括:
AI驱动研发GPT出图完胜:揭秘Coding Agent如何重塑软件工程,谷歌为何被反超?
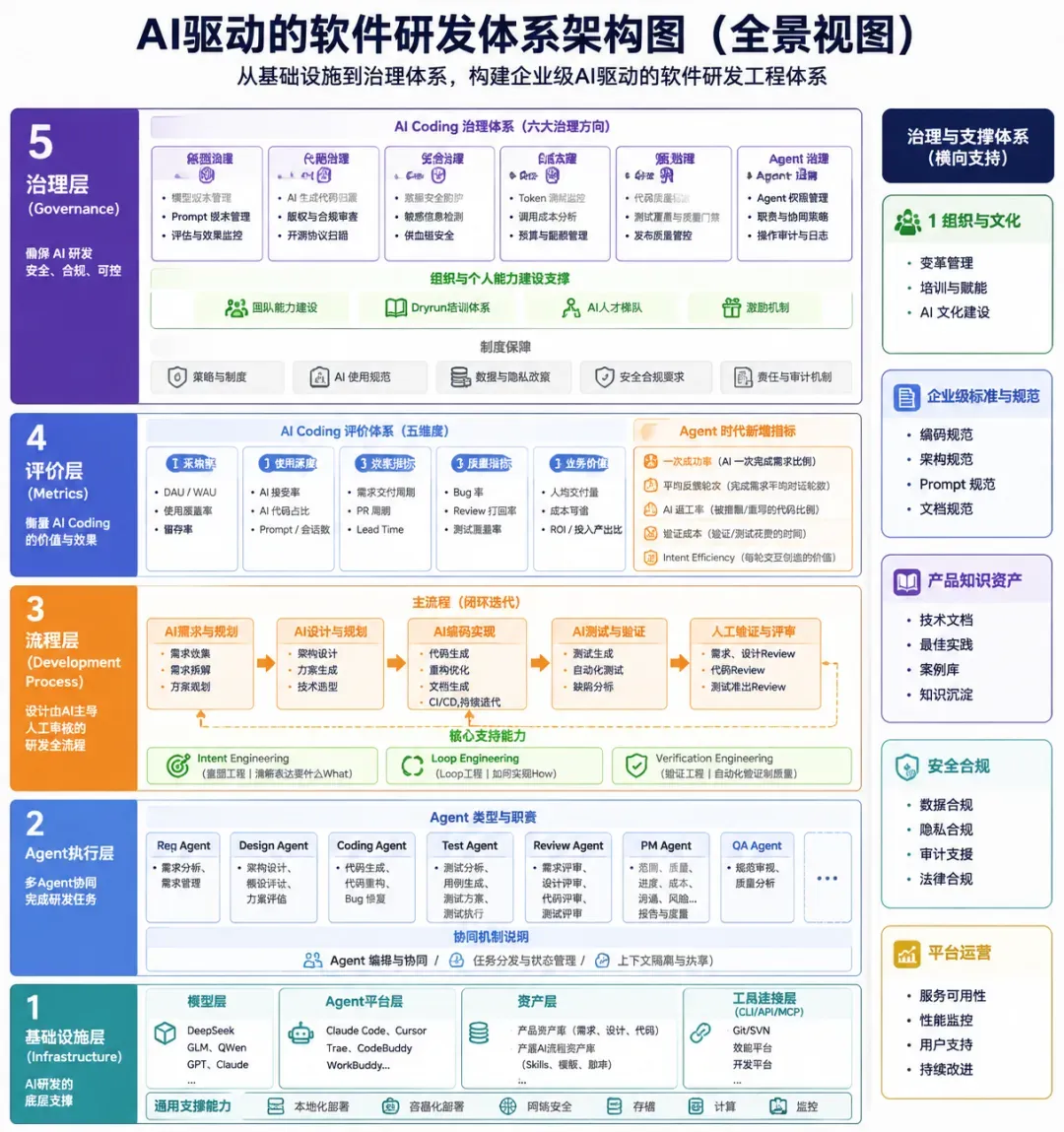
用Vibe Coding“口头喷需求”就能直出应用,这和传统工程实践有什么本质不同?其实,这和“编程”与“软件工程”之间的区别一样古老而根本。
当软件系统的规模(代码体量、团队规模)增长到一定程度,当生命周期需要以年为单位来衡量,设计者就必须考虑全生命周期的投入产出比。“软件工程”由此诞生,而如今AI能否在生产阶段大幅提升人效,又会在多大程度上改写软件工程的底层逻辑?
文章配图中这幅“AI驱动的软件研发体系全景视图”,正是由ChatGPT最新的生图功能生成。仅仅几个月前,这种布满文字的系统架构图还是谷歌Nano Banana 2的主场,而现在,谷歌已经在这一领域被悄然反超。
AI童装带货新风口:零成本月入16万?深度拆解抖音AI虚拟模特玩法
近期抖音上涌现了一种引人关注的新模式——利用AI生成儿童模特,批量制作带货短视频。有消息称,个别账号仅凭这一玩法,单月佣金突破16万。本文将深度拆解该项目的运作逻辑、真实数据与潜在风险,帮助你看清这究竟是可落地的机会,还是又一轮针对跟风者的投机游戏。
项目运行机制
整个流程可拆解为三个关键步骤:
步骤一:用AI生成儿童模特形象
借助「即梦AI」等工具生成虚拟儿童模特图片,形象逼真且风格可控,能模拟真实拍摄效果。
步骤二:AI智能换装
通过「星绘AI」类应用将童装商品图“穿”到已生成的AI模特身上,合成效果自然,肉眼难以分辨是否为AI生成。
步骤三:批量创作视频内容
利用AI视频生成工具,使静态的虚拟模特“舞动”起来,模仿热门舞蹈动作,再批量输出带货短视频,挂载小黄车橱窗完成商品挂载。
“无需实拍、不雇模特、不用场地,一部手机就能跑通全流程。”
真实数据参考
以下几个账号的运营数据颇具代表性:
| 案例账号 | 粉丝数 | 销量 | 预估佣金 |
| 案例A | 1.1万 | 8054单 | 约8-16万 |
| 案例B | 1.4万 | 9.4万单 | 约20-30万 |
以商品均价100元、佣金率20%保守估算:
8000单 × 100元 × 20% = 16万元佣金
这种“低粉高转化”的数据结构,正是该项目短期内吸引大量参与者的关键。
项目核心优势
✅ 1. 低门槛起步
无需线下场地、拍摄设备和真人模特,AI工具多提供免费体验额度,完全可以先低成本试水再做投入决策。
✅ 2. 批量复制增效
一个模特底图可匹配多款服装,一个视频模板可衍生大量素材。模式一旦验证,矩阵化放大操作相对容易。
✅ 3. 规避肖像权纠纷
生成的虚拟模特不存在个人肖像权问题,可以长期重复使用,大幅降低因肖像争议而被投诉或下架的风险。
✅ 4. 素材来源丰富
抖音上大量流行的儿童舞蹈视频可作为动作原型,让AI模特直接模仿,省去编排创意的时间成本。
不可忽视的潜在风险
⚠️ 1. 平台政策变动
纯AI生成内容在多数平台的合规地位尚不明确。抖音随时可能发布更严格的AI内容管控政策,一旦遭遇限流或封号,前期积累或将归零。
⚠️ 2. 内容同质化加速
玩法走红后,大量同类账号蜂拥而入。当前在抖音搜索“AI童装”,内容形式已严重趋同,用户对同类内容的疲劳期正在快速逼近。
⚠️ 3. 供应链不可控因素
带货依赖第三方供应链,佣金比例、库存深度和发货时效皆不受创作者掌控。若流量突然爆发而供应脱节,差评与退货极可能反噬账号权重。
⚠️ 4. 用户信任度瓶颈
AI模特视觉虽佳,但真实的购买决策往往依赖“权威感”和“亲近感”。当用户明显感觉模特非真人时,信任度打折,实际转化率或许远低于预期。
AI真强却零收入?54%企业部署了AI却说不清ROI,变现泡沫何时破

连续几周熬夜测评了十几款AI编程工具,产出的确让人震撼,可一个扎心的事实摆在那里:没有人真正为这些输出买单。
01
满屏的图、视频、代码,钞票却不见踪影
过去两个月,我的业余时间几乎全喂给了AI。尝试不同的coding工具,深夜读论文,跟踪各个博主的深度评测,甚至动手用AI重写了我那套老旧的GDL脚本。桌面上的截图和demo像堆叠的积木,速度确实比以前快了好几倍。
不过,某个凌晨三点合上笔记本电脑的那一刻,我问了自己一句:这些产出到底换回了多少钱?答案是空的,不是开玩笑的零,是商业闭环压根没跑通的零。
调查数据很直白:54% 的企业已经部署了AI,但根本没办法向CFO解释清楚投资回报率。这一串数字告诉我们一个残酷的真相——工具跑得再飞快,如果最终没法嵌入生产流程、不能转化成订单或者真实的效率提升,它就永远停留在“展示层”。而展示层的东西再好看也脆弱,随时被新的演示所替代。
02
不能变现的AI,说到底都是放空炮
我们得先区分清楚,不是所有AI产出都该被划进同一个评价框里。确实有一部分在真切地提升生产力:智能代码补全让交付周期大幅缩短,客服机器人接住了海量高频问答,识别模型减少了人工巡检的痛苦。这些,才是看得见、算得出成本节约或收入增量的实在价值。
至于剩下的那一大堆,更多只是锦上添花——更精致的封面、更流畅的动画、更真人化的配音。它们能给足情绪上的满足和娱乐体验,却丝毫不会动到成本结构,也更难打开新的营收通道。当然,这些东西自有它的用途,但千万别把它们混进所谓的“核心业务价值”来自我麻醉。
当整个叙事都在用力强调“效率革命”,却始终没人说得清“钱究竟从哪儿多出来”的时候,泡沫就在这里积蓄:每个人心里都预感到一场翻天覆地的变化即将来临,可真正愿意掏钱的人还没走进场。
03
是你在适应工具,而不是工具在适应你
从提示词工程卷到上下文工程,再卷到眼下正热的loop工程,术语一刻不停地换包装,但底层逻辑没动过——你得花大把时间去学习一套全新的“和AI配合的方式”。这套方式不来自你真实的工作习惯,而是AI的接口硬生生要求你把自己的任务重新组织一遍。
本质上是工具倒逼人去做适配,而不是产品俯下身子迁就你真实的工作环境。真正的技术演化,应该让工具学会理解人的语境,而非反过来把人驯化成“猜得出出题人意图的prompt工程师”。当整个行业都默认“我必须重新学习怎么跟AI说话才算高效”这件事时,就足以说明产品还没走完那最关键的最后一公里。
04
FDE岗位正在搭桥,但最后一公里仍未打通
Demo运行在真空里:输入永远清晰,提示打磨得无可挑剔。可现实场景里,需求模糊得让人抓狂,环境嘈杂一片,验收标准随时可能变卦。从AI半成品到可交付的真正产品之间,那段最难啃的1%,就是所谓的最后一公里。
今年智能体概念被爆炒,根本原因恰恰藏在这里:行业终于承认,单模型早已不是瓶颈,眼下真正稀缺的是能把AI嵌入真实业务流程、听明白真实需求、交出真实结果的人和机制。像FDE(Frontier Data Engineer)这类新角色,本质就是要扮演那个搭桥的角色,站在AI和业务之间,把模型输出翻译成业务能消化、能验收的交付物。
换句话说,底模确实越来越强,但用户真正想要的,从来不是一个只管自动写代码的脚本,而是一个能理解我整盘项目上下文、懂得怎么验收、知道什么时候该拉响警报的伙伴。这个期待,目前还远远没有被满足。
05
等一等,并不丢人
只要眼睛没瞎,谁都看得出AI的演进在加速。这是事实。但加速并不意味着所有人都必须立刻躬身入局。假如你眼下的工作流里还没有一个必须靠AI才能打通的痛点,那等一等、让生态再成熟一点,完全是一件合理的事。
真正成熟的蝴蝶不会催你赶路。蛋糕当然会变大,但不是每一个位置都需要你去做第一个拓荒的人。先行者有机会抓到第一波红利,同样也有可能被后来碾压式涌入的巨大资源直接拍倒。路是你自己的,选择之前,先掂量自己的成本,也看清楚风险。
如果你不会用、用得不好,很大概率是因为工具还没进化到能真正听懂你工作语境的那一步。这不是你的错。承认这一点,远比硬着头皮假装“我们已经改变了世界”要诚实得多。
有些工具,注定先在底层工程师手中跑通,然后才慢慢向下渗透。你不用着急,但也千万别假装自己已经看见了未来。