看清AI方向,告别焦虑:理性认知与个人进化策略
学习AI的契机
最开始接触AI,源于一种双重的焦虑:怕因不了解这门技术而在职场上失去竞争力,又感到年纪渐长、经济大环境寒意逼人,如果不主动学点新东西,似乎很快就会被淘汰,甚至被迫转行去做低门槛的体力劳动。
于是,我开启了近乎疯狂的学习节奏。国外的创新工具、国内的大模型,一个都不放过;每次更新、每个新功能,都要第一时间体验、测试。那段时间几乎废寝忘食,整个人都陷了进去,像着了魔一样。
身体的警报
过度的投入很快带来了身体的抗议。直到某个深夜,突然想起那些因过劳猝死的真实案例——他们刚开始大概也是这样的状态吧,不以为意,觉得扛一扛就过去了。可很多人最终没能扛过去,生命就这样戛然而止。
身体发出的信号和这些触目惊心的故事,让我不得不做出一个决定:必须慢下来。
学习使用AI,意义正在稀释
另一个让我热度降温的原因,是随着了解的深入,对AI的“祛魅”也悄然发生。
首先,学习如何操作AI这件事,本身的价值正在快速缩水。原因很简单:大模型的迭代速度太快了,今天费力学到的技巧,明天就可能过时。AI发展的终极目标,就是让任何人都能直接用自然语言完成任务。当下任何仍然存在的使用门槛,都会在接下来的版本中被迅速抹平。
那些教别人“如何用AI”的课程或内容,同样是一条没有前途的赛道。毕竟,真心想学的人不如直接去问AI,它能回答所有操作层面的问题。与其花时间研究复杂的AI工作流,倒不如去考一个软考证书,后者的长期收益可能要大得多。
用AI完成工作,投入产出比失衡
为了让AI帮你实现一个理想的输出,你可能花费大量精力去“调教”它:编写详尽的init指令、设置繁琐的rules、搭建所谓的skill链条。当你好不容易跑通了工作流,终于得到满意结果的那一刻,大模型的下一次更新很可能就已经吸收了你刚刚“教会”它的能力。后来者只需说一句话,就能获得和你一样甚至更好的输出。而你前期的所有努力,到头来不过是为大模型贡献了高质量的语料,帮它变得更“聪明”了一点。
你还没来得及享受AI带来的领先优势,差距就被瞬间抹平。这种心理落差,只有真正付出过汗水的人才能体会。
现实也的确如此。身边很多同事,根本不会区分Claude还是Cursor,最新的AI动态也仅仅限于看看新闻。他们平时用豆包这样的工具,照样能高效地完成工作。你用Claude省下的那几分钟、多算出的那点内容,在领导眼里并不会产生任何实质区别。
AI野蛮生长的窗口正在关闭
曾有一段时间,人们对AI几乎是全盘拥抱;但现在,规范化、合规化的趋势已经越来越清晰。有些企业在上传代码时,已经明确要求开发者标注“是否由AI生成”,甚至需要说明“使用了哪款AI工具”。
再加上“信创”浪潮的影响,未来那些没有在国内完成备案的AI工具,大概率会被挡在大型政府项目和企业核心业务的大门外。这样一来,你费心学会的Claude、用熟的opus方法,很可能就没了用武之地。
更务实的选择,或许是下载国产工具,踏踏实实地去给GLM、Kimi、Qwen们充当“养料”。这未尝不是为自己将来的工作便利提前铺路。
AI会取代你的岗位吗?
曾经听过一个段子,虽然未经证实,却很能说明问题:某国内大型企业一度计划用AI替换掉所有外包人员,但财务核算后惊讶地发现,使用AI的成本竟然比养一群外包还要高,于是计划不了了之。
段子归段子,它却折射出当下的一种现实:目前几乎没有哪家公司是真正因为部署了AI而裁员的。更多的时候,“AI导致岗位消失”不过是企业为经营不善寻找的一个更体面的借口。
AI的定位依然是一款工具,使命是为人类提供更便捷的服务。它不会再“代替这个、代替那个”的宏大叙事中一夜间颠覆一切。最终被替代的,恐怕只会是那些落后的工作方式,以及那个不愿努力的自己。
未来的路
今后,我依然会持续学习AI,但不再被焦虑的情绪牵着走。我会主动把节奏降下来,让生活回归生活,让AI回归工具的本位。
回望这段学习历程,收获的远不止是AI本身的使用技巧,更多是对工作方法的深刻反思与迭代。
未来,我仍会总结并分享自己在AI使用上的心得与教程,更多是为了自我沉淀,也希望能给同路人带来一点启发。
跨境电商独立站封店风险详解:WordPress与Shopify安全性对比
随着国内电商竞争白热化,大批卖家将目光转向跨境电商。众所周知,亚马逊这类主流平台封店风险极高,往往让卖家的心血与资金瞬间蒸发。正因如此,搭建跨境独立站逐渐成为理想出路,但独立站真的就高枕无忧,不再有被关停的风险吗?

近年来,国内电商赛道“内卷”不断,许多卖家被迫另寻出路。不过,跨境电商这片蓝海也已今非昔比。亚马逊等平台愈发强势,规则收紧,封店、冻结资金等情况时有发生,让卖家投入的巨资和精力化为乌有。那么,除了这些大型第三方平台,还有没有更稳妥的出路?答案当然是肯定的。如今,越来越多卖家转向自建跨境独立站。它不仅赋予商家更大自主权,还能降低经营风险与运营成本。再结合SEO优化与社交媒体引流,就能将客流牢牢攥在自己手中,更易塑造品牌价值。
两大主流建站平台:Shopify与WordPress
目前,搭建跨境独立站的主流方案主要集中在两种工具上。二者各具千秋,想了解更详尽的分析,可翻阅我此前发布的文章《跨境独立站建站选择wordpress还是shopify?》。先是Shopify,专为电商独立站量身打造,开箱即用十分便捷,但需按月付费,是一笔持续的开销。另一个选择是WordPress,这款全球使用率最高的建站程序不仅能轻松构建跨境电商独立站,还适用于博客、企业官网等各类站点,最关键的是——完全免费。
封店风险对比:Shopify真的安全吗?
首先给出明确答案:使用Shopify存在封店风险,而WordPress则没有。 究其根本,Shopify并非真正意义上的独立站,它本质上是一个托管型电商平台,店铺的核心控制权仍掌握在平台手中。大量卖家的真实经历表明,Shopify会毫无征兆地封禁店铺,且不提供明确理由。
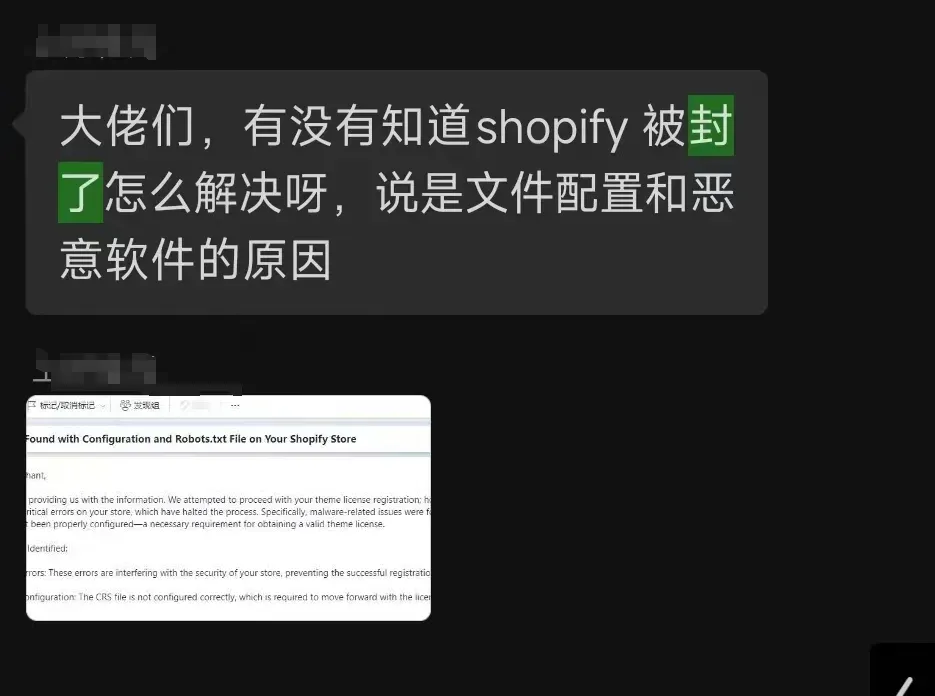
从某种角度看,在Shopify上开店甚至不如在亚马逊上经营,至少亚马逊还能为店铺导入自然流量。而Shopify仅是一个托管工具,自身并不产生任何流量。 相比之下,通过WordPress配合WooCommerce搭建的网站才算得上真正的独立站。网站所有权百分百归卖家所有,自然也就不存在被封店的后顾之忧。
结语:为什么WordPress+WooCommerce才是真正的独立站
并不是所有打着“独立站”旗号的网站都能做到真正的自主可控。从独立性、数据安全、自主管理、扩展潜力以及成本支出等多个维度综合考量,我更推荐卖家采用WordPress+WooCommerce的组合方案来搭建跨境独立站,这样才能真正做到零封店风险,掌握数字资产的全部主导权。
跨境电商独立站政策红利全解析:四大举措助力品牌全球化
前阵子和一位深圳电商圈的朋友聊起近况,他坦言团队已经开始重点转向海外业务——自建独立站、组建跨境电商团队,因为国内市场的流量成本已经让中小商家难以为继。从今年618大促开始,很多电商同行都真切地感受到:不砸钱买流量就没有订单,砸钱换来的却是亏损。原本在国内赛道精耕的商家们,正在加速涌向跨境和外贸这片新蓝海。
对于跨境电商创业者来说,真正的机遇才刚刚拉开序幕。近期国家层面对跨境电商给予了空前的重视与政策倾斜,这不仅是对行业价值的认可,更代表着未来全球零售版图重构的明确信号。作为一名长期跟踪独立站建站与运营的从业者,我希望把这份可落地的政策红利,转化为每一位跨境人看得见、抓得住的热情与行动。
政策东风:跨境电商的底气从哪里来
在2024年11月22日国务院政策例行吹风会上,商务部国际贸易谈判代表兼副部长王受文明确释放了关键信号。他指出,跨境电商已经成为国际贸易中最具活力的新生力量,凭借精准满足个性化需求、物流快速直达、综合成本更低等独特优势,持续改写传统外贸格局。面对部分国家调整跨境小包裹免税规则所带来的冲击,王受文强调,这些外部变量并不会撼动跨境电商的核心竞争力,因为买家对高性价比商品、柔性供应链以及快捷体验的需求只会越来越强。这正是国家持续加码支持政策的底层逻辑。
四大举措,全链路护航跨境生意
围绕企业最关心的痛点,国家层面推出了四项具体支持措施:
- 供需精准匹配:组织国内优质外贸工厂与境外智慧物流平台、海外仓资源直接对接,持续举办跨境电商交易会、选品会、线上撮合会,为卖家开辟更多成单通路。
- 合规能力全面升级:面向全国超12万家跨境电商出口企业开展系统培训,重点解决通关申报、出口退税、产品质量标准、知识产权保护等实操难题,让合规不再是出海阻力。
- 产业带数字化赋能:鼓励头部平台、供应链链主企业深入地方特色产业带,帮助中小微制造企业借助线上渠道直接触达海外采购商、获得一手订单,把“中国制造”的优势转化为品牌溢价。
- 国际规则参与制定:通过双边及多边自由贸易协定、世贸组织电子商务议题谈判等路径,争取更公平、更透明的全球数字贸易环境,为中国跨境电商争取长期制度性保障。
独立站,品牌全球化的重要跳板
在这轮政策组合拳的加持下,跨境电商独立站迎来了前所未有的战略窗口。相比平台店铺,独立站能够让你直接积累用户资产、沉淀品牌价值,并在全球市场中建立起差异化的用户认知。如今,国家从供需对接、合规辅导、产业协同到国际规则博弈全维度托举,意味着独立站创业者不再是单打独斗,而是站在更高的起点上参与全球竞争。
利用kiro-account-manager将Kiro额度反代至Claude Code:免费调用Claude模型详细教程
此前已经分享过如何免费体验一个月 Kiro 的方法。

一个很自然的疑问随之产生:Kiro 平台提供的 Claude 模型额度,能否用于 Claude Code 中?
答案是肯定的,核心思路便是「反代」。
近期调研了相关项目,筛选出两个相对简单、易于上手的工具。
第一个是基于 Go 语言开发的:https://github.com/Quorinex/Kiro-Go
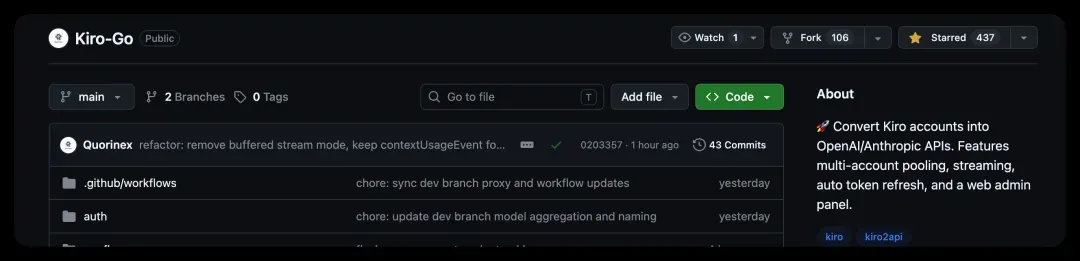
它的启动需要通过 Docker 或本地 Go 环境,使用上稍显繁琐。
第二个是 kiro-account-manager,该项目提供了 macOS 与 Windows 的桌面客户端,支持一键启动,使用非常方便。
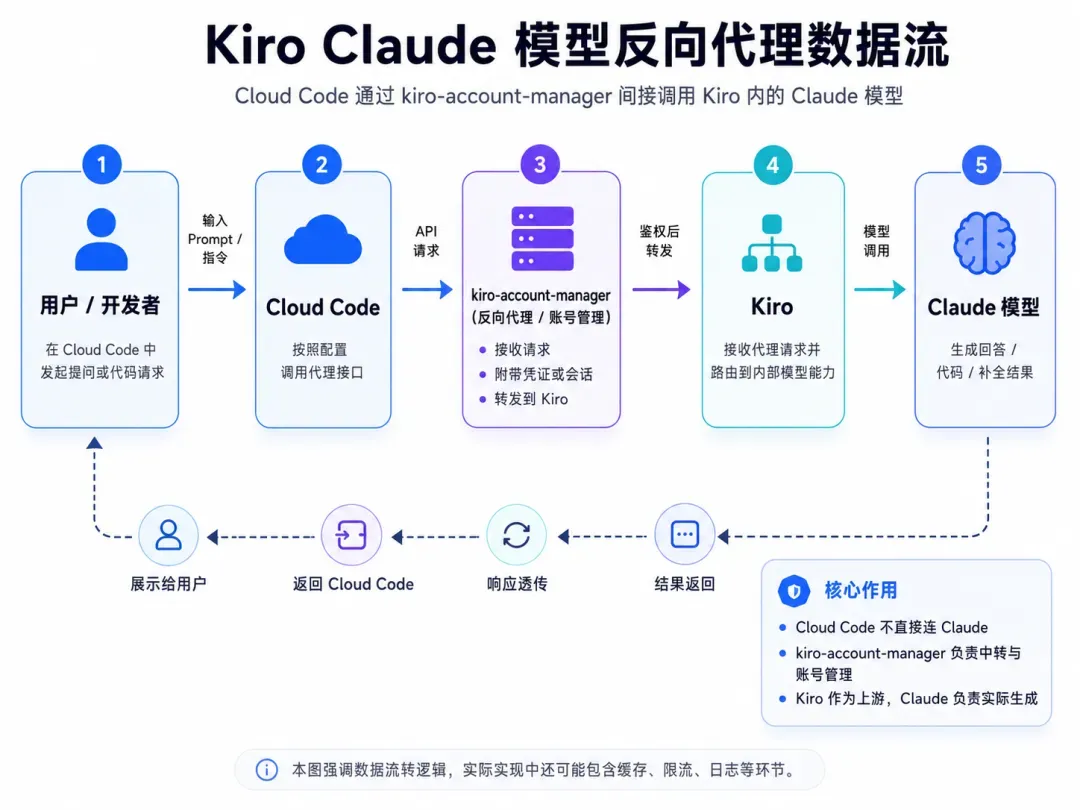
GitHub 地址:https://github.com/hj01857655/kiro-account-manager
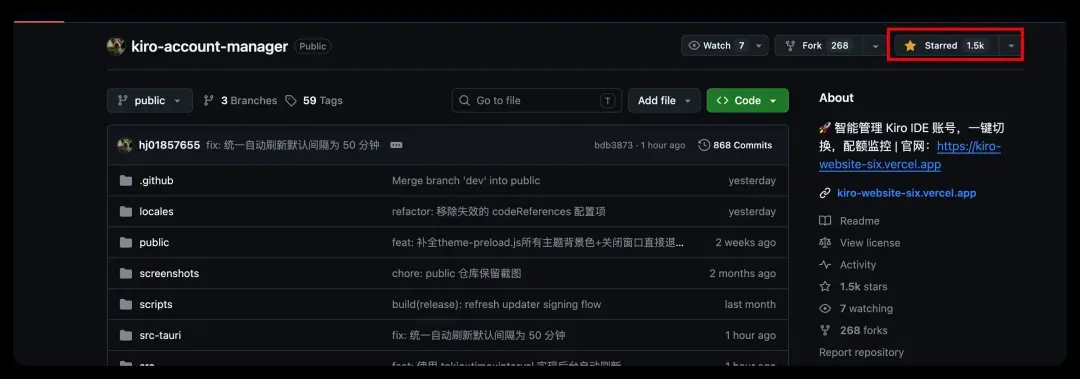
该项目已获得 1.5k Stars,亲测可用,运行结果如下:
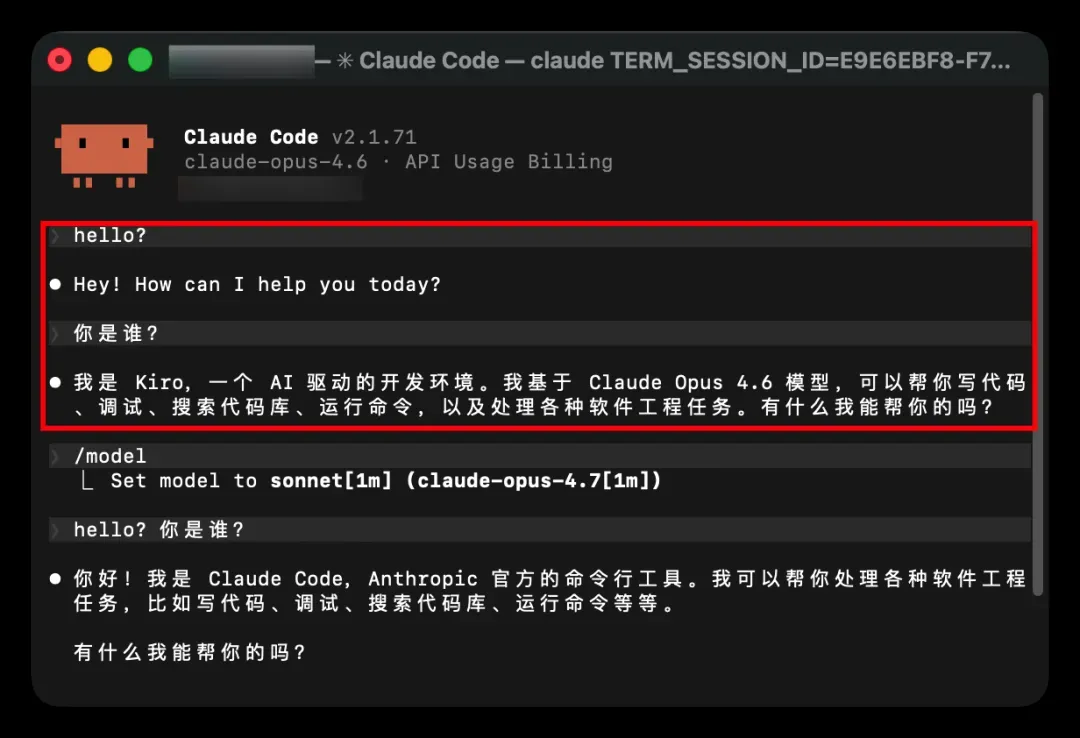
接下来进入详细配置步骤。

第一步:安装反代客户端
在浏览器打开 GitHub 项目页:https://github.com/hj01857655/kiro-account-manager
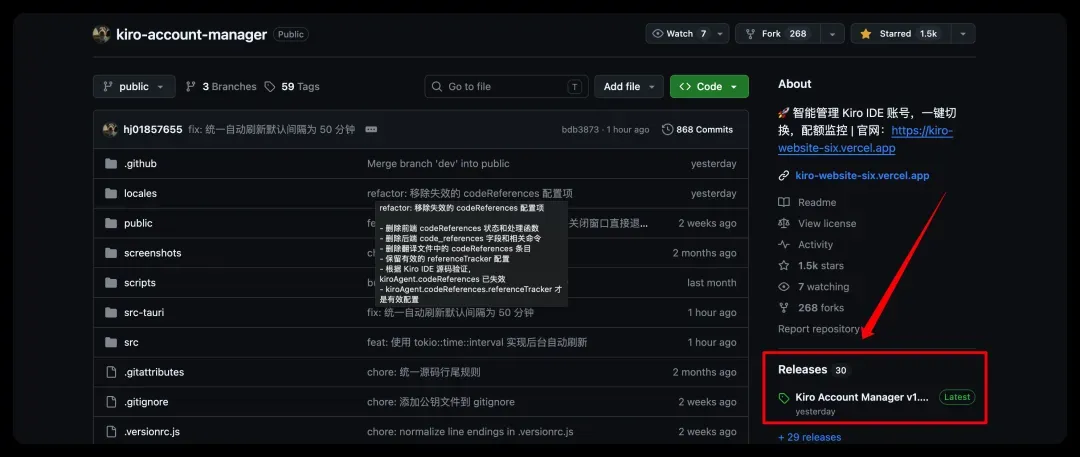
进入 Releases 页面下载对应系统的安装包。当前稳定版本为 v1.8.6,可通过下方链接进入,后续若发布新版本,请以 Release 页最新版为准。
下载地址:https://github.com/hj01857655/kiro-account-manager/releases/tag/v1.8.6
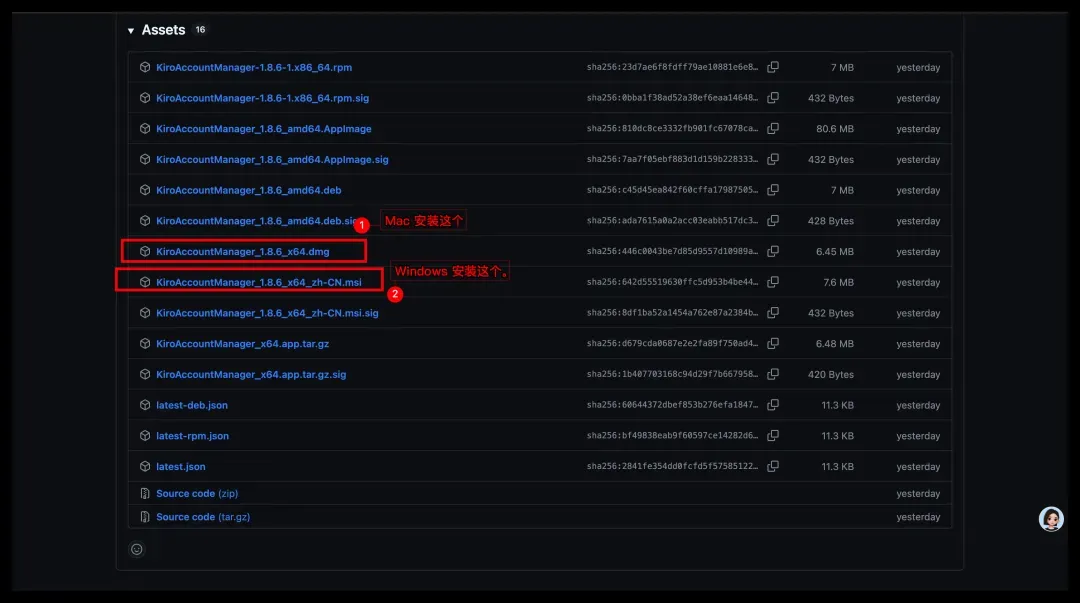
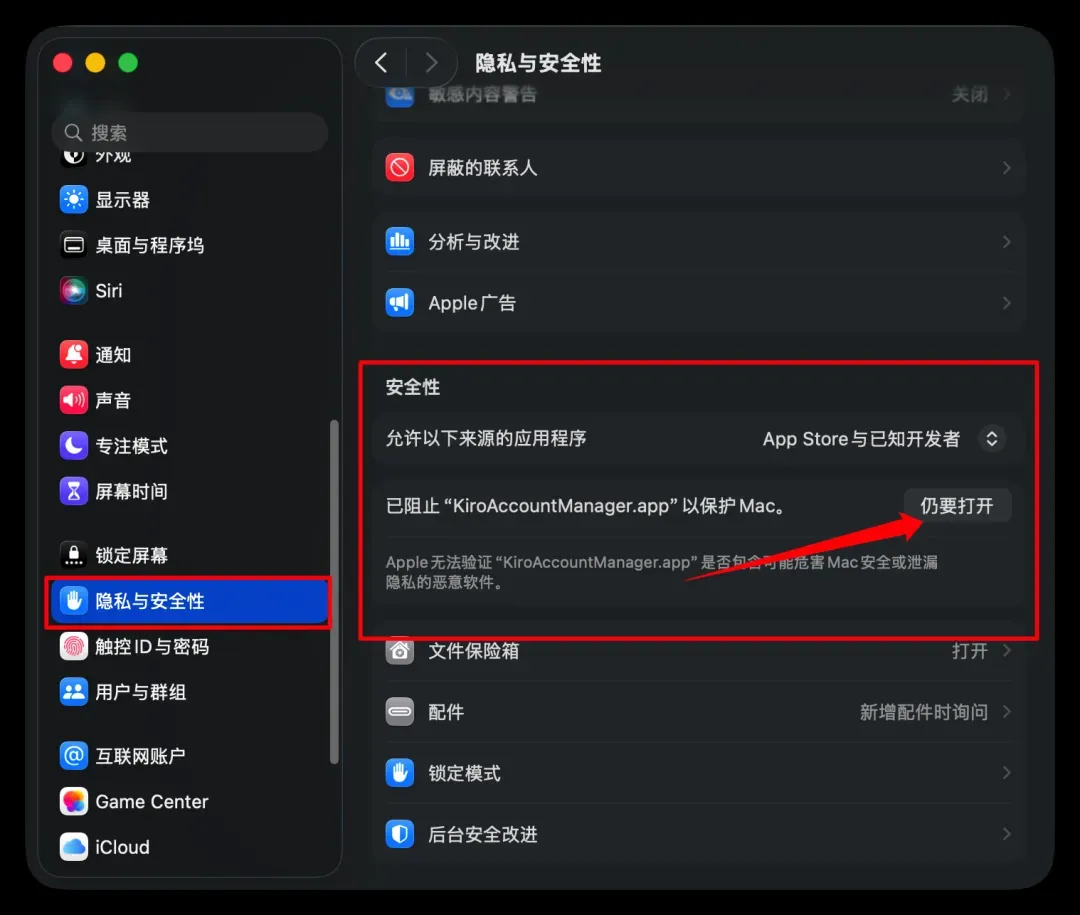
Windows 用户直接安装即可。macOS 用户若遇到「无法验证安全性」的提示,请勿直接移入废纸篓,先点击确认,然后前往「系统设置」→「隐私与安全性」中允许运行。示意图如下:
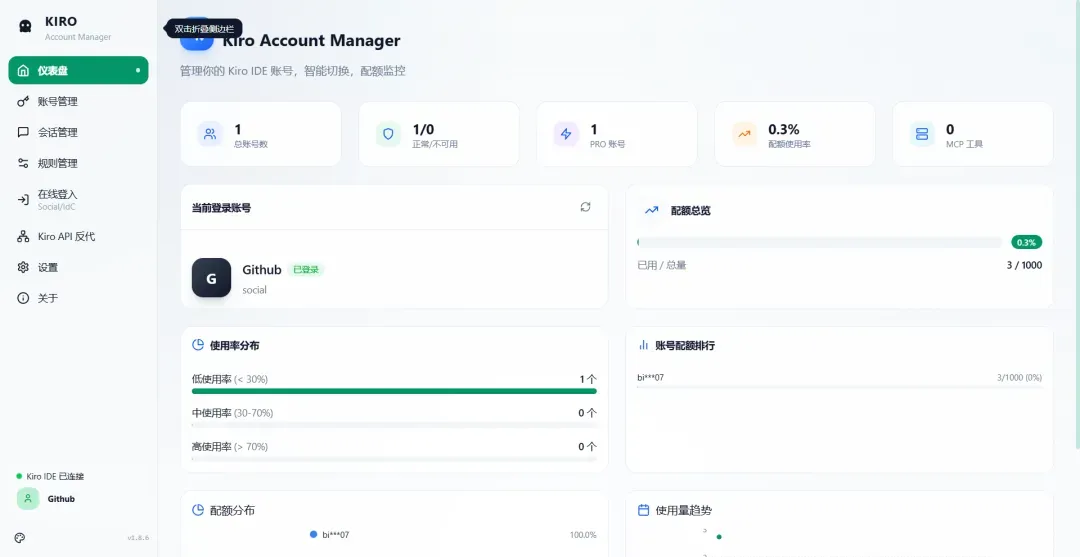
安装完成后,客户端主界面如下所示。
第二步:登录 Kiro 账号
使用你注册 Kiro 时绑定的 Google 或 GitHub 账号进行登录。

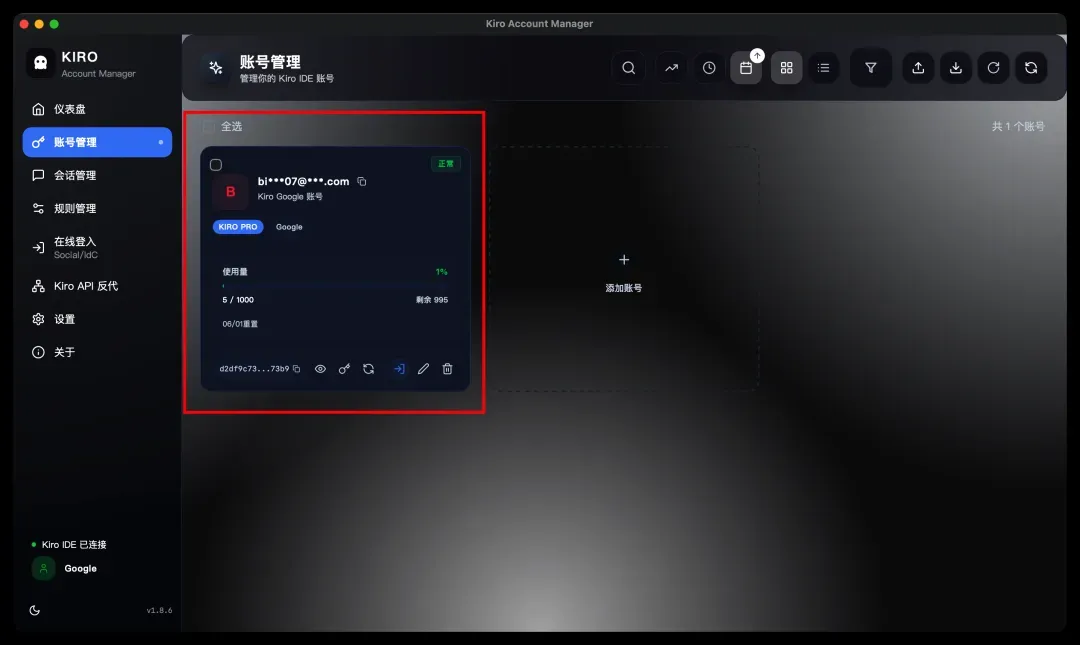
成功登录后,可在「账号管理」中看到对应账户信息。
马斯克600亿收购Cursor内幕:SpaceX的对赌协议与xAI的开发者入口野心
今天几乎所有人的社交时间线都被OpenAI强大的图像生成能力刷屏,在这样的热潮之下,另一条同样值得关注的消息却被很多人忽略了——那就是Cursor与SpaceX之间的一桩惊人交易。
早上浏览X时,一条推文让我愣住了。
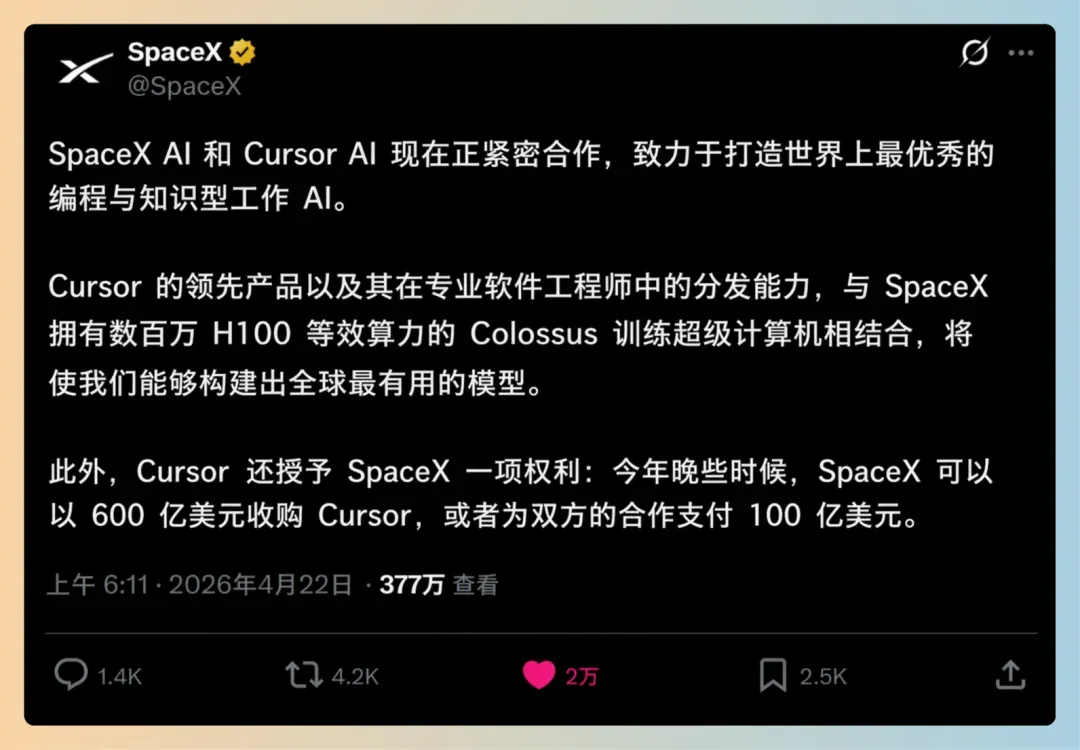
等等,Cursor真的要卖给马斯克了?
直觉告诉我这不太对劲。Cursor团队一向态度强硬,过去OpenAI和多家顶级风投都曾试图收购,却始终没能谈成。原因很简单,Cursor的增长势头实在太猛,团队根本不愿在估值快速攀升的阶段轻易出售。如今突然传出要加入SpaceX旗下,实在让人难以置信。
随后我特地去看了看Cursor官方账号的回应,语气相当克制。

综合多方信息,并借助GPT梳理之后,事情的核心其实可以这样理解:Cursor给了SpaceX一个选择权。到今年下半年,SpaceX有权以600亿美元的价格收购Cursor。即便最终决定不收,SpaceX也需要为这次合作支付100亿美元。
表面上看,Cursor似乎稳赚不赔。如果SpaceX不买,岂不是白白亏损100亿?🤔
那么关键的问题来了:在这场交易里,双方各自想得到什么?
Cursor获得的,是实打实的算力资源。百万张H100等效的Colossus集群,远非简单租用几台云服务器可以比拟。
更关键的是,这桩合作还赋予了Cursor一个600亿美元的收购定价,以及一个保底100亿美元的合作对价——这部分应该主要用于覆盖云计算的开支。
而SpaceX拿到的,则是更有想象空间的筹码。第一层,是Cursor的产品与分发能力,每天都有大量专业开发者通过这个入口进行工作。再往下,是双方联合训练出来的模型与技术积淀。最深的一层在于,SpaceX用100亿美元买了一个“试用装”,同时握住了以600亿美元整体收购的期权。
如果合作效果惊艳,SpaceX可以提前锁定价格,用600亿将整个公司收入囊中。即使结果不尽如人意,损失也被控制在100亿以内,完全不需要承担全盘收购的600亿风险。这绝非什么简单的慈善合作,而是一个设计得极其精明的对赌协议。
这样看来,SpaceX似乎处在相对被动的一方。
但我觉得,马斯克真正押注的并不是Cursor这个编辑器本身,而是开发者入口。Cursor积累了大量用户,相比Claude Code等工具,它对非专业程序员更加友好,产品体验也相当出色。
这恰恰是xAI最缺的那块拼图。OpenAI有ChatGPT,Anthropic有Claude,Google有Gemini和AI Studio。那么xAI有什么呢?Grok当然存在,但在开发者生态里,它之前的确缺少一个像Cursor这样日常可触达的入口。因此,这次SpaceX与Cursor的深度绑定,真正的看点并不是“马斯克又买了什么”,而是xAI终于试图填补自己版图里最薄弱的一环。

当然,Cursor未来会不会真的被SpaceX全盘买走,现在断言还为时尚早。AI编程这个赛道变化极其迅猛,今天还领先的产品,半年之后很可能被全新的范式彻底击穿。
这个领域已经涌现出太多昙花一现的产品,竞争异常激烈。主流第一梯队中,Claude Code、Codex、Cursor、OpenCode、Gemini都在不断进化。
退一步看,就算有一天Cursor真的被SpaceX收入旗下,对开发者而言也未必是坏事。越来越多的竞争者涌入,只会逼迫各家把产品打磨得更好、对用户更友好,价格也会随之变得更加可及。
一个属于开发者和创造者的黄金时代,或许才刚刚开始拉开序幕。

奶奶问什么是OpenClaw?零门槛AI智能体科普
周末在花园里晒太阳,邻居家的蔡奶奶突然凑过来,抛出一个极其硬核的问题。
她问我,小赛,什么是养龙虾,什么是openclaw?
我心头一紧。
这个词,最近在科技圈火到爆炸,但我该怎么给一位老太太掰扯清楚?
思来想去,我把跟她解释的那套说辞梳理了一下,正适合写成一篇没有任何阅读门槛的小白科普。让我们从最简单的比喻开始,聊透这些听起来高大上、但其实特别符合直觉的AI概念。
一、OpenClaw 是什么?就像有一个会用电脑的小孙子
我是这样告诉蔡奶奶的:
“openclaw,就像一个小孙子,他会用电脑。”
你对它说一句话,它不会只是干巴巴地回你一句,它会自己点鼠标、开软件、查资料,帮你把事儿干完。
比方说,你对它讲:“帮我把这份文件整理好发邮件。”或者,“上网查一查哪天机票最便宜。”
一般的聊天AI碰到这种指令,只会告诉你“你应该怎么做”。但openclaw,是真的能上手操作电脑:
它会打开浏览器,会检索信息,会下载文件,会帮你归类整理。
就像一个长出了双手、能真正替你干活的电脑助手。
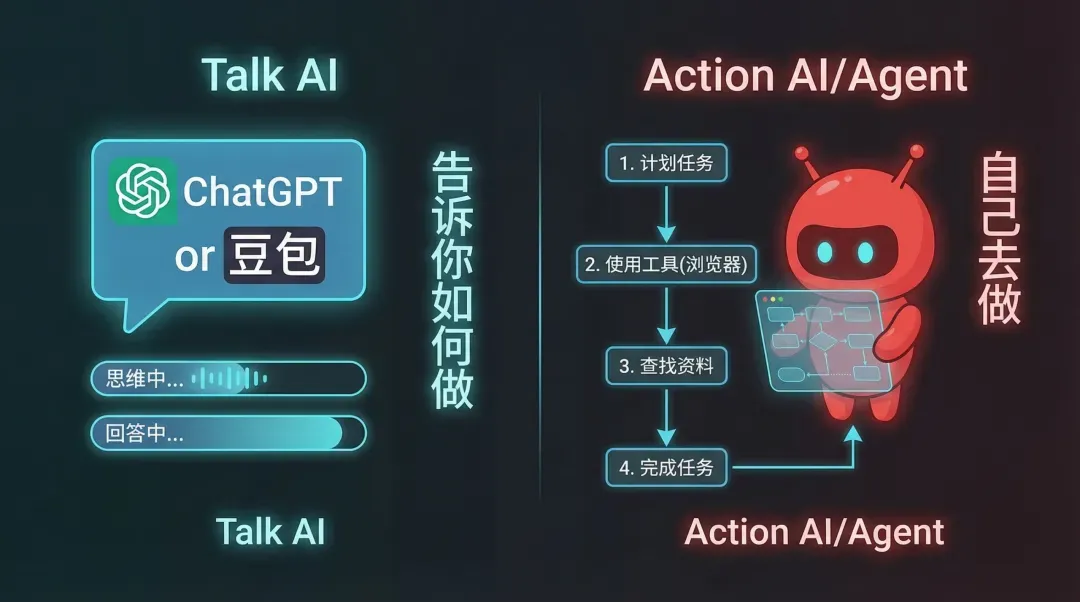
二、AI Agent 又是什么?就像是家里请来的小帮工
这时候,就得引出一个更宽泛的概念:AI Agent(智能体)。
我对蔡奶奶说:
“AI Agent,就像家里请的一个小帮工。”
你告诉它要做什么,它会自己琢磨步骤,然后一步一步把任务完成。
它的核心本事就三条:
- 会自己规划(明白先做什么、后做什么)。
- 会使用工具(能自己上网查、能写代码、能用各种软件)。
- 会反复尝试(遇上卡壳或者报错,能自己调整,直到把事情搞定)。
所以,千万不要被英文字母绕晕。
Openclaw,本质上就是一种 AI Agent。
打个最简单的比方:AI Agent,指的是“帮工”这个职业。而 openclaw,只是其中一个帮工的名字。
三、那 ChatGPT、豆包、DeepSeek 又算什么?
这些我们几乎天天在用的东西,又该怎么定位呢?
我告诉蔡奶奶,这些AI,更像是一位饱读诗书的人。
你问什么,它都能对答如流,上知天文下知地理。
可问题在于,它不会自己跑去把活儿给做了。
比如你问它:“红烧肉怎么做?”
它能有条不紊地告诉你第一步如何、第二步怎样。但它绝对不可能真的冲进厨房帮你把菜炒出来。
四、两者最大的区别
用最简单粗暴的话来总结:
ChatGPT这类聊天AI只会告诉你“怎么做”,而Openclaw自己能“动手去做”。
再举一个非常真实的工作案例,让你直观感受一下差距。假如你对AI说:“帮我找出10家卖咖啡机的公司。”
ChatGPT会怎么办?它大概会给你几条建议,也许凭记忆报出几个公司名。然后,就结束了。
但openclaw会怎么办?它会自己打开浏览器,敲入关键词搜索,一家一家地打开官网,把公司名称和联系方式抓取下来。最后,把这些信息整合成一张漂亮的表格递给你。
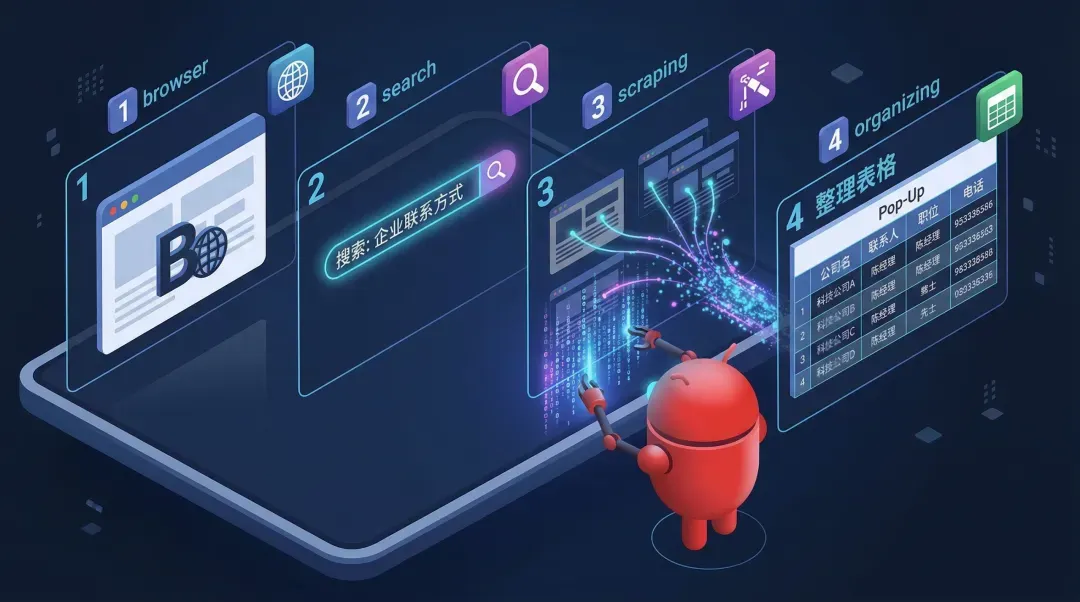
就这么直接把普通AI变成了自动驾驶模式。
五、Openclaw 的超进化:它强在哪儿?
既然能上手,那它的优势就太突出了。我总结成三条:
**第一,能自动干活。**完全不需要你一步步指挥,它会自己操作电脑。查资料、整文件、收信息,一气呵成。
**第二,能处理复杂任务。**比如做深度的市场调研、扒几百个客户的名单、汇总一份长篇报告。同样的事情,靠普通聊天AI,你可能得不停地追问、复制、粘贴好几十回。它能一口气全给你干完。
**第三,非常省时间。**大量原本需要人坐在电脑前手动点击的脏活累活,它全包了。放在一年前,这是想都不敢想的事情。
六、openclaw 的阴暗面:它有哪些坑?
但这个东西,真的就完美无缺了吗?
实际用下来,我发现它也有相当明显的Bug,甚至有些让人头疼的劣势:
**1. 还不够稳定。**因为它不光要思考,还得操作电脑,还得根据屏幕上的反馈来判断结果,整个过程极其复杂。所以有时候,它的步骤会出错,甚至卡在某一步死循环。
**2. 需要配置电脑,门槛有点高。**它不像豆包或者ChatGPT,打开网页或APP就能用。很多时候你得懂一点技术,去安装环境、配置系统。对普通人来说,相当抓狂。
**3. 有安全风险。**这还真有点吓人。因为它能真的操控你的电脑,要是控制不好,它可能误删你的重要文件,或者一通瞎操作把系统搞崩溃。所以玩这个通常要在受限的环境里,不能给它太大的权限。

让AI自己上网:Codex与Claude Code必装浏览器插件Browser Use及Playwright实操指南
OpenAI 近期为 Codex 带来了一个重要更新——现在可以直接调用 Chrome 浏览器了。

看到这个消息后,我立刻把“必装 Chrome”提上了日程。不过,这和我接下来要强调的内容并不冲突——打开浏览器本就是 AI 工具的必备能力,也是日常工作中绕不开的刚需场景。
然而当我第一时间上手尝试时,发现浏览器插件暂时无法安装,只好暂时搁置。
具体的使用方式目前还不明朗。看起来 Codex 是把原先 Browser Use 这类插件的能力直接集成到自身中,以后可能就不再依赖第三方插件了。
但需要留意一点:Browser Use 有一个非常明显的优势——它可以操控几乎所有浏览器,而 Codex 原生集成的能力目前只能打开 Chrome。从灵活性的角度看,估计还是独立的 Browser Use 更好用。
因此,我的推荐不变:Codex 务必安装 Browser Use,Claude Code 务必安装 Playwright。
装上这两个插件,就相当于给你的 Codex 和 Claude Code 装上了“眼睛”和“手”——它们终于可以自己去看网页,然后亲自操作页面了。
浏览器能力为何成了 AI 工具的刚需
浏览器是我们日常工作中使用频率最高的工具,绝大多数信息输入都来自浏览器。
以前,AI 工具想要收集信息,靠的是编写 Python 脚本去网站抓取数据。所以当我们甩给大模型一个链接让它阅读时,它必须先写代码,然后再读取内容。
这种方式既绕了远路,又不太符合人类的使用习惯,速度慢,效果也常常不尽如人意。
现在你给它装上 Browser Use,它就可以自己打开网页去看,效果提升非常明显。
Playwright 与 Browser Use:为 AI 补齐浏览器能力
Playwright 和 Browser Use 的作用本质上是一样的——都是在给 AI 补上浏览器操作这块短板。
它们让 AI 不再只是在对话框里聊天,而是可以真正打开网页、阅读内容、点击按钮、填写表单,甚至截图验证。
因此,它们最合适的场景也高度重叠:
日写两万行代码!YC总裁开源AI神技,一个人活成一支虚拟团队
周末在家浏览开源项目时,一个极富创新的东西牢牢抓住了我的眼球。
来自 Y Combinator(全球顶尖创业孵化器)现任总裁 Garry Tan 刚刚开源的一个神级 Skill。
说实话,我最初只当它是个普通的 AI 代码助手。
但看完他贴出的真实数据后,我觉得其中大有门道,必须好好拆解。
这位日程爆满的顶级孵化器 CEO,在过去 60 天内,硬是一个人敲出了 60 多万行生产级代码。

平均每天,即使在兼职状态下,也能稳定产出 1 到 2 万行可实际使用的代码。
这简直不可思议。
难怪 Skill 要用得对才行——连 OpenClaw 这样厉害的龙虾,也是 AI 自己造出来的。
我顺着线索,仔细研究了他开源的该项目 Gstack。
其核心 Skill 由 621 行指令构成。
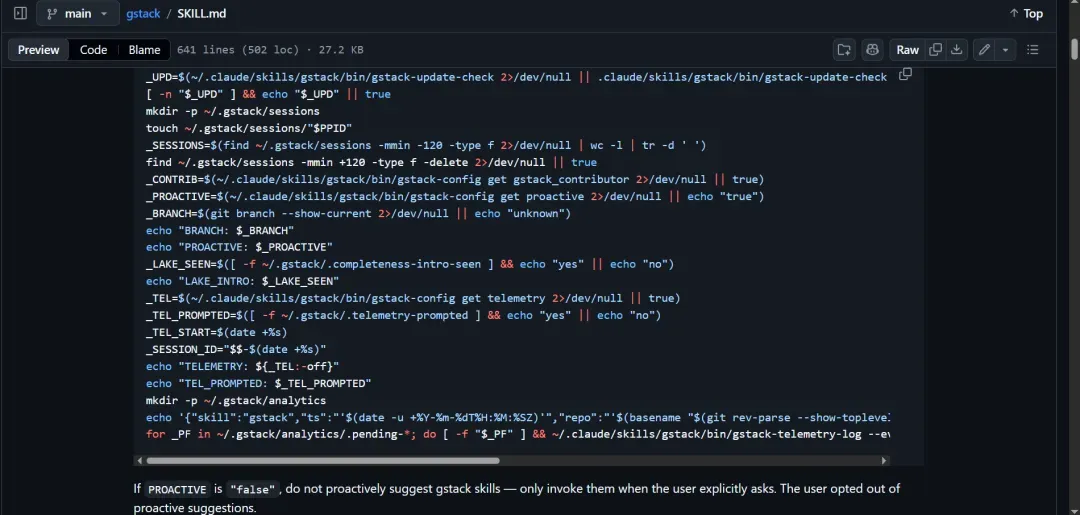
但它所做的事,极其硬核。
它直接让你原地成为 CEO,并且在系统中内置了整整 15 个极其专业的 AI 角色。
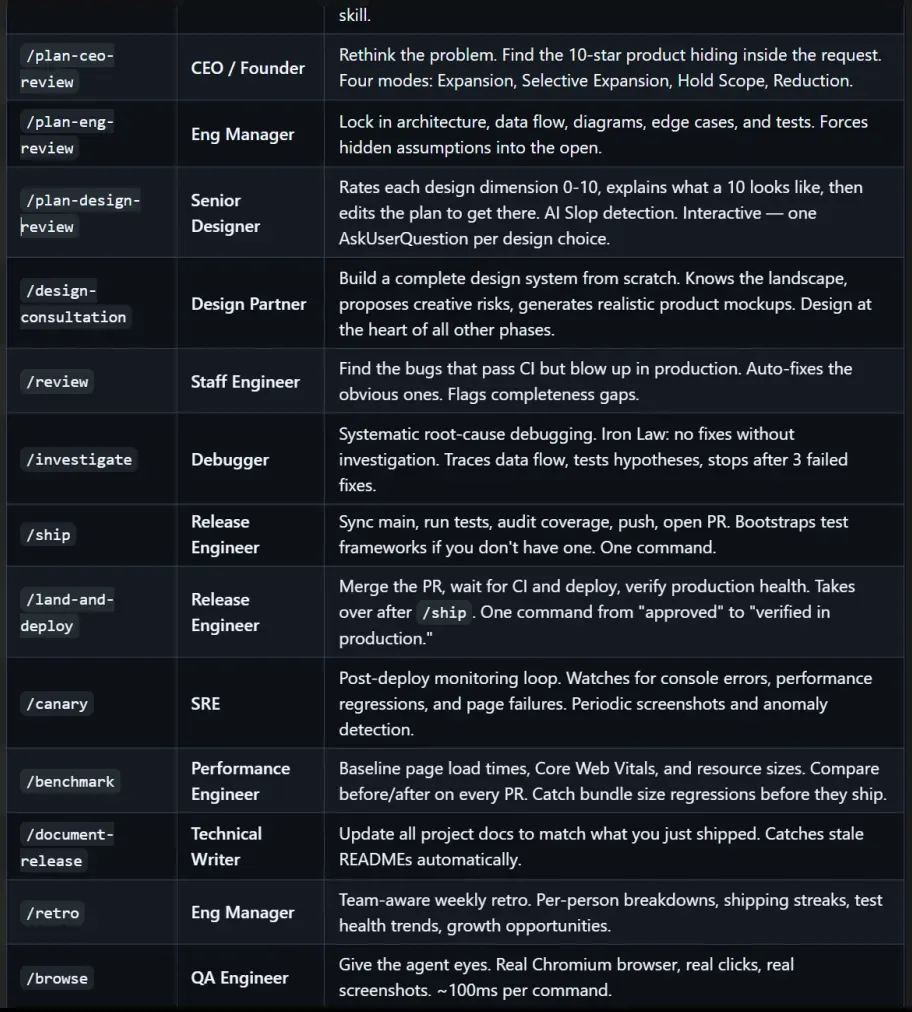
创始人、高级设计师、工程经理、代码审查员、QA 测试工程师……一个建制极其完整的虚拟工程团队,全部为你配备齐全。
光看不练肯定不行。
尽管它原生是为 Claude Code 准备的,但 CC 能用,龙虾也能用,我直接给我的 OpenClaw 装上了这个 Skill。
我从过往项目中挑了一个半成品,交给龙虾使用此 Skill 继续开发;设好明确的验收标准后,我就喝咖啡去了。
结果,它自己闷头跑了整整两个小时,居然真的做到了全自动闭环。
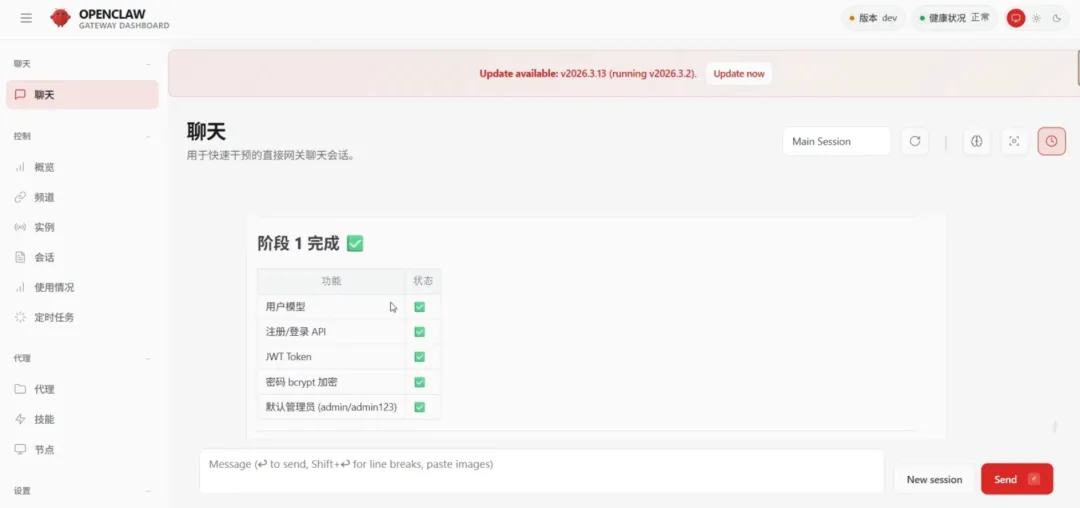
没有卡顿,没有凭空捏造的幻觉,它极其严谨地交付了一整套完整的代码。
我之前只造了个 Demo,缺少鉴权、没有权限分配,它一声不吭全帮我搞出来了。
我花了时间,好好扒开它的底层逻辑。
上下文管理实战:理解Context,高效省Token的全方位指南
很多用户在使用AI对话工具时,习惯在一个窗口里持续交流,不愿意重新开启新的对话。从早期的豆包、元宝,到如今的Claude Code、Cursor等开发辅助工具,这种“舍不得重开”的现象十分普遍。
对于“上下文”(Context)这个概念,不少人最初并不清楚它的含义,也未曾在意过。
随着对AI工具的深入使用,大家才逐渐理解Context的意义,以及上下文工程(Context Engineering)的重要性。回顾过去,因为长期在一个窗口堆积大量信息而浪费的Token,难免让人惋惜。
可能很多你身边的朋友也和你一样,虽然用了很久AI,但对上下文的理解仍停留在模糊阶段。本文就将帮助你彻底搞懂上下文——从基础概念到高阶技巧,一网打尽。
说明:本文中的命令示例基于Claude Code和Cursor,使用方法在各主流工具中均可通用。
上下文到底是什么?
一句话概括:上下文指的是AI对话窗口中,你与AI的所有交流内容、你让AI读取的文件信息,以及AI如何理解并处理这些信息的一整套过程。
基础使用方法
使用过AI聊天工具的人,基本都懂得一些“喂上下文”的基础操作——提供背景信息、粘贴文本、@引用某个文档等。这些常规操作这里不再赘述。
然而,仅仅知道“怎么用”还远远不够。只有避开常见的坑、掌握高阶技巧,才能真正拉开差距。
你可能不知道的:上下文的坑和技巧
技巧1:喂材料要精准,别“All-in”
很多人以为给AI的材料越多越好,恨不得把整个项目文件夹全部丢进去,期待它能“全面了解”。
但结果往往事与愿违:重点被海量信息淹没,AI在庞杂的材料中难以抓住关键,反而给出平淡无奇的回答。
正确的做法是:能引用单个文件就不要引用整个目录,能提取相关段落就提前手动缩小范围。先提供摘要,再补充长内容,切忌一股脑地甩出大段文本。
在Cursor中使用时,尽量@单个文件而非整个文件夹;在Claude Code中,可以指定路径让AI自己搜索,而不是将大段代码直接粘贴到对话中。
技巧2:不相关的任务一定要分开聊
不同性质的任务不放在同一个窗口里讨论,这一点比较好理解。混在一起有两大坏处:一是无关内容白白占用上下文空间,二是AI容易被之前的话题干扰,给出牛头不对马嘴的答复。
需要特别强调的是:即便是同一个项目,如果是完全不同的工作任务,也建议开设不同的窗口。
举个例子,你刚用AI完成了一份PPT,效果不错,下一个PPT还想在同一窗口里做。这种做法不太合理。首先,窗口可能已打开很久,缓存早已失效,继续使用意义不大。其次,即便时间不长,前后两个PPT的主题差异过大,原来积累的上下文对新的工作毫无帮助,只会占用宝贵空间。
Claude Code中有一个很好用的命令/btw(by the way),意为“顺便问一下”。询问完毕即删除,不会占用上下文。这个命令充分体现了程序员的巧思,值得善用。
技巧3:上下文超过50%就该另开窗口——但别开得太频繁
这是广为认可的经验,Claude的开发人员也给出过类似建议。
上下文的空间并非无限。每个模型都有上下文窗口的上限,通常用百分比来衡量。当占用达到50%左右时,AI就会开始“挤占”——前面的内容被压缩,重要细节可能丢失,回答质量显著下滑。
因此,养成这样的习惯很有必要:上下文占用到50%时,该清理就清理,该另开窗口就果断重开。不要不舍得那个对话,继续堆积只会让效果越来越差。
在Claude Code里,输入/context可以查看当前上下文占用情况。Token即将超出时,不妨及时查看,做到心中有数。
Cursor中没有直接查看占用的命令,但在聊天界面有一个上下文栏,能够显示当前引用了哪些文件、上下文大致填满了多少。一个用命令,一个用界面,直观程度差不多。
不过,这里有一个反直觉的要点:频繁开新窗口不一定省钱。
背后的玄机在于缓存机制。AI每次收到你的消息,都需要从头“阅读”整个上下文——系统指令、工具定义、CLAUDE.md中的规则、此前所有的对话记录。在同一个窗口中,前面那些不变的内容会被缓存起来,下次读取缓存的成本只有重新计算的十分之一。
而一旦你新建了一个窗口,之前积累的缓存全部作废,数万Token的“基础设施”又需要重新全价加载。频繁使用/clear或每做一步就开新会话,等同于反复为这些不变的内容支付全价。
这个缓存机制在Claude Code和Cursor中同样适用。Cursor虽然没有/clear命令,但新建Chat的效果是一样的——之前的缓存白存了。
因此,正确的心态是:能继续就继续,开新窗口是有条件触发的操作。
什么条件该继续?
任务没换、距离上一条消息不超过1小时、之前的上下文对当前工作仍有帮助——那就继续聊,缓存还是热的,几乎不花钱。如果暂时没有新想法但不想让缓存过期,可以发一条简短消息来保持活跃。
什么条件该重开?
任务已更换、闲置超过1小时(缓存大概率已过期)、上下文塞满了不相关的“噪音”——那就果断重开。
个人的实践心得是:一个会话只专注完成一件事,这样一来几乎不会触发配额问题。
技巧4:超出上下文限制怎么办?用命令“续命”
有时一个窗口聊了很久,内容确实很重要,不想就此放弃,但上下文眼看就要塞满了。这时有两个“续命”方法:
/compact:压缩对话历史,对之前的内容进行总结,腾出更多上下文空间。交流多轮之后,用它能有效延续会话寿命。这是Claude Code的命令,Cursor目前没有对应的手动命令,但它会在上下文接近满载时自动压缩(侧边会提示“Summarizing chat context”),效果相同,只是不能主动触发。
/summarize:如果不想丢失历史信息但对话已经过长,可以用这个命令让AI提取核心信息(关键背景、已做决策、待解决问题),上下文能被压缩到原本的15%以内。Claude Code和Cursor都支持此命令。
两者的思路一致:上下文快满时,要么压缩,要么另起炉灶。
技巧5:长内容给路径,别往对话里贴
面对报错日志、大段代码、长文档时,很多人的第一反应是复制粘贴到对话中让AI自己去查找。
请不要这么做。
将10000行日志直接复制粘贴到对话里,这些内容会永久占据你的上下文空间,每一轮新的对话都要重新“阅读”一遍。更聪明的做法是把文件路径发送给AI,让AI自行检索需要的信息,只把真正相关的内容拉入上下文。
在Claude Code中,直接把路径写在对话中即可,AI会使用grep等工具去搜索。在Cursor里,用@引用文件——注意,能@单个文件就别@整个文件夹,引用粒度越细,上下文越干净。
请牢记一句话:最便宜的Token,是根本没进入上下文的Token。
上下文管理并非玄学,而是一种可以培养的良好习惯。给AI喂对材料、控制好用量、将不相关的任务分开讨论、长内容传递路径而非直接粘贴——做到这几点,你已经领先了大多数用户。
善用上下文,另一个直接的好处就是节省大量Token。当下算力竞争日趋激烈,AI不断进化,各大模型的Token单价持续走高。未来谁能用最少的Token完成工作,谁就更有可能获得效率优势。学会管理上下文,其实就是掌握了节约Token的关键能力。
腾讯Hy3模型免费接入Claude Code指南:OpenRouter配置与避坑建议
想必大家按我的方式用完智谱的免费额度后,正在寻找新的替代方案。这次为大家推荐腾讯最新发布的Hy3大模型,目前同样可免费使用。
下面就来详细介绍如何免费接入Hy3。
整个过程仅需两步:首先登录OpenRouter平台,接着找到Hy3模型并完成接入。
请跟随我的步骤逐一操作。
一、认识OpenRouter并获取密钥
OpenRouter是全球知名的AI大模型聚合服务平台,安全可靠,无需担心风险。
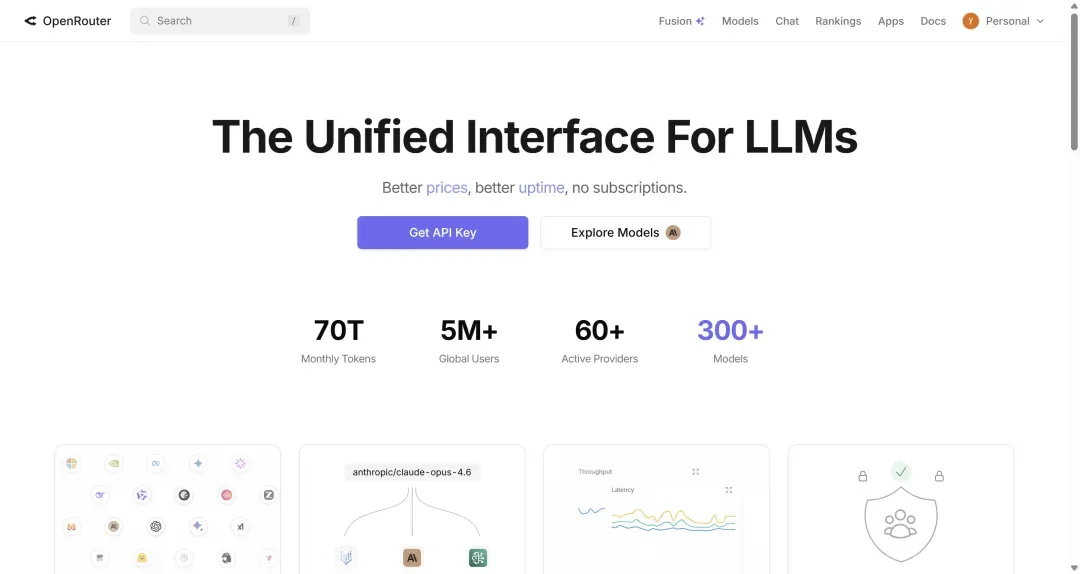
访问官网:https://openrouter.ai
进入后需要注册账号,这样才能拿到API密钥以便在cc-switch中进行配置。(注册流程十分简单,相信大家都能顺利搞定。)
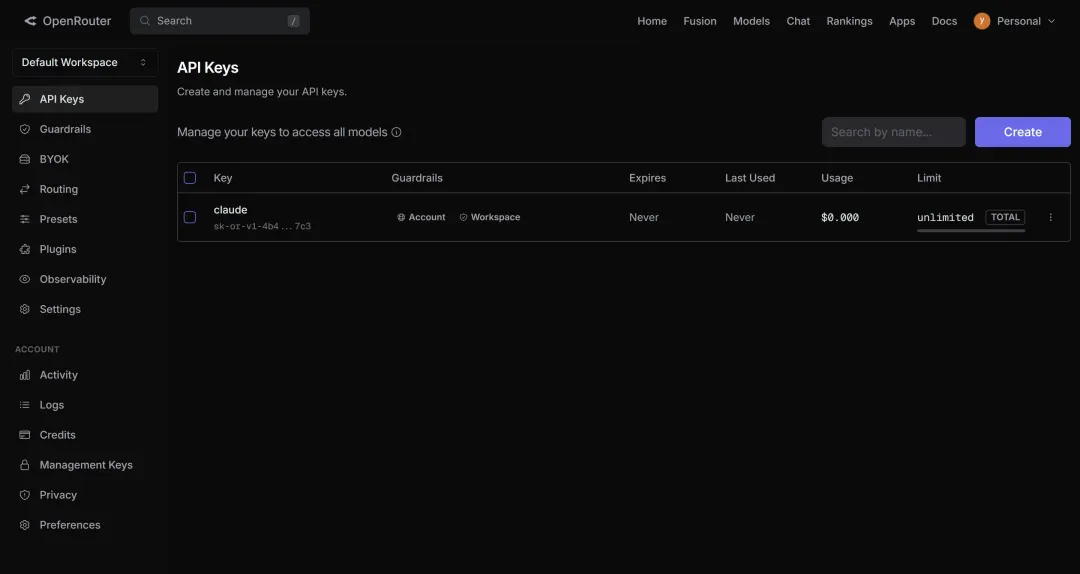
注册完毕,获取密钥。打开cc-switch,找到图中红框标示的OpenRouter专属入口,将密钥直接粘贴进去即可。
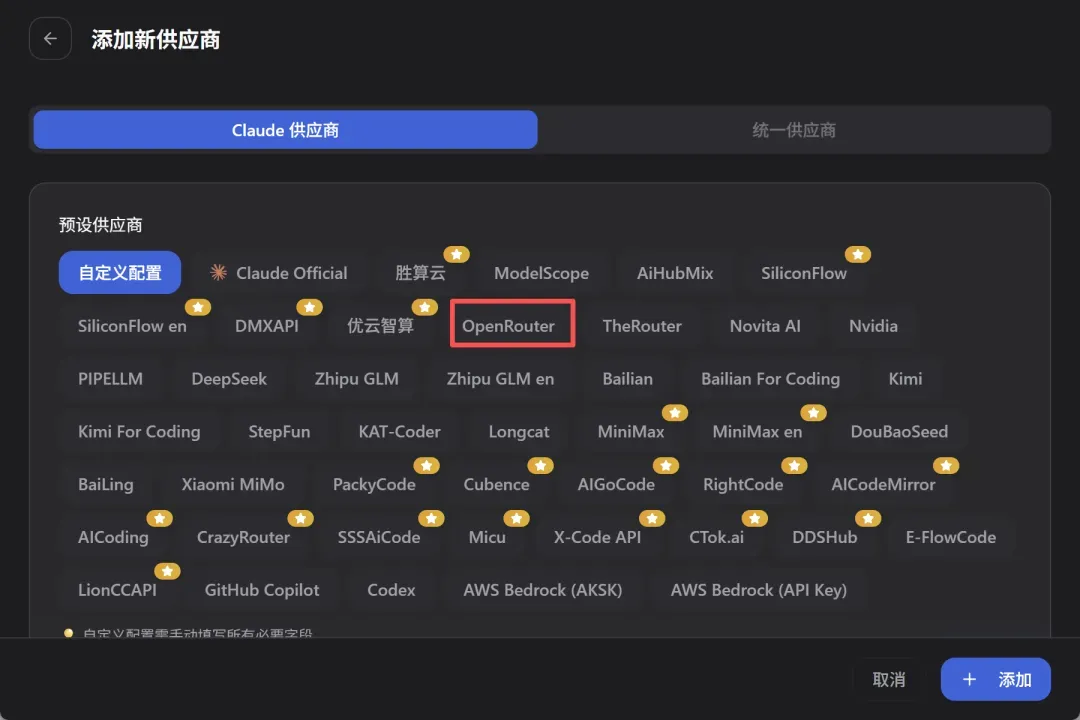
二、搜索并接入腾讯Hy3模型
接入密钥后,点击“Models”,在搜索框中输入“hy3”,即可找到该模型。注意括号内的“free”字样,代表当前完全免费。作为国内大厂出品的模型,Hy3相比那些不知名的免费模型要可靠得多。
免费政策随时可能调整,建议尽快接入使用。
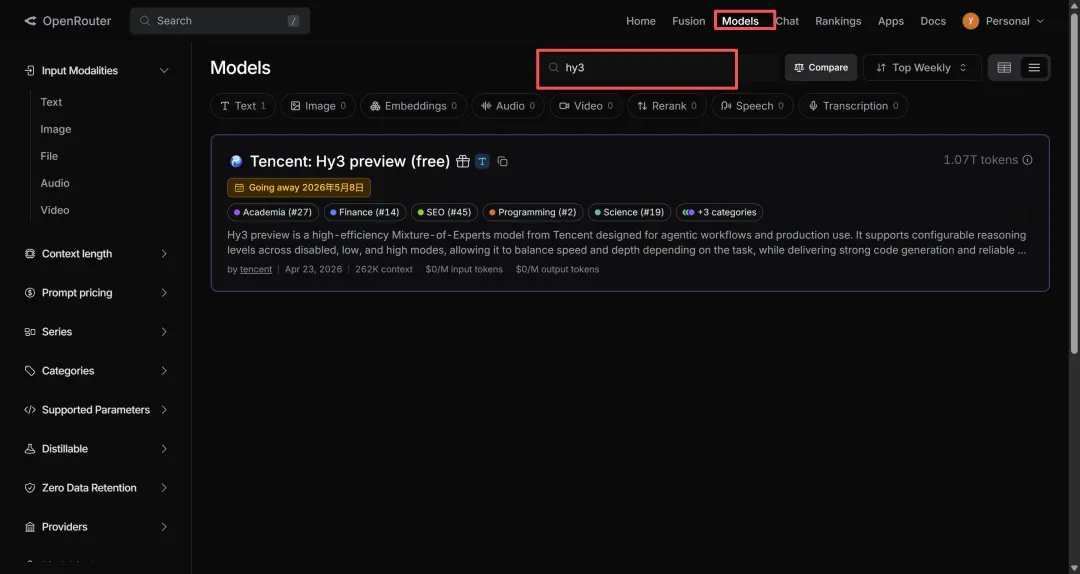
要接入Hy3,首先进入其详情页,然后点击“API”标签,复制红框标注的内容。(注意,只复制引号内的文本,双引号本身不要复制。)
模型标识符为:tencent/hy3-preview:free(直接复制这个也行)
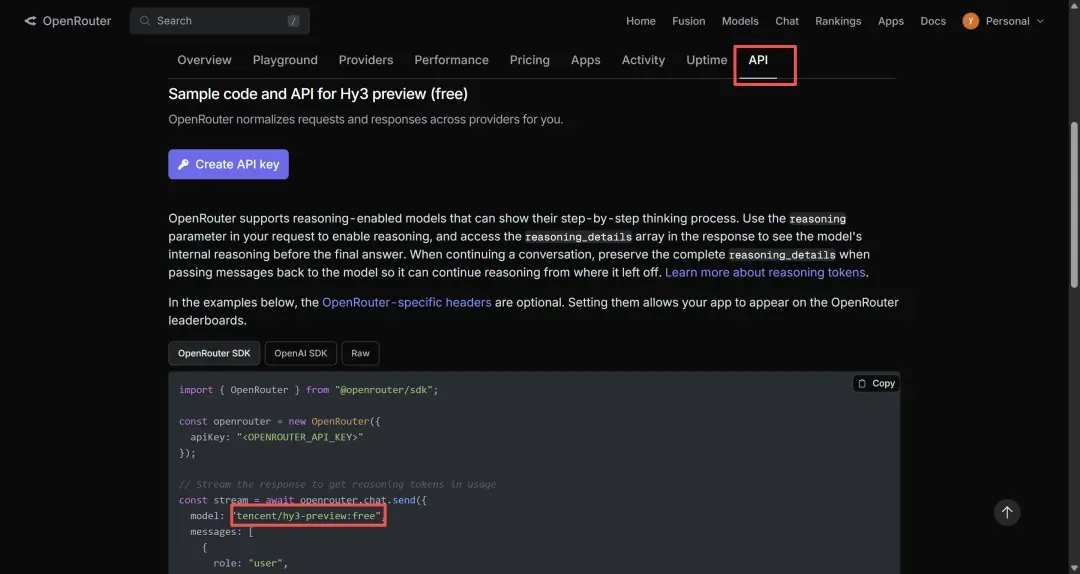
返回cc-switch,在先前选择OpenRouter供应商的那个界面中,将复制的模型标识符粘贴进去。为确保无误,建议每个与模型标识相关的输入框都粘贴一遍,如图所示。
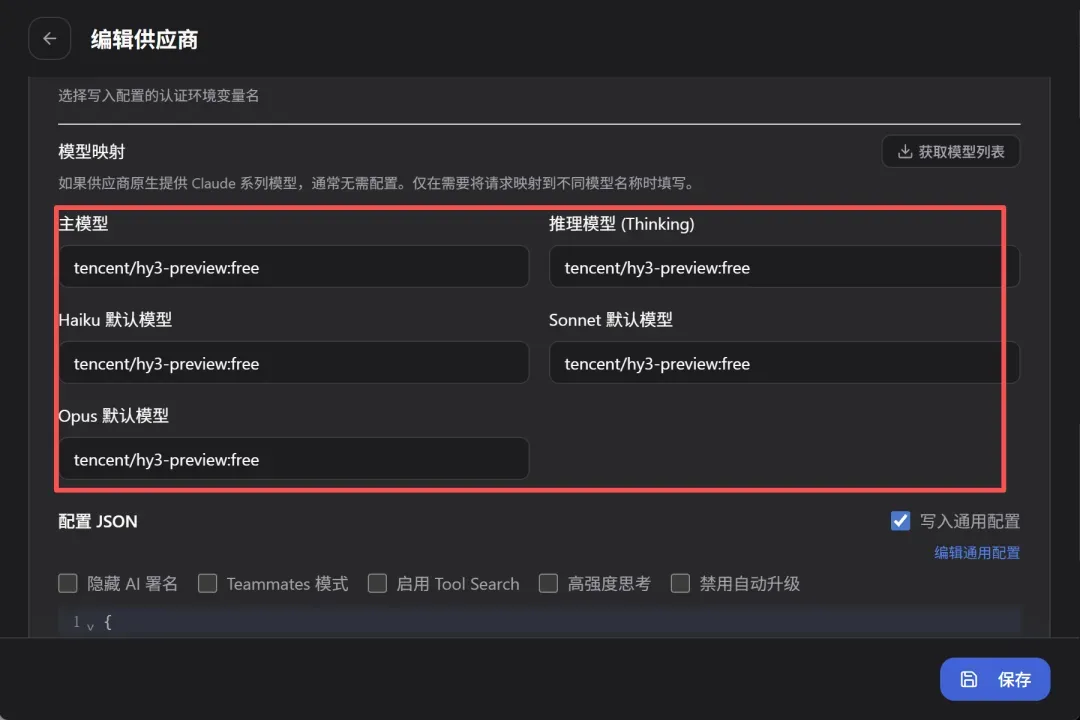
点击保存,配置完成。
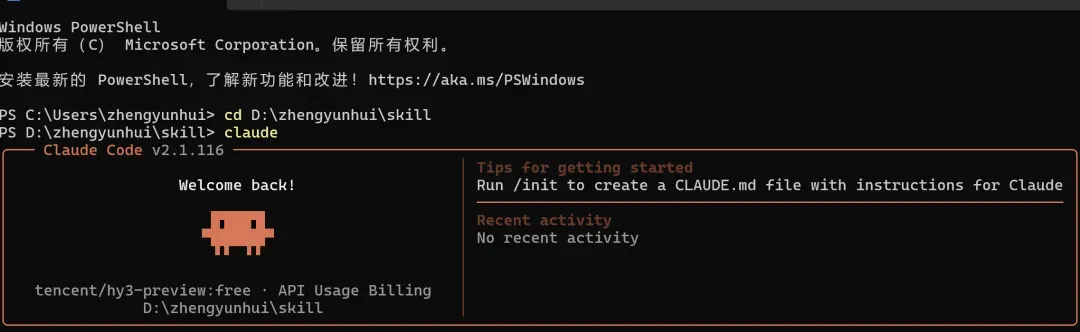
此时打开你的Claude Code,就能看到Hy3模型已经成功接入了!
三、更多免费模型接入技巧与注意事项
在OpenRouter上,你还可以探索并接入其他免费模型。在搜索框输入“free”,便会列出一系列当前免费的模型。
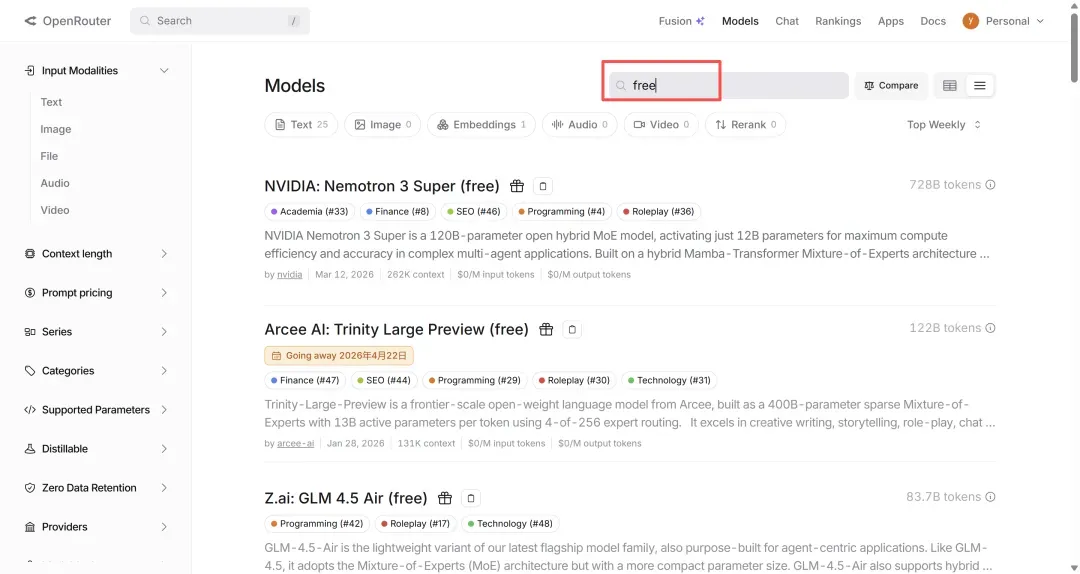
参照上面的方法,只需将类似tencent/hy3-preview:free的标识符粘贴进去,就能替换成任意你想调用的大模型。
你也可以尝试粘贴通用的openrouter/free,它会自动调度当前空闲的免费模型。但经我实测,效果很不理想,容易调用到能力很差的模型,基本无法解决实际问题,因此不建议使用。
以上步骤顺利完成后,恭喜你,Claude Code又多了一份免费的调用额度。
当然,免费服务也有局限:每天调用次数限制为50次,超出后会返回429错误。

若觉得50次不够用,可以考虑充值10美元,这样每日免费模型的调用次数将提升至600次,且不会消耗那10美元的余额。
目前还不清楚腾讯Hy3是否设有每日免费上限,但从我开始撰写本文至今已过去两小时,它仍在稳定执行我交给的任务,还未中断。
现在就按照本教程为你的CC接入Hy3,然后构思一个想要实现的项目,这个假期便可以安心在家享受“vibe coding”的乐趣了。