腾讯云 Hy Token Plan:专为 Agent 工作负载打造的高性价比订阅方案
腾讯云 · Hy Token Plan
腾讯云全新推出 Hy Token Plan,
一款专注 Agent 工作负载的高性价比套餐
腾讯云基于自研混元 Hy3 Preview 模型推出 Hy Token Plan,个人版最低 28 元/月,为 Agent 工作负载量身定制的专属订阅方案。
从 Coding Plan 再到 Agent Plan,各大云厂商的价格与技术博弈日趋激烈。继火山方舟的 Agent Plan 深度解析之后,腾讯云携 Hy Token Plan 强势入局。如果说火山方舟的优势在于“模型生态丰富”,那么腾讯云这次打出的牌则是“精准”与“省钱”。
Hy Token Plan 是一款专门面向 Agent 工作负载的专属订阅计划,直接针对当前 Coding Plan 实用性不足的痛点。个人版最低仅需 28 元/月,对于频繁调用 API 的 Agent 工具(如 OpenClaw、Hermes)而言,无疑是一个极具吸引力的新选择。
01
🚀 产品核心优势
与市场上通用化的 Token 订阅不同,Hy Token Plan 有着极其垂直的产品定位:专为 Agent 工作负载打造。
它基于腾讯 2026 年 4 月全新发布的自研混元Hy3 Preview模型构建。

提示词写作的底层手艺:从开口说话到精准掌控AI的思维路径
越是深入探索AI工具,越能体会到:真正起决定性作用的,其实是最原始的那一点——你是否会写提示词(prompt)。
知名技术大V卡帕西一直把一句话挂在置顶位置:
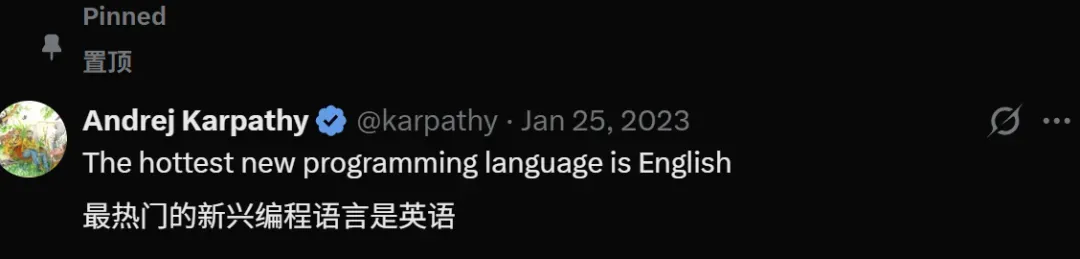
含义很简单:只要你会说话,能把问题描述给AI,它就能帮你实现。这句话从根子上点明了提示词的基础价值和不可替代性。
然而,“会说话”和“会表达”之间隔着巨大的鸿沟。我用一段亲身经历来说明这点。
用Word编辑任务的实战教训
有一次,我想让AI帮忙优化一个方案文档,其中某个章节不符合要求,需要修改。我把整个方案丢给AI,并指出这个章节不行,得优化。我当时写的提示词如下:
帮我优化一下这个方案,要求:
- 按照“数据采集—数据治理—数据分析—数据展示”的结构,重新组织下一级内容。
- 当前文档中的文字内容不动,只是把它们归到对应的板块下面。
- 标题、字体都要和原文档保持完全一致。
接着我把那份文档也附了上去。
我自认为描述已经足够清晰,结果AI交付的成果却一塌糊涂。我分别在Claude Code、Workbuddy、Codex里用这段提示词跑了一遍,甚至切换了不同模型,硬是折腾了五个小时,也没得到满意的结果。
我复盘下来,情况是:
- Claude Code + MiMo:内容改得可以,但格式完全对不上。
- Workbuddy + hy3:格式还能用,可内容质量不行。
- Codex + ChatGPT:内容和格式都还过得去,但耗时极长,整个过程将近拖了一小时。
我深入观察了每个工具和大模型处理这项任务的方式,发现它们背后的处理流程大相径庭。在梳理了各自的优劣势之后,我总结出一条最佳处理路径,然后把提示词改写成这样:
给我优化一下这个方案,优化方法是:
- 先把这份Word文档转成Markdown格式,然后再去读取里面的内容。
- 找到XX章节,将该章节的内容按照“数据采集—数据治理—数据分析—数据展示”的结构编写。编写完成后,生成一份新的Markdown文档。
- 把生成的Markdown文档转换回Word格式,具体做法是:
1)将原Word文档中“数据设计”这一部分整体复制到新Word文档中。
2)将Markdown里的内容按同样格式转换进去,同时保留原文档的标题格式、字体和编号样式。
- 把生成的新Word文件复制回原文档中(这一步你也可以手动复制,自行选择)。
神奇的事情发生了。原本每个AI工具都会花大量时间、效果还不理想的同一个任务,随着这条提示词的改写,全部给出了符合我预期的成果,而且整体工作时间也明显缩短。我不由得发自内心地感叹:提示词这件事,真的太重要了。
写提示词,真的是一门手艺活儿
现在很多面试中都会出现一个高频问题:“你写提示词的原则是什么?”网上能找到一套标准答案,大家可以自行搜索。
但我想说的不是那个标准答案,而是我本人对提示词的理解。
首先,提示词的复杂度取决于你要完成的工作的复杂程度。简单的事情,随便问就行,没什么可说的,正如大神卡帕西所言,会说人话就好。
而面对复杂任务时,第一要务是你自己必须先把“到底要什么”想清楚,然后再组织成提示词,交给AI。如果自己都表达得含含糊糊,反而不要描述太多——半明不白的提示词更容易把AI带偏,还不如用一句话直接交代。这就好像一位不懂装懂的领导胡乱指挥,结果同样糟糕。
当你用一句话把意图说清楚时,AI至少会基于自己的推断形成思考闭环,做出来的东西有基本的逻辑。随后你再进行微调,甚至推倒重来,就都随你掌控了。
复杂工作的另一种处理方法就是拆分,也就是项目管理中的WBS(工作分解结构)。把大任务拆成一个个小包,为每个小包装写好提示词,再按照先后顺序依次喂给AI。这也是非常原始但有效的办法。想起来去年我用豆包写方案时,就是自己先把章节结构搭好,把每个小节要写什么明确告诉豆包,然后由它一段一段地输出。现在大模型越来越聪明了,生成一个完整方案的便捷性已经大大提高,不再需要逐段复制粘贴。
但即使如此,用AI工具写方案时,“读取资料—撰写方案—转为Word”这些环节,仍然需要拆分开来。
这样做的好处,首先是让你作为“项目经理”拥有了里程碑和检查点。哪个环节出问题,就可以直接在这个环节调整,充其量这叫“变更”;要是等整个完整交付以后再改,就成了“返工”。返工的成本远比变更高得多。把这个逻辑照搬到AI工作流程里也是一样:过程中发现错误,及时修正,不会对后续产生连锁影响。这正是项目拆分思想的精妙之处。
结语
AI不是万能的,并非所有事情都可以一股脑儿丢给它完成。说到底,AI是基于预训练数据集运转的,它的能力存在明确的边界,一旦任务超出了它的数据覆盖范围,它也会“宕机”。
而你的工作有着极强的特殊性,背后许多坑、许多经验,只有你自己清楚。大模型一开始做这件事时并没有现成的参考,必须由你来讲清楚,它才能规避那看不见的陷阱。
而你究竟能否讲清楚,能否将提示词写成结构化、流程化、清晰化的表达,直接决定了AI能否真正帮你把这份工作漂亮地完成。
外贸独立站必备:8大Google工具深度解析与实战指南
根据 Statista 统据,2023 年谷歌搜索引擎的全球市占率高达 93.12%,对于中国出口电商与跨境贸易企业而言,Google 广告几乎是触达海外用户、驱动询盘与成交的必经之路。正因如此,熟悉并善用谷歌搜索引擎,成为每一位外贸独立站运营者无法回避的课题。
好在谷歌围绕网站运营生态,打造了一系列强大且完全免费的工具,能帮助站长快速诊断问题、洞察趋势、优化表现。下面我们将逐一解读这些值得每一位外贸人选掌握的谷歌利器。
Google Search Console(谷歌站长工具)
Google Search Console(谷歌站长工具)是网站管理者不可或缺的中央控制台,其核心价值在于全方位监控指向网站的外部链接。透过这个平台,你可以准确掌握哪些网站引用了你的内容,从而精准把握外链全貌。一旦发现来源可疑或对排名有害的垃圾外链,站长工具便允许你主动“拒绝”这些链接,清除其对网站的负面影响。这种主动防御能力,是维护网站健康、确保搜索引擎表现持续向上的关键护盾。定期使用谷歌站长工具,可以让你在问题萌芽阶段就及时拦截,为网站赢得更稳健的搜索排名。
入口:https://search.google.com/search-console
PageSpeed Insights
PageSpeed Insights 是 Google 推出的免费网页性能测评工具,它的任务就是对加载速度进行全方位体检。该工具会深度扫描你的页面,基于多项关键指标给出综合评分,并附上一份针对性极强的优化清单。通过这些建议,你能精准定位拖慢网站速度的瓶颈——比如未压缩的图片、阻塞渲染的资源等,从而有针对性地提速,显著改善用户浏览体验。
入口:https://pagespeed.web.dev/
Google Analytics(谷歌分析)
Google Analytics(谷歌分析)是谷歌官方的数据分析利器,帮助卖家实时追踪网站流量、用户来源、转化事件等核心数据。值得新手特别留意的是,GA 系统需要一到两周的数据积累周期才能呈现有效分析,因此强烈建议在启动任何广告投放之前就完成安装,这样一上线即可捕捉到高质量的数据信号,为后续优化提供可靠依据。
入口:https://analytics.google.com/analytics/web/provision/#/provision
Google Trends(谷歌趋势)
Google Trends(谷歌趋势)是一款与百度指数功能类似的免费趋势探针。基于谷歌庞大的搜索数据,它能够展现任何话题或关键词在不同时间段、不同地区的搜索热度变化以及相关查询的分布情况。无论你是要验证产品季节性,还是挖掘新兴市场兴趣点,谷歌趋势都能为你提供直观的数据参考。
入口:https://trends.google.com/trends/?geo=US
Google 全球商机洞察
谷歌全球商机洞察(Market Finder)是一个专为出口企业设计的情报工具。它能够结合你的网站产品,智能分析潜在的海外高价值市场,呈现竞争对手格局以及各渠道广告投放的成本与收益数据。当你准备将产品推向全球,却不知何处切入时,只需借助该工具即可快速获取市场排名、获客成本、行业概况等关键情报,从而准确锁定最适合产品出海的目标市场。
入口:https://marketfinder.thinkwithgoogle.com/intl/en_us

谷歌广告联盟(Google AdSense)
谷歌广告联盟(Google AdSense)是谷歌旗下久经考验的广告变现平台。它允许网站主在自己的页面上展示与内容高度相关的广告,并从中获取收益。网站主只需简单管理广告位,谷歌的智能算法便会自动匹配最合适的目标广告,实现流量价值的最大化。对经营者来说,AdSense 不仅是变现渠道,更是一个免费观察竞争对手素材创意的绝佳窗口。
入口:https://adsense.google.com/start/
谷歌广告资料库
2023年7月起,谷歌推出一项新的广告透明度政策,正式上线广告资料库(Ads Transparency Center)。这一工具类似 Meta 的广告图书馆,用户可以通过品牌名称搜索其正在投放的广告,还能按地区、格式进行过滤,并查看广告的最后投放日期。对于外贸运营者而言,这意味着可以更轻松地研究竞品的广告素材、创意策略与投放节奏,为自身的广告优化提供一手参考。
入口:https://adstransparency.google.com

Chrome 应用商店扩展程序
Chrome 应用商店集结了数不胜数的浏览器扩展,可大幅提升跨境电商的工作效率。标签页管理类插件能帮助你轻松处理多任务切换、标签合并与批量操作;信息提取插件则可以一键抓取网页中的文字、图片等核心内容;广告拦截扩展为你营造无干扰的整洁浏览环境;安全检测类插件还能自动拦截恶意网站,保护账号与数据安全。善用这些轻量级工具,往往能让独立站的日常运营事半功倍。
入口:https://chromewebstore.google.com/
一键解析GitHub仓库内核:三款AI利器深度拆解项目架构
面对复杂的 GitHub 仓库无从下手?只需输入仓库地址,这些工具就能带领你快速拆解核心逻辑,彻底理解项目架构。
深度拆解引擎:DeepWiki
开源仓库:https://github.com/AsyncFuncAI/deepwiki-open
在线访问:https://deepwiki.com/
DeepWiki-Open 是一个开源工具,能够将任何代码仓库(无论是 GitHub、GitLab 还是 BitBucket)瞬间转变为结构精美、交互丰富的 AI 驱动 Wiki 文档站点。你只需粘贴仓库 URL,它便会自动解析代码库,生成包含 Mermaid 可视化图表的详尽文档,并将所有内容整理成易于导航的 Wiki,全程无需人工编写。
DeepWiki 的核心运作机制本质上是执行一个多阶段处理流水线:它克隆目标仓库,将每个源文件读取并分块,然后将这些代码块嵌入向量数据库以实现智能检索,最后通过实时 WebSocket 连接,逐页流式传输 LLM 生成的文档。最终呈现的是一个精致的 Wiki,包含架构图、组件拆解、数据流可视化以及相互交叉引用的页面——所有这些都在一个支持明暗主题切换的 Web 界面中呈现。
该系统还内置了 Ask 功能,允许你借助检索增强生成(RAG)技术直接与仓库进行对话;更有 Deep Research 模式,能够对复杂主题进行多轮迭代式深度调研,在多达 5 轮研究循环中综合各项发现,最终给出全面详尽的解答。
中文开源解读专家:Zread
在线访问:https://zread.ai
Zread 是由智谱 AI 推出的一款 AI 驱动、完全免费的 Github 项目阅读神器。它通过结构化代码分析与深度知识萃取,一键生成清晰易懂的 GitHub 项目中文文档,帮助开发者迅速掌握优秀项目的核心架构、实现逻辑与最佳实践。
- 一键生成项目文档:只需要输入 GitHub 仓库地址,Zread 就能自动梳理项目脉络,输出内容涵盖目录架构、代码流程图、核心功能拆解以及使用指南等,极大降低开源项目的学习门槛。
代码知识图谱交互器:GitNexus
项目地址:https://github.com/abhigyanpatwari/GitNexus
核心理念:将代码视为知识图谱,实现实时交互
你可以将代码库想象成一个活生生的有机体。单个文件是细胞,函数和类是蛋白质,导入语句是突触连接,而调用链则是神经通路。传统的代码搜索工具——比如 grep、IDE 的查找引用,甚至基于 LSP 的跳转到定义——只能让你一次检查一个细胞。GitNexus 则构建了完整的神经系统:它映射每一个细胞,追踪每一条通路,把相关的细胞分组为功能性器官(集群),并记录神经触发的完整序列(执行流)。这张结构图持久化保存在本地图数据库中,并通过 Model Context Protocol (MCP) 提供给 AI Agent,赋予它们任何提示词工程都无法复刻的能力:对代码架构的真正理解。
一行JavaScript代码实现AI自动化:深度解析阿里巴巴开源项目PageAgent

开源地址:https://github.com/alibaba/page-agent
Page Agent 是一个完全运行在浏览器中的 AI 驱动自动化框架。它彻底摆脱了传统自动化方案对无头浏览器、Python 运行环境或浏览器扩展的依赖,以极其轻量的页内 JavaScript 库形式存在。这意味着任何 Web 应用都能通过自然语言直接控制,完全不需要后端基础设施。
该项目由阿里巴巴开发,基于 MIT 许可证维护,当前版本 1.6.1。整个工程采用 TypeScript monorepo 架构,借助 npm workspaces 统一管理,并使用 Vite 作为构建工具。
Page Agent:连通大语言模型与现实网页的桥梁
Page Agent 的根本价值在于,它在大语言模型与可交互的 Web 页面之间建立了一座通道。你只需用一句自然语言发出指令,例如 “点击登录按钮并填入我的邮箱”,代理就会自主观察页面状态、推理下一步行动,并在循环中反复执行 DOM 操作,直至任务完成。
其突出优势之一,是基于文本的 DOM 操作策略。Page Agent 不会通过屏幕截图依赖多模态 LLM——那类方案不仅成本高,响应也慢。相反,它会从实时 DOM 树中提取出结构清晰且经过精简的交互元素文本表示。LLM 直接根据这些文本进行推理,判断需要和哪个元素交互、执行何种动作。这样既快速又轻量,并且几乎可以对接所有兼容 OpenAI 接口的模型。
分层架构与自主执行循环
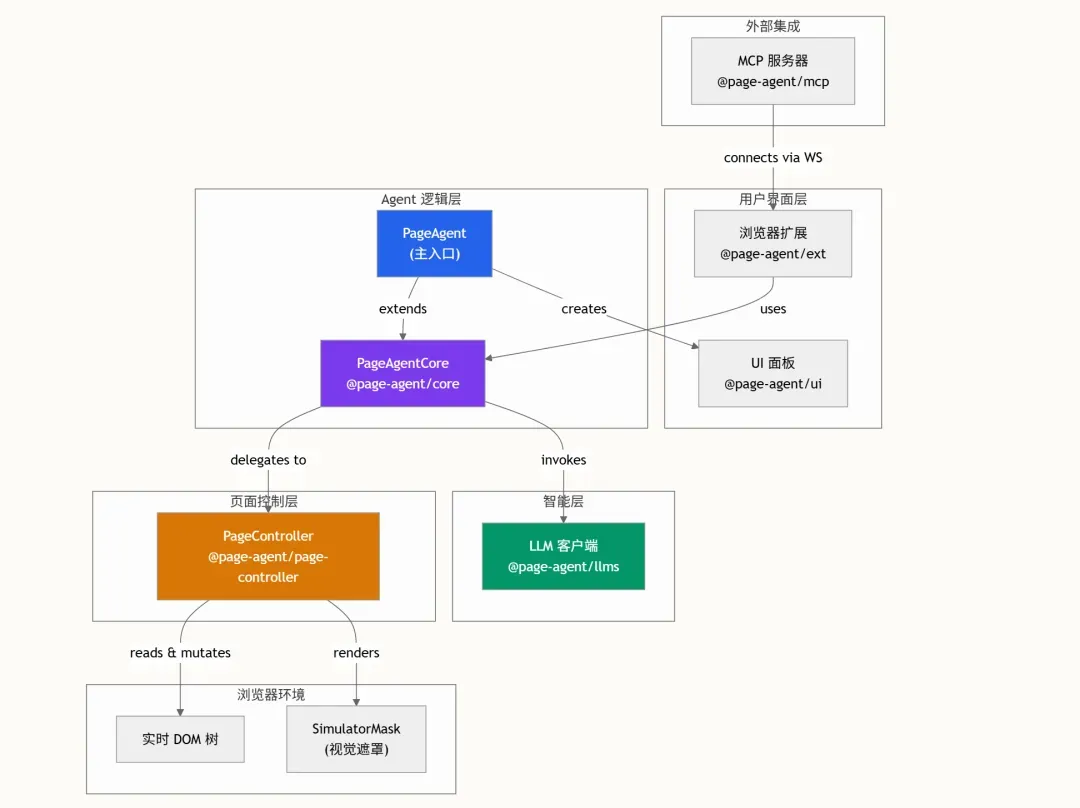
Page Agent 采用分层架构,每一层的职责都被封装在独立的包中。各层之间通过异步、面向接口的方式进行通信,从而保证了高度的解耦和可测试性。
Agent 执行循环是整个系统的核心,它严格遵循 ReAct(推理 + 行动)模式,并融入了独有的“行动前反思”机制。在每一轮循环中,代理都会先观察页面状态,回顾之前的子目标与进度,规划接下来的动作,然后执行。这一循环不断重复,直至任务被标记为完成或者达到预设的最大步数。

Page Agent 是一个纯客户端 ReAct 循环,完全在浏览器内运行——无需 Python、无头浏览器或任何后端改造。它把页面的 DOM 读取为结构化文本,通过 LLM 推理出下一步,并利用浏览器原生的元素 API 去执行操作。
开箱即用的智能工具集
Page Agent 内置了一套供 LLM 在任务执行过程中调用的工具。每一个工具都通过 Zod schema 定义并进行输入校验,实际的 DOM 操作则委托给 PageController 来完成。
一周消耗超6亿Tokens:Hy3免费模型深度体验与反思
Hy3 的试用期结束了,也来晒一下这段时间的消耗成绩。
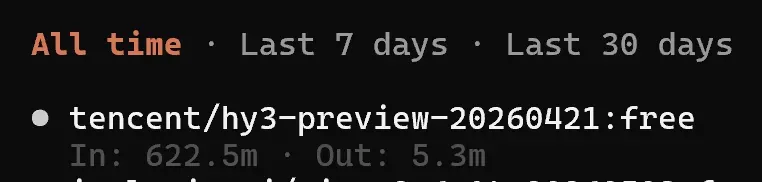
输入 Token 一共用掉了 6.225 亿,输出 Token 约为 530 万。
这么大的输入量,主要和我大量整理知识库的工作有关。我也用 Hy3 尝试开发了一款软件,运行了大约一小时左右,开发效果还算可以。页面能正常打开,交互也形成了闭环。
不过实际使用中,生成的软件并没有满足客户需求,于是决定重构。但重构的进展非常不顺利,整整折腾了一天,到最后什么也没搭出来,代码还被改崩了。
不得不吐槽的一点是,Hy3 在 OpenRouter 上的速度明显受限,用起来非常慢。但考虑到是免费额度,也只能忍一忍了。它的上下文窗口似乎只有 128K,跑两个任务就会提示空间不足。我是通过 Claude Code 接入的,每次上下文用满以后,压缩过程都极其耗时,甚至好几次直接自动中断。现在也分不清到底是 Claude Code 还是 Hy3 的原因。
所以后来我干脆直接执行 /clear 指令,反正免费资源,大不了再让模型重新读取一遍所有项目文件,放开来用。
再分享一件让我心情舒畅的小事。

根据当前 Hy3 的收费规则,我让豆包帮忙换算了自己消耗的 Token 对应的费用:
- 输入费用:622.5 × 0.066 = $41.085
- 输出费用:5.3 × 0.26 = $1.378
- 总费用:$41.085 + $1.378 = $42.463
换算成人民币大约是 306 元。如果按老一辈“省下的就是挣下的”这种说法,那这个月已经“挣”了 306 元,想起来也挺有意思。当然,跟大神们比起来不过是九牛一毛,还需要继续努力,把需要整理的工作和其他耗 Token 的任务积攒起来,等下一波优质模型免费窗口期再抓住机会。
Hy3 停供之后,后遗症立刻显现出来。好几个依托大模型搭建的网站都面临宕机,尤其是那个用来演示的知识库问答站点,以前别人抱怨响应慢,现在索性完全不可用了。这样看来,Hy3 的免费额度确实为各个项目的推进帮了很大的忙。能用的时候没觉得多珍贵,还总吐槽它,一旦没有了,又开始怀念。
总的来说,Hy3 作为一个下位替代或兜底模型完全没有问题。就像团队里专做脏活累活的成员,让它去承担关键重任可能难以胜任,那种任务需要 Claude 或 ChatGPT 这样的精英级模型,但如果只是整理知识库,调用 Opus 就显得太过奢侈,而这正是 Hy3 这类模型的价值所在。
盈利暴涨却狠裁4000人,Block的AI重构真相
公司没亏钱,却裁掉一半人
多数人默认:企业裁员必定因为亏损、财务危机,是“断臂求生”的无奈之举。
但这一次,逻辑完全不同。
2月26日,美国金融科技巨头Block宣布裁员近4000人。这家原本约万人规模的公司,计划瘦身至不足6000人,几近“腰斩”。许多员工仍在工位上处理日常事务,变动却突然砸下,令人措手不及。
然而,Block非但没有陷入困境,反而正处于业绩爆发期。股东信显示,2025年全年毛利润达103.6亿美元,同比增长17%。旗下Cash App用户增长企稳,Square支付规模持续扩大,各项业务都在稳步向上。盈利持续攀升,业务版图不断扩张,却一次性砍掉近四成人员?
CEO Jack Dorsey在X平台发文正式公布裁员决定(全文翻译见下图)。
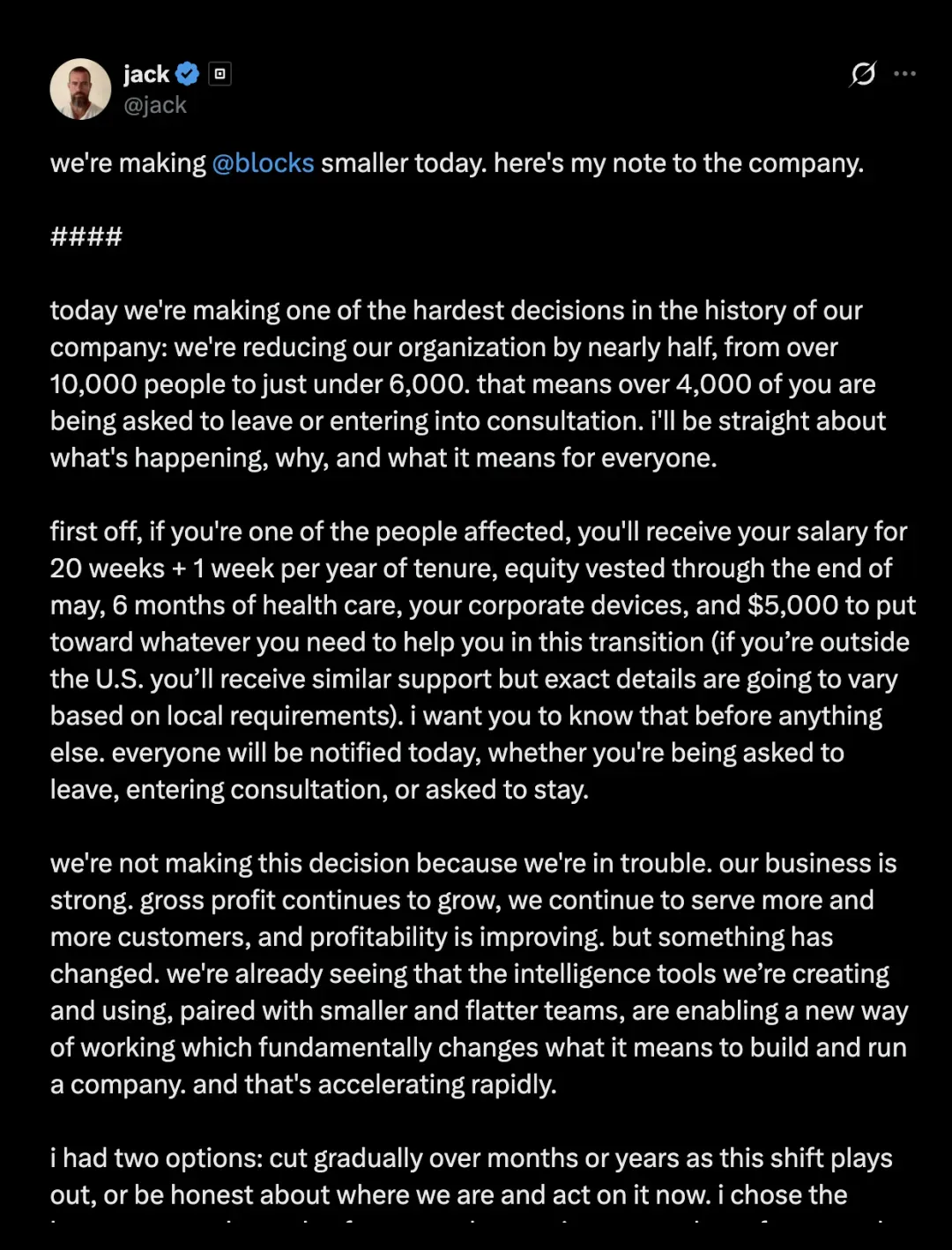
该帖于北京时间凌晨5点发布,迅速斩获超过4000万阅读量。
他在帖中直言不讳:公司并非因为遇到困难而裁人,而是因为智能工具正在彻底改变组织运行方式。与其在未来几年慢慢瘦身,不如当下一次性完成重构。“钝刀子割肉”式的分批裁员只会反复消耗团队士气,他选择了“长痛不如短痛”——果断、激进。
那么,资本市场对这场“疯狂”手术作何反应?
Block盘后股价一度暴涨超过24%!资本永远用真金白银表达立场。
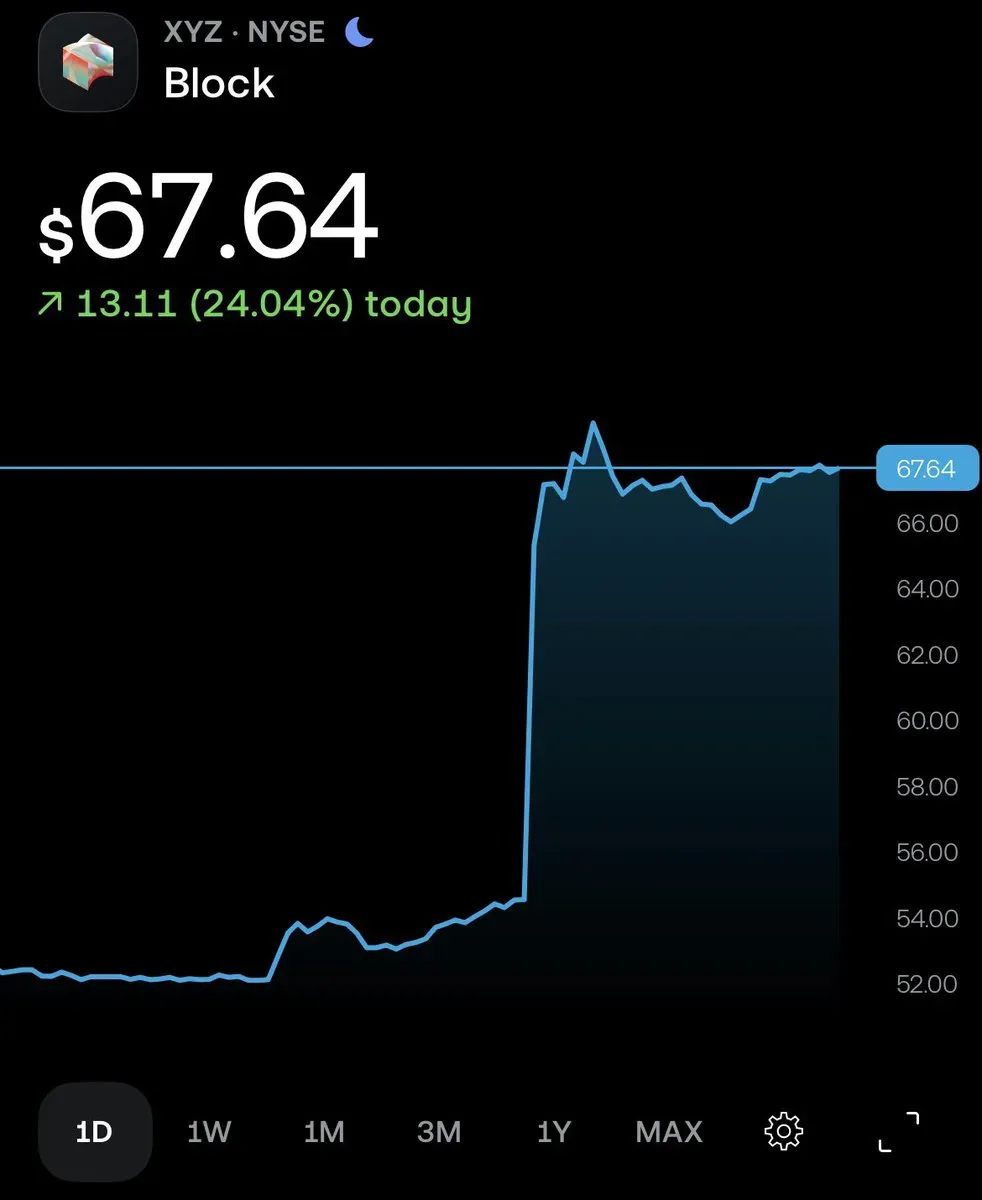
市场传递的信号毫不含糊:拥抱AI驱动的组织重构,是绝对利好。
值得一提的是,Block的掌舵人Jack Dorsey亦是推特(Twitter)的联合创始人兼前CEO。

当年,他将推特售予另一位更具颠覆精神的人物——埃隆·马斯克,也就是特斯拉、SpaceX、StarLink背后的那个男人。
对Jack Dorsey来说,这并非首次做出“反常识”决策。但这次行动早已超越个人选择,它是不可逆的时代抉择。
Block,到底是一家什么样的公司?
你可以把Block理解为“美国版的收钱吧+支付宝+东方财富”的超级融合体。

它搭建了一个庞大且盈利的金融生态闭环,核心板块有三个:
第一,服务商户的 Square。
可视为升级版的收钱吧或拉卡拉,为美国千万中小商户提供POS机、支付系统、经营管理软件,甚至信贷服务。
第二,服务个人的 Cash App。
相当于美国人的“支付宝”或微信支付,个人转账、日常消费、小额贷款,乃至直接买卖股票,功能一应俱全。

第三,押注未来的比特币战略。
Block对比特币生态野心极大,从自研挖矿芯片到比特币钱包、支付整合,全链条布局。
左手牵起千万商家,右手拉着亿万个人用户,脚下还踩着前沿技术,业务壁垒极深,护城河极宽。
然而,正是这样一家居于金字塔尖的公司,主动按下了“组织重构”的加速键。这才是最令人后背发凉之处。

残酷真相:规模不再依赖“堆人”
整件事最反常的地方在哪里?
传统逻辑中,一家巨头若突然裁员40%,市场必定恐慌抛售,因为那意味着公司“不行了”。可Block裁员消息公布后,资本非但没有悲鸣,反而起身鼓掌。
为什么?
因为华尔街读懂了Jack Dorsey的潜台词:这不是“降本”,而是彻底的重构。背后是边际人力成本正被AI无情颠覆。
前些日子,华尔街研究机构Citrini Research发布了一份震动业界的报告——《2028全球智能危机》。

报告中提出了一个令人深思的概念:“幽灵GDP”(Ghost GDP)。
什么意思?
随着AI大幅提升生产率,财富会迅速向掌握“AI能力”和“算力基础设施”的公司集中。企业发现,原来不需要维持庞大的人力规模,也能创造出同等甚至更高的利润。

在传统商业世界里,有一条坚如磐石的法则:规模增长 ≈ 人员增长。
要做大业务,就得雇用更多销售、更多客服、更多程序员。营收与员工数,几乎是线性绑定关系。
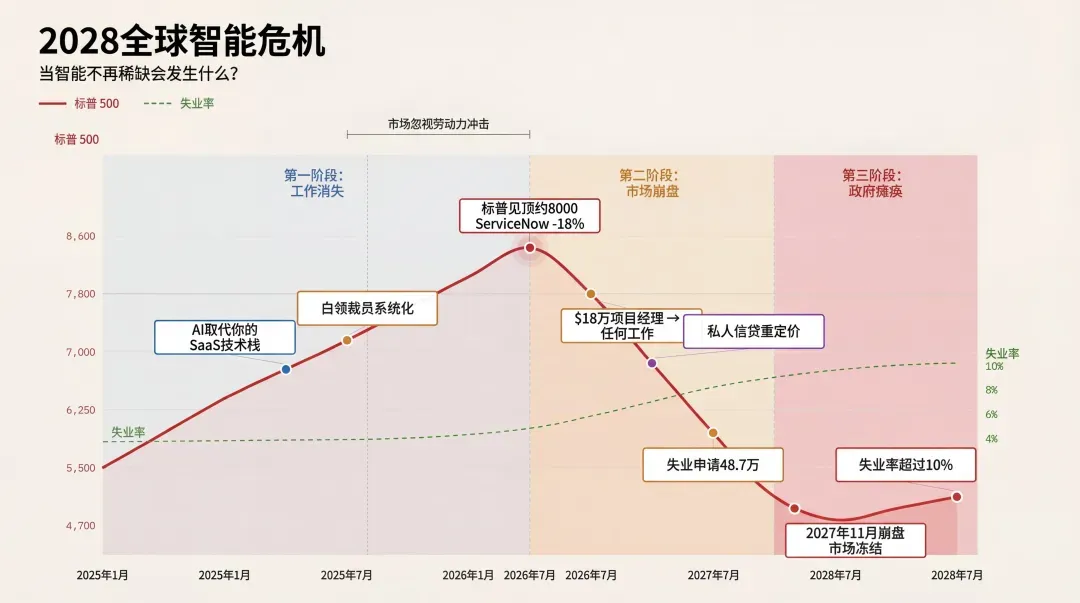
然而,AI一击便将这一常识粉碎。
今天的公式变成了:规模增长 ≠ 人员增长。
AI成为了那个可怕的“指数级杠杆”。同样数量的人,可以撬动过去十倍、百倍的产出。当产出越来越不依赖人力,而越来越仰仗智能时,理性的企业家会怎么选?
资本天生逐利,他们必然会削减边际成本日益上升的人力,调高边际成本趋近于零的AI权重。
因此,Jack Dorsey作为AI时代的先锋,看透了这一点:如果未来注定要压缩人力规模,不如现在就一次性切换至“小团队+强智能工具+高杠杆输出”的全新形态。

自主AI研究员Autoresearch彻夜炼丹:零配置驱动GPT优化实验
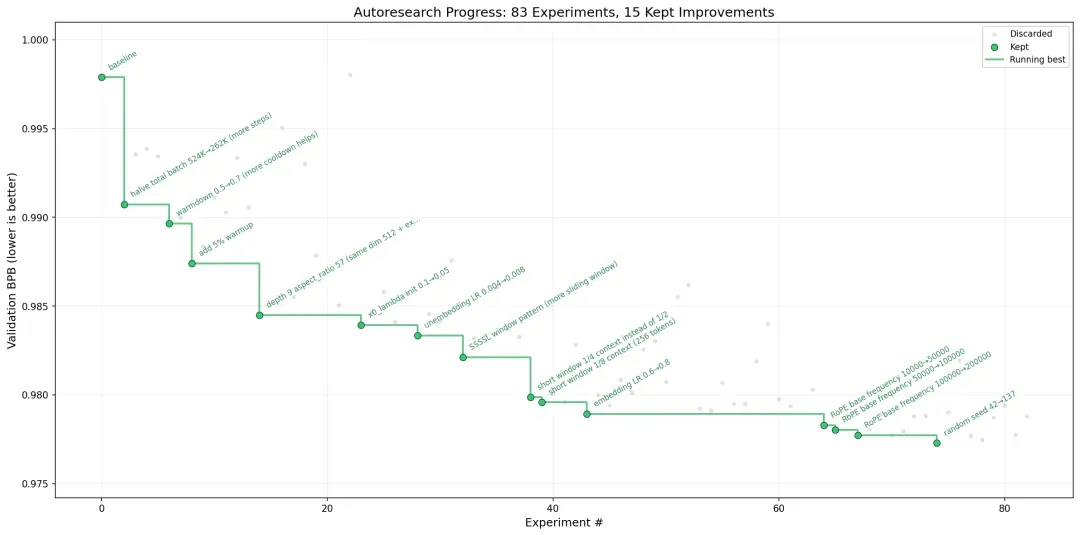
Autoresearch 是由 Andrej Karpathy 发起的一个纯粹由 AI 自主驱动的机器学习研究实验。它的核心理念非常直接:给 Agent 提供一个真实的 GPT 训练环境,让它自行修改代码、进行 5 分钟的短期训练、评估结果,然后决定保留还是放弃每一次改动。当你在夜间休息时,这位 Agent 可能已经完成了近 100 次实验,每一次都是为了降低验证损失而做出的认真尝试。这不是一个演示玩具,而是一套极简却严肃的预训练研究框架——在这里,研究员永远不需要睡觉。
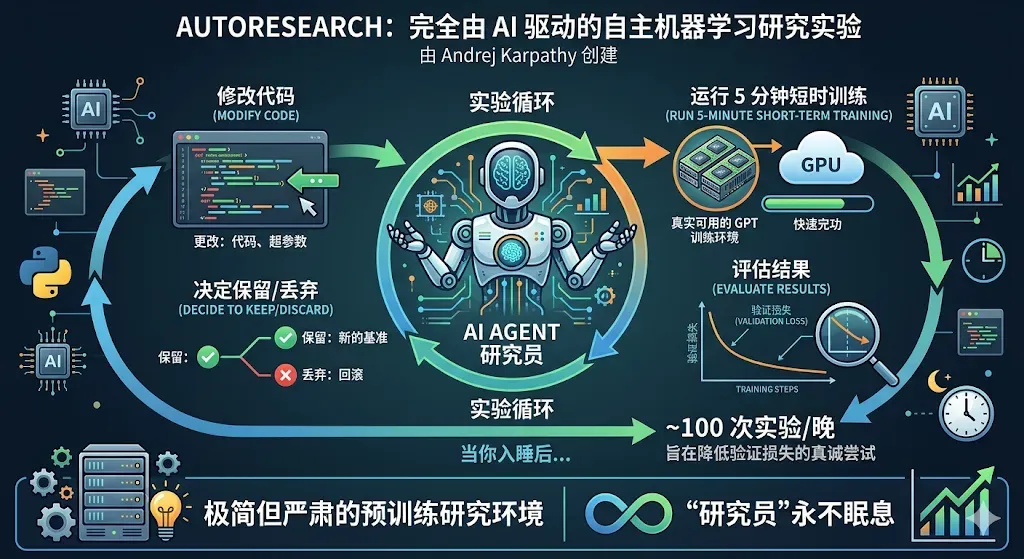
项目地址:https://github.com/karpathy/autoresearch
整个代码库刻意保持极度的简洁——仅由三个核心文件和少量辅助文件构成,没有任何配置框架。极简就是架构本身。通过将问题约束在单 GPU、单个可编辑文件和单一指标上,该项目彻底消除了基础设施开销,使 Agent(或你本人)能够在固定的时间预算内,全神贯注于如何更有效地训练 transformer。
整体架构:动静分离的设计哲学
整个系统围绕固定部分与可变部分之间的清晰职责划分而构建。理解这条界线是掌握 autoresearch 其他一切内容的关键。
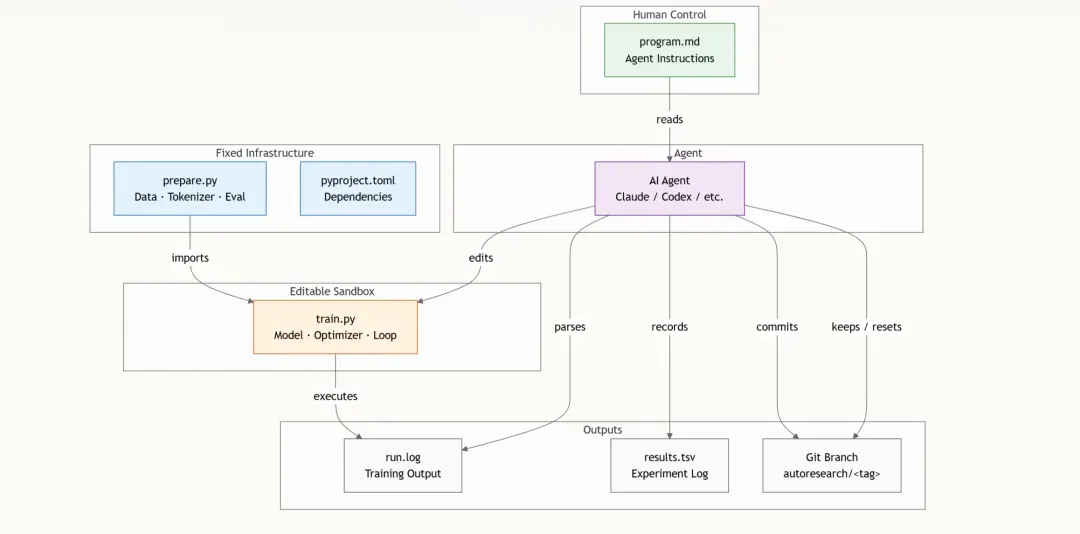
绿色部分由人类编写,蓝色代表不可变的基础设施,橙色是 Agent 可自由发挥的试验场,紫色的 Agent 负责编排实验循环,而灰色的输出则完整记录发生的一切。
项目文件清单
代码库的结构印证了其设计的简洁性。每个文件都承担着明确的职责,整个代码库中有意义的 Python 代码不到 1000 行。
autoresearch/
├── prepare.py ├── train.py # ✏️ 可编辑——GPT 模型、优化器、训练循环
├── program.md # 🤖 Agent 提示——AI 研究员的指令
├── pyproject.toml # 🔧 配置——项目依赖(由 uv 管理)
├── analysis.ipynb # 📊 分析——用于检查实验结果的 Notebook
├── progress.png # 📈 可视化——来自某次通宵运行的实验结果图表
├── README.md # 📖 文档——项目说明
└── uv.lock # 🔒 锁定——固定的依赖版本
这三个关键文件映射出一个三角形角色设计:
2026 CLI复兴:开源命令行如何成为AI时代的终极接口
不是复古,是 AI 正在长出“手和脚”
无需怀疑,当你打开 GitHub Trending,前十热榜里近七成都是 CLI 工具。
| 项目 | Stars | 今日新增 | 类型 |
|---|---|---|---|
| Claude Code (Anthropic) | 105,308 | +8,764 | AI 编程 CLI |
| OpenAI Codex | 72,419 | +1,416 | AI 编程 CLI |
| VibeVoice (Microsoft) | 34,962 | +1,085 | 语音 AI CLI |
| larksuite/cli (飞书官方) | 6,167 | 当日还在更新 | 企业协作 CLI |
| cc-connect | 4,004 | 8 小时前 | AI×飞书/钉钉桥接 |
而早已成名的 CLI 更不在少数:
GitHub CLI (gh) - 230k+ stars
Vercel CLI - 15k+ stars
Netlify CLI - 3k+ stars
Notion CLI - 2k+ stars
Slack CLI - 1k+ stars
一眼望去,几乎全是“广为人知的软件+CLI”。
2026跨境电商建站终极对决:WordPress与Shopify谁更胜一筹?
在跨境电商领域的起跑线上,选择一个得心应手的建站平台,往往决定了独立站未来是乘风破浪还是举步维艰。WordPress与Shopify作为两大主流选项,各自吸引了无数卖家的关注。它们本质上的区别,远不止表面上的易用或功能之差。下面,我们从初学者最关心的几个维度,全面拆解这两种方案的优势与暗礁,帮助你迈出稳健的第一步。

一、WordPress自建独立站:灵活性与控制权之王
1. 突出优势
- 生态系统极其完整:WordPress是全球使用率最高的建站程序,不但功能强大,而且拥有海量的主题模板与功能插件,几乎能实现你能想到的所有常规需求。庞大的用户社区意味着遇到问题几乎都能找到现成的解决方案。
- 真正的自主掌控:你对网站拥有绝对主权,可以随心修改代码,实现任何个性化功能。不受第三方平台的规则限制,所有的数据和流程都掌握在自己手里。
- 完全开源,无封店之忧:这是许多卖家最看重的一点。WordPress本身是开源软件,搭建的跨境独立站不存在平台单方面封禁的风险,经营策略更加灵活,尤其对经营特殊品类的卖家来说,是重要的安全保障。
- 建站门槛持续降低:程序成熟,网络上有大量详细教程,即使没有技术背景,按照步骤操作也能快速让网站上线。
- 长期成本极具优势:借助WordPress能以极低甚至零预算起步,仅为服务器和域名付费,大大降低了跨境创业初期的试错成本和日常开销。
2. 潜在劣势
- 资源消耗与优化门槛:作为全能型程序,WordPress对服务器资源有一定要求,要想保持长期稳定运营,需要进行一定的性能优化,对新手小白可能是一个学习关卡。
- 需要自行解决服务器:这意味着你得购买单独的服务器或主机,不过整体成本仍然可控,远低于Shopify的持续性订阅支出,属于可管理的投入。
二、Shopify托管独立站:开箱即用的双刃剑
1. 显著优势
- 专为电商打造,上手极快:Shopify是SaaS模式的电商服务平台,开箱即用,操作界面直观,对毫无技术基础的跨境卖家十分友好,能快速开启销售。
- 模板和插件配套完整:同样拥有丰富的主题库和插件市场,只不过优质资源大部分需要额外付费才能使用。
2. 不可忽视的劣势
- 持续使用成本居高不下:需要按月缴纳订阅费用,并且套餐价格不低,对预算有限的新手来说是一笔持续的压力。
- 扩展成本层层叠加:免费模板和插件相对基础,一旦想实现个性化功能,各种付费主题和App叠加费用会使成本急剧上升。
- 交易佣金蚕食利润:每笔订单都会被抽取一定比例的佣金,日积月累,长期运营的隐形支出相当可观。
- 独立性匮乏,封店是最大硬伤:Shopify并非真正意义上的独立站,而是托管平台。你的店铺随时可能因违反其政策而被处以封禁,而且许多封店理由并不透明。一旦被封,辛苦积累的流量和品牌资产都会付诸东流,甚至原有域名也可能无法继续使用。
- 非开源生态,灵活性受限:相比于WordPress的开源自主,Shopify的生态相对封闭,自主性和可定制深度都明显不足。
三、如何抉择:结合预算与长期规划的理性建议
综合来看,WordPress与Shopify各有千秋,但也都有显而易见的短板。如果你的资金非常有限,又想以最低成本涉足跨境创业试水,WordPress无疑是更理智的选择。虽然初期需要花一些时间学习搭建和优化,但它能帮你免除月租和佣金的高负担,同时彻底杜绝封店风险。
反之,如果你预算充足,并且极度不愿意花时间在技术细节上,只求快速上手卖货,那么Shopify的便利性或许会吸引你。但务必意识到,托管平台背后的封店风险如同高悬的利剑,一旦落下,之前的投入可能瞬间归零。
而对于那些预算尚可,但希望长期运营成本更可控、品牌资产完全自主掌握的朋友,同样建议转向WordPress。毕竟,把店铺的未来死死绑在别人的规则上,绝非长久之计。
特别提醒:如果你决定选用WordPress,但又缺乏搭建经验,在寻找付费服务时一定要多加甄别。目前市面上不少宣称“专业建站”的人,实际上只是草草学完了安装流程,建出来的只是一个未经优化的空壳。WordPress真正考验的是针对长期运营的深度调优,而不是装上一个模板就万事大吉。谨慎选择,避免成为被“割韭菜”的对象。