Kimi全新长思考模式深度体验:媲美DeepSeek的推理能力究竟如何?
引言
AI助手领域的竞争正在迈向新的阶段。DeepSeek凭借其开创性的长思考模式一度成为现象级工具,然而近期的网络波动与频繁攻击让不少用户陷入“想用却用不上”的窘境。就在这个节点,笔者注意到Kimi也悄然上线了类似的长思考功能——它能否成为我们期待的完美替代方案?一番实测下来,答案逐渐清晰。
长思考模式:为AI注入深度推理基因
所谓长思考模式,并不仅仅是回答字数的增加,而是让模型在生成最终回复之前,像一位思维缜密的顾问一样进行多轮、多步骤的内部推演。它会把问题掰开揉碎,将逻辑链条毫无保留地呈现出来,既有结论,更见脉络。无论是涉及复杂知识点,还是需要权衡比较的决策,这种模式都能给出层次分明、让人信服的解答。
真实场景评测:Kimi长思考模式的工作流
笔者让Kimi模拟了一次典型的商业分析任务,其思考过程与DeepSeek的体验极为相似,每一步推理都清晰可见。
测试指令非常简单:仅提供公司名称,要求Kimi比较两个域名的价值,刻意不给出任何额外信息。
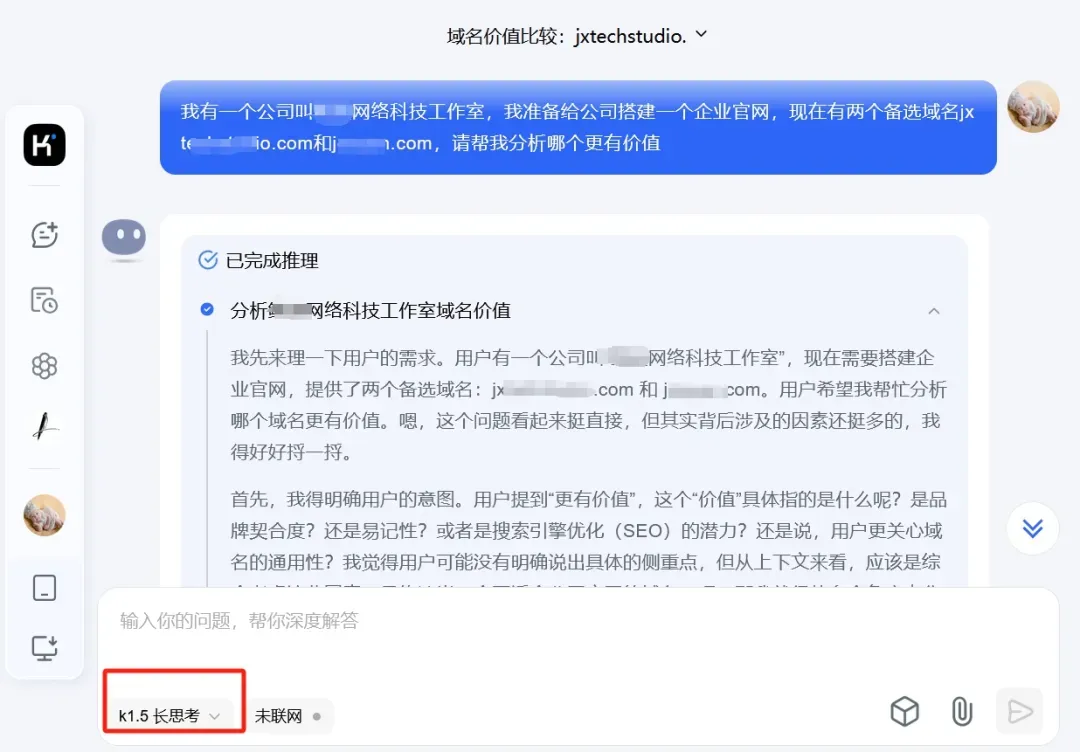
出人意料的是,Kimi的长思考模式不仅没有“卡壳”,反而自动构建了一套完整的评价体系。它从品牌契合度、搜索引擎优化(SEO)潜力、国际化拓展空间、用户记忆与输入习惯、长期品牌建设可行性、市场价值与投资回报等十余个维度展开了系统性推理,最终给出的分析结果逻辑严密,颇具实操参考意义。即使在信息极度有限的情况下,这种深思熟虑的分析能力依然让人眼前一亮。
总结
Kimi此番推出的长思考模式,在DeepSeek服务尚不稳定的背景下,精准地切入了用户的深层需求。它并非简单的“补齐短板”,而是用扎实的推理表现证明了国内AI在深度问答领域的最新进展。对于那些依赖高质量分析、又需要稳定服务的用户来说,Kimi正在成为一个值得托付思考的新选择。
Kimi注意力残差新架构:训练效率提升25%,高中生参与研发获马斯克点赞
💡 重构Transformer的记忆方式,在几乎不增加推理延迟的前提下,将训练成本降低约20%。
📌 核心亮点
3月16日,月之暗面Kimi团队发表了一篇题为Attention Residuals(注意力残差) 的研究论文。

命名虽显专业,但核心思路异常明快:
🧠 让模型学会“选择性记忆”,而不是把每一层信息都不加区分地叠加起来。
在Kimi自家的大模型上,该技术带来了可观的收益:
⚡ 训练效率提升25%(可节省约20%的算力与电力成本)
🐢 推理延迟增加不足2%,几乎不影响实际体验
📈 各项能力均获改善,尤其在数学推理和代码生成方面表现突出
更具吸引力的是,这套方案属于即插即用,无需调整原有模型架构的其他部分。
01
记忆负担:AI为什么要学会选择性关注
要理解这项技术,我们需要先看看当前模型是如何“记忆”信息的。
📚 从日常学习说起
假设你每天学习一些新知识:第一天学A,第二天学B,第三天学C……到了第100天,头脑中理应有A+B+C+……第100天的全部内容。
但如果每天的重要性完全相等,你将所有知识以“均匀”的方式刻入大脑,就会出现:
📉 早期知识(比如第一天的A)被后来大量信息所稀释,难以清晰回忆
🔍 想要定位某条具体知识时,需要在混杂的背景中费力搜索
🎒 记忆负担逐日加重,处理效率不断下滑
这正是当下AI模型面临的困境。
🏢 把模型看作一栋百层建筑
你可以将一个AI模型想象成一栋100层的大楼。信息从第1层进入,逐层向上传递,经过第2层、第3层……直至第100层,最终形成输出。每一层对信息做出加工,并将处理结果交给下一层。
传统的做法是:
第N层的输出 = 第N层的处理结果 + 第N-1层的输出
这样层层累加,似乎每一层都“记住”了前面所有层的特征。
乍看很理想,但两个问题随之而来:
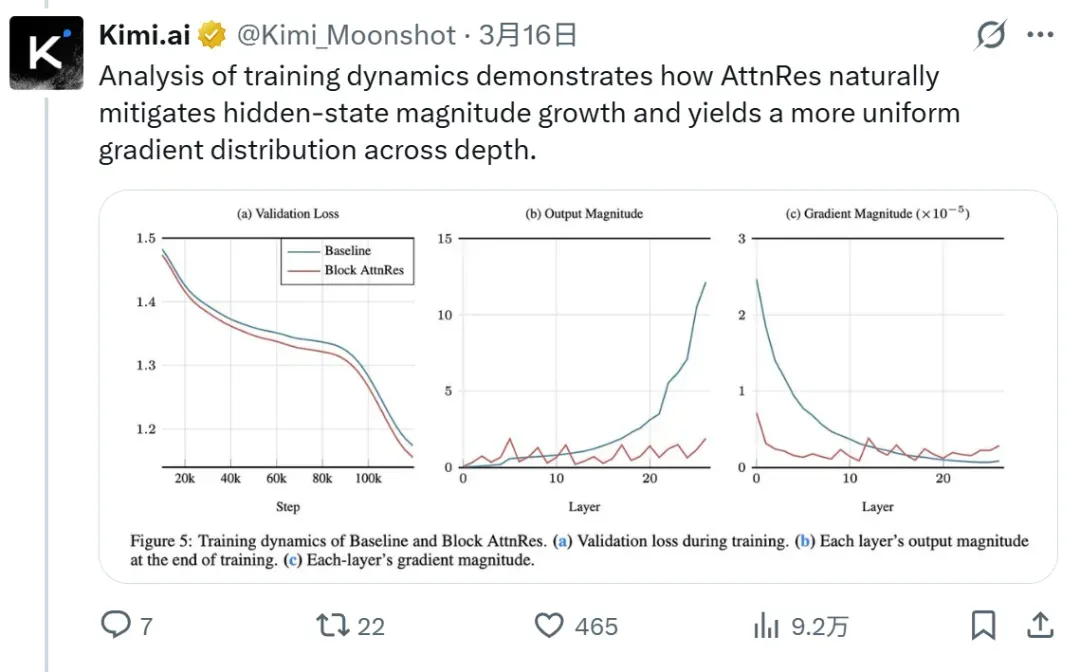
📝 所有层的贡献被同等对待 — 就像把每天的日记都用相同的字号、相同的墨水记录下来,重要信息和琐碎细节混在一起,区分变得困难
📦 信息不断堆积 — 到了高处,早期输入已被稀释得所剩无几,想回溯最初的细节就需要付出极高代价
Kimi团队注意到,这种现象在学术界被称为“PreNorm Dilution”(预归一化稀释)。通俗地说,就是:信息被平均分配,导致关键部分难以凸显,不重要的内容却占用了大量容量。
02
解决方案:让模型自行决定“该记住什么”
团队的思路很直接:
✨ 既然“记住一切”会出问题,那就让网络自己学会决定哪些信息值得保留,哪些可以略过。
🎯 一个更贴近的类比
准备一次大考时,有两种复习策略:
❌ 传统方法:把教材从第一页背到最后一页,每一行都力求记住
✅ 高效策略:先梳理大纲,找出核心章节,对重点部分投入更多精力,次要内容快速浏览
显然,后者的效率远高于前者。
AttnRes(注意力残差)所做的,正是类似的选择性聚焦。
当第N层需要信息时,它不再简单地“把前面所有层的输出求和”,而是:
🤔 首先判断:“我现在最需要关注哪些信息?”
👀 然后“回望”之前的各个层
⭐ 对关键层赋予更高权重,对次要层降低权重
➕ 最后将这些层的信息加权聚合
用公式可以表达为:
MiMo V2.5 Pro深度评测:Claude Code最佳国产搭档,百万上下文极致性价比
昨天凌晨,小米悄无声息地上线了 MiMo-V2.5 和 MiMo-V2.5-Pro,API 接口也同步开放。

近期大模型的更新节奏密得惊人:上周 Claude Opus 4.7,这周 Kimi K2.6,昨天 MiMo-V2.5-Pro,还有姚顺雨带队的全新 HY3,今天又发了 GPT-5.5,估计 DeepSeek V4 也快亮相了……真是一个蓬勃的时代。
我一直对 MiMo 系列模型抱有好感,自从罗福莉加入小米后,小米大模型的实力提升肉眼可见。当然,最根本的原因是我做了十二年米粉,对小米的设计和硬件发自内心地喜欢,家里的电器几乎清一色是小米,这份感情自然也延续到了他们的模型上。
昨天下午完整试完 MiMo-V2.5-Pro 之后,不得不说,这个模型完全可以跟 GLM-5.1、Kimi K2.6 正面掰手腕,表现着实超出了我的预期。可以说它已经扎扎实实地挤进了第一梯队,开发者社群里也都在热议。
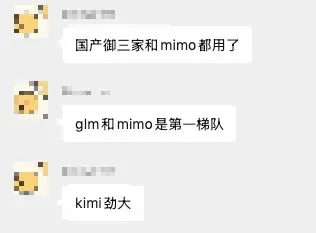
按老规矩,先看一眼跑分。虽然现在各家都在“赢学”里打转,但大致还是能看出一些端倪。
在 AA 榜单上,MiMo-V2.5-Pro 与 Kimi K2.6 并列开源第一。
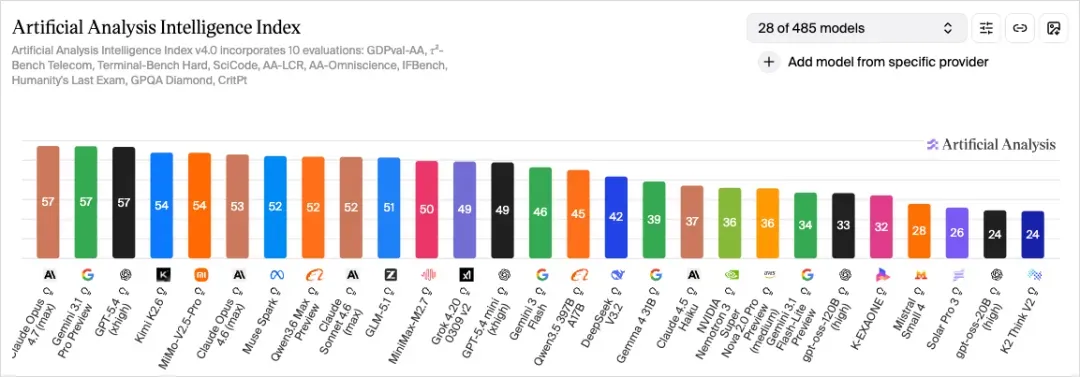
成绩相当亮眼,相较于小米自家过往的模型,进步也很明显。
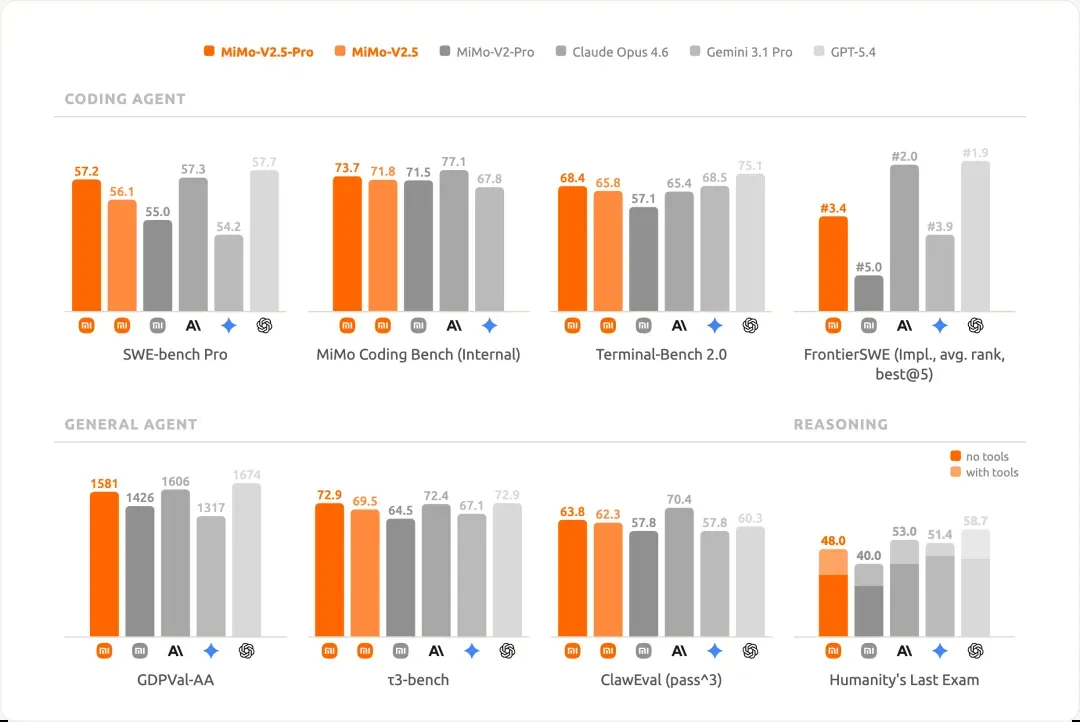
上下文窗口直冲 100 万 token,如今百万级上下文几乎成了头部模型的标配,今天发布的 GPT-5.5 也支持了 1M 上下文。
价格方面,我以前总是放在最后提,但这一次必须提前说,因为性价比实在太高,而且刚上线时用的人不多,接入 API 后速度飞快,体感完全不像某些国产模型那样动辄延迟好几秒。
API 调用的定价是:0 到 256k token 范围内,每百万 token 输入 ¥7 / 输出 ¥21;在 256k 到 1M token 区间,则是输入 ¥14 / 输出 ¥42。
MoneyPrinter V2 vs Turbo:AI自动视频赚钱工具深度对比与选择指南
近日在 GitHub 上发现,MoneyPrinterV2 单日 Stars 数飙涨 1700 多,势头相当猛。
点进去一看,简介写得极其直白——
“Automate the process of making money online”。
坦率讲,这类打着“AI 赚钱”旗号的项目我见得太多了,大多只是噱头。但这个确实有点意思:它不是那种“AI 写文案然后卖课”的套路,而是实打实地能帮你批量生成视频。
更有趣的是,这个项目还有一个中文版叫 MoneyPrinterTurbo,Stars 已经突破 5 万,差不多是原版的 3 倍。
我花了一个下午把两个版本都完整跑了一遍,下面把真实的对比结论分享出来。
01 项目背景与定位
MoneyPrinterV2(原始版本)
作者:FujiwaraChokiStars:18,660(今日 +1,772🔥)定位:面向全球市场的赚钱自动化语言:Python 3.12+
MoneyPrinterTurbo(中文增强版)
作者:harry0703Stars:50,681(累计)定位:专注中文短视频一键生成语言:Python 3.11+
简而言之,V2 是原始项目,Turbo 则是针对中文用户深度优化的增强版本。
02 核心功能一览
| 功能 | V2 | Turbo |
| 视频生成 | ✅ YouTube Shorts | ✅ 抖音/快手/视频号 |
| 文案生成 | ✅ AI 自动 | ✅ AI 自动 + 自定义 |
| 语音合成 | ✅ 基础 TTS | ✅ 多服务商 + GPT-SoVITS |
| 字幕生成 | ✅ | ✅ 可调字体/位置/描边 |
| 素材来源 | ✅ 网络爬取 | ✅ Pexels + 本地素材 |
| 批量生成 | ❌ | ✅ 一次生成多个选最佳 |
| Web 界面 | ❌ | ✅ 开箱即用 |
| API****接口 | ✅ | ✅ |
| 一键部署 | ❌ | ✅ 百度网盘/Google Drive |
Turbo 对国内用户明显更友好,功能也更加齐全。
oh-my-claudecode:让 Claude Code 自动组队协作,多模型混用效率提升 3 倍+
核心关键词:
Claude Code、AI 团队协作、oh-my-claudecode
一个人干活太慢?那就让 AI 自己组队!本文详细解读 oh-my-claudecode 开源项目,教你如何驱动多个 Claude Code AI 模型组成虚拟团队,自动协作完成开发任务。支持多模型混用、一键启动 AI 工作组,整体开发效率可提升 3 倍以上。
Image
01 痛点:单个 AI 编程效率低下,Claude Code 上下文受限
你是否也有过这样的感受:
让 Claude Code 单独实现一个功能,
从描述到编码,再到调试,一套流程走下来,不知不觉已经过去了半小时。
一旦遇到更复杂的项目,单个 AI 就更容易出现上下文窗口超限、顾此失彼,甚至写到后面就忘了前面已经做过的约定。
这就像让一个人同时扮演:产品经理 + 架构师 + 前端 + 后端 + 测试。
不仅累,效率还十分低下。
这正是 oh-my-claudecode 希望解决的根本问题。
02 解决方案:oh-my-claudecode 让多个 AI 自动组队协作
今天要介绍的开源项目,叫做 oh-my-claudecode(简称 OMC)。
它的核心理念非常直观:
既然单个 Claude Code 干活太慢,那就让多个 AI 自动组队分工协作!
这个项目目前在 GitHub 上已经收获了 12,045 个 Star,仅今日就增加了 576 个。
Qwen3-Coder 终端编程实战指南:三步接入,效率跃升70%
一、Qwen3-Coder:定义终端智能编程的新范式
通义千问最新开源的 Qwen3-Coder 已成为大模型编程领域的标杆之作,其核心技术亮点令人瞩目:
- 突破性架构设计:采用 4800 亿参数 MoE(混合专家)架构,但每次推理仅激活 350 亿参数,实现了高性能与低资源消耗的卓越平衡。
- 超长上下文理解:原生支持 256K token(约 19 万汉字),借助 YaRN 技术更可将上下文窗口扩展至百万级 token,轻松应对超大规模代码仓库。
- 三大任务霸主地位:在智能体编程(Agentic Coding)、浏览器自动化控制(Browser-Use)以及工具调用(Tool-Use)这三大前沿领域,全面刷新开源模型的最优表现。
- 比肩顶级闭源模型:综合性能与 Claude Sonnet 4 不相上下,但调用成本仅为其五分之一,性价比惊人。

终端环境下的实际接入效果展示,直观呈现其强大的代码生成与调试能力:
二、三步完成 Qwen3-Coder 接入(全平台通用)
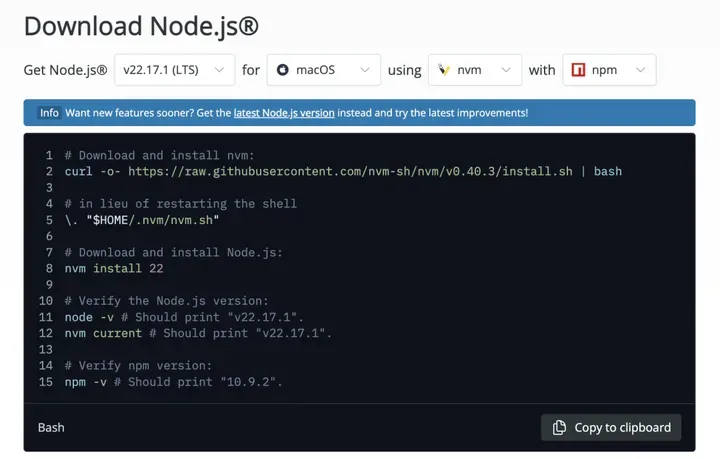
▶ 步骤1:环境准备
请先安装 Node.js v20 及以上版本,下载地址:https://nodejs.org/en/download
安装完成后,在终端执行以下命令,确认环境就绪:
# 验证 Node.js 安装
node -v
▶ 步骤2:一键安装 Qwen-Code 工具
通过 npm 全局安装官方提供的终端编程组件:
npm install -g qwen-code

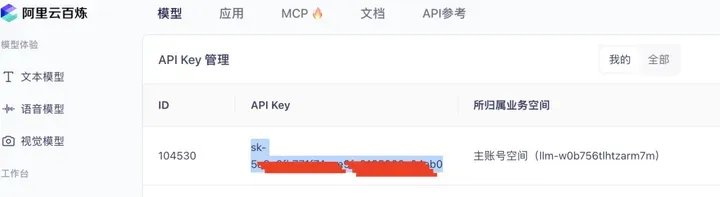
▶ 步骤3:配置 API 密钥与模型
- 前往阿里云百炼平台,申请并获取您的专属 API Key。
- 在项目根目录(或用户主目录)新建
.env文件,写入以下配置内容:
OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_MODEL="qwen3-coder-plus"

TrendRadar:AI驱动的开源热点监控利器,53K Star,一站式信息筛选与推送方案
人人都能拥有专属信息秘书。TrendRadar 是一个让信息获取更高效、更智能的开源项目。
信息爆炸时代,资讯铺天盖地,如何从海量内容中精准抓取真正关心的话题,已成为一大痛点。
今天在 GitHub 上引起广泛关注的项目 TrendRadar,目前已经揽获 53K+ Star。它解决的核心问题非常简单且实用:怎样在信息洪流中,只花最少的时间,看到最相关的内容。
项目核心定位
TrendRadar 本质上是一套热点监控与智能推送工具。它会定时轮询多个主流平台的实时热点,再根据你预先设定的关键词库进行精筛,最后将加工后的信息推送到手机、电脑等终端。
覆盖的平台十分全面:
国内资讯:微博、知乎、B站、抖音、小红书、百度、今日头条、澎湃新闻
科技领域:36氪、虎嗅、少数派、IT之家、稀土掘金、V2EX
国际视野:GitHub Trending、Hacker News
除了热门榜单,它还支持 RSS 订阅源,可以将个人博客、技术周刊等散落的内容统一纳管,形成集中的信息流。

核心功能解析
智能关键词过滤
只需在配置文件中列出你关注的主题词,比如:
[技术]
AI
Python
Docker
[行业]
新能源
芯片
系统就会自动从所有抓取的热点中,筛选出包含这些关键词的条目。同时支持正则表达式,可以定义更复杂的匹配规则,确保不会漏掉重要信息,也不会被无关内容淹没。
AI 分析与深度洞察
这是 TrendRadar 最亮眼的能力。除了直接推送原始新闻,你还可以让 AI 模型对每条内容进行推理:提取当天核心热点、判断热度变化趋势、分析舆论倾向(正面/负面/争议)、发现跨平台的关联话题,甚至给出简短的趋势研判与建议。
支持的模型涵盖 DeepSeek、OpenAI、Gemini、Claude 等,你可以根据成本、效果和隐私偏好自由选择。
多平台即时推送
推送渠道几乎覆盖了所有日常工作场景:
团队协作:企业微信、飞书、钉钉
即时通讯:Telegram、Slack
传统触达:邮件
移动通知:Bark、ntfy(iOS/Android 推送)
高度自定义:通用 Webhook(可对接任意 HTTP 服务)
推送时间同样灵活,比如设置每个工作日的早 8 点和晚 8 点各发送一份报告,让你不用时刻盯着屏幕也能掌握动态。

快速部署指南
Docker 一键启动(最快30秒部署)
docker run -d \
--name trendradar \
-v $(pwd)/config:/app/config \
-v $(pwd)/output:/app/output \
wantcat/trendradar:latest
只需挂载配置与输出目录,系统就能立刻运行。
VibeCoding 告别 AI 失忆:两大 9K+ Star 项目帮你节省 98% Token
在 VibeCoding 过程中,我们几乎总会撞上一个棘手的状况:
AI 编程助手频频“失忆”
来看看两个 Star 数超过 9K 的项目,分别给出了怎样的解决思路:
context-mode:专攻 AI Agent 上下文优化——最高减少 98% 的 token 消耗
claude-context:Claude Code 的代码搜索 MCP——把整个代码仓库变成可用的上下文
有趣的是,这两个项目瞄准的是同一个痛点,但走的路子却刚好相反。
01 几乎所有人都踩过的坑
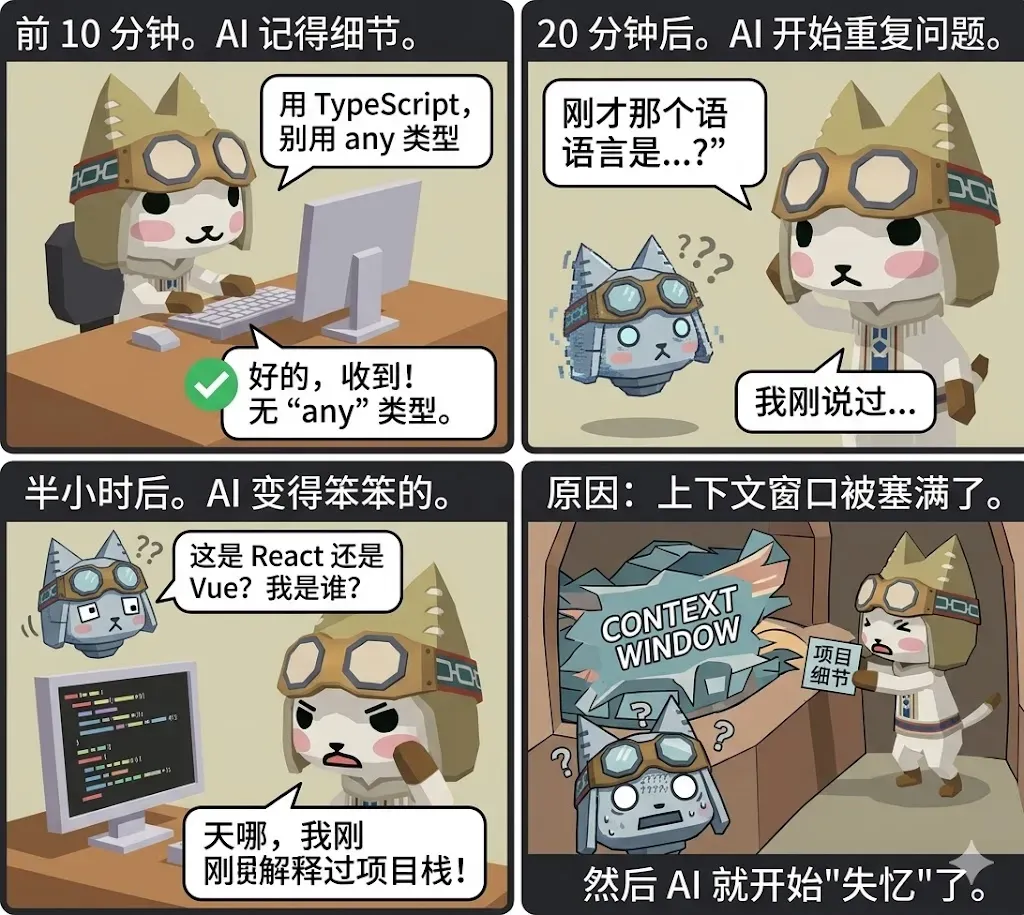
用 AI 辅助写代码的时候,你多半经历过这样的循环:
最初 10 分钟,AI 记得你说过的每一个要求。你嘱咐“用 TypeScript,禁止 any 类型”,它规规矩矩照办。
20 分钟过去,它开始重复询问你早就回答过的事情。
半小时之后,它变得迟钝又茫然,甚至问你“这是 React 还是 Vue?”
不用多想,上下文窗口已经被塞得满满当当。
紧跟着,AI 就开始出现“健忘症”。
02 Context Mode:用“暴力压缩”对抗遗忘
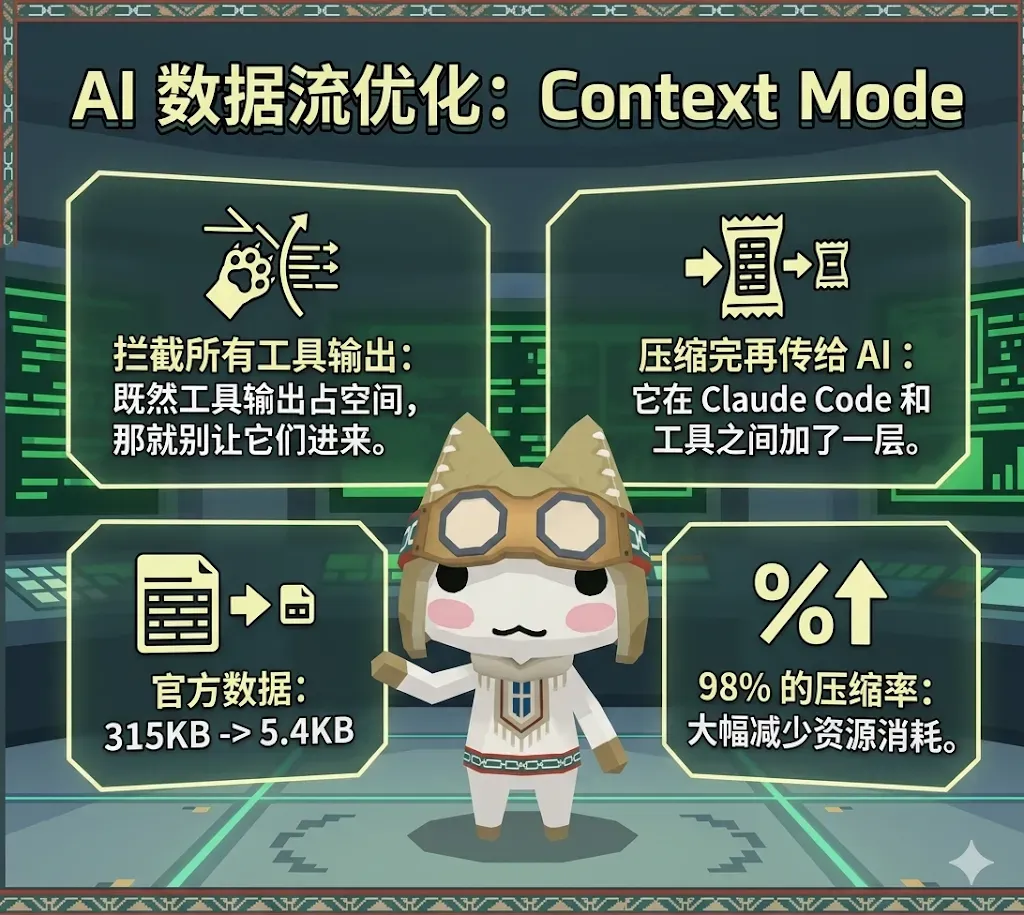
Context Mode 的思路相当直白:
既然工具输出太占地方,那就直接拦下来,别让它塞进上下文。
它在 Claude Code 和各种工具之间插了一层拦截器,把每一次工具产出的内容先压缩,再把浓缩结果传给 AI。
官方提供的数据是,从 315KB 压缩到 5.4KB,压缩率高达 98%。
它是怎么做到的?
我读过它的实现思路,核心是一个三阶段的处理流水线:
第一阶段:剔除明显的噪声
重复出现的调试日志进度条里循环刷屏的信息(如“50%...51%...52%...”)
第二阶段:提取真正有价值的信息
错误描述警告提示状态变更(比如“构建成功”)
第三阶段:建立可检索索引 被压缩掉的内容并不会凭空消失,而是持久化存储在本地数据库中。AI 后续可以通过语义搜索重新找回这些信息,而不必让它们一直占着上下文窗口。
WordPress vs Shopify:跨境电商独立站封店风险全面深度剖析
前言
随着国内电商的竞争愈发激烈,越来越多的卖家开始向跨境电商赛道转型。众所周知,亚马逊这类大型第三方平台对商家的约束日益严苛,经常出现毫无预兆的封店与资金冻结,导致辛苦积累的投入全部化为乌有。于是,跨境独立站成了很多人眼中的最佳替代方案。但一个关键问题随之而来:独立站是不是就一定不会被封店?

近年来,国内电商的内卷化让不少从业者难以持续,纷纷转战海外。然而,现阶段的跨境电商早已不再是当初的蓝海,亚马逊等平台对卖家的审核与管控越来越严格,动辄就出现封号、冻结资金的情况,给卖家带来巨大的财务损失。面对诸如此类的困境,是否还有其他破解之道?答案是肯定的。
如今,越来越多的卖家开始搭建属于自己的跨境电商独立站。独立站能够赋予他们更高的自主权,风险明显降低,成本也更加可控。结合搜索引擎优化(SEO)以及社交媒体推广,卖家能够将流量主动权牢牢抓在自己手里,更有利于打造独特的品牌IP。
主流建站平台有哪些?
第一种是 Shopify,这是一款专为电商独立站打造的托管式解决方案,开箱即用,但需要按月付费。
第二种是 WordPress 建站程序,它是目前全球使用最广泛的建站系统,不仅能搭建跨境电商独立站,还可以用来创建博客、企业官网等各类网站,而且完全免费。
独立站究竟有没有封店风险?
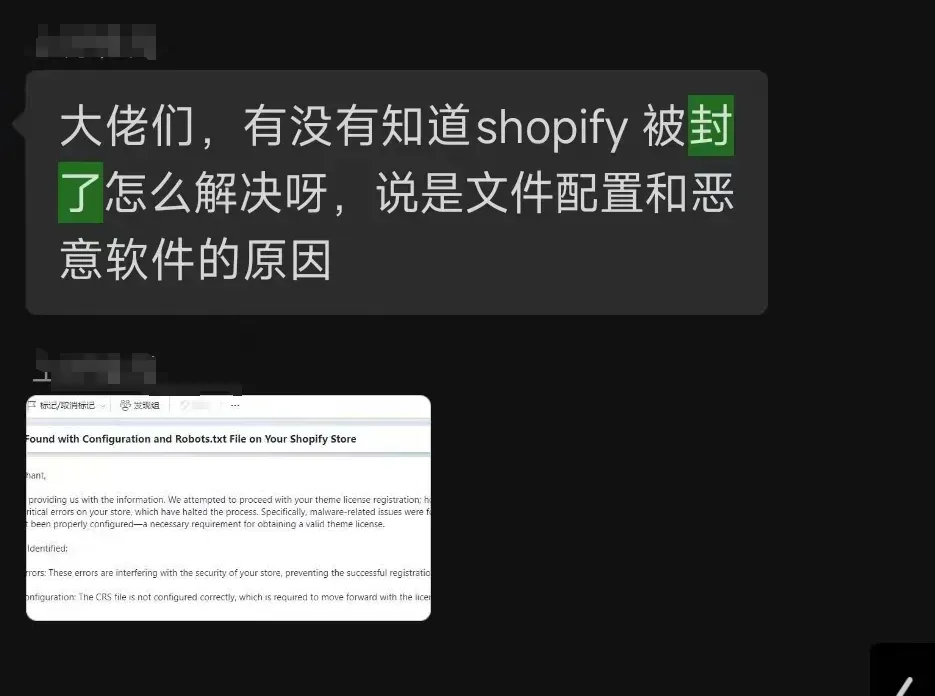
结论很明确:使用 Shopify 依然存在封店风险,而 WordPress 则基本没有此类风险。
严格来说,Shopify 并不能算真正意义上的独立站,它更接近于一个网站托管与建造平台,店铺的最终所有权依旧掌握在 Shopify 手中。根据众多用户的实际经验,Shopify 仍会随时封店,并且通常不会告知具体的封禁原因。
从某种角度来说,用 Shopify 搭建电商站点甚至不如直接经营亚马逊店铺。毕竟,亚马逊本身还具备自带流量的属性,而 Shopify 只是一个纯粹的托管平台,自身并不会为卖家导入任何流量。
相比之下,采用 WordPress 搭配 WooCommerce 这种组合来搭建独立站,才能真正实现“独立”。网站的所有权完全归卖家个人所有,也就意味着不会被平台无故封禁。
总结
并非所有打着“独立站”旗号的方案都真正做到了独立。综合考量独立性、安全性、自主可控性、扩展能力以及成本开销等多个维度,更推荐卖家选择 WordPress + WooCommerce 的建站方案,来打造属于自己的跨境独立站。
阿里云可观测Prometheus实战:全方位监控ClickHouse数据库
引言
ClickHouse 是一款专为在线分析处理(OLAP)设计的列式数据库管理系统(DBMS),其核心优势在于极高的数据压缩率和极快的查询响应速度。同时,它原生支持 SQL,在大宽表聚合分析场景中表现卓越,因而被广泛采用。本文将结合阿里云可观测监控 Prometheus 版,介绍如何对开源 ClickHouse 进行端到端的监控实践。
一、ClickHouse 简介
(一)核心特性
- 列式存储与压缩:
查询时仅扫描相关列,大幅减少 I/O 与网络传输,显著提升分析效率。 - 完整的 DBMS 功能:
支持 DDL(数据定义语言),可在线创建、修改或删除数据库、表及视图,无需重启服务;支持 DML(数据操作语言),灵活进行查询、插入、修改和删除。 - 权限控制:
可按用户粒度设定数据库或表的操作权限,保障数据安全。 - 数据备份与恢复:
提供数据导出导入机制,满足生产环境的容灾需求。 - 分布式管理:
支持集群模式,可自动管理多个数据库节点。
(二)典型适用场景
- 需要进行复杂聚合分析的 OLAP 环境;
- 要求稳定承载大量数据写入;
- 查询频率不是极高;
- 不需要事务、复杂表间 join 等高级 DBMS 特性。
(三)核心概念
- ClickHouse 集群(Cluster)
物理上由多个 ClickHouse Server 实例组成分布式数据库,每个实例可包含一个或多个副本(Replica)及分片(Shard)。逻辑上,一个集群可容纳多个数据库(Database)。 - 分片(Shard)
在超大规模数据处理场景中,单台服务器存在瓶颈。ClickHouse 将数据分散存储在多台服务器上,每台负责一部分数据,每台服务器即称为一个分片。 - 副本(Replica)
为了保障数据高可用与安全,ClickHouse 会将数据冗余存储到两台或多台服务器,这些备份节点即为副本。 - 数据库(Database)
集群中的顶层逻辑容器,内部包含表(Table)、列(Column)、视图(View)、函数及数据类型等。 - 表(Table)
数据的基本组织形式,由多行多列构成。
二、ClickHouse Metrics 监控参考模型
我们从指标采集、监控大盘和告警规则这三个维度,构建 ClickHouse 监控闭环。
(一)指标采集
1. 主机节点监控
通过 Node-Exporter 实现对集群/ECS 节点的 CPU、内存、磁盘、inode 等基础设施指标的采集。