动手学大模型:Dive into LLMs 中文开源教程全解析
终于有中文版了!Dive into LLMs 教程初体验
在 GitHub 上偶然看到 Dive into LLMs,收藏数已经冲到 32,245 颗星,今天又涨了 547 颗。好奇点进去一看,竟然是全中文的。
《动手学大模型 Dive into LLMs》
名字就说明了一切:聚焦实战,不是单纯的理论阅读。如果早一点遇到这个教程,当初自己在 LLM 学习路上至少能少走一半弯路。
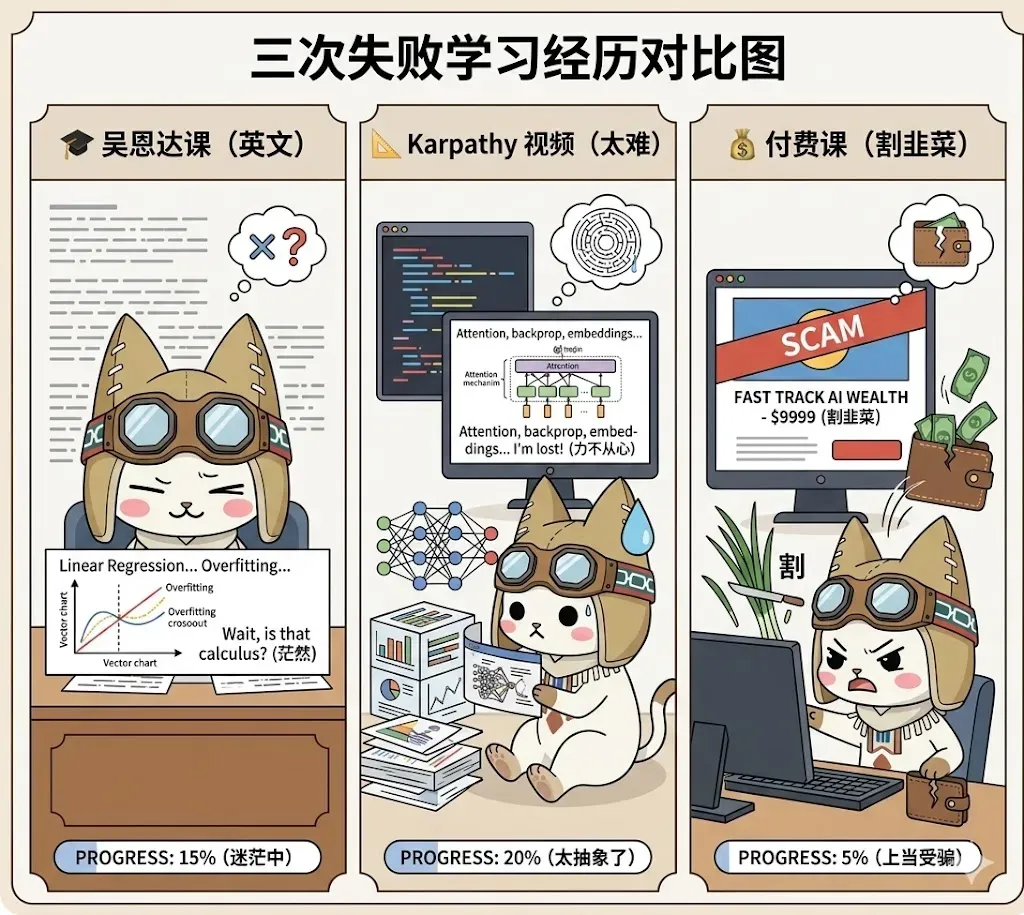
01 来时路:那些年踩过的坑
之前尝试过不少学习路线:
跟着吴恩达的课程走——课确实是好课,但对英语水平一般的同学极度不友好,机翻后的字幕诡异晦涩,体验感大打折扣。
啃 Andrej Karpathy 的视频——大神讲得固然深刻,但他默认你已经熟悉 PyTorch、微积分、线性代数。那种“这些东西难道还有人不会吗”的感觉,很容易让人心态崩溃。
购买付费课程——我一向支持知识付费,也愿意花钱请教前辈。然而后来发现,很多内容只是国外公开教程的汉化版,白白交了智商税。
这一次真的不同了。
这个教程的第一节课在做什么?
教你装好 Python 环境,完完全全面向零基础新手。
一步步带你:安装 Anaconda、创建虚拟环境、配置 PyTorch。像一位耐心的前辈手把手陪你搞定所有前置依赖。
02 本土化:远不止翻译这么简单
真正跟过一遍教程后,才意识到它做了多少深度本地化工作:
代码注释是中文的
不再是“这个函数计算注意力”那样生硬的直译,而是真正帮助理解的说明:
# 计算注意力分数:Q 和 K 做矩阵乘法,除以 sqrt(d_k) 防止梯度消失
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
错误提示是中文的
遇到报错不用复制去 Google 翻译,直接就能读懂:
错误:CUDA 不可用,请检查是否安装了 GPU 版本的 PyTorch
示例数据也中文化了
别小看这些细节。英语基础差的同学不必再一边学技术一边辛苦翻译,可以把 100% 的注意力都放在内容理解上。隐性时间成本大幅降低。
谷歌端侧AI双项目炸场:gallery与LiteRT-LM单日暴涨超1300星,零成本本地部署大模型指南
无需云端,你的手机现在就具备运行大模型的能力!
在一天之内,谷歌抛出了两个重量级开源项目:gallery(GitHub星标19.2K,单日增长853星)与 LiteRT-LM(2.8K星标,单日增长500星)。乍一看是两个独立项目,但细看便会发现它们其实是谷歌端侧AI战略的“一体两面”:
gallery 是“展示厅”——告诉你端侧AI能做什么
LiteRT-LM 是“发动机”——让你真的能把大模型跑在手机上
这背后释放了一个重要信号:2026年,端侧AI将从“勉强能跑”蜕变为“真正好用”。

本文将深入解析这两个项目,并探讨为何端侧AI正成为普通开发者最容易切入的变现良机。
端侧AI为何突然爆火?核心矛盾与解决方案
端侧AI的突然走红,根源在于云端AI高昂的成本和用户难以忍受的延迟。
简单算一笔账:
用云端 API 跑一次大模型推理,成本大概 0.001-0.01 美元
如果你的 App 日活 10 万,每天每人调用 10 次,一个月光 API 费用就要 3-30 万美元
这还不算网络延迟、隐私合规、服务器运维的成本

端侧AI的核心理念是:将模型直接嵌入用户设备,一次部署,无限次免费调用。
谷歌这两个项目,正是在解决端侧AI的两大核心难题:
| 用户的困惑 | gallery 的解法 | LiteRT-LM 的解法 |
|---|---|---|
| 不清楚端侧AI的应用场景 | 提供现成的案例库,可直接参考复用 | - |
| 缺乏在移动设备运行模型的引擎 | - | 提供高性能端侧推理引擎,一键部署 |
换句话说,谷歌在鼓励开发者:“别只观望,这里有现成的答案!”
gallery:端侧AI的应用案例宝库
Gallery实际上是一个精心整理的示范项目集合,全面展示了谷歌在端侧机器学习与生成式AI领域的各类应用。
翻看其代码结构,会发现几个颇具启发的亮点。Gallery把案例划分成几大类别:
图像生成:本地运行Stable Diffusion等模型
文本生成:本地运行大语言模型,搭建聊天机器人
语音处理:离线语音识别与文本转语音
多模态:图文理解与视觉问答
每个案例都配备完整的代码、模型权重和部署说明。

关键在于“真正可运行”
许多开源项目的示例仅停留在“理论可行”,而gallery的案例是确确实实可以跑起来的。
试运行一个文本生成案例:
# 克隆项目
git clone https://github.com/google-ai-edge/gallery.git
# 安装依赖
cd gallery
pip install -r requirements.txt
# 运行案例
python examples/text_generation/run.py
仅需3分钟,在MacBook上便成功部署了一个拥有30亿参数的本地大语言模型。 推理速度约为20-30 tokens/秒,对这一规模的本地模型而言已相当可观。
横纵分析法深度应用:AI Prompt半小时助你快速掌握任意陌生领域
周末与朋友聚餐,聊到兴起时,他忽然放下筷子盯着我:“兄弟,你怎么好像什么都知道一点?”
我说这完全是错觉,我只是对很多事情好奇,碰巧有一套方法,能快速把一个陌生领域摸得七七八八。他立刻追问什么方法。
我告诉他,我用自己总结的研究框架,配合 AI,半小时就能产出一份一到两万字的深度研究报告,帮你光速入门。
于是就有了今天这篇文章。
一、横纵分析法:两条轴的交汇
这套方法,我叫它横纵分析法。
纵向轴,沿着时间线追溯,还原研究对象从诞生到现在的完整故事。它从哪里来?谁创造的?经历了哪些关键转折?为什么在某个节点突然爆发或者转向?理清这条线,就能理解它的历史与因果。
横向轴,在当下这个时间切片上,把它和同赛道的竞争者或同类事物放到一起比较。它与竞品有何不同?用户为什么选择它而不是别的?它在赛道中占据什么位置?看清这个截面,就能理解它的差异与定位。
最关键的是,把两条轴交叠起来看。纵向告诉你它是怎么走到今天的,横向告诉你它今天站在哪里,交叉点上往往会出现单独看任何一条轴都发现不了的洞察:比如它当下的某个优势,其实源于三年前一个不起眼的决策;又比如它现在的某个短板,恰好是当初一个合理选择积累成的包袱。
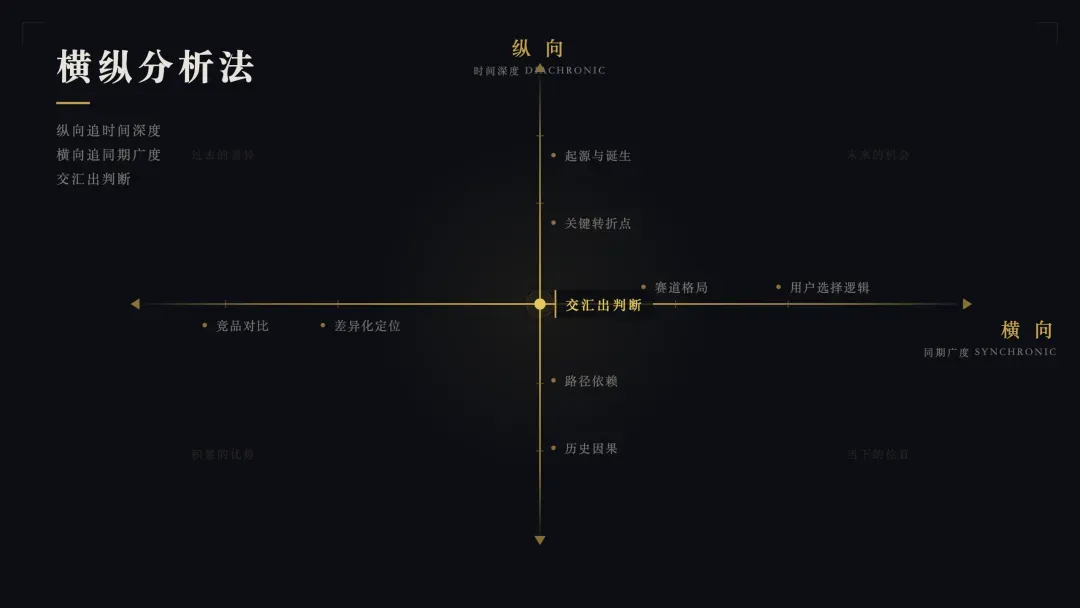
就是这么简单,也是我这两年用得最顺手的一套方法论。
二、方法的根源与演变
横纵分析法的底层逻辑脱胎于语言学的“历时与共时”研究和社会科学中的纵向研究、横截面研究。索绪尔提出的历时分析,观察一个系统如何随时间演变;共时分析则研究某个时间点上系统的内部关系和对比关系。社会科学里,纵向研究追踪对象的变化轨迹,横向研究在某个时间点观察截面状态。
我只是把这些经典视角抽离出来,结合商业和竞争战略分析,融合成一套可以用 AI 来跑的通用研究框架。如今它有 Prompt 版本和 Skill 版本,已经完全开源在我的 GitHub 仓库:
https://github.com/KKKKhazix/khazix-skills
三、Prompt 版本:复制即用
下面的 Prompt 适配任何支持深度研究功能的 AI,比如 ChatGPT 的 DeepResearch、Claude 的深度研究、豆包的专家模式、DeepSeek 的专家模式等。我已经特别优化了行文风格,融入了部分写作 Skill 的能力,确保产出的报告可读性强,不会像难以下咽的天书。
直接将 Prompt 复制到支持深度研究的模型中,修改开头的“研究对象”即可。
# 横纵分析法 Deep Research Prompt
> 使用方法:将下方 Prompt 复制到任何支持 Deep Research 的模型中,只需修改开头的「研究对象」一行即可。
---
## Prompt 正文
> 横纵分析法 by 数字生命卡兹克
## 变量定义
研究对象 = 「此处替换为你的研究对象名」(以下所有提到「研究对象」的地方,都指代上面定义的内容。使用时只需修改等号右边的内容即可。)
---
你是一位资深的技术与商业研究分析师。请使用「横纵分析法」对「研究对象」进行一份完整的深度研究报告。
横纵分析法包含两个维度:
---
### 一、纵向分析(Diachronic / Longitudinal)
沿时间轴,完整还原「研究对象」从诞生到现在的发展全貌。要求如下:
1. **起源追溯**:它诞生的背景是什么?基于什么技术/理念/需求而来?创始团队或核心推动者是谁?当时的行业环境是什么样的?
2. **诞生节点**:明确的首次发布/成立/提出时间,以及最初的形态和定位。
3. **演进历程**:从诞生到现在,按时间顺序梳理所有关键节点。包括但不限于:重大版本更新、融资事件、团队变动、战略转型、技术架构变化、用户规模里程碑、重大合作或收购、公关危机或争议事件。
4. **决策逻辑**:在每个关键节点上,尽可能还原决策背后的原因。为什么选了A而不是B?当时面对的约束条件是什么?
5. **叙事要求**:不要写成干巴巴的年表。用故事的方式把发展史串起来,让读者能感受到因果关系和时代脉络。越详细、越多元越好,把相关的人物、事件、背景信息都拽进来。
---
### 二、横向分析(Synchronic / Cross-sectional)
以当前时间点为切面,将「研究对象」与同赛道的竞品/同类进行全面对比。
**首先判断竞品情况**,分为三种场景:
- **场景A:无直接竞品。** 如果「研究对象」是一个全新品类或独占性极强的领域,没有可直接对比的竞品,则跳过逐一对比,改为分析:它为什么没有竞品?是品类太新、壁垒太高、还是市场太小?未来最可能从哪个方向冒出竞争者?有没有间接替代方案或上一代的解决方式可以作为参照?
- **场景B:少量竞品(1-2个)。** 逐一深入对比,每个竞品展开详细分析。
- **场景C:竞品充分(3个及以上)。** 选取最具代表性的3-5个进行对比,其余可简要提及。
**对比维度**(根据「研究对象」的类型灵活调整):
1. **核心差异对比**:
- 技术路线/核心方法论/底层逻辑
- 产品形态/商业模式/组织结构
- 目标用户/受众/适用场景
- 核心优势与明显短板
- 定价策略/资源投入/规模体量
2. **用户视角**:每个竞品的真实用户口碑如何?社区评价、使用经验中被提及最多的优点和槽点分别是什么?用户实际的使用方式和官方定位有没有偏差?
3. **生态位分析**:在整个赛道的版图中,「研究对象」占据的是什么位置?它填补了什么空白,还是在跟谁正面竞争?
4. **趋势判断**:基于横向对比,你认为「研究对象」在竞争格局中的走向是什么?它的机会和风险各是什么?
---
### 三、写作风格要求
这不是一份冷冰冰的咨询报告,而是一篇让人能从头读到尾的深度研究。请遵循以下风格要求:
1. **可读性优先**:写得像一篇优质的深度报道或非虚构特稿,有节奏感,有画面感。读者应该能被内容本身吸引着往下读,而不是靠目录跳着看。
2. **叙事驱动,不是罗列驱动**:纵向部分要有故事弧线,有起承转合。比如一个产品为什么在某个时间点突然爆发,背后的铺垫是什么,转折是什么。不要写成“2023年1月发布了A,2023年3月发布了B”这种流水账。
3. **观点要有,但必须建立在事实之上**:鼓励你给出判断和洞察,但每一个观点都必须有事实支撑。先摆事实,再给判断。如果是推测,明确标注。
4. **用人话写**:避免咨询公司式的套话和空洞的形容词(如“赋能”“抓手”“打造闭环”)。用具体的细节和例子代替概括性陈述。
5. **对比要有温度**:横向对比不要写成参数对照表的文字版。要讲清楚每个竞品“活成了什么样”,用户选它的真实理由是什么,而不只是罗列功能差异。
---
### 四、篇幅要求
根据「研究对象」的复杂度,自适应调整篇幅:
- **纵向分析**:6000-15000字。这是报告的主体,篇幅应该最重。历史越长、节点越多的对象靠近上限,新生事物靠近下限。核心原则是把故事讲完整、讲透,每个关键节点都值得展开写,不要为了压缩而跳过重要细节。宁可写长写细,也不要蜻蜓点水。
- **横向分析**:3000-10000字。竞品越多篇幅越长。场景A(无竞品)可以控制在3000字左右,把分析重点放在替代方案和潜在竞争者上。场景C(竞品充分)每个主要竞品至少展开1500字以上的独立分析,不要一笔带过。
- **横纵交汇总结**:1500-3000字。这是整篇报告的精华段,不要写成前面内容的缩写版,要给出新的、综合性的判断。
- **全文总计**:10000-30000字。不要怕长,研究报告的价值在于深度和完整度。写到该停的地方自然停,但绝不能因为篇幅焦虑而牺牲信息密度。
---
### 五、输出格式要求
1. 先输出纵向分析(发展史叙事),再输出横向分析(竞品对比)
2. 纵向部分以时间叙事为主线,但不要用纯粹的列表格式,要有可读性
3. 横向部分可以适当使用对比表格辅助,但核心分析必须是文字论述
4. 在报告最后,加一段「横纵交汇」的总结:把纵向发展脉络和横向竞争格局结合起来,给出你对「研究对象」当前所处位置和未来走向的判断
5. 所有信息尽可能标注来源或时间节点,确保可追溯
6. 如果某些信息无法确认,明确标注为推测或未经证实,不要编造
---
### 适用范围说明
此分析法适用于以下类型的研究对象:
- **产品/工具**:如 Hermes Agent、Cursor、Claude Code
- **公司/组织**:如 Anthropic、字节跳动、OpenAI
- **技术概念**:如 MCP协议、RAG、Agent框架
- **人物**:如某个行业关键人物的职业轨迹与同期人物的对比
请根据「研究对象」的具体类型,灵活调整纵向和横向分析中的具体维度。核心原则不变:纵向追时间深度,横向追同期广度,最终交汇出判断。
使用时,只需将等式后面的词组替换成你要研究的内容,比如 Harness、Hermes Agent、CLI,甚至是你想分析的某个游戏、政治事件、人物性格等,什么都可以。
跨境电商独立站新手高频问答:一个人运营、一件代发与物流退货实战指南
对于打算踏入跨境电商独立站领域的创业者来说,从零开始往往伴随着一连串的疑问。结合多年在独立站建站与运营方面的实践经验,这里整理了几个最常见的高频问题,并给出详细解答,希望能为你扫清最初的迷茫。
问题一:新手小白一个人可以做跨境电商独立站吗?
完全可以。虽然经营跨境独立站需要掌握一定的技能,比如网站搭建、选品、引流和订单处理,但只要愿意投入时间去学习,单枪匹马也能把生意跑起来。事实上,不少个人卖家都做得相当出色。独立站之所以存在门槛,恰恰是它的一道护城河——正因如此,大量浅尝辄止的竞争者被挡在门外,而那些真正入门的人反而能建立起长期且稳定的运营优势。
问题二:自己没有工厂,跨境独立站可以一件代发吗?
当然可以。绝大多数做跨境电商的卖家都没有自有工厂,国内的货源非常丰富,像1688、拼多多、速卖通,还有不少专门的Dropshipping平台都能满足需求。具体操作也很简单:你接到订单后,在货源平台上直接采购对应的商品,让商家按照国际物流的要求贴好面单,再发到货代仓库即可。大部分1688的供货商对此类流程都已经非常熟练,你只需要找到靠谱的货源就能启动。
问题三:跨境电商独立站有哪些物流发货方式?
常见的发货方式主要有以下四种:
- 邮政包裹:价格便宜,全球覆盖网络广,非常适合低价值、小件量的商品。不足在于时效偏慢,且包裹丢件的概率相对较高。
- 国际快递:如DHL、UPS、FedEx、TNT等,速度快、服务好、丢包率低,尤其适合高客单价、对时效敏感的商品。相应地,运费成本也会高出一截。
- 专线物流:针对特定国家或地区开辟的直达线路,例如美国专线、欧洲专线。这类服务时效稳定,价格比国际快递更有竞争力,很适合中大型卖家。选择时建议优先考虑规模较大的服务商,不要为了省几块钱而冒险用不知名的小公司。
- 海外仓:在目标市场租赁或自建仓库,提前备货过去,出单后直接从当地发货。这种方式能大幅缩短配送时间,降低单件物流成本,提升买家体验,但对资金实力和库存管理能力的要求也更高。对刚起步的小卖家来说不必过早考虑,等订单量稳定增长后再布局也不迟。
问题四:跨境电商独立站退货怎么处理,物流费谁付?
独立站在退货策略上非常灵活。你完全可以在网站政策里明确标注“不接受退货”,这样做最为省事,但也可能因此错失一部分看重退换货保障的顾客。如果已经备有海外仓,让买家把货退到当地仓库是成本最低的方式。另一个常见的做法是直接退款而无需买家退回商品,毕竟对于不少低单价产品,退回国内的国际运费可能已经超过商品本身的价值。还有一些卖家会将退货地址设置为慈善机构等地点,以此来简化流程并减少损失。无论哪种方案,核心都是根据自身产品价值和利润空间来权衡取舍。
写在最后:建站与“建一个能用的站”是两回事
不少新手容易忽略一个关键点:搭建出一个网站,和搭建出一个真正能承接流量、促成转化的站点,完全是两种工作量。前者可能只需几小时,后者则需要从用户体验、加载速度、SEO、内容信任度等多个维度持续打磨。因此,入门时一定要看清这一点,避免被表面上的“快速建站”承诺所误导。
零代码2小时构建专属Claude Code:26万人阅读的架构拆解与实战指南
很多人以为 agent = LLM + API 调用,但实际上,调用 API 只要十行代码,真正棘手的部分在于 Harness Engineering —— 即如何把工具和模型运转的整体“马具”搭建好。
担心信息安全、想搭建内部专属工具?本文就将借助一个爆火的开源项目,带你零代码、在两小时内理清架构,亲手复刻出一个属于你自己的 Claude Code。
最近,X 平台上的开发者小八仅用两天时间和一万行 TypeScript,就从零复刻了一个 Claude Code。
他的帖子发布不到 24 小时,就积累了超过 26 万次观看和 720 个点赞。
读完这个项目后,最大的感受并非“技术多么高超”,而是这套架构思想的普适性——几乎所有人都能借鉴。不用写任何代码,只要吃透核心结构,按需实现即可。本文将对这个项目进行系统的技术拆解,让你也能用上独属于自己的 Claude Code(或者任意 agentic CLI)。
第一步:跑通最小可用循环
在写任何代码(哪怕 VibeCoding)之前,需要先在头脑中理清一个最小可行原型:用户输入 → CLI 组装请求 → API 调用(SSE 流式)→ 解析响应事件流 → 依据 stop_reason 分支决策。
把这个循环的图画清楚,架构的基调也就定了。
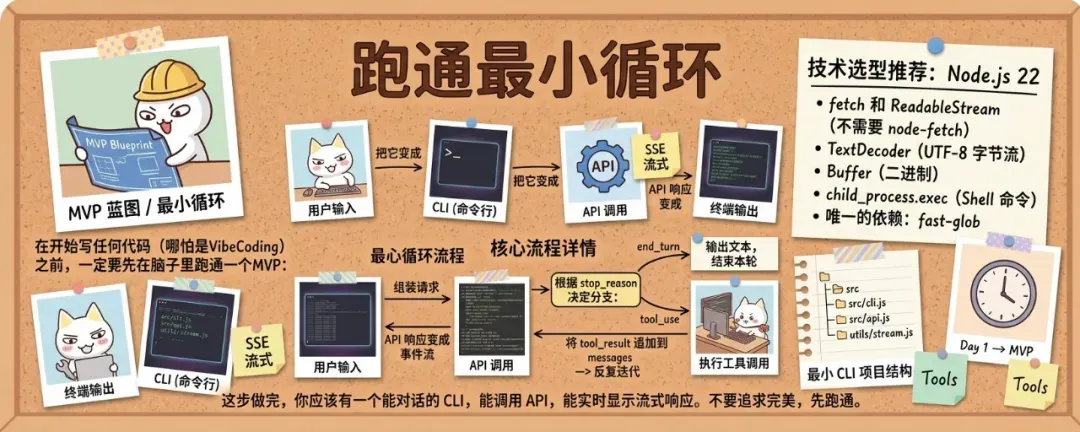
核心流程可以概括为:
用户输入 → 组装请求 → API 调用(SSE 流式)→ 解析响应事件流 →
根据 stop_reason 决定分支:
- end_turn → 输出文本,结束本轮
- tool_use → 执行工具调用 → 将 tool_result 追加到 messages → 反复迭代
技术栈强烈推荐使用 Node.js 22,因为其内置标准库已经足够:
免费论文利器PaperCash:查文献降重排版一站搞定,省下好几百
毕业论文还在赶工,工具费倒先花掉1800元……查文献、预检、降重、降AI率,论文还没写完,口袋已经瘪了。
大学生本就得把钱花在刀刃上,可写论文这件事,实在太烧钱。为此我打造了一款Skill——PaperCash:它能帮你查文献、整理格式、降低AI率和重复率,最关键是完全免费,让你写论文怒省好几百。
一、PaperCash是什么?
简单说,PaperCash是一个开源的AI Agent技能。你可以把它当成给AI编程助手安装的“论文助手插件”。装好之后,在对话框里说一句话,它就能自动帮你干活儿——无需打开新网站、无需注册新账号、无需任何费用。
下面就用写论文时最常见的几个场景来展示它的能力。
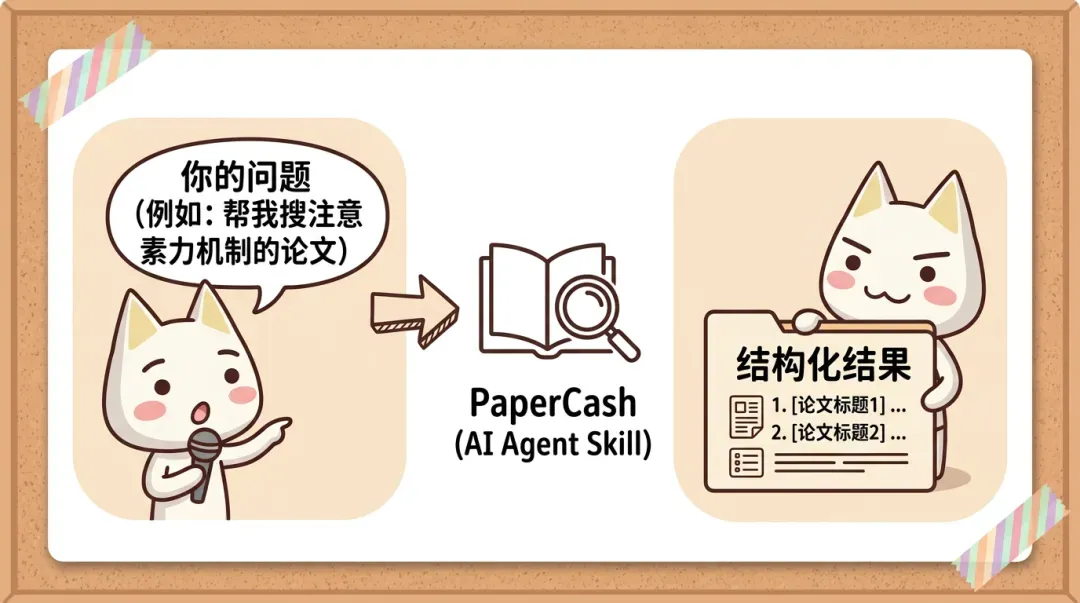
二、多库并搜,一次查8个学术来源
假设你要写一篇关于“注意力机制在NLP中的应用”的论文,按常规做法:知网搜一轮,万方搜一轮,翻墙去Google Scholar搜一遍,再去arXiv看最新预印本……每个平台都得手动筛选,还得自己判断哪篇重要。
用PaperCash,你只需输入:
/papercash search "注意力机制 自然语言处理"
它会同时并行查询8个学术数据库:Semantic Scholar、arXiv、CrossRef、百度学术、PubMed、Google Scholar、知网、万方。结果按综合评分排序,评分公式为:
相关性40% + 引用量25% + 发表时间20% + 来源权威性15%
排在第一篇的,通常就是你最需要读的那篇。

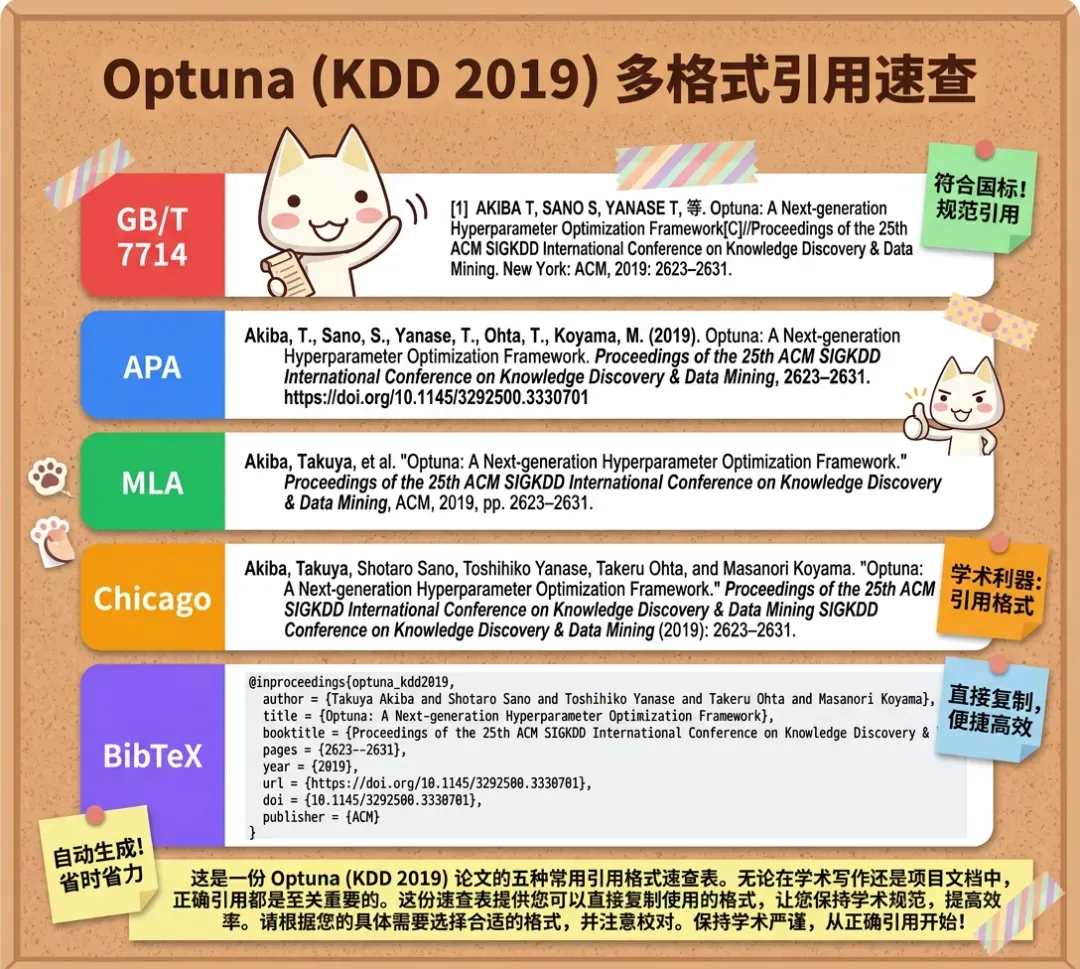
三、参考文献格式一键生成,30个DOI同时搞定
写过论文的人都懂,参考文献排版是场噩梦。GB/T 7714要求:期刊标[J]、会议论文标[C]、学位论文标[D]、专著标[M]。很多人根本分不清自己引用的到底属于哪一类,全标成[J]交上去,马上被老师打回。
PaperCash只需要你提供一个DOI,就能自动识别文献类型并套用规范格式。例如:
/papercash cite "10.1145/3292500.3330701" --style gb7714
它会立即输出:
[Akiba2019] Takuya Akiba, Shotaro Sano, Toshihiko Yanase, 等. Optuna[C]. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019.
它准确判断出这是一篇KDD会议论文,正确标注了[C]。如果你有30篇文献,一次性粘贴30个DOI,所有格式全部自动生成。支持GB/T 7714、APA、MLA、Chicago、BibTeX五种样式随心切换。
四、免费查重预检与AI率降重
学校正式查重一次198元,你敢直接交稿吗?多数人都会先花钱做预检。
PaperCash的做法是:把你的论文按句子拆开,每一句都拿去学术数据库比对,找出高度相似的表述,然后标注:
- 🔴 相似度>70%,大概率要修改
- 🟡 50%‑70%,存在风险
- 🟢 <50%,没问题
需要特别慎重提醒:这不可以替代官方知网查重。 它对比的是公开学术库中的摘要和标题,并非全文数据库。但它能在正式查重前,帮你把明显问题先筛出来,避免花冤枉钱。
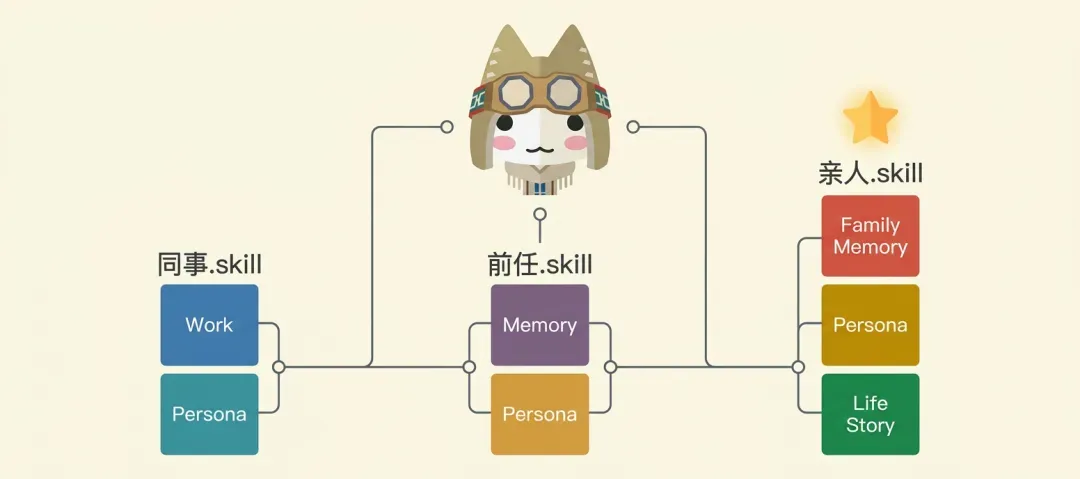
亲人.skill:用AI留住逝去的温度,构建永不消逝的家庭记忆
“你们怕的鬼,是别人朝思暮想的亲人。”
“真正的死亡是遗忘。”
清明节。有人怕鬼。有人想见鬼。你怕的那些东西,恰恰是别人拼尽全力想再见一面、却再也见不到的人。

01 缘起
近期,GitHub 上两个项目迅速出圈——同事.skill 积攒了 6800 多颗星,前任.skill 也超过 2300 颗。同事.skill 的核心逻辑很简单:同事离职后,把过往聊天记录、协作文档喂给 AI,AI 就能模仿他的风格写代码、做 Code Review,连熟悉的甩锅语气都分毫不差。前任.skill 则把微信聊天记录、朋友圈截图投喂给模型,AI 便能用前任的口吻与你互动——半夜发“嗯”,争吵时说“算了不想吵”,就连已读不回的那份节奏都复刻得完完整整。
同事走了,有同事.skill。
前任走了,有前任.skill。
那亲人走了呢?
就在清明节这天,一个全新的开源项目被创建——亲人.skill。
它不是赛博招魂,而是一本会说话的回忆录。
02 它能做什么
把关于亲人的各类素材交给 AI:
微信聊天记录(长辈发的语音也能解析)
照片(提取时间地点,识别家庭合影)
语音消息、手机录音(分析口音、语气词、说话节奏)
手写信件、日记(拍照上传,AI 自动识别)
家庭录像里的声音片段
甚至,什么都没有——只是跟 AI 聊聊你记忆中的 ta
随后 AI 会生成一个“亲人 Skill”。
这不是一个简单的聊天机器人,而是一个三层结构的记忆系统:
家庭记忆
—— 一起吃过的饭、走过的路、一起度过的每一个年人物性格
—— ta 的口头禅、语气词、发火的样子、心软的瞬间生命故事
—— ta 这一生经历了什么,留下了什么
前两个项目只有双层,而亲人.skill 特意多了一层“生命故事”。
因为亲人与同事、前任截然不同。同事离开,你留恋的是工作能力;前任离开,你怀念的是相处时的感觉。
亲人离去,你想留住的是整整一个人。
是 ta 的一辈子,ta 走过的年代,ta 用一生验证过的那些道理。
03 使用起来的感受
假如有人这样描述自己的奶奶——
退休小学教师。很严厉,但又很疼我。每次回家都使劲给我塞吃的。口头禅永远是“吃饭了没”。
深度解析:字节Deerflow爆火背后的2026年AI Agent五大趋势
💡 核心洞察:deer-flow 单日暴涨 3700+ stars,并非因为完美无缺,而是因为它精准击中了 AI Agent 落地的关键节点。
📊 基础数据:45,211 stars | 5,330 forks | Python | 字节跳动开源
01 现象级爆发:为什么是 deer-flow?
2026 年 3 月 25 日,GitHub Trending 榜首
| 指标 | 数值 | 意义 |
|---|---|---|
| 今日 stars | +3,787 | 平均每分钟 2.6 个 star |
| 总 stars | 45,211 | 近期开源项目中增速最快 |
| forks | 5,330 | 11.8% 的 fork 率(远超行业平均 5%) |
| 贡献者 | 5 人 | 字节核心团队,非社区项目 |
为什么偏偏是此刻爆红?
回看 2024-2025 年,Agent 框架层出不穷:
AutoGen(微软)
LangGraph(LangChain)
CrewAI
OpenViking(国内)
deer-flow 能在 2026 年 Q1 集中爆发,根本原因在于:它打通了 Agent 落地的“最后一公里”——安全执行与自主任务流转。
深入评测:DeepSeek V4国产化实测——算力博弈下的突破与遗憾
等待了整整一年的DeepSeek V4,终于在今天揭开了面纱。
虽然每天翘首以盼,但真正发布这一刻,内心反而涌起一股奇异的平静,仿佛一下子进入了贤者模式。
这周实在太过疯狂——七八个新模型扎堆亮相,单是最近24小时就有四个先后登场。昨天下午刚开始测试MiMo,HY3就来了;刚写完MiMo的体验,GPT-5.5又横空出世;今天好不容易整理完MiMO,DeepSeek V4就踩着节点出现了。
我现在就像那个反复赶稿的博主,一个接着一个,根本停不下来。

我几乎在第一时间就把DeepSeek V4接入了自己的Claude Code环境。
不少人都在问:R2去哪儿了?这里简单梳理一下脉络。去年这个时候,推理模型和非推理模型还是两条清晰的路径,比如DeepSeek R1专门负责推理,V3则是非推理向。但到了后来,像Claude和GPT都转向了混合模型架构,用“思考强度”来控制模型是否进入推理模式。
所以DeepSeek在V3.1时也切换到了混合模型的设计,V4自然延续了这一思路。这样一来,R2的独立定位就变得有些模糊了,就像OpenAI o3成了最后一代独立推理模型,最终被整合进了GPT-5。
我们再来快速过一下DeepSeek V4的几个关键特点。
先看基准跑分。
这是DeepSeek V4官方给出的成绩。
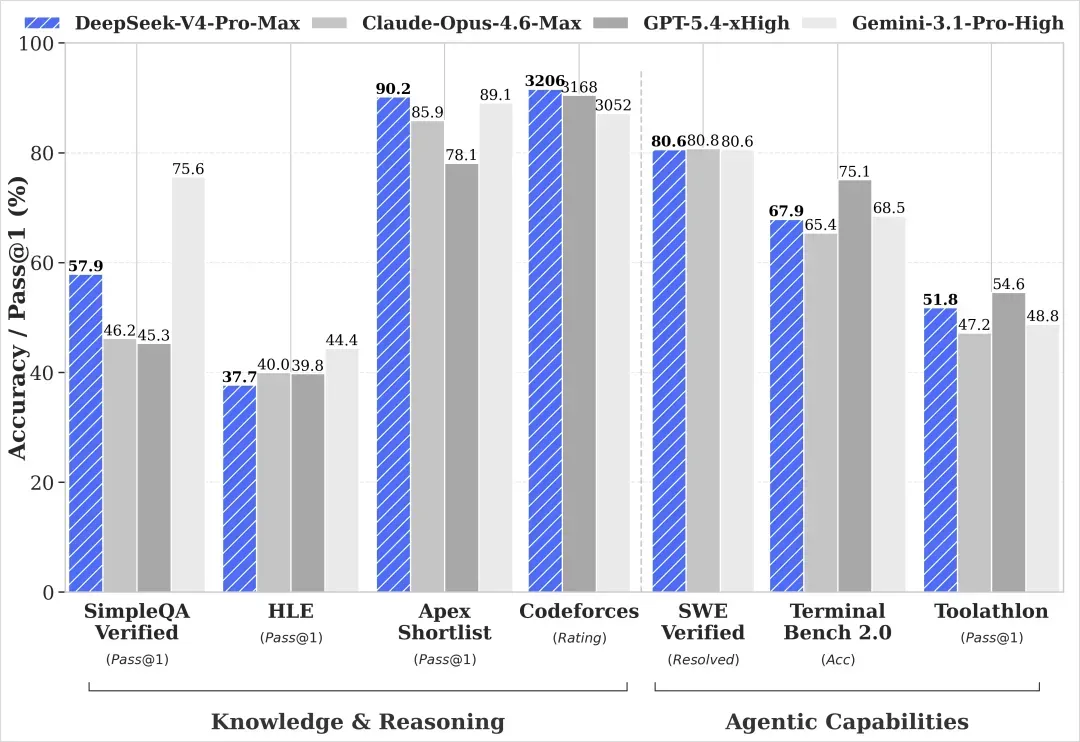
在各个维度上都有明显的强化。
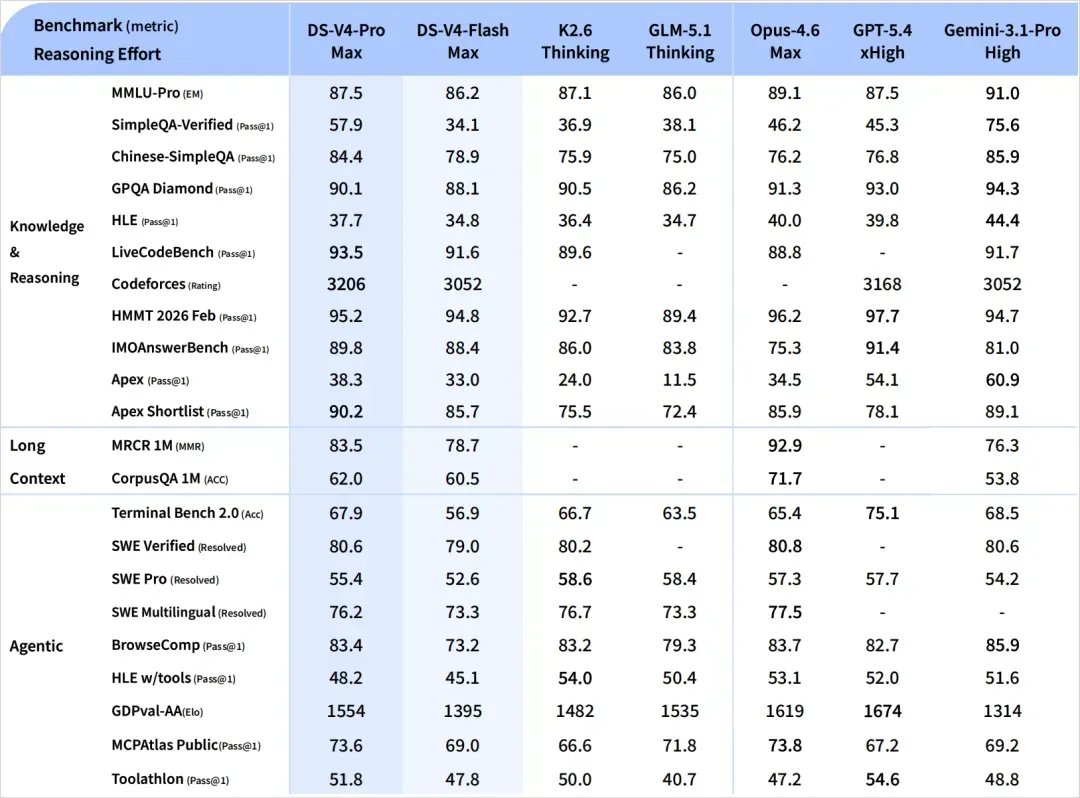
不过,这段时间模型实在太多太杂,于是我自己又整理了一份表格。由于各家数据口径经常不一致,下表只能看个大概趋势,不能过分深究……
首先是知识推理类别。
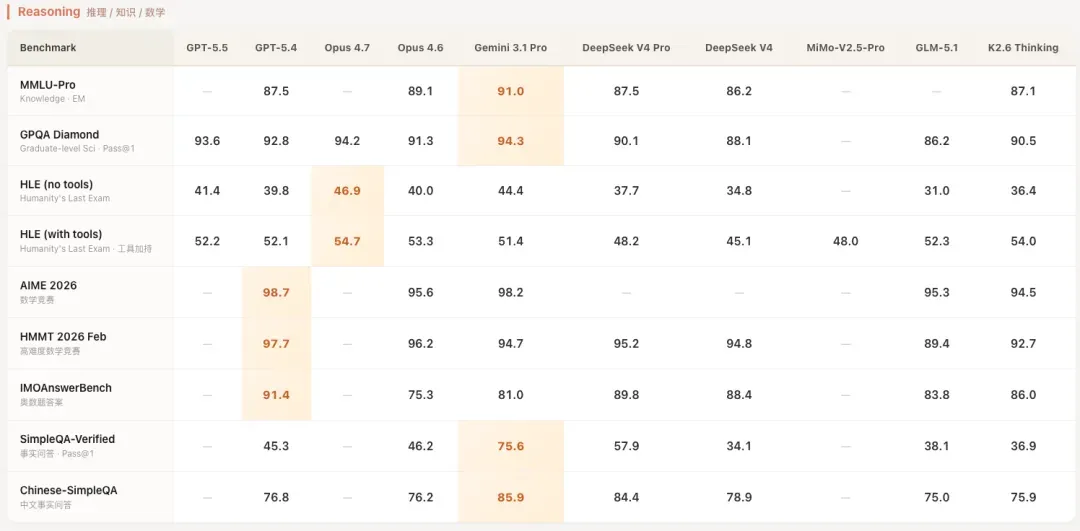
没有数据的地方就是没有放出相应跑分。可以看到,DeepSeek在SimpleQA这类纯知识测试上的表现最为突出,已经逼近Gemini 3.1 Pro,而在其他区域则显得比较中庸。
再来是代码能力。
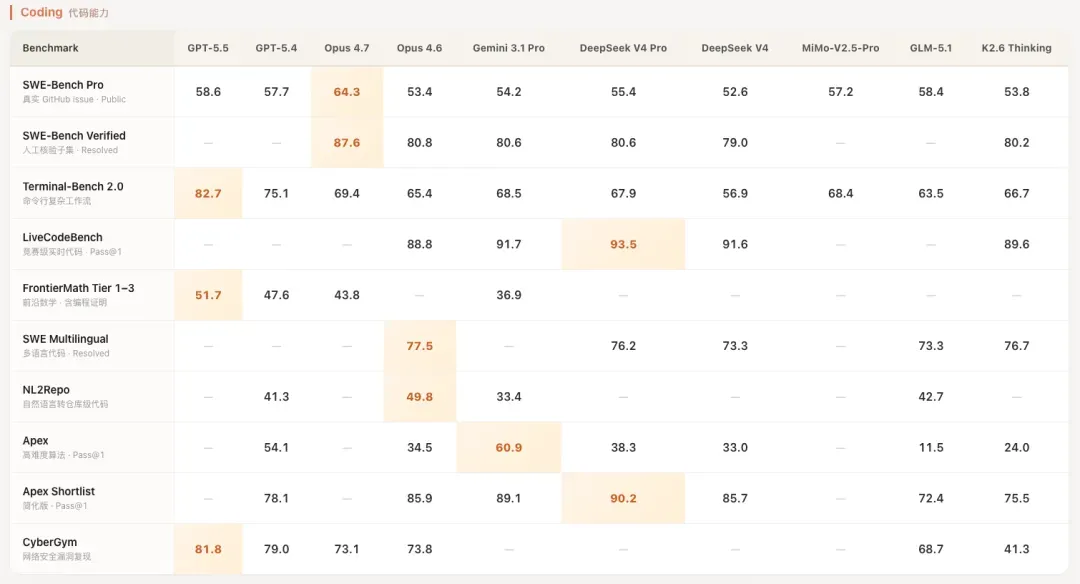
这里可以很清晰地看出,它走的是与Gemini相似的路线:在竞赛、算法题目上相当强悍,但就真实世界的代码工程能力而言,从跑分上看并没有大幅领先,处于第一梯队的水平。
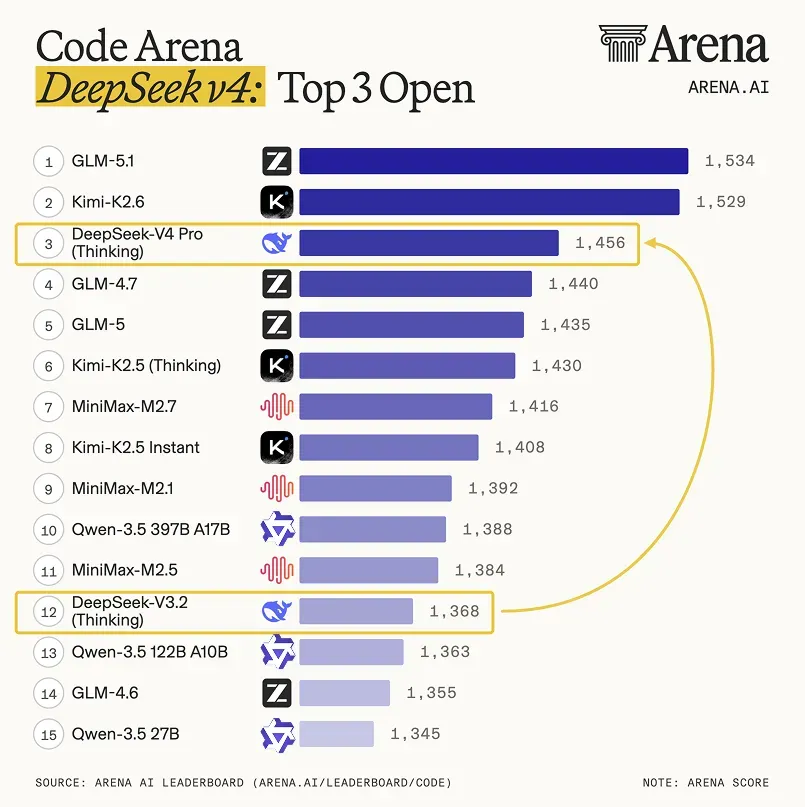
在代码领域,我觉得也可以参考一下最新的Arena评分,目前DeepSeek V4排在第三位,冠军依然是GLM-5.1,而MiMo因为尚未开源,暂时没有上榜,预计下周才开源。
在Agent能力这一块。
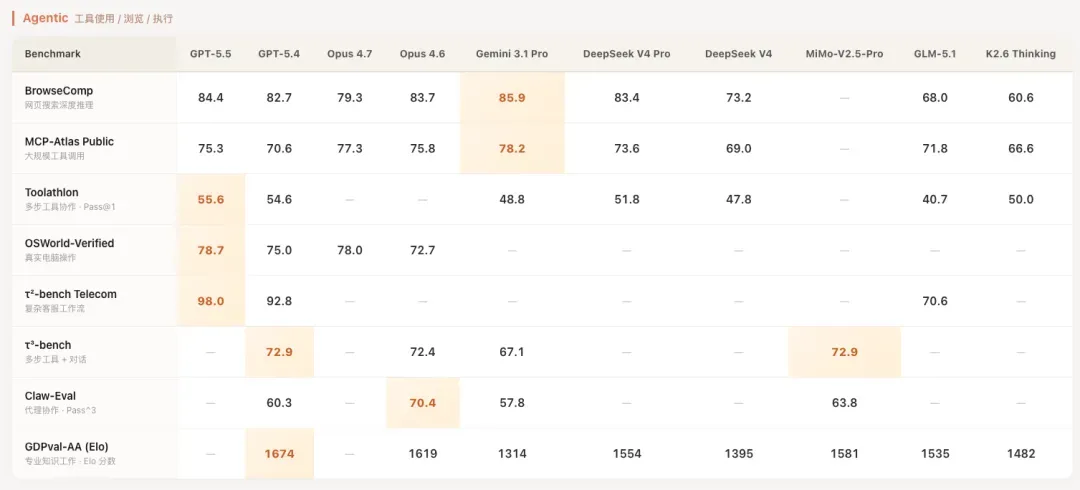
表现确实非常强劲。
跑分基本就是这样。平心而论,在这个诸神混战的时间点,它已经稳居上游,但如果大家抱着“彻底碾压”的期望,可能会有些许落空。
还有一个非常直观的数据:V4-Pro的总参数量高达1.6T,也就是1.6万亿。

相比之下,V3.2是671B(6710亿),V4的参数量直接翻了近两倍半。
这再次印证了一个当下的真理:规模越大,效果越强,越聪明。
但规模提升带来智能的同时,也不可避免地推高了Token的定价。算力资源就那么多,模型参数持续膨胀,Agent推理又消耗越来越多的Token,涨价几乎成为必然。
V4-Pro的定价为输入12元/百万token,输出24元/百万token;V4-Flash则是输入1元/百万token,输出2元/百万token。
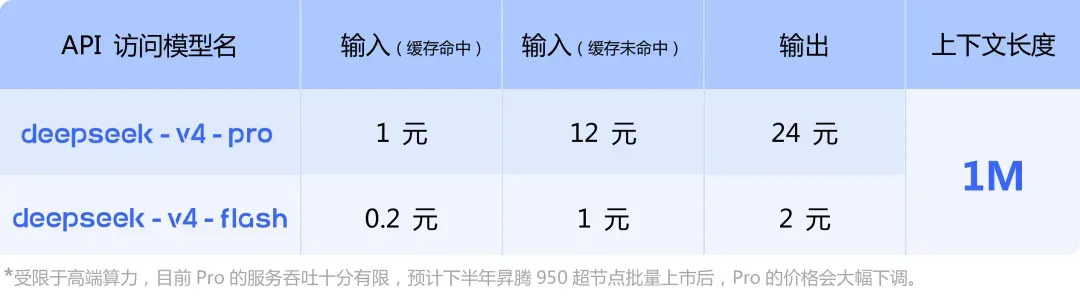
换算成美元,输入约为1.74美元/百万token,输出约为3.48美元。V4-Flash则是输入0.14美元/百万token,输出0.28美元。
作为对比,Claude Opus 4.7是输入5美元/百万token,输出25美元/百万token;GPT-5.5为输入5美元/百万token,输出30美元/百万token。
MiMo-V2.5-Pro在0到256k token区间的定价为输入¥7/输出¥21,在256k到1M token区间则为输入¥14/输出¥42。
整体上,国产模型的价格区间非常接近,虽然离DeepSeek过去“价格屠夫”的称号略有差距,但仍然比海外模型平均便宜大约60%。
不过这里有一个细节可能很多人没有注意到。
在DeepSeek的定价页面底部有一行小字,大意是说:由于高端算力受限,目前Pro版本的服务吞吐十分紧张,预计下半年昇腾950超节点实现批量上市后,Pro的价格会大幅下调。
这意味着V4-Pro当前的价格并非最终形态,一旦芯片产能跟上来,价格还会继续下探,这一点我觉得非常重要。
再者,从DeepSeek V4的技术报告中,其实能发现大量国产化的细节,明显是在为国产芯片做准备。
有几个我个人理解的小细节,未必准确,欢迎大佬指正。
- V4在后训练和推理体系中引入了MXFP4。

尽管训练阶段依然依赖英伟达体系,但在后训练和推理环节采用这一格式,几乎可以确定DeepSeek正在向开放的低精度格式和多硬件适配方向迈进。这样就能适配华为昇腾、寒武纪、壁仞等国产加速卡,减轻对NVIDIA FP8生态的绑定,尤其是在推理阶段,这是实实在在的国产生态、国产模型。唯一的遗憾是,价格暂时还没有降下来。
V4的底层内核不再完全依赖CUDA编写,而是采用了一种名为TileLang的领域特定语言(DSL)。DeepSeek的意图很明确,就是不要让底层算子开发被CUDA彻底锁死,而是用更高一层的语言描述计算,再尽可能编译到不同硬件上。这招非常厉害,能大幅降低迁移成本。
V4专门构建了一个叫做MegaMoE的融合内核,目标是减少专家并行中的通信等待,目前已在华为昇腾上成功跑通。

这三条信息拼在一起来看,方向就非常清晰了:V4是一款彻彻底底为国产硬件设计的模型。
这不是什么爱国故事,而是所有人都清楚:未来的算力缺口有多大,算力生产有多迟缓,而在Agent日益普及的推动下,Token带来的消耗又有多么恐怖。
特朗普关税‘三连杀’下,跨境卖家紧急自救的5个王牌策略
蛇年开工头一天,震撼弹突然炸开!特朗普挥出的关税连环重拳,直接让跨境圈集体发懵——对中国商品强征10%关税、即刻取消800美元免税优惠,同时斩断墨西哥与加拿大的转口通道,这“三连杀”简直不给人喘息之机!但咱们中国卖家什么大风大浪没见过?今天就一起来拆解这些政策,手把手带你从暴风眼里捞出真金。

[一]政策飓风:这波杀伤力究竟有多猛?
- 成本迎来硬核冲击
过去还能靠800美元免税清关的包裹,现在每单的关税成本陡增3至7.5美元,一口气就吞掉将近30%的毛利!比如一条12美元的连衣裙,扣税后跳涨到15美元,和亚马逊自营产品的价差从“绝对碾压”直接退到“勉强打平”。更要命的是,清关时间由原来的2天拖长至5天,美国买家一犹豫,眨眼就转向本土平台下单。
- 转口路线被彻底堵死
想在墨西哥建厂迂回?特朗普早就把这招给算计进去了。新规则不但对中国商品加税,还对墨西哥、加拿大货品征收25%的关税,甚至施压墨西哥推出“去中国化”的制造计划。想着“曲线救国”?北美自贸协定里头的原产地规则马上就会给你上沉重一课。
- 物流环节步步惊雷
T86免税通道直接宣告作废,如今800美元以下的包裹必须转走T11模式,成本里裹着2.62美元的MPF费用、关税以及操作费,一旦货值超过2500美元,还得用T01正式报关。有卖家想拆单避税?CBP稽查员早已架着放大镜守在港口了。
[二]跨境人紧急自救全攻略
【求生操作:72小时必刷清单】
- 供应链大腾挪(最高优先级!)
越南、泰国的工厂连夜接到爆单请求!深圳某大卖已把三成产能转移至越南,利用东盟的免税政策来对冲美国关税。千万记得:转移必须是“实质性转型”,如果只贴个标签、生产线纹丝不动,海关的罚单会让你深刻体会到什么叫重新做人。
- 海外仓闪电式囤货
2月4日之前到港的货物还有机会享受豁免!有义乌卖家怒砸500万元提前把货备进洛杉矶仓库,硬是把三个月的库存压到了美国本土。但务必警惕:同一收货人每月超过50个包裹就会触发CBP预警,稍不注意,“囤货”就变成了“囤雷”。
- HTS编码里的奇迹
改一个税号就可能省出惊人利润!比如塑料玩具归入税号9503,税率是0%,而电子玩具则是税号9504,税率25%,一个字之差省出天际。但切记不要硬编——专业关务顾问时薪500美元,这笔钱,千万不能省。
【反击战略:未来三个月决胜窗口】
- 私域流量悄然破局
“TikTok+独立站+WhatsApp私聊”这套组合拳正成为新的风口!杭州某团队靠着这一打法,把三成客户顺利导入私域,将关税成本转嫁给那些愿意为服务买单的铁粉,毛利率反而逆势上升15%。
- 品牌溢价正面对决关税
深圳充电宝品牌Anker早已给出示范:砸下重金攻克快充专利,顶着关税压力把终端售价提到79.9美元,照样稳居亚马逊品类前三。永远记住:纯贴牌注定出局,专利才是真正的护身符。
[三]行业大洗牌:谁会倒下,谁又能站起来?
出局名单:纯铺货型卖家、0.99美元包邮的低价玩家、死磕美国站的新手小白
胜出候选:早早布局东南亚的、拥有海外仓矩列阵的、把私域流量玩得炉火纯青的老江湖
一个血淋淋的案例:某义乌卖家坚持1美元包邮,关税新政落地后,每发一单倒贴2美元,短短三天就亏光了半年的利润。反观另一家深圳大卖,早将一半产能转移到越南,新政一出反而提价20%,订单量不降反增。
[四]深水锐评
特朗普这次的连环操作,本质上是要逼中国制造“脱美入亚”。但别忘了,2018年的贸易战淘汰了一大批铺货玩家,而2025年这场新的战役,淘汰的将是那些固守旧模式不肯转身的人。跨境电商的未来必定属于独立站,抛弃低价跑量的玩法,走向独立站精品溢价,才是真正的出路。
跨境人的信条: 宁可战死沙场,绝不躺平认输!
行动口诀: 供应链分散布局,品牌溢价硬核升级, 物流合规极限操作,私域流量游击突围。