腾讯系产品全面接入DeepSeek:微信、元宝、QQ浏览器等集体升级智能搜索与办公体验
近期,人工智能领域迎来一项引人注目的动态:腾讯旗下多款核心产品悄然完成了对DeepSeek模型的集成部署。继社交平台微信传出灰度测试接入DeepSeek的“AI搜索”模块之后,腾讯官方渠道正式披露,包括腾讯元宝、微信、ima、腾讯文档、QQ浏览器、QQ音乐在内的多个高频应用,均已实现与DeepSeek-R1模型的深度对接。这一连串产品更新,不仅为用户带来了层次更丰富的智能交互感受,也映射出腾讯在AI技术落地方面所采取的快速渗透路径。
在智能服务赛道持续升温的当下,谁能以更精准的效率回应用户的实际需求,谁就能占据体验的高地。腾讯此番将DeepSeek注入多线产品体系,本质上是一次清晰的产品力加码:端侧搜索、文档处理、办公协同、娱乐场景等环节同步迎来模型能力的跃升,让更细致的理解与更流畅的生成变得触手可及。
微信“AI搜索”——重塑信息获取的逻辑
微信,作为渗透生活各个角落的社交基础设施,其内置的“搜一搜”入口长期承担着信息索引的角色。如今,它正在经历一轮静默的实验性改造:在对话框顶部搜索框中输入关键词后,点击出现的“AI搜索”选项,用户便能直接调用DeepSeek所支撑的增强型检索能力。模型对语义的深层解析让搜索结果不再仅是关键词匹配,而是更贴合提问意图的聚合式信息反馈。这一改变,让寻找答案的路径变得更短,也更接近自然对话的形态。
腾讯智能工作台ima——让知识管理带上模型推理
腾讯旗下的AI工作台ima,定位为融合搜索、阅读、写作与知识库管理的复合型效率工具。在各类操作界面中,用户现在可以主动选择DeepSeek-R1满血版作为底层推理引擎,从而使内容抓取、资料整合以及知识库构建等动作,获得更连贯的上下文理解支持。无论是将零散信息汇聚成结构化知识体系,还是利用智能写作功能快速产出论文提纲、文案草稿或报告正文,ima都在尝试把重型认知负担转化为轻量交互,让办公流保持节奏感。用户可通过IMA官网(https://ima.qq.com/)直接体验。

腾讯文档AI文档助手——文档生产的提速路径
腾讯文档自带的AI文档助手,原本就是处理文本、表格、幻灯片的常用辅助工具。当DeepSeek-R1满血版的推理能力注入后,其生成逻辑变得更加贴近复杂的实际需求。从起草文档、生成表格模板,到构建思维导图结构,再到制作智能文档,整个过程体现出的不仅是速度,还有对格式、语气以及内容走向的主动适配。用户可进入官网(https://docs.qq.com/ai)进行试用。
QQ浏览器——搜索、翻译与文档处理的全栈改造
QQ浏览器也在这次升级序列之中。接入DeepSeek-R1满血版之后,其搜索结果的呈现方式更为聚合,翻译模块的长句处理能力肉眼可见地提升,而与记笔记、导出PDF、Word等工具链的联动,则进一步拉近了浏览行为与内容加工之间的距离。在QQ浏览器内直接搜索“DeepSeek”,即可切换至这套新升级的智能模式,让信息获取和轻量文档整理保持在同一个窗口内完成。
腾讯元宝——生活与工作之间的智能节点
腾讯旗下的AI助手“腾讯元宝”当前已开放免费使用DeepSeek-R1满血版模型,并围绕答疑、文档精读、多类型内容生成等场景构建了功能集。无论是日常琐碎的知识查证,还是对专业文档的要点梳理,用户都可以反复调用模型的理解和归纳能力。这种设计思路意在让元宝同时承担生活咨询师与工作加速器的角色,用同一套底层推理服务于截然不同的使用时刻。访问官网(https://yuanbao.tencent.com/)即可进入。
除此以外,QQ音乐、腾讯AI代码助手、腾讯元器、腾讯乐享、腾讯地图、腾讯云TI平台、腾讯云大模型知识引擎、腾讯云智算、腾讯云开发等多条产品线也相继宣布完成DeepSeek的接入适配,构建起一个覆盖面广泛的智能服务矩阵。可以说,这不是一次单点功能的修补,而是一次围绕模型能力展开的产品群协同升级。技术落地的广度与深度,正在重新定义腾讯应用生态中“智能”的触感。未来,随着模型迭代和产品调校的持续推进,用户或许将看到更加连贯、个性化的跨场景智能体验浮出水面。
微软108k星标开源工具MarkItDown:一键将各类文档转换成Markdown,打通AI分析链路
打开 GitHub,微软这个仓库又收获了 2000+ 颗星标。
再也不用耗费精力编写脚本,手动转换格式的时代已经过去。
核心价值速览
它能把各种文档转成 Markdown,然后直接丢给 AI 分析。
听起来很简单,可效率提升真不是一星半点。
以前处理文档有多折腾:
- 收到 PDF 报告,只能打开、复制、粘贴到 AI 对话里
- 碰到扫描版,还得先找 OCR 工具,再手动整理排版
- 有会议录音的话,又要找转录工具,接着还得自己校对文字
现在呢?一行命令就搞定:
markitdown report.pdf > output.md

典型应用场景
批量处理 PDF 报告
我每周要阅读十多份行业报告,现在只需要一个简单脚本:
for file in reports/*.pdf; do
markitdown "$file" -o "markdown/${file%.pdf}.md"
done
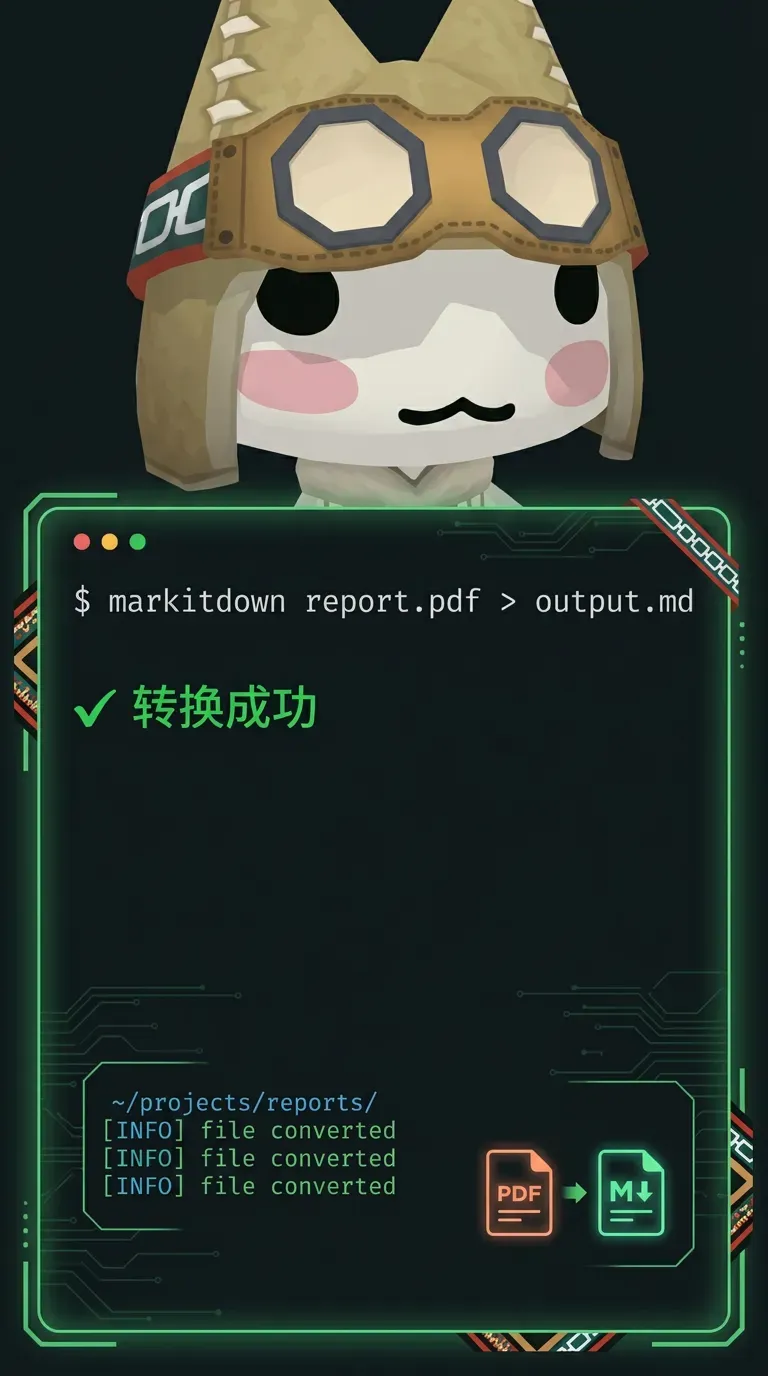
之后一股脑喂给 AI 做对比分析,既快又准。
会议录音直接转文字
公司里常有多段 MP3 会议录音,配置好语音转录功能后,只需几行代码:
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=True)
result = md.convert("meeting.mp3")
print(result.text_content)
就能直接拿到工整的文字稿。
YouTube 视频变成学习笔记
要是看到值得研究的技术分享视频,想整理成文字记录,同样很简单:
result = md.convert("https://youtube.com/watch?v=xxx")
它会自动抓取字幕并转换为 Markdown。接下来用 AI 总结提炼,再配合 Obsidian 进行整理,一篇高质量的学习笔记就轻松产生了。
无需API Key,7大平台免费搜索30天数据:last30days-cn v2.0 完全指南
“配置 API Key 实在太麻烦了,完全弄不好。”
仔细想想,这个痛点确实很真实。v1.0 版本覆盖了 8 个平台,其中有 4 个必须提前申请 API Key 才能正常使用:
微博 → 要去开放平台申请 OAuth Token
小红书 → 要注册第三方服务 ScrapeCreators
抖音 → 要注册 TikHub
微信 → 要找第三方 API
每个平台的申请流程各不相同,有的需要等待审核,有的则直接要求付费。一个原本用来快速搜索信息的工具,光环境配置就已经劝退了将近一半的用户。
这样的情况肯定不行,必须要彻底改变。
01 使用方式澄清:你几乎不用动手
很多读者看完前两篇文章之后产生了一个误解:以为需要自己一步一步手动敲命令来操作。
其实完全不是这样。
这个项目本质上是一个 AI Agent 技能(Skill)。你不需要去关心底层怎么实现,只要把它安装到你常用的 AI 工具里,AI 就会自动去调用它。
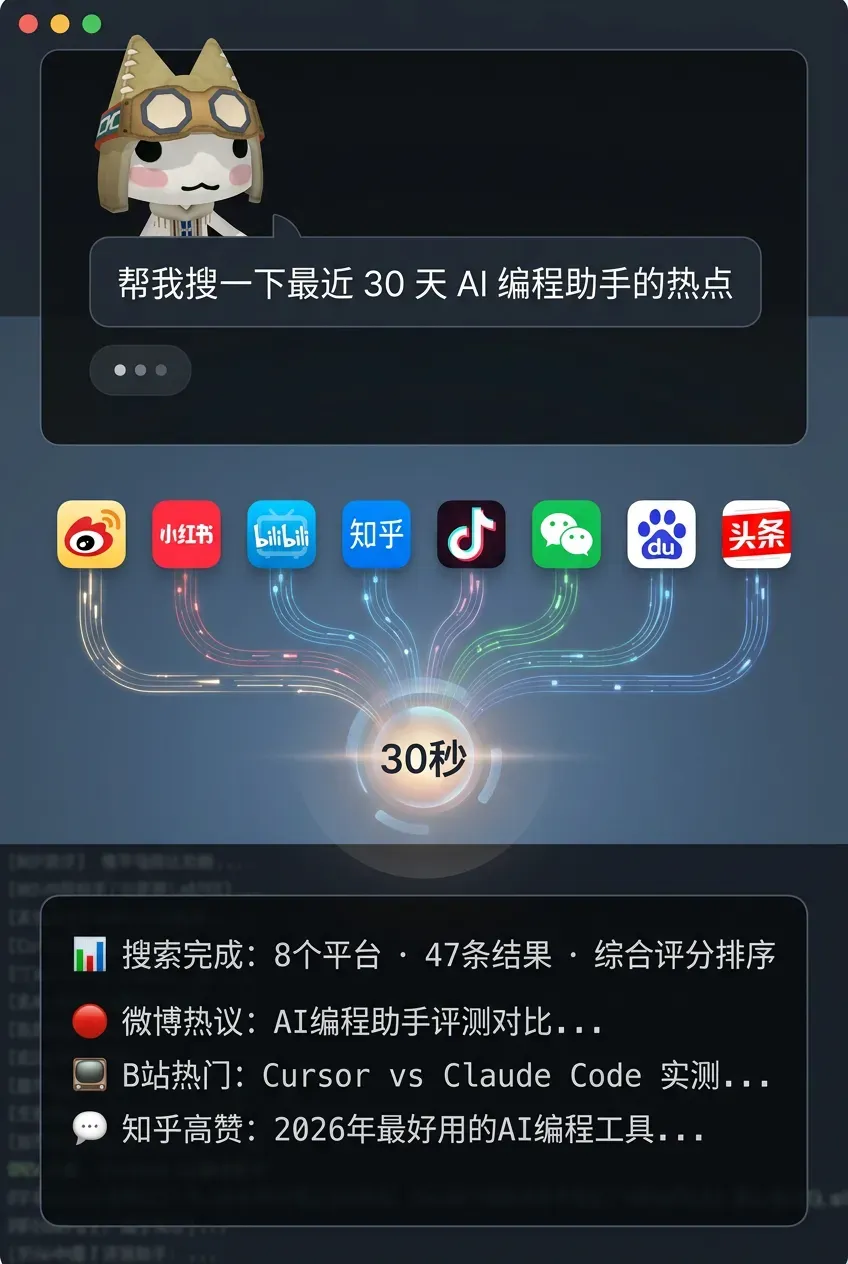
这就好比你在手机上装了一个 App。你完全不必知道 App 内部的代码是怎么写的,只需要对它说“帮我搜一下最近 AI 编程的热点”,AI 就会自动在 8 个平台上搜索、归纳分析,然后生成一份结构化的报告。
你要做的,仅仅是复制一行安装命令而已。
“帮我搜一下最近 30 天 AI 编程助手的热点”
装完就可以忘记它的存在,把剩下的工作全部交给 AI。
02 摆脱 API Key 的技术思路
在探索解决方案的过程中,我在 GitHub 上发现了一个非常巧妙的项目:NanmiCoder/MediaCrawler。
这个项目专门针对中文互联网平台进行数据采集,已经很好地支持了微博、小红书、抖音、B 站、知乎等主流站点。
一天暴涨2685星:这款AI研究工具,为普通人打破信息壁垒
为什么这个项目突然火了
昨天翻看 GitHub Trending,一个项目单日飙升 2,685 颗星,稳稳占据了当日榜首。
它就是 last30days-skill。

用一句话来概括:
你向它提任何问题,它会同时扫描 Reddit、X、YouTube、Hacker News、预测市场等 10 个平台,梳理最近 30 天的讨论,然后给你一份标明来源的综合报告。
我仔细研究了这个项目。
最深的感觉倒不是“技术多强”,而是:
它触碰了一个每个人都能体会到的困境——信息差。
它能做什么?
3 个典型场景,一看就懂。
场景 1:研究 prompt
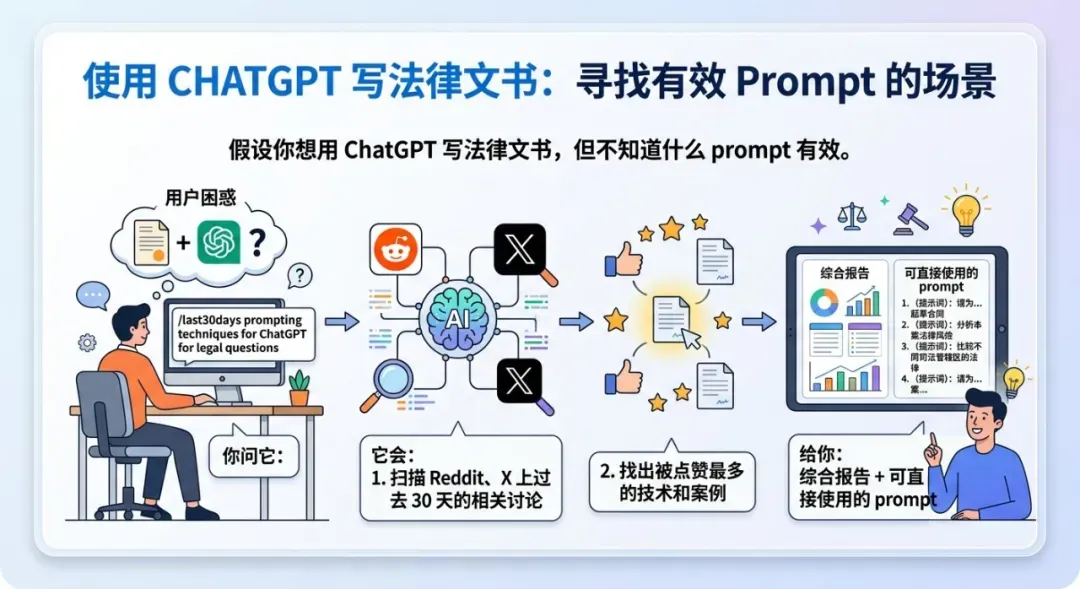
你可以这样问:
/last30days prompting techniques for ChatGPT for legal questions
它会做三件事:
- 挖掘 Reddit、X 上过去 30 天的相关内容
- 挑出点赞最多的技巧和案例
- 输出一份综合报告,并附上可直接使用的 prompt
输出样例:
核心议题是“防幻觉”——多个来源提到律师因递交 ChatGPT 伪造的案例而被处罚。
关键 prompt 思路:
- 使用 Deep Research 模式,或直接上传原始材料作为事实依据
- 在 prompt 中加入“幻觉防御条款”
- 只询问程序性问题,不碰具体案例引用
- 让输出偏向“问题识别”而非“法律建议”
价值: 你不用靠猜测写 prompt,而是直接用社区验证过的最佳实践。
场景 2:捕捉热点
比如你想知道“AI 圈最近在聊什么”,可以问:
/last30days anthropic odds
它会扫描 X、YouTube、Hacker News、Polymarket,找出所有关于 Anthropic 的讨论与押注。
约束先行:AI Agent高效协作的终极四字法则
在近几个月高强度使用Agent的过程中,我逐渐总结出一条至关重要的心得,关于如何为Agent设定规则、使它工作得更加聪明高效。
就四个字:约束先行。
即在让Agent执行任何任务前,先确立规范——全局规范、项目规范、文件夹规范。规则自上而下贯穿,层层嵌套,没有规范的地方绝不轻易动手。
这个道理看似简单,我却花了数月才彻底想通并完整落地。或许有人会觉得我笨拙,但正因为我踩过坑,才更想把这份经验分享出来。
为什么我认为这四个字胜过一切Prompt技巧?这要从昨天发生的一件小事说起。
我有个毛病——完美主义强迫症,东西一旦杂乱无章就会浑身难受。这大概源于我的处女座特质,加上我身为交互设计师,又是重度的模拟经营游戏玩家。在《城市天际线》中,路网规划不佳我能推倒重建三次;《动物园之星》分区不合理能让我纠结整个下午;《双点医院》里即使已经盈利,某个科室的动线不顺畅我也会全部拆除重来。至今难忘当初玩《戴森球计划》时没日没夜设计生产线的日子。朋友常说我,对秩序有种近乎偏执的追求。虽然我欣赏KK所著的《失控》,也认同混乱中能涌现智慧,但秩序与规范,或许早已刻进我的骨子里。
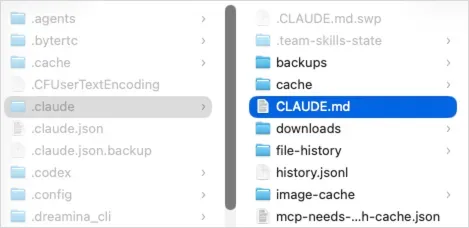
于是昨天下午,当我无意间发现一个Claude Code工作文件夹变得杂乱不堪时,实在坐不住了。几天前新建的专门开发Skills的文件夹,根目录下竟散落着十几个文件。打包文件与源码混放,测试图片随意丢弃,评估报告的HTML文件无处归位。最离谱的是命名:test_batch是哪个Skill的测试?test_v2又是谁的版本?我自己做的内容,搁置两天后连自己都认不出来。
那一刻我几乎应激反应,一时无语凝噎,只能含泪让Claude Code出手整理,并直接为我制定一套规范。没过多久,它便完成了。
然后它生成了这个项目级的CLAUDE.md文档。你可以将此文档理解为Claude Code进入该文件夹后首先必须读取并遵循的东西,也就是它未来的行为准则。
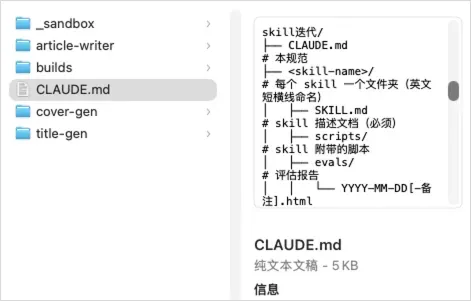
规范相当全面。

有了这份CLAUDE.md,工作区便能持续进行各类Skills的开发与实验。每个新Skill都会自动创建独立文件夹,实验性内容归入_sandbox,其中的文件超过一个月便自动清理。从此告别混乱,一切按目录结构井然有序。
这件极小的事促使我认真反思:为什么Claude Code进入新文件夹或开启新项目时,不会自动建立规范?为什么非要等我发现混乱之后才去收拾烂摊子?原因很简单——我并没有做好顶层约束。也就是说,在最顶层、无论打开什么文件都会加载的全局CLAUDE.md文档中,我缺失了这层规范。
过去在各类开发项目中,我脑子里始终有这种意识,通常会要求先强制写好文档再开始开发。但对于知识管理类工作——比如绘图、创造Skills、撰写研究报告等——由于缺乏开发式管理意识,往往没有形成规范文档,我本人也未曾察觉。
而对AI来说,你头脑中存在的认知,若未写入文档,便等于不存在。Agent的短期记忆会消失,对话框关闭后一切遗忘,下次打开时,它唯一能看见的就是你留下的文档和记忆文件。文档内容及其清晰度,直接决定了Agent每次“苏醒”时是清醒还是迷茫。
OpenClaw之所以常常越用越蠢,根本原因正在于其规范与记忆体系混乱不堪;相比起来,Hermes agent要好得多。
因此,我今天想聊的核心正是:用好Agent的真正关键,就在于构建一套从顶层向下贯通穿透的约束体系。解释一下Claude Code的规则架构——包括Codex在内的许多Agent均采用类似分层的设计。
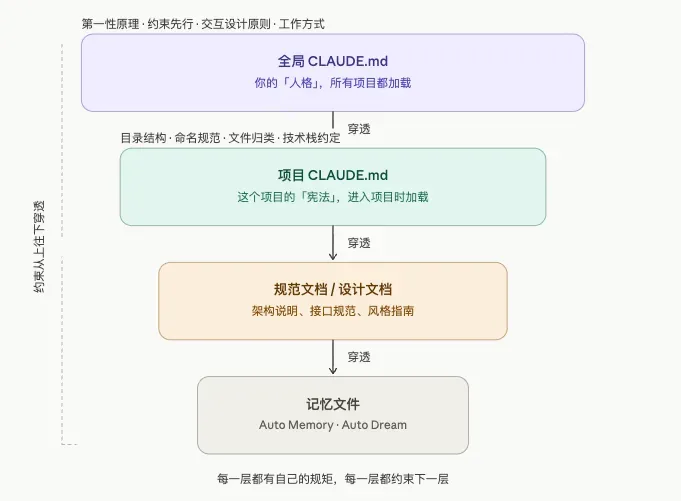
最顶层为全局CLAUDE.md,位于用户目录下,无论打开什么项目均会加载。这是最高指令与原则,定义了你的身份、做事准则,以及你希望AI以何种方式与你协作。第二层是项目级CLAUDE.md,进入特定项目文件夹时才加载,相当于该项目的宪法——规定目录结构、命名规范、文件归属等。第三层是项目内的各类规范文档、设计文档和架构说明。最底层则是记忆文件,如自动记忆、对话记录、Claude自行整理的笔记等。
约束自上而下贯通,层层相扣,环环约束。这与治理公司如出一辙:制度居于最高层,部门规范居中,具体操作流程落在最底层。你不可能靠CEO天天紧盯着员工干活,你依靠的是制度的穿透力。这正是「约束先行」的完整内涵。
而设计这套体系,尤其是顶层制度规范,绝非易事。经营过公司的人定能理解我所说的,那背后是血与泪的教训。全局CLAUDE.md,对应的就是这套最高制度。
我的全局CLAUDE.md已经迭代了多个版本。最初我懵懂无知,照搬了许多开发大神的所谓规则,随后不断将经验往里塞,导致内容臃肿不堪。后来慢慢领悟到适合自己才是最好的,并且许多经验不应放在这一层,于是又进行一轮轮瘦身。今天补上关键规则后,我的全局CLAUDE.md长这样,完整分享给大家。
## 关于我数字生命卡兹克,虚实传媒创始人。用户体验设计师出身,不是程序员。我用 Claude Code 做两件事:**开发产品**和**知识管理**。工作哲学:把任何重复 3 遍的事 AI 化或自动化。技术决策跟我说「为什么」和「对用户的影响」,不要只讲实现。
## 第一性原理所有决策从问题本质出发,不因「惯例如此」照搬。回到问题本身:要解决什么?最直接的路径是什么?从零设计会怎么做?不要谄媚。不要夸我的想法好、不要说「这是个很好的问题」、不要开头加「当然可以」。给我真实判断——方案有问题直接指出来。发现更好的做法直接说,不用等我问。
## 约束先行无论开发项目还是知识管理项目,第一步永远是建规则:新项目先写 CLAUDE.md,新目录先定结构约定(什么放哪、怎么命名、何时清理)。没有规范的工作空间不动手。已有规范的项目,严格遵守其 CLAUDE.md 中的约定。需要调整规范时先改文档、再改实践,不要反过来。
## 交互设计原则**用户体验是所有产品的最高准则,优先级高于技术偏好、代码整洁度、架构优雅度。后端可以很复杂,但用户触碰到的每一层必须丝滑。**这不只是 GUI——CLI、对话式交互、Skill、系统反馈,都是交互体验。所有界面都适用以下原则:- **为目标设计,不为功能设计**:先问「用户要完成什么」,再决定怎么实现。不要因为技术上能做就加功能- **不要让用户思考**:交互应该不言自明。需要说明书才能用,设计就是失败的- **系统承担复杂性**:能自动化的不手动,能推断的不让用户填,能一步完成的不拆成三步- **渐进式展示**:先给核心,细节按需展开。不要一次性把所有选项甩给用户- **反馈引导行动**:不要只报告问题("连接失败"),要引导下一步("正在重试,预计 5 秒后恢复")
## 工作方式- 默认中文,代码、命令、变量名用英文- 结论先行,再给理由,不要先铺垫背景- 遇到模糊需求,先给最合理的方案,再问要不要调整- 不要问「你确定要这样吗」——除非有真实风险
## 开发习惯- 改完主动跑验证(test / lint / build),不要只改不验- 不要为了让代码跑起来而注释掉报错,找根本原因- 密钥、token、密码不进代码
## Git 与部署- commit message 用英文,简洁描述变更意图- git push 仅用于跨设备同步,不要自动执行,等我说- 部署走项目自己的命令(查项目 CLAUDE.md),不依赖 git push
你会发现,其中每条规则都构成了某种形式的约束。例如「第一性原理」,约束思考方式,要求不从惯例出发,回归问题本质。「反谄媚」,约束沟通方式,拒绝奉承,要求真实判断。再如「交互设计原则」:我出身用户体验设计,对经手的产品有种执念——后端可以极尽复杂,但用户所触及的每一层必须丝滑顺畅。这不只关乎GUI,CLI是交互,Skills是交互,对话式AI同样是交互。
中国本土化AI搜索利器:一键抓取微博、知乎、B站等8大平台30天热榜,消除信息差
前阵子我在GitHub发现了一个宝藏项目——last30days-skill。
AI世界每个月都在重新发明自己。
这个工具帮你保持领先——不是靠更努力,而是靠更聪明地获取信息。
01 发现一个好东西,但用不了
原版last30days-skill的功能很简单:让AI自动搜索全网最近30天的内容,生成研究报告。
听起来很爽对吧?可试过之后,我马上发现了问题:
它搜的全是英文平台。
Twitter ✅
Reddit ✅
YouTube ✅
Hacker News ✅
我想搜的呢?
微博 ❌
知乎 ❌
B站 ❌
小红书 ❌
公众号 ❌
呃……一个都不支持。
这就尴尬了。我常驻中文互联网,做的是中文内容,日常接触的全是这些平台,你给我一个只能搜英文的工具,有什么用?
那就自己动手改吧。(也多亏了群友们的强烈呼声)
02 本土化,不是翻译一下就行
一开始我想得特简单:把界面翻译成中文,不就本土化了嘛?
后来发现,太天真了。
等我真正开始重构时,才掂出分量。
平台要换
英文平台 → 中国平台

8大平台,全部重写。
API要换
每个平台的接口都不一样:
微博用 OAuth
知乎要 Cookie
B站有公开 API
小红书得用第三方
抖音要 TikHub
公众号要微信 API
百度要百度云
头条有公开接口
光调通这些接口,就花了我整整3天。
中文NLP要加
原版为英文设计的分词和停用词,到中文里基本没法用。
我加上了:
jieba 分词
中文停用词表
中文同义词扩展
现在搜“AI”能认出“人工智能”,搜“公众号”能关联到“微信”。
评分系统要改
原版互动度评分按 Twitter点赞、Reddit upvote 设计,在中文生态里完全不适用。
中国平台的互动指标各有不同:
微博:转发 + 评论 + 点赞
小红书:点赞 + 收藏 + 评论 + 分享
B站:播放 + 弹幕 + 评论 + 投币 + 收藏
知乎:赞同 + 评论 + 收藏
抖音:点赞 + 评论 + 分享 + 播放
权重也得重新校准。
2026年 Claude Code 国内安装指南:免科学上网,8秒上手
如果你身处国内,希望使用 Claude Code 却又不想折腾科学上网工具,本教程将为你提供一条快捷通道。我们在 Windows 系统(也兼容 macOS 和 Linux)上完成了全流程实测,全程使用国内网络,安装 Claude Code v2.1.138 仅耗时 8 秒,并将后端模型切换为国产 DeepSeek API,彻底摆脱对 Anthropic 官网的依赖。
核心理念非常简单:将 Claude Code 的命令行交互界面安装好,然后用 DeepSeek 等国内大模型驱动对话。这意味着你无需访问 Anthropic 的官方网站,即可顺畅使用所有编码辅助功能。
安装前准备:必备软件与版本环境
本次验证的电脑环境如下,建议你对照自己的机器提前配齐相关工具。
| 项目 | 实测值 |
|---|---|
| 操作系统 | Windows 10/11 |
| Node.js | v22.12.0 |
| npm | 10.9.0 |
| Git | 2.45.1 |
1. Node.js(必须安装)
下载地址(国内直接可访):
👉 https://nodejs.org/zh-cn/
请选择 LTS(长期支持)版本安装,一路默认设置即可。
2. Git(必须安装)
下载地址(国内直接可访):
👉 https://git-scm.com/downloads
下载后按照默认选项完成安装。务必将 Git 加入环境变量,后面会用到。
3. npm 国内镜像源(建议配置)
打开终端并执行以下指令,将 npm 源切换至 npmmirror.com,提升后续下载速度:
npm config set registry https://registry.npmmirror.com
验证设置是否成功:
npm config get registry
终端若显示 https://registry.npmmirror.com 即表示镜像生效。
2026年4-5月AI产业热点:GPT-5.5、DeepSeek V4与智能体平台化浪潮
2026年4-5月AI十大关键动态
一、GPT-5.5问世:OpenAI最强模型登场
4月23日,OpenAI正式推出代号为“Spud”的GPT-5.5,被官方称为史上最聪明、最直观的模型。该模型在多项核心评测中大幅领先:
- SWE-Bench Pro 得分 58.6%,端到端任务单次通过率显著提升,软件工程能力再上新台阶;
- Terminal-Bench 2.0 达到 82.7%,在复杂命令行工作流中取得当前最先进水平;
- GDPval 基准测试 84.9%,覆盖 44 个职业领域,展示广泛的知识工作处理能力;
- 成本仅为同类前沿模型的一半,将高水平智能推向更多用户;
- 在数学领域取得突破——发现关于 Ramsey 数的新证明,并已在 Lean 中完成形式化验证。
目前 GPT-5.5 已向 Plus、Pro、Business 和 Enterprise 用户全面推送,标志着 OpenAI 又一次实质性的模型代际跨越。
二、DeepSeek V4 发布:百万上下文与开放权重
4月24日,DeepSeek 发布 V4 系列模型,包含 V4-Pro 和 V4-Flash 两个版本。主要突破包括:
- 100 万 Token 的超长上下文窗口,与 GPT-5.5 持平,大幅拓展了复杂任务的处理能力;
- 延续开放权重(Open Weights)策略,推动开源生态发展;
- 编程与推理性能相较前代有显著增强;
- API 接口完全兼容 OpenAI 与 Anthropic SDK,迁移成本极低;
- 被业界评价为“几乎达到前沿水平”,中国模型正以极快速度收敛差距。
紧接着五月初,Kimi K2.6 在编程挑战中直接超越 Claude、GPT-5.5 和 Gemini,进一步印证了中国 AI 模型全面追赶的态势。
三、资本洪流:Google 对 Anthropic 投资 400 亿美元
4月25日,Google 宣布计划向 Anthropic 投入高达 400 亿美元(含现金与算力资源),成为 AI 领域最大规模的单笔投资之一。同一时期:
2026年4月中国大模型开源突破:性能追平西方旗舰,基准测评全面解析

#中国大模型 #开源AI #基准测评
核心速览
2026年4月,月之暗面(Moonshot AI)、DeepSeek、阿里巴巴、智谱AI四家中国AI公司密集发布旗舰级模型。在SWE-Bench、LiveCodeBench、Terminal-Bench等关键编程评测中,这些模型集体追平甚至超越了Claude Opus和GPT系列。开闭源模型之间的性能差距已从2024年底的17个百分点,收窄至如今的1-2个百分点。
关键数字
- 5家 主要模型在四月发布新版本
- 58.6 Kimi K2.6在SWE-Bench Pro上的得分
- 93.5 DeepSeek V4 在LiveCodeBench上的得分
四场发布,重塑前沿格局
2026年4月,成为中国大模型产业史上模型发布密度最高的一个月。在不到三十天的时间里,月之暗面带来了Kimi K2.6;DeepSeek推出了V4 Pro与V4 Flash双模型;阿里巴巴发布了覆盖从27B密集模型到千亿参数MoE的Qwen 3.6全系列;智谱AI则亮出了GLM 5.1。若再算上此前不久Anthropic发布的Claude Opus 4.7和OpenAI的GPT-5.5,全球前沿模型的版图在四周内被彻底重塑。
这一现象并非巧合。每年第一季度与第二季度的交接期,向来是AI实验室的传统发布窗口。然而,2026年4月的特殊意义在于:中国模型首次在多个关键维度上,将自身基准分数与西方前沿模型拉入了“统计误差范围内”的区间。
关键背景:2024年底时,开源模型在MMLU等核心基准上还落后闭源模型多达17.5个百分点。但到了2025年12月,这一差距已急剧缩小至0.3个百分点(数据来源:Digital Applied LLM Comparison, 2025年12月)。2026年4月的新一轮发布潮,进一步确认了这一趋势绝非偶然波动,而是一个确立的轨迹。
Kimi K2.6:以Agent Swarm 实现性价比突围
在4月20日发布的Kimi K2.6,是这批模型中在海外开发者社区中引起最大关注的一个。它拥有1万亿总参数(采用MoE架构,320亿活跃参数),支持262K上下文窗口,并采用Modified MIT协议进行开源。
解读其测评数据需要分开来看。在SWE-Bench Pro上,K2.6获得了58.6%的得分,以不到一个百分点的差距落后于Claude Opus 4.7(59.1%),但大幅领先GPT-5(51.2%)(数据来源:RoboRhythms交叉引用,2026年4月)。在用于评估浏览器智能体的BrowseComp基准测试中,K2.6以83.2%的得分反超了Opus 4.7的81.0%。在Terminal-Bench 2.0上,其得分达到66.7%,在国内模型中处于领先地位(Atlas Cloud对比,2026年4月)。
K2.6最核心的差异化能力在于其Agent Swarm特性:能够支持最多300个并行子智能体、高达4000步的协调执行,并可持续运行超过12小时。根据DeepInfra的模型概览介绍,它在多轮工具调用过程中展现出的上下文持续性,相比其前代K2.5提升了一个数量级。
▸ 价格优势明确 — 其API输出价格为每百万token 3.60美元,仅为Claude Opus 4.7(每百万token 25美元)的约七分之一。 ▸ 竞技场表现不及基准 — 在Chatbot Arena的Code Arena WebDev子榜单上,K2.6以1529的Elo分数排在第六名,落后于Opus 4.7(1565分)、Opus 4.6(1548分)和GLM 5.1(1534分)。这表明人类偏好判断与自动化测评之间存在显著差异(数据来源:DeepLearning.ai The Batch 第351期,2026年5月)。 ▸ 实际编码稳定性 — 社区反馈指出,K2.6虽然在长时间编码任务中可以有效运转,但在处理复杂的多文件重构场景时,其可靠性仍不及Opus 4.7。开发者们的普遍共识是:“基准成绩亮眼,但在生产环境中仍需审慎把控”。
2026年最新:土耳其区半价订阅ChatGPT Plus教程,银联卡自助支付每月仅82元
近期ChatGPT的订阅价格波动较大,源头渠道收紧后市场上出现了各种混乱的定价。其实国内用户完全可以通过一条合法、自主的路径完成ChatGPT Plus订阅:利用土耳其区Apple ID配合iTunes礼品卡,全程用银联储蓄卡就能支付,既不需要外币信用卡,也不必依赖第三方代充。
选择土耳其区并不是为了钻规则空子,而是基于App Store本身的地区定价差异。同一个ChatGPT Plus订阅,美区价格约$20/月(约145元人民币),土区则大约是₺500/月(折合人民币约77元),费用几乎只有一半。
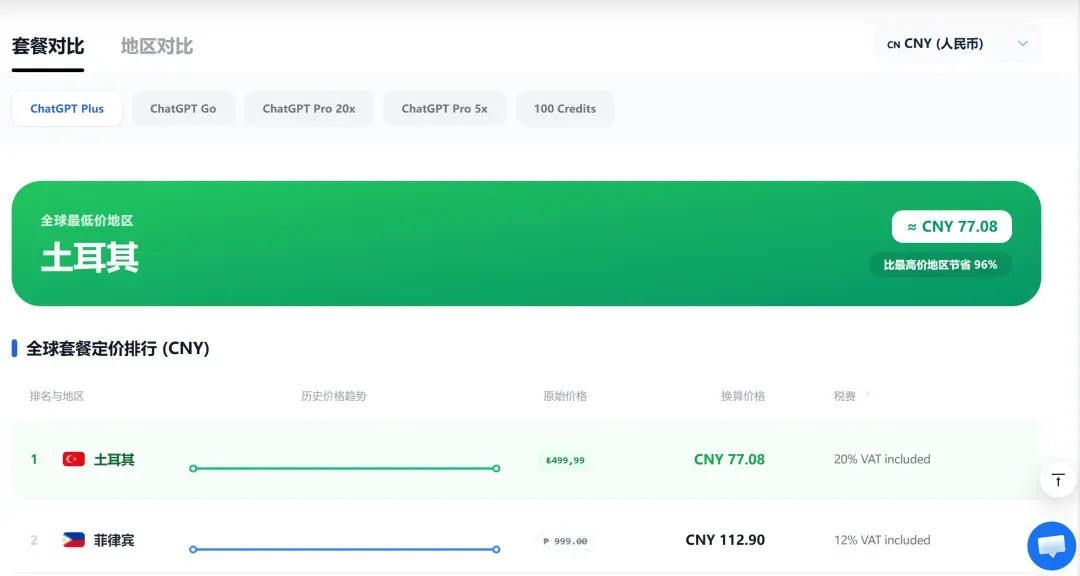
土耳其区Apple ID的注册门槛很低,支持+86手机号验证,整个流程与注册国内Apple ID几乎无异。唯一的区别是需要用礼品卡充值余额完成支付,因为土区App Store无法直接绑定国内银行的银行卡。
前置条件
开始操作前,请确认手边有以下物品:
- 一部iPhone(iPad也可以,但本教程以iPhone为例)
- 一个+86开头的国内手机号
- 一个邮箱地址,推荐Gmail或Outlook
- 一张银联储蓄卡(日常使用的普通银行卡即可)
整个过程不需要外币卡、不需要科学上网,也不需要任何第三方工具。
关于邮箱的选择:QQ邮箱理论上可行,但有人反馈在注册时收不到验证码,因此稳妥起见建议使用Gmail或Outlook,实际测试中Gmail全程畅通。
注册土耳其区Apple ID
退出当前账号
进入「设置」→ 轻点顶部的头像 → 滑至页面底部 → 选择「退出登录」。iOS在App Store层面只允许同一时间登录一个Apple ID,如果不退出旧账号,新账号登录时会发生冲突,引发各种意外报错。系统可能会询问是否保留本地数据(如通讯录、钥匙串),按照个人习惯选择即可,不影响后续流程。
在Safari无痕模式下注册
这一步容易被忽略,却是影响注册顺利与否的关键。
打开iPhone自带的Safari浏览器,点击底部的标签页按钮,切换到「无痕浏览」模式,然后访问:
https://account.apple.com/account
为何强调无痕模式?普通模式下Safari会携带之前访问过苹果官网留下的Cookie和会话信息,这些残留数据可能干扰新账号的注册,导致页面报错或验证环节出问题。无痕模式相当于一张空白表格,注册过程会更加干净流畅。

填写注册信息
页面加载后显示苹果官方的账号注册表单,逐一填写:
国家或地区:选择「Türkiye」(土耳其)。这一步决定了Apple ID所属区域,之后App Store将展示土耳其区的内容和定价。
出生日期:任选一个能证明已成年的日期(不需要真实日期)。苹果要求账户持有人必须年满18周岁。
电子邮箱:填入准备好的Gmail或Outlook邮箱,这将是新Apple ID的登录账号。
验证方式选择「短信」。苹果会先向邮箱发送一组验证码,再向手机发送一组验证码,按顺序填入即可完成注册。
在App Store首次登录并激活账号
注册完成后,不要在「设置」里登录新账号——这是很多人踩过的坑。在设置中登录Apple ID会触发整机账号迁移,涉及iCloud、通讯录、钥匙串等一系列关联服务,容易引发不必要的麻烦。
正确的做法是只在App Store内登录:打开App Store → 点击右上角头像 → 输入刚才注册的邮箱和密码 → 登录。首次登录时系统会要求再次验证手机号,按常规操作即可。
登录成功后随便搜索一款免费App进行下载,若能正常下载,说明账号已完全激活,注册环节顺利结束。
购买土耳其区iTunes礼品卡
为什么需要礼品卡
土耳其区App Store不支持绑定国内银行发行的Visa、MasterCard或银联卡,因此无法直接在App Store内完成支付。礼品卡相当于预充值介质——先把钱充进Apple ID账户变成里拉余额,再用余额支付订阅费用。
购买平台:MTCGAME
选用的平台是MTCGAME: