Claude Code 便携版制作全攻略:Windows 免配置批量部署方案
在 Windows 环境下批量部署 Claude Code 是否可行?答案是肯定的。我们可以直接在 Claude Code 内提出需求,将当前可运行环境打包为便携版本,以便在其他 Windows 设备上使用。只需解压即可运行,无需额外配置。
最终输出的目录结构:
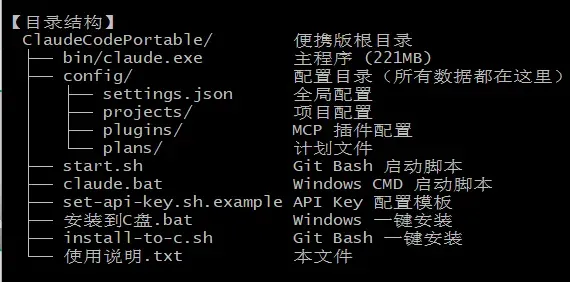
便携版启动脚本:
#!/bin/bash
# Claude Code 便携版启动脚本 (Git Bash)
# 获取脚本所在目录SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# 清理可能影响的环境变量unset ANTHROPIC_API_KEY
# 创建 ~/.local/bin 目录(claude 会检查此目录)mkdir -p "$HOME/.local/bin"
# 如果 ~/.local/bin 中没有 claude.exe,则从便携版复制if [ ! -f "$HOME/.local/bin/claude.exe" ]; then cp "$SCRIPT_DIR/bin/claude.exe" "$HOME/.local/bin/claude.exe" echo "✓ 已复制 claude.exe 到 $HOME/.local/bin"fi
# 设置配置目录(便携版内部)export CLAUDE_CONFIG_DIR="$SCRIPT_DIR/config"
# 禁用自动更新(便携版手动更新)export DISABLE_AUTOUPDATER=true
# 内置 API 配置export ANTHROPIC_BASE_URL="https://ark.cn-beijing.volces.com/api/coding"export ANTHROPIC_MODEL="ark-code-latest"export ANTHROPIC_AUTH_TOKEN="ark-your-key"
# 启动 Claude Code(优先使用 ~/.local/bin 的)exec "$HOME/.local/bin/claude.exe" "$@"
实际上,便携版的核心就是 config 目录,只需将原先的 ~/.claude 目录拷贝过来即可。经过对比,这两个目录几乎完全一致。但在制作便携版之前,务必要清理会话和历史信息,若分发给多人使用,存在信息泄露的风险。
Cloudflare 功能全景解析:全球云+AI开发者工具链实用指南
作为现代开发者,你或许已经习惯 vibe coding、调用各种 AI 接口,正跃跃欲试搭建网站、开发 SaaS 甚至打造智能代理。创意从来不缺,缺的是一张能够回答“该选哪朵云”的全局地图。Cloudflare 远不止 CDN,它是一整套全球云与 AI 深度融合的开发者工具链。这篇文章将为你一次讲清它能解决哪些场景、相比国内云有哪些真实优势,以及需要避开的坑。

330+ 全球数据中心 | 50+ AI 推理模型 | 100K 免费请求/天
三大核心场景:一次性覆盖你的全部需求
你的技术栈无非需要支撑三块:后端 API、网站交付、AI Agent 基础架构。Cloudflare 对每个场景都准备了精准的产品组合。
场景一:敏捷后端 API – Workers + D1 极速上线
用 Workers 搭配 D1(或 KV),就能搭建完全无服务器的 API。Workers 是一类运行在 Cloudflare 全球 330+ 城市边缘节点的函数,写完代码执行 npm run deploy 即可秒级发布,没有任何冷启动。D1 是基于 SQLite 的持久化数据库,在 Worker 内部直接执行查询,既不需要连接池管理,也不用操心实例规格。KV 则专为缓存、会话、配置等信息设计,可实现毫秒级读写。假设你要做一个建筑领域的 GDL 参数序列化服务:Workers API 接收参数,存入 D1,然后通过 Webhook 触发 ArchiCAD 自动生成模型,整个过程零服务器维护。
场景二:动静态网站 – Workers + R2 一步到位
动态内容(API 路由、表单提交)依旧由 Workers 处理,大型文件(BIM 模型、高清截图、PDF 等)则放进 R2 对象存储。R2 完全兼容 S3,不存在厂商锁定风险。结合内置的 CDN 和 Images 优化服务,可以自动完成全球加速与图片压缩。DNS 利用 Cloudflare 的免费权威 DNS 托管,再也不用单独购买解析服务。
Codex插件装超15个就变笨?2026年十大顶级插件与避坑完全指南(附百万安装数据)
有人给 Codex 一口气挂了二十多个插件,结果它反应越来越慢、越来越爱胡说——还以为是模型本身不行。其实每条激活的插件都在悄悄吃掉上下文窗口,平均每条约占 24 个 token 的系统提示。一旦同时挂着 15 个以上,注意力被冲散,回答质量断崖式下跌。插件不是装得越多越强,是装得越准越强。这篇文章会拿 Codex 生态最大插件市场 OpenClaw Bazaar 的真实安装量数据,告诉你到底该装着哪 10 个、哪些绝对不该碰。
一、概念先掰清楚:Plugin ≠ Skill,别和之前的文章搞混
之前我们聊过 Codex 的 Skills(像 grill-me、mcp-builder 那种教 Agent 怎么编码的 SKILL.md 规范文件)。这次要讲的则是 Plugins(插件),两者完全不是一回事:
| 维度 | Skill(技能) | Plugin(插件) |
|---|---|---|
| 形态 | 单个 SKILL.md 文件 | 打包了 skills + agents + hooks + 配置的“应用包” |
| 解决的问题 | “怎么编码”(行为规范、工作流) | “接什么、干什么实事”(联网、收发邮件、查日历、操作数据库等) |
| 典型例子 | grill-me(规划审问)、mcp-builder | Web Browsing(浏览器)、Telegram(机器人)、Email(邮件管家) |
| 创建方式 | $skill-creator | $plugin-creator (把多个 skill 打包成可分发插件) |
一句话:Skill 是给 Agent 立“规矩”,Plugin 是给 Agent 装“手脚”。 本文只聚焦后者——那些真正让 Codex 能动手干活的扩展。
数据源自哪里:OpenClaw Bazaar
榜单的全部数据来源于 OpenClaw Bazaar——Codex 生态中收录最全、安装量排名最透明的插件市场,目前索引了 2,300 多个社区插件。
Hermes Agent看板革新:用阻塞分类与重复计数器终结无限重启
2026年5月,NousResearch在GitHub Issue 29320中披露了一起典型的生产事故:CI runner资源饱和导致4个看板任务在7小时内疯狂重启超过230次。每次Agent启动都会完整加载上下文、发现环境,然后在24-30秒内因相同的外部阻塞而退出;下一轮调度又重新认领、重新启动,如此循环,直到人类注意到异常。这种“记忆失忆症”让事件历史被数百条“仍然阻塞,无变化”的记录淹没,白白消耗了宝贵的Provider计算额度。
为了解决这一问题,Hermes Agent看板新增了两项核心机制:类型化阻塞原因和重复计数器。当同一个Agent因相同外部原因反复阻塞时,系统不再无限重启任务,而是自动将决策权转移给人类。
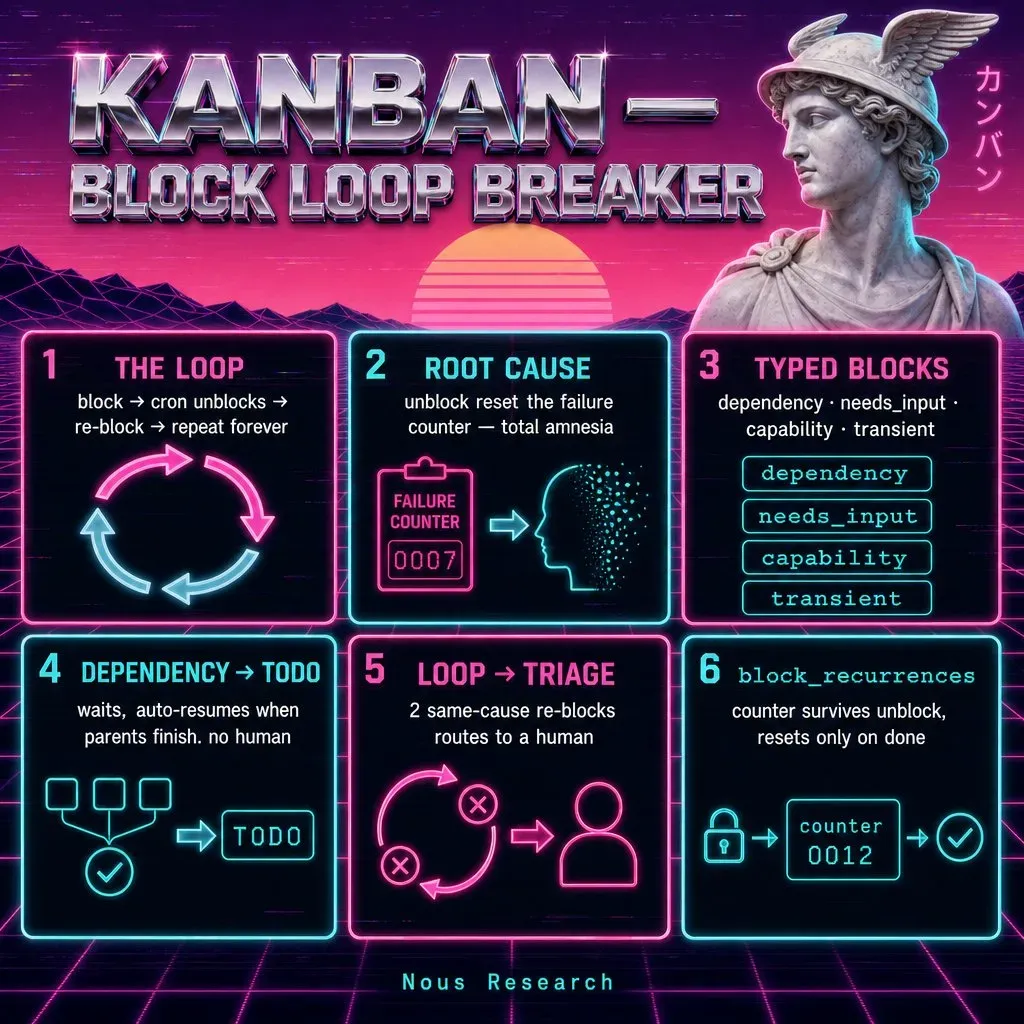
Nous Research 发布的 KANBAN BLOCK LOOP BREAKER 信息图,展示了死循环问题、根因分析和六步修复方案
阻塞原因类型:为每次阻塞贴上标签
新版本将阻塞原因归纳为四种类型,每类对应不同的处理策略:
- dependency——等待父任务完成。此类阻塞不消耗人类注意力,任务状态回退到
todo,父任务完成后自动恢复至ready。 - needs_input——需要人类提供信息或决策。任务直接路由到人类处理。
- capability——超出当前 Agent 能力范围。同样路由给人类,可能需要更换 Agent 配置。
- transient——临时性问题,如网络波动、API限流。这类通常值得重试,但也会被纳入重复计数。
关键区别:dependency 类型走“自动恢复”路径,无需人类干预;其余三类都可能触发“重复→升级”逻辑。
重复计数器:记住 Agent 的“卡住”历史
每个任务现在携带一个 block_recurrences 计数器。当 Agent 调用 kanban_block 时,系统会检查当前阻塞原因是否与上次相似(模糊匹配)。若相似,计数器加一;若原因改变,计数器归零。
计数器的生命周期经过了精心设计:它在任务被 unblock 时不会被重置(因为问题可能并未真正解决),只有当任务变为 done 时才彻底归零。这意味着如果一个任务连续三次因相同原因阻塞、被人类解开两次、第三次再次阻塞,计数器会准确地累加到第三次相同阻塞。
重要阈值:默认计数达到 5 次时,任务会自动升级到 triage 列,Dispatcher 停止认领,等待人类介入。
Circuit Breaker:切断无限重启的回路
三项机制协同作用,构建了一个完整的断路器。当一个任务因 CI runner 饱和而被阻塞,事件链条如下:
- 第 1 次阻塞:Agent 发现 CI 仍在排队,调用
kanban_block(reason="CI queued, unchanged")。 - 第 2–4 次:Dispatcher 重新认领,新 Agent 启动后再次发现同样条件,阻塞并增加计数。
- 第 5 次:计数器触及阈值。任务状态转为
blocked,Dispatcher 标记circuit_open诊断标记,不再自动认领。 - 人类通过 Dashboard 或 CLI 看到标记,决定是解除阻塞、修改任务,还是直接完成。
这套机制与已有的 failure_limit(连续崩溃次数限制)相互补充。failure_limit 负责处理 Agent 崩溃、超时等“被动失败”,而重复计数器负责处理 Agent 主动阻塞且原因不变的“循环式卡死”。
Mac mini 进化全史:从初代到 M4,一部苹果小钢炮的传奇与职场学生党购机指南
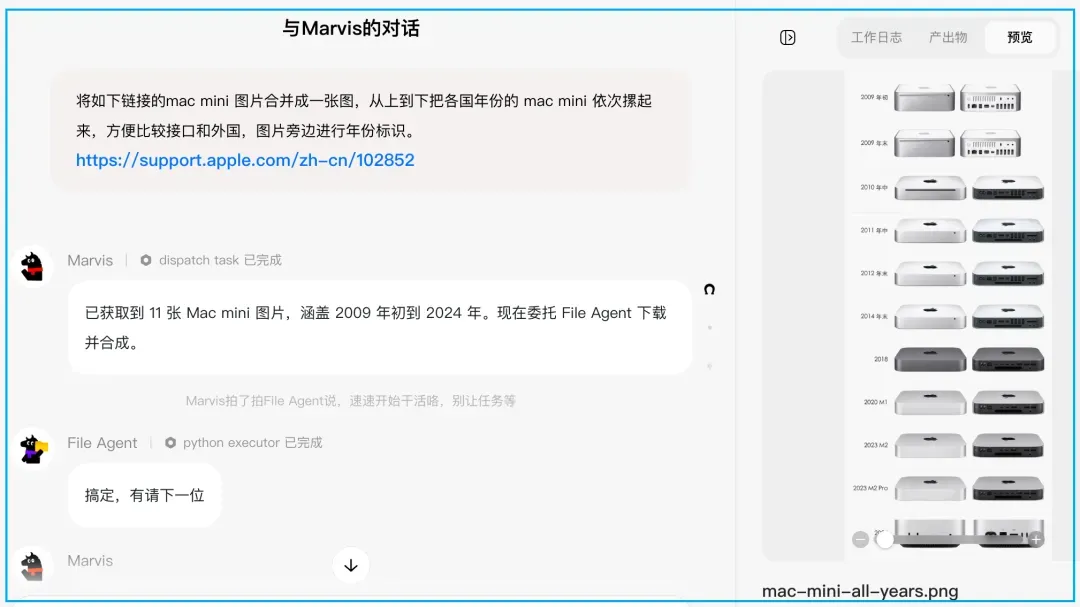
下方是利用 Marvis 工具合成的 Mac mini 各代机型外观对比图,按年份纵向排列,方便直观比较接口与机身变化:

生成该图的提示词如下: 将 Apple 官方支持页面(https://support.apple.com/zh-cn/102852)中的各年份 Mac mini 图片整合为一张纵向排布图,自上而下依次堆放不同年代的 Mac mini,并在每款旁边标注对应年份,以便对比接口和外观演变。
有兴趣的朋友也可以自己动手尝试:
我在去年双十一购入了一台 Mac mini M4,实际体验下来,响应速度比之前使用的 32GB 内存 Windows 主机还要快。日常工作时,一整个屏幕铺满各类窗口依然流畅丝滑,完全不会出现卡顿,它的 16GB 统一内存究竟是如何做到的,确实让人惊叹。

当时价格非常诱人,最基础的 16+256 版本最低曾落到 2600 元左右,我入手的则是 16GB+1TB 版本,花了 4000 元,平时放在办公室使用,完全胜任高频工作需求。

对于大一新生来说,如果没有购买笔记本的刚需,Mac mini M4 是苹果生态中最实惠的入门产品之一。用它来编程、查阅资料、完成作业都毫无压力,还能在某种程度上避免沉迷游戏,把更多精力放在学习上。
如果初期不太习惯 macOS 操作逻辑,后续会推出一系列入门教程,包教包会。尤其推荐 iPhone + Mac mini 的组合,手机与电脑之间的剪贴板同步、文件互传等功能极为顺滑,能大幅提升效率。
OpenAI GPT-5.6太阳系模型矩阵发布:Sol旗舰、Terra均衡、Luna高吞吐开启分层定价新范式
OpenAI 在 6 月 27 日释放了一个不容忽视的信号:下一代模型不再沿用单一版本号,而是按需求切分为三档——GPT-5.6 Sol 定位前沿旗舰,GPT-5.6 Terra 追求日常高效,GPT-5.6 Luna 专攻高吞吐与低成本。这也是 OpenAI 首次在正式产品线中以旗舰、均衡、批量的三层结构,彻底替代过去的单一旗舰打法。
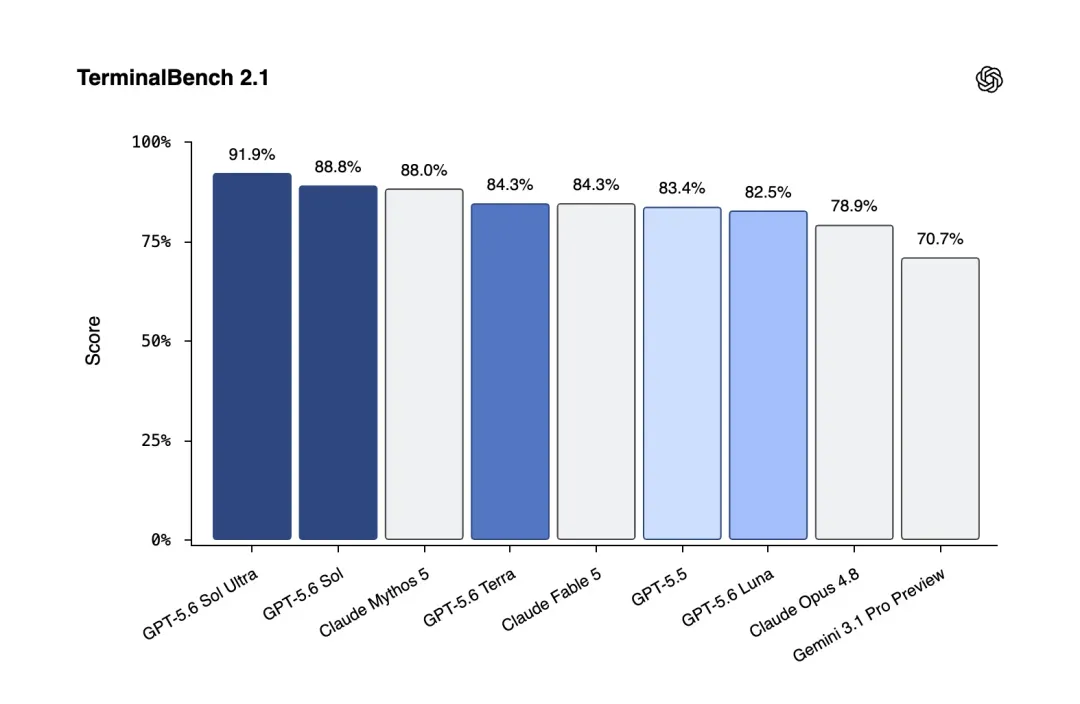
Sol、Terra、Luna 的命名绝非一时兴起,而是将太阳系层级直接绑定到模型身份上。太阳、地球、月亮的视觉映射,让用户一眼就能判断三者在能力、成本和适用场景上的距离。这种命名比单纯的 Pro/Max/Base 更容易传播,也更能塑造一个完整的产品家族,而非补丁列表。
三个产品线分别适配哪些场景?
Sol 是 OpenAI 的“最大模型”,专为极致性能而设,擅长复杂推理、长上下文和多模态输入。Terra 是默认选项:响应质量足够、延迟更稳定、价格也在可接受范围内。Luna 属于刚需启动型,适合高并发、可丢弃的流水线以及大批量解析任务。
- Sol:对任务质量要求最高,且用户愿意支付一倍的单价。
- Terra:覆盖大多数日常助手、企业应用和流量入口。
- Luna:负责批量 JSON 结构化、批量标签、在线分类等可并行且对延迟不敏感的任务。
为何要同时拉出三条产品线?
单一旗舰模型的商业模式有一个天然瓶颈:中小客户嫌贵,大客户又嫌容量天花板太低。Sol、Terra、Luna 的真正目的,就是按客单价分层收割,同时避免中小开发者因价格门槛而流失。表面上用户是在选“模型”,本质上是在选成本结构。
此次三条产品线同步进入 limited preview,说明它们在生产环境的冷启动还未完全完成,仍需真实流量来打磨吞吐量和稳定性。对于普通用户而言,Luna 的性价比最高,但 Sol 的圈层壁垒最低——任务越复杂,它的优势才越能体现出来。
普通 AI 开发者现在该如何判断?
优先申请 Terra preview:绝大多数工作流都能跑通,而且是成本结构最均衡的节点。把 Sol 留作压测、安全样本或者客户演示时的升档选项,不要一上来就用 Sol 铺满生产流量。

QQ 邮箱 Agent Mail 内测:AI 接管收发,40 年电子邮件范式正在被改写
最近,QQ 邮箱团队悄然开启了「Agent Mail」的内测——一个专门为 AI 智能体而设的邮箱服务,允许你的 AI 工具直接接入专属邮箱,自主完成邮件的收发与管理。我第一时间尝试了接入,发现 Qodex、Claude Code、OpenClaw、TRAE Work、Workbuddy、Qoder Work、MiniMax Agent、Kimi Work 等主流 Agent 均已支持。接入之后,只需用日常语言向你的 Agent 发出指令,就能自动处理邮件。
例如,我对 Claude Code 讲了一句:“给老板写一封邮件,告诉他方案已经完成,附件马上发送。语气务必十分谦逊,带一点恰如其分的赞扬,但不能让老板觉得我在刻意讨好。”片刻过后,我的真实收件箱里就收到了一封完整邮件——抬头、正文、结尾落款一应俱全,措辞圆融不油腻,甚至比我自己斟酌后的文字更显老练。

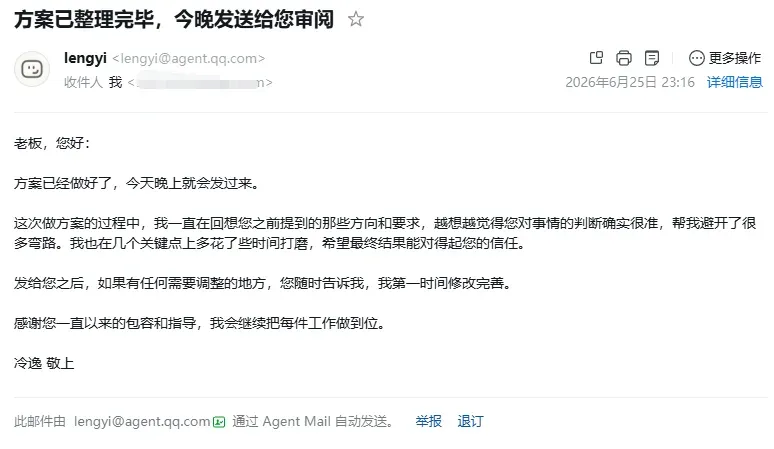
这不仅仅意味着“让 AI 替你生成文案再手动粘贴”的初级自动化,而是标志着 Agent 可以直接操控邮箱,进行端到端的邮件处理——撰写、发送、分类、摘要,全流程由 AI 一手包办。

上手实测与接入指南
极简注册流程
注册过程极其简单。访问 agent.qq.com 页面,通过微信扫码进入邮箱开通流程。扫码后需要在手机端确认,首次使用会引导你创建一个邮箱地址。

建议抢占一些有趣地址,例如 tokens、agents、skills 或 anthropic 等仍有空余名额,但 ponyma 这类知名标识已被系统保留。每个微信号可以创建两个邮箱地址。
创建完毕之后,就可以前往 Qodex、Claude Code 等 Agent 工具中,接入 Agent Mail 的命令行接口(CLI)了。
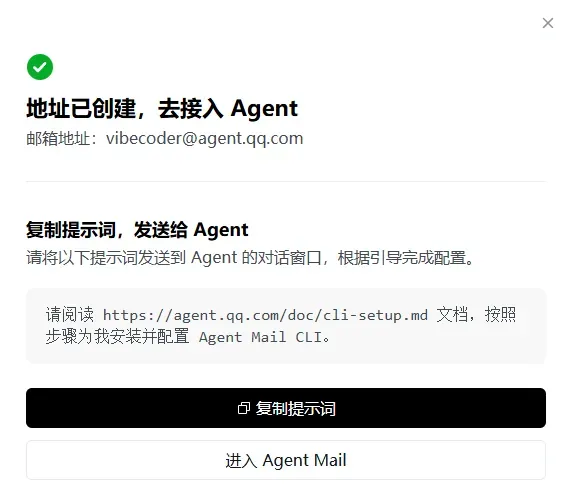
以 Claude Code 为例接入 Agent Mail
以下演示以 Claude Code 为例。只需将下面这段提示词转发给 Claude Code,它便会自行完成安装和配置:
请阅读 https://agent.qq.com/doc/cli-setup.md 文档,按照步骤为我安装并配置 Agent Mail CLI。
Snøhetta疗养院总体规划:让阿尔托的‘医疗器械’重新为健康疗愈而生
当建筑的每个构件都在参与治疗,改造就不再是风格选择,而是对医疗逻辑的重新翻译。
Alvar Aalto设计的患者房间中,洗手盆特意偏置,以防溅水扰及邻床病人。天花板漆成暗绿色,因为卧床者目光多落于天花,深色表面可减少眩光。这些安排并非装饰,而是治疗处方的空间等价物。九十年后,Snøhetta的总体规划要回应一个更棘手的问题:当固有的疾病不再流行,这座被Aalto称为“医疗器械”的建筑,还能为谁实施疗愈?

松林中的Paimio疗养院主楼,1929–1933。七层患者翼楼如屏风般展开,其余体量呈扇形向北铺陈。这一构图随后成为Aalto作品中的常见手法。
从通风阳台到营造人文关怀
Paimio疗养院虽非Aalto的第一座现代主义作品,却首次让他将“对人的关注”从理念一直落进每一处节点。1928年赢得竞赛时,Aalto刚结束欧洲旅行,到访了Jan Duiker的Zonnestraal疗养院。他吸收了现代主义的功能分区和大片玻璃语汇,却又加入了自己的演绎:每一个细节都为患者的感知体验服务。
患者房间是最清晰的例证。两人间里,洗手盆偏置并设计了防溅曲线,确保一人洗漱不扰另一人。灯具被安排在病人视线之外,天花选择暗绿色消弭眩光——这些在现在看来是“人性化设计”,对当时而言则是从结核病治疗流程中推演出的空间参数。Aalto将整座建筑称为“医疗器械”,这既非修辞,而是功能描述。
彼时结核病的疗法核心是新鲜空气、阳光和绝对静养。每层尽端的阳光阳台使病床可以直接推入;顶层大晒台则为恢复期患者而设。Aalto与妻子Aino设计了全楼的家具与内饰,包括后来成为Artek标志产品的Paimio椅,其座椅倾角专为辅助患者呼吸姿态而定。整座建筑是一件“总艺术”,将建造形式、技术革新与日常节律编织成一个不可分割的整体。

患者翼楼的立面节奏:水平长窗与深色窗框制造对比,屋顶晒台为患者提供户外疗愈空间。白色抹灰与彩色窗框是Aalto现代主义语言的标识。
Snøhetta的解读:不模仿,但回应本质
Snøhetta介入时面对的局面十分复杂。这座建筑于1993年被列入芬兰建筑保护法保护范围,2004年进入联合国教科文组织预备名录,2026年7月将迎来“阿尔托作品”世界遗产提名的最终决定。保护等级极高,但建筑的实际使用已停滞多时。2014年后它曾作为儿童康复中心运转,2018年挂牌出售,保护问题一度引发争议。
Paimio基金会2020年成立后启动了综合复兴进程。Snøhetta的总体规划与ALA Architects和Mustonen Architects(阿尔托建筑遗产专家)合作完成,并由Snøhetta创始人Kjetil Trædal Thorsen亲自带队。Evergreen Capital担任国际酒店开发顾问。
规划的核心判断在于:酒店与健康中心是这座建筑最适宜的新用途,辅以文化活动。这一判断的合理性在于它找到了原设计与新功能之间的结构同构——结核病疗养需要静卧、阳光、新鲜空气和与自然的接触;当代wellness所需的正是同一组条件。

原阳光阳台将被恢复为敞开的户外空间。Snøhetta移除了此前被封堵的玻璃面板,让患者翼楼与森林景观重新建立直接关系。
新介入:可识别的层叠
Snøhetta方案中最值得关注的并非造型,而是他们对“新旧关系”的构造处理。病房被改为酒店客房时,新加入的卫浴单元被设计成“独立式家具”——涂漆桦木贴面的箱体,与原建筑的墙壁和楼板保持视觉分离。这意味着进入房间的人能立即辨认出哪些是1930年代的原物,哪些是2020年代的新介入。这种“可读性”恰是优秀保护改造的核心伦理。
原手术翼将被改造为灵活的礼堂空间,打通两层,容纳约200人。墙面采用桦木板条,从Aalto的原建筑语言中提取材料语汇,同时解决当代的声学和技术设备集成需求。新入口直接通至礼堂,使文化活动可以独立于酒店的日常运营举办,理顺了整个场地的动线。
室外方面,后立面原来的沥青前院计划以石板重新铺装,接引新的植被,让自然更趋近建筑。建筑师还恢复了Aalto原规划中存在的后院步道,这条步道在后来的使用中被取消。

疗养院的标志性特征:与自然的联结。细长的开放式阳台从房间外的走廊进入,是新规划中将被保留和修复的核心空间。
从结核治疗到当代康养:功能延续的逻辑
Snøhetta规划中最耐人寻味的一笔在底层:一个可直接通往户外和周围森林的低层水疗中心。这一动作将“治疗”的内涵从1930年代的结核病静养延展为当代的健康管理:水疗、桑拿、林间漫步、文化参与。功能改变,但“建筑作为治疗工具”的逻辑始终如一。规划中的文化空间(礼堂、活动区)又进一步将这座建筑从私人酒店拉回公共领域,使其重获当年作为国际对话场所的角色。
值得关注的时间节点:2026年7月底,联合国教科文组织将对“阿尔托作品”世界遗产提名做出最终裁决。如果通过,Paimio疗养院将跻身全球最重要的文化地标之列。Snøhetta的规划在此时公布,既是为申报提供专业背书,也是为申报成功后的运营提前铺设路径。

鸟瞰Paimio疗养院建筑群与周围松林的关系。Snøhetta恢复的后院步道和新建的树木广场将更深地将建筑编织进场地肌理。

礼堂空间的桦木板条墙面,融合了声学与技术设备。Snøhetta从Aalto的材料语汇中提取建造语言,却用当代的构造需求重新诠释。
可迁移的建造逻辑
• 当原功能消逝时,先在程序层面寻找与原设计“结构同构”的新用途,而非从形式风格出发进行适应性改造——Paimio从结核疗养到wellness酒店的转换,前提是两者共享“光、空气、自然接触”的治疗参数。
• 新增建造必须与原物可区分。Snøhetta用“独立式家具”策略处理卫浴单元,让新旧之间的构造关系透明,这种可读性本身就是对保护伦理的建造表达。
• 尊重原建筑的语言但不必复制它。桦木板条墙从Aalto的材料体系出发,解决的是当代的声学和集成需求。好的回应不是模仿形式,是用相同的材料伦理面对今天的建造问题。
SOP标准化能力:从个人经验到组织可复制的核心引擎
最近我们在推进飞书知识库的搭建工作,这个过程中,我对SOP(标准作业程序)的理解比以往更深了一层。过去我只是“知道它很重要”,更多停留在认知层面。直到公司业务变得越发复杂——覆盖多个国家、多个团队、多条产品线和流程节点,问题也开始层出不穷,我才真切地感受到:一家公司如果没有SOP,终将被自身的复杂度拖垮。
一、经验的流失:为什么很多公司有能力,却没有沉淀
回顾过往,我们的SOP体系并不健全。虽然有一些制度文档、表格数据和复盘资料,但很多流程操作充其量只有一个粗糙的指引,远未达到标准化程度。这些文件散落在企业微盘里,查找极不方便,新人入职后很难快速定位相关资料并上手工作。跨部门协同也十分费力。明明以前有人做过类似的事情,但隔段时间,大家又会从头问起、重新摸索,甚至重踩一遍同样的坑。这其实是巨大的资源浪费。
当企业发展到一定阶段,最大的浪费往往不在于人力成本,而在于组织经验没有被系统地留存。大多数经验和做法最终停留在某个人的脑海里。这个人在时,事情能正常运转;这个人一旦离开,流程就中断,经验也随之消失。如果不把这些隐性知识显性化,公司就永远在循环支付昂贵的“遗忘税”。
二、SOP的成熟度,决定了公司的发展上限
我认为,SOP的成熟水平在相当程度上决定了一家企业的成长天花板。一个SOP做得不好的公司,很难发展成大规模组织。随着人员扩张、业务增长,缺少完善的标准化体系,内部复杂度会急剧攀升,最终拖累公司的长期生存能力和市场竞争能力。如果企业无法将个人的“优秀能力”转化为组织的“标准动作”,规模就永远无法突破。靠人治,天花板极低;靠系统,才能实现复制和放大。 当然,除非你的目标就是维持一个十来人的小团队,那另当别论。
三、知识库的本质不是存储文件,而是沉淀可复用的方法
因此,这次做飞书知识库的迁移,我们的重心并非简单搬运企业微盘里原有的文件,而是重新梳理每个部门的工作流程与业务体系。一个有真正价值的知识库,绝不是一个“资料仓库”,它应当是公司的“方法库”。它需要回答这几个核心问题:这件事到底怎么做?由谁负责?做到什么标准?过程中有哪些常见陷阱?出现问题如何应对?新人怎样快速上手?做得好和做得差,差异点在哪里?这些内容,才是真正有生命力的组织资产,而其核心就是SOP。
四、SOP的本质:将个人能力固化,降低组织不确定性
不少人对SOP存在误解,认为它就是写写流程、搞形式主义,对业务没有帮助,反而增加管理负担。(当然,这或许源于视角不同。老板大多想推行SOP,因为他要和公司长期走下去;而部分员工可能觉得干不了几年,何必费时费力又对提成没有直接产出。)但SOP的真正目的不是为了“管人”,而是为了降低组织运行的不确定性。
举例来说,一个清关流程,如果没有SOP,每次都要靠人反复询问:资料谁准备?编码谁确认?节点谁跟进?异常找谁?许多环节都需要展开解释,甚至不同人理解还存在差异。时间一久,推诿扯皮就在所难免。但如果有了SOP,每个节点的责任人、操作标准和异常处理方式都写得清清楚楚,事情就会顺畅得多。这不是把问题复杂化,这恰恰是把复杂问题简单化。公司越大,越不能依赖口头沟通和个人的经验直觉,因为这些都极不稳定。真正稳定的,一定是流程、标准和系统。
五、优秀企业的底层能力:把一切标准化
放眼全球,许多能够穿越周期、实现规模化扩张的卓越企业,背后都具备极强的标准化能力。比如麦当劳在全球拥有海量门店,如何保证口味一致性,确保每一家店铺都能成功存活?它把选址、装修、出餐、服务、供应链、培训等全部动作做成了标准。要开新店、培养新员工,只需按照标准动作执行即可。再看丹纳赫,从工业领域跨界到医疗行业,跨度巨大,为什么依然能够成功?它厉害的地方不仅在于并购,更在于并购之后用其DBS体系对企业进行重构。它将并购动作、经营动作、管理动作和改善动作,提炼为一套可复制的方法论。买来的公司不是闲置在那里,而是通过这套体系持续改造。这背后的本质,同样是SOP的能力——将经验流程化、标准化、系统化的能力。商业竞争走到深处,比拼的正是**“把一切标准化的能力”**。
六、AI时代,SOP是必不可少的地基
还有一个不可忽视的要点,就是AI时代的到来。未来企业要落地AI化,前提条件就是数据和SOP的标准化。如果一家公司的数据口径模糊不清,流程、责任边界和操作标准混乱,就算给你再强大的AI大模型和智能体,也很难真正发挥价值。AI要想帮助公司做判断,首先公司自身得有清晰的流程和准确的数据——什么叫异常?什么叫合格?什么算风险?什么情况需要预警?什么情况需要升级处理?如果这些都没有标准,AI最多变成一个更聪明的聊天工具。然而,当公司已经将大量流程标准化、关键节点数据化、经验显性化后,AI就能顺畅地嵌入流程,它能够做提醒、做分析、做复盘,甚至可以辅助决策。SOP并非会在AI时代被淘汰的东西,恰恰相反,它是公司走向AI化的地基。 没有SOP的企业,未来或许连参与AI竞争的资格都没有。
七、管理者真正要抓的,是把经验留在组织里
很多管理者疲于奔命,身心俱疲,除了不敢放权之外,还有一个关键原因——公司没有建立起沉淀能力。任何事情都要问老板,任何异常都需要老板拍板,组织尚未形成自运行的系统。知识库建设、SOP梳理和流程优化,这些事情确实是慢功夫,短期内不会产生直接的销售业绩,但它们实质上是在为公司减少未来的反复消耗。今天多沉淀一个流程,明天就少一次重复沟通;今天多写清楚一个标准,明天新人就少踩一个坑;今天多复盘一个案例,未来团队就多积累一份判断能力。公司真正的竞争力,不仅在于做成过一件事,更在于能否将做成这件事的方法沉淀下来,并不断复制。 从经验到流程,从流程到标准,再从事标准到系统——这条路走得很慢,但极其重要。千万不要在低效的内耗里,假装忙碌。
阿里通义Wan团队发布实时视频对话模型Wan-Streamer:端到端全双工,AI真的能看见你
阿里通义Wan团队正式发布了Wan-Streamer v0.1,一个端到端的实时音视频交互基础模型。它完全抛弃了ASR、LLM、TTS与数字人模块的拼装思路,转而让一个Transformer同时承担文本、音频和视频的输入输出。模型侧延迟控制在200毫秒,全链路交互延迟约550毫秒,实时输出达25fps,首次在单一模型中实现了亚秒级、全双工的视频通话体验。
6月23日,团队在arXiv公开论文并上线演示站点,随即在海外科技社区引起震动。Min Choi的一条推文“我们完了,阿里刚刚展示了Wan-Streamer。AI智能体现在能看到你、听到你,并实时用视频回复你。这已经不只是语音模式了”获得了超24万次浏览,评论区反复出现一句话:This changes everything。读完论文和演示,可以明确地说,这并非又一篇普通AI论文,而是交互范式的一道分水岭。
Wan-Streamer重塑实时交互
当前的实时对话系统大致分为两类。一类是纯语音方案,如GPT-4o Realtime、豆包Voice和Gemini Live,响应敏捷却没有可视形象,你只能听到声音,看不到任何面孔、眼神或动作。另一类是音视频数字人方案,通过ASR语音识别、LLM、TTS语音合成和动画模块串联完成,每个模块间的边界都在叠加延迟,而且绝大多数系统从不公开端到端的真实响应时间。
Wan-Streamer彻底改写了这套流程。它用一个Transformer完成感知、推理、生成、回复时机判断、话轮管理和跨模态同步,没有任何外挂的ASR、LLM、TTS或动画模块,所有能力在同一个模型中联合优化。
| 方案类型 | 代表系统 | 交互形式 | 延迟指标 |
|---|---|---|---|
| 纯语音方案 | GPT-4o Realtime / 豆包 / Gemini | 无可见形象,纯音频交互 | 0.23 ~ 3.6s(端到端) |
| 数字人拼接方案 | StreamAvatar / LPM / Hallo-Live | 多模块拼接,仅计渲染 | 0.35 ~ 1.2s(不含大脑) |
| Wan-Streamer | 单一端到端Transformer | 同步音视频 + 全双工 | 0.2s / 0.55s(全链路) |
表中的关键差异在于,纯语音方案报告的是端到端延迟,数字人方案只报告渲染阶段的延迟(刻意隐去外部LLM、ASR、TTS的耗时)。Wan-Streamer是唯一一个同时输出同步音视频、如实公开端到端全链路时间,并把总延迟压到一秒以内的模型。
一个Transformer完成所有任务
Wan-Streamer的核心架构看似直接,实现却极为复杂:整个交互过程被建模为一条因果流,视觉帧、音频片段和文本token交错成一个序列,由block-causal attention协同调度。每个新进来的观测单元立即可用,每个生成的单元立刻输出并写回交互历史。整个技术栈从头到尾维持因果性——因果VAE、因果编码器、因果解码器,连同block-causal attention环环相扣。语言部分用next-token prediction训练,输出离散token;音频和视频部分则在连续潜在空间中通过条件flow matching联合生成,并以同一份上下文作为条件,使语音、动作和外观作为一个耦合整体去噪。这意味着嘴唇动作与语音韵律源自同一个底层表示,无需任何外部对齐工具。
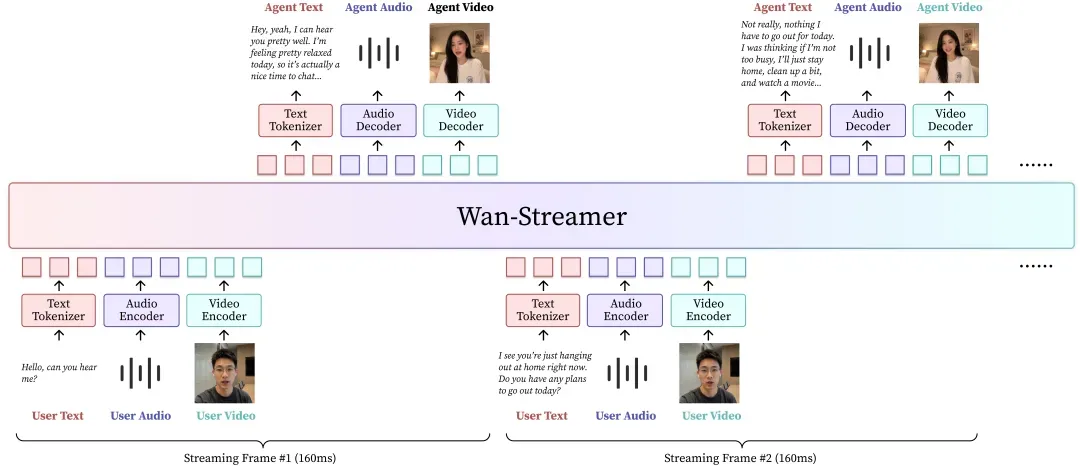
Wan-Streamer总体框架:在同一个Transformer中,语言、音频、视频的输入与输出交错建模,由block-causal attention统筹增量式流式生成。
Thinker-Performer双GPU流水线
为了将模型侧延迟压缩到200毫秒,部署时Wan-Streamer被拆分成两个角色。Thinker GPU负责因果编码、短序列token-causal Transformer计算、KV-cache构建以及上一帧的音视频解码与输出。Performer GPU则专职运行flow-matching求解器,为下一帧生成音视频潜在表示。两个GPU流水线重叠工作,解码与去噪互不阻塞。只要performer的计算时间加上通信开销能塞进160毫秒的流式单元内,系统就能维持实时吞吐。signal-to-signal全路径约200毫秒,叠加大约350毫秒的双向网络延迟后,总交互延迟稳定在550毫秒左右。
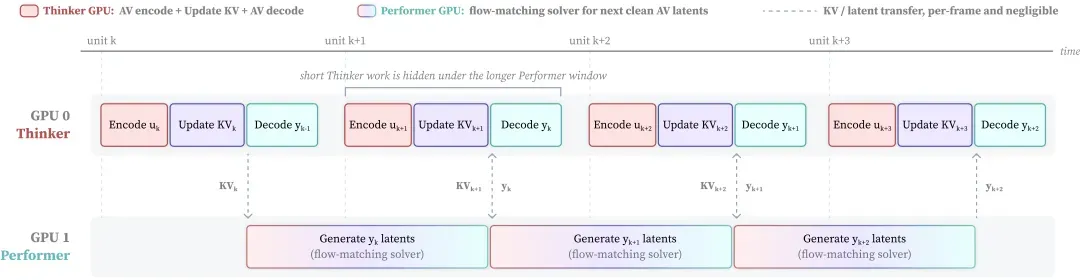
Thinker-Performer并行重叠:当前帧感知、上一帧解码、KV通信与下一帧去噪在相邻的流式单元之间以流水线方式执行。
分阶段训练与滚动蒸馏
训练分为三个阶段。第一阶段是独立任务预训练,模型学习单模态的理解与生成,包括图像转文本、ASR、TTS和视频生成。第二阶段进入端到端交互训练,接触真实的人际对话录音,学习轮次礼仪、打断时机以及长对话中的身份保持。第三阶段是滚动蒸馏,训练学生模型在连续步骤中基于自身的历史输出保持稳定,防止长期生成中出现质量漂移。这一设计值得特别注意:流式推理中,微小误差会在时间累积下导致视频或音频逐渐劣化。Wan-Streamer让学生模型在训练时就模拟这种误差累积,强制其学会自我纠正。
演示内容一览
官网放出了四段未经剪辑的预录演示:中文男声模拟居家的视频通话,聊刮胡子和选电影;中文女声轻松讨论八卦与周星驰的《功夫》;英文疲惫女生在车内对话,诉说自己的疲倦;英文自然对话谈论无意识刷手机和关闭通知。当前v0.1版本的分辨率为192p,25fps,团队表示后续很容易扩展到更高分辨率。更具里程碑意义的是一段实时录屏——左侧用户画面,右侧AI智能体实时回应,下方同步呈现文本流。这是目前唯一公开的端到端实时视频对话演示。
这意味着什么
Wan-Streamer的意义不在于某一项指标的突破,而是证明了一件根本性的事情:全双工音视频交互可以用一个模型原生实现。200毫秒的模型侧延迟让AI的响应速度真正进入人类自然对话的范畴——人类对话中的平均反应时间大约在200至300毫秒之间,Wan-Streamer恰好落在这个区间。可以判断,接下来的领域将明显分化为两条路线:以Wan-Streamer为代表的端到端统一模型将率先在消费级场景落地,如客服、教育、陪伴和直播;而以阿里云百炼数字人API等为代表的模块化编排方案,在企业高度定制化的场景中依然保有优势——客户需要换形象、换声音并细粒度控制每一环节。两条路线并不互斥,但Wan-Streamer的出现无疑将技术天花板向上推了一截。
保持理性:v0.1仍处于早期阶段
v0.1依然是概念验证:192p分辨率、双GPU部署、尚未开源,距离消费级产品还有相当距离。论文中展示的全双工能力目前只在文字描述中体现,演示为预录片段,真实的联网对话中,模型的倾听行为、打断处理以及长时间对话的一致性还需要更广泛的开放验证。