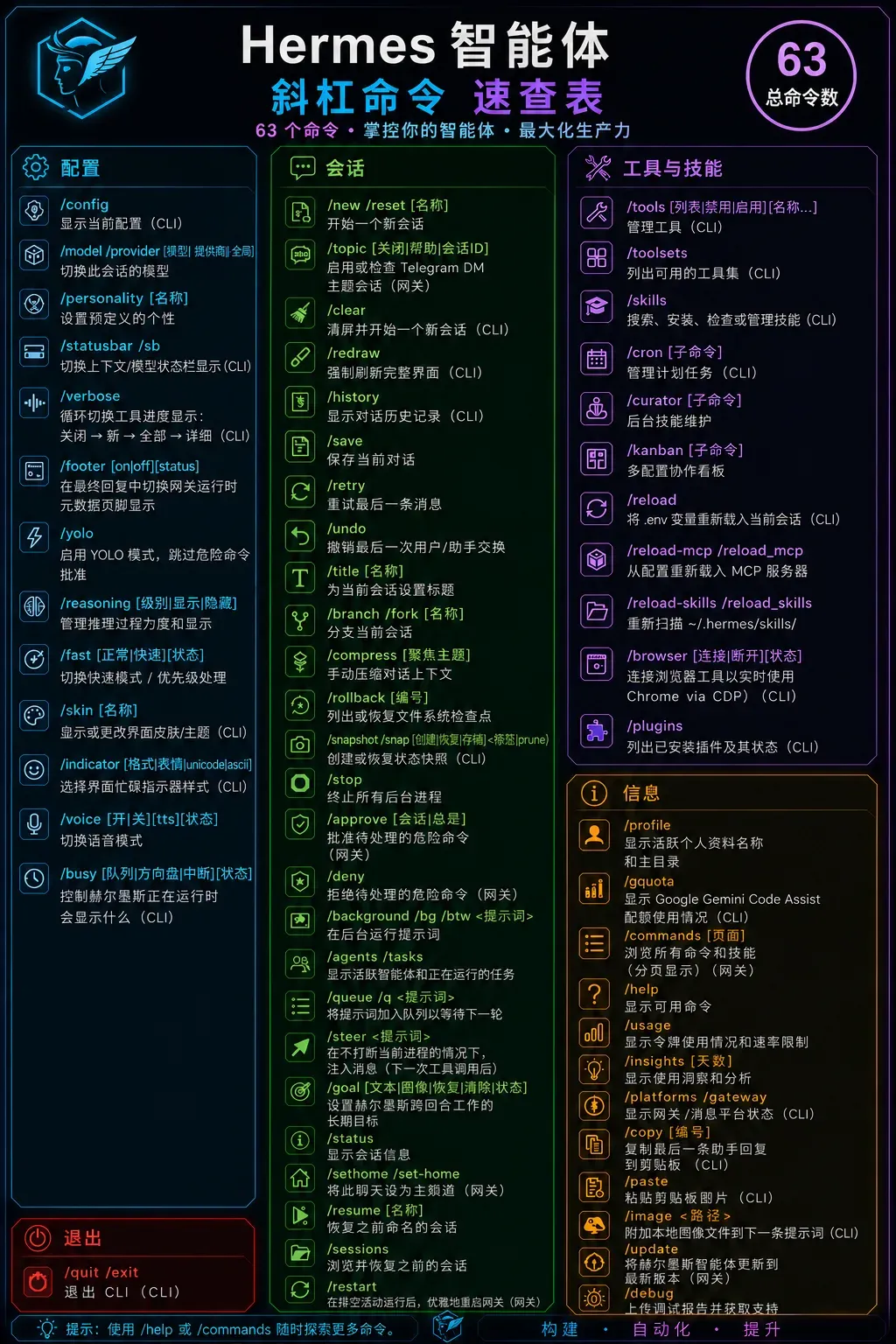
Hermes Agent 60+斜杠命令速记指南:四抽屉结构让你告别死记硬背
直击要点
Hermes Agent 内置了超过 60 条斜杠命令,逐条记录根本不现实。正确的方法在于理解命令框架的“四抽屉结构”——只要记住分类逻辑和核心动词,使用时按“类别 + / + Tab”就能轻松找到。
60+ 内置命令,/Tab 自动补全,这已经是日常的命令行体验。然而命令越记越多,记了又忘,忘了又查,是所有 CLI 用户的常态。Hermes Agent 的斜杠命令多达六十余条,如果只靠死记硬背,一周之内就会混作一团。
但命令不是用来背的,而是用来理解的。这六十多条命令可以被拆成 四个抽屉,每一个抽屉对应一类操作。记住抽屉的结构,比强行记住每一条命令本身重要得多。
命令分类的四大维度
无论打开哪个工具的帮助文档,最先该看的不是命令列表,而是分类。Hermes 的斜杠命令天然地落在四个维度上:
- 会话(Session) — 关于当前对话如何开始、如何保存、如何回溯
- 模型与工具(Model & Tools) — 用什么模型、开什么工具、装什么技能
- 配置(Config) — 人格、主题、语音、推理深度等全局设定
- 信息(Info) — 用量统计、帮助、系统状态
这四类对应四种不同的意图。当你要做某一件事时,先判断它属于哪个抽屉,再到对应的抽屉里寻找具体命令。
第一维度:会话命令——管理对话时间线
会话命令解决的正是“对话生命周期”的问题。记住一个核心原则:会话命令的动词都和时间线相关——开始、继续、撤回、保存、分叉。
/new或/reset— 新建会话(清空历史,生成新 ID)/resume [名称]— 回到之前命名的会话/title [名称]— 为当前会话命名,方便后续/resume/retry//undo— 重试上一条 / 撤回上一轮交换/save//history— 保存到磁盘 / 查看对话历史/compress [焦点]— 手动压缩上下文(把记忆落地、对话总结)/branch//fork— 从当前对话分叉,探索另一条路径/background [提示]— 后台运行一个任务,不阻塞当前对话
速记方法:想象一条从左到右的时间线。/new 在最左侧,/resume 是跳回时间线上的某一点,/save 好比拍张快照,/branch 则是分出岔路。理解了时间线,这些命令之间的关系就一目了然。
Hermes Agent与OpenClaw双修全攻略:从原理到安装,一文读懂自我进化型AI Agent

本文概览
第一部分 解密 Hermes Agent:会自学的 AI 助手
第二部分 Hermes 与 OpenClaw 架构对比
第三部分 手把手安装 Hermes Agent
第四部分 如何选择:Hermes 还是 OpenClaw?
第五部分 总结与思考
全文约4000字,阅读约需10分钟。
OpenClaw(常被称作“龙虾”)的浪潮还未平息,Hermes Agent 已强势入场。AI 圈永远没有空窗期,只有不停歇的更新迭代。
这款由 Nous Research 推出的开源项目,采用 MIT 许可证,主打开源优先和去中心化理念,迅速吸引了大量原本使用“龙虾”的用户,将目光投向了它。
第一部分:解密 Hermes Agent:会自学的 AI 助手
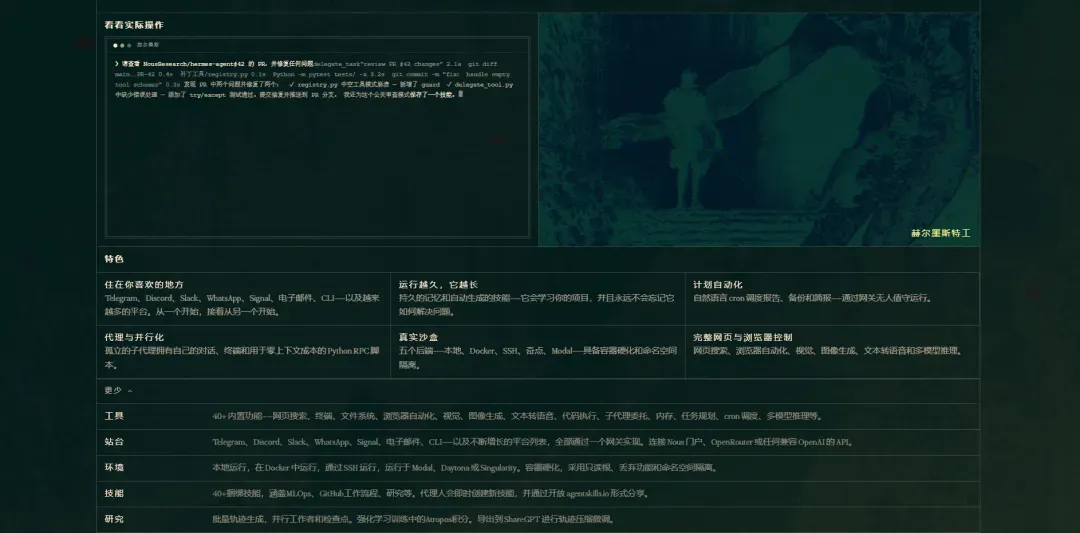
Hermes Agent 最亮眼的设计在于,它试图打造一个 越用越聪明的 AI 代理,并内建了完整的学习循环。
多数 Agent 框架遵循“接收任务 → 规划 → 执行 → 返回结果”的流程,而 Hermes 在这条链路的末端,额外植入了关键步骤:
接收任务 → 规划 → 执行 → 评估 → 提取模式 → 生成技能 → 下次更优
oh-my-claudecode:为Claude Code装上多智能体大脑,让AI自主规划、并行执行、省钱高效
Claude Code 已经很强了,但如果我们能让它“自己规划任务、自己调度团队、自己重试直到成功”呢?
oh-my-claudecode 正是这样一个多智能体编排插件:它赋予 Claude Code 5 种执行模式、32 个专业 Agent,并且完全不需要额外学习。
01 项目简介:它到底解决了什么问题?
Claude Code 原生的交互方式是“一问一答”,你指挥一步,它执行一步。oh-my-claudecode 则在其之上叠加了多智能体编排层,把复杂任务拆解开,分派给专业 Agent,支持并行推进,并自动重试。
它精准击中了三个核心痛点:
- 复杂任务缺乏全局规划:原版 Claude Code 需要你手动拆解步骤,而插件能够自动将任务分解并交给相应专家 Agent
- 并行处理能力不足:原生模式是串行执行,插件可以实现 3-5 倍的并行加速
- 成本使用不够精细:插件会智能路由模型(简单任务用 Haiku,复杂任务用 Opus),平均可节约 30-50% 的 token 消耗
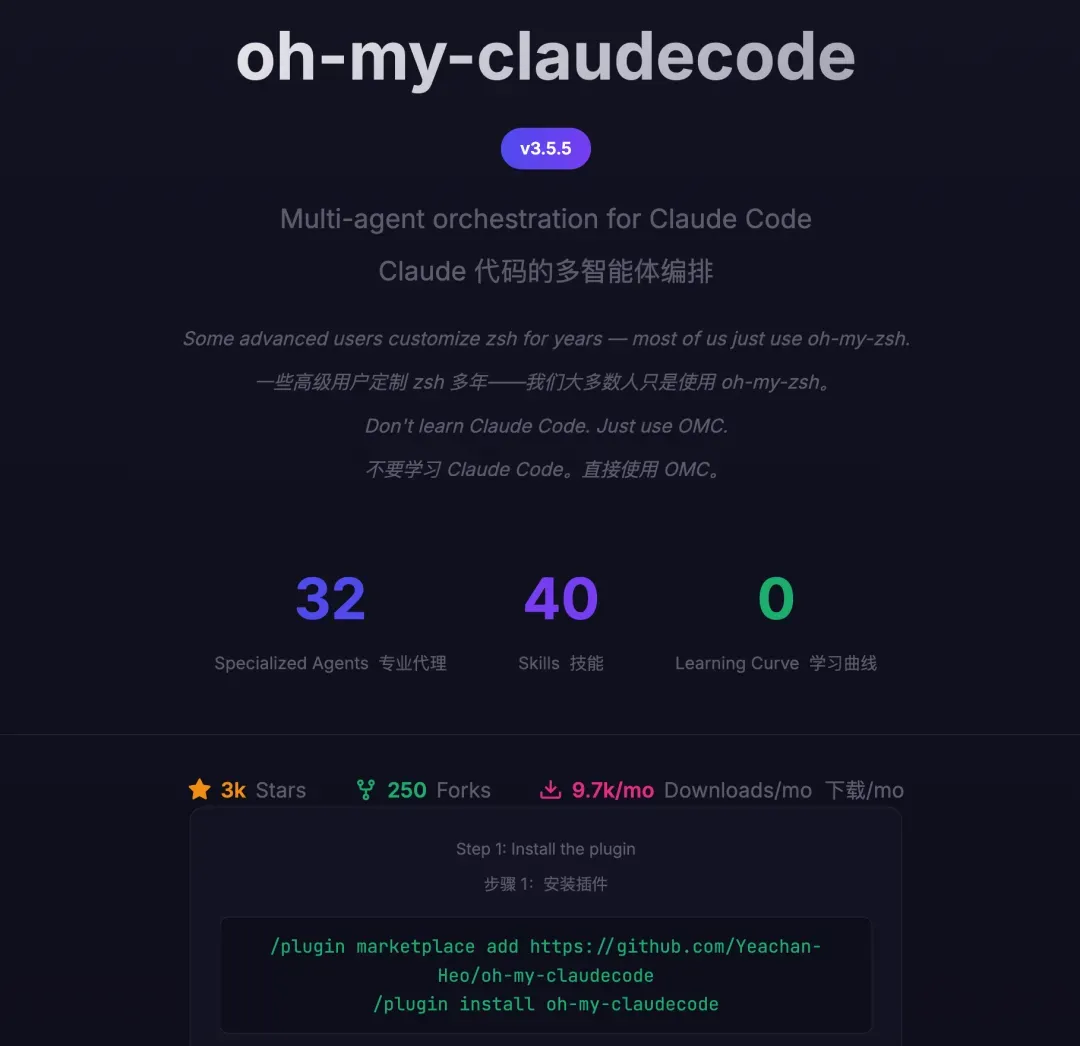
1.1 几个关键概念快速扫盲
- Claude Code:Anthropic 官方出品的命令行工具,让你在终端里直接让 Claude 写代码、调试、重构。oh-my-claudecode 则是它的增强插件。
- Multi-agent Orchestration:多智能体编排,可以理解成“项目经理 + 专业团队”。一个负责拆解任务,分配工作,多个专业 Agent 各自领走自己擅长的部分。
- Magic Keywords:魔法关键词。插件内置了
autopilot、ralph、ulw、eco、plan等快捷指令,告别复杂的命令记忆。 - Model Routing:智能模型路由。根据任务的难度自动选择模型(Haiku 或 Opus),既高效又节约成本。
02 核心功能
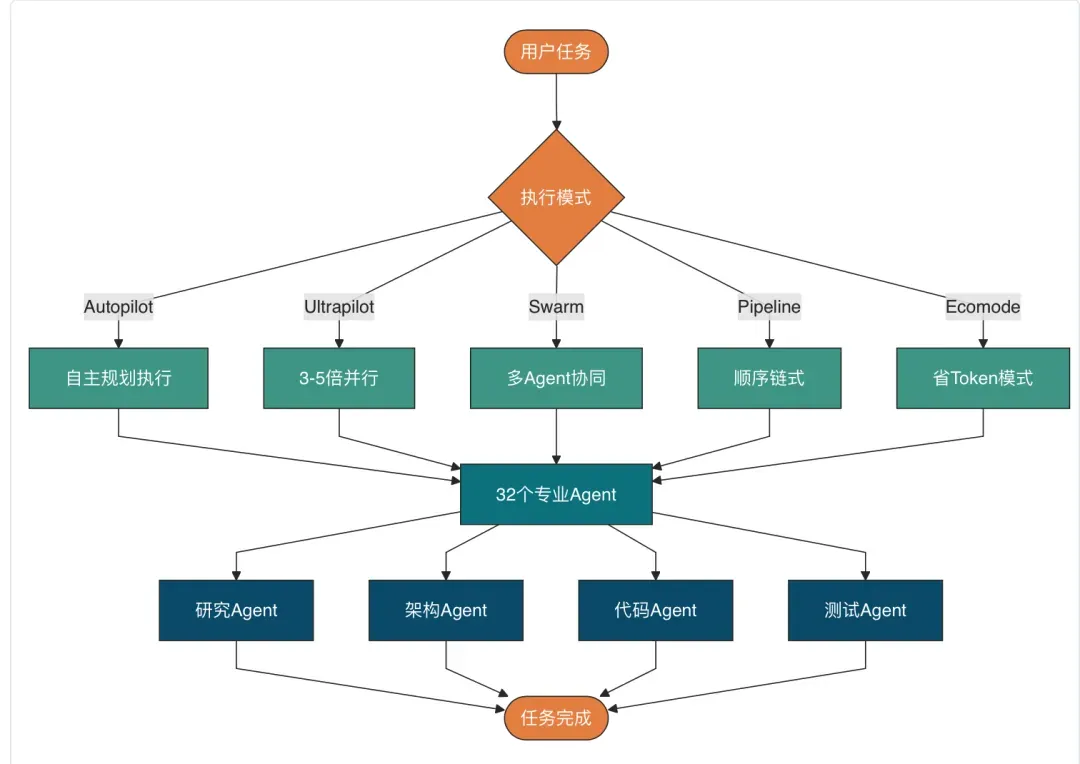
2.1 五种执行模式,覆盖所有工作流
| 模式 | 速度 | 适合场景 | 解析 |
|---|---|---|---|
| Autopilot | 快 | 全自主工作流 | 给定目标,自动规划、执行、验证 |
| Ultrapilot | 3-5 倍加速 | 多组件系统 | 最大化并行,同时处理多项独立任务 |
| Ecomode | 快且省 30-50% | 预算敏感项目 | 简单任务用 Haiku,复杂任务才动用 Opus |
| Swarm | 协同执行 | 并行独立任务 | 多 Agent 各司其职,互不阻塞 |
| Pipeline | 顺序执行 | 多阶段处理 | 按阶段顺序进行,前一步的输出是下一步的输入 |
实际体验:
OnlySwitch:Mac菜单栏极简主义利器,一键整合40+系统开关
你的 Mac 菜单栏是不是已经挤满了各种小图标?AirPods 连接器、暗黑模式切换、隐藏桌面图标、屏幕保持常亮……每个功能都装一个独立 App,结果顶部菜单栏比股票交易大厅还热闹。
直到我发现了一个叫 OnlySwitch 的开源项目——它把所有这些常用功能全部整合进一个菜单栏图标里,点击就能展开 40+ 个开关,还支持快捷键、桌面小组件、甚至 AI 控制模式。
更让我惊喜的是:这是一款完全免费开源的工具,在 GitHub 上收获了 5.4k+ Star,并且支持 18 种语言(包括中文),更新频率相当活跃。
01 菜单栏极简主义,为什么非它不可?
说句大实话:Mac 的菜单栏空间寸土寸金,但很多系统功能的切换入口却藏得特别深。
现实痛点很直接:
- 功能分散:开关暗黑模式要去"系统设置 → 显示",隐藏桌面图标要右键桌面,连接 AirPods 要点蓝牙图标……每次操作都要回忆三秒钟"在哪儿来着"。
- 菜单栏爆炸:为了方便,你安装了一堆小工具(Hidden、Dozer、监控 App),结果菜单栏比股票交易大厅还热闹,真正重要的图标反而被挤得看不全。
- 效率低下:有些高频操作(比如"开会时快速静音麦克风"“演示时隐藏桌面图标”)需要多个步骤,开会前一分钟还在手忙脚乱地调整。
OnlySwitch 的解决思路很直接:把所有常用开关塞进一个菜单栏图标,点击展开就能看到全部功能,支持快捷键触发,还能把常用功能做成桌面小组件。
02 详解 OnlySwitch:它到底是个什么神器?
一句话定义
OnlySwitch 是一款All-in-One 风格的 macOS 菜单栏开关管理工具,提供 40+ 个原生开关,支持快捷键、桌面小组件、自定义脚本和 AI 控制。
核心功能
OnlySwitch 的亮点可以概括为四个方面:原生开关丰富、快捷键支持、扩展能力强大、AI 控制模式。
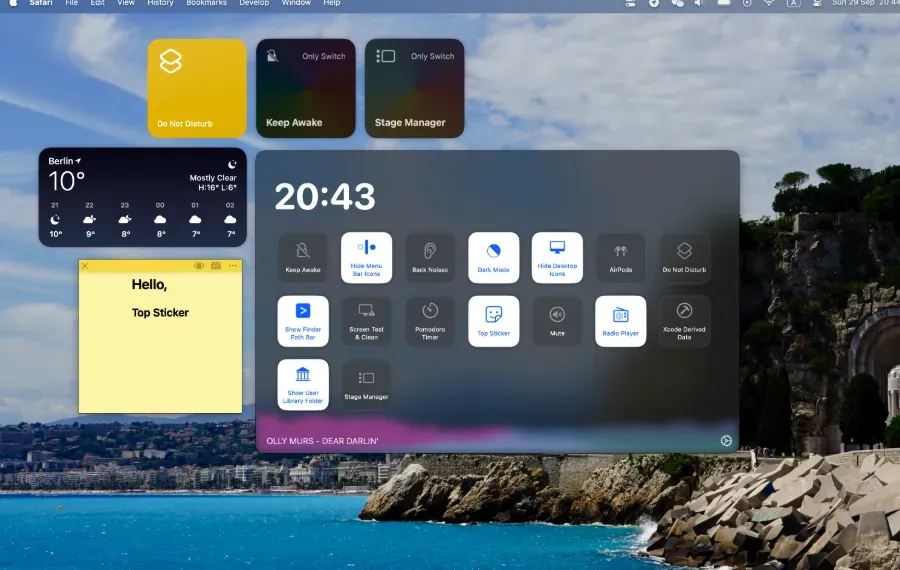
在原生开关层面,它提供了 40+ 个常用功能的快速切换。包括隐藏 MacBook 刘海、暗黑模式、AirPods 连接、屏幕保持常亮、隐藏桌面图标、静音麦克风、显示隐藏文件、清空废纸篓、 Spotify/Apple Music 控制、屏幕测试与清洁、番茄钟计时器等。这些功能覆盖了日常使用 90% 的场景需求。

在快捷键层面,它允许为每个开关绑定全局快捷键。你可以设置 ⌘ + ⇧ + D 快速切换暗黑模式,或者 ⌘ + ⇧ + A 快速连接 AirPods。对于键盘流用户来说,这意味着不用把手从键盘上移开就能完成大部分操作。
OpenClaw龙虾如何引爆一人公司创业潮:AI自主Agent重塑组织与个人能力边界
01 公司为什么存在?
“龙虾”这一类自主Agent能力的跃迁,使OPC(One Person Company)迅速成为焦点。伴随关注度升温,各地官方也开始积极推动OPC创业。
很多人仅仅把OPC当作“小公司”或“个体创业”,但这远没有触及本质。要真正理解OPC,先要回到一个根本问题:公司到底为什么而存在?
最常见的答案可能是“合作”。然而更精确的说法是,公司的本质是用一种组织架构来弥补个体能力的局限性。
一个人的精力、学习速度和所能完成的任务范围都是有限的。因此,任何复杂的业务都需要被切分——有人做产品,有人跑销售,有人搞运营。分工一旦形成,协调就变成必要,于是流程、管理层级和各种制度应运而生。效率确实提升了,却同时带来了沟通成本、管理成本和协同摩擦。一个任务在多个角色之间传递,信息不断被转译,推进速度被拖慢,决策也被层层稀释。
更要紧的是,传统公司起步本身就需要招人、搭班子、融资,这些门槛所形成的压力,极大抑制了普通人创业的积极性。
02 龙虾带来的改变
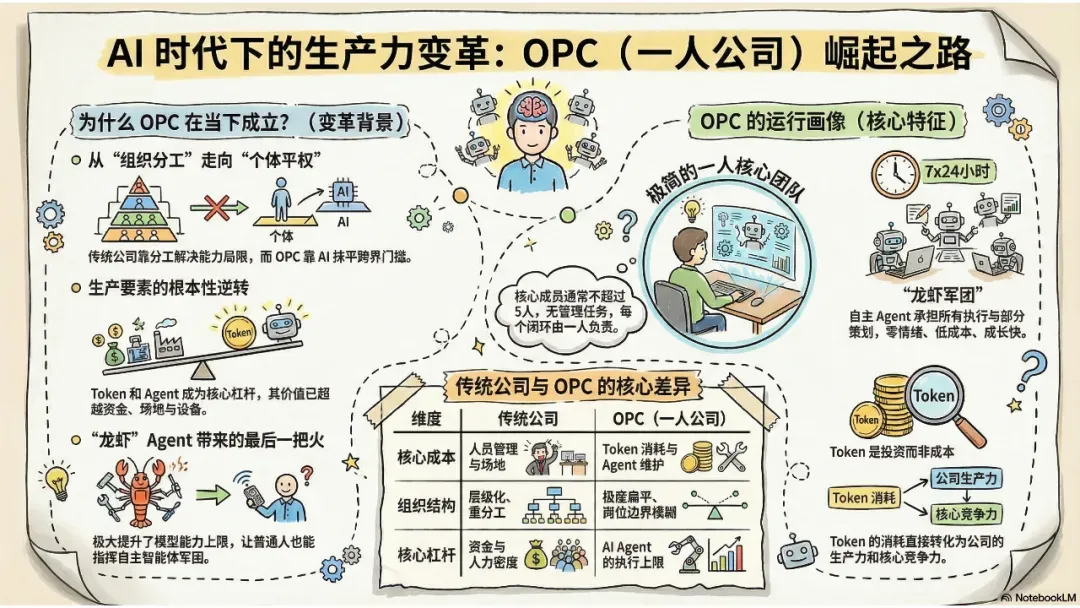
以OpenClaw(龙虾)为代表的自主Agent,正展现出一种全新的“工作能力”:连续执行任务、自主纠错、处理模糊指令,并且能够7×24小时不间断运转。更关键的是,这种能力不再被少数技术团队垄断,而是直接交到了每一个普通人手里。原先需要工程师和产品团队才能搭建的东西,如今一个人就能直接调用。
有了龙虾作为能力杠杆,跨界变得异常轻松。过去严格的职能分工是因为个人能力存在天花板,但现在,一个人可以同步推进产品设计、技术实现和运营推广等多个方向,组织协作的刚性需求被大幅削弱。一个人带着一群Agent,就能完成过去一个完整团队才能覆盖的工作闭环,这直接让OPC从概念走向现实。
03 OPC是一种新的组织形态

OPC把公司从复杂的层级结构中拉回到“一个核心主体 + 一组可协作的Agent”的形态,由此带来的改变主要集中在三个方面:
个体的能力边界被显著拓宽。跨领域不再遥不可及,一个人可以同时驱动产品、技术和运营等不同业务线,这种复合能力也直接映射到公司本身的生存能力上。
资金门槛迅速下降。生产成本变得更低,试错变得轻量化,Agent的使用成本远低于传统的人力配置。过去很多必须“先投入、再验证”的事情,现在可以边跑边调整,风险和成本都变得可控。
组织形态也在急剧收缩。团队规模更小,层级极简,刚性分工被打破,岗位边界逐渐消融。以往围绕“管理人”的能力开始弱化,而“做出判断、确定方向”的能力变得越来越核心。
OPC的团队人数通常不超过五个,很多情况下甚至不需要专门的人事管理。每个人的职责相对独立,工作交叉少,真正需要频繁沟通的场景并不多见。在整个业务闭环中,往往只出现一位关键负责人。
因此,OPC真正考验的是认知密度,难点在于你是否能持续做出高质量的决策。Agent可以同时推进多条线索,大量信息不断涌入,如果没有足够清晰的判断框架,就很容易陷入混乱。
04 Token,是新的生产资料
过去公司依赖人力、时间和组织运转;在AI时代,产出依赖于token。每一次调用、每一轮执行都在消耗token,同时也直接转化成结果。投入和产出之间的关联前所未有地紧密。
token用得越频繁,产出就越密集;试错成本极低,一个想法可以被迅速验证。不舍得燃烧Token的OPC,就像一家舍不得开灯的工厂,省下的不是成本,而是机会。
自主Agent,尤其是像龙虾这样的工具,让一个人能够跨界完成曾经需要一个团队才能完成的工作,严重冲击了传统的组织形态,同时极大降低了资金门槛,使得OPC在AI时代真正成为可能。
随着这股趋势持续升温,线下已经涌现出真实的创业浪潮。不过在热闹背后,更需要认识到未来的市场可能会更加细分。OPC时代真正稀缺的,并不是“会用AI”的能力,而是独立的判断、审美品味,以及对自己究竟想要什么的清醒认知。
OpenWork:开源可审计的本地AI代理桌面应用,重塑Claude Work体验
体验过 Claude Work(Anthropic 推出的 AI 工作助手)的人,大多会被它流畅的交互所折服:无需在终端中死记硬背命令,也不必从成堆的脚本输出里大海捞针——你只要选定工作区、输入任务,然后安静地看着 AI 一步步完成;遇到需要确认的敏感操作时,点击授权即可。整个过程更像是在使用一款精心设计的产品,而非一堆拼凑起来的工具链。
然而,它的局限性也同样突出:Claude Work 所提供的,本质上是一个优雅却封闭的“云端闭源产品体验”。当你开始考虑数据掌控权、操作可追溯性、能力可扩展性这类工程化需求时,就会发现很难将其无缝嵌入团队的现有体系。
这正是 OpenWork 存在的价值。
OpenWork 是一款开源的“类 Claude Work”桌面应用:底层由 OpenCode 驱动,上层则提供清晰的引导式界面,把“选取工作区 → 启动任务 → 实时查看进度/计划 → 处理权限 → 复用模板/技能”这一完整链路包装成可交付的产品。它让代理式工作(agentic work)变得更像一个可控、可复用、可持续运转的工作系统,而不是终端里一次性的试验。
01 为何需要 Claude Work 的替代方案?
Claude Work 的确强大,但这份强大更多体现在精巧的产品形态与生态闭环上。对于个人试用来说的确足够舒服,可一旦涉及安全合规、工程管理或者深度定制需求,其短板立刻暴露:
1)闭源带来的不确定性
封闭的代码库让你几乎无法:
- 自行审计数据如何流转、如何存储
- 自定义工作流和能力边界
- 按照团队规范进行二次开发和集成
2)高度依赖云端
当任务执行、历史记录、数据存储全部集中在云端时,很多隐忧自然浮现:
- 合规压力(特别是涉及企业代码、客户资料、敏感文档)
- 网络稳定性与持续成本
- 供应商锁定(流程、数据、使用习惯全部绑定在一款产品上)
3)扩展性受产品策略制约
你想添加“技能”——比如接入公司内部接口、封装一套固定工作流,或者安装一个 OpenCode 插件时,闭源产品往往要么不开放、要么只提供有限的支持,最终你只能“凑合着用”。
如果你更看重本地运行、操作可审计、自由扩展,那么 OpenWork 所瞄准的方向,正好填补了这些需求。
02 OpenWork 是什么?
OpenWork 是一款可扩展的开源桌面应用,带有 Claude Work 风格的工作流: 它在桌面端将 OpenCode 的能力精心组织为清晰的任务流——选择 workspace,启动 run,实时查看执行情况与计划变动,必要时处理权限请求,最后把高频操作沉淀为模板和技能。
RTK开源工具:四层压缩策略化解Token焦虑,命令输出成本直降80%
不久前,一位开发者用 Claude Code 重构一个老项目,干了一下午,效果不错——代码改动完成,测试通过,Git 提交也正常进行。
但当他顺手查看 token 用量时,直接傻眼:一个下午竟然烧了 6000 多万 token,套餐余额告急。
明明只改了几十个文件,怎么消耗这么多?翻看对话历史才恍然大悟,真正的“罪魁祸首”根本不是自己写的代码,而是那些命令输出。
npm install跑一次,依赖树打印几百行;cargo test执行完,99% 的通过信息全是绿色文字;git status列出一堆 untracked 文件——这些内容全被原封不动地塞进了 LLM 的上下文窗口。
而 AI 真正需要的信息,可能只有 5%,剩下 95% 都是毫无价值的日志噪音。
如果您也遇到过类似的问题,那 **RTK(Rust Token Killer)**这个工具值得您花三分钟了解一下。

需要提前说明一下:RTK 的本质是做一种权衡——用更少的上下文,换取更低的成本。在大多数场景下,被压缩掉的都是“噪音”,对结果影响很小;但在极少数需要完整上下文的场景(比如复杂调试),或许需要手动查看原始输出。
本文接近 6000 字,建议收藏,通过本文您将掌握:
- RTK 的四层压缩策略:每种策略分别针对什么类型的命令输出,如何实施压缩
- Auto-Rewrite Hook 的工作机制:RTK 如何在不改动主循环的情况下透明拦截命令输出
- 真实的 token 节省数据与成本换算:省下来的 token 到底值多少钱
- 与其他省 token 方案的对比:不同场景该选用什么工具
RTK 是什么
RTK是一个用 Rust 编写的 CLI 代理工具,专门为 AI 编程助手设计。它的定位十分清晰:在命令输出到达 LLM 之前做一轮智能压缩,去除噪音,只保留信号。
用一句话概括它的设计哲学:您照常使用 Claude Code,照常执行命令,只是 token 消耗在不知不觉中降下来了。
因为是用 Rust 编写的,RTK 的启动延迟不到 10ms,内存占用不足 5MB,单一二进制文件,零依赖。这些特性意味着它几乎不会成为您工作流中的负担。
Screen Studio太贵?试试这款免费开源的录屏神器OpenScreen
Screen Studio 虽然被很多用户视为产品演示视频的首选,但 每月29美元的订阅费 让相当一部分人停下了尝试的脚步。
现在,OpenScreen 以开源替代方案的身份出现了:完全免费、零水印、允许商用,它整合了屏幕录制、手动缩放、裁剪、注释、背景美化等一系列核心能力——足以满足那些只想“做一条好看的产品演示”的朋友。
- Screen Studio:体验出色,但价格不菲
如果你曾制作过产品演示、技术教程,或者只是希望录出一段“漂亮”的屏幕视频,多半听说过 Screen Studio。它最吸引人的地方在于:
- 光标智能跟随与自动缩放:让观众的注意力始终聚焦在你操作的位置
- 丝滑流畅的动效:缩放、平移自然而顺畅
- 一键美化:通过背景、阴影、圆角等元素,瞬间打造“苹果风”质感
然而绕不开的成本是:$29/月或 $89 永久买断。对于偶尔录制一段视频的用户而言,这个定价确实有些高。
- OpenScreen:为谁而生?
OpenScreen 是一个开源的屏幕录制与美化工具,目标很明确——成为 Screen Studio 的“免费简化版”。
作者在项目里诚恳地写道:
“这不是 Screen Studio 1:1 的克隆。如果你需要全部高级功能,我建议去支持原版(他们做得真的非常出色)。但如果你只想要一个免费、开源、够用的工具,OpenScreen 就是为你准备的。”
2.1 主要亮点
| 特点 | 说明 |
|---|---|
| 完全免费 | 没有订阅,没有一次性购买,也没有隐藏消费 |
| 无水印 | 导出的视频干干净净,不带任何标记 |
| 开源 | 采用 MIT 协议,代码完全透明 |
| 支持商用 | 无论是个人项目还是商业用途,都放心使用 |
| 跨平台 | 同时支持 macOS、Windows 与 Linux |
- OpenScreen 能做什么?
3.1 录制功能
- 全屏录制:捕捉整个屏幕的内容
- 应用窗口录制:只录制你指定的某个应用窗口
3.2 编辑功能
完成录制后,OpenScreen 提供了一系列实用的编辑操作:
| 功能 | 说明 |
|---|---|
| 手动缩放(Zoom) | 自由添加缩放效果,并自定义深度、位置与时长 |
| 裁剪(Crop) | 将屏幕上不想展示的区域隐藏掉 |
| 片段修剪(Trim) | 剪掉视频中多余的部分 |
| 运动模糊(Motion Blur) | 让缩放和移动看起来更加平滑自然 |
| 注释(Annotations) | 轻松添加文字、箭头、图片等标注 |
Warp开源即爆火:Rust驱动的AI终端5万星深度解析与终端横评
Warp 已在 GitHub 正式开源,不到 10 小时便收获 3.2 万星,截至目前已突破 5.14 万星,这一数字在开发工具领域相当震撼。
Warp 本质上是一款功能极度丰富的现代终端,AI 能力只是锦上添花,但功能丰富的代价是资源占用在同品类中处于最重一档。 无论你是否使用它的 AI 功能,都需要接受约 200 MB 以上的内存占用。
AI 功能是否好用暂且不论,对绝大多数开发者来说,终端最核心的需求就两个字——快和稳。Warp 在基础性能上确实做得不错,即便关闭所有花哨功能,Block 模型带来的交互体验也让人很难再回到过去。不过,不少用户最近已开始评估切换至 Ghostty,后续我们会进行实测并分享体验。
本文接近 6500 字,建议收藏。阅读后你将深入了解:
- Warp 的四个核心设计:Block 模型、AI 原生集成、Agent 调度中心、自研 GPU UI 框架,各自解决了哪些痛点
- 为什么要开源:创始人给出的三个理由及其背后的商业逻辑
- 2026 年终端生态全景对比:Warp、Ghostty、Kitty、Alacritty、iTerm2 五款终端如何选择
- 真实使用体验与局限:长期用户踩过的坑
Warp 的诞生背景与定位
先说一下背景。Warp 的创始人 Zach Lloyd 来头不小,他曾是 Google 的首席工程师,参与并领导过 Google Sheets 相关工程,还担任过 TIME 的临时 CTO。2020 年,Zach 创办 Warp,希望从零重做每个开发者每天都会使用、但长时间缺乏变化的终端。
为什么是终端?因为在 Zach 看来,终端和代码编辑器一样,是几乎每个开发者每日必用的工具,但终端的核心交互模型已很久没有本质变化:输入命令、等待输出、滚动查看、再输入。Warp 官方也指出,现代终端本质上仍在模拟早期的物理终端,许多体验数十年如一日。
Warp 从 2020 年开始开发,主体采用 Rust 构建。2022 年 4 月,Warp 首次公开发布 macOS Beta;2023 年 3 月加入 Warp AI;2024 年 2 月正式登陆 Linux,随后扩展至 Windows;2026 年 4 月,Warp 正式宣布客户端开源。
WorkBuddy + DeepSeek V4:一键生成五一打卡清单,腾讯文档秒同步
五一假期出游的懒人福音来了!用AI工具WorkBuddy,一句话就能自动生成专属打卡清单,手机端直接查看,连攻略都不用自己翻。
没错,就算在人挤人的五一,我也没停下实战笔记的分享。其实这趟行程我提前就用AI全部安排好了,临行前轻松搞定,现在我人已经在路上了!
WorkBuddy刚完成一波更新,专家中心就悄悄上线了一个新角色——美团生活助手,还特别标注了“五一旅游推荐”,显然是专为假期准备的。
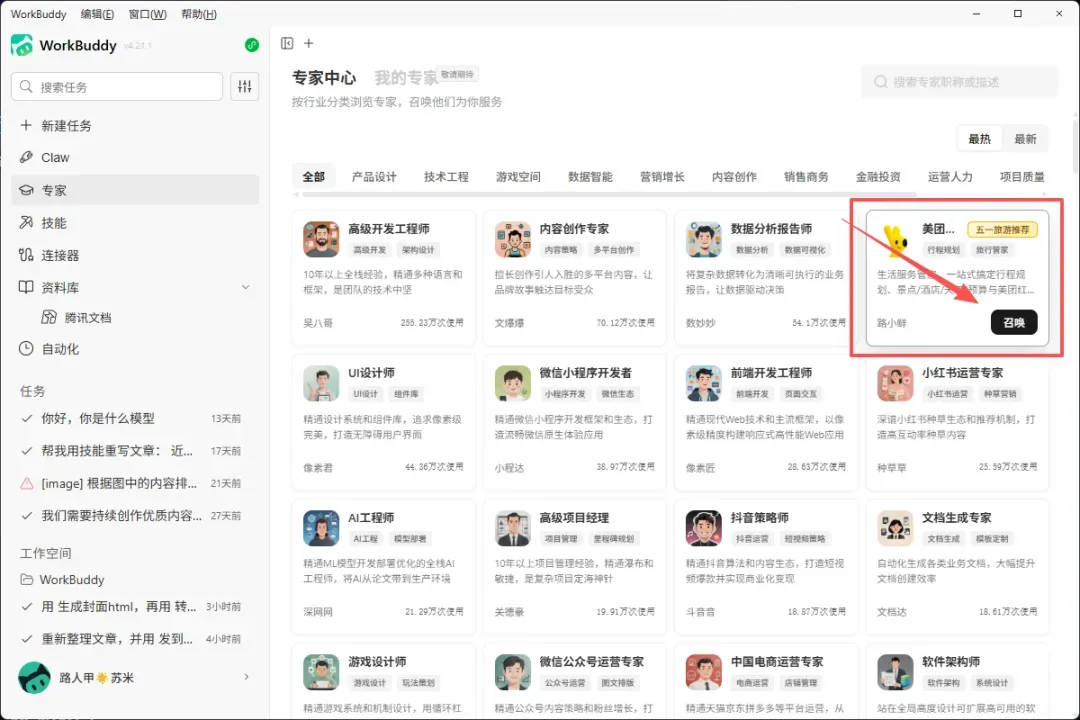
不用再自己去查零散的攻略,配合最新上线的DeepSeek V4模型,只需要一句自然指令,就能直接生成全套行程单。
调用专家与DeepSeek V4模型
迫不及待地想体验下?让专家中心的美团助手给我定制一份五一旅游规划,同时启用最新出炉的DeepSeek V4模型,看看能碰撞出怎样的火花。
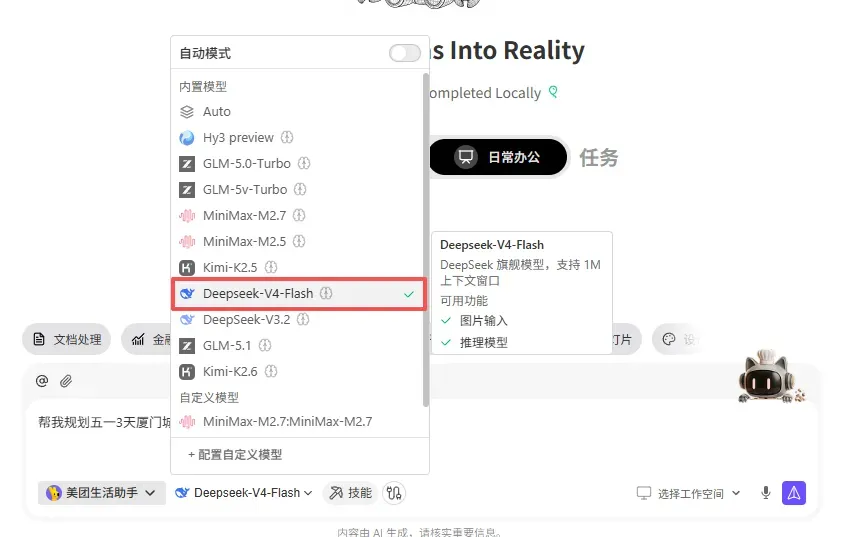
只用一句话下发任务,行程规划瞬间呈现。

一键授权同步腾讯文档,告别电脑
难道出门还要背台笔记本?想把排好的行程分享给家人怎么办?别发愁,WorkBuddy刚刚打通了腾讯文档,提供一键授权连接,彻底解决这个痛点。
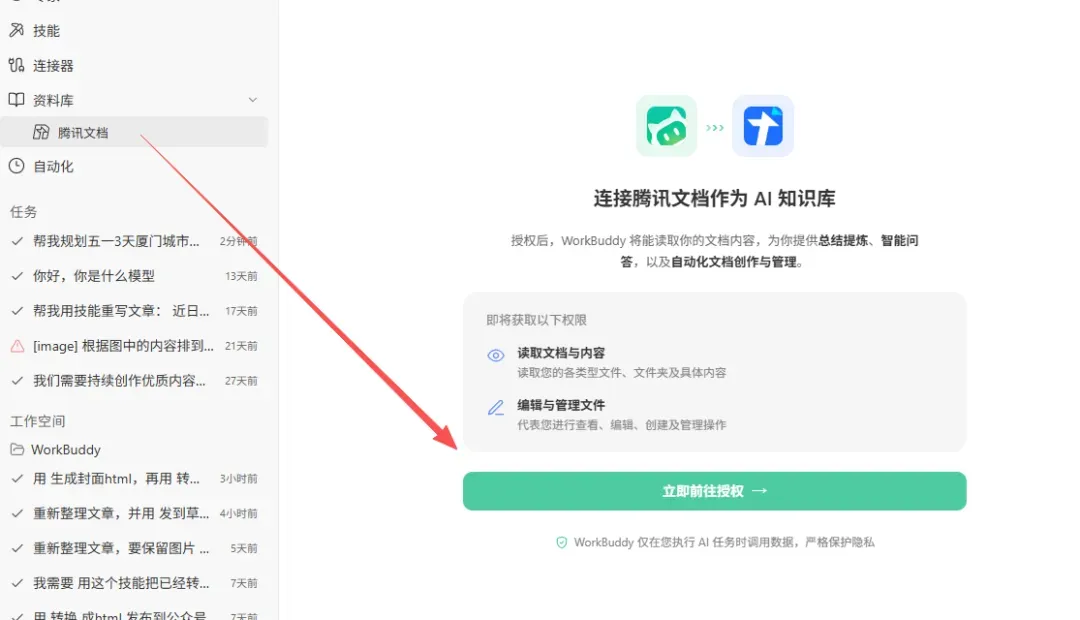
只需用手机扫一扫完成授权,腾讯文档的创建、编辑、查看、管理等权限就全部到位了,全程不需要打开电脑。
继续对着WorkBuddy说一句“把行程整理到腾讯文档”,剩下的事交给它。
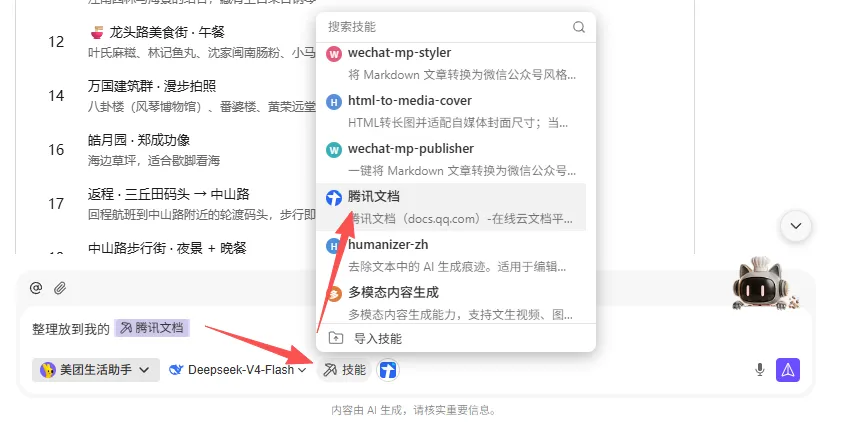
搞定!行程已经自动写入新建的在线文档。

现在拿出手机,打开“腾讯文档”小程序,刚刚创建的行程文档就安静地躺在列表里。点开即可查看,还能直接转发到家庭群,全家人都能同步出行计划。

还能更进一步:秒变旅游打卡清单
眼下特种兵式打卡旅行不是很火吗?那就直接把行程单改造成“打卡清单”样式。

每完成一项就☑️划掉,旅途进度一目了然。
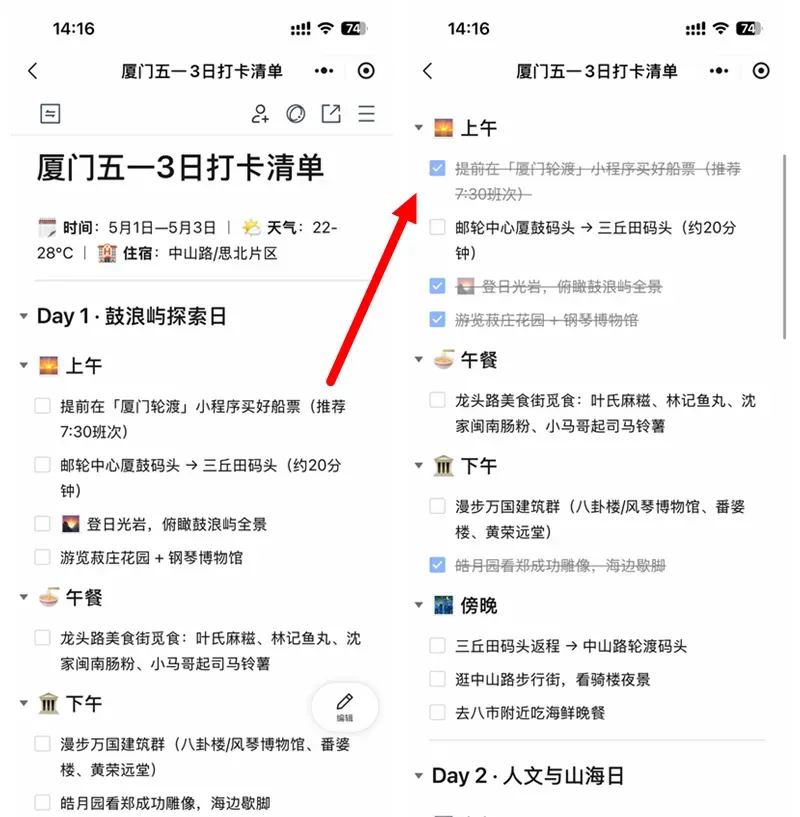
今天的实战笔记虽然短小精悍,但绝对干货。核心思路就是要把AI工具的能力压榨到极致——省下查攻略、做表格的时间,出发前多睡半小时不香吗?学以致用,赶紧动手试试吧!祝大家五一玩得开心~