WorkBuddy 涨价背后的积分博弈:免费套餐能不能挺住?省赚秘籍教你从容应对154%涨幅
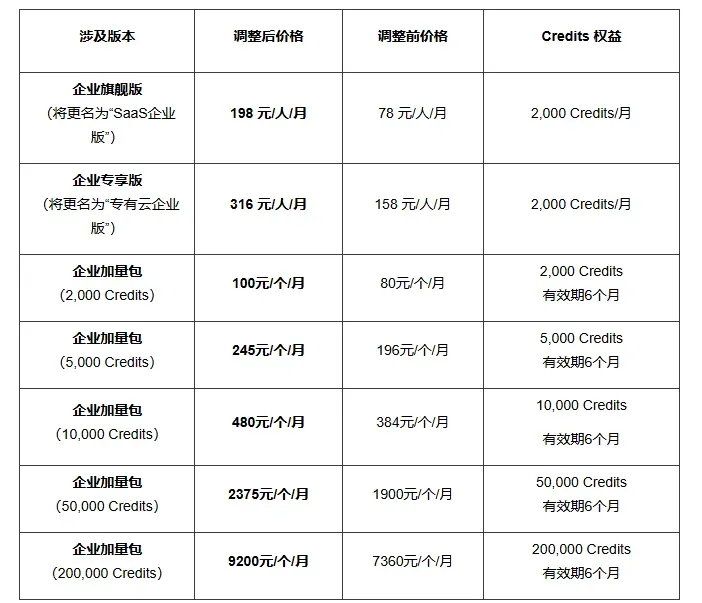
腾讯云近日发布了 CodeBuddy、WorkBuddy 计费方案调整公告。其中企业旗舰版将更名为“SaaS 企业版”,企业专享版将更名为“专有云企业版”,新计费方案定于 2026 年 5 月 15 日起执行。
腾讯云 CodeBuddy & WorkBuddy(5 月 15 日生效)
- 企业旗舰版:78 元/人/月 →198 元/人/月,涨幅约 154%
- 企业专享版:158 元/人/月 →316 元/人/月,涨幅约 100%
- 企业加量包同步上调约 25%
不久前,我的日常小任务几乎都交给了 WorkBuddy,没想到转眼就宣布涨价~
不过今天这篇文章的重点不在于如何挑选套餐,对于像我这样用量不大的用户,如何以最低成本把工具用到极致才是真正要解决的问题。
首先,核心思路就一个字:省!
如果掌握了下面要说的两招,只要 WorkBuddy 免费套餐还在,就根本不需要纠结该选哪个套餐。相关详细图文教程可以参考以往发布的“WorkBuddy 积分节省指南与自定义模型教学”(可自行搜索查阅)。
第二大要点是:赚!
下面这些就是我最近积攒到的:
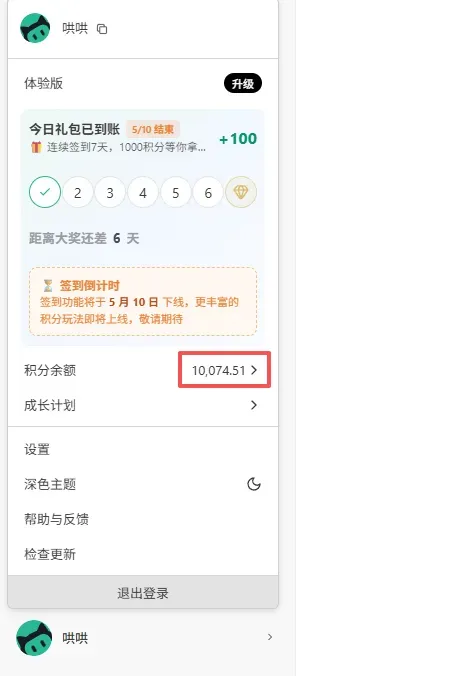
积分究竟怎么赚到手?
每日签到可领 100 积分,连续签到满 7 天还能额外再拿 1000。
请注意:签到活动将在 5 月 10 日截止(直到快下线才通知,好在之前已有“WorkBuddy 安装后必做的几件事”帖子提醒过大家,可回溯参考)。
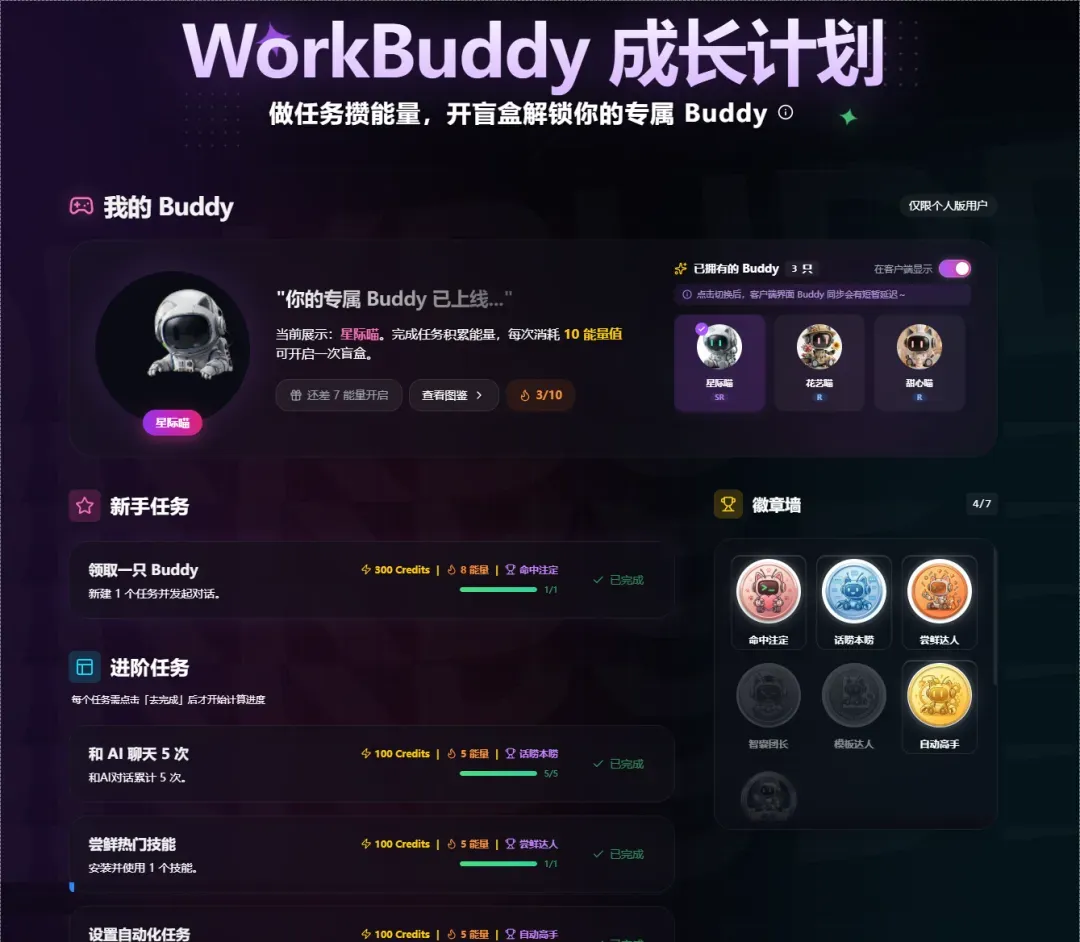
如果签到入口关闭了,也不要着急!除了签到,最新的成长计划里还安排了各式各样的任务:
把能完成的任务全部做完——
前期赠送的积分相当于“免费试玩”,等活动一结束,就得实打实地掏钱了。更何况,现在各大模型厂商的 Token 价格也在持续走高。
所以,现在请立刻完成这几件事:
- 马上签到:坚持连续 7 天,一共能领到 1700 积分。
- 清完任务:把“成长计划”里的所有项目都刷一遍。
- 牢记截止日:死盯 5 月 10 日这个最后期限。
WorkBuddy进阶实战:6个高阶技能助你突破办公效率瓶颈
在上一期内容中,我们介绍了打工人必备的四个核心技能:docx、pptx、xlsx 以及 腾讯文档,借助 WorkBuddy 已经能轻松应对日常大部分工作。可实际工作中总会冒出一些“硬骨头”——扫描版合同需要提取条款,竞品数据分散在十几个网页里,临时需要一张配图却翻遍素材库也找不到合适的……这些进阶场景,单靠基础技能很难摆平。为此,我们整理了6个进阶技能实操,帮你把 WorkBuddy 的能力天花板再向上抬一个档位。
下面进入实操环节:
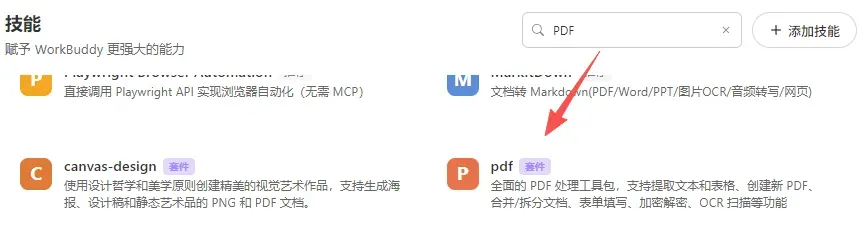
技能一:PDF 文档处理
核心技能: pdf
适用场景: 处理合同、报告或论文时,最让人头疼的就是从 PDF 里复制内容——格式全乱、表格支离破碎,扫描版更是连文字都选不上。pdf 技能插件可以直接读取、提取、合并 PDF,甚至能对扫描件进行 OCR 识别并转成可编辑文字,省去逐页手动输入的煎熬。
在技能商店搜索 pdf,选择官方套件版即可安装。
上周收到一份30多页的合作合同扫描件,老板让我梳理关键条款……
提示词: “请帮我读取这份 PDF 合同文件,提取以下关键信息:1. 合同主体及有效期;2. 付款条款与违约金条款;3. 知识产权归属;4. 保密协议核心内容。将提取结果整理为结构化的 Word 文档输出。”
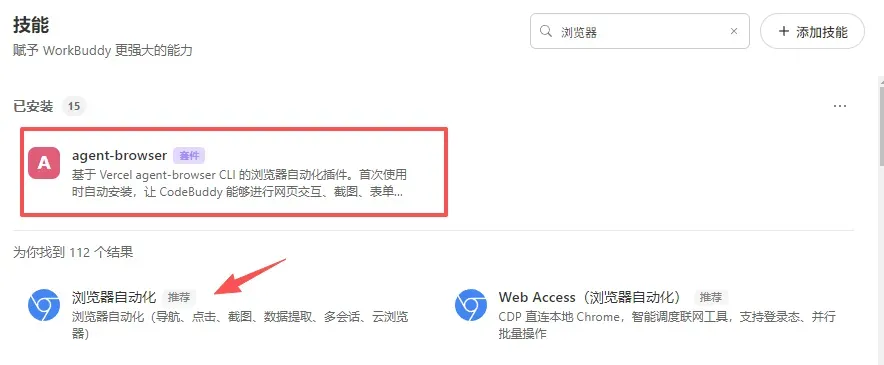
技能二:浏览器自动化
核心技能: agent-browser(官方套件)或 browser-use
适用场景: 做竞品调研、数据采集或批量网页操作时,手动逐个打开页面复制粘贴,简直是在消磨时间。浏览器自动化技能能够直接操控浏览器,完成网页截图、表单填充、批量数据抓抓取等工作,真正实现“解放双手”。
推荐优先使用官方的 agent-browser 套件,近期上线的 browser-use 体验也很不错,大家不妨都试试看哪个更顺手。
前阵子做竞品分析,需要对比5个产品在官网上展示的功能和定价……
提示词: “请帮我打开以下竞品官网页面:[粘贴网址列表]。逐一截图并提取每个产品的:核心功能介绍、定价方案、目标用户描述。将所有信息汇总为一份 Excel 竞品对比表。”
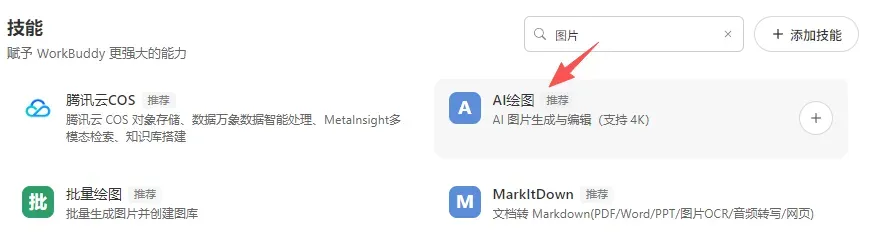
技能三:AI 图像生成
核心技能: Nano Banana Pro
适用场景: 写推文需要配图、做方案需要封面、公众号文章需要头图——次次找素材都找到头秃。AI 绘图技能可以直接根据文字描述生成图片,无论是封面设计、插图还是产品效果图都能搞定,再也不用求设计师排期了。
提示词: “请帮我生成一张科技感的公众号封面图,尺寸 900x383 像素,主题是 AI 工具效率提升,配色以紫色渐变为主,风格简洁现代,包含几何装饰元素。”
技能四:实时联网搜索
核心技能: Perplexity 搜索
WorkBuddy三种执行模式详解:Craft、Plan、Ask的最佳选择策略
第一次打开 WorkBuddy 时,我最大的感触并不是操作复杂,而是入口太多,压根不知道从哪里入手。
界面上密密麻麻的选项看起来都和效率提升有关,可一旦真点进去,很容易选错路径。同一个任务,用了不同的模式,最终输出差别巨大,有时甚至会得到完全不符合预期的结果。
后来我花时间把它的底层逻辑梳理了一遍,重新走了一次完整的使用流程,才发现其实并不难。下面就把 WorkBuddy 的三种模式,以及对应的选择思路,整理出来供你参考。
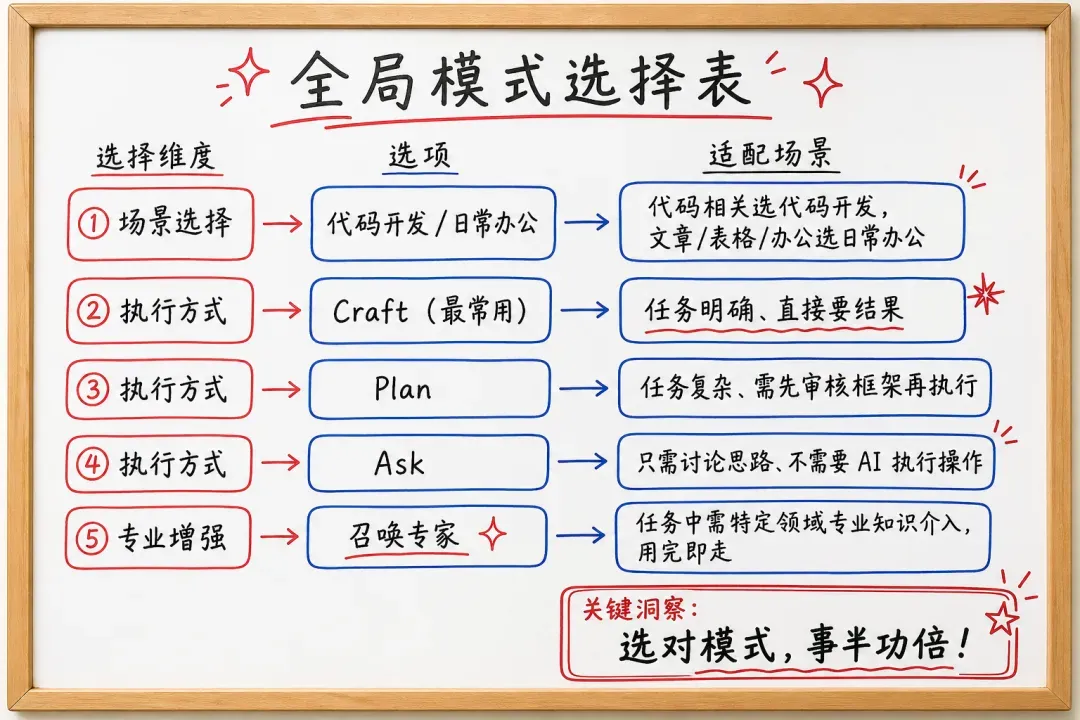
选对模式,不仅省积分,更能大幅提升交付质量!
一、定位工作领域:代码开发 vs 日常办公
进入 WorkBuddy 后,最先看到的就是两个切换按钮——「代码开发」和「日常办公」,含义非常直给。
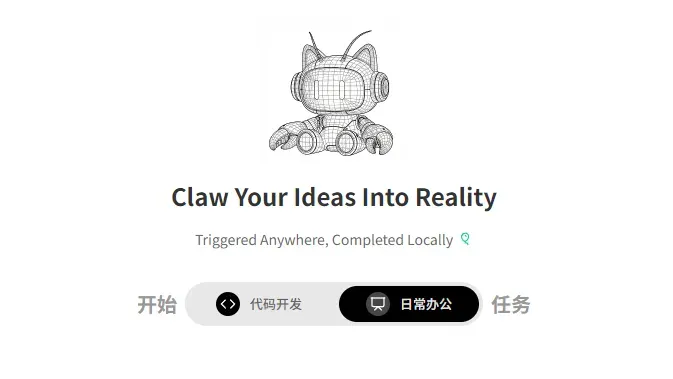
这一步只需要根据你的任务属性二选一:
| 场景选项 | 功能范围 | 适合人群 | 典型任务 |
|---|---|---|---|
| 代码开发 | 生成代码、调试 Bug、撰写技术方案、操作开发环境 | 程序员、技术人员 | 写 Python 脚本、修复代码报错 |
| 日常办公 | 文本创作、表格处理、资料整理、邮件撰写 | 所有职场人士 | 写公众号文章、制作配图、整理会议纪要 |
操作建议:只要不涉及写代码,不管你是要写文章、做配图,还是整理素材,直接切到「日常办公」就可以。
二、理解三大执行引擎:Craft、Plan、Ask
在对话框下方展开,就能看到 Craft、Plan、Ask 这三种模式。它们决定了 AI 会以什么方式处理你的指令。
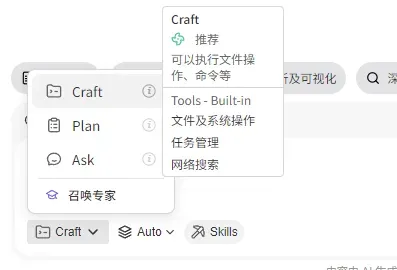
三者的核心差别在于:是否自动执行,以及是否有中间确认环节。
假如我们以“帮我写一篇 WorkBuddy 的使用教程”为例,三者的处理方式完全不同:
| 执行方式 | 技术特征 | 交互流程 | 结果呈现 |
|---|---|---|---|
| Craft | 直接执行,没有中间确认 | 输入指令 → AI 直接操作 | 直接输出完整的教程成品 |
| Plan | 先出计划,确认后再执行 | 输入指令 → AI 拆解步骤(如:1.调研 2.大纲…)→ 用户确认 → AI 操作 | 先给出框架,再出成品 |
| Ask | 只给建议,不执行任何操作 | 输入指令 → AI 分析结构与方法 | 输出编写建议,不生成正文 |
适配性分析:
阿里云百炼Token Plan选购指南:三档套餐怎么选最划算?2026最新分析
阿里云百炼的 Coding Plan 已成过去式,仅剩少量用户还可续费一个月,取而代之的是全新上线的 Token Plan。现在无需抢购,随时可以购买,不再限购!
大家最关心的无非两点:团队版起步价 198 元/月,到底是贵了,还是更香了?
01
产品定位
Token Plan 瞄准的正是企业开发场景。它最大的特点就是可以灵活调用多个模型:用户按需使用,所有消耗都通过 Credits 统一抵扣,不必再为不同模型单独付费。

生态兼容方面,这套方案已经无缝对接了主流编程工具和各类热门 Agent,可以丝滑嵌入团队既有的技术栈。同时,产品设计了标准、高级、尊享三个坐席,用来精准覆盖从轻度到重度不同级别的使用需求。
🔒 预算可控性:采用包月订阅,直接从模式上规避了按量付费可能出现的“账单炸弹”风险。
数据安全与服务稳定性
**数据隐私:**明确承诺不会利用客户的对话数据训练模型。这对企业级客户来说不是加分项,而是底线。
**服务保障:**多租户隔离架构,确保高峰时段也不会排队卡顿。经历过 Coding Plan“一码难求”的用户,都深知稳定供给有多珍贵。
02
现状与局限
客观地看,目前的方案也还有一些遗憾。
最新模型支持尚不到位
目前暂未接入 Kimi K2.6、GLM-5.1、MiniMax-2.7 以及 DeepSeek v4 等前沿版本。特别是 GLM-5.1 的缺席,可能会让一部分用户在决策时陷入犹豫。
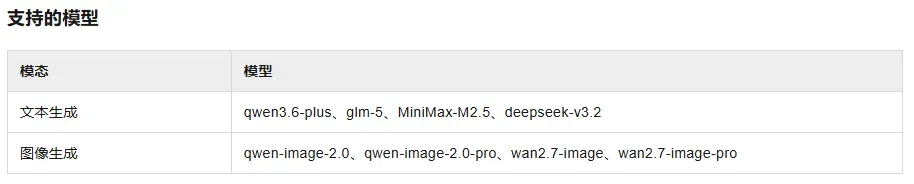
当前可用的模型包括:
**文本生成:**qwen3.6-plus、glm-5(非 5.1 版本)、MiniMax-M2.5、deepseek-v3.2
**图像生成:**qwen-image-2.0 系列、wan2.7-image 系列
虽然这些型号并非最新版,但应对常规业务场景,功能仍然足够扎实。
03
选型建议:三档怎么选
哪些人适合现在入手?
个人开发者:如果你对模型迭代有极致追求,建议先观望,等模型库更新后再行动。
企业用户:如果你的核心诉求是预算可控、数据合规、服务高可用,那么 198 元/月的起步价,性价比非常突出。
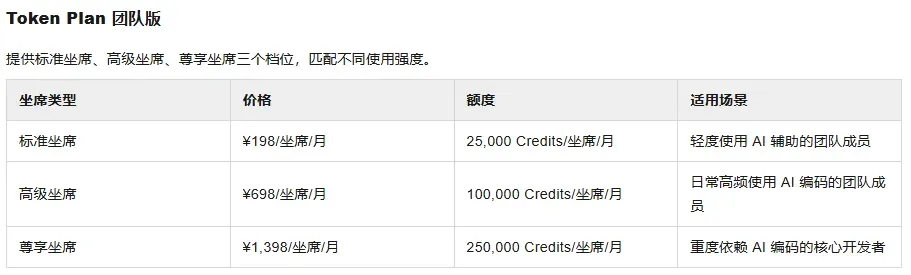
我们的判断
🎯 198 元的入门门槛到底值不值?直接说结论:它是目前最适合团队协作的方案。从过去的“抢购资源”转向“稳健服务”,这正是阿里云百炼的一次关键战略转身。
04
核心价值拆解
为什么叫团队版?因为它确实是为团队场景量身定做的。
理由一:统一 Credits 计量体系
百炼采用统一的“Credits”来计量一切用量,不管是对话、编程还是图像生成,都走同一个资源池结算。一个资源池,所有模型通用,透明又高效。
理由二:主流模型矩阵自由切换
从ChatGPT到ClawToken经济学:AI从模型走向系统,万亿美元赛道的底层逻辑
在看过英伟达CEO黄仁勋2026年GTC的主题演讲之后,如果把具体的产品参数暂时搁在一边就会发现,他反反复复在强调一个核心脉络:AI正在从“模型时代”,快速跨入“系统时代”。
模型的能力当然还在持续提升,但行业真正的重心已经悄然转移——AI不再满足于“会说话”,而是开始“会做事”,进而一步步走入真实的物理世界。
计算本身的形态也随之发生了根本性的变化:计算从训练阶段大幅溢出到推理阶段,从单次调用演进为多轮调度,从云端延伸至本地,再进一步渗透到物理世界的每一个角落。
AI,正在从一个“回答问题的工具”,转变为一个“持续运行的系统”。

这是一条再清晰不过的产业路线。
大模型的进化史:一部Token消耗指数级增长史
如果试着把过去三年压缩成一条演进线,大致会呈现出下面这样的图谱。
第一阶段:以ChatGPT为标志 Transformer架构与大规模预训练的成熟,让语言生成终于变得稳定可用。模型能够直接完成表达与归纳,AI第一次真正像人类一样“开口说话”,完成了一次表达能力的巨大跃迁。
第二阶段:DeepSeek R1为代表的变革 这一阶段不单单是推理能力的增强,更叠加了开源模型的大爆发。借助强化学习和推理链,模型开始主动生成中间步骤再推导出结论,计算的重心被显著拉向推理阶段,处理路径大幅延长,Token的消耗也因此急剧攀升。与此同时,开源模型的快速迭代,将强大的推理能力下沉到更广泛的开发者与企业环境里,不仅加速了技术的扩散,也让“可控、可部署”的AI真正变成现实。
第三阶段:Manus、Genspark、Lovable——Agent雏形初现 模型被嵌入到更复杂的系统当中,依靠工具调用、任务拆解以及多轮执行,完成过去难以单次达成的复杂目标。此时,一次用户请求不再仅仅对应一次推理,而是一整串调度链条,计算开始在多个模块之间持续流动。
第四阶段:Claude Code——本地执行能力走向成熟 模型开始直接进入真实的运行环境,可以操作代码、文件以及系统接口。上下文的边界从一段提示词扩展为完整的执行环境,推理结果则能够立即转化为可落地的实际操作,生成能力与执行能力前所未有地融合在一起。
第五阶段:OpenClaw——执行能力的系统化 Agent、本地执行能力和工具生态被进一步整合成持续运行的有机系统,能够支撑长任务、多阶段反馈。计算不再被“请求”所触发,而是以“进程”的形式长期存在,具备连续性与状态保持能力。
这条演进主线有一个贯穿始终的共同特征:每向前迈出一步,Token的消耗就上一个新的台阶。
AI产业的竞争重心,正从单一的“模型竞赛”,悄然转变为全方位的“Token经济”。
- 推理模型让每一个简单问题都消耗更多的Token;
- Agent系统会持续、不间断地调用模型,Token已经变成某种“流量”;
- 长任务、多步骤交互,使得Token像电力一样形成持续计费的模式。
Token的使用量正在快速攀升,而与此同时,Token的单位成本却在持续走低。每百万Token的价格会越来越便宜,这几乎没有什么悬念。
真正关键的是两条曲线之间的速度差:
我们认为,Token成本下降的速度,很可能赶不上需求膨胀的速度。因此,即便每个Token变得更便宜,每个人消耗掉的Token数量却只会更多。两者叠加的结果是,总体支出非但没有下降,反而在节节攀升。
这正是Token越来越像一种基础资源的根本原因——单位价格长期下降,而总消耗量却屡创新高。
Agentic AI:一场系统级软件革命的开幕
以OpenClaw为代表的Agentic AI之所以会骤然爆火,关键就在于它恰好踩在了软件进化的一条关键拐点上。
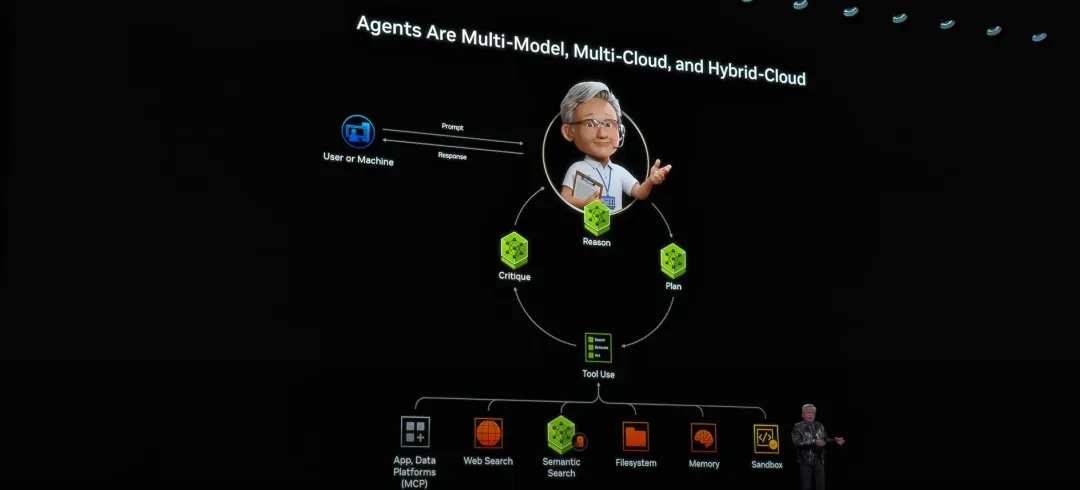
传统的软件交互模式是人点击按钮 → 软件执行固定逻辑 → 返回既定结果。
而现在的模式正在被彻底重塑:人只需要下达一条自然语言指令 → Agent自动拆解任务 → 协同调用多个模型、工具和数据源 → 最终交付完整成果。
两者之间最本质的差别在于,软件从一个固化的功能集合,升级为能够自主完成任务的执行者。
正如黄仁勋在演讲中所描绘的,Agent有能力查阅资料、编写代码、制定规划、运行模拟、调用外部API,并且天然具备将复杂问题拆分为多个有序步骤的能力。
它早已超越单一模型的范畴,进化为一个包罗万象的综合系统,涵盖:
- 多模型(语言、视觉、语音)
- 多工具(搜索、数据库、软件接口)
- 多环境(本地、云、多云架构)
- 持续上下文(长期记忆)
这在实质上是在一步步改写整个软件生态的底层逻辑。过去,编写代码的核心是定义逻辑;而今天,构建系统的核心是编排能力。
因此,你会清晰地看到:
- OpenAI:持续深耕工具调用(function calling),最新的GPT-5.4已经原生支持「computer use」,能直接查看屏幕、操控鼠标和键盘。
- Anthropic:重点强化Agent的长周期循环,安全运行数天之久,同时推出Claude Computer Use以及多代理协作能力。
- 开源社区:OpenClaw彻底爆发,短短两个月GitHub星标就飙升至25万以上,成为目前最实用的自托管Agent框架。
而NVIDIA给自己的定位,并不是再做一款Agent产品,而是干脆成为Agent的基础设施层(NeMo、Blueprint、推理系统等)。
物理AI:AI开始理解真实世界的法则
如果说Agent的主战场还局限在“数字世界”之内,那么物理AI则标志着人工智能第一次大规模地进军真实世界。
两者的难度完全不在同一个量级上。语言模型只需要解析语义的对错,而物理AI必须真正洞悉现实世界的物理法则:物体遵守质量守恒、受力会产生反馈、动作天然附带延迟、世界呈现连续不断的状态变化。
换个说法:语言模型解决的是逻辑上的“对不对”,物理AI则必须直面现实中的“能不能做到”。
从零构建多Agent系统:拆解Claude Code核心架构,84行代码到团队协作
很多人用过 Claude Code,也听过“Agent”“Tool Use”“Subagent”这些词,但如果被问到“Claude Code 底层到底怎么运转的”,大概率会沉默。
市面上能把 AI 编程 Agent 的架构从头到尾拆明白的教程,说实话几乎找不到。要么太学术,满篇论文术语;要么太浅,讲完“调用 API”就收工了。
有一个开源项目Learn Claude Code(GitHub 56.5K+ Star),干的事很简单:从 84 行核心循环开始,每一步只加一个机制,最终搭出一个完整的多 Agent 系统:工具调用、规划、子代理、记忆、任务调度、多 Agent 协作……
这个项目也有很多人推荐了,最近作者对整体教程做了大幅升级,这篇文章会把其中的关键设计抽丝剥茧,一步步讲透。
一共19 课,4 个阶段,代码透明,改动可追溯。

本文接近 8500 字,建议收藏,通过本文你将搞懂:
- Agent 的核心循环到底长什么样:一个 while 循环怎么撑起整个系统
- 从单 Agent 到多 Agent 需要解决哪些问题:上下文爆炸、任务编排、并发冲突,一个不落
- 每个机制的底层设计逻辑:每个机制都解决了一个真实痛点,没有多余的设计

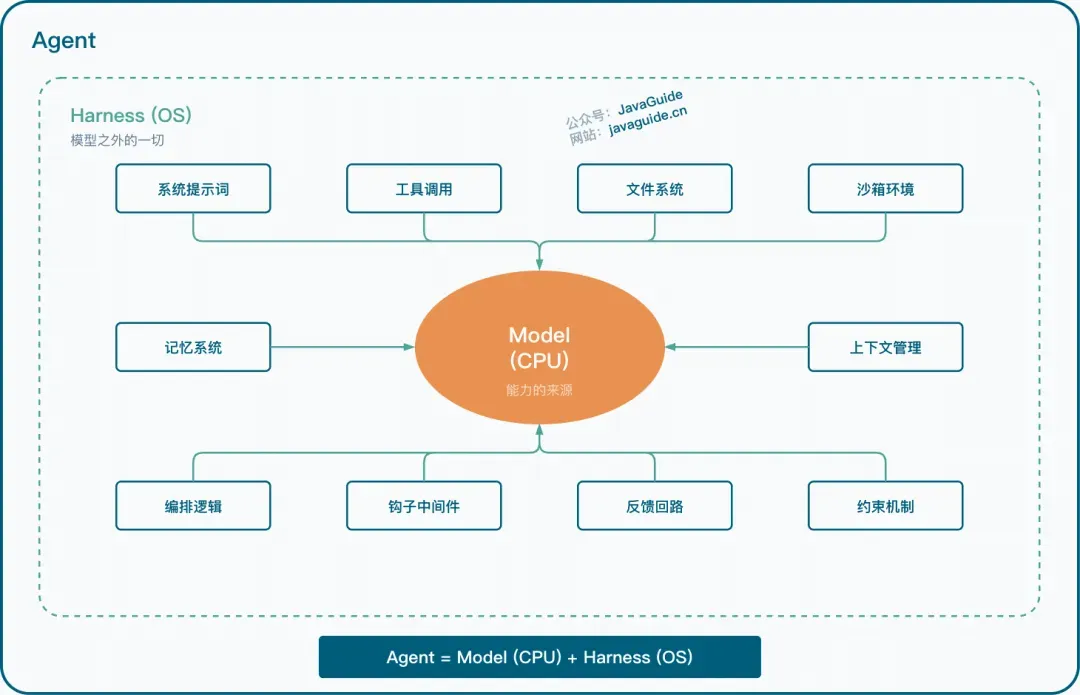
一个核心认知:Model 是司机,Harness 是车
在聊代码之前,先搞清楚一件事。
智能来自模型训练,不是来自你写的代码。 这句话是 Learn Claude Code 整个项目的哲学基础。
打个比方:大模型是司机,你写的 Agent 框架是车。司机的驾驶技术是车企(Anthropic、OpenAI 们)通过海量训练数据练出来的,你没法替司机踩油门。但你能造一辆好车——给司机配上方向盘、仪表盘、刹车和安全带。
这辆车的名字就是前段时间刷爆技术圈的:Harness。
Harness 包含什么?工具(让 Agent 能读写文件、跑命令)、知识(按需加载的领域文档)、上下文管理(防止对话过长导致失忆)、权限控制(防止 Agent 瞎删东西)。模型负责思考和决策,Harness 负责提供手脚和边界。
大模型时代提示词革命:告别流程指令,释放模型创造力——OpenAI官方指南解读
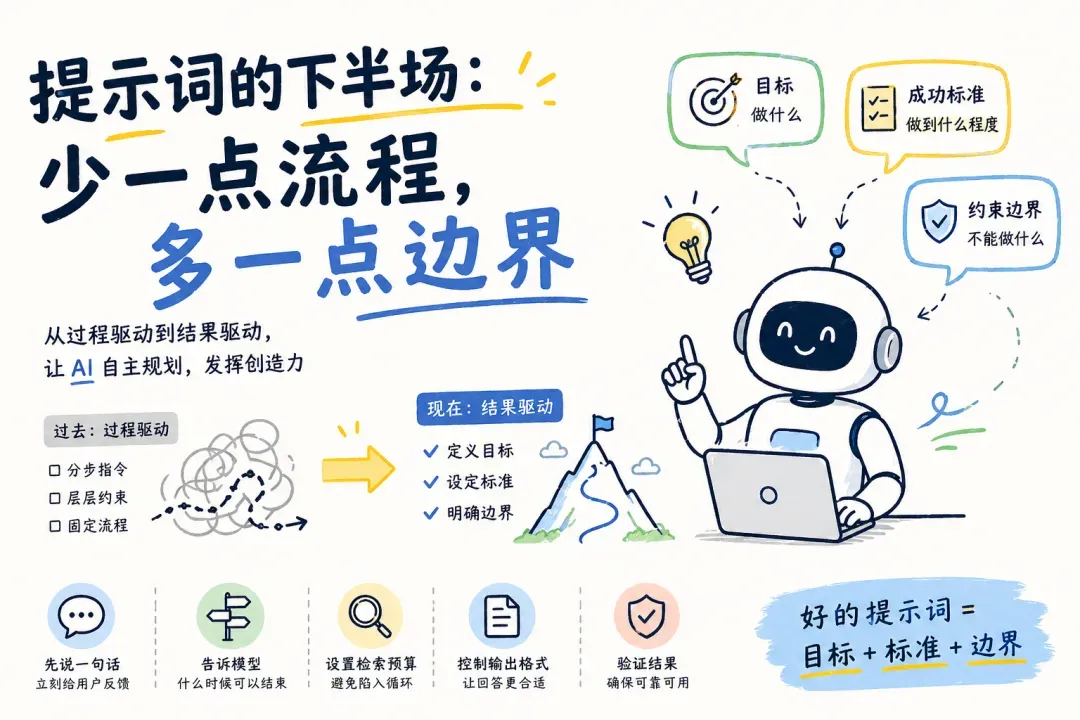
本文大纲:
PART 1 范式迁移:从“过程驱动”走向“结果驱动”
PART 2 人格与协作风格:赋予AI“生命感”
PART 3 一句话化解“为何没有反应”的体验痛点
PART 4 停止规则:让模型知道“何时可以结束”
PART 5 检索预算:避免模型陷入无限检索循环
PART 6 输出格式的精细控制
PART 7 结果验证:让模型主动自检
PART 8 模板总结与实战示例
全文约3800字,预计阅读时间9-10分钟。
近期研读了OpenAI为GPT-5.5发布的官方提示词指导文档,深受震动。一个明显的信号是:若想真正激活模型的创造力,过去那种事无巨细、步骤严密的提示词,极可能让模型变得迟钝、僵化。
过去两年间,无数实践者构建了大量“提示词宝典”:详尽的分步指令、层层嵌套的逻辑约束、满屏的ALWAYS和NEVER标记。在模型早期推理能力尚显稚嫩时,这确实是必需的——我们需要像带实习生一样,将每一步都拆解得清清楚楚,牵着它走。但大语言模型的推理效率已然发生质的飞跃,它们现在能够自主规划执行路径、灵活调用工具、综合多源信息并做出判断。曾经那些精雕细琢的“过程控制”指令,此刻却成了有效信号中的“噪音”,挤压了模型的自主决策空间,最终让它产出的答案变得机器化、缺乏灵气。
要让新一代模型发挥最佳效能,核心已不再是“工序式指令”,而是“目标定义”。如果把旧提示词比作给新手列出的详细操作清单,那么新范式更像是给一个经验丰富的协作者阐明使命与边界:你只需告诉它想要什么成果、成功的标准是什么,然后放手让它发挥。
具体到写法上,有几点实用调整值得关注:
- 收起步骤式指令,转化为目标+评价标准。
- 将强制流程替换为约束条件和优先级。
- 把“必须按A/B/C顺序执行”变为“结果需覆盖A/B/C,并请解释选择的逻辑”。
这样一来,模型便拥有了选择路径的自由度,而不必被锁死在人为预设的线性流程中。
另一个同等重要的变化是“容许不确定性”。传统提示词习惯于把所有边界都收紧,新方法反其道而行:只清晰划定绝不可逾越的界限,其余交由模型自主判断。
以“自我驱动”的方式与最新大模型对话,正是其提示词哲学的根本法则。
01 范式迁移:从“过程驱动”走向“结果驱动”

旧时代的提示词常常长成这样:
场景:保险理赔资格审核智能体,需结合政策文件与账户数据进行判定
提示词:(过度控制流程)
先读取用户保单文件,再读取账户数据,接着逐字段比对,
然后列出所有可能的例外情形,再得出资格结论,最后返回结果。
模型能力大幅提升后,更好的写法是定义结果和标准:
解决用户的问题,端到端处理好后再回复。
完成标准:
资格判断须基于现有政策和账户数据得出
所有允许的操作须在最终回复前执行完毕
最终答复必须包含:completed_actions、customer_message、blockers
若证据不足,只询问最小必要字段
两者的根本差别不在于字数,而在于“控制方式”。前者试图约束执行路径,后者仅定义终点与边界,把路径选择权完全交给模型。
一个有效的结果导向型提示词,通常包含三个核心要素:
- 目标(outcome)
- 成功标准(success criteria)
- 约束边界(constraints)
02 人格与协作风格:赋予AI“生命感”

许多使用者习惯用硬性规则来管控模型的“说话方式”,比如“避免术语”“保持简洁”等。这类规则在边缘场景下往往容易失效,且让模型语气变得拧巴。曾被社区调侃的“人格”设定,又在新模型中强势回归。实践证明,通过定义人格(Persona)和协作风格(Collaboration Style),输出效果要好得多。二者的区别可简单理解为:
- 人格:听起来像什么样的人(语气、温度、表达方式)
- 协作方式:如何推进任务(何时提问、何时直接执行、如何处理不确定性)
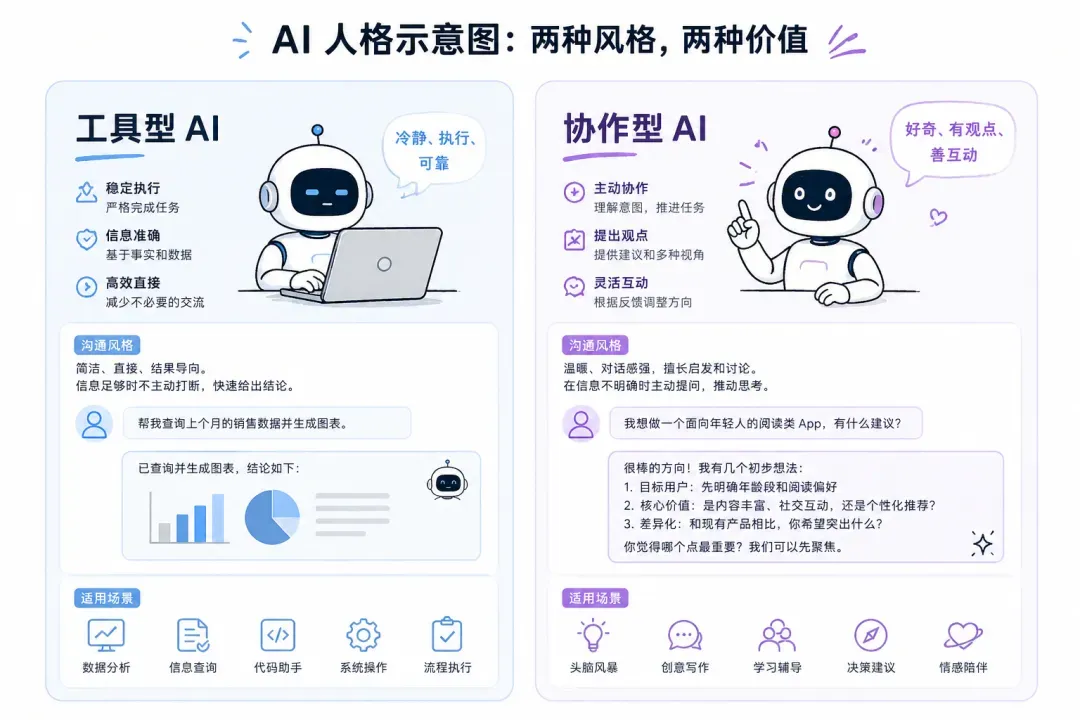
1. 稳健任务型助手的人格范例
适用场景:内部工具助手、代码助手、企业知识库问答——用户目标明确,希望助手直接解决问题,无需多余寒暄
人格
你是一名务实的协作者:友善、稳定且直接。
豆包收费在即:如何判断AI工具付费是否值得?深度拆解使用场景与效率效益
五一假期刚过,我们不聊教程,来谈一个备受瞩目的消息——豆包,可能马上要收费了。
打开苹果 App Store 的豆包下载页
可以看到详情里已经新增了订阅服务。
同时我也刷到不少相关的讨论帖,评论区很有意思。
有人说,是不是以后所有 AI 都得收费了?也有人觉得,反正自己用得也不多,无所谓。
但我今天想探讨的核心问题是:这笔钱,花得到底值不值?
收费背后的逻辑
在算这笔账之前,有一个更底层的问题绕不开:它为什么要收费?
很多人第一反应是,平台要开始赚钱了。可如果你对大模型的运行方式稍有了解,就会发现情况远不止这么简单。
每一次你发送消息,背后都会跑起一整套推理流程:模型在运算,GPU 在运转,电力在持续消耗。
我此前查看过一些行业数据,也咨询过做 AI 基础设施的朋友,这类服务的成本确实不低,而且会随着调用量持续攀升。
用户规模越大,成本就越高。
因此,免费更像是一种阶段性策略,用来拉新、培养用户习惯;一旦用户体量成型,收费几乎是早晚的事。
理解这一层之后,再回头看,你会发现关注点已经变了:不再是“它为什么收费”,而是“这件事对你来说意味着什么”。
两类截然不同的使用者
慢慢地你会发现,人其实可以被分成两种类型。
1. 轻度使用:顺手型
一类人,用 AI 就是偶尔顺手查个东西。比如提个问题、写几句文案、偶尔生成张图片。这种用法跟传统搜索差别不大,只是更便捷一些。需求不高,频率也不高。想一想,这种情况下需要专门花钱吗?大多数时候确实没必要。
2. 重度工作:依赖型
还有一类人,用法完全不一样。他们每天都会打开 AI,不是消遣,而是在工作:写方案、做分析、整理资料、批量产出内容。对他们来说,AI 更像是长期协作的工具,甚至是一台“效率放大器”——你投入一小时,它可能帮你省下三小时。这种感觉,时间越长越明显。
也正因如此,他们对稳定性、响应速度以及能力上限格外看重。
至此,答案已经慢慢浮现——你是偶尔用用,还是每天离不开?
很多人会说,那我就看价格便不便宜。这确实是个参考角度,但并不关键。
现在主流 AI 工具的月订阅费,几十到上百元不等,实际差距没有想象中那么大。豆包的定价看似略低,这没错,可便宜并不代表它一定适合你。
如果你的工作主要围绕中文内容和日常办公,本土模型在体感上确实更顺手,这一点不少人都有体会。
但如果你需要查阅英文资料、编写代码或者进行复杂分析,使用体验可能就会有差异。
也就是说,你买的不是“AI”,而是“某种能力组合”。自然要看你最常用的是哪一类能力。
常见的陷阱与真正的差距
聊到这里,有一个很常见的坑,我自己也曾踩过。
不少人最初觉得,多用几个工具总能在能力上更强,于是开始逐个订阅。结果一个月过去,钱花了不少,产出却没有明显变化。
回头审视才发现,问题很简单:工具变多了,但使用方式并没有改变,仍然是随意提问、碎片化使用。
这种情况下,多一个工具,不过是多一个浏览器标签页罢了。
再看另一类人,就很有意思了。他们可能只用一款工具,甚至是免费版,却会反复打磨提示词,把流程拆解得清清楚楚。
比如写内容时,先让 AI 生成框架,再逐步细化修改;做分析时,使用固定的提问模板,让输出结果更稳定。
久而久之,效率差距便会逐渐拉开。你会发现,他们并非工具更好,而是用法更深。
因此,一个核心问题变得很清晰:你欠缺的究竟是工具,还是使用工具的能力?
这个问题如果不想透,很容易一直花冤枉钱。
豆包收费,其实是一种提醒
再回头看豆包收费这件事,其实就不复杂了。它更像一个信号,提醒你:你究竟是在“用 AI”,还是仅仅“装了一个 AI”?
如果你现在还不确定自己的答案,不妨换个更简单的判断方式:
你每天用 AI 的时间,有没有超过一小时?
你有哪项工作,是离开 AI 就会明显变慢的?
如果都没有,说明你仍处于轻度使用阶段,继续用免费版完全没问题。
工作流、Skill与Agent深度辨析:加法与减法两种落地路径全解析
工作流、技能包(Skill)和智能体(Agent)三者究竟有什么区别?普通用户又该如何选择使用?近来很多人一谈到AI,就会下意识地默认Agent是万能解法,好像只要把任务丢给它,一切就能自动完成。然而一旦进入真实的工作场景,你很快就会发现,实际情况要复杂得多。
面对同一件事,有人会先把流程拆得很细,能自动化的部分尽量自动化;而另一些人却更愿意先让Agent全盘跑起来,边跑边把那些不够稳定的环节逐步收束。这两种思路,我认为都对,只是走的路径不同。一种是加法:一层层增加AI的参与度和自主性。另一种是减法:先让Agent放手去做,再把能够固化的部分慢慢剥离出来。本文就打算把这两种路径讲清楚。
一、三大核心概念的根本差异
很多人把工作流、Skill、Agent混为一谈,但它们实际上对应着三种完全不同的事情。用一个比喻来锚定这三个概念:
工作流:把确定的事做完
工作流就像流水线。你设计好每一个步骤,AI严格按照你指定的路径执行。输入明确,输出可预期,过程可复现。它适合那些你已经彻底想清楚、反复做过的事。比如:
- 每天定时抓取某个网站的内容
- 将表格里的数据清洗后归档
- 收到新消息后自动转发到群组
- 按照固定格式生成日报
这类任务的特点是流程固定,结果可预期。最适合用脚本、命令行和自动化工具解决。能用工作流搞定的,就不必让Agent出场。因为Agent处理这类事务,往往就像用大炮打蚊子,速度慢、成本高,还容易引入不必要的随机性。
Skill:把一种方法封装起来
Skill是可复用的方法模块。它是你总结出来、经过验证的做事方式。这件事怎么拆解、怎么表达、怎么评判质量,可以反复调用,也可以传递给他人使用。它解决的是这样一种问题:
- 流程整体固定
- 但每次内容会变化
- 需要一定的理解和判断
- 每次都要用同一种方法论去处理
例如给一条资讯打分:你需要判断它的重要性、相关性、时效性,再综合给出结果。这种场景下,你很难把规则完全写死,因为每条资讯的内容千变万化。这类任务就适合用Skill。它像一个被封装好的能力单元,输入内容,输出判断结果。
需要注意的是,Skill并不一定非要由Agent调用。很多时候,Skill可以只是一个好用的提示词模板,或者是工作流中的一次大模型调用。它的核心在于“能不能复用”。
Agent:只追求结果
Agent就像一名员工。你只需要给出目标,它会自己想办法。它会主动查找资料、做出决策、应对意外情况。适合那些你不知道具体该怎么做,或者不想干预过程的事情。这类任务的特点是:
- 目标清晰
- 但中间路径并不明确
- 过程中不断涌现新信息,需要随时调整策略
例如:
- 做一份复杂的竞品研究
- 撰写一篇需要大量资料整合的深度文章
- 临时处理一个没有固定模板的新任务
- 根据中间结果不断修正方向
这类任务的价值就在于它需要思考、判断和探索。

三者的核心差异其实只有一条:你对这件事的确定程度。你越清楚要做什么、怎么做,就越靠近工作流这一端;你越不清楚具体路径、只知道目标,就越倾向于Agent。而Skill居于中间,是你掌握了方法、不想每次都从头推演的地方。
二、两种实践路径:加法与减法
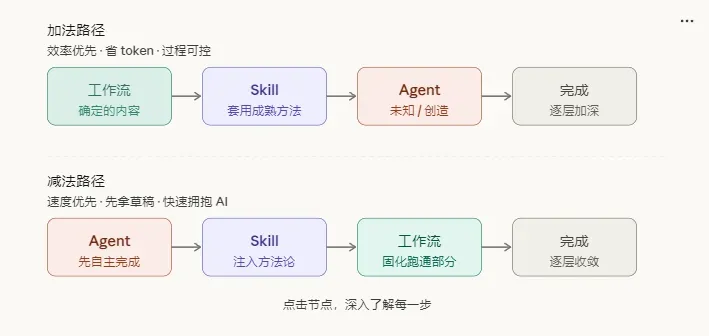
目前使用AI的方式,大致可以分为两条路线。
第一种:加法路径(效率优先)
先用工作流完成你确定的内容,再用Skill实现有方法论支撑的内容,最后才让Agent去处理你还不清楚的事。只在必要的地方投入成本。已经想清楚的事,不需要AI自主发挥,直接用工作流执行即可,省token、结果稳定。有成熟方法的部分,套用Skill,不用每次重新摸索。只有真正需要创造、探索、应对未知的部分,才交给Agent。
- 适合谁用:对某个工作流程已经很有经验的人。比如你是一名内容运营,每周撰写行业简报,格式固定、信息来源固定——前80%用工作流和Skill跑完框架,最后那一部分观点和洞察再用Agent补充。效率拉满,成本最低。
- 核心心态:对AI出错的容忍度低,追求过程可控。
路径大致是:工作流 → Skill → Agent。
这条路线的优点很明显:
- 更省token
- 系统更稳定
- 结构更清晰
- 后期更容易维护
它适合长期使用、适合高频任务,也适合已经比较明确的业务场景。但代价是前期需要想得比较细,需要先把结构搭出来。对很多人而言,启动可能会慢一点。
第二种:减法路径(速度优先)
先让Agent自主完成,再在Agent产出的成果上,用Skill和工作流去弥补漏洞。先拿到一个80分的版本,再慢慢打磨。很多人在用AI之前会卡在“我不知道怎么开始”。减法路径直接绕开这个障碍,先让Agent完整跑一遍,哪怕有漏洞,你至少有了一个可以修改的起点。然后再用Skill把自己积累的方法论套进去修正,用工作流固化那些已经跑通的环节。
- 适合谁用:刚开始拥抱AI的人,或者面对一个完全陌生领域的任务。比如你第一次写一份市场调研报告,完全不知道结构长什么样,先让Agent出一稿,看看它是怎么拆解的,再判断哪里对、哪里需要用自己的方法论补上。
- 核心心态:愿意接受AI出错,把AI的输出当作草稿而非终稿。
减法路径有一个隐性风险:如果Agent的方向从一开始就跑偏了,后续补救的成本反而可能更高。所以减法路径更适合边界清晰的任务,哪怕过程不确定,目标也要清楚。
路径大致是:Agent → Skill → 工作流。
这条路线的优点是:
- 上手快
- 试错快
- 更容易拥抱AI
- 更适合探索阶段
它适合你还不知道最优解是什么的时候。先让Agent走一遍,很多问题自然会暴露出来。跑着跑着,你才知道哪些地方值得固化,哪些地方值得优化。但代价也很明显:前期可能更贵、更慢,也更容易把一堆事情塞进一个大的会话里,最后导致上下文越来越乱。
三、路径并非对立,而是循环
这两条路其实像一个循环。你可以先用减法,让Agent帮你快速跑通问题;然后再用加法,把不稳定的部分慢慢沉淀下来。
比如你经营一个资讯站点。一开始,你可以先让Agent帮你判断哪些内容值得看、哪些需要记录、哪些需要排序。跑了一段时间后你就会发现:
- 抓取来源是固定的,那就可以脚本化
- 打分逻辑是稳定的,那就可以封装成Skill
- 只有少数复杂情况,才需要Agent再做一次判断
最终,系统会慢慢演变成:
七牛云AI平台免费开放5款大模型:含DeepSeekV4系列,赠送300万Tokens额度
七牛云AI平台近期推出了五款完全免费的大模型,覆盖日常对话、复杂推理、编程辅助和智能代理构建等多个高频应用场景。对于希望低成本探索不同模型能力的开发者来说,这是一个颇具吸引力的机会。
五款免费模型速览
目前平台提供的零元体验模型如下:
国内模型(3 款)
- 阿里千问 Qwen3.5-35B-A3B — 通义千问系列的最新MoE架构模型,35B总参数量中仅激活3B,在保持推理质量的同时显著提升效率
- 智谱 GLM-4.5-Air — 智谱AI推出的轻量化版本,适用于常规对话和文本内容生成
- 美团 Longcat-Flash-Lite — 美团自研的轻量模型,重点优化了响应速度
国外模型(2 款)
- Arcee Trinity Large Preview — Arcee AI发布的大参数预览版本,专注基于隐私保护数据训练
- NVIDIA Nemotron 3 Super 120B — 英伟达出品的MoE架构模型,120B总参数中仅激活12B,性能表现突出
免费额度:300 万 Tokens
通过邀请链接或官网注册,用户均可领取 300 万 Tokens 的免费额度。这些Tokens可直接用于API调用,平台当前已上线DeepSeek-V4-Flash和DeepSeek-V4-Pro两款模型。

300万Tokens对于模型测试和轻度使用场景来说绰绰有余,但如果面临高频调用需求,仍建议合理规划用量。
注册与配置指南
步骤一:创建账号
访问七牛云AI平台官网,完成账号注册并登录。
邀请链接地址:https://s.qiniu.com/ryAVve

登录系统后,点击左上角的 「AI 大模型」 菜单进入管理控制台。
步骤二:获取 API Key
在控制台找到 「API Key」 功能选项,点击创建按钮即可生成你的专属API密钥。
步骤三:访问模型广场
进入 「模型广场」 页面,能够查看完整的免费模型目录及详细参数说明。
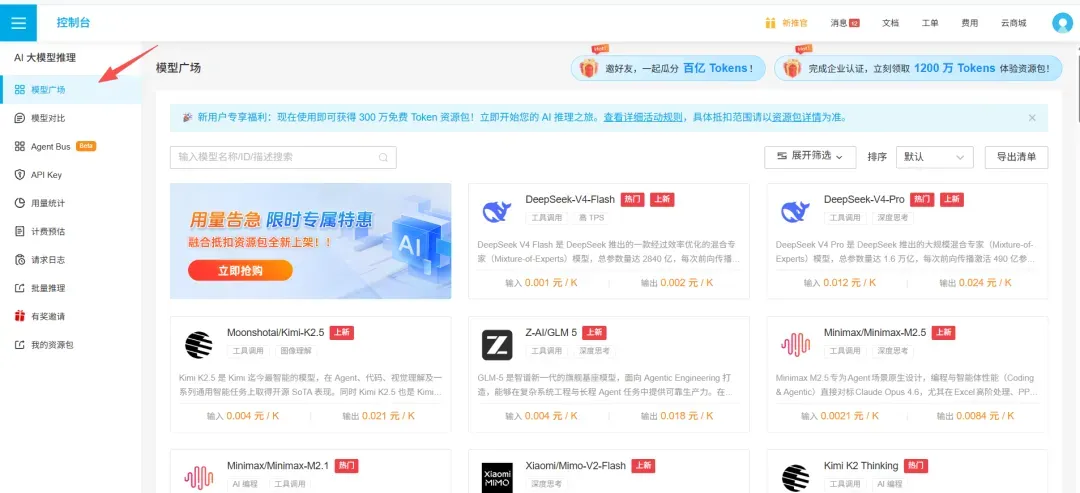
各模型详情介绍
1. 阿里千问 Qwen3.5-35B-A3B
模型 ID:qwen3.5-35b-a3b