商汤日日新Token Plan免费公测:三大模型 API 领取与接入指南
这个假期里,商汤日日新(SenseNova)悄然推出了 Token Plan 免费计划。注册就能直接领取 API Token,免费调用他们最新上线的三个大模型,不需要绑定信用卡,也没有隐藏的消费门槛。
很多人可能对商汤不太熟悉,但此前我们已经实测过他们旗下的几款应用,比如办公小浣熊、SekoAI 短视频等产品,体验相当顺畅。

这一次,商汤正式发布了新一代原生多模态模型 SenseNova U1,在多模态理解和生成能力上做了大幅提升,同时保持了低延迟和高并发。
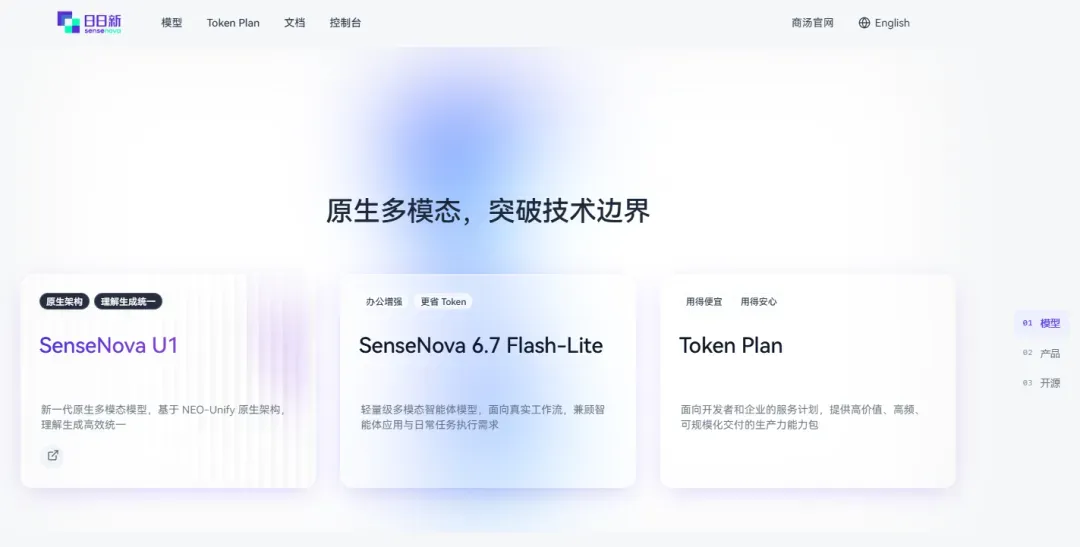
随之而来的 Token Plan 正在免费公测,是的,没有听错,是没有任何付费障碍的公测阶段,所有注册用户都能立刻获得额度。
免费模型一览
目前免费计划中一共开放了三个模型:
| 模型 | 说明 | 调用限额 |
|---|---|---|
deepseek-v4-flash | DeepSeek V4 Flash 版本,响应极快 | 每5小时150次 |
sensenova-u1 | 商汤自研原生多模态U1模型 | 1500次 |
sensenova-u1-fast | 商汤U1快速版本 | 1500次(部分用户反馈暂不可用) |
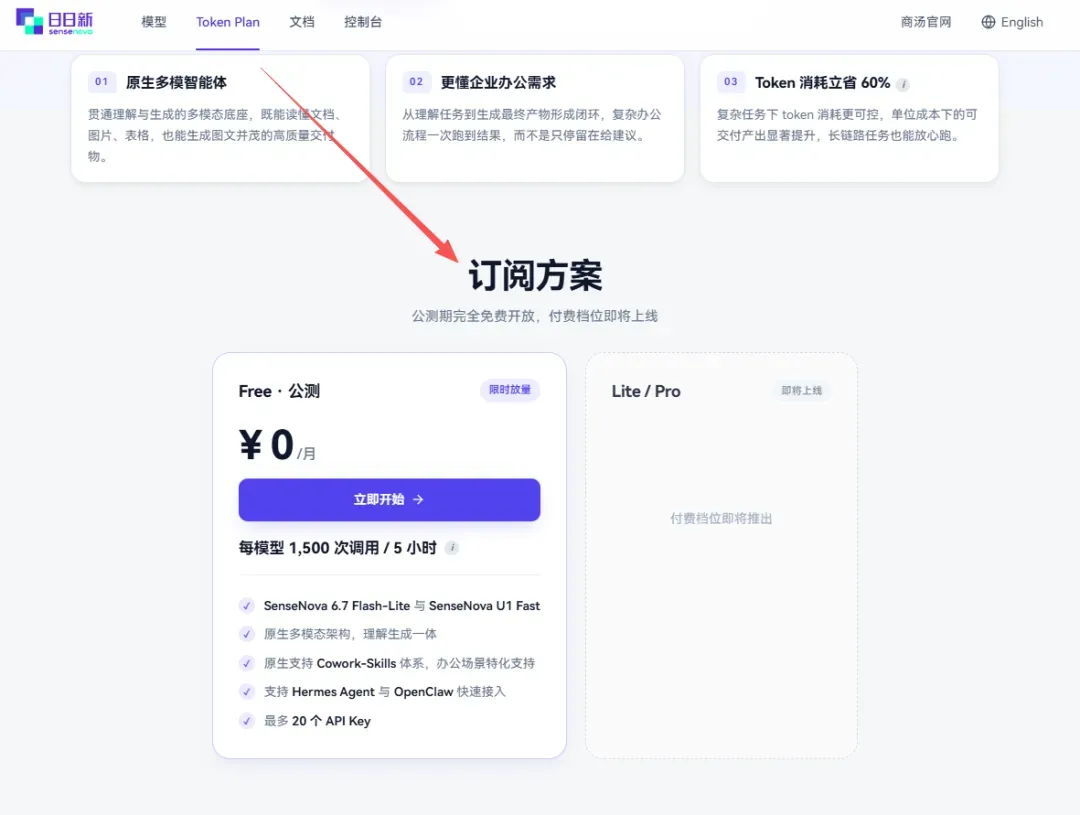
三步完成领取
操作非常直接,只需完成下面几步:
- 访问商汤日日新官网:sensenova.cn/token-plan
- 注册或登录你的账号
- 在 Token Plan 页面点击「立即开始」,系统会自动跳转并为你创建好对应的 API Key
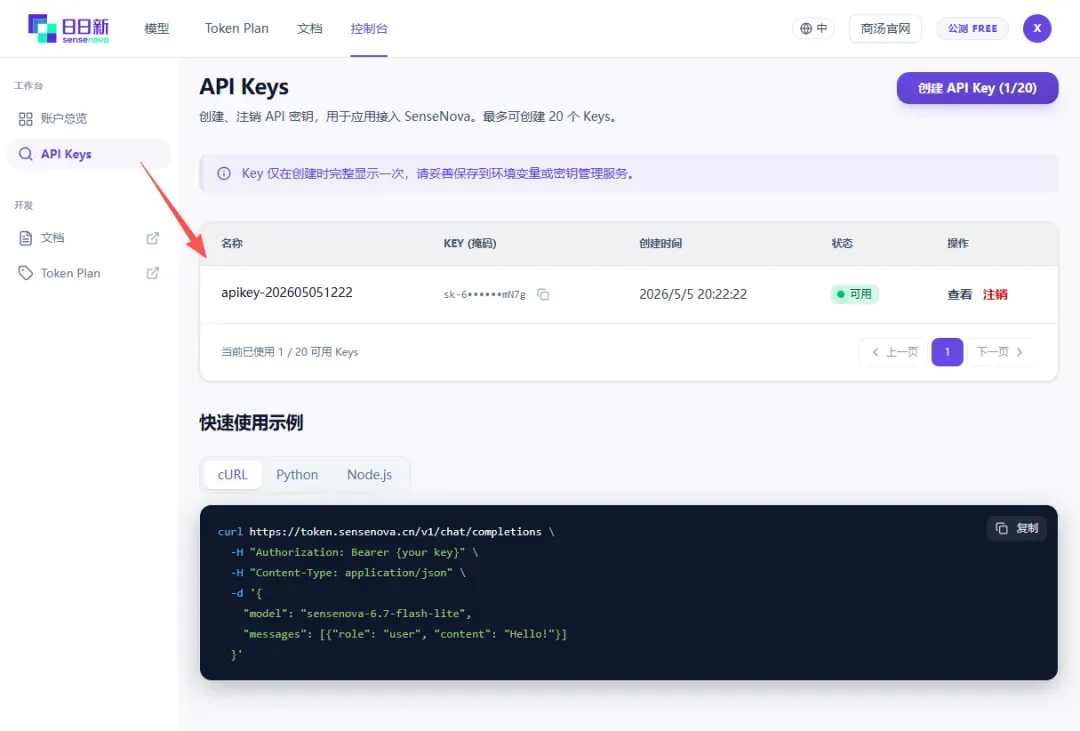
API 端点和格式完全兼容 OpenAI,你可以直接使用熟悉的调用方式:
curl https://api.sensenova.cn/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
]
}'
快速接入现有工具
由于接口兼容 OpenAI,这套免费额度可以直接配置到以下工具当中:
五一假期零打扰指南:20分钟用WorkBuddy搭建断网工作交接系统
假期人刚到海边,微信弹窗响了:“那个文件在哪个文件夹?” 正在看展,领导来电:“XX方案现在到哪一步了?” 其实,同事和领导并不想打扰你,根本原因是你走了,但工作没断。
这个五一,我在关机前花了20分钟,用 WorkBuddy 做了三件事,目标就是:5天假期,微信零弹窗,手机彻底安静。今天直接把这套“断网SOP”拆给你,无需动脑,复制粘贴就能用。
核心解法
假期被打扰,本质上是没有提前搭建一套“信息管理系统”。用 WorkBuddy 提前把不确定性转化为“标准化清单”,别人能自己找到答案,自然就不再找你。
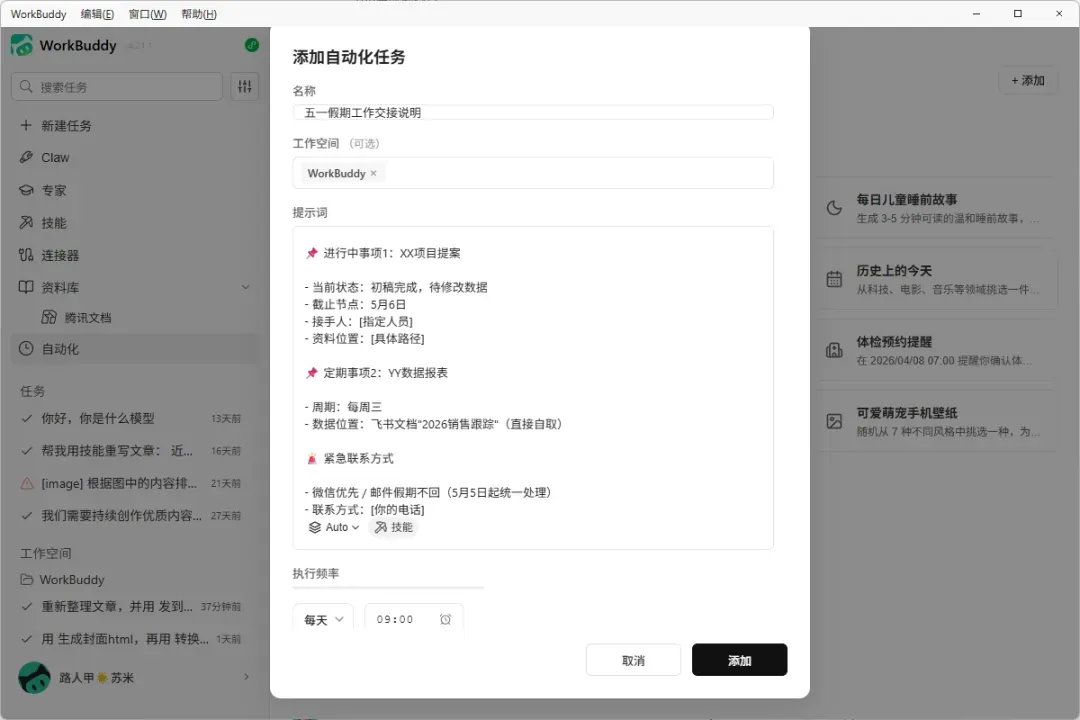
🛡️ 第一件事:生成工作清单表(5分钟) 一份无死角的工作交接单
❌ 过去的做法: 口头交代一句“XX事你盯着点”,结果假期一半时间在接电话解释细节。
✅ 现在的做法: 把手头的待办事项交给AI,让它生成一张“工作清单”表格,工作问题直接能从表中找到答案。
👉 直接复制以下提示词发给 WorkBuddy:
我五一(4月30日-5月4日)放假,需要生成一份工作交接清单表格。
手头正在推进的事项:
- XX项目提案,5月6日客户要查看,初稿完成,还需修改第三部分数据
- YY同事的数据报表(每周三需提供),数据已整理在飞书“2026销售跟踪”文档
- 如有紧急情况,微信优先,邮件假期期间不查收 请帮我生成一份结构清晰的交接说明,可以直接发给团队。
💡 WorkBuddy 会直接生成这样的清单:
【五一假期工作交接说明】
🗓 假期时间:5.1—5.5|5.6恢复正常办公
📌 进行中事项1:XX项目提案
- 当前状态:初稿完成,待修改数据
- 截止节点:5月6日
- 接手人:[指定人员]
- 资料位置:[具体路径]
📌 定期事项2:YY数据报表
- 周期:每周三
- 数据位置:飞书文档“2026销售跟踪”(可直接取用)
🚨 紧急联系方式
- 微信优先 / 假期邮件不回复(5月5日起统一处理)
- 联系方式:[你的电话]
🎯 拿到结果后怎么做: 群发。有了这份清单,80%的“弱紧急”问题会被自动拦截,因为大家都知道去哪找资料、找谁对接。
⏳ 第二件事:搭建“自助客服”(5分钟) 定制差异化的自动回复
❌ 过去的做法: 设置“我在休假,稍后回复”,对方心里只会想:那稍微催一下好了。
✅ 现在的做法: 用AI撰写“有态度、有边界”的文案,直接告诉对方“别等了,紧急就打电话,非紧急节后处理”。
👉 直接复制以下提示词发给 WorkBuddy:
帮我写3个五一假期自动回复,放假时间5.1-5.4,5.6恢复正常办公。
紧急联系方式:电话[你的号码]。非紧急事宜统一5月5日处理。要求:
- 邮件版(对外客户,正式但不冰冷)
- 微信版(同事/熟人,轻松直接)
- 紧急说明版(留给真正有急事的人,极简)
💡 WorkBuddy 会精准输出三个版本:
小米凌晨开源MiMo-V2.5双旗舰,MIT协议全面商用,百万亿Token激励计划正式启动
今日凌晨,小米 MiMo 团队正式释出新一代双旗舰模型 MiMo-V2.5-Pro 与 V2.5,均采用极为宽松的 MIT 开源协议,彻底扫清商用、微调及二次开发的授权障碍。性能方面同样惊艳,在 GDPVal-AA、τ³-bench、ClawEval 三大通用 Agent 核心基准测试中,新模型实现对近期大热的 DeepSeek V4 Pro 的全面反超,开源领域的最佳成绩(SOTA)在短时间内再次易主。
而这仅仅是序幕,真正慷慨的部分才刚刚开始。伴随模型开源,小米同步推出了 MiMo Orbit 计划——一项专门面向 AI builder 的“创造者百万亿 Token 激励计划”(100 T)。
🎁 成功申请的用户最高可获得内含 16 亿 Credits 的 Token Plan,价值约 659 元。申请地址:https://100t.xiaomimimo.com/

申请信息
- 邮箱
- 常用的 AI 开发 / Agent 工具
- 主要使用的模型
- 描述使用 Agent 以及 AI 工具的成果
- 附件证明
- GitHub 项目地址或者在线演示地址
实测到账:2 亿 Credits 即刻入账
今晨提交申请,中午查看时发现已经到账。活动真实有效,还没上车的朋友请抓紧!本次我领取到的是 2 亿 Credits 的 Token Plan:
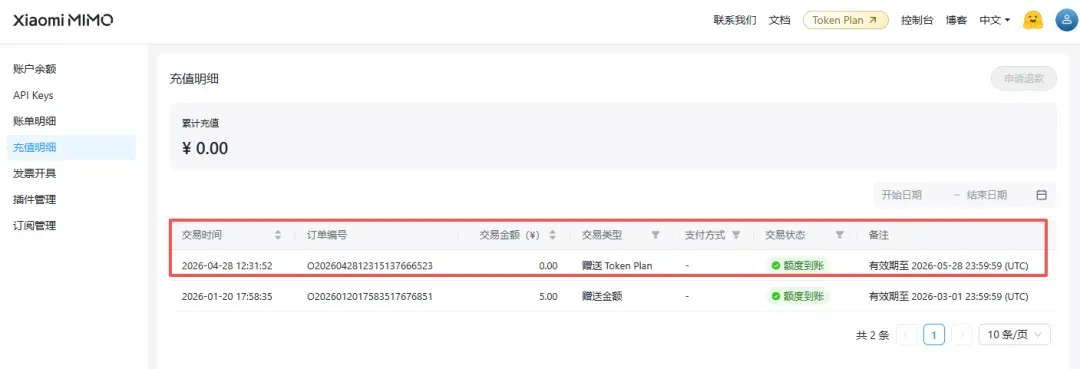
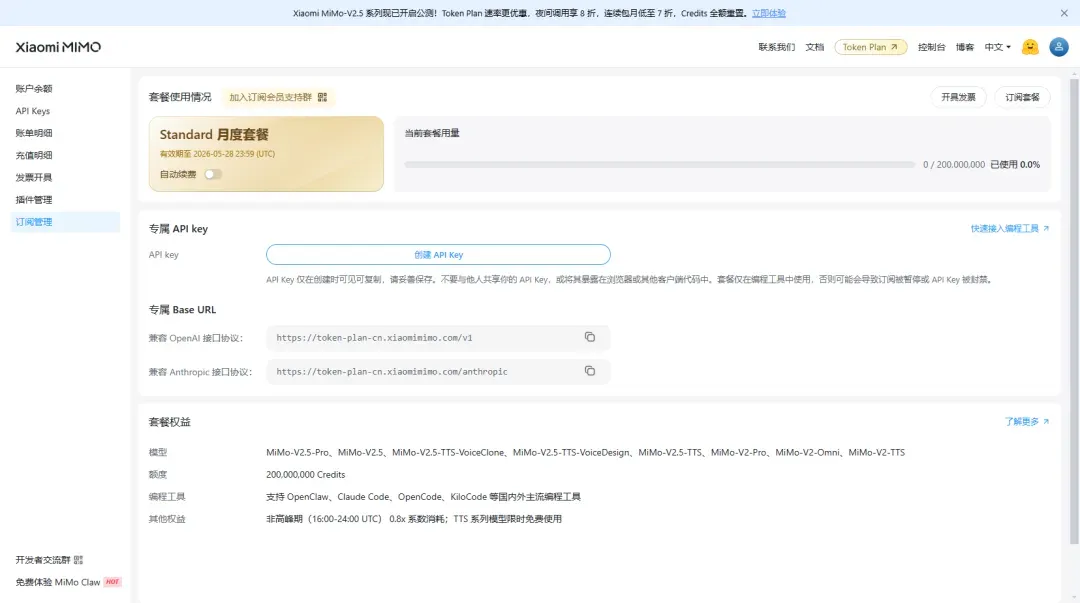
核心参数速览:V2.5 双模型架构一览
| 维度 | MiMo-V2.5-Pro | MiMo-V2.5 |
|---|---|---|
| 架构 | MoE (1 Dense + 69 MoE 层) | 原生全模态 |
| 参数量 | 1.02T 总参 / 42B 激活 | 310B 总参 |
| 上下文窗口 | 1M Tokens | 1M Tokens |
| 核心场景 | 复杂 Agent、长程 Coding | Multimodal Agent |
| 开源协议 | MIT (彻底放开商用) | MIT |
用 Markdown 构建 Agent 记忆:透明、可审计、零迁移成本的轻量方案
前面我们聊了很多向量库、知识图谱和复杂的记忆框架,你可能会问:有没有更轻量的 Agent 记忆存储方案?
为什么 Markdown 能作为 Agent 记忆
Markdown 在本质上是一种人和 Agent 都能直接读写的“显式长期记忆”。它不依赖数据库,不需要向量引擎,也不用配置复杂的检索管线。
它的核心优势在于透明、可审查、可版本化、低成本:
- 透明可审计:任何时候打开文件,都能看到 Agent 记住了什么、写入了什么,零黑箱。
- 持久化:文件直接保存在磁盘上,不依赖进程存活。崩溃、重启、换机器,记忆依然完整。
- 版本控制:记忆可以提交到 Git,随时回滚、分支、进行 Code Review,协作得心应手。
- 零迁移成本:标准格式,无供应商锁定。切换模型或框架,只需迁移文件即可。
- 成本极低:本地存储几乎不产生费用,而向量数据库却可能显著推高成本。
Manus 把文件系统视作结构化的外部记忆;Claude Code 则把 CLAUDE.md 和 Auto Memory 做到了明确的产品化;OpenClaw 等 Agent 项目和社区实践中,也频频出现类似的文件化记忆思路。它们共同说明了一个事实:在很多 Agent 场景中,文件系统 + Markdown 已经是一个足够扎实的长期记忆方案。
Claude Code 的 CLAUDE.md 机制
Claude Code 的记忆系统采用双轨制:CLAUDE.md(人工编写) 和 Auto Memory(自动积累)。
CLAUDE.md:该写什么、不该写什么
CLAUDE.md 本质上是一份给 AI 新人看的 onboarding 文档。写得不好还不如不写——一份臃肿的 CLAUDE.md 会让真正重要的规则淹没在噪音中。
该写的内容:
- 技术栈和版本信息:框架版本差异往往是 AI 犯错的源头。不标注 Spring Boot 版本,它更容易生成训练数据中更常见的版本用法。
- 常用命令:构建、测试、lint、启动——全部放在代码块中。代码块里的命令 Claude 倾向于原样执行,而写在自然语言里的命令,它可能按自己的理解去改写。
- 架构决策及背后原因:光写规则不够,写清楚“为什么”能让 Claude 举一反三。例如“不要直接写 SQL,用 QueryWrapper”——补充上“因为 SQL 审计系统依赖 Wrapper 解析来记录操作日志”之后,Claude 在其他需要生成查询的地方也会自觉使用 Wrapper。
- 团队约定和项目特有坑点:提交信息格式、分支命名规范、环境变量依赖。这些 Claude 从代码里读不了,但一个新人入职必然会问。
不该写的内容:
月薪差4倍,生活成本低7倍:数据透视全球化如何划出中美不同轨迹

同一场全球化的雨,滴进两个不同的屋檐
过去三十年,全球化像一部高速运转的财富引擎,推着中美两国企业的利润冲向历史高点。但同一笔红利落到地面上,却如河流分岔,形成了截然不同的风貌。这不是一篇输出立场的文字,而是一组数字试图讲述的故事。
最近,一份生活成本对比数据在社交网络上被反复讨论。数据背后的问题很直接:同样是全球化的受益者,为什么中国和美国的城市面貌相差如此之大?要回答,不能只看账面工资,得看每一美元背后隐藏的实际购买力。
数据揭开的反差
先看实际到手收入。Numbeo 2026 年 5 月的最新数据给出:中国平均税后月薪约 1,007 美元,美国则约为 4,276 美元。单看纸面,美国是中国的 4.2 倍。
但钱不是印在存折上被观赏的,它需要流进柴米油盐、水电宽带里。在这个花钱的环节,差距不仅没有缩小,反而放大出来。
一份平价简餐:中国 2.84 美元,美国 20 美元——差距逼近 7 倍。一打鸡蛋:中国 1.57 美元,美国 4.41 美元。一杯卡布奇诺:中国 2.95 美元,美国 5.32 美元。一磅普通白米:中国 0.43 美元,美国 2.09 美元。以更少的美元,在中国能撬动更多的实物商品。这不仅是汇率波动的结果,更是经济体系在底层设计上的差异——它决定了基础民生消费的保护垫有多厚。
基础设施服务的落差更显著。宽带每月费用:中国 11.23 美元,美国 72.43 美元,差了 6.4 倍。手机月费:中国 8.95 美元,美国 60.90 美元。基本的水电气暖开销:中国 51.89 美元,美国 210.49 美元。这些不是可有可无的奢侈品,而是现代人维持体面生活的必须项,中国以更低的价格完成了基本公共服务的覆盖。
住房:那块最沉重的拼图
生活成本核算里,住房永远是最扎眼的一块。早几年,北京房价收入比一度贴在 37 倍附近,上海 38 倍,深圳甚至摸到 40 倍——那确实是市场高烧时期的峰值。
然而,最近一轮持续数年的房地产深度调整改写了数据。根据全国主要城市房价及收入统计,到 2025 年底,50 城平均房价收入比已从 2021 年的 13 倍压缩到约 9 倍。北京降至大约 22 倍,上海 21 倍左右,深圳依然最高,约 26 倍。从“不可能”滑向“很困难”,虽然依然沉重,但方向是明显的回调。
2025年OpenClaw零基础一键部署教程:免费、小白也能轻松上手
OpenClaw自今年1月爆火以来,热度持续攀升,至今未减。最初令我印象最深刻的两个特点是:它可以实现7×24小时不间断的输出与执行;同时,还能通过移动端聊天工具远程调度,让它按你的指令主动“干活”。这里所说的“干活”,指的是真正产出有实际价值的结果,而不是仅仅停留在理论推演。
不过,让OpenClaw真正跑起来,原本需要不少准备:购买服务器、编写代码、配置API……这一整套流程就足以劝退大多数普通用户。光是部署步骤,就要耗费不少时间和精力。
但AI进化的速度远超想象。仅仅过去一个多月,部署OpenClaw的难度就已经大幅降低,现在即使是零基础用户,也能在几分钟内轻松搞定。
今天,我们将分享三种“不需要买服务器,也无需配置API”的OpenClaw部署方法,一键启动,小白也能无门槛上手。
方法一:通过Kimi部署OpenClaw
早在除夕当天,Kimi就正式推出了Kimi Claw,直接把OpenClaw集成到了云端环境中,而且支持7×24小时持续在线。
部署方式
在Kimi上部署OpenClaw非常简单,只需两个步骤。
首先,通过浏览器打开官网 https://www.kimi.com/,并完成登录。
之后,在左侧工具栏中点击“Kimi Claw”,再点击“创建”。
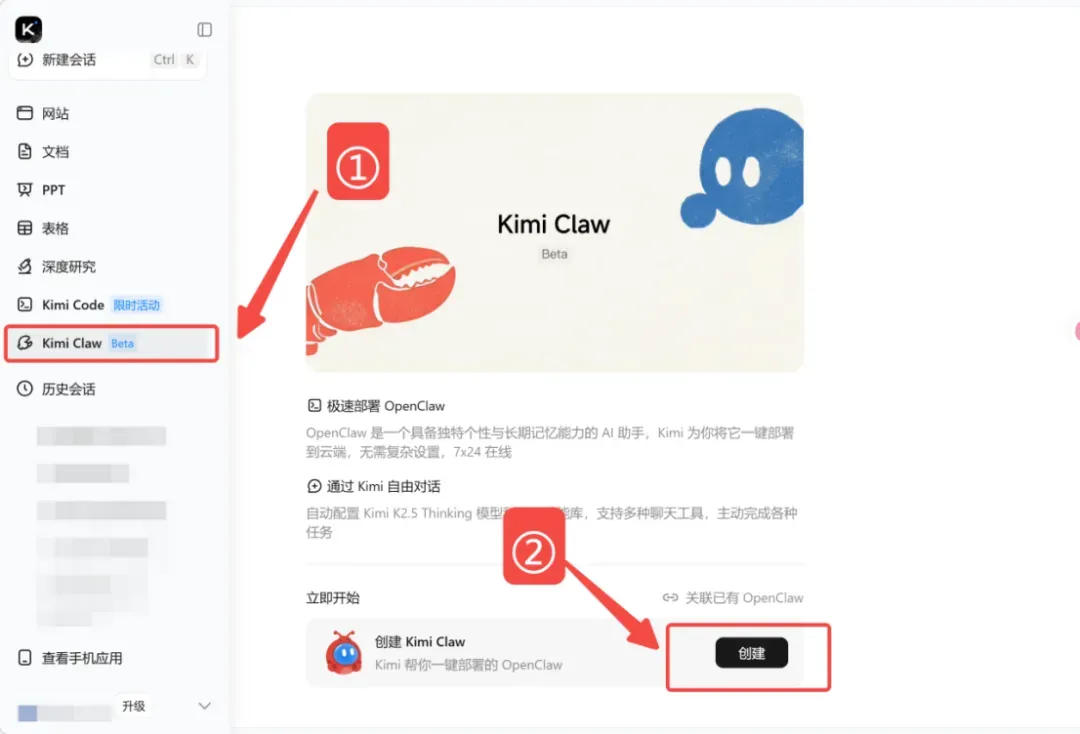
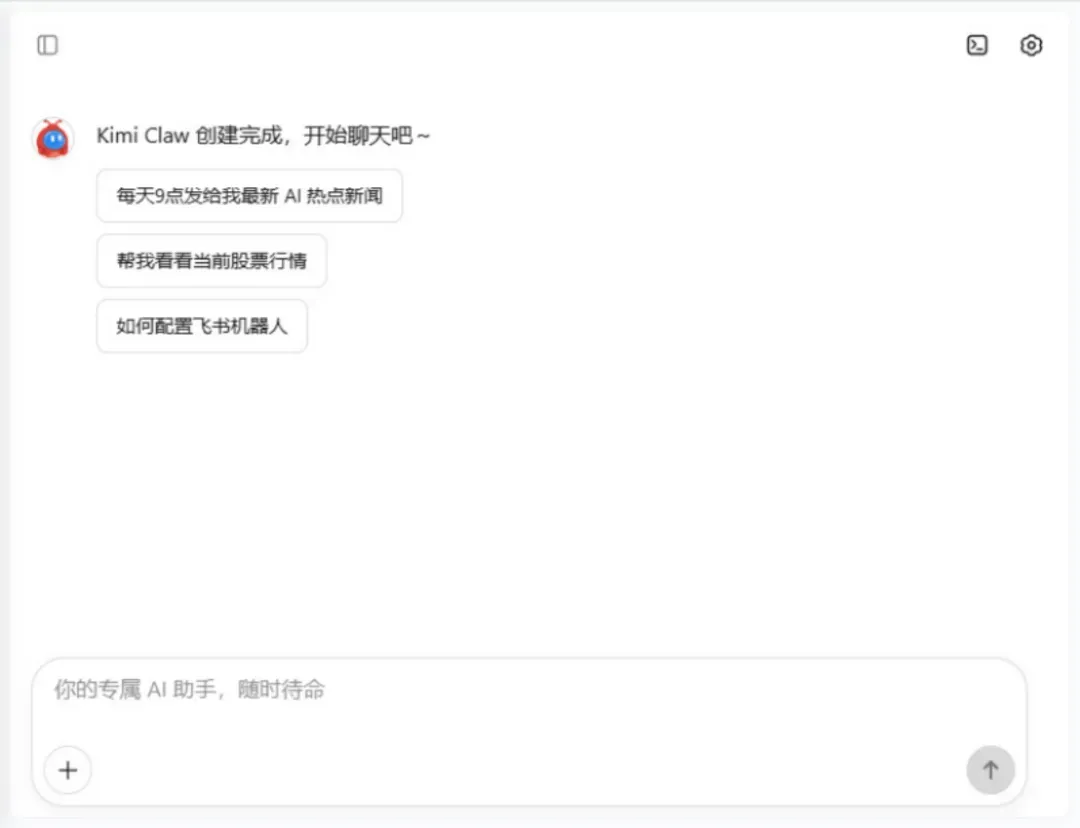
几秒钟后,属于你个人的Kimi Claw就会自动创建完成,过程非常轻量化。
如何使用OpenClaw
刚刚部署好的OpenClaw不会立刻变成完全契合你口味的专属助理,需要先做一些“调教”。你完全可以通过直接对话的方式,来定义它的工作方式和回应风格。
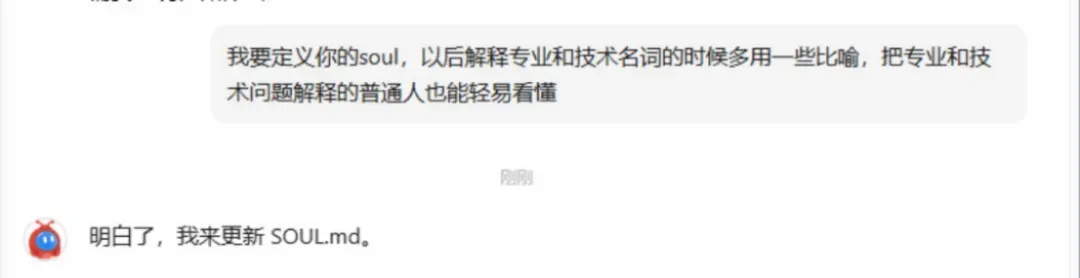
除了定义回复风格,你还可以告诉Kimi Claw你的身份、工作内容、偏好与禁忌。随着长期使用和适时调整,它会越来越懂你,执行方式也会更有“人情味”。
接下来,你还可以把它接入到日常办公软件中,比如很多职场人高频使用的飞书。这样,Kimi Claw就能以“专职下属”的身份进入你的工作流。
接入飞书也非常直接,只需在聊天框里询问“如何在飞书上设置Kimi Claw机器人”或类似问题,Kimi Claw就会生成详细的配置指南和操作流程。
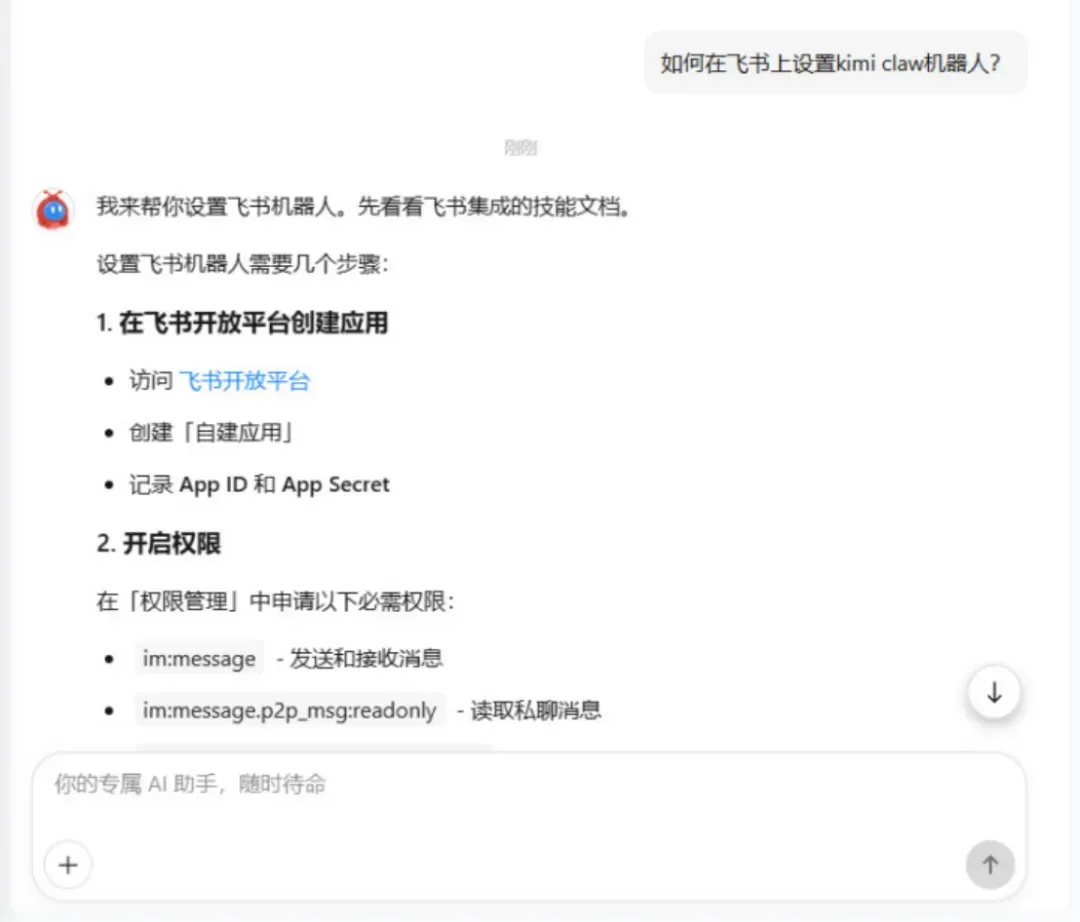
按照步骤完成设置后,一个7×24小时在线、能拉群、能分享、会主动执行任务的工作助理就上线了。
方法二:通过MiniMax部署OpenClaw
在MiniMax上部署OpenClaw同样非常简单,不过这个方案需要科学上网才能访问。
首先,打开MiniMax Agent的官网:https://agent.minimaxi.com。之后,切换到MaxClaw页面,点击“立即开始”。
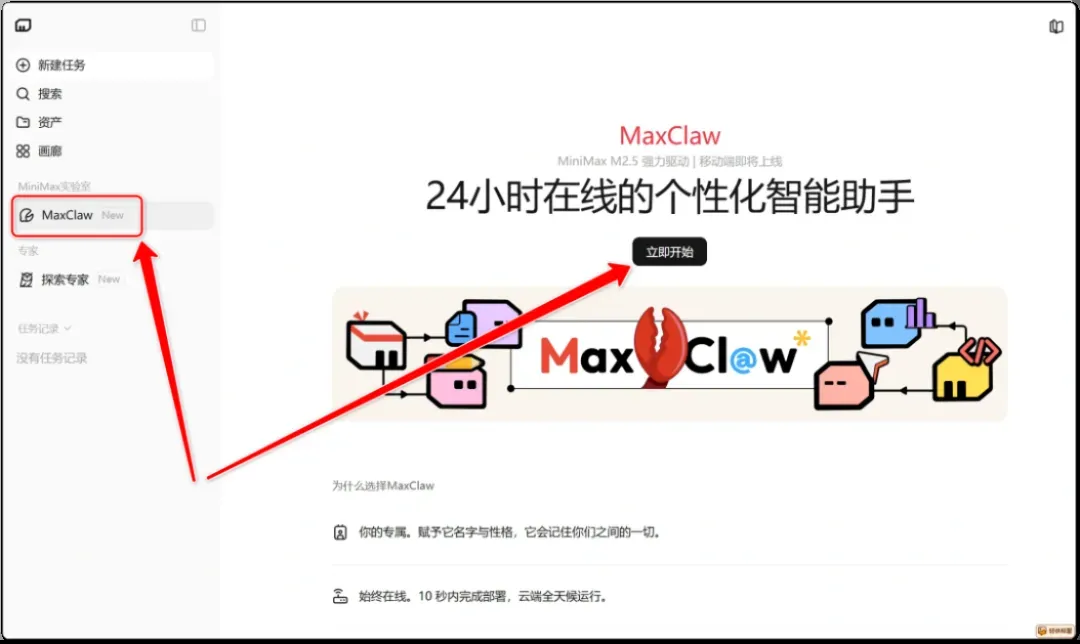
接着,你可以在官方预设的7套专家配置中,挑选一个适合自己的,然后点击“准备好了”。
整个过程不超过十秒,专属于你的MaxClaw就会被创建出来。
如何使用OpenClaw
你可以直接在MiniMax平台上给出任务指令。例如,输入“每天早上8点,搜索科技新闻,去重后只留5条,中文,附链接”,MaxClaw便会立即执行,并返回整理好的结果。

同样,MaxClaw也可以部署到飞书,操作方式和在Kimi中几乎一致:直接在对话框询问,它会一步步引导你完成配置。

方法三:通过百度App部署OpenClaw
前面两种部署方案主要适合在电脑端操作,而接下来的方式则更简单直接——你只需要一部手机就能完成,尤其适合没有电脑的用户。
部署方法
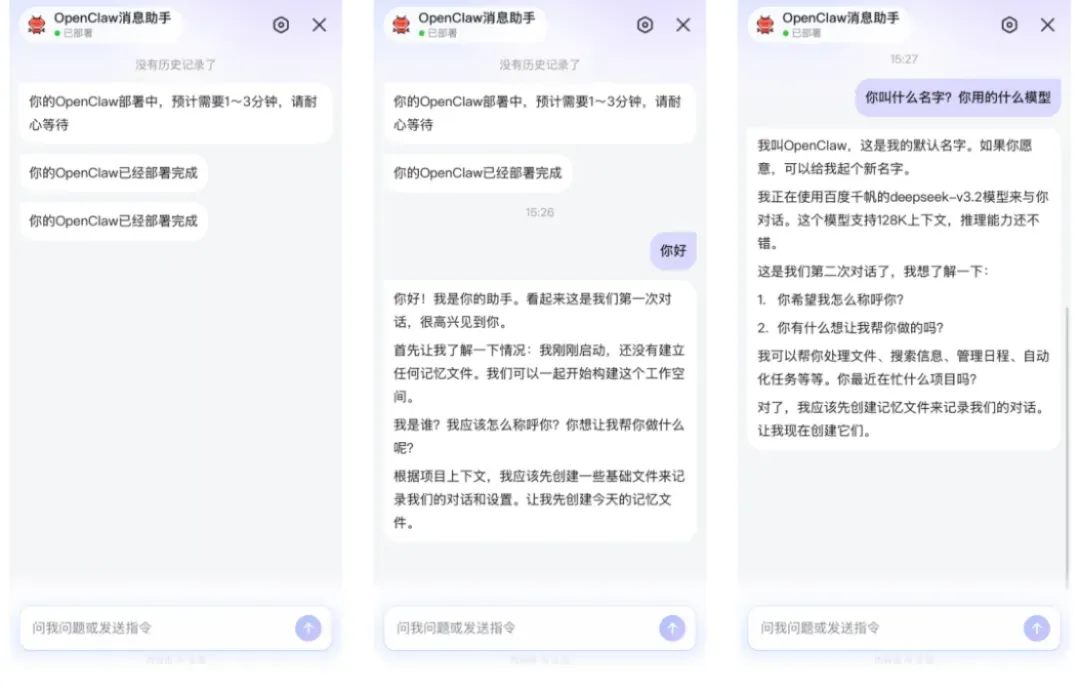
首先,在手机上下载并安装【百度App】,完成登录。
接着,在百度App中搜索“OpenClaw”相关关键词,点击搜索结果中最大的Banner图片。页面上会提示“限时免费”,也就是说,这次部署不需要额外付费,大家可以零成本尝试。
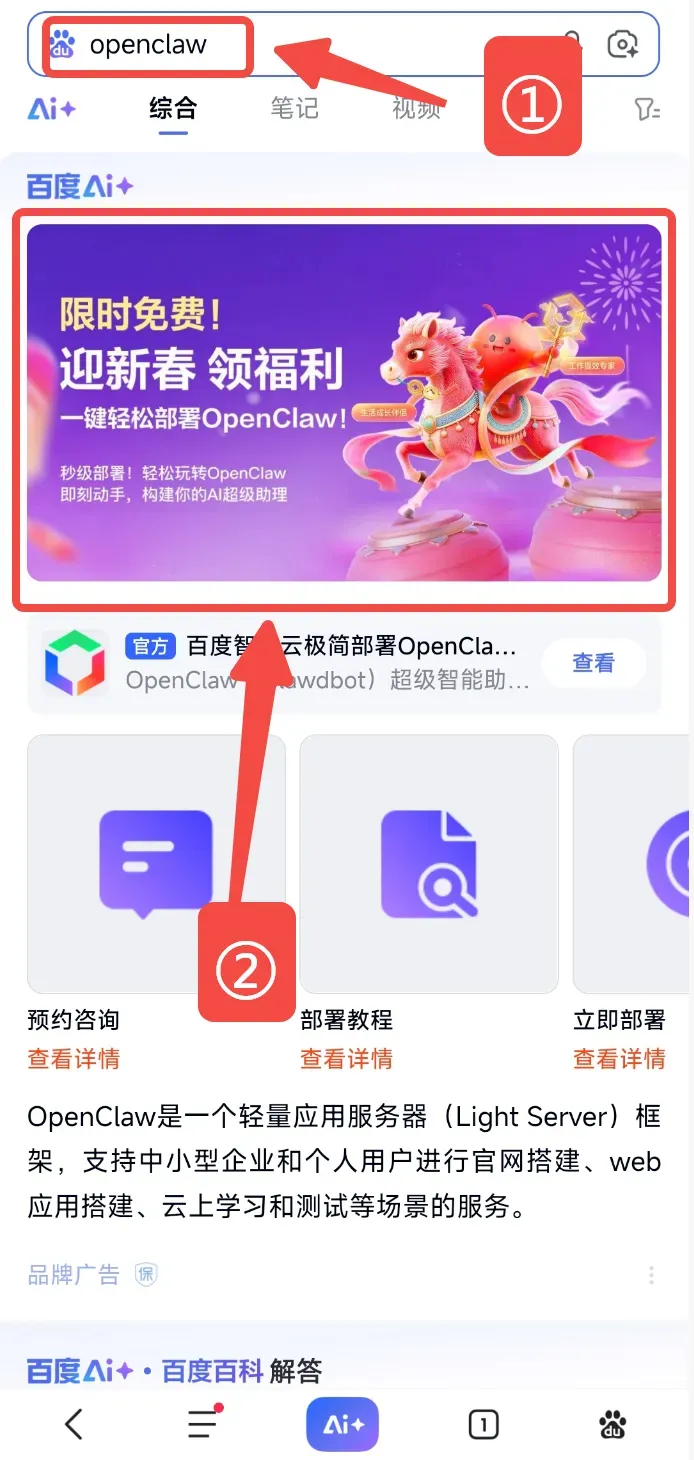
页面会跳转到一个免费活动界面,直接点击下方的领取按钮即可。完成领取后,界面会再次变化,只需点击“立即部署”。

大约等待1到3分钟,OpenClaw就能全部部署完毕。你完全不需要操作命令行,也不需要下载任何安装包,所有底层环境都已经由平台内置好。这种一键部署的方式,对新手极为友好。
如何使用OpenClaw
部署成功后,直接在百度App里就能调用,默认使用的底层模型是DeepSeek V3.2。
结语
曾经有人说过:“成功部署OpenClaw的人,正在逃脱永远的底层阶级。”这句话听起来或许有些贩卖焦虑的意味,但如果拨开表象,背后其实隐藏着非常现实的洞察:AI Agent正在从根本上改写我们生产力的底层逻辑。如今,这些“一键部署”的方案,也让更多人有机会平等地拥抱这种全新的工作方式。
2026 AI资讯自动化监控方案:覆盖100+信源,每日5分钟,多睡一小时

核心亮点
每天花45到60分钟刷X追踪AI动态,投入产出的比值越来越低。大量注意力被情绪化帖子和同质化内容吞噬。借助OpenClaw+Hermes双栈搭建的监控体系,可同时覆盖国内外100余个信源,你只需花5分钟就能消化当日所有关键动向,月均开销还不到一杯咖啡的钱。
- 100+ 稳定监控的信源
- 5 min 日均阅读时长
- $15 月度费用上限
在X上捕捉AI信息,效率断崖式下滑
很多人把X当成AI资讯的首要来源,但这种模式存在四个结构性缺陷,不是多关注几个账号就能解决的:
- 信息噪音——X信息流里大约七成内容与你关心的领域不搭界。热点事件、骂战、推广和无聊话题比比皆是,真正对你有用的AI条目不足三成。
- 被动接收——算法决定你能看到什么,而不是你在主动筛选。除非你24小时在线,否则重要信息被漏掉几乎是必然。
- 平台壁垒——X上的信息仅仅是冰山一角。GitHub新项目发布、ArXiv最新论文、科技媒体的深度分析并不会自动出现在你的时间线里。
- 时间黑洞——随手点开,滑一滑,半个小时就蒸发了。早晚各刷一遍,一天少说消耗一小时。一年下来就是365个小时,足以系统学会一项新技能。
2026年AI资讯工具全景图
过去两年,AI资讯聚合赛道涌现出一批优秀产品。它们共同解决的核心问题就是:把“人追信息”转变为“信息追人”。大致可以分成两类:
SaaS类:即开即用,适合不想费心折腾的用户
- Nudget($4.99/月)——支持YouTube、X、Reddit、Substack、RSS等14种信源类型。AI每日自动提炼摘要,提供Chrome插件一键订阅,是目前体验最平滑的聚合服务。
- Hey Silas($6.58/月)——每天扫描200多个信源后输出5件最要紧的事。内置11种视角滤镜,可以分别从投资人、创业者等不同角度解读同一条新闻。
- Readless($4.90/月)——专注邮件简报整合。把你30多份newsletter转发给Readless,它会自动去重、汇总并生成一份10分钟能读完的每日简报。
Agent框架类:完全自主可控,适合愿意深入定制的用户
当你的需求超出SaaS工具的边界,例如要监控特定GitHub仓库的Release、追踪个别KOL的言论变化,或者需要跨平台推送(同时发送Telegram、微信和邮件),Agent框架就该上场了。
OpenClaw
- 全球超过34万GitHub Stars
- 社区沉淀了1.3万+种技能
- 集成24个消息平台
- 内置tech-news-digest技能,开箱即用
Hermes Agent
- 11万+GitHub Stars
- 具备自我学习优化的工作流
- 本地SQLite持久化记忆
- 内置claw migrate数据迁移工具
搭建一套自动化的监控系统
这套体系的底层逻辑是“一次配置,持续按需送达”。无论选用哪种框架,大体流程都一致:
- 选择底座——看重生态丰富度的话优先选OpenClaw(内置tech-news-digest技能,配置即运行)。若更追求稳定性可考虑Hermes(cron定时任务不漂移,能持续自我学习优化)。你也可以双栈并行,让OpenClaw负责编排,Hermes执行具体任务。
- 配置信源——搭建四层数据管道:RSS(46+个源)、X KOL(44+个账号)、GitHub Releases(19+个仓库)、Web Search(4+个主题搜索),全面覆盖各类信息维度。
- 设定质量分——对信息进行加权打分:优先信源+3分,多源交叉验证+5分,时效性+2分,互动热度+1分。最终只推送排名前12条,确保重要内容不被噪声淹没。
- 规划推送——每天早晨7点自动生成简报,通过Telegram、Discord或邮件投递。你端起咖啡时,最新资讯已经在等你了。
OpenClaw用户可以直接安装社区技能:
clawhub install tech-news-digest
配置好信源和推送渠道后,设定每天7点自动执行
需要注意:这套系统运行一个月大约消耗360K tokens,成本在5到15美元之间。如果自己用Python脚本搭配免费模型跑日常任务,甚至可以几乎压到零成本。
信源策略:广度和精度如何兼得
信源选对了,整个体系就成功了八成。以下是经过实战检验的有效配置思路:
国内信源
▸ 36氪 —— 中文媒体中AI产业报道密度最高,每天更新多条。
▸ 机器之心 —— 技术解析深入,论文解读和开源项目追踪到位。
▸ 腾讯云开发者社区 —— 每周提供AI简报汇总,覆盖信源广。
▸ 知乎AI精选 —— 深度分析多,适合理解技术背后的逻辑。
2026 年 OpenCode 安装配置完全指南:从零到上手
如果 2026 年你的开发效率还没有翻倍,很可能是工具链还没升级。
开源、不绑定模型、75+ 种模型自由选择——这个运行在终端里的 AI 编程代理,或许会让你重新理解「AI 辅助写代码」这件事。本文从零开始,带你 10 分钟跑通 OpenCode。
认识 OpenCode:开源的 AI 编程代理
OpenCode 是一个完全开源的 AI 编程代理(AI Coding Agent),它驻留在你的终端中,可以用自然语言帮你完成代码编写、调试、重构等一系列软件工程任务。
一句话说明它的核心定位:
不绑定任何一个模型,不锁定任何一种 IDE,不收取任何许可费用——OpenCode 把 AI 编程的自主权交还给开发者。
它的工作流大致是这样的:
你:帮我写一个带 JWT 认证的用户登录 API
OpenCode:
✅ 分析项目结构
✅ 创建 auth/jwt.go
✅ 更新 routes/user.go
✅ 添加中间件鉴权
✅ 运行测试 → 全部通过
三种使用形态,覆盖不同场景
OpenCode 提供三种使用形态,几乎能适配所有开发环境:
| 形态 | 启动方式 | 适合场景 |
|---|---|---|
| 终端界面(TUI) | 在命令行中输入 opencode | 服务端开发、SSH 远程、服务器运维 |
| Web 网页版 | opencode web 启动浏览器界面 | 需要图形界面、团队协作演示 |
| IDE 扩展 | 在 VS Code / Cursor 集成终端中运行 | 日常开发,边写边问 |
OpenCode
2026国产AI编程模型深度实测:与Claude差距仅2.7%,月费却省90%,怎么选最划算?
先说结论
能换,但别全换。
这可不是拍脑门说的。斯坦福大学刚发布了一份423页的权威报告,核心数据非常直接:
中美顶尖AI模型的实际差距,已经缩小到 2.7%。
两年前,这个差距还是300分的量级,如今只剩 39分。
更关键的是——国产模型的价格,只有Claude的1/50,是GPT的1/90。
2.7%的性能差,乘以50倍的价格差。
这笔账,你是不是也该好好算算?
📌 2.7%到底意味着什么?
先别急着质疑,看看数据来源。
出处:斯坦福大学HAI研究所《2026年AI指数报告》,全球AI领域最严谨的年度评估,全文423页,并非自媒体杜撰。
评测方法:Arena排行榜,全球百万用户的盲测——两个模型匿名对决,你投哪个好用,结果就倾向哪方,相当于“盲品红酒”,非常直观。
差距演变:
| 时间 | 美国第一 | 中国第一 | 差距 |
|---|---|---|---|
| 2023年5月 | GPT-4(1320分) | ChatGLM-6B(~1020分) | 300分 😱 |
| 2025年2月 | 美国头部模型 | DeepSeek-R1 | 首次打平! |
| 2026年3月 | Claude Opus 4.6(1503分) | Dola-Seed-2.0(1464分) | 39分 = 2.7% |
2023年那会儿,国产模型连GPT-4的影子都追不上。
而今天,这差距已经微乎其微,日常使用你很难感知到。
💰 算一笔真实账单:你一年多花了多少钱?
先亮出数据来源,绝不是随口估算:
- Claude Code官方数据(2026年4月29日更新):企业部署中每位开发者日均成本 $13,月费 $150-250(约 ¥1,027-1,712)
- 开发者日均Token消耗:日常AI编程大约 300-400万tokens/天(有程序员实测反馈:“一觉醒来几百块没了”)
海外方案 vs 国产Coding Plan一览
现在国产模型厂商基本都推出了Coding Plan(编程订阅方案),可以直接在Claude Code、Cursor、Cline等工具里切换,体验几乎一致。
模型厂商直营套餐(单一模型,编程能力最顶尖):
| 平台 | 核心模型 | 入门档 | 推荐档 | 旗舰档 |
|---|---|---|---|---|
| 智谱 GLM | GLM-5.1 | ¥49/月(Lite) | ¥149/月 (Pro) | ¥469/月(Max) |
| Kimi Code | Kimi K2.6 | ¥49/月(Andante) | ¥99/月 (Moderato) | ¥199/月(Allegretto) |
| MiniMax | M2.7/M2.5 | ¥29/月 (Starter) | ¥49/月(Plus) | ¥199/月(Max极速) |
| DeepSeek | V4 Pro/V4 Flash | 按量计费,无订阅 | ~¥264/月 (重度) | ~¥88/月(中度) |
聚合平台(多模型切换,适合多面手):
2026国产大模型编程能力终极排行:五大旗舰性能价格全对比
内容摘要:2026年4月,国产大模型迎来爆发时刻——DeepSeek V4 Pro、GLM-5.1、Kimi K2.6、MiniMax M2.7、Qwen3.6-Max-Preview 五款编程专长模型同场较量。本文基于 SWE-bench、Terminal-Bench 等权威评测,综合 API 价格、开源生态与真实应用场景,为你提供最硬的选型参考。
⚠️ 免责声明:文中数据均来源于各厂商官方公告及 SWE-bench、Artificial Analysis、DataLearner 等公开测试平台,部分指标可能随模型迭代更新,请以官方最新发布为准。
📊 核心参数速览
| 模型 | DeepSeek V4 Pro | GLM-5.1 | Kimi K2.6 | MiniMax M2.7 | Qwen3.6-Max-Preview |
|---|---|---|---|---|---|
| 开发方 | 深度求索 | 智谱AI | 月之暗面 | MiniMax | 阿里云 |
| 亮相时间 | 2026年4月 | 2026年3月 | 2026年4月 | 2026年4月 | 2026年4月 |
| 参数规模 | 1.6T MoE (激活49B) | 754B MoE | 万亿级 | 未公开 | 未公开 |
| 上下文窗口 | 1M tokens | 200K tokens | 128K tokens | 1M tokens | 1M tokens |
| SWE-bench Verified | 80.6% 🥇 | 77.8% | 80.2% | 78.0% | 未公布 |
| SWE-bench Pro | 55.4% | 58.4% 🥇 | 58.6% 🥇 | 56.22% | 57.3% |
| Terminal-Bench 2.0 | 67.9% | 未公布 | 66.7% | 56.2% | 65.4% |
| 开源许可 | MIT ✅ | 开源 ✅ | MIT ✅ | 未开源 | 未开源 |
| API 输入价 (¥/百万tokens) | ¥3 🥇 | ¥5 | ¥4 | ¥2 | ¥2 |
| 订阅套餐月费 | 按量付费 | ¥49-469/月 | ¥49起/月 | ¥29/月(Token Plan) | 百炼 ¥200/月 |
| 核心亮点 | 开源+性能双冠 | 8小时超长任务 | 300智能体协作 | 自进化模型 | 六项基准登顶 |
🔍 深度对比分析