2026国产大模型巅峰对决:DeepSeek、Kimi、MiMo、GLM四大模型横向评测与选型指南
一周之内,四连击,AI圈彻底疯狂
2026年4月下旬,四条重磅消息让整个AI圈瞬间沸腾。如果你恰好在那一周刷开朋友圈,看到的会是:
- 4月20日 – Kimi K2.6 开源,一举登顶 SWE-bench Pro 全球第一
- 4月23日 – 小米 MiMo V2.5-Pro 发布,罗福莉率队,开源模型并列榜首
- 4月24日 – DeepSeek V4 Pro 预览版上线,百万级上下文窗口炸裂开源社区
- 4月8日(同月)– 智谱 GLM-5.1 出场,SWE-bench Pro 首次超越 Claude Opus 4.6
面对这套“组合拳”,你大概率会问:这一波四个模型谁更强?我该押注哪一个? 别急,本文把它们拉到同一条起跑线,一项一项拆给你看。
📌 硬实力先过招:基础参数横评
以下所有维度都是四家同时公开的,杜绝任何“田忌赛马”式对比。
| 维度 | DeepSeek V4 Pro | MiMo V2.5 Pro | Kimi K2.6 | GLM-5.1 |
|---|---|---|---|---|
| 发布时间 | 4月24日 | 4月23日 | 4月20日 | 4月8日 |
| 架构 | MoE | MoE | 多模态MoE | MoE |
| 总参数量 | 1.6T 🏆 最大 | 309B | 1.1T | 744B |
| 激活参数 | 49B | 15B 🏆 最省 | ~320B | ~40B |
| 上下文 | 1M 🏆 | 1M 🏆 | 256K | 200K |
| 多模态 | ❌ 纯文本 | ❌ 纯文本 | ✅ 图文+视频 | ❌ 纯文本 |
| 开源协议 | MIT | MIT | ✅ 开源 | MIT |
| 开源生态 | 全面适配 | 全芯片首发 | 主流框架 | 昇腾原生 |
| 国产算力 | 华为昇腾适配 | 燧原/英伟达等 | 未强调 | 10万颗昇腾910B 🏆 |
🔥 逐一深挖:四大模型各有何种绝技?
1. DeepSeek V4 Pro —「超长上下文之王」
总参数量达1.6T,是目前所有开源模型中体格最庞大的选手。
2026年AI编程工具选型决策树:基于90天实盘测试的Claude Code、Cursor、Codex深度解析
网上各类“AI编程工具横评”早已铺天盖地,表格数据眼花缭乱。可看完你依旧迷茫——因为它们都在比谁更强,却没告诉你该用哪个。这篇文章反其道而行。我用了90天,在真实项目中交替使用Claude Code、Cursor和Codex,记录了每一次切换的原因与最终结果,画出了一张照做就行的决策树。
实验设计:90天真实项目轮换测试
实验周期:2026年1月–4月
项目背景:一个中等规模的电商平台(Spring Boot + Vue3 + MySQL,约15万行代码,8人团队)
测试方式:
- 每天随机选定一个工具作为“主力”,记录完成率、出错次数、耗时
- 遇工具无法解决的场景,马上切换到另一个,并记下切换原因
- 月底汇总,按场景分类统计
不是实验室的纯净数据,而是搬砖现场的真实反馈。
90天下来,总共记录了347次有效任务执行:
- Claude Code:118次
- Cursor:152次
- Codex:77次
先看一张总览图,后面再一一拆解。
角色画像:三个AI伙伴的鲜明性格
正式对比之前,先给每个工具画一幅“人设”,方便你对号入座。
Cursor:你的影子搭档
像谁:那个坐你旁边,你打字他帮你补全的敏捷同事
口头禅:“我知道你要写什么,放着我来。”
Cursor的核心体验可以用一个词概括——跟手。你刚敲出函数签名,它已经预判了实现;你改了一处配置,它自动同步三个关联文件。这种灵感般的补全体验,至今无人能复刻。
但它有一个致命短板:它只能理解你眼前打开的上下文。一旦涉及跨模块、跨服务的复杂改动,它就开始“猜”,猜错了还得你手动收拾残局。
Claude Code:你的技术顾问
像谁:那个每次遇到难题首先想起来请教的架构师
口头禅:“先别急着写,让我看看整个项目的情况。”
Claude Code的强项是全局洞察。它不急着补全代码,而是先摸清项目架构、模块关系、依赖链路,然后再动手。这种“想清楚再干活”的风格,在复杂任务中优势显著。
代价呢?**慢,而且贵。**同一个简单任务,Claude Code的耗时可能是Cursor的2–3倍,Token消耗是Codex的6倍。用它写CRUD,明显大材小用。
Codex:你的外包执行队
像谁:你甩需求过去,它干完交活的远程团队
口头禅:“你先忙别的,我搞完了叫你。”
Codex的核心理念是异步委托。你提交一个任务,它就在独立沙箱里修改代码、跑测试、生成diff。你可以同时处理其他事情,等它完成再来验收。
问题在于反馈环路太长。你没法实时看到它的操作,也无法中途纠偏。一旦理解有偏差,它可能埋头跑了10分钟,产出完全跑偏的结果,你还得重新来过。
核心发现:数据背后的真相
发现一:80%的日常任务,Cursor就是最优解
347次任务中,约277次(80%)属于“日常编码”:写新接口、修小Bug、补测试用例、调整样式。这些任务的共同特征是:改动范围小、上下文需求低、反馈要即时。
| 工具 | 完成率 | 平均耗时 | 需要手动修改比例 |
|---|---|---|---|
| Cursor | 94% | 2.3分钟 | 12% |
| Claude Code | 91% | 5.1分钟 | 8% |
| Codex | 82% | 4.7分钟(含等待) | 24% |
Cursor在这类任务中完胜——不是因为它更聪明,而是它的交互模式(Tab补全+内联编辑)天然适配轻量级改动。你无需离开编辑器,也不用写长prompt,一键Tab就完事。
关键洞察:日常编码最重要的不是“AI多聪明”,而是“AI多跟手”。
发现二:复杂任务中,Claude Code的“慢”反而是胜手
约47次任务属于“复杂任务”:跨模块重构、架构设计、疑难Bug定位、性能调优。它们的共同特点是:改动范围大、影响链路长,一处改错就全线崩溃。
| 工具 | 一次通过率 | 平均回滚次数 | 耗时 |
|---|---|---|---|
| Claude Code | 89% | 0.3次 | 8.2分钟 |
| Cursor | 67% | 1.4次 | 6.5分钟 |
| Codex | 54% | 2.1次 | 12.8分钟(含等待+重试) |
Cursor虽快,但在复杂任务里“快”反而成了劣势——它太急于给你答案,容易忽略跨模块的副作用。改一次不行改两次,两次不行改三次,总耗时反而超过Claude Code。
2026年AI编程省钱终极指南:7招实现月费从¥500到¥100的跨越
摘要:Claude Code月费已飙升至200美元以上?Cursor重度使用也要升级套餐?2026年AI编程工具百花齐放,但选错工具真的会“烧钱”。本文整理了7大省钱策略,涵盖免费额度、国产Coding Plan、Prompt缓存、模型路由等实战技巧,附上各平台真实价格对比,帮你把月度开销从500元以上压到100元以内。
⚠️ 免责声明:本文中的价格与额度信息基于2026年4月各平台公开数据,可能随平台调整而变动,请以官方最新公布为准。
📊 先看真相:AI编程工具的真实月费
你以为的花费 vs 实际花费
| 工具 | 表面价格 | 重度使用实际月费 | 费用陷阱 |
|---|---|---|---|
| Claude Code | $20/月 | $50-200+/月 | Agent模式一次提问可触发5-30次API调用 |
| Cursor Pro | $20/月 | $20-40/月 | 高用量需升级至Ultra($200/月) |
| GitHub Copilot | $10/月 | $10/月 | 包月制,成本最可预见 |
| OpenClaw | 按量付费 | $200-600/月 | 13小时实测烧掉$200 |
| DeepSeek API | ¥2/百万tokens | ¥30-100/月 | 单价极低,但重度使用仍需控制 |
💡 关键认知:编程工具中,一次提问通常会触发5-30次模型调用(包括代码分析、生成、验证等),因此实际消耗远超你所以为的“一次提问”。
🆓 策略一:善用免费额度,零成本起步
各平台免费额度一览
| 工具 | 免费额度 | 免费内容 | 适用人群 |
|---|---|---|---|
| Gemini CLI | 1000次/天 | Gemini 2.5 Pro + Flash | 大文件分析、学习研究 |
| GitHub Copilot Free | 2000次补全/月 | 代码补全 + 限量Chat | 轻度使用、体验 |
| Cursor Hobby | ~50次/月 + 200次补全 | 基础补全与Chat | 偶尔使用 |
| Kimi 网页/APP | 每日免费额度 | K2.6模型对话 | 日常问答 |
| DeepSeek 官方 | 小量免费额度 | V4 Pro对话 | 体验模型能力 |
| 阿里云百炼 | 首月¥7.9 | 8+模型全家桶 | 新用户尝鲜 |
零成本组合方案
方案 A:纯白嫖党
2026年GPT-Codex 90天进化实录:GPT-5.5、内置浏览器与插件生态,编程工具变身全能工作平台
90天,3个新模型,1个全新插件生态,1次桌面端大革命。如果你还在用2月份的Codex,那它已经变得你几乎认不出了。
发生了一场「质变」
2026年2月5日,我曾写过一篇《GPT-5.3-Codex重磅发布:代码能力提升150%》,那时我深信这就是2026年AI编程工具的天花板。
我低估了OpenAI的节奏。
此后的90天里,OpenAI一口气完成了下面这些更新:
| 时间 | 事件 | 重要性 |
|---|---|---|
| 3月5日 | GPT-5.4上线,1M上下文窗口+原生Computer Use | 🔥🔥🔥🔥🔥 |
| 3月17日 | GPT-5.4 mini上线,速度快2倍以上 | 🔥🔥🔥🔥 |
| 3月25日 | 插件系统Plugins发布 | 🔥🔥🔥🔥 |
| 4月7日 | 旧模型大规模下线(gpt-5.1全系列) | 🔥🔥🔥 |
| 4月16日 | Codex App大更新:内置浏览器、Computer Use、Memories | 🔥🔥🔥🔥🔥 |
| 4月23日 | GPT-5.5上线 | 🔥🔥🔥🔥🔥 |
| 4月30日 | Codex CLI 0.128:/goal工作流、插件市场 | 🔥🔥🔥🔥 |
这并不是一个简单的版本迭代。
这是Codex从“编程工具”跃迁为“全能工作平台”的质变。
你是否已经感到「代差」?
如果你是在2月份入坑的Codex用户,此刻很可能还困在这些旧习惯里:
❌ 还在用gpt-5.3-codex作为默认模型
❌ 还不知道Codex已经有了桌面App(可不止是CLI)
❌ 还在使用--full-auto模式(已经废弃)
❌ 没试过让Codex操作浏览器
❌ 没体验过Codex的插件生态
而紧跟更新步伐的开发者已经开始这样工作:
✅ 使用GPT-5.5完成最复杂的架构设计
✅ 让Codex直接操作桌面应用,自动测试交互
✅ 通过/goal管理跨天、跨会话的长期任务
✅ 安装插件扩展Codex的能力边界
✅ 在内置浏览器中实时预览前端效果
这不是一点点的差距,而是整整一个时代的落差。
3分钟速览:如今的Codex到底是什么?
它究竟是什么?
2026年2月的Codex:一款强大的AI编程终端工具。
2026年5月的Codex:一个覆盖编程、测试、设计、文档、项目管理的全能AI工作平台。
四大产品形态
| 形态 | 面向谁 | 核心能力 | 上线时间 |
|---|---|---|---|
| Codex CLI | 终端开发者 | 命令行AI编程 | 2025年4月 |
| Codex IDE扩展 | IDE用户 | VS Code / Cursor集成 | 2025年8月 |
| Codex Cloud | 团队协作 | 云端任务、Code Review | 2025年5月 |
| Codex App | 所有人 | 桌面应用,全能工作平台 | 2026年2月 |
重点:这四个产品形态共享同一套账号体系,任务可以在不同终端间无缝切换。
2026年OpenClaw AI树莓派实战指南:自主机器人集成与自动化前景
当价格亲民的单板计算机与高度自主的人工智能代理相遇,会擦出怎样的火花?答案正孕育于日益壮大的 OpenClaw AI 树莓派集成生态中。本文将系统拆解这一技术栈,盘点最具代表性的硬件产品,提供从零搭建的操作指引,并深度解读其对开发者及企业的战略意义。
解密 OpenClaw AI 树莓派平台
OpenClaw AI 树莓派方案,是指在树莓派微型计算机(通常为 Pi 4 或 Pi 5)上部署 OpenClaw AI 框架。这究竟能为普通用户与开发者带来哪些改变?
核心框架
OpenClaw 是一款采用 MIT 许可证的开源个人 AI 助手运行时。与传统仅输出文本的云端聊天机器人截然不同,它是一个能够执行实际操作的 AI 代理:可以运行终端命令、管理文件、发送邮件,并借助 Telegram、WhatsApp 和 Discord 等平台自主运转(来源:2026年2月24日09:15)。
为何选择树莓派?
将这类自主 AI 部署在树莓派上,相当于把推理与任务执行迁移至低成本的本地设备。这种做法彻底摆脱了对云服务的强依赖,极大压缩了物理硬件控制的延迟,并从根本上保障了数据隐私。配备 8.00 GB 内存的树莓派 5 被视为承载这一方案的理想环境,能够让 AI 以守护进程的方式全天候后台运行。

例如,即将面世的 OpenClaw 迷你 AI 主机 ED‑CLAWBOX,专门为 OpenClaw 端侧私有化部署量身打造。整机采用铝合金 CNC 加工外壳,精致小巧(100×100×19 mm),重量仅有 247 克。接口方面十分齐全:双 HDMI 输出(标准 + Micro)、千兆以太网、双频 Wi‑Fi/蓝牙 5.0、USB 3.0 接口等。设备预装了极术社区开源的 JishuShell 管理面板,无需繁琐配置,数分钟内即可获得一个完全本地化、数据私有的 AI 工作站。无论是开发调试、多任务并行处理,还是需要 7×24 小时稳定运行的场景,ED‑CLAWBOX 都凭借低功耗、高性能以及完整的树莓派生态兼容性,成为探索 AIoT 应用的理想硬件基石。
2026年最新Claude Code国内安装全攻略:零门槛接入国产免费模型,无需魔法即装即用
前段时间有个朋友突然找我。
“我好想用Claude Code,可死活装不上,你能帮我看看吗?”
我问卡在哪一步,他说打开那个黑色的窗口,照着输了一行命令就报错,完全看不懂什么意思,然后就把窗口关了。
我远程帮他折腾了一会儿,装好之后他立刻开始用,兴奋得不行。
挂掉电话之后我就想,可能很多人都卡在这一步。不是不想用,而是那个黑色窗口一出现就让人心里打退堂鼓。
今天把整个安装过程完完整整写清楚,哪怕你一行代码都没写过,照着做也能顺利装好。
01
再次认识Claude Code:它到底能帮你做什么
1、先别把它当成程序员的专属工具
很多人一听到Claude Code,下意识就觉得这是写代码的人才用的东西,跟自己没关系。
这个误解其实挡掉了不少人。
做内容的朋友:直接说清楚你的需求,它就能给你生成完整的文章。我平时借助它来写公众号初稿,一篇20分钟就能搞定。
做运营的朋友:每周都要整理周报,用它能五分钟就跑完数据汇总,空出来的时间就可以去做真正需要判断和决策的事。
想做副业的朋友:只要描述清楚想要什么样的小工具,几分钟就能给你一个直接可用的成品。不会写代码完全没关系。我帮那个朋友做的第一个工具,就是一个自动整理文件名的脚本,他现在每天还在用。
2、在国内根本用不了?这个认知一样害了很多人
不少人觉得Claude Code在国内没法用,原因是Claude本身在国内打不开。
但这个想法其实并不准确。
Claude Code本质上是一个Agent框架,打个比方,它就是一个工具的“壳子”。这个壳子可以装载各种“大脑”,也就是说,可以接入国内的模型,比如DeepSeek、GLM、Kimi,只要接上,我们照样能正常使用。
所以,国内用户完全可以先把框架装好,然后接一个国产的免费模型,整个工具就跑起来了。梯子、国外手机号、Visa卡这些统统都不需要。
02
一步步安装Claude Code
第一步:安装Git(打好基础)
这里以Windows系统为例来介绍。
Git是Claude Code正常运行的前提条件,如果没装,直接就会报错。
先按“Win+R”调出任务栏搜索框,输入“powershell”,打开Windows PowerShell。
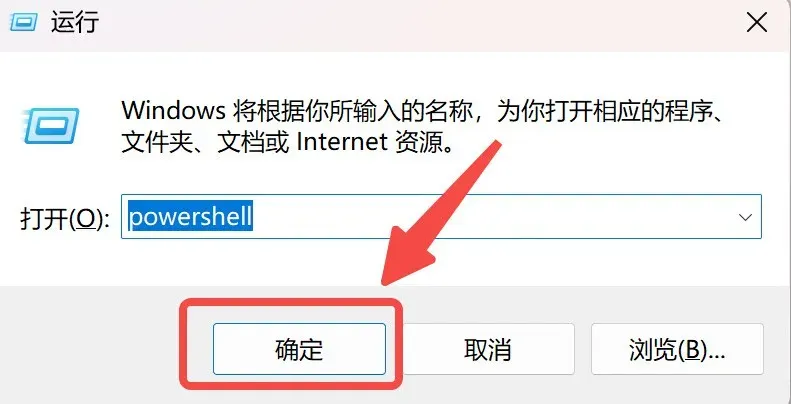
接着,粘贴下面这行命令,然后回车:
winget install Git.Git
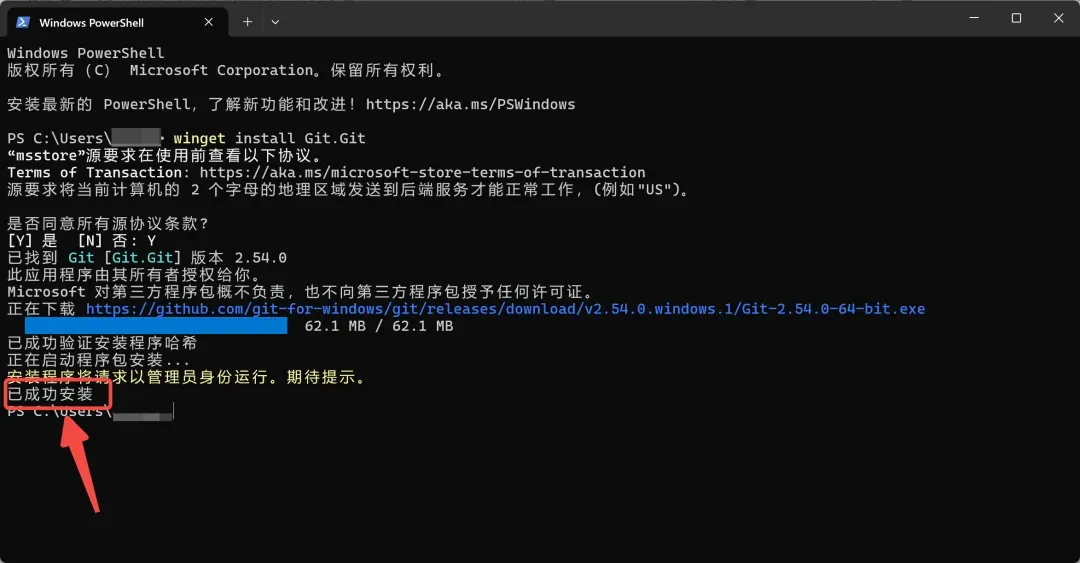
等它跑完,显示安装成功就可以了。
第二步:装Claude Code框架(把“壳子”装好)
Git装好之后,继续在PowerShell里粘贴下面这行命令,回车:
winget install Anthropic.ClaudeCode
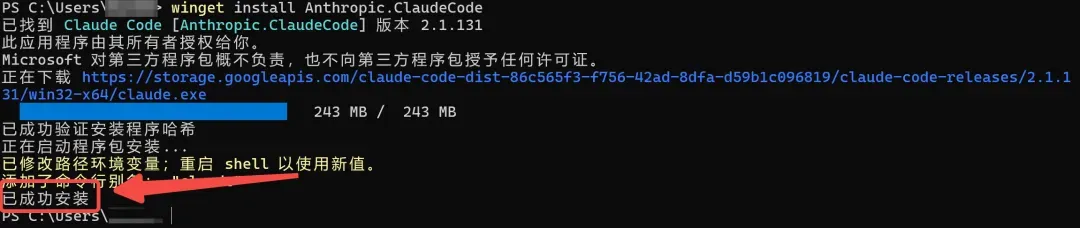
安装完成后,输入claude,如果能正常显示界面,就说明成功了。
第三步:接入免费的大脑(真正让它动起来)
框架有了,还需要给它配一个模型,它才能真正开始干活。
这里推荐用CC Switch来管理模型,它支持可视化切换,不用每次都手动去改配置文件。
到下面这个地址下载安装包:
github.com/farion1231/cc-switch/releases
找到以.msi结尾的文件,点击下载。
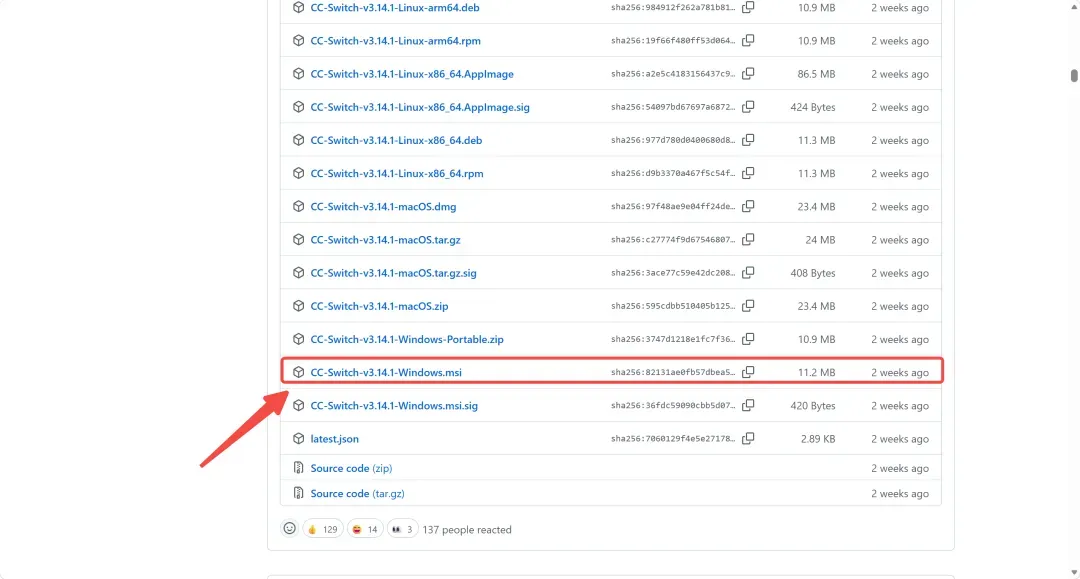
下载后双击打开文件,一路点击“Next”完成安装,然后打开应用。
我们以阿里云百炼为例来说明。
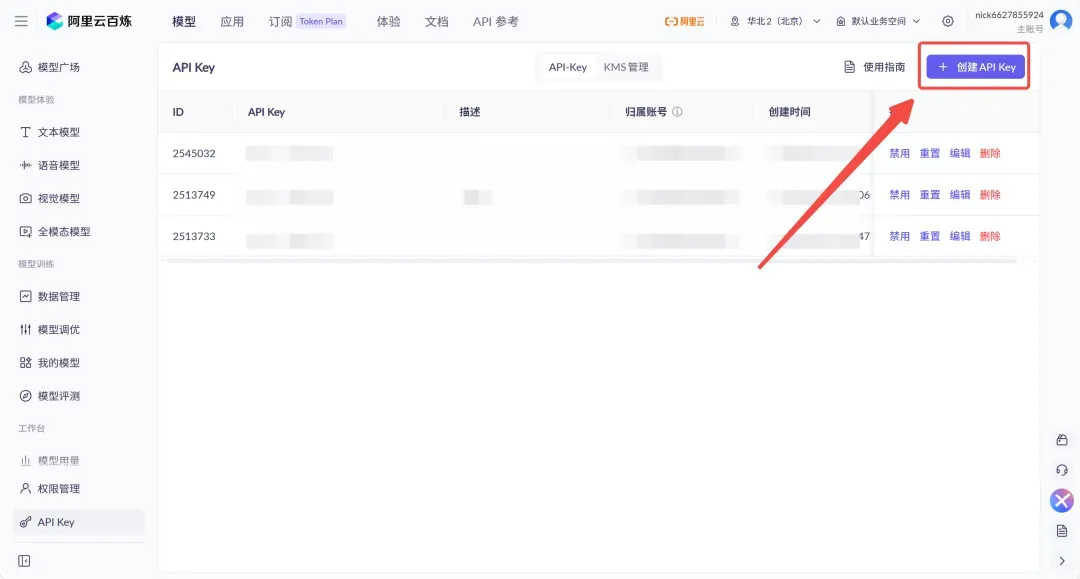
阿里云百炼对新注册并完成认证的用户,各个模型都有免费额度,国内直接连接,访问很稳定。
去 bailian.console.aliyun.com 注册,认证完成后创建一个API Key,复制下来备用。
打开CC Switch,点击Claude栏右上角的加号,新增一个模型配置,选择Bailian,把刚才的API Key粘贴进去,点击添加。
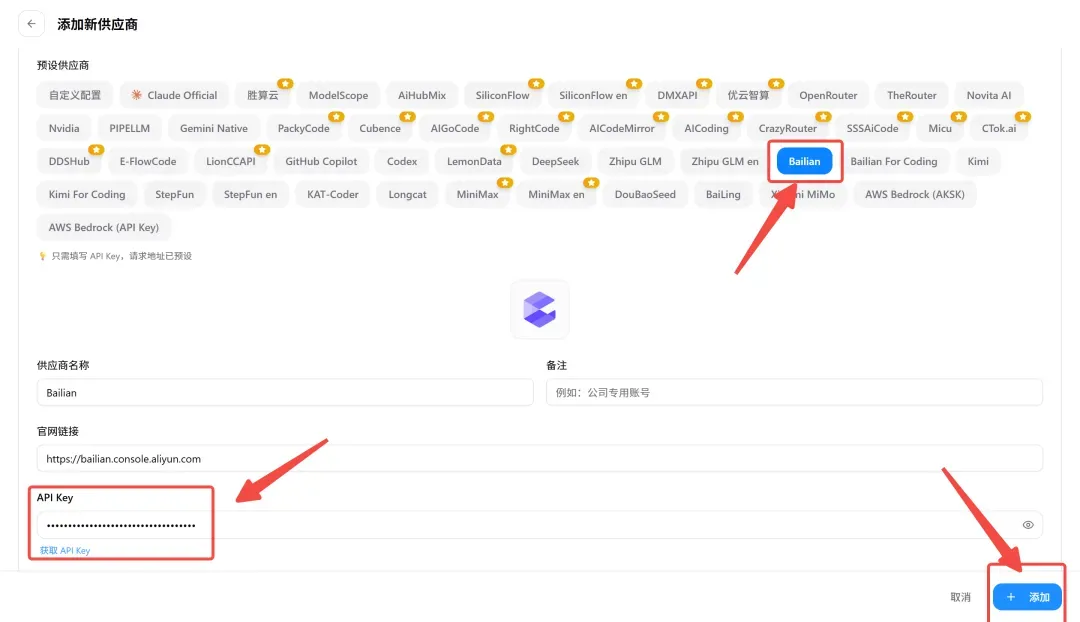
这样就搞定了。如果以后想换DeepSeek、GLM或者Kimi,用同样的方法再配置一个,随时都能切换。
第四步:正式启动(到这里就全部装好了)
回到PowerShell,输入:
2026最新Codex高级提示模板30例:效率翻倍,覆盖全流程实战
越来越多的开发者发现,同样使用 Codex,有人一句 prompt 就能搞定整个模块,而有人却需要反复拉扯、效率极低。差距就在于提示词的组织方式。本文依据 OpenAI 官方 Codex Prompting Guide 以及社区公认的实践经验,提炼出 30 套经过严格验证的高级 Prompt 模板,完整覆盖项目初始化、代码审查、调试、重构、部署等全流程环节,真正做到复制即可使用,助你告别低效沟通。
核心概念速览
Codex Prompt 四要素
OpenAI 官方建议,每个 Prompt 都应当包含以下四个关键部分:
| 要素 | 说明 | 示例 |
|---|---|---|
| 目标(Goal) | 一句话概括你要完成什么任务 | “为订单表单添加实时校验逻辑” |
| 上下文(Context) | 指定涉及的文件、目录、文档或错误信息 | “相关文件:src/components/OrderForm.tsx” |
| 约束(Constraints) | 明确不能触碰的边界以及必须遵守的规范 | “不引入新依赖,保持与现有 API 签名兼容” |
| 完成条件(Done when) | 如何验证任务已正确完成 | “所有单元测试通过,构建无错误” |
Codex vs Claude Code 快速对比
| 特性 | Codex | Claude Code |
|---|---|---|
| 配置文件 | AGENTS.md + config.toml | CLAUDE.md + settings.json |
| 技能系统 | .agents/skills/SKILL.md | .claude/skills/*.md |
| 子代理 | .codex/agents/*.toml | Agent Team 模式 |
| Hook 系统 | .codex/hooks.json | .claude/settings.json |
| 规划模式 | /plan 或 Shift+Tab | /plan |
| 代码审查 | /review | 代码审查 Agent |
| 分支隔离 | Git Worktree | Worktree |
| 推理强度 | low / medium / high / xhigh | 无(自动调节) |
如何使用本文?
根据你当前的工作任务,找到对应的分类,直接复制模板,将 [方括号] 中的占位内容替换为自己项目的实际情况即可。
2026最新Windows零基础部署OpenClaw小龙虾全流程:飞书集成实战指南
当下最炙手可热的AI工具,非OpenClaw(代号「小龙虾」)莫属。
那么,这只“小龙虾”到底能为你做些什么呢?
• 自动抓取网站数据
• 解决各类系统报错问题
• 执行重复性的测试任务
• 甚至帮你规划日程、整理文件
这些不是科幻电影中的贾维斯,而是OpenClaw真正能够落地执行的实际工作。然而,对于大多数普通用户来说,接触它的门槛并不低——步骤繁琐、安装报错、配置容易出错……也正因如此,即使这只龙虾能力强大,仍有不少人在了解过后选择放弃。
今天,我们将用最通俗的语言,带你从零开始,在Windows系统上部署属于你的第一只“小龙虾”,并通过飞书这类日常聊天工具直接指挥它工作。
01 准备工作:部署前的基础环境检查
正式安装OpenClaw之前,一定要先完成基础环境配置,提前检查前置条件,能够帮你避免90%以上的报错隐患。
系统:Windows 10\11 64位
内存:最低2GB,推荐4GB以上(本地运行大模型建议8GB+)
硬盘:预留至少500MB存储空间(含依赖包和安装文件)
网络:保持稳定联网(下载依赖以及调用云端大模型时需要网络,本地模型则可离线使用)
软件:安装Node.js 22或更高版本
此外,还需要牢记以下三点核心提醒:
1)全程使用管理员权限操作终端,否则很容易因为权限不足而报错;
2)安装路径不要包含中文、空格或特殊符号(例如“我的文件夹”“Open Claw”);
3)在安装过程中不要关闭终端窗口,也不要断开网络连接,耐心等待所有依赖下载完成。
02 零基础安装 OpenClaw「小龙虾」
步骤1:以管理员身份运行PowerShell并设置执行策略
点击Windows左下角搜索框(或使用Win键+R组合键),输入「PowerShell」→ 右键点击「Windows PowerShell」→ 选择「以管理员身份运行」→ 在弹出的权限提示中点击「是」。
在打开的终端中输入以下命令:
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser
出现选项时输入字母A确认。

步骤2:执行一键安装脚本
将下面这行命令完整复制,粘贴到PowerShell窗口中,然后按下回车键:
iwr -useb https://openclaw.ai/install.ps1 | iex
如下图所示,命令行开始运行就说明已经在安装进程中。
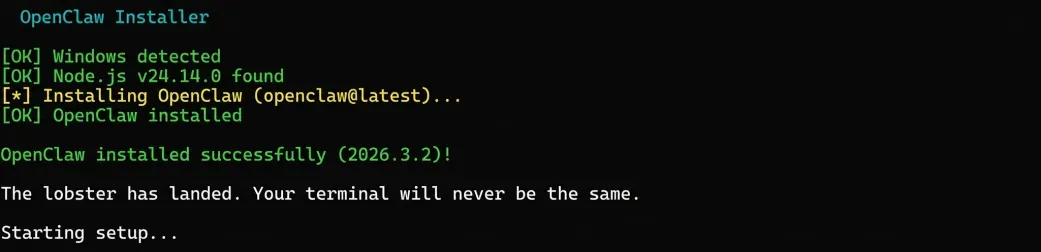
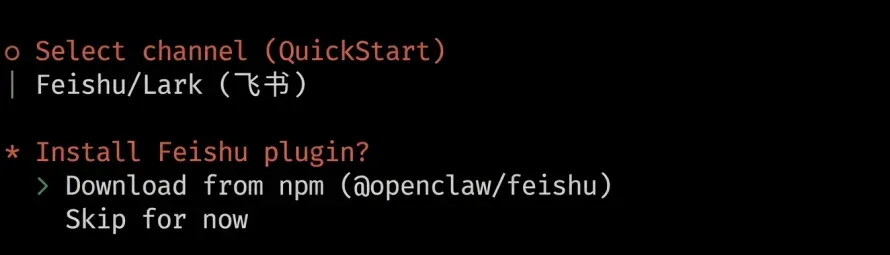
接下来会先后弹出两个选项窗口,分别用于确认默认权限规则和选择引导模式。我们全部使用默认选项,即选择“Yes”和“QuickStart”,按两次回车键即可继续。

之后是选择所使用的的大模型,这里我们选用国内的智谱 GLM,即 Z.AI,你也可以根据自己的喜好切换到列表中任意一个大模型。
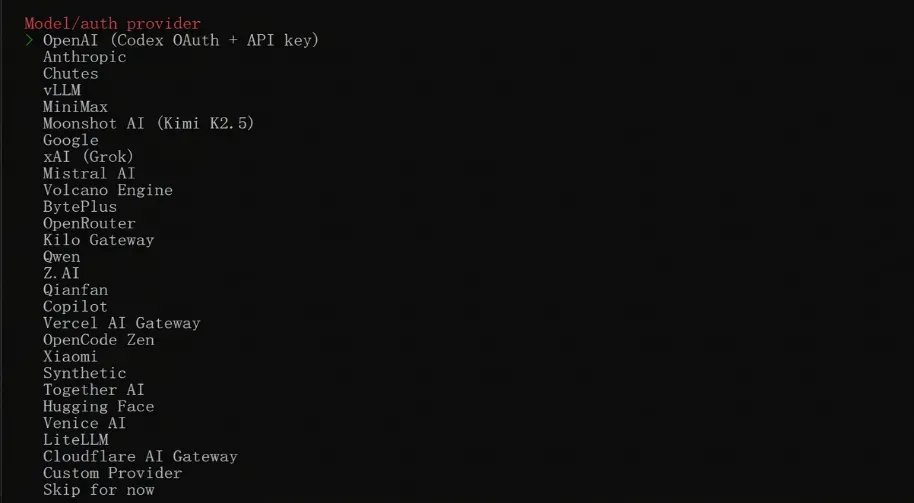
确定认证方式后,选择现在输入 API Key。
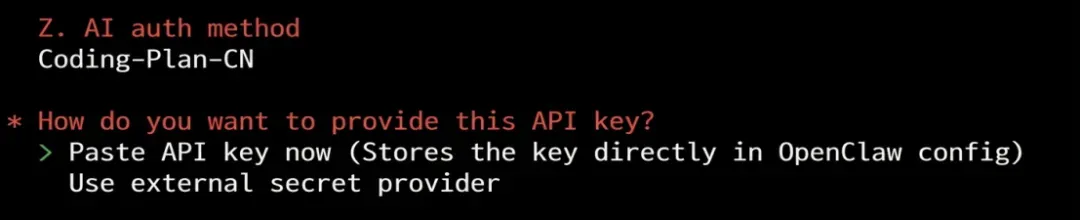
接下来是模型选择,我们保持默认的 GLM-5 模型。

在集成平台列表中,除了飞书外多为国外软件,我们可以选择飞书,也可以选择最后一项暂时跳过。这里我们选择飞书。
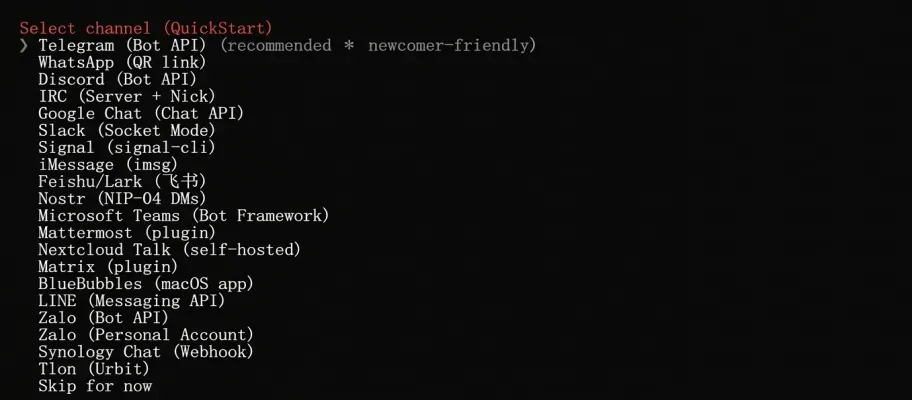
然后选择第一项安装飞书插件。
AI Agent正在吞噬软件:未来电脑或将告别传统应用

2026年5月,Hermes Agent悄然超越OpenClaw,登上OpenRouter日活跃排名榜首。46天,12.4万颗GitHub星标。这两个数字,使这款由Nous Research推出的开源AI智能体,一跃成为GitHub历史上增长速度最快的项目。
同样是在5月,OpenClaw的GitHub星标数冲破37万大关。这个去年11月才诞生的周末副项目,被黄仁勋在GTC 2026大会上称作“人类史上最受欢迎的开源项目”。从CNBC到TechCrunch,从The Verge到各类垂直媒体,报道铺天盖地;而跨越22个通讯平台的触角,从硅谷一直延伸到北京,从WhatsApp蔓延到微信。
Hermes和OpenClaw,一个以系统化的工程底蕴和自进化循环见长,一个凭借社区驱动的病毒式渗透狂飙。它们是2026年AI Agent浪潮的一体两面。在OpenRouter的日榜上,两者交替领先,每天的拉锯战都在重演。
01 · 两个项目,一场浪潮
Hermes Agent的时间线起点定格在2026年2月26日。当天,Nous Research发布了一条推文、一条curl命令、一份MIT协议的开源Agent。没有鲜花,没有通稿。三个月后,12.4万星标、370位贡献者、登顶OpenRouter日榜,比OpenClaw达到同等星标数整整提前了两周。
OpenClaw的故事则更加不可思议。2025年11月,奥地利开发者Peter Steinberger为自己打造了一个私人AI助手,取名Clawdbot。代码在几周内被疯狂fork,随后几度更名,从Moltbot到OpenClaw。如今,37万星标、370位贡献者、139个Release,一个原先的业余小项目摇身一变,成为全球最大的开源AI智能体生态。
“Just as Windows ushered in the PC era, OpenClaw will usher in the era of personal agents.” — Jensen Huang, GTC 2026
黄仁勋在GTC 2026的主旨演讲中,花了很大篇幅谈论OpenClaw。他的判断直截了当:这不是一个工具,这是一个操作系统——智能Agent计算机的操作系统。就像Windows开启了PC时代,OpenClaw将开启个人Agent时代。这并非修辞,而是一种宣言。
02 · 桌面上的抢夺战
与开源Agent的跃进几乎同步的,是另一条战线上的白热化对决:Claude Code和OpenAI Codex在桌面端的全面接火。
2026年2月,OpenAI推出Codex桌面应用,以macOS原生、多Agent并行、深度Git工作流和Skills市场为卖点。一个月后,Anthropic为Claude Code带来桌面伴侣,新增远程Mac控制与Cloud Sandbox能力。仅仅又过去一个月,Codex便上线了Computer Use功能,Agent能够像人类一样操作Mac应用,同时发布111个新插件、Atlas浏览器引擎和图生成能力。两天不到,Claude Code以Agent Teams架构重建予以回击。
节奏快到让人觉得荒诞。一方发布新功能,另一方必定在一周内迎头赶上。双方都在不断加码:浏览器控制、插件生态、并行Agent、沙箱执行、自动化调度。
表面看是产品层面的攻防,底层逻辑却清晰:大模型不甘心仅仅蜷缩在API后面。2025年,所有人还在比较谁的模型智商更高。到了2026年,模型能力趋同,竞争的核心变成谁更能深度嵌入你的工作流。一个藏在API背后的模型,无法培育任何用户粘性;而一个常驻你桌面的Agent,却可以。
2025.11 OpenClaw(原名Clawdbot)问世,始于一个周末的兴趣项目。
2026.02 Hermes Agent发布;OpenAI推出Codex桌面应用。
2026.03 GTC 2026:黄仁勋称OpenClaw为“Agent时代的操作系统”。
2026.04 Codex Computer Use上线;Claude Code以Agent Teams架构重建。
2026.05 Hermes Agent登顶OpenRouter日榜,与OpenClaw交替居于第一。
AI编程实战:Claude Code + Superpowers七阶段工作流搭建Spring Boot 3.5 RESTful API脚手架全记录
用 Superpowers 工作流从零构建 Spring Boot 脚手架
遵循 Superpowers 七阶段工作流,全程使用 Claude Code 与 GLM 5.1 驱动,从零搭建一套可运行的 Spring Boot 3.5 + MyBatis-Plus + Redis RESTful API 服务。
核心概念(3分钟理解)
这是什么?
这是一篇动手实录。我打开 Claude Code,将 GLM 5.1 作为 Coding Plan Provider,严格按 Superpowers 工作流推进,从零搭建一个 Java API Server 脚手架的全过程。
最终产物是一个包含用户注册、登录鉴权和受保护接口的 RESTful API 服务,可以直接用作 Spring Boot 后端项目的起点。
为什么重要?
系列第 21 篇展示了 Go 语言版的 API Server 脚手架。本文则是 Java 版本 —— 采用国内企业最广泛使用的 Spring Boot 技术栈,借助同样的 Superpowers 工作流,展示 AI 编程如何提升 Java 开发效率。