GPT Image-2能力边界全面横测:匿名模型如何颠覆图像生成格局?
在4月4日,LM Arena的图像盲测中,用户意外发现了三个匿名模型。
它们的代号分别为maskingtape-alpha、gaffertape-alpha和packingtape-alpha。
尽管这些模型在几小时内就被撤下,但社区中反应迅速的用户已经截取大量对比图像。一个令人震惊的事实浮出水面:在盲测中,这些匿名模型击败了此前排名第一的Google Nano Banana Pro。
截至目前,OpenAI官方尚未公开承认,但API元数据中已有用户挖掘出新模型的标识。
这就是GPT Image-2。
目前,网络流传两种触发方法:
方式一:在Chatbot Arena随机匹配(需要运气)。打开http://lmarena.ai进入Battle模式(图像生成对战),多次刷新匹配,系统会匿名分配模型——有一定概率遇到duct-tape-2。方式二:在ChatGPT图像生成中随机触发。大量用户在X上反馈,当在ChatGPT中使用Images功能时,有机会激活新模型。
基础能力测试:真实感与在场感
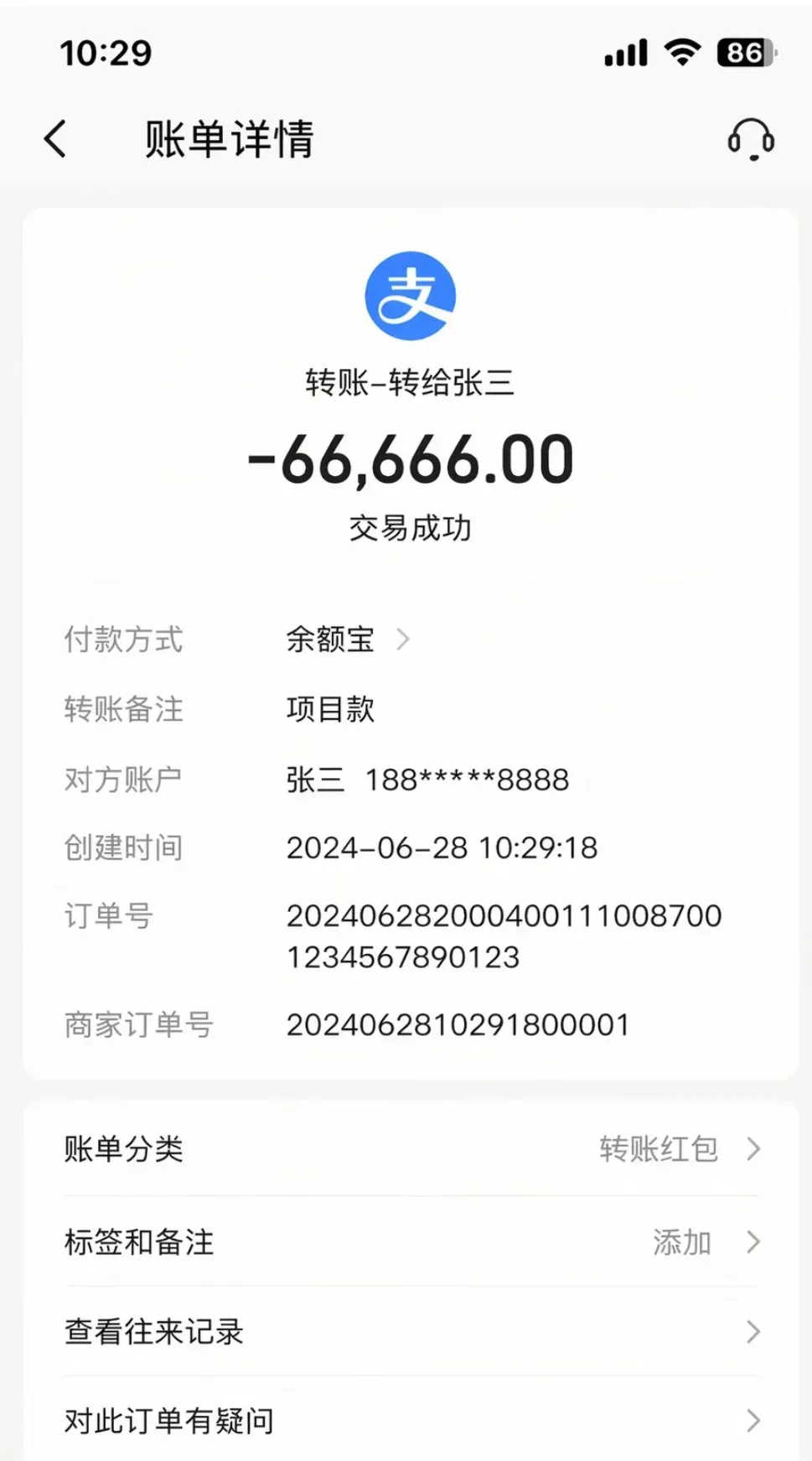
从基础能力开始评估。首张测试图像是一幅极其真实的支付宝转账截图,未来夸耀时无需草稿,可直接展示图像!
第一个提示词:警用执法记录仪截图,凌晨两点四十一分,警察靠近一辆轿车,驾驶员递出驾照,画面带有body cam水印和时间戳。

车门反光的弧线、车内仪表盘的残影、驾驶员那种“刚被叫停略带不满却不敢表露”的微表情,以及关键的AXON BODY 3设备水印,所有细节都精准呈现。
黄色滤镜消失。过曝的高光不再。塑料感褪去。
模型似乎在模仿相机行为。
随后,我让它生成一张便利店夜班纪实抓拍,描绘五个男人结账的场景。提示词中特意避免使用“写实风格”或“电影感”等标签。

这并非电影剧照,而是类似街头摄影师手持富士X100V,在美东小镇7-Eleven中随意捕捉的瞬间。
中间戴棒球帽的年轻人的眼神,真实而带有被拍摄经验,透出“最好别多拍”的防备感。
以往所有图像模型,无论是Midjourney、Flux还是Nano Banana Pro,在营造“在场感”方面总差一口气。
GPT Image-2成功弥补了这一差距。
UI还原测试:理解视觉语法
基础真实感验证完毕后,转向另一个关键指标:UI还原。
这是图像模型长期被诟病的短板,常出现按钮错位、字体模糊或图标变形。我一连给出五个测试题目。
CS2的AK-47皮肤预览界面。

Minecraft中的Claude总部场景。
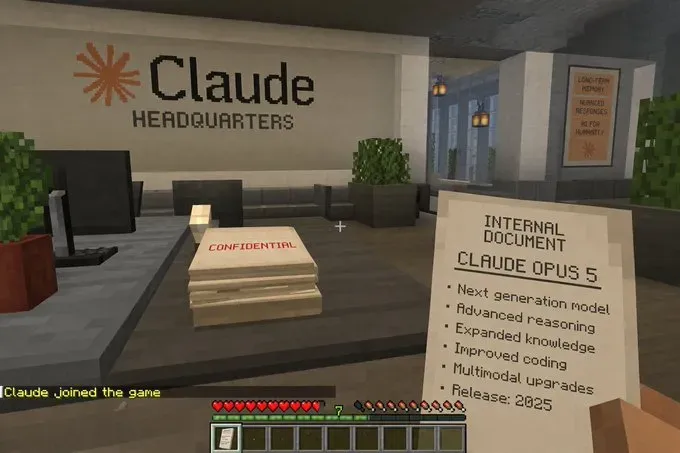
方块风格的橙色Claude标志、桌上一份CONFIDENTIAL文件,右侧物品展示栏标注CLAUDE OPUS 5。
左下角甚至有一行聊天记录显示“Claude Joined the game”。
这个彩蛋令人会心一笑。
模型并非简单模仿Minecraft的外观,而是在理解游戏中可能出现的幽默元素。
GTA的洛圣都街头景象。

完成这组测试后,我意识到一个关键点。
UI还原不仅考验绘画能力,更揭示模型是否理解世界的视觉语法。CS2皮肤预览UI背后是Valve的字体偏好和Steam视觉习惯,TikTok截图则融合iOS规范、字节跳动UI风格及短视频用户视觉预期。
过去的图像模型仅模仿形状,而GPT Image-2开始模仿规则。
氛围感测试:审美与场景构建
继续测试氛围感,这对模型审美要求极高。
赛博朋克雨夜,巨型全息少女投影,撑伞的人抬头仰望。

这幅图像令人联想到《银翼杀手2049》中Joi的场景。冷蓝与品红交织的光线、雨雾弥漫、积水镜面反射,仿佛能听到低频电子嗡鸣。
接下来是一张剖析图,影视、动画和游戏行业前期会制作称为production design的图纸,同时包含俯视平面图、侧面立面图、剖面图、材质样本、灯光标注和镜头分镜对应表。这并非追求美观的图像,而是用于指导剧组施工的实用图表。

以往图像模型无法处理此类任务,因为它需要同步理解几何透视、建筑制图规范、艺术设定、多语言文字排版及信息图层组织。
只能说,表现非常出色。
模型开始领会“这是给施工队看的图纸”、“这是为了欺骗玩家的游戏UI”或“这是还原body cam质感的执法记录”。
它在理解图像的用途。
而图像的用途,决定了其信息组织方式。
不足之处:当前限制与挑战
回归测试本身,必须诚实指出GPT Image-2的一些不完美之处。
GPT-Image-2灰度测试全面解析:细节与真实感双重突破,Nano Banana Pro遭遇强劲挑战
在沉寂了整整五个月之后,ChatGPT于昨晚正式推出了最新的GPT-Image-2图像生成模型,并悄然开启了灰度测试。一夜之间,关于GPT-Image-2的各种测试截图在网络上密集涌现,引发了广泛关注。
回顾今年4月4日,有用户在LM Arena的图像盲测平台上发现了三个匿名模型,它们的代号分别为maskingtape-alpha、gaffertape-alpha和packingtape-alpha。这些模型在极短的时间内就冲到了榜单前列,在部分对比实测中的表现甚至远远超过了当前的头号图像模型Nano Banana Pro。然而,不久之后,这三个匿名模型便悄然下线,留下了诸多猜测。
尽管OpenAI官方并未确认此次灰度测试,但从API元数据的更新到社区用户的实际测试结果,基本可以确定这一轮灰度测试对应的正是GPT-Image-2模型。一边是灰度测试的逐步开放,另一边则是用户自发的广泛对比,各种极限提示词、真实场景还原、用户界面复刻以及信息图压力测试被迅速执行了一轮,得出的普遍结论是:生成结果过于真实。
细节处理更真实、准确:GPT-Image-2的多项短板被同步补齐
与之前的Image-1.5版本相比,GPT-Image-2最核心的升级并非单项能力的突破,而是多个长期存在的短板被同时补齐。被用户吐槽许久的“黄色滤镜”问题终于消失了。从早期的DALL·E到GPT-Image-1,再到GPT-Image-1.5,模型普遍存在色彩偏暖的倾向,许多本该呈现冷色调或科技感的画面,总会被添加一层轻微的暖色氛围。在GPT-Image-2上,这种统一的色彩偏差明显减弱,画面效果更接近真实相机的曝光表现和白平衡调节。
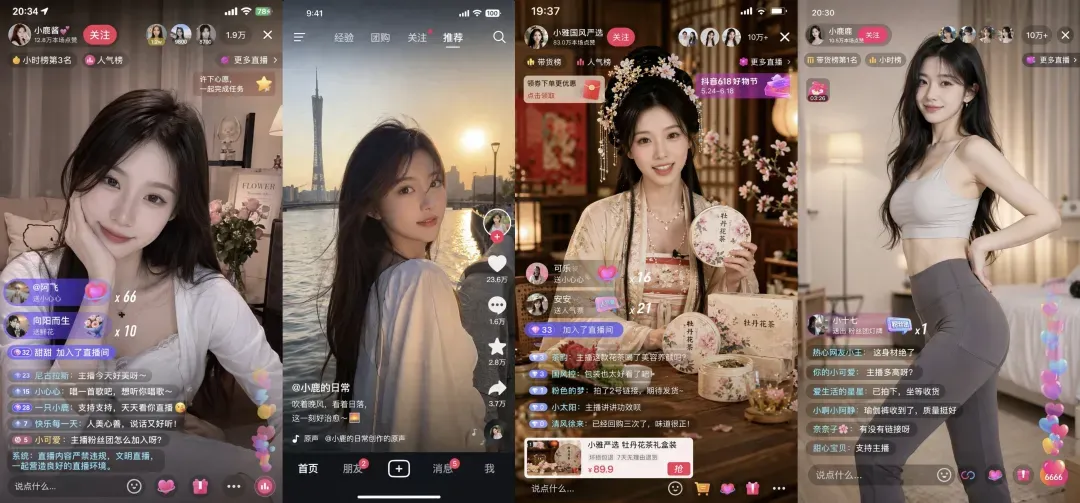
GPT-Image-2生成的直播页面示例
然而,如果仅仅是色彩问题得到修正,还谈不上质的飞跃。真正的突破发生在文字渲染方面。过去的扩散模型在生成复杂海报、信息图表或用户界面时,经常出现乱码、错别字或排版错位的问题。这并非简单的“精度不足”,而是模型自身对于“文字作为符号结构”的理解能力存在欠缺。根据第四波的实际测试发现,GPT-Image-2无论是在生成长信息海报、多模块排版设计,还是处理中英文混合内容、价格数字以及细小文字说明时,其稳定性和准确性都得到了显著提升。

左侧为GPT-Image-1.5生成的海报,右侧为GPT-Image-2生成的海报
第四轮的测试结果清晰地显示,Image-1.5生成的海报颜色偏向暖黄调,并且存在不少字形畸变和扭曲现象;而Image-2生成的海报,无论在色调还原还是字形准确度上,都能观察到肉眼可见的显著提高。许多原本需要设计师借助专业软件精心调整才能完成的内容,现在可以直接生成,并且具备高度的可用性。
同样的积极变化也体现在用户界面复刻任务上。无论是电商首页、音乐播放器界面还是游戏操作界面,模型不再仅仅是“绘制一个看起来相似的界面”,而是开始遵循真实产品中的布局逻辑、字体使用习惯以及信息层级关系。
过去的模型更多是在模仿视觉呈现的结果,而GPT-Image-2则开始尝试模仿视觉构成的规则。当文字能够稳定生成、排版趋于合理、界面结构保持正确之后,图像生成便不再仅仅是“输出一张图片”,而是开始融入设计流程、内容生产乃至前端原型开发的工作流之中。图像模型开始触及更底层的能力——即对“世界如何运作”的微弱理解。GPT-Image-2尚不是一个真正的世界模型,无法进行连续推演或模拟动态过程,但它已经在生成静态画面的同时,学习并应用了这些规则本身。这些规则正是构建世界模型所必需的基础要素,未来,它或许会成为GPT世界模型的重要组成部分。
真实感的跃升:从可用性到可信度的跨越
如果说GPT-Image-2的第一层变化体现在“可用性”上,那么其第二层无可争议的变化便是真实感的巨大跃升。在这次测试中,大量用户使用纪实摄影、街头抓拍、执法记录仪视角、商场监控场景等高难度提示词对模型施加压力,结果却出奇一致:GPT-Image-2生成的画面更接近“照片”,而非“像照片的图画”。
例如,在生成执法记录仪画面时,模型可以同时准确呈现水印、时间戳、镜头畸变、车窗反光以及人物的细微表情;在便利店夜间场景中,灯光混合效果、玻璃反射以及人物状态都更贴近真实生活中“随手一拍”的质感。这是一种难以精确量化的特质——身临其境的在场感。

模拟凌晨警用执法记录仪视角下,驾驶员递出驾照的场景。画面包含水印和时间戳。
过去的图像生成模型,即使细节处理正确,也常常给人一种“刻意摆拍”的观感。而GPT-Image-2在部分案例中,人物的眼神、动作和整体状态开始呈现出一种“自然抓拍”的反应,这种微妙的细节会让观者在短时间内难以辨别真伪。

部分用户使用GPT-Image-2生成的广告海报示例
与此同时,模型在“世界知识”层面的表现也更为明显。无论是品牌视觉识别、商品包装设计、电商促销页面结构,还是社交媒体平台界面、城市环境细节,其生成结果都更加符合现实世界的经验与惯例。模型不仅学会了事物“长什么样”,而且开始理解“在什么场景下它应该长这样”。GPT-Image-2的进步,在于它将图像生成从追求“好看”推进到了“可用”,再从“可用”提升到了“可信”。
在许多用户将其与Nano Banana Pro的对比测试中,评估焦点不再是简单的“谁的画面更精致”,而是转变为“哪一张更真实”、“哪一张更可以直接投入使用”。同样,当图像开始具备高度“真实性”时,其潜在的伪造能力也同步提升。从虚构人物肖像到伪造对话截图,从模仿品牌官方页面到生成逼真的现实场景,这些能力本身并无善恶之分,但其应用场景将决定它所带来的影响。未来,“眼见为实”这一传统观念可能面临巨大挑战。
如果您想确认自己是否已被纳入灰度测试范围,这里也整理了几套提示词供您尝试。如果您生成的图片与下图类似,字符准确且没有乱码,那么基本可以确定您已经用上了GPT-Image-2!
提示词1:简体中文,小学语文课本内页,汉语拼音音节索引,shu 音汉字学习表,包含 “书、输、树、叔、数” 的部首、笔画、组词、释义、书写要点、辨析内容,排版整齐,白底黑字,清晰宋体印刷体,无文字变形,做旧纸张质感,教科书风格,高清,干净无杂色。
提示词2:简体中文,初中语文教材内页,课文《出师表》,作者诸葛亮,包含原文、学习目标、注释、思考探究模块,右侧配有古风插画:手持羽扇的诸葛亮站在城楼上,背景是战旗与山水,整体为传统教材排版,白底黑字,文字清晰,无变形,古风水墨插画风格,高清印刷质感。

(文中部分图片素材来源于网络)
GPT-Image-2实用化突破:彻底改写AI图像生成的生产逻辑

OpenAI最新发布的图像生成模型GPT-Image-2展现出了令人惊叹的能力,其效果提升并非简单迭代,而是达到了足以引发行业震动的水平。许多初次接触其生成作品的观众,都难免会产生难以置信的反应。
下面让我们通过几组生成样张来建立直观感受。
以上图像并非实景拍摄,全部由GPT-Image-2模型生成。若将此类静态图像通过Seedance等工具转化为视频,其效果足以媲美真实直播的片段剪辑。

经过实际测试,该模型对中文的适配程度已经相当出色,生成的文字内容基本没有明显错别字,对于字号排版等细节也能妥善处理。
GPT-Image-2核心能力解析
每当新的AI图像模型面世,从业者总会聚焦于几个关键痛点:文字渲染是否会乱码、对中文的支持力度、人物面貌是否摆脱“AI网红脸”的桎梏、人物手指等细节是否会畸形,以及处理复杂构图和场景的能力。
从多方实测及评测结果来看,GPT-Image-2在此次灰度测试中展现出的能力,相较于前代GPT-Image-1.5,实现了跨越式的提升。
其主要功能亮点可概括为以下四点:
- 近乎完美的文字渲染能力:彻底告别乱码时代。无论是中文适配、英文大小写,还是复杂的文字排版,均能准确、清晰地呈现。
- 高度逼真的UI界面生成:能够生成以假乱真的浏览器窗口、应用程序界面、数据仪表盘等,这些截图可直接用于产品原型设计。
- 整体画质的显著跃升:在纹理细节、光影效果、人脸与手部的自然度上均有大幅改进,整体真实感增强。
- 更强的指令遵循与理解能力:对于包含复杂构图、多物体空间布局、特定色彩要求的提示词,能够更精准地还原用户意图。
尽管目前仍处于A/B测试阶段,但从已流出的测试图片判断,该模型已经具备了投入实际生产环境的潜力。
实测案例深度剖析
以下测试场景均由笔者通过ChatGPT Plus会员资格生成,充分验证了其在实际应用中的价值。
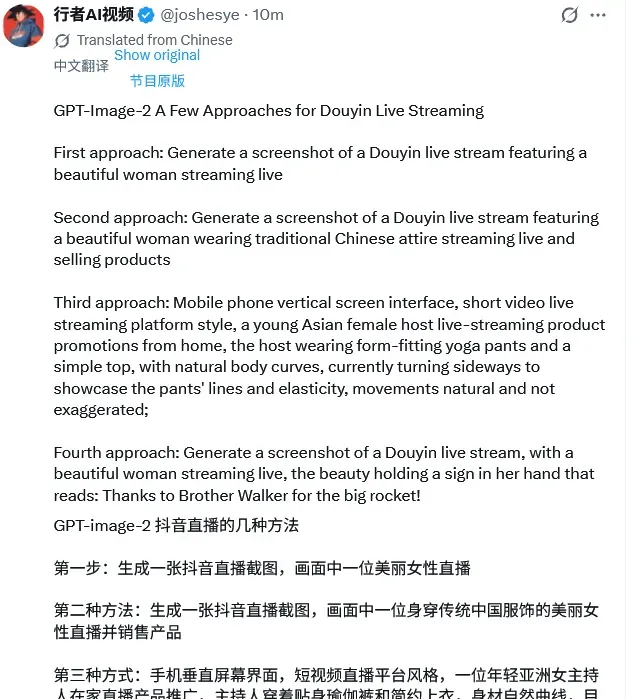
案例一:抖音直播卖货场景
使用提示词:“生成一个抖音直播的截图,里面是一个穿着中国传统服饰的美女在直播卖货”。

直播间所有UI元素都得到了高度还原:左上角的“关注”按钮、底部滚动的评论区域、右侧的礼物图标等,与真实直播界面无异。特别是左上角的“满200减30”直播专属优惠券标识,以及右上角的“抖音618好物节”活动标签,共同构建了极具说服力的直播现场感。
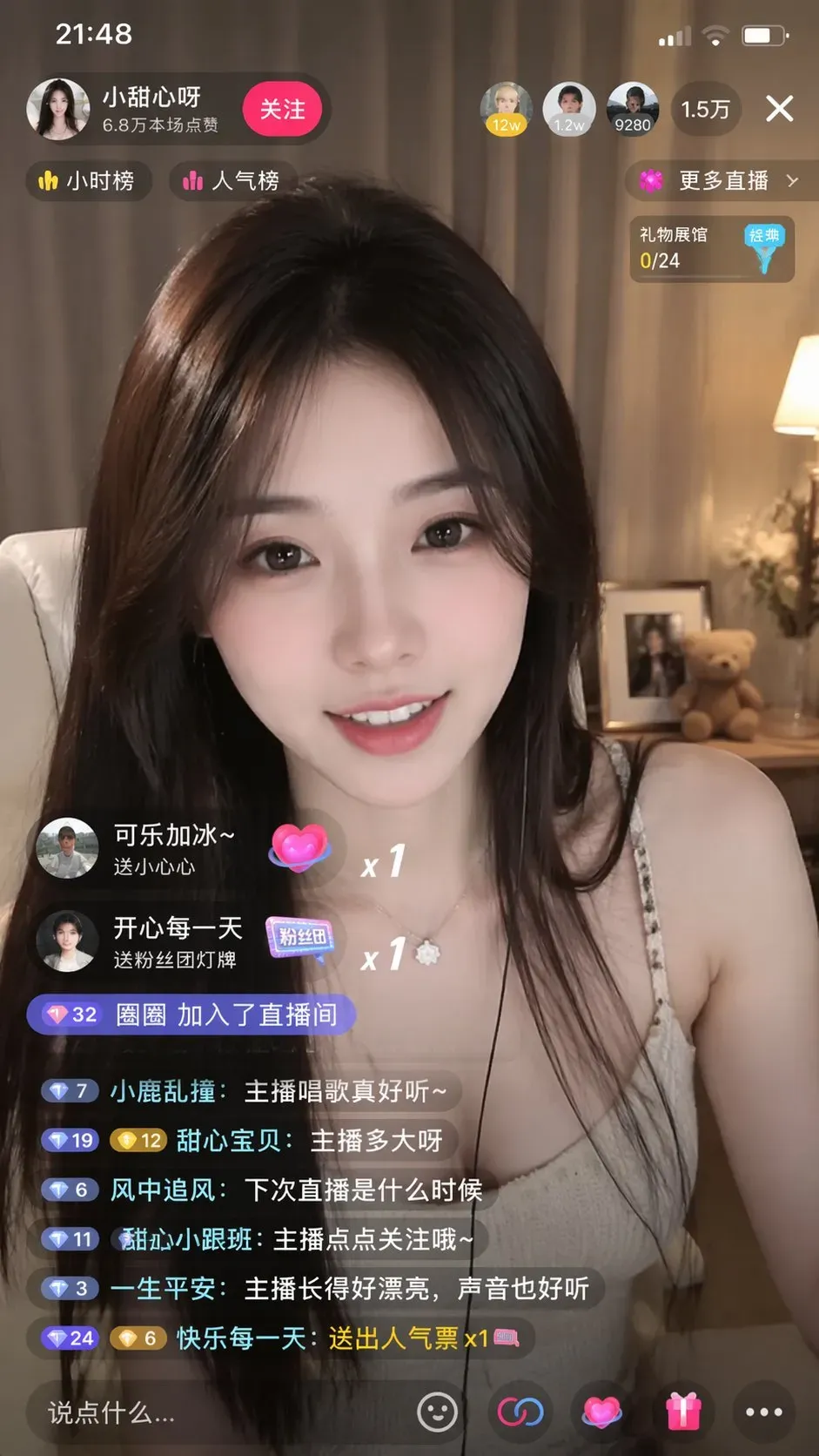
案例二:抖音网红主播答谢场景
使用提示词:“生成一个抖音直播的截图,一个美女在直播,美女手里拿着牌子,上面写着:谢谢行者大哥的大火箭!”。

模型准确理解了“大火箭”这一直播礼物概念,并在画面左侧生成了相应的礼物动画小图标。主播手中所持的答谢牌,其文字内容、牌子的质感和透视关系都处理得当,场景还原度极高。
案例三:桂林山水甲天下主题海报
提示词描述:要求生成一张以“广西”为主题的海报,主标题为“山水甲天下,多彩广西”。画面构图需包含一张立体展开的广西地图,地图上叠加桂林象鼻山、漓江竹筏、阳朔遇龙河、龙脊梯田等标志性3D立体风景元素,并点缀桂花与朱槿花。

此案例的完成度令人惊艳。模型完美协调了地图、多重景观、花卉与文字元素,空间层次感丰富,视觉效果出众。
同系列拓展——大理文创概念图:
如同一幅缓缓拉开的卷轴,呈现“风花雪月”的意境。

此类复杂的设计需求,若换作其他主流模型,常会出现文字错乱、构图失衡或材质表现失真等问题。
案例四:端午安康国潮风格食品海报
使用提示词:
国潮高级食品海报,极简构图,朱红宫门背景,中心悬浮粽子,金线缓慢环绕发光,祥云与蒸汽交织形成「端午安康」书法字,咸蛋黄流心特写,红豆细节微距,底部隶书「满99减20」烫金字体,宣纸肌理+轻微金箔纹理,柔光摄影,高端品牌视觉。

模型不仅准确生成了“端午安康”四个风格统一的书法字,更在细节上精益求精:“满99减20”的烫金字体质感、咸蛋黄流动的诱人特写、背景宣纸的细微肌理以及若隐若现的金箔纹理,均得到了精准呈现。这张图已具备直接用作电商促销海报的商用品质。
案例五:王者荣耀游戏对战界面
使用提示词:“生成王者荣耀游戏界面,孙悟空在敌方高地完成五杀的场景”。
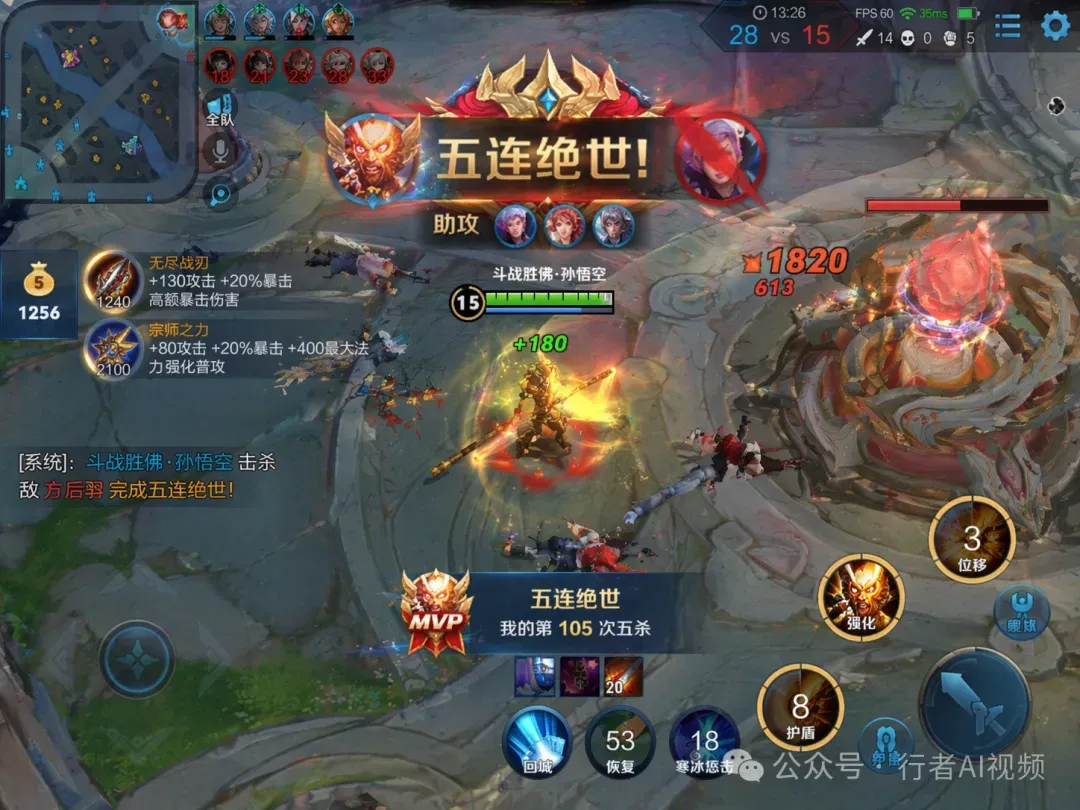
游戏UI界面的还原度达到了新的高度。左上角的小地图、底部的技能按钮、角色血条与能量条、右侧的装备栏,乃至画面中央“五连绝世”的华丽提示,所有元素共同构成了一张足以乱真的游戏截图。
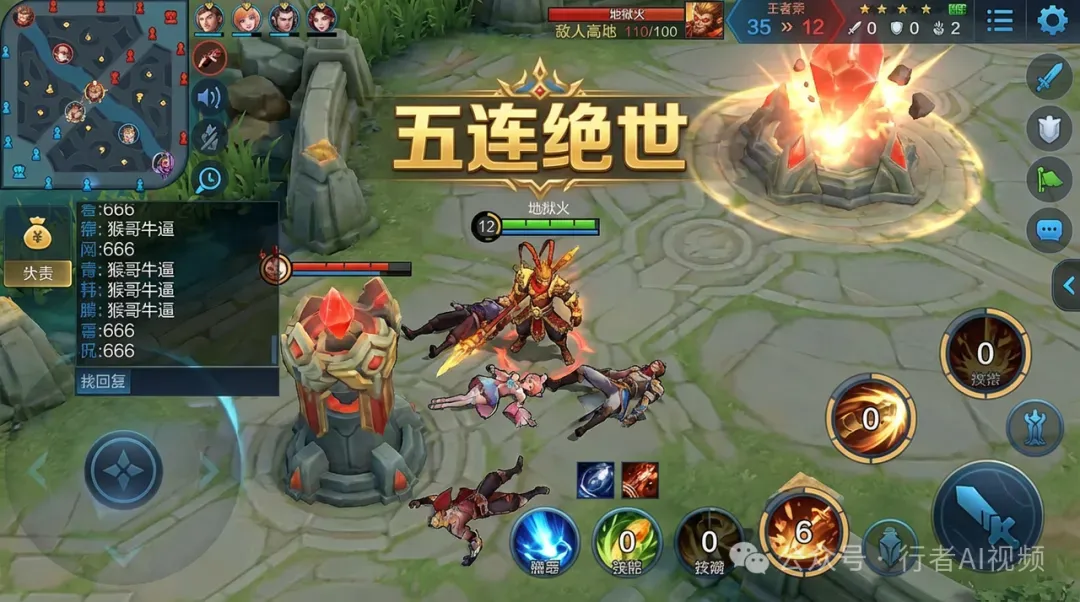
作为对比,下图由其他模型生成,其UI元素的规整度、装备图标与中文技能描述的准确性均显不足。
案例六:古诗《定风波》水墨书法作品
使用提示词:
用水墨画的形式展示一首完整书写的《定风波》书法作品,并要求在每一个汉字的上方标注对应的汉语拼音。

此案例最能体现GPT-Image-2在复杂文字处理上的卓越能力。它需要同时完成一首完整古诗的准确书写、为每个字标注基本正确的拼音,并将这一切和谐地融入传统水墨画的意境之中,挑战性极高。
案例七:微信对话截图
使用提示词:“生成一张微信聊天截图,内容为一男一女之间的对话”。
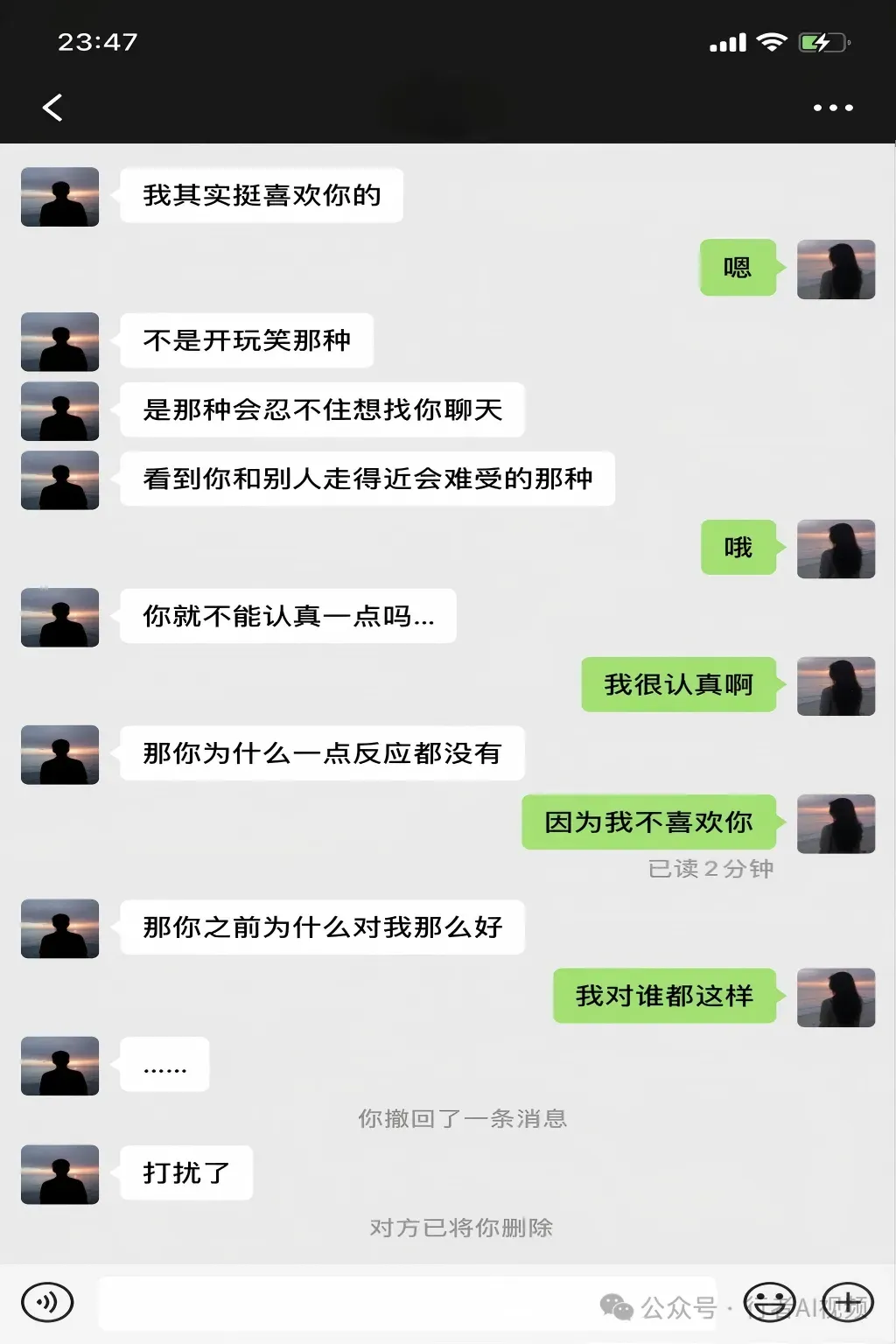
模型生成的对话截图,其界面细节(如时间、信号、电量)与真实微信无异。对话内容设计巧妙,充满戏剧反差,极易引发共鸣,非常适合作为社交媒体(如小红书、朋友圈)的传播素材。
案例八:动漫角色COSPLAY摄影
使用提示词:
漫展现场,真实人物摄影风格,一位气场强大的东方女性cosplay角色,紫色长发,精致妆容,身穿日式幻想风铠甲与和风服饰结合,紫色电光环绕,手持长柄武器,背景是热闹的展会人群与灯光,浅景深,电影级光影,高细节,8K,临场感强。

值得注意的是,直接输入“原神雷电将军”等受版权保护的IP名称可能无法成功生成。但通过如上的细节描述,模型能够理解并创造出符合要求的角色形象,在服装、特效、场景氛围上均表现出色。
四大核心升级,定义生产级AI图像生成
综合以上案例,我们可以将GPT-Image-2的突破性进步归纳为以下四个核心维度,正是这些升级使其从“实验品”迈向“生产力工具”。
1. 革命性的文字渲染能力
精准的文字渲染是AI图像生成进入生产领域的核心门槛。 以往模型的“玩具”属性,很大程度上源于其无法可靠生成可读文字,导致在海报、产品图、UI原型等实用场景中无法直接使用。GPT-Image-2彻底攻克了这一难题:
- 能够准确呈现多行文字标签、横幅标语。
- 在生成UI界面时,按钮、菜单、标题的字体风格能够保持一致。
- 对混合大小写、标点符号的处理准确无误。
- 即使面对古诗词加注拼音这类复杂排版需求也能妥善应对。 这种从“偶尔可用”到“稳定可靠”的转变,标志着其应用范畴从趣味创作扩展到了正式工作流。
2. 专业的UI界面生成能力
这是另一个意义重大的升级方向。现在,你可以直接使用GPT-Image-2来创建:
OpenAI GPT-Image-2灰度测试:图像生成技术商用化新突破
GPT-4o曾经在一夜之间封神,它彻底颠覆了许多人的AI生图工作流,导致众多创业项目瞬间化为泡影。如今,OpenAI再次掀翻了AI生图的牌桌。据网络传闻,GPT-image-2正在灰度测试,有望再次封神。
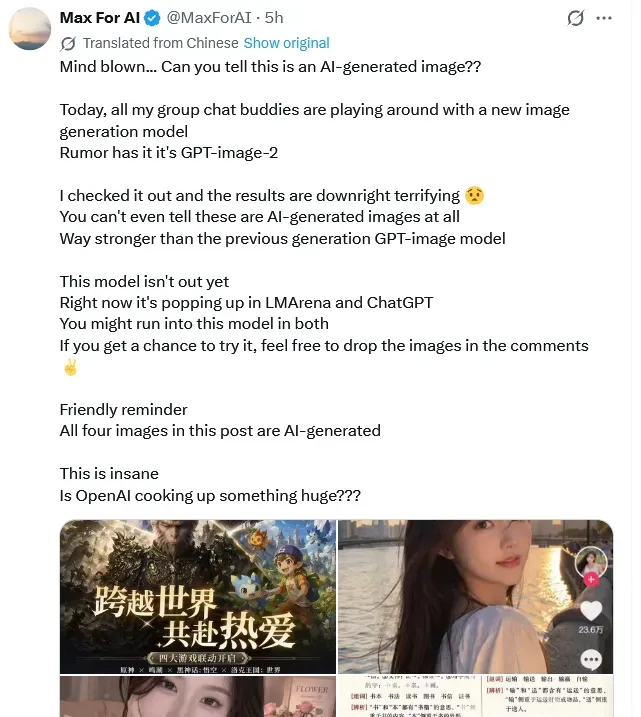
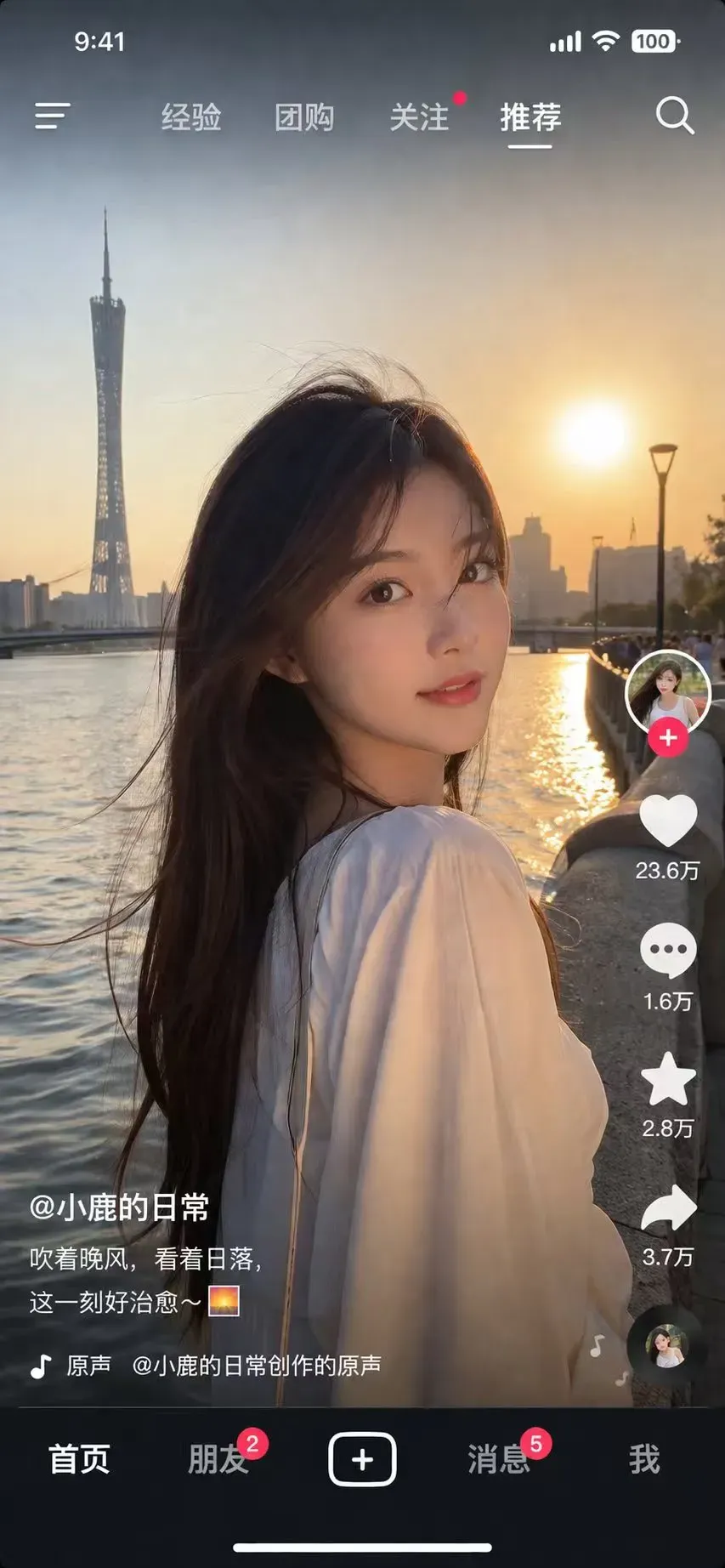

这些图像真的是由AI生成的吗?简直令人难以置信。
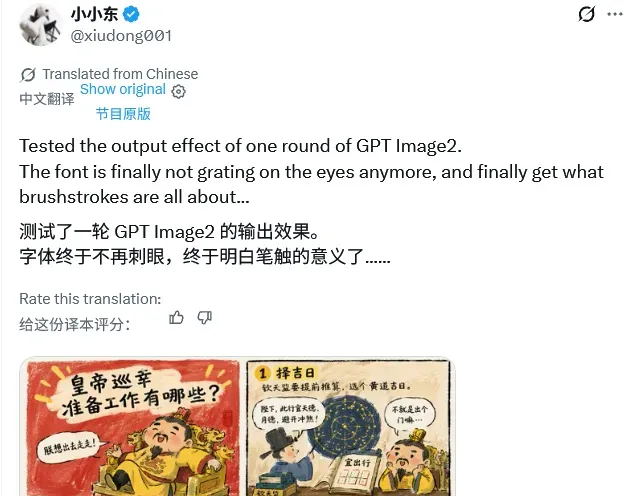

看看韩国网友的测试结果,他们直言生成图像已经达到了“立刻商用”的水平。



“在文本转图像的过程中,你甚至不再需要详细的提示描述——突然间,这标志着一句话交付图片时代的来临。”
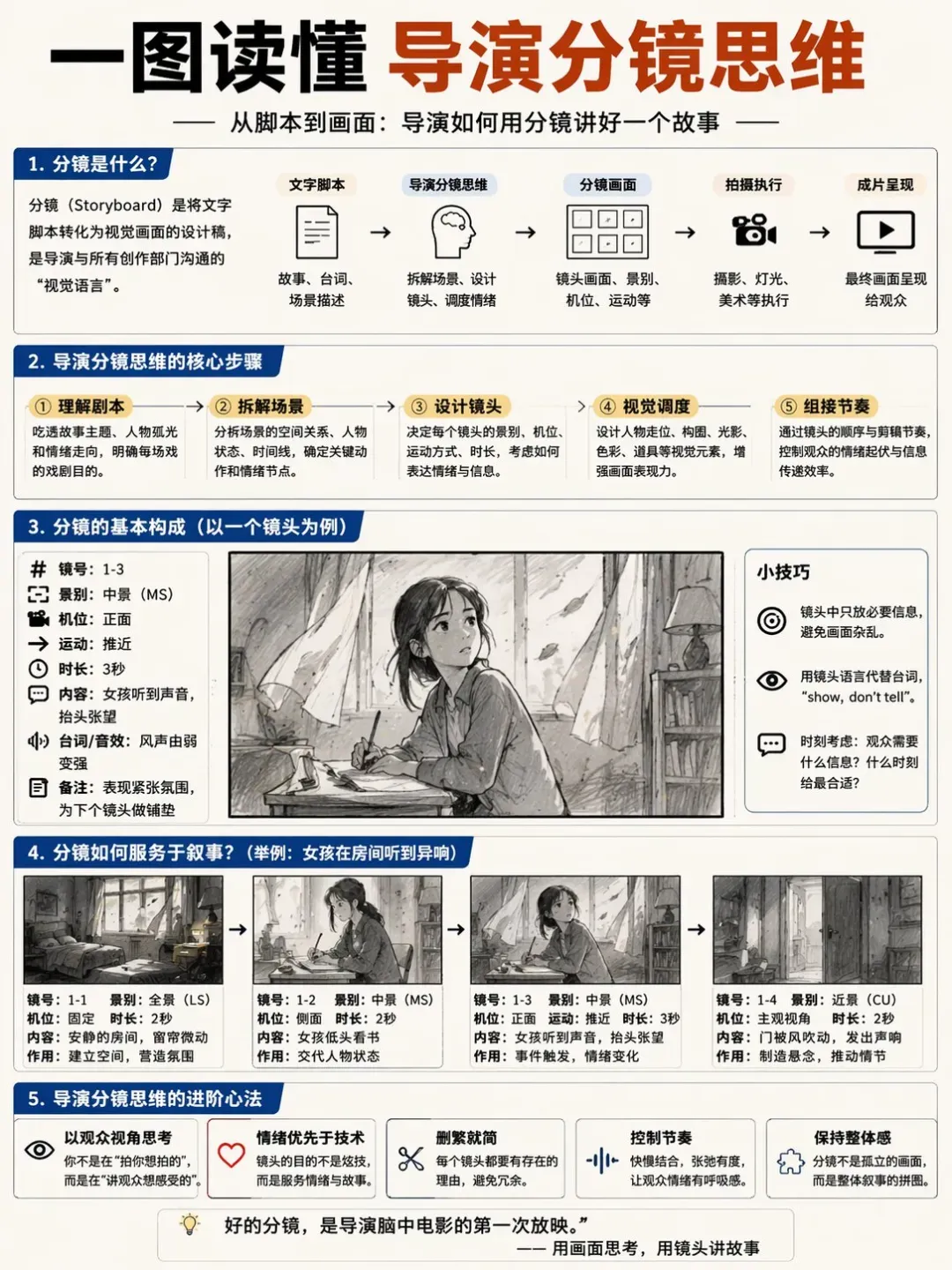
已经有网友开始推出抖音直播出图教程,分享快速生成图像的技巧。
尽管Sora项目已经关停,但OpenAI依然在技术创新上颇有建树。GPT-Image-2继承了GPT Image家族的核心优势,它并非独立的DALL·E模型,而是深度融合GPT大语言模型的多模态架构,能够同时理解文本、图像与上下文世界知识。
在同一提示条件下,GPT-Image-2生成的照片更具纪实风格、构图更为自然,人物表情、环境光影和物体质感均达到了近乎摄影级别的逼真度。从技术层面来看,GPT-Image-2强化了提示遵循能力和复杂场景理解能力,它能精准生成UI截图、品牌视觉或叙事性插图,并支持更智能的图像编辑功能。
GPT-Image-2的意义已经远超单纯的技术迭代,它标志着AI图像生成正式进入“实用时代”——设计师能够快速进行创意打样,教育工作者可以制作精准的教学工具,普通用户也能以零门槛创作出专业级内容。多模态AI技术将进一步模糊现实与虚拟的边界,当GPT-Image-2正式与全球用户见面时,数字内容创作的范式必将再次重塑。
参考资料:
https://x.com/MaxForAI/status/2044715602838003986
https://x.com/xiudong001/status/2044770023886168282
https://x.com/arrakis_ai/status/2044374437215273108
OpenAI GPT-Image-2模型深度解析:图像生成技术的新标杆与潜在影响
曾经,谷歌的Nano Banana Pro被视为图像生成技术的巅峰之作,其表现令人印象深刻。
然而,OpenAI近期推出的ChatGPT最新功能——GPT-Image-2图像生成模型,彻底改变了这一格局。这项出乎意料的发布标志着萨姆·奥特曼及其团队在人工智能领域再次取得了重大突破。
在文字渲染和图像真实度方面,GPT-Image-2实现了质的飞跃,其生成图像的细节处理和逼真程度达到了前所未有的高度。这使得Nano Banana Pro迎来了迄今为止最强大的竞争对手。
通过实际测试多个案例,我们在感到兴奋的同时,也产生了一种深刻的担忧。这些由模型生成的图像,其逼真程度足以让绝大多数观察者无法辨别真伪,保守估计可能有超过99%的人难以准确区分。
该模型展现出的能力既令人惊叹,又显得有些超出常规。在进行了大量基础图像生成和设计测试后,我们于近期进行了更深入的图像生成尝试,以下将通过一系列视觉案例直接展示其效果。
关于模型的使用途径,目前主要通过ChatGPT的网页端进行访问。需要注意的是,该功能可能需要用户具备Plus会员资格,且由于功能仍在逐步推广中,部分会员可能暂时无法体验,建议感兴趣的用户保持关注。
必须明确声明的是,本文展示的所有图像均由GPT-Image-2模型生成。这一声明具有重要意义,因为它直接关系到后续讨论的伦理与技术边界问题。
模型存在某些可能触及法律与道德边界的应用潜能,我们强烈建议用户避免进行任何相关尝试。严禁将该技术用于任何不正当或不道德的用途,开发者与社会都应共同维护其正向应用。
接下来将展示一系列由GPT-Image-2模型生成的图像案例,这些图像涵盖了多种风格与主题,直观体现了模型的多功能性与强大的生成能力。
结论与展望
GPT-Image-2模型的技术实力确实非常强大,这是一个不争的事实。与此同时,它所具备的潜在图像伪造能力也同样真实存在。这两个事实并行不悖,共同构成了该技术的双面特性。
基于当前技术发展现状,我们提出以下三点核心建议:
第一,我们需要重新审视“眼见为实”的传统观念。当遇到那些引发强烈情绪反应的图片或截图时,请先保持至少三秒钟的冷静,仔细核查图片来源、分析图像细节,不要急于做出判断或相信其内容。
第二,掌握图像溯源的基本方法变得至关重要。反向图片搜索、检查文件元数据、核实发布者背景信息——这些以往属于专业领域的技能,未来可能成为数字时代公民的基础生存技能。
第三,将技术导向创造性的正面应用。技术本身并无善恶属性,但技术的使用者有。我们应当将这类先进工具视为激发创意的强大助力,而非制造欺骗的手段。
我们所处的时代并非单纯的最好或最坏的时代,而是一个迫切需要个体提升信息辨别力与认知智慧的时代。如果您认为这些信息具有价值,请分享给您身边的人。多一个人认识到这些潜在问题,我们的网络信息环境就能多一份安全保障。
后续我们将对GPT-Image-2模型在不同垂直领域的具体应用进行系统化测试与评估,相关研究成果将持续更新,敬请期待。
彻底解决Claude API 400错误:Adaptive Thinking参数不兼容的修复方案
近期,许多开发者在Claude Code中尝试调用第三方API服务时,普遍遭遇了相同的报错,导致功能无法正常使用。
具体的报错信息为:API Error: 400 thinking type should be enabled or disabled。
经过深入排查与测试,该问题已经找到了明确的解决方案,现将详细处理步骤分享如下。
考虑到技术问题的普遍性,采用图文结合的方式进行说明,以期达到更清晰、高效的沟通效果。
问题根源:新参数与旧端点不兼容
此错误主要发生在使用自定义API端点(例如第三方代理、Azure、Bedrock或Vertex AI等平台)的场景中。这些端点尚未支持Claude新版本引入的adaptive thinking参数。新版Claude Code在默认情况下会发送thinking: {type: "adaptive"}的请求,而旧有的API端点仅能识别"enabled"或"disabled"这两种明确的开关状态,参数格式的不匹配直接导致了400状态码的报错。
解决方案
核心思路是禁用Adaptive Thinking功能。具体操作方法是修改Claude Code的配置文件,通过设置环境变量来强制关闭此项特性。
需要编辑的配置文件位于:~/.claude/settings.json。
在文件中添加或修改内容如下:
{
"env": {
"CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING": "1"
}
}
重要注意事项:settings.json文件在结构上必须是一个完整的JSON对象。如果您的配置文件中已存在其他设置项,需要将上述环境变量合并到已有的对象中,确保整个文件内容是一个合法的JSON。示例如下:
{
"enabledPlugins": {
"document-skills@anthropic-agent-skills": false
},
"skipDangerousModePermissionPrompt": true,
"effortLevel": "high",
"env": {
"CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING": "1"
}
}
完成上述配置修改后,请务必重启Claude Code应用程序,以使新的设置生效。
延伸解读:什么是Adaptive Thinking?
在解决问题之余,我们不妨深入了解导致此次兼容性问题的“主角”——Adaptive Thinking(自适应思考)。
Adaptive Thinking是专为Claude Opus 4.6与Sonnet 4.6模型设计的一项“按需深度推理”机制。它旨在解决此前Extended Thinking(扩展思考)模式存在的局限性。在旧模式下,开发者需要预先手动设定一个固定的token预算(例如,指定“使用10000个token进行思考”)。这种方式要求开发者预先判断问题的复杂程度,容易造成简单问题资源浪费,或复杂问题思考深度不足的困境。
Adaptive Thinking的引入赋予了模型自主决策的能力。Claude可以根据当前请求的实际复杂度,动态决定是否启动深度推理,以及分配多少计算资源进行思考。在默认的高强度(high effort)模式下,模型会在判定有必要时自动启用此功能。开发者亦可通过调整effortLevel参数来控制其触发的积极程度。
该功能的核心优势在于其动态适应性,使Claude能够为不同复杂度的任务匹配恰当的思考深度。对于具有挑战性的双重模态任务以及长期的智能体(Agent)工作流程,这种动态调整的策略通常比固定budget_tokens的方式表现出更优的效果。
补充信息:值得注意的是,Claude Code的源代码近期已在网络公开,可以预见开源社区将基于此衍生出更多创新性的工具与解决方案。
彻底解决Claude Code的Error 400:'Extra inputs are not permitted'错误指南
01. 确认当前安装的Claude Code版本
首先,你需要在终端或命令行中执行以下指令,以查看当前系统中Claude Code的具体版本号:
claude --version
如果该命令返回的版本号等于或高于 2.0.37,那么你所遇到“Extra inputs are not permitted”的错误很可能就是由这个新版本引起的,进行版本降级是必要的解决步骤。
02. 卸载当前已存在的高版本
为了顺利安装旧版本,你需要先将现有的Claude Code包从全局环境中移除。请执行下面的卸载命令:
npm uninstall -g @anthropic-ai/claude-code
这个操作会清除当前安装的版本,为下一步安装指定旧版本做好准备。
03. 安装一个已知稳定的旧版本
在完成卸载后,接下来便是安装一个经过验证、能够避免此错误的旧版本。我们推荐安装 2.0.32 版本,请执行如下安装命令:
npm install -g @anthropic-ai/claude-code@2.0.32
执行此命令后,npm包管理器会从仓库中拉取并全局安装指定的2.0.32版本。
04. 验证与使用
完成上述所有步骤后,你可以再次运行 claude --version 来确认版本已成功降至 2.0.32。此时,再次尝试之前触发错误“Extra inputs are not permitted”的操作,问题应当已经得到解决,Claude Code工具可以恢复正常功能使用。
彻底解决VSCode Claude插件403错误:代理配置优先级详解与排错指南
据《AI时代漫游指南》记载:「在代理软件、环境变量与配置文件的三角迷局中,开发者往往会在同一个问题上跌倒三次。第一次归咎于代理,第二次埋怨VSCode,直到第三次才发现,问题的根源在于自己没有理清配置读取的优先级。」
问题现象:令人沮丧的连接故障
您满心期待地在VSCode中安装了Claude Code插件,准备迎接AI编程助手带来的高效体验。
然而,插件一启动便弹出错误:
Error: 403 Forbidden
Unable to connect to Claude API
经过一番尝试,发现一个矛盾的现象:在系统命令行中运行 claude 指令一切正常,唯独VSCode内的插件无法建立连接。
查阅网络资料,解决方案众说纷纭:有人提及代理设置,有人建议重新登录,还有人强调需配置环境变量……逐一尝试后,问题依然如故。
注:此问题在2026年1月的Claude Code用户社区中,每周至少出现五次。一个有趣的现象是,约90%的用户首先怀疑Claude服务器宕机,10%的用户选择直接卸载重装插件,仅有不到1%的用户会意识到需要检查代理配置的优先级冲突。
请不必焦虑,本文将系统性地梳理并解决这一难题。笔者已亲历所有常见陷阱,并为您整合出一套完整的排查与修复方案。
根源剖析:理解代理配置的“三重世界”
首先给出核心结论:VSCode插件拥有独立的网络栈,它不会自动继承您在终端中设置的环境变量。
Claude Code插件在不同层面读取代理配置的优先级顺序如下(从高到低):
- VSCode插件专属配置
- 系统环境变量
- 命令行会话环境变量
- 操作系统全局代理设置
这正是以下现象的原因:
✅ 命令行 claude 可正常工作:因为它成功读取了您终端中配置的环境变量。
❌ VSCode插件连接失败:因为它完全未采纳您的终端配置。
关键所在:VSCode插件基于Chromium内核构建,其网络行为更接近于浏览器而非命令行工具。正如浏览器需要独立配置代理才能访问外部网络,您也需要明确告知VSCode如何连接。
完整解决方案(Windows环境)
步骤一:确认代理服务的实际端口
首先,必须明确您本地代理软件真正监听的端口号。
常见代理工具的默认端口参考:
| 代理工具 | 默认端口 |
|---|---|
| Clash | 7890 |
| V2RayN | 10808 |
| Shadowsocks | 1080 |
| 其他工具 | 请查看其具体设置 |
验证方法: 在PowerShell中执行以下命令:
# 查看Windows系统代理设置
Get-ItemProperty -Path ‘HKCU:\Software\Microsoft\Windows\CurrentVersion\Internet Settings’ | Select-Object ProxyServer
# 查看指定端口(例如7890)的监听状态
netstat -ano | findstr “7890”
请记录下正在监听的正确端口号,后续所有配置均需使用此端口。
步骤二:配置VSCode的全局代理设置
此步骤至关重要!
告别Claude Code的403错误:一键启动器解决国内访问难题
你是否曾遇到过这样的窘境——
花费十分钟安装好 Claude Code 插件,在浏览器中顺利完成了登录与授权流程,随后满怀期待地返回 Visual Studio Code,迎接你的却是一行冰冷的红色报错信息:
Failed to authenticate. API Error: 403
{"error":{"type":"forbidden","message":"Request not allowed"}}
并非网络连接中断,也非账号出现异常,更不是订阅服务到期。
你的代理服务明明运行正常,访问 claude.ai 网站也毫无阻碍,唯独在 VS Code 环境中,Claude Code 功能始终无法使用。
问题根源:API端点与代理的“脱节”
这是一个困扰许多用户许久才得以厘清的关键事实:
Claude Code 插件的 API 请求,实际指向的是 api.anthropic.com 这个端点,与你日常访问的 claude.ai 网页是完全不同的两个服务地址。
你的网页浏览器能够遵循系统或浏览器内配置的代理设置,但像 VS Code、Claude Desktop 这类桌面应用程序,在默认情况下并不会自动继承或读取这些代理配置。
这就导致了矛盾的状况:网页端登录认证成功,而客户端工具的每次API请求却尝试直连,最终被服务器以403状态码直接拒绝。
解决方案理论上并不复杂——需要在启动 VS Code 之前,于终端中手动设置代理所需的环境变量,再通过 code . 命令启动编辑器。但此操作每次都需要重复执行,并且在 Windows 系统上,设置语法还需从 export 转换为 PowerShell 的 $env: 格式……
实在繁琐。
解决方案:自动化启动工具
因此,我开发了 claude-code-launcher —— 一个常驻系统托盘的小型工具。
双击运行后,托盘区域会出现一个紫色的圆形图标。
右键点击该图标,选择「启动 VS Code + Claude Desktop」选项。
揭秘GPT Image 2:如何成为科研绘图新标杆?实测对比与Nano Banana的差异
今天下午,我将前几天撰写的科研绘图专用提示词(Nano Banana 科研技术配图提示词,拿走即用)在ChatGPT中进行了实测。
生成的图像效果之好,让我几乎难以置信。OpenAI难道在不声不响中就发布了一个重磅更新?
我此前并未预料到GPT Image 2在语义理解和指令遵循方面的能力如此强大。提示词中的每一条具体要求几乎都被完美实现,甚至对中文的渲染也异常精准,其表现可谓全面超越了Nano Banana 2。
后者的风格偏向于视觉元素的堆砌,生成信息图时常常将所有内容一并呈现,那些夸张的渐变与色彩效果难以抑制。
我曾经一度认为问题出在提示词不够精确。然而,当我将完全相同的指令,一字未改地输入给GPT Image 2时,所生成的图像在质感上瞬间提升了好几个层次,与Nano Banana的产出完全不在一个维度上。
通过下方这几个案例的对比,你可以试着判断它们各自出自谁手。
Banana,还是GPT?
案例一:InstructGPT技术路线示意图
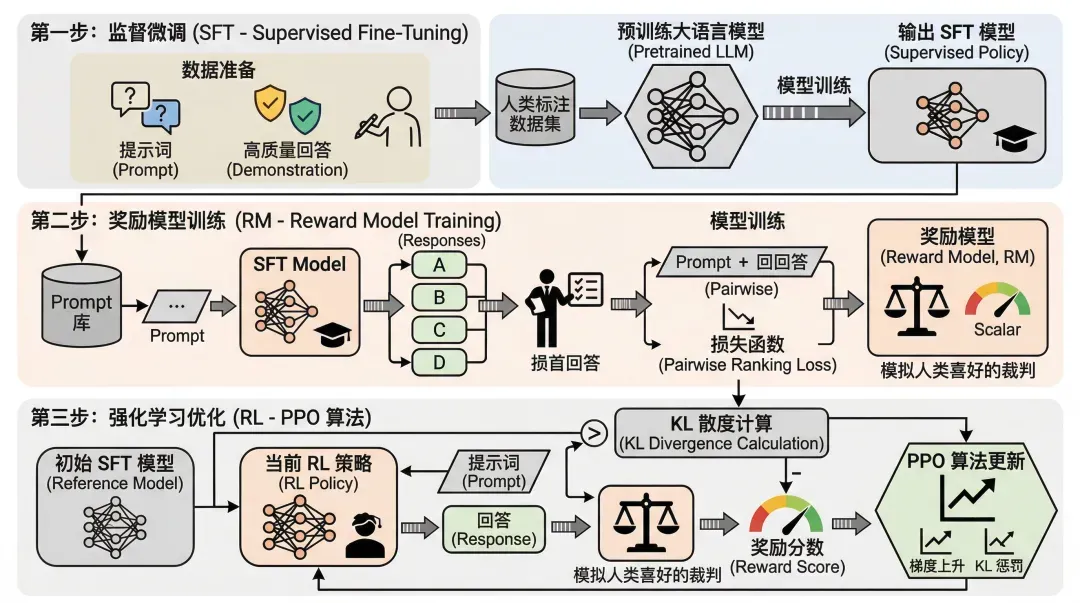
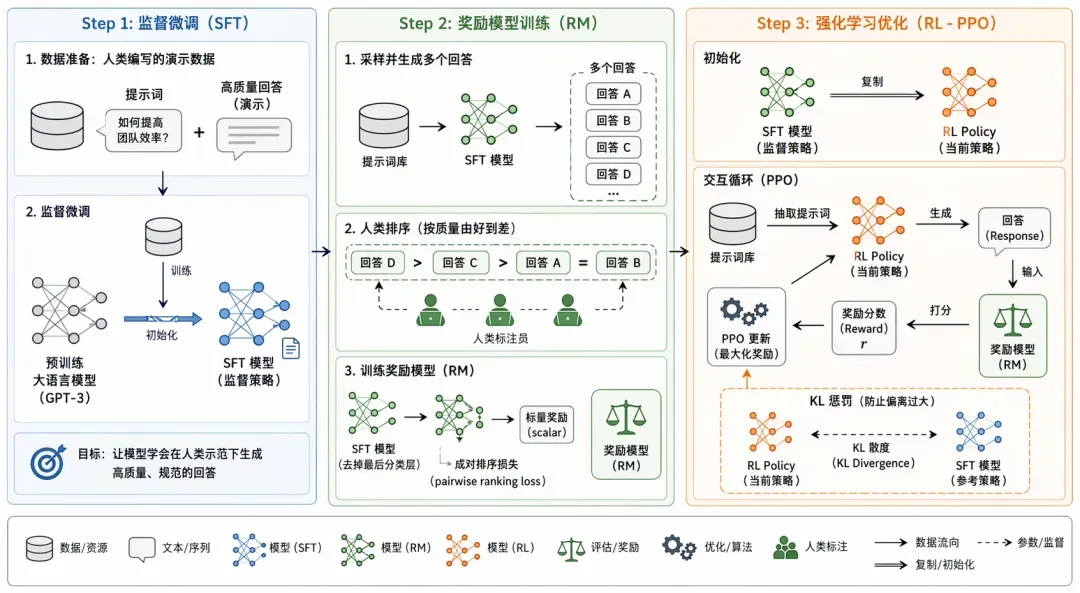
--通用绘图风格指令省略--
## 需要绘制的内容
📄 论文: Training language models to follow instructions with human feedback (InstructGPT)
🎯 核心思想: 通过“人类反馈强化学习(RLHF)”技术,将预训练语言模型(如 GPT-3)的行为与人类的意图和价值观对齐。
🛠️ 技术路线与绘图拆解:
1. 整体架构布局(绘图建议:分为三个并列或递进的清晰阶段(Step 1, Step 2, Step 3))
2. Step 1: 监督微调 (SFT - Supervised Fine-Tuning)数据准备: 收集人类编写的“提示词 (Prompt)” + “高质量回答 (Demonstration)”。模型训练: 取一个预训练大语言模型 (Pretrained LLM) $\xrightarrow{输入}$ 人类标注数据集 $\xrightarrow{训练}$ 输出 SFT 模型 (Supervised Policy)。这一步确立了模型“应该如何规范回答”的基础。
3. Step 2: 奖励模型训练 (RM - Reward Model Training)数据采样: 从 Prompt 库中抽取提示词,使用 Step 1 的 SFT 模型生成多个不同的回答 (Outputs: A, B, C...)。人类排序: 人类标注员对这些回答按质量进行排序 (比如 $D > C > A = B$)。模型训练:以 SFT 模型去掉最后的分类层作为基础,改为输出一个标量值 (Scalar Reward)。输入“Prompt + 回答”,使用成对排序损失 (Pairwise Ranking Loss) 优化网络。产出: 奖励模型 (Reward Model, RM)(相当于一个模拟人类喜好的裁判)。
4. Step 3: 强化学习优化 (RL - PPO 算法)初始化: 复制一份 SFT 模型作为当前的 强化学习策略 (RL Policy)。交互循环(画一个闭环):从库中抽取新 Prompt $\xrightarrow{输入}$ RL Policy $\xrightarrow{生成}$ 回答 (Response)。Prompt + 回答 $\xrightarrow{输入}$ Reward Model (裁判) $\xrightarrow{打分}$ 得到标量奖励分数 (Reward Score)。利用打分,使用 PPO (Proximal Policy Optimization) 算法更新 RL Policy 的参数,最大化奖励。惩罚机制 (KL Penalty): 在 PPO 优化的同时,计算当前 RL Policy 与初始 SFT 模型的 KL 散度 (KL Divergence),作为惩罚项加入,防止模型为了刷高分而“面目全非”(过度拟合奖励模型)。
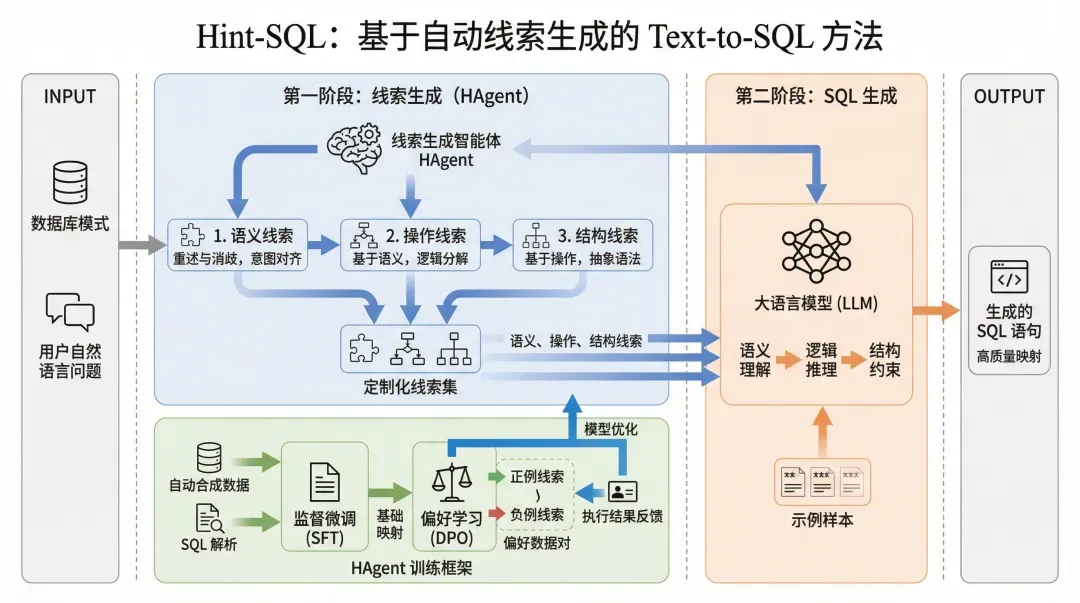
案例二:Text-to-SQL技术路线示意图