PGConf.Dev 2026精要:冯若航阐述PostgreSQL扩展交付之道——构建人人可用的pgext.cloud生态
在2026年PGConf.Dev大会上,Pigsty的作者冯若航带来了一场名为“Extensions for Everyone”(为所有人而构建的扩展)的演讲。这篇整理稿提炼了演讲的核心内容,并提供了在线PPT链接:https://vonng.com/work/extensions-for-everyone。
开篇:扩展的超能力与共享交付的价值
0. 扩展,属于每一个人的工具箱
各位来宾,我今天分享的主题是“让每一个PostgreSQL用户都能轻松获取扩展”。
它围绕扩展的交付展开,探讨一个共享的交付层,如何让用户、扩展作者、厂商乃至PostgreSQL内核开发者都从中获益。

1. 讲者简介:冯若航与Pigsty
我叫冯若航,是开源PostgreSQL发行版Pigsty的作者和维护者。
过去两年间,我一直在为数百个PostgreSQL扩展做编目、构建、打包与测试,横跨不同的PG大版本和Linux平台。所以今天的内容不是理论推导,而是一份来自一线的务实报告。
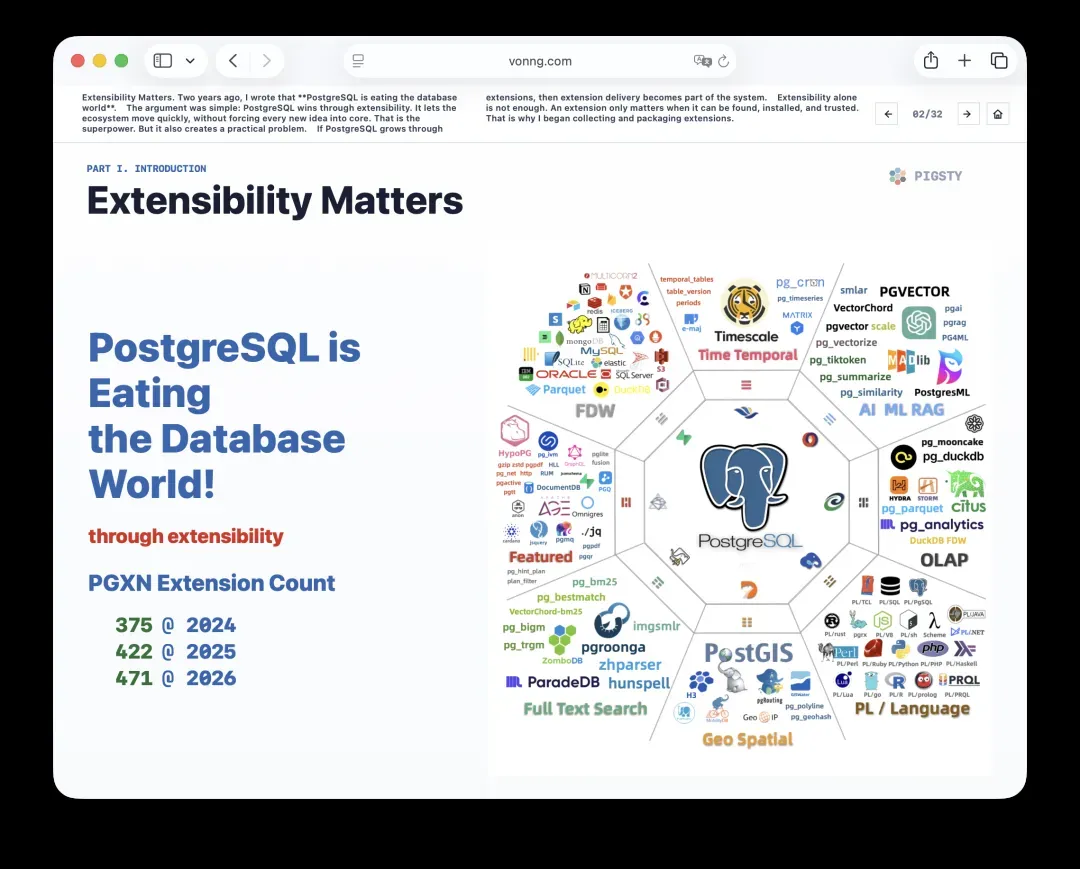
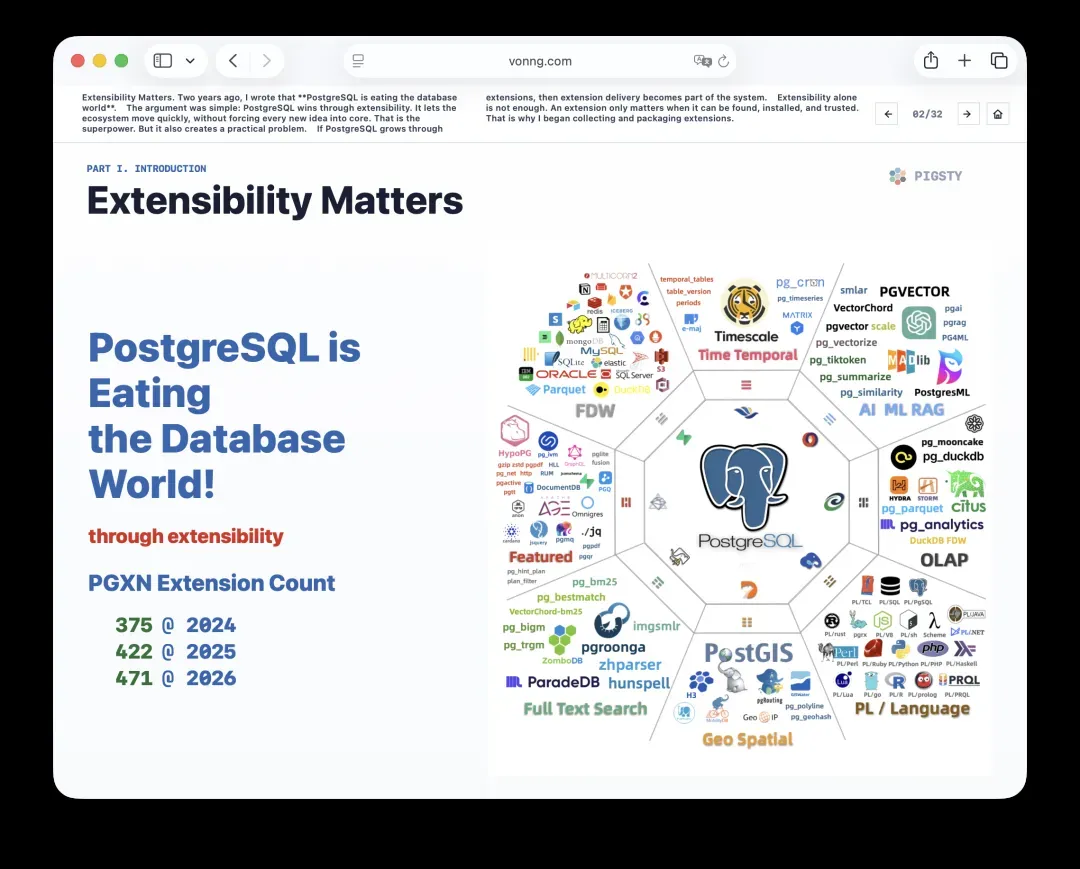
2. 可扩展性:PostgreSQL吞噬数据库世界的动力
两年前我就写过一篇文章,指出PostgreSQL正在吞噬整个数据库世界。
核心论点很直接:PostgreSQL的成功源自它卓越的可扩展性。这种能力让生态可以快速进化,而不必把每一个新特性都硬塞进内核。这是PostgreSQL的超能力,但也随之带来了一个非常现实的挑战。
如果PostgreSQL通过扩展来成长,那么扩展的交付本身就成了系统的一部分。
光是可扩展还不够。一个扩展只有被用户发现、被顺利安装、被充分信任,才具备真正的意义。
这就是我着手收集和打包扩展的起点。
3. 两年之后:一个百万下载的开源基础设施
两年后,我搭建起了一套名为pgext.cloud的开源基础设施,专注于PG扩展的交付。
目前它已经覆盖了16个Linux目标平台和5个活跃的PostgreSQL大版本。把PGDG和contrib计算在内,可交付的扩展集合大约有511个。
这个仓库现在每月提供大约一百万次下载。已有几家PostgreSQL厂商借助它来分发自己的扩展。但今天要谈的重点并不是这个仓库本身。
更重要的是,我们在维护这张覆盖矩阵的过程中学到了什么。这才是我想和大家分享的内容。
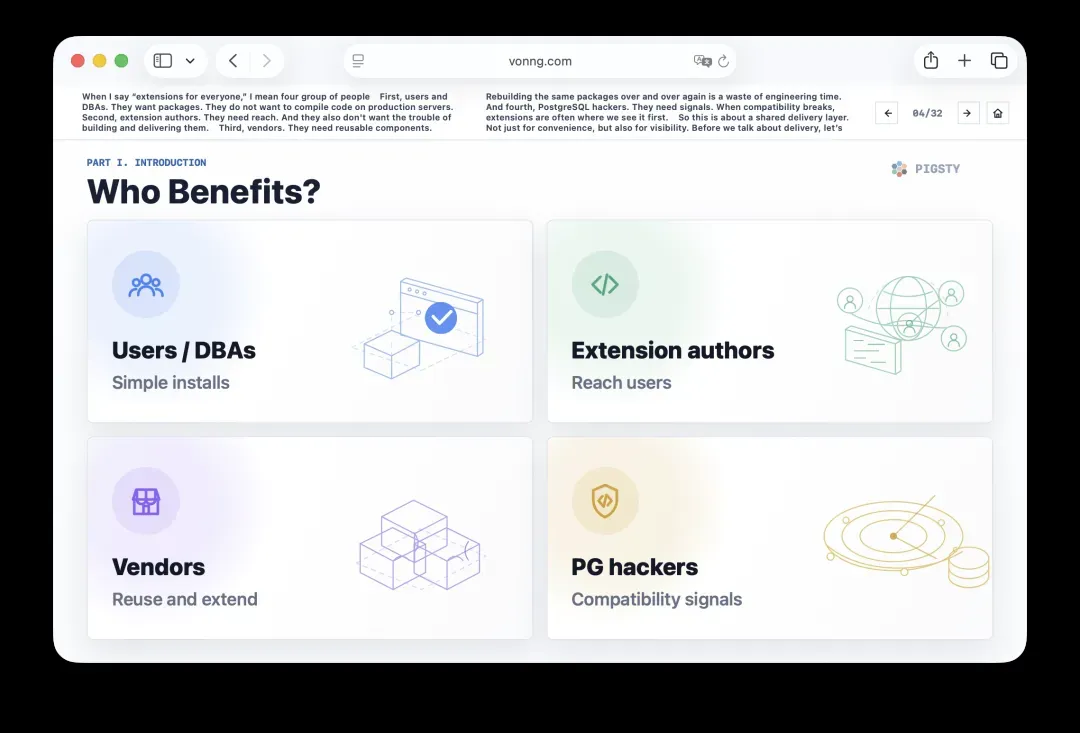
4. 四类受益者
当我说“人人都能用上的扩展”时,指的是四类人。
第一类是终端用户和数据库管理员。他们需要现成的二进制包,而不是在生产服务器上编译代码。
第二类是扩展作者。他们需要触达用户,也不想被构建和交付这些琐碎事务拖累。
第三类是厂商。他们需要可以复用的组件。反复重新构建同一批包,是对工程时间的巨大浪费。
第四类是PostgreSQL内核开发者。他们需要反馈信号。当内核改动导致兼容性被破坏时,扩展往往是最早暴露问题的地方。
所以,这件事的本质是一个共享交付层。它不仅让工作更省力,也提供了可见性和反馈通路。在深入交付之前,我们先要了解生态系统本身,弄清楚我们到底在交付什么。
生态全景:一个庞大而散乱的扩展星系
5. 星系级条目数:1600+个候选项
PostgreSQL到底有多少扩展?社区里有一个众人维护的GitHub列表,收录了一千多个条目。我自己维护的目录目前跟踪着大约1,617个条目。
但这个数字需要背景信息:一些项目还在活跃开发中,一些已经无人维护;有些只能在特定云上使用;有些依赖专有的PostgreSQL分叉;还有一些仅仅是想法和示例。因此,1,617这个数字并不意味着有1,617个可以直接安装的扩展。
它真正表明的是,生态的边界非常巨大,而且相当混乱。
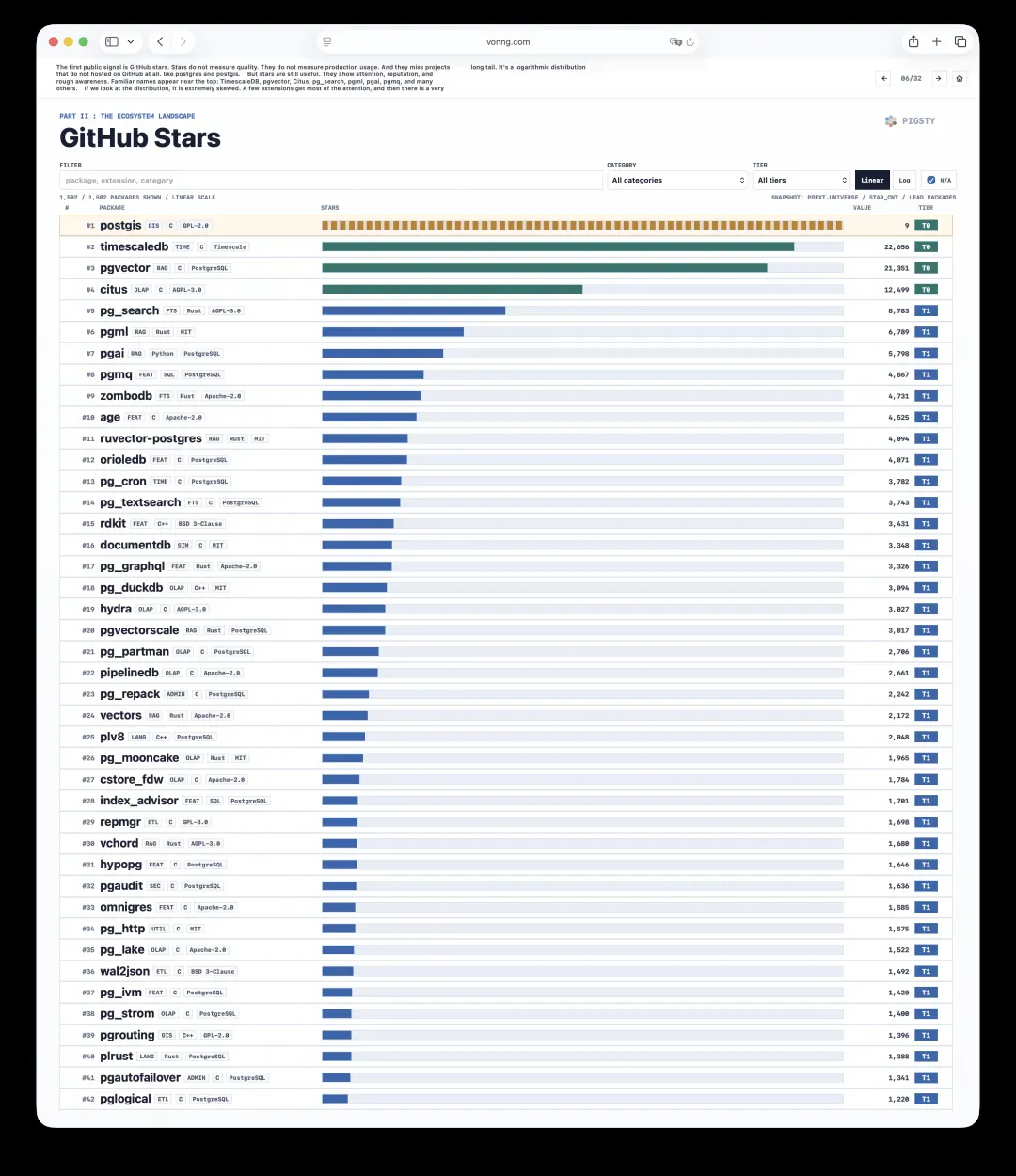
6. GitHub星标:关注度的快照
第一个公开的信号是GitHub星标。星标既不能衡量质量,也不能代表生产环境的使用情况,还会遗漏掉那些根本不托管在GitHub上的项目,比如PostgreSQL本身和PostGIS。
但星标仍然有价值。它反映了关注度、声誉和大概的认知度。排在榜单前列的都是熟悉的名字:TimescaleDB、pgvector、Citus、pg_search、pgml、pgai、pgmq等等。
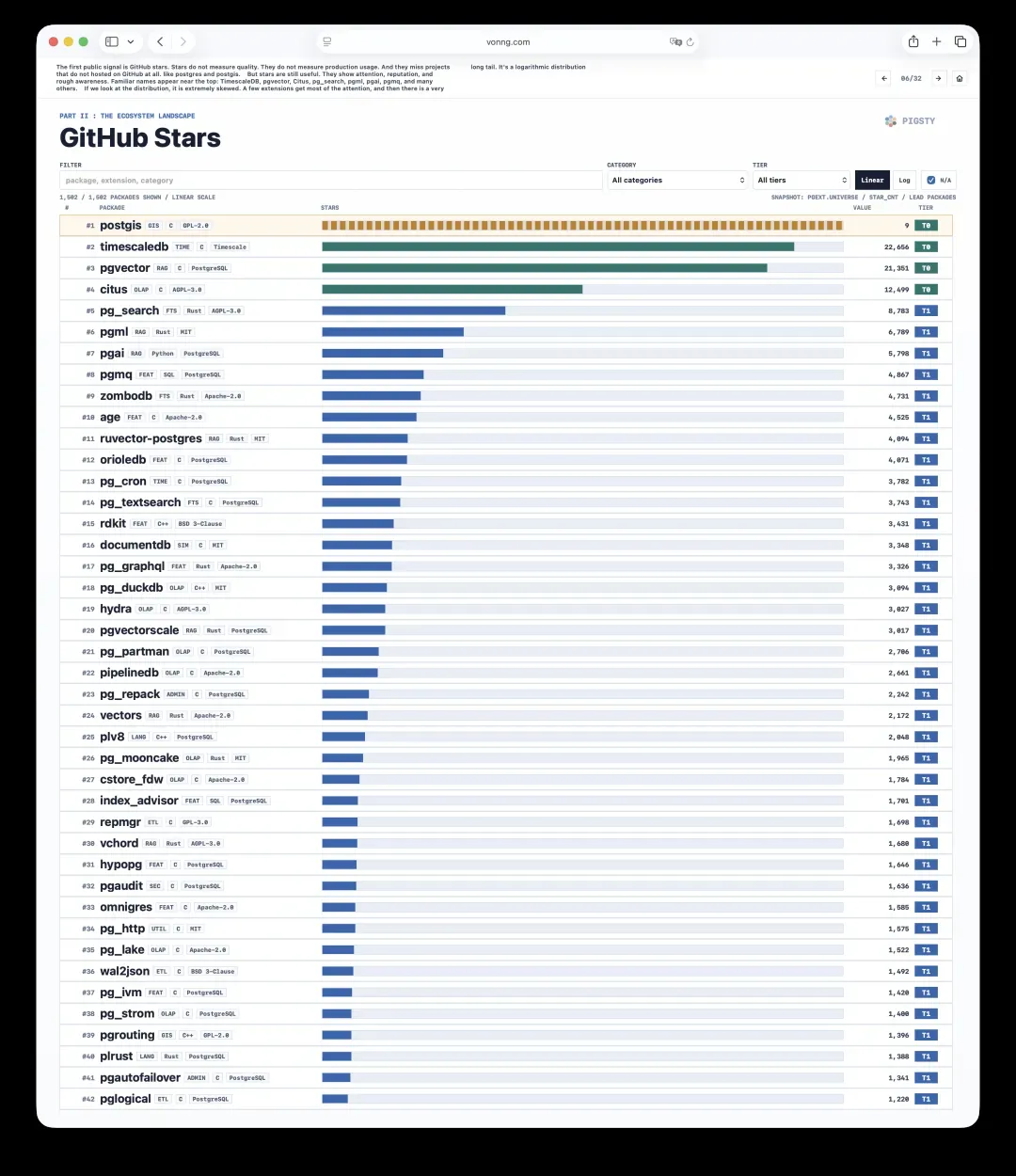
观察其分布会发现,它高度倾斜——少数扩展吸走了绝大部分注意力,后面拖着一根长长的尾巴,呈现典型的对数分布。
7. 星标梯队:从四大天王到长尾
把扩展按星标数量级分组,可以得到一个简单的层级模型。
第零层:四大天王——PostGIS、TimescaleDB、pgvector、Citus,每家的星标都突破了一万。
第一层:44个扩展,星标在一千到一万之间。
第二层:大约152个扩展,星标在一百以上。
第三层:大约373个扩展,星标超过十个。
再往下就是约748个星标低于十的长尾扩展。
这并不是质量排行榜。有些热门项目早已不再活跃,比如pgml或zombodb;而某些低星标的扩展却非常实用。
不过这些层级向我们揭示了一件事:可见的生态远比已被发现的生态要小得多。把第零层到第三层加总,大约有570个超过十星的扩展,这与实际可交付的规模十分接近。
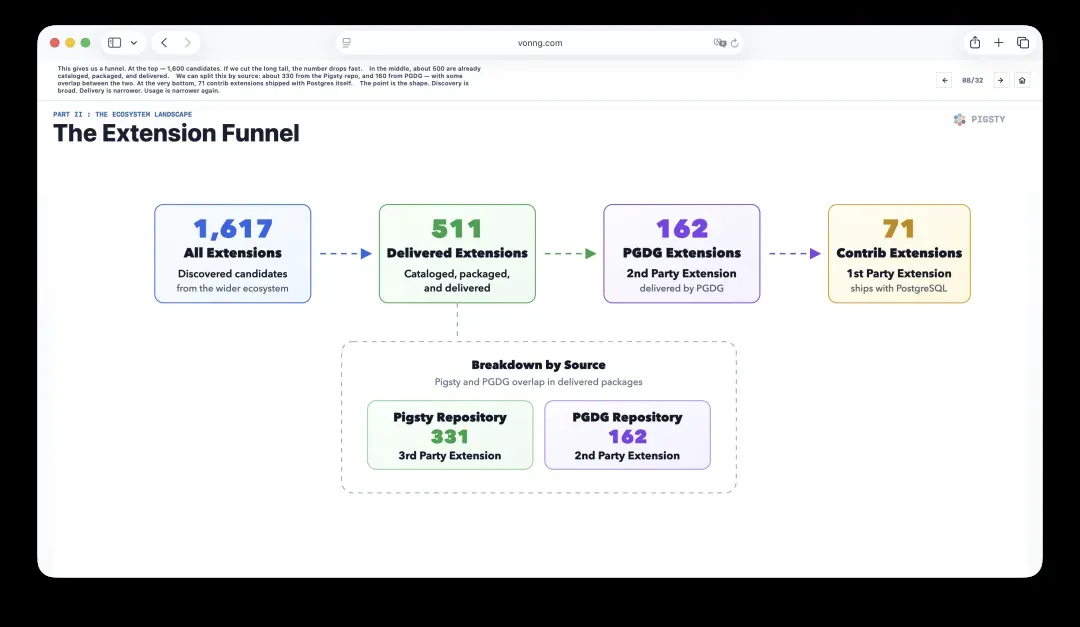
8. 扩展漏斗:从发现到实用
由此,我们得到了一个漏斗模型。顶部约有1,600个候选项。一旦将长尾截断,数量会急剧收缩。
中间,大约有500个扩展已经被编目、打包并进入交付阶段。
从来源拆分看,大约330个来自Pigsty仓库,160个来自PGDG,两边存在一些重叠。最底层是PostgreSQL自带的71个contrib扩展。
这个漏斗的形状很重要:发现面很宽,实际交付的范围窄得多,而真正广泛使用的又更窄。
9. 维度分析:32种观察角度
这个目录跟踪的维度远不止星标,还包括语言、许可证、分类、最近发布日期、仓库状态、打包状态、PG版本支持以及操作系统支持。你可以从多达32个不同的维度浏览扩展。
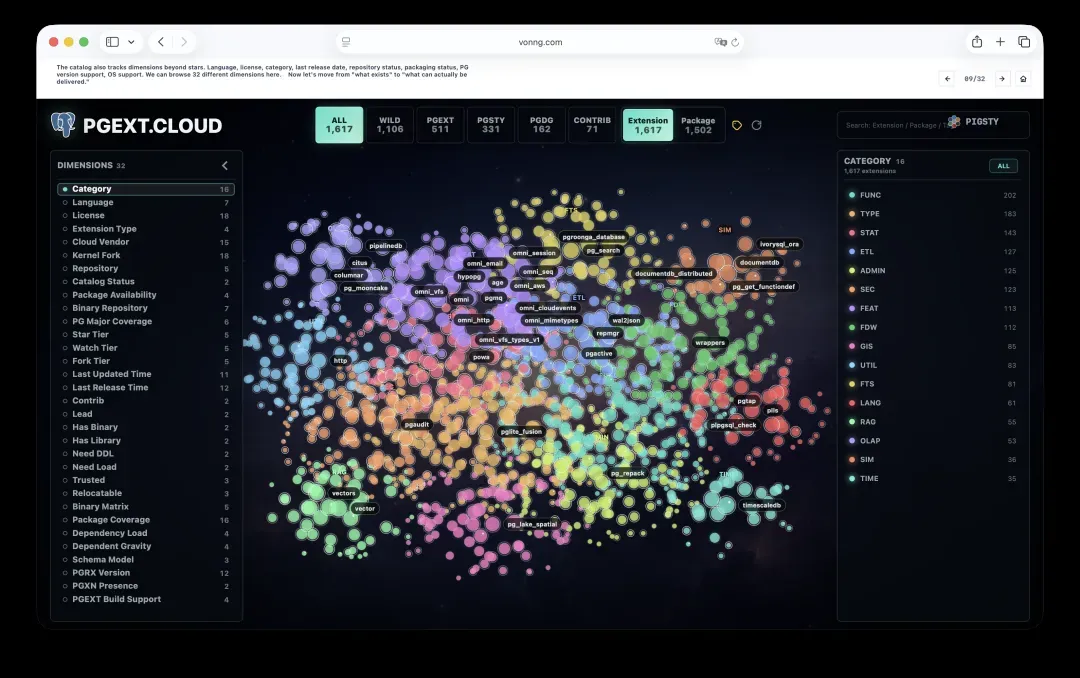
在线浏览入口:https://pgext.cloud/galaxy/
现在,让我们从“存在什么”过渡到“什么真的可以交付”。
交付层:从目录到仓库的工程现实
10. 现状:80个构建槽位的矩阵挑战
打包PostgreSQL扩展绝非易事。难点并不在于包格式本身有多神秘,而在于组合矩阵太过庞大。我们面对的是5个活跃的PG大版本乘以16个Linux平台,也就是每个扩展存在80个构建槽位。真正能覆盖全部槽位的扩展屈指可数。
Christoph和Devrim维护的PGDG YUM与APT仓库已经搭建起坚实的基础。它们承载了大量最重要的扩展,总计大约150个包。但仍存在缺口,比如Rust扩展,以及一些未被覆盖的操作系统与PG版本组合。
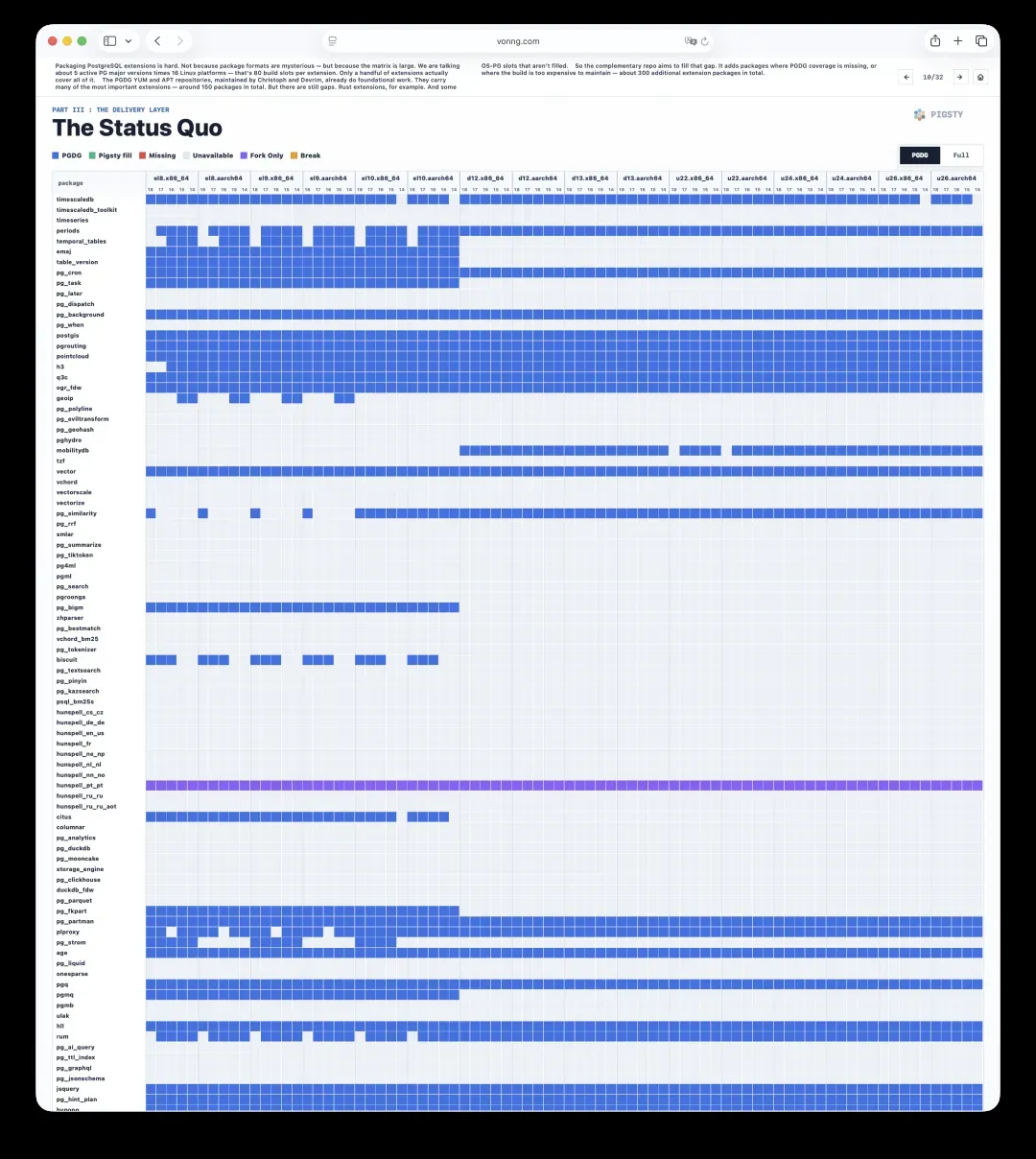
因此,这个互补仓库的目标就是填补这些空白。在PGDG覆盖不到,或构建成本过高、难以维护的领域,额外交付包文件。整体上我们额外提供了大约300个扩展包。
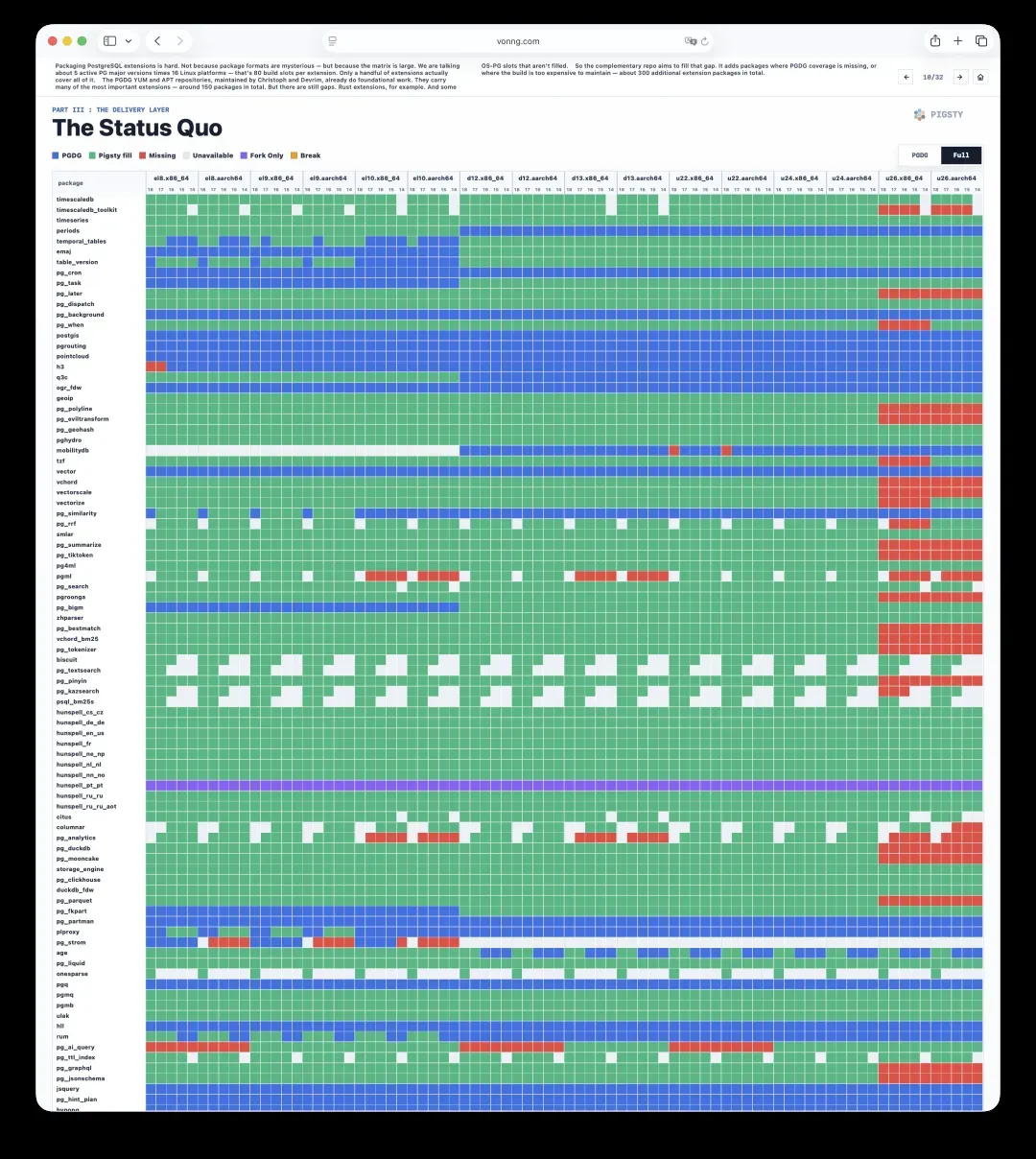
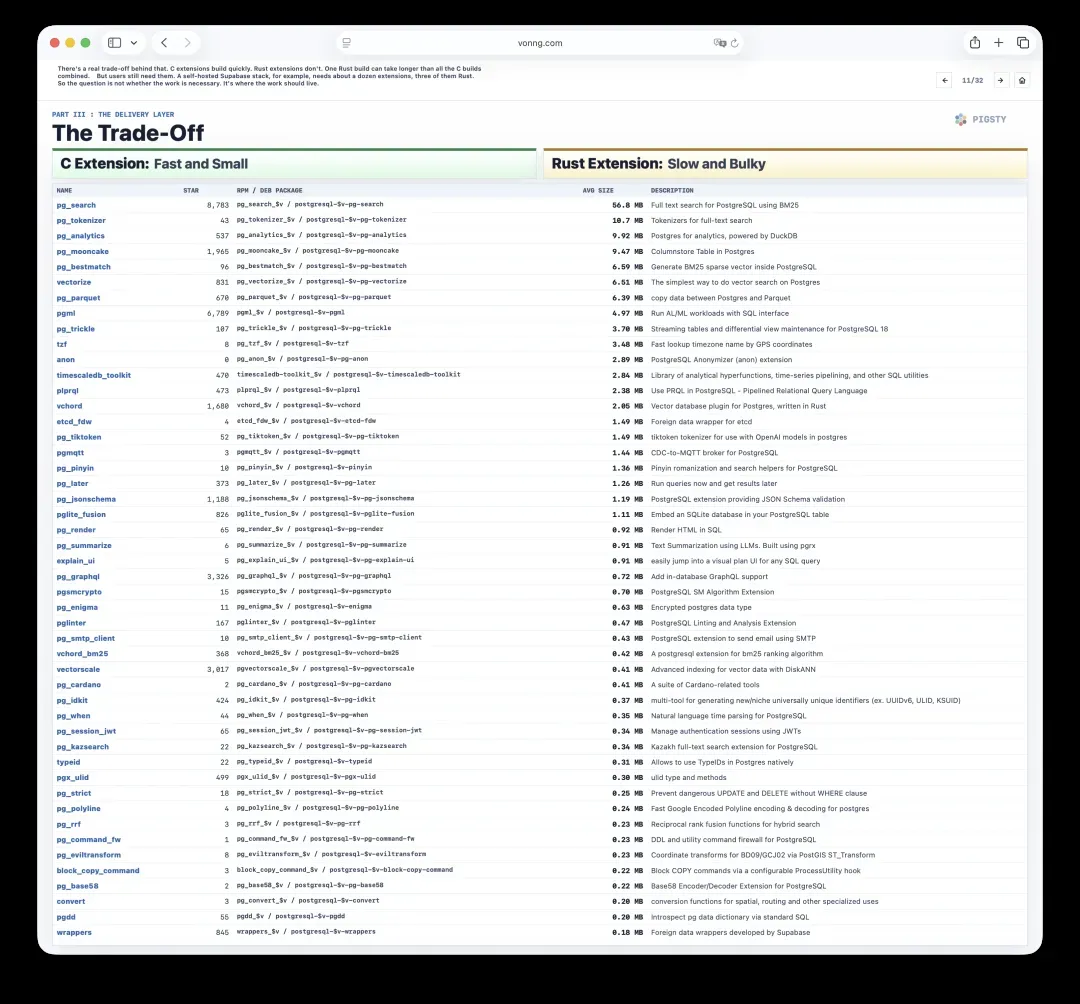
11. 取舍:C扩展与Rust扩展的成本差距
这背后有着真实的取舍。C扩展构建得很快,Rust扩展则不然。一个Rust扩展的构建时间,有时比所有C扩展加起来还要长。
但用户仍然需要它们。举个例子,自托管的Supabase技术栈大约需要十多个扩展,其中三个是Rust扩展。所以问题不在于这件事值不值得做,而在于这项工作应该放在哪里完成。
12. 为什么Linux原生包依然关键?
容器镜像能够减少一部分矩阵维度,这一点我完全认同。有了容器,每个扩展只需为5个PG大版本和2种CPU架构构建,也就是10个槽位,规模缩减了8倍。
但是Linux原生包依然重要。大量用户仍然通过系统自带的包管理器(APT或YUM)来安装PostgreSQL。而且大多数Postgres Docker镜像本身,也是从PGDG APT仓库以Debian包形式安装扩展。
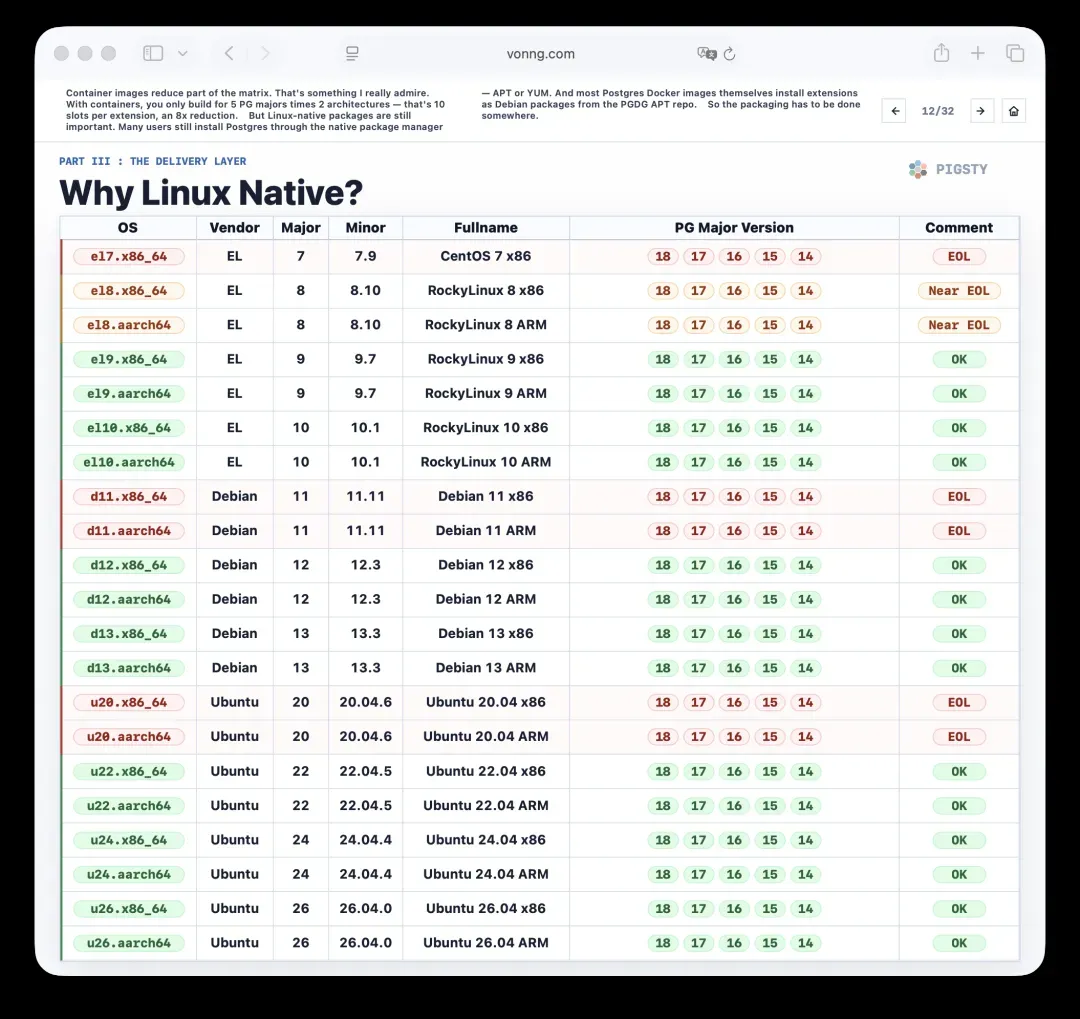
因此,这些原生包的打包工作总得有人来完成。
13. 基础设施四件套:目录、仓库、CLI和构建矩阵
为了将这些RPM和DEB扩展包交付给用户,我们围绕它构建了一整套开源基础设施,包含四个部分:用于发现的目录,用于交付的仓库,一个可选的CLI工具用来简化访问。
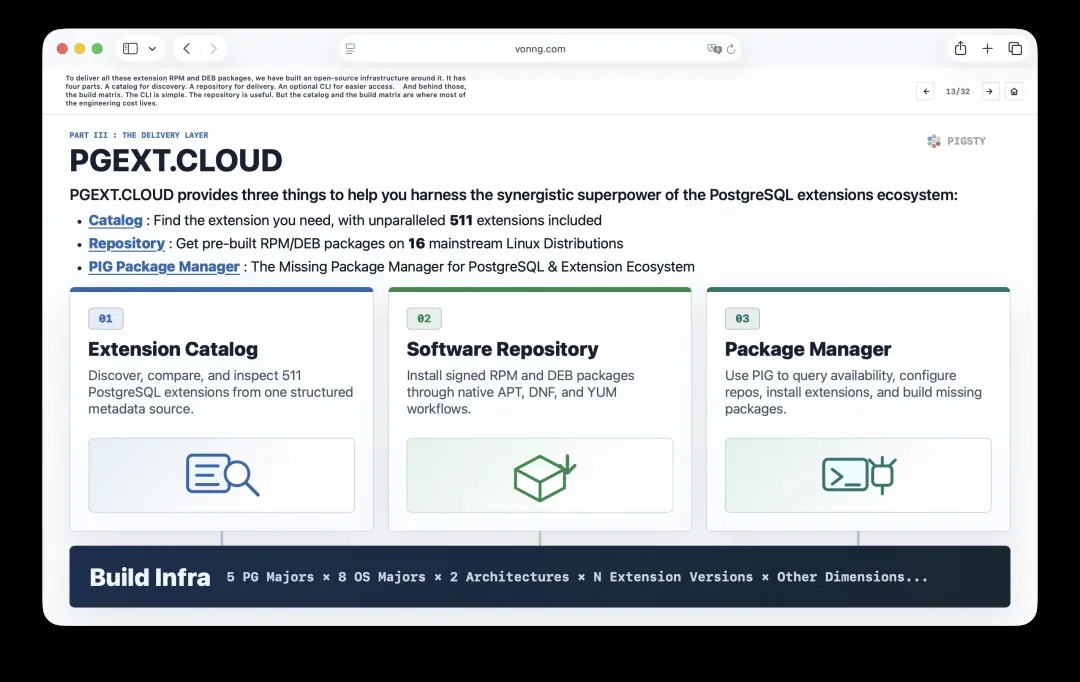
在所有这些组件的背后,是构建矩阵。CLI很简洁,仓库很有用,但目录和构建矩阵才是绝大部分工程精力的消耗点。
14. 扩展目录:结构化的真实之源
目录是整个体系的事实来源。它不是一个营销页面,而是一个带有结构化元数据的数据库,描述着扩展的一切:维度、标签、依赖关系、可用性矩阵,以及关于安装、配置和构建的备注。
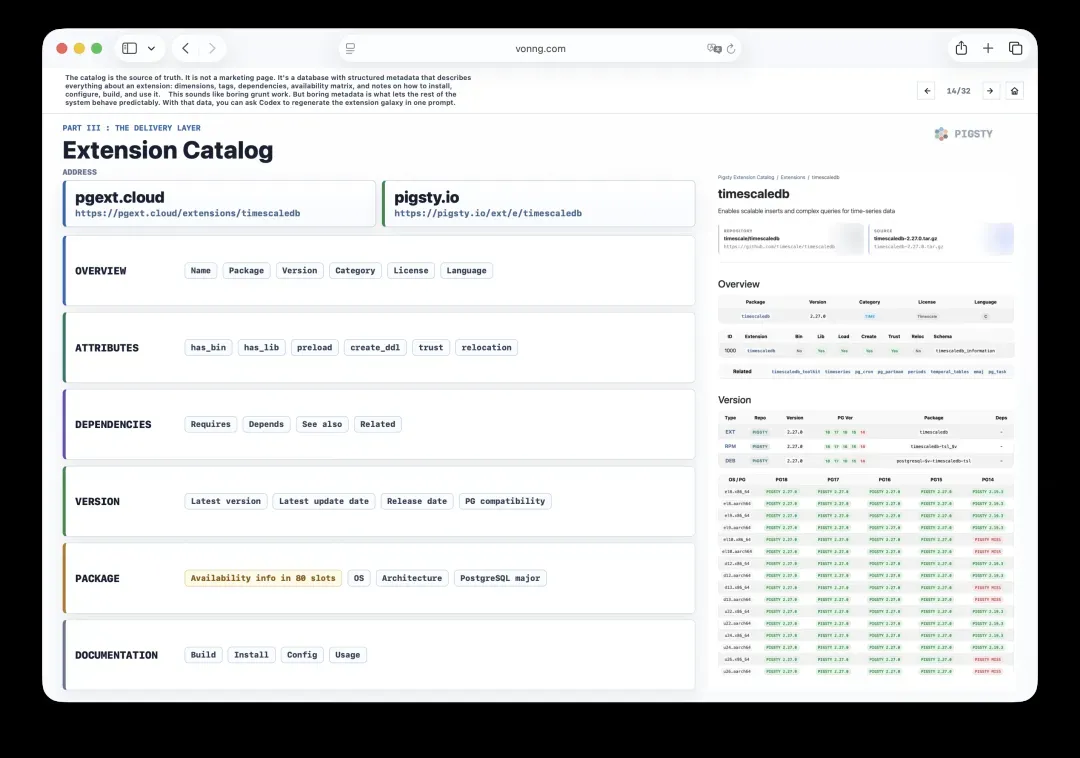
这听起来像是枯燥的脏活累活。但恰恰是这些看似平淡的元数据,让系统的其余部分能够可预测地运转。有了这些数据,你甚至可以让Codex用一句提示词重新生成扩展星系图。
15. 目录细节:从universe版到详细版
目录是交付路径的一部分。网站和CLI工具都将它作为权威的事实来源。
目前这些元数据会定期导出为若干个CSV文件。它有两个版本:一个universe版本,收集着1,600个扩展的通用元数据;另一个详细版本,覆盖其中511个已交付的扩展。
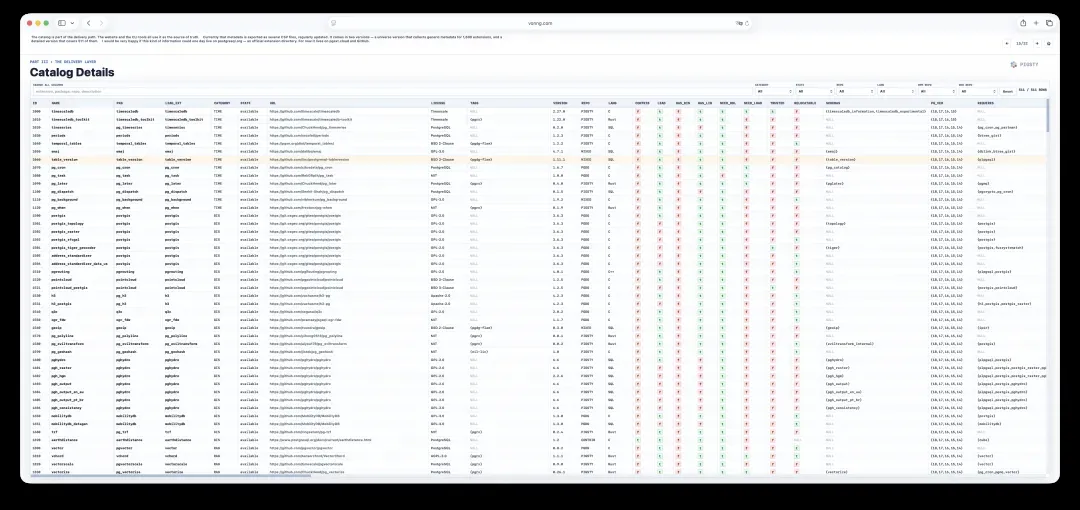
如果未来这类信息能放在postgresql.org上,成为官方扩展目录,我会感到非常高兴。现在它暂时栖息在pgext.cloud和GitHub上。
16. 页面访问量:需求的风向标
目录网站同样能给出页面访问量数据。它们虽然不等于生产环境的使用量,但能告诉我们用户在关注什么。这极其有用,可以帮助判断哪些扩展值得优先投入打包精力,哪些类别正在变得活跃。
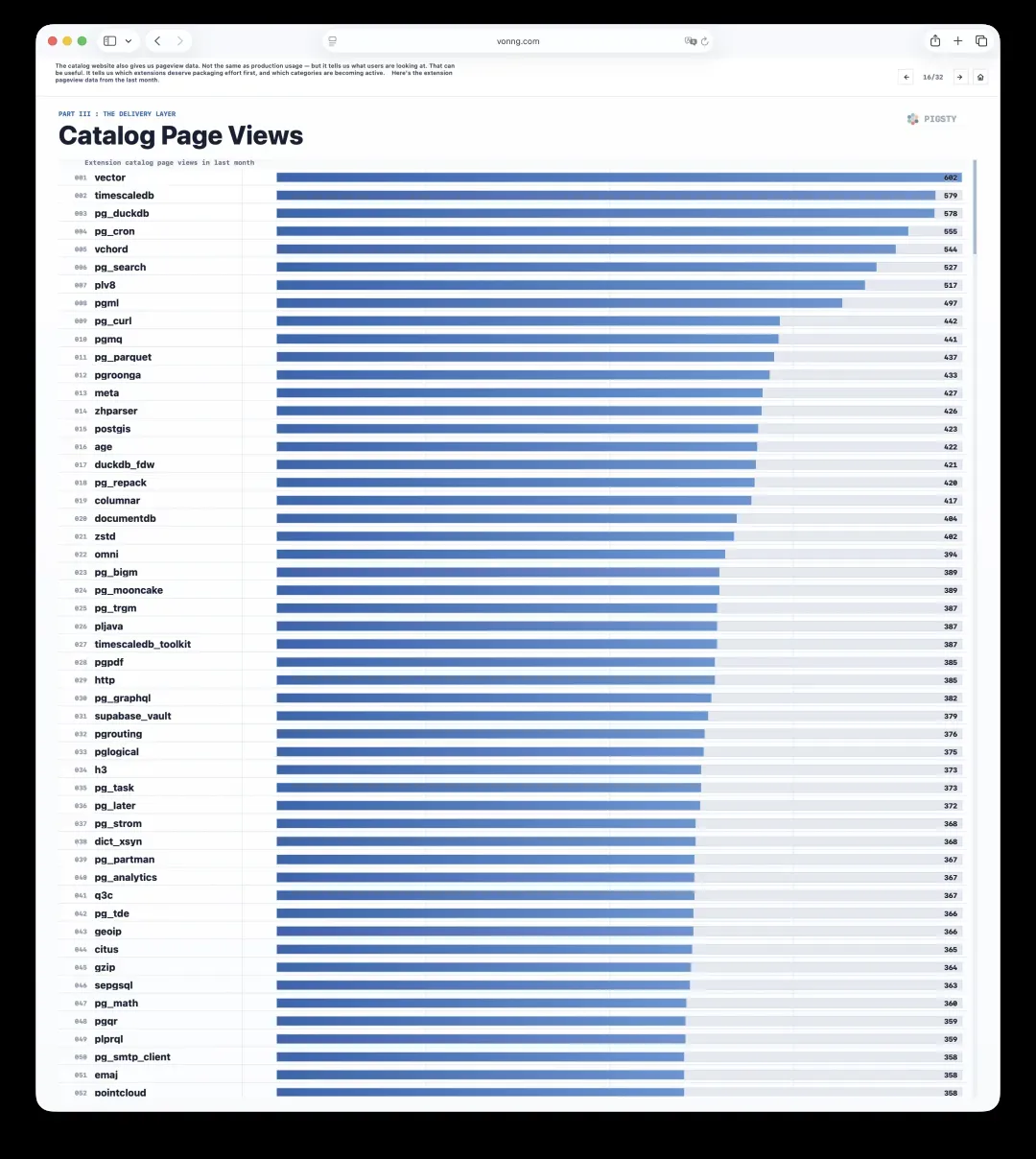
以下是过去一个月各个扩展页面的访问量数据。
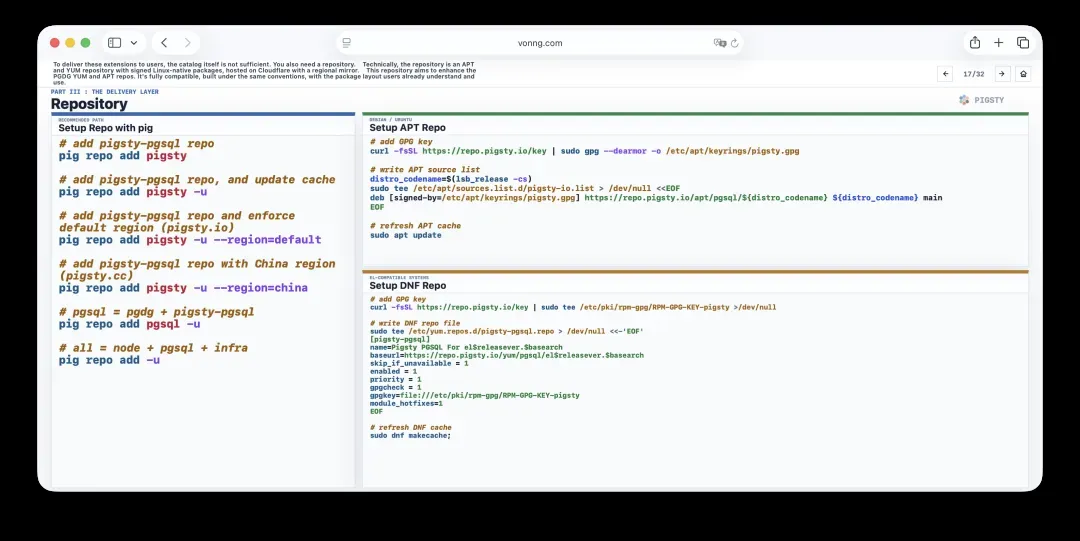
17. 仓库:兼容并增强PGDG的APT/YUM源
要把扩展交付给用户,光有目录还不够,还需要一个仓库。
从技术上讲,这个仓库是一个APT与YUM仓库,提供带签名的Linux原生包,托管在Cloudflare上并带有区域镜像。
该仓库的目标是增强PGDG的YUM和APT仓库。它与PGDG完全兼容,遵循同样的约定,使用用户早已熟悉的包布局。
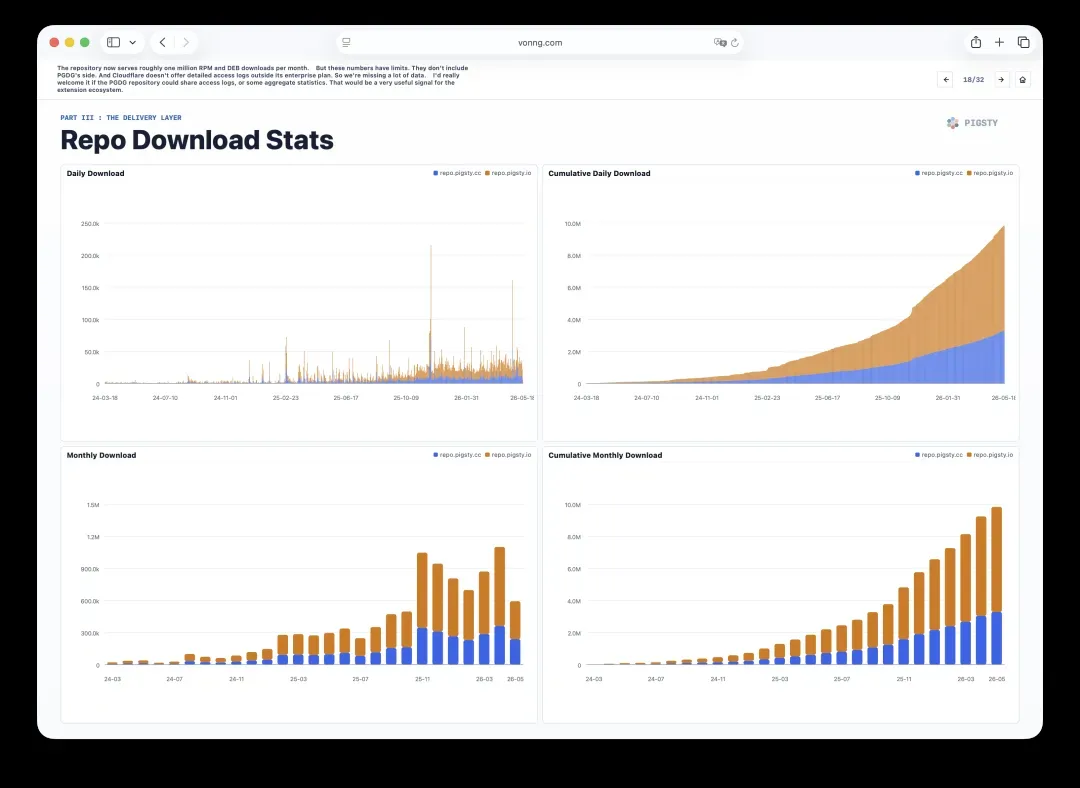
18. 仓库下载量:局部但有偏的信号
眼下这个仓库每月大约提供一百万次RPM和DEB下载。
不过这些数字有局限性。它不包括PGDG那一侧的数据,而Cloudflare在企业版之外不提供详细访问日志,因此我们缺失了很多信息。
如果PGDG仓库能共享访问日志,或者至少提供一些聚合统计,我会非常欣赏。那将是扩展生态中极为宝贵的信号。
19. 从下载数据还能发现什么?
即便下载数据是局部的、存在偏差的,它仍然有用。它可以揭示哪些PG大版本依然活跃,哪些操作系统目标需要重视,以及某个包组合是否有足够的需求来支持继续维护。
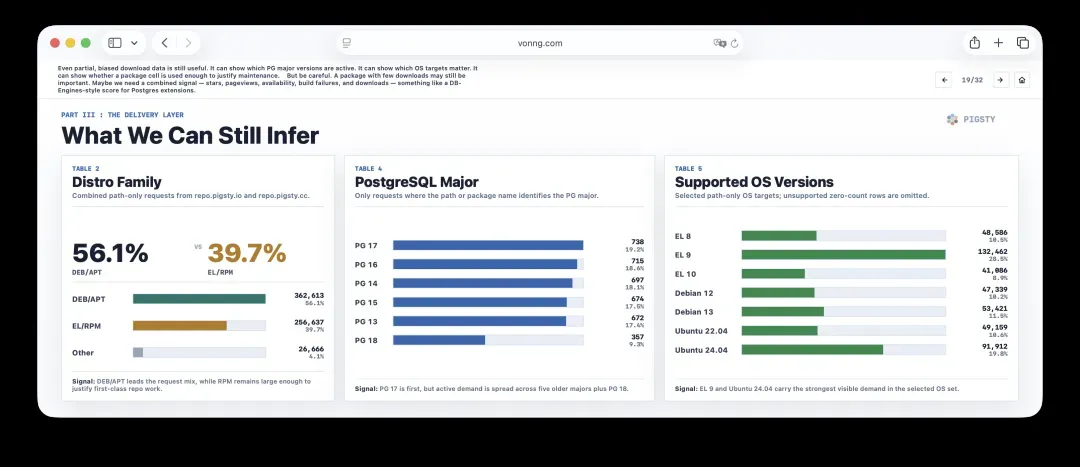
但需要保持警惕:下载量低的包同样可能非常关键。或许我们需要一个综合指标,把星标、页面访问量、可用性、构建失败和下载量融合起来,形成类似DB-Engines风格的PostgreSQL扩展评分。
20. CLI工具PIG:借力系统包管理器
有了目录和仓库,扩展的交付基本上就解决了。你可以直接使用系统包管理器dnf或apt从PGDG和PGEXT仓库安装扩展。
此外,我们还有一个完全可选的专用命令行工具,叫PIG。它用Go编写,仅有4 MB。名称的含义是“piggyback on the OS package manager”,即借力系统包管理器。它会隐藏所有复杂度,让用户直接完成安装。
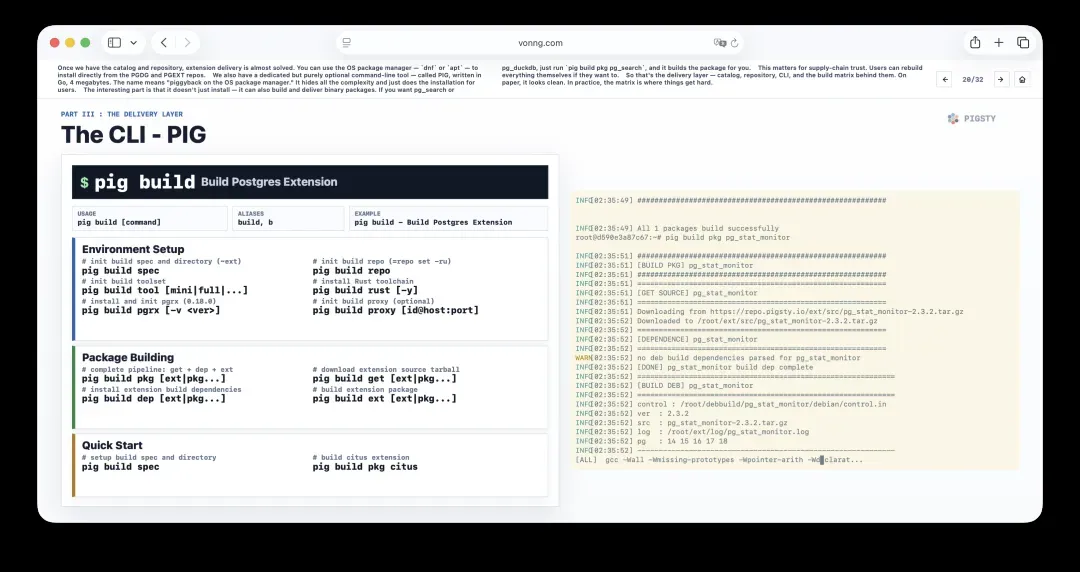
有意思的是,它不仅能安装,还能构建和交付二进制包。如果你需要pg_search或pg_duckdb,只需运行pig build pkg pg_search,它便会帮你构建包。
这对于供应链信任很有意义——用户如果愿意,完全可以自行重建所有内容。
这就是交付层:目录、仓库、CLI以及它们身后的构建矩阵。纸上谈兵看起来很清晰,但在实际工程中,矩阵才是真正困难的地方。
野外维护:矩阵爆炸下的惨痛教训与解决方案
21. 扩展矩阵:远不止80个槽位
上一章我们将矩阵描述为每个扩展80个槽位。
但5个PG版本乘以16个Linux平台,只是一个过度简化的模型。真实情况要混乱得多,包含的因素远远超过行和列。
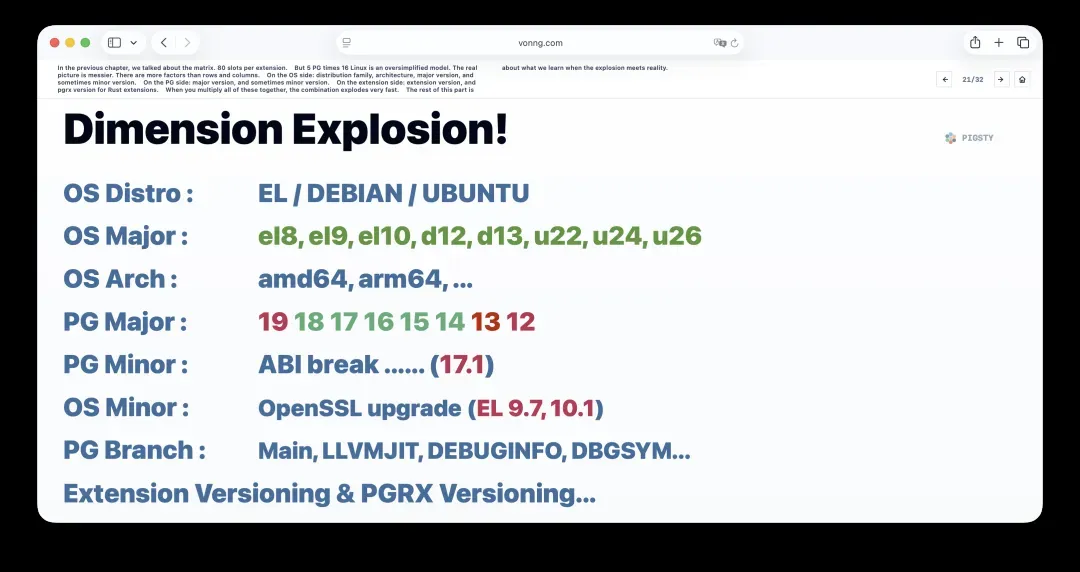
在操作系统侧,有发行版家族、CPU架构、大版本,有时还有小版本。
在PG侧,有大版本,有时也有小版本。
在扩展侧,有扩展自身的版本;对于Rust扩展,还涉及pgrx版本。
把这些因素相乘,组合数量就会极快地膨胀。
接下来我要讨论的,就是当这种爆炸式复杂度撞上现实之后,我们学到的一手教训。
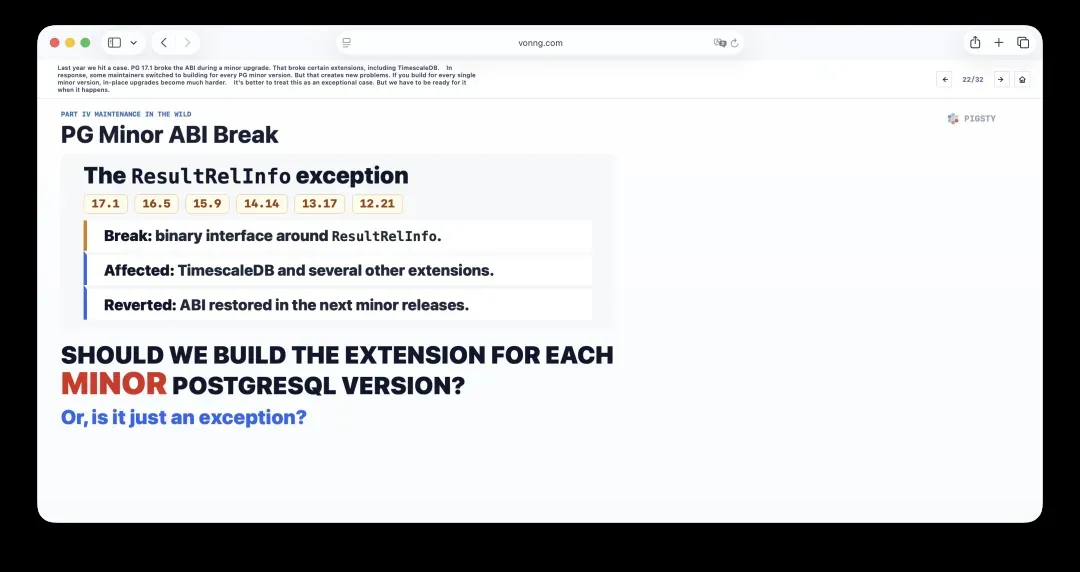
22. PG小版本ABI破坏:例外还是常态?
去年我们遇到过一个案例:PG 17.1的一次小版本升级破坏了ABI,导致包括TimescaleDB在内的一些扩展出现问题。
作为应对,部分维护者开始为每一个PG小版本分别构建。但这又会制造新的麻烦——如果每个小版本都独立构建,原地小版本升级就会困难许多。
更合理的做法是将其视为例外情况来处理,但当它确实发生时,我们必须有所准备。
23. 操作系统小版本引发的兼容性地震
有时,甚至操作系统的小版本更新也会击穿构建。
例如,EL将OpenSSL版本从3.2升级到3.5后,若干扩展在链接阶段便会失败。
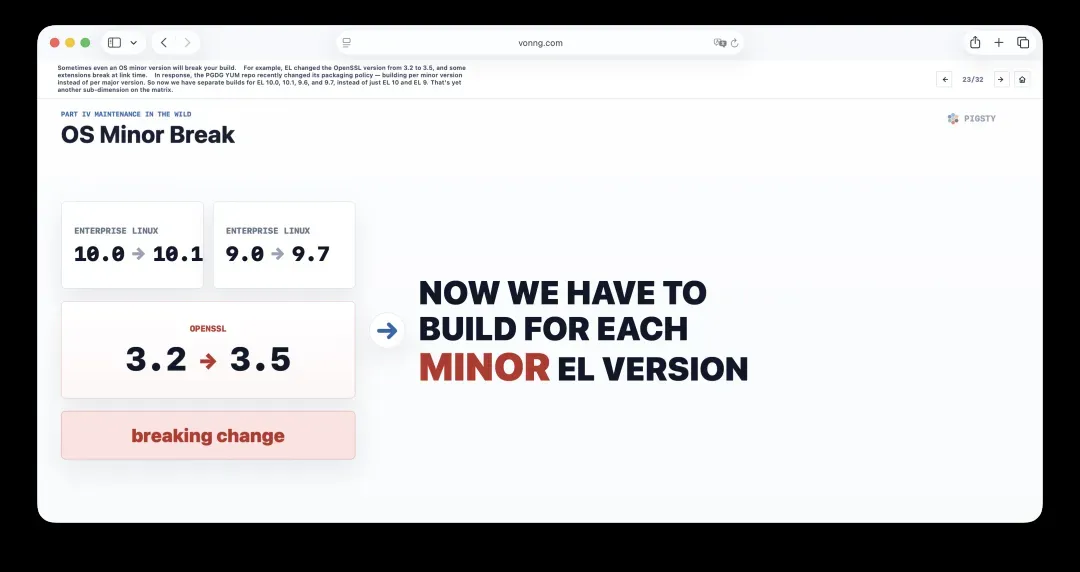
作为回应,PGDG YUM仓库最近调整了打包策略,从按大版本构建转向按小版本构建。于是现在我们有了EL 10.0、10.1、9.6、9.7的独立构建,而不仅仅是EL 10和EL 9,这又为矩阵增加了一个子维度。
24. Rust问题:构建成本与新维度
Rust扩展正在快速增长,为生态引入了新人和新想法。Rust社区用一套名为pgrx的框架来编写这些扩展,但也因此带来了几个新挑战。
第一是构建成本。Rust构建很慢,也很吃磁盘空间。一个Rust扩展的构建时间,可能超过所有C扩展的总和。
第二是pgrx自身也有版本——如0.16、0.17、0.18——而这些版本并不能互相替代。我耗费了大量时间将Rust扩展对齐到特定的pgrx版本上,但随着时间推移,版本偏移又会卷土重来。
所以Rust不仅仅是增加了一门编程语言,它还增加了一条全新的兼容性维度。
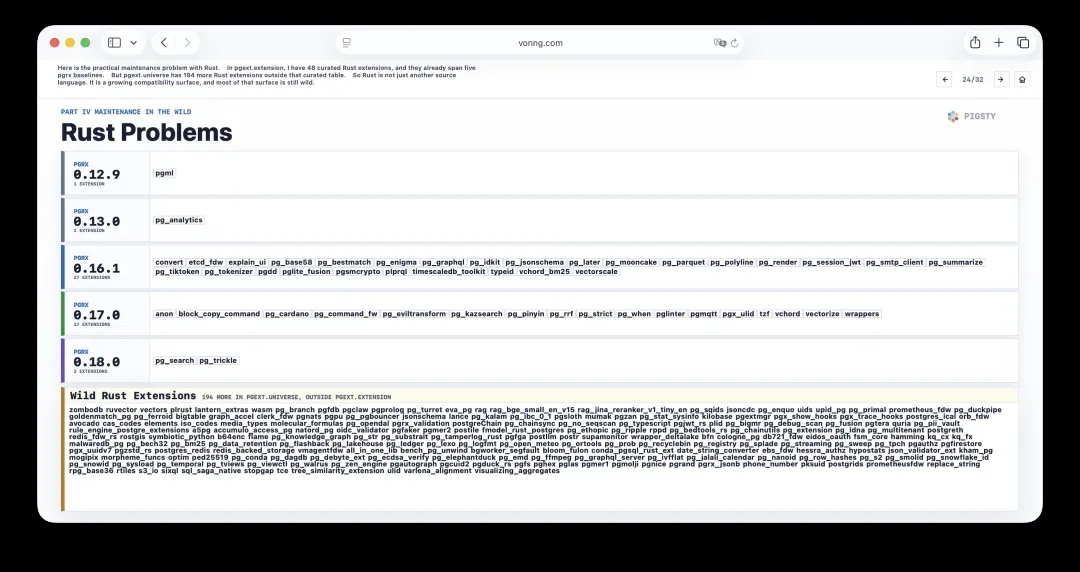
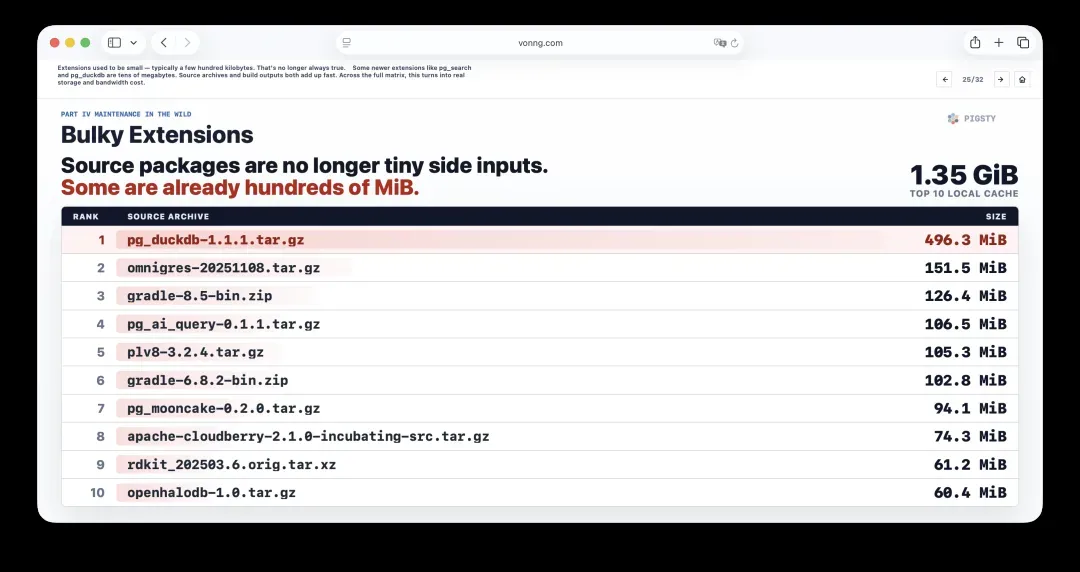
25. 臃肿的扩展:大小与成本的新现实
以往的扩展通常很小,典型体积只有几百KB。现在的情况已大不相同。
一些新扩展,如pg_search和pg_duckdb,体积可达数十MB。源代码归档和构建产物都会迅速膨胀。一旦放到完整矩阵中,便会演变为真实的存储和带宽成本。
26. 命名冲突:访问方法的领地之争
矩阵是一种复杂度,扩展之间的冲突是另一种。
去年,我讲过Citus和Hydra争夺同一个columnar名字的问题。今年我们又迎来了一个新例子:bm25。现在有三个扩展暴露了名为bm25的访问方法:
· ParadeDB的pg_search · Timescale的pg_textsearch · TensorChord的vchord_bm25
与Citus和Hydra的情形不同,这三个扩展可以同时安装,但你无法在同一个数据库里把它们全部创建出来,因为访问方法名称会产生冲突。
这不单是打包问题,更是生态元数据层面的问题。如果目录记录的不只是包名,还包括扩展对象、库和访问方法,作者就可以在发布前主动检查冲突。

27. 库冲突:共享libduckdb的协调难题
另一个类似的案例是,三个基于DuckDB的扩展都想使用同一个共享库:libduckdb。
包管理器看到的是磁盘上的文件,PostgreSQL看到的是共享库和control文件,用户看到的则是CREATE EXTENSION。这三层的理解可能彼此错位。
实际的解决方案,是把其中两个扩展挂载为pg_duckdb之下的子扩展。这个方法能跑通,但协调起来仍然颇费周折。教训很简单:名字也是兼容性的一部分,而且名字真的会冲突。
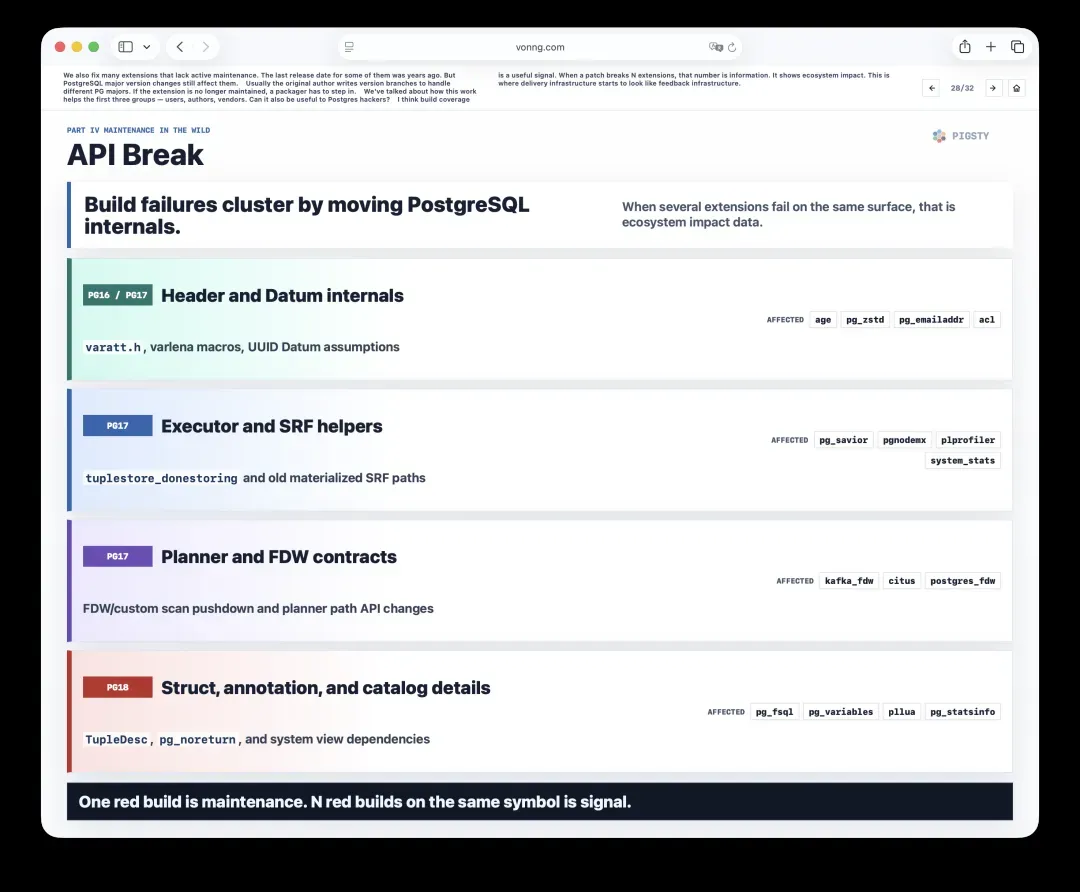
28. API破坏与构建覆盖率:面向内核开发者的反馈
我们还修复了大量缺乏活跃维护的扩展。有些扩展自上次发布以来已经沉寂多年,但PostgreSQL大版本的变化依然会影响它们。
通常,原作者会为不同的PG大版本维护不同的分支。如果扩展已经无人维护,打包者就必须接管这项工作。
前面我们说到,这项工作能帮助用户、作者和厂商。那么它对PostgreSQL内核开发者也有用吗?
我相信,构建覆盖率是一种有价值的信号。当一个补丁破坏了N个扩展时,这个数字本身就是信息,它揭示了生态影响。到了这一步,交付基础设施便开始转变为反馈基础设施。
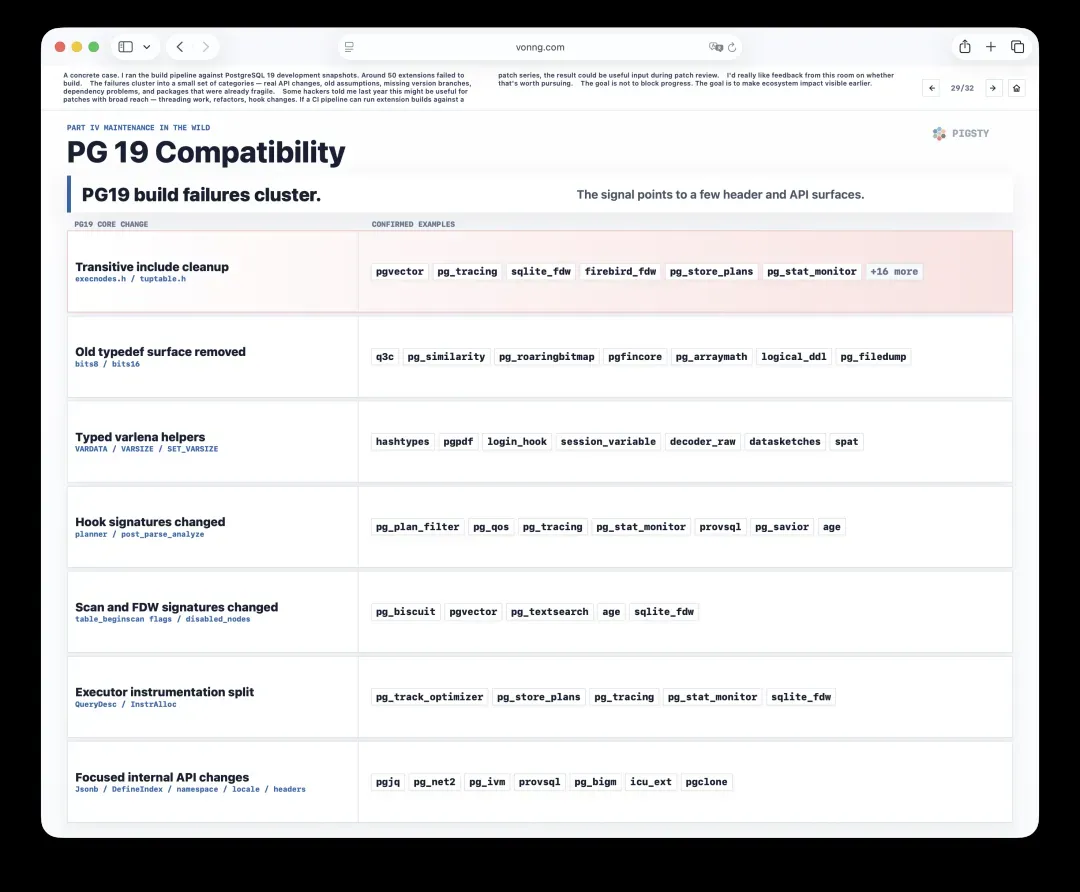
29. PG 19兼容性:五十余个扩展构建失败
一个具体的案例是,我用PostgreSQL 19的开发快照跑了一遍构建流水线。大约50个扩展构建失败。
这些失败集中在少数几个类别:真正的API变更、过时的假设、缺失版本分支、依赖问题,以及原本就已脆弱的包。
去年有内核开发者告诉我,这对那些影响面广泛的补丁可能很有用,比如线程化工作、重构、hook变化。假如CI流水线能针对某个补丁系列运行扩展构建,那么其结果就能成为补丁评审过程中的有益输入。
我很想听听在座各位的反馈:这件事值不值得继续推进?目标就是让生态影响更早地变得可见。
30. 让它可维护:AI工具与一人维护者的现实
一个绕不开的现实问题是可维护性。所有这些工作目前都是由一个人完成的。我经营着一家一人公司,也维护着一人运营的发行版Pigsty,已经持续了大约五年。
近期这件事变得容易了一些,原因在于AI工具的加持。去年,每一个构建spec都是手工编写的。积累到足够多的示例之后,增加新扩展已经变得非常直接。上个月,我在两天之内新增了50个扩展。
社区开发者Yurii Rashkovskii曾描述过一个名为PGPM的想法:URL in, RPM out——给你一个URL,吐出一个RPM。有了Codex和Claude Code,这个想法正在成为现实。
AI也降低了测试成本。我们可以从扩展文档驱动冒烟检查,更早捕获行为回归。AI现在可能还写不出能提交给PostgreSQL内核的补丁,但它显然已经足以胜任构建与打包的重复劳动。我维护着一个MinIO分叉,用来修复CVE和bug,几乎完全依赖Codex和Claude Code——它确实运行在生产环境里。
这就是一个维护者让511个扩展组成的矩阵持续演进的可行之路。
31. 三个问题:邀请社区共同建设
最后我想说,扩展是PostgreSQL生态的共同财富。我希望这项工作能帮助用户、作者、厂商以及PostgreSQL内核开发者,一起建设更好的PostgreSQL。
我想带着三个问题离开这个会场:
第一,哪些目录指标真正有用?页面访问量、下载量、包可用性、构建失败、最近发布日期、对象冲突——哪些应该被公开展示,哪些仅仅是噪音?
第二,扩展构建覆盖率能否辅助补丁评审?它是否可以充当API、ABI和行为变化的早期预警信号?
第三,其中一些元数据是否应该更贴近PostgreSQL社区基础设施?比如放在postgresql.org下,与PGDG整合,还是留在别处?
扩展是共同的基础设施,交付是可扩展性的一部分。如果我们改善交付,PostgreSQL的超能力就能惠及更多人。
32. 致谢与在线访问
感谢大家的聆听。
本次演讲没有使用传统PPT,而是用Codex直接生成了在线交互式幻灯片,您可以在 https://vonng.com/work/extensions-for-everyone/index.html 浏览完整的在线版本。