Qwen3.7Max性能称雄但成本惊人,与Gemini、Opus真实对比全解析
近期 Qwen3.7 系列热度持续走高,“国产最佳、世界第二”的评价屡见报端。原本对闭源模型已兴致缺缺,但大量读者反复催促,再次勾起实测的兴趣。

不得不说,Qwen 每次更新的封面图还是相当会玩且养眼,不过自家的 Image 系列似乎已经很久没有开源了。
一、价格一探究竟
准备开测时,才发现手边缺少趁手的接入渠道。原本可用的 CodingPlan 即将到期且无法续费,改用 TokensPlan 则最低月费 198 元起,稍高配置便跃至 698 元,对比 Opus4.8 仅需 140 元不到,实在不太划算。无奈之下,只能直奔官方 API。
查看官方价目表:
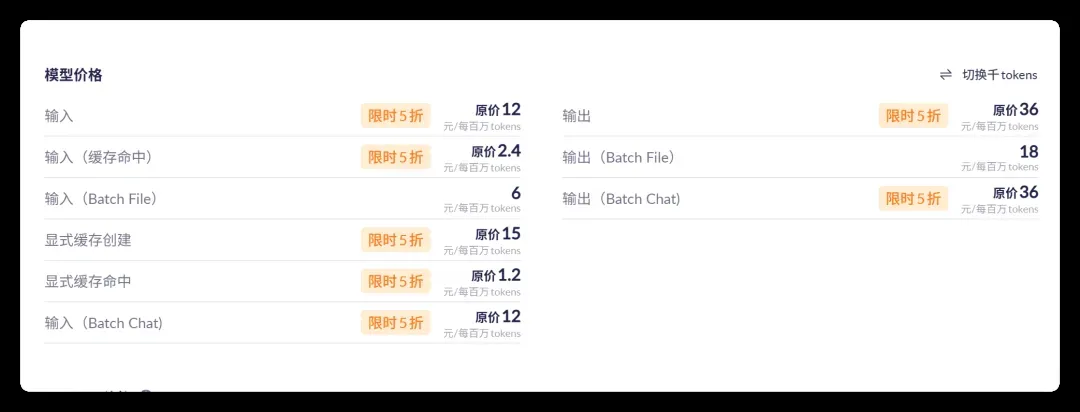
输入 12 元/百万 Token,输出 36 元/百万 Token,缓存 2.4 元/百万 Token。这个定价实在不能算便宜。好在目前有五折活动,并附赠 100 万 Token。不过 100 万 Token 大致相当于一个上下文的容量,在长程任务中可能转瞬即光。
二、官方基准表现速览
实测之前,先来看官方给出的基准成绩。
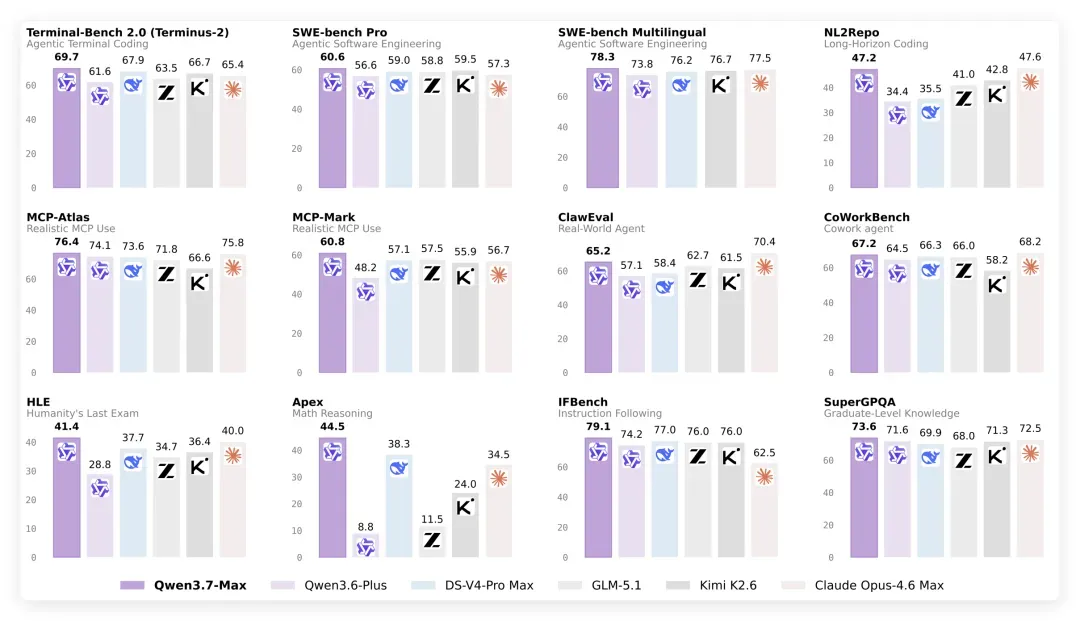
整体来看,确实颇具统治力。官方称其基本实现对 DeepSeek V4、GLM5.1、Kimi K2.6 以及 Opus4.6Max 的全方位超越。
官方博客的核心描述十分高调:
Qwen3.7-Max 致力于成为全能的智能体基座——无论是编写和调试代码、自动化办公流程,还是在跨越数百乃至数千步的长周期任务中持续自主执行,都能胜任。
Qwen3.7-Max 的核心优势在于智能体能力的广度与深度:
- 编程方面,从前端原型开发到复杂的多文件工程均能驾驭;
- 办公与生产力方面,通过 MCP 集成和多智能体协作实现工作流自动化;
- 长周期自主执行方面,在一项长达 35 小时、超过 1,000 次工具调用的全自主内核优化实验中保持了连贯推理,充分验证了其持久稳定的执行能力;
- 此外,无论部署在 Claude Code、OpenClaw、Qwen Code 还是其他框架下,都能稳定发挥出色的跨框架泛化能力。
关键词很明确——“全能的智能体基座”,优势落在智能体能力的广度与深度。
三、正式实测开始
尽管 Qwen 有自家原生工具,但为了统一对比,本次测试依然统一使用 Claude Code 环境。只需稍作配置即可开始。
在 JCode 中添加配置,填写 API Key、BaseURL,并指定 qwen3.7-max 模型:
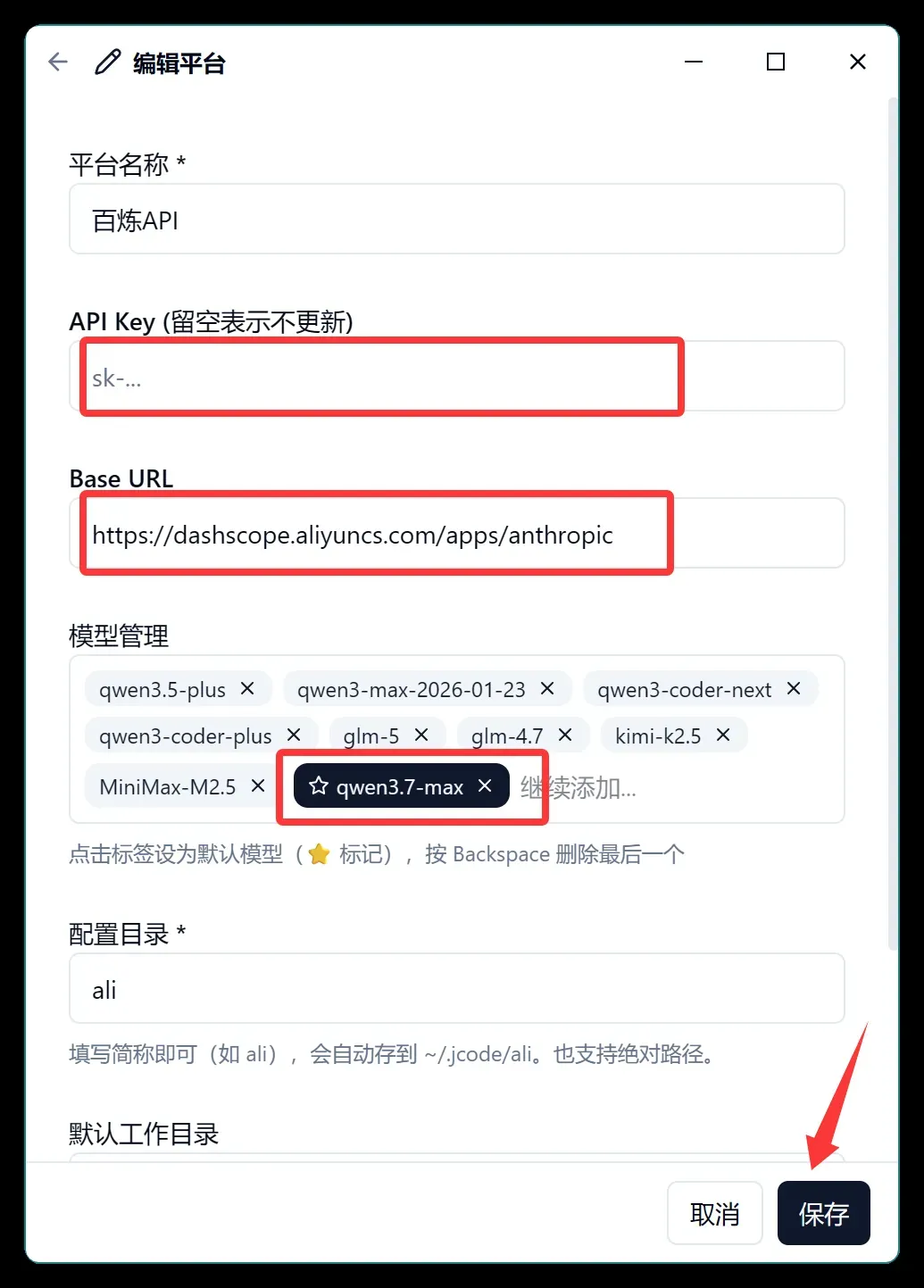
保存后一键启用 CC:

确认配置生效后,正式开测:
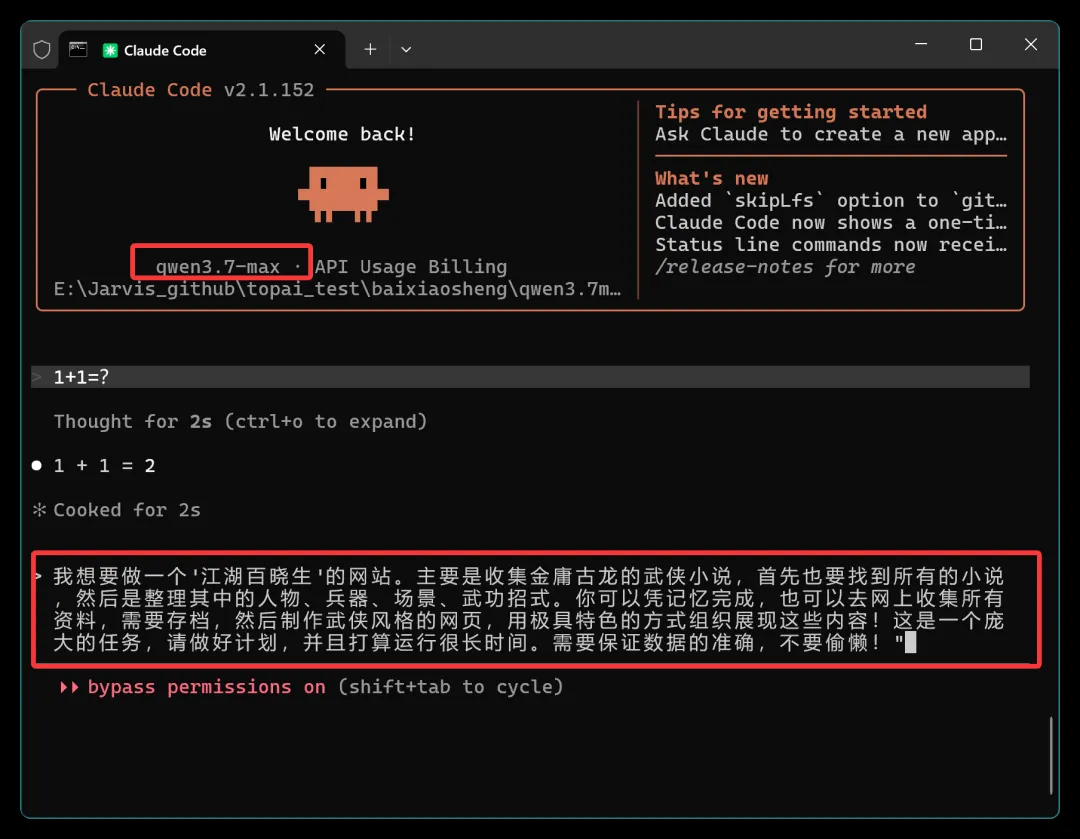
本次测试目标是创建一个名为《江湖百晓生》的网站。这个项目的背景在此前多篇文章中已有详述。由于 Qwen3.7Max 在前端开发方面宣称表现突出,并在竞技场中排名居前:
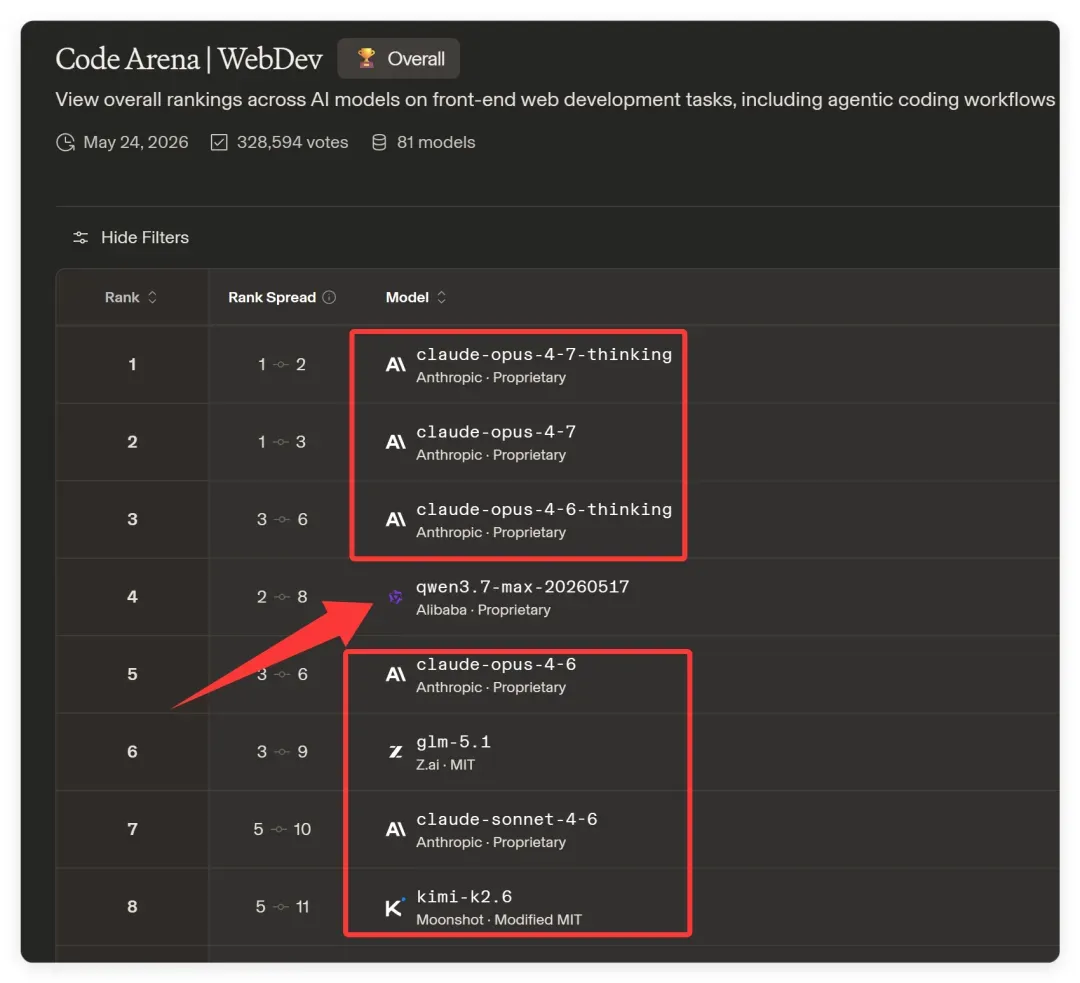
因此该项目十分契合——它极度考验数据处理、个性化设计以及主题匹配能力。同时,近期已用 Gemini3.5Flash、MiMo 和 Opus4.7 完成同样任务,正好可以横向对比。
四、多模型网页生成对比
为了让大家快速抓住要点,直接先看成品再看过程。
Qwen3.7Max 生成的网站首屏:
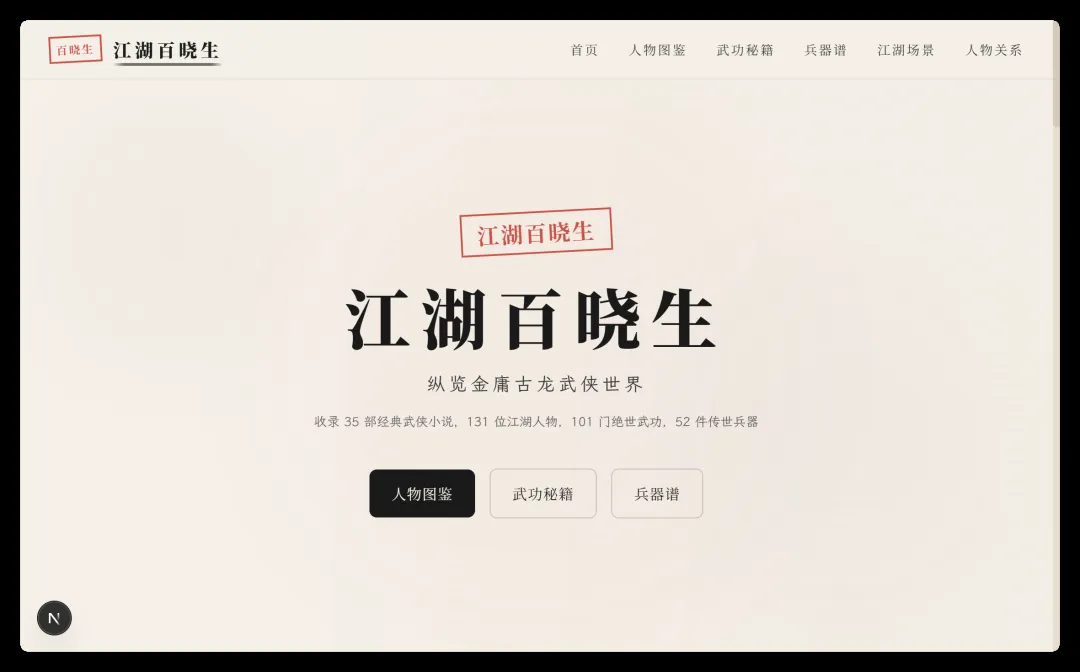
第一印象尚可,整体偏小清晰淡雅。布局规整,不存在错乱,字体、配色中规中矩,内容疏密适中。
但好坏往往是对比出来的。下面是其他选手的同题表现。
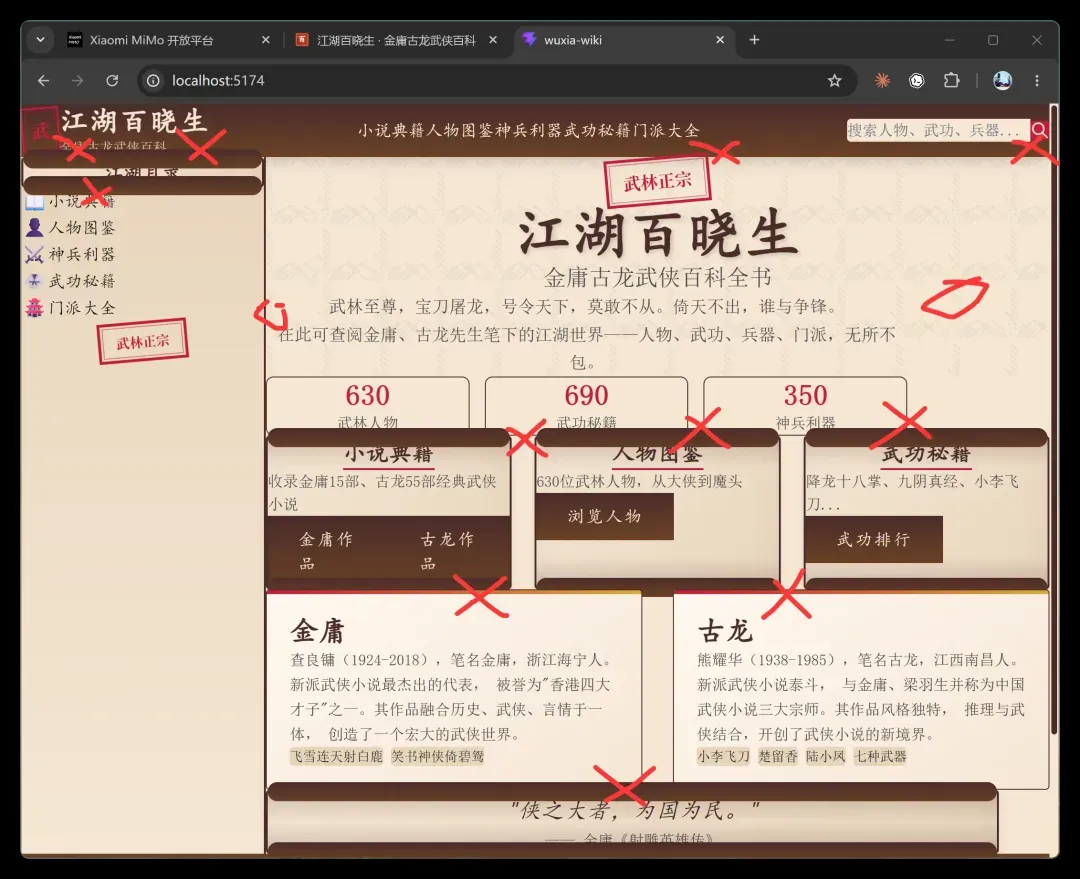
小米 MiMo2.5Pro 的首屏效果:
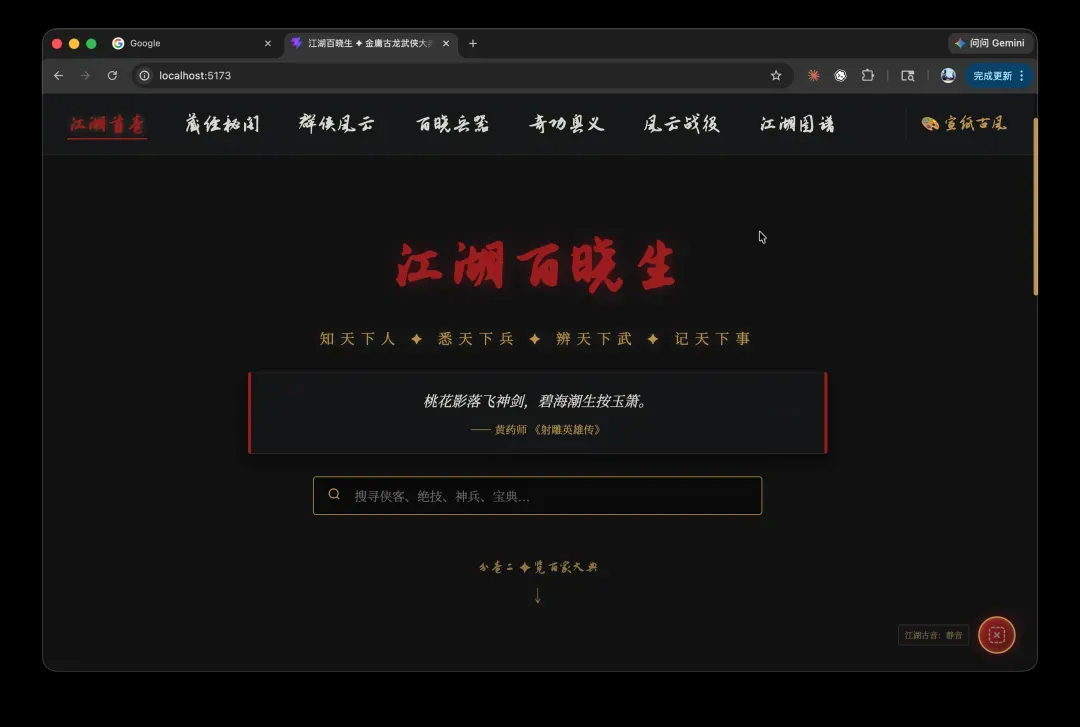
Gemini3.5 的效果:
Opus4.7 的效果:
对比之下感受如何?
MiMo 的表现令人皱眉,首轮结果无论是布局、审美还是数据质量都极不理想,基本没有继续评价的空间。Qwen3.7 整体稳定,找不到明显问题,但问题恰恰出在过于平淡——黑色按钮偏现代风,配色无张力,字体无风格,各页之间同质化严重,缺少武侠应有的豪迈和冲击力。首屏描述也显得机械:“纵览金庸古龙武侠世界,收录35部经典武侠小说,131位江湖人物,101门绝世武功,52件传世兵器”。
Gemini3.5 则完全不同,整体大胆奔放,充满情绪张力。金、红、黑的配色需要一定勇气,配文也十分精辟:
第一句点题:
“知天下人、悉天下兵、辨天下武、记天下事”第二句援引经典:
“桃花影落飞神剑,碧海潮生按玉箫。” - 黄药师《射雕英雄传》
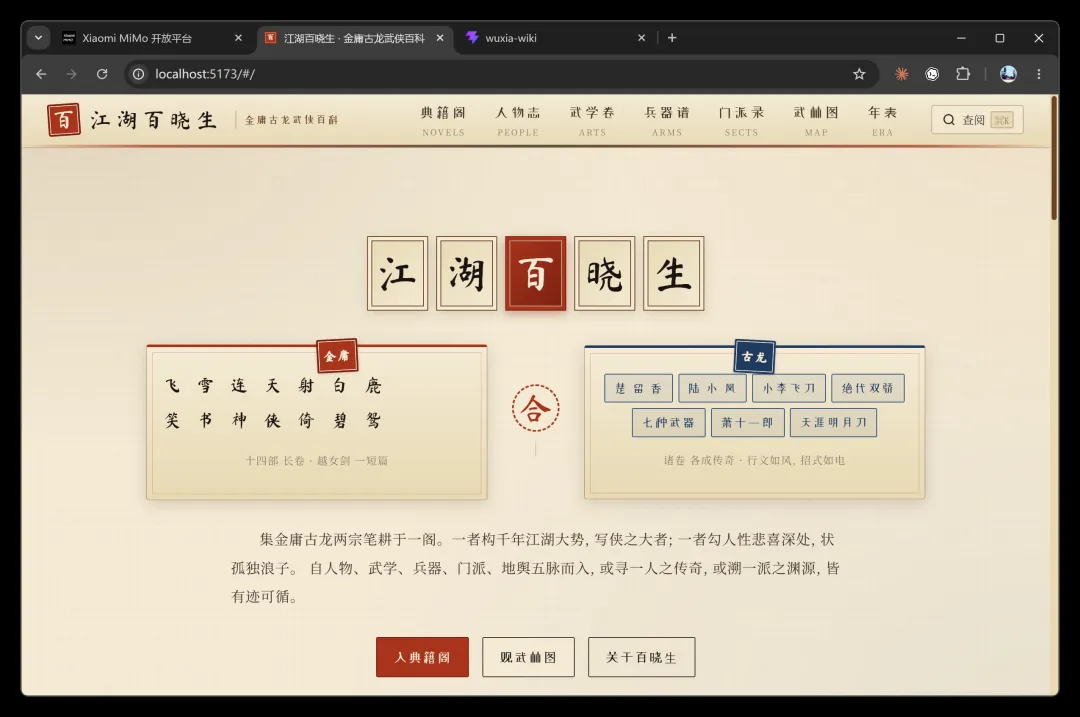
这种一句一重天的笔法,能瞬间唤起人物与场景记忆。其首页命名为“江湖首卷”,藏书阁设计更是寥寥数笔线条便勾出书籍轮廓,极富韵味:
单独的人物卡片也做得相当到位。
Opus 4.7 则走精致、全面且沉稳的路线。连标签栏的小图标都精心设计,头部字体颇具武侠之气,“金庸”“古龙”双峰并立,一目了然。首屏配以经典联句“飞雪连天射白鹿,笑书神侠倚碧鸳”,并附上一段序文:
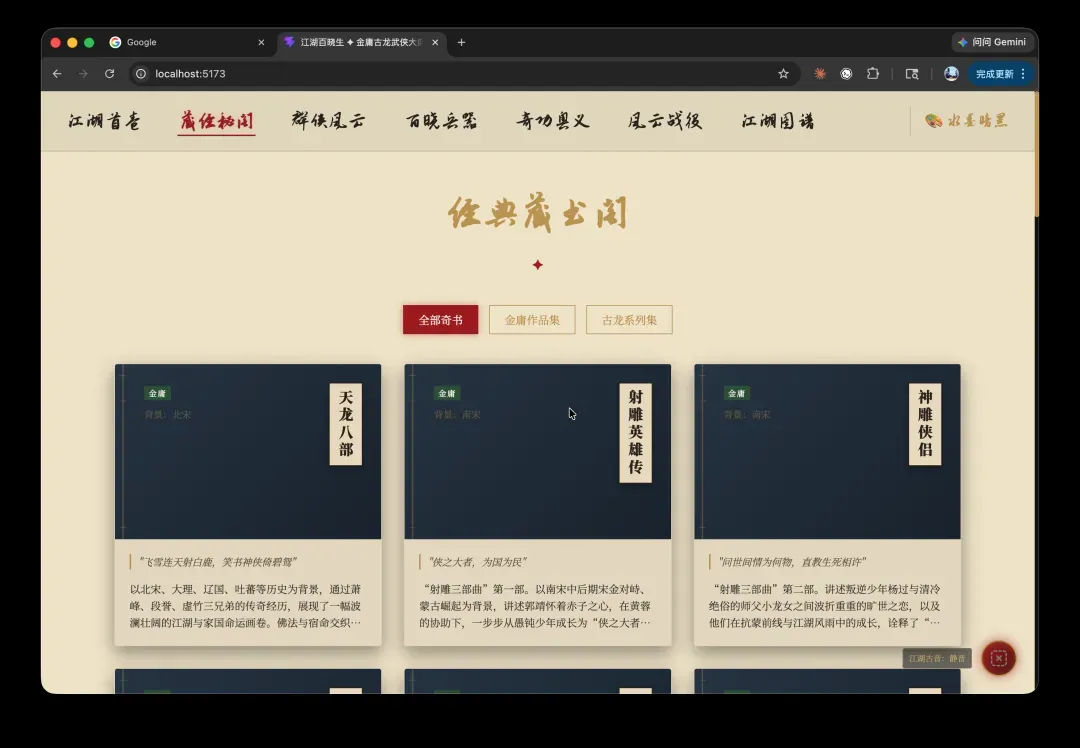
集金庸古龙两宗笔耕于一阁。一者构千年江湖大势,写侠之大者;一者勾人性悲喜深处,状孤独浪子。自人物、武学、兵器、门派、地舆五脉而入,或寻一人之传奇,或溯一派之渊源,皆有迹可循。
这段序文功底深厚,精致内敛。更令人叫绝的是,Opus 4.7 甚至生成了武林地图和年表:
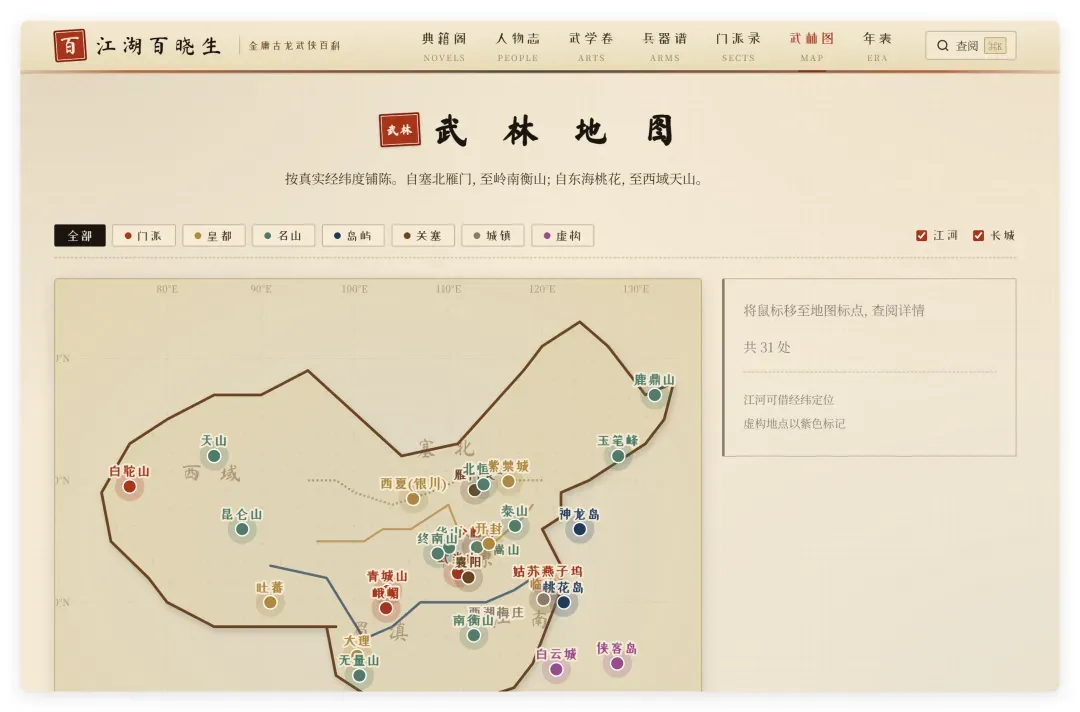
还能叠加长江黄河,并提供门派、皇帝、名山、岛屿等筛选,每个元素均可查看介绍。Opus 在做任何系统时,只要指令清晰,总能做到中上水准,前端设计、后端逻辑均无短腿。
强者做出来的网页基本可以直接上线,弱者则需反复返工,而且未必改得好。
五、开发全流程复盘
看完结果,再来回顾 Qwen3.7Max 的开发过程。整体上较为稳健。接到需求后,成功激活 Plan 模式,依次就技术栈、数据源、设计风格、数据格式等逐一问询:
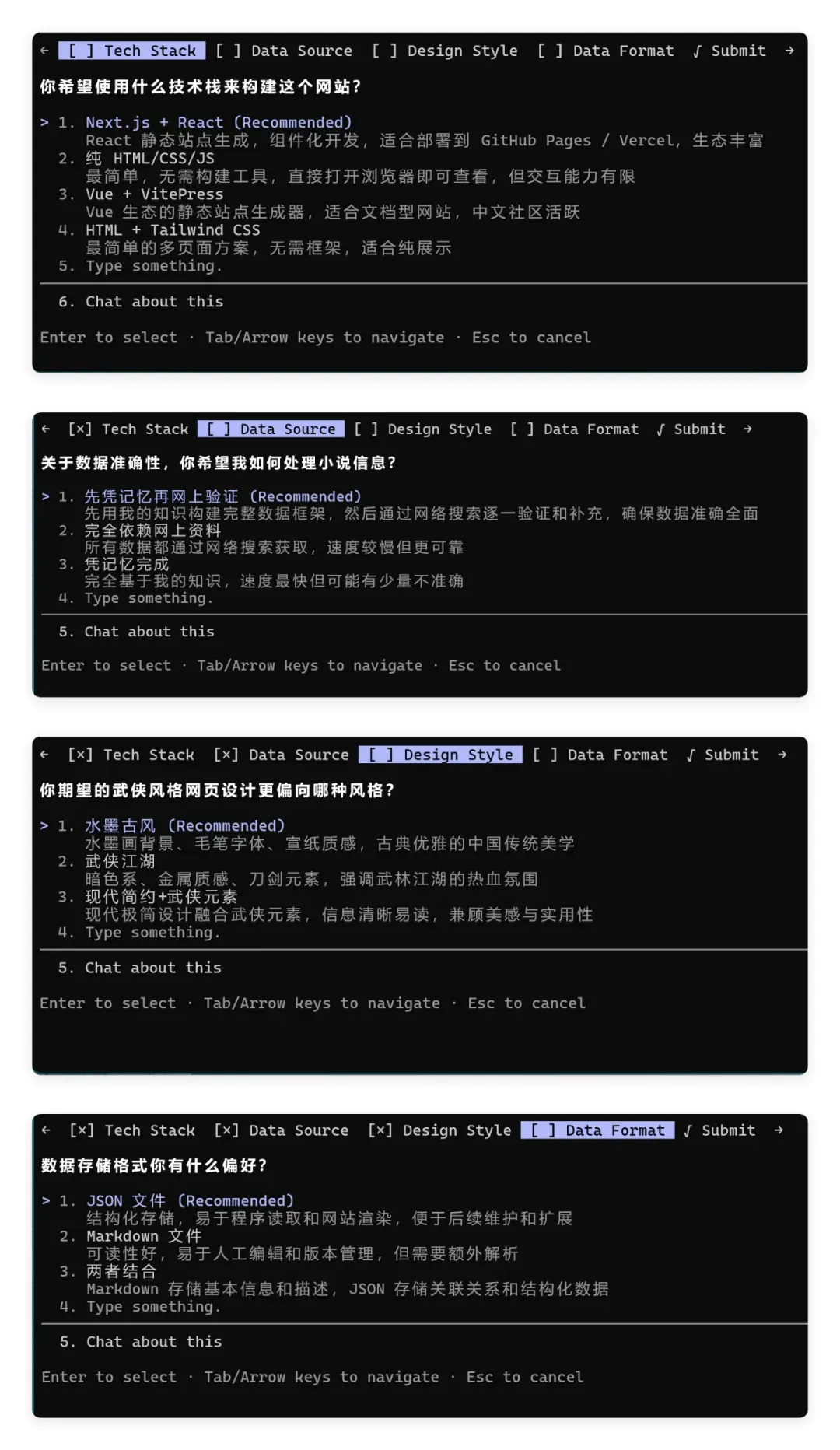
基本依其建议进行选择:
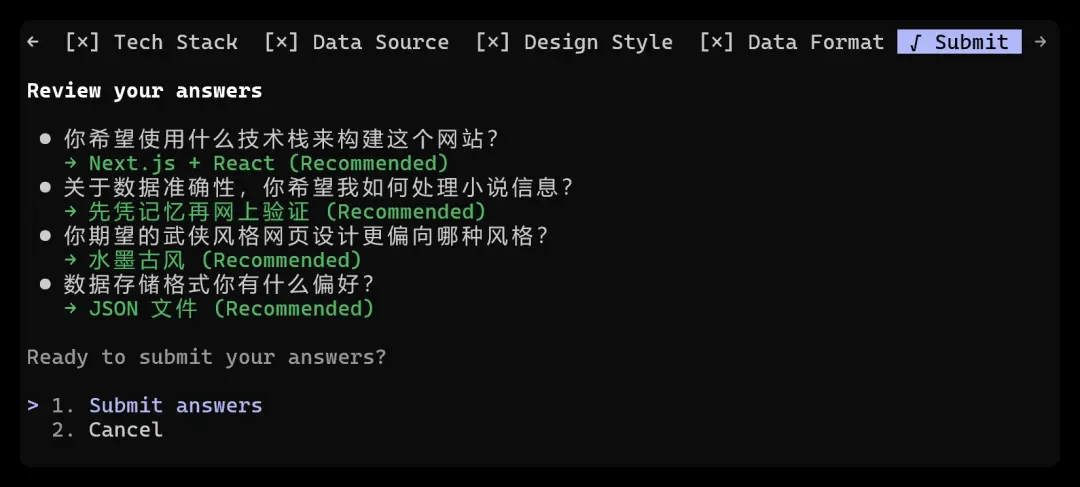
这应该算是当时情境下的最优方案了。现在模型在计划制定阶段普遍表现不错,MiMo 的规划同样可圈可点,问题往往出现在执行落地环节。
计划的核心内容概要:
- 🏗️ 技术栈:Next.js + React + TypeScript + Tailwind CSS
- 🎨 设计风格:水墨古风(宣纸底色、墨色朱砂配色、毛笔字体)
- 📊 数据规模:金庸 15 部 + 古龙 20 部经典,每部整理人物/武功/兵器/场景
- 📄 页面数量:约 10 种页面类型,含人物关系图谱等特色交互
- 💾 数据格式:结构化 JSON,约 80-100 个数据文件
下面是其执行流程和待办:
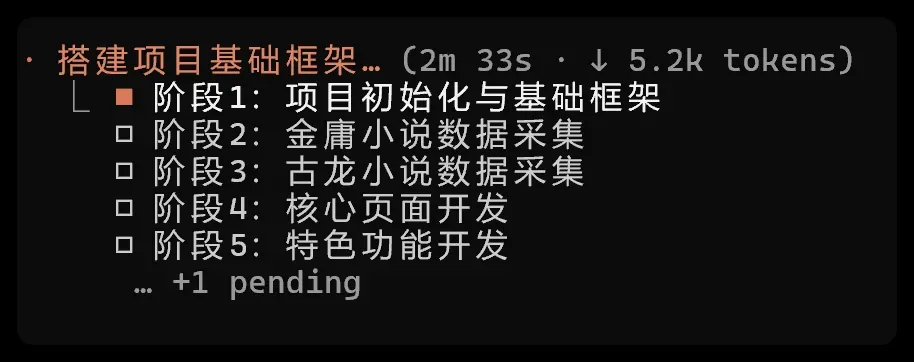
顺序安排合理:先搭建基础架构,再收集数据,随后进行核心页面与特殊功能开发,最后收尾验收。
最终汇报如下:
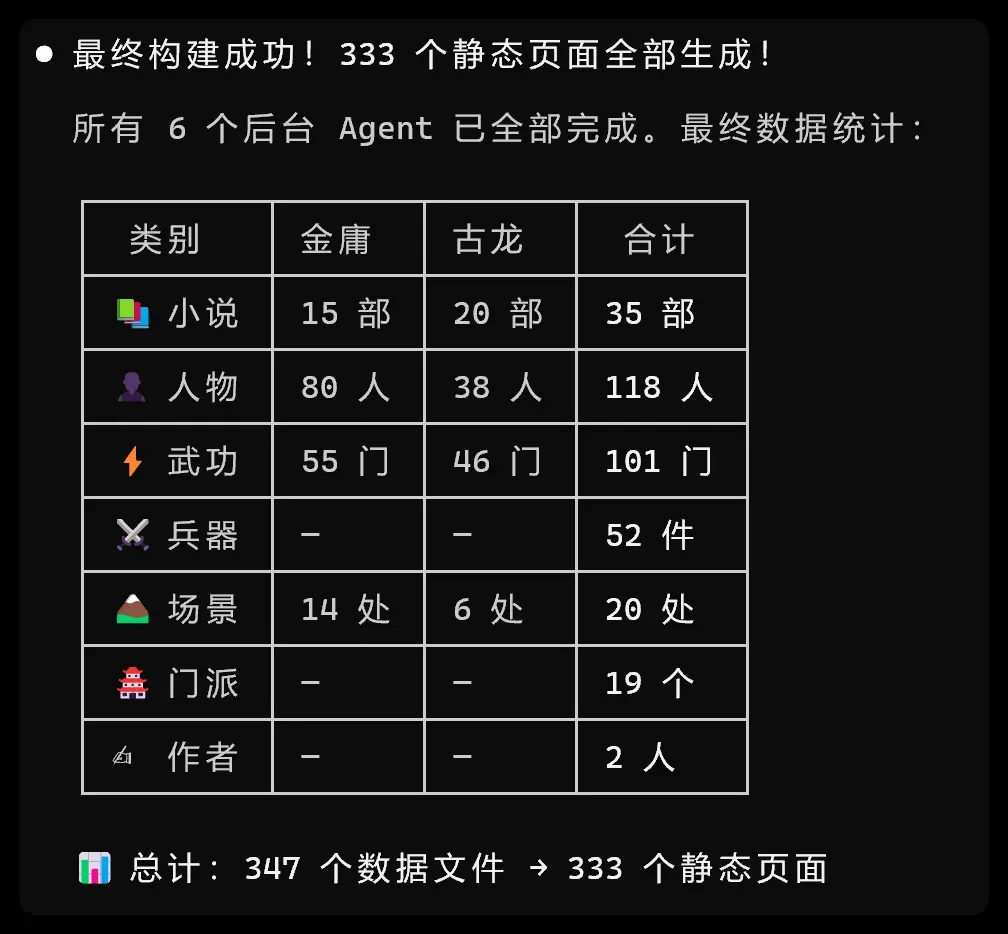
全程耗时 38 分钟,所得数据由模型根据训练记忆生成,作为首个开发测试版本勉强够用。
全程费用 37 元:
折算下来几乎一分钟一块钱。测试全程未让模型联网抓取数据,完全凭记忆输出,但 Token 消耗依然偏大。初始赠送的 1M 配额瞬间耗尽,随后金额快速攀升,原本预估 10 元封顶,实际接近预期的四倍。因此未再进行第二轮优化,若补充数据,Token 恐怕会进一步狂飙——颇有“用不起”的实感。
相比之下,DeepSeek 测试数十个实例仅消耗二十余元,价格差距悬殊,而能力差异却未拉开同等量级。
六、九大前端考题闯关
除主项目外,还用一套共九个各有侧重的有趣案例进行测试:
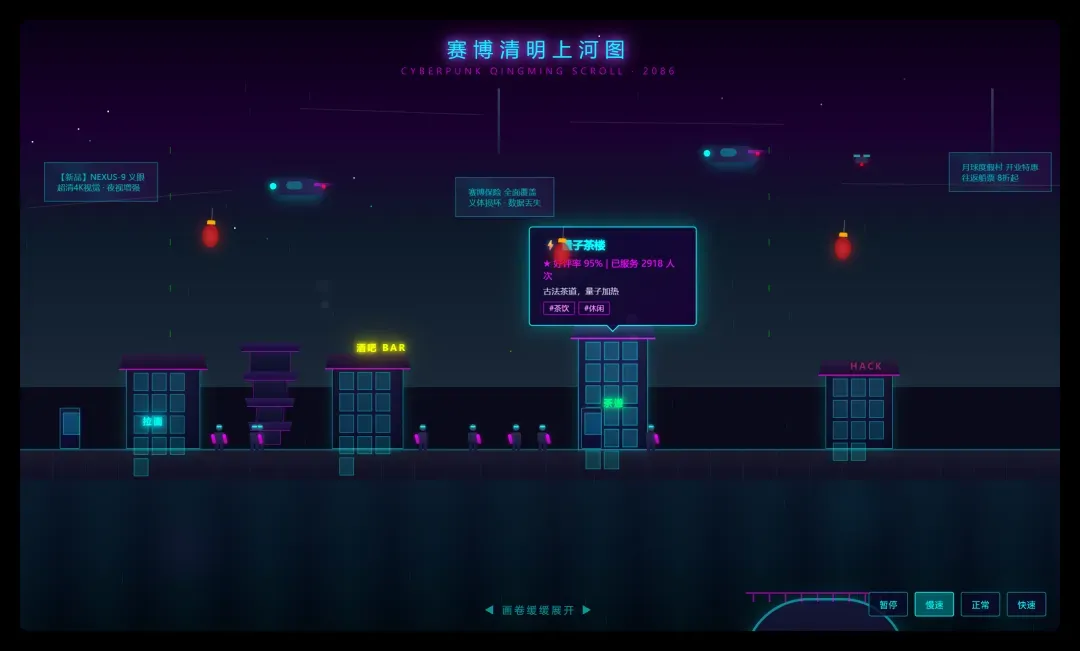
例如赛博朋克版清明上河图:
古诗版黑客帝国汉字雨:

华丽版人机对战五子棋:

最终结果:九个案例中出现一个翻车,因 JS 错误导致失效;还有一个“分形烟花秀”在开发过程中多次卡死。其余八个案例均正常产出,页面布局和设计感维持中上水平。该测试在 Qwen 官网的网页设计功能中完成,可能受内置系统提示优化加持。
七、独立项目《掌门日记》实战
另一项测试是《掌门日记》,颇费脑筋。
此前 MiMo 直接在此任务上翻车失败。Qwen3.7 则成功渲染了首页:

然而好景不长,随即出现 JS 错误——模板表达式括号未闭合,导致输入无效,无法进入主界面。代码稳定性仍有待提升,容易犯低级错误。修复后界面如下:
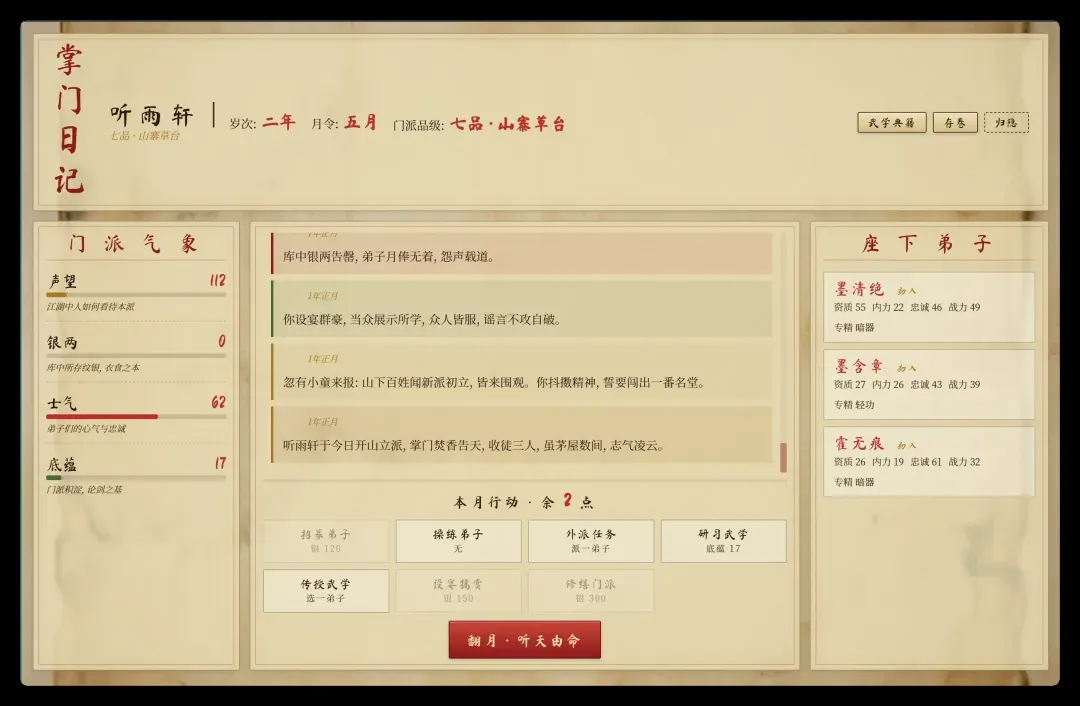
平心而论,布局和风格尚可。审美上有些 GPT5.5 的方正精致感,布局能力或许更胜一筹。更有趣的是,它在生成网页时还自动配上了背景图片,例如五子棋的棋盘、掌门日记的大背景和窗口背景。尽管不清楚其背后的生成逻辑,但图片风格与整体定位融合得相当不错,有背景图的界面质感能瞬间提升一个档次。
毕竟挂名 Max,能力在线,界面也不差。但代码稳定性还需打磨,几次低级错误足以让人心生顾虑。当前更先进的一些模型已能深度解析需求,并与主题高度融合,自动生成具有风格张力的话术和视觉细节。例如 Opus4.7 与 Gemini3.6 在设计武侠百科时,会自主输出武侠味浓郁的文字,选用特色字体,将风格渗透到细枝末节。相比之下,Qwen3.7 还略显粗糙,需要细细打磨。
综合看,Qwen3.7 的测试体验不算糟糕,但也没有太多令人拍案的亮点。再看价格——如果不打折,单次类似测试可能直奔 80 元以上,实在缺乏性价比。当手边已有 Opus4.8 Pro、GPT5.5 Plus、GLM5.1 专业版,加上价格亲民的 DeepSeek API 时,又有什么理由去选择一个贵得突兀的选项呢?难道只因为它更贵吗。