Qwen3-0.6b Docker浏览器部署全攻略:本地运行大语言模型完整指南
Qwen-Web 是一款设计用于在本地浏览器环境中直接运行 Qwen3-0.6b 大型语言模型的开源项目,其核心优势在于实现零安装流程、不进行任何日志记录,并且完全保障用户数据的本地私密性。
您可以通过在线演示地址提前体验该项目的基本功能与交互界面。
在线演示地址
部署与安装步骤
本项目推荐使用 Docker Compose 进行快速部署,以下为完整的服务配置代码块。
services:
qwen-web:
image: heizicao/qwen-web:latest
container_name: qwen-web
ports:
- 8443:443
restart: always
操作使用指南
完成容器部署后,在浏览器地址栏中输入 https://您的NAS_IP地址:8443 即可访问应用主界面,请务必注意该服务强制使用 HTTPS 安全协议进行连接。
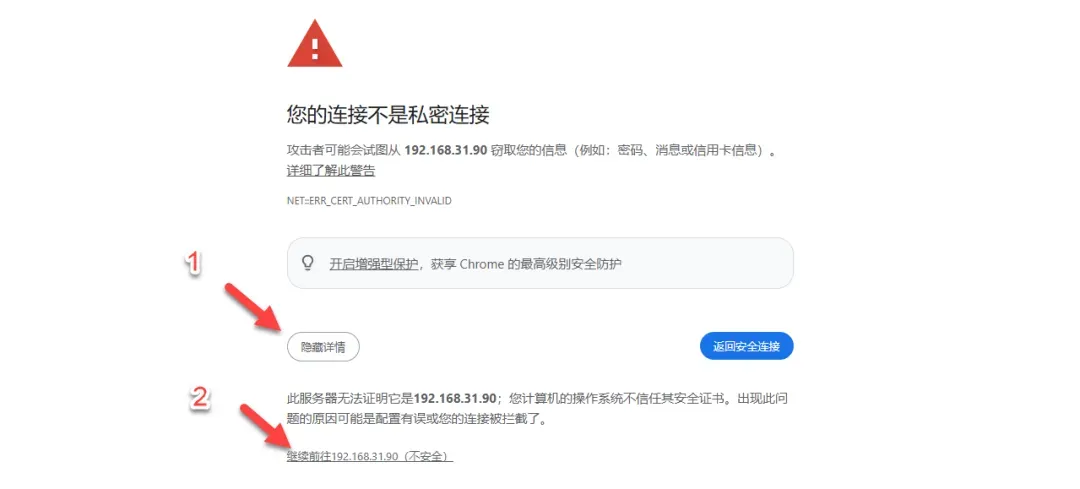
温馨提示:若浏览器提示“您的连接不是私密连接”,属于自签名证书的正常现象,请手动选择“继续前往”或类似选项即可正常访问。
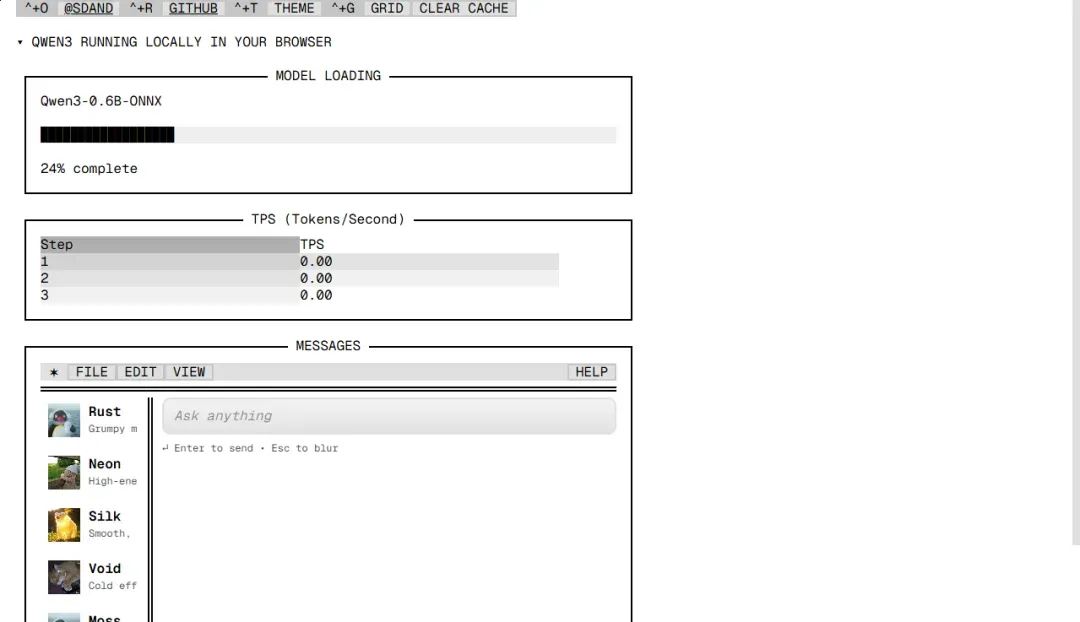
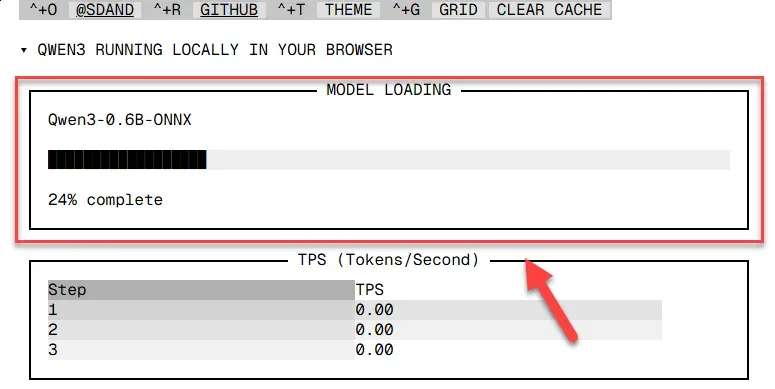
每次通过网页首次访问时,系统都需要从本地加载 Qwen3-0.6b 的模型文件到内存中,此过程可能需要短暂等待。
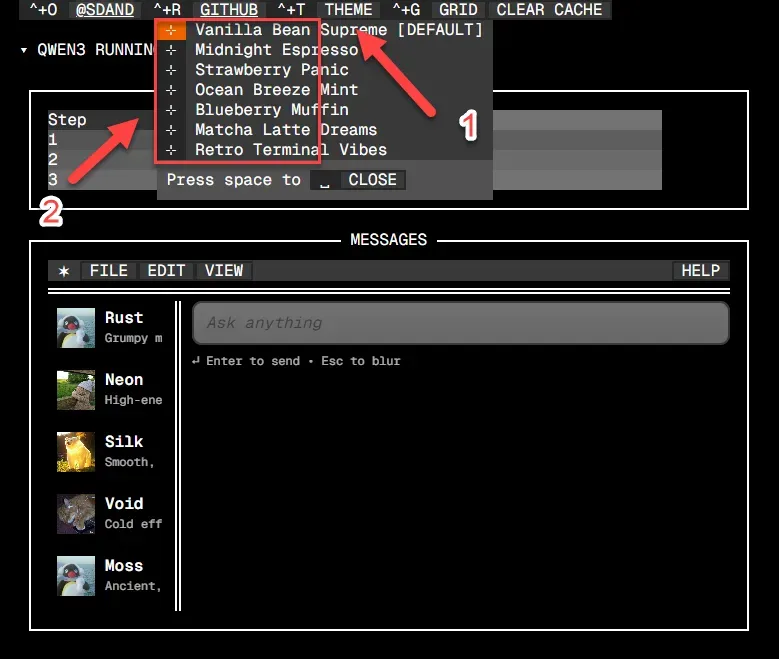
界面顶部的导航栏提供了颜色主题切换功能,用户可以根据个人偏好选择浅色或深色显示模式。
应用背景支持添加网格化视觉效果,这一设计元素能够增强界面的科技感与层次感。
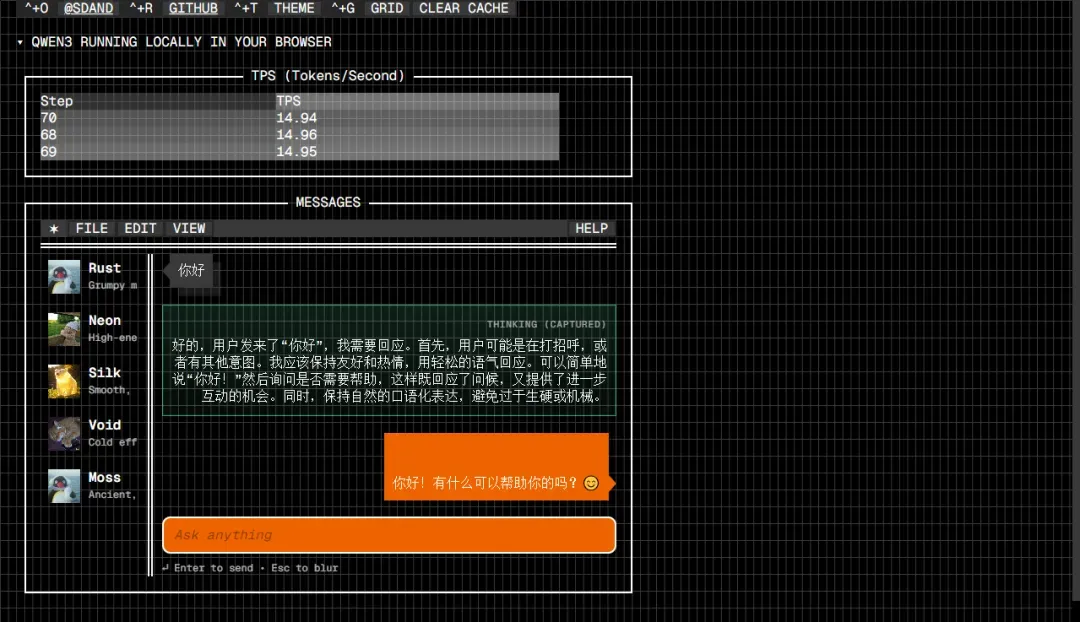
在输入框键入问题并按下回车键后,模型将开始生成思考过程并输出回答内容。
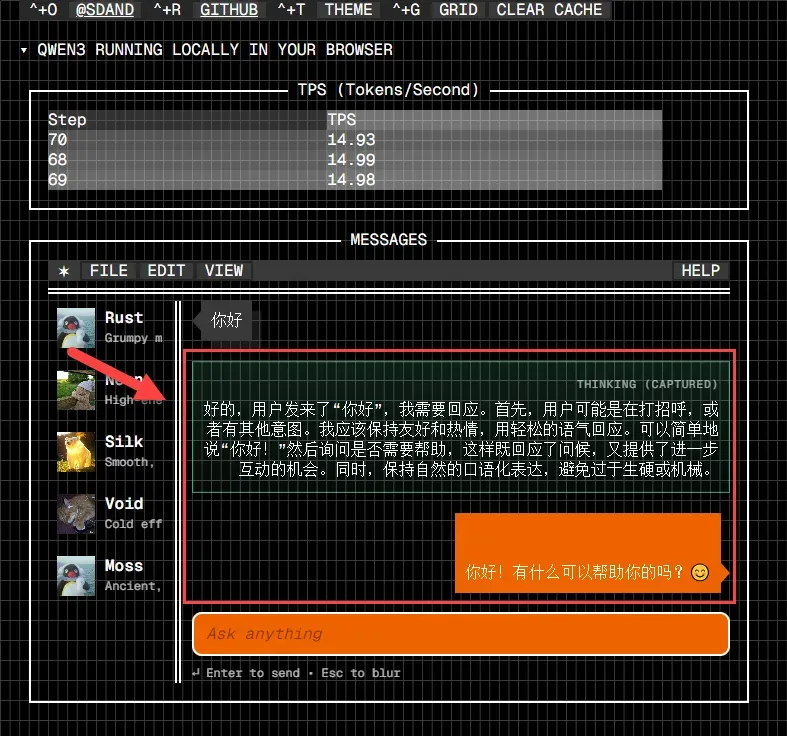
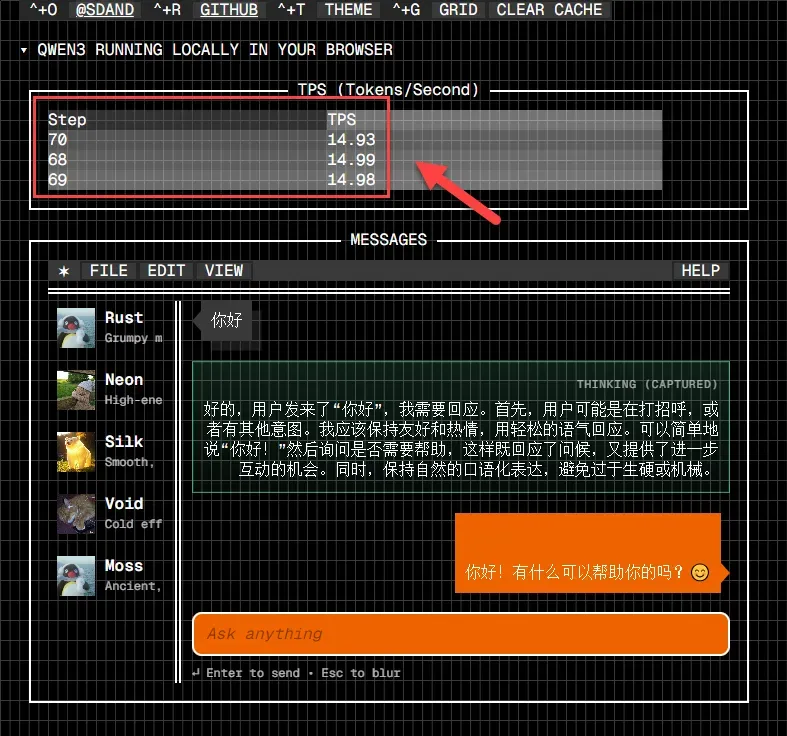
界面会实时显示模型的回复速度,例如示例中的 14.93 TPS(每秒生成标记数)。由于答案生成过程伴有完整的“思考链”展示,实际交互体验中的响应速度感知尚在可接受范围内。
左侧边栏预设了多个对话角色模板,用户可以直接选择特定角色以开启具有不同风格和背景的聊天会话。
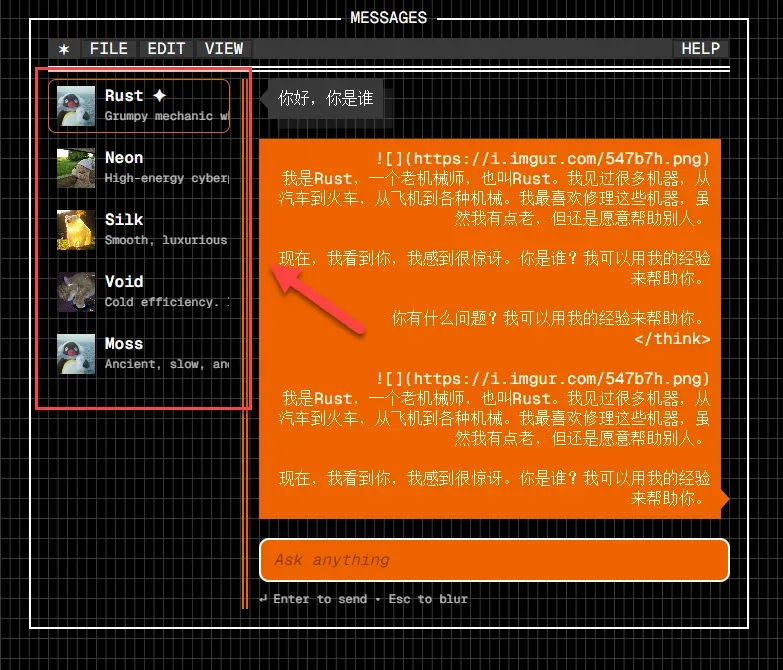
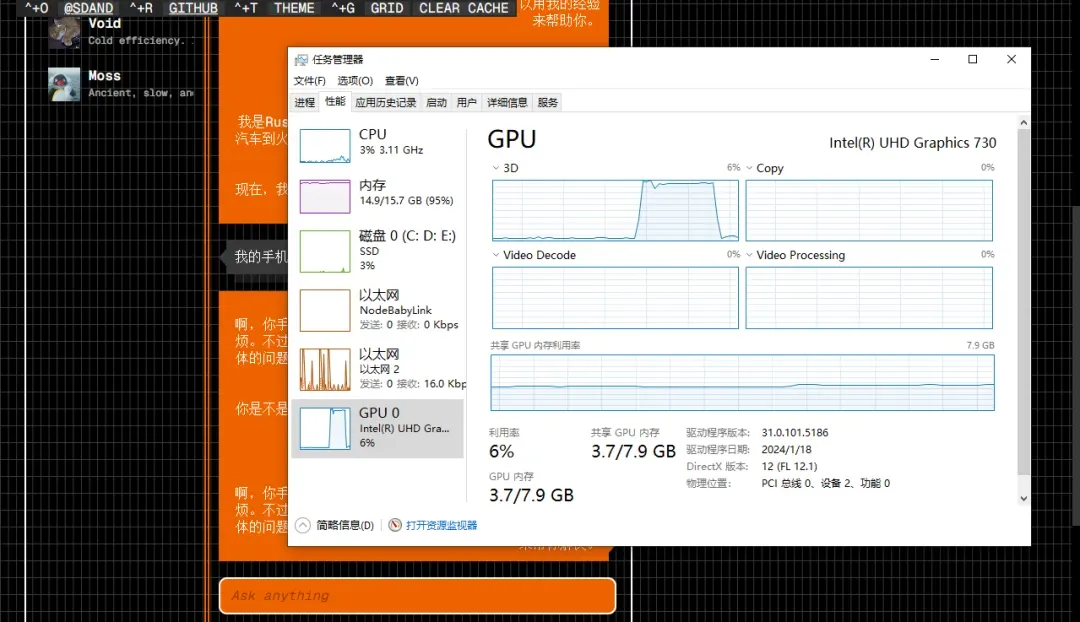
整个网页聊天过程中的模型推理计算,均通过 WebGPU 技术调用您设备本地的 GPU 硬件资源来完成,无需依赖远程服务器。
项目总结与综合评估
该项目在概念和实践层面都颇具新意,成功实现了在标准浏览器环境中本地化运行 Qwen3 系列大型语言模型。其技术核心在于利用现代 WebGPU 接口,使得网页应用能够直接调度终端设备的 GPU 进行高性能计算与图形渲染。不过,当前版本仍存在一些可优化的空间,例如对个人电脑界面的适配尚不完善,且模型在运行过程中偶现响应停滞或意外输出英文回复的缺陷。尽管如此,从技术探索和娱乐体验的角度出发,它依然是一个富有乐趣的工具,既能满足运行前沿语言模型的好奇心,也可作为测试本地 GPU 计算性能的一个轻量级基准场景。
综合推荐指数:⭐⭐⭐(创意新颖,值得尝试)
实际使用体验:⭐⭐(界面相对简单,偶发性问题影响流畅度)
部署流程难度:⭐(配置极其简单,近乎一键完成)