Qwen-AgentWorld:单一模型原生模拟7大代理环境,35B版本即超GPT-5.4
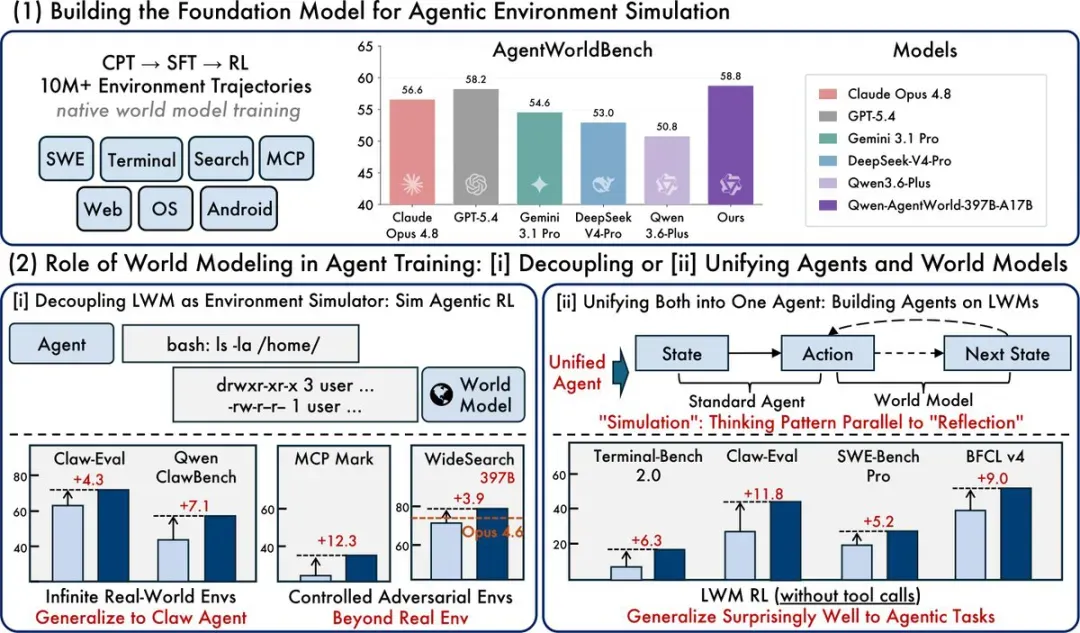
Qwen 团队开源了语言世界模型 Qwen-AgentWorld,它在一个模型内部直接模拟七类代理环境,不再仅仅把环境当成工具调用,而是将环境建模本身变成了训练目标。总参数量 35B、激活参数 3B 的版本性能就超越了 GPT-5.4,397B 版本更登顶 AgentWorldBench 榜首;模型可以零样本迁移到未曾见过的环境,而且用虚拟环境做强化学习,效果甚至优于真实环境训练。
| 指标 | 数值 |
|---|---|
| 统一模拟域 | 7 |
| MoE 总参/激活 | 397B / 17B |
| AgentWorldBench Overall | 58.71 |
大型语言模型正在被不断推入“更会行动”的训练赛道,但一个基础问题被长期忽视:模型自己在环境中行动时,环境自身长什么样?谁帮它提前知道执行终端命令后 shell 会返回什么、点击 Android 按钮后界面会发生什么变化、在搜索框输入关键词后页面会怎样跳转?Qwen-AgentWorld 把“环境建模”从事后拼凑的补充方案,拉回到训练目标的第一天。
语言世界模型究竟是什么
机器人领域早就有了“世界模型”的概念:给定当前画面和一个动作,预测下一帧画面。语言世界模型做的是同一件事,只不过将输入输出全部变成了文本——Agent 的工具调用、终端输出、搜索片段、网页跳转、Android 屏幕状态,统一用自然语言序列来表达。模型的任务是:看到上一步的动作,准确说出下一步的环境观察会是什么。
这听上去像是一种简单的“补全”,但作者把它定义为环境模拟器。如果模型能够稳定预测后续状态,甚至可以施加可控扰动,或者虚构出内在一致的新世界,它本质上就是一个可编程的环境生成器,不再只依赖真实系统的回放。
七个环境域,一套模型管线
在此之前,任何语言世界模型都只覆盖一到两个领域。Qwen-AgentWorld 把 MCP、Search、Terminal、SWE、Android、Web、OS 这七种环境的交互数据统一纳入一条训练管线。
训练过程分为三个阶段:
- CPT(持续预训练):向模型注入真实环境的状态转换轨迹和专业语料,让它先学会“下一步通常是什么样的”这类常识。
- SFT(监督微调):激活“下一个状态预测”的推理格式,让模型将“动作→状态”写成可读的思维链。
- RL(强化学习):利用混合 rubric 规则和模型评分的奖励,进一步推高模拟保真度。
这三种训练方式不是可选项,而是一条完整的流水线。作者特别强调:并不是先训练一个通用语言模型,再在上面“加一点世界建模”;世界建模目标从 CPT 阶段起就是原生目标,这就是所谓“原生世界模型”。
为什么比 GPT-5.4 更值得关注
AgentWorldBench 从五个维度给每一个预测的环境观察打分:格式正确性、事实正确性、一致性、逼真度、质量。Qwen-AgentWorld-397B-A17B 以 58.71 分位居第一,超过 GPT-5.4 的 58.25 和 Claude Opus 4.8 的 56.59。
AgentWorldBench 前五(综合)
- Qwen-AgentWorld-397B-A17B:58.71
- GPT-5.4:58.25
- Claude Opus 4.6:57.80
- Qwen3.5-397B-A17B(未做 LWM 训练):54.74
这些数字背后的差距在于:Qwen-AgentWorld 在终端和 SWE 等系统交互型环境上明显占优,而这正是多数命令行 Agent 真正工作的场景。35B 版本相比同样规模、但未经过世界建模训练的 Qwen3.5-35B-A3B 提升了 8.66 分,说明这一训练范式独立有效。
更重要的是泛化能力:模型在真实环境上训练之后,能够零样本外推到全新的真实环境(论文中给出了 Claw Agent 示例),还能通过注入控制指令制造可控扰动,甚至构造出完全虚构但内部一致的世界,让 Agent 在虚拟世界中训练之后,在真实任务上反而表现更强。
“不是让模型更懂文字,而是让模型先懂环境。”
关键判断:世界建模不是 Agent 的“选修课”。当 Agent 进入更长的行动链路、使用更多工具、面对更复杂的系统环境时,对状态的误判会层层累积,最终导致失败。先把“环境理解”单独训练好,再让 Agent 去调用,是一条更稳妥的工程路径。
对个人开发者和创业者的实用价值
并不是只有大厂才需要世界模型。即便你只是个人开发者或 AI 应用创业者,下面三件事也可以直接落地:
- 低成本做 Agent 评测:AgentWorldBench 是公开的基准测试,可以直接评测你自己微调的 CLI Agent 在终端、SWE、OS 等场景中的真实能力。
- 用虚拟环境做 RL 微调:不用触碰生产环境就能生成可控、可污染、可虚构的训练轨迹,显著降低数据采集的风险和成本。
- LWM 预热作为通用能力:Qwen-AgentWorld 论文发现,即使不针对任何下游任务做额外的 Agent 训练,仅凭世界模型预热,就能让七个 Benchmark 同时提升,最高提升 +12.79。
直接把模型当成工具使用
给定一段工具调用历史,让模型预测下一个环境状态,可用于轨迹验证、异常检测或交互式 mock 服务。
通过 SGLang 或 vLLM 部署为 OpenAI 兼容 API,模型 ID 使用 Qwen/Qwen-AgentWorld-35B-A3B。
适用范围与限制
35B 版本吞吐友好,在 4 张 A100/H100 或同等算力上即可使用 SGLang/vLLM 部署;397B 版本则需要更高的硬件配置。目前开源权重和 benchmark 采用 Apache 2.0 协议,可用于商业评测和二次训练。论文已将 MCP、Search、Terminal、SWE、Android、Web、OS 七种环境的评测 prompt 全部公开,实验可以直接复现。
适合:正在从事 Agent RL、Agent 评测、工具调用训练的个人开发者和小团队。
不适合:只做普通对话、不需要与环境交互的应用,这个模型并不会比通用聊天模型更有优势。