构建智能进化引擎:数据飞轮在RAG客服系统中的实践与应用
在之前的探讨中,我们曾指出,决定RAG(检索增强生成)系统效果上限的关键因素,往往不是模型本身,而是数据工程的质量。
具体到AI客服应用场景,相较于法律、医疗等高严肃性领域,其业务属性决定了以下特点:
- 数据允许存在一定程度的缺失或不完整性。
- 用户提问通常带有口语化、情绪化色彩,甚至可能存在表达模糊的情况。
- 知识库很难在初始阶段就覆盖所有潜在的客户问题。
因此,当知识库出现信息缺口、导致AI无法有效回答时,这些问题本身不应被视为失败案例,而应被视作后续系统优化的重要输入来源。这正是引入 “数据飞轮”策略 的核心逻辑。
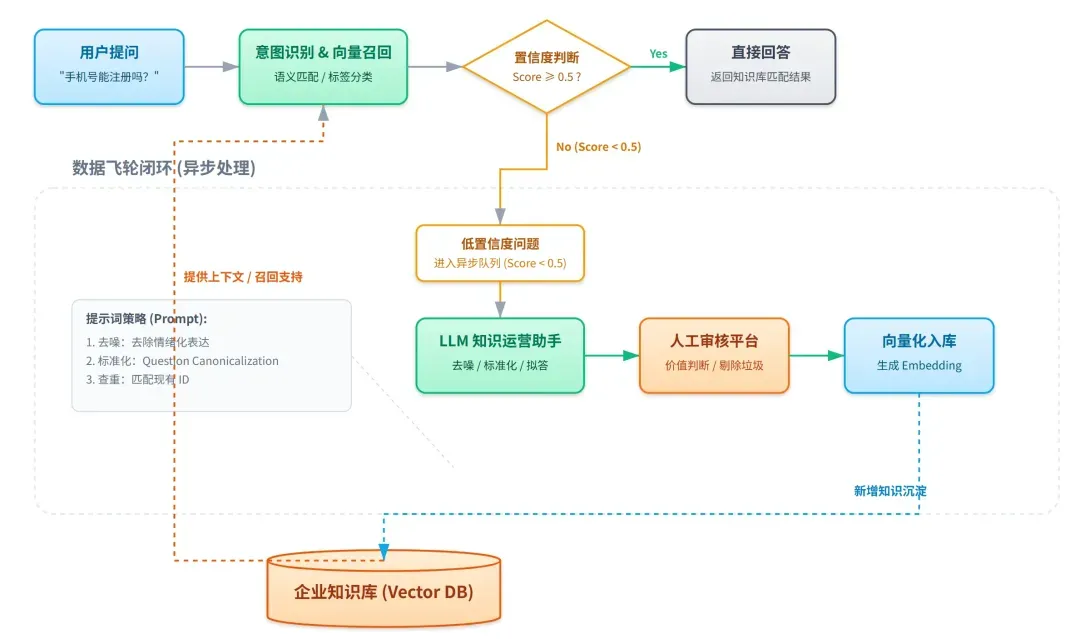
本文将简要解析数据飞轮系统的概念及其在AI客服中的实践路径。
数据飞轮:一个持续优化的闭环
数据飞轮本质上是一种持续反馈的闭环优化机制。
其核心流程是:从真实的用户交互中持续收集数据 → 进行处理与提炼 → 用于优化系统 → 再将优化成果反馈至系统本身,从而使得AI在真实的业务流中越用越精准。
在AI客服场景下,数据飞轮的首要目标并非“将所有遇到过的用户问题都收入知识库”,而是实现:
- 精准识别哪些用户问题真正值得沉淀为知识。
- 最大限度地降低人工处理和干预的成本。
- 持续地填补那些具有真实业务价值的知识缺口。
下文将结合具体的系统设计思路,阐述在AI客服中如何有效地收集低置信度问题,并利用这些反馈持续优化知识库。
置信度:衡量匹配质量的关键指标
正如前文所述,AI客服处理流程的第一步是意图识别。当用户发起提问后,系统会执行以下操作:
- 首先为问题打上相应的分类标签(例如:“产品咨询”、“售后投诉”)。
- 在对应的标签类别下,进行向量检索以召回相关知识片段。
- 每一条被召回的知识条目,都会附带一个“置信度”分数。
这个置信度分数代表了两层含义:
- 用户问题与知识库内容在语义上的匹配程度。
- 分数越高,通常意味着命中的知识越精准;分数越低,则往往暗示着知识库在该领域存在缺失或覆盖不足。
设定阈值:触发数据飞轮的信号
在实际系统中,我们设定了一个关键阈值来启动优化流程。例如,将 置信度阈值 设定为0.5:
- 当召回的置信度分数大于或等于0.5时,系统会直接进入正常的回答生成流程。
- 当置信度分数低于0.5时,则判定当前知识库的匹配度不足。
此时,这条低置信度的问题数据不会直接丢弃,而是会进入异步处理队列,成为数据飞轮流程的起点。
提示词工程:结构化处理原始问题
为了将用户原始、非结构化的提问转化为可入库的标准知识,我们设计了专门的提示词,用于引导模型进行数据整理:
你是智能客服的知识运营助手。你要把“用户原话”整理成可入库的标准问题,并尝试与候选问题合并。
目标:
1) 去噪:去掉情绪、口语、无关碎片,只保留核心诉求
2) 标准化:输出“真实意图”的标准问题,用中文,尽量像FAQ标题
3) 合并:判断是否与候选问题同一意图;如果是,返回 matched_question_id;否则返回 null
4) 初步解答:基于标准问题给出一段中文初步解答;如果信息不足,说明需要用户补充哪些信息
约束:
- normalized_question 必须是单行文本,长度不超过 120 字
- 如果候选列表里没有同一意图的问题,matched_question_id 必须为 null
- 只返回严格 JSON,不要输出多余内容
候选问题(JSON数组):
%s1
用户原话:
%s2
输出JSON:
{
"normalized_question": "string",
"matched_question_id": 123,
"ai_suggested_answer": "string"
}
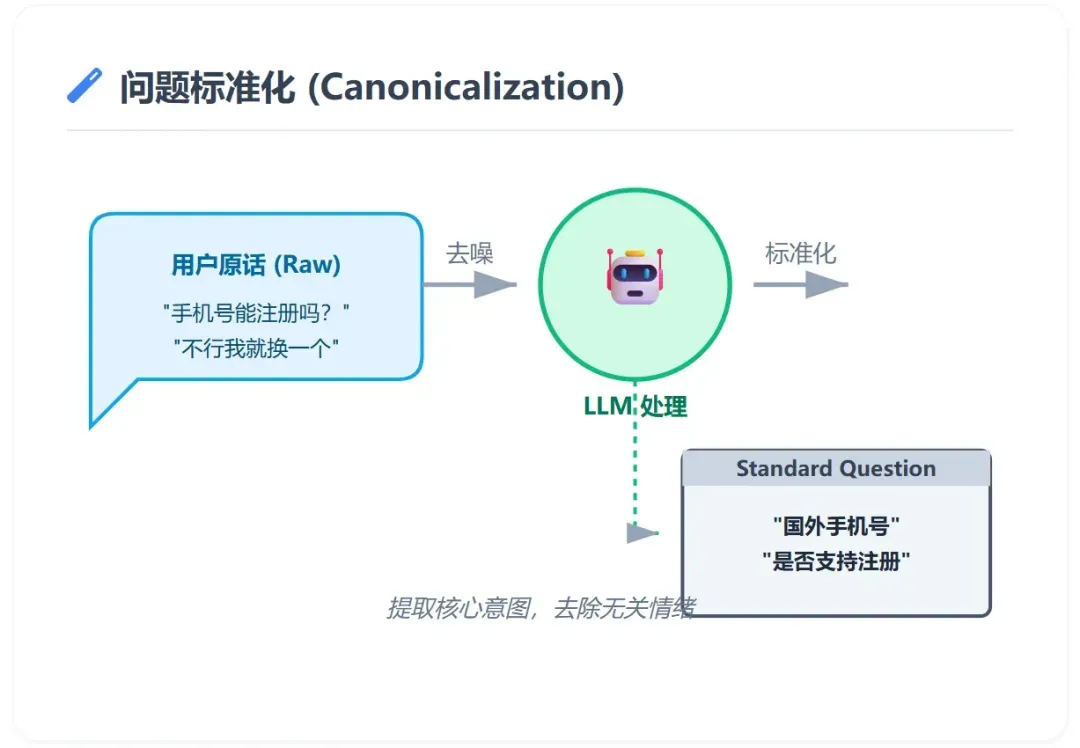
问题规范化:从口语到标准问法
基于上述提示词,模型将完成两个关键任务:
- 生成一个示例性的参考答案。
- 将用户原话转化为标准、清晰的问题表述。
例如,用户提问:“我在日本,用 +81 的手机号能不能注册啊?不行我就换国内的”,经过模型处理后,可能被规范化为:“国外手机号(非中国大陆)是否支持平台注册?”
这一步在信息检索领域,通常被称为“问题规范化”(Question Canonicalization),是提升知识库检索效率的基础。
流程分工:前后台协同作业
经过模型初步处理后的标准化数据,会进入入库评审流程。在此流程中,前后台各有分工:
- 用户端(前台):主要负责数据的自动化采集与初步筛选,将低置信度问题自动归入待处理队列。
- 运营端(后台):由人工进行最终审核,并决定是否将问题-答案对正式写入知识库。
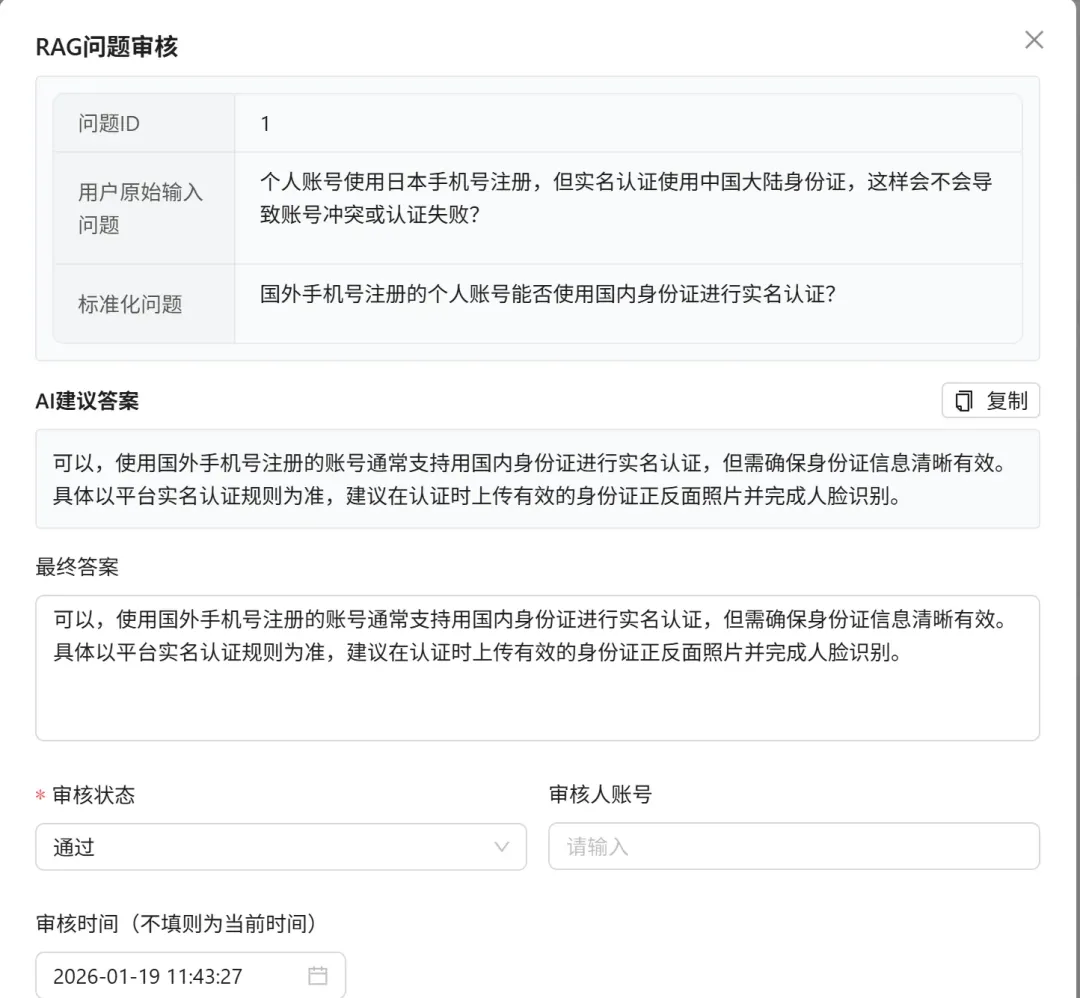
人工审核:把好知识入库的质量关
并非所有被识别出的低置信度问题都值得沉淀为知识。在后台管理界面,人工审核员需要依据一定标准进行判断:
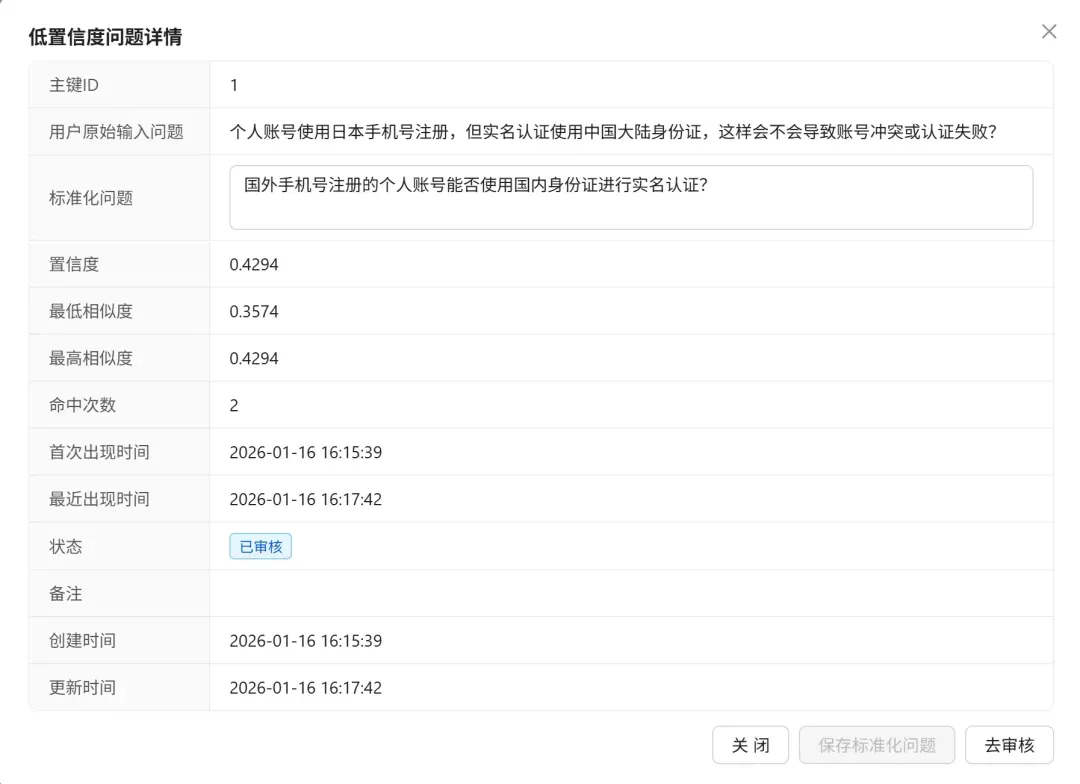
当面对一条低置信度问题时,审核员需要判断:
- 这是否是一个真实、合理的业务问题?
- 问题中是否包含垃圾信息、无意义内容或不当言论?
- ……
同时,也需要认识到,有些问题并不适合入库:
- 出现频率极低的“边缘”问题,维护成本高于收益。
- 具有强时效性的问题,其答案会很快过期。
- 系统可能存在误判,有些“低置信度”问题实则知识库中已有覆盖。
只有通过审核的问题,才会进入后续的向量化处理流程。系统通常还会记录相似问题的出现频次,作为判断该问题重要性的辅助指标。
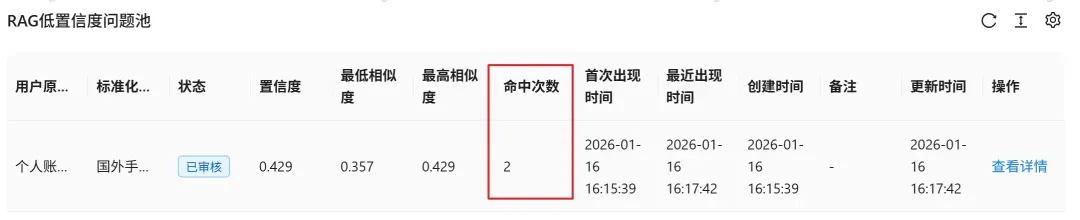
效果验证:量化飞轮的优化成果
当一个问题-答案对被审核通过并完成向量化后,知识库中便新增了一条元数据。

此后,当用户再次提出语义相近的问题时:
- 向量检索能够准确命中这条新增的知识。
- AI客服据此能给出更准确、贴合的回答。
通过系统的召回日志,可以直观地看到这种优化效果:
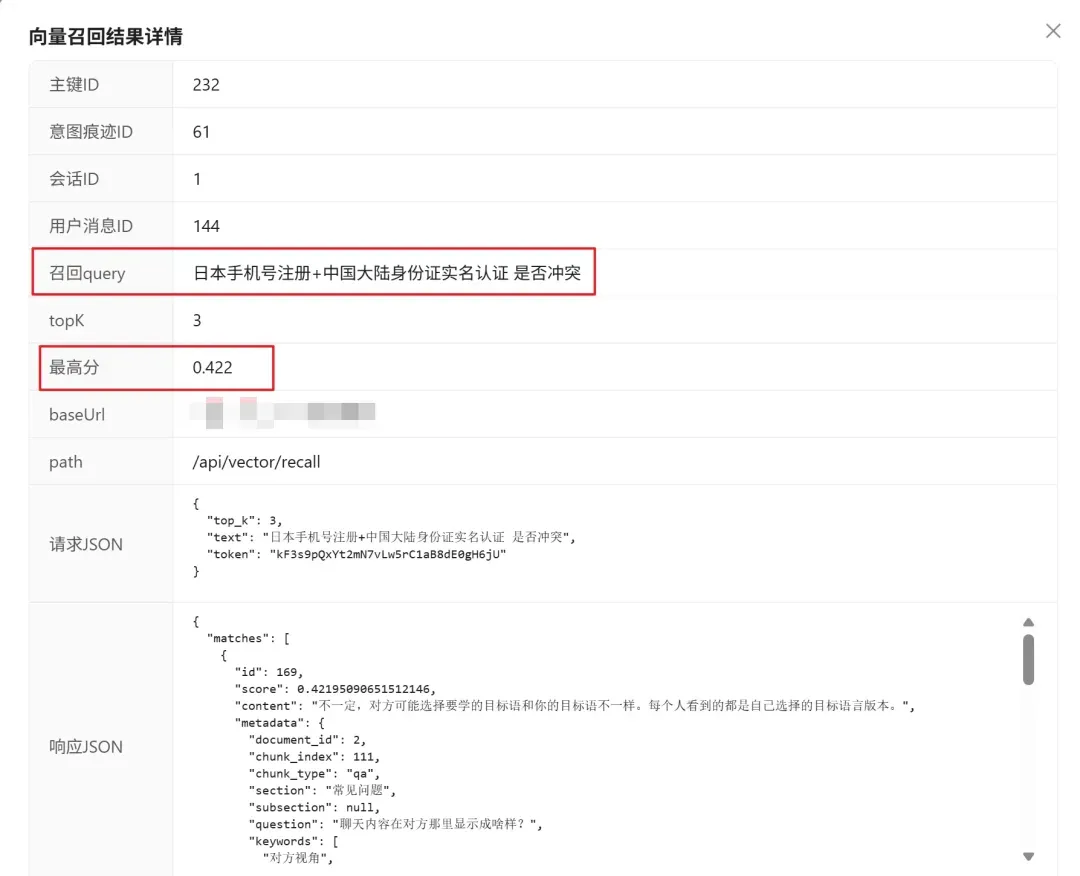
在数据飞轮运行之前,针对某类问题的初始召回分数可能仅为0.422。 而在数据飞轮持续运行、知识库得到补全后:
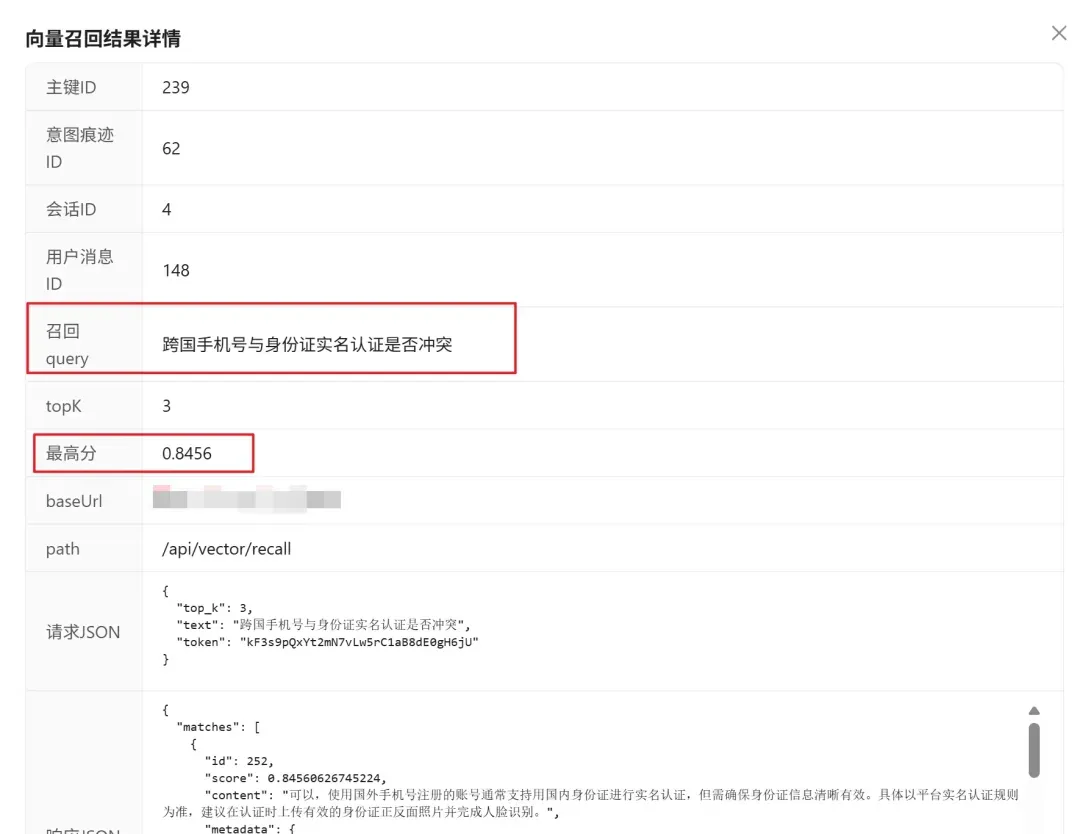
可以清晰地看到,相同或类似问题的召回置信度提升到了0.8以上,这标志着检索质量获得了显著改善。
总结:从静态库到进化系统
通过上述解析,我们不难理解数据飞轮的核心机制、实施方法及其在AI客服场景中的价值。在实际业务中,AI客服必然会遭遇:
- 看似奇怪但实则合理的用户提问。
- 业务规则中的边缘或长尾场景。
- 表达极不规范、难以直接匹配的问题。
如果系统依赖的是一个静态不变的知识库,那么这些问题只会反复出现、反复回答错误。而引入 数据飞轮 机制后,局面将彻底改观:
- 知识库能够在真实业务交互中持续生长和补全。
- AI客服的回答质量,会随着系统运行时间的积累而自然提升。
- 人工只需专注于“关键决策”(如审核),而非陷入“重复劳动”(如手动添加每一个问题)。
至此,我们可以得出一个核心结论:一个优秀的AI客服系统并非一次性建设工程,而是一个“被真实用户持续训练和优化”的有机体。
那些低置信度的问题不应被视为系统的缺陷,恰恰相反,它们是 驱动下一轮知识进化的宝贵燃料。
真正成熟、健壮的AI客服系统,其能力并非源于“初始阶段构建一个完美的知识库”,而是依赖于 “数据飞轮”的持续运转,结合必要的人工审核兜底,在长期的业务运行中不断迭代、逼近最优解。