RAG技术探析:向量库并非必需品,检索增强生成的核心在于可靠知识源
当前,我们可以将人工智能项目大致划分为三种主要类型。
第一类是工作流AI,以Agent平台(如Coze、Dify)为代表,通常结合AI表格和多维表格等工具,主要目标是优化企业内部流程,实现降本增效。
第二类和第三类都属于AI知识库范畴。其中一类专注于单轮问答,不涉及复杂的意图识别和模型记忆功能;另一类则致力于多轮对话,对数据质量和系统工程架构要求极高,这也是普通开发者较少涉足的AI技术深水区。
一提到AI知识库,人们自然会联想到一个与之紧密相关的概念——RAG(检索增强生成)。紧随其后的,向量库(或向量数据库)也会进入大家的视野。然而,根据我的实际项目经验来看:RAG技术通常是必要的,但向量库或许并非如此,至少在我观察到的实际应用案例中,真正广泛使用它的公司并不算多。
至于背后的原因,让我们展开进一步的探讨。
RAG的必要性
我第一次接触RAG技术是在两年多以前。事实上,当时我并没有意识到这就是RAG,因为相关的中文资料非常有限。我的关注点完全集中在产品目标上,需求也很明确:
在医疗在线问诊场景下,当患者已经确诊某种疾病时,所提供的治疗建议绝不能直接依赖大语言模型的通用知识,而必须严格依据本地的权威药品知识库。
这个需求的实现方案其实相对直接。得益于公司历史积累的、结构较为完善的药品数据库,其中药品说明书记录了清晰的适应症映射关系。因此,我们只需要在最终生成治疗方案时,将这些经过验证的数据放入提示词(Prompt)中即可:
你是一名专业的医疗顾问,必须严格根据提供的权威药品信息为患者提供建议。
【患者确诊的疾病】
{用户输入的疾病名称}
【权威药品清单(必须严格遵守)】
{从您知识库中检索到的相关药品信息,例如:
- 药品A:用于治疗[疾病A]、[疾病B]。用法:一次一片,一日一次。禁忌:孕妇禁用。
- 药品B:用于治疗[疾病A]、[疾病C]。用法:一次两粒,一日两次。禁忌:对本品过敏者禁用。
}
【你的任务】
请基于且仅基于上方【权威药品清单】中的信息,为患者提供治疗建议。
【你必须遵守的规则】
1. **禁止编造**:绝不能推荐清单之外的任何药品,也绝不能添加清单中未提及的功效或副作用。
2. **核心内容**:你的回答必须包含:
- 推荐哪几种药(必须来自清单)。
- 简要的用法用量(必须来自清单)。
- 最重要的禁忌或警告(必须来自清单)。
3. **安全兜底**:如果清单为空,你必须回答:“未在药品库中找到标准治疗方案,请立即咨询医生。”
4. **最终建议**:在结尾必须加上:“以上信息仅供参考,用药前请咨询医生并仔细阅读说明书。”
现在,请开始你的回答:
从上述场景中可以清晰地看到,整个过程完全没有用到向量库。唯一可能出现的问题是:用户输入的确诊疾病名称,无法与我们知识库中预定义的“适应症”字段精确匹配,导致检索不到数据,也就是系统泛化能力不足。例如:
- “房颤” 与 “心房颤动”;
- “灰指甲” 与 “甲真菌病”、“皮肤癣菌所致甲感染”;
- ……
处理这类问题通常有两种思路。一是直接扩展原有的知识库,为每个疾病增加“别名”或“相似名称”字段。另一种方案则是引入向量库,试图通过语义相似度来解决泛化问题。
然而,扩展别名的方案是确定且稳定的,而向量库的策略本质上是一种概率性匹配(相似度匹配),这自然会引入不确定性,甚至可能引发新的问题,例如过度泛化:
“高血压”和“颅内高压”在通用语境下都含有“高压”一词,但在医学上是截然不同的两种疾病。如果在此处匹配错误,后果将非常严重。
因此,在实际应用中,向量库的角色有时会显得有些尴尬。它似乎并非与RAG技术存在必然的绑定关系?
向量库在RAG中的定位
RAG技术本身未必一定要使用向量库。它的核心是 “检索”与“生成” ,而检索的方式可以多种多样:
- 关键词检索: 像传统搜索引擎一样,使用BM25等算法进行关键词匹配。
- 语义检索: 使用向量库进行embedding相似性搜索,这也是当前的主流做法之一。
- 混合检索: 结合关键词检索和语义检索,取长补短。
- 基于规则或知识图谱的检索: 利用预设规则或结构化的知识网络进行精准查找。
毫无疑问,向量库和向量搜索技术正是搭乘RAG这辆快车,从一个相对小众的领域,一跃成为AI基础设施中的明星组件。
它的出现,有效地解决了传统关键词检索无法理解查询语义的痛点。例如,当用户搜索“苹果”时,系统应该能同时返回关于“Apple Inc.(苹果公司)”和“水果苹果”的相关信息。
不过,向量库能成为“明星”,或许与以下厂商的大力推广密不可分:例如开源的Milvus及其商业版Zilliz Cloud。它们投入了大量资源进行市场教育(包括技术布道、文档编写、社区活动),极大地普及了向量数据库的概念。最终形成的印象是:一提RAG必谈向量库,一深入向量库就绕不开Milvus。
除此之外,腾讯云的VectorDB、阿里云的OpenSearch、华为云的GaussDB等国内云服务也都集成了向量检索能力。国际市场则更为多元。总而言之,我的看法是:
RAG的应用需求催热了向量库市场,而向量库厂商之间的激烈竞争与技术推广,又反过来让RAG解决方案变得更强大、更易用,共同推动了这场AI应用开发的变革。
然而,核心要点在于:RAG对于构建可靠的AI知识库确实是必备环节,但向量库在多数情况下只是一个可选的“增强工具”,甚至很多时候并非必需。那么,新的问题随之而来:究竟在什么场景下才会真正用到向量库呢?
向量库的适用场景
根据我的观察,当前使用向量库的场景,多半源于项目团队存在一定的“惰性”。他们不愿意投入精力进行精细化的数据清洗,或者只希望用AI对数据进行简单的预处理,例如:将大量非结构化文档(如技术手册、历史客服问答记录)直接“丢”进向量库,然后期待系统能自动检索出有效信息。
这里的逻辑听起来很简单:传统的关键词检索容易遗漏那些语义相似但用词不同的内容,而向量检索能更好地解决这一问题。
但实际情况往往如何呢?只能说:在绝大多数严肃的生产环境中,丢弃原始、未经清洗和结构化的文档,仅仅依赖向量库的语义检索来获取答案,其效果常常令人失望,甚至可能引发灾难性的后果。
原因如前所述,向量搜索返回的是最“语义相似”的文本块(chunks),而不一定是最“相关”或最“准确”的答案。一个查询可能返回十几个语义相关但上下文无关的文本片段,这迫使大语言模型(LLM)不得不耗费大量算力去甄别、筛选和总结,极大地增加了产生“幻觉”(即编造信息)的风险。
例如,查询“某产品的定价策略”,可能返回包含“定价”、“策略”等词语的董事会纪要片段、市场分析报告摘要,甚至某位员工的个人建议邮件,而不是官方的、最新的定价文档。
这些问题,在你最初决定“偷懒”时就已经埋下了伏笔。使用AI自动切割文档,很容易导致重要信息被割裂、上下文不连贯。
因此,要想用好向量库,“偷懒”是不可能的。通常需要在初步检索后,结合各种策略(如元数据过滤、重排序Rerank)进行结果精炼。而为了实现这些过滤条件,在最初的数据处理阶段就需要进行大量的额外标注工作。既然已经在做标注和结构化了,那么为什么不从一开始就采用更精确的检索方式,反而要绕道向量库呢?
综上所述,我们回归本质:RAG的核心目标是确保AI生成的答案来源于预先定义好的、可信的知识源。
向量库是一种高级工具,旨在解决RAG中“检索”环节的语义泛化问题。但在引入泛化能力的同时,它也带来了不确定性。因此,必须借助其他技术(如元数据过滤、混合搜索、结果重排)来约束这种不确定性。
而许多人设想的——直接丢弃杂乱无章的原始文档,指望向量库和LLM的组合能创造奇迹——这属于典型的**“愿望式编程”**。其结果必然是不稳定、不可靠的。
正因为上述原因,向量库在实际生产中的应用效果并不理想。许多团队根本不用它,甚至有些尝试使用的团队也因为觉得麻烦而逐渐弃用。
那么,是否存在替代技术呢?答案是肯定的,例如接下来要介绍的PageIndex。
PageIndex:一种基于推理的检索新思路
PageIndex是一个基于推理的RAG系统。它模拟了人类专家通过树状搜索在长文档(如手册、报告)中定位信息的过程,使大语言模型能够通过思考与推理,找到最相关的文档章节。其检索过程主要分为两步:
- 为文档生成目录式的树状结构索引。
- 通过树搜索算法实现基于推理的检索。
该项目是开源的,但目前知晓度还不高。
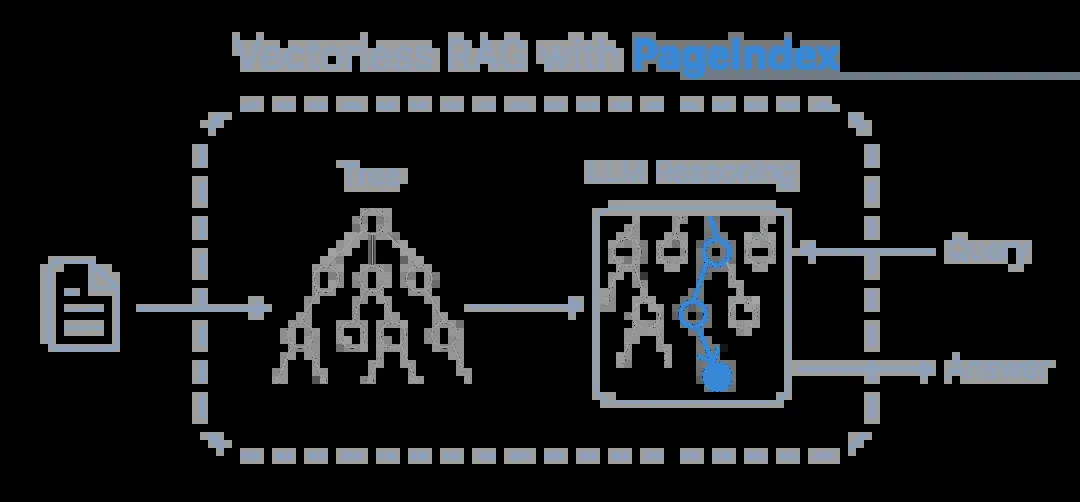
PageIndex的核心理念是:检索不应是一次性的、机械的匹配动作,而应是一个由推理驱动的、渐进式的探索过程。其标准操作流程(SOP)如下:
- PageIndex OCR: 将PDF等文档转换为保留原有层级结构(标题、章节)的Markdown格式。
- 生成树形索引: 基于OCR结果,生成一个类似目录(Table of Contents)的JSON树状结构。
- 基于树搜索的检索: 在生成的树上进行搜索(支持基于LLM推理和基于规则值两种方式),返回相关的内容节点、页码以及完整的检索路径轨迹,避免了传统“top-k”检索的盲目性。
与基于向量库的RAG相比,PageIndex采用的是逐步缩小范围的逻辑,依靠推理在树状结构上逐层定位,而非简单的向量近邻查找。这个概念可能有些抽象,让我们通过一个案例来理解。

假设我们有一份内容庞大的文档,经过PageIndex解析后,会形成如下结构:

为了更直观地说明,我们假设手中有一份某公司的《XXX 2024年年度报告》,共计约120页。它将经历以下处理流程:
第一步:文档层级化解析
PageIndex的OCR引擎会将PDF识别成对大模型友好的Markdown格式,并尽可能保留标题、小节、表格、列表等层级信息。结果可以按页、按节点或拼接方式获取。例如,报告中的一个片段可能被解析为:
# 7 经营情况讨论与分析(MD&A)
## 7.2 收入与成本
### 7.2.1 毛利及毛利率
... 2024 财年,公司毛利率为 **38.4%**(见合并利润表注释 3)...
第二步:构建树状索引
对OCR产物进行“树生成”操作,形成一个轻量级的JSON结构。每个节点都包含标题、node_id、页码索引和简要摘要,天然形成了一个“可导航”的目录:
{
"title": "Management’s Discussion and Analysis",
"node_id": "0004",
"page_index": 35,
"nodes": [
{
"title": "Results of Operations",
"node_id": "0005",
"page_index": 40,
"nodes": [
{
"title": "Gross Margin",
"node_id": "0006",
"page_index": 45,
"summary": "2024 年毛利率及同比变动,影响因素为产品结构与成本控制..."
}
]
}
]
}
树生成过程不需要向量库,也无需对文档进行传统的“切块”。每个节点附带的页码与摘要,使其特别适合处理长文档(如财报、法律或技术手册)。
第三步:执行树搜索
当用户实际进行查询时,例如提问:“公司2024年的毛利率是多少?”
系统会在预先构建好的树状索引上逐层推理和定位相关节点,自动搜集所有相关信息,并返回相关段落、页码以及完整的检索轨迹:
{
"query": "What is the gross margin for FY2024?",
"retrieved_nodes": [
{
"title": "Gross Margin",
"node_id": "0006",
"relevant_contents": [
{
"page_index": 46,
"relevant_content": "For fiscal year 2024, the Company’s gross margin was **38.4%** ..."
}
]
},
{
"title": "Consolidated Statements - Notes",
"node_id": "0012",
"relevant_contents": [
{
"page_index": 102,
"relevant_content": "Note 3: ... gross margin of **38.4%** for FY2024 ..."
}
]
}
],
"trajectory": [
{"from": "root", "to": "Management’s Discussion and Analysis", "reason": "与经营指标相关"},
{"from": "Management’s Discussion and Analysis", "to": "Results of Operations", "reason": "涉及经营结果"},
{"from": "Results of Operations", "to": "Gross Margin", "reason": "直接回答毛利率"}
]
}
该框架支持基于LLM推理和基于规则值的两种树搜索模式。它能返回透明的节点访问轨迹和精准的页码引用,无需手动调整“top-k”参数。需要注意的是,当前其SDK暂时仅支持单文档检索。
最后:信息整合与生成
将检索到的结果作为“证据”段落,输入给最终的回答模型,并要求模型严格基于这些证据生成答案,并附带引用。这种可溯源的方式在实践中很受青睐:
系统:你是严谨的财报助手。只允许依据“evidence”作答;若证据冲突或缺失,明确说明。
用户问题:{query}
evidence:
- {page_index: 46, content: "... gross margin was 38.4% ..."}
- {page_index: 102, content: "... gross margin of 38.4% for FY2024 ..."}
输出:answer(中文),citations(按页码列出)
公司的 2024 财年毛利率为 38.4%。依据见年报“Gross Margin”小节与合并报表注释。
证据页: p.46, p.102。
可以看到,PageIndex的逻辑非常清晰,易于理解。但新的问题也随之而来!
PageIndex面临的挑战:数据与查询处理
首先,用户的提问方式千差万别(泛化问题)。传统RAG的一个痛点是严重依赖用户提问的“措辞”。如果用户表达不准确,检索就会失败。这也是人们引入向量库试图解决的问题,但向量库只解决了一部分,同时又带来了新的不确定性。
PageIndex采取的策略是:不相信用户的原始提问是进行检索的最佳形式。其内置的推理器(Reasoner)核心工作之一,就是对原始查询进行重写、分解和优化。
这一逻辑相当于将原本希望由向量库承担的“语义泛化”任务,移交给了大语言模型的推理能力。
相当于 将“查询泛化”从依赖“静态的嵌入向量相似度”转变为依靠“推理驱动的动态查询规划”。
以下是一个推理器工作的简化案例:
用户原始提问:“苹果那个最牛的手机芯片咋样了?”
推理器优化后查询:“Apple A17 Pro芯片性能评测”、“iPhone 15 Pro Max芯片规格”
它主要解决了用户提问中措辞不专业、口语化的问题,将其转化为知识库中更可能存在的标准术语和规范表述。
此外,它还能处理复杂的多问题拆解,例如:
用户原始提问:“对比一下iPhone 15 Pro和三星Galaxy S24 Ultra的摄像头传感器尺寸。”
推理器分解为:
子查询1:“iPhone 15 Pro主摄像头传感器尺寸”
子查询2:“Samsung Galaxy S24 Ultra主摄像头传感器尺寸”
总而言之,PageIndex并不直接使用用户的原始提问进行检索,而是利用LLM强大的推理和理解能力,将用户的模糊意图“翻译”成知识库更容易“理解”的规范查询语言,从而增强了对多样化、模糊化提问的泛化能力。
紧接着是第二个挑战:PageIndex检索到的内容就一定完全相关吗?如何处理不相关或质量不高的信息?
PageIndex的设计包含一个循环流程。在生成最终“响应”的阶段,解答器(Answerer)的一个重要职责是评估已检索到的信息是否相关且足以回答问题。
如果解答器判断最新检索到的片段与问题无关或质量不佳,它会将这一反馈“传递”给推理器,触发新的检索思路,例如:“刚才找到的内容不适用,我们需要调整搜索方向。”
解答器的另一个任务是对检索结果进行重排序,评估每个片段与问题的相关性。如果现有结果仍不理想,系统可能会进入新一轮的检索循环,直到获得满意的信息为止。
不得不说,这种思路很好,与我们进行数据工程处理的逻辑非常相似。然而,PageIndex的一个明显缺点是它需要多次调用大模型进行推理,因此Token消耗更大,成本也相对更高。
总结与展望
得益于大语言模型基础能力的飞速发展,尤其是上下文窗口长度的显著扩展,历史上的一些辅助技术可能会逐渐淡出舞台中心,例如几乎与RAG绑定的向量库。
当然,我并非要全盘否定向量库的价值。本文的目的在于打破一种技术惯性思维——不要因为业界广泛讨论某种技术,就认为它是唯一或必然的技术路径。所有的技术选型失误,最终都会转化为真金白银的试错成本。
向量库凭借其解决语义泛化问题的潜力,以及在厂商大力推广下成为市场热点,几乎与RAG形成了“绑定”印象。但这常常让我们忽略了最本质的问题:
我们的知识究竟以何种形态存在?是高度结构化的数据库条目,还是杂乱无章的非结构化文档?不同的数据形态,理应匹配不同的检索增强方案。
向量库是一把出色的“瑞士军刀”,尤其擅长处理泛化的、非结构化的语义搜索。但对于高度结构化的确定性数据,它可能并非最优解,盲目选用只会为系统引入不必要的复杂性。
而像PageIndex这类 “推理即检索” 的新范式,其实也并非革命性的创举。早在一年多前,许多数据工程项目中就已经采用了类似的“查询理解-路径检索”思想。 它的核心突破在于跳出了 “嵌入-匹配” 的传统框架,尝试用大模型本身的推理能力,去模拟人类查阅复杂文档时的逻辑思维过程。
它揭示了一个新的趋势:未来的RAG系统,其智能性将不仅仅体现在最终“生成”环节的LLM上,更将前置并深度融合到“检索”过程本身的推理逻辑中。
最后,技术选型永远是一场权衡。在向量库的概率性语义匹配与PageIndex的高成本推理检索之间,并无绝对的优劣之分。在实际项目中,我们往往需要结合使用多种技术:用规则和结构化查询处理确定性需求,用向量库泛化模糊的语义查询,再用推理能力解决复杂的多步、深层问题。
重申一个基本原则:实践是检验真理的唯一标准。只要技术方案能有效地解决你的实际问题,那就是好的方案。技术本身只是工具,解决问题才是最终目的。
回归本源,RAG的核心使命从未改变:坚定不移地将AI生成的答案,锚定在最权威、最准确、最可信的知识源之上。 希望本文的探讨能为大家带来一些启发。